aca unit5 - copy
TRANSCRIPT

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 1/30
Subject : ADVANCED COMPUTER ARCHITECTURE
Department : Computer Sc. & Engineering
Course B.Tech 7th Semester
ौी ह ष ऽ य स हा यक आ चाय)
सगं णक ि वजान ए वम भ िया ऽक ि व भा ग
Echelon Institute of Technology
Unit 5Concurrent Processors1. Vector Processors
2. Vector Memory
3. Multiple Issue Machines
4. Comparing Vector and Multiple Issue Processors
Shared Memory Multiprocessors
1. Basic Issues: Partitioning, Synchronization and Coherency
2. Types of Shared Memory Multiprocessors
3. Memory Coherence in shared Memory Multiprocessors

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 2/30
Shared Memory Multiprocessors
Shared Memory MultiprocessorsMultiprocessors are usually designed for at least one oftwo reasons – Fault Tolerance
– Program Speed up
• Fault Tolerant Systems: n identical processors ensure that failure of one
processor does not affect the ability of the multiprocessor to continue with
program execution.
• These multiprocessors are called high availability or high integrity systems.
• These systems may not provide any speed up over a single processor
system.
• Program Speed up: Most multiprocessors are designed with mainobjective of improving program speed up over that of single processor.
• Yet fault tolerance is still an issue as no design for speedup ought to comeat the expense of fault tolerance.
• It is generally not acceptable for whole multi processor system to fail if anyone of its processors fail.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 3/30
Shared Memory Multiprocessors
• Basic Issues: Three basic issues are associated withdesigns of multiprocessor systems.
– Partitioning
– Scheduling of tasks
– Communication and synchronization
Partitioning
• This is the process of dividing a program into tasks, each of
which can be assigned to an individual processor for
execution.
• The partitioning process occurs at compile time.
• The goal of partitioning process is to uncover the maximum
amount of parallelism possible within certain obvious
machine limitations.
Suppose a program P is converted into
a parallel form Pp. This conversion
consists of partitioning Pp into a set of
tasks Ti.
Pp consists of tasks, some of
which can be executed
concurrently (parallel).

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 4/30
• Program partitioning is usually performed with someprogram overhead.
• Overhead affects speedup.
• The larger the size of the minimum task defined by thepartitioning program, the smaller the effect of programoverhead.
• If uniprocessor program P1 does operation O1, then parallelversion of P1 does operations Op, where Op ≥ O1.
• If available parallelism exceeds the known number ofprocessors, or several shorter tasks share the same
instruction / data working set, Clustering is used to groupsubtasks into a single assignable task.
Partitioning
The detection of parallelism is done by one of three methods.
1. Explicit statement of concurrency in high level language.
Programmers to define boundaries among tasks that can be
executed in parallel.
2. Programmers hint in source statement which compilers can use
or ignore.
3. Implicit parallelism sophisticated compilers can detect
parallelism in normal serial code and transform program code for
execution on multiprocessors.
Partitioning
Grouping tasks into
process clusters.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 5/30
Scheduling• Associated with each program’s flow of control among the
sub-program tasks.
• Each task is dependent on others.
Scheduling• Scheduling is done both statically (at compile time) anddynamically (at run time).
• Statically scheduling is not sufficient to ensure optimumspeedup or even fault tolerance.
• The processor availability is difficult to predict and may varyfrom run to run.
• Runtime scheduling has advantage of handling changingsystem environments and program structures also havingdisadvantage of run time overhead.
Major run time overheads in run-time scheduling:
1. Information gathering: information about dynamic state of theprogram and the state of the system.
2. Scheduling
3. Dynamic execution control: clustering or process creation
4. Dynamic data management: providing of tasks and processorsin such a way to minimize the required amount of memoryoverhead delay.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 6/30
Run Time Scheduling Techniques1. System load balancing:
• Objective is to balance the systems loading.
• Dispatching the number of ready tasks to each processor’s
execution queue.
2. Load balancing: relies on estimates of the amount of
computation needed within each concurrent sub-task.
3. Clustering: pair wise communication process information
developed to minimize inter-process communication.
4. Scheduling with complier assistance: block level
dynamic program information is gathered at run time.5. Static scheduling / custom scheduling: inter-process
communication and computational requirements can be
determined at compile time.
Scheduling
Synchronization and Coherency

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 7/30
Synchronization and Coherency• Multiprocessor configuration having high degree of task
concurrency, the tasks must follow an explicit order andcommunication between active tasks must be performed in anorderly way.
• The value passing between different tasks executing on differentprocessors is performed by synchronization primitives orsemaphores.
– semaphore is a variable or abstract data type that provides asimple but useful abstraction for controlling access by multipleprocesses to a common resource in a parallel programmingenvironment.
• Synchronization is the means to ensure that multiple processorshave a coherent or similar view of critical values in memory.
• Memory coherence is the property of memory that ensures that a
read operation returns the same value which was stored by thelatest write to same address.
• In complex systems of multiple processors the program order ofmemory related operations may be different from order in whichoperations are actually executed.
Different degrees of operation ordering in multiprocessors:
1. Sequential Consistency
2. Processor Consistency
3. Weak Consistency
4. Release Consistency
Synchronization and Coherency
Fig. a: Sequential Consistency: result of
any execution is same as operations of all
processors executed in some sequential
order.
Fig. c: Weak Consistency: Synch.
Operations are performed before any
subsequent memory operation is performed
and all pending memory operations are
performed before any synchronization
operation is performed.
Fig. d: Release Consistency: Synch.
operations are split into acquire (lock) and
release (unlock) and these operations are
processor consistent.
Fig. b: Processor Consistency: Loads
followed by store to be performed in
program order. But store followed by load is
not necessarily performed.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 8/30
Types of Shared Memory
Multiprocessors
Types of Shared Memory
Multiprocessors
The variety in multiprocessors results from theway memory is shared between processors.
1. Shared data cache, shared memory.
2. Separate data cache but shared bus –shared memory.
3. Separate data cache with separate buses
leading to a shared memory.4. Separate processors and separate memory
modules interconnected with a multi-stageinterconnection network.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 9/30
Types of Shared Memory
Multiprocessors2. Separate data cache but shared bus-shared
memory
Types of Shared Memory
Multiprocessors4. Separate processors and separate memory
modules interconnected with a multi-stageinterconnection network.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 10/30
Memory Coherence in
Shared Memory
Multiprocessors
Memory Coherence in Shared
Memory Multiprocessor
• Each node in a multiprocessor system possesses a localcache.
• Since the address space of the processor overlaps,different processors can be holding (caching) the samememory segment at the same time.
• Further each processor may be modifying these cachedlocation simultaneously.
• Cache coherency problem is to ensure that all cachescontain same most updated copy of data.
• The protocol that maintains the consistency of data in allthe local caches is called the cache coherency protocol.
– Snoopy Protocol
– Directory Protocol

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 11/30
Snoopy Protocol
• A write is broadcast to all processors in the system.Broadcast protocols are usually reserved for shared busmultiprocessors.
• All processors share memory through a common memorybus.
• Snoopy protocols assume that all of the processors areaware and receive all bus transactions (snoop on the bus).
Bus
Processors
Snoopy Protocol
Snoopy Protocol
Memory

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 12/30
Snoopy protocols are further classified based on the type of
action local processor must take when an altered line isrecognized.
There are two types of actions:
• Invalidate: all copies in other caches are invalidated beforechanges are made to data in a particular line. The invalidatesignal is received from the bus and all caches which groups thesame cache line invalidate their copies.
• Update: Writes are broadcast on the bus and caches sharingthe same line snoop for data on the bus and update the contentsand state of their cache lines.
Snoopy Protocol
Snoopy Protocol
Three processors (P1, P2 and Pn)
having consistent copy of block X
in their local caches.
Using write invalidate, processor P1
writes its cache from X to X' and all
other copies are invalidated via
bus.
Write update demands the new
block content X' be broadcast to
all cache copies via bus.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 13/30
Directory Based Protocols
Directory Based Protocols• These protocols maintain the state information of the
cache lines at a single location called directory.
• Only the caches that are stated in the directory and are
thus known to posses a copy of the newly altered line,
are sent write update information.
• Since there is no need to connect to all caches, in
contrast to snoopy protocols, directory based protocols
can scale better.
• As the number of processor nodes and number of cache
lines increase, the size of directory can become verylarge.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 14/30
• Based on action taken by local processor interms of invalidate or update cache lines, thereis important distinction among directory basedprotocols depending on directory placement.
– Central Directory: Directories specifying lineownership or usage can be kept with memory(central).
– Distributed Directory: Directories specifying
line ownership or usage can be kept with theprocessor-caches (distributed).
Directory Based Protocols
• Central Directory:
– Memory will be updated on a write update.
– Directory is associated with the memory and contains information for
each line in memory.
– Each line has a bit vector which contains a bit for each processor
cache in the system.
Directory Based Protocols
Centralized directory structure
Directory size (bits) = Number of caches x Number of memory lines

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 15/30
• Distributed Directory:
– Memory has only one pointer which identifies the cache that last
requested it. A subsequent request to that line is then referred to that
cache and requestor Id is placed at the head of list.
– Main memory is generally not updated and the true picture of the
memory of the memory state is found only in group of caches.
Directory Based Protocols
Directory size (bits) = Number of memory lines x [ log2 (number of caches)]
Concurrent Processors

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 16/30
Concurrent Processors
• Processors that can execute multiple instructions at thesame time (Concurrently)
• Concurrent processors can make simultaneous access tomemory and can execute multiple operationssimultaneously.
• Processor performance depends on compiler ability,execution resources and memory system design.
There are two main types of concurrent processors.
– Vector Processors: single vector instruction replacesmultiple scalar instructions. It depends on compilers abilityto vectorize the code to transform loops into a sequence ofvector operations.
– Multiple Issue Processors: Instructions whose effects areindependent of each other are executed concurrently.
Vector Processors

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 17/30
Vector Processors• A vector computer or vector processor is a machine
designed to efficiently handle arithmetic operations onelements of arrays, called vectors.
• Such machines are especially useful in high-performancescientific computing, where matrix and vector arithmetic arequite common. Supercomputers like Cray Y-MP is anexample of vector Processor.
• Vector processor is an ensemble of hardware resources,including vector registers, register counters etc.
• Vector processing occurs when arithmetic or logicaloperations are applied to vectors.
• Vector processors achieve considerable speed up inprocessor performance over that of simple pipelinedprocessors.
Vector Processors
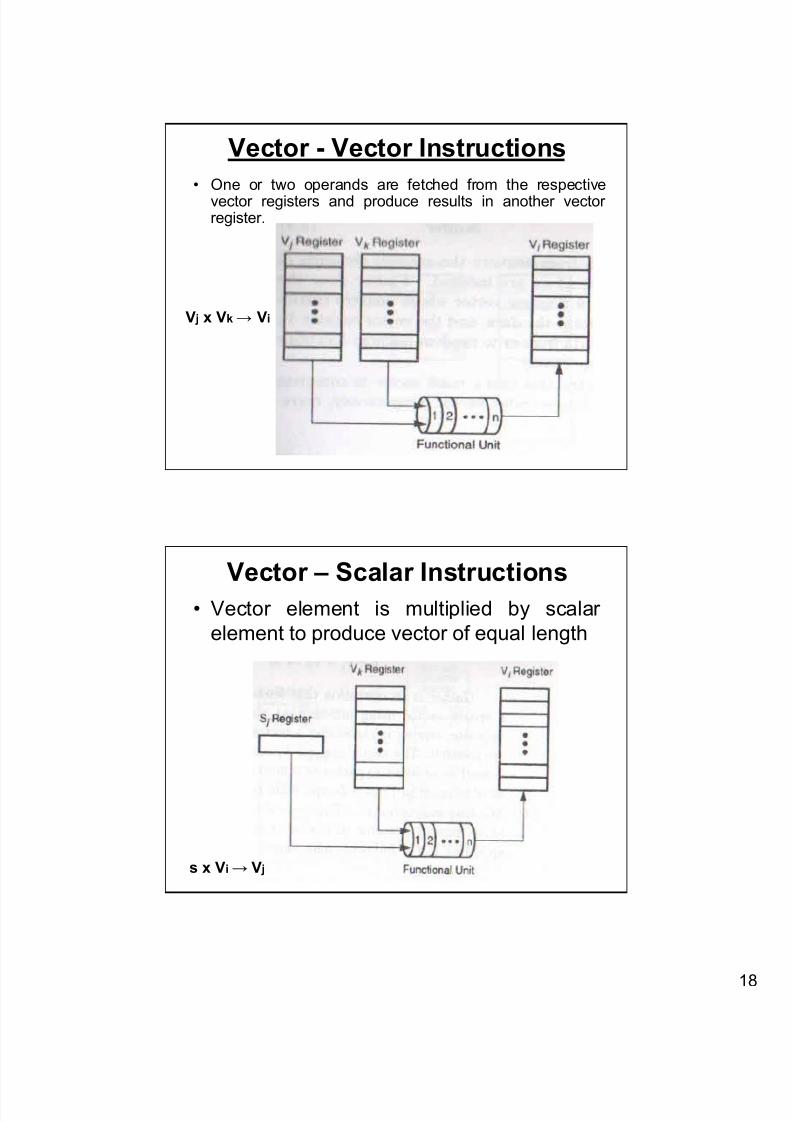
Six types of Vector Instructions
1. Vector – Vector Instruction
2. Vector – Scalar Instructions
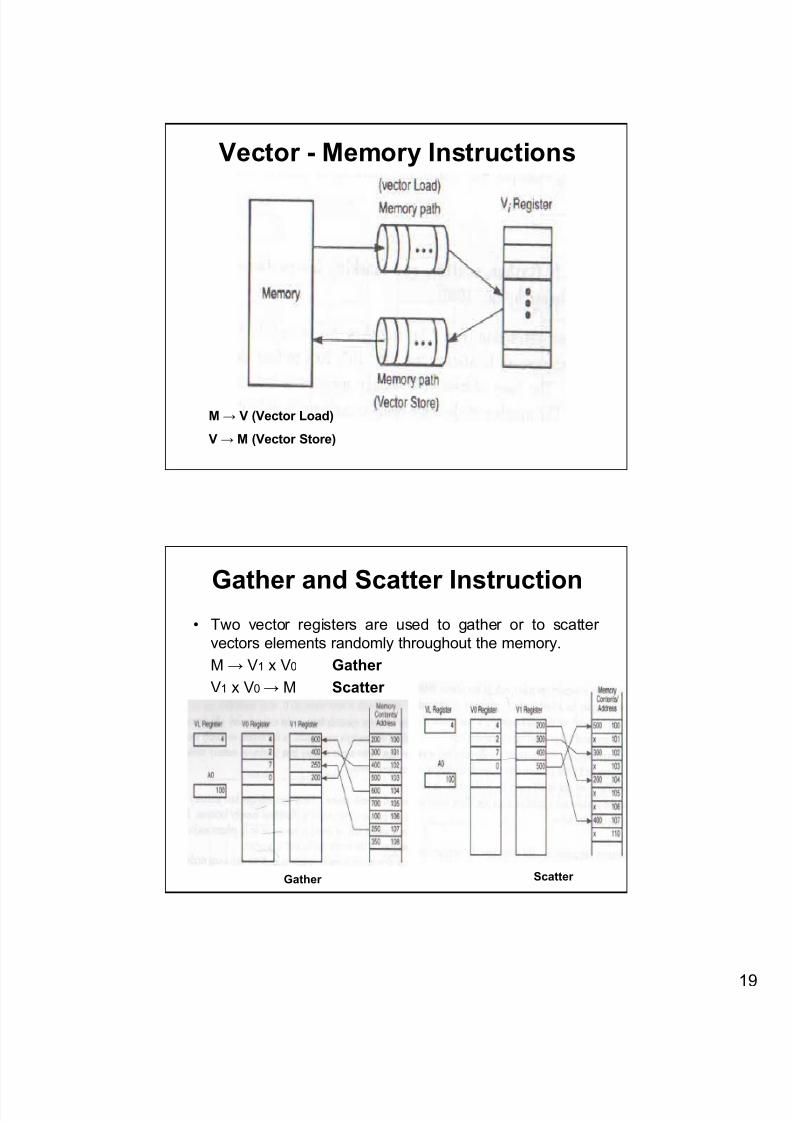
3. Vector – Memory Instructions
4. Vector - Reduction Instruction
5. Gather and Scatter Instructions
6. Masking Instructions
8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 18/30
Vector - Vector Instructions
• One or two operands are fetched from the respectivevector registers and produce results in another vectorregister.
V j x Vk → Vi
Vector – Scalar Instructions
• Vector element is multiplied by scalar
element to produce vector of equal length
s x Vi → V j
8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 19/30
Vector - Memory Instructions
M → V (Vector Load)
V → M (Vector Store)
Gather and Scatter Instruction• Two vector registers are used to gather or to scatter
vectors elements randomly throughout the memory.
M → V1 x V0 Gather
V1 x V0 → M Scatter
Gather Scatter

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 20/30

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 21/302
Vector Memory
• Simple low order interleaving used in normal pipelined
processors is not suitable for vector processors.
• Since access in case of vectors is non sequential but
systematic, thus if array dimension or stride (address
distance between adjacent elements) is same as
interleaving factor then all references will concentrate on
same module.
• It is quite common for these strides to be of the form 2k or
other even dimensions.
• So vector memory designs use address remapping and use
a prime number of memory modules.
• Hashed addresses is a technique for dispersing addresses.
• Hashing is a strict 1:1 mapping of the bits in X to form a new
address X’ based on simple manipulations of the bits in X.
•A memory system used in
vector / matrix accessing
consists of following units.
– Address Hasher
– 2k + 1 memory modules.
– Module mapper.
This may add certain
overhead and add extra
cycles to memory access
but since the purpose of
the memory is to access
vectors, this can be
overlapped in most cases.
Vector Memory

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 22/302
Modeling Vector Memory Performance
• Vector memory is designed for multiple simultaneous requests to
memory.• Operand fetching and storing is overlapped with vector execution.
• Three concurrent operand access to memory are a commontarget but increased cost of memory system may limit this to two.
• Chaining may require even more accesses.
• Another issue is the degree of bypassing or out of order requeststhat a source can make to memory system.
• In case of conflict i.e. a request being directed to a busy module,the source can continue to make subsequent requests only if notserviced requests are held in a buffer.
• Assume each of ‘s’ access ports to memory has a buffer of sizeTBF/s which holds requests that are being held due to a conflict.
• For each source, degree of bypassing is defined as the allowablenumber of requests waiting before stalling of subsequentrequests occurs.
• If Qc is the expected number of denied requests per
module and m is the number of modules, then buffer size
must be large enough to hold denied requests.
Buffer = TBF > m. Qc
• If n is the total number of requests made and B is the
bandwidth achieved then
m . Qc = n-B (denied requests)
Modeling Vector Memory Performance
Typical Buffer entries include:
1. Request source ID.
2. Request source tag. (i.e VR number)
3. Module ID
4. Address for request to a module
5. Scheduled cycle time indicating when module is free.
6. Entry priority ID

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 23/302
Gamma (γ) – Binomial Model
• Assume that each vector source issues a request each cycle(δ =1) and
each physical requestor has the same buffer capacity andcharacteristics.
• If the vector processor can make s requests per cycle and there are t
cycles per Tc, then
Total requests per Tc = t . s = n
This is same as n requests per Tc in simple binomial model.
• If γ is the mean queue size of bypassed requests awaiting service then
each of γ – buffered requests also make a request.
• From memory modeling point of view this is equivalent to buffer
requesting service each cycle until module is free.
Total request per Tc = t . s + t . s . γ
= t. s(1 + γ)= n (1 + γ)
Using simple
binomial
equation:
Calculating γ opt
• The γ is the mean expected bypassed request queue per source.
• If we continue to increase number of bypass buffer registers we can
achieve a γ opt which totally eliminates contention.
• No contention occurs when B = n or B(m,n,γ) = n
• This occurs when ρa = ρ = n/m
• Since MB/ D/1 queue size is given by
Q = ρa2 – p ρa / 2(1- ρa) = n(1+γ) –B /m
• Substituting ρa = ρ= n/m and p=1/m we get:
Q=( n2 - n) / 2((m2 - nm) = (n/m )(n-1) /(2m-2n)
• Since Q = (n(1+γ) – B) /m
So mQ = n(1+γ) – B
Now for γopt (n - B) =0
So γopt = m/n Q
So γopt = n - 1/ 2m-2n
And mean total buffer size (TBF) = n γopt
To avoid overflow buffer may be considerably larger may be 2 x TBF

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 24/302
Multiple Issue Machines
Multiple – Issue Machines
• These machines evaluate dependencies amonggroup of instructions, and groups found to beindependent are simultaneously dispatched tomultiple execution units.
• There are two broad classes of multiple issuemachines – Statically Scheduled: detection process is done by the
compiler.
– Dynamically Scheduled: Detection of independent
instructions is done by hardware in the decoder at runtime.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 25/302
Statically Scheduled Machines
• Sophisticated compilers search the code at compile time andinstructions found independent in their effect are assembled intoinstruction packets, which are decoded and executed at run time.
• Statically scheduled processors must have some additionalinformation either implicitly or explicitly indicating instructionpacket boundaries.
• Early statically scheduled machines include the so called VLIW(Very long instruction word) machines.
• These machines use an instruction word that consists of 8 to 10instruction fragments.
• Each fragment controls a designated execution unit.
• To accommodate multiple instruction fragments the instructionword is typically over 200 bits long.
• The register set is extensively multi ported to supportsimultaneous access to multiple execution units.
• To avoid performance limitation by occurrence of branchinstructions a novel compiler technology called tracescheduling is used.
• In trace scheduling branches are predicted where possibleand predicted path is incorporated into a large basic block.
• If an unanticipated ( or unpredicted) branch occurs duringthe execution of the code, at the end of the basic block theproper result is fixed up for use by a target basic block.
Statically Scheduled Machines

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 26/302
Dynamically Scheduled Machines
• In dynamically scheduled machines detection ofindependent instruction is done by hardware atrun time.
• The detection may also be done at compile timeand code suitably arranged to optimizeexecution patterns.
• At run time the search for concurrent instructionsis restricted to the localities of the last executinginstruction.
Superscalar Machines
• The maximum program speed up available inmultiple issue machines, largely depends onsophisticated compiler technology.
• The potential speedup available from multi-flowcompiler using trace scheduling is generally lessthan 3.
• Recent multiple issue machines having moremodest objectives, are called SuperscalarMachines.
• The ability to issue multiple instructions in a singlecycle is referred to as Superscalar implementation.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 27/302
Comparing Vector and
Multiple Issue Processors
• The goal of any processor design is to provide cost
effective computation across a range of
applications.
• So we should compare the two technologies based
on following two factors.
– Cost
– Performance

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 28/302
Cost Comparison• While comparing the cost we must approximate the area used
by both the technologies in the form of additional / requiredunits.
• The cost of execution units is about the same for both (for
same maximum performance).
• A major difference lies in the storage hierarchy.
• Both rely heavily on multi ported registers.
• These registers occupy significant amount of area. If p is the
no of ports, the area required is
Area = (No of reg +3p)(bits per reg +3p) rbe.
• Most vector processors have 8 sets of 64 element registers
with each element being 64 bit in size.• Each vector register is dual ported ( a read port and a write
port). Since registers are sequentially accessed each port can
be shared by all elements in the register set.
• There is an additional switching overhead to switch each of n
vector registers to each of p external ports.
Switch area = 2 (bits per reg).p. (no of reg)
• So area used by registers set in vector processors (supporting
8 ports) is
Area = 8x[(64+6) (64+6)] =39,200 rbe.
Switch area = 2 (64).8.(64) = 8192 rbe.
• A multiple issue processor with 32 registers each having 64
bits and supporting 8 ports will require
Area = (32+3(8))(64+3(8)) =4928 rbe
• So vector processors use almost 42,464 rbe of extra area
compared to MI processors.
• This extra area corresponds to about 70,800 cache bits
(.6 rbe / bit) i.e. approximately 8 KB of data cache.
• Vector processors use small data cache.
Cost Comparison

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 29/302
• Multiple issue machines require larger data cache to ensure high
performance.
• Vector processors require support hardware for managing access to
memory system.
• Also high degree of interleaving is required in memory system to
support processor bandwidth
• M.I machines must support 4-6 reads and 2-3 writes per cycle. This
increases the area required by buses between arithmetic units and
registers.
• M.I machines should access and hold multiple instructions each
cycle from I- cache
• This increases the size of I-fetch path between I-cache and
instruction decoder/ instruction register.
• At instruction decoder multiple instructions must be decoded
simultaneously and detection for instruction independence must be
performed.
Cost Comparison
Performance Comparison• The performance of vector processors depends primarily on twofactors
– Percentage of code that is vectorizable.
– Average length of vectors.
We know that n1/2 or the vector size at which the vector processorachieves approx half its asymptotic performance is roughly the sameas arithmetic plus memory access pipeline.
For short vectors data cache is sufficient in MI machines so for
Short VectorsM.I .processors would perform better than equivalentvector processor .
•As vectors get longer the performance of M.I. machine becomes muchmore dependent on size of data cache and n1/2 of vector processorsimprove.
•So for long vectors performance would be better in case of vectorprocessor.
•The actual difference depends largely on sophistication in compilertechnology.
•Compiler can recognize occurrence of short vector and treat thatportion of code as if it were a scalar code.

8/13/2019 ACA Unit5 - Copy
http://slidepdf.com/reader/full/aca-unit5-copy 30/30
References
• Computer Architecture by Michael J.Flynn
• Advanced Computer Architecture by Kai Hwang
धनयवाद
ौी ह ष ऽ य