a system for social network extraction of web complex structures
TRANSCRIPT

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 1/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
A system for social network extraction of web
complex structures
Amir Ansari, Mehrdad Jalali
Department of Software Engineering
Mashhad Branch, Islamic Azad University, Mashhad, Iran .
Abstract—A social network is social structure composed of nodeswhich generally are individually or organizationally and are con-nected based on several common traits. Currently, social net-works are applied in wide parts of the web. Its popularity is due
to discovery of connections hidden in the web and its representa-tion in a visual manner. Social networks are used in many levels
from households to nations. They play an important role in find-ing solutions to problems, management of organizations and inindividual’s success rate to meet their goals. It is difficult to de-fine social web structure and resulting structures are often verycomplex, unperceivable and unusable. They are usually limited to
specific usage and production steps of a network for each struc-ture are not provided comprehensively and homogenously. In
present study we present a comprehensive system to discover
social networks from each structure and we have used web usagemining techniques to discover hidden data existing in web server
log file and used these data to remove social network challenges.In this system, a novel architecture has been provided for users
clustering. We will use site structure to achieve better results anddelete users review pages. Results of analysis indicate that thiskind of discovery can be used for most applications and struc-
tures and this system will discover all available connections inweb site as much as possible.
Keywords- Social Network, Social Network extraction, Social Network Analysis, Web Usage Mining
I. I NTRODUCTION
With growing increase in information volume and web de-velopment, methods and techniques are needed that enablediscovering useful information from available data. Web min-ing is one of study areas that discover information from docu-ments and web services by using data mining techniques. Webmining is divided to 3 classes including: web content mining,web structured mining, web usage mining [1]. Web content
mining discovers useful information's such as text, picture andvoice from web documents contents. Web structured miningdiscovers structural information from web and determines cor-relation graph pattern in the site. And web usage mining dis-covers useful patterns from data produced in relationships be-tween users and web servers. Applications of these kinds of discoveries are usually including web personalization creatingcomparative web sites, user modeling and etc. Increasinglyusage of technique is sue to using data in which all the merri-ments of user are gartered in an homogenous manner by webserver without direct intervention of user. Additionally all havethis dataset and user is not required to create inter system pro-file.
A social network is social structure compotes of nodeswhich are generally individual or organizational and are con-nected to each other through some traits. Nowadays, socialnetworks are considered as most popular web services webrecent world recognizes internet social networks not only as a
base for being familiar to friends but also as a network of col-lective communications Among challenges in this subject arespecialty of net work, its complexity and lack of any compre-hensive system to mine social network from any kind of sites.For this purpose, a comprehensive system is required the abilityto implement for any kind of structure and application. In
present study, we will present a system for social network ex-traction that in addition of being able to implement in any sitecould discover useful networks from available data in webserver log file by using Web Usage Mining techniques. Thissystem is not limited to any site or structure. And it is able toextract all aspects of social networks such as commercial, cul-tural, personal, political and military aspects. In addition, sug-gested system has an acceptable speed to extract informationand mapping social network and it will resolve problems re-lated to new users.
In section 2, related works are described. In section 3, sug-gested system and its component are defined. System evalua-tion is described in section 4 and analyzing extracted socialnetwork is provided in section 5. Finally conclusions are de-scribed in section 6.
II. R ELATED WORKS
In recent years, social networks are growing seriously. So-cial networks generally are very attractive places which have
been programmed using newest technologies. Every single
part has been programmed and they are derived very purpose-
fully to achieve all objectives defined for website. Now, inter-net social networks not only are bases for being familiar to
friends, but also are networks of collective communications.
For this purpose, some studies have been performed in thisrespect and other related subjects that some of them will bereferred subsequently.
In [2] by using web usage mining, relationships between
web pages and their observation in user sessions are discov-ered through correlation rules. These relations usually are used
for personalization. Additionally relationships between users
are achieved through their item series. K-means algorithm is
used for improving this method in which users interactions areclustered. A cluster of interaction represents users with similar
67 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 2/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
behaviors. Using this method is not suitable for data with largescale.
In [3] a system called WebPUM is introduced. It performs
online prediction using web usage mining and suggests a new
technique for classifying user movement patterns which usesthis technique for predicting users’ future behavior. In this
technique new algorithm of graph division was used for mod-
eling user movement patters and greatest common subse-
quence algorithm was used to classify user activities.Another method based on clustering in web-CANVAS has
been provided. In this method users with similar movement
pattern are places in same cluster [4]. In this technique due to predefined and stationary definition of clusters, some limita-
tions will be created for improving the web site in future [3].
Various methods have been developed to recognize web
communities which are divided to methods based on Hyper-link analysis and methods based on graph theory. Among me-
thods based on hyperlink analysis we can refer to studies per-
formed in [5] and [6]. Method offered in [5] receives a prima-ry of pages as input and discovers their communities. In thismethod, RPA algorithm (related page algorithm) is used to
define similar pages. By using this algorithm, similar pages
are divided to groups and web communities are achieved.Technique offered in [6] is one of most important methods of
recognizing web communities. In this method, Hub and Au-
thority page series are introduces as web communities. An
authority page is containing valuable information's on a certainsubject. A hub page is containing some links to authority pag-
es. This technique recognizes Hub and Authority pages by
using HITS algorithm. Due to rapid growth of web pages anddependence of this algorithm to web site structure, there are
some problems related to using it in real world.In [8] a system has been developed to extract a social net-
work from web called referring web. This system will focuson names of individuals within web pages. Search engine pro-
vides the relationship between these names. Amount of rela-
tionship between two individuals x, y will be achieved byquery from “x and y” in search engine. Tow persons are more
strongly related if they have more similarity in home papas,
scientific articles and organizational charts. Achieved similari-
ty will provide a path from a person to another person.In [9,10,11,12], methods based on graph theory we used.
But due to rapid growth of web and large scale data, usingalgorithms based on graph theory is not possible due to being
time-consuming. Web communities are defined as concen-trated parts in graphs obtained through relationship between
users and how they mover in web pages. In [9], web com-
munities are obtained by using two part complete graphs withtrawling technique. In [10], web communities are obtained
through discovering all two part complete k3,3 graphs and
integrating them to each other. In [11,12], by using maximum
current algorithm, nods with higher number of inter collectionlinks compared to numbers of out collection are considered as
web communities.
In [13], a system called Flank has been described to ex-tract, compress and online presentation of social networks for
virtual web communities. These social networks are provided
using web page analysis, E-mail messages, magazines andself-created profiles (FOFA files). Web mining components
used in Flink are consistent to [8]. In this method for discover-
ing related names, it has attempted to count the frequency of
concurrently repetition of two names with each other with helpof describing conceptual query within a search engine.
In [14,15], wide spread studies have been conducted on
virtual web. PANKOW system provides pattern based inter-
pretation through web knowledge. Nomination of an identityin several verbal patterns makes virtual concept designation.
Virtual relationship between samples and their concepts is
provided through sending query to Google API library. Pat-terns with greatest consistency refer to a concept of identity
nomination on the web. Main idea in PANKOW refers to self
annotate. This idea with access to web general data and struc-
ture, tries to virtual interpretation of local sources, in turn itwill cause self-set up in semantic web.
In [16], it attempted to extract a web by using log file
which reflects users’ movement manner. For this purpose, ithas utilized statistical techniques and data mining, associationrules mining, frequent closed patterns and sequential associa-
tion rules. By using these techniques, high frequency items in
the collection are discovered and resulted in formations aresend to site manager for making advertisements purposeful.
Among benefits of this technique is graphically representation
of users’ movement manner in the site using algorithms such
as frequent closed pattern and association rules mining in logfile with high volume to define frequent items has time com-
plexities. In addition it is not involving dynamic pages.
In summary, most works performed to mine social net-works have used auxiliary systems, user profiles or log files.
Works conducted to mine social networks generally were spe-cifically designed such as for commercial educational purpos-
es. In techniques used to mine social networks usually graph- based methods are utilized which are not useable for large
scale data due to being time-consuming and requiring huge
memory space. So there is a need to a system for mining socialnetworks from log files due to richness and homogeneity of all
users information's in this file. This system should mine all the
relationships and aspects required for social networks.
III. PROPOSED SYSTEM
System proposed in present study is for mining social net-work from log file available in web server. Figure 1 shows ar-chitecture of this system.
Figure 1. proposed system's architecture
68 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 3/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
This system uses log file. Web server records all accessesof users in log file. There are several kinds of different struc-tures of log file which are provided according to web server arrangements. In log files with different structures usually in-formation's such as services IP address, application time, appli-
cation page and html status reagent code are common. This fileusually has large volume and is consist of additional informa-tion's. For mining the pattern from contents of log file, a stepcalled data preparation must be applied on this file data, so thataccess to consistent data being possible. This step is including:data collection, data cleaning, session identification, user iden-tification and data summarization.
1) Data collection: In this step we will attempt to collectlog files from several web servers related to this site.
2) Data cleaning: This step will clean up web crude data. Itwill review available data and remove its additional items.When user requests a page, this request will be recorded in logfile and page contents such as picture, voice, video, … will be
recorded in the file as a new request from user without his/ her direst intervention. Applications recorded through robots andweb creepers such as CGI scripts and information's relating toweb page such as pictures, voices, video files, …. are consi-dered as additional information's [17]. Correct recognition of additional information's and removing them will improve re-sults quality in output.
3) Session identification: User session indicates its beha-vior. Then correct identification of these sessions is very im-
portant. A user session is a set of pages visited by him/ her dur-ing a certain visit.
S= < p1, p2, …, pn >
Various discovering methods are used to identify userssessions [20]. Discovery methods are classified to two time-
based methods and subject-based methods. In time-based me-
thods, a set of pages visited by user are considered as one ses-
sion, if those pages are in a lower time scale or equal to a de-
fine time scale. This certain time is defined as session visit
time and it various between 25.5 minutes are considered as
proposition. A shortcoming for this technique is elasticity
which may misdirect the system in identifying sessions end;
subject-based methods refer to a series of visited pages or refer
to competing a conceptual unit of work by user. This methods
shortcoming is finding the relationship between pages or de-
fining a conceptual unit of work. In present study, we have
used time-based method.4) User identification: Users identification from log file is
most important step in data preparation. There are various me-thods to identify user. Several systems introduce their usersthrough login. But this technique is not acceptable due to usersavoidance to do this act, uncertainty on accuracy of informa-tion's entered by users and lack of this ability for all sites to usethis purpose. Simplest way is designating distinct IP addressesfor every user. But precision of this method is low due to proxyservers available [18]. Cookies are also useful to identify visi-tors of a site. But it is not uses usually because it is consideredas a threat for security and privacy and because users link through different machines to server. Discovering techniques
are used due to these problems. In [17], web site structure isintegrated to log file to discover users. Presumably a new user has accessed to the site if request IP address in a page is sameas IP address requested in another page and there is no directlink between these pages. In [19] user identification is per-
formed thought integrating information's available in eventrecording file such as IP address, kind of operation system andreviewing software. In present study we will identify users us-ing technique developed in [19].
5) Data summarization: Amount of time a user resides in a page, will identify value of that page from user view point andthis parameter is of great importance. If residing time of user inthe page P is low, this page has low importance from user view
point. Valuing filter delete those pages that have been request by user and have low value. Totally it is not genuine to delete pages with low visiting time since the amount of time a user reside in a page is not dependent only on his/ her interest to that
page. Amount of page visiting time is also dependent to proper-
ties and content of that page. Statistical tests may define someof these properties. For example users spend lower time insearching pages compared to content pages. Web pages aredivided into three categories. Firstly, review pages which thereare not much content and generally are including list of links tocontent pages. These pages are used only for reviewing the site.Secondly, content pages which are including data favorites for user. Thirdly combination pages with properties of both per-vious groups. Boundary between these classifications is notdefining due to strong dependency on User view point andhis/her behavior. A page may be considered as search page byone user and being considered as content page by another user.
Extracted information in final steps of preparation are includ-
ing all the pages available in the site, site users, pages
screened by every user, time spent in each page by every user
and sessions of all users. We use these information and statis-
tical techniques to derive average time spent in each page by
every user and the number of events in each page among all
sessions as well as to find the number of users, pages and ses-
sions. Extracted information is arranged in encoded manner to
increase system speed. Pages with similar names but different
parents have different codes. This collection is placed in User
Data relation data base.
A. Novel Multi – level clustering architecture (NMLC – SN)
Proposed architecture is consisted of steps including sitestructure mining, outliers deletion, user interest discovery, us-
ers clustering and compressing steps relating to this part are performed sequentially and use data sets available in User Datadatabase. Each step uses data sets prepared by previous step.Each step will be described as follows.
1) Site structure mining: This step aims to site structure
mining to help better representation of social network as well
as its compression. We will use all the pages available in site
which are present in User Data database for site structure min-
ing. For this purpose, we will use BFS algorithm as follows:
a) Finding structure root (root is located in level 0 anddoesn’t contain a parent).
69 http://sites.google.com/site/ijcsis/
ISSN 1947-5500
8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 4/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
b) Discovering nods available in level I .
c) Record level I nodes in the database as a node name,node code, number and level of father.
d) Add one to level I and go to step 2 until no new nodes
are found.
Graph without cycles and undirected the structure to be ob-tained.
2) outliers deletion: This step aims to delete unuseful
pages to improve quality of mined social network. In this step,
pages with low access and average time spent in all accesses
are called outlier pages. These pages, due to low effect on
system, make scattered clusters, in turn, this causes social
network with large unusefull information. Pages will low
access are those pages towhich users display lowest interest.
Pages with low average spent time are composed of search
pages or pages to which users show low interest. Parameters α,
β are used as filter to delete outlier. pages with number of access lower than α and average spent time of access lower
than β second will be deleted. These parameters must be
arranged in a manner that contain lowest amount of data loss
and being involved all outliners. It’s worth mentioning that
values of these parameters vary for each site. That is, content
and average spent time for all site pages effect on α and β
values. For example, if lowest average spent time for all site
pages is 30, predefined value of 15 is not suitable for β. this
value may be defined by an expert person or site manager.
3) User interest discovery: This step aims to discover
interested pages of every user. In this step the number of visits
of every user for each page are calculated . the number of visit
for each page indicates user interest to that page. A threshold
has been considered for the number of visits for each page
which is placed in µ. So, we will delete each page with the
number of visits lower or equal to threshold limit µ. pages to
which users are not interested are those which users visited
them lower than other site pages. If these pages are used in
clustering, they will cause that users being placed in wrong
clusters additionally some clusters will low user number will
be created which are considered as noise from end users view.
Value of parameter µ is defined based on the need of social
network applicator. If person needs a network with all details,
he may consider this parameter in low value and if he needs a
network will lower details, he may increase this value. 4) Users clustering: This step aims to cluster users based
on their behavior or pages values. For this purpose, surveyed
pages and the number of visits of difined page by every user
will be transformed to this step. Table I represents a sample of
information collected in previous step which is used in this
step to clustering users.
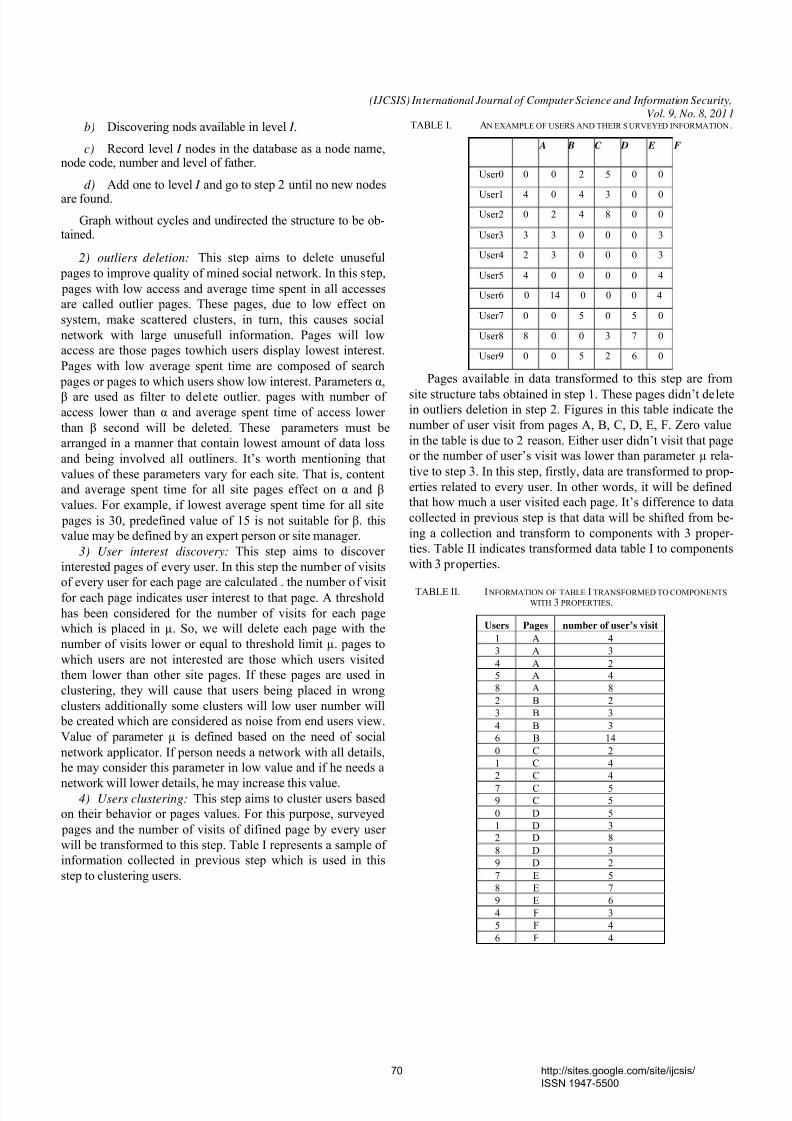
TABLE I. A N EXAMPLE OF USERS AND THEIR S URVEYED INFORMATION.
A B C D E F
User0 0 0 2 5 0 0
User1 4 0 4 3 0 0
User2 0 2 4 8 0 0
User3 3 3 0 0 0 3
User4 2 3 0 0 0 3
User5 4 0 0 0 0 4
User6 0 14 0 0 0 4
User7 0 0 5 0 5 0
User8 8 0 0 3 7 0
User9 0 0 5 2 6 0
Pages available in data transformed to this step are from
site structure tabs obtained in step 1. These pages didn’t deletein outliers deletion in step 2. Figures in this table indicate the
number of user visit from pages A, B, C, D, E, F. Zero value
in the table is due to 2 reason. Either user didn’t visit that page
or the number of user’s visit was lower than parameter µ rela-
tive to step 3. In this step, firstly, data are transformed to prop-
erties related to every user. In other words, it will be defined
that how much a user visited each page. It’s difference to data
collected in previous step is that data will be shifted from be-
ing a collection and transform to components with 3 proper-
ties. Table II indicates transformed data table I to components
with 3 properties.
TABLE II. I NFORMATION OF TABLE I TRANSFORMED TO COMPONENTS
WITH 3 PROPERTIES.
Users Pages number of user’s visit
1 A 4
3 A 3
4 A 2
5 A 4
8 A 8
2 B 2
3 B 3
4 B 3
6 B 14
0 C 2
1 C 4
2 C 4
7 C 59 C 5
0 D 5
1 D 3
2 D 8
8 D 3
9 D 2
7 E 5
8 E 7
9 E 6
4 F 3
5 F 4
6 F 4
70 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 5/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
For user clustering, users visited a certain page will be
placed in same cluster because they have common interests.
As well, because in previous steps, we applied parameters to
delete outlier pages, intermediate pages and those pages really
are not interested by users, these pages are truly interested byusers visiting them. Table III indicates table II information
clustering.
TABLE III. TABLE II INFORMATION’S CLUSTERING.
Cluster Users
0 1,3,4,5,8
1 2,3,4,6
2 0,1,2,7,9
3 0,1,2,8,9
4 7,8,9
5 4,5,6
After user’s clustering we will designate a weigh for each
cluster to show their importance rate. By weighing, the impor-
tance of each provided cluster will be determined. Clusters
arrangement according to importance of each cluster will be
performed and clusters with low or no importance will be de-
leted. Weighting for clusters will be determined based on need
of social network applicator.Weight of each cluster will be defined in 2 ways:
a) the number of users in each cluster, which define the
number of users in the cluster.
b) the number of visits to that page by all the users which
determines a certain page clustering has been performed
according to it, how much was visited by all cluster users.
the number of users in each cluster represents movement path and users focus on certain pages in the site. the number of
visit to a page by all the users represents valuables pages in thesite. Each cluster’s weight is determined based on weight of
other clusters . and will be given through following relation:
=
∑
(1)
In this equation, W i is the weight designated for eachcluster which is [0..1]. wi is cluster weight according to
method used to determine the weight and denominator is the
total weight of all clusters. Table IV shows cluster’s weight
obtained in table III by both described methods.
TABLE IV. CLUSTER WEIGHT OBTAINED IN TABLE III
Cluster cluster’s weight
based on Number of
users in the cluster
cluster’s weight based
on Number of page
views by users
0 0.2 0.193
1 0.16 0.202
2 0.2 0.138
3 0.2 0.174
4 0.12 0.165
5 0.12 0.128
After defining cluster weight, we will apply a threshold
limit which deletes the clusters with low importance or
clusters not considered by applicator. Value is a threshold
limit for clusters weights. clusters with weight lower than
threshold limit will be deleted. This will deleted additional
cluster in the network. Defining parameter value is based on
need of social network applicator. This value deletes a number
of crests in the network. The crests indicate rate of details inextracted social network.
5) Compression: This step aims to better representation
and decrease of complexities available in social network. This
step is only for networks extracted based on weighting of the
number of users in the clusters. Compression in this step is
conducted through discovering similar clusters. Similar
clusters are clusters in which subtraction of all users of each
cluster with subscription of all users of each clusters is equal
to empty. This way will decrease the number of clusters,
compresses and better shows social network. For example
assume that user 1 belongs to clusters A, B, C and user 2 also
belongs to clusters A, B, C user 3 belongs to cluster A, B.
Than A, B may be called a cluster called AB and users 1, 2, 3 being plased in it and users 1 and 2 being placed in cluster C.
In Figure 2, this example can be observed.Clusters
UsersC B A
***1
***2
**3
⇓ Clusters
UsersC A,B **1
**2
*3
Figure 2. An example of compression
IV. SYSTEM EVALUATION
In this section, evaluation parameters used in this studywill introduced.
A. Evaluation parameters
Information retrieval metrics such as Recall, Precision and
F-Measure have been used to test accuracy and efficiency
[21,22].
1) Recall: It is a common metric using for evaluation of
utility of proposed algorithm and acts as equation 2:
Recall = ∩
Where Th is all the members within the cluster obtained by
expert and Tr is all the Members within the cluster obtained by
the system.
2) Precision: A common metric using to evaluate usefulness
of proposed algorithm and acts as equation 3:
Precision =∩
71 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 6/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
3) F-measure: is another evaluation metric which isobtained using parameters precision (P) and Recall (R) as
equation 4:
F =
=
This metric is used to represent the relationship betweenRecall and precision.
V. A NALYSIS OF MINED SOCIAL NETWORK
In present study CTI dataset has been used to create andanalyzing social network. System used in tests had Intel Pen-
tium T4400 @ 2.2 GHz processor, Ram 3.0 GB, Hard Disk 320 GB and windows XP SP3 operating system. implementing
proposed system has been performed by using VB.Net pro-
gramming language from Microsoft visual studio.Net 2008
collection, Microsoft Sql Server 2005 and Pajek software [23].A social network is representation of relationship or arc be-
tween factors and persons A social network is a G = (V, E)
graph where V is a series of heads each indicating the persons
and E is a series of crests each indicating relationship between persons. Figures 3 and 4 represent site structure which has
been obtained in step 1 from NMLC – SN architecture.
Figure 3. site structure without representation of leaf pages
Figure 4. representation of a user’s movement path from root to leaf series
At the end of step 1, tree’s height obtained from site structure
is set 8. In figure 2, due to leaf abundance, site structure has
been indicated without its leafs. Figure 3 represents a certain
user’s movement path with information related to its pages.We had set α value as 3 and β value as 5. In figure 5, influence
of α and β parameters have been represented. The more lower
values we set for these parameters, the lower pages will be
deleted. We have set µ equal to 1. Figure 6 indicates effect of
µ parameters have been represented. Low value of this para-
meter will delete lower numbers of records and users from
dataset. But it is possible that pages, to which user is not inter-ested, not being deleted correctly.
72 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 7/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, N o. 8, 2011
Figure 5. Effects of α and β parameters Figure 6. . Effects of µ parameter By implementation of system with designated values for
each parameter on introduced dataset, we have obtained 2417
clusters. Users clustering has been conducted by both kinds of
weightings to clusters. Figure 7 represents 13 clusters of ex-
tracted clusters with their users located in them. Figures indi-cated in figure 7 represent the code related to a given cluster’s
users.
Figure 7. A part of extracted social network
Figure 8 represents parameter effect on users clustering based on clusters weighting with the number of cluster users.
Figure 9 indicates parameter effect on users clustering basedon clusters weighting with all the visits of cluster users.
Figure 8. effect of parameter on users clustering based on
weighting clusters with the number of cluster users
0
200
400
600
800
1000
1200
1400
1600
1800
2000
α=1 α=2 α=3
N u m b e r o f p a g e
s d e l e t e d
β=5 β=6 β=7 β=8
0
1000
2000
3000
4000
5000
6000
µ=1 µ=2 µ=3 µ=4 µ=5
Number of user deleted Number of record deleted
0
500
1000
1500
2000
2500
N u m b e r o f c l u s t e r s
73 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 8/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011
Figure 9. Effect of parameter on users clustering based on
cluster weighting with total number of cluster users visits By implementing system compression step with values
designated to every parameter on defined dataset and equalto zero, we obtained 1491 clusters.
To evaluate the system with metrics defined in previoussection, 150 users have selected randomly with equal probabil-ity. Relationships between users have been extracted by an
expert. In the first examination, Recall metric obtained was
0.8236, precision was 0.9375 and F-Measure was 0.8769. Insecond test groups size was set to 6 which is minimum size of
extracted groups. Results of this test are shown in figure 10.
Figure 10. Results of second test’s recall and precision
In third test, group size was set to maximum size in ex-
tracted groups. Results of this test are shown in figure 11.
Figure 11. result of third test’s recall and precision
Among benefits of proposed system compared to other me-
thods is acceptable speed in network production. Consumedmemory rate, better efficiency due to lack of using frequent
close patterns and association rules mining, extraction of vari-ous social networks according to applicator’s need and ability
to mine social networks from all sites.
VI. CONCLUSIONS AND FUTURE WORKS
In present study, we will introduce available challenges in
social networks mining and we will develop a system for re-
moving available challenges. In this system, by consideringaverage spent time in each page by every user, we will obtain
importance rate of each page. This way, we attempted to de-lete false positive associations and traits. We will offer a com-
prehensive system for social network mining which removes problems available in social networks in a manner. The system
has the capacity to mine social network from any site. Despite
recording false information in web pages, this system, due to
using Web Usage Mining techniques, could construct user’svirtual community from within log file of web server. It is able
to offer various social networks for political and military func-
tions for discovering information from given parts with re-quired activity. Additionally in e-learning function, it tries to
identify superior active teachers and interesting courses for students. It is used in electronic commerce sites for making
advertisements and proposed product systems purposeful. It isable to discover some parts with high activity when using in-
formation from portable web server’s log file and could help
to organization manager to improve this part through offeringsome recommendations. The system, according to persons
location and geographical aspect, could suggest server location
to improve server efficiency proposed system has an accepta-
ble speed to extract information and drawing social networks.To improve the system, semantic web techniques may be used
to extract the relationships between pages and their relations tousers.
R EFERENCES
[1] R. Cooley, B.Mobasher and J.Srivastava, ‘Web Mining Information andPattern Discovery on the World Wide Web’ , Information Gatheringfrom Heterogeneous Distributed Environments, December 2001.
[2] Mobasher, B., Cooley, R., & Srivastava, J. “Creating adaptive Web sites
through usage-based clustering of URLs”. Paper presented at theknowledge and data engineering exchange, Chicago, IL, USA (pp. 19– 25) 1999.
[3] Mehrdad Jalali, Norwati Mustapha, Md. Nasir Sulaiman, AliMamat,“WebPUM: A Web-based recommendation system to predict
user future movements”, Expert Systems with Applications 37 (2010)6201–6212.
[4] Cadez, I., Heckerman, D., Meek, C., Smyth, P., & White, S.“Visualization of navigation patterns on a Web site using model-basedclustering”. Paper presented at the proceedings of the sixth ACMSIGKDD international conference on data mining and knowledgediscovery, Boston, Massachusetts, United States 2000.
[5] Toyoda, M., Kitsuregawa, M., “Creating a Web Community Chart for Navigating Related Communities”, In Proc. of Hypertext 2001, pp.103-112, 2001.
[6] Gibson, D., Kleinberg, J. M., Raghavan, P., “Inferring WebCommunities from Link Topology”, In Proc. of the 9th ACMConference on Hypertext and Hypermedia.Pittsburgh, PA, pp. 225-234,1998.
[7] Kleinberg, J., “Authoritative Sources in a Hyper-linked Environment”,Proc. of ACM-SIAM Symposium on Discrete Algorithms, 1998. Alsoappears as IBM R esearch Report RJ 10076(91892) May 1997.
0
500
1000
1500
2000
2500
N u m b e
r o f c l u s t e r s
0
20
40
60
80
100
16.67 33.33 50 66.67 83.33 100
P r e c i s i o n
Recall
0
20
40
60
80
100
10 20 30 40 50 60 70 80 90 100
P r e c i s i o n
Recall
74 http://sites.google.com/site/ijcsis/
ISSN 1947-5500

8/4/2019 A System for Social Network Extraction of Web Complex Structures
http://slidepdf.com/reader/full/a-system-for-social-network-extraction-of-web-complex-structures 9/9
(IJCSIS) International Journal of Computer Science and Information Security,
Vol. 9, No. 8, 2011 [8] H. Kautz, B. Selman, and M. Shah. “The hidden Web”. AI magazine,
18(2):27–35, 1997.
[9] Kumar, R., Raghavan, P., Rajagopalan, S., Tomkins, A., “Trawling theWeb for Emerging Cyber-Communities”, Proc. of the 8th WWWConference, 1999.
[10] Imafuji, N., Kitsuregawa, M., “Effects of Maximum Flow Algorithm onIdentifying Web Community”, Proc. of 4th international workshop onweb information and data management. ACM Press, NY, pp.43-48, 2002
[11] Flake, G., Lawrence, S., Giles, C.L., “Efficient Identification of WebCommunities”, 6th ACM SIGKDD International Conference onKnowledge Discovery and Data Mining. Boston, MA, pp. 150-160,
2000.
[12] Flake, G. W., Lawrence, S., Giles, C. L., Coetzee, F. M., “Self-Organization & Identification of Web Communities”, IEEE Computer,Vol.35, No.3, pp. 66-71, 2002.
[13] P. Mika. “Flink: Semantic web technology for the extraction andanalysis of social networks”. Journal of Web Semantics, 3(2), 2005.
[14] P. Cimiano, S. Handschuh, and S. Staab. “Towards the self-annotatingweb”. InProc. WWW2004, pp. 462–471, 2004.
[15] P. Cimiano, G. Ladwig, and S. Staab.Gimme´ . “the context: Context-driven utomatic semantic annotation with cpankow”. In Proc. WWW
2005, 2005.[16] Muhaimenul Adnan , Mohamad Nagi , Keivan Kianmehr, Radwan
Tahboub , Mick Ridley ,Jon Rokne, “Promoting where, when and what?
An analysis of web logs by integrating data mining and social network techniques to guide ecommerce business promotions”, Springer-Verlag2010 SOCNE DOI 10.1007/s13278-010-0015-3.
[17] R. Cooley, B. Mobasher and J. Srivastava, “Data Preparation for MiningWorld Wide Web Browsing Patterns”, Knowledge and InformationSystems, 1:1, 5-32, 1999.
[18] D. Pierrakos, G. Paliouras, C. Papatheodorou and C. D. Spyropoulos,
“Web Usage Mining as a Tool for Personalization: A Survey”, User Modeling and User-Adapted Interaction, 13: 311-372, 2003.
[19] Spiliopoulou, M., Mobasher, B., Berendt, B., & Nakagawa, M. “AFramework for the evaluation of session reconstruction heuristics inWeb-usage analysis”. INFORMS Journal on Computing, 15(2), 171– 190, 2003.
[20] M. Spiliopoulou, L. C. Faulstich and K. Wilker, “A Data Miner Analyzing the Navigational Behavior of Users”, Proceedings of theWorkshop on Machine Learning in User Modeling of the ACAI99,Chania, Greece, 54-64, 1999.
[21] Symeonidis, P., Nanopoulos, A., Manolopoulos, Y., ”A Unified
Framework for Providing Recommendations in Social Tagging SystemsBased on Ternary Semantic Analysis”, IEEE Transactions onKnowledge and Data Engineering, Volume: 22 Issue:2, 179 – 192, 2010.
[22] Ian H. Witten, Eibe Frank, “Data Mining Practical Machine LearningTools and Techniques, Second Edition”, 2005.
[23] Batagelj V, Mrvar A (1998) Pajek—program for large network analysis.http://vlado.fmf.uni-lj.si/pub/networks/pajek/
75 http://sites.google.com/site/ijcsis/
ISSN 1947-5500