a cgra-based approachfor accelerating convolutional neural networks
TRANSCRIPT

A CGRA-based Approach for Accelerating
Convolutional Neural Networks Masakazu Tanomoto, Shinya Takamaeda-Yamazaki,
Jun Yao, and Yasuhiko Nakashima
Nara Institute of Science and Technology (NAIST), Japan
E-mail: shinya_at_is_naist_jp
IEEE MCSoC'15 @Torino September 23, 2015

Outline
n Motivation: Deep learning on embedded computers l Target: Convolutional Neural Network (CNN)
n Our approach: CGRA-based CNN acceleration l EMAX (Energy-aware Multi-mode Accelerator eXtension)
l Mapping CNN on EMAX
n Evaluation l Performance per memory bandwidth
l Performance per area
n Conclusion
MCSoC15 Shinya T-Y, NAIST 2

Deep learning n Recognition (Convolutional Neural Network (CNN))
l Extracting high-level features automatically from raw data
l Ex) Image, speech, and text recognition, image search
n Reinforcement learning (Deep Q-Network (DQN)) l Learning appropriate strategy for controlling something
l Ex) Gaming AI, Robot control
MCSoC15 Shinya T-Y, NAIST 3
Playing Atari 2006 automatically (Human-level control through deep reinforcement learning [Nature'15])
Extracted features of human and cat (Building High-level Features Using Large Scale Unsupervised Learning [ICML'12])

Convolutional Neural Network (CNN)
n Nesting multiple processing layers l Convolution: Multiple small matrix-matrix multiplications
• Each weight matrix corresponds to a learned feature map
• Feature can be automatically learned by error propagation
l Pooling and Max-out: selection from multiple values
l Full connection: Large matrix-matrix multiplication
n Performance Bottleneck: Convolution l Numerous small matrix-matrix multiplication with stencil
MCSoC15 Shinya T-Y, NAIST 4
Input Layer Hidden Layers Output Layer
Convolution Pooling Max Out Convolution Full Connection

Motivation: DNN on embedded computers n Machine learning on IoT: Learning and decision on edge
computers will become more important l Sending all data to data centers?: Network traffic problemL
l Decision on data centers?: Very long latencyL
n Challenge: Energy efficient embedded accelerators l Why not GPU?: GPU is very energy hungry and requires
absolute energy • Not only energy efficiency, but also absolute peak energy amount is
important
l Why not ASIC?: Limited capability of algorithm customization • Algorithms of machine learning are rapidly evolving
l Why not FPGA?: Energy overhead to building computing logics
l CGRA? MCSoC15 Shinya T-Y, NAIST 5
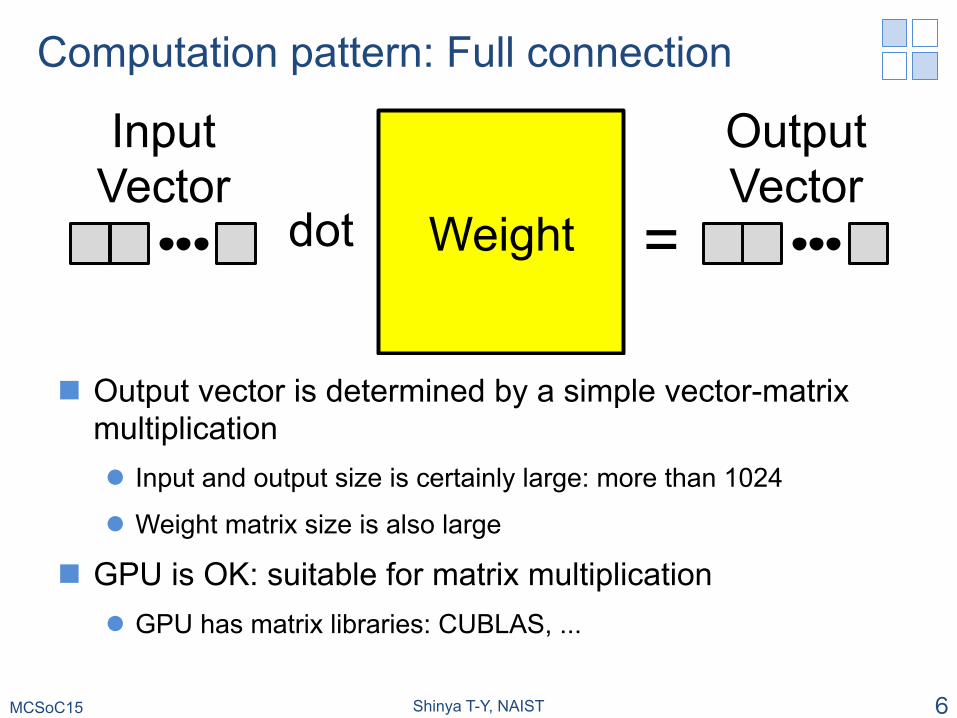
Computation pattern: Full connection
n Output vector is determined by a simple vector-matrix multiplication l Input and output size is certainly large: more than 1024
l Weight matrix size is also large
n GPU is OK: suitable for matrix multiplication l GPU has matrix libraries: CUBLAS, ...
MCSoC15 Shinya T-Y, NAIST 6
dot� =�Weight
Output Vector
Input Vector

Computation pattern: Convolution
n A value of the result matrix is calculated by numerous matrix-matrix multiplication with a small weight matrix l Weight matrix size is usually small: from 3 to 8
n I know GPU is very fast for matrix-matrix multiplication l Really?
MCSoC15 Shinya T-Y, NAIST 7
3 dot�
Weight Weight Weight
=� Weight Weight Next dot�
Weight Weight Weight
dot�Weight
Weight Weight

SGEMM performance on GPU
n GPU is fast, if the matrix size is large enough l GPU is throughput-oriented processor
l In case of small matrix, parallelisms and memory bandwidth are not exploited efficiently
MCSoC15 Shinya T-Y, NAIST 8
0
5
10
15
20
25
0
50
100
150
200
250
64 128 256 512 1024 2048 4096
# ac
tive
war
ps p
er a
ctiv
e cy
cle
Perf
orm
ance
[GFL
OPS
]
Matrix size
warp/cycle (small kernel) GFLOPS warp/cycle (large kernel) NVIDIA
Jetson TK1 (GK20A)

Preprocessing for Convolution on GPU
n In order to use fast matrix multiplication library of GPU, data duplication is usually utilized l Converting sub-regions into a single large matrix
n Faster than the naive convolution, but still just a performance overhead
MCSoC15 Shinya T-Y, NAIST 9
3 k=3�
k=3�
n�
n�Input vector�
[n-3,n-3]
[n-1,n-1]
Duplication� Duplication�
[0,0] [0,1] [0,2] [1,0] [1,1] [1,2] [2,0] [2,1] [2,2]
[0,1] [0,2] [0,3] [1,1] [1,2] [1,3] [2,1] [2,2] [2,3]
Duplication�
9 (=k2)�
(n-2)2�
Temporal array for matrix multiplication�

Our approach: EMAX Energy-aware Multi-mode Accelerator eXtension n A CGRA of local memory based PEs with several buses
l Each PE has a local memory for data locality
MCSoC15 Shinya T-Y, NAIST 10 In
terc
onne
ctio
n
DRAM
CPU Core
PE PE PE PE
Mem
ory
Inte
rface
EMAX�
PE PE PE PE
PE PE PE PE

Real Chip of EMAX n 12.5mm x 12.5mm in 180nm technology
MCSoC15 Shinya T-Y, NAIST 11

Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 12
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�

Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 13
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�
LMM: Local Memory
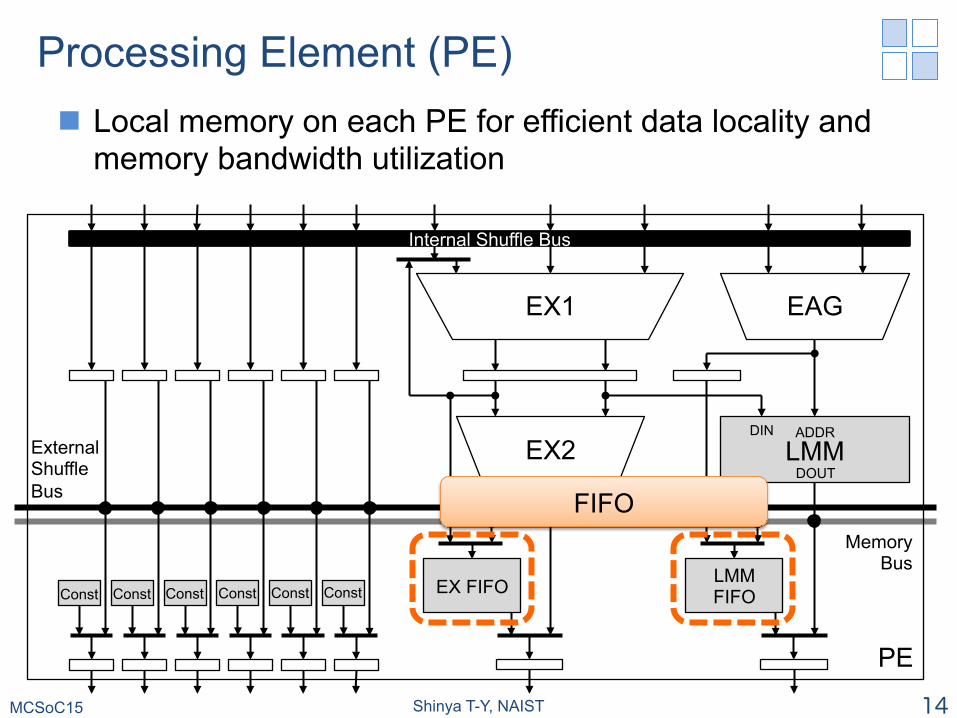
Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 14
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�
FIFO
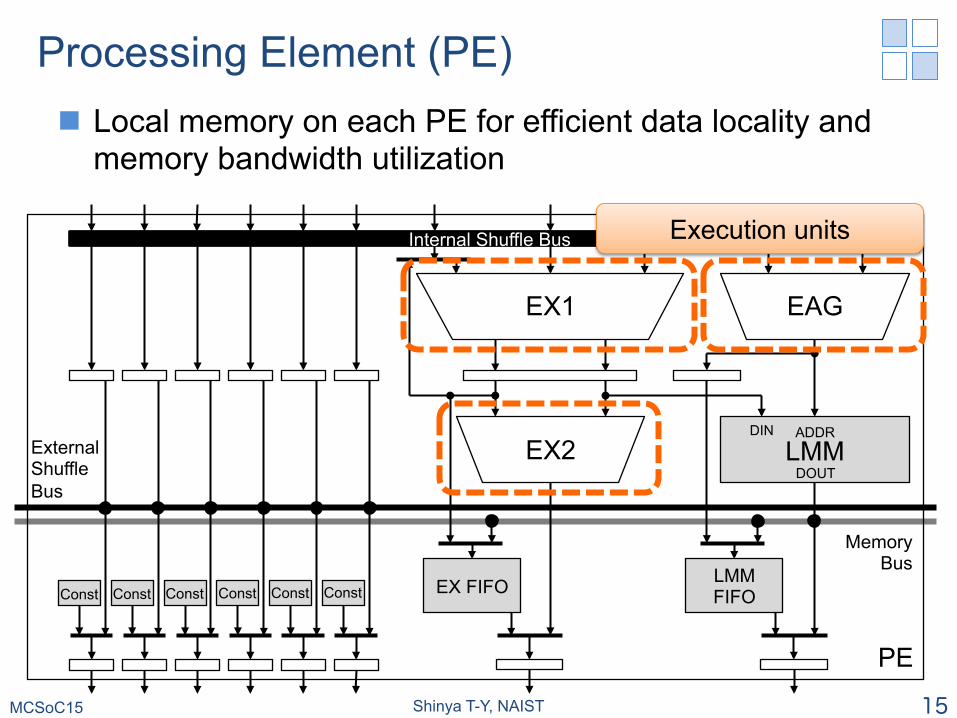
Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 15
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�
Execution units

Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 16
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�
Constant registers

Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 17
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�
Internal Shuffle Bus
External Shuffle Bus

Processing Element (PE) n Local memory on each PE for efficient data locality and
memory bandwidth utilization
MCSoC15 Shinya T-Y, NAIST 18
EX1�
LMM
EX FIFO LMM FIFO
DIN ADDR�
DOUT EX2�
EAG�
Memory Bus�
PE�
Internal Shuffle Bus
External Shuffle Bus�
Const� Const� Const� Const� Const� Const�
Memory Bus

EMAX instruction
MCSoC15 Shinya T-Y, NAIST 19
Type1: row#, col#, dist [count] ALU_OP & MEM_OP RGI LMM_CONTROL Type2: row#, col#, dist [count] ALU_OP Type3: row#, col#, dist [count] & MEM_OP RGI LMM_CONTROL�
32-bit operation add/add3/sub/sub3 16-bitx2 operation mauh/mauh3/msuh3 Misc operation mulh/mmrg3/msad/minl/minl3/mh2bw/
mcas/mmid3/mmax/mmax3/mmin/mmin3 Load from EX_FIFO ldb/ldub/ldh/lhuh/ld Floating Point Operation fmul/fma3/fadd
32-bit operation and/or/xor 16-bitx2 operation mauh/mauh3/msuh3
Load from LMM or LMM_FIFO ldb/ldub/ldh/lhuh/ld Store to LMM stb/sth/st/cst
(a) Instruction format�
(a) EX1 operation�
(b) EX2 operation�
(c) LMM operation�

Forward propagation
n Weight matrix is constant in the inter-most loop l Assigned into constant registers
n Index of In increases linearly l Burst bulk transfer from the external memory
MCSoC15 Shinya T-Y, NAIST 20
Operations per activation of EMAX�
Operations per clock cycle on EMAX�
for(i1=0; i1<InDim; i++){ for(j1=0; j1<(Nimg-Nk+1); j1++){ for(i2=0; i2<OutDim; i2++){ for(j2=0; j2<(Nimg-Nk+1)*(Nbatch); j2++){ for(ky=0; ky<Nk; iy++){ for(kx=0; kx<Nk; kx++){ Out[i2][j1][j2] += Weight[i1][i2][ky][kx]*In[i1][j1+ky][j2+kx]; } } } } } } �
InDim: Dimension of input data, OutDim: Dimension of output data Nimg: Side length of input data, Nbatch: Bath size (= # number of pixels) Nk: Convolution window size�

Forward propagation
n Weight matrix is constant in the inter-most loop l Assigned into constant registers
n Index of In increases linearly l Burst bulk transfer from the external memory
MCSoC15 Shinya T-Y, NAIST 21
Operations per activation of EMAX�
Operations per clock cycle on EMAX�
for(i1=0; i1<InDim; i++){ for(j1=0; j1<(Nimg-Nk+1); j1++){ for(i2=0; i2<OutDim; i2++){ for(j2=0; j2<(Nimg-Nk+1)*(Nbatch); j2++){ for(ky=0; ky<Nk; iy++){ for(kx=0; kx<Nk; kx++){ Out[i2][j1][j2] += Weight[i1][i2][ky][kx]*In[i1][j1+ky][j2+kx]; } } } } } } �
InDim: Dimension of input data, OutDim: Dimension of output data Nimg: Side length of input data, Nbatch: Bath size (= # number of pixels) Nk: Convolution window size�

Forward propagation
n Weight matrix is constant in the inter-most loop l Assigned into constant registers
n Index of In increases linearly l Burst bulk transfer from the external memory
MCSoC15 Shinya T-Y, NAIST 22
Operations per activation of EMAX�
Operations per clock cycle on EMAX�
for(i1=0; i1<InDim; i++){ for(j1=0; j1<(Nimg-Nk+1); j1++){ for(i2=0; i2<OutDim; i2++){ for(j2=0; j2<(Nimg-Nk+1)*(Nbatch); j2++){ for(ky=0; ky<Nk; iy++){ for(kx=0; kx<Nk; kx++){ Out[i2][j1][j2] += Weight[i1][i2][ky][kx]*In[i1][j1+ky][j2+kx]; } } } } } } �
InDim: Dimension of input data, OutDim: Dimension of output data Nimg: Side length of input data, Nbatch: Bath size (= # number of pixels) Nk: Convolution window size�

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 23
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 24
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil
3x3 weight matrix in constant registers

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 25
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil
3 Input data sets in LMMs Same read data is forwarded via FIFOs

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 26
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil
Reading data from the constant register, LMM, and execution unit in the previous stage
Operation result is passed to the next stage

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 27
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil
Final result is stored into LMM in the next stage

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 28
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil
Write back the previous data to the main memory

CNN on EMAX (3x3 convolution)
MCSoC15 Shinya T-Y, NAIST 29
LMM OP EX1/EX2 FIFO OP Const
Const w[0][2]
in[i-1][] LMM LD�
FIFO Const
FIFO Const
FMUL Const w[1][2]
in[ i ][] LMM LD�
FMUL FIFO Const
FMUL FIFO Const
w[0][1] w[0][0]
w[1][1] w[1][0]
FMA Const w[2][2]
in[i+1][] LMM LD�
FMA FIFO Const
FMA FIFO Const
w[2][1] w[2][0]
Preload FMA FMA FMA
LMM LD�out[i][j]
FADD Preload
FADD
Drain FADD
LMM ST
Preload a next input (in[i+2][]) from memory
Preload a next input (out[i+1][]) from memory
Drain the previous result to memory
Loop Control
Mem
ory
Inte
rface
Store the current result to LMM
Column�Row�
Weight values are assigned on constant registers. Input data are stored on LMM
0�
1�
2�
3�
4�
5�
6�
7�
0� 1� 2� 3�
Next input data set as stencil
Load the next input data from the main memory

Evaluation setup n Benchmark: deep learning datasets and networks
l Imagenet (Alexnet-2), CIFAR10, MNIST (Lenet)
n Hardware: l CPU (Corei7, ARM), GPU (Desktop, Mobile), EMAX
l Metric: Performance per bandwidth, Performance per area • Estimation from actual LSI of EMAX and software simulations
MCSoC15 Shinya T-Y, NAIST 30

Performance per memory bandwidth n EMAX achieves better performance in embedded class
datasets
MCSoC15 Shinya T-Y, NAIST 31
0
2
4
6
8
10
12
14
16
18
Alexne
t-2
CIFAR10
-1
CIFAR10
-2
CIFAR10
-3
CIFAR10
(Avg
)
Lene
t-1
Lene
t-2
Lene
t (Avg
)
Operations/Byte�
EMAX GTX980 GK20A Core i7 ARM

Performance per memory bandwidth n EMAX achieves better performance in embedded class
datasets
MCSoC15 Shinya T-Y, NAIST 32
0
2
4
6
8
10
12
14
16
18
Alexne
t-2
CIFAR10
-1
CIFAR10
-2
CIFAR10
-3
CIFAR10
(Avg
)
Lene
t-1
Lene
t-2
Lene
t (Avg
)
Operations/Byte�
EMAX GTX980 GK20A Core i7 ARM
Alexnet: since matrix size is large,
desktop GPU is 3.17x better

Performance per memory bandwidth n EMAX achieves better performance in embedded class
datasets
MCSoC15 Shinya T-Y, NAIST 33
0
2
4
6
8
10
12
14
16
18
Alexne
t-2
CIFAR10
-1
CIFAR10
-2
CIFAR10
-3
CIFAR10
(Avg
)
Lene
t-1
Lene
t-2
Lene
t (Avg
)
Operations/Byte�
EMAX GTX980 GK20A Core i7 ARM
CIFAR-10: 1.41x better than
mobile GPU
Lenet: 1.75x better than
mobile GPU

Performance per area n EMAX achieves much better performance in embedded
class datasets: CGRA is better for embedded systems?
MCSoC15 Shinya T-Y, NAIST 34
0
100
200
300
400
500
600
700
800
Alexne
t-2
CIFAR10
-1
CIFAR10
-2
CIFAR10
-3
CIFAR10
(Avg
)
Lene
t-1
Lene
t-2
Lene
t (Avg
)
Are
a Pe
rf [F
LOPS
/Tr]� EMAX GTX980 Corei7

Performance per area n EMAX achieves much better performance in embedded
class datasets: CGRA is better for embedded systems?
MCSoC15 Shinya T-Y, NAIST 35
0
100
200
300
400
500
600
700
800
Alexne
t-2
CIFAR10
-1
CIFAR10
-2
CIFAR10
-3
CIFAR10
(Avg
)
Lene
t-1
Lene
t-2
Lene
t (Avg
)
Are
a Pe
rf [F
LOPS
/Tr]� EMAX GTX980 Corei7
Alexnet: since matrix size is large,
desktop GPU is 2.2x better

Performance per area n EMAX achieves much better performance in embedded
class datasets: CGRA is better for embedded systems?
MCSoC15 Shinya T-Y, NAIST 36
0
100
200
300
400
500
600
700
800
Alexne
t-2
CIFAR10
-1
CIFAR10
-2
CIFAR10
-3
CIFAR10
(Avg
)
Lene
t-1
Lene
t-2
Lene
t (Avg
)
Are
a Pe
rf [F
LOPS
/Tr]� EMAX GTX980 Corei7
CIFAR-10: 1.76x better than
mobile GPU
Lenet: 1.95x better than
mobile GPU

Conclusion n A CGRA-based acceleration approach of convolutional
neural network (CNN) for embedded accelerators l EMAX (Energy-aware Multi-mode Accelerator eXtension)
n EMAX outperforms GPU in embedded class data sets l 1.75x better performance per memory bandwidth
l 1.95x better performance per area (≒ energy)
MCSoC15 Shinya T-Y, NAIST 37
Inte
rcon
nect
ion
DRAM
CPU Core
PE PE PE PE
Mem
ory
Inte
rface
EMAX�
PE PE PE PE
PE PE PE PE