a bandwidth-aware memory-subsystem resource management using non-invasive resource profilers for...
TRANSCRIPT

A Bandwidth-aware Memory-subsystem Resource Management using Non-invasive Resource Profilers for Large CMP SystemsDimitris Kaseridis, Jeffery Stuecheli, Jian Chen and Lizy K. John
Department of Electrical and Computer Engineering, The University of Texas at Austin, TX, USA, IBM Corp., Austin, TX, USA
Reviewed by: Stanley Ikpe

Overview Terminology Paper Breakdown Paper Summary
Objective Implementation Results
General Comments Discussion Topics

Terminology Chip Multiprocessor (CMP): multiple processor cores on
a single chip Throughput: measure of work done; successful messages
delivered Bandwidth (memory): rate at which data can be
read/stored Quality of Service (QoS): ability to provide priority to
applications Fairness: ability to allocate resources Resources: utilities used for work (cache capacity and
memory bandwidth) Last Level Cache (LLC): largest (slow) cache memory (on
or off chip)

Paper Breakdown Motivation: CMP integration provides
opportunity for improved throughput. Adversely, sharing resources can be hazardous to performance.
Causes: Parallel Applications; each thread (core) puts different demands/requests on common (shared) resources.
Effects: Inconsistencies in performance, resource contention (unfairness).

Paper Breakdown So how do we fix this?? Resource Management: control the
allocation and use of available resources.
What are some of these resources? Cache capacity Available memory bandwidth

Paper Breakdown How do we go about resource
management?? Predictive work monitoring: intuitively infer
what resources will be used. Non-invasive (hardware) method of profiling resources (cache capacity and memory bandwidth)
System-wide resource allocation and job scheduling by identifying over-utilized CMPs (BW) and reallocate work.

Baseline Architecture
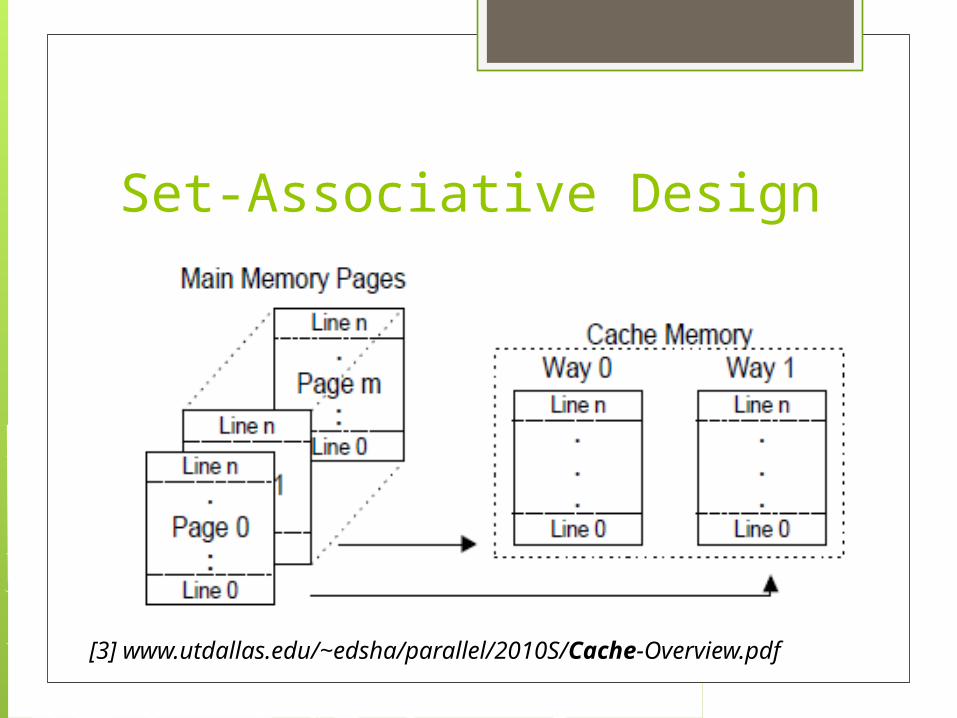
Set-Associative Design
[3] www.utdallas.edu/~edsha/parallel/2010S/Cache-Overview.pdf

Objectives Create an algorithm to effectively
project memory bandwidth and cache capacity requirements (per core).
Implement for system-wide optimization of resource allocation and job scheduling.
Improve potential throughput for CMP systems.

Implementation Resource Profiling: prediction scheme
to detect cache misses and bandwidth requirements Mattson’s stack distance algorithm (MSA):
method for reducing the simulation time of trace-driven caches. (Mattson et al. [2])
MSA-based profiler for LLC misses: K-way set associative cache implies K+1 counters. Cache access at position i increments counter i. If cache miss increment counter K+1.

MSA-based profiler for LLC misses

Implementation MSA-based Profiler for Memory
Bandwidth: the memory bandwidth required to read (due to cache fills) and write (due to cache dirty write-backs to main memory)
•Hits to dirty cache lines indicate write-back operations if cache capacity allocation < stack distance.•Dirty Stack Distance used to track largest stack distance at which a dirty line accessed•Dirty counter projects write-back rate and Dirty bit marks the greatest stack distance of dirty line

Write-back pseudocode

Write-back Profiling Example
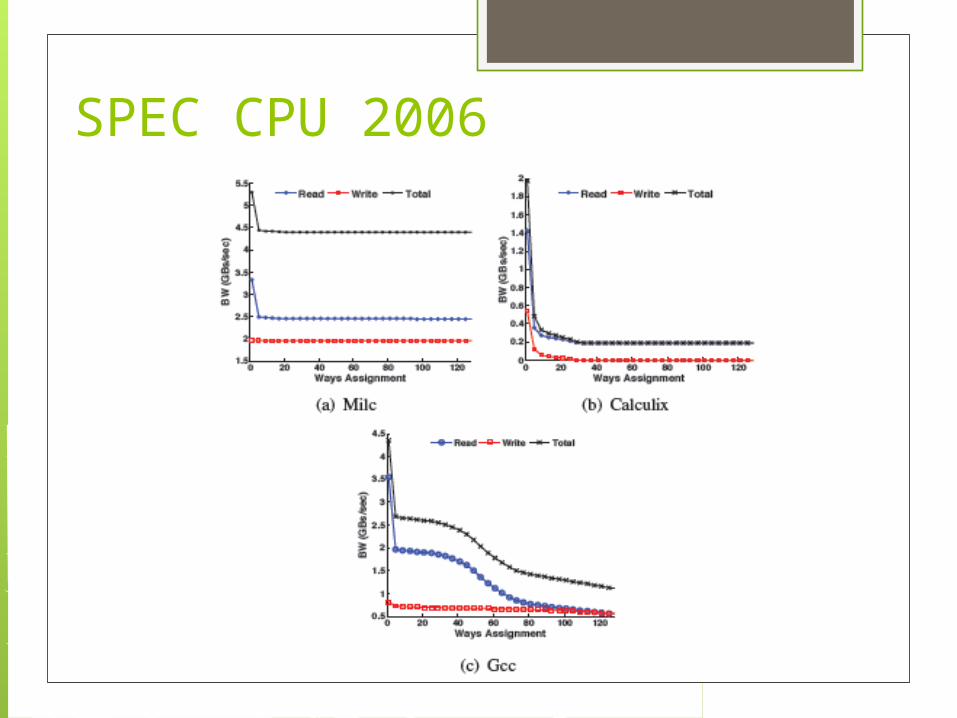
SPEC CPU 2006

Implementation Resource Allocation: compute Marginal-Utility
for a given workload across a range of possible cache allocations to compare all possible allocations of unused capacity (n new elements, c already used elements)
Intra-chip partitioning algorithm: Marginal-Utility figure of merit measuring amount of utility provided (reduced cache misses) for a given amount of resource (cache capacity). Algorithm considers ideal cache capacity and distributes specific cache-ways per core.

Algorithm

Implementation Inter-chip partitioning algorithm: find an efficient
(below threshold or bandwidth limit) workload schedule on all available CMPs in system. A global implementation is used to mitigate misdistribution of workload. Marginal-Utility algorithm along side bandwidth over-commit detection allow additional workload migration
•Cache capacity: estimate optimal resource assignment (marginal-utility) and intra-chip partitioning assignment. Algorithm performs workload swapping so each core is below bandwidth limit.•Memory Bandwidth: Memory bandwidth over-commit algorithm finds workloads with high/low requirements and does shifting to undercommitted CMPs

Algorithm

Example

Resource Management Scheme
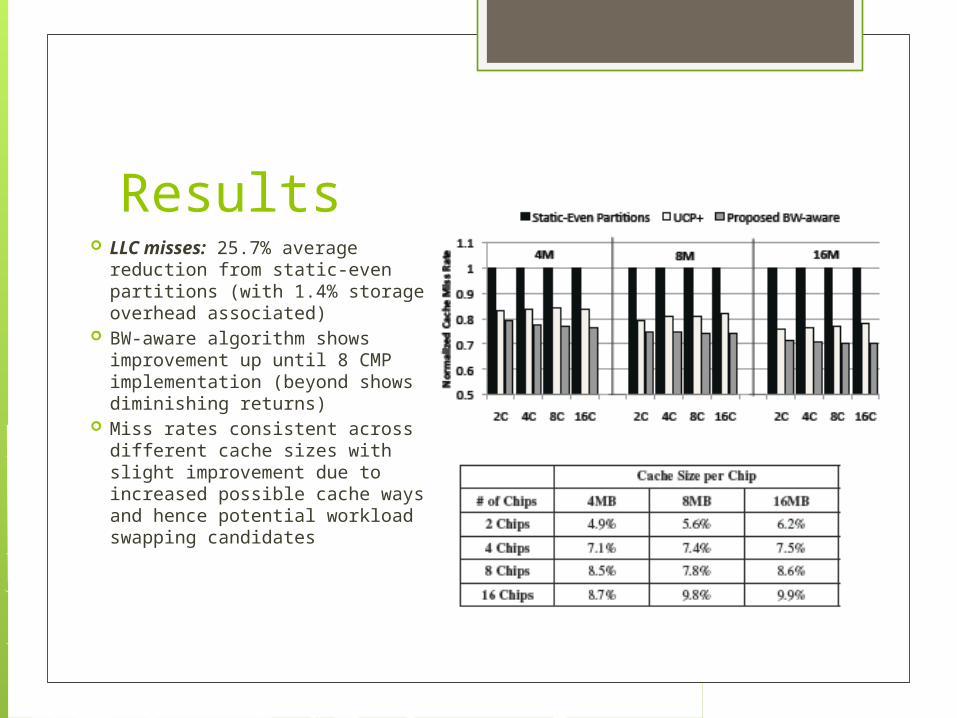
Results LLC misses: 25.7% average
reduction from static-even partitions (with 1.4% storage overhead associated)
BW-aware algorithm shows improvement up until 8 CMP implementation (beyond shows diminishing returns)
Miss rates consistent across different cache sizes with slight improvement due to increased possible cache ways and hence potential workload swapping candidates

Results Memory Bandwidth: reduction
of the average worst-case chip memory bandwidth in the system (per epoch).
Figure of merit used is long memory latencies associated with overcommitted memory bandwidth requirements by specific CMPs
UCP+ algorithm (Marginal-Utility/Intra-chip) shows average of 19% improvement over static-even. (Also increases with number of CMPs due to random workload selection of average worst-case bandwidth .
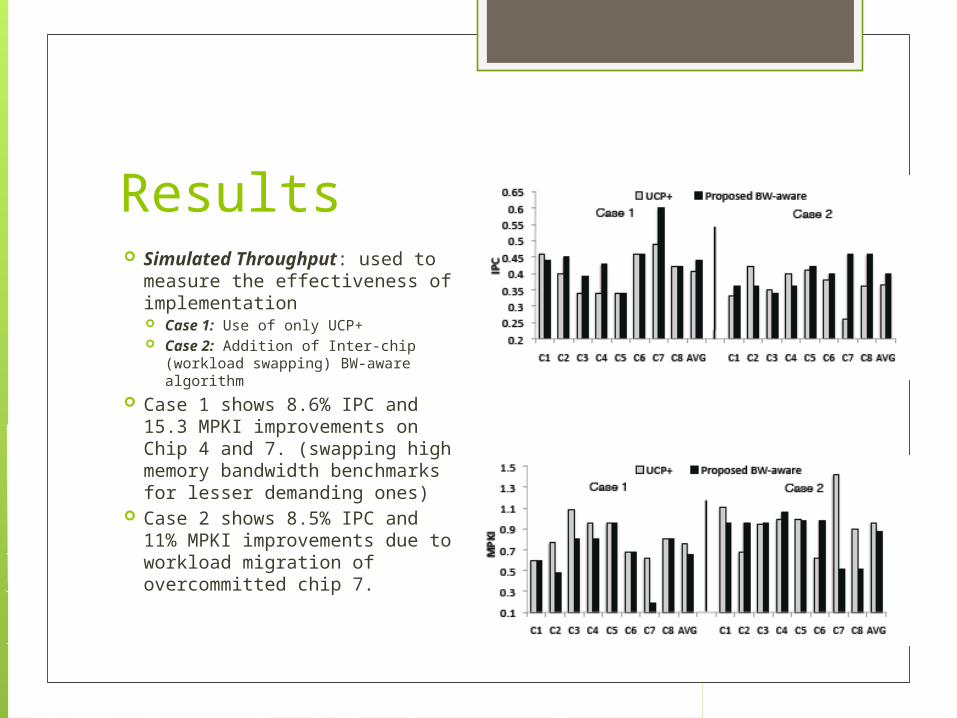
Results Simulated Throughput: used
to measure the effectiveness of implementation Case 1: Use of only UCP+ Case 2: Addition of Inter-chip
(workload swapping) BW-aware algorithm
Case 1 shows 8.6% IPC and 15.3 MPKI improvements on Chip 4 and 7. (swapping high memory bandwidth benchmarks for lesser demanding ones)
Case 2 shows 8.5% IPC and 11% MPKI improvements due to workload migration of overcommitted chip 7.

Comments No detailed hardware implementation of
“non-invasive” profilers “Large” CMP systems not demonstrated
due to complexity Good implementation of resource
management Design limited (additional cores) Cache designs (other than set-
associative)

References [1] D. Kaseridis, J. Stuecheli, J. Chen and L. K.
John, “A Bandwidth-aware Memory-subsystem Resource Management using Non-invasive Resource Profilers for Large CMP Systems”.
[2] R. L. Mattson, “Evaluation techniques for storage hierarchies”. IBM Systems Journal, 9(2):78-117, 1970.
[3] www.utdallas.edu/~edsha/parallel/2010S/Cache-Overview.pdf

Discussion Topics How can an inter-board partitioning
algorithm be implemented? Is it necessary?
What causes diminished returns beyond 8 CMP chips? Can it be circumvented?