4. seminář matematickÁ statistika
DESCRIPTION
4. Seminář MATEMATICKÁ STATISTIKA Bodové a intervalové odhady, testování hypotéz pro jeden soubor, testování hypotéz pro dva soubory. Bodové a intervalové odhady. est G = g, nám říká, že statistika g je odhadem charakteristiky základního souboru G . Například : - PowerPoint PPT PresentationTRANSCRIPT

4. Seminář
MATEMATICKÁ STATISTIKA
Bodové a intervalové odhady, testování hypotéz pro jeden soubor, testování
hypotéz pro dva soubory
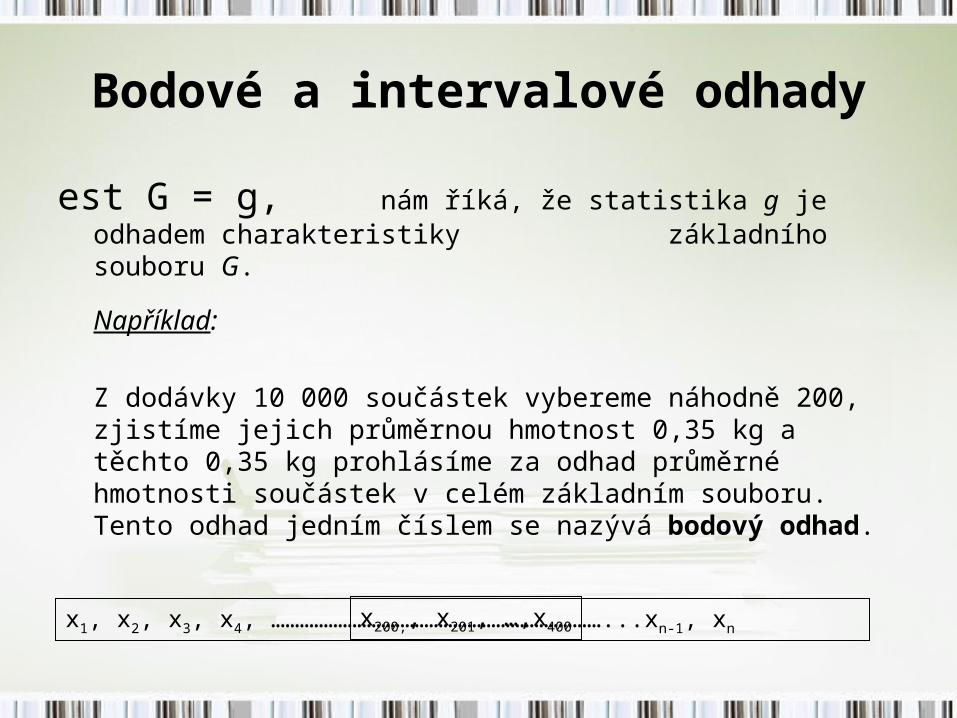
Bodové a intervalové odhady
est G = g, nám říká, že statistika g je odhadem charakteristiky základního souboru G.
Například:
Z dodávky 10 000 součástek vybereme náhodně 200, zjistíme jejich průměrnou hmotnost 0,35 kg a těchto 0,35 kg prohlásíme za odhad průměrné hmotnosti součástek v celém základním souboru. Tento odhad jedním číslem se nazývá bodový odhad.
x1, x2, x3, x4, ……………………………………………………………...xn-1, xnx200,, x201, …,x400

Chceme tedy, aby střední hodnota výběrové statistiky byla
rovna odhadované charakteristice. Jestliže platí E(g) = G, nazýváme výběrovou statistiku g nezkresleným (nevychýleným, nestranným) odhadem charakteristiky základního souboru. Nestrannost tedy znamená, jestliže při opakovaných výběrech kolísá odhad kolem teoretické hodnoty symetricky na obě strany, odhad je nestranný.
• Jestliže při rostoucím rozsahu výběru zkreslení E(g) – G mizí, tj. jestliže mluvíme o asymptoticky nezkresleném odhadu.
• Jestliže rozptyl odhadů při opakovaných výběrech je malý, mluvíme o vydatnosti nebo eficienci.
• Dále požadujeme, aby odhad byl konzistentní, tj. aby se odhad g pro rostoucí rozsah výběru blížil odhadované charakteristice základního souboru, tj. aby pro libovolně malé ε > 0 platilo
0)(lim
GgEn
1lim
GgPn
,tedy s rostoucím počtem pozorování se odhad blíží k teoretické hodnotě s pravděpodobností 1.

Intervaly spolehlivosti mohou být zkonstruovány buď jako jednostranné nebo dvoustranné. U jednostranných intervalů je udána buď jen horní mez Gh, nebo dolní mez Gd. V případě, že je udána pouze horní mez Gh, mluvíme o intervalu pravostranném. Je-li udána pouze dolní mez, jde o konfidenční interval levostranný.
Jsou-li konečně udány obě meze, konstruujeme interval dvoustranný.
1)(
)(
h
h
GGP
GGP
1)(
)(
h
h
GGP
GGP
.1)(
,2
)()(
hd
hd
GGGP
GGPGGP
Stanovíme-li tedy 95%, resp. 99% interval spolehlivosti na základě výběrových dat, pokryje tento interval s pravděpodobností rovnou 95 %, resp. 99 % skutečnou hodnotu odhadované charakteristiky základního souboru při opakovaném použití pokusu a celé procedury.

Příklad využití konfidenčních intervalů:
Intervaly spolehlivosti pro střední hodnotu při neznámé směrodatné odchylce – jednovýběrový t-interval nebo t-interval.

Příklad:
Má být zřízeno nové vlakové spojení mezi Prahou a Ostravou. V průběhu jednoho roku byl v náhodně vybrané dny zjišťován počet cestujících na trase Praha-Ostrava. Ze 30 shromážděných dat byly vypočteny aritmetický průměr a výběrová směrodatná odchylka . Určete 99% interval spolehlivosti pro střední hodnotu počtu cestujících.

Odhad relativní četnosti základního souboru
• Předpokládejme, že máme náhodný výběr o rozsahu n ze základního souboru s podílem p nebo ekvivalentně z alternativního rozdělení s parametrem p. Nestranný odhad podílu p, ze kterého vyjdeme při konstrukci intervalu spolehlivosti je výběrový podíl . Normovaná náhodná veličina má přibližně normované normální rozdělení. Tudíž pro U platí
p̂
p̂ ˆ / 1 /U p p p p n
1 / 2 1 / 2 1P u U u
Pro oboustranný interval spolehlivosti pak platí vztah
1 / 2 1 / 2
ˆ ˆ ˆ ˆ1 1ˆ ˆ 1
p p p pP p u p u
n n
pro pravostranný
1
n
p1pupP 1
a pro levostranný
1
n
p1pupP 1
Interval spolehlivosti pro podíl p základního souboru nebo parametr p alternativního rozdělení nazveme jednovýběrový interval nebo krátce interval pro p.
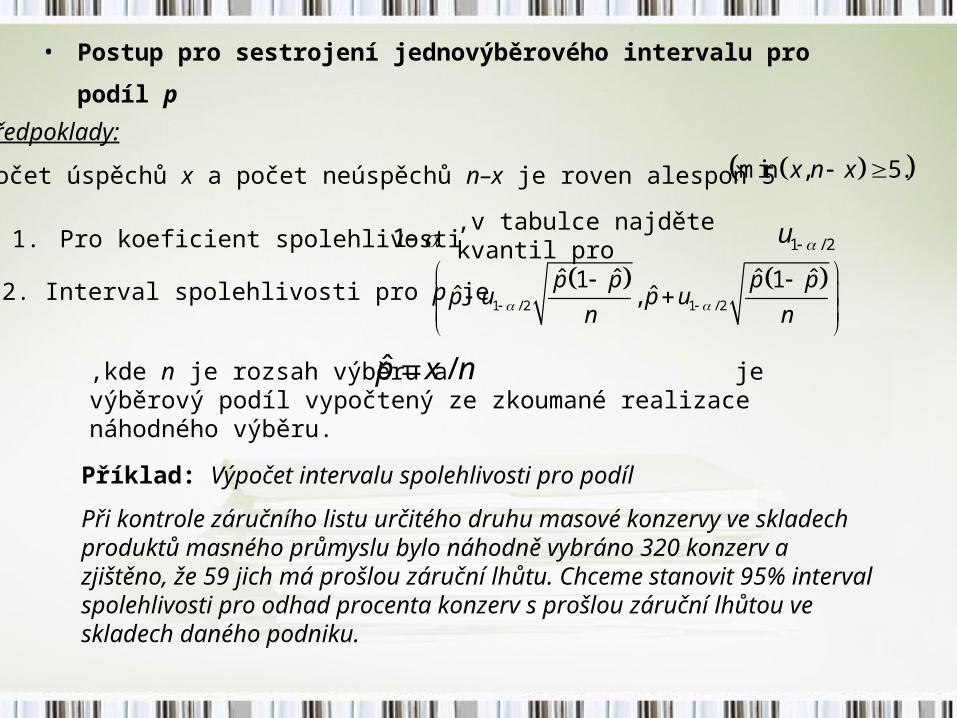
• Postup pro sestrojení jednovýběrového intervalu pro podíl
p Předpoklady:
Počet úspěchů x a počet neúspěchů n–x je roven alespoň 5 min , 5.x n x
1. Pro koeficient spolehlivosti 1 ,v tabulce najděte kvantil pro 1 / 2u
2. Interval spolehlivosti pro p je 1 / 2 1 / 2
ˆ ˆ ˆ ˆ1 1ˆ ˆ,
p p p pp u p u
n n
,kde n je rozsah výběru a je výběrový podíl vypočtený ze zkoumané realizace náhodného výběru.
ˆ /p x n
Příklad: Výpočet intervalu spolehlivosti pro podíl
Při kontrole záručního listu určitého druhu masové konzervy ve skladech produktů masného průmyslu bylo náhodně vybráno 320 konzerv a zjištěno, že 59 jich má prošlou záruční lhůtu. Chceme stanovit 95% interval spolehlivosti pro odhad procenta konzerv s prošlou záruční lhůtou ve skladech daného podniku.

Testování hypotéz
Předpoklad, který jsme vyslovili o určité charakteristice či tvaru rozdělení v základním souboru, nazýváme nulovou hypotézou (někdy též testovanou hypotézou) a značíme ji H0. Hypotézu o konkrétní hodnotě průměru v základním souboru, kterou jsme uvedli jako příklad, bychom zapsaliH0: µ= µ0.Proti této nulové hypotéze stavíme jinou hypotézu, tzv. hypotézu alternativní H1, která nějakým způsobem popírá konstatování, formulované nulovou hypotézou. Např. proti uvedené nulové hypotéze můžeme vymezit alternativní hypotézy ve formě
a)b)c)
01 : H
01 : H
01 : H

Etapy testovacího postupu
I. Formulace hypotézy
I.I Volba hladiny významnosti (je to pravděpodobnost, že se dopustíme chyby prvního druhu)
II. Volba testového kritéria (základ pro rozhodnutí, zda nulová hypotéza by měla být zamítnuta)
III. Sestrojení kritického oboru (množina hodnot testové statistiky, která vede k přijetí či zamítnutí hypotézy)
IV. Výpočet hodnoty testového kritéria
V. Formulace závěrů testu
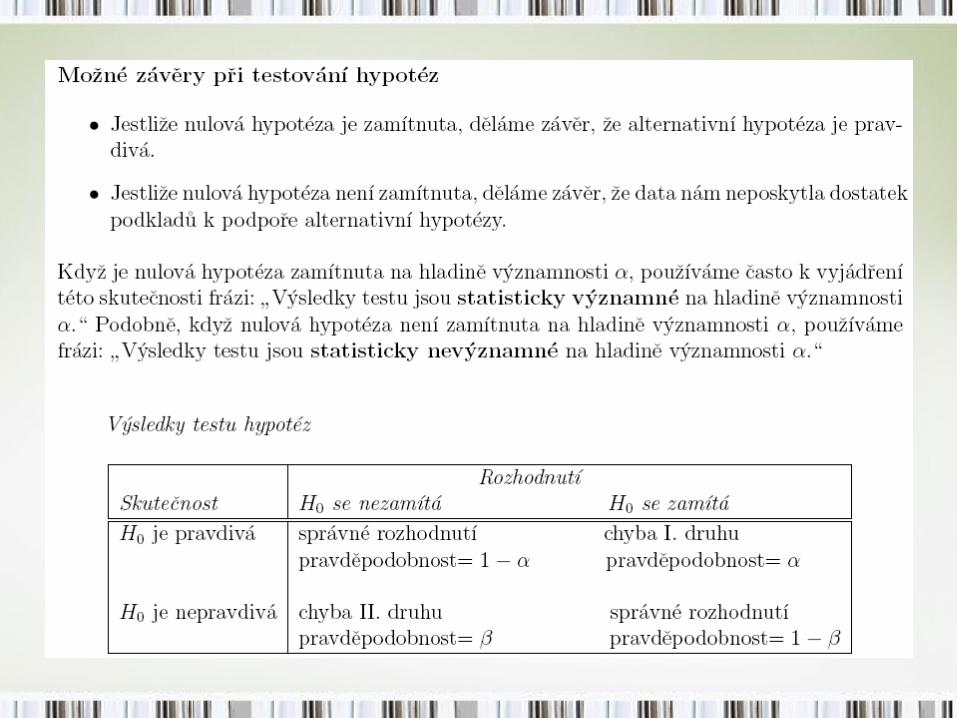

Obor zamítnutí nulové hypotézy pro danou hladinu významnosti α je určen tak, aby
W 0H 0X ,P T W H
(tj. pravděpodobnost, že testová statistika nabude hodnoty z kritického oboru za platnosti nulové hypotézy, je rovna α ). Pravděpodobnost chyby prvního druhu α je tedy definována předchozím vztahem.
Pravděpodobnost chyby druhého druhu β je pak X .AP T W H
poznámka: doplňkem oboru zamítnutí je a značí obor přijetí nulové hypotézy H0.
W W

Test hypotézy o střední hodnotě při známém rozptylu 2
Skutečná hladina významnosti α je rovna pro normální rozdělení a je pouze přibližně rovna α pro výběry z jiných než normálních rozdělení.
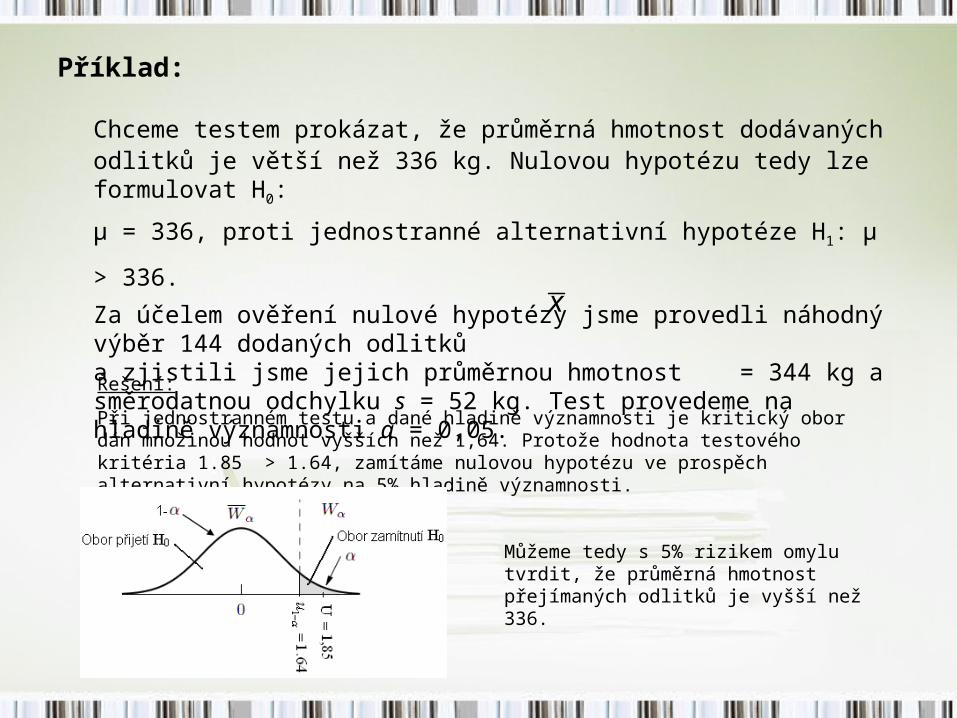
Příklad:
Chceme testem prokázat, že průměrná hmotnost dodávaných odlitků je větší než 336 kg. Nulovou hypotézu tedy lze formulovat H0:
μ = 336, proti jednostranné alternativní hypotéze H1: μ > 336. Za účelem ověření nulové hypotézy jsme provedli náhodný výběr 144 dodaných odlitků a zjistili jsme jejich průměrnou hmotnost = 344 kg a směrodatnou odchylku s = 52 kg. Test provedeme na hladině významnosti α = 0,05.
x
Řešení:
Při jednostranném testu a dané hladině významnosti je kritický obor dán množinou hodnot vyšších než 1,64. Protože hodnota testového kritéria 1.85 > 1.64, zamítáme nulovou hypotézu ve prospěch alternativní hypotézy na 5% hladině významnosti.
Můžeme tedy s 5% rizikem omylu tvrdit, že průměrná hmotnost přejímaných odlitků je vyšší než 336.
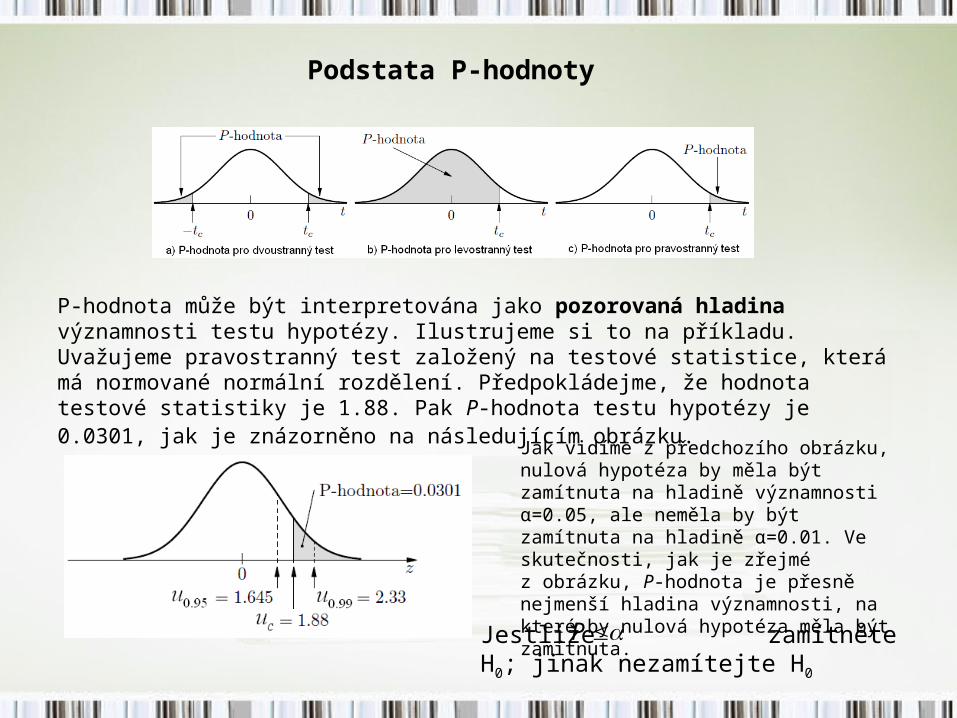
Podstata P-hodnoty
P-hodnota může být interpretována jako pozorovaná hladina významnosti testu hypotézy. Ilustrujeme si to na příkladu. Uvažujeme pravostranný test založený na testové statistice, která má normované normální rozdělení. Předpokládejme, že hodnota testové statistiky je 1.88. Pak P-hodnota testu hypotézy je 0.0301, jak je znázorněno na následujícím obrázku.
Jak vidíme z předchozího obrázku, nulová hypotéza by měla být zamítnuta na hladině významnosti α=0.05, ale neměla by být zamítnuta na hladině α=0.01. Ve skutečnosti, jak je zřejmé z obrázku, P-hodnota je přesně nejmenší hladina významnosti, na které by nulová hypotéza měla být zamítnuta.
Jestliže zamítněte H0; jinak nezamítejte H0
P
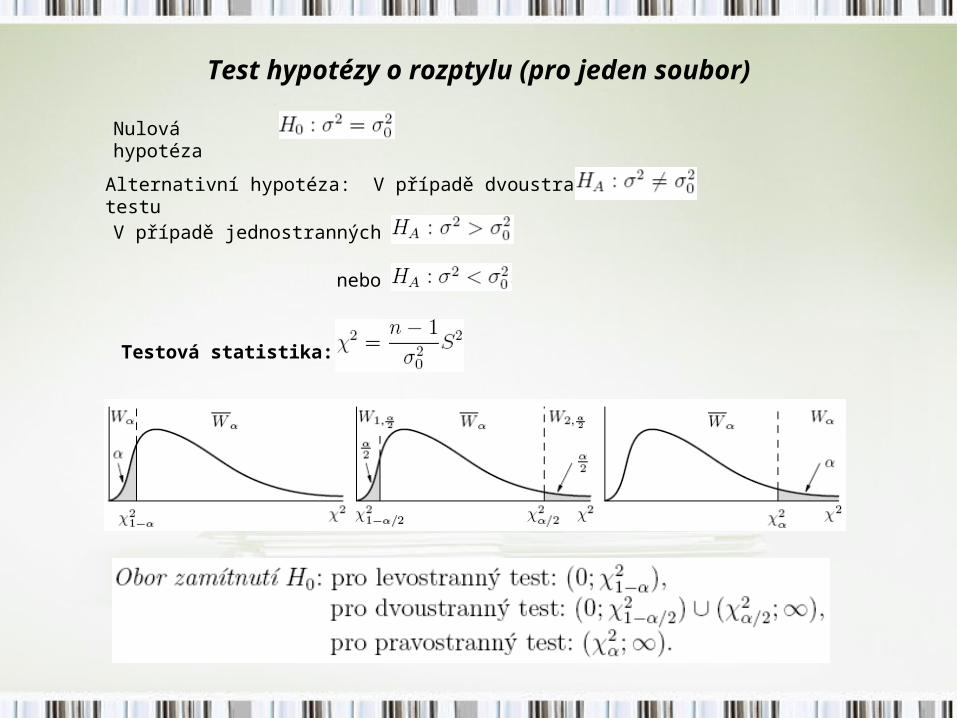
Test hypotézy o rozptylu (pro jeden soubor)
Nulová hypotéza
Alternativní hypotéza: V případě dvoustranného testu
V případě jednostranných testů:
nebo
Testová statistika:
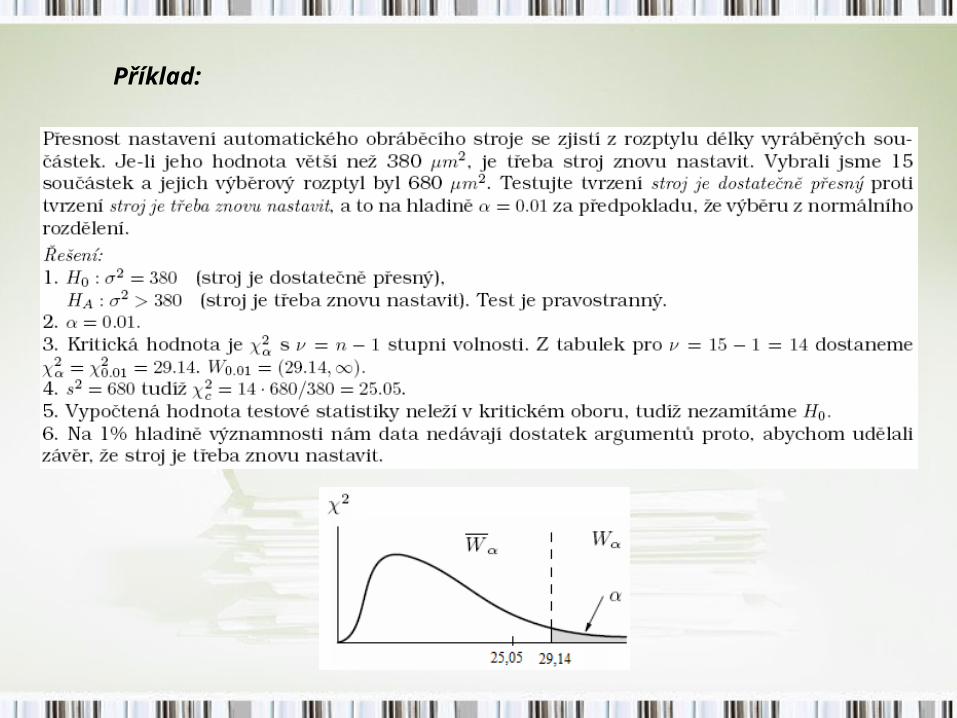
Příklad:

Test hypotézy o shodě dvou středních hodnot

Příklad:

Test hypotézy o shodě dvou rozptylů

Příklad:

Děkuji za pozornost