28/07/2005speech and nlp experiences with indian language morphology monojit choudhury rs, cse, iit...
TRANSCRIPT

28/07/2005 Speech and NLP
Experiences with Indian Language Morphology
Monojit ChoudhuryRS, CSE, IIT Kharagpur

28/07/2005 Speech and NLP
When do we need MA/MS?
Store all words
Advantages: Less effort for NLP Less time for processing
Disadvantages: More words more space more search time How to tackle unseen words

28/07/2005 Speech and NLP
Therefore, we need MA/MS when
The language is morphologically rich large number of affixes concatenation of affixes/compounding Example: Turkish, German, Sanskrit …
The language is morphologically productive Speakers/writers can coin new words by following
morphological rules Example: German, Sanskrit …

28/07/2005 Speech and NLP
A Problem to ponder
How do we decide whether a language is morphologically rich and/or productive?
Linguistically Difficult (enumerate all morphological processes) Fuzzy/Subjective
Can you suggest some formal technique?
Hint: Statistics

28/07/2005 Speech and NLP
Vocabulary GrowthBENGALI
(3019565,182848)
HINDI
(2967438, 121603)
200,000
CORPUS SIZE ( N ) 3,500,000
VOCAB
SIZE ( V(N) )

28/07/2005 Speech and NLP
Another Estimate
How many different forms of a verb are there in English Hindi Bengali Telugu Sanskrit

28/07/2005 Speech and NLP
Another Estimate
How many different forms of a verb are there in English – 5 Hindi – ~20 (without causation) Bengali – ~170 (without causation) Telugu – ~1000 Sanskrit – ~51480 (with derivational affixes)
~3960 (otherwise)

28/07/2005 Speech and NLP
Three basic concerns
While designing a morphological analyzer/generator one must consider
Productivity of a ruleMorphological paradigmsIrregular morphology

28/07/2005 Speech and NLP
Productivity of a Rule
Rule Example Productivity
VR + tA jAtA, letA
NR + ikadainika,
sAmAjika
Adj + imA lAlimA, niilimA

28/07/2005 Speech and NLP
Productivity of a Rule
Rule Example Productivity
VR + tA jAtA, letA *****
NR + ikadainika,
sAmAjika**
Adj + imA lAlimA, niilimA X

28/07/2005 Speech and NLP
Productive Rules for Bengali/Hindi
Inflectional Morphology Verb Noun Adjectives Pronouns
Derivational Morphology Compounding Prefixation Suffixation
Emphasizing in Bengali i and o

28/07/2005 Speech and NLP
Productive Rules for Bengali/Hindi
Inflectional Morphology Verb Noun Adjectives Pronouns
Derivational Morphology Compounding Prefixation Suffixation
Emphasizing in Bengali i and o

28/07/2005 Speech and NLP
Three basic concerns
While designing a morphological analyzer/generator one must consider
Productivity of a ruleMorphological paradigmsIrregular morphology

28/07/2005 Speech and NLP
Morphological paradigms
Classes of words that inflect similarlyHindi Noun roots take 4 inflections
Singular, direct laDakA, laDakii Plural, direct laDake, laDakiyA.N Singular, oblique laDake, laDakii Plural, oblique laDako, laDakiyo.N
How many paradigms for nouns?

28/07/2005 Speech and NLP
How to identify the paradigms?
Paradigms may be based on Syllable structure (e.g laDakii, nadii, sakhii) Gender (e.g. dhobii vs. nadii) Semantics (e.g. lohA vs. dohA)
Which of these distinctions can be identified automatically? How?

28/07/2005 Speech and NLP
Paradigms for Bengali Nouns
Bengali noun inflections: Classifier Suffixes TA, gulo, rA etc. Case Markers er, ke, der, te etc. Emphasizers i, o
Paradigms are based on semantics Inanimate objects take TA, gulo Animate objects take rA, dera

28/07/2005 Speech and NLP
Three basic concerns
While designing a morphological analyzer/generator one must consider
Productivity of a ruleMorphological paradigmsIrregular morphology

28/07/2005 Speech and NLP
Irregular Morphology
All languages feature irregular morphology English: ox – oxen, go – went Hindi: jAnA – gayA, karanA – kiyA Bengali: yAoYA – gela, AsA – ela
Better to list them as exceptions and treat separately
Bengali has only 4 exceptional verbs, Hindi has 2

28/07/2005 Speech and NLP
So, we decided to
Build MS/MA for Hindi & Bengali Cover only inflectional morphology Cover only verbs, nouns and adjectives
We also identified the morphological paradigms Irregular verbs/nouns

28/07/2005 Speech and NLP
Now we need to decide
The list of possible affixes There attributes Morphotactics
And then design/build The Input/output specification The lexicon structure The FST structure Lexicon and FST search strategy

28/07/2005 Speech and NLP
A Case Study: Bengali Verb Morphology
The information coded by affixes:Finite forms
Tense: Past, present, future Aspect: simple, continuous, perfect, habitual Modality: Order, request Person: 1st, 2nd normal (tumi), 2nd familiar (tui),
3rd (se), Honorific 2nd and 3rd (Apani, tini) Polarity: positive/negative
Non-finite forms: e, te

28/07/2005 Speech and NLP
Morphotactics
Root Aspect Tense Person +/- Gloss
kar
(to do)
eChi
(perfect)
l
(past)
Ama
(1st)
Φ
(+)I had done
karCh
(cont.)
Φ
(present)
i
(1st)
Φ
(+)I’m doing
karΦ
(simple)
b
(future)
i
(2nd fam)
Φ
(+)You’ll do
karΦ
(perfect)
Φ
(pre/pst)
i
(1st)
ni
(-)
I’ven’t done
I’d not done

28/07/2005 Speech and NLP
Morphotactics
Root + aspect + tense +
person + emphasizer + polarity
Root + modality + person + emphasizer
Root + aspect1 + emphasizer +
aspect2 + person + polarity

28/07/2005 Speech and NLP
Verb Suffix Table
TAM/ Person 1st 2nd, familiar 2nd, normal 2nd & 3rd formal 3rd
Ind, Pr, Simple i isa’ ena’ e
Ind, Pr, Cont chhi chhisa’ chha chhena’ chhe
Ind, Pr, Perfect echhi echhisa’ echha echhena’ echhe
Ind, Pa, Simple lAma’ li le lena’ la
Ind, Pa, Cont. chhilAma’ chhili chhile chhilena’ chhila
Ind, Pa, Perfect echhilAma’ echhili echhile echhilena’ echhila’
Ind, Future ba bi be bena’ be
Habitual Past tAma’ tisa’ te tena’ ta
Imperative - .h/ una’ uka’
Neg, Perfect ini isa’ni ani ena’ni eni

28/07/2005 Speech and NLP
Orthographic Changes
kar + eChilAm kareChilAmkhA + eChilAm kheYeChilAmhAr + eChilAm hereChilAmkarA + eChilAm kariYeChilAmtolA + eChilAm tuliYeChilAmkhAoYA + eChilAm khAiYeChilAmde + eChilAm diYeChilAm

28/07/2005 Speech and NLP
Orthographic Classes (Paradigms?)
$ V
a’ A oYA
aha [haoYA] (to happen)
kara’ [karA](to do)
karA [karAno](do, causative)
saoYA [saoYAno](undergo, causative)
AkhA [khAoYA]
(to eat)jAna’ [jAnA]
(to know)jAnA [jAnAno]
(to inform)khAoYA [khAoYAno]
(to feed)
idi [deoYA](to give)
likha’ [lekhA](to write)
ni~NrA [ni~NrAno] --
e --dekha’ [dekhA]
(to see)dekhA [dekhAno]
(to show)deoYA [deoYAno](give, causative)
oso [so;oYA](to lie down)
tola’ [tolA](to pick)
tolA [tolAno](pick, causative)
so;oYA [so;oYAno](lie, causative)
u/au -- --ghumA [ghumAno]
(to sleep)--

28/07/2005 Speech and NLP
FSM for Recognizing Bengali Verb Class
28/07/2005 Speech and NLP
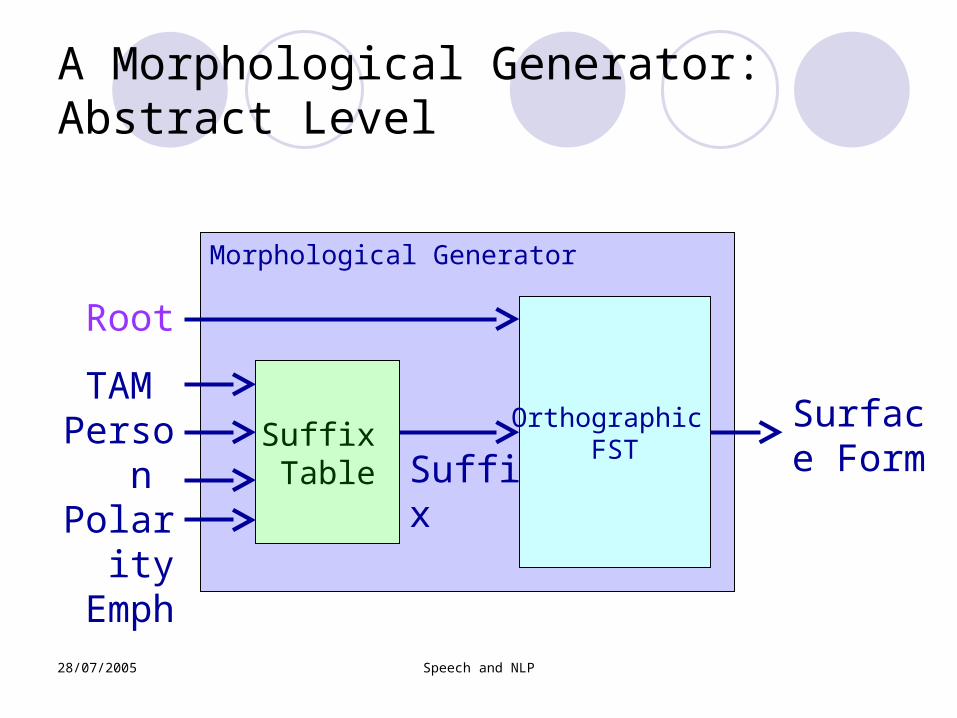
A Morphological Generator: Abstract Level
Root
TAM Person
Polarity
Emph
Morphological Generator
Suffix Table
Orthographic FST
Suffix
Surface Form

28/07/2005 Speech and NLP
A Morphological Generator: Implementation
Root
TAM Person Polarity
Emph
Morphological Generator
Surface Form
Root Class Recognizer
Orthographic Rules
for each Root class
SuffixTable
EmphAdder
Irregular Root Handler

28/07/2005 Speech and NLP
Implementation: More Facts
Memory Requirement Root Class Recognizer: FSM with 26 states Suffix Table: 56 suffixes (emphasizers not incl.) Orthographic Rule Tables: 19×56 = 1064 rules
Time Requirement Root Class Recognizer: scans the root once (r) Suffix Selection: just table look up (constant) Orthographic Rules: scans root + suffix once (r+s) Emphasizer Adder: Constant time Total time: O(r+s)

28/07/2005 Speech and NLP
Now we need to decide
The list of possible affixes There attributes Morphotactics
And then design/build The Input/output specification The lexicon structure The FST structure Lexicon and FST search strategy

28/07/2005 Speech and NLP
A Morphological Analyzer:Abstract Level
Trie: A data structure also called a suffix tree. (from Information Retrieval)
Basic Notions: Note that Bengali verb morphology only has suffixes Scan a given word from right to left (backward) If the substring seen is a valid suffix, see if the remaining part
of the input is a valid stem/root Take care of orthographic changes
We shall see that trie is just another way to implement FST with some nice properties

28/07/2005 Speech and NLP
Trie: Construction
Make a list of all valid suffixes NULL, i, Chi, li, eChi, YeChi, lAma, elAma
Construct the trie recursively by inserting each of the suffixes (right to left)
Every state where a suffix ends is marked as a final state
Every final state consists of TAM, Person, Polarity information Rewrite rules for generation of the root

28/07/2005 Speech and NLP
Trie: Search
Reverse the input word Traverse the trie starting from the root (start
state) At every final state apply the orthographic rule to
the rest of the string Let r be the string obtained. Search for r in the
root lexicon If found, output the attributes Continue the search

28/07/2005 Speech and NLP
Trie: Computational Issues
Time Complexity Searching the trie is linear on input length Searching the lexicon can also be linear
Space Complexity In general linear in number of affixes Can be reduced further by constructing DAWG

28/07/2005 Speech and NLP
Trie vs DAWG
Trie More space Linear Search Easy to construct Easy to insert &
delete Final states have
unique attributes
DAWG Less space Linear search Exponential construction Difficult to delete and
insert A final state can have
ambiguous attributes

28/07/2005 Speech and NLP
Morphological Analyzer:Implementation Details
Size of Trie: 300 states Size of root lexicon: 600 verb rootParadigm Information: Not requiredNoun, verb and adjectives are separately
analyzed Tries can be merged but no significant gain Root lexicons are also distinct
Rule compilation

28/07/2005 Speech and NLP
Summarizing
Decide whether to go for MA/MS Identify the productive morphological processes
and corresponding irregularities Identify the paradigms and morphological
attributes Specify the morphotactics, affix list Gather a Machine readable root lexicon Choose appropriate computational technique Design, implement and test A good interface for rule-editing is desirable