1 quality of experience control strategies for scalable video processing wim verhaegh, clemens...
Post on 22-Dec-2015
215 views
TRANSCRIPT

1
Quality of Experience
Control Strategies for Scalable Video Processing
Wim Verhaegh, Clemens Wüst,
Reinder J. Bril, Christian Hentschel, Liesbeth Steffens
Philips Research Laboratories, the Netherlands

2
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments
Overview
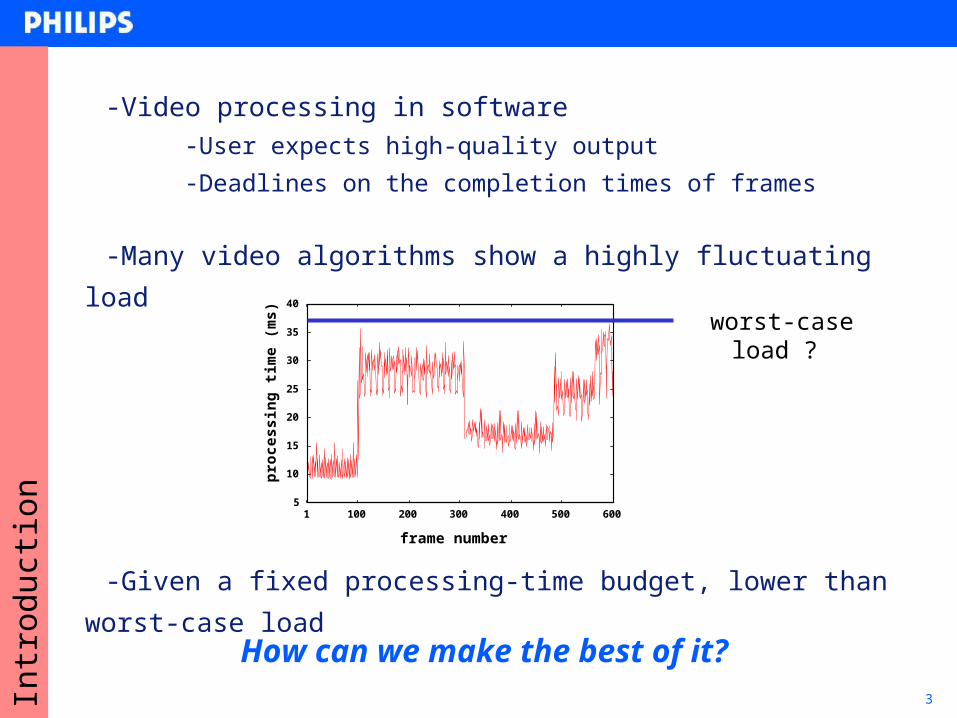
3Intr
oduc
tion
5
10
15
20
25
30
35
40
1 100 200 300 400 500 600
pro
cessin
g t
ime (
ms)
frame number
worst-case load ?
How can we make the best of it?
-Video processing in software-User expects high-quality output
-Deadlines on the completion times of frames
-Many video algorithms show a highly fluctuating load
-Given a fixed processing-time budget, lower than worst-case load

4
Our Approach
Intr
oduc
tion
1. Asynchronous, work-preserving processing•Using buffers
2. Scalable Video Algorithm (SVA)•Frames can be processed at different quality levels
•Trade-off picture quality and processing needs
3. Soft real-time task, hence we allow occasional deadline misses
4. QoS trade-off• Deadline misses
• Picture quality
• Quality fluctuations
QoS measure reflectsuser-perceived quality

5
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments
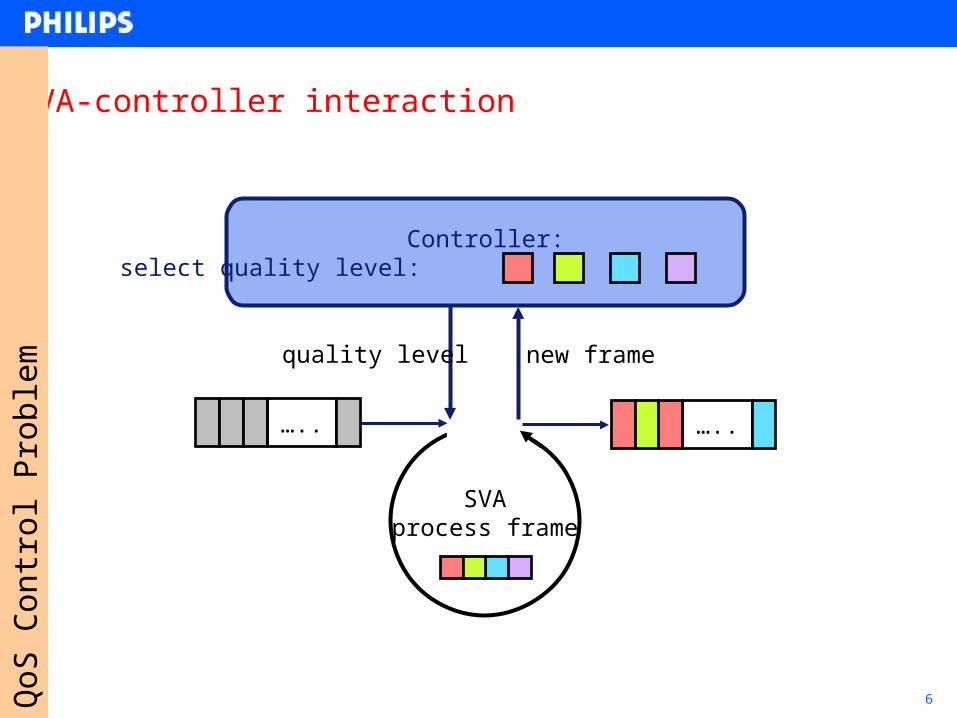
6
…..…..
SVA-controller interaction
SVAprocess frame
….. …..
QoS
Con
trol
Pro
blem …..
quality level new frame
Controller:select quality level:
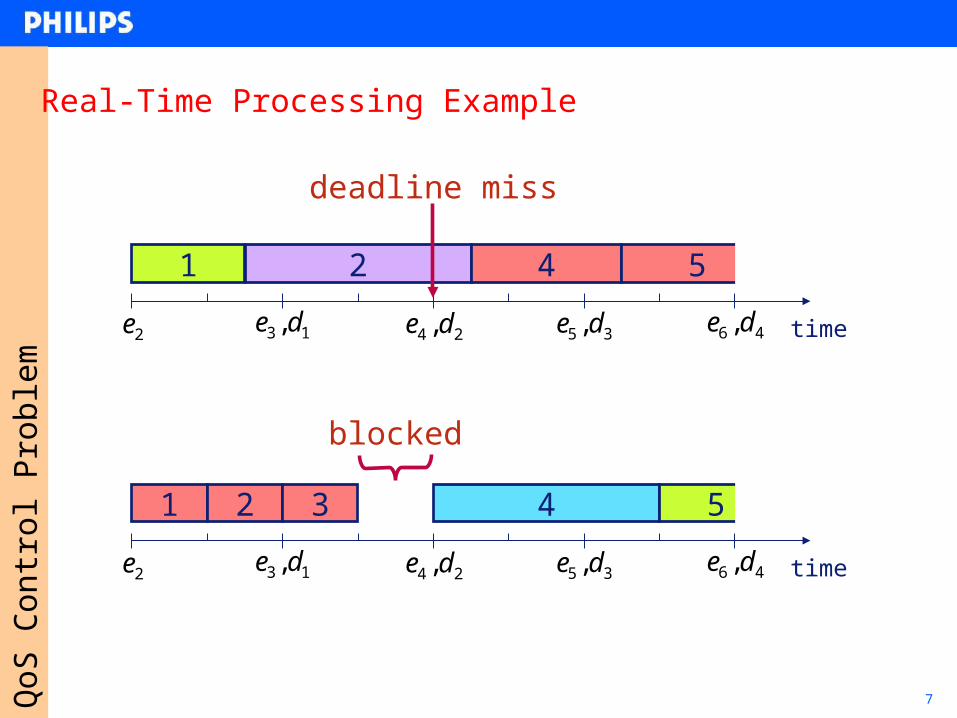
7QoS
Con
trol
Pro
blem
Real-Time Processing Example
time13 ,de 24 ,de 35 ,de 46 ,de2e
1 2 4 5
deadline miss
time13 ,de 24 ,de 35 ,de 46 ,de2e
1 2 4 53
blocked

8
Revenue for processed frame
QoS
Con
trol
Pro
blem
Sum of:
• reward for selected quality level
• penalty for each deadline miss
• penalty for changing the quality level
50
500
5,000
10
50
500
100
10
50
1,000
100
10
0q 1q 2q 3q
0q
1q
2q
3q
Current quality level
Pre
vio
us q
ua
lity
leve
l4 6 8 10
0q 1q 2q 3q
Current quality level
Deadline miss: 10,000
Revenue8 - 10,000 - 100 = -10,092

9
QoS measure
QoS
Con
trol
Pro
blem
- Average revenue per frame
- Reflects the user-perceived quality, provided that the revenue
- parameters are well chosen
- At each decision point, select the quality level
- Goal: maximize the QoS measure
- Difficult on-line problem:
- what will the future bring?
QoS Control Problem

10
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments
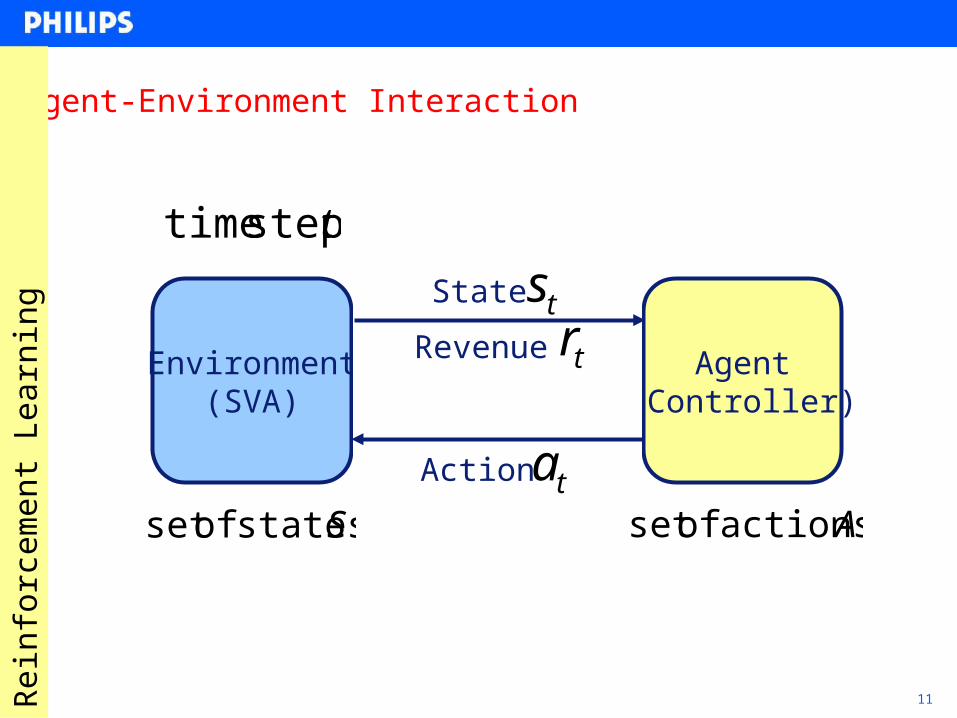
11
Agent-Environment Interaction
Rei
nfor
cem
ent
Lear
ning
Environment(SVA)
Agent(Controller)
0step time 1step time tstep time
Sstates ofset Aactions ofset
Action 0a
State 0s
Action 1a
State 1sRevenue 1r
Action ta
Revenue trState ts

12Rei
nfor
cem
ent
Lear
ning
Agent’s goal
-Maximize the expected return
-Discounted return at time step t
10
iti
it rR
Selecting actions
- Policy :
- stores for each state a single action
- to be chosen
Ss As )(
infinite time horizon
discount parameter

13Rei
nfor
cem
ent
Lear
ning
Markov Decision Process
- We assume a memoryless state signal:
state and action predict state and revenue
- Hence, the reinforcement learning task is a
- Markov Decision Process (MDP)
- We assume a finite MDP:-Finite state set , finite action set
-One-step dynamics:
1tr1tsts ta
S A
},|'Pr{ 1' aassssp tttass
}',,|{ 11' ssaassrEr ttttass

14Rei
nfor
cem
ent
Lear
ning
Value functions
- State value of state under policy
-Action value of state under policy
-A policy is better than or equal to a policy if
-We are looking for an optimal policy
}|{)( ssREsV tt
Ss
'
SssVsV )()( '
Ss
},|{),( aassREasQ ttt

15Rei
nfor
cem
ent
Lear
ning
Solution approach
- Compute an optimal policy OFFLINE (= before )
-Requires transition probabilities
-Requires expected revenues
-Algorithms: policy iteration, value iteration, …..
- Compute an optimal policy ONLINE, at the discrete time steps,
- using the experienced states and revenues
-Algorithms: SARSA, Q-Learning, …..
0t
assp '
assr '

16
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments
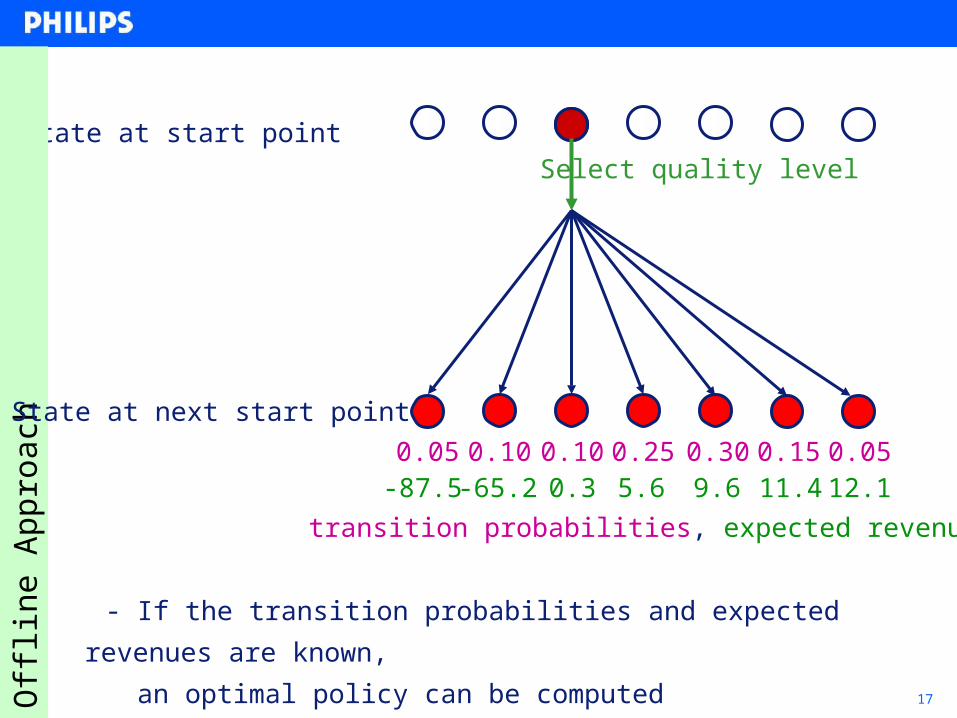
17
Select quality levelState at start point
0.05 0.10 0.10 0.25 0.30 0.15 0.05
transition probabilities, expected revenues
Off
line
App
roac
h
State at next start point
-87.5 -65.2 0.3 5.6 9.6 11.4 12.1
- If the transition probabilities and expected revenues are known,
- an optimal policy can be computed

18Off
line
App
roac
h
- Decision moments = start points
- State
- progress interval (discrete!!!)
- previous quality level
- Action = select quality level
- Transition probabilities and expected revenues:
computed using processing-time statistics
time13 ,de 24 ,de 35 ,de 46 ,de2e
1 2 4 5
1t 2t 4t 5t
- Progress: measure for the amount of budget left until the deadline
- of the frame to be processed
0
0.2
0.4
0.6
0.8
1
10 15 20 25 30 35 40 45
cum
ula
tive p
rob
ab
ility
processing time (ms)
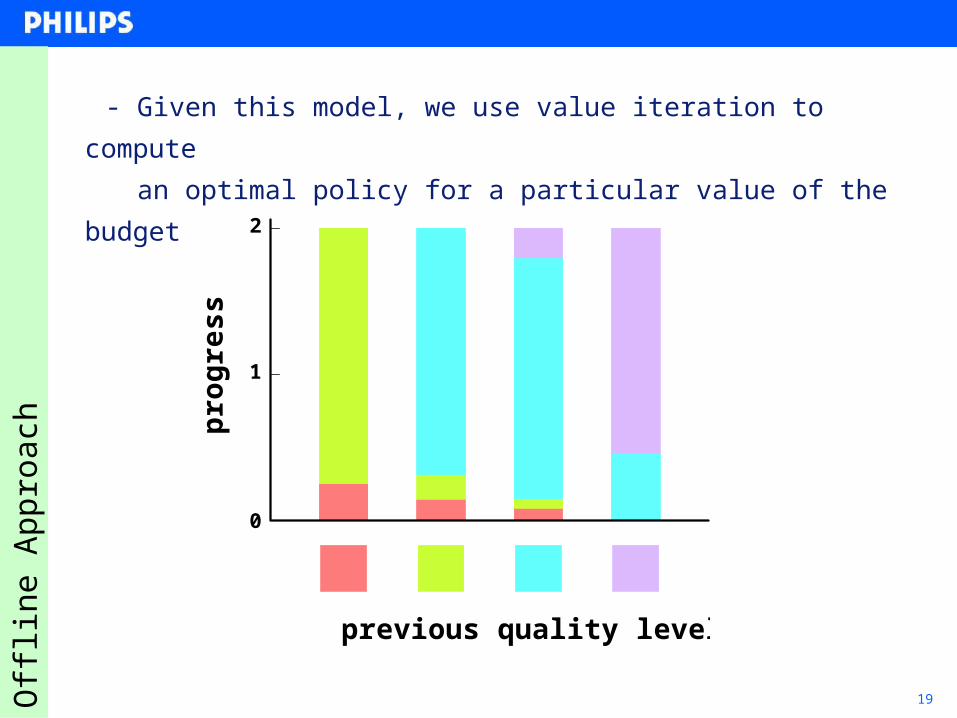
19Off
line
App
roac
h
previous quality level
pro
gre
ss
0
1
2
- Given this model, we use value iteration to compute
- an optimal policy for a particular value of the budget

20
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments

21Onl
ine
App
roac
h
- Based on learning Q-values
- State = progress, previous quality level
- Action = select quality level
- At each decision point - Given the state transition , action , and revenue ,
- the controller first updates (learns) Q-value
- Next, given state , the controller selects action
for which is maximal
-Default: one Q-value updated; also do exploring actions
ts ta),( tt asQ
Q-Learning
t
),( 11 tt asQtt ss 1 tr1ta

22
0q
1q
2q3q
0 4.0 8.0 2.1 6.1 2progress
prev
ious
qua
lity
leve
l
State Space
- Progress (continuous)
- Previous quality level
- We learn Q-values
- only for a small set
- of states
- To select the quality
- level, given the state,
- we interpolate between
- the learned Q-values
Onl
ine
App
roac
h
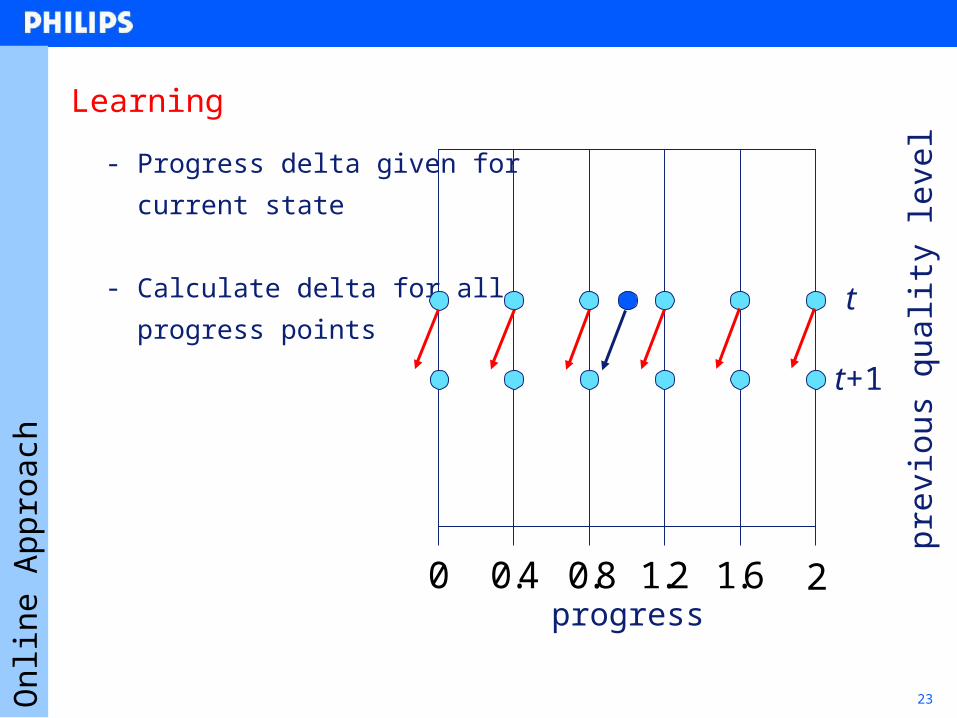
23
0 4.0 8.0 2.1 6.1 2progress
prev
ious
qua
lity
leve
l
Learning
- Progress delta given for
- current state
-
- Calculate delta for all
- progress points
Onl
ine
App
roac
h
t
t+1
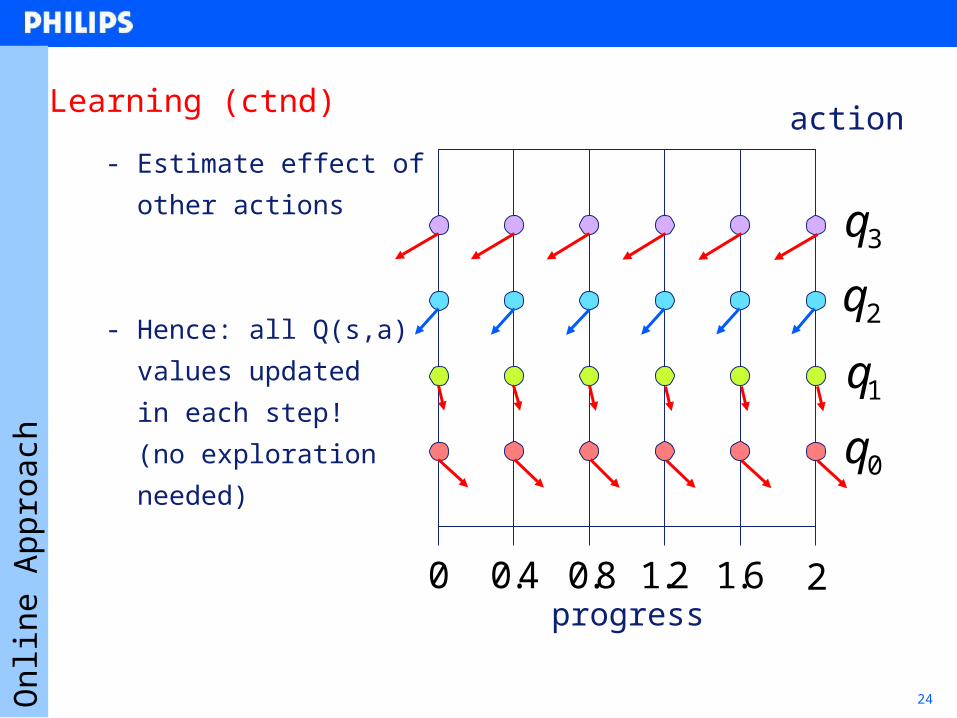
24
0q
1q
2q3q
0 4.0 8.0 2.1 6.1 2progress
Learning (ctnd)
- Estimate effect of
- other actions
- Hence: all Q(s,a)
- values updated
- in each step!
- (no exploration
- needed)
Onl
ine
App
roac
h
action

25
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments
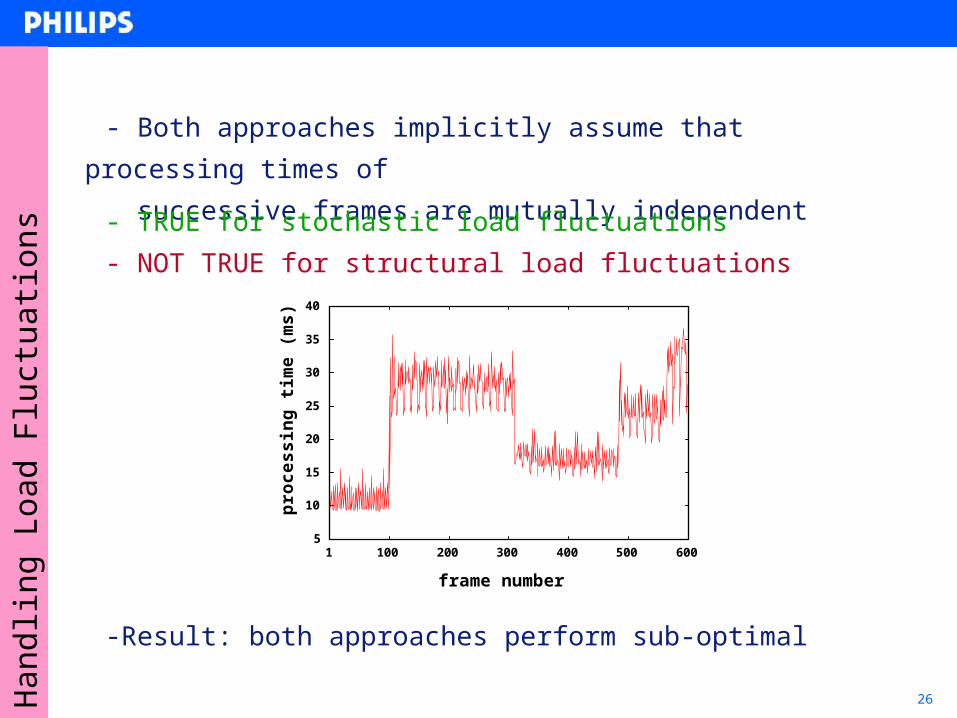
26Han
dlin
g Lo
ad F
luct
uatio
ns
- Both approaches implicitly assume that processing times of
- successive frames are mutually independent
-Result: both approaches perform sub-optimal
- TRUE for stochastic load fluctuations
- NOT TRUE for structural load fluctuations
5
10
15
20
25
30
35
40
1 100 200 300 400 500 600
pro
cessin
g t
ime (
ms)
frame number
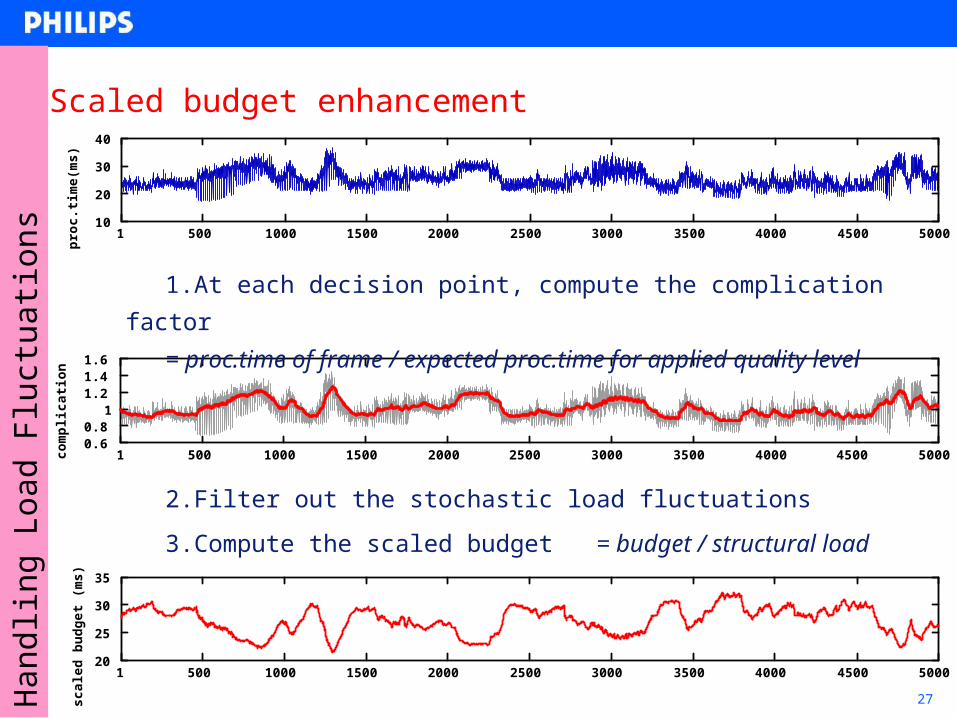
27
Scaled budget enhancement
Han
dlin
g Lo
ad F
luct
uatio
ns
0.6 0.8
1 1.2 1.4 1.6
1 500 1000 1500 2000 2500 3000 3500 4000 4500 5000complication
20
25
30
35
1 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
scaled budget (ms)
10
20
30
40
1 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
proc.time(ms)
1.At each decision point, compute the complication factor
= proc.time of frame / expected proc.time for applied quality level
2.Filter out the stochastic load fluctuations
3.Compute the scaled budget = budget / structural load

28
Scaled budget enhancement
Han
dlin
g Lo
ad F
luct
uatio
ns
Adapt offline strategy
- Compute a policy for many different values of the budget b
- During run time, at each decision point:
- Compute the scaled budget
- Compute the state of the SVA
- Apply the policy corresponding to the scaled budget,
- and use the state to select the quality level
- Interpolate between policies
Adapt online strategy
- Add scaled budget directly to the state

29
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments

30Sim
ulat
ion
Exp
erim
ents
-Scalable MPEG-2 decoder-TriMedia 1300-180MHz platform
-Quality levels (based on IDCT pruning):
-Sequence `TV’
-(five episodes of ‘Allo ‘Allo, 230,936 frames, 2.5 hours)
-Latency: 3 periods (= work ahead of at most 2 periods)
-Control strategies: OFFLINE, OFFLINE*, ONLINE*, Q0,…,Q3
-For each control strategy, we simulate processing sequence `TV’
-for a fixed value of the processing-time budget
-Revenues: based on input of video experts (slide 8)
0q 1q 2q 3q
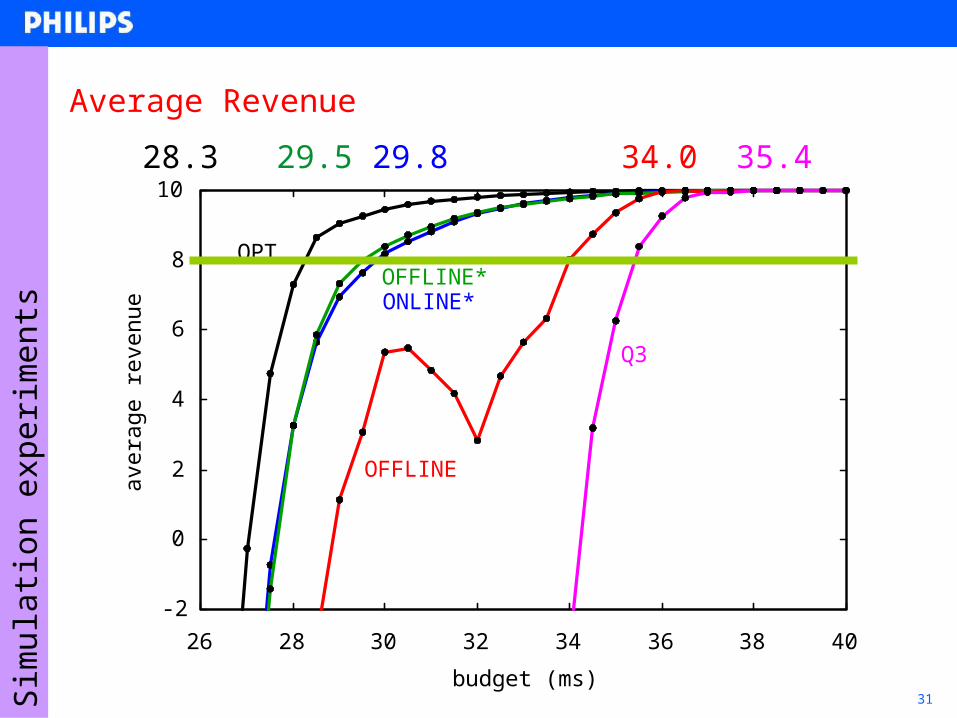
31
Average Revenue
Sim
ulat
ion
expe
rimen
ts
-2
0
2
4
6
8
10
26 28 30 32 34 36 38 40
avera
ge r
evenue
budget (ms)
OPT
ONLINE* OFFLINE*
OFFLINE
Q3
28.3 29.5 29.8 34.0 35.4

32
Deadline misses
Sim
ulat
ion
expe
rimen
ts
0
200
400
600
800
1000
1200
26 28 30 32 34 36 38 40
num
ber
of
deadlin
e m
isse
s
budget (ms)
OPT
ONLINE* OFFLINE*
OFFLINE
Q3
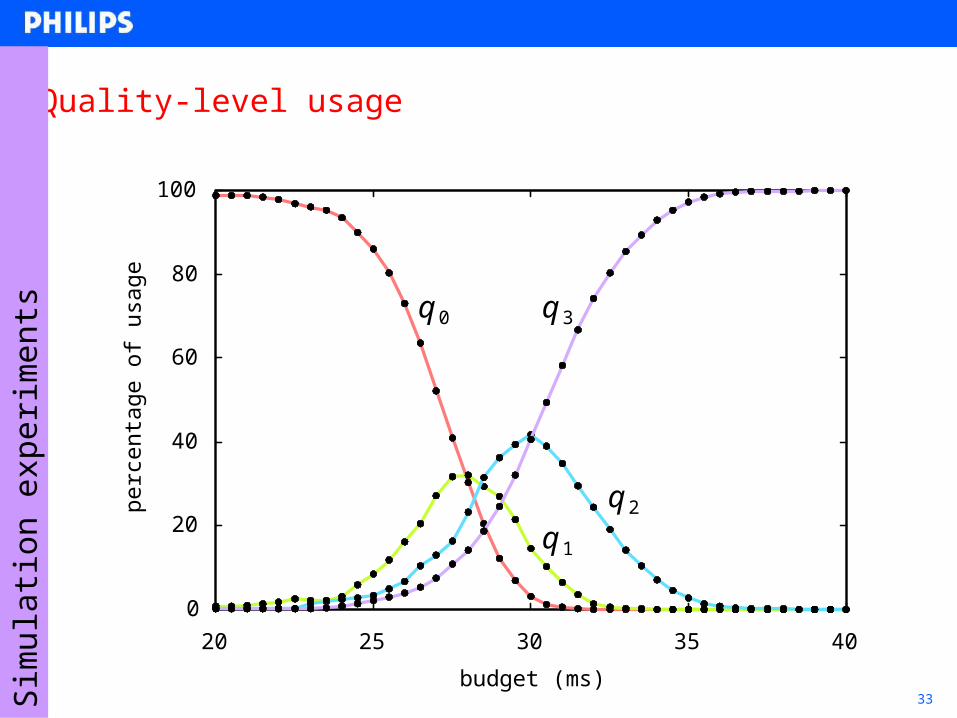
33
Quality-level usage
Sim
ulat
ion
expe
rimen
ts
0
20
40
60
80
100
20 25 30 35 40
perc
enta
ge o
f usa
ge
budget (ms)
q 0 q 3
q 1
q 2
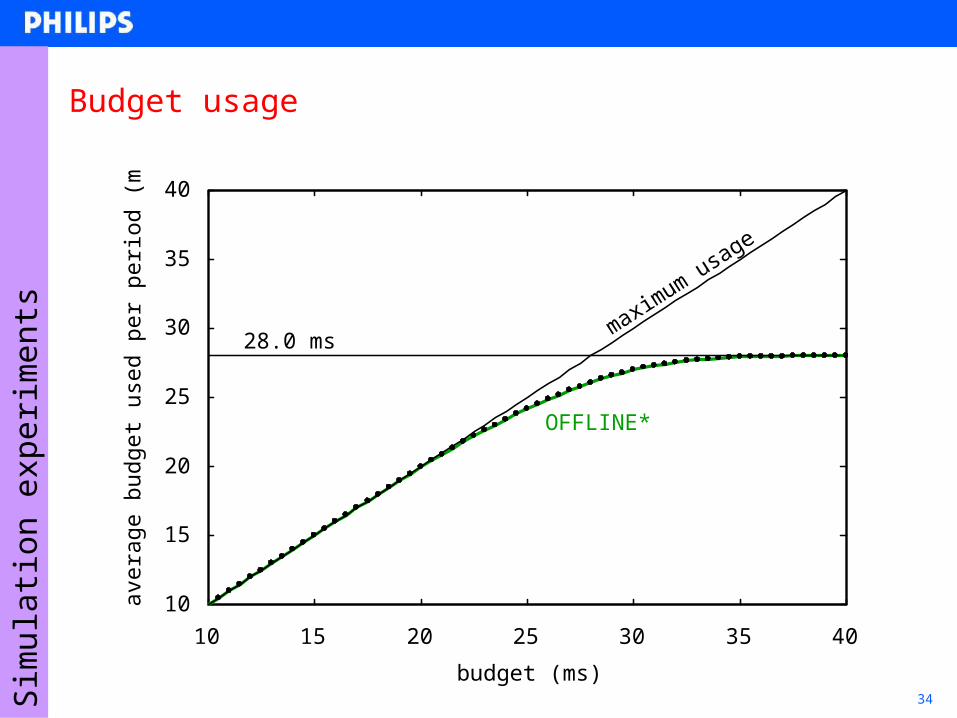
34
Budget usage
Sim
ulat
ion
expe
rimen
ts
10
15
20
25
30
35
40
10 15 20 25 30 35 40
avera
ge b
udget
use
d p
er
peri
od (
ms)
budget (ms)
maximum usa
ge
28.0 ms
OFFLINE*
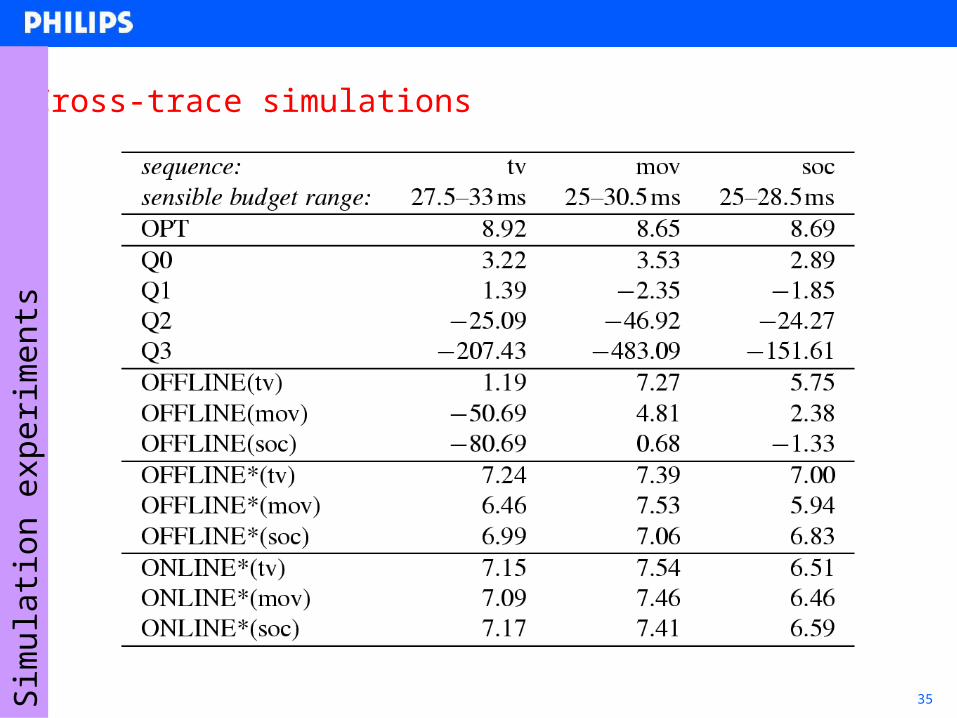
35
Cross-trace simulations
Sim
ulat
ion
expe
rimen
ts

36
Introduction
QoS Control Problem
Reinforcement Learning
Offline Approach
Online Approach
Handling Load Fluctuations
Conclusion
Simulation Experiments

37Con
clus
ion
-Problem-Video processing algorithm with highly fluctuating load
-Fixed processing-time budget, lower than worst-case needs
-How to optimize the user-perceived quality?
-Approach-Asynchronous work-preserving processing
-Scalable video algorithm
-QoS trade off: deadline misses, processing quality, quality fluctuations
-Control strategies-Offline, online, scaled budget enhancement
-Simulation experiments-OFFLINE* and ONLINE* perform close to optimum
-OFFLINE* and ONLINE* are independent of the applied statistics