1 from the seminar support for non-standard datatypes in dbms held by brendan briody accelerating...
Post on 20-Dec-2015
214 views
TRANSCRIPT

1
from the seminarsupport for non-standard datatypes in dbms
Held by Brendan Briody
Accelerating XPath Location Steps

2
Overview
1. Introduction- Awareness of tree structured data (XML ...).
- Problem with recursion and RDBMS.
2. Tree Traversals & Mappings (part 1)- Traversing trees to obtain information.
- pre and post mapping to orthogonal coordinates, discovering their relationships and introducing corresponding XPath axes.
3. Axes and Query windows - Representing nodes in 5- dimensional descriptors and defining query
windows for XPath axes.
4. Representation in SQL- Applying descriptors to a relational table and performing analogue SQL queries according to XPath expressions.

3
5. Shrink-Wrapping the // Axis Discovering equations to shrink-wrap window ranges to minimise query Query time comparison shrunk and non-shrunk windows.
6. Tree Mapping (part 2) Stretching - a different pre/post node assignment idea to avoid misled query scans of shrink-wrapping. Advantages / Drawbacks of shrinking
and stretching.
7. Benchmarking Accel – Schema against Edge Mapping
Performance tests in query time in dependency of document sizes and tree variations.
Overview

4
1. Introduction
Awareness of tree structured data in the everyday ITworld and combination with RDBMS.
How can we achieve this ?
RDBMS
Gain information independent of tree type ! >>
5
3
4
6
7
7
4 1 5
6 2
5
f g
h
b c
d e
aPrePost 0
Traversal direction 1
2 0 3
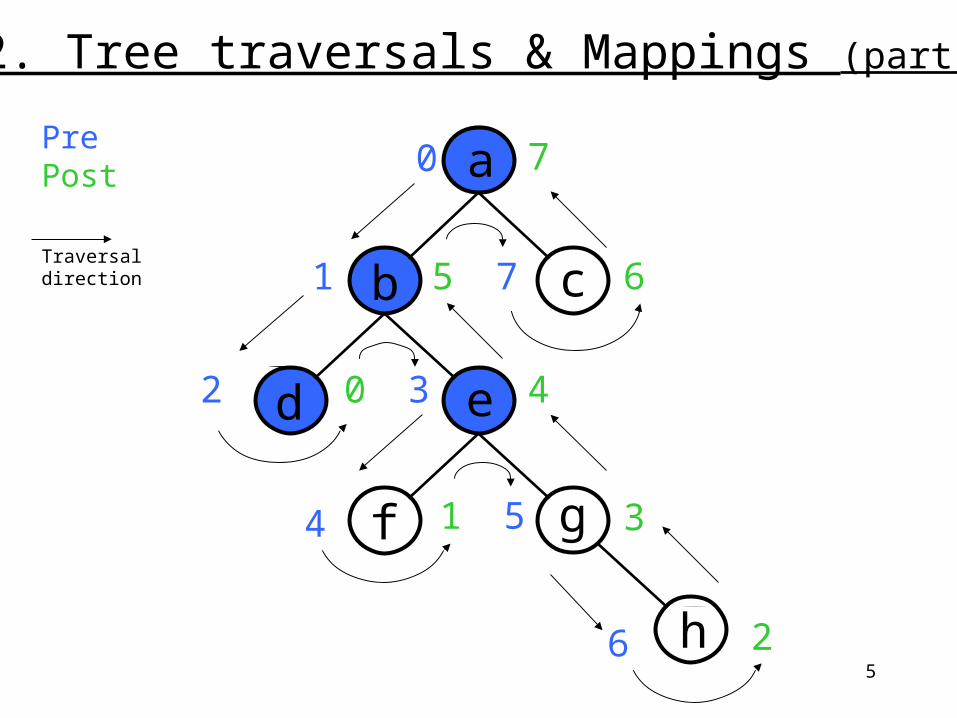
2. Tree traversals & Mappings (part 1)

6
Nod
e
pre
post
a 0 7
b 1 5
d 2 0
e 3 4
f 4 1
g 5 3
h 6 2
c 7 60
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8pre
po
st
a
b
c
d
e
f
g
h
2. Tree traversals & Mappings (part 1)

7
b c
d e
f g
h
a
Context node0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8pre
po
st
a
b
c
d
ee
f
g
h
3.1 XPath Major Axes

8
b c
d e
f g
h
a
e/descendant::*
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8pre
po
st
a
b
c
d
ee
f
g
h

9
b c
d e
f g
h
a
e/preceding::*
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8pre
po
st
a
b
c
d
ee
f
g
h

10
b c
d e
f g
h
a
e/ancestor::*
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8pre
po
st
a
b
c
d
ee
f
g
h

11
b c
d e
f g
h
a
e/following::*
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8pre
po
st
a
b
c
d
e
f
g
h

12
4. Axes and Range Queries
We have now successfully transformed recursive queries into range queries.To support all XPath Axes though we need a little more information.
- child / parent , following / preceding siblings „par(v)“ value characterises these axes too - attribute is distinguished by a att(v) Boolean - tag(v ) holds the node or attribute name
The result is a 5-Dim descriptor but giving us a 5-dimensional region:
descr(v) = (pre(v),post(v),par(v),att(v),tag(v))

13
Axis αQuery window(α,v)
pre postpost par att tag
child <(pre(v), ),
[[0,post(v))),
pre(v), false
,* >
descendant <(pre(v), ),
[[0,post(v))), *
, false
,* >
descendant-or-self <[pre(v), )
, [[0,post(v)]]
, *, false
,* >
parent<[par(v), par(v)]
, ((post(v), ))
, *, false
,* >
ancestor <[0,pre(v)), ( (post(v),
)), *
, false
,* >
ancestor-or-self <[0,pre(v)], [[post(v),
)), *
, false
,* >
following <(pre(v), ), ( (post(v),
)), *
, false
,* >
preceding <(0,pre(v)),
((0,post(v))), *
, false
,* >
following-sibling <(pre(v), ), ( (post(v),
)), par()
, false
,* >
preceding-sibling <(0,pre(v))
, ((0,post(v)))
, par(), false
,* >
attribute <(pre(v), ),
[[0,post(v))),
pre(v), true
,* >
Now instead of discrete pre/post values we define intervals [..) , (..].. (..) ....
4. Axes and Query windows

14
Specify SQL relational scheme with descriptor.
5-column Table accel
Pre value can be considered as primary key
Query(e /α) = SELECT v’.* FROM Query(e) v , accel v’
WHERE v’ INSIDE window(α,v)
Idea of rectangular region query windows in pre /post plane. Optimised support by R- and B-Trees. To be continued..
4. Representation in SQL
pre post par att tag

15
4. Representation in SQL
Creating conventional SQL Queries from XPath expressions:Ex.: /descendant::n1/preceding-sibling::n2We get
SELECT v2.* FROM accel v1, accel v2 WHERE 0 < v1.pre AND v1.tag = n1 AND v2.pre < v1.pre AND v2.post < v1.post AND v2.par = v1.par AND v2.tag = n2

16
5. Shrink wrapping the // axis
Knowledge taken from specific properties of pre/post ranks to shrink window
size(e) = level(e)- pre(e) + post(e) (1) 3 = 2 - 3 + 4
For the right most leaf of the sub treewe can say
size(e) = pre(h) - pre(e) (2) 3 = 6 - 3
f g
h
e3 4
4 1 5 3
6 2
Level 2
Level 3
Level 4

17
Using height(t) instead of level(e):
Node h has max pre-order and node f has min post order rank
pre(h) ≤ post(e) + height(t)
post(f) ≥ pre(e) – height(t)
The value height(t) of a document tree is assigned at document loading time.
From equation(2)formed to pre(h) = pre(e) + size(e) and replacing size(e) with (1) leads to pre (h) = post(e) + level(e)
For a useful estimation we can also for sure say that:Level(e) ≤ height(t)
f g
h
e3 4
4 1 5 3
6 2
Level 2
Level 3
Level 4
5. Shrink wrapping the // axis

18
5. Shrink wrapping the // axis
Attribute and leaf „l“ access
Knowledge of pre(l) and post(l) differingby height:post = pre – height(t)
We are left with a shrunk-wrapped regionthat minimizes query time considerably.
With a B-tree based XPath accelerator on top of a IBM DB2 and an XML instance of 1.1 MB (21051 nodes) we get
Query t shrunk [s] t[s] # Nodes
//open_auction//description 0.2 53 120
//open_auction//description//listitem 0.32 55.5 126
//open_auction//description//listitem//keyword 0.34 124 90

19
Independent pre/post scans result to possible results but also yield false hits.
6. Tree Mapping (part 2)
False pre scan hits
False post scan hits

20
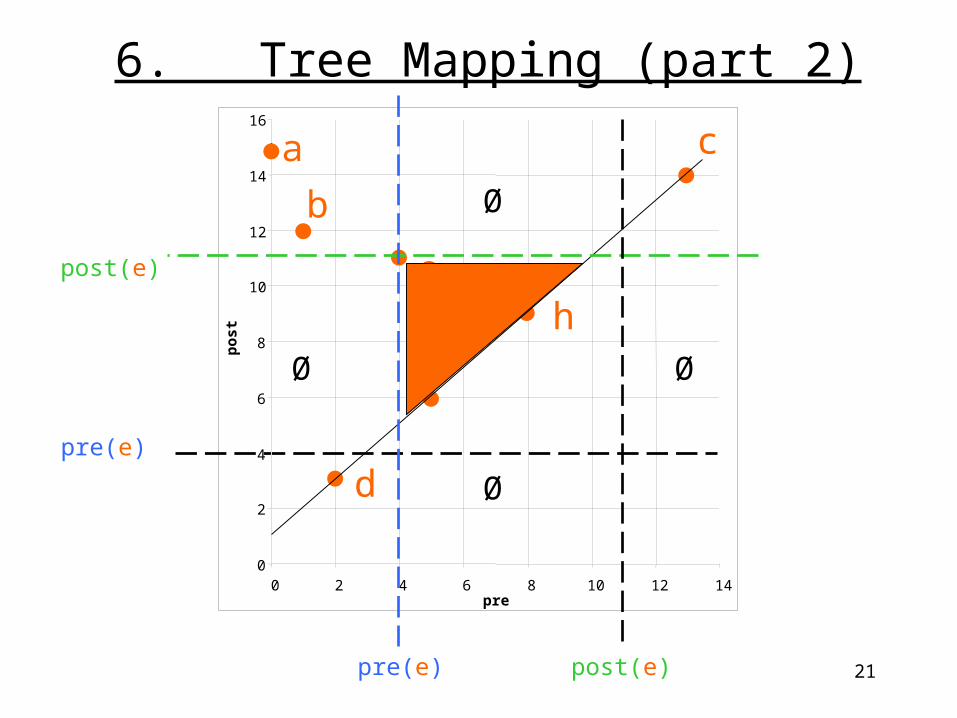
6. Tree Mapping (part 2)Use a different type of pre post assignment to avoid false pre post scans
10
11
14
15
13
5 6 7
8 9
12
f g
h
b c
d e
a0
1
2 3 4
Called stretching
21
6. Tree Mapping (part 2)
a
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14pre
po
stb
c
d
eg
f
h
pre(e)
post(e)
pre(e) post(e)
Ø
Ø Ø
Ø

22
6. Tree Mapping (part 2)
Advantages and drawbacks of stretching:
- avoids incorrect pre post scans by stretched mappings a seen in previous slide- all axis query windows work as before- pre and post of a context node are still unique- estimation of subtree size is accurate : size(v) = ½ (post(v) - pre(v) –1)- relationships are still maintained due to relationships and not absolute values.
Drawback: The pre and post values are not dense.

23
7. Benchmarking Accel – Schema against Edge Mapping
0,01
0,1
1
10
100
1000
0,1 1 10 100
MB
tim
e[s] Edge map
XPath Accel
Measurements performed on:Intel i586 ~ 1 GHz CPU,2.4 Linux Kernel, ext2 Filesystem, EIDE hard disk, 256 MB RAMNo other processes active
File size [MB] 0,11 0,55 1,1 11 55 110
Edge map [s] 0,17 0,7 1,5 20,4 98,8 197
XPath Accel[s] 0,03 0,25 0,34 2,4 22,9 44