1. data mining (or kdd) let us find something interesting! definition := “data mining is the...
TRANSCRIPT

1. Data Mining (or KDD)
Let us find something interesting!
Definition := “Data Mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” (Fayyad)

Why Mine Data? Scientific Viewpoint Data collected and stored at
enormous speeds (GB/hour)
– remote sensors on a satellite
– telescopes scanning the skies
– microarrays generating gene expression data
– scientific simulations generating terabytes of data
– GIS
Traditional techniques infeasible for raw data Data mining may help scientists
– in classifying and segmenting data
– in Hypothesis Formation

Ch. Eick: Data Mining
2.1 Supervised Clustering
Applications of Supervised Clustering Include:a. Learning Subclasses
b. for Region Discovery in Spatial Datasets
c. Distance Function Learning
d. Data Set Compression (reduce size of dataset by using cluster representatives)
e. Adaptive Supervised Clustering
class 1class 2unclassified object
H
F
E
L
JI
D
c. Supervised Clusteringb. Semi-supervised Clusteringa. Unsupervised Clustering
CB
A
Attribute1 Attribute1Attribute1
Attribute2 Attribute2 Attribute2
K
unclassified object
class 1class 2
G
Ch. Eick
Ch. Eick: Data Mining
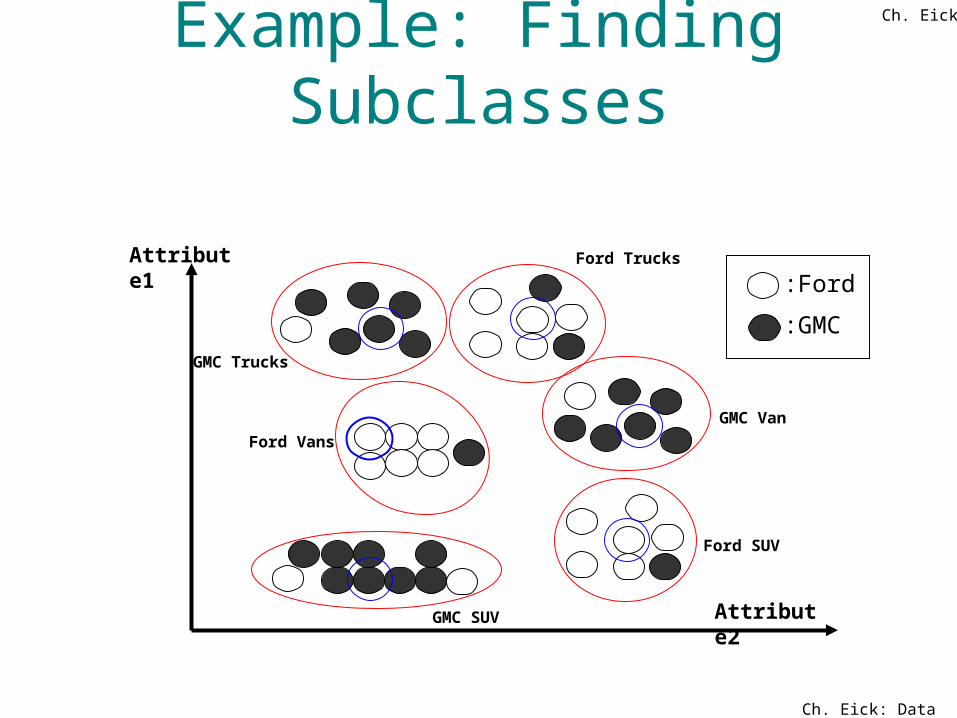
Example: Finding Subclasses
Attribute2
Ford TrucksAttribute1
Ford SUV
Ford Vans
GMC Trucks
GMC Van
GMC SUV
:Ford
:GMC
Ch. Eick

Ch. Eick: Data Mining
SC Algorithms Investigated1. Representative-based Clustering Algorithms
1. Supervised Partitioning Around Medoids (SPAM).
2. Single Representative Insertion/Deletion Steepest Decent Hill Climbing with Randomized Restart (SRIDHCR).
3. Supervised Clustering using Evolutionary Computing (SCEC)
2. Agglomerative Hierarchical Supervised Clustering (AHSC)
3. Grid-Based Supervised Clustering (GRIDSC)
1. Naïve approach
2. Hierarchical Grid-based Clustering relying on data cubes
3. Grid-based Clustering relying on density estimation techniques

Ch. Eick: Data Mining
2.2 Spatial Data Mining (SPDM) SPDM := the process of discovering interesting, useful, non-trivial patterns from
(large) spatial datasets. Spatial patterns
– Spatial outlier, discontinuities • bad traffic sensors on highways
– Location prediction models • model to identify habitat of endangered species
– Spatial clusters • crime hot-spots , poverty clusters
– Co-location patterns • identify arsenic risk zones in Texas and determine if there is a correlation
between the arsenic concentrations of the major Texas aquifers and cultural factors such population, farm density and the geology of the aquifers etc.
Idea: Reuse the supervised clustering algorithms that already exist by running them with a different fitness function that corresponds to a particular measure of interestingness.
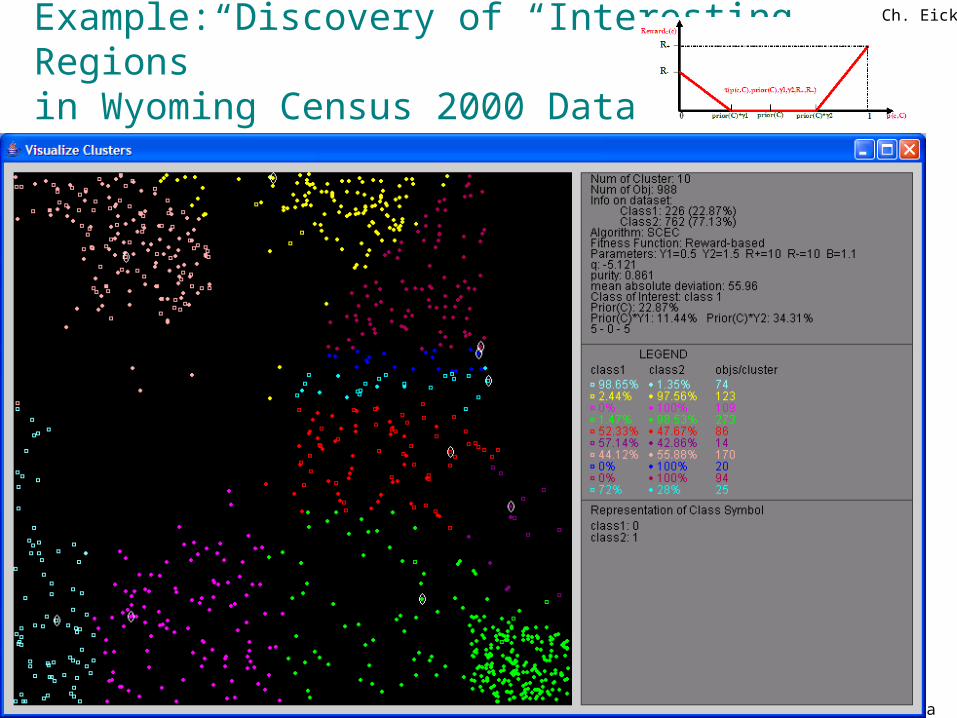
Ch. Eick: Data Mining
Example: Discovery of “Interesting Regions” in Wyoming Census 2000 Datasets
Ch. Eick

Ch. Eick: Data Mining
2.3 Distance Function LearningExample: How to Find Similar Patients?
Task: Construct a distance function that measures patient similarity
Motivation: Finding a “good” distance function is important for:– Case based reasoning
– Clustering
– Instance-based classification (e.g. nearest neighbor classifiers)
Our Approach: Learn distance functions based on training examples and user feedback

Ch. Eick: Data Mining
The following relation is given (with 10000 tuples):Patient(ssn, weight, height, cancer-sev, eye-color, age,…) Attribute Domains
– ssn: 9 digits
– weight between 30 and 650; mweight=158 sweight=24.20
– height between 0.30 and 2.20 in meters; mheight=1.52 sheight=19.2
– cancer-sev: 4=serious 3=quite_serious 2=medium 1=minor
– eye-color: {brown, blue, green, grey }
– age: between 3 and 100; mage=45 sage=13.2
Task: Define Patient Similarity
Motivating Example: How To Find Similar Patients?
f
fjif
ji
wpf
woopfoo
1
*)(1
,),(
Ch. Eick: Data Mining
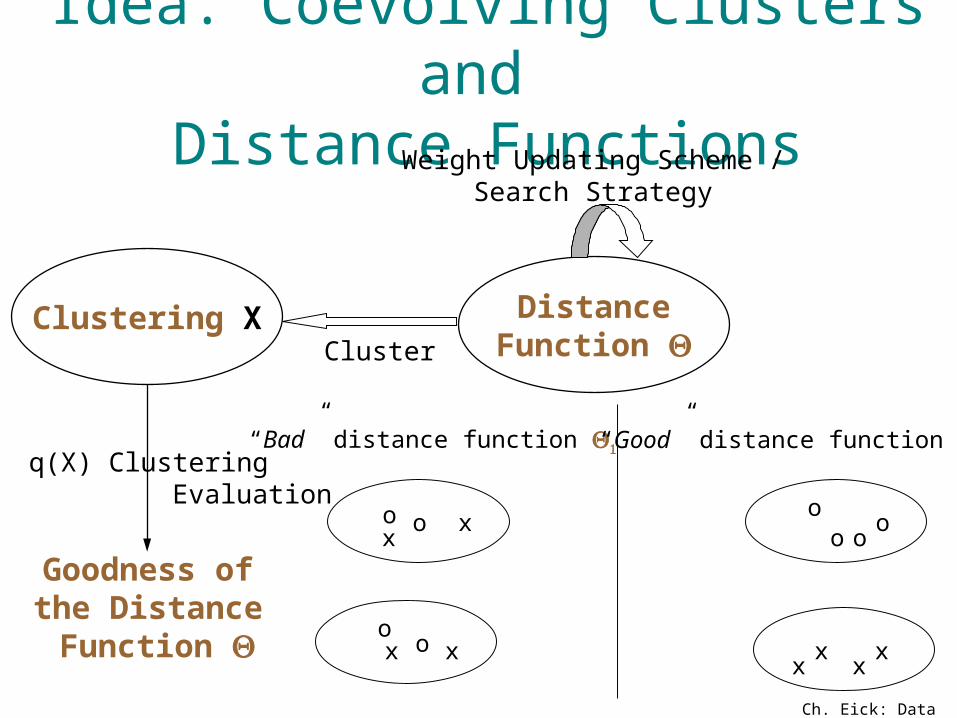
Idea: Coevolving Clusters and Distance Functions
Clustering X DistanceFunction Cluster
Goodness of the Distance Function
q(X) Clustering Evaluation
Weight Updating Scheme /Search Strategy
x
x x
x
o
oo
o
xx
oo
xx
oo
oo
“Bad” distance function “Good” distance function
xx
oo
Ch. Eick: Data Mining
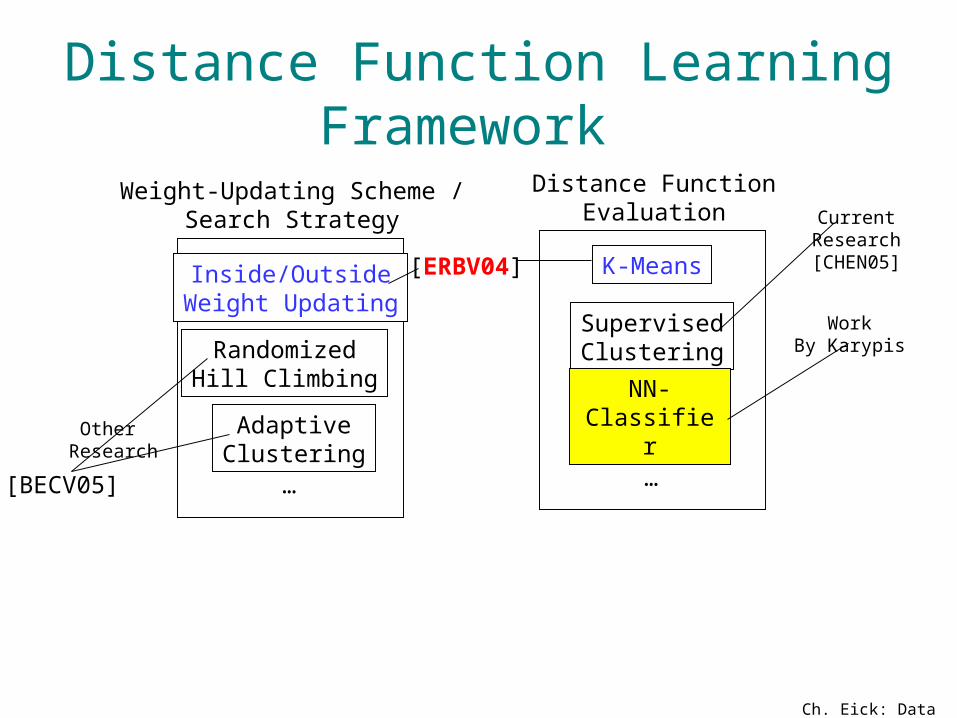
Distance Function Learning Framework
RandomizedHill Climbing
AdaptiveClustering
Inside/OutsideWeight Updating
K-Means
SupervisedClustering
NN-Classifier
Weight-Updating Scheme /Search Strategy
Distance FunctionEvaluation
… …
WorkBy Karypis
[BECV05]
Other Research
[ERBV04]
CurrentResearch[CHEN05]
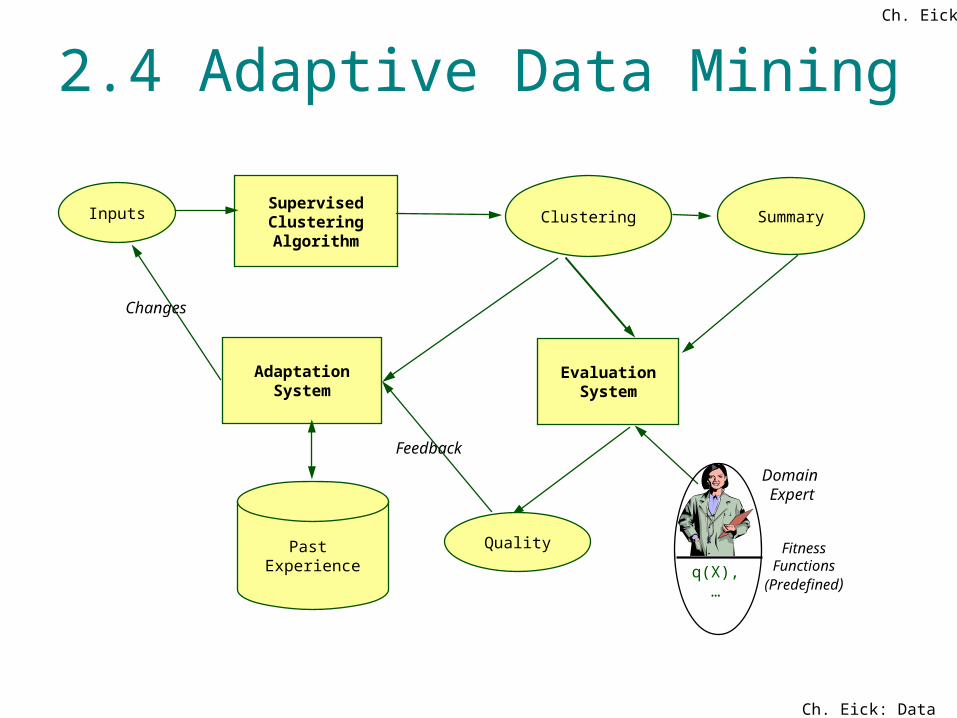
Ch. Eick: Data Mining
Supervised ClusteringAlgorithm
Inputs Clustering
Quality
AdaptationSystem
Changes
Past Experience
Feedback
EvaluationSystem
Summary
Domain Expert
q(X),…
FitnessFunctions
(Predefined)
2.4 Adaptive Data MiningCh. Eick

Ch. Eick: Data Mining
2.5 Signatures of Data SetsInput: a set of classified examplesOutput: Signatures in the dataset that characterize
1. how the examples of a class distribute (in relationship to the examples of the other classes) in the dataset
2. how many regions dominated by a single class exist in the data set3. which regions dominated by one class are bordering regions dominated by
another class?4. where are the regions, identified in step 2 and 3, located5. what are the density attactors (maxima of the density function) of the classes
in the data setWhy are we creating those signatures?– As a preprocessing step to develop smarter classifiers– To understand why a particular data mining techniques works well / do not work
well for a particular dataset meta learningMethods employed: density estimation techniques, supervised clustering, proximity
graphs (e.g. Delaunay, Gabriel graphs),…
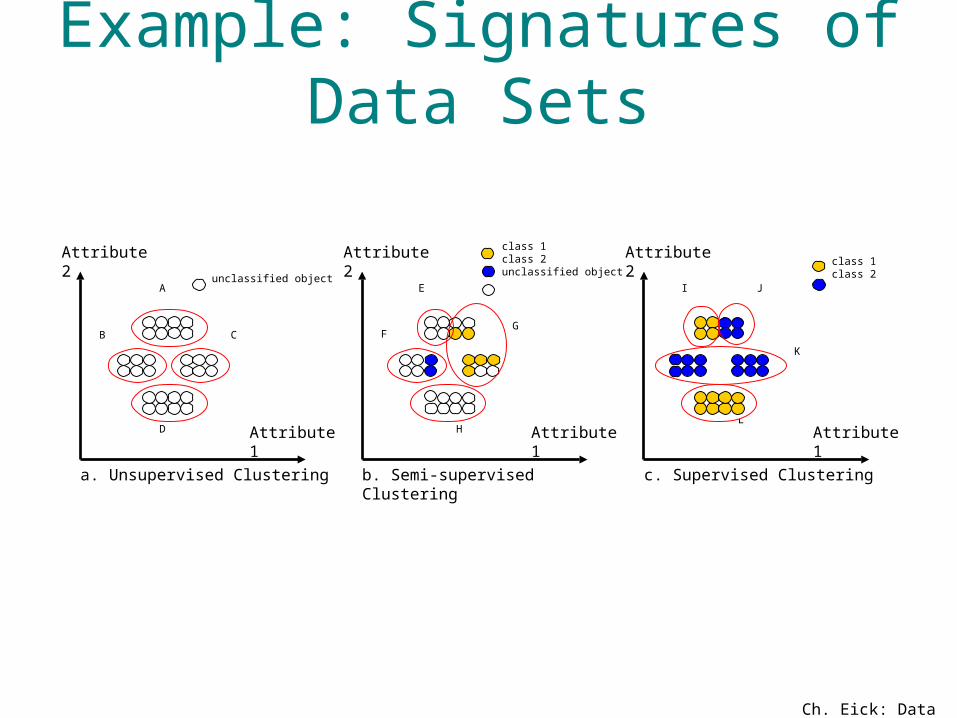
Ch. Eick: Data Mining
Example: Signatures of Data Sets
class 1class 2unclassified object
H
F
E
L
JI
D
c. Supervised Clusteringb. Semi-supervised Clusteringa. Unsupervised Clustering
CB
A
Attribute1 Attribute1Attribute1
Attribute2 Attribute2 Attribute2
K
unclassified object
class 1class 2
G
Ch. Eick: Data Mining
Attribute 1
Attribute 2
Attribute 1
Attribute 2
Attribute 2
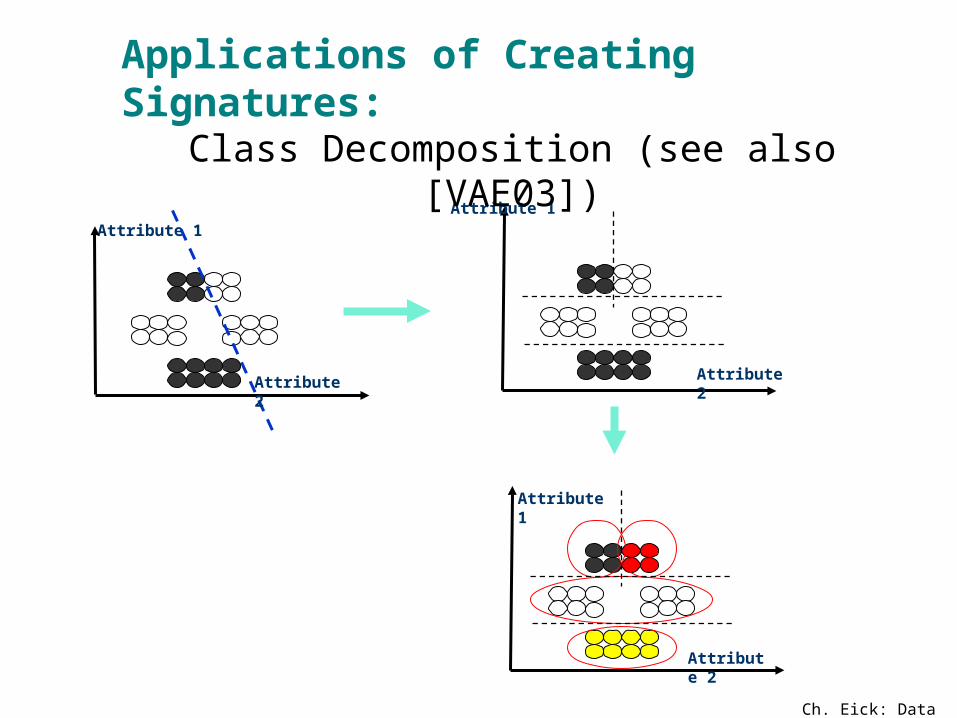
Applications of Creating Signatures:Class Decomposition (see also [VAE03])
Attribute 1

Ch. Eick: Data Mining
2.6 Research Christoph F. Eick 2005-2007
Measures of Interestingness
Clustering for Classification
Supervised ClusteringEditing /Data Set Compression
Spatial Data Mining Adaptive Clustering Distance FunctionLearning
Mining Data StreamsOnline Data MiningMining Sensor Data
Mining Semi-Structured DataWeb Annotation
File Prediction EvolutionaryComputing
Creating SignaturesFor Datasets

Ch. Eick: Data Mining
Goal: Development of data analysis and data mining techniques and the application of these techniques to challenging problems in physics, geology, astronomy, environmental sciences, and medicine.
Topics investigated:
Meta Learning Classification and Learning from Examples Clustering Distance Function Learning Using Reinforcement Learning for Data Mining Spatial Data Mining Knowledge Discovery
3. UH Data Mining and Machine Learning Group (UH-DMML) Co-Directors: Christoph F. Eick and Ricardo Vilalta
3. UH Data Mining and Machine Learning Group (UH-DMML) Co-Directors: Christoph F. Eick and Ricardo Vilalta