1 cache-conscious concurrency control of main-memory indexes on shared-memory multiprocessor systems...
TRANSCRIPT

1
Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems
By: Sang K. Cha, Sangyong Hwang, Kihong Kim and Kunjoo Kwon
Presenter: Kaloian Manassiev

2
Presentation Plan
Need for main-memory DBs Special considerations for in-memory operation Main-memory indexing structures and
concurrency control OLFIT Evaluation Conclusions

3
Main Memory DBMS Database resident in memory
Read transactions simply read the in-memory data. Update transactions do in-memory updates and write update log to the
log disk. Occasionally, checkpoint the dirty pages of the in-memory database to
the disk-resident backup DB to shorten the recovery time.
Backup DB
Primary DB
LoggingCheckpointing
Log
MMDBMS
Slide borrowed from time4change by Sang K. Cha

4
Q: Is Disk Database with large buffer the same as Main Memory Database?
No! Complex mapping between disk and memory
E.g., traversing index blocks in buffer requires bookkeeping the mapping between disk and memory addresses
Large Buffer
Database Log
recordData Blocks
Index Blocks
disk address
• Disk index block design is not optimized against hardware cache misses.
Slide borrowed from time4change by Sang K. Cha
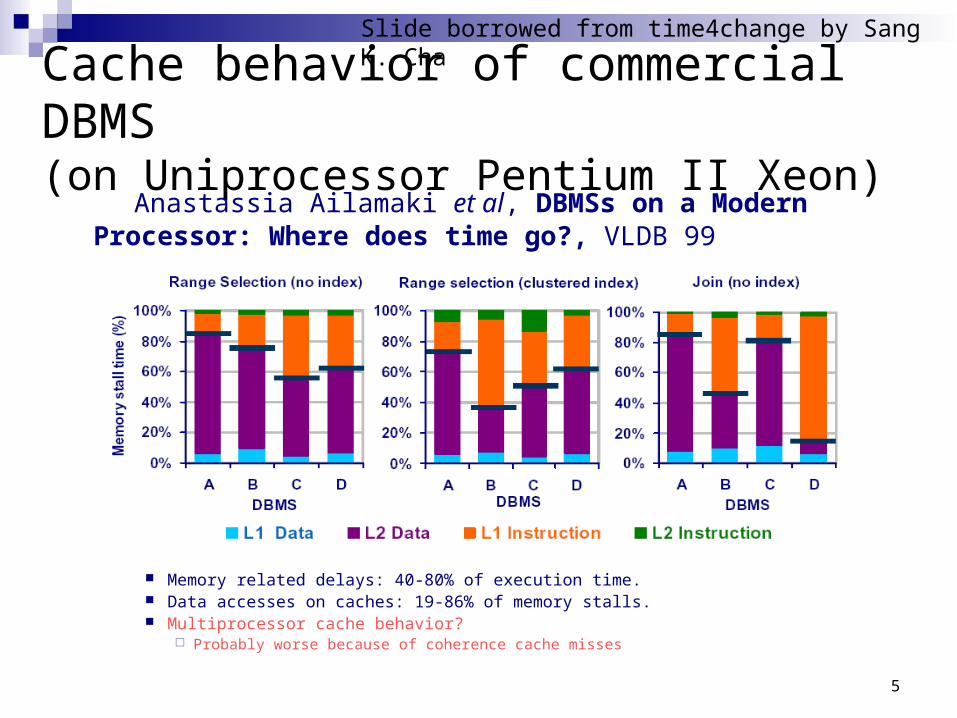
5
Cache behavior of commercial DBMS(on Uniprocessor Pentium II Xeon)
Memory related delays: 40-80% of execution time. Data accesses on caches: 19-86% of memory stalls. Multiprocessor cache behavior?
Probably worse because of coherence cache misses
Anastassia Ailamaki et al, DBMSs on a Modern Processor: Where does time go?, VLDB 99
Slide borrowed from time4change by Sang K. Cha

6
Main-memory database index structures Plain old B+-Tree – too much data stored
in the nodes => low fanout, which incurs cold and capacity cache misses

7
Main-memory database index structures (2) T-Tree – small amount of data stored in
the nodes, but traversal mainly touches the two end keys in the node => poor L2 cache utilisation
…
…

8
Main-memory database index structures (3) CSB+-Tree – keeps only one child pointer per
node and combines child nodes with a common parent into a group
Increased fanout, cache-conscious, reduces the cache miss rate and improves the search performance
23 4734 58
CSB+-tree:
Does not consider concurrent operations!

9
Concurrency control
Lock coupling

10
Concurrency control (2)
Blink-TreeRemoves the need for lock coupling by linking
each node to its right neighbour
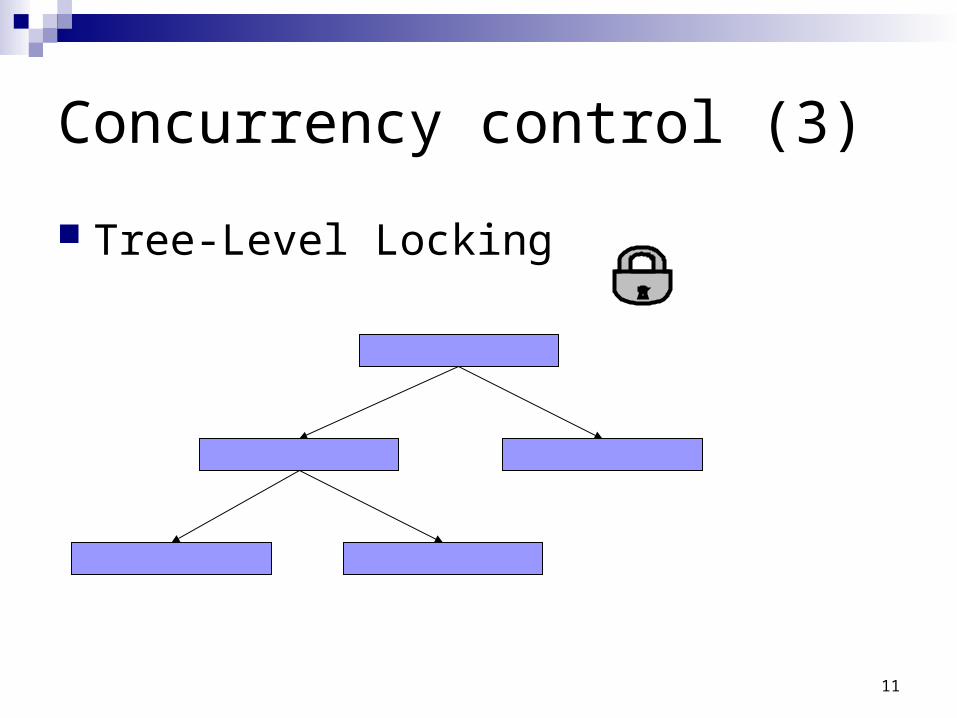
11
Concurrency control (3)
Tree-Level Locking

12
Concurrency control (4)
Physical VersioningUse Copy-On-Write so that updaters do
not interfere with concurrent readersSeverely limits the performance when
the update load is highNeeds garbage collection mechanism to
release the dead versions

13
OLFIT
Probability of update with 100% insert workload (10 Million keys)

14
OLFIT (1)
Node structure
CCINFO

15
OLFIT (2)
Node read

16
OLFIT (3)
Node update

17
OLFIT (4)
Node split
Node deletionRegisters the node into a garbage collector
?

18
Evaluation
Algorithms & parameters

19
Evaluation (1)
Search performance
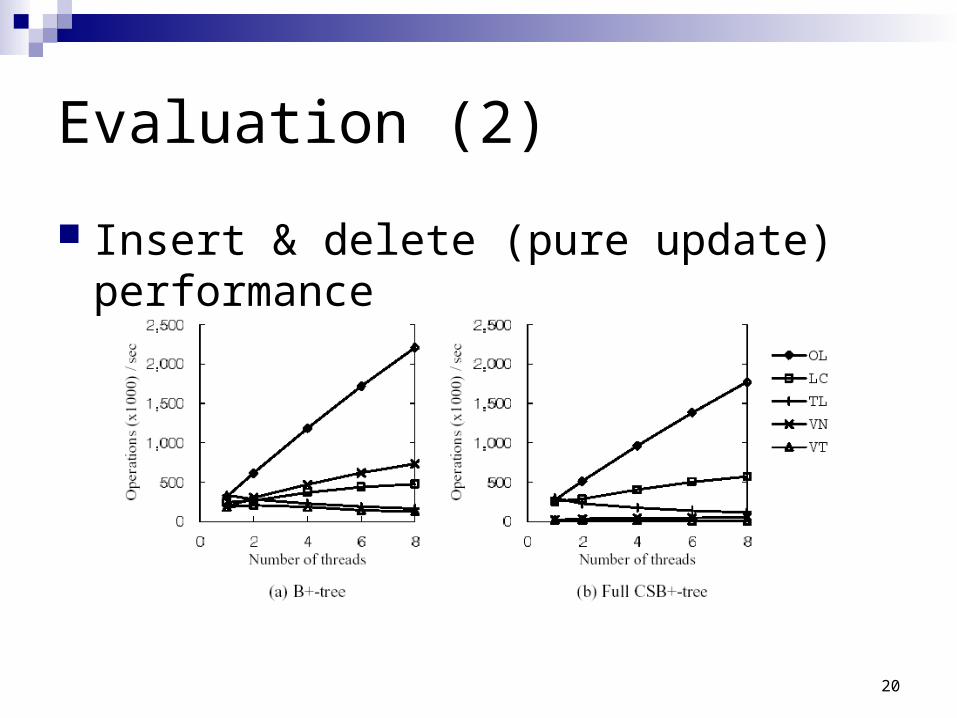
20
Evaluation (2)
Insert & delete (pure update) performance

21
Evaluation (2)
Varying update ratio performance (ST)

22
Evaluation (3)
Varying update ratio performance (MT)

23
Conclusions (pros)
Good algorithm, does not interfere with readers or other updaters
Minimises L2 cache misses Avoids operating system locking calls If used in a database, should put the
database transactional concurrency control on top of it

24
Conclusions (cons)
Uses busy waiting The evaluation only considers very small key
sizes, so busy waiting is not a problem It would be interesting and more validating to
see the performance of this algorithm when the key sizes are longer, as is the case with databases. Then, the cost of busy waiting and retries will be more pronounced

25
Questions?