xebicon'16 : utiliser le deep learning pour interpréter des photographies par yoann benoit,...
TRANSCRIPT

@xebiconfr #xebiconfr
Utiliser le Deep Learning
pour interpréter des photographies
YoannBenoit

@xebiconfr #xebiconfr
Le Deep Learning
1
2

@xebiconfr #xebiconfr
Reconnaissance d’images
3
1a

@xebiconfr #xebiconfr
Reconnaissance vocale
4
1b

#XebiConFr5

@xebiconfr #xebiconfr
Analyse de sentiments sur des photographies
2
6

@xebiconfr #xebiconfr
Mais pour quoi faire ?
7
2a
Nouveau plugin Google Photos ?
Satisfaction clients via vidéo ?

@xebiconfr #xebiconfr
Sur quoi nous entraîner ?
8
2b
Colère Tristesse

@xebiconfr #xebiconfr
Quelques exemples
9
2c
Surprise Joie

@xebiconfr #xebiconfr
Quelques chiffres
10
2d
Images 48x48 pixels Plus de 30 000 images labellisées
7 sentimentscolère, dégoût, peur, joie, tristesse,
surprise, neutre
Performance Humaine :Entre 60 et 65%

@xebiconfr #xebiconfr
En quoi ce problème est-il difficile ?
● Système visuel humain extrêmement complet
● L’être humain est très bon pour donner du sens à ce qu’il voit○ Mais ce travail est fait de manière
inconsciente
11
2e

@xebiconfr #xebiconfr
En quoi ce problème est-il difficile ?
● Très difficile d’exprimer de manière algorithmique ce qui permet de reconnaître une image
● Machine Learning○ Large échantillon d’images pour
lesquelles on connaît le label=> Apprentissage automatique de règles
12
2f

@xebiconfr #xebiconfr
Les Réseaux de Neurones
3
13

@xebiconfr #xebiconfr
De quoi est composé un Réseau de Neurones ?
14
3a
De neurones ...

@xebiconfr #xebiconfr
De quoi est composé un Réseau de Neurones ?
15
3a
De neurones ...
Associés en réseau …

@xebiconfr #xebiconfr
Comment fonctionne un Réseau de Neurones ?
16
3b
Softm
ax
Chaque neurone intermédiaire représente
une somme pondérée des valeurs des neurones de la
couche précédente, associés à une fonction
d’activation
La dernière couche (softmax) est une
normalisation de la couche de sortie afin que
les résultats correspondent à des probabilités
(sommant à 1)

@xebiconfr #xebiconfr
Tout est une histoire de matrices
17
3c
Y = xW + bclasses = softmax(Y)
[4, 2][1, 4][1, 2][2]

@xebiconfr #xebiconfr
Tout est une histoire de matrices
18
3d
Y = XW + bclasses = softmax(Y)
[4, 2][K, 4][K, 2]Avec des batches d’images ...
[2]

@xebiconfr #xebiconfr
Tout est une histoire de matrices
19
3e
Y = f(XW1 + b1) W2 + b2
classes = softmax(Y)
[3, 2][3][K, 2]
[2][K, 4][4, 3]
fonction d’activation

@xebiconfr #xebiconfr
Comment trouver les poids ?
20
3f
Back-propagation: Mise à jour des poids en fonction du gradient des erreurs, de la dernière couche à la première

@xebiconfr #xebiconfr
Comment trouver les poids ?
21
3f
Back-propagation: Mise à jour des poids en fonction du gradient des erreurs, de la dernière couche à la première

@xebiconfr #xebiconfr
Comment trouver les poids ?
22
3f
Back-propagation: Mise à jour des poids en fonction du gradient des erreurs, de la dernière couche à la première

@xebiconfr #xebiconfr
TensorFlow
● Framework de programmation open-sourcé par Google en 2016
● Aujourd’hui en version 0.11● APIs en Python, C++● Principalement utilisé pour l’entraînement et
l’utilisation de Réseaux de Neurones, et plus particulièrement pour le Deep Learning
23
3g
Aujourd’hui l’un des frameworks les plus utilisés pour le Deep Learning, avec une documentation très riche.

@xebiconfr #xebiconfr
Commençons simplement :SR
(Softmax Regression)
4
24

@xebiconfr #xebiconfr
Softmax Regression
25
4a

@xebiconfr #xebiconfr
Softmax Regression
26
4a
Inputs(= pixels)

@xebiconfr #xebiconfr
Softmax Regression
27
4a
Inputs(= pixels) Classes
(= sentiment)

@xebiconfr #xebiconfr
Softmax Regression
28
4a
Inputs(= pixels) Classes
(= sentiment)
Poids

@xebiconfr #xebiconfr
Softmax Regression - Résultats
29
4b
44.5%Nombre d'itérations
Prob
abili
té

@xebiconfr #xebiconfr 30

@xebiconfr #xebiconfr
Approfondissons un peu :TNN
(“Tiny Neural Network”)
5
31

@xebiconfr #xebiconfr
Tiny Neural Network
32
5a

@xebiconfr #xebiconfr
Tiny Neural Network
33
5a
Inputs(= pixels)
Classes(= sentiment)
Poids

@xebiconfr #xebiconfr
Tiny Neural Network
34
5a
Inputs(= pixels)
Classes(= sentiment)
Poids
Couche cachée / intermédiaire

@xebiconfr #xebiconfr
Softmax Regression - Résultats
35
5b
44.5%

@xebiconfr #xebiconfr
Tiny Neural Network - Résultats
36
5c
56%

@xebiconfr #xebiconfr 37

@xebiconfr #xebiconfr
Continuons sur notre lancée :MSNN
(“Medium Size Neural Network”)
6
38

@xebiconfr #xebiconfr
Medium Size Neural Network
39
6a

@xebiconfr #xebiconfr
Medium Size Neural Network
40
6a
Inputs(= pixels)
Classes(= sentiment)
Poids
Couches cachées

@xebiconfr #xebiconfr
Tiny Neural Network - Résultats
41
6b
56%

@xebiconfr #xebiconfr
Medium Size Neural Network - Résultats
42
6c
57.2%

@xebiconfr #xebiconfr 43

@xebiconfr #xebiconfr
Allons-y gaiement :BFNN
(“Big Fat Neural Network”)
7
44

@xebiconfr #xebiconfr
Big Fat Neural Network
45
7a

@xebiconfr #xebiconfr
Big Fat Neural Network
46
7a
Inputs(= pixels)
Classes(= sentiment)
Poids
Couches cachées
@xebiconfr #xebiconfr
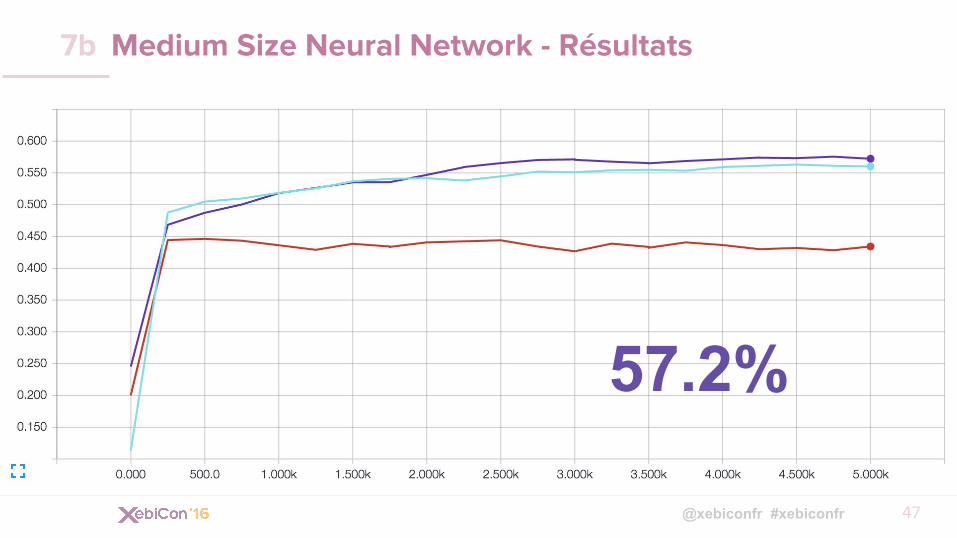
Medium Size Neural Network - Résultats
47
7b
57.2%

@xebiconfr #xebiconfr
Big Fat Neural Network - Résultats
48
7c
58.1%

@xebiconfr #xebiconfr 49

@xebiconfr #xebiconfr
Pourquoi les résultats ne s’améliorent pas ?
50
7e
● Normalement, un réseau plus profond permet d’apprendre des fonctions plus complexes
Mais ...● Différentes vitesses d’apprentissage des
poids selon les couches● La mise à jours des poids d’une couche
dépend de celle des poids de la couche suivante (back-propagation)

@xebiconfr #xebiconfr
Quelles solutions ?
51
7f
Changement d’architecture de réseau ?
Algorithme d’apprentissage plus avancé ?
Changement de fonction d’activation ?

@xebiconfr #xebiconfr
Nombre de paramètres à estimer
52
7g
2304 pixels * 7 poids + 7 biais
= 16 135
paramètres

@xebiconfr #xebiconfr
Nombre de paramètres à estimer
53
7g
2304*384 + 384+
384*7 + 7 =
887 815paramètres
2304 pixels * 7 poids + 7 biais
= 16 135
paramètres

@xebiconfr #xebiconfr
Nombre de paramètres à estimer
54
7g
2304*384 + 384+
384*7 + 7 =
887 815paramètres
2304*500 + 500 + 500*300 + 300 + 300*150 + 150 +
150*7 + 7=
1 349 007paramètres
2304 pixels * 7 poids + 7 biais
= 16 135
paramètres

@xebiconfr #xebiconfr
Nombre de paramètres à estimer
55
7g
2304*384 + 384+
384*7 + 7 =
887 815paramètres
2304*500 + 500 + 500*300 + 300 + 300*150 + 150 +
150*7 + 7=
1 349 007paramètres
2304*1000 + 1000 + 1000*750 + 750 + 750*500 + 500 + 500*300 + 300 + 300*150 + 150 +
150*7 + 7=
3 627 757paramètres
2304 pixels * 7 poids + 7 biais
= 16 135
paramètres

@xebiconfr #xebiconfr
Soyons plus intelligents :CNN
(Convolutional Neural Network)
8
56

@xebiconfr #xebiconfr
Réfléchissons un peu
57
8a
● Est-ce une bonne idée d’utiliser des réseaux de neurones où tous les neurones entre deux couches sont connectés entre eux ?
● Ce type de réseau ne prend pas en compte la structure spatiale de l’image

@xebiconfr #xebiconfr
Réfléchissons un peu
● Est-ce une bonne idée d’utiliser des réseaux de neurones où tous les neurones entre deux couches sont connectés entre eux ?
● Ce type de réseau ne prend pas en compte la structure spatiale de l’image
58
8a

@xebiconfr #xebiconfr
Réfléchissons un peu
59
8a
● Est-ce une bonne idée d’utiliser des réseaux de neurones où tous les neurones entre deux couches sont connectés entre eux ?
● Ce type de réseau ne prend pas en compte la structure spatiale de l’image

@xebiconfr #xebiconfr
Réfléchissons un peu
60
8a
● Est-ce une bonne idée d’utiliser des réseaux de neurones où tous les neurones entre deux couches sont connectés entre eux ?
● Ce type de réseau ne prend pas en compte la structure spatiale de l’image

@xebiconfr #xebiconfr
Réfléchissons un peu
61
8a
● Est-ce une bonne idée d’utiliser des réseaux de neurones où tous les neurones entre deux couches sont connectés entre eux ?
● Ce type de réseau ne prend pas en compte la structure spatiale de l’image

@xebiconfr #xebiconfr
Réfléchissons un peu
Peut-on trouver une architecture qui tire avantage de cette structure ?
62
8b

@xebiconfr #xebiconfr
Réfléchissons un peu
63
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
64
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
65
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
66
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
67
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
68
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
69
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
70
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
71
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Réfléchissons un peu
72
8b
Peut-on trouver une architecture qui tire avantage de cette structure ?

@xebiconfr #xebiconfr
Hypothèses principales
● Associations locales○ Tous les pixels ne sont pas connectés à tous les neurones
cachés○ Les connexions sont faites dans des petites zones localisées
de l’image
● Mêmes poids et biais pour tous les neurones d’une même couche○ Tous les neurones d’une même couche cachée détectent le
même pattern (ex : un coin)
● Pooling○ Souvent utilisés juste après une couche de convolution○ Condenser l’information autour d’une région (max/mean)
73
8c

@xebiconfr #xebiconfr
Première architecture utilisée
74
8d

@xebiconfr #xebiconfr
Première architecture utilisée
75
8d

@xebiconfr #xebiconfr
Première architecture utilisée
76
8d
ConvolutionsCouche dense

@xebiconfr #xebiconfr
Big Fat Neural Network - Résultats
77
8e
58.1%

@xebiconfr #xebiconfr
Convolutional Neural Network 1 - Résultats
78
8f
62.8%

@xebiconfr #xebiconfr 79

@xebiconfr #xebiconfr
Deuxième architecture utilisée
80
8h

@xebiconfr #xebiconfr
Deuxième architecture utilisée
81
8h

@xebiconfr #xebiconfr
Deuxième architecture utilisée
82
8h

@xebiconfr #xebiconfr
Deuxième architecture utilisée
83
8h
Convolutions Couche denseConvolutions

@xebiconfr #xebiconfr
Convolutional Neural Network 1 - Résultats
84
8i
62.8%

@xebiconfr #xebiconfr
Convolutional Neural Network 2 - Résultats
85
8j
64.7%

@xebiconfr #xebiconfr 86

@xebiconfr #xebiconfr
Take Aways
9
87

@xebiconfr #xebiconfr
BE SMART!
● Exploiter au mieux la structure de vos données.
● Certaines architectures sont plus adaptées pour les images, d’autres pour le texte, etc.

@xebiconfr #xebiconfr
TEST AND LEARN!
● Pas de règles absolues sur les structures de réseaux de neurones qui fonctionnent le mieux.
● Tester intelligemment différentes structures et essayer de comprendre pourquoi l’une fonctionne mieux que l’autre.

@xebiconfr #xebiconfr
DO NOT REINVENT THE WHEEL!
● L’écosystème autour du Deep Learning est en croissance continue.
● De plus en plus de frameworks sont disponibles et bien documentés (TensorFlow, Keras, etc.).
● Commencer avec des exemples connus puis se perfectionner par rapport aux données à disposition.

@xebiconfr #xebiconfr
HAVE FUN!
● Introduction à TensorFlow - Martin Görner (Google)
https://docs.google.com/presentation/d/1TVixw6ItiZ8igjp6U17tcgoFrLSaHWQmMOwjlgQY9co/pub?start=false&loop=false&delayms=3000
● Neural Networks and Deep Learning - Online Book
http://neuralnetworksanddeeplearning.com/
● TensorFlow documentationhttps://www.tensorflow.org/

@xebiconfr #xebiconfr
MERCI =)