web mining in the cloud hadoop/cascading/bixo in ec2 ken krugler, bixo labs, inc. acm data mining...
TRANSCRIPT

QuickTime™ and a decompressor
are needed to see this picture.

Web Mining in the CloudHadoop/Cascading/Bixo in EC2
Ken Krugler, Bixo Labs, Inc.
ACM Data Mining SIG
08 December 2009
QuickTime™ and a decompressor
are needed to see this picture.

About me
Background in vertical web crawl– Krugle search engine for open source code– Bixo open source web mining toolkit
Consultant for companies using EC2– Web mining– Data processing
Founder of Bixo Labs– Elastic web mining platform– http://bixolabs.com

Typical Data Mining

Data Mining Victory!

Meanwhile, Over at McAfee…

Web Mining 101
Extracting & Analyzing Web Data
More Than Just Search
Business intelligence, competitive
intelligence, events, people, companies,
popularity, pricing, social graphs, Twitter
feeds, Facebook friends, support forums,
shopping carts…

4 Steps in Web Mining
Collect - fetch content from web
Parse - extract data from formats
Analyze - tokenize, rate, classify, cluster
Produce - “useful data”

Web Mining versus Data Mining
Scale - 10 million isn’t a big number
Access - public but restricted– Special implicit rules apply
Structure - not much

How to Mine Large Scale Web Data?
Start with scalable map-reduce platform
Add a workflow API layer
Mix in a web crawling toolkit
Write your custom data processing code
Run in an elastic cloud environment

One Solution - the HECB Stack
Bixo
Cascading
Hadoop
EC2
QuickTime™ and a decompressor
are needed to see this picture.

EC2 - Amazon Elastic Compute Cloud
True cost of non-cloud environment– Cost of servers & networking (2 year life)– Cost of colo (6 servers/rack)– Cost of OPS salary (15% of FTE/cluster)– Managing servers is no fun
Web mining is perfect for the cloud– “bursty” => savings are even greater– Data is distilled, so no transfer $$$ pain

Why Hadoop?
Perfect for processing lots of data– Map-reduce– Distributed file system
Open source, large community, etc.
Runs well in EC2 clusters
Elastic Map Reduce as option

Why Cascading?
API on top of Hadoop
Supports efficient, reliable workflows
Reduces painful low-level MR details
Build workflow using “pipe” model

Why Bixo?
Plugs into Cascading-based workflow– Scales with Hadoop cluster– Rules well in EC2
Handles grungy web crawling details– Polite yet efficient fetching– Errors, web servers that lie– Parsing lots of formats, broken HTML
Open source toolkit for web mining apps

SEO Keyword Data Mining
Example of typical web mining task
Find common keywords (1,2,3 word
terms)– Do domain-centric web crawl– Parse pages to extract title, meta, h1, links– Output keywords sorted by frequency
Compare to competitor site(s)
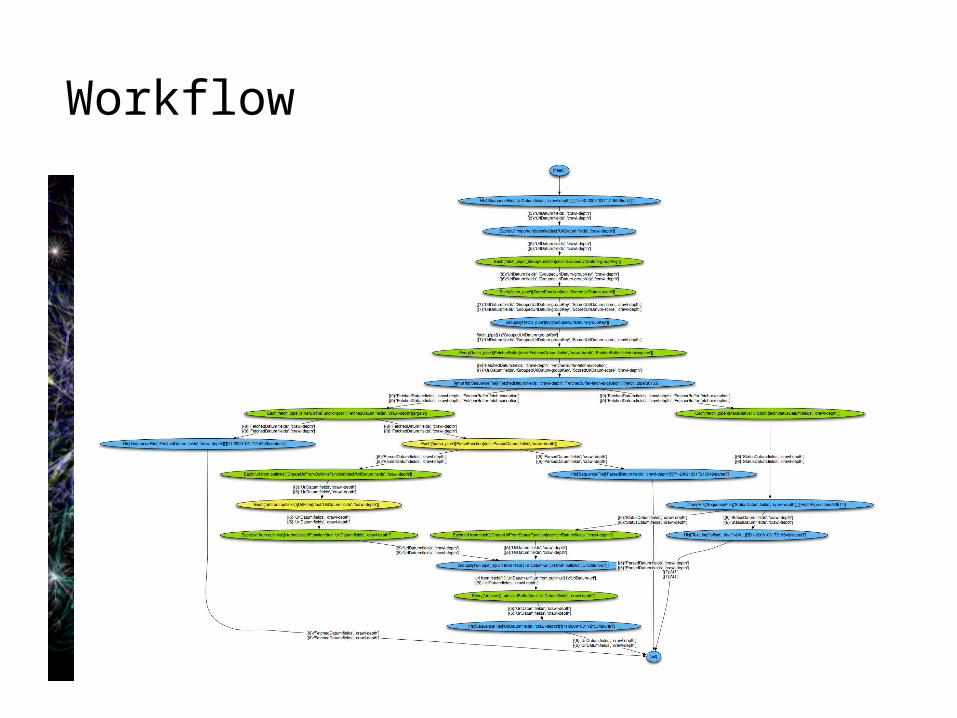
Workflow

Custom Code for Example
Filtering URLs inside domain– Non-English content– User-generated content (forums, etc)
Generating keywords from text– Special tokenization– One, two, three word phrases
But 95% of code was generic

End Result in Data Mining Tool

What Next?
Another example - mining mailing lists
Go straight to Summary/Q&A
Talk about Web Scale Mining
Write tweets, posts & emails
“No minute off-line goes unpunished”

Another Example - HUGMEE
HadoopUsers whoGenerate theMostEffectiveEmails

Helpful Hadoopers
Use mailing list archives for data (collect)
Parse mbox files and emails (parse)
Score based on key phrases (analyze)
End result is score/name pair (produce)

Scoring Algorithm
Very sophisticated point system
“thanks” == 5
“owe you a beer” == 50
“worship the ground you walk on” == 100

High Level Steps
Collect emails– Fetch mod_mbox generated page– Parse it to extract links to mbox files– Fetch mbox files– Split into separate emails
Parse emails– Extract key headers (messageId, email, etc)– Parse body to identify quoted text

High Level Steps
Analyze emails– Find key phrases in replies (ignore signoff)– Score emails by phrases– Group & sum by message ID– Group & sum by email address
Produce ranked list– Toss email addresses with no love– Sort by summed score

Workflow

Building the Flow

mod_mbox Page

Custom Operation

Validate

This Hug’s for Ted!

Produce
Back

Web Scale Mining
Bigger Data– 100M pages versus 1M pages
Bigger Breadth– 100K domains versus 1K domains
Bigger Clusters– 50 servers versus 5 servers

Web Scale == Endless Heuristics
Document features detection– Charset– Mime-type– Language– Many noisy sources of “truth”
Duplicates detection– Quest for the perfect hash function
Spam/porn/link farm detection

Web Scale == Challenges
All web servers lie
Edge cases ad nauseam
Avoiding spam/porn/junk
Focusing on English content
Scaling to 100K domains/100M pages– Avoid bottlenecks
– Fix large cluster issues

Public Terabyte Dataset
Sponsored by Concurrent/Bixolabs
High quality crawl of top domains– HECB Stack using Elastic Map Reduce
Hosted by Amazon in S3, free to EC2 users
Crawl & processing code available
Questions, input? http://bixolabs.com/PTD/

Web Scale Case Study - PTD Crawl
Robots.txt - Robot Exclusion Protocol– Not a real standard, lots of extensions
– Many ways to mess it up (HTML, typos, etc)
Great performance when all is well– 25K pages/minute fetching
– 50K pages/minute parsing
Hadoop 0.18.3 vs. 0.19.2– Different APIs, behavior, bugs
– At painful cluster tuning stage


Large Scale Web Mining Summary
10K is easy, 100M is hard– You encounter endless edge cases– There’s always another bottleneck– Cluster tuning is challenging
Web mining toolkit approach works– Easier to customize/optimize– Easier to solve problems
Back

Summary
HECB stack works well for web mining– Cheaper than typical colo option– Scales to hundreds of millions of pages– Reliable and efficient workflow
Web mining has high & increasing value– Search engine optimization, advertising– Social networks, reputation– Competitive pricing– Etc, etc, etc.

Any Questions?
My email:
Bixo mailing list:
http://tech.groups.yahoo.com/group/bixo-dev/

QuickTime™ and a decompressor
are needed to see this picture.