vmugit uc 2013 - 08a vmware hadoop
TRANSCRIPT

© 2009 VMware Inc. All rights reserved
Confidential © 2011 VMware Inc. All rights reserved © 2013 VMware Inc. All rights reserved
Big Data – Pivotal Hadoop

Agenda
q New Approach for Managing Data
q Big Data - Our Vision
q Pivotal Hadoop
q Data Direct for Hadoop (Serengeti)
q Real-Time Hadoop Business Analytics (Cetas)

Agenda
q New Approach for Managing Data
q Big Data - Our Vision
q Pivotal Hadoop
q Data Direct for Hadoop (Serengeti)
q Real-Time Hadoop Business Analytics (Cetas)
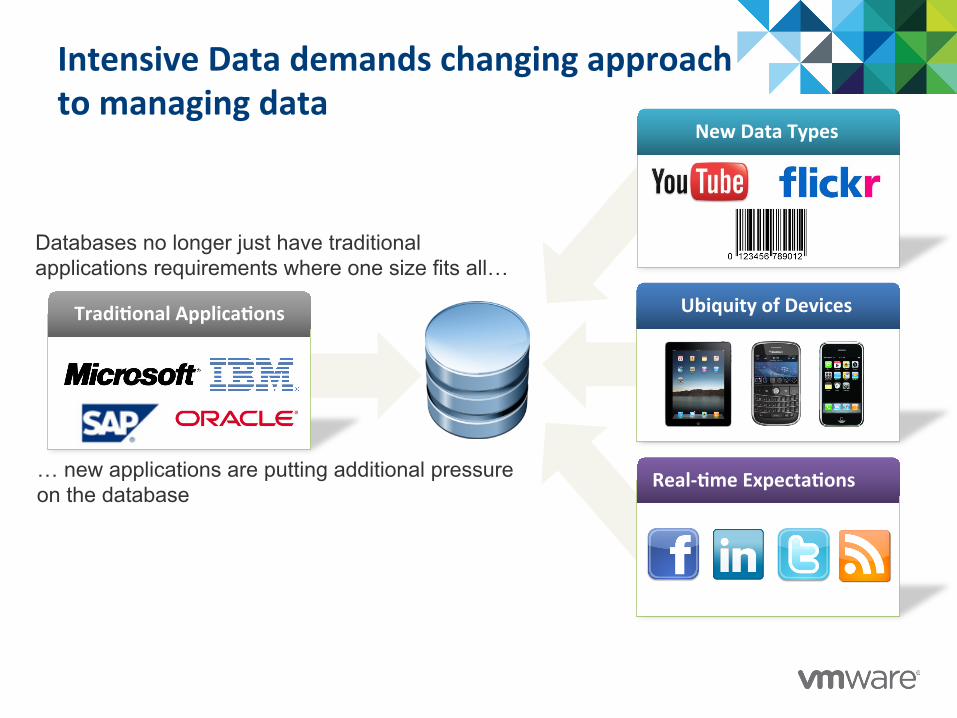
Intensive Data demands changing approach to managing data
Ubiquity of Devices
New Data Types
Real-‐@me Expecta@ons
Tradi@onal Applica@ons
Databases no longer just have traditional applications requirements where one size fits all…
… new applications are putting additional pressure on the database

The Database is Being Stretched
§ Petabytes vs. Gigabytes
§ Democratize BI
“Big data in general is defined as high volume, velocity and variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and
decision making.”
“Techniques and technologies that make capturing value from data at an extreme scale economical.”
Big Data

The Database is Being Stretched
Big Data
§ Petabytes vs. Gigabytes
§ Democratize BI
Fast Data § Low latency expectations § Horizontal scale

The Database is Being Stretched
Big Data Flexible Data
§ Petabytes vs. Gigabytes
§ Democratize BI
§ Multi-structured data § Developer productivity
Fast Data § Low latency expectations § Horizontal scale

Agenda
q New Approach for Managing Data
q Big Data - Our Vision
q Pivotal Hadoop
q Data Direct for Hadoop (Serengeti)
q Real-Time Hadoop Business Analytics (Cetas)

What is Hadoop?
§ Apache Open Source Project § Hadoop Core includes:
– Distributed File System (HDFS) ▪ Stores and distributes data
– Map/Reduce ▪ Distributes application and
processing of data
§ Written in Java § Runs on:
– Linux, Mac OS/X, Windows, and Solaris
– Commodity hardware

Why is Hadoop Important?
1. Hadoop reduces the cost of storing & processing data to a point that keeping all data, indefinitely is suddenly a very real possibility – AND – that cost is halving every 18 months
2. MapReduce makes developing & executing massively parallel data processing tasks trivial compared to historical alternatives (e.g. HPC / Grid)
3. Schema on Read paradigm shifts typical data preparation complexity to analysis phase rather than acquisition phase
The cost and effort to consume and extract value from data has been fundamentally changed
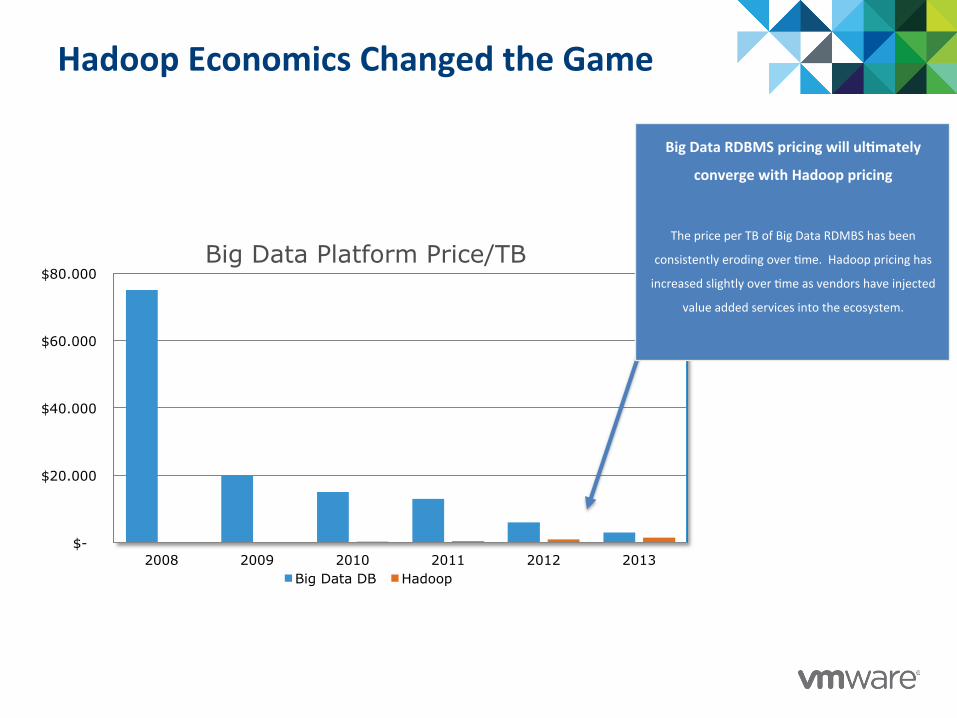
Hadoop Economics Changed the Game
$-
$20.000
$40.000
$60.000
$80.000
2008 2009 2010 2011 2012 2013
Big Data Platform Price/TB
Big Data DB Hadoop
Big Data RDBMS pricing will ul@mately
converge with Hadoop pricing
The price per TB of Big Data RDMBS has been
consistently eroding over :me. Hadoop pricing has
increased slightly over :me as vendors have injected
value added services into the ecosystem.
Hadoop Massive adop@on
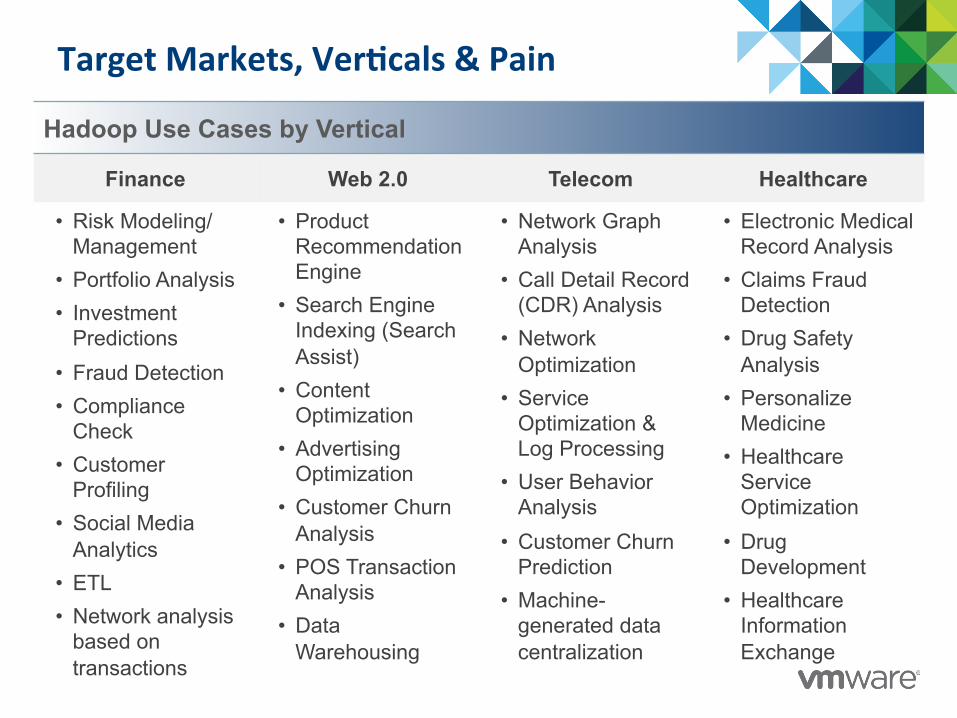
Target Markets, Ver@cals & Pain
Hadoop Use Cases by Vertical
Finance Web 2.0 Telecom Healthcare
• Risk Modeling/Management
• Portfolio Analysis • Investment
Predictions • Fraud Detection • Compliance
Check • Customer
Profiling • Social Media
Analytics • ETL • Network analysis
based on transactions
• Product Recommendation Engine
• Search Engine Indexing (Search Assist)
• Content Optimization
• Advertising Optimization
• Customer Churn Analysis
• POS Transaction Analysis
• Data Warehousing
• Network Graph Analysis
• Call Detail Record (CDR) Analysis
• Network Optimization
• Service Optimization & Log Processing
• User Behavior Analysis
• Customer Churn Prediction
• Machine-generated data centralization
• Electronic Medical Record Analysis
• Claims Fraud Detection
• Drug Safety Analysis
• Personalize Medicine
• Healthcare Service Optimization
• Drug Development
• Healthcare Information Exchange

Our Big Bets for the Future
1. HDFS becomes the data substrate for the next genera:on of data infrastructures
2. A set of integrated, enterprise-‐scale services will evolve on top of HDFS – stream inges:on, analy:cal processing, and transac:onal serving
3. Provisioning flexibility and elas:city become cri:cal capabili:es for this data infrastructure
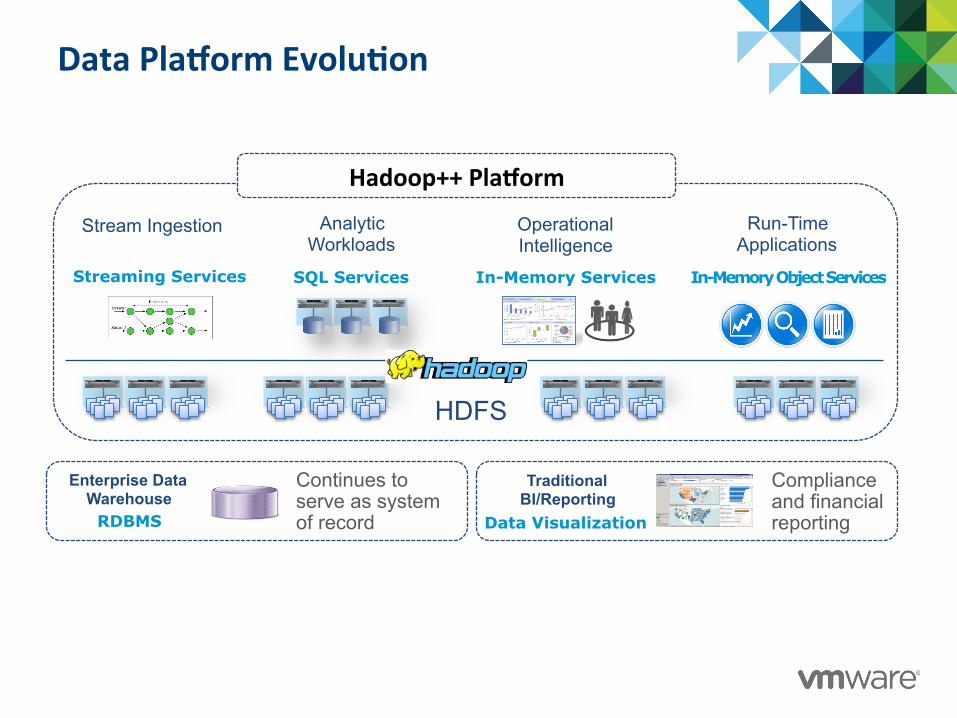
Data PlaRorm Evolu@on
Analytic Workloads
SQL Services
Operational Intelligence
In-Memory Services
Run-Time Applications
In-Memory Object Services
Stream Ingestion
Enterprise Data Warehouse RDBMS
Continues to serve as system of record
HDFS
Streaming Services
Data Visualization
Compliance and financial reporting
Traditional BI/Reporting
Hadoop++ PlaRorm
Data Visualization

Mul@-‐Target Deployment Model
deploy Public Cloud
Private Cloud
On Premise
Portable
Elastic
Promotable
HW abstracted
Manageable

Agenda
q New Approach for Managing Data
q Big Data - Our Vision
q Pivotal Hadoop
q Data Direct for Hadoop (Serengeti)
q Real-Time Hadoop Business Analytics (Cetas)

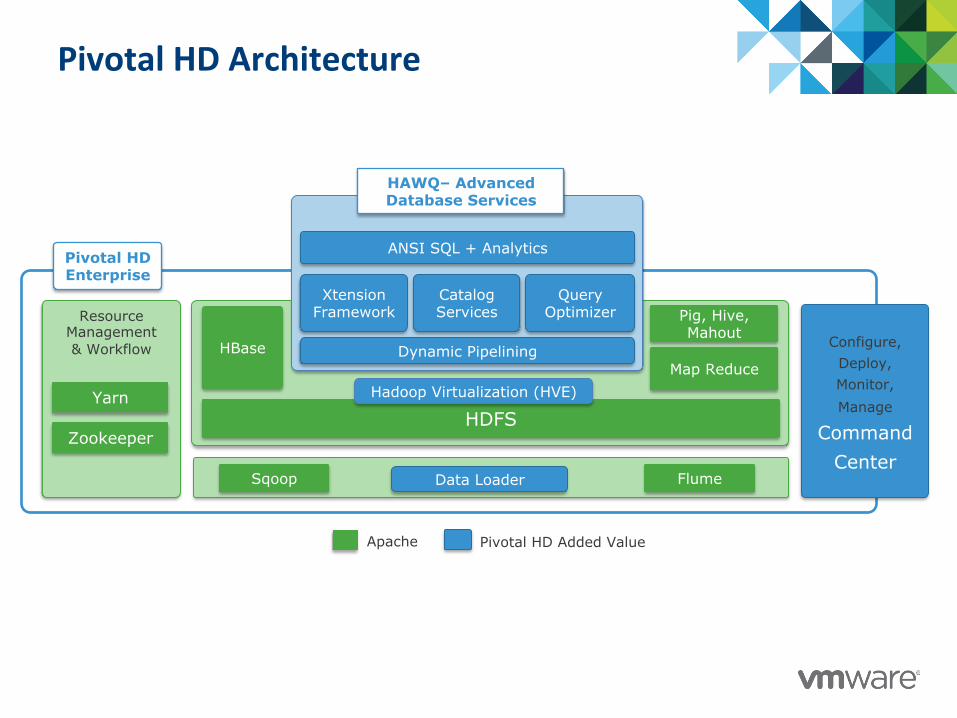
Pivotal HD Architecture
HDFS
HBase
Pig, Hive, Mahout
Map Reduce
Sqoop Flume
Resource Management & Workflow
Yarn
Zookeeper
Apache Pivotal HD Added Value
Configure, Deploy, Monitor, Manage
Command Center
Hadoop Virtualization (HVE)
Data Loader
Pivotal HD Enterprise
Xtension Framework
Catalog Services
Query Optimizer
Dynamic Pipelining
ANSI SQL + Analytics
HAWQ– Advanced Database Services

HAWQ: The Crown Jewels of Greeplum
q High-‐Performance Query Processing § Mul:-‐petabyte scalability § Interac:ve and true ANSI SQL support § Programmable analy:cs
q Enterprise-‐Class Database Services • Column storage and indexes • Workload Management
q Comprehensive Data Management § ScaTer-‐Gather Data Loading § Mul:-‐level Par::oning § 3rd Party Tool & Open Client Interfaces
10+ Years Massively Parallel Database R&D to Hadoop

HAWQ Benchmarks
User intelligence 4.2 198
Sales analysis 8.7 161
Click analysis 2.0 415
Data explora:on 2.7 1,285
BI drill down 2.8 1,815
47X
19X
208X
476X
648X
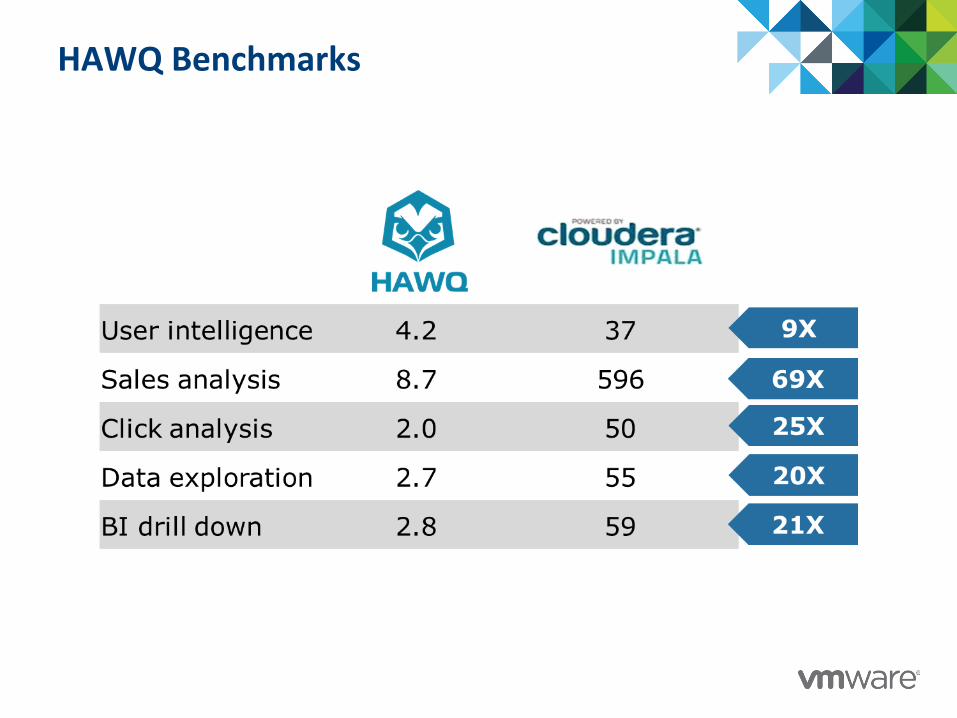
HAWQ Benchmarks

This Changes Everything
§ TRUE SQL interfaces for data workers and data tools § Broad range of data format support – operate on data-‐in-‐place or op:mize
for query response :me § Single Hadoop infrastructure for Big Data inves:ga:on AND analysis

World’s Largest Hadoop Engineering Team
q Over 300 engineers commiTed to embracing and extending Hadoop plaborm
q Deep innova:on bets across: § HDFS/Storage § SQL Processing § Management & Opera:ons § Analy:cs § Data Management & Catalog § Workload & Resource
Management
q Deep technical leadership from:
§ Yahoo
§ Microsof
§ Amazon
§ Neblix
§ HortonWorks
§ Oracle
§ Teradata
§ IBM
§ VMWare

Core Hadoop Components
q HDFS – The Hadoop Distributed File System acts as the storage layer for Hadoop
q MapReduce – Parallel processing framework used for data computa:on in Hadoop
q Hive – Structured, data warehouse implementa:on for data in HDFS that provides a SQL-‐like interface to Hadoop
q Sqoop – Batch database to Hadoop data transfer framework
q Flume – Data collec:on loading u:lity
q Pig – High-‐level procedural language for data pipeline/data flow processing in Hadoop
q HBase – NoSQL, key-‐value data store on top of HDFS
q Mahout – Library of scalable machine-‐learning Algorithms
q Spring Hadoop – Integrates the Spring framework into Hadoop

Pivotal HD Enterprise with ADS (HAWQ)
q Core Hadoop Components
q Installa@on and Configura@on Manager (ICM) – cluster installa:on, upgrade, and expansion tools.
q GP Command Center – visual interface for cluster health, system metrics, and job monitoring.
q Hadoop Virtualiza@on Extension (HVE) – enhances Hadoop to support virtual node awareness and enables greater cluster elas:city.
q GP Data Loader – parallel loading infrastructure that supports “line speed” data loading into HDFS.
q Isilon Integra@on – extensively tested at scale with guidelines for compute-‐heavy, storage-‐heavy, and balanced configura:ons.
q Advanced Database Services (HAWQ) – high-‐performance, “True SQL” query interface running within the Hadoop cluster.
§ Xtensions Framework – support for ADS interfaces on external data providers (HBase, Avro, etc.).
§ Advanced Analy@cs Func@ons (MADLib) – ability to access parallelized machine-‐learning and data-‐mining func:ons at scale.
§ Unified Storage Services (USS) and Unified Catalog Services (UCS) – support for :ered storage (hot, warm, cold) and integra:on of mul:ple data provider catalogs into a single interface.

Leveraging Full Power of the Family

Agenda
q New Approach for Managing Data
q Big Data - Our Vision
q Pivotal Hadoop
q Data Direct for Hadoop (Serengeti)
q Real-Time Hadoop Business Analytics (Cetas)

Data Director for Hadoop – 1/3
q Project Serengeti - Open Source project initiated by VMware to enable rapid deployment of a Hadoop cluster (HDFS, MapReduce, Pig, Hive) on a virtual platform
q Data Director for Hadoop – Commercial product

Data Director for Hadoop – 2/3
More comprehensive feature-set than the Web console, and provides a greater degree of control of the system
CLI console serengeti> cluster create --name dcsep serengeti> cluster list name: dcsep, distro: apache, status: RUNNING NAME ROLES INSTANCE CPU MEM(MB) TYPE ----------------------------------------------------------------------------- master [hadoop_namenode, hadoop_jobtracker] 1 6 2048 LOCAL 10 data [hadoop_datanode] 1 2 1024 LOCAL 10 compute [hadoop_tasktracker] 8 2 1024 LOCAL 10 client [hadoop_client, pig, hive] 1 1 3748 LOCAL 10

HVE on topology changes for virtualized plaRorm
• D = data center
• R = rack
• N = node group
• H = host
H1 H2 H3 H4 H5 H6 H7 H8 H9 H10 H11 H12
R1 R2 R3 R4
D1 D1
/
N1 N2 N3 N4 N5 N6 N7 N8
H13

Hadoop Virtualiza@on Extensions (HVE)
PIVOTAL HD is the only Hadoop distribution that natively integrates HVE.
BACKGROUND
§ Project HVE is an open source project managed by VMware data team
§ Delivers patches to the Apache Open Source community
§ Goal of HVE is to refine Hadoop for running on virtualized infrastructure
WHAT HVE BRINGS TO HADOOP
§ Network topology – adds addi:onal “NodeGroup” layer for physical host
§ Replica Placement Policy – verifies no two replicas are placed on 2 VMs within the same physical host
§ Balancer Policy – Automated balancing between VMs on the same host
§ Task Scheduling Policy – Define NodeGroup-‐level locality and determine priority between node-‐level and rack-‐level
BENEFITS
Will enable compute/data node separa3on without losing locality
§ Current Hadoop 3-‐:er network topology not ideal for virtual deployments (Data center à Rack à Host)
§ HVE enables Hadoop to support mul:ple-‐layer network topology for more effec:ve virtual deployments (Data center à Rack à NodeGroup à Host)
§ Higher u:liza:on through shared resources
§ Faster on-‐demand access through elas:c resources

Agenda
q New Approach for Managing Data
q Big Data - Our Vision
q Pivotal Hadoop
q Data Direct for Hadoop (Serengeti)
q Real-Time Hadoop Business Analytics (Cetas)

Real-‐Time Hadoop Business Analy@cs Cetas – 1/3 q Extend the capabilities (and the offering) with a Real-Time Analytics As
A Service q Business users in SMB and Large Enterprises can leverage Cetas
Analytics to automatically extract actionable business insights:
q Data Classification and Machine learning algorithms for data analytics that is Innovative and state-of-the-art
q Rich Platform for Data Modeling & Predictive Analytics
q Provides birds-eye view and detailed drill down of business from Big data
q Easy to use interface for business users, analysts, data scientists, and data engineers
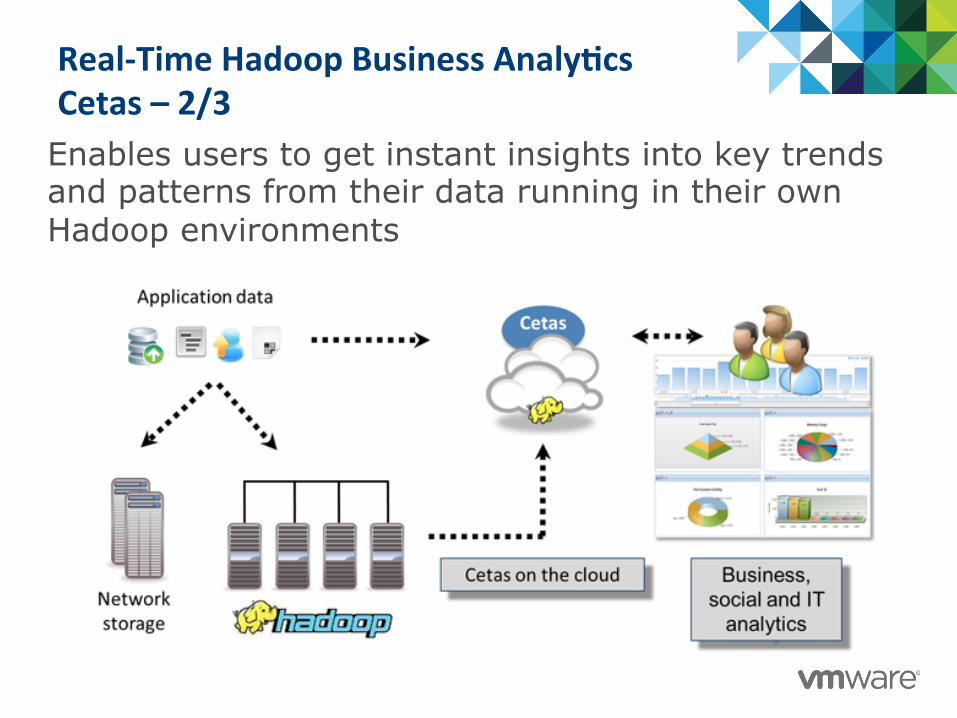
Real-‐Time Hadoop Business Analy@cs Cetas – 2/3 Enables users to get instant insights into key trends and patterns from their data running in their own Hadoop environments

Real-‐Time Hadoop Business Analy@cs Cetas 3/3 Ability to leverage existing Hadoop deployments and other data streams and provide a single analytics processing

Thank You!