· web view4.7.2 robot exclusions and relative privacy austlii has a responsibility not to...
TRANSCRIPT

The Journal of Information, Law and Technology
The AustLII Papers - New Directions in Law via the InternetGraham Greenleaf, Andrew Mowbray and Geoffrey King
With contributions from Simon Cant, Kirsty Magarey, Tim Moore, Daniel Austin, Philip Chung, Trina Cairns and David Irvine of AustLII
****************************************
Graham Greenleaf, Associate Professor in Law and Co-Director of AustLII, University of New South Wales ([email protected])
Andrew Mowbray, Senior Lecturer in Law and Co-Director of AustLII, University of Technology, Sydney ([email protected])
Geoffrey King, Lecturer in Law and Manager of AustLII, University of Technology, Sydney ([email protected])
This is a refereed published on 30 June 1997
Citation: Greenleaf et al, ‘Greenleaf G et al, 'The AustLII Papers - New Directions in Law via the Internet', 1997 (2) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/jilt/leginfo/97_2gree/>

AbstractAustLII is a University-based organisation specialising in research and teaching in computerisation of law, and which operates one of the largest free law sites on the web. This collection of papers provides an account of the development and operation of AustLII’s first two years of providing free public access to Australian law, and an overview of new directions in AustLII’s work. While the papers constitute a coherent whole and have been published here as a single article, each paper describes a distinct aspect of AustlII’s work and we have therefore used the terminology of ‘paper’ to signify this distinct character.
The papers cover the following topics:
1. AustLII’s roles, which provides a general introduction to AustLII’s work including the databases and technical issues.
2. Managing large scale hypertext databases provides a detailed description of the technical aspects of AustLII’s work including database management, search engine and automation of hypertext markup.
3. Indexing Law on the Internet describes the indexing mechanisms developed and used by AustLII.
4. The Politics of Public Legal Information describes the ‘political’ issues involved in securing the datasets, the development of principles of providing free and effective access to public information and financing of the AustLII project.
5. New legal services via the web - AustLII’s research on legal inferencing describes the research and development work on legal inferencing to provide ‘expert’ legal services linked to the AustLII database.
6. Indigenous Peoples’ Legal Issues via Internet describes AustLII’s work on developing a dataset on aboriginal materials and attempts to communicate this data effectively to both indigenous and non-indigenous communities including remote communities as part of a project on reconciliation and social justice.
Keywords: electronic legal information, Australian World Wide Web, indigenous people, legal education, legal research, legal information, search engine, hypertext markup, indexing on the Internet, managing large hypertext of databases, web based legal services, access to legal information.


1. AustLII’s rolesAustLII is a University-based organisation specialising in research and teaching in
computerisation of law, and which operates one of the largest free law sites on the web.
1.1 Two years of free public access to law, 1995-97The Australasian Legal Information Institute (AustLII - http://www.austlii.edu.au/) came into reality in July 19951 when it provided legislation (Australian Commonwealth Consolidated Statutes), case law (High Court decisions), and indexes (‘Australian Law on the Net’) via the Internet. These papers presented at AustLII’s first Conference on law on the Internet (25-27 June 1997) provide a collection of papers on AustLII’s first two years of providing free public access to Australian law, and an overview of new directions in AustLII’s work. This introduction provides background to AustLII and covers some other matters not dealt with in the conference papers.
AustLII is a joint facility of the Law Faculties of the University of Technology, Sydney (UTS), and the University of New South Wales (UNSW). It has two part-time Co-Directors2, a full-time staff of six3, and a number of part-time employees and research associates4. AustLII’s primary materials staff and servers are located at UTS, and secondary materials and special projects staff are at UNSW, though these divisions are flexible. AustLII’s management team (its Co-Directors and Manager) are jointly responsible for AustLII’s overall direction, supported by a Management Committee with three other academic members5.
1.2 What is AustLII? - more than a web siteAustLII is best known as a web site, but there are a number of dimensions to its operations, including research in legal computerisation, education, and involvement in public policy issues concerning legal information. We describe AustLII as a University-based organisation specialising in research and teaching in computerisation of law, and which operates one of the largest free law sites on the web. These aspects of AustLII are summarised here, and detailed in the rest of the paper.
1.2.1 Free access to public legal information via the webThe initial purpose of AustLII’s creation with funding from academic sources, was to provide a ‘research infrastructure’ for research in Australian law, by the free provision of primary and secondary Australian legal materials on the World Wide Web, using innovative methods of hypertext and text retrieval. It quickly became apparent that practising lawyers and administrators and community organisations used AustLII as much as academics and students.
AustLII’s funding sources and aims broadened to reflect the interests of those sectors as well, most notably due to support from the Law Foundation of New South Wales (NSW). Public
1 AustLII came into formal existence on 1 January 1995 when it received its first grant funds, and dropped the ‘prototype’ status from its web pages in July 1995.2 Andrew Mowbray (UTS) and Graham Greenleaf (UNSW).3 Geoffrey King, AustLII Manager; Philip Chung, Primary Materials Manager; Trina Cairns (Treaties Project Officer), Kirsty Magarey (Indigenous Law Project Manager), Simon Cant (Inferencing Research Project Officer) and Daniel Austin (Primary Materials Officer). 4 Part-time staff include David Irvine (Secondary Materials Project Officer) and Tim Moore (Honorary Research Associate, indigenous law project). See http://www.austlii.edu.au/austlii/personnel.html for all personnel details.5 Robert Watt (UTS), Joe Ury (UNSW)and Alan Tyree (University of Sydney).

organisations, such as the Department of Foreign Affairs and Trade, the Council for Aboriginal Reconciliation and AUSTRAC, and business organisations such as the Australian Business Chamber also identified AustLII as the vehicle for development and publication of their resources, and have provided funding to achieve this. AustLII has developed into a resource providing access to over 3 GB of Australian legal information, funded via a ‘stakeholder model’ that is discussed later.
1.2.2 Research into legal computerisationAustLII’s techniques of computerising legal information have developed from the ‘DataLex’ research (Greenleaf G et al; 1995b) over the past decade, and its massive automated hypertext mark-up and integration of text retrieval with hypertext represent research outcomes not duplicated elsewhere. By controlling and developing its own key software, AustLII is of necessity research-oriented, but it also aims to be a centre of research into legal computerisation. Access to very large quantities of computerised legal data, hypertext links and other mark-up data, and usage data6, gives AustLII opportunities to conduct research on legal computerisation that are rarely available to academic researchers. The relationship between theoretical research and the demands of a large-scale production system produce a valuable research dynamic. However, we also aim to carry out and facilitate theoretical research which is not driven by the immediate needs of AustLII’s ‘production system’.

AustLII’s front page (http://www.austlii.edu.au/)
AustLII is conducting research into the development of new legal services using legal inferencing (‘artificial intelligence’) over the web (detailed in the paper ‘New legal services via the web’); on innovative methods of text retrieval; on methods of providing web resources to diverse audiences (particularly remote Aboriginal communities), and on improvements to legal indexing. Separate papers in this collection deal with all of these research projects. Much of this research is funded by the Australian Research Council, giving AustLII an additional source of funding, but other research is simply conducted by AustLII staff in the course of developing AustLII.
1.2.3 Education in computerised legal research and legal computerisationAustLII’s personnel teach undergraduate and postgraduate courses, and Continuing Legal Education courses, on computerised legal research at AustLII’s two sponsoring Universities. They also teach elective subjects on the development of computer applications for lawyers, using AustLII and its techniques as a teaching platform. The AustLII Guide to Legal Research on the Net) can be downloaded for individual use or as a University teaching resource. AustLII’s Conference on ‘Law
via the Internet ‘97’, presenting papers from 40 speakers from seven countries and most Australian jurisdictions, is the most recent example of this educational role.
1.2.4 A commitment to free access to public legal informationThe philosophy on which AustLII is based, and which motivates its staff, is a commitment to maximising free access to ‘public legal information’. AustLII pursues - through example, advocacy and negotiation - a public policy that courts, legislatures and the like should provide their legal information in standardised computerised form, at cost, with whatever added value they can best provide, free of restrictions on re-use or re-sale, to whoever wishes to distribute it or add value to it.
AustLII is funded by grants from public bodies and private organisations that are ‘stakeholders’ in free dissemination of particular classes of legal information. Access to AustLII’s web resources is free, and is not funded by advertising. We intend to maintain this approach.
1.3 AustLII’s databases - Half way to an Internet public law library AustLII’s web service comprises (as at June 1997) 50 separate searchable databases comprising almost half a million pages of HTML, amounting to 3 gigabytes of ‘raw’ text (before mark-up and indexing). These pages contain almost 13 million hypertext links, mainly to other resources within the AustLII site. There are about 60,000 decisions of courts and tribunals on the system, and about 400,000 sections of legislation. Details are in the following paper.
The maintenance, management and development of the AustLII site is therefore a larger task than confronts most web site managers. One of the most important attractions of AustLII to many of its users - and to providers of content - is the ‘critical mass’ of legal materials (particularly primary legal materials) which we have assembled. Before discussing AustLII’s techniques and technical features, we will outline these contents.
Database menu - http://www.austlii.edu.au/databases.html
AustLII now receives decisions from an increasing number of courts and tribunals by e-mail. As a result, decisions of the High Court are usually provided on AustLII on the day on which they are

delivered, and decisions of other courts such as the Federal Court and the Industrial Relations Court of Australia are provided within a week of their receipt from the court. Amendments to legislation from NSW and South Australia are also being received by AustLII on at least a fortnightly basis. The currency of legislative databases is now shown on the database’s opening page, and with case-law, via the list of recent cases on the database’s opening page.
1.3.1 Primary legal materials - cases, legislation, treaties and official decisionsPrimary legal materials (cases, legislation, treaties, and official decisions) are the essential ‘raw materials’ of legal research and legal practice, and are the core of AustLII’s databases. We aim to build a comprehensive free national law library of all Australian legislation, case law from all courts and the most significant tribunals, all treaties to which Australia is a party, and the decisions of the most important administrative bodies (including industrial awards). These primary legal materials present a degree of consistency as texts which makes them relatively amenable to massive automated mark-up, as discussed in the following paper.
Legislation - towards a national legislation collectionAustLII holds the complete legislation of five of Australia’s nine jurisdictions (Commonwealth, New South Wales (NSW), Australian Capital Territory (ACT), South Australia (SA) and the Northern Territory (NT)), including the two largest. This includes both Consolidated Acts and Regulations in all cases, and sessional (‘Numbered’) Acts and Regulations databases in some cases. Current Victorian legislation has been added, and more is being added when available. Approval has been given to add Western Australian legislation, and a licensing agreement is being finalised. Negotiations with the two remaining jurisdictions, Queensland and Tasmania, have been unsuccessful at this stage (see Paper 4).
AustLII receives Commonwealth and Australian Capital Territory legislative data via the Commonwealth Attorney-General’s SCALE service, but sources its NSW, SA, NT and Victorian data direct from the Offices of Parliamentary Counsel and other Departments in those jurisdictions, and will soon do so with ACT legislation.
Case-law - Superior Courts and small tribunalsAustLII’s case-law databases comprise all Commonwealth courts and many of the most significant Commonwealth tribunals7, and an increasing collection of State and Territory case law8. Some case law from five State and Territory Supreme Courts (NSW, ACT, NT, SA and Tas) is included, and discussions are still underway with the three remaining jurisdictions. Approval has been obtained in principle for inclusion of decisions from a number of other State and Territory courts and tribunals, and development of these databases will proceed as resources permit. A recent addition has been the transcript of High Court cases since the beginning of 1997.
It is a high priority for AustLII to include current case law from the superior courts, both because of the importance of free public access to these cases, and because of high demand from AustLII users. However, we believe that we serve a very valuable role in carrying the decisions of increasing numbers specialist tribunals which are often quite small (in administrative law, anti-discrimination, planning matters and elsewhere), because the decisions of these bodies are often not readily available at all, particularly to people in other jurisdictions.
The historical sets of case law on AustLII are in most cases due to our receiving these back sets from the Commonwealth Attorney-General’s SCALE service which has been available on the Internet since January 1997 as SCALE PLUS. SCALE’s service to the Australian community in developing and preserving in public hands an electronic archive of Australian case law (principally Commonwealth materials) should be applauded, and has been a vital factor in AustLII’s establishment. AustLII now receives the data to update the majority of these case-law databases directly from the courts and tribunals concerned, by e-mail or ftp, or on disk in some cases. For

some courts and tribunals we still receive the data via SCALE service, but we are progressively moving toward direct updates, so as to increase the speed by which cases are available on AustLII.
Other primary materials databasesWe have a number of other databases of types of primary materials that are more difficult to classify: treaties and other international agreements; official decisions of agencies; and decisions of non-government organisations which nevertheless have an authoritative status. These include New South Wales Industrial Awards, Australian International Treaties 1945 -, Australian Tax Office Determinations and Rulings 1990- and Australian Press Council Decisions 1976-.
1.3.2 Secondary legal materials - interpreting and reforming the lawThere are numerous ‘secondary’ sources of legal information which are created by public organisations, for the purposes of interpreting, investigating, explaining or reforming the law. These include the reports of law reform commissions, royal commissions, and numerous government departments and agencies. The Internet home pages of many of these organisations are becoming valuable secondary resources in themselves. Non-commercial legal publications such as University and public interest law journals are another potential source of free access secondary materials. The other principal source of secondary legal materials is, of course, the writings of practitioners, academics and others published by commercial legal publishers. These are starting to appear as chargeable resources on the Internet services of these legal publishers, but are unlikely to appear in significant quantities on a free resource such as AustLII (with some exceptions for back issues), for obvious reasons.
AustLII does not yet have the resources to embark on the creation of a national collection of public secondary sources of law, (even for major categories such as law reform commission and royal commission reports), although we have been successful in obtaining resources for some specialised collections (see below). AustLII itself only maintains a modest collection of secondary legal materials at present9, however it does act as host for various organisations’ home pages which are usually maintained by the organisation concerned10.
In addition to resource limitations, the multiplicity of sources of secondary legal materials which are created by public bodies or otherwise available for public access, the frequency with which they are now appearing on the World Wide Web in one form or another, and the more limited value that AustLII’s automated mark-up techniques can add to them, makes it impractical and to some extent unnecessary for AustLII to aim to host a large centralised collection of Australian secondary legal materials.
AustLII’s future strategy in relation to ‘public’ secondary legal materials is therefore likely to concentrate on the following:• to provide a comprehensive Internet index of such materials via AustLII’s Australian Links index;• to provide remote SINO search facilities over selected secondary legal materials, via use of our targeted web spider (see Paper 3, ‘Indexing law on the Internet’);• to continue to seek funding and permissions to create a central collection of some key resources such as law reform commission reports;• to continue to advocate the need for free access to public secondary legal documents, whether they are provided via AustLII or elsewhere;• to continue development of specialised funded collections (see below).
AustLII will therefore seek to position itself as a central access point for Australian public secondary legal information.

1.3.3 Specialised funded collections of primary and secondary materialsAlthough AustLII does not yet have the resources to create a national collection of public sources of secondary legal materials, we have received funding to create a number of specialised collections.
The Australian Treaties LibraryThe Department of Foreign Affairs and Trade has provided funds for AustLII to build a comprehensive Australian Treaties Library, as part of the Commonwealth Government’s commitment to make the treaty-making process more accessible. The Library contains the full text of Treaties to which Australia is a party, 1945-1997; an Index to these treaties; National Interest Analyses 1996 - (the new ‘explanatory memoranda’); a List of Multilateral Treaty Actions Under Negotiation; the ‘Trick or Treaty?’ Report (the Australian Senate Legal and Constitutional References Committee Report that led to the project), an Australia and International Treaty Making Information Kit, the Select Documents on International Affairs series and other documents. It also contains the text of an Australian-drafted United Nations General Assembly Resolution - Electronic Treaties Database (December 1996) supporting the availability of treaties via the Internet.
As far as we are aware, Australia is the only country to have such a collection of the treaties to which it is a party available on the Internet. We have concentrated to date on mounting the collection of treaty texts. The next steps in the project are to ‘add value’ by creating extensive hypertext links, within treaties, from treaties to primary legal materials on AustLII (such as ‘Noteups’ from a treaty to legislation implementing the treaty and decisions considering the treaty).
The Reconciliation & Social Justice Library and Internet ProjectAustLII and the Council for Aboriginal Reconciliation, have created the Reconciliation and Social Justice Library, which already contains over 100 megabytes of text, making it the largest secondary law resource on AustLII. It is part of a more general Internet project on indigenous legal issues, discussed in detail in the concluding paper in this series.
The Australian Human Rights Information Centre (AHRIC)The Human Rights Centre at the University of New South Wales, under a grant from the Commonwealth Attorney-General’s Department, is funding AustLII to develop the Internet component of the Australian Human Rights Information Centre (AHRIC). The focus of the project is Australia’s compliance with its international human rights obligations. The content provided by the treaties and indigenous law projects are of assistance in the development of AHRIC, and the three projects are developing in tandem.
The Industrial Law LibraryThe most recent AustLII specialised collection to receive funding is our Industrial Law Library, for which the Australian Business Chamber has provided funding. AustLII’s databases already include industrial legislation from most jurisdictions, complete NSW Awards, the decisions of the Industrial Relations Court of Australia 1994-, the Industrial Relations Commission of Australia 1988-, and Industrial Commission of New South Wales 1995- . These resources, and industrial

decisions and awards from other jurisdictions for which we have obtained permission, are the start of what we hope will develop into a national collection of legislation, decisions and awards in the areas of industrial and employment law.
1.3.4 LINKS and web spiders- Indexes of Internet legal resourcesAustLII’s Internet indexes of Australian and World legal resources use AustLII-developed software to provide indexes with both a subject index and an author/source index, and which may be searched for both individual link entries and index categories. 'Australian Links' was the runner-up in the Australian Society of Indexers inaugural web indexing awards. It contains links to over 1000 legally-related Australian web resources . We have also commenced an international index, ‘World Links’, intended to provide links to principal resources for all countries and regions, but only to provide a level of detail for countries in the Asia-Pacific region (where existing indexes are not very comprehensive). Both indexes are being developed further under ARC-funded research into Internet indexing.
These indexes are about to take on added significance as the 'launch pad’ for a new AustLII service, a 'targeted web spider’ which will allow non-AustLII legal web sites to be searched using AustLII’s SINO search engine. Details of the LINKS indexes and their relationship to the targeted web spider are in the paper ‘Indexing law on the Internet’.
1.3.5 International content on AustLIIAustLII has until now had an ‘Australia-only’ focus, but we have a medium-term plan to extend its collections to included free access to some English-language information on the laws of some other Asia-Pacific countries, particularly those with significant trade or other links with Australia, where funding is available and where AustLII’s participation would be particularly valuable. This role is unlikely to be extensive. Discussions have commenced in some cases.
The availability of the targeted web spider will provide another option for involvement with non-Australian legal materials, as AustLII will be in a position to provide local searching via SINO of key regional legal materials in English which are already available on the net. This is discussed in the paper ‘Indexing law on the Internet’. We see AustLII as having a regional role in providing better access to English language legal materials, more so than as the original host of such materials.
1.4 Large scale automation of law on the web - AustLII’s technical basisThe following paper ‘Managing large scale hypertext databases’ provides technical details of AustLII’s software, file management, and techniques for creating and managing large scale legal hypertexts. This paper gives non-technical background to AustLII’s approach, from a user perspective. AustLII’s approach to computerising legal materials is based on Mowbray and Greenleaf's 'DataLex' research (1984-1995) (Greenleaf et al; 1995b), but has now gone considerably beyond that basis.
A major element of AustLII’s technical basis is that all of our key software and web interfaces are written by AustLII personnel, so can be developed and customised to suit the needs of the legal materials we deal with, and the ways in which we wish to integrate the different tools. This includes the SINO search engine and its web interface, the Findacts automated mark-up software, the YSH inferencing engine, the WYSH web interface to YSH, the Feathers Internet indexing software and interface, and the Gromit/Wallace targeted web spider. All of these strangely named beasts are discussed in the following papers.

1.4.1 'Rich' and automated hypertextCreation and maintenance of hypertext links in large and complex bodies of text is very difficult. This is particularly so where text undergoes regular change, as is the case with statutes and regulations. If hypertext links are inserted in source documents manually, large or complex hypertext systems become impractical. The 13 million links in AustLII’s data at present obviously could not be inserted manually, or even checked manually after insertion.
Most legal materials available via the WWW at present have only a ‘basic’ level of hypertext functionality, consisting primarily of 'hierarchical' links (e.g. tables of contents, footnotes) and (if needed) sequencing links (e.g. 'next', 'previous'). AustLII specialises in providing 'rich' hypertext, through the addition of numerous 'lateral' or 'internal' hypertext links. These include links within sections to definitions, links to cross-references between sections or between cases, or to references to sections in cases, and not only hierarchical or sequential links. The creation of such 'lateral' links is complex as the link text must usually be recognised in the body of the anchor node, and will often occur in non-standard forms. By and large, few lateral links exist within the legal documents available via the web at present11.
AustLII’s mark-up software eliminates manual marking up of hypertext links, and all links are inserted automatically (except for some introductory pages). Automated mark-up scripts are written for each category of document which has a reasonably regular form (statutes, regulations, cases, some types of commentary etc.). The mark-up scripts are based on heuristics concerning the textual regularities that can be used to identify such link-creating features as the presence of defined terms (e.g. quoted terms followed by “means” or “includes”); context-limiting factors for the scope of defined terms; the various forms of references to sections of Acts or regulations; the names of Acts or Regulations (and heuristics to identify which jurisdiction the legislation comes from); and citations of cases that are contained in other AustLII databases (mainly through formal citation patterns, not through case names).
As with any heuristics, they do not purport to achieve 100% accuracy, or 100% recognition of all potential links. However, the mis-identification of a link (for example, a link to s99 in the wrong Act) is unlikely to prove more than a minor irritation to a user (at least one with any familiarity with legal materials), and the failure to identify a potential link has no adverse effects (unless users make erroneous assumptions that all defined terms are highlit), but is merely a basis for future improvement. Indirect evidence of user satisfaction with the current linking practices is that we receive almost no ‘feedback’ e-mail from users complaining about bad or missing links, except where links from a table of contents malfunction, and users think they cannot access the text at all.
One reason for removing any ‘manual’ involvement in the creation of hypertext, even for ‘fine tuning’ or error-correction, is that no text on AustLII is ever regarded as finally marked-up. Apart from the fact that the mark-up scripts are being tuned constantly to improve the heuristics, additions to available databases on AustLII change the hypertext links that can be created from many other databases. For example, legislation from a new Australian jurisdiction may require new links to be added from all case-law databases, and from some other legislation databases, as well as from secondary materials. AustLII’s practice is to re-create whole databases or sets of databases whenever desirable. The whole collection can be rebuilt overnight, from the raw source files we hold, broken into over 500,000 files and 13 M new links created (see the following paper for performance details).
Example of AustLII’s hypertextAs an example of what is meant by 'rich' hypertext, all of the underlined text in the example below provides hypertext links which have been created automatically as described above (the 'Noteup' links are described later).

From the heading, hierarchical links are provided to the index of all legislation [Index] and to the Table of Contents of the Privacy Act [Table]. Sequential links are provided to the next section [Next] and the previous section [Previous]. Associative links are provided to the date the Act was last consolidated and to its legislative history [Notes]. In the text of the section, associative links are provided to internal definitions ('Commissioner', 'tax file number information'), to internal cross-references ('Schedule 2'), and to external cross references (sections of the Acts Interpretation Act 1901).
‘Usermark’ - automating links to AustLII from anywhereAustLII’s Usermark facility allows any other web page developer with pages that refer to legislation or (some) cases on AustLII to simply enter the URL of the page, and AustLII sends back a copy of the HTML for the page which has in it hypertext links to every Act, section or case on AustLII. Hundreds of links to AustLII can be created immediately, without the need for any manual linking, allowing others to ‘add value’ to their pages with links to AustLII.
Integration between hypertext and text retrieval - automated ‘Noteups’ of sectionsWhen a user is viewing on AustLII the hypertext of any section of an Act or Regulation (such as in the Privacy Act s17 example above), selection of the [Noteup] option triggers a pre-stored search over all case law, legislation, and secondary materials in AustLII’s databases. Materials referring to a section can therefore be found without users having to master search syntax. The pre-stored search triggered by the [Noteup] option is actually a search for the hidden link text in all hypertext links to s17, ‘pa1988108 s17’. No attempt is made to automatically construct search terms which reflect all the variations of textual ways in which references to s17 may appear. Instead, AustLII’s hypertext mark-up scripts have ‘recognised’ most variant ways of referring to s17, and have, in effect, ‘regularised’ them by embedding a textually uniform reference to s17. The [Noteup] option then exploits this imposed uniformity. ‘Noteups’ are therefore (only) as comprehensive as the mark-up of text that proceeds them.
1.4.2 The SINO search engine - AustLII’s free text retrieval engine, SINO, is described in detail in the following paper. SINO accepts search queries using operators similar to those used in virtually all search languages with

which Australian lawyers are familiar. Operators from different languages may be combined in one search (Greenleaf et al; 1997a).
AustLII released its new search interface, shown in part below, in June 1997. It is a major advance over the previous interface. The SINO search engine has also been rewritten in many respects, both to enable the new interface to be implemented, and to increase the speed of searching and the return of search results.
There is now a choice of three search forms - Standard (shown below), Guided (step-by-step use of the Standard Search form) and Extended (customised selection of databases).
The new SINO search form - http://www.austlii.edu.au/cgi-bin/sinoform.pl
1.4.3 Four search and display methodsThere are now four distinct methods of searching and displaying results, two of which are new. The two methods which are largely unchanged are Boolean search with Long Results display (the previous standard search method) and Freeform search with Ranked Results display (the only previous form of ranked results display), although SINO now returns results much more quickly. The two new methods, Boolean search with Short Results display and Boolean search with Ranked Results display are described briefly below, and the relevance ranking algorithm is outlined in the following paper. The addition of these options now gives AustLII a comprehensive set of search options suitable for the most inexperienced to the most expert users.
Boolean search with Short Results displayThe initial search results only lists the total number of documents retrieved, and then each database name which contains documents satisfying the search, plus the number of documents in that database satisfying the search (the ‘short results’ page). The short results option makes it less necessary to limit searches to particular databases, as the user can now more easily select which databases are of interest after the search is complete, without having to wade through pages of results.
Boolean search with Ranked Results displayA Boolean search with ranked results is the most sophisticated search option offered on AustLII. It allows all AustLII connectors and operators to be used to carry out the search. However, the search

results are then displayed with documents ranked according to (i) how many search terms they contain; and (ii) a ‘score’ indicating how often the search terms appear. Overall ranking is indicated by a %. The difference between this method and Freeform Searching (which also uses relevance ranking for displays) is that this method allows the ranked set of documents to have more precision (because ‘and’ and ‘near’ connectors can be used to limit what is found) and more recall because truncation (*) and synonyms can more safely be used in these searches. Relevance ranking adds precision to searches after the search is complete, by ranking the results in likely order of relevance. The best way to use this search method is to do a fairly broad search even though it might find a lot of irrelevant documents and then rely on the ranking mechanism to display the most relevant documents first.
‘Freeform’ searching - relevance ranking for beginnersAustLII also provides ‘freeform’ searching with relevance ranking display. No search connectors may be used in ‘freeform’ searching and if used are ignored. All common words are also disregarded. It is similar to Alta Vista’s simple search method.
1.4.4 Other new features of the search interfaceCustomised database selectionThe Extended Search Form provides check-boxes to allow any combination of AustLII databases to be searched. Customised sets of databases may be constructed from selections at 4 levels, including combinations from different levels:
• All databases of a type (e.g. ‘All legislation’);• All databases of a jurisdiction (e.g. ‘South Australia: All primary materials’);• All caselaw, or all legislation, from a jurisdiction (e.g. ‘New South Wales: All cases’; or• Individual databases.
The ‘context’ display
At the head of every document displayed as a result of a search, a [Context] button now appears, selection of which takes the user to the location on the page containing the first occurrence of the user’s search term. Each search term subsequently displayed is preceded by a ‘context arrow’ which links to the previous occurrence of the search term, and is followed by a ‘context arrow’ linked to the next occurrence of the search term. The user can therefore navigate directly from one contextual display of the search terms to the next.
1.5 Usage and recognition - the ‘user base’Usage of AustLII has risen constantly, as shown by the following figures for the number of successful HTML requests (‘hits’) per month: 36,000 in July 1995; 146,417 in January 1996; 457,346 in July 1996; 813,361 in October 1996; to 1.5 million in May 1997. At present (June 1997) we usually receive about 4,200 separate users per business day, peaking at about 200 concurrent users, and accessing about 65,000 pages per day.
One of the most revealing statistics concerns the ‘Superleague’ decision of the Federal Court. It was available on AustLII within a few hours of being delivered in court (the Friday of the long weekend). By Monday afternoon of the holiday the full decision had been downloaded 1,300 times, and there were 2,500 downloads within the first week. This would amount to over $200,000 worth of photocopies from the Registry.

AustLII’s users now come from the whole community, including educational institutions (about 30%), the legal profession and business (20%), community organisations (15%), government (10%), and 20% from overseas. These percentages have not changed a lot since AustLII’s inception, except that business usage has risen considerably in comparison with government use.
AustLII has also received ‘industry’ recognition, including winner of 'Best Professional Services Site' and 'Top 5 Most Popular Web Sites' in the 1996 Australian Internet Awards, and runner up in the Australian Society of Indexers inaugural web indexing award.
International recognition has also been forthcoming. An encouraging note for the world-wide development of public legal information institutes like AustLII was struck in the first United Kingdom Court of Appeal decision to be published on the Internet (Bannister v SGB plc). In his opening remarks, Lord Justice Saville commented:
If this country was in the same happy position as Australia, where the administration of the law is benefiting greatly from the pioneering enterprise of the Australasian Legal Information Institute (AUSTLII), we would have been able to make this judgment immediately available in a very convenient electronic form to every judge and practitioner in the country without the burdensome costs that the distribution of large numbers of hard copies of the judgment will necessarily impose on public funds.
2. Managing Large Scale Hypertext Databases
This paper discusses the AustLII system from a technical perspective, in contrast to the ‘user perspective’ of the Introduction. It sets out the history of the system, some of the approaches that we use and some current ideas for future development.
2.1. Technical HistoryThe initial problem was that although we needed to plan for the creation of a very large database service, we had to achieve a production level system within a very short time frame. Our funding was for the period of one year and was fairly limited. In this time, we had to establish the hardware infrastructure, recruit staff, write the software, gather permissions to publish the data, commission a production level service, and create enough of a user base to justify continuing operations and funding.
Whilst the task was fairly significant, there were a number of factors which worked in our favour.
As part of previous work on the DataLex Project (Greenleaf et al, 1992), we had developed an automated approach to hypertext creation (particularly in relation to legislation) which we felt could be scaled up to the levels which would be necessary for the sort of system that we were proposing. Although the free text retrieval tools we were using at this time12, proved to be less scaleable, the experience that had been gained in creating these meant that we could quickly write new software which was up to the task.
The level of funding which we had available13, meant that the initial technical team was very small (Andrew Mowbray, Geoff King and Peter van Dijk). This gave us tremendous flexibility and allowed us to build something very rapidly.
We had very good support from one of the initial data providers. David Grainger, the manager of the Commonwealth Attorney-General’s system SCALE, provided us with a copy of the

complete Commonwealth consolidated legislation and regulations and AGPS provided us with the necessary permissions to publish this data.
With a large degree of youthful enthusiasm and naivety, we bought the necessary hardware, employed the first AustLII employee (Geoff King) and created a prototype system. The initial offering contained Commonwealth legislation and regulations marked up in a fairly sophisticated hypertext form (which included many of the features which are present in the current system - hypertext references to Act names, section references, definitional terms and so on).
At this point, two very important things had been established: firstly that the DataLex hypertext markup technology was scaleable (at least to the extent that it could deal with the legislation of an entire jurisdiction); and secondly, that there was demand for the sort of Internet service that we were proposing. Within a matter of weeks, we were recording accesses from around 400 sites per day (with daily page accesses reaching about 10,000 hits).
For the first few weeks of operation, we used the Glimpse search engine. It quickly became apparent that this software could not deliver the sort of performance that we would require. Over a three week period a new free text retrieval engine (which came to be called SINO) was written. The main aims of this new piece of software are probably best summarised as Mowbray described them at the time (Mowbray, 1995):
The main things I have tried to achieve in building SINO are as follows:
annoy Peter (and to a lesser, but still significant extent - Geoff). They still feel that I could be doing something more productive
write something that anyone could use for free to air services like AustLII
provide a much more respectable search language and interface than was available on any of the existing public domain products (particularly from an Australian lawyers' perspective)
produce something that is fast (no real magic needed here, just a conventional inverted file approach with a few smarts borrowed from my old free text system -Airs)
don't get too hung up about index sizes (the AustLII indexes are running at 30% of text size, which to my mind is more than acceptable)
try to keep indexing times within sensible limits (AustLII's Sparc 20 is taking about an hour to index 60,000+ files containing 250+M)
keep it portable so that it will at least run under Windows and on the Mac as well as under UNIX
try not to produce 1/4G spill files again!
Despite the light hearted approach of the time, SINO quickly (within a few days) became the AustLII search engine.
Over the rest of 1995, we received permissions to publish a lot more data14. For the most part, our technical efforts were directed at rationalising the hypertext markup approaches and the search engine to deal with the increasing number of databases. The emphasis remained upon achieving fast massively automated hypertext markup of the Commonwealth Attorney-General Department’s data. This data came as extracts from the main Commonwealth AG’s SCALE database. Our aim was to achieve totally automated data conversion (we had little choice given the volumes of the data and the size of the technical team which had by this stage been reduced to two - Geoff and Andrew).

At the end of 1995 and the beginning of 1996, AustLII started to receive data directly from courts and governments. Some of these early data providers included the NSW government (legislation), the Commonwealth Industrial Relations Court and the NSW Land and Environment Court. The provision of this sort of data posed new challenges. It involved us for the first time in document management and in additional data conversion issues. The approach was to convert this material into an intermediate format and then let the established hypertext markup tools take over. For the most part, we were quite surprised to see that our underlying markup technologies continued to work well.
Much of 1996, continued in a similar vein. We were faced with a growing number of different data formats and were being expected to perform automated editorial work to deal with data inconsistencies. This added another layer of complexity on what were doing, but through a process of “pre-processing” to intermediate form proved to be sustainable. In March 1996, we recruited the second AustLII employee (Philip Chung) to help deal with this. During 1996, the reliance on pre-processed data from Commonwealth Attorney-General’s continued to decrease. As demand increased (to its current levels of around 1.5M hits per month with accesses coming from over 4,000 sites per business day), the hardware was upgraded and a system of load sharing between a number of server machines was introduced.
2.2 Current System Dimensions and ConfigurationThe size of the AustLII collection has grown steadily since the system was established. The current dimensions of the collection as at the time of writing are as follows:
Number of searchable databases / collections: 50 databasesNumber of searchable documents: 470,000 documentsRaw text database size15: 3,007,000,000 bytesNumber of automatically maintained hypertext links: 12,900,000 links
The current usage figures are:
Average number of pages accessed per business day: 65,000 pages per dayAverage number of users/sites per business day: 4,200 users per dayMaximum number of concurrent users / sessions16: 200 concurrent users
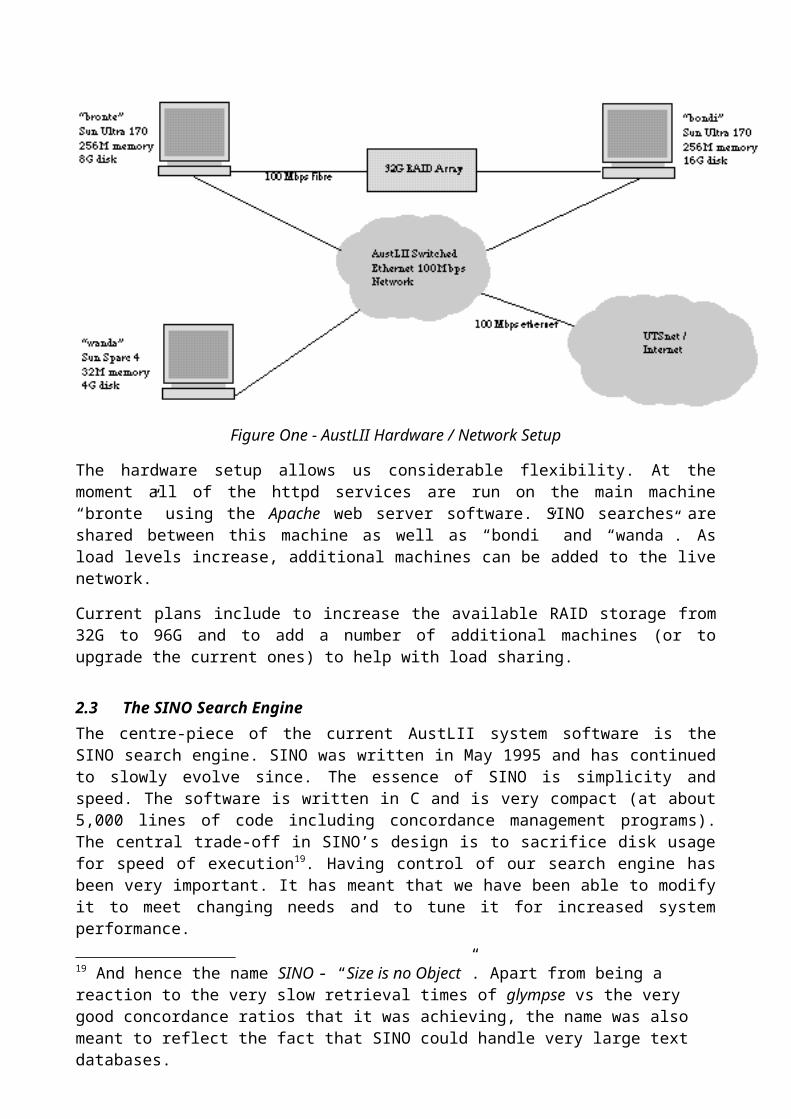
The current hardware configuration which directly supports the live system17 consists of three Sun Microsystems servers18. Two of these are linked directly via a 100Mbps fibre interface to the main 32G RAID disk array. The machines are linked via a 100Mbps switched ethernet network which is connected to the UTS network via 2 100Mps fibre connections. UTS is the hub of the university regional network and is directly connected to Telstra’s Internet point of presence in Padington via a 10Mbps pipe.
The organisation of the hardware is as set out in the following diagram:

Figure One - AustLII Hardware / Network Setup
The hardware setup allows us considerable flexibility. At the moment all of the httpd services are run on the main machine “bronte” using the Apache web server software. SINO searches are shared between this machine as well as “bondi” and “wanda”. As load levels increase, additional machines can be added to the live network.
Current plans include to increase the available RAID storage from 32G to 96G and to add a number of additional machines (or to upgrade the current ones) to help with load sharing.
2.3 The SINO Search EngineThe centre-piece of the current AustLII system software is the SINO search engine. SINO was written in May 1995 and has continued to slowly evolve since. The essence of SINO is simplicity and speed. The software is written in C and is very compact (at about 5,000 lines of code including concordance management programs). The central trade-off in SINO’s design is to sacrifice disk usage for speed of execution19. Having control of our search engine has been very important. It has meant that we have been able to modify it to meet changing needs and to tune it for increased system performance.
The concordance ratio (that is the size of the text indexed versus the size of the index files) is currently running at about 40%. Although the concordance size is large (1.2), given the amount of text which is being indexed (over 3G), this does not present serious difficulties. In execution, the SINO search interface uses very little memory. For Boolean searches, the amount of memory which is used per search is around 250K. For freeform (“conceptual”) searches, this figure increases to about 400K. The size of the temporary files that it generates are fairly large (up to 200M for complex searches).
In order to maximise search times, concordances are stored in a very efficient format. Although concordance building on the current model is very memory intensive (using up to 64M of core memory), the build times are very fast. A typical build on one of the Sparc Ultras (in out of peak hours of usage) is taking around 6 hours to re-create a concordance for the whole of the AustLII database. In sustained terms, the SINO database creation utility (sinomake) is running at about 500M of text (or 90,000 documents) being processed per hour.

The AustLII SINO database is maintained using a single concordance. This means that users can conduct searches across all of the 50 AustLII “databases” without significant performance degradation. Improvements to the way that database “masking” is handled, however, has also meant that there are performance advantages where users restrict the database search scope.
From an interface perspective, the SINO interface presents an “interactive” model which is suitable for processing by custom written scripts. We currently use a set of perl programs for this purpose. A typical SINO session goes something like:
sino> set options rankedsino> set mask au/cases/cth/high_ctsino> set display file title ranksino> search bananasino: total-docs 7: message: 7 matching documents foundau/cases/cth/high_ct/173clr33.htmlCALIN v. THE GREATER UNION ORGANISATION PTY. LIMITED (1991) 173 CLR 33100au/cases/cth/high_ct/124clr60.htmlKILCOY SHIRE COUNCIL v. BRISBANE CITY COUNCIL (1971) 124 CLR 6075au/cases/cth/high_ct/115clr10.htmlMEYER HEINE PTY. LTD. v. CHINA NAVIGATION CO. LTD. (1966) 115 CLR 1066...sino>
Figure Two - Low level communication with SINO
This sort of approach is very flexible and means that SINO searches can be easily shared across a number of machines using a standard UNIX sockets approach.
The SINO user search parser is very forgiving. It will accept searches in a number of standard search languages which legal researchers might be familiar with. The current search syntaxes which are recognised include Lexis, Status, Info-One (now Butterworths On-line), DiskROM, C and agrep. The desire to handle all of these command languages mean that there have been a number of tradeoffs (eg the use of characters such as minus for a Boolean not in Status). Nevertheless, the compromise is designed to work in the majority of cases and seems generally to work well.
2.3.1 Relevance ranking and ‘freeform’ searchesAs well as conventional Boolean searches, SINO also supports “freeform” (that is, “conceptual”) searches. Both now display results using relevance ranking (see the Introduction). ‘Freeform’ searches do not involve the need for operators or other formal syntax and are designed for users who do not have experience with Boolean systems or who wish to be lazy.
Freeform searches are processed as follows (similar elements except the first are also used in our Boolean retrieval with relevance ranking):
All non-alphabetic characters are stripped and common (non-indexed) or non-occurring words are removed.
Based on the relative infrequency of the remaining search terms, SINO builds the biggest list of matching documents (that is, any document which contains at least one search term) that it can within set memory constraints.
The system then ranks these on the basis of (a) how many search terms appear; then (b) how many “weighted” hits appear. The “weighted hits” are calculated according to a formula which gives preference based on how early word “hits” appear in a document, how commonly the word occurs and (inversely) on the document size.

This is the current formula which is used - we stress that there is no magic in this, but it does yield a sensible result:
(a * b + (c * (d/((e+1)+1))) * 100 / ((a + 1) * b);where:a = the total number of search termsb = the largest number of occurrences for any of these search termsc = the number of occurrences for this wordd = a constant to reflect how early a word must occur to deserve special weighting (currently 300)e = the document offset for this word in the current document
Figure Three - the Current SINO Freeform Ranking Algorithm
The effect of this ranking algorithm is to yield a percentage. A document receives 100% where it contains all of the search terms and the greatest number of ranked hits. The relative “importance” of other documents is proportional to this figure.
As is the case with most conceptual ranking systems of this type, the “correctness” of the search results is best judged from a study of their usefulness from a user perspective. Whilst it is a bit difficult to gauge this with total accuracy, it appears from user feedback and on the basis of our own experience that the approach seems to work well. The ranking mechanism for Boolean search results works on a similar basis.
In summary, we maintain that SINO is the fastest, most flexible, and (most importantly to its author at least), the most elegant search engine that is available for use on legal web sites.
2.4 Document ManagementFrom the outset, it was clear that we had to adopt a sustainable document management regime. The solution which we adopted was to maximise the use of the UNIX file system on the computers that we were using.
The raw UNIX file organisation provided us with a mechanism to achieve most of our objectives. It provides an elegant mechanism for organising documents (including such matters as added dates, updated dates, and database/directory organisation) without the requirement of more complex custom written software. It was also a very efficient way of handling things (without need to resort to separate document management databases). Despite the limitations, this fairly simplistic approach has proved to work.
In order to encourage other web sites to link directly to our pages, we have had to maintain a static set of file hierarchies and file names. The file naming hierarchy which we have adopted is as follows:
/country (/au)/legis (legislation)
/jurisdiction (act, cth, nsw, nt, sa, tas or vic)/consol_act (consolidated acts)/consol_reg (consolidated regulations)/num_act (numbered acts)/num_reg (numbered regulations)
/cases (judgments)/jurisdiction (act, cth, nsw, nt, sa, tas or vic)
/court (a court designator20)/other (secondary materials)
Figure Four - The AustLII Directory Hierarchy

Although the case file and directory names continue to be something of a problem (there being no existing way of actually referring to a judgment! (Greenleaf et al 1996)), we have adopted a standard way of referring to legislation. Individual sections always take the form “s123.html” and schedules are stored as “sch123.html”.
The act or regulation entries are stored under short form directory entries which include the first letter of each word of the act or regulation followed by the year and then a checksum which is based on the remaining letters in the act/regulation name. The reasons why we have adopted such a seemingly complex approach are set out in the following section (along with a copy of the algorithm which we use for determining this).
2.5 Hypertext markupHypertext markup on AustLII (nearly 13 million links) is done on a massively automated basis. There is no manual editing of hypertext links. The main reason for this is one of resources. The data is constantly changing (particularly in the case of legislation) and new data is constantly being added to the system. We do not have the very large team of editors necessary to maintain the links on a manual basis.
The main aim of the hypertext markup approach is to achieve the richest possible set of hypertext cross references possible on a completely automated basis. Prior to the start of the AustLII project, we had already gathered a number of years experience in automated markup. The markup attempts to achieve three basic things :
it should be as rich is as possible it should minimise the number of erroneous links it should be as simple as possible (both for speed and maintainability)
Unfortunately, of course, these factors tend to contradict each other. There is always a temptation to modify the scripts to take care of very isolated examples. As changes are made, however, there are often side effects which can stop other parts of the markup working properly or which tend to introduce an unacceptable number of errors and slow down the overall markup times. The current markup essentially represents a design compromise which seeks a balance between the constraints.
The mechanics of marking up raw materials are implemented as a number of “markup scripts”. These are written in a combination of C and perl. The most important of these scripts are independent of the source data formats. Currently we receive our data in a number of forms, including: word processing files (Microsoft Word, Word Perfect and RTF), database dumps (BRS, Status and HTML) and as plain text. A system of pre-processing is used to convert these to the various intermediate formats which are used by the main markup processes.
The total size of the code which is involved in the markup scripts is quite small (less than 10,000 lines of source). There are currently about 60 individual modules (a lot of which are very small and are used for pre-processing).
As was discussed in the previous section, we rely heavily on the use of file organisation for document management. Currently, there are no separate document control databases. Partly because of this and partly for reasons of markup efficiency, all hypertext links on the system can be mapped on a “one way” basis. The central idea is that whenever a potential link is found, it is possible to determine an appropriate destination without any database lookups (other than perhaps a check to make sure that the target HTML file actually exists).

This problem is dealt with in the main by the persistent naming conventions discussed above. Acts and regulations are something of a special problem. By and large, all references to Acts and Regulations tend to involve a complete recital of the short name of the instrument. The approach which we have adopted is to convert these references to a quasi-unique file name abbreviation which is determined by the following algorithm:
char *uniq_pref(s)char * s;{ static char buf[MAXLINE]; char * s1, * s2 = buf; long count = 0; for (s1 = s; *s1; s1++) { if (isdigit(*s1)) *(s2++) = *s1; else if (isalpha(*s1) && (s1 == s || isspace(*(s1-1)))) { if (isupper(*s1)) *(s2++) = tolower(*s1); else *(s2++) = *s1; } if (islower(*s1)) count += (*s1 - 'a'); else if (isupper(*s1)) count += (*s1 - 'A'); } sprintf(s2, "%ld", count); return buf;}
Figure Five - The Legislation Name to Target Directory Name Algorithm
The effect of this algorithm, is to create a short relatively unique file / directory name for an act or regulation. It consists of the first letter from each word in the act title, followed by the year and then a checksum which is based upon all of the other letters which go to make up the name. An Act name such as the Trade Practices Act 1974 becomes tpa1974149 and the Historic Shipwrecks Act 1976 becomes hsa1976235.
Although this approach is not at all perfect, an analysis of all of the legislative databases on AustLII shows that it is functional without any intra-jurisdictional duplication. As between jurisdictions, of course, it is sometimes the case that different states will enact legislation with identical names and years. This issue is dealt with by “seeding” the markup scripts with some idea of a “default jurisdiction” (ie if the markup process is dealing with the NSW Supreme Court, it gives priority to NSW legislation).
The markup scripts are highly heuristic and designed to pick up a number of salient text features. Some of the things which we currently aim to identify and add hypertext links for are:
references to Act names references to sections of Acts (both internally and externally) references to other structural legislation elements (parts, schedules etc.) references to legislatively defined terms references to case citations

Although some of these can be dealt with without reference to any contextual matters, a lot of these items are highly context sensitive. This is particularly the case in relation to legislation markup. The current legislative markup scheme depends upon a number of sequential passes through the raw text. The approach is summarised as follows:
Figure Six - Legislative Hypertext Markup
For the most part, all markup is done ahead of time. Dynamic markup is kept to an absolute minimum in order to maximise system performance. The major exception to this is in relation to the noteup functions which are included for all legislative documents and some cases. The noteup function allows users to conduct canned SINO searches which are based upon stored URL addresses. The effect of noteups is to perform a “reverse hypertext lookup” thereby returning related documents which refer to the current document.
2.6 Future plansNow that the database is relatively stable, we are taking the opportunity to redesign several system elements. The nature of the markup work is changing from a model which is based on large scale conversion of pre-prepared collections to one where further editorial control is required.
Some of the things that we are doing to address this include a proposed new directory / file organisation for case law and the adoption of a more flexible intermediate file format. The cases law reorganisation is already partially implemented for some databases. The idea is to move to a system of years and judgment numbers. This poses several challenges for older materials where it will probably be necessary to impose a degree of arbitrary organisation. The file format issue is a much larger problem. At the moment, files are stored and dealt with in their original source form. Over the remainder of the year, we propose to convert all of the data into a simplified SGML format on a largely automated basis.
3. Indexing law on the Internet
3.1 The problems of finding law on the InternetThere are essentially only two types of tools which help users find legal materials on the Internet:
• ’Intellectual’ indexes where individual web pages are classified by hand according to various classificatory schemes. Usually, such indices only provide the title, URL and perhaps a brief description of each site indexed. Yahoo! is a well known general example.
• ‘Robot’ indexes where a program traverses the web, downloading every page it encounters, so that every word on every page can be indexed by a remotely located search engine. When the search engine displays a URL as a result of a search, that URL is to the original site, not to a mirror on the remote site. Alta Vista is perhaps the best known general example. The advantage is, of course, that it is possible to search for every word indexed, at least using Boolean operators.

Viewed from the perspective of an Australian user of Internet legal materials, finding Australian legal information on the Internet is difficult, for at least the following reasons:
• As the quantity of Australian legal material on the Internet grows, it is difficult to maintain intellectual indexes, at least with any depth of indexing of significant sites. The best that can be hoped for is that sites with significant legal materials are identified.
• There are no satisfactory ‘Australian only’ robot indexing sites providing both extensive coverage and a useful search engine. To use Alta Vista or other Internet-wide search engines to limit searches to Australian law is not easy, as discussed below.
• Many sites containing valuable legal information do not have search engines at all, so searching at word level is not possible. Users are also confused by multiple search engines.
So, in Australia it may be possible to find most useful sites of legal materials, but it is often difficult to know what is on them. If we generalise the problem to that of finding Internet legal information world-wide, the problems are variations on the Australian situation:
• While there are many multi-country intellectual indices to law on the Internet, none are even remotely comprehensive, and many are US-oriented with a slight international gloss. Some very good indices do exist for particular countries such as Canada, and for some subject matter areas, but they are often difficult to find from the multi-country indices. It is therefore difficult to find a good place to start.
• There are very good Internet-wide robot indexes, such as Alta Vista, but they are not as comprehensive as people often assume. For example, Alta Vista apparently only indexes about 600 pages of even the largest web site21. Furthermore, well-behave robots adhere to the robot exclusion standard, by which web servers tell robots which pages they may not index on a site. Because of the effects of some robots on server performance, and for other reasons, many servers exclude robots. Such factors lead to estimates that even the largest Internet-wide search engines only index about 20% of the estimated 150 million web pages.
• It is difficult to make searches precise enough to find only legal materials using Internet-wide robot indexes, because they index predominantly non-legal material. It is usually necessary to try to impose some ad hoc search limitation (in addition to the real search terms) such as ‘law or legislation or code or court’ or some such, to try to stem the flood of irrelevant information (or more likely, to fool the relevance ranking into putting legally oriented material first).
• It is also difficult for most users to limit searches to materials concerning laws of particular countries22, and failure to do so will usually result in the search being flooded with material from North America and other ‘content rich’ parts of the Internet.
• When you do find a site containing valuable legal information it will often not have a search engine at all, so searching at word level is not possible. Users are also confused by multiple search engines.
So the problems of finding legal materials world-wide are that it is both difficult to find which useful sites exist for a particular country or subject, and also difficult to find what is on such sites as are known.
3.2 AustLII’s approach - A robot targeted by an intellectual indexOur approach to solving these problems rests on these propositions:
• Robot indexing of remote law sites, and a sufficiently powerful search engine, are necessary;
• Searching robot indexed sites will work much better if (i) only law sites are indexed (to remove non-legal ‘noise’); and (ii) such sites are indexed comprehensively ;
• Significant law sites which normally exclude robots may allow a law-oriented robot to index them, by request. The number of requests may be manageable.
• A comprehensive intellectual index is needed to identify the law sites worth indexing, and therefore to ‘target’ the robot.
AustLII has a suitable search engine (SINO), its own Internet indexing software (Feathers) which can be used to ‘target’ a robot, and a sufficiently comprehensive index of law on the Internet, at least for Australian law (Australian Links). A robot (or ‘web spider’ as we prefer to call it) called Gromit, and a ‘harness’ or means of directing it (called Wallace) by using an intellectual index. The targeted web spider will soon play a significant role in AustLII’s future developments. AustLII’s research on Internet law indexing is supported by an Australian Research Council small grant for 1997.
The rest of this paper describes the components of AustLII’s targeted web spider, and indicates some of the roles it may play.
3.3 AustLII’s Links - Australian and World web indices to law
3.3.1 History of AustLII’s web indicesAustLII was launched in July 1995 with an Index to Australian Law on the Net, a conventional hypertext index based around a source/author index approach. The index was maintained periodically by Graham Greenleaf until it reached about 500 entries a year later, at which point the maintenance of ‘hand-tooled’ web pages, lack of search capacity, and lack of a subject index became problems which had to be addressed.
Geoffrey King wrote the Chain indexing software for a new user interface to the Links indices, for hierarchical browsing, for editing and maintenance of index entries, and for an interface to the SINO search engine. We then settled new source and subject index categories, all data from the old index was transferred into the new one, and symbolic links were added to make the whole structure work. The new Links indices were launched in October 1996, and ‘Australian Links’ was the runner-up in the Australian Society of Indexers inaugural web indexing awards in 1996. Index entries have grown to about 1,500 by mid-1997, of which over 1,000 related to Australian law sites. At this point the Chain indexing software also required redevelopment to satisfy new demands.
3.3.2 Operation of the Links indicesThe Australian Links index can be used in three principal ways:
• as a Source index which categorises the sites according to their source or 'author';• as a Subject index, which categorises the same sites according to over 50 heads of legal subject matter; or • by Searching the index, from a search window at the top of each page, which allows Boolean and proximity searching (using AustLII’s SINO) over both the index categories and index entries. Searches may be over the whole index, or limited to those sub-categories lower in the index tree.
Users may submit links to be added to the index, but they are edited and approved by the index editors before they are added.
The following example shows the ‘Administrative law’ subject index page.

http://www.austlii.edu.au/links/Australia/Subjects/Administrative_Law/index.html
3.3.3 The new AustLII index software - FeathersThe indexing software has now been rewritten, with the new software (‘Feathers’) and interface to be released in July 1997. It will result in major changes in the way that the links are maintained, and in the editing facilities available to those who maintain it. It will allow considerable customisation of the appearance of index pages, so that they can appear in a consistent style with text collections and other resources, which will be valuable for our special projects and teaching resources. Another major aspect of the rewrite is to allow interaction between Feathers and the targeted web spider discussed below.
3.4 The targeted web spider - Gromit (and Wallace!)Gromit is a specialist web robot. It targets selected legal web sites, namely a subset of the URLs contained in AustLII’s Links Internet indices, selected for their high value legal content. Gromit Web Robot (Gromit) is a single program that recursively downloads all text files on a site for indexing by AustLII's SINO Search Engine.
We call Gromit a Targeted Web Spider, as it is not designed to traverse the Web generally, its downloading being limited to the site specified in the original URL specified when it is invoked. For example, if Gromit is invoked to download the URL http://actag.canberra.edu.au/actag/ (ie the ACT Lawnet site), any linked pages that fall below the original URL (ie lower down in the file hierarchy on the same server) will be downloaded. Linked pages outside that scope are ignored. The Gromit robot is not allowed to wander "off site".
Normal operation for remote indexing purposes (as opposed to mirroring) is in text only mode, so image links will also be ignored, as will any links that do not appear to be of the MIME type text/html or text/plain.

Gromit maintains a local cache of downloaded documents, so that they can be indexed by AustLII's SINO Search Engine. The cached documents are not available for browsing or downloading via AustLII's servers - users must go to the original host in order to browse or download.
3.4.1 Wallace the Gromit harnessGromit is not intended to be used directly by a human operator. Typically, it runs under the control of Wallace, a control script that fires off Gromit processes over blocks of URLs. AustLII’s new software for the Links indices, Feathers, will invoke Gromit processes in relation to those sites selected by the editors of the indices. A separate version of Gromit to access protected databases on remote servers, with permission, is also available.
Wallace is a harness program for Gromit. Wallace instructs Gromit as to which sites it should download, and monitors its progress. Wallace runs a number of spider processes at any one time, but limits the maximum number of spiders to a preset limit. When one spider finishes, another is started automatically to download a different site. Wallace reads the list of links to download from a remote mSQL database using the Perl DBD and DBI modules. The database is expected to be in the format maintained by the Feathers links system
Wallace first downloads all the URLs in the database that are marked for indexing or mirroring. It then sorts the URLs by host name. URLs are grouped into host bands (that is, they all contain the same host name) and these bands are passed as URL lists to the web spider (gromit) for downloading. Wallace runs its spiders concurrently. There may be a web spider running for each host band at the same time, up to a maximum of 10. The user can modify the maximum number of spider processes. As one spider completes, another is started, until all host bands have been downloaded.
3.4.2 Impact on other sitesGromit is a relatively unobtrusive robot, designed to have minimal impact on the sites it visits. The robot, designed and implemented by AustLII staff, has been written in Perl 5, and uses the LWP library. In particular, the LWP::RobotUA object is used as the basis for Gromit. That module, together with other measures taken in the program, minimises impact on web performance because:
• It obeys the Robots Exclusion Protocol so as to not visit areas where robots are not welcome. Specifically, it obeys directives in the robots.txt file in the root directory of servers (see Robots Exclusion at The Web Robots Pages).
• No one site is accessed twice by the robot within a 2 minute period.
• The robot caches downloaded documents for later indexing, and will issue a HEAD request for a page before attempting to download fresh versions of already cached pages. On those web sites that support such mechanisms, Gromit will take advantage of the If-Modified-Since and Last-Modified HTTP headers, reducing server load for those machines.
• A notorious problem with web spiders is that they can saturate a remote site with requests, slowing down the remote server and denying access to other web users. By grouping sites into bands, no one site is accessed simultaneously by Gromit, since Gromit processes URLs in consecutive order.
Gromit is still under development, and during this initial stage will not be running unattended. Further information can be obtained on the page ‘Gromit Web Robot - Information for Web Managers’.

3.4.3 Mirror sites on AustLIIAustLII has been granted permission to mirror certain legal sites. The Gromit robot is used to download these sites and keep the mirrors updated. When mirroring, Gromit rewrites local URLs to use the mirror copies of documents, and also downloads any graphics or other files that may be referenced there.
3.4.4 Checking for bad linksA by-product of the development of the web spider is that it will also be used to check the validity of all links in AustLII’s indices, so as to improve the quality of the indices.
3.5 Project DIAL - A challenge for Internet law indexingAustLII’s management team are involved in a consultancy project for the Asian Development Bank, Project DIAL (Development of the Internet for Asian Law). It is a feasibility study of the potential use of the Internet to assist those involved in the development of legislation in the developing member countries (DMCs) of the Bank. One method of assistance which is envisaged is the DIAL Index of legislative and other resources already on the World Wide Web, so as to provide ready access to comparative legal materials from other countries.
The prototype DIAL Index, which will be located on AustLII, will be based principally around a subject index of matters which are of particular interest to those drafting legislation in DMCs (‘Privatisation’, ‘Environment’ etc.), but will also have indexes which classify materials by the country they concern, by international organisations etc. The prototype DIAL Index will provide a very extensive testing ground for methods of intellectual indexing of legal web sites world-wide, but particularly in the Asia-Pacific region, and of the use of a targeted web spider to provide word-level searching of remote sites. The flexibility of the new SINO interface which allows searches to be limited to any combination of available databases will be put to very extensive use in the design of an interface to accommodate the needs of Project DIAL. The end result is intended to be a very extensive set of links and searches on each subject matter, which gives users access to a wide range of comparable legislative resources in many countries.
It should be stressed that the Asian Development Bank has not made any decision whether Project DIAL will proceed beyond prototype stage, or about the software, servers etc. which might be employed in the final system.
3.6 The targeted web spider and AustLII’s future directionsOne international application of the targeted web spider is mentioned above. Despite the availability of numerous Australian web sites for law, AustLII will be able to be an even more comprehensive starting point for Australian legal research. The new SINO interface allows construction of searches over varying combinations of Australian and overseas materials, and for searches over single sites which do not otherwise have a search engine. Mirroring of other sites will allow automated hypertext links to materials in AustLII ’s collection to be added (where permitted).

4. The politics of public legal information
4.1 50% politics, 50% techniqueWe always say that AustLII is ‘approximately 50% politics’, by which we mean that innovative techniques of computerising legal information count for little unless you can obtain the data that you wish to publish in some useable form, permission to publish it, and the necessary funds to continue doing so. When you propose to provide free public access, all of these elements require the creation of a constituency which will support this goal, or at least reluctantly acquiesce.
In this paper, we will give an informal outline of various aspects of ‘the politics of AustLII’, and attempt to answer some of these questions:• Was AustLII necessary?• What policies should public bodies adopt to best facilitate access to legal information?• Is it possible to sustain free public access to legal information?• Why is it crucial to create new citation standards to make public access effective? • Is it possible to reconcile privacy with public access to case law?
4.2 Computerising law in Oz - A chequered pre-historyThe computerisation of legal information in Australia has been a very political matter since its inception. It had two very different starting points.
4.2.1 SCALE and the preservation of public legal informationFollowing a 1973 initiative of then Attorney-General Lionel Murphy, the Commonwealth Attorney-General’s Department established the SCALE system in 1977, using the STATUS retrieval software to search Commonwealth legislation (1977) and High Court decisions (1980) See Greenleaf et al (1988, Ch 4) for a history of developments to 1988, from where the following paragraphs are derived.. Other Commonwealth and A.C.T. databases were added slowly, but the original plans to add State and Territory materials were overtaken by events for a time. Another Labour Attorney-General, Gareth Evans, decided that Commonwealth materials would not be allowed go on any system other than SCALE.
SCALE used much the same version of the STATUS software for twenty years until it migrated to the Internet as SCALEplus. It never received a great deal of use outside the public sector and some University law schools, and so did relatively little to put access to the law in public hands. However, it performed the inestimable public service of collecting Commonwealth and A.C.T. legislation and case law (and some State and Territory materials) in computerised form (and a very consistent one at that), and keeping it in public hands, for those twenty years until more sophisticated delivery systems could deliver what it had long only promised.
When AustLII (and eventually SCALEplus) arrived with new technologies, the availability of the ‘old’ SCALE’s data only required a political decision in order to make free public access a reality. Even before those events, the availability of SCALE data to the creators of the DiskROM CD-ROMs in the early 1990s had created the first convincing demonstration of the real potential of computerised legal information - and showed that the monopolistic alternative to which we now turn, was a dead end.

4.2.2 The CLIRS monopoly, Info-One and lost opportunitiesIt is easy to forget that throughout the 1980s all States and Territories (except Queensland, which did nothing effective at all) used their claimed control over copyright in legislation and case law23
to grant the company originally called CLIRS (Computerised Legal Information Retrieval System), (owned by Computer Power Pty Ltd) a monopoly over the computerisation of this information for varying periods of years extending into the early nineties.
The monopolistic approach of the ‘80s was compounded by the ‘STATUS Standard’ by which the Standing Committee of Attorneys-General (SCAG) decided that no-one would be allowed to tender to computerise any Australian cases or statutes unless they agreed to provide retrieval features identical to those of STATUS, in addition to a list of other requirements. So the CLIRS/SCALE oligopoly was created.
After complex legal and commercial disputes the CLIRS system changed owners numerous times, changed its name to Info-One, and was a considerable commercial failure, redeemed somewhat in its final stages by a successful LawPac CD-ROM series of case-law. The CLIRS/Info-One decade could be summarised by saying that the data was very extensive, access was unacceptably expensive (at one point ludicrously so), the legal profession largely hated or ignored it, and few ever used it (except some University law schools with free accounts). The system probably never had more than ten simultaneous commercial users - AustLII already regularly receives nearly 200.
Finally, in 1995 Info-One was sold to Butterworths, and has now migrated to the Internet as a substantial part of the case-law content of Butterworths Online. On the one hand we are fortunate that extensive case law databases are at least available to those who can afford to pay for them - and in the hands of a publisher with expertise in this area.
On the other hand, it means that there was a whole decade when the computerisation of legal information was illegal by anyone other than the CLIRS/Info-One monopoly, and this is a monopoly benefit that Butterworths has now acquired. This is Butterworths’ good fortune, but is the result of flawed public policy (over which they had no control). In addition, during this period the development of competitive - or even slightly innovative - approaches to legal information systems was largely frozen in Australia.
4.2.3 NSW sees the lightA small light at the end of the tunnel was created by the NSW government’s decision in 1994 to grant a general public licence in relation to the reproduction of legislation. It also provided copies of part or all of the NSW legislation in computerised form, updated regularly, with no restrictions on the commercial re-use of the information. It even sold legislation on demand on floppy disks over the counter. This innovative approach helped create a proliferation of disk-based products which added value in various ways to NSW legislation. More important, in doing so, the NSW government demonstrated that different public policies were possible, and its approach illustrated most of the elements that AustLII has since argued are part of a sound policy for public legal information.
4.3 Why was AustLII necessary?This was the environment that made AustLII necessary: no effective or affordable public access to legal information; a lack of competition in the provision of commercial products; and such products as did exist were largely the recycling of primary legal materials with little value-adding but very high prices. Electronic legal publishing equalled on-line services with few users, and it was easier to make a modest profit by selling some hundreds of copies of a CD-ROM of primary materials at relatively high prices than to provide pervasive commercial access to the profession, let alone the public.

Only two and a half years ago, at the beginning of 1995, there was no reason to expect that any free public access to legislation or case law whatsoever would ever be possible in Australia. The philosophy of ‘user pays’ predominated in government thinking. There was no guarantee that SCALE would reach the Internet as a free service, as discussed below. No legislature had published its own legislation free on the Internet as the Northern Territory has now done or Victoria will do soon. No court or tribunal in Australia had made its decisions available free, and many were still wedded to the notion of subsidising the court through photocopy sales. It was even difficult to obtain small quantities of data in computerised form for academic research or teaching purposes.
4.3.1 Creating AustLII - ‘Let’s turn this around’As has been described in other papers, we (Mowbray and Greenleaf) had already developed software and an approach to computerising legal information through our ‘DataLex Project’ from 1985-94. We decided to try to use the Internet to end the situation described above. We obtained an academic grant to create a ‘research infrastructure’, sufficient to purchase a server and to employ a staff member (King) for a year or so24. The application was supported by the Deans of all Australian law schools. Our stated aims in obtaining the funding were:
• to provide basic legal information via the Internet, which would support legal research and teaching in Universities (which AustLII certainly has done);
• to provide a demonstration and future platform for innovations and research in computerisation of law (which these papers illustrate).
However, we were conscious that - with luck - this would give an opportunity to pursue a broader agenda:
• to provide access to basic legal information to the general community, and the smaller and more remotely located parts of the legal profession, who had been ill-served until then;
• to create convincing examples of high quality free public access to primary legal materials, so as to make it very difficult for governments, courts and legislatures to create ‘user pays’ systems without bringing public opprobrium on themselves;
• to collect and preserve ‘public legal information’ in the hands of a public institution (an academic one) with the express aim of not commercialising it;
• to provide an alternative to commercial legal publishers so that they would be more likely to moderate their prices, and to add more value to primary legal materials if they wanted to have something to sell.
These aims have been partly satisfied by AustLII’s history to date, but nothing can be taken for granted, as the rest of this paper will illustrate.
4.3.2 ‘Crash through or crash’ - Commonwealth legislationOur most urgent problem in getting AustLII started was ‘political’ in the broad sense we use it here: we had no large-scale data in computerised form, nor permission to publish it if we obtained it. Fortunately, we had some experience in obtaining licences from the Australian Government Publishing Service (AGPS) to publish small collections of Commonwealth legislation on disk as part of our previous ‘DataLex’ work, and so we sent in a standard licence request to AGPS to publish Commonwealth legislation (generally) on the Internet. SCALE gave us a copy of the whole Commonwealth legislation to test the scaling-up of our mark-up techniques. To our surprise, the AGPS licence arrived. Holding both the data and a licence to publish on the Internet in our hands, we did so - perhaps, in our enthusiasm, slightly in advance of finalising negotiations. We were

receiving 200 to 300 users a day within a week, most from the Commonwealth government, and the numbers snowballed from there. Fortunately, no one in Canberra then felt it was politic to tell us to take the data down.
AustLII’s publishing of Commonwealth legislation came at a rather sensitive time, as the Commonwealth was still considering making the system that eventually became SCALEplus a ‘user pays’ service of some kind. This option was obviously less viable in light of what AustLII was now very publicly willing and able to do as a free service, and it was eventually shelved.
4.3.3 Leading from the top - the High CourtHaving made significant progress with legislation, we immediately shifted focus to case law, and found a sympathetic reception from the Marshal of the High Court, who requested SCALE to provide us with a copy of the full text of the Court’s decisions back to 1947. We published the decisions, with extensive hypertext links to Commonwealth legislation. Andrew Mowbray then wrote the SINO search engine, and the general model for AustLII’s operation was in place.
In our view, free Internet access to a huge database of High Court decisions sent the right signal to every court and tribunal in Australia: that court decisions should be available to the public, and the Internet was an appropriate medium to achieve this. By ‘leading from the top’, our co-operative relationship with the Court has continued to demonstrate what can be achieved in Internet publishing of case law. We now publish decisions of the Court within a day of them being handed down, the bulletin of the Court’s special leave and reserved decisions, and selected transcripts. AustLII also hosts the Court’s home pages.
4.3.4 New South Wales breakthroughsThe next milestones in free access to law came from New South Wales. The New South Wales Law Foundation agreed to provide funding to AustLII to provide Internet access to Australia-wide primary legal materials. The Law Foundation’s own ‘Foundation Law’ Internet service (which originally ran on AustLII’s computers) encouraged the NSW legal profession to migrate to the Internet. The NSW Attorney-General agreed to provide complete NSW legislation. The Supreme Court, Land and Environment Court and Industrial Court all agreed that we could publish their decisions, with assistance from the Law Foundation and the NSW Attorney-General’s Department.
Just as important, Law Foundation Chairman Justice Vince Bruce was instrumental in negotiations with the Commonwealth Attorney-General’s Department which resulted in a general agreement that AustLII could publish databases on SCALE where the court or tribunal concerned gave its consent. This resulted in another 15 large databases on AustLII by early 1996. From that point on in late 1995 our relationship with SCALE and the Commonwealth Attorney-General’s Department matured into the very extensive and co-operative one that has remained ever since. Our relationships with Commonwealth A-G and the NSW Law Foundation have been two cornerstones of AustLII’s success, and the freeing of legal information in Australia.
The fact that AustLII now holds a copy of most of SCALE’s data is significant beyond the fact that it now gives users a choice between two free Internet services. It helps to ensure that the data will remain on a free public access facility. In an era of outsourcing of the Commonwealth government’s IT, privatisation of the Attorney-General’s legal practice, and public tenders for functions of AGPS, there can be no certainty about free provision of legal information by government agencies.
Funding from public interest organisations like the Law Foundation, and academic sources, also played a political role. It enabled us to take the ‘high moral ground’ with the ‘data holders’ of public legal information, along the lines of ‘we are willing to do all the hard work to provide this

information free to the public, and organisation X is willing to fund it, if only you will licence it to us / release it into the public domain’. This approach is effective, but it depends on the necessary funding from public sources being maintained. That is discussed below.
4.4 AustLII’s policies on ‘public legal information’ AustLII's existence is based on the belief that it is in the public interest that public authorities should aim to maximise access to the ‘public legal information’ that they control. By ‘public legal information’ we include primary legal materials (legislation, case law, treaties, awards and administrative decisions); and at least those secondary legal materials created with public funding, under a duty to report, and with a purpose of public access (law reform reports, justice statistics etc.).
We argue that public authorities (such as courts, legislatures and Royal Commissions, and law reform commissions) should aim to maximise access to this ‘public legal information’ by removing all unnecessary impediments to its wide dissemination. In the first paper published about AustLII in 1995 (Greenleaf et al; 1995a), we argued that the effective provision of public legal information depended on public authorities (the sources of the data) providing that data according to six principles, which we set out unchanged in the sub-headings below. Our experience since then, reflected in the comments that follow, has reinforced our view that they are sound principles .
It is worth stressing that the six principles below have little to do with any special provision of data to AustLII: adoption of these principles by public authorities is for the benefit of all legal publishers, commercial and non-commercial alike.
AustLII’s advocacy of these principles takes many forms: negotiations with data providers and governments, conference papers, public campaigns against recalcitrants (link to http://www.austlii.edu.au/austlii/availability.html), and (probably most important) the force of example provided by the existence of AustLII and the extent of use that it receives.
Each of these six principles should be read as ‘public authorities should provide public legal information ...’:(i) ... in a completed form, including such additional information as is best provided at source’;(ii) ... in an authoritative form, including acceptable citations and numbering - medium-neutral and vendor-neutral citation;(iii) ... in a form facilitating dissemination;(iv) ... on a marginal-cost-recovery basis equally to anyone who wishes to obtain it;(v) ... with no restriction on re-use for any purpose, and no licence fees ;(vi) ... but while still preserving a copy in the care of the public authority.
4.4.1 (i) ... in a completed form, including such additional information as is best provided at sourceIt is necessary for cost-effective and reliable publishing of judgments by more than one publisher, that courts and tribunals accept the responsibility of producing one definitive ‘unreported’ version of a judgment. At least when it comes to computerised copies, the practice of courts is very variable: many are excellent, but some courts still have no effective methods of collecting all judgments centrally in computerised form, and sometimes supply them with judgments in the same case on different disks.
Other parties (such as publishers) should not have any role in assisting courts ‘tidy up’ their judgments prior to the official release by the court, because of the risk of copyright claims being asserted by them. AustLII’s data has been affected by one claim by a legal publisher to copyright in aspects of judgements which made it impossible for us to disentangle the ‘publisher’s additions’

from what would have been in the original judgment. However, this has not been a serious problem as yet.
The additional information provided should include catchwords nominated by the judge (as recommended by the Australian Institute of Judicial Administration in Olsson (1992)), and the consolidation of amending legislation by Parliamentary Counsel (a process not yet completed in some Australian jurisdictions). The inclusion of catchwords in judgments is still only sporadic but increasing.
4.4.2 (ii) ... in an authoritative form, including acceptable citations and numbering - medium-neutral and vendor-neutral citationIt should be in an authoritative form, in the sense that includes citations and numbering such that it can be cited to any court in an acceptable way. This is not a problem with legislation, but is with case citations, discussed further below.
4.4.3 (iii) ... in a form facilitating dissemination Where official bodies have created this data in computerised form as a by-product of their normal work, it is in the public interest that it should be available in that form. Two years ago, provision on disk in ASCII would have been the best that was obtainable in many cases. Now, our experience is that many courts and tribunals have no difficulty in e-mailing their judgments to multiple recipients (usually publishers) on a daily or weekly basis, sometimes in enhanced formats such as RTF.
4.4.4 (iv) ... on a marginal-cost-recovery basis equally to anyone who wishes to obtain itPublic policy should support maximising public access to the law. Its dissemination should not be regarded as a ‘profit centre’ supporting other aspects of the operation of the judicial system. The outputs of the legislative, judicial and law reform processes should not be subject to ‘user pays’ criteria, because maximum public access to this information is necessary for the proper operation of the judicial system and the democratic system.
4.4.5 (v) ... with no restriction on re-use for any purpose, and no licence fees Public policy should support the maximum dissemination of the law (including the creation of value-added products for resale), and in the forms to make it most understandable. The methods by which legal data is best disseminated are still unsettled and changing rapidly, and there are markets for the same source information with different features and at different prices. Fostering competition in the provision of different types of legal products seems to be the only way to meet the public interest.
4.4.6 (vi) ... but while still preserving a copy in the care of the public authorityOffices of Parliamentary Counsel need to preserve computerised copies of legislation archives, and courts and tribunals should keep computerised back-sets of their own decisions, irrespective of how widely they distribute them at the time of creation. Back sets need to be available from public authorities, so that new entrants into the computerisation of law are not effectively excluded by all electronic copies of the data being held in private hands. With legislation, archiving of copies of amended sections over time will enable the creation of far more valuable computerised legislation, able to provide the law as it stood at a specific date.
Courts and legislatures have been using computers to produce documents for many years, but some have made little effort to keep computerised archives in public hands. More State and Territory

materials would have remained in public hands despite the CLIRS/Info-One monopoly, if this approach had been adopted more extensively.
This agenda is not unduly idealistic. The New South Wales Government's approach to the dissemination of legislation is a model implementation of at least elements (i) - (v), and the approach taken in many other jurisdictions is now fairly close (although licence fees of a percentage of income are charged in some cases). Many courts and tribunals also adopt principles (iii) - (v), but others still require very high licence fees.
4.5 Is AustLII sustainable?AustLII is funded entirely by grants from public institutions - academic, governmental, public-funded and philanthropic - and from business organisations. AustLII's formation in 1995 was funded by an academic grant25 ($110,000), and by its two host Universities ($25,000 each). In 1995/96 the Law Foundation of New South Wales made its first grant to AustLII (approximately $135,000 for 9 months), to support the inclusion of Australia-wide primary legal materials, and has renewed the grant at similar rate for the two successive financial years. Having been successful in gaining Australian Research Council competitive funding, and grants from other organisations for 1997, AustLII already has committed funding exceeding $800,000 for the three financial years 1997-200026. Taking into account reasonable expectations of other continuing annual funding, we are very confident that AustLII will receive approximately $400,000 per year for the next three financial years to July 2000. This funding is sufficient to maintain AustLII’s current staff levels, and its equipment, but no more than that.
The point of summarising these matters is to demonstrate that AustLII will be able to at least carry out its core activities (including research and collection expansion on current projects) into the next century. In the short term AustLII is therefore ‘sustainable’ - it is not likely to disappear overnight.
4.5.1 The ‘stakeholder model’We believe that AustLII is sustainable beyond the short term. One of the original ideas behind AustLII was that the provision of modest funding by a range of significant stakeholders in access to legal information could provide a long-term funding basis. The ‘stakeholder model’ is one that sees corporate representatives of classes of users, and data providers who wish to publish their data widely, being willing to contribute a share of the costs of running a free access service which includes the data in which they have a special interest, recognising that the system will also be used by ‘free riders’ who do not fall within any of the target groups of users. One of the attractions is that many stakeholders are interested in certain types of core data such as legislation or decisions of appeal courts (or at least parts thereof), and so each stakeholder only pays a small portion of the costs of making this data available. No doubt this is crude economics, but it makes sense to many ‘stakeholders’. Of course, AustLII is not the only organisation that could offer to provide access to data on this model.
We envisage that these stakeholders will, over time, include a mix of organisations falling into at least these categories:
• business, trade union and professional organisations (including the legal profession);• tribunals that have a strong interest in having their decisions more widely known, particularly small ones whose decisions are not often published by commercial publishers;• government agencies with a strong interest in wider availability of a class of information (for example, the Department of Foreign Affairs and Trade in relation to treaties);• community interest organisations (such as the Law Foundation);• the academic legal community, for research and teaching purposes.

AustLII has to date been able to publish the decisions of every court or tribunal that wishes to have its decisions published. We request courts and tribunals to consider making a small contribution toward AustLII’s overall running costs, but have not yet turned case law away because funding was not available.
It is much more difficult to manage secondary legal materials unless specific project funding is available. All AustLII ‘core’ operations must now be supported from project-specific funding, so all such projects must carry a portion of AustLII’s core costs (management and infrastructure).
4.5.2 An alternative model - Sex with your statutesOne alternative funding model now used by many web resources is advertising, but AustLII has no intention of adopting this model. Why should it be necessary to be bombarded by advertisements in order to do legal research on a University-based facility? Many Internet search engines now determine the advertisements that users see by the search terms they enter. It seems no coincidence that when you search one popular Australian search engine for ‘sex discrimination’, you get back lurid advertisements for sex aids. We have no interest in running AustLII on the basis of consumer manipulation.
4.5.3 The complementary model - Added value, lower priceFunding considerations are not complete without reiterating that we believe AustLII serves a role in prompting commercial legal publishers to add more value to the primary legal materials they publish, and to keep their prices moderate. Similarly, AustLII must cause governments and courts to think twice about charging for electronic access to public legal documents. In fact, whether AustLII has played a significant role in this or not, Australia is now better served by both commercial and free-to-air electronic legal resources than any county we know. Others think we are ‘the lucky country’ in this respect27 - but sometimes you have to make your own luck.
4.6 A new case citation standard - vendor and medium neutralA very encouraging example of cooperation emerging between Australian commercial and non-commercial legal publishers is occurring in the area of reforms to citation methods to accommodate the demands of electronic publishing. AustLII made its initial proposals on this topic at the Australian Institute of Judicial Administration Annual Conference in Wellington, New Zealand in September 1996 (de la Fosse and Finaly 1997), and in submission to the Council of Chief Justices in January 1997. Butterworths made its views public in early 1997. The Council of Chief Justices’ Electronic Appeals Project (de la Fosse and Finaly 1997) is to cover the question of court-designated citations. The Councils of Law Reporting have also discussed the matter.
In June 1997 representatives of Butterworths, LBC Information Services, CCH Australia, Pink Ribbon (the citator publishers) and AustLII held the first of what promises to be a series of very constructive meetings. Our interpretation (other participants may have a different perspective) of the discussions is that there is a general acceptance of the inevitability of a court-designated method of citation emerging, in parallel with new forms of publisher-designated citations. There also seemed to be general agreement emerging that both forms of citation would have to accommodate four elements: year (of decision or publication), case number (court-issued or publisher-issued), court or series abbreviation, and paragraph number (uniform across citations, and stemming from court’s numbering). However, many issues of detail arise, and will take considerable discussion to resolve, between publishers, the courts, court reporting bodies and other interested parties.
The following parts of this section of the paper reproduce the position that AustLII submitted to the Council of Chief Justices, and to the recent publishers meeting, as a summary of our thinking so far

on this issue. The details of this issue are complex (even though the basic principles are clear), so we expect that our initial views will be modified as all the interested parties explore the issue.
4.6.1 Need for a court-designated case citation standardOne of the most pressing needs in the development of a policy for public legal information is for a method of citing the decisions of courts and tribunals that is independent of any particular publisher or particular medium of publication. These issues including details of US and Canadian developments are discussed at greater length inGreenleaf et al (1996). Such a ‘medium-neutral’ and ‘vendor-neutral’ citation would be designated by the court that made the decision. A court-designated case citation standard would have many advantages: writers would be able to cite other decisions without making assumptions about the particular publications available to their readers; readers would be able to find decisions cited in whatever ‘court reports’ they have at hand (print or electronic); the creation of automated hypertext links and searches would be enhanced greatly; potential copyright difficulties in citation use would be avoided; and the official citation for a case will be known as soon as a court or tribunal releases it. Most print publishers would also continue to use their own ‘parallel’ citations, to indicate their own selectivity, ordering and print volume location.
A citation standard can be put together in various ways using only court-designated citation elements, and that is susceptible to automated recognition and processing. The simplest approach, and the one that we consider is most desirable, would have three elements.
The basis of any such citation must be an authoritative unique decision number allocated by the court or tribunal, preferably with the number series recommencing each calendar year. Decision numbers should be continuous, and the sequence unalterable. Each court should only use one sequence.
In order to distinguish between courts, a new system of unique court descriptors needs to be developed - standard abbreviations for each court. In some senses, this is similar to the existing system for abbreviating the names of series of law reports (e.g. ‘CLR’, ‘ALJR’), but is non-proprietary and court-specific. Any naming scheme should preferably not be limited (at least potentially) to indicating Australian jurisdictions, but be capable of application to any other jurisdiction and still give a world-wide unique identifier.
There appears to be developing agreement, at least in North America, that continuous paragraph numbering across a decision is the appropriate method of internally referring to parts of judgments (‘pinpoint citation’). Paragraph numbering is needed because page numbering is print-medium-specific (and specific to particular publishers), irrelevant to computerised judgments, and too coarse. Some Australian courts already use paragraph numbering within individual judgments. However, as both Canadian and US reports have recognised, paragraph numbering needs to be made more absolute and should be continuous across all judgements in a decision.
4.6.2 An open case citation standard - AustLII’s proposalsOur interim conclusion, pending further research and experiment, is that a vendor and medium neutral citation standard something like the following is desirable:
[1996] 194 HCA 23
The brackets around the date are possibly unnecessary, but they make it appear more familiar as a case citation (at least in Anglo-Australian publishing), and they may assist automated recognition of citation commencement. The decision number allocated by the Court (‘194’) follows, then the Court abbreviation, then the paragraph number. We have concluded that, if a citation of the

decision as a whole is intended, no paragraph number should be given28, so the citation for the above decision as a whole would be simply ‘[1996] 194 HCA’ .
On an experimental basis, recent decisions in some AustLII caselaw databases are now given such a citation, where we have court-designated or tribunal-designated decision numbers available to us. This can be considered an ‘AustLII citation’ in the same fashion as commercial legal publishers provide their own citations for cases, but differs in that anyone else is welcome to adopt it.
The initial approach we have taken to court designators is to use the normal abbreviation for a court or tribunal (which is usually obvious), followed by ‘A’ for ‘Australia’ where a Commonwealth court or tribunal is concerned (e.g. HCA, FCA, FamCA, IRCA). Where a State or Territory court or tribunal is concerned, we are considering placing the standard abbreviation for the jurisdiction before the court or tribunal abbreviation, simply because this feels more consistent with previous citation patterns (e.g. NSWSC, VICAAT).
Development of the most appropriate Australia-wide abbreviation scheme, particularly if possible international compatibility is considered, will require discussion, research and experiment. Any decision on a permanent standard series of court and tribunal abbreviations would, in our view, be a matter principally for the courts and tribunals concerned. Our experimental court abbreviations can be readily altered across the whole of the AustLII databases.
For example, the decision described as Industrial Relations Commission Decision 2704/1996 is also given the AustLII citation ‘[1996] 2704 IRCommA’, reflecting AustLII’s file naming conventions, which for this case results in the URL
http://www.austlii.edu.au/au/cases/cth/IRCommA/1996/2704.html
Similarly, for the recent Federal court decision listed in AustLII as Terrence Golby & Anor v Commonwealth Bank of Australia [1996] 1136 FCA (24 December 1996), the citation ‘[1996] 1136 FCA’ has been provided by AustLII. The citation reflects the URL29
http://www.austlii.edu.au/au/cases/cth/federal_ct/1996/1136.html
These AustLII citations will provide a convenient method for anyone to cite a case appearing in an AustLII database without having to recite a whole URL, as the case can be easily found on AustLII using the citation. It will also allow the creation of automated links to these cases. Experimental use of this approach to citation by AustLII will give us some experience in the practicalities of alternative citation methods, and may also help to encourage courts and tribunals to take an interest in the development of a uniform system of vendor neutral and medium neutral citation. Before any uniform system is adopted finally, there will obviously need to be considerable consultations with, and perhaps discussions between, courts, tribunals, and potential publishers and users of their decisions.
4.7 Privacy and the Internet Publication of decisions on the Internet raises some difficult issues, one of which is the privacy of those whose personal affairs are reported in decisions. These decisions are now available to wider scrutiny than printed law reports or CD-ROMs, due to the level of public access to the Internet, and free availability.
4.7.1 Lessons from the Family CourtIn May 1996 AustLII found itself the centre of media controversy concerning its provision of decisions of the Family Court of Australia, with allegations of invasions of privacy and possible breach of publication restrictions in the Family Law Act 1975 (Cth) s221. The decisions were provided to AustLII by the Family Court via the Commonwealth Attorney-General's Department‘s

SCALE system. AustLII decided to suspend the Family Court database until these issues were resolved, and the Commonwealth Attorney-General’s Department did likewise on SCALE. On 19 June 1996 the Commonwealth Attorney-General and Minister for Justice, Darryl Williams QC, released a News Release headed ‘Internet Material Cleared’30, stating that the publication on AustLII was not in breach of any privacy laws or the Family Law Act, and their availability was supported by the Family Court and the Family Law Council. The database has been restored to AustLII.
From AustLII’s point of view, the episode is significant in a number of respects, which are of general relevance to other courts and tribunals. It reinforced our conviction that it must be the responsibility of the public bodies providing data containing personal information to make decisions concerning the appropriate balance between privacy interests and the public interest in publication. Publishers like AustLII cannot edit or censor the content of court decisions31. However, it is appropriate for courts and other public bodies to re-assess their publication practices concerning questions such as anonymisation, in light of the different accessibility of materials via Internet, as has been done by the Family Court in this instance. This also ensures that the decisions remain the same, irrespective of the medium of publication.
The initial apparent criticism of AustLII from some sections of the media caused a storm of e-mail from AustLII’s supporters, and within a few days a number of newspapers and magazines had published editorials defending AustLII’s role in publishing these decisions . Since then, there has been little criticism of the continuing publication, in the press or elsewhere.
4.7.2 Robot exclusions and relative privacy AustLII has a responsibility not to encourage inappropriate use of the databases, so (for example) we exclude robots from indexing any of our case-law databases32, so that searches over general Internet search engines cannot inadvertently reveal that a person is involved (say) in Family Law proceedings. When we detect robots attempting to index our case law, we exclude them from access. If we became aware of other inappropriate access, we could also take steps to exclude it. In short, in order for anyone to find case law on AustLII, they have to come to AustLII - a rather boring looking non-sensational legal database - and search for it there.
5. New legal services via the web - AustLII’s research on legal inferencing
Legal inferencing technology has advanced considerably over the last two decades. However, such systems have generally taken the form of in-house compliance or document generation systems in large corporations or government agencies. The development of the World Wide Web has created new opportunities both in terms of increasing the accessibility of such systems to the public as well as enabling the development and maintenance costs to be spread widely over multiple knowledge engineers. Further, large repositories of legal information such as AustLII, SCALE Plus and Butterworths Online represent a greater wealth of digital supporting materials, with better currency, than has previously been available to be integrated with inferencing systems.
Legal inferencing systems can be used to develop and deliver a wide range of innovative legal services over the World Wide Web. These will include services customised to the circumstances of the particular inquirer (or client), such as (i) advice on availability of government benefits, (ii) advice on requirements for licences, (iii) interactive ‘interviews’ to complete legally-oriented application forms; and (iv) interactive generation of customised legal documents. All of these services will depend on complex automated inferences being drawn from large underlying bodies of constantly changing law. This paper33 outlines how such new legal services are being developed in the AustLII context.

5.1 AustLII’s inferencing researchAs part of AustLII’s role as a research centre in computerisation of law, we are conducting a three year research project34 into the development of legal inferencing systems which use the Internet, and into how their integration into large scale legal information systems like AustLII can result in the development of new legal services via the Internet.
This research project builds on two principal sources, the ‘DataLex’ research (1985-94), and the development of AustLII (1995-97). The ‘DataLex’ research project(Greenleaf et al; 1995b) on the computerisation of legal information was done mainly in relation to ‘stand-alone’ collections of legal information, and was unrelated to the web. That research led to two principal conclusions.
First, the most useful decision support systems based on inferencing also incorporate hypertext and text retrieval techniques to allow the user to investigate questions posed by the inferencing system. We are now able to use AustLII as the foundation on which to build legal inferencing systems as part of large-scale decision-support systems. AustLII - its data, indexes, software and usage - provides the necessary infrastructure for this research.
Second, “quasi-natural language” (English like) rulebases have advantages over more traditional symbolic rulebases. The advantages of quasi-natural language inferencing engines are accentuated where the knowledge engineer is any lawyer with a web site. The simple and intuitive syntax of such inferencing engines becomes critical in this context.
5.2 Project goalsThe project goals address the key issues in implementing effective legal inferencing over the web, common to both rule-based and case-based legal inferencing, including:
(1) An efficient method of inferencing using remote rulebases This involves a choice between having the processing of inferences conducted by the user’s machine, or having a third party server process the inferencing session. At present we have approached the issue by allowing users to invoke the AustLII wysh server which then retrieves the relevant remote knowledgebase(s) and handles the inferencing session. Alternatives which may be explored during the course of the research are implementing the inference engine in a cross platform language such as Java or porting it to various platforms to be invoked as a browser plug-in. Both of these latter two solutions require significantly more development work than our current solution.
(2) An efficient solution to the problem of stateless inferencing Having adopted the inferencing server approach the problem arises of how the necessity for an inferencing system to retain both user-provided and inferred ‘facts’ in working memory can be best reconciled with the essentially ‘stateless’ nature of the HyperText Transmission Protocol (HTTP)? An HTTP server does not in itself maintain state (ie retain knowledge of past user behaviour) between user requests, so as to link them to the same user. A variety of techniques may be used to solve this problem including embedding session identifiers in CGI form-based requests, ‘magic cookies’, ports tied to one host, and (common but unreliable) heuristic assumptions about repeated requests from the one host. However any solution must be efficient in processing and memory terms at both the server and client ends. We discuss our current solution below.
(3) Permitting interaction between distributed knowledgebases The more challenging issue (‘cooperative’ inferencing) is how to enable different knowledge-base developers to develop knowledge-bases on their own web sites (all remote from the site of the inferencing software), which interact with others’ knowledgebases when invoked by users. Again, there are essentially two potential solutions: (a) multiple inferencing sessions may be conducted to deal with different parts of the problem (the cooperating agent model); or a single session could be conducted using knowledge from a variety of distributed knowledgebases. While inferences are being handled by a

single server, or if inferencing is conducted by the user agent, the most appropriate approach is probably to conduct a single inferencing session. This allows more finely tuned control on the sharing and hiding of knowledge between different parts of the knowledgebase. However, the distributed inferencing agent model may be more appropriate if knowledgebases or knowledge “webs” become too large to be efficiently dealt with by a single inferencing server or user agent.
(4) Facilitating cooperative knowledgebase development Once knowledgebases can interact other issues are raised. How can an underlying ‘ontology’ for legal inferencing, and use of a common interface, be best developed so that knowledge representations developed independently by different developers, and located on different servers, can interact to draw legal inferences?(Gruber Year) What tools can be developed to assist developers in ascertaining what knowledge already exists on remote sites? What standards, methodologies and associated tools can be developed to ensure that knowledgebases are as reuseable, and generic as possible? Should developers specify what knowledgebases may be invoked to solve sub-problems or should inferencing servers or user agents provide facilities so that users can search for relevant knowledgebases during the course of an inferencing session?
Other issues made more significant by web-based inferencing include the possibility of sharing or reusing ontologies from other disciplines as well as more generalised common sense ontologies. Use of other types of knowledge, and permitting legal knowledgebases to be used by non-legal inferencing systems, raises the issue of whether knowledge should be stored in a more open form
23 The copyright issue are complex and will not be dealt with here, because they can be avoided.24 An ARC ‘Mechanism C’ grant for $110,000. Dr Tom Gedeon of Computer Science at UNSW was also one of the investigators named in the grant, as has been our co-applicant on other research funding applications.25 The Australian Research Council (ARC) ‘Mechanism C’ fund.26 Principally from the Australian Research Council; the Law Foundation of New South Wales; Council for Aboriginal Reconciliation; Department of Foreign Affairs and Trade; Australian Business Chamber; AUSTRAC and the Human Rights Centre / Commonwealth Attorney-General.27 See the United Kingdom Court of Appeal’s comments at the end of the Introduction, for example.28 The alternative, that the final number should be ‘1’, is rejected because it would be ignored in creating hypertext links (and is therefore unnecessary for the main purpose), is unlikely to be used consistently, and because there may be need to interpose publisher-specific materials (eg headnotes) before the decision proper starts.29 Except that we are about to change our file names to now use ‘FCA’ instead of ‘federal_ct’.30 Internet Material Cleared
Selected decisions of the Family Court of Australia are being restored to the Internet and on-line services.
Contrary to media reports, there is no unauthorised material such as case files available on this database.
Family Court decisions on the database have been available for many years in commercial law reports.
Services provided by the Australasian Legal Information Institute (AustLII) and related on-line services provided by the Attorney-General's Department were temporarily suspended pending an assessment of the database material.
That assessment has been completed and I am satisfied that the Department, AustLII, the Law Foundation of New South Wales and the Family Court have acted appropriately in providing selected and edited Family Court decisions through the electronic services. The services provide accurate copies of selected decisions in a form that is determined by the Family Court to be appropriate for reporting. The publication of such decisions does not breach any prohibition on publication or privacy legislation, and their continued availability has been supported by the Family

such as the knowledge interchange format (KIF). As well, or alternatively in relation to some problems, specialist intelligent agents may be used in relation to non-legal sub-problems. In this case inter-agent communication standards such as the knowledge query and manipulation language (KQML) need to be considered.
(5) Integrating inferencing in the web. How can the interface and process of legal inferencing be best integrated, on the World Wide Web, with the hypertext and text retrieval presentation of the underlying legal texts, particularly when these are very large-scale, not project-specific, distributed, and constantly changing? The initial issue for us was how well our prior ‘DataLex’ research on integration (Greenleaf et al, 1995b) could be extended to accommodate the additional demands of the ‘unlimited’ web context. This has been accomplished partly by means of real time mark-up of
Law Council. The Chief Justice of the Family Court believes there are adequate safeguards to ensure that inappropriate material is not published. The SCALE service has therefore been restored and the AustLII service will be re-established shortly.
31 However, if AustLII does become aware of apparently inappropriate content in a decision, its policy is to inform the court or tribunal concerned, so that that body can decide whether the decision should be withdrawn temporarily while it reconsiders the publishable form of the decision and, if necessary, supplies replacement copies to all publishers.32 See http://www.austlii.edu.au/austlii/privacy.html for AustLII’s Privacy Policy.33 This paper was written concurrently with a paper for the 6th International Conference on Artificial Intelligence and Law (6 ICAIL), Melbourne, July 1997 (Greenleaf, Mowbray, King, Cant and Chung ‘More than wyshful thinking: AustLII’s legal inferencing via the World Wide Web’), reporting on the same project, so there is necessarily some overlap between the two papers.34 Funded by an Australian Research Council Major Grant for 1997-99 of $170,000; preliminary 1996 funding of $8,000 came from an ARC Small Grant. Simon Cant is AustLII’s ARC Infrencing Project Officer.6 Subject to privacy considerations - see AustLII’s Privacy Policy at http://www.austlii.edu.au/austlii/privacy.html7 Commonwealth courts and tribunals: High Court of Australia Decisions 1947- High Court of Australia Transcripts 1996- High Court of Australia Bulletins 1995- Administrative Appeals Tribunal Decisions 1976- Australian Industrial Relations Commission Decisions 1988- Australian Industrial Property Organisation Decisions 1981- Family Court of Australia Decisions 1988- Federal Court of Australia Decisions 1977- Human Rights and Equal Opportunity Commission Decisions 1985- Immigration Review Tribunal Decisions 1990- Industrial Relations Court of Australia Decisions 1994-1997 National Native Title Tribunal Decisions 1994- Refugee Review Tribunal Decisions 1993-
8 New South Wales Supreme Court of New South Wales Decisions 1995- Industrial Commission of New South Wales Decisions 1995- Land and Environment Court of New South Wales Decisions 1988- Residential Tenancies Trinunal of New South Wales Decisions 1986- Northern Territory Supreme Court of the Northern Territory Decisions 1986- Northern Territory Anti-Discrimination Commission Decisions 1995-

knowledgebases to include links to relevant supporting legal materials and also by allowing embedded searches.
(6) Effective use of user feedback. Can usage patterns of legal inferencing systems on the web (including the hypertext / retrieval interactions) be captured in meaningful ways and used in the aggregate as feedback to refine such systems? Effective use of usage patterns raises difficult issues of interpreting the data, as well as privacy considerations, but is such a valuable and available resource in web-based services that it cannot be ignored. AustLII voluntarily adheres to the privacy principles set out in the Privacy Act 1988 (Cth). Any monitoring of user behaviour will be developed in accordance with privacy principles.
South Australia Supreme Court of South Australia Decisions 1989- District Court of South Australia Decisions 1997- Environment Resources and Development Court of South Australia Decisions 1997- South Australian Consolidated Acts South Australian Consolidated Regulations Tasmania Supreme Court of Tasmania Decisions 1987- Resource Management and Planning Appeal Tribunal of Tasmania Decisions 1996- Victoria Administrative Appeals Tribunal of Victoria Decisions 1994- 9 New South Wales Law Reform Commission Reports are the largest collection.10 Australian Commercial Disputes Centre Australian Community Legal Centres Australian Human Rights Information Centre Australian Institute of Judicial Administration Council for Aboriginal Reconciliation Federal Court of Australia High Court of Australia Human Rights and Equal Opportunity Commission New South Wales Law Reform Commission Privacy Committee of New South Wales Refugee Review Tribunal Western Australian Information Commisioner
11 Cornell's intellectual property statutes are an exception - see http://www.law.cornell.edu/statutes.html ; some Butterworths Online databases also contain extensive internal links.12 AIRS - a component of the DataLex Workstation. 13 The initial grant from the DEET “Mechanism C Research Infrastructure Scheme” was for $110,000 which was matched by grants of $25,000 each from UTS and UNSW.14 In October 1995, the Law Foundation of NSW agreed to fund the primary material on AustLII. The chariman on the Foundation, Justice Vince Bruce, was instrumental in obtaining permissions for the remainder of the SCALE materials. By the end of the year, we had permissions to publish around 20 databases.15 This figure reflects the total number of bytes that are indexed. It does not include non-indexed files (such as tables of contents and the like) and does not reflect the size of the raw HTML files after they have been divided into files.

(7) Attempt to resolve the tension between ‘readability’ and expressive power. The ‘DataLex’ research (Greenleaf G et al; 1995b, part 4.2) argues for the necessity for ‘English-like’ knowledge representations in legal inferencing, but this demand poses problems in properly utilising predicate logic. The work by Johnson and Mead SoftLaw Corporation is of relevance to, but does not resolve, this problem. This issue is not particular to web-based inferencing, but cannot be avoided in resolving other problems. More particular to the web context is the problem of making the knowledgebases as reusable for legal and non-legal inferencing as possible. This involves use of a standard knowledge representation format. However, to use such a standard (e.g. KIF) as the primary knowledge representation language may make knowledgebases far less accessible to maintainers and developers, and transparent to users. Accordingly, knowledge sharing may require conversion utilities.
(8) Tools to assist in ‘scaling up’ Which elements (if any) of the development of legal knowledge representations (particularly legislation-based ones) are capable of complete or partial automation, so as to assist with the problems of scaling-up legal inferencing? Can both the web availability of representations of the underlying texts on a large scale, and the hypertext and text retrieval relationships captured in those texts, be used to assist large-scale scaling-up?
This is probably the most challenging and intractable issue. Anything approaching complete automated conversion of legislation into knowledge-bases is unattainable (at least in this project), as it would involve solving many of the major problems of automated processing of natural language. Our goals are limited to attempting to find whether there is any extent to which legislation may be automatically ‘pre-processed’ so that the task of the human expert who must convert it into a knowledge-base is reduced - particularly where large-scale knowledge-bases are planned. In other words, it is an attempt to produce a ‘useful first cut’ of a knowledge-base, not the finished product. Reasons for optimism in relation to this limited goal are (i) the ‘quasi-natural language’ knowledge representation we use is, in effect, a formal paraphrasing of legislation; and (ii) our previous experience in automated heuristic processing of legislation with hypertext mark-up tools.
5.3 Research on legal inferencing over the webThere is as yet little published work or examples in the field of legal rule-based inferencing over the net. For more details of related research see Greenleaf et al (1997b) The principal web resource on legal inferencing, Durham’s Guide To AI and Law Resources, contains links to a wide array of resources on AI and law, but only three on legal inferencing over the web, despite the list of over 30 academic Centres and projects that have web sites. SoftLaw Corporation (Canberra, Australia) 16 For the purposes of this calculation, a user “session” is treated as any period of use from a single site where usage is not interrupted by a period of more than half an hour.17 This excludes development machines, most of which are used for data conversion work. These machines include “cogee” (a Sparc 4) and 5 PCs and Macs.18 Two Sparc Ultra 170s with 256M of memory called “bronte” and “bondi” and one Sparc 4 with 32M called “wanda” (like the fish!).19 And hence the name SINO - “Size is no Object”. Apart from being a reaction to the very slow retrieval times of glympse vs the very good concordance ratios that it was achieving, the name was also meant to reflect the fact that SINO could handle very large text databases.20 Existing court designators take various forms. In line with AustLII’s recommendations to standard citation, these designators are being standardised to be equivalent to the cited format. 21 E-mail from John Pike, webmaster of the American Federation of Scientists, quotes confirmation from Alta Vista that 600 is about the maximum for any one site. 22 On Alta Vista, using a search for Vietnamese legal materials for example, this requires a search which is limited to materials which are located on a server in Vietnam (the ‘domain:vn’ delimiter) or contain ‘Vietnam or Viet Nam’ - and this is still somewhat hit or miss.

and the Centre for Legal Process (Sydney, Australia) have an application running on the web using Softlaw’s STATUTE software.(Kellow; 1997) (Johnson and Dayal;1997)
In domains other than law, there appears to be considerable relevant work. Stanford Knowledge Systems Laboratory’s (KSL) Network Services aims to make all of their research software and research results available over the web’, and will be relevant to this project’s research on the co-operative development of ontologies for particular domains. The Stanford KSL research forms part of the ARPA Knowledge Sharing Effort (KSE), a consortium to develop conventions facilitating the sharing and reuse of knowledge bases and knowledge based systems.(Neches R and Gruber T; 1994) Other parts of this effort which are likely to be relevant to our research include the Knowledge Query and Manipulation Language (KQML) (Finin T and Fritzson, R; 1994) and the Knowledge Interchange Format (KIF),(Genesereth M and Fikes R; 1992) both of which are likely to be relevant to enable the inferencing system to interact with other information systems or intelligent agents over the Internet or other networks. Also valuable are ontologies available over the web from Stanford KSL (Rice J et al; 1995) and Cycorp’s Cyc ontology.
5.4 AustLII’s WYSH systemAustLII’s web inferencing project has been underway for less than a year, but significant progress has been made in relation to issues (1)-(5) as indicated above, and background work undertaken in relation to (7) and (8). Issue (6) remains untouched as yet.
5.4.1 The YSH inference engineThe YSH inference engine written by Mowbray (1991-1994) (See Greenleaf G et al (1995b) for a description of its features) which formed part of the DataLex WorkStation software is the basis of AustLII’s web inference engine. In summary, YSH implements rule-based inferencing, with rules being both forward and backward chaining by default, but able to be declared to be FORWARD, BACKWARD, DAEMON or other rule types. The ‘(quasi) natural language’ knowledge representation is close to a paraphrase of ordinary English (at least as used in statutes!), with keywords such as ONLY IF, EQUALS etc. Dynamic information is stored as facts with Boolean (yes/no/unknown) values or non-Boolean (numbers, amounts, dates or genders). Named subjects declared to be a PERSON, THING, or PERSONTHING will be instantiated and correct pronouns used in dialogues. All inferencing dialogues are generated ‘on the fly’ from the knowledgebase. YSH also provides limited forms of automated document generation and case-based reasoning, both of which are integrated with the rule-based component.(Greenleaf et al; 1994)
5.4.2 The wysh web interface to YSHAll aspects of YSH’s inferencing now work over the web, via the wysh (for ‘web-ysh’) user interface to YSH,35 a Common Gateway Interface (CGI) application. Knowledgebases developed for YSH can be placed on a web page and they will then run without alteration through the wysh interface (examples are given below). The inferencing server approach was adopted because it allows access from a wide range of browsers (unlike a Java based solution), is not limited by the processing capacity of the user agent hardware and, initially, allowed more rapid development of a working system based on the YSH inferencing engine.
Wysh is able to read knowledgebases out of HTML pages, irrespective of the web server on which those knowledgebases are located. The only HTML tags which are needed are the <!--ysh> and <!--/ysh-->, to indicate where on a web page a ysh knowledgebase begins and ends. The YSH and the wysh interface are now available to anyone who wishes to use them over the web to develop applications. There are two ways for knowledgebase developers to use wysh.

Anyone who wishes to publish a YSH knowledge base on their web page can do so by adding a link which passes the location of the knowledgebase and various other optional parameters to the wysh CGI script. For example, the following HTML enables the intellectual property knowledgebase, located on a web page on a different AustLII server to be run using wysh:.
<A HREF="http://www.austlii.edu.au/do/wysh?rulebase=http://www2.austlii.edu.au/~graham/wysh/ipwstn.html&markup=ON">Run consultations </A> using the IP Knowledgebase (1991- 94)
Selecting this link results in a consultation starting, as described below. Links such as this may be located on the page on which the knowledgebase is located, or on any other page. For example, the link which invokes a knowledgebase for s15 of an Act could be located as a ‘Consult’ button on the web page for the text of that section.
The second way in which wysh can be used is via the ‘wysh manual start page’ shown below. It is designed for small rulebases to be tested and amended, and includes mechanisms by which the consistency of knowledgebases, and automatically inserted hypertext links, can be checked.
Figure: The wysh ‘manual start’ page, with a small rulebase to be tested
5.4.3 The ‘wysh index’ - sample knowledgebases, other aidsDemonstration wysh knowledgebases, and tools to assist knowledgebase development can be accessed from the ‘wysh index’
Example knowledgebases include those concerning Australian privacy law36 and intellectual property law,37 reflecting work done for the previous DataLex WorkStations (Greenleaf et al; 1995b). There are also some small examples used for teaching purposes.

5.4.4 The user interface to wysh applicationsOnce the consultation is started, the user is presented with a choice of goals, and a dialogue commences. The example below is from our intellectual property knowledgebase.
The following goals are defined:
1) Copyright Act 1968 - s29 (Publication) 2) Copyright Act 1968 - s31 (Exclusive Rights) 3) Copyright Act 1968 - s32 (Subsistence) 4) Copyright Act 1968 - s33 (Duration) Please select a goal ?
Having selected a goal, the user then engages in a dialogue, mainly through variants of the screen below. ‘Facts’ displays user-supplied facts (which may be retracted one at a time using ‘Forget’ or ‘Forget n’). ‘Conclusions’ displays interim conclusions (with explanations elicited using the command ‘How n’). ‘Why?’ explains the current question. All dialogues are generated from the knowledgebase with the types of hypertext links shown below.
Figure: wysh interface showing interim conclusions and current question
5.4.5 An approach to the ‘state’ problemA number of different approaches were considered as solutions to the problem of statelessness on the web. Broadly, as noted earlier, two approaches to the underlying architecture can be adopted. One approach is to rewrite the inferencing engine for the user's machine as either a Java applet or as a browser plug-in. The second approach implements a client-server model, maintaining the inferencing engine at the server end and providing a simple forms based interface for the client.
At this stage of the project, the latter approach has been adopted. This avoided both a major rewrite of the inferencing engine and the many problems still remaining with cross-platform code. In keeping with AustLII’s general philosophy, we also favoured an approach which was consistent with the cross-platform and user-interface concerns of the World Wide Web.
The decision to remain with a client-server approach led us to an analysis of two different approaches at the server end. An early solution created a dedicated HTTP server for each remote session. Although simple to implement, this approach had major overheads and was abandoned in favour of an approach which maintained as much functionality in the standard HTTP server as

possible. Our current implementation uses a simple CGI interface to connect to one of a number of stateful YSH sessions which run via internal UNIX domain sockets.
This approach allows for each session to maintain state and interact in a fast and secure manner with the CGI script which handles the bulk of the user-interface. The advantages of this approach include the ability of our interface to be used on any HTML 2.0 or later browser (graphical or text-based). We are able to update our expert system shell as required and there are a minimal number of complex cross-platform issues to deal with. Authentication between individual transactions in a 'session' is handled with a combination of a 'session id' and host-based authentication. Cookies would also provide an appropriate method of authentication.
It is envisaged that the issue of architecture will be readdressed in the near future, with more thought being given to the possibility of a Java based solution.
5.4.6 Cooperative inferencing using wysh‘Cooperative inferencing’ allows wysh knowledgebase developers to declare in their rulebases that other rulebases on web pages located anywhere on the web are to be ‘included’ in consultations running using their rulebase.
Other knowledgebases are ‘read in’ to a wysh knowledgebase by use of the INCLUDE keyword and the URL of the knowledgebase to be included. For example, in this small knowledgebase, two other knowledgebases are read in.
INCLUDE http://sandpit.austlii.edu.au/~aial/ foitest/foi_s11_b.html INCLUDE http://sandpit.austlii.edu.au/~aial/ foitest/foi_s11_a.html
PERSON a personTHING the documentGOAL RULE Freedom of Information Act 1982 (Cth) s11 PROVIDESa person has a legally enforceable right under s11 to obtain access to a document ONLY IF s11(a) applies OR s11(b) applies (wysh example - FOI s11)
The INCLUDE function will also read any knowledgebases which are INCLUDEd in any of the knowledgebases it finds. Multiple knowledgebases may therefore be ‘chained’ together by hypertext links, without any one knowledgebase listing all of the ‘cooperating’ knowledgebases. However, wysh will not reload the same knowledgebase twice, thereby avoiding infinite loops.
At present, all INCLUDEd knowledgebases are read before an inferencing session commences. This is effective while the number and size of chained knowledgebases remains manageable. Other more efficient mechanisms of deciding when to read which knowledgebases (or parts thereof) are under consideration.
5.4.7 Tools to assist in the development of cooperative knowledgebasesThe potential advantages of cooperative inferencing are considerable, as it takes advantage of the web’s inherent facilitation of a number of parties contributing small components of an overall solution to a problem. However, a directly or indirectly INCLUDEd knowledgebase may be changed or added to without the knowledge of others who INCLUDE it, a problem typical of hypertext on the web, but with more significant consequences for knowledgebases. These factors give a new importance to a number of issues, including problems of transparency, the need for conflict resolution rules, and the value of shared ontologies, which we have not yet explored fully. They also indicate a need for specialised tools which, among other things, index and allow searching over rules. Such tools may be developed during the course of the research.

To enable users to see the content of other knowledgebases that are being included, it is useful to make the URLs that follow each INCLUDE into live hypertext links to those knowledgebases.
At present the most useful tool for knowledgebase developers is the ‘Check Fact Cross References’ button on the wysh manual start page. This indicates which rules contain references to particular facts. Therefore, developers can ensure that the facts which they expect to invoke rules contained in another knowledgebase will in fact invoke those rules.
5.4.8 Integrating inferencing into the webKnowledgebases and inferencing sessions need to be linked to the legal sources on which they are based.(Greenleaf G et al; 1995b) This is achieved in a number of ways with wysh: by automated hypertext links to AustLII legislation; by explicit hypertext links from rulebases; and by pre-stored searches linked to rulebases.
Automated hypertext links from rulebasesWhen a wysh inferencing session is invoked from a hypertext link from a web page, the inclusion of ‘&markup=ON’ after the URL of the target knowledgebase will result in the knowledgebase being ‘marked up’ by AustLII’s automated mark-up scripts, so that all dialogues, explanations and reports will be presented to users with hypertext links out to any legislative references.
The mark-up software uses heuristics to create links to names of Acts, to specific sections of Acts, and to cases identified by certain case citations (e.g. ‘CLR’ references to the Commonwealth Law Reports), provided the materials are contained on AustLII. One full reference to a piece of legislation (including a year) in the knowledgebase is normally required, but the heuristics then attempt to determine which subsequent (or prior) section references are to that Act. If a default jurisdiction is specified (an option), the software will attempt to process links for that jurisdiction first, and will resolve any ambiguities in legislation names in favour of that jurisdiction. The automated linking works with a high degree of accuracy over AustLII’s more than 400,000 sections of legislation.
For example, in the small knowledgebase above, the references to ‘s11(a)’ and ‘s11(b)’ result in automatic correct links to s11 of the Freedom of Information Act 1982 on AustLII. These links appear in questions, reports and explanations. If the user follows a hypertext link to the text of s11, and then selects the ‘[Noteup]’ button at the head of that section, it will cause a pre-stored search of the whole AustLII database, for all cases and other legislation referring to that section (26 cases, one other section and one tax ruling, at the time of writing). In this way, wysh users can be led seamlessly from inferencing to hypertext to text retrieval.
Since the linking process is dynamic, being re-run every time a consultation is commenced, new links may be created if new material (for example, another jurisdiction’s legislation) is added to AustLII after the knowledgebase was created.
This automated hypertext linking of knowledgebases to sources is therefore capable of speeding up the development process as well as assisting users to determine the currency of a rulebase (discussed further below).
Explicit hypertext linksThe LINK ... TO keywords allow for additional hypertext links to be explicitly defined in a knowledgebase. In the above example, the knowledgebase for s11(b) contains an explicit link to the statutory definition of ‘document of an agency’:
The link could be to any document anywhere on the web.

Pre-stored searchesIn the above example, the knowledgebase for s11(b) contains a different form of explicit link, a search over AustLII for any document referring to an ‘official document of a Minister’ (with display by relevance ranking using ‘freeform’ searching):
By the same means, searches over non-AustLII resources (e.g. Alta Vista) may be embedded.
An answer to ‘knowledgebase - lag’A crucial ‘real world’ problem of legal inferencing systems is that the development of knowledgebases (like other value-added secondary sources such as legal textbooks) must necessarily lag somewhat behind the case law and legislation that they embody, yet users in legal practice value and require resources that reflect the law as it is ‘up to the minute’.
An important aspect of the three forms of links from knowledgebases to textual sources described above is that they start to provide one of the few ways to do anything practical about this problem. If the inferencing dialogue can also direct users to more recent textual sources to assist in the checking of its generated conclusions, then the use of knowledgebases in legal practice is more likely. Links to a constantly updated set of textual sources such as AustLII are likely to reveal sources more recent than the knowledgebase. The embedding of search expertise in key terms, and the ability to ‘[Noteup]’ links to legislation by stored searches, are useful bridges to a dynamic text collection.
The next step is to utilise features more specific to a particular consultation in constructing automated ‘updating’ searches. One possibility is to take the principal conclusions generated by an inferencing session and automatically transform that text into a ‘freeform (relevance ranking’ search of AustLII, possibly limited to texts dated after the last update of the knowledgebase. In a related fashion,(Daniels J and Rissland E; 1997) one can use the output of a CBR system to construct document queries.
Advantages of knowledgbases as web pagesFinally, there are a number of advantages in the original wysh knowledgebase (not just a copy of it) being published on a web page, or pages. The transparency of the knowledgebase is enhanced by the ‘visibility’ of the original.(Greenleaf G et al; 1995b) The knowledgebase can have the same hypertext mark-up as other texts (links to statutory provisions, defined terms etc.), and as will be used in the inferencing dialogues.
The knowledgebase is searchable at the same time as cases and statutes are being searched, so users can ‘find’ not only texts that are relevant to their search requests, but consultations as well. One advantage of using a ‘quasi-natural language’ knowledge representation is that it is possible to search for parts of a knowledgebase using the same search queries as a search over the source texts. The ability to break a knowledgebase into separate pages (a by-product of cooperative inferencing) also improves the effectiveness of searches, as the document unit searched (e.g. a knowledgebase for one section of an Act) can be isomorphic with the document units of the source texts.
5.5 Current and future workThe first stage of AustLII’s inferencing research has resulted in the full migration of the DataLex approach to legal inferencing to the World Wide Web. YSH knowledge-bases now run over the web through the wysh interface. All of the forms of integration between inferencing, hypertext, and text retrieval explored there are now operative on AustLII.
However, this work extends the DataLex approach in significant ways. The wysh interface provides one solution to the problem of maintaining state in web interactions, while not requiring anything more than the standard HTML and CGI facilities of the web. Our initial approach to remote and

cooperative inferencing provides a means for wysh knowledgebases to interact with other wysh knowledgebases located anywhere on the web. We have developed a variety of automated and customised means of linking knowledgebases and inferencing dialogues to a large dynamic ‘real world’ legal information system.
Over the next two years the project is likely to advance in two main directions: (i) all of the initial components will be developed further, either by refinement or replacement and (ii) the issues of scaling up will then become central, and will be tested by developing a number of large-scale applications in the context of the AustLII databases.
5.5.1 A new inferencing engineAn inferencing engine which handles predicate logic, but which retains the quasi-English and declarative nature of YSH rules is currently being developed. The new engine will allow new operators including “A” and “ALL”. It will also allow inheritance between objects for the purposes of type checking. Accordingly, an object “author” may be defined such that it is a subtype of “person”. Accordingly, any rule that deals with “person”s will also be able to answer a relevant query from another rule in relation to “author”s. Further, any range checking that applies to a parent such as “a person’s birthday” will automatically apply to any object which is a subtype of that object such as “a child’s birthday”.
Lastly, it is intended that operators will be added to allow scoping, and precedence to be specified. Accordingly, phrases such as “for the purposes of this section” and “subject to section 13” will be able to be appropriately interpreted by the inference engine. There is some question as to whether adding such operators will lower the rigour demanded of knowledge base developers by not requiring them to construe the semantic structure of a statute and thereby allow errors and inconsistencies to appear in the rulebase more easily.
5.5.2 Scaling-up knowledgebase developmentBackground work is also underway in the partial natural language processing of legislative texts. It is anticipated that the initial approach will involve drawing from legislative texts a series of complete clauses connected, where possible, by conjunctions (and/or/etc.) or subordinating conjunctions (if/provided/etc.). This will require identifying such structural words (conjunctions and subordinate conjunctions) in the text. This will quite probably involve some user input in determining which of the potentially structural words are and should be treated as structural words.
31(1) For the purposes of this Act, unless the contrary intention appears,
copyright, in relation to a work, is the exclusive right:
(a) in the case of a literary, dramatic or musical work, to do all or any
of the following acts:
(i) to reproduce the work in a material form;
(ii) to publish the work;
(iii) to perform the work in public;
(iv) to broadcast the work;
(v) to cause the work to be transmitted to subscribers to a
diffusion service;
(vi) to make an adaptation of the work;

(vii) to do, in relation to a work that is an adaptation of the
first-mentioned work, any of the acts specified in relation to
the first-mentioned work in subparagraphs (i) to (v),
inclusive; and ...
For example in converting s31(1) of the Copyright Act (extracted below) into a rule, ideally the sentence would not be repeated for each type of work. Therefore, in the phrase “literary, dramatic or musical work” the user would indicate that the comma and the word “or” should not be treated as structural. However each of the rights would ideally be dealt with in a separate rule, particularly if there are further definitions or case law which relate to each. Therefore, the semicolons and the “and” between the paragraphs should be treated as structural.
Having gone through the process of identifying structural words, a number of other difficult problems are faced.
The first problem is ellipsis. As indicated, ideally a separate rule would be associated with each right. In the above example, all but the first right omit the beginning portion of the sentence. This is because that beginning portion is assumed to apply in relation to each right. In order to produce a series of simple clauses, the beginning of the sentence needs to be inserted before each of the rights giving:
copyright, in relation to a work, is the exclusive right to reproduce the work in a material form and
copyright, in relation to a work, is the exclusive right to publish the work and ...
Ellipsis of this kind is extremely common in statutory texts. While it can generally be dealt with easily, it may require human input to determine exactly what portion of the initial clause is missing from subsequent clauses (or what portion of the last clause is missing from earlier clauses). While heuristics may be able to be used by software to make judgements about this, human input would probably be better at this early stage than after processing, when it will involve looking for wrong interpretations in the text.
Another problem is anaphora. In the existing inference engine (and also in the engine currently being developed) references to named subjects or objects must be explicit. However, in English texts, references to a noun are often by way of a pronoun, known in this context as an anaphor. For example in the phrase below, the word “He” is an anaphor which refers to my dog.
My dog has fleas. He needs a flea collar.
Often such references can be difficult to resolve, particularly without semantic understanding of the sentence. Where the pronoun is within the same clause, it may not be necessary to resolve it since any question produced by the inference engine which is based on that clause should be meaningful to the ultimate user regardless of whether the anaphor has been replaced by the relevant noun. However, where a pronoun is used to refer to a noun in a previous or later clause, the reference will need to be resolved. Fortunately, this form of anaphora is not traditionally common in legislative texts because of its tendency to introduce ambiguity. Further, this resolution can be assisted by heuristics, although ultimately a human will need to decide what the reference is to.
Once a first cut, consisting of simple clauses connected where appropriate by conjunctions, has been produced, the developer will need to ensure that corresponding clauses have identical wording in order to guarantee that backward and forward chaining proceeds correctly. Tools may also be developed to assist with this process by identifying possible matching clauses. Other clauses will need to be completely reworded to be turned into an appropriate rule.

5.5.3 Embedding inferencing in AustLII’s databasesOnce we are in a position to produce some reasonably large legal knowledge-bases, the question arises of how can these best be made accessible to users. The availability of the very large scale legal source materials such as are found on AustLII presents valuable opportunities to embed knowledge-based systems in the context of such materials - an opportunity not previously available. This is the complement of the question of how to make source materials available from inferencing sessions, which was discussed above.
The DataLex research suggested two primary approaches which are also relevant in the web context:
(1) Adding ‘Infer’ buttons to pages of legislation where there is an associated knowledgebase so that users can commence an inference session in the course of browsing through a section. This may be useful not only in allowing conclusions to be drawn in relation to a specific fact situation but also in allowing a user to be understand the structure and interaction of the section they are looking at and related sections.
(2) Allowing returning knowledgebases as results in searches. This may give users a more useful version of the relevant legislative provisions, depending of course on their aim and expertise in the area.
Both techniques should be valuable in encouraging users to try using inferencing software. This has been one of the major barriers in integrating inferencing systems in government agencies and other work places. Familiarity with the inferencing process among Internet users may increase the popularity, and hopefully therefore the resources available for the development of, knowledgebases and inferencing tools generally.
5.6 Conclusion - New legal services via the webThe web creates new opportunities for delivering computerised legal services to lawyers and the public. The wysh project seeks to take maximum advantage of these opportunities in a manner which is capable of developing a momentum beyond the wysh project itself.
The key aspects to achieving this momentum from a user perspective are:
(1) A non-platform or browser specific system for conducting inference sessions using remote knowledgebases.
(2) A simple self explanatory user interface.
(3) Hypertext links to up-to-date supporting materials to enable users to investigate questions both to determine an appropriate answers and to ensure that the knowledgebase is up-to-date.
(4) Transparent rulebases so that users can satisfy themselves, where unsure, that the rulebase is in fact a correct interpretation of the relevant law.
(5) Ready access from a high usage legal database (AustLII), both from searches and from sections or other nodes within the database.
The key aspects to achieving momentum from a developer perspective are:
(1) Simple invocation of the inference engine.
(2) Simple integration with existing knowledgebases, making any individual developer’s task comparatively small.

(3) Simple syntax so that non-programmers can develop knowledgebases.
(4) Tools to assist in developing and maintaining knowledgebases.
The ultimate goal, a web of legal knowledge maintained and extended by distributed unrelated legal knowledge engineers, should be of great benefit to both lawyers and the public.
6. Indigenous peoples’ legal issues via Internet
6.1 AustLII’s indigenous law projectReconciliation between the indigenous and non-indigenous peoples of Australia is of fundamental importance to the future of the country, as acknowledged by all Australian political parties and successive Australian governments in bipartisan support for the Council for Aboriginal Reconciliation38. This project aims to find how best to utilise the resources of the Internet to advance the task of furthering reconciliation.
In the aftermath of the Wik decision and the Bringing them Home Report, the political climate may have changed, but the legal issues affecting indigenous peoples and reconciliation have become more complex. The need for the more effective access to these materials that this project promises to deliver has become more urgent.
In 1995-96, the Council for Aboriginal Reconciliation and AustLII jointly created the first stage of the Reconciliation and Social Justice Library on the Internet, and established a productive working relationship and recognition of common goals. This large-scale prototype project involved over 100 MB of texts, most notably the full text of the 97 volumes of the Reports of the Royal Commission on Aboriginal Deaths in Custody. These reports had gone out of print, and the master disk copies had been lost. The Council reversed these circumstances by having all 97 volumes re-captured using optical character recognition, and then made widely available through CD-ROM and through AustLII’s web facilities.
AustLII and the Council then jointly obtained a collaborative research grant from the Australian Research Council39 for 1997-99, so as to utilise the complementary expertise of the Council and its Secretariat in indigenous history and legal matters, and the expertise of AustLII in research and development in the computerisation of legal materials.
AustLII’s Project Manager for the Reconciliation and Social Justice Internet Project is Kirsty Magarey. Tim Moore, formerly the Secretary to the Council for Aboriginal Reconciliation, is providing assistance with various aspects of the project in an honorary capacity.
6.1.1 The project’s goalsThe project aims to achieve the following main research goals:
• to determine what are the significant historical materials concerning parliamentary, constitutional and legislative matters of relevance to Aboriginal and Torres Strait Islanders since the constitutional conventions of the 1890s;• to develop further innovative techniques pioneered by AustLII for large-scale hypertext mark-up integrated with text retrieval over the World Wide Web, so as to create a completed 'Reconciliation and Social Justice' collection freely available on the Internet, and in a form which makes these texts easy to use but facilitates sophisticated research uses;• to develop and test other Internet-based means of communicating information concerning the reconciliation process, so as to integrate the 'Reconciliation and Social Justice' collection into a comprehensive resource which meets the needs of widely differing audiences, indigenous and non-

indigenous; and• through a pilot project of Internet connection and training, and usage monitoring, to test the value of these resources to one important audience, remote indigenous communities.
The project aims to make the Internet a key resource in the process of reconciliation. In doing so, it will create a permanent, free and universally accessible resource for reconciliation which will continue the Council's work after the formal end of the Council's functions at the end of the year 2000.
The project will also enable AustLII to achieve technical advances which will flow on into all other aspects of AustLII's work (and that of others communicating large scale texts via the Internet), and in particularly will lay the foundations for massive integration of primary and secondary legal materials.
The legal/historical research is also challenging, as these historical sources have not been documented fully40.
6.1.2 Key issues for reconciliationThe Council has identified eight key issues as being central to the reconciliation process:-
• a greater understanding of the importance of the land and sea in Aboriginal and Torres Strait Islander societies;
• better relationships between Aboriginal and Torres Strait Islander peoples and the wider community;
• recognition that Aboriginal and Torres Strait Islander cultures and heritage are a valued part of the Australian heritage;
• a sense for all Australians of a shared ownership of their history;
• a greater awareness of the causes of disadvantage that prevent Aboriginal and Torres Strait Islander peoples from achieving fair and proper standards in health, housing, employment and education;
• a greater community response to addressing the underlying causes of the unacceptably high levels of custody for Aboriginal and Torres Strait Islander peoples;
• greater opportunity for Aboriginal and Torres Strait Islander peoples to control their destinies;
• agreement on whether the process of reconciliation would be advanced by a document or documents of reconciliation
This identification of reconciliation priorities assists us to set project priorities and the classification of information collected for the project.
6.2 The Reconciliation and Social Justice Library The Reconciliation and Social Justice Library is the central resource of the project. The collection contains over 100 megabytes of text, making it the largest secondary law resource on AustLII, and one of the largest in Australia.

The most important initial content of the Library was the full text of all 97 Reports of the Royal Commission on Aboriginal Deaths in Custody, including the 85 Individual Deaths reports. Individual death reports on the web site are preceded by a cultural warning which is relevant to non-indigenous users of these reports41. The collection also includes extensive research materials from the Council for Aboriginal Reconciliation , the Aboriginal and Torres Strait Islander Commission (ATSIC) , the Australian Institute of Health (AIH) , the Australian Institute of Aboriginal and Torres Strait Islander Studies (AIATSIS) , the Australian Law Reform Commission (ALRC) , the Department of Prime Minister and Cabinet, the House of Representatives Standing Committee on Aboriginal and Torres Strait Islander Affairs, the Aboriginal and Torres Strait Islander Social Justice Commissioner and a growing range of non-governmental organisation’s quality material. AustLII is also the World Wide Web host for the Council for Aboriginal Reconciliation's own home page.
Recent additions to the Library include the full text of the Review of the Aboriginal and Torres Strait Islander Protection Act 1984 by Justice Elizabeth Evatt, occasional papers of the Australian Institute of Criminology on Aboriginal deaths in custody, a guide to the findings of the Royal Commission into Aboriginal Deaths in Custody, numerous papers on the Wik decision and its implications, and the Community Guide to the Report of the National Inquiry into the separation of Aboriginal and Torres Strait Islander children from their families. Items that are being added at present include the full text of the aforementioned Report (the ‘Stolen Generations’ Report).
To date, the collection priorities for the Library have been to establish means of obtaining permissions and data for materials on current indigenous law issues in Australia, particularly those relating to the Aboriginal Deaths in Custody, Native Title, and ‘Stolen Generations’ issues. We decided it was a priority to first capture the key documents which will have long-term importance in the ongoing debates in Australia from now to the year 2000 when this project and the Council’s current mandate both complete.
6.2.1 'History of indigenous legal/constitutional issues' component The legal/historical research component of the project involves the identification, through archival research and otherwise (commencing with the constitutional conventions of the 1890s) of the key constitutional, parliamentary or legislative material of relevance to Aboriginal and Torres Strait Islander people. This will include parliamentary committee reports, legislation over the years and its attendant debate at varying stages in the development of indigenous issues (such as the 1967 Referendum legislation and debate and the official "yes" and "no" cases for the Referendum).
We propose to use two bibliographic resources commissioned by the Council42 as starting points to identify these key historical resources, and then obtain advice on collection priorities from experts in the field including Council members and staff. It will be necessary to determine and implement the best means of data capture of those materials in computerised form, having first obtained the

necessary copyright and other permissions. Some priority will be given to material already in computerised form.
6.2.2 Collection difficulties - A centralised or partly distributed facility?We have experienced some difficulties in obtaining permissions for some materials which are already in digital form, including from two Parliamentary Committees dealing with Aboriginal and Torres Strait Islander issues. Their reason given has been that the Commonwealth Parliament intends to place the material on its own web site and our requests to provide access via the Library as well have so far been refused.
The development of AustLII’s targeted web spider will, we hope, provide an answer to this problem (see Paper 3 ‘Indexing Law on the Internet’). Where materials cannot be obtained for inclusion on AustLII in the Library, we will endeavour to use the web spider so that the materials will still be searchable on AustLII, in effect as part of the Library, using the SINO search engine as a consistent interface no matter where the materials are located. Indigenous legal materials not on AustLII will be a priority target of the web spider.
Other refusals or delays in creating access have been due to copyright concerns of authors - or the need to make a profit from the sale of hardcopy. As set out in a previous paper, AustLII’s view is that when a publicly funded body produces a public document it should maximise access to the information, including by Internet publishing.
With respect to copyright concerns there has been a paradoxical spin off from the changing political climate mentioned earlier in this paper. As threats to the reconciliation process have developed from various sectors of Australian society (and Pauline Hanson and ‘One Nation’ are only the most obvious of these) authors have often become more enthusiastic and committed to publishing their materials on the Internet.
6.2.3 Linkages between the Library and AustLII’s primary legal materialsAustLII has very extensive case law and legislation affecting indigenous peoples in its primary legal materials databases, quite separate from the Library. At present, there are too few links either way between the Library and the primary materials databases - they are not tightly integrated, and this reduces the utility of both.
We do not yet have effective enough ways of automatically inserting large numbers of ‘outgoing’ links from the secondary materials to cases and legislation on AustLII, because the citation patterns in these secondary materials, which are often far less consistent than statutory or judicial citations, produce limited results from our current mark-up software.
For similar reasons, we have few ‘incoming’ hypertext links from primary legal materials (or other secondary materials) into the major documents into the Library. However, we are considering experimenting with automated insertion of hypertext links from cases, legislation etc. using a small glossary of key phrases such as ‘aboriginal deaths in custody’.
6.3 Interaction and current issues - keeping users informedThe project has a number of elements which aim to use the Internet's potential for interaction with its users to provide current information about developments in indigenous legal issues and the reconciliation process. The Reconciliation and Social Justice News Mailing List will provide news to subscribers about developments in the Internet Project and the Library, and a similar list operated for the Council will provide current news about reconciliation and social justice. These e-mail lists may be automatically converted to hypertext ('hypermail').

Taking our cue from the first of the eight items identified by the Council as a key issue in the Reconciliation process mentioned earlier in this paper (i.e. a greater understanding of the importance of the land and sea in Aboriginal and Torres Strait Islander societies), and from the statements on Native Title by the Council’s current Chairman, Mr. Patrick Dodson, that an appropriate resolution of the Native Title issue is central to the process of Reconciliation, project staff drew the attention of Library users to the recent announcement by the Clerk of the Senate that electronic petitions were an acceptable means of submitting a petition. The Indigenous Law Centre at UNSW and Fr Frank Brennan SJ decided to sponsor an on-line petition to the Senate and were then given technical support by project staff. As well as having interesting broader implications for the use of the Internet in the democratic process, the on-line petition is generating a significant database of individuals concerned about the resolution of the Native Title issue and more generally concerned at Australia’s treatment of its Indigenous Peoples43. In its first few weeks, it received 3000 signatories, and the number continues to grow.
6.4 Internet indexing problems and indigenous legal issuesPart of the project involves determining how to best link the Library to other relevant sites concerning indigenous affairs, both overseas and in Australia. The general problems of Internet indexing, and AustLII’s approach to them, are set out in ‘Indexing Law on the Internet’.
The Australian Links index already contains the start of what will become a comprehensive index to Australian indigenous law materials. The next step will be to use this index to direct the targeted web spider to make those sites which contain material which are significant to the Library searchable via SINO and easily identifiable and accessible through the new SINO interface.
The project also aims to index the major overseas sites for indigenous law. For example, in the present context of the Wik debate, links to current information on land negotiation processes on other jurisdictions will provide valuable legal and socio-political information to indigenous communities and their organisations through information on processes such as the British Columbia treaty negotiations, or on negotiations in northern Québec, on the web pages of the Grand Council of the Crees (Eeyou Astchee).
British Columbia treaty negotiations site
Another topical instance of the Library being utilised by those interested in linkages between Australian and international materials on reconciliation occurred when those responsible for the recent advertisement placed in the UK press to coincide with the visit by the Prime Minister were seeking out the text of the apology made by the Queen to the Maori people in 1985. They turned to

the Library to find the information, and links to the New Zealand site containing the information are now included in the Library.
6.4.1 Beyond law One of the Council’s key elements of reconciliation is an increased understanding by both indigenous and non-indigenous Australians of the unique historical and cultural circumstances of Australia's indigenous peoples, based on effective community-wide access to detailed information relating to indigenous history, legal position and culture.
Part of the ‘Indigenous Links’ aspect of the project will assist encourage the exploration of indigenous culture in Australia at sites such as Yotha Yindi’s pages, or the Tandanya National Aboriginal Cultural Institute, or from around the world such as the Mayan art and culture of indigenous peoples in Mexico.
6.5 Internet access by remote indigenous communitiesThe final aspect of the Reconciliation and Social Justice Internet Project arises from the Council’s concern that its electronic resources for reconciliation would not be sufficiently available to remote indigenous communities. The project involves connection of a pilot group of such communities to the Internet, and a monitoring and evaluation project on the effectiveness and utility, over a period of time, of their Internet access, both to the project’s resources and to more general Internet resources.
One research aim of this project is find how to provide effective access to the same very large and complex collection of materials to groups of people with very different needs. Remote indigenous communities are one of the most important identifiable 'audiences' for this particular set of Internet materials, but they are also a challenging audience to reach effectively via the Internet, for reasons including cultural differences, unfamiliarity with information technology, and poverty. If we can find how to create effective access for remote indigenous communities to this collection, we should be able to generalise the results to create valuable 'virtual views' of AustLII's many other collections of information.
In mid 1997 AustLII wrote to sixteen communities or organisations in the Top End of the Northern Territory whose contact details were provided by the Northern Land Council as being recommended by that Council’s staff as appropriate for consideration in the project. Each of them was sent a questionnaire as to whether or not they have computer facilities and, if so, whether their computers are Apple or IBM. Five communities have responded seeking that they be considered and one wrote thanking the Council and AustLII for the invitation but indicating that they already have a functioning web site. After consultation with NT members of the Council, connection through an ISP with a Darwin PoP is expected in the near future.
In addition, the NSW Minister for the Environment has authorised commencement of negotiations between the NSW National Parks and Wildlife Service and the Mutawintji Local Aboriginal Land for the first agreement for returning a significant area of the NSW National Parks estate to Aboriginal ownership and management under a leaseback arrangement similar in broad principles to a number of models applying in the Northern Territory. AustLII is investigating the possibility that, because of the significance of these negotiations for indigenous communities in the eastern states, it may be possible and desirable to connect the Land Council to the Internet under the Council’s program. We may include on AustLII facilities so that information on Mootwingee and the negotiations for its hand back can be made available for other indigenous communities or interested parties through the web.

A process for monitoring and analysing the usage by these communities of the Internet (and particularly the Council’s resources) will be established, probably involving the following: (i) user-initiated ‘feedback’ mechanisms via the Internet, for non-systematic collection; (ii) researcher initiated mail-outs (electronic and/or paper) to users of conventional surveys concerning use (iii) periodic site visits (say, quarterly) and interviews at selected communities; (iv) reports by the ISP; (v) reports provided by local ‘Australians for Reconciliation’ coordinators, organised by the Council; and (iv) computerised collection and analysis of detailed usage pattern information, by the ISP and by AustLII. This research raises significant privacy considerations with which care must be taken.
6.6 Measuring project successWe will be measuring the success of the project by a number of quantitative means, including the following: increases in usage of the Council’s Internet resources, at various measurable stages of the project; particular measurements of usage and satisfaction by remote communities; measures of the intensity (and accuracy) of hypertext interlinking between the Council’s materials and other materials; other measurable project innovations; overall increase in density of hypertext linkages in all AustLII materials; and overall increases in AustLII usage (difficult to attribute to single causes).
However, the more important measures of success will be qualitative. Overall, we will have to attempt to evaluate and document the extent to which Internet communications have assisted reconciliation, probably by calling on subjective evaluations of other people, indigenous and non-indigenous. The ongoing utility of the resources created will also need evaluation. On the technical side, publication of research papers on the innovations of the project, and their adoption by others, will be the long-term measure.
AcknowledgmentsThanks to:
Daniel Austin ([email protected]) contributed to Chapter 3;
Simon Cant ([email protected]) co-authored Chapter 5;
Kirsty Magarey ([email protected]) and Tim Moore ([email protected]) contributed to Chapter 6;
The work and ideas of all of AustLII's staff is reflected at various points, in particular, contributions from Philip Chung ([email protected]), Trina Cairns ([email protected]) and David Irvine ([email protected]) from AustLII;
Thanks also to Jill Matthews for proof-reading;
'The AustLII papers' were prepared as background papers for presentations by AustLII staff at the Law via theInternet 97 Conference, Sydney, Australia, 25-27 June 1997.
ReferencesDaniels, J and Rissland, E, 1997 ‘Finding legally relevant opinions in case opinions’ Proc. Sixth International Conference on Artificial Intelligence and Law , Association for Computing Machinery , 1997.

De la Fosse and Finlay (AustLII Conference proceeedings)
Finin T and Fritzson R 1994 ‘KQML - A Language and Protocol for Knowledge and Information Exchange’, Technical Report CS-94-02, Computer Science Department, University of Maryland, UMBC <http://www.mmt.bme.hu/research/ai/lib/kbkshtml/kbks.html>.
Greenleaf, Mowbray and King (1997a) ‘Legal Research on the Internet : the AustLII Guide to Law on the Web’, (AustLII: 1997)
35 Written by King and Cant, 1996-7.36 Gunning and Greenleaf, 1994.37 Greenleaf and Mowbray, 199438 The Council for Aboriginal Reconciliation is a cross-cultural and cross-party organisation established in 1991 by an Act of the Commonwealth Parliament supported unanimously by both the House of Representatives and the Senate. Establishment of a formal and ongoing reconciliation process was the final recommendation of the Royal Commission into Aboriginal Deaths in Custody. Parliament set the Council the task of promoting a process of reconciliation between Aboriginal and Torres Strait Islander peoples and the wider community. It emphasised that this process should be based on an appreciation of the unique position of Aboriginal and Torres Strait Islander peoples as the indigenous peoples of Australia and should foster an ongoing national commitment to address Aboriginal and Torres Strait Islander disadvantage. Parliament also asked the Council to report on whether a document or documents of reconciliation would advance the process and if so to make recommendations on the form and content of such documents. The Council's Secretariat is provided by the Aboriginal Reconciliation Branch of the Department of the Prime Minister and Cabinet and is based in Canberra.
39 ‘Furthering Aboriginal reconciliation and social justice via Internet communications to diverse audiences’, ARC Collaborative Research Grant, 1997-99.40 Although some work has been done by ATSIC to list some of the historical sources, no research has yet provided a list of any completeness of these materials. No central collection of material is held and holdings in places such as the various national, state or territory libraries or their parliamentary libraries or the library of the Australian Institute of Aboriginal and Torres Strait Island Studies are fragmented and impossible to access on an integrated basis. Whilst some elements of the material envisaged to be researched in the historical phase of the project has been dealt with in earlier literature on Australia's indigenous people or elements of it have been touched upon by the leading contemporary historian in the field, there is no aggregated collection of source documents available which covers all the material expected to be discovered during this phase. Indeed, until the late 1970's, the legislative impact on indigenous people of Commonwealth or State enactments (save with respect to those highly paternalistic pieces of legislation which were "for the protection of Aborigines"), was often noted in passing (if at all) although of far reaching effect. As these areas are now of significance to indigenous people as they relate to establishing the basis for the denial of full citizenship rights in Australian society, considerable original research will need to be undertaken to establish the legislative routes of early post colonial exclusion of indigenous people from full Australian citizenry.41 http://www.austlii.edu.au/rsjlibrary/rciadic/individual/ - ‘The Council for Aboriginal Reconciliation draws your attention to the cultural sensitivity of issues and material in these individual death reports. The Council asks that, in accessing and using these reports, you be aware of this and of the sensitivities of the living relatives and friends of those whose deaths are recorded in these documents. Readers of these materials should be aware that, in some indigenous communities, use of the

Greenleaf, Mowbray, King, Cant and Chung (1997b)‘ More than wyshful thinking - AustLII’s legal inferencing via the World-Wide-Web’, Proceeedings of the 6th International Conference on Artificial Intelligence and Law (6ICAIL), Melbourne, July 1997.
Greenleaf G, Mowbray A, King G & Chung P (1996) ‘AustLII and the Courts: public information in the public interest' Australian Institute of Judicial Administration Annual Conference, Wellington, New Zealand, September 1996.
Greenleaf G, Mowbray A, King G and van Dijk P (1995a) 'Public access to law via Internet: the Australasian Legal Information Institute’(1995) Journal of Law & Information Science, Vol 6 Issue 1 <http://austlii.law.uts.edu.au/austlii/libs_paper.html>.
Greenleaf G, Mowbray A and van Dijk P (1995b) 'Representing and using legal knowledge in integrated decision support systems - DataLex WorkStations' Artificial Intelligence and Law , Vol 3 , 1995, Kluwer, 97-142.
Greenleaf G, Mowbray A and van Dijk P (1994) DataLex WorkStations Developers Manual (2nd Edition)(1994:Datalex Pty Ltd)
Greenleaf G , Mowbray A, Tyree A, (1992) 'The DataLex Legal Workstation - Integrating tools for lawyers', Vol 3 No 2 Journal of Law and Information Science (1992) 219 -240 (also in Proc. Third Int. Conf. on Artificial Intelligence and Law, ACM Press, 1991).
Greenleaf G, A Mowbray and D Lewis (1988) Australasian Computerised Legal Information Handbook, (Butterworths: 1988)
Gruber, T. R., ‘Toward Principles for the Design of Ontologies Used for Knowledge haring" in Formal Ontology in Conceptual Analysis and Knowledge Representation, ed N. Guarino and R. Poli, Kluwer Academic Publishers
Johnson Peter and Dayal Surendra (1997) ‘Smart Government: Internet Delivery of Public Services’ Proceeedings of the ‘Law via the Internet 97’ Conference, Sydney, Australia, 25-27 June 1997.
Kellow Philip ‘Legal expert systems and the Internet’, Proceeedings of the ‘Law via the Internet 97’ Conference, Sydney, Australia, 25-27 June 1997.
name of a dead person may cause offense and distress. Any reader of these materials proposing to down load any portion of these individual death reports for any purpose should be aware of the sensitivities and seek advice on what culturally appropriate proceedures and safeguards need to be adopted in using this material. A number of reports of individual deaths do not record the individual's name. In these instances, the Royal Commission ordered the suppression of the name of the deceased at the request of the individual's family and for cultural reasons.’
42 The Constitution Centenary Foundation and Keys Young resources.43 http://www.austlii.edu.au/unsw/centres/ilc/index.html ; From the Petition: ‘On-line petitions to the Senate have become possible since Senator Stott Despoja's announcement that the Clerk of the Senate will accept electronic petitions (http://www.democrats.org.au/democrats/media/1997/04/227nsd.html). For those interested in the Senate's Procedures regarding petitions they can be viewed at http://www.austlii.edu.au/unsw/centres/ilc/odgers.html.’

Mowbray A ‘Sino - yet another search engine for the Web’ AustLII May 1995.
Neches R and Gruber T 1994, "The Knowledge Sharing Effort", 26 July 1994 <http://www-ksl.stanford.edu /knowledge-sharing/papers/kse-overview.html>.
Olsson, Justice Trevor ‘Guide to Uniform Production of Judgments’, AIJA, 1992.
Rice J, Farquhar A, Piernot P, and Gruber T (1995) ‘Using the Web Instead of a Window System’, Stanford Knowledge Systems Laboratory <http://www-ksl-svc.stanford.edu:5915/doc/papers/ksl-95-69/ksl-95-69-linearized.html>
Links· AustLII Guide to Legal Research on the Net - http://www.austlii.edu.au/austlii/guide/ · AustLII Australian Links - http://www.austlii.edu.au/links/Australia/· AustLII World Links - http://www.austlii.edu.au/links/World/· AustLII’s Usermark - http://www.austlii.edu.au/austlii/usermark/· AustLII Funding Information - http://www.austlii.edu.au/austlii/funding.html for funding
details.· Australian indigenous law materials -
http://www.austlii.edu.au/links/Australia/Subjects/Aboriginals_and_Torres_Strait_Islanders/index.html
· Australian Treaties Library - http://www.austlii.edu.au/au/other/dfat/ · AHRIC - http://www.austlii.edu.au/au/other/ahric/· Availabilty of Queensland and Tasmanian legislation -
http://www.austlii.edu.au/austlii/availability.html
· Bannister v SGB plc - http://www.open.gov.uk/lcd/order17.htm· Bringing them Home - Report of the National Inquiry into the separation of Aboriginal and
Torres Strait Islander children from their families, June 1997 - see http://www.austlii.edu.au/rsjlibrary/hreoc/stolen_summary/
· British Columbia treaty negotiations - http://www.aaf.gov.bc.ca/aaf/negotiat/tables/sechelt/
· Cyc ontology - http://ai.iit.nrc.ca/ai_point.html· Council for Aboriginal Reconciliation http://www.austlii.edu.au/car/
· Durham Bibliography - http://www.dur.ac.uk/~dla0www/centre/web_ai_a.html· Grand Council of the Crees (Eeyou Astchee) - http://www.gcc.ca/· Law via the Internet ‘97’ - http://www.austlii.edu.au/austlii/conference/· Mayan Art - http://www.artemaya.com· Multi-country intellectual indices to law - http://www.austlii.edu.au/links/World/Indices/ and
http://www.austlii.edu.au/links/World/ for many examples.· Newspaper Editorials relating to AustLII publishing family court decisions
http://www2.austlii.edu.au/~graham/family_court/faminfo.html · Online wysh example - http://sandpit.austlii.edu.au/~aial/foitest/foi_s11.html· Raupatu Settlement - http://www.tainui-corp.co.nz/raupatu/· Reconciliation and Social Justice Library -
http://www.austlii.edu.au/au/other/car/carl_menu.html· Reconciliation and Social Justice Library - http://www.austlii.edu.au/rsjlibrary/· Reconciliation and Social Justice News Mailing List -
http://www.austlii.edu.au/rsjlibrary/subscription.html

· Reports of the Royal Commission on Aboriginal Deaths in Custody - http://www.austlii.edu.au/rsjlibrary/rciadic/
· SINO interface - http://www.austlii.edu.au/do2/form.pl?formtype=extended.· Tandanya National Aboriginal Cultural Institute -
http://www.webmedia.com.au/tandanya/Tandanya.html· Yotha Yindi’s pages - http://www.YothuYindi.com