utilizing local evidence for blog feed search
TRANSCRIPT

Utilizing local evidence for blog feed search
Yeha Lee • Seung-Hoon Na • Jong-Hyeok Lee
Received: 18 March 2011 / Accepted: 8 August 2011 / Published online: 26 August 2011� Springer Science+Business Media, LLC 2011
Abstract Blog feed search aims to identify a blog feed of recurring interest to users on a
given topic. A blog feed, the retrieval unit for blog feed search, comprises blog posts of
diverse topics. This topical diversity of blog feeds often causes performance deterioration
of blog feed search. To alleviate the problem, this paper proposes several approaches based
on passage retrieval, widely regarded as effective to handle topical diversity at document
level in ad-hoc retrieval. We define the global and local evidence for blog feed search,
which correspond to the document-level and passage-level evidence for passage retrieval,
respectively, and investigate their influence on blog feed search, in terms of both initial
retrieval and pseudo-relevance feedback. For initial retrieval, we propose a retrieval
framework to integrate global evidence with local evidence. For pseudo-relevance feed-
back, we gather feedback information from the local evidence of the top K ranked blog
feeds to capture diverse and accurate information related to a given topic. Experimental
results show that our approaches using local evidence consistently and significantly out-
perform traditional ones.
Keywords Blog feed search � Blog distillation � Passage-based retrieval �Pseudo-relevance feedback
A preliminary version of this work was presented in Lee et al. (2009).
Y. Lee (&) � J.-H. LeeDivision of Electrical and Computer Engineering, POSTECH, Pohang, South Koreae-mail: [email protected]
J.-H. Leee-mail: [email protected]
S.-H. NaDepartment of Computer Science, National University of Singapore, Singapore, Singaporee-mail: [email protected]
123
Inf Retrieval (2012) 15:157–177DOI 10.1007/s10791-011-9176-6

1 Introduction
Many users have been using blogs (or weblogs) to express their thoughts or opinions about
a wide range of topics including political issues, product reviews and diary-like private
posts. As the number of blog users has increased, the importance of blogs as an information
source has risen. As a result, the need for a customized elaborate search system, which
aims to find useful information in the blogosphere, has grown. Several commercial search
engines such as Google1 and Technorati2 have started to provide blog search services.
Nowadays, it has become common for blog users to search for blog feeds (e.g. RSS,
ATOM) relevant to topics that interest them, and then subscribe to the feeds using a feed
reader such as an RSS reader. In this scenario, a key issue is how to identify blog feeds that
are relevant and dedicated to a given topic. This task is blog feed search, which is one of
the most important blog search services. The Blog Distillation task of TREC Blog Track
(Macdonald et al. 2008; Ounis et al. 2009; Macdonald et al. 2010) also reflects the
increasing interest in blog feed search.
A straightforward approach for blog feed search would be to apply existing retrieval
models developed in ad-hoc retrieval. For example, we can view a blog feed as a virtual
document by concatenating all constituent posts belonging to the blog feed, and then
readily apply existing retrieval models without any modification. In fact, most previous
work on blog feed search used this approach as the baseline system (Macdonald et al.
2008; Ounis et al. 2009; Macdonald et al. 2010).
However, blog feed search has some characteristics that limit the performance of the
straightfoward approach. First, the retrieval unit is a blog feed, which is an aggregation of
its constituent posts, not a single blog post. In this regard, blog feed search should consider
how to model the relationship between the relevance of blog posts and the blog feed, in
response to a given topic. Second, most blog feeds contain topically diverse blog posts,
depending on a blogger’s interest. In other words, a blog feed generally addresses a large
number of topics. The topical diversity of blog feeds makes it difficult for blog feed search
systems to find out which blog feeds are relevant to users’ information needs. Third, blog
feed search has to deal with more noisy data than traditional search tasks. The blog corpus
is not as topically coherent as the news corpus, and may also have non-topical contents
such as spam blogs and blog comment spam, which advertise commercial products and
services (Kolari et al. 2006). Therefore, feed search techniques should be robust to this
noisy environment.
Among the above characteristics, this paper focuses on the performance deterioration
caused by the topical diversity of blog feeds. To mitigate this problem, our approaches are
motivated by the passage retrieval technique, which is one of the most effective techniques
to deal with topical diversity at document level for ad-hoc retrieval. We introduce globalevidence and local evidence for evaluating the relevance of a blog feed in response to
a query. These two types of evidence correspond to document-level and passage-level
evidence for passage retrieval, respectively. Whereas global evidence is derived from all
the constituent posts within a feed, local evidence is defined using a few blog posts that are
highly relevant to a query.
Different from most previous studies that use only global evidence to estimate the
relevance of a blog feed, we explicitly define and take advantage of the local evidence on
both initial retrieval and pseudo-relevance feedback (PRF). For initial retrieval, we propose
1 http://blogsearchgoogle.com/2 http://www.technorati.com/
158 Inf Retrieval (2012) 15:157–177
123

an approach to integrate the global evidence with the local evidence, and verify that the
usage of local evidence is effective in mitigating the topical diversity problem of blog feed
search. Furthermore, we present a novel document selection approach for PRF, based on
the local evidence of a blog feed. While several research work have looked at the initial
retrieval model for blog feed search, PRF has not been well studied on blog feed search,
despite its importance. Our approaches select feedback documents based on local evidence
of the top ranked blog feeds in order to improve the ‘‘precision’’ and ‘‘aspect recall’’
(Kurland et al. 2005) of feedback information, which are two important factors affecting
the performance of the feedback model. Experimental results show that the proposed
method achieves MAP scores that are 6, 2 and 11% better than the best results of TREC 07,
08 and 09, respectively. These results are notable in that our work is the first successful
feedback approach for blog feed search in a ‘‘closed setting’’ using only a test collection. In
general, it is the common interest to investigate whether the PRF, in the context of the
closed setting, improves performance over the baseline for various retrieval tasks including
ad-hoc retrieval and web search (Rocchio 1971; Yu et al. 2003; Zhai and Lafferty 2001;
Na et al. 2008a; Lavrenko and Croft 2001). Furthermore, to the best of our knowledge,
while the existing work which reported the improvements on PRF for blog feed search is
based on an external resource, we improve the performances of the blog feed search
without resorting to any other resources.
The rest of the paper is organized as follows. In Sect. 2, we present the issue of topical
diversity that motivates our work, and address feed search models using the global and
local evidence of a blog feed. In Sect. 3, we conduct several experiments to evaluate the
performance of our proposed methods, and discuss the difference between our approach
and previous work. In Sects. 4 and 5, we describe our approaches for PRF, and compare the
results with traditional feedback approaches. In Sect. 6, we briefly survey related work on
blog feed search. Finally, we conclude the paper and discuss future work in Sect. 7.
2 Initial retrieval model for blog feed search
2.1 Motivation: topical diversity of blog feeds
Topical diversity is a problem not only for blog feed search, but also for ad-hoc retrieval at
the document level. A document can contain diverse topics, particularly when it is long. As
a result, long documents are likely to be over-penalized by a retrieval algorithm even
though they are relevant to a given topic, resulting in poor retrieval performance (Salton
et al. 1993).
Many approaches have been proposed to solve this problem. One of the effective
approaches is passage retrieval, in which the relevance score of a document is boosted by
an additional score estimated using passage-level evidence. Passage retrieval has turned
out to significantly improve the baseline using only traditional document-level evidence
(Callan 1994; Kaszkiel and Zobel 1997; Kaszkiel and Zobel 2001; Salton et al. 1993;
Na et al. 2008b; Bendersky and Kurland 2010).
Passage-level evidence has also been applied to PRF (Allan 1995; Na et al. 2008a),
namely passage-based feedback which uses passages as the context for query expansion
instead of documents. Passage-based feedback has been reported to result in significant
improvements over conventional document-based feedback.
The topical diversity has a greater negative impact on blog feed search than on ad-hoc
retrieval, because a blog feed which is the retrieval unit of blog feed search consists of
Inf Retrieval (2012) 15:157–177 159
123

many blog posts. A blog feed usually contains more topics than a document, and the topics
of the feed are likely to be less coherent than those of the document. This means that even
if a blog feed is relevant to a given topic, a large number of posts within the feed can be
irrelevant.
In practice, most relevance judgments currently used for blog feed search regard a blog
feed as relevant even if only some of the posts within the feed are relevant. For example,
Seo and Croft (2008) introduced several criteria for relevance judgments, where relevant
feeds are divided into three levels according to the proportion of relevant posts in a feed.
Their minimum cutoff criterion to determine if a blog feed is relevant is whether at least
25% of all the posts within the feed are relevant.
2.2 Retrieval framework
To deal with the topical diversity of a blog feed, this paper proposes a novel approach
based on passage retrieval. We first define the global and local evidence of a blog feed. To
achieve this, we make correspondences between a document and a blog feed, and a passage
and a subset of blog posts within the feed. Then, we evaluate the global evidence using all
the constituent posts within the feed, corresponding to the document-level evidence in
passage retrieval. We also estimate the local evidence using a subset of the blog posts,
corresponding to passage-level evidence.
In the following sections, we address how the evidence affects the relevance of a blog
feed in response to a given query.
2.2.1 Global evidence and local evidence
Global evidence can be estimated using the overall information of a blog feed (i.e. all
constituent posts). This addresses one of the important issues for evaluating the relevance
of a blog feed to a query. Global evidence reflects how much the feed is devoted to a given
query. Given the query, we evaluate the devotedness of a blog feed using the proportion of
relevant blog posts within the feed. We assume that the more devoted a blog feed is to a
given query, the more likely it is to be relevant.
Local evidence can be evaluated using a subset of blog posts within a blog feed. As the
definition of a passage is important for passage retrieval, the way local evidence is defined
is also a critical issue. In this paper, we utilize a set of the T most relevant posts within a
blog feed to evaluate the local evidence of the feed in response to a given query. We
assume that the top-ranked posts can be a representative sample of the feed about a query
topic, conceptually corresponding to a passage in passage retrieval.
2.2.2 Combination of evidence
Global and local evidence have their own limitations in terms of blog feed search. First,
global evidence tends to prefer a small blog feed (i.e. a feed with a small number of posts)
to a large one, because small feeds are less likely to contain diverse topics. Second, local
evidence uses only a few relevant posts within a blog feed, and thus cannot identify which
blog feed is more devoted to a given query.
To overcome the limitations of each type of evidence, our retrieval model combines
both global and local evidence. Let R(Q, F) be the relevance score of a blog feed F in
160 Inf Retrieval (2012) 15:157–177
123

response to a query Q. We use linear interpolation to combine the two types of evidence as
follows:
RðQ;FÞ ¼ ð1� aÞRGðQ;FÞ þ aRLðQ;FÞ ð1Þ
where RG and RL are the relevance scores estimated using the global and local evidence,
respectively, and a is a weight parameter to control the relative importance of the two types
of evidence.
2.3 Basic retrieval models
Since a blog feed consists of a number of blog posts, there may be several approaches for
representing the blog feed according to the granularity level. From previous work on blog
feed search (Elsas et al. 2008; Macdonald and Ounis 2008; Seo and Croft 2008; Mac-
donald et al. 2008; Ounis et al. 2009), we can observe that there are two ways to represent
a blog feed. In this study, we use the models proposed by Elsas et al. (2008) in order to
represent a blog feed: ‘‘Large Document Model’’ (LDM) and ‘‘Small Document Model’’
(SDM).
Let L be a subset of a blog feed F, which will be defined differently according to the
type of evidence (i.e. global or local).
First, LDM regards a blog feed as a single large document represented by concatenating
all the constituent posts within it. Then, the relevance score of the feed is estimated using
the relevance score between the virtual document and a query. Therefore, most ad-hoc
retrieval techniques can be applied to LDM.
RLDMðQ;FÞ ¼ ScoreðQ;VDÞ ð2Þ
where VD is a virtual document represented by concatenating the blog posts within the set
L, and Score(Q, VD) can be evaluated using (4) to be defined later.
LDM has some problems which arise from representing a blog feed by concatenating all
posts within it without any consideration of the relationship among the posts (Seo and
Croft 2008).
Second, SDM regards a blog feed as a collection of all the blog posts within it. Then, its
relevance score is evaluated by summing up the relevance score of each post in response to
a query. The score function for SDM is defined as follows:
RSDMðQ;FÞ ¼X
D2L
ScoreðQ;DÞPðDjLÞ ð3Þ
where P(D|L) means the probability of selecting a blog post D, given the set L, and
Score(Q, D) can be evaluated using (4).
There are many possible approaches to estimate the probability P(D|L) (Elsas et al.
2008). However, we assume the probability P(D|L) has a uniform distribution because our
interest is in exploring the influence of global and local evidence on the performance of the
blog feed search.
The remaining issue is how to define the subset L of a blog feed F. We construct the
subset L according to each evidence, as follows:
1. Global Evidence: L consists of all blog posts within a feed F, i.e. L = F.
2. Local Evidence: L is a set of top T ranked blog posts within a feed F in response to a
given query, denoted by Top(T, F).
Inf Retrieval (2012) 15:157–177 161
123

Then, we can define two different models for each type of evidence, depending on
which representation (LDM or SDM) is used. First, global evidence has the following two
models:
– Global Large Document Model (GLD), RGLDM, uses global evidence with the LDM
for feed representation (i.e. L = F in (2)). GLD was used as the baseline for many
systems on the Blog Distillation task (Macdonald et al. 2008; Ounis et al. 2009;
Macdonald et al. 2010), and the results show that this model is effective without
resorting to any other techniques or resources.
– Global Small Document Model (GSD), RGSDM, uses global evidence with the SDM for
feed representation (i.e. L = F in (3)).
Similarly, local evidence has the following two models:
– Local Large Document Model (LLD), RLLDM, uses local evidence with the LDM for
feed representation (i.e. L = Top(T, F) in (2)). Unlike the GLD, the virtual document is
represented by a concatenation of blog posts relevant to a query, not all of the posts
within the blog feed F.
– Local Small Document Model (LSD), RLSDM, uses local evidence with the SDM for
feed representation (i.e. L = Top(T, F) in (3)).
2.4 Combined models
Four models are possible in (1) using two global models (GLD and GSD) and two local
models (LLD and LSD) as follows:
– GLD1LLD: GLD for RG(Q, F), and LLD for RL(Q, F), formulated by R(Q, F) =
(1 - a)RGLDM(Q, F) ? aRL
LDM(Q, F).
– GLD1LSD: GLD for RG(Q, F), and LSD for RL(Q, F), formulated by R(Q, F) =
(1 - a)RGLDM(Q, F) ? aRL
SDM(Q, F).
– GSD1LLD: GSD for RG(Q, F), and LLD for RL(Q, F), formulated by R(Q, F) =
(1 - a)RGSDM(Q, F) ? aRL
LDM(Q, F).
– GSD1LSD: GSD for RG(Q, F), and LSD for RL(Q, F), formulated by R(Q, F) =
(1 - a)RGSDM(Q, F) ? aRL
SDM(Q, F).
2.5 Relevance score function
The remaining issue is the score function to evaluate the relevance between a document
and a query. Since LDM views a blog feed as a large document, we need a score function
to estimate the relevance between a large document (blog feed) and a query. For SDM, we
also need a score function to evaluate the relevance between each blog post and a query. To
this end, we use one of the representative state-of-the-art retrieval models, the KL-diver-
gence language model (Lafferty and Zhai 2001).
Let hQ and hD be a query language model and a document language model, respectively.
We use Dirichlet smoothing (Zhai and Lafferty 2004) to estimate the document language
model. Our score function is as follows:
ScoreðQ;DÞ ¼def X
w2Q\D
PðwjhQÞ � log 1þ tf ðw;DÞlPðwjCÞ
� �þ log
llþ jDj ð4Þ
162 Inf Retrieval (2012) 15:157–177
123

where tf(w, D) is the frequency of term w within a document D; PðwjCÞ ¼ ctfwjCj : ctfw is the
number of times term w occurred in the entire collection and l is a smoothing parameter.
In the initial retrieval, a query language model is estimated by using the maximum
likelihood estimate. We then update the query language model based on feedback docu-
ments. In Sect. 4, we address novel feedback approaches to improve the performance of the
blog feed search.
3 Retrieval experiments
We investigated the influence of global and local evidence on the performance of blog feed
search according to varying the weight parameter a. The experimental results show that our
models based on passage retrieval are simple, but effective for blog feed search.
3.1 Experimental setup
3.1.1 Data set
The TREC Blogs06 and Blogs08 collections (Macdonald 2006; Macdonald et al. 2010)
were used for our experiments. Each collection is a big sample from the blogosphere.
Table 1 shows the statistics of the collections. For the TREC 2009 Blog Distillation task,
we evaluated the topical relevance of a blog feed with only 39 topics3 that have at least one
relevant blog (Macdonald et al. 2010).
We only used permalinks (blog posts) for the experiments. We discarded the HTML
tags of the blog posts. The posts were also processed by stemming using the Porter
stemmer and eliminating stopwords using the INQUERY words stoplist (Allan et al.
2001).
3.1.2 Parameter setting and evaluation measures
We evaluated four basic models, GLD, GSD, LLD and LSD, using only the title field of
each topic as a query. We also evaluated four combined models, GLD?LLD, GLD?LSD,
GSD?LLD and GSD?LSD. Each model has a few parameters. The global models (GLD
and GSD) have one parameter, i.e. the parameter l for Dirichlet smoothing. The local
models (LLD and LSD) have two parameters, i.e. the smoothing parameter l and T which
controls the number of posts used to estimate the local evidence of their feed. In addition to
these parameters, the combined models have a weight parameter a.
Table 1 Statistics for the testcollections
Task Collection # Docs Topics
2007 Blog distillation Blogs06 3,215,171 951–995
2008 Blog distillation 1,051–1,100
2009 Blog distillation Blogs08 28,488,766 1,101–1,150
3 These 39 topics were used to obtain the official evaluation results in the TREC 2009 Blog Distillation task.
Inf Retrieval (2012) 15:157–177 163
123
We trained the parameters using the 07 topics for evaluating the performance of the 08
topics, and vice-versa. Then, the parameters for the 09 topics are trained using the 07 and
08 topics. We selected the parameters resulting in the best MAP score.
Similar to the Blog Distillation task, we retrieved the 100 most relevant blog feeds in
response to each query. We used the mean average precision (MAP) and the precision at
rank 10 (Pr@10) as the evaluation measure.
3.2 Results and discussion
Table 2 shows the performance of each model. We performed the Wilcoxon signed rank
test to examine whether or not the improvement of the combined models over the baseline
(GLD) was statistically significant. The baseline outperformed other basic models for all
the topic sets. These results are similar to those from previous work (Macdonald et al.
2008; Ounis et al. 2009).
The best performance was obtained from GSD?LSD. Compared with the basic models,
all the combined models improved the performance significantly and consistently. This
confirms our hypothesis that the combined approach reduces the risk of separately using
each type of evidence, and leads to better performance. An interesting observation is that
the best performance of the basic models resulted from using Large Document Model4
(GLD), but the best performance of the combined models resulted from using Small
Document Model (GSD?LSD). This implies that the interaction of the global and local
evidence for blog feed search is better captured by SDM than LDM.
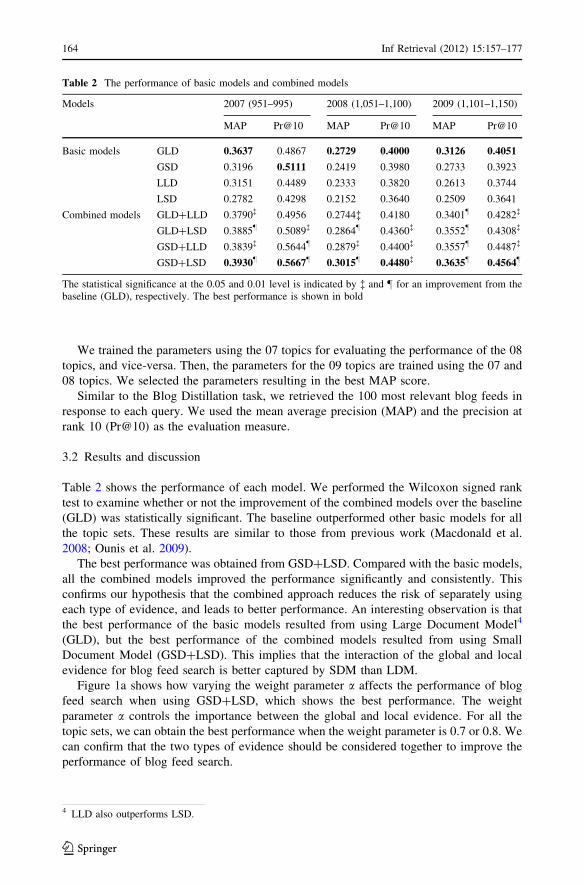
Figure 1a shows how varying the weight parameter a affects the performance of blog
feed search when using GSD?LSD, which shows the best performance. The weight
parameter a controls the importance between the global and local evidence. For all the
topic sets, we can obtain the best performance when the weight parameter is 0.7 or 0.8. We
can confirm that the two types of evidence should be considered together to improve the
performance of blog feed search.
Table 2 The performance of basic models and combined models
Models 2007 (951–995) 2008 (1,051–1,100) 2009 (1,101–1,150)
MAP Pr@10 MAP Pr@10 MAP Pr@10
Basic models GLD 0.3637 0.4867 0.2729 0.4000 0.3126 0.4051
GSD 0.3196 0.5111 0.2419 0.3980 0.2733 0.3923
LLD 0.3151 0.4489 0.2333 0.3820 0.2613 0.3744
LSD 0.2782 0.4298 0.2152 0.3640 0.2509 0.3641
Combined models GLD?LLD 0.3790� 0.4956 0.2744� 0.4180 0.3401} 0.4282�
GLD?LSD 0.3885} 0.5089� 0.2864} 0.4360� 0.3552} 0.4308�
GSD?LLD 0.3839� 0.5644} 0.2879� 0.4400� 0.3557} 0.4487�
GSD?LSD 0.3930} 0.5667} 0.3015} 0.4480� 0.3635} 0.4564}
The statistical significance at the 0.05 and 0.01 level is indicated by � and } for an improvement from thebaseline (GLD), respectively. The best performance is shown in bold
4 LLD also outperforms LSD.
164 Inf Retrieval (2012) 15:157–177
123
Figure 1b shows the influence of the parameter T on the performance of blog feed
search when using GSD?LSD. T controls how many blog posts are used for the local
evidence of a blog feed in response to a given query. We can obtain the best performance
when T is set to 2. This reveals that using a few highly relevant posts within a blog feed is
effective in evaluating the local evidence.
3.3 Comparison with other approaches
In the experiments, we showed that the use of local evidence is quite helpful in improving
the performance of blog feed search. Some previous researchers had already utilized
similar methods.
Macdonald and Ounis (2008), motivated by the Voting Model for the expert search task,
suggested expCombSUM. In expCombSUM, the highly relevant posts have a large effect
0 0.2 0.4 0.6 0.8 10.15
0.20
0.25
0.30
0.35
0.40
0.45
alpha
MA
P
07 MAP08 MAP09 MAP
0 2 4 6 8 10 12 150.20
0.25
0.30
0.35
0.40
0.45
The number of T
MA
P
07 MAP08 MAP09 MAP
(a)
(b)
Fig. 1 MAP scores for varying the parameters, a and T, under the GSD?LSD retrieval model. a MAPscores for varying the weight parameter a, b MAP scores for varying the value of T
Inf Retrieval (2012) 15:157–177 165
123

on the relevance score of a blog feed. Due to its weighted approach using query-relevant
scores, expCombSUM plays a similar role to local evidence. Elsas et al. (2008) also
proposed the Entry Centrality Component as a part of the Small Document Model. The
component estimates a probability distribution to measure the similarity between a blog
post and its feed, and controls the weight of each post to evaluate the relevance between its
feed and a query.
However, these approaches are different from ours in some respects. They consider all
constituent posts within a blog feed. Although the posts are differently weighted, the
approaches can be regarded as using weighted global evidence. In contrast, our model
actively finds local evidence corresponding to the passage-level evidence for passage
retrieval. Furthermore, whereas their approaches can only be applied in SDM, our model
provides a more flexible and expanded framework, in the sense that two types of evidence
can be estimated regardless of representation methods (e.g. LDM or SDM).
One of the most similar approaches to our model is the PCS-GR model suggested by
Seo and Croft (2008). PCS-GR is an approach combining their Global Representation and
Pseudo-Cluster based Selection, corresponding to our GLD?LSD approach. Like our
results, they showed that the combining approach results in significant improvements in
their well-designed experiments. However, our motivation is different from theirs.
Whereas they introduced a combining approach to penalize topically-diverse feeds, we
proposed a combining approach to avoid ‘‘over-penalizing’’ topically-diverse feeds. The
local evidence of a blog feed plays a similar role to the passage-level evidence of passage
retrieval. In addition, our approach provides a general framework by integrating global and
local evidence, including PCS-GR as a special case (i.e. GLD?LSD).
4 Feedback model for blog feed retrieval
In the previous section, we showed how local evidence is explored for the initial retrieval
of blog feed search, and verified that local evidence is helpful in improving retrieval
performance. In this section, we further explore local evidence in terms of PRF, and
propose novel feedback approaches based on local evidence.
4.1 Limitations of naive feedback approaches
Before addressing our feedback methods, we present two naive approaches for PRF and
show why they are not desirable.
Because the retrieval unit of blog feed search is a blog feed, not a document, a blog feed
is also a natural feedback unit. In this regard, a naive feedback model is an All-Postsapproach, which chooses all constituent posts in the top-ranked feeds as feedback docu-
ments. However, due to the topical diversity of the blog feed, even if a blog feed is
relevant, it does not mean that all of its constituent posts are relevant to a query. Fur-
thermore, if some of the top-ranked feeds chosen for the feedback are irrelevant, almost all
of the posts within them could be irrelevant. Therefore, the All-Posts approach has
potentially high risk of selecting many irrelevant posts, which decrease the precision of the
feedback information.
Another naive model is a Post-Level approach, which applies the traditional feedback
approach to blog feed search. The approach first performs a post-level retrieval and then
uses the top-ranked posts as feedback documents, without considering which feed they
come from. Unlike the All-Posts approach, the Post-Level one does not suffer from the low
166 Inf Retrieval (2012) 15:157–177
123

precision of feedback information. However, the feedback information can be biased
toward a dominant aspect within the top-ranked posts. In other words, the Post-Level
approach may suffer from ‘‘aspect recall’’ (Kurland et al. 2005), one of the important
properties which determines feedback quality.
With regard to query expansion for blog feed search, previous work has addressed some
properties of blog feed search queries: ‘‘. . . Given the nature of feed search, queries maydescribe more general and multifaceted topics, likely to stimulate discussion over time. If aquery corresponds to a high-level description of some topic, there might be a widevocabulary gap between the query and the more nuanced and faceted discussion in blogposts’’ (Elsas et al. 2008).
This property can make the aspect-recall problem of the Post-Level approach more
serious, because the vocabulary gap may make the top N ranked documents more likely to
be biased to a certain aspect of a given query. As a result, the feedback documents selected
using the Post-Level approach will cover only a few aspects of a query.
4.2 Feed based selection
A blog feed consists of posts with diverse topics depending on the bloggers’ interests or
inclinations. Thus, for a given query, the blog posts from different feeds may present
different perspectives or facets of a topic, although they address information about the
same topic. In other words, all (unknown) aspects of a query are scattered over all the
relevant feeds, and their relevant posts. Therefore, if we gather information from various
blog feeds, we can obtain more diverse information about a query so that it can cover the
various aspects of the query topic, and this leads to the improved performance of PRF.
However, this approach can have the same problem as the All-Posts approach. To solve
this problem, motivated by passage-based feedback, we propose Feed-Based Selectionwhich first selects as many feeds as possible for PRF, and then gathers only a few posts
within each of them, in order of the relevance between posts and the query. In other words,
Feed-Based Selection uses local evidence on the top-ranked blog feeds. This method
corresponds to passage-based feedback in ad-hoc retrieval where the scope of the feedback
context is narrowed into the passage, rather than using the entire document context.
The Feed-Based Selection has two important characteristics that allow it to handle the
problems of two naive approaches, All-Posts and Post-Level. First, it only uses the highly
relevant posts of a top-ranked feed (local evidence), not entire posts (global evidence). In
contrast with the All-Posts approach, it can alleviate the low precision problem caused by
the topical diversity of a blog feed. Second, it collects more diverse information from as
many feeds as possible. As a result, it allows a system to learn much more about the aspects
of a query than the Post-Level approach, and leads to an increase in aspect recall.
Similar to the initial retrieval model presented in Sect. 2, one of the most important
issues is how to define the local evidence of each blog feed. We propose two approaches
for defining local evidence: Fixed Feed Based Selection and Weighted Feed BasedSelection.
4.3 Fixed feed based selection (FFBS)
FFBS uses the top K ranked feeds to gather feedback documents. FFBS considers the top
K ranked feeds as equally relevant to a given query regardless of their relevance to the
query indicated by the relevance score.
Inf Retrieval (2012) 15:157–177 167
123

Let FBFFBS be a set of blog posts chosen by using FFBS. We can define FBFFBS as
follows:
FBFFBS ¼ djdm;k 2 Fk; k ¼ 1 � � �K;m ¼ 1 � � �M� �
ð5Þ
where dm,k indicates the mth blog post, ranked in order of a score obtained by 4, within the
kth ranked feed, and Fk represents the kth ranked feed. In this paper, FFBS-K-M indicates a
FBFFBS with K and M.
4.4 Weighted feed based selection (WFBS)
Similar to FFBS, WFBS also uses top K ranked feeds to construct feedback documents.
However, WFBS chooses a different number of blog posts from each blog feed according
to their relevance score. To achieve this, we assign differnet weights to the top k feeds in
order of their relevancy.
Let N be the total number of feedback documents and FBWFBS be a set of blog posts
chosen by using WFBS. We can define FBWFBS as follows:
FBWFBS ¼ djdm;k 2 Fk; k ¼ 1 � � �K;m ¼ 1 � � �Mk
� �ð6Þ
where Mk indicates the number of blog posts selected from each feed, and we define Mk as
follows:
Mk ¼WFkP
j WFj� N ð7Þ
where WFi indicates the weight of the ith ranked blog feed. In practice, Mk should be an
integer number, so it is rounded to the nearest integer. WFBS-K-N denotes a FBWFBS with
K and N.
There may be several methods to assign the weight WFi, but this paper uses a simple
method defined as follows:
WFi ¼ K � iþ 1 ð8Þ
where WFi is an inverted measure with respect to i, i.e. the blog feed with the highest score
has a weight of K and the Kth feed has a weight of 1.
5 Feedback experiments
In this section, we investigate the influence of several document selection approaches on
the performance of PRF.
5.1 Experiment setup
For feedback experiments, we used GSD?LSD as a baseline retrieval model, because it
showed the best performance among the initial feed retrieval models in Sect. 4. The
baseline model, GSD?LSD, is also used to perform PRF based on the expanded query
model.
To update the query language model, we used model-based feedback (Zhai and Lafferty
2001).
168 Inf Retrieval (2012) 15:157–177
123
hQ0 ¼ ð1� aFÞhQ þ aFhF ð9Þ
where aF controls the influence of the feedback model, and the feedback model hF is
estimated by using a generative model of feedback documents.
5.1.1 Document selection approaches
We built several sets of feedback documents. Each set includes 10 documents as feedback
documents. The document sets used for feedback are as follows:
– TOP-10: 10 documents are chosen according to the relevance of the document. This
approach is the Post-Level document selection.
– Feed3All-Posts: All posts from the top 3 ranked feeds are chosen as feedback
documents.
– Feed5All-Posts: All posts from the top 5 ranked feeds are chosen as feedback
documents.
– FFBS-3-3: 10 documents are chosen using FFBS with K = 3 and M = 3.
– FFBS-5-2: 10 documents are chosen using FFBS with K = 5 and M = 2.
– WFBS-3-10: 10 documents are chosen using WFBS with K = 3 and N = 10.
– WFBS-5-10: 10 documents are chosen using WFBS with K = 5 and N = 10.
5.2 Experimental results
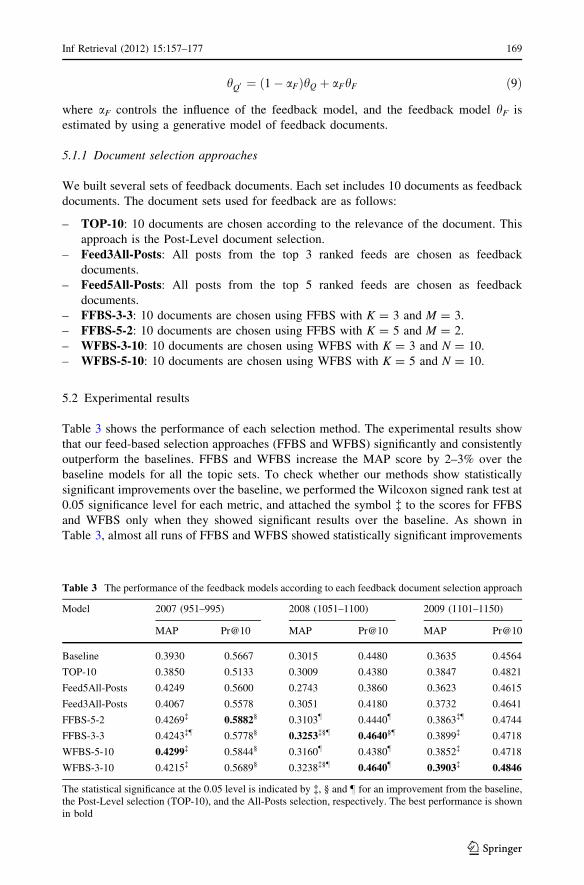
Table 3 shows the performance of each selection method. The experimental results show
that our feed-based selection approaches (FFBS and WFBS) significantly and consistently
outperform the baselines. FFBS and WFBS increase the MAP score by 2–3% over the
baseline models for all the topic sets. To check whether our methods show statistically
significant improvements over the baseline, we performed the Wilcoxon signed rank test at
0.05 significance level for each metric, and attached the symbol � to the scores for FFBS
and WFBS only when they showed significant results over the baseline. As shown in
Table 3, almost all runs of FFBS and WFBS showed statistically significant improvements
Table 3 The performance of the feedback models according to each feedback document selection approach
Model 2007 (951–995) 2008 (1051–1100) 2009 (1101–1150)
MAP Pr@10 MAP Pr@10 MAP Pr@10
Baseline 0.3930 0.5667 0.3015 0.4480 0.3635 0.4564
TOP-10 0.3850 0.5133 0.3009 0.4380 0.3847 0.4821
Feed5All-Posts 0.4249 0.5600 0.2743 0.3860 0.3623 0.4615
Feed3All-Posts 0.4067 0.5578 0.3051 0.4180 0.3732 0.4641
FFBS-5-2 0.4269� 0.5882§ 0.3103} 0.4440} 0.3863�} 0.4744
FFBS-3-3 0.4243�} 0.5778§ 0.3253�§} 0.4640§} 0.3899� 0.4718
WFBS-5-10 0.4299� 0.5844§ 0.3160} 0.4380} 0.3852� 0.4718
WFBS-3-10 0.4215� 0.5689§ 0.3238�§} 0.4640} 0.3903� 0.4846
The statistical significance at the 0.05 level is indicated by �, § and } for an improvement from the baseline,the Post-Level selection (TOP-10), and the All-Posts selection, respectively. The best performance is shownin bold
Inf Retrieval (2012) 15:157–177 169
123

over the baseline on MAP. This means that the feed-based approaches (FFBS and WFBS)
are effective to improve the performance of PRF.
Furthermore, FFBS and WFBS show better performance than the two naive approaches:
All-Posts (Feed3All-Posts and Feed5All-Posts) and Post-Level (TOP-10). To see whether
the improvement is statistically significant, we again performed the Wilcoxon signed rank
test, and attached § and } only when they showed significant results over All-Posts and
Post-Level, respectively.5 We found that the majority of runs of FFBS and WFBS show
statistically significant improvements over both of the naive approaches.
The All-Posts and Post-Level methods did not show reliable performance. They did not
show any improvement over the baseline for most topic sets. First, the failure of the All-
Posts approach provides good evidence that it suffers from low precision of feedback
information. In particular, for the 08 topics, the top K feeds used for PRF are likely to
contain many irrelevant feeds, because the initial performance for the 08 topics is relatively
low. Thus, as K increases for the 08 topics, the feedback documents constructed using the
All-Posts include too many irrelevant documents to improve the performance of PRF.
Actually, when using K = 5, the performance deteriorated more seriously than when
K = 3. This result explains why we need to use local evidence for PRF.
Second, for the 07 and 08 topics, the failure of the Post-Level approach supports our
proposal for the feed-level selection. Post-Level suffers from low aspect recall so that it
can only cover a few relevant aspects of a query. In contrast, our approaches enable the
system to increase the aspect recall, because the feedback documents are chosen from
various feeds which reflect the diverse aspects relevant to a query. Finally, this leads to the
improved performance of the feedback model.
We compare our approaches with the top 3 performing runs6 of the TREC 07, 08 and 09
Distillation task in Table 4. The results are obtained from (Macdonald et al. 2008; Ounis
et al. 2009; Macdonald et al. 2010). Our feedback approaches significantly and consistently
improve the results of the best runs for all tasks. In particular, for the 07 task, WFBS-5-10
achieved about a 6% increase of the MAP score over the TREC ’07 best run. FFBS-3-3
accomplished more than a 2% increase of the MAP score over the TREC ’08 best run.
WFBS-3-10 also increased the MAP score by 12% over the TREC ’09 best run.
Note that in Table 4, we only quote the official results of the top performing runs from
TREC, and we did not implement them. Furthermore, we did not apply the significance test
such as the Wilcoxon signed rank test between our methods and the TREC runs. Therefore,
it is unclear what caused the difference in performances between our methods and the runs.
The performance differences might be caused by several factors such as the method for
preprocessing documents, the way for selecting parameters or the effectiveness of each
algorithm for blog feed search. It will be valuable to implement the top performing
algorithms and directly compare the results. We leave this issue for a remaining work.
5.3 Influence of K and M on performance
Figure 2 shows the performance of FFBS and All-Posts according to varying K and
M parameters.
5 FFBS or WFBS were compared with All-Posts using the same K. That is, FFBS-5-2 and WFBS-5-10 werecompared with Feed5All-Posts.6 The runs are the automatic title-only runs sorted by MAP.
170 Inf Retrieval (2012) 15:157–177
123
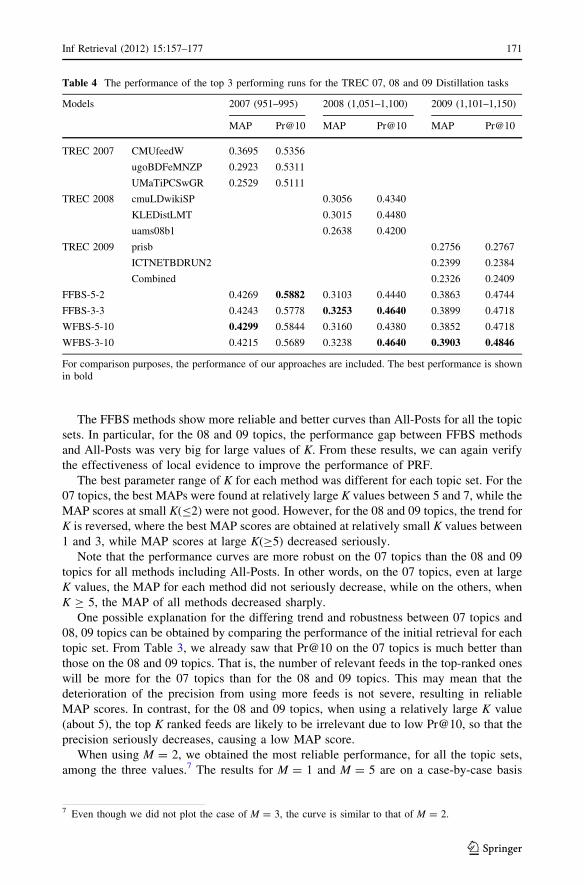
The FFBS methods show more reliable and better curves than All-Posts for all the topic
sets. In particular, for the 08 and 09 topics, the performance gap between FFBS methods
and All-Posts was very big for large values of K. From these results, we can again verify
the effectiveness of local evidence to improve the performance of PRF.
The best parameter range of K for each method was different for each topic set. For the
07 topics, the best MAPs were found at relatively large K values between 5 and 7, while the
MAP scores at small K(B2) were not good. However, for the 08 and 09 topics, the trend for
K is reversed, where the best MAP scores are obtained at relatively small K values between
1 and 3, while MAP scores at large K(C5) decreased seriously.
Note that the performance curves are more robust on the 07 topics than the 08 and 09
topics for all methods including All-Posts. In other words, on the 07 topics, even at large
K values, the MAP for each method did not seriously decrease, while on the others, when
K C 5, the MAP of all methods decreased sharply.
One possible explanation for the differing trend and robustness between 07 topics and
08, 09 topics can be obtained by comparing the performance of the initial retrieval for each
topic set. From Table 3, we already saw that Pr@10 on the 07 topics is much better than
those on the 08 and 09 topics. That is, the number of relevant feeds in the top-ranked ones
will be more for the 07 topics than for the 08 and 09 topics. This may mean that the
deterioration of the precision from using more feeds is not severe, resulting in reliable
MAP scores. In contrast, for the 08 and 09 topics, when using a relatively large K value
(about 5), the top K ranked feeds are likely to be irrelevant due to low Pr@10, so that the
precision seriously decreases, causing a low MAP score.
When using M = 2, we obtained the most reliable performance, for all the topic sets,
among the three values.7 The results for M = 1 and M = 5 are on a case-by-case basis
Table 4 The performance of the top 3 performing runs for the TREC 07, 08 and 09 Distillation tasks
Models 2007 (951–995) 2008 (1,051–1,100) 2009 (1,101–1,150)
MAP Pr@10 MAP Pr@10 MAP Pr@10
TREC 2007 CMUfeedW 0.3695 0.5356
ugoBDFeMNZP 0.2923 0.5311
UMaTiPCSwGR 0.2529 0.5111
TREC 2008 cmuLDwikiSP 0.3056 0.4340
KLEDistLMT 0.3015 0.4480
uams08b1 0.2638 0.4200
TREC 2009 prisb 0.2756 0.2767
ICTNETBDRUN2 0.2399 0.2384
Combined 0.2326 0.2409
FFBS-5-2 0.4269 0.5882 0.3103 0.4440 0.3863 0.4744
FFBS-3-3 0.4243 0.5778 0.3253 0.4640 0.3899 0.4718
WFBS-5-10 0.4299 0.5844 0.3160 0.4380 0.3852 0.4718
WFBS-3-10 0.4215 0.5689 0.3238 0.4640 0.3903 0.4846
For comparison purposes, the performance of our approaches are included. The best performance is shownin bold
7 Even though we did not plot the case of M = 3, the curve is similar to that of M = 2.
Inf Retrieval (2012) 15:157–177 171
123
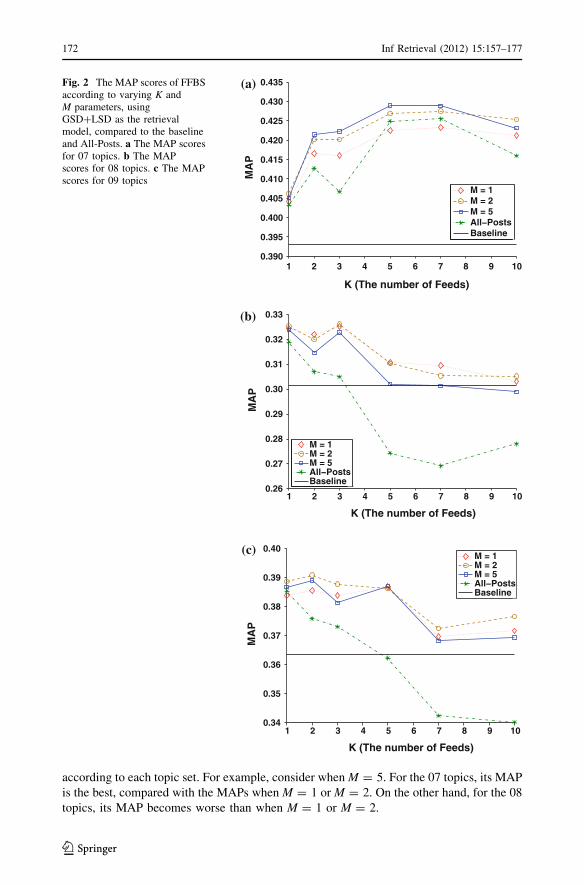
according to each topic set. For example, consider when M = 5. For the 07 topics, its MAP
is the best, compared with the MAPs when M = 1 or M = 2. On the other hand, for the 08
topics, its MAP becomes worse than when M = 1 or M = 2.
1 2 3 4 5 6 7 8 9 100.390
0.395
0.400
0.405
0.410
0.415
0.420
0.425
0.430
0.435
K (The number of Feeds)
MA
P
M = 1M = 2M = 5All−PostsBaseline
1 2 3 4 5 6 7 8 9 100.26
0.27
0.28
0.29
0.30
0.31
0.32
0.33
K (The number of Feeds)
MA
P
M = 1M = 2M = 5All−PostsBaseline
1 2 3 4 5 6 7 8 9 100.34
0.35
0.36
0.37
0.38
0.39
0.40
K (The number of Feeds)
MA
P
M = 1M = 2M = 5All−PostsBaseline
(a)
(b)
(c)
Fig. 2 The MAP scores of FFBSaccording to varying K andM parameters, usingGSD?LSD as the retrievalmodel, compared to the baselineand All-Posts. a The MAP scoresfor 07 topics. b The MAPscores for 08 topics. c The MAPscores for 09 topics
172 Inf Retrieval (2012) 15:157–177
123
5.4 Comparison of cluster centroid algorithm
As discussed in Sect. 4, our feed based selection is derived by considering the aspect recall.
There is existing work for the ad-hoc retrieval task related to increasing the aspect recall.
This work is called the Cluster Centroid approach (Shen and Zhai 2005). Cluster Centroid
clusters the feedback documents to maximize the diversity of the feedback information (i.e.
aspect recall). Cluster Centroid consists of the following 3 steps: 1) Group the top
N documents into K clusters, 2) Select a centroid document from each resulting cluster, and
3) Use all such K centroid documents for feedback documents. Since Cluster Centroid does
not use any information about the relationship between the posts and their feed, it can be
viewed as an automatic method to construct feeds by regarding a cluster as a pseudo feed.
We re-implemented the Cluster Centroid method in the same setting used in their exper-
iment, by using the K-Medoid clustering algorithm (Kaufman and Rousseeuw 1990), and
J-Divergence (Lin 1991) as the distance function between clusters. For a fair comparison to
the previous section, we fix the number of clusters K to 10.
Table 5 shows the results of Cluster Centroid, according to the number of top posts
N for clustering, where the feedback model is GSD?LSD. Note that when N = 10, the
Cluster Centroid corresponds to TOP-N, since each post creates a separate cluster. The
Cluster Centroid method outperforms the baseline for some N values by about 0.2%, 0.9%
and 2.6% for the 07, 08 and 09 topics, respectively. This result of Cluster Centroid is
important, because it confirms the view we previously discussed on the aspect recall, i.e.,
using diverse information is helpful to improve the performance of PRF for blog feed
search.
Our approaches are still notable, due to the improvements over Cluster Centroid. In
particular, for the 07 and 08 topics, our best approaches show about 3.4% and 1.5%
increases of MAP over Cluster Centroid, respectively. From these results, we can verify
that the feed-level information used in our methods is important for improving the retrieval
performance, because it captures a realistic structure between posts and feeds that Cluster
Centroid cannot automatically recognize.
Table 5 The performance of K = 10 Cluster Centroid with N under the GSD?LSD method
N 2007 (951–995) 2008 (1,051–1,100) 2009 (1,101–1,150)
MAP Pr@10 MAP Pr@10 MAP Pr@10
10 0.3850 0.5133 0.3009 0.4380 0.3847 0.4821
20 0.3955 0.5422 0.3086 0.4500 0.3850 0.4795
40 0.3911 0.5356 0.3069 0.4520 0.3901 0.4897
60 0.3802 0.5133 0.3066 0.4520 0.3780 0.4846
80 0.3949 0.5356 0.3100 0.4420 0.3832 0.4795
100 0.3926 0.5333 0.3071 0.4500 0.3827 0.4692
Baseline 0.3930 0.5667 0.3015 0.4480 0.3635 0.4564
Best 0.4299 0.5844 0.3253 0.4640 0.3903 0.4846
Approach (WFBS-5-10) (FFBS-3-3) (WFBS-3-10)
The best performance is shown in bold. For comparison purposes, the performances of the baseline and ourbest approaches for each task are included
Inf Retrieval (2012) 15:157–177 173
123

6 Related work
Since the TREC blog distillation task was introduced, many approaches have been sug-
gested for blog feed search. Most approaches are motivated by other well-studied retrieval
tasks such as the expert search task (Soboroff and de Vries 2007) and the resource selection
task in distributed information retrieval.
Elsas et al. (2008) and Arguello et al. (2008), (2009) treated blog feed search as a
resource ranking problem by using the ReDDE federated search algorithm (Si and Callan
2003). They proposed two blog representations based on granularity, and also suggested a
query expansion approach using Wikipedia for blog feed search. For PRF, Elsas et al.
(2008) proposed knowledge-intensive feedback, using Wikipedia as external knowledge.
Despite its notable results, their approach is not a closed solution that only uses the given
test collection, which is different from our approaches.
Seo and Croft (2008), (2009) dealt with blog feed search by using cluster-based retrieval
for distributed information retrieval. They also divided blog sites into three types based on
topical diversity, and considered several methods for penalizing blog sites with diverse
topics.
Macdonald and Ounis (2008) and He et al. (2009) regarded blog feed search as an
expert finding task. They used the adaptable Voting Model for the expert search task
(Macdonald and Ounis 2006), and proposed several techniques that aim to boost blog feeds
where a blogger has shown a central or recurring interest in a topic area. Carman et al.
(2009) also used a similar approach, using the Voting Model. In contrast to Macdonald and
Ounis’s work, they used non-content features for each blog in addition to existing content-
level features, and applied the Learning-to-Rank (Yue et al. 2007) approach to combine the
features and obtain a single retrieval function.
Nunes et al. (2009) suggested several strategies using temporal features for blog feed
search. They examined whether or not the maximum temporal span covered by the relevant
posts is a positive criterion in the feed search, and also investigated how the dispersion of
relevant blog posts in a blog feed would impact this task. Wang et al. (2009) proposed a
reduced document model by indexing text between certain tags, and used the PageRank of
a blog feed with its query likelihood score. Balog et al. (2008) and Weerkamp et al. (2008)
proposed two language models based on expert finding techniques, and some blog-specific
features such as document structure, social structure, and temporal structure.
7 Conclusion and future work
In this paper, we have addressed several approaches for initial retrieval and pseudo-
relevance feedback on blog feed search. Our key concern was the topical diversity of a
blog feed. Motivated by passage retrieval techniques, we presented global and local evi-
dence of blog feeds, corresponding to the document-level and passage-level evidence of
passage retrieval. We estimated global evidence using all constituent posts within a blog
feed, and local evidence using highly relevant posts within a blog feed in response to a
given query. We proposed a series of methods for evaluating the relevance between a blog
feed and a given query, using the two types of evidence.
In addition, we investigated the pseudo-relevance feedback method for blog feed search.
Our feedback approaches, motivated by passage-based feedback, gathered feedback
information using the local evidence of top K ranked feeds. The proposed methods have
two advantages. First, the usage of various feeds enables the feedback model to locate the
174 Inf Retrieval (2012) 15:157–177
123

feeds that discuss different aspects of the topic of a given query. In other words, it increases
the aspect recall of feedback information. Second, the usage of the local evidence provides
the feedback model with information relevant to a query. That is, it increases the precision
of feedback information. Experimental results on TREC distillation for the 07, 08 and 09
topics showed that the proposed feedback approach significantly and consistently out-
performed the baseline.
Many studies remain for future work. First, for the initial retrieval, we used a simple
uniform distribution as P(D|L) in (3). It would be interesting to investigate other methods
to estimate P(D|L) such as Entry Centrality (Elsas et al. 2008). Furthermore, we would like
to investigate other techniques for blog feed search such as link analysis and temporal
profiling. These techniques have the potential to improve the performance of blog feed
search. Second, for pseudo-relevance feedback, we will explore a probabilistic approach
for selecting the relevant local posts, instead of using the current threshold-driven method.
References
Allan, J. (1995). Relevance feedback with too much data. In Proceedings of the 18th annual internationalACM SIGIR conference on research and development in information retrieval (pp. 337–343).
Allan, J., Connell, M. E., Croft, W. B., Feng, F. F., Fisher, D., & Li, X. (2001). INQUERY and TREC-9. InProceedings of the ninth text REtrieval conference (pp. 551–562).
Arguello, J., Elsas, J. L., Callan, J., & Carbonell, J. G. (2008). Document representation and query expansionmodels for blog recommendation. In Proceedings of the 2nd international conference on weblogs andsocial media.
Arguello, J., Elsas, J. L., Yoo, C., Callan, J., & Carbonell, J. G. (2009). Document and query expansionmodels for blog distillation. In Proceedings of the seventeenth text REtrieval conference.
Balog, K., de Rijke, M., & Weerkamp, W. (2008). Bloggers as experts: Feed distillation using expertretrieval models. In Proceedings of the 31st annual international ACM SIGIR conference on researchand development in information retrieval (pp. 753–754).
Bendersky, M., & Kurland, O. (2010). Utilizing passage-based language models for ad hoc documentretrieval. Information Retrieval, 13, 157–187.
Callan, J. P. (1994). Passage-level evidence in document retrieval. In Proceedings of the 17th annualinternational ACM SIGIR conference on research and development in information retrieval(pp. 302–310).
Carman, M., Keikha, M., Gerani, S., Gwadera, R., Taibi, D., & Crestani, F. (2009). University of Lugano atTREC 2008 blog track. In Proceedings of the seventeenth text REtrieval conference.
Elsas, J. L., Arguello, J., Callan, J., & Carbonell, J. G. (2008). Retrieval and feedback models for blog feedsearch. In Proceedings of the 31st annual international ACM SIGIR conference on research anddevelopment in information retrieval (pp. 347–354).
He, B., Macdonald, C., Ounis, I., Peng, J., & Santos, R. L. (2009). University of Glasgow at TREC 2008:Experiments in blog, enterprise, and relevance feedback tracks with terrier. In Proceedings of theseventeenth text REtrieval conference.
Kaszkiel, M., & Zobel, J. (1997). Passage retrieval revisited. In Proceedings of the 20th annual internationalACM SIGIR conference on Research and development in information retrieval (pp. 178–185).
Kaszkiel, M., & Zobel, J. (2001). Effective ranking with arbitrary passages. Journal of the American Societyfor Information Science and Technology, 52(4), 344–364.
Kaufman, L., & Rousseeuw, P. J. (1990). Finding groups in data: an introduction to cluster analysis. NewYork: Wiley.
Kolari, P., Java, A., & Finin, T. (2006). Characterizing the splogosphere. In Proceedings of the 3rd annualworkshop on weblogging ecosystem: Aggregation, analysis and dynamics, 15th World Wid Webconference.
Kurland, O., Lee, L., & Domshlak, C. (2005). Better than the real thing?: Iterative pseudo-query processingusing cluster-based language models. In Proceedings of the 28th annual international ACM SIGIRconference on research and development in information retrieval (pp. 19–26).
Inf Retrieval (2012) 15:157–177 175
123

Lafferty, J., & Zhai, C. (2001). Document language models, query models, and risk minimization forinformation retrieval. In Proceedings of the 24th annual international ACM SIGIR conference onresearch and development in information retrieval (pp. 111–119).
Lavrenko, V., & Croft, W. B. (2001). Relevance based language models. In Proceedings of the 24th annualinternational ACM SIGIR conference on research and development in information retrievalpp. 120–127.
Lee, Y., Na, S. H., & Lee, J. H. (2009). An improved feedback approach using relevant local posts for blogfeed retrieval. In Proceeding of the 18th ACM conference on Information and knowledge management(pp. 1971–1974).
Lin, J. (1991). Divergence measures based on the shannon entropy. IEEE Transactions on InformationTheory, 37, 145–151.
Macdonald, C., & Ounis, I. (2006a). Voting for candidates: Adapting data fusion techniques for an expertsearch task. In Proceedings of the 15th ACM international conference on Information and knowledgemanagement (pp. 387–396).
Macdonald, C., & Ounis, I. (2006b). The TREC Blogs06 collection: Creating and analysing a blog testcollection. Techincal report, Department of Computing Science, University of Glasgow.
Macdonald, C., & Ounis, I. (2008). Key blog distillation: Ranking aggregates. In Proceeding of the 17thACM conference on Information and knowledge management (pp. 1043–1052).
Macdonald, C., Ounis, I., & Soboroff, I. (2008). Overview of the TREC-2007 blog track. In Proceedings ofthe sixteenth text REtrieval conference.
Macdonald, C., Ounis, I., & Soboroff, I. (2010). Overview of the TREC-2009 Blog Track. In Proceedings ofthe eighteenth text REtrieval conference.
Na, S. H., Kang, I. S., Lee, Y., & Lee, J. H. (2008a). Applying complete-arbitrary passage for pseudo-relevance feedback in language modeling approach. In Proceedings of the 4th Asia informationretrieval conference on information retrieval technology (pp. 626–631).
Na, S. H., Kang, I. S., Lee, Y., & Lee, J. H. (2008b). Completely-arbitrary passage retrieval in languagemodeling approach. In Proceedings of the 4th Asia information retrieval conference on informationretrieval technology (pp. 22–33).
Nunes, S., Ribeiro, C., David, G. (2009). FEUP at TREC 2008 blog track: Using temporal evidence forranking and feed distillation. In Proceedings of the seventeenth text REtrieval conference.
Ounis, I., Macdonald, C., & Soboroff, I. (2009). Overview of the TREC-2008 blog track. In Proceedings ofthe seventeenth text REtrieval conference.
Rocchio, J. J. (1971). Relevance feedback in information retrieval. In G. Salton (Ed.), The SMART retrievalsystem: Experiments in automatic document processing, Prentice-Hall series in automatic computation(Chap. 14, pp. 313–323). Englewood Cliffs, NJ: Prentice-Hall.
Salton, G., Allan, J., & Buckley, C. (1993). Approaches to passage retrieval in full text information systems.In Proceedings of the 16th annual international ACM SIGIR conference on research and developmentin information retrieval (pp. 49–58).
Seo, J., & Croft, W. B. (2008). Blog site search using resource selection. In Proceeding of the 17th ACMconference on Information and knowledge management (pp. 1053–1062).
Seo, J., & Croft, W. B. (2009). UMass at TREC 2008 blog distillation task. In Proceedings of the seven-teenth text REtrieval conference.
Shen, X., & Zhai, C. (2005). Active feedback in ad hoc information retrieval. In Proceedings of the 28thannual international ACM SIGIR conference on research and development in information retrieval(pp. 59–66).
Si, L., & Callan, J. (2003). Relevant document distribution estimation method for resource selection. InProceedings of the 26th annual international ACM SIGIR conference on research and development ininformaion retrieval (pp. 298–305).
Soboroff, I., & de Vries, A. P. (2007). Overview of the TREC 2006 enterprise track. In Proceedings of thefifteenth text REtrieval conference.
Wang, J., Sun, Y., Mukhtar, O., & Srihari, R. (2009). TREC 2008 at the University at Buffalo: Legal andblog track. In Proceedings of the seventeenth text REtrieval conference.
Weerkamp, W., Balog, K., & de Rijke, M. (2008). Finding key bloggers, one post at a time. In Proceeding ofthe 2008 conference on ECAI 2008: 18th European conference on artificial intelligence (pp. 318–322).
Yu, S., Cai, D., Wen, J. R., & Ma, W. Y. (2003). Improving pseudo-relevance feedback in web informationretrieval using web page segmentation. In Proceedings of the 12th international conference on WorldWide Web (pp. 11–18).
Yue, Y., Finley, T., Radlinski, F., & Joachims, T. (2007). A support vector method for optimizing averageprecision. In Proceedings of the 30th annual international ACM SIGIR conference on research anddevelopment in information retrieval (pp. 271–278).
176 Inf Retrieval (2012) 15:157–177
123

Zhai, C., & Lafferty, J. (2001). Model-based feedback in the language modeling approach to informationretrieval. In Proceedings of the tenth international conference on information and knowledge man-agement (pp. 403–410).
Zhai, C., & Lafferty, J. (2004). A study of smoothing methods for language models applied to informationretrieval. ACM Transactions on Information Systems, 22(2), 179–214.
Inf Retrieval (2012) 15:157–177 177
123