università di padova - tim pdf/work/relazioni/statistica... · il test di normalità anderson...
TRANSCRIPT

Università di Padova
DDiippaarrttiimmeennttoo ddii TTeeccnniiccaa ee GGeessttiioonnee ddeeii
ssiisstteemmii iinndduussttrriiaallii
Corso di Laurea Specialistica in Ingegneria Civile
Elaborato di analisi statistica a.a. 2005-2006
Prof. L. Salmaso
Dott. L. Corain

INDICE 1) STATISTICA A 1 CAMPIONE .......................................................................................................
1.1)Statistica descrittiva ad un campione: tabella ed istogramma di frequenza, indici di sintesi ...... 1.2)Statistica inferenziale ad un campione sulla media: intervallo di confidenza, verifica di ipotesi ............................................................................................................................................................ 1.3) Statistica inferenziale ad un campione sulla proporzione: intervallo di confidenza, verifica di ipotesi .................................................................................................................................................
2) STATISTICA A 2 CAMPIONI ........................................................................................................
2.1) Statistica descrittiva a due campioni: tabella e poligoni di frequenza, confronto principali indici di sintesi ................................................................................................................................... 2.2) Statistica inferenziale a due campioni sulle medie: verifica di ipotesi sulle varianze, verifica di ipotesi sulla differenza delle medie ................................................................................................ 2.3) Statistica inferenziale a due campioni sulle proporzioni: test Z, test Chi-quadro ......................
3) STATISTICA A C CAMPIONI .......................................................................................................
3.1) Anova 1 via ................................................................................................................................. 3.2) Regressione lineare multipla.......................................................................................................

1) STATISTICA A 1 CAMPIONE
1.1) Statistica descrittiva Il primo passo dell’esercitazione consiste nell’estrazione dei dati dal dataset. Il campione a cui facciamo riferimento per la nostra analisi è quello dei valori dei provini portati a rottura in prove interne per barre di acciaio di diametro 16mm. Con gli strumenti della statistica descrittiva andiamo a rappresentare il campione:
Interne rottura diam 16613612617622603613615609623621587592617604573583595619616591
Descriptive Statistics: Interne rottura diam 16 Variable N Mean Median TrMean StDev SE Mean Interne 20 606,25 612,50 607,17 14,58 3,26 Variable Minimum Maximum Q1 Q3 Interne 573,00 623,00 592,75 617,00
Tabella di frequenza Snervamento frequenza
Intervallo assoluta % 572,5-575,5 1 5 575,5-582,5 0 0 582,5-587,5 2 10 587,5-592,5 2 10 592,5-597,5 1 5 597,5-602,5 0 0 602,5-607,5 2 10 607,5-612,5 2 10 612,5-617,5 6 30

617,5-622,5 3 15 622,5-627,5 1 5
totale complessivo 20 100
575 585 595 605 615 625
95% Confidence Interval for Mu
595 605 615
95% Confidence Interval for Median
Variable: C1
A-Squared:P-Value:
MeanStDevVarianceSkewnessKurtosisN
Minimum1st QuartileMedian3rd QuartileMaximum
599,427
11,086
596,882
0,8080,030
606,250 14,578
212,513-8,6E-01-3,0E-01
20
573,000592,750612,500617,000623,000
613,073
21,292
616,765
C2: 16
Anderson-Darling Normality Test
95% Confidence Interval for Mu
95% Confidence Interval for Sigma
95% Confidence Interval for Median
Descriptive Statistics
Dai grafici ottenuti possiamo ricavare numerose informazioni sul campione. Esso presenta asimmetria negativa, cioè abbiamo che la media risulta essere minore della mediana. Ciò si può rilevare dall’indice di Skewness e dalla forma della curva. Il test di normalità Anderson-Darling ci dice che, assumendo un indice di significatività pari ad alpha=0.05 la distribuzione non può essere assunta normale, grazie al confronto col p-value. Tra i grafici troviamo anche il Boxplot, con cui possiamo avere un’idea immediata di quali sono il valore centrale e la varianza del nostro campione. Nella “scatola” è contenuto il 50% dei nostri dati e la linea all’interno indica il valore della mediana; i due valori estremali del contenitore sono detti primo e terzo interquartile. 1.2) Statistica inferenziale ad un campione sulla media: intervallo di confidenza, verifica di ipotesi rispetto al valore assegnato (colonna "1 sample test mean", alternativa a due code) One-Sample T: Interne rottura diam 16 Test of mu = 610 vs mu not = 610 Variable N Mean StDev SE Mean Interne rott 20 606,25 14,58 3,26
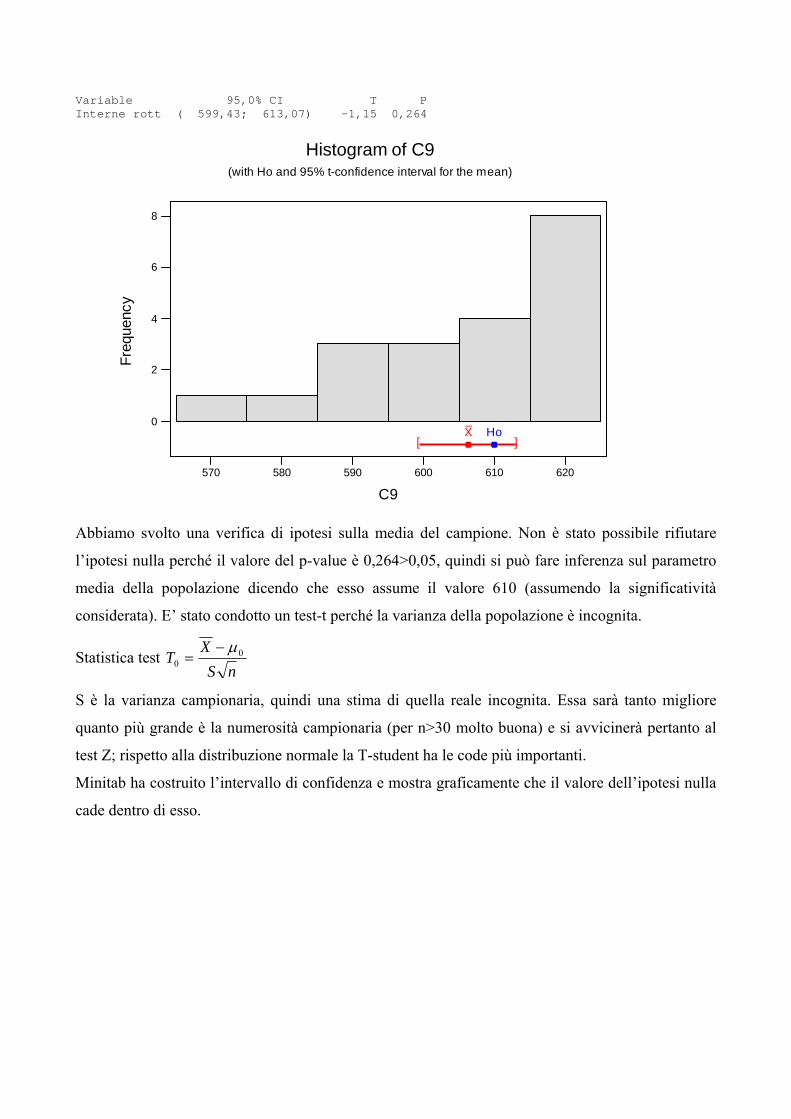
Variable 95,0% CI T P Interne rott ( 599,43; 613,07) -1,15 0,264
620610600590580570
8
6
4
2
0
C9
Freq
uenc
y
Histogram of C9(with Ho and 95% t-confidence interval for the mean)
[ ]X_
Ho
Abbiamo svolto una verifica di ipotesi sulla media del campione. Non è stato possibile rifiutare
l’ipotesi nulla perché il valore del p-value è 0,264>0,05, quindi si può fare inferenza sul parametro
media della popolazione dicendo che esso assume il valore 610 (assumendo la significatività
considerata). E’ stato condotto un test-t perché la varianza della popolazione è incognita.
Statistica test nS
XT 0
0μ−
=
S è la varianza campionaria, quindi una stima di quella reale incognita. Essa sarà tanto migliore
quanto più grande è la numerosità campionaria (per n>30 molto buona) e si avvicinerà pertanto al
test Z; rispetto alla distribuzione normale la T-student ha le code più importanti.
Minitab ha costruito l’intervallo di confidenza e mostra graficamente che il valore dell’ipotesi nulla
cade dentro di esso.

1.3) Costruire una tabella che calcoli la proporzione di campioni "non di qualità" in base alla soglia assegnata (colonna "no quality threshold")
Interne rottura diam 16 Test qualità(>600) 613 conforme 612 conforme 617 conforme 622 conforme 603 conforme 613 conforme 615 conforme 609 conforme 623 conforme 621 conforme 587 non conforme 592 non conforme 617 conforme 604 conforme 573 non conforme 583 non conforme 595 non conforme 619 conforme 616 conforme 591 non conforme
TOTALE non conformi 6
In questa tabella sono riassunti i valori del campione messi a confronto con la quantità di soglia, che
per la nostra esercitazione è pari a 600; solo i valori di rottura maggiori di questa quantità sono
conformi.
1.4) Statistica inferenziale ad un campione sulla proporzione: intervallo di confidenza, verifica di ipotesi rispetto al valore assegnato
Test and CI for One Proportion Test of p = 0,3 vs p > 0,3 Exact Sample X N Sample p 95,0% Lower Bound P-Value 1 6 20 0,300000 0,139554 0,584
Abbiamo studiato la proporzione di barre non conformi, andando a costruire l’intervallo di
confidenza, e quindi svolgendo la verifica di ipotesi 0H : p=0.3 e 1H : p>0.3. Usiamo come
statistica test
)1( 00
00 pnp
npXZ
−
−=

sulla popolazione binomiale conforme/non conforme.
Il test è a una coda, infatti l’ipotesi alternativa ammette solo un confronto unilaterale (>). Il p-value
ci dice che l’ipotesi nulla non può essere rifiutata perché esso risulta essere >0,05, pertanto la
probabilità di trovare barre non conformi si può assumere non maggiore del 30%.

2) STATISTICA A 2 CAMPIONI
2.1) La seconda parte dell’esperienza consiste nell’estrarre dal dataset i dati relativi alla rottura in
prove interne per il diametro di barra 10 mm e nel confronto col campione precedente.
Andando ad analizzare con la statistica descrittiva il secondo campione:
630620610600590
95% Conf idence Interv al f or Mu
610605600
95% Conf idence Interv al f or Median
Variable: Diametro 10
598,000
8,560
598,782
Maximum3rd QuartileMedian1st QuartileMinimum
NKurtosisSkewnessVarianceStDevMean
P-Value:A-Squared:
609,765
16,439
609,318
631,000611,500602,500595,750589,000
200,2784990,758186126,682 11,255604,050
0,5170,315
95% Conf idence Interv al f or Median
95% Conf idence Interv al f or Sigma
95% Conf idence Interv al f or Mu
Anderson-Darling Normality Test
Descriptive Statistics
Interne rottura diam 10 590 605 609 631
623 601 610 589 598 598 591 612 613 617 604 604 598 601 595 592
Interne rottura diam 16 613612617622603613615609623621587592617604573583595619616591

Possiamo fare un confronto col precedente:
• Per questo campione si può assumere una distribuzione approssimatamente normale, infatti il test di normalità Anderson Darling ci fornisce un p-value di 0,517 e quindi non è possibile rifiutare l’ipotesi nulla;
• A differenza del primo, questo campione presenta asimmetria positiva, ossia il valore della media è maggiore di quello della mediana;
• Il secondo campione presenta un range interquartile meno esteso rispetto al precedente, ciò significa che i valori si concentrano più vicini alla mediana;
• Anche la varianza è molto maggiore (126 contro 212) testimoniando ancora la maggior vicinanza dei dati al valor medio;
• I due indici di Skewness dei campioni differiscono di segno, infatti il primo presenta asimmetria negativa, il secondo positiva.
2.2)Statistica descrittiva a due campioni: tabella e poligoni di frequenza, confronto principali indici di sintesi
Usiamo gli strumenti della statistica descrittiva per confrontare le caratteristiche delle distribuzioni
dei due campioni. Possiamo notare come la loro media sia piuttosto simile, ma il valore delle
mediane è piuttosto lontano; ciò accade a causa della forte asimmetria del campione avente 16 come
diametro. Dai boxplots si può notare come il nuovo campione sia distribuito simmetricamente, a
differenza dell’altro.
Descriptive Statistics: 10 vs 16 Variable C2 N Mean Median TrMean StDev C1 10 20 604,05 602,50 603,39 11,26 16 20 606,25 612,50 607,17 14,58 Variable C2 SE Mean Minimum Maximum Q1 Q3 C1 10 2,52 589,00 631,00 595,75 611,50 16 3,26 573,00 623,00 592,75 617,00

10 16
570
580
590
600
610
620
630
Diametro
Rot
tura
Boxplots di Rottura per Diametro
10 16
570
580
590
600
610
620
630
Diametro
Rot
tura
Dotplots di rottura per diametro

2.3) Statistica inferenziale a due campioni sulle medie: verifica di ipotesi sulle varianze, verifica di ipotesi sulla differenza delle medie
Vogliamo confrontare le due popolazioni, e in particolare le medie. Prima di tutto, visto che le varianze delle popolazioni non sono conosciute, andiamo a svolgere un test per verificare l’ipotesi di uguaglianza. Questo viene effettuato dal programma con il Levene’s test e la statistica test f a una coda. L’ipotesi nulla e quella alternativa sono:
0H : 2
221 σσ =
1H : 22
21 σσ ≠
2318138
95% Confidence Intervals for Sigmas
10
16
630620610600590580570
Boxplots of Raw Data
-rottura-
P-Value : 0,373Test Statistic: 0,811
Levene's Test
P-Value : 0,268Test Statistic: 0,596
F-Test
Factor Levels
16
10
Test for Equal Variances for -rottura-
Abbiamo quindi verificato l’uguaglianza delle varianze, infatti il valore del p-value supera quello della soglia di significatività. Pertanto andiamo ad effettuare un test sulle medie, tenendo conto del risultato appena ottenuto. Ipotesi nulla e alternativa sono rispettivamente:
0H : 21 μμ =
1H : 21 μμ ≠

La statistica test che useremo è :
21
2121
11)(
nnS
XXT
p +
−−−=
μμ
Dove Sp è lo stimatore pooled della varianza, calcolato proporzionalmente alle varianze e alle numerosità campionarie. Two-Sample T-Test and CI: -rottura-; -diametro- Two-sample T for -rottura- -diametr N Mean StDev SE Mean 10 20 604,1 11,3 2,5 16 20 606,3 14,6 3,3 Difference = mu (10) - mu (16) Estimate for difference: -2,20 95% CI for difference: (-10,54; 6,14) T-Test of difference = 0 (vs not =): T-Value = -0,53 P-Value = 0,596 DF = 38 Both use Pooled StDev = 13,0
1610
630
620
610
600
590
580
570
-diametro-
-rot
tura
-
Boxplots of -rottura by -diametr(means are indicated by solid circles)
Il p-value 0,596>0,05 ci dice che bisogna accettare l’ipotesi nulla; si può pertanto assumere uguaglianza delle medie per le due popolazioni.
21 μμ =

1μ = media pop. φ16 2μ = media pop. φ10 Anche graficamente si può vedere la vicinanza delle medie (dal grafico dei boxplot). 2.4) Statistica inferenziale a due campioni sulle proporzioni: test Z, test Chi-quadro
3) STATISTICA A CAMPIONI
Vogliamo studiare la tensione di rottura avendo a disposizione 5 campioni di provini di barre di acciaio aventi diverso diametro. Abbiamo pertanto un fattore (il diametro) con cinque diversi livelli di trattamento.
Costruire una tabella di riepilogo con media e dev. std. della variabile di interesse, rispetto a tutti i gruppi Diam 10 Diam 12 Diam 14 Diam 16 Diam 18 590 580 617 613 621 605 581 623 612 620 609 598 589 617 615 631 597 627 622 620 623 586 593 603 633 601 574 605 613 622 610 580 571 615 621 589 584 601 609 623 598 614 600 623 607 598 580 576 621 634 591 595 614 587 631 612 606 616 592 629 613 613 607 617 640 617 623 625 604 626 604 593 606 573 602 604 606 623 583 618 598 591 606 595 619 601 597 593 619 614 595 634 598 616 605 592 631 599 591 621Media 604,05 598,15 604,45 606,25 621,05Deviazione standard 11,25529 17,59269 15,46635 14,57783 9,681643

1816141210
640
630
620
610
600
590
580
570
Diametro
Rot
tura
Dotplots of Rottura by Diametro
10 12 14 16 18
570
580
590
600
610
620
630
640
Diametro
Rot
tura
Boxplots of Rottura by Diametro
Dai grafici riportati si possono valutare a colpo d’occhio la tendenza centrale, la dispersione e l’allontanamento dalla simmetria dei valori dei nostri cinque campioni.
3.1) ANOVA UNA VIA
L’analisi della varianza (anova) si utilizza per confrontare le medie quando vi sono più livelli di un
singolo fattore.

Nel nostro caso abbiamo valori di tensioni di rottura ottenute per cinque diversi diametri delle barre
di acciaio; il nostro fattore di interesse è pertanto il diametro e siamo in presenza di cinque
trattamenti.
Se vi fossero solo due metodi di trattamento, l’esperimento potrebbe essere analizzato usando il test
t a due campioni, come abbiamo fatto in precedenza.
I risultati ottenuti nella tabella precedente possono essere descritti per mezzo del seguente modello
statistico lineare
ijiijy ετμ ++= µ= �media generale della variabile risposta
iτ = effetto sulla media dell’i-esimo livello del fattore (i=1,2,3,4,5)
=ijε errore casuale
Gli effetti dei trattamenti sono definiti come scarti dalla media generale µ, pertanto vale la seguente uguaglianza:
∑=
=a
ii
10τ
Lo scopo di questo test è di verificare l’uguaglianza tra le medie iμ e questo equivale ad una
verifica di ipotesi per l’ipotesi nulla: 0...: 21 ==== aHo τττ
L’ipotesi alternativa viceversa risulta essere che almeno uno dei iτ sia non nullo e quindi la
variazione dei livelli del fattore non influenza la risposta media.
L’analisi della varianza suddivide la variabilità dei dati in due parti: una considera la distanza della
media per un trattamento dalla media generale, e l’altra invece la differenza dei dati dalla media del
proprio specifico trattamento, e quindi dovuta all’errore casuale.
EiTrattamentT SSSSSS +=
Dividendo per i gradi di libertà definiamo le seguenti quantità:
)1/( −= aSSMS iTrattamentiTrattament media quadratica
)]1(/[ −= naSSMS EE errore quadratico medio Che ci servono per la verifica di ipotesi per cui useremo la statistica test F:

E
iTrattamento MS
MSF =
e potremo rifiutare l’ipotesi nulla se essa cade nell’intervallo )1(,1, −−> naaffo α ossia i livelli dei
fattori influenzano la variabile risposta.
Col software Minitab abbiamo ottenuto questi risultati:
One-way ANOVA: Rottura versus Diametro Analysis of Variance for Rottura Source DF SS MS F P Diametro 4 5825 1456 7,42 0,000 Error 95 18651 196 Total 99 24477 Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev ---------+---------+---------+------- 10 20 604,05 11,26 (-----*-----) 12 20 598,15 17,59 (-----*-----) 14 20 604,45 15,47 (-----*------) 16 20 606,25 14,58 (-----*-----) 18 20 621,05 9,68 (-----*-----) ---------+---------+---------+------- Pooled StDev = 14,01 600 610 620 Fisher's pairwise comparisons Family error rate = 0,281 Individual error rate = 0,0500 Critical value = 1,985 Intervals for (column level mean) - (row level mean) 10 12 14 16 12 -2,90 14,70 14 -9,20 -15,10 8,40 2,50 16 -11,00 -16,90 -10,60 6,60 0,70 7,00 18 -25,80 -31,70 -25,40 -23,60 -8,20 -14,10 -7,80 -6,00
Dalla nostra analisi risulta pertanto che i diversi trattamenti influenzano la media; il p-value viene
infatti segnato come 0.
Uno strumento che ci da Minitab per la comparazione diretta tra due campioni è la Fisher pairwise
comparisons: nella matrice che si crea se l’intervallo derivante dal confronto tra un campione e
l’altro comprende lo 0, allora non posso rifiutare l’ipotesi nulla e pertanto le medie sono uguali.

Nel nostro caso si può vedere come il campione avente diametro 18 si discosti da tutti gli altri.
Ora andiamo a verificare l’adeguatezza del modello con i grafici:
403020100-10-20-30-40
20
10
0
Residual
Freq
uenc
y
Histogram of the Residuals(response is Rottura)
600 610 620
-40
-30
-20
-10
0
10
20
30
40
Fitted Value
Res
idua
l
Residuals Versus the Fitted Values(response is Rottura)
10 20 30 40 50 60 70 80 90 100
-40
-30
-20
-10
0
10
20
30
40
Observation Order
Res
idua
l
Residuals Versus the Order of the Data(response is Rottura)

403020100-10-20-30-40
3
2
1
0
-1
-2
-3
Norm
al S
core
Residual
Normal Probability Plot of the Residuals(response is Rottura)
3.2) REGRESSIONE LINEARE MULTIPLA SiO2 CaO TiO2 Al2O3 K2O
57,86 4,44 1,01 21,11 2,153,98 3,14 0,89 24,67 3,9162,83 1,99 0,88 17,94 2,38
52,6 1,32 0,95 26,14 3,4455,35 0,89 0,93 25,53 4,0357,87 0,51 0,95 23,41 3,2952,85 1,04 1 26,53 3,5854,19 0,92 0,96 26,6 4,0653,98 1,05 0,97 26,81 4,12
52,9 1,39 0,99 27,54 4,0255,56 1,02 0,94 25,77 4,1651,59 1,22 1,06 29,31 3,3953,55 1,06 0,96 26,88 4,0952,58 3,27 0,84 23,44 3,8857,92 6,75 0,96 18,24 2,0355,99 0,99 0,97 25,71 4,0660,48 1,19 0,94 22,38 3,3259,68 1,16 1 21,87 3,3656,78 1,14 1,02 24,97 3,56
57,5 0,98 0,91 23,88 3,9253,6 0,86 0,94 25,53 4,09
54,53 1,67 0,89 25,13 4,0656,83 2,3 0,95 23,63 3,6856,94 1,03 0,98 25,52 3,947,84 6,54 0,72 20,44 3,660,26 1,06 0,93 21,72 3,0959,03 4,88 0,97 18,52 1,99
61,7 4,38 0,91 18,33 2,0760,39 0,57 0,91 21,84 3,1557,79 4,85 1 20,79 1,9462,49 2,25 0,84 17,17 2,2760,18 1,7 0,8 20,91 3,74
57,3 5,44 1,04 20,97 2,11

52,27 1,94 0,97 26,94 3,92 La regressione lineare multipla consiste nel trovare una relazione lineare tra una variabile risposta dipendente e delle variabili indipendenti, dette regressori; formalizzando:
nn xxY βββ +++= ...110 +εi
Y variabile risposta 0β valore dell’intercetta
kβ coefficiente di regressione,
iε termine di errore casuale
La nostra esercitazione consiste nello svolgere una regressione lineare multipla sui componenti di un tipo di ceramica. Bisogna selezionare le variabili significative e costruire il modello. Regression Analysis: SiO2 versus CaO; TiO2; Al2O3; K2O The regression equation is SiO2 = 72,5 - 1,40 CaO + 22,9 TiO2 - 1,58 Al2O3 + 0,701 K2O Predictor Coef SE Coef T P Constant 72,475 4,300 16,86 0,000 CaO -1,4012 0,1556 -9,00 0,000 TiO2 22,892 5,414 4,23 0,000 Al2O3 -1,5753 0,1856 -8,49 0,000 K2O 0,7011 0,7953 0,88 0,385 S = 1,102 R-Sq = 91,3% R-Sq(adj) = 90,0% Analysis of Variance Source DF SS MS F P Regression 4 367,309 91,827 75,66 0,000 Residual Error 29 35,198 1,214 Total 33 402,508
Il primo modello costruito presenta tutte quattro le variabili; dal test-t risulta che una di queste non è significativa, e pertanto la scartiamo e costruiamo un nuovo modello con tre variabili. Regression Analysis: SiO2 versus CaO; TiO2; Al2O3 The regression equation is SiO2 = 75,2 - 1,46 CaO + 19,0 TiO2 - 1,43 Al2O3 Predictor Coef SE Coef T P Constant 75,246 2,923 25,74 0,000 CaO -1,4650 0,1373 -10,67 0,000 TiO2 18,950 3,042 6,23 0,000 Al2O3 -1,42861 0,08193 -17,44 0,000

S = 1,098 R-Sq = 91,0% R-Sq(adj) = 90,1% Analysis of Variance Source DF SS MS F P Regression 3 366,37 122,12 101,37 0,000 Residual Error 30 36,14 1,20 Total 33 402,51
La verifica mi dice che tutte le tre variabili sono significative, quindi posso fermare la procedura ed ho ottenuto il modello lineare che volevo. Minitab da la possibilità di selezionare automaticamente le variabili significative; basta impostare il programma sul metodo stepwise e lui produce un risultato uguale a quello da noi ottenuto. Stepwise Regression: SiO2 versus CaO; TiO2; Al2O3; K2O Backward elimination. Alpha-to-Remove: 0,05 Response is SiO2 on 4 predictors, with N = 34 Step 1 2 Constant 72,48 75,25 CaO -1,40 -1,46 T-Value -9,00 -10,67 P-Value 0,000 0,000 TiO2 22,9 19,0 T-Value 4,23 6,23 P-Value 0,000 0,000 Al2O3 -1,575 -1,429 T-Value -8,49 -17,44 P-Value 0,000 0,000 K2O 0,70 T-Value 0,88 P-Value 0,385 S 1,10 1,10 R-Sq 91,26 91,02 R-Sq(adj) 90,05 90,12 C-p 5,0 3,8
Ora per verificare il modello andiamo ad osservare i grafici dei residui:

-2,5 -2,0 -1,5 -1,0 -0,5 -0,0 0,5 1,0 1,5 2,0
0
1
2
3
4
5
6
7
8
Residual
Freq
uenc
y
Histogram of the Residuals(response is SiO2)
I residui si distribuiscono approssimativamente in maniera normale. Nel grafico dei quantili per i residui possiamo notare un andamento lineare.
210-1-2
2
1
0
-1
-2
Nor
mal
Sco
re
Residual
Normal Probability Plot of the Residuals(response is SiO2)
Gli altri grafici ci mostrano che sono verificate l’omoschedasticità e l’indipendenza dei valori dei residui.
50 52 54 56 58 60 62 64
-2
-1
0
1
2
Fitted Value
Res
idua
l
Residuals Versus the Fitted Values(response is SiO2)

5 10 15 20 25 30
-2
-1
0
1
2
Observation Order
Res
idua
l
Residuals Versus the Order of the Data(response is SiO2)