universidad de colombia - unal.edu.co
TRANSCRIPT



UNIVERSIDAD
NACIONAL DE COLOMBIA Sede BogJtá
colección textos

J. HUMBERTO MAYORGA A.
Es estadístico con maestría en ciencias-estadística
en la Universidad Nacional de Colombia.
En la actualidad es profesor asociado, vinculado
al departamento de estadística de la Facultad de
Ciencias. Su labor docente, principalmente en las
áreas de teoría estadística, probabilidad y análisis
multivariado, ha estado acompañada por el
desempeño de labores de gestión académica como
director de la carrera de estadística y de actividades
de extensión universitaria en el servicio de
consultoría estadística que el departamento presta
a los sectores público y privado.

Inferencia estadística

J. Humberto Mayorga A. Profesor del Departamento de Estadistica Facultad de Ciencias
Inferencia estadística
Universidad Nacional de Colombia FACULTAD DE CIENCIAS
BOGOTÁ

© Universidad Nacional de Colombia Facultad de Ciencias Departamento de Estadística
© J. Humberto Mayorga A.
Primera edición, 2004
Bogotá, Colombia.
UNIBIBLOS
Director general Francisco Montaña Ibáñez
Coordinaci6n editorial Dora Inés Perilla Castillo
Revisi6n editorial Fernando Carretero
Preparaci6n editorial e impresi6n Universidad Nacional de Colombia, Unibiblos [email protected]
Carátula Camilo Umaña
ISBN 958-701-374-3 ISBN 958-701-138-4 (obra completa)
Catalogación en la publicación Universidad Nacional de Colombia
Mayorga Alvarez, Jorge Humberto, 1951-Inferencia estadística 1 J. Humberto Mayorga A. -- Bogotá: Universidad Nacional de Colombia, 2004 XX,300 p.
ISBN: 958-701-374-3
l. Estadística matemática 2. Probabilidades I. Universidad Nacional de Colombia. Facultad de Ciencias. Departamento de Estadística
CDD-21 519.541 M473i 1 2004

Al eterno recuerdo de mi padre,
Héctor Mayorga (1918-2003)
y al grato recuerdo de mi hermana,
Myriam Mayorga (1958-2004)

Contenido
Prólogo vii
Introducción ix
1 Distribuciones Muestrales 1 1.1 La inferencia estadística como un soporte epistemológico. 2 1.2 Preliminares de la inferencia estadística . . . . . . . 5 1.3 Preliminares de convergencia de variables aleatorias 12 1.4 Características generales de algunas estadísticas. 17 1.5 Estadísticas de orden. . . . . . . . . . . . . . . . . . 25
1. 5.1 Distribución de las estadísticas de orden . . . 27 1.5.2 Distribución del rango, semirrango y mediana de
la muestra. . . . . . . . . . . . . . . . . . . . . 29 1.5.3 Distribución de la función de distribución de la
muestra .......... . 1.6 Momentos de estadísticas de orden 1.7 Demostración de los teoremas 1.8 Ejercicios . . . . . . . . . . . . . .
2 Estimación puntual de parámetros 2.1 Métodos clásicos para construir estimadores
2.1.1 El método de máxima verosimilitud 2.1.2 El método de los momentos 2.1.3 El método por analogía ... 2.1.4 Estimación bayesiana
2.2 Criterios para examinar estimadores 2.2.1 Concentración, un requisito de precisión
III
30 31 34 57
65 67 68 79
83 84 89 90

iv CONTENIDO
2.2.2 Consistencia, un requisito ligado al tamaño de la muestra . . . . . . . . . . . . . . . . . . . . . . .. 94
2.2.3 Suficiencia, un requisito de retención de información 96 2.2.4 Varianza mínima, un requisito de máxima precisión 108 2.2.5 Completez, un requisito de la distribución muestral116 2.2.6 Robustez, un requisito de estabilidad. 123
2.3 Demostración de los teoremas ................ 126 2.4 Ejercicios . . . . . . . . . . . . . . . . . 135
3 Estimación por intervalo de parámetros 147 3.1 Conceptos preliminares. . . . . . . . . . 148 3.2 El método de la variable pivote . . . . . 149 3.3 Estimación de promedios bajo Normalidad. 157
3.3.1 Intervalos confidenciales para el promedio de una población ....................... 157
3.3.2 Estimación de la proporción poblacional ...... 161 3.3.3 Intervalo confidencial para la diferencia de prome-
dios basado en una muestra pareada ........ 162 3.3.4 Intervalos confidenciales para la diferencia de prome
dios en poblaciones independientes . . . . . . . . . 163 3.4 Estimación de varianzas bajo Normalidad ......... 165
3.4.1 Intervalos confidenciales para la varianza de una población . . . . . . . . . . . . . . . . . . 165
3.4.2 Intervalos confidenciales para el cociente de va-rianzas de dos poblaciones independientes 169
3.5 Ejemplos numéricos de aplicación . . . . . . . . 173 3.6 Tamaño de la muestra simple bajo Normalidad 175 3.7 Estimación bayesiana por intervalo 177 3.8 Demostración de los teoremas . . . . . . . . . . 178 3.9 Ejercicios ....... . 182
4 Juzgamiento de hipótesis 187 4.1 Elementos básicos . . . . . . . . . . . . . . . . . . . 189 4.2 Tests más potentes ...................... 201 4.3 Juzgamiento de hipótesis sobre promedios bajo Normalidad218
4.3.1 Juzgamiento de la hipótesis nula Ho : j), = j),o ... 218 4.3.2 Juzgamiento de la hipótesis nula Ho : j),l - j),2 = 60 227
4.4 Juzgamiento de hipótesis sobre varianzas bajo Normalidad 237 4.4.1 Juzgamiento de la hipótesis nula Ho : (72 = (76. .. 237

CONTENIDO
4.4.2 Juzgamiento de homoscedasticidad 4.5 Juzgamiento de proporciones ... 4.6 Ejemplos numéricos de aplicación. 4.7 Tamaño de la muestra .
v
.240
.242
.246
.249 4.8 Juzgamiento secuencial. . . . . . . . 252 4.9 Juzgamiento del ajuste. . . . . . . . 261
4.9.1 Juzgamiento del ajuste por medio del método de Pearson . . . . . . . . . . . . . . . . . . . . . . . . 262
4.9.2 Juzgamiento del ajuste por medio del método de Kolmogorov-Smirnov . . 268
4.10 Demostración de los teoremas . 273 4.11 Ejercicios . 280
Bibliografía 289

Prólogo
La escritura de este libro siempre estuvo animada por el deseo obstinado de secundar el trabajo que realiza el estudiante en el salón de clase y fuera de éste, pues entiendo que, en definitiva, es el estudiante quien aprehende los conceptos como fruto de sus quehaceres académicos, conceptos inducidos más por sus dudas, por sus dificultades y por algunas contradicciones con algunos de sus preconceptos, que por una exposición frente al tablero. Según mi criterio, el profesor, como acompañante en la formación profesional, se convierte solamente en orientador, animador y crítico.
Con ese espíritu quise que este libro se constituyese en una juiciosa preparación de clase de la asignatura inferencia estadística, preparación que recopila las memorias de cada una de las oportunidades en las cuales fui el encargado del curso a lo largo de mis años como docente en la U niversidad Nacional de Colombia. De esa recopilación mucho se desechó y corrigió, pues las preguntas de los estudiantes confundidos, las preguntas inteligentes y las respuestas sobresalientes como las equivocadas en las evaluaciones, generalmente suscitaron la reflexión acerca de las formas y los contenidos de los guiones de la clase.
No pretendo publicar un texto más, pues los hay de una calidad inmejorable, algunos clásicos cuya consulta es obligada y otros de reciente edición que han incorporado nuevos desarrollos conceptuales. El texto pretende apoyar el trabajo académico del curso, especialmente con el propósito de optimizar el tiempo y la calidad de la exposición de los temas, dando paso a la utilización del tablero acompañado de la tecnología audiovisual como posibilidad para profundizar algunos de los temas y como medio para tratar las preguntas e inquietudes estudiantiles y no como instrumento transcriptor de frases y gráficas.
En este libro expreso mis apreciaciones personales, semánticas y conceptuales promovidas por la percepción que tengo sobre la estadística y
vii

VIll PRÓLOGO
particularmente sobre la inferencia estadística, concepción que he madurado y apropiado, a partir de las reflexiones con profesores del Departamento de Estadística, de discusiones informales y dentro de eventos académicos. Su contenido y organización responden a la forma tradicional como he realizado el curso, a las limitaciones de un semestre académico para su desarrollo y a los requisitos curriculares exigidos a los estudiantes en el mismo.
La circunstancia de mi año sabático, disfrutado durante el 2002, hizo posible la redacción y digitación de este texto, pues fueron múltiples las ocasiones fallidas de organizar en un libro el material de la clase, debido a las ocupaciones derivadas de mis compromisos académicos, administrativos y de servicios de asesoría estadística que la Universidad Nacional me encargó. El texto inicialmente fue publicado por la Facultad de Ciencias como notas de clase, versión que sirvió de guía del curso de inferencia estadística dictado durante el primero y segundo semestres de 2003 para las carreras de Matemáticas y Estadística.
La versión actual recoge sugerencias de profesores y de estudiantes y las modificaciones fruto de las experiencias en el citado curso.
Finalmente, creo que debo agradecer a mis alumnos, pues ellos son el motivo para organizar las ideas que presento en torno a la inferencia estadística, y a la Universidad Nacional de Colombia que aceptó como plan de actividades de mi año sabático, la elaboración de este texto.

Introducción
Este trabajo ha sido concebido como texto guía en el desarrollo de la asignatura inferencia estadística, que cursan los estudiantes del pregrado en Estadística y de la carrera de Matemáticas. Puede apoyar igualmente algunos temas de la asignatura estadística matemática de la maestría en Estadística. El requisito natural e inmediato para abordar los temas de cada uno de los capítulos del libro es un curso de probabilidad, y por supuesto los cursos de cálculo.
Se adaptaron términos de uso corriente en los textos de estadística a formas idiomáticas que semánticamente sean más fieles al concepto. Igualmente, se precisaron algunas expresiones comunes para mayor claridad conceptual.
El texto consta de cuatro capítulos que pueden desarrollarse durante un semestre académico con seis horas semanales de clase tradicional. Cada capítulo está estructurado en tres partes: exposición de los temas, demostraciones de los teoremas y los ejercicios correspondientes. Esto no significa que el manejo del texto deba llevarse en el orden propuesto. El objetivo de esta organización es que la presentación de los temas exhiba continuidad y que las demostraciones y los ejercicios tengan su sitio especial. Los ejercicios no están ordenados por su complejidad ni por el tema tratado, para no encasillarlos. El estudiante se acerca a un ejercicio con información y trabajo previos; su organización de ideas y búsqueda de caminos debe evaluar si con los elementos estudiados hasta un cierto punto le es posible abordar el ejercicio particular. Sin embargo, el profesor puede sugerir la realización de alguno o algunos ejercicios cuando haya culminado un tema o parte de éste.
El primer capítulo, fundamento del texto, ubica sintéticamente a la inferencia estadística dentro del problema filosófico secular de la inducción. Retoma el tema de la convergencia de sucesiones de variables aleatorias, y expone las ideas preliminares de la inferencia estadística.
ix

x INTRODUCCIÓN
El segundo capítulo presenta los métodos corrientes de construcción de estimadores y los criterios para examinar las estadísticas en su calidad de estimadores.
En el tercer capítulo se aborda el método de la variable pivote para construir intervalos confidenciales y se hace algún énfasis en los intervalos confidenciales bajo Normalidad. En el cuarto capítulo se adopta la expresión juzgamiento de hipótesis a cambio de prueba, docimasia o cotejo, porque esta acepción está más cerca del sentido de la toma de decisiones estadísticas e igualmente se da un espacio importante en el juzgamiento de hipótesis bajo Normalidad.

Capítulo 1
Distribuciones Muestrales
"El conocimiento que tenemos del mundo está basado en la elaboración de un modelo de la realidad, modelo que puede cotejarse con la experiencia tan sólo de manera parcial y ocasionalmente... Este modelo se construye teniendo en cuenta la utilización que hacemos del mismo ... ".
Jerome S. Bruner (On Cognitive Growth).
Antes de entrar en materia, es preciso destinar unos párrafos para introducir un bosquejo del contexto en el cual la inferencia estadística puede ubicarse, más como exposición de ideas generales que una disquisición filosófica al respecto. Ese contexto está contenido dentro de un problema más general de carácter epistemológico, que el lector puede profundizar con las copiosas publicaciones sobre el tema. Posteriormente, por tratarse de uno de los fundamentos sobre el cual la inferencia estadística erige algunos de sus conceptos, se incluye la sección 1.3 a manera de un extracto de la convergencia de sucesiones de variables aleatorias, tema que forma parte de un curso previo de probabilidad, pero que se retoma por su carácter y por su utilidad próxima.
1

2 CAPÍTULO 1. DISTRIBUCIONES MUESTRA LES
1.1 La inferencia estadística como un soporte epistemológico
La inferencia inductiva, procedimiento que utiliza la lógica para generalizar a partir de hechos particulares o a partir de la observación de un número finito de casos, es uno de los temas que ha ocupado a filósofos y científicos de todos los tiempos, desde la época de Aristóteles, tres siglos antes de Cristo, hasta la actualidad.
Varios filósofos antiguos formados en el empirismo gnoseológico, convencidos de que la observación era la única fuente segura de conocimiento, fueron los primeros en proponer la inducción o inferencia inductiva como método lógico. Tempranamente, la inducción se convierte en un tema de mucha controversia que aún se mantiene; si para Aristóteles, quien planteó inicialmente el procedimiento inductivo, la ciencia es "conocimiento demostrativo" , por el contrario para Sexto Empírico, uno de los filósofos del escepticismo, la ciencia es "comprensión segura, cierta e inmutable fundada en la razón". Así, mientras Sexto Empírico rechaza la validez de la inducción, Filodemo de Gadara, filósofo seguidor del epicureísmo, defiende la inducción como método pertinente.
y la controversia, llamada el problema de la inducción o también conocida como el problema de Hume, reside precisamente en que mientras la inferencia deductiva avala la transferencia de la verdad de las premisas a la conclusión, es decir, a partir de premisas verdaderas toda deducción es cierta, a costa de no incorporar nada al contenido de las premisas, la inducción por su parte que va más allá de las premisas, por su carácter amplificador, puede dar lugar a conclusiones falsas. En pocas palabras, la controversia se centra en la validez que puedan tener los razonamientos inductivos, puesto que las conclusiones por medio de la inducción no siempre serán verdaderas.
Algunos pensadores medievales también se preocuparon de la inducción. El inglés Robert Grosseteste, al utilizar en su trabajo científico los métodos aplicados por sus discípulos de Oxford en óptica y astronomía, reabre en la Edad Media el tema de la inducción; si bien varios filósofos de la época orientaron sus reflexiones hacia los métodos inductivos, los ensayos y trabajos de Francis Bacon inspirados en la reorganización de las ciencias naturales, constituyeron el apogeo del método inductivo.
No obstante, según Hume, las leyes científicas no tienen carácter universal, es decir son válidas únicamente cuando la experiencia ha

1.1. LA INFERENCIA ESTADÍSTICA COMO UN SOPORTE EPISTEMOLÓGICO 3
mostrado su certidumbre y tampoco tienen la función de la previsibilidad. Popper, filósofo de la ciencia, conocido por su teoría del método científico y por su crítica al determinismo histórico, en el mismo sentido de Hume, afirma que no puede existir ningún razonamiento válido a partir de enunciados singulares a leyes universales o a teorías científicas. Más recientemente, Bertrand Russell mantiene la posición de Hume de la invalidez de la inducción, pero considera que ella es el camino para incrementar la probabilidad, como grado racional de creencia, de las generalizaciones.
La conocida Ley débil de los grandes números incluida en la cuarta parte del trabajo más sobresaliente de Jacob Bernoulli, Ars Conjectandi, publicado después de su muerte en 1713, y el también conocido teorema de Bayes publicado cincuenta años más tarde, aportaron nuevos elementos a la discusión al constituirse en argumentos matemáticos que sustentan la posibilidad de inferir probabilidades desconocidas a partir --de frecuencias relativas. Sin embargo, según Popper, sustituir la exigen-cia de verdad por la validez probabilística para las inferencias inductivas no lo hace un procedimiento legítimo.
Durante las primeras décadas del siglo pasado, a raíz de los importantes avances de la ciencia ocurridos a finales del siglo XIX y a principios del siglo XX, avances que no podían pasar inadvertidos para los pensadores, obligaron a los filósofos a revisar muchas de las ideas de los clásicos y es así como un grupo de hombres de ciencia, matemáticos y filósofos, se organizan en 1922 en torno al físico Moritz Schlick, profesor de filosofía de la ciencia de la Universidad de Viena, convirtiéndose en un movimiento filosófico internacional, principal promotor del positivismo lógico (también llamado neopositivismo, neo empirismo o empirismo lógico), movimiento conocido como Círculo de Viena, conformado entre otros, además de Schlick, por Hahn, Frank, Neurath, Kraft, Feigl, Waismann, Cadel, y Carnap; Einstein, Russell y Wittgenstein eran considerados miembros honoríficos y Ramsey y Reinchenbach como miembros simpatizantes del mismo.
Este movimiento filosófico se dedicó a muchos y variados temas de la filosofía de la ciencia, y por supuesto al problema de la inducción. En síntesis, puede afirmarse que el hilo conductor de las ideas del Círculo de Viena fue la defensa de una visión científica del mundo a través de una ciencia unificada ligado al empleo del análisis lógico en el sentido de Russell.

4 CAPÍTULO 1. DISTRIBUCIONES MUESTRA LES
Pero, respecto a la inducción, el Círculo no cerró la discusión; concretamente para Popper y sus seguidores, la escuela del refutacionismo, el método científico no utiliza razonamientos inductivos, sino razonamientos hipotético-deductivos. Así se acopien datos y hechos particulares dentro del procedimiento de evaluación de una hipótesis que dan paso a una conclusión de carácter general, no existe como tal un razonamiento inductivo. Para el refutacionismo, la ciencia se concibe como una sucesión de conjeturas y refutaciones: se proponen conjeturas para explicar los hechos, que luego serán refutadas para promover nuevas conjeturas. En síntesis, según Popper y su escuela, ninguna teoría científica puede establecerse en forma concluyente.
Sin embargo, para Feyerabend y Kuhn, en otro momento de gran controversia en este tema, las décadas del 60 y 70, la práctica científica no está en correspondencia con este proceder racional ni tampoco puede lograrlo, porque en gran medida existen supuestos relativos a la objetividad, a la verdad, al papel de la evidencia y a la invariabilidad semántica. Según Feyerabend, no existen principios universales de racionalidad científica; el crecimiento del conocimiento es siempre específico y diferente como tampoco sigue un camino de antemano fijado.
Dentro de esta controversia, a la inferencia estadística no se le ha eximido del problema de la inducción. Ronald Fisher, considerado por muchos el padre de la estadística, defendió el papel inductivo que conlleva el juzgamiento de hipótesis 1. Sin embargo, un sector de científicos y filósofos consideran que tanto la estimación de parámetros como el juzgamiento de hipótesis tienen dirección inductiva pero el razonamiento o inferencia que se lleva a cabo es de carácter deductivo.
En fin, la historia y la filosofía de la ciencia tuvieron un enorme auge a lo largo del siglo pasado, continúan acopiando y estructurando reflexiones y argumentos sobre la inducción, pero al no ser el propósito de esta sección tratar el proceso lógico de la inducción desde el punto de vista filosófico, ni tampoco pretender su recuento histórico, ni mucho menos asumir una posición respecto a ella, se omiten nombres de muy destacados pensadores contemporáneos. Lo que realmente motiva incluir los párrafos anteriores es poner de manifiesto de manera muy concisa que el problema de la inducción es filosófico con 23 siglos de existencia, al cual generaciones de filósofos y científicos se han dedicado.
y más allá del debate epistemológico y metafísico contemporáneo
1 La denominación juzgamiento de hipótesis se justificará en el capítulo 4.

1.2. PRELIMINARES DE LA INFERENCIA ESTADÍSTICA 5
dentro de la filosofía de la ciencia, gran parte de la ciencia actual frente a una naturaleza entrelazada de azar concomitante con una variabilidad inherente, reconoce de una u otra manera que el ensanche de su cuerpo conceptual requiere la participación imprescindible de la estadística. Mucho antes de la omnipresencia del computador, de los avances vertiginosos de la teoría y de los métodos estadísticos de los últimos tiempos, Hempel en 1964, en su libro Aspectos de la explicación científica, se refería a los dos modelos de explicación de tipo estadístico: "El modelo estadístico deductivo, en el que las regularidades estadísticas son deducidas de otras leyes estadísticas más amplias, y el modelo estadístico inductivo, en el que los hechos singulares se explican subsumiéndolos bajo leyes estadísticas".
En esta dirección, cuando en los quehaceres científicos, tecnológicos o administrativos se recurre a la estadística para organizar y orientar sus procesos y métodos, y cuando se recurre a ella para apoyar argumentos y decisiones, ese recurso suele convertirse, desde uno de los puntos de vista, en un proceso de inducción específicamente que puede clasificarse como de inducción amplificadora, de manera análoga a como Francis Bacon vio en la inducción el procedimiento esencial del método experimental, o convertirse en una serie de actividades ligadas a un procedimiento propio de la ciencia o la tecnología, en un procedimiento hipotéticodeductivo, como lo entiende la escuela popperiana. Para cualquiera de los dos puntos de vista que se asuma, la estadística brinda un respaldo exclusivo en la inferencia.
1.2 Preliminares de la inferencia estadística
Dentro del contexto del parágrafo anterior, cabe formularse varias preguntas:
1. ¿Cuál es el objeto para el cual son válidos los enunciados generales producto de la inducción, de la decisión o la estimación que realiza una aplicación estadística?
2. ¿Cuáles son las unidades que permiten obtener la información de casos particulares como punto inicial en el citado proceso?
3. ¿Cuáles son los principios que rigen este proceso tan particular de inferencia?

6 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
La pregunta (1) indaga por el conjunto de todos los elementos que en un determinado momento interesan a un investigador, a un gestor o a un tomador de decisiones. Elementos diferentes entre sí pero que tienen una o varias características comunes que los hacen miembros del conjunto en consideración. Al respecto, en algunas disciplinas científicas esas características comunes se denominan criterios de inclusión, complementados con los criterios de exclusión, para definir concisamente la pertenencia de un elemento al conjunto y para precisar igualmente la pérdida de la calidad de pertenencia del elemento.
Para referirse a ese conjunto mencionado, el lenguaje corriente de la estadística utiliza el término población; ese agregado o colección de las unidades de interés es, en últimas, el objeto receptor del producto del proceso de inducción, de la decisión o de la estimación.
La segunda pregunta parece confundirse con la primera. Aunque la pregunta se refiere a esas entidades que corresponden a los hechos particulares, a los casos singulares, a ese conjunto finito de casos, que son examinados durante la primera etapa de la inferencia, la reunión de todas las unidades posibles constituye ese conjunto que se ha llamado población. Pero su estricta determinación radica en que cada una de esas unidades será, en sentido metafórico, un interlocutor con el investigador. Interlocutor, porque la investigación puede entenderse, de manera análoga, como un proceso comunicativo: el investigador pregunta, la naturaleza responde. Esas unidades pueden denominarse unidades estadísticas de manera genérica para subsumir en esa denominación otras como unidad experimental, unidad de análisis, sujeto o caso.
Como en casi todas las oportunidades, de hecho no existe la posibilidad de "dialogar" con todas las unidades estadísticas, debido a imperativos que lo impiden, asociados a varios aspectos. Por ejemplo, cuando el tamaño de la población, es decir, el cardinal del conjunto que reúne a todas las unidades estadísticas, es ingente; o cuando la respuesta de la unidad implica su desnaturalización o deterioro; igualmente, cuando ese "diálogo" es oneroso, o cuando los resultados de la investigación se requieren con apremio.
A ese subconjunto de unidades que se aludía como el conjunto finito de casos examinados durante la primera etapa del proceso de inferencia, circunscrito al subconjunto de unidades estadísticas elegidas por medio de procedimientos estadísticos formales, por supuesto, se le designa corrientemente como muestra.

1.2. PRELIMINARES DE LA INFERENCIA ESTADÍSTICA 7
A diferencia de las dos preguntas anteriores, cuyas respuestas son en últimas acuerdos semánticos, la tercera requiere respuestas a partir de elaboraciones conceptuales, las cuales se darán gradualmente con el desarrollo de los capítulos objeto de este texto; pero aquí, de una manera sucinta, se esboza el fundamento de las respuestas.
La estadística facultada para sustentar y conducir procesos de inducción, decisión y estimación muy característicos, cuenta con la inferencia estadística como la fuente conceptual que nutre, avala y licencia la estructura y el funcionamiento de métodos y procedimientos estadísticos. Para el desarrollo de cada una de sus dos componentes, relativos a la estimación de parámetros y el juzgamiento de hipótesis, la inferencia estadística tiene como punto de partida la referencia o el establecimiento de modelos para representar variables observables o no observables, modelos que pueden ser explícitos o generales.
Semánticamente, el vocablo modelo responde a varias acepciones, particularmente dentro del lenguaje científico y tecnológico. Sin embargo, el sentido que la estadística le confiere al término consiste en una traducción de un aspecto de la realidad a un lenguaje simbólico, como uno de los recursos para representar de manera simplificada su comportamiento, que habilite procesos de generalización que incluyan sus aspectos fundamentales y que faciliten su descripción o permitan la toma de decisiones.
La factibilidad de representar variables muy disímiles asociadas con fenómenos de distintos campos del saber a través de un mismo modelo de probabilidad, le permite a la inferencia estadística detenerse en el modelo mismo para convertirlo en su objeto de estudio. A partir de su estructura, de las expresiones matemáticas asociadas a su naturaleza y con ellas de la presencia y papel que desempeñan los parámetros, se construyen y evalúan posibles estimadores de estos últimos, y de igual manera se derivan y evalúan procedimientos que permitan juzgar afirmaciones sobre el modelo.
En consecuencia, los principios que avalan procesos de carácter estadístico, tratados por la inferencia estadística y motivo de la tercera pregunta, consisten en métodos y criterios relacionados con la construcción de estimadores y test y con el examen de la aptitud e idoneidad de los mismos, y que tal como se anunció, la descripción y el desarrollo de los citados principios son en definitiva el contenido mismo de este texto.
Definición 1.2.1. Una muestra aleatoria es una sucesión finita de

8 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
variables aleatorias Xl, X 2 , . .. ,Xn independientes e idénticamente distribuidas. De manera más general, una sucesión de variables aleatorias Xl, X2, ... , independientes y con idéntica distribución, también se denomina muestra aleatoria. En el caso de una sucesión finita, el valor n recibe el nombre de tamaño de la muestra o tamaño muestral.
La definición anterior revela que en el contexto estadístico el término muestra presenta dos acepciones: ser un subconjunto de unidades estadísticas elegidas por métodos estadísticos formales y la adjetivada como aleatoria expuesta en la definición anterior, ésta referida a una sucesión de variables aleatorias. Lo mismo le ocurre al término población: denota al conjunto completo de unidades estadísticas objeto de estudio y ahora se le concibe como una variable aleatoria, en el sentido que se expone a continuación.
El acceso al estudio de ese conjunto de unidades estadísticas se lleva a cabo mediante el examen de las características o respuestas de sus integrantes, interpretadas como variables; el discernimiento de la esencia ya no individual sino colectiva de las unidades es en suma el motivo de la investigación o estudio. Por ello, el comportamiento de las variables se convierte entonces en un elemento revelador de características y propiedades que sustentan la descripción de la colectividad, las explicaciones o las decisiones a que haya lugar.
El comportamiento real de una o varias variables es un comportamiento reflejo de la naturaleza de la población, que no siempre es posible conocer. Por tanto, acudir a modelos de probabilidad para emular el comportamiento poblacional es un recurso legítimo que reduce carencias, permite aprovechar las virtudes propias del modelo y hace posible la utilización de un lenguaje universal, por supuesto sobre la base de una escogencia juiciosa del modelo.
Entonces, un aspecto de las unidades estadísticas observado, medido o cuantificado en una variable (o varios aspectos utilizando un vector para disponer las variables) se le abstrae como una variable aleatoria (o un vector aleatorio) que tiene asociado un modelo particular. Esta variable aleatoria que representa una variable en la población suele denominársele igualmente población.
Según estas consideraciones, la sucesión X I ,X2 , ... ,Xn de la definición anterior denominada muestra aleatoria, además de ser un elemento del ámbito conceptual de la teoría estadística, puede vincularse con la información específica acopiada de un subconjunto de n unidades es-

1.2. PRELIMINARES DE LA INFERENCIA ESTADÍSTICA 9
tadísticas de las cuales se dispone de los valores Xl, X2, . .. ,Xn , correspondientes a una variable denotada por X. En otros términos, el valor Xi puede entenderse como una realización de la correspondiente variable aleatoria Xi, i = 1,2, ... , n; por eso es habitual encontrar recurrentemente la expresión "sea Xl, X 2 , ... ,Xn una muestra aleatoria de una población con función de densidad ... ". El contexto en el cual se encuentre el vocablo población delimita la acepción en uso: un conjunto o una variable aleatoria. Las constantes constitutivas del modelo probabilístico elegido para representar una población, llamadas usualmente parámetros, se disponen en un vector de k componentes, k = 1,2, ... , que puede denotarse como () al cual se le designa como parámetro del modelo.
Definición 1.2.2. Sea Xl, X2, ... ,Xn , una muestra aleatoria de una población cuya función de densidad o función de probabilidad depende de un parámetro (), vector de k componentes, y sea además t una función de dominio ~n y recorrido ~q con q :s; n, tal que t(Xl , X 2 , ..• , X n ) es un vector aleatorio de q componentes, q = 1,2, ... ,n, función que no depende de ningún componente del vector (), ni de constantes desconocidas, también llamadas parámetros que cuantifican rasgos generales en la población cuando no se asume un modelo específico. En estas condiciones, el vector aleatorio t(Xl , X2, ... ,Xn ) recibe el nombre de estadística.
La dimensión de la estadística estará dada por el valor de q; una estadística es unidimensional cuando q = 1, bidimensional cuando q = 2, Y así sucesivamente.
Como el aspecto determinante en la naturaleza de una estadística es su no dependencia funcional de parámetros, se le resalta por medio del siguiente ejemplo.
Ejemplo 1.2.3. Asumiendo el modelo gaussiano para representar una variable en la población, y si Xl, X 2 , . .. ,Xn es una muestra aleatoria de la población así modelada, son estadísticas entre otras
• Xl + X 2 + ... + X n = Xn
n

10 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
• (Xn , S~)
• (X1 ,X2 , ... ,Xn )
Las tres primeras estadísticas son unidimensionales, la cuarta bidimensional y la última de dimensión q = n.
Puesto que los parámetros p, y (j son las constantes características del modelo gaussiano, particularmente las dos siguientes variables aleatorias no son estadísticas:
n
t (Xi -Xn)2 z=l (j
¿ (Xi - p,)2
y i=l
n-1
El contenido semántico que se les da en estadística tanto al término estimar como al término estimación, para referirse a su acción o efecto, proviene de una de las acepciones corrientes que tiene el segundo vocablo. El significado en mención de aprecio o valor que se da y en que se tasa o considera algo2 , no sugiere un cálculo aproximado de un valor como equivocadamente se entiende, porque no hay referentes para calificar su aproximación, pero sí los hay para el proceso que genera las estimaciones, tampoco sugiere un proceso adivinatorio. Debe entenderse como la realización formal de un avalúo, es decir, en llevar a cabo un proceso que exige de manera imprescindible el contar con información de ese algo del cual se quiere fijar su valor. Por tanto, la calidad de la estimación depende directamente de la calidad original y de la cantidad de información que se posea. Consecuentemente, una cantidad insuficiente de información genera estimaciones no fiables, como las genera una gran cantidad de información de calidad exigua.
A manera de sinopsis, considerando simultáneamente tanto la cantidad de información como su calidad y utilizando el plano cartesiano para su representación, en la figura 1.1 se adjetivan distintas circunstancias en calidad y cantidad de información que constituye el insumo en el proceso de estimación.
El proceso de inferencia sería inigualable si se contara con toda la información de excelente calidad, circunstancia prácticamente no factible. Esta situación ideal, antagónica con la peor cualificación de la información (una escasa cantidad de información de pésima calidad) no es la
2Real Academia Española (2001). Diccionario de la lengua española. Vigesimasegunda edición. Madrid: Espasa Calpe S.A.

1.2. PRELIMINARES DE LA INFERENCIA ESTADÍSTICA 11
100%¡,.,.,.,. ....... .-~~~_-_-_-_-_-] ~./ 1
~u I I ~Q), I I
I I
o Calidad 100%
Figura 1.1: Diagrama de calidad y cantidad de información.
única que debe censurarse dentro del proceso de estimación. Igualmente censurable es contar con una acumulación exorbitante de información de deficiente calidad que no propicia un buen resultado, ni tampoco mantener el mejor nivel de calidad de la información en una cantidad minúscula de la misma.
La calidad de la información, de la cual este texto no se ocupa porque se pretenden propósitos de otro tipo, debe asegurarse a partir del diseño, construcción y calibración de instrumentos para el registro de la información, dentro de la organización y ejecución de las actividades de acopio de información y durante el proceso de almacenamiento y guarda de la información.
Definición 1.2.4. Una estadística con dimensión igual al número total de componentes k del vector e o al número de componentes desconocidos, estadística cuyas realizaciones son utilizadas para llevar a cabo estimaciones del parámetro del modelo probabilístico asumido, o de sus componentes, se denomina estimador y a las citadas realizaciones o valores particulares se les conoce como estimaciones.
Definición 1.2.5. El modelo probabilístico que rige el comportamiento de una estadística o de un estimador se denomina distribución mues-

12 CAPÍTULO 1. DISTRIBUCIONES MUESTRA LES
tral de la respectiva estadística o del respectivo estimador.
Algunos autores se refieren a la distribución de la variable aleatoria que representa a la población, como la distribución original de las observaciones o modelo original, y a la distribución muestral de una estadística como la distribución reducida o modelo reducido.
Definición 1.2.6. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con momentos ordinarios y centrales /-l~ y /-lr respectivamente. Los momentos muestrales, ordinarios y centrales de orden r, r = 1,2, ... , cumplen en la muestra funciones análogas a los momentos poblacionales /-l~ y /-lr, se denotan y definen como
1 n
M: n = -" Xi , n~ i=l
1 n _
Mr,n =;; ¿(Xi - Xnf· i=l
El caso particular cuando r = 1, esto es, el primer momento ordinario muestral, M{ n = X n , es llamado de manera más corriente promedio , muestral o promedio de la muestra. Por otra parte, se prefiere como varianza muestral en cambio del segundo momento muestral, por razones que posteriormente se justificarán, a la expresión
1 n
n _ 1 ¿(Xi - Xn)2. t=l
1.3 Preliminares de convergencia de variables aleatorias
Para aprestar los elementos que se requieren en la inferencia estadística, es preciso abordar de una manera sucinta los tipos de convergencia de variables aleatorias en razón de que posteriormente el crecimiento del tamaño de muestra permite derivar propiedades interesantes de algunas estadísticas, y por tanto el propósito de esta sección es presentar los tipos más corrientes de convergencia de variables aleatorias.
Por medio de {Xn }, n = 1,2, ... , se describe una sucesión de variables aleatorias Xl, X 2 , .. . , la cual es una sucesión de funciones medibles

1.3. PRELIMINARES DE CONVERGENCIA DE VARIABLES ALEATORIAS 13
{ X n ( w)} definida en un espacio muestral O, Y teniendo en cuenta que todas las variables aleatorias constituyentes de la sucesión están consideradas en el mismo espacio de probabilidad (O, A, P).
En primer lugar, siendo {Xn } una sucesión de variables aleatorias y c un número real, el conjunto {wIXn(w) = c} E A, de manera que
P [lim X n = c] = 1 n-->oo
esté siempre definido. Se dice que la sucesión de variables aleatorias {Xn } converge casi
seguro a cero o converge a cero con probabilidad uno si:
P [lim X n = o] = 1. n-->oo
Además, si las variables aleatorias Xl, X 2 , . .. , y la variable aleatoria particular X están definidas en el mismo espacio de probabilidad, se afirma que la sucesión de variables aleatorias {Xn } converge casi seguro a la variable aleatoria X, si la sucesión de variables aleatorias {Xn - X} converge casi seguro a cero; este tipo de convergencia también se conoce como convergencia fuerte y se simboliza como
Ejemplo 1.3.1. Si el comportamiento probabilístico de cada una de las variables aleatorias de la sucesión {Xn } se modela por medio de la distribución de Bernoulli de manera que X n "" Ber((!)n), entonces
En efecto,
P [ lim X n = O] = 1 n-->oo
puesto que P[Xn = O] = 1 - (!r· Como V [Xn ] = ar [1- (!rJ, puede notarse el decrecimiento de dicha varianza en cuanto n se incrementa, es decir, X n va perdiendo el carácter de variable aleatoria porque su varianza va tendiendo a cero, esto es, la variable va asumiendo rasgos de una constante.
En segundo lugar, se dice que la suceSlOn de variables aleatorias {Xn } converge en probabilidad a la variable aleatoria X, hecho simbolizado como

14 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
si lim P [lXn - XI < E] = 1, para E > O. Para referirse a la convergen-n->oo
cia en probabilidad también puede utilizarse convergencia estocástica, convergencia en medida o convergencia débil.
Específicamente dentro de la convergencia en probabilidad y debido al uso principal que tendrá en la construcción de estimadores por el llamado método de los momentos, se enuncia el siguiente teorema.
Teorema 1.3.2. Siendo las variables aleatorias X~j) , Xj, j = 1,2, ... , k,
Y la función 9 : IR.k -----7 IR. continua, tal que tanto g(X~l), X~2), ... ,X~k))
como g(X1 , X2, . .. ,Xn ) sean variables aleatorias, entonces si X:.p ~ X j implica que
g(X~l), X~2), ... , X~k)) ~ g(X1 , X 2, . .. , X n).
Corolario 1.3.3. Si X n ~ X Y W n ~ W, entonces
1. X n + Wn ~ X + W.
p 2. X n Wn ---+ XW.
3. aXn + bWn ~ aX + bW; a, b constantes.
4· ~ ~ ~; P[Wn =1= O] = P[W =1= O] = 1.
5. X~ ~ X2.
6. ln ~ 1-; P[Xn =1= O] = P[X =1= O] = 1.
Un tercer tipo de convergencia se conoce como convergencia en momento de orden r . En este caso cada variable de la sucesión de variables aleatorias {Xn } y X poseen el momento ordinario de orden r. En estas circunstancias se afirma que la sucesión de variables aleatorias converge en momento de orden r a la variable aleatoria X, lo cual se representa como
Xn~X
si lim E [(IXn - XIY] = O. Particularmente, si r = 1 suele decirse que n->oo
la sucesión de variables aleatorias {Xn } converge en valor esperado a la variable aleatoria X. De manera similar, cuando r = 2, la convergencia se conoce como convergencia en media cuadrática.

1.3. PRELIMINARES DE CONVERGENCIA DE VARIABLES ALEATORIAS 15
Un cuarto y último tipo de convergencia de variables aleatorias se refiere a una sucesión de variables aleatorias {Xn }, cuya correspondiente sucesión de funciones de distribución Fl (x), F2 (x), ... , se considera. De esta manera, la sucesión de variables aleatorias {Xn } converge en distribución a la variable aleatoria X, cuya función de distribución es F(x), hecho denotado
d X n ---+ X
si lim Fn(x) = F(x) para todo x, donde F(x) es continua. n-too
Teorema 1.3.4 (Teorema de Lévy). Considerando la variable aleatoria particular X y la sucesión de variables aleatorias {Xn}, definidas sobre el mismo espacio de probabilidad, y siendo {ljJn (t)} la sucesión de funciones características correspondientes a las variables de la sucesión {Xn },
X n .!!... X si y sólo si lim IjJn(t) = ljJ(t) n-too
para t E IR Y 1jJ( t) la función característica de la variable aleatoria X, continua en cero.
Teorema 1.3.5 (Teorema de Lévy). Versión para funciones generatrices de momentos. Considerando la variable aleatoria particular X y la sucesión de variables aleatorias {Xn}, definidas sobre el mismo espacio de probabilidad, y siendo {Mn(t)} la sucesión de funciones generatrices de momentos correspondientes a las variables de la sucesión {Xn}, las cuales existen para t real en algún intervalo alrededor de cero,
X n .!!... X si y sólo si lim Mn(t) = M(t) n-too
para t real en algún intervalo alrededor de cero y M(t) la función generatriz de momentos de la variable aleatoria X.
Ejemplo 1.3.6. En los cursos generales de probabilidad y estadística, se demuestra que cuando es apropiada la utilización del modelo Binomial, pero el número de repeticiones n es grande y simultáneamente la probabilidad de éxito 7r es muy pequeña, es decir n ---+ 00 y 7r ---+ 0, es lícito utilizar el modelo de Poisson con ,\ = n7r. La legitimidad de este proceder es respaldada por motivos de convergencia en distribución. Si Xl, X 2, ... , X n , ... , representa una sucesión de variables aleatorias tales

16 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
que X n rv Bin(n,7r), condicionado el producto n7r a permanecer constante en el valor A, y como Mxn(t) = (1- 7r + 7rett, entonces
lim Mxn(t) = lim [1 - 7r (1 - et)t = lim [1 - ~ (1- et)]n n~oo n~oo n~oo n
= eA(et-l) ,
A = n7r, límite reconocido como la función generatriz de una variable aleatoria con distribución de Poisson con parámetro A. Es decir,
X n ~ X rv Poiss(A).
Teorema 1.3.7. Sea {Xn} una sucesión de variables aleatorias.
X n ~ c si y sólo si lim Fn(x) = F(x) n-too
siendo c una constante, Fn(x) la función de distribución de X n y F(x) una función de distribución tal que F (x) = O para x < c y F (x) = 1 para x :2: c.
Ejemplo 1.3.8. Si Xl, X 2 , ... ,Xn es una sucesión de variables aleatorias tales que X n rv x2(n), la sucesión de variables aleatorias {Yn },
con Yn = ~, converge en probabilidad al valor 1. El examen del lim MYn (t) permite concluir la convergencia enunciada de la suce-n~oo
sión, a la luz del teorema 1.3.7. En efecto, como X n rv x2 (n), luego
M Xn (t) = (1 - 2t)-~, M Yn (t) = (1 - ~) -~. Entonces
lim (1 - 2t) -~ lim (1 - ht)-* = et siendo h = -h2
. n~oo n h~O
Esto significa que Fx(x) es una función tal que Fx(x) = O para x < 1 Y Fx(x) = 1 para x :2: 1; es decir, se trata de una constante igual a t. En
consecuencia, el teorema anterior permite concluir que Yn ~ 1.
Entre los diferentes tipos de convergencia existen relaciones que es necesario destacar. El siguiente teorema las reúne.
Teorema 1.3.9. Estando las variables aleatorias Xl, X2, ... y la variable particular X definidas sobre el mismo espacio de probabilidad (D,A,P):

1.4. CARACTERÍSTICAS GENERALES DE ALGUNAS ESTADÍSTICAS 17
1. Si {Xn } converge casi seguro a la variable aleatoria X con probabilidad 1, implica que {Xn } converge en probabilidad a la variable aleatoria X.
2. Si {Xn } converge en valor esperado a la variable aleatoria X, implica que {Xn } converge en probabilidad a la variable aleatoria X.
3. Si {Xn } converge en probabilidad a la variable aleatoria X implica que {Xn } converge en distribución a la variable aleatoria X.
4. Siendo r > s, la convergencia de una sucesión de variables aleatorias {Xn } en momento de orden r implica la convergencia de la sucesión en momento de orden s.
De manera gráfica las relaciones que enuncia el teorema 1.3.9 se pueden recapitular en la figura 1.2.
Convergencia casi segura , ~~/ Convergencia en valor esperado
~~---~-., Convergencia en probabilidad
} Convergencia en
distribución
Figura 1.2: Relaciones entre algunos tipos de convergencia de variables aleatorias.
1.4 Características generales de algunas estadísticas
Los momentos muestrales, además de cumplir funciones análogas a los momentos poblacionales como se incorporó en la definición 1.2.6, son es-

18 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
tadísticas de uso frecuente que con la garantía de la existencia de determinados momentos poblacionales, sus distribuciones muestrales poseen propiedades generales respecto a su posición y a su dispersión en la forma como el siguiente teorema lo indica.
Teorema 1.4.1. Si X l ,X2, ... ,Xn es una muestra aleatoria de una población representada por la variable aleatoria X con varianza a 2 y con momento ordinario J-l~r' r = 1,2, ... , entonces el valor esperado y la varianza del momento muestral ordinario son, respectivamente:
I l- I E[Mr,n - J-lr
V[M:,nl = ~ [E[x2rl - (E[Xr ])2]
= ~ [J-l~r - (J-l~)2] .
Corolario 1.4.2. Según las hipótesis del teorema 1.4.1,
E[Xnl = J-l~ = J-l
_ a2
V[Xnl =-. n
Teorema 1.4.3. Si Xl, X2, .. . , X n es una muestra aleatoria de una población con valor esperado, también llamado promedio poblacional, J-l y varianza a2, conocida como varianza poblacional, y existiendo además el momento central de orden cuatro J-l4, entonces
2 [1 ~ - 2] 2 E[Snl = E n _ 1 ~(Xi - X n) = a
V[Snl = - J-l4 - --a ,n > 1. 2 1 ( n - 3 4) n n-1
El tamaño de la muestra es un elemento sustancial tanto para las disquisiciones en la teoría de la estadística como para la utilización de la misma. La pregunta, por su magnitud, es quizá de las más inquietantes para el investigador en la búsqueda de respaldo a la confiabilidad de su investigación; el tamaño muestral es uno de los aspectos con los cuales se certifican o descalifican estudios. Es, en definitiva, un punto obligado para dilucidar.

1.4. CARACTERÍSTICAS GENERALES DE ALGUNAS ESTADÍSTICAS 19
La incidencia relevante del tamaño de la muestra en la distribución muestral de muchas estadísticas gira alrededor del tema conocido como distribuciones asintóticas. En particular, a medida que vaya incrementándose el tamaño de la muestra, el promedio muestral adquiere unos rasgos propios que los siguientes teoremas describen.
Teorema 1.4.4 (Ley débil de los grandes números). Si las variables aleatorias Xl, X2, . .. ,Xn constituyen una muestra aleatoria de una población con valor esperado ¡.L y varianza 0-2 , entonces
Xl + X2 + ... + X n P -------- ~ ¡.L.
n
La nota de la demostración del teorema anterior destaca el hecho que
P [-E < X n - ¡.L < E] ~ 1 - Ó
0-2
para n entero mayor que &2' E > O, Ó > O; lo cual permite determinar
la magnitud del tamaño muestral según prefijados requisitos. Esta cota para el tamaño de la muestra debe entenderse dentro del contexto de una población infinita y una muestra simple.
Ejemplo 1.4.5. ¿Cuál debe ser el tamaño de la muestra para tener una probabilidad de 0.95 de que el promedio muestral no difiera de ¡.L en más de una cuarta parte de la desviación estándar? En esta situación, E = 0.250-, Ó = 0.05; por lo tanto:
0-2
n > ( ') )2 ( ) = 320. 0 ..... 50- 0.05
Modificando parcialmente las condiciones del teorema 1.4.4 en el sentido de no hacer ninguna mención de la varianza 0-2 , es posible reiterar la convergencia en probabilidad del promedio de la muestra, como lo presenta el siguiente teorema.
Teorema 1.4.6 (Teorema de Khintchine). Si Xl, X2, ... , X n es una muestra aleatoria de una población con valor esperado ¡.L, entonces
- P X n ~ ¡.L.
De manera más general, la convergencia en probabilidad de los momentos muestrales ordinarios a los momentos poblacionales ordinarios está avalada por el siguiente teorema.

20 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Teorema 1.4.7. Si Xl,X2, ... ,Xn es una muestra aleatoria de una población para la cual el momento central /-l2r existe, entonces
, p , Mr,n ---+ /-ln r = 1,2, ...
Para cerrar esta relación de teoremas que giran alrededor de la idea de la ley débil de los grandes números, se incluye el siguiente teorema que puede entenderse como una generalización de la citada ley.
Teorema 1.4.8. Si Xl, X 2, ... es una sucesión de variables aleatorias tales que E[Xil = /-li Y V[Xil = o'¡ son finitos y p(Xi , X j ) = O, i =J- j, para i,j = 1,2, ... , entonces
1 n siendo 7ln = - L /-li
n i=l
- - p X n - /-ln ---+ O
La ley fuerte de los grandes números es un conjunto de teoremas referentes a la convergencia casi segura de sucesiones de variables aleatorias. El teorema siguiente es el más divulgado de todos y fue enunciado originalmente por Kolmogorov.
Teorema 1.4.9 (Ley fuerte de los grandes números). Si las variables aleatorias Xl, X 2, . .. , X n constituyen una muestra aleatoria de una población con valor esperado /-l, entonces la sucesión {X n - /-l} converge casi seguro a cero.
Teorema 1.4.10. Si Xl, X 2, .. . , X n es una muestra aleatoria de una población con valor esperado /-l y varianza a 2 , entonces
S 2 a.s. 2 n ------> a
y en consecuencia S~ E,. a2 .
Con la denominación de teorema del límite central debe entenderse más a un conjunto de teoremas concernientes a la convergencia en distribución de la suma de un número creciente de variables aleatorias al modelo gaussiano, que a la más popular de sus versiones. Es un conjunto de teoremas fundamentales de la estadística, pues constituyen puntos de apoyo sustanciales de la inferencia estadística y de las aplicaciones.
Dentro de la citada denominación de teorema del límite central se incluyen variantes como la versión original conocida como la ley de los

1.4. CARACTERÍSTICAS GENERALES DE ALGUNAS ESTADÍSTICAS 21
errores, derivada de los trabajos de Gauss y Laplace sobre la teoría de errores, que permitió el surgimiento de las versiones más antiguas referentes a variables con distribución de Bernoulli, debidas a De Moivre y Laplace en los siglos XVI y XVII; se incluyen, además, las versiones de Lindeberg-Lévy y Lindeberg-Feller, que son consecuencia de un trabajo iniciado por Chevyshev y Liapunov a finales del siglo XIX, encaminado a la búsqueda de una demostración rigurosa. Por su parte, se integran las versiones de Bikelis y aquellas adaptadas para los casos multivariados, aquellas para el caso de variables dependientes.
En particular, la versión clásica o teorema de Lindeberg-Lévy, la versión más difundida, corresponde al siguiente teorema, resultado al que llegaron de manera independiente J.W.Lindeberg y P.Lévy en la segunda década del siglo XX.
Teorema 1.4.11 (Teorema del límite central (Lindeberg-Lévy)). Si Xl, X 2 , ... , X n es una muestra aleatoria de una población con valor esperado J.l y varianza (72 finitos, considerando la variable aleatoria
Z _ X n - J.l
n-a
Vn
entonces la sucesión de variables aleatorias {Zn} converge en distribución a una variable aleatoria con distribución Normal estándar.
En pocas palabras, esta difundida versión determina que
foCXn - J.l) ~ Z rv N(O, 1). (7
El teorema del límite central es la mejor justificación de la existencia del modelo gaussiano y del énfasis que de él se hace reiteradamente. Por otra parte, lo admirable del teorema radica en que no importa el modelo regente del comportamiento probabilístico de la población, y en que la exigencia de finitud del valor esperado y la varianza es fácil satisfacerla en las aplicaciones.
Para finalizar estas consideraciones acerca del teorema del límite central se presenta una versión especial la cual corresponde al teorema de Lindeberg-Feller.
Teorema 1.4.12 (Teorema del límite central (Lindeberg-Feller)). Si Xl, X2, . .. es una sucesión de variables aleatorias independientes tales

22 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
que su valor esperado JLi y su varianza (J"; son finitos, i = 1,2, ... y asun
miendo que T~ 2: (J"'f ----+ 00 y además i=l
n ----+ 00, entonces
que max {~} ----+ O cuando l:Si:Sn T n
f: (Xi - ¡ti) d ~ N(O, 1) i=l ----+ Z
Tn
si y sólo si para cada E > O,
lim ~ t ( r (x - JLi)2 fi(X)dX) = O n-too Tn i=l J1X-J.Li I ?ETn
siendo fi(x) la función de densidad de la variable aleatoria Xi, para i = 1,2, ...
Definición 1.4.13. Siendo Xl, X 2, ... , X n una muestra aleatoria de una población con distribución de Bernoulli con probabilidad de éxito 7r, esta probabilidad recibe el nombre de proporción poblacional, y a la estadística X n = Pn se le conoce como proporción muestral, o proporción en la muestra.
El teorema de Lindeberg-Lévy es una forma general que incluye el caso particular cuando Xl, X2, ... , X n es una muestra aleatoria de una población con distribución de Bernoulli de valor esperado JL = 7r, (O < 7r < 1) y varianza (J"2 = 7r (1- 7r). Este caso particular corresponde a la versión más antigua del teorema del límite central, debida a Laplace.
n Por tanto, siendo Pn = ~ 2: Xi = ~ Y 7r = P[Xi = 1], i = 1,2, ... , n,
i=l determinando la variable aleatoria
Tn - n7r Zn = Jn7r(l - 7r)
Pn -7r
V7r (I:7r)
la sucesión de variables aleatorias {Zn} converge en distribución a una variable aleatoria con distribución normal estándar.
Teorema 1.4.14 (Teorema del límite central (Laplace». Siendo Xl, X2, . .. ,Xn una muestra aleatoria de una población con distribución

1.4. CARACTERÍSTICAS GENERALES DE ALGUNAS ESTADÍSTICAS 23
de Bernoulli de valor esperado 1f, entonces
lim ~ P[Tn = k] = lim P[z' S Zn S z"] n-+oo L.-t n-+oo
an:::;k:::;bn
= <I> (z") - <I>( z')
siendo an = n1f + z' Jn1f(l - 1f) Y bn = n1f + z" Jn1f(l - 1f).
Este teorema garantiza entonces que siendo a, b enteros tales que a < b, Y contando con un tamaño de muestra suficientemente grande, la probabilidad P[a S Tn S b] puede aproximarse por medio de
( b - n1f) (a - n1f )
<I> Jn1f(l _ 1f) - <I> Jn1f(l - 1f) .
b Sin embargo, como P[a S Tn S b] = I: P[Tn = k], cada término
k=a
P[Tn = k] puede aproximarse por medio del área entre k - ~ y k + ~ bajo la curva de la función de densidad de una variable aleatoria con distribución normal de valor esperado n1f y varianza n1f(l - 1f), como se sugiere en la figura 1.3, área equivalente al área bajo la curva de la función de densidad de una variable aleatoria normal estándar entre k-!-nn k+!-nn
2 y 2 , de manera que Jnn(l-n) Jnn(l-n)
P[a < Tn < b] ~ <I> 2 - <I> 2 . (
b + .! - n1f ) ( a - .! - n1f )
- - Jn1f(l - 1f) Jn1f(l - 1f)
Cuando el comportamiento de una población se asume regido por el modelo gaussiano, se pueden deducir propiedades específicas adicionales para el promedio y varianza muestrales, propiedades que hacen explícitas los siguientes teoremas.
Teorema 1.4.15. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población con distribución Normal de valor esperado 11 y varianza (72, entonces
_ ((72) X n rv N 11, --;;: .

24 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
/t'" k-! k k+!
Figura 1.3: Aproximación de la probabilidad P[Tn = k].
Teorema 1.4.16. Si Xl, X 2 , ... , X n es una sucesión de variables aleatorias independientes tales que Xi rv N (J-li, (77), entonces
u = t (Xi:' J-li) 2 rv X2 (n ). i=l t
Corolario 1.4.17. Cuando la sucesión de variables aleatorias constituye una muestra aleatoria de una población con distribución Normal, de valor esperado J-l y varianza (72,
u = t ( Xi:' J-l) 2 rv x2(n). t=l
Teorema 1.4.18. Si Xl, X 2 , •.. ,Xn es una muestra aleatoria de una población con distribución Normal de valor esperado J-l y varianza (72,
entonces las estadísticas X n y S; son dos variables aleatorias estadísticamente independientes.
Teorema 1.4.19. Si XI,X2 , ... ,Xn es una muestra aleatoria de una población Normal de valor esperado J-l y varianza (72, entonces
~ (Xi - Xn)2 = (n -1)S; rv 2( _ 1) 6 2 2 X n . i=l
(7 (7
Con supuestos menos taxativos, el promedio y la varianza muestrales presentan un comportamiento muy particular. Los siguientes teoremas destacan la marcada autonomía de las estadísticas X n y S;.

1.5. ESTADÍSTICAS DE ORDEN 25
Teorema 1.4.20. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población cuya función de densidad es simétrica, entonces
La expresión usual de la varianza muestral incluye el promedio de la muestra, es decir, la varianza podría entenderse como función de éste. Sin embargo, su presencia en la expresión puede considerarse aparente puesto que la varianza de la muestra puede prescindir del promedio muestral en la forma como lo garantiza el siguiente teorema 3.
Teorema 1.4.21. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población para la cual no se asume un modelo de probabilidad específico, entonces
En síntesis, el promedio y varianza de la muestra son estadísticas tales que bajo el modelo gaussiano son estadísticamente independientes; bajo un modelo de probabilidad cuya función de densidad es simétrica, las estadísticas no están correlacionadas, yen cualquier situación la varianza de la muestra no depende funcionalmente del promedio de la muestra.
1.5 Estadísticas de orden
U na modalidad especial de estadísticas la integran las llamadas estadísticas de orden. Éstas desempeñan papeles importantes en algunas aplicaciones como en las cartas de control estadístico de la calidad y como en el fundamento y manejo de algunos conceptos en estadística no paramétrica. Además de estos y otros usos, las estadísticas de orden son particularmente los estimadores apropiados de parámetros que rigen el recorrido de la población y, así mismo, se utilizan en el juzgamiento de hipótesis referentes a estos parámetros. Por ser estimadores y sustentar reglas de decisión en poblaciones especiales es menester exponer algunos elementos y consideraciones acerca de su distribución.
3 Jorge E. Ortiz P. (1999), Promedio aritmético y varianza en grupos finitos de datos numéricos. Boletín de Matemáticas. Vol. VI, No. 1, pp. 43-51.

26 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Definición 1.5.1. La k-ésima estadística de orden, k = 1,2, ... ,n, correspondiente a una muestra aleatoria Xl, X 2 , ... ,Xn , denotada por Xk n, está definida de la siguiente manera: ,
Xk,n = min {{Xl, X 2, ... , Xn} - {Xl,n, X 2,n, ... , Xk-l,n}}
siendo
X l,n : mínimo de la muestra
Xn,n : máximo de la muestra
Al conjunto de estadísticas de orden Xl,n, X2,n, ... ,Xn,n se le designa con el nombre de muestra aleatoria ordenada.
A partir de las estadísticas de orden pueden definirse otras estadísticas como:
• El rango muestral:
R = Xn,n - Xl,n
• El semirrango muestral:
SR = Xl,n + Xn,n 2
• La mediana muestral:
X!!±.! n 2 '
, si n es impar
M e =
X!! n + X~+l,n si n es par 2' ,
2
• La función de distribución empírica o función de distribución muestral:
1 n
Fn(x) = -;;;, L1(-oo,xj(Xi). i=l

1.5. ESTADÍSTICAS DE ORDEN 27
Es decir:
0, S2 X < Xl,n
k ,
n
1, si x 2: Xn,n, k = 1,2, ... ,n - 1
1.5.1 Distribución de las estadísticas de orden
Las estadísticas heredan en menor o mayor medida los rasgos del modelo elegido para representar el comportamiento poblacional. Específicamente, la distribución muestral de las estadísticas de orden incluye de manera explícita las funciones de densidad y distribución de la población como lo registran los siguientes teoremas.
Teorema 1.5.2. Siendo Xl,n, X 2 ,n, ... ,Xn,n las estadísticas de orden o la muestra ordenada de una población con función de distribución Fx(x), entonces para k = 1,2, ... ,n
FXk,n (y) = :t (~) [Fx(y)]j[l - Fx(y)]n-j. j=k J
Corolario 1.5.3. Para los casos especiales del mínimo y máximo de la muestra se tiene:
FX1,n (y) = 1 - [1 - Fx(y)]n
FXn,n (y) = [Fx(y)t·
Teorema 1.5.4. Siendo Xl, X 2 , .•. , X n una muestra aleatoria de una población con función de distribución continua Fx(x), la función de densidad de la k-ésima estadística de orden, k = 1,2, ... ,n, es
La función conjunta de densidad de la j-ésima estadística de orden y la k-ésima estadística de orden fXj,n,xk,Jx, y) es
Cn,j,k[Fx(x)F-l [Fx (y) - Fx(x)]k-j-l [1- Fx(y)]n-k fx(y)fx (x)I(x,oo) (y)

28 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
para 1 :S j < k :S n, con Cn,j,k = n!j[(j - 1)!(k - j - 1)!(n - k)!]. La función conjunta de densidad de las estadísticas de orden es
fX"n,X2,n, ... ,Xn,n (Y1, Y2,"" Yn) = {n! rr fX(Yi) ,=1
O
Y1 < Y2 < ... < Yn
en otros casos
Ejemplo 1.5.5. Siendo Xl, X2, ... , X n una muestra aleatoria de una población con distribución Uniforme en el intervalo (a, (3), determinar la función de densidad de la k-ésima estadística de orden.
1 fx(x) = j3 _ a 1(a,(3) (x)
x-a Fx(x) = j3 _ a 1(a,(3) (x) + 1[(3,00) (x)
n. y - a y - a 1 ,
[ ] k-1 [ ] n-k [ ]
fXk,n(Y) = fI. 1\1f~ 1.\1 (3-a 1- (3-a (3_a I (o:,{J)(Y)
n! (1) n k-1 n-k .. (3 - a (y - a) ((3 - y) I(O:,{J) (y).
La distribución de la k-ésima estadística de orden es la de una variable aleatoria con distribución Beta en el intervalo (a, (3) con parámetros k y (n - k + 1), cuando la población es Uniforme en el intervalo (a, (3).
Nota. Una variable aleatoria X con distribución Beta en el intervalo (0,1) puede generar una variable aleatoria Y con distribución Beta en el intervalo (a, (3) mediante la relación
y = a + (j3 - a)X.
Teorema 1.5.6. Sea Xl, X 2 , ... , X n, una muestra aleatoria de una población con función de distribución Fx(x) continua. Para p fijo, si xp
denota al único percentil lOOp poblacional, entonces
k-l ( ) P[Xj,n < xp < Xk,n] = L 7 pl(1 - p)n-l.
I=J

1.5. ESTADÍSTICAS DE ORDEN 29
1.5.2 Distribución del rango, semirrango y mediana de la muestra
Las estadísticas correspondientes al rango y semirrango son funciones del máximo y mínimo muestrales. Por tanto, la determinación de su distribución parte de la consideración de la distribución conjunta de X 1,n y Xn,n
fX1,n,xn,n(x,y) = n(n -1) [Fx(Y) - Fx(x)t-2 fx (x)fx (y)I(x,oo) (y).
Definidas las estadísticas
R = Xn,n - X 1,n
T = X 1,n + Xn,n 2
se considera la siguiente transformación
r r x = t --
2 y = t+-
2
cuyo jacobiano es ax ax
1
ar at -2 1 =1 ay ay 1 1
ar at 2
con lo cual fR,T(r, t) = n(n-1) [Fx (t +~) - Fx (t - ~)r-2 fx (t -~) fx (t + ~). En consecuencia, para r > 0, se tiene
fR(r) = l: fR,T(r, t)dt
fr(t) = l: fR,T(r, t)dr
La distribución de la mediana está dependiendo del tamaño de la muestra. Si éste es entero impar, su distribución está totalmente determinada, pues corresponde a la distribución de la estadística de orden n!l. En la situación en la cual n es par, la mediana es función de las estadísticas de orden X!!o n y X!!o+l no Así, al tomar n = 2m, m = 1,2, ...
2' 2'
fXTj,n,XTj+l,n (x, y) = fXrn,n,Xrn+l,n (x, y)
[(~2~i~!J2 [FX(X)]m-l[l - FX(X)]m-l fx(x)fx(y)

30 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
con x < y. Considerando la transformación u = X!y, v = y, se tiene que
f:E±J¿ ( u) = fu ( u) 2
= .. 2(2m)!_~ 100 [Fx(2u - v)]m-l[1 - Fx(v)]m-l fx(2u - v)fx(v)dv
1.5.3 Distribución de la función de distribución de la muestra
La función de distribución empírica o de la muestra tiene varios usos, especialmente en métodos y conceptos de la estadística no paramétrica. Su gráfico se convierte en un indicativo de una primera aproximación al ajuste que brinda el modelo. Algunos aspectos de su distribución se presentan a continuación.
P [Fn(X) = ~] = (~) [Fx(x)]k[1 - Fx(x)t-k
donde k = 0,1,2, ... ,n. En efecto, denotando la variable aleatoria
Zi = IC-oo,x] (Xi)
n luego Zi rv Ber(Fx(x)); por tanto ¿ Zi rv Bin(n, Fx(x)) y por consi-
guiente i=l
E[Fn(x)] = Fx(x)
V[Fn(x)] = Fx (x)[1 - Fx(x)]. n
Teorema 1.5.7. Siendo Xl, X 2, ... ,Xn una muestra aleatoria de una población con función de distribución Fx(x), entonces
p Fn(x) -t Fx(x)
para un valor x dado.
Teorema 1.5.8 (Teorema de Glivenko-Cantelli). Si Xl, X2, ... , X n es una muestra aleatoria de una población con función de distribución Fx(x), entonces Fn(x) converge uniformemente a Fx(x), esto es, para cada f > 0,
lim P [ sup IFn(x) - Fx(x)1 < f] = l. n-->oo -oo<x<oo

1.6. MOMENTOS DE ESTADÍSTICAS DE ORDEN 31
-- Xo
Figura 1.4: Esquema de las funciones de distribución Fn(x) Y Fx(x).
Teorema 1.5.9. Siendo Xl, X 2 , •.. ,Xn una muestra aleatoria de una población con función de distribución Fx (x), la sucesión de variables aleatorias
{ fo[Fn(x) - Fx(x)] } JFx(x)[l - Fx(x)]
converge en distribución a una variable aleatoria con distribución Normal estándar.
1.6 Momentos de estadísticas de orden
Los teoremas 1.5.2 y 1.5.4 puntualizan respectivamente la función de distribución y la función de densidad de la k-ésima estadística de orden. En principio, garantizada la existencia del momento de interés r
y determinada explícitamente la función de distribución Fx(x), podría formalizarse el citado momento de la k-ésima estadística de orden con base en las referidas funciones de distribución o de densidad. Sin embargo, su logro depende de la complejidad de la integración requerida para su cálculo, dado que algunas veces se alcanza únicamente por medio de integración numérica. A manera de ejemplo, considerando el comportamiento poblacional como indiferente para cualquier valor del intervalo (O, 1), el valor esperado, la varianza y el momento de orden r de la estadística de orden k es factible determinarlos.
Ejemplo 1.6.1. Siendo X 1,n, X2,n, ... ,Xn,n una muestra ordenada de

32 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
una población con distribución Uniforme en el intervalo (0,1)
k E[Xk,nl = n + 1
k(n-k+1) V[Xk,nl = (n + 2)(n + 1)2
1
[j(n - k + 1)]"2
p(Xj,n, Xk,n) = k(n _ j + 1) ,
En efecto, en primer lugar, de manera general
j < k.
r n. r+k-1 n-k , 11
E[Xk,nl = (k _ 1)!(n _ k)! O X (1 - X) dx
n! (k _ 1)!(n _ k)!f3(r + k, n-k + 1)
Y utilizando la relación f3(a, b) = ~~a)~(~: , entonces
E[Xr l= n! r(r+k)r(n-k+1) k,n (k - 1)!(n - k
particularmente,
n!(r + k - 1)! (r + n)!(k - 1)!'
E[X 1 - nIkI _ k k,n - (n + 1)!(k - 1)! - n + 1
V [Xk,nl = E[X~,nl - (E[Xk,n])2
1:Sk:Sn
E[X2 1 _ n!(k + 2 - 1)! _ k(k + 1) k,n - (n + 2)!(k - 1)! - (n + 1)(n + 2)
V X _ k(k + 1) k2 k(n - k + 1) [ k,nl - (n + 1)(n + 2) (n + 1)2 (n + 2)(n + 1)2
Por otra parte, denotando E[Xj,n, Xk,nl = 6., se tiene que
n! {l r . . ó. = -,. Jo Jo xJy(y - X)k-J-l(l - y)n-kdxdy
n! {l [r . .] ·'Jo
y(l-yt-k Jo xJ(y-x)k-J-1dx dy

1.6. MOMENTOS DE ESTADÍSTICAS DE ORDEN
Realizando la sustitución v = ~ y
33
~ = (j _ l)!(k -7!- l)!(n _ k)! 11
y(l - yt-k
[yk,6(j + 1, k - j)] dy
n! (j _ l)!(k _ j _ l)!(n _ k)!,6(l + j, k - j),6(k + 2, n-k + 1)
j(k+1) -E[X. X 1 (n + l)(n + 2) - ),n, k,n
con lo cual
jk Cov(X. X ) _ j(k + 1) ),n, k,n - (n + l)(n + 2) (n + 1)2
j(n - k + 1) k(n - j + 1)
j < k.
j<k
Por tanto, como caso especial, la correlación entre el mínimo y máximo de la muestra bajo comportamiento poblacional Uniforme en el intervalo (0,1) es
1 p(X1 n, X n n) = -. , , n
Como ya se mencionó, en algunos casos se requiere integración numérica para determinar momentos de una estadística de orden. Sin embargo, es posible presentar expresiones que permiten aproximar el valor esperado y varianza de la k-ésima estadística de orden.
El desarrollo de estas expresiones se basa en una expansión en serie de Taylor y en que si X es una variable aleatoria con función de distribución Fx(x) continua, la variable aleatoria Y = Fx(X) tiene distribución Uniforme en (0,1), entonces
Finalmente se hace una breve alusión a la distribución asintótica de las estadísticas de orden.

34 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
El estudio de la distribución asintótica de la k-ésima estadística de orden incluye dos casos a saber: (1) cuando n tiende a infinito y ~ permanece fijo; (2) cuando n tiende a infinito y k o n-k permanecen finitos.
Para algunos efectos, el primer caso es de mayor interés; el teorema siguiente se adscribe a ese caso.
Teorema 1.6.2. Sea Xl, X 2 , ... ,Xn una muestra aleatoria de una población cuya función de distribución Fx(x) es estrictamente monótona. Asumiendo que xp es el percentillOOp poblacional, es decir, Fx(xp ) = p, entonces la estadística de orden [np] + 1 tiene distribución asintótica Normal con valor esperado xp y varianza ,~(l;-p~,~.
Particularmente, si p = ~ (XO.5 corresponde a la mediana poblacional) y siendo la población Normal con valor esperado f.L y varianza (12, la mediana muestral tiene distribución Normal con valor esperado f.L y varianza ~~2 •
Con este teorema relativo a la distribución asintótica de la k-ésima estadística de orden concluye la introducción a las ideas preliminares de la inferencia estadística, presentación que además entreabre el contexto filosófico en el cual se desempeña, que describe las características más relevantes de algunas estadísticas y registra como estadísticas especiales a las estadísticas de orden. Con esto se da paso a la exposición de los argumentos que sustentan las afirmaciones de los enunciados de los teoremas relacionados y finalmente a la serie de ejercicios cuyo desarrollo complementará la reflexión sobre estos temas iniciales y será un componente más en la aprehensión de los conceptos expuestos en este primer capítulo.
1.7 Demostración de los teoremas
Teorema 1.3.7 . Sea {Xn } una sucesión de variables aleatorias.
X n L c si y sólo si lim Fn(x) = F(x) n-tOO
siendo c una constante, Fn(x) la función de distribución de X n y F(x) una función de distribución tal que F(x) = O para x < c y F(x) = 1 para x ~ c.

1. 7. DEMOSTRACIÓN DE LOS TEOREMAS 35
Demostración. Suponiendo que X n .!!..., e, entonces para E > O
lim P [IXn - el < E] = 1 = lim P [e - E < X n < e + E] n----+CX) n---+oo
= lim [Fn(e + E) - Fn(e - E)] n-->oo
= lim [Fn(e + E)] - lim [Fn(e - E)]. n---+oo n---+CX)
La imagen de cualquier función de distribución es un valor que pertenece al intervalo [0,1], luego la única posibilidad para que la igualdad anterior se dé es que
lim Fn(e + E) = 1 Y lim Fn(e - E) = O n----+oo n---+oo
hecho revelador de que Fn(x) -----+ F(x), siendo F(x) una función de distribución tal que
si x < e
si x ~ e
es decir, F(x) es la función de distribución de una constante e. Suponiendo ahora que Fn(x) -----+ F(x) con F(x) = I[c,oo) (x), es decir
lim Fn(x) = F(x). n-->oo
Entonces:
lim Fn(e - E) = O para E > O Y lim Fn(e + E) = 1 n-+oo n---+CX)
luego
lim [Fn(e + E) - Fn(e - E)] = 1 = lim P [e - E < X n < e + E] n--+oo n---+oo
= lim P [lXn - el < E] n-->oo
lo cual significa que X n .!!..., e.
Teorema 1.3.9
o
Algunos apartes de la demostración pueden consultarse en A First Course in Mathematical Statistics (G. Roussas, pp. 133 a 135) yen Basic Probability Theory (R. Ash, pp. 204 Y 205).
Teorema 1.4.1. Si Xl, X 2 , .. . , X n es una muestra aleatoria de una población representada por la variable aleatoria X con varianza 0"2 y

36 CAPÍTULO 1. DISTRIBUCIONES MUESTRA LES
con momento ordinario /-l~r' r = 1,2, ... , entonces el valor esperado y la varianza del momento muestral ordinario son, respectivamente:
E[M;,nl = /-l~
V [M;,nl = ~ [E[x2rl - (E[Xr])2]
= ~ [/-l~r - (/-l~ )2] .
Demostración. El valor esperado del momento ordinario de orden r puede determinarse mediante dos argumentos. En primer lugar, utilizando las propiedades del valor esperado se tiene que
E[M;,n[ ~E [~tX[] ~ ~tE[Xn, r=1,2, ...
En segundo lugar, como todas las variables aleatorias de la sucesión tienen la misma distribución, por constituir una muestra aleatoria, E[X[] = /-l~, para i = 1,2, ... , n, en consecuencia
, l¿n, 1( ')_ , E[Mr nl = - /-lr = - n/-lr - /-lr' , n n
i=l
De manera similar puede determinarse la varianza del momento ordinario de orden r. De las propiedades de la varianza se puede afirmar que
V[M;,n[ ~V [~tX[] ~ > [txr], r = 1,2, ...
y debido a que las variables aleatorias son independientes, pues constituyen una muestra aleatoria, lo son también las variables Xí, X 2, ... , X~, con lo cual
V[M;,nl = ~2 t V[X[] = ~2 t [E[X;rl - (E[X[])2] i=l i=l
y como las variables tienen distribución idéntica,
V[M;,nl = ~2 t (/-l~r - (/-l~)2) = ~ (/-l~r - (/-l~)2) . D i=l

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 37
Teorema 1.4.3. Si Xl, X 2, ... ,Xn es una muestra aleatoria de una población con valor esperado, también llamado promedio poblacional, ¡..t y varianza 0-2, conocida como varianza poblacional, y existiendo además el momento central de orden cuatro ¡..t4, entonces
2 1 ( n - 3 4) V[Snl =;;, ¡..t4 - n _ 10- ,n > 1.
Demostración. Para determinar el valor esperado de la varianza muestral, es necesario previamente verificar la identidad
n
¿)Xi - ¡..t)2 = (n - l)S~ + n(Xn - ¡..t)2. i=l
Sumar y restar X n es el punto de partida en la verificación de la identidad, de manera que n n n
¿)Xi-¡..t)2 = I)Xi -Xn+Xn -¡..t)2 = ¿ [(Xi - X n) + (Xn - ¡..t)]2. i=l i=l i=l
Así mismo, después de desarrollar el cuadrado indicado n n n
i=l i=l i=l n
n n porque ¿(Xi - X n ) = ¿ Xi - nXn = nXn - nXn = 0, y por tanto
i=l i=l
n
¿(Xi - ¡..t)2 = (n - l)S~ + n(Xn - ¡..t)2. i=l
Con el anterior recurso,
2 [1 ¿n 2 n - 2] E[Snl = E - (Xi - ¡..t) - -(Xn - ¡..t) n-l n-l
i=l
~ n ~ 1 [t,E[(Xi - 1')2]- nE[(Xn - 1')2]].

38 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Como E[(Xi - tI)2] = V[XiJ, E[(Xn - tI)2] = V[Xn] y teniendo en cuenta que todas las variables aleatorias de la sucesión tienen la misma distri bución,
E[S~] = _1_ [~a2 _ n (0'2)] = _1_[na2 _ 0'2] = 0'2. n-1 ~ n n-1
i=l
La demostración del segundo enunciado del teorema es uno de los ejercicios de este capítulo. O
Teorema 1.4.4. Si las variables aleatorias Xl, X2, . .. , X n constituyen una muestra aleatoria de una población con valor esperado tI y varianza 0'2, entonces
Xl + X2 + ... + X n P ---=~----'~--- --+ tI·
n
Demostración. La herramienta procedente para sustentar el desarrollo de esta demostración es la desigualdad de Chevyshev, la cual asegura que si X es una variable aleatoria con valor esperado tIx Y varianza al finita,
1 P[lX - tIxl < raxl 2: 1 - 2" para cada r > O.
r
Aplicando esta desigualdad al caso especial de la variable aleatoria X n, __ __ 0'2
teniendo en cuenta que E[Xnl = tI Y V[Xnl = -, como lo manifiesta n
el corolario 1.4.2,
P [IXn - tIl < r .:nJ 2: 1 - :2 para cada r > o.
Utilizando el remplazo E = r :In, se tiene que E > O Y
0'2 P[iXn - tIl < El 2: 1- -2·
nE
De manera que
2
lim P [1 X n-tI I < El 2: lim 1 - a 2 = 1 n--+oo n--+oo nE
es decir: lim P[iXn - tIl < El = 1
n--+oo
lo cual significa que X n !!.. tI, como lo afirma la ley débil de los grandes números.

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 39
()2 Nota. La cota 1 - -2 crece en cuanto n crece. Si se fija la cota en
nE 1 - 6, O < 6 < 1, significa que existe un tamaño de muestra mínimo n,
-- ()2 para el cualP[IXn-¡L1 < El2=: 1-6. En otros términos: 1--
2 > 1-6,
nE es decir,
()2 P[ -E < X n - ¡L < El 2=: 1 - 6, para n > 6E2 ' o
Teorema 1.4.6. Si Xl, X 2, .. . , X n es una muestra aleatoria de una población con valor esperado ¡L, entonces
-- p X n ~ ¡L.
Demostración. Utilizando la función generatriz de momentos de la variable que representa a la población Mx(t), o en su defecto la función característica rP x (t),
MXn(t) = E [etXn
] = E [exp (~Xl + ~X2 + ... + ~Xn)]. Como las variables constituyen una muestra aleatoria, ellas son independientes, con lo cual
n n
MxJt) = rr E [e~Xi] = rr E [e~x] i=l i=l
entonces:
MX (t) = [1 + ¡L (!) + ~E[X2l (!)2 + ... jn n 1! n 2! n
lim MX (t) = lim [1 + ¡Lt + o (!)] n = e¡.tt n---+oo n n---+oo n n
función generatriz que corresponde a la función generatriz de una constante ¡L. (O es el símbolo "o pequeña" usado en el estudio de las serieé). Esto significa que
-- d X n ~ ¡L
y con base en el teorema 1.3.7 se concluye que
-- p X n ~ ¡L. D
4Sobre la "notación Q"véase Tom M. Apostol (1988) Calculus Vol 1. Segunda edición. Editorial reverté, col. s.a, p. 351

40 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Teorema 1.4.7. Si X I ,X2, ... ,Xn es una muestra aleatoria de una población para la cual el momento central /-l2r existe, entonces
I P I Mr,n ----+ /-lr, r = 1,2, ...
Demostración. Como la sucesión Xí, X2", ... , X~ conforma un conjunto de variables aleatorias independientes e idénticamente distribuidas porque la sucesión Xl, X2, .. . , X n es una muestra aleatoria, entonces sólo resta aplicar el teorema relativo a la ley débil de los grandes números utilizando la sucesión Xí, X2", ... , X~, con lo cual se puede afirmar que
n
~ L [X[] LE [Xí] = /-l~. n i=l
o
Teorema 1.4.9 La demostración puede consultarse en el texto Probability and Statistical Inference (Robert Bartoszynski y Magdalena Niewiadomska-Bugaj (1996). pp. 430 a 431).
Teorema 1.4.11. Si Xl, X 2, ... , X n es una muestra aleatoria de una población con valor esperado /-l y varianza (72 finitos, considerando la variable aleatoria
Zn = X n - /-l a
Vii
entonces la sucesión de variables aleatorias {Zn} converge en distribución a una variable aleatoria con distribución Normal estándar.
Demostración. La estrategia para esta demostración consiste en el uso de la función generatriz de momentos y de sus propiedades, para lo cual se asume la existencia de la función generatriz de momentos de la población. Se apoya la demostración en el desarrollo en serie de McLaurin de la función generatriz de momentos, demostración que también se puede llevar a cabo utilizando la función característica.
Denotando como M Zn (t) la función generatriz de momentos de la

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 41
variable aleatoria Zn, se tiene:
Como las variables de la sucesión Xl, X2, . .. ,Xn son variables aleatorias independientes por tratarse de una muestra aleatoria, las variables Yl , Y2 , ... ,Yn también lo son, siendo Yi = Xi;/!, i = 1,2, ... , n y por tanto,
y como las variables Yl , Y2 , ... ,Yn tienen la misma distribución, cuya
función generatriz de momentos es MYi (Jn) My (Jn), i = 1,2, ... , n, entonces
El desarrollo en serie de McLaurin de la función generatriz My(t) evaluada en el valor Jn es
My (_t_) = 1 + ¡..tl _t_ + ~ ¡..t2 (_t_) 2 + ~ ¡..t3 (_t_) 3 + ... yn (J yn 2! (J2 yn 3! (J3 yn
Dado que el valor esperado es igual a cero, si existen ¡..t~ = ¡..tr, r = 1,2, .. o, y además la varianza es igual a uno,
M y (_t ) = 1 + ~ (J2 (_t )2 + ~¡..t3 (_t )3 + ... yn 21 (J2 yn 31 (J3 yn 1[12 1 3 1 4 ] = 1 + - -t + --¡..t3t + -¡..t4t +... . n 21 3!yn 4!n

42 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Efectuando el remplazo Qn(t) = 1rt2 + 3!fo1L3t3 + 4}n1L4t4 + ... y dado
que Mzn(t) = [My CÍn) r, Mzn(t) = [1 + ~Qn(t)r
lim MZn (t) = lim [1 + ~Qn(t)] n n->oo n->oo n
= exp ( lim Qn(t)) n->oo
= e~t2
porque los coeficientes de t 3 , t 4 , . .. tienden a cero cuando n -t 00, y porque 5 siendo {en} una sucesión que tiende a e,
{en }n lim 1 + - = é.
n->oo n
Además, e~t2 se reconoce como la función generatriz de momentos de una variable aleatoria con distribución Normal estándar. Como
• 1 t2 11m Mzn(t) = Mz(t) = e 2
n->oo
de acuerdo con el teorema de Lévy, Zn ~ Z, Z rv N(O, 1). o
Teorema 1.4.12 Los elementos que se requieren para el desarrollo de la demostración de este teorema están más allá del alcance de este texto.
Teorema 1.4.15. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población con distribución Normal de valor esperado IL y varianza (J2, entonces
_ ((J2) X n rv N IL, -;;: .
5yu Takeuchi (1976). Sucesiones y series. Tomo 1, Bogotá. Editorial Limusa, p. 20.

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 43
Demostración. Nuevamente se elige a la función generatriz de momentos como medio para llevar a cabo esta demostración. Siendo
Mx(t) = exp (P,t + t0-2t2)
la función generatriz de una variable aleatoria X, X rv N(p" 0-2 ),
MxJt) = E [etXn
]
= E [cxp (t~ ~Xi) 1
= E [IT exp ~Xil· ~=l
Debido a la independencia de las variables que constituyen la muestra aleatoria,
Finalmente, como las citadas variables están idénticamente distribuidas, de acuerdo con el modelo gaussiano,
MxJt) = g Mx (~)
= g cxp H + ~a' m') = [expH+~a2m')r = exp (P,t + t : t2
)
lo cual permite deducir que X n rv N (p" ~). o
Teorema 1.4.16. Si Xl, X 2, ... ,Xn es una sucesión de variables aleatorias independientes tales que Xi rv N (p,i, o-i), entonces

44 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Demostración. La variable aleatoria Zi = Xi - ¡.ti, para i = 1,2, ... ,n, ai
es una variable aleatoria con distribución Normal estándar; por tanto, se puede afirmar que Zl rv X2 (1). Con el concurso de la función generatriz de momentos, puede establecerse que
[ t t Z¡] [ n 2] Mu(t) = E [etU
] = E e i=1 = E g etZi .
Como la sucesión Zl, Z2, ... , Zn es una sucesión de variables aleatorias independientes,
n n n ( 1 )~ Mu(t) = II E [e tZ
¡] = II Mz¡(t) = II 1 _ 2t i=l i=l i=l
(1 ~ 2t) ~ Hecho que permite concluir que U rv x2 (n). o
Teorema 1.4.18. Si Xl, X 2, ... , X n es una muestra aleatoria de una población con distribución Normal de valor esperado ¡.t y varianza a2, entonces las estadísticas X n y S~ son dos variables aleatorias estadísticamente independientes.
Demostración. Esta demostración está orientada a la determinación de la independencia de X n, (XI-Xn), (X2-Xn), ... , (Xn -Xn) para luego
n concluir la independencia entre X n y ¿ (Xi - Xn)2.
i=l En primer lugar, la función generatriz de momentos M(t, it, t2, ... ,tn) de las variables aleatorias X n, (Xl - X n), (X2 - X n), ... ,(Xn - X n),
siendo c = (~a) n y dx = dXl ... dxn , es
c r exp [fXn + tl(Xl - xn) + ... + tn(xn - xn) - t (Xi - :)2] dx. J~n 2a i=l
En segundo lugar, al considerar la integral sobre Xi, i 1,2, ... ,n se tiene
¡eX) '2-1 exp { [t + nti _ (it + t2 + ... + t )] Xi _ (Xi - ¡.t) 2 } d . J-oo v.:.7ra n n 2a2 Xt

1.7. DEMOSTRACIÓN DE LOS TEOREMAS
que al efectuar el remplazo:
1[ n 1 1 1 n :;:;: t + nti - ~.=l ti =:;:;: [t + n(ti - t)] , con t = - :L:>i.
. n í=l
La integral anterior puede expresarse como
foo 1 { 1 (x· - J-t)2} --exp -[t+n(tí-t)]Xí- t dXí -00 .,f2i[(J n 2(J2
cuyo valor es finalmente
{J-t[ ( -)] (J2[t+n(tí -t)]2} exp - t + n tí - t + . n 2n2
Por consiguiente:
n y como ¿ (tí - t) = 0, entonces
í=l
45
hecho que revela plenamente la independencia de las variables aleatorias X n, (Xl - X n), (X2 - X n), ... , (Xn - X n) .
.. - -2 -2 -2 Por consIgUIente, X n, (Xl - X n) ,(X2 - X n) , ... , (Xn - X n) es un conjunto de variables aleatorias independientes e igualmente lo son X n
n y ¿(Xí - Xn)2. En consecuencia, X n y S~ son estadísticamente inde
í=l pendientes. O
Teorema 1.4.19. Si Xl, X 2, ... , X n es una muestra aleatoria de una población Normal de valor esperado J-t y varianza (J2, entonces
~ (Xi - X n ? _ (n - l)S~ 2( ) ~ -'-----,2:::---'--- - 2 r"V X n - 1 . (J (J í=l

46 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Demostración. De la demostración del teorema 1.4.3 se tiene que
Por tanto,
luego
n n ~ 2~ -2 - 2 L)Xi - ¡.t) = L.)Xi - X n) + n(Xn - ¡.t) . i=l i=l
n ¿ (Xi - ¡.t)2 i=l
(J2
n - )2 2 ¿(Xi-Xn n(Xn-¡.t) i-l + (J2 (J2
[ (
i~(Xi - ¡.t)2)] E exp t 2 (J
_ E [ (( n - 1) S~ n (X n - ¡.t) 2
) ] - exp t 2 + t 2 (J (J
= E [exp (t (n -(J;)S~) ] E [ (t n(X:; ¡.t)2) ]
puesto que X n y S~ son estadísticamente independientes. Debido a que
entonces
es decir:
n)2 -)2 ¿ (Xi - ¡.t 2 n(Xn - ¡.t rv X2(1), i=l rv X (n) Y (J2 (J2
(_1 ) 'i = E [exp [t (n - 1) S~]] (_1 ) ~ 1 - 2t (J2 1 - 2t
[ [ (n - l)S~]] = (_1 ) n;-l
E exp t 2 1 2 (J - t 1
t < -. 2
Expresado de otra manera:
n - )2 2
¿ (Xi - Xn
(n - l)Sn rv x2(n _ 1). i-l ?
2 (J (J o

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 47
Teorema 1.4.20. Si Xl, X2, . .. , X n es una muestra aleatoria de una población cuya función de densidad es simétrica, entonces
- 2 cov(Xn, Sn) = O.
Demostración. La demostración de este teorema se realizará mediante inducción matemática sobre el tamaño de muestra. Previamente a aquélla, y con el fin de incluirlos en la demostración, es necesario aprestar tres elementos:
1. Si X, Y son dos variables aleatorias independientes,
cov(X,XY) = E[Y]V[X]
2. Si la función de densidad de una variable aleatoria X es simétrica respecto a E[X],
cov(X, X2) = 2E[X]V[X]
3. Y finalmente las relaciones
- 1 (- ) X n+l = -- nXn + X n+1 n+l
2 2 n ( - )2 nSn+1 = (n - l)Sn + -- X n+l - X n n+l
En primer lugar, al ser X, Y independientes también lo son X2 y Y. Por ello
cov(X, XY) = E[X2y] - E[X]E[XY] = E[Y]E[X2] - E[Y](E[X])2
es decir, cov(X, XY) = E[Y] [E[X2] - (E[X])2] = E[Y]V[X]. En segundo lugar, si la función de densidad es simétrica respecto a E[X],
E [(X - E[X])3] = O = E [X3 - 3X2 E[X] + 3X (E[X])2 - (E[X])3]
= E [X3] - 3E [X 2] E[X] + 2 (E[X])3
con lo cual E [X3] = 3E [X2] E[X] - 2 (E[X])3.
cov(X, X2) = E [X3] - E[X]E[X2]
= 3E[X2]E[X] - 2 (E[X])3 - E[X]E[X2]
= 2E[X]E[X2] - 2 (E[X])3
= 2E[X] [E[X2] - (E[X])2]
=2E[X]V[X]

48 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Por último:
- 1 n+1 1 [n 1 1 -X n+l = --1 ¿::Xi = --1 ¿::Xi + X n+1 = --1 [nXn + X n+1]
n + i=l n + i=l n +
n+l n+l 2 '"' ( -)2 '"' ( - - - )2 nSn+1=~ X i -Xn+1 =~ Xi-Xn+Xn-Xn+l
i=l i=l n+l
= ¿:: [(Xi - Xn)2 + 2 (Xn - X n+1) (Xi - X n) i=l
+ (Xn - X n+1)2]
n
= (n - l)S~ + (Xn+1 - Xn)2 + 2 (Xn - X n+1) ¿:: (Xi - X n) i=l
+ 2 (Xn - X n+1) (Xn+1 - X n) + (n + 1) (Xn - X n+l)2
n Como ¿ (Xi - X n) = 0,
i=l
nS~+l = (n - l)S~ + (Xn+1 - Xn)2 + 2 (Xn - X n+1) (Xn+1 - X n)
+ (n + 1) (X n - X n+1)2 2 ( - )2 = (n - l)Sn + X n+1 - X n
+ (Xn - X n+1) [2Xn+1 + (n - l)Xn - (n + l)Xn+1]
Realizando los remplazos:
(n + l)Xn+1 = nXn + X n+1 y - - 1 (- ) X n - X n+l = -- X n - X n+1 n+1
se tiene
2 2 ( - )2 nSn+1 = (n - l)Sn + X n+1 - X n
(X n-X n+ 1) [ - (- )] + 2Xn+1 + (n - l)Xn - nXn + X n+1 n+1
2 ( -)2 (Xn +1 - X n ) ( - ) = (n - l)Sn + X n+1 - X n - 1 X n+1 - X n n+
2 n ( - )2 = (n - l)Sn + --1 X n+1 - X n n+

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 49
Entrando en materia, y teniendo en cuenta que E[Xi ] = p" V[Xi ] = (72,
para i = 1,2, ... , n, al considerar una muestra de tamaño n = 2,
2 2 82 = _1_ ~ (X. _ X ) 2 = (Xl - X 2 )
2 2-1L...- t 2 2 i=l
(x 8 2) (Xl + X2 (Xl - X 2)2) COV 2, 2 = cov 2 ' 2
= lcov (Xl + X 2, (Xl - X 2)2)
= l [COV (Xl + X2, xí - 2XI X2 + Xi)]
= l [COV(XI, xí) - 2cov(XI, X I X2 ) + COV (Xl, Xi)]
+ l [cov(x2,xí) - 2COV(X2,XIX2) + COV (X2,Xi)]
1 = 4: [2E[XI]V[XI] - 2E[X2]V[XI] - 2E[XI]V[X2]
+2E[X2]V[X2]]
porque Xl tiene la misma distribución de X 2 y además son variables independientes,
cov (X 2, 8~) = l (2p,(72 - 2p,(72 - 2p,(72 + 2p,(72) = O
Por hipótesis de inducción, cov (Xn, 8~) = o. Ahora para una muestra de tamaño n + 1, cov (Xn+1, 8;+1) = .6.
.6. = cov (~lXn + -l-Xn+l, (n - 1)8~ + _1_ (Xn+l - Xn)2) n+ n+1 n+1
= n - 1 cov (Xn, 8;) + ( n )2 COV (Xn, (Xn+l - Xn)2) n+1 n+1
n - 1 ( 2) 1 ( ( - )2) + n(n + 1) cov X n+1,8n + (n + 1)2 cOV X n+1, X n+1 - X n
Como cov (Xn, 8~) = O Y X n+l , 8~ son independientes,
cov (Xn+l , 8~+1) = (n: l)2cOV (Xn, (Xn+l - Xn)2)
+ (n ~ 1)2 cOV (Xn+l ' (Xn+l - Xn)2)

50 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Ahora,
cov (Xn, (Xn+1 - Xn)2) = COV (Xn, X~+l - 2XnX n+1 + X~) = COV (Xn , X~+1) - 2cov (Xn, XnXn+l )
+COV (Xn,X~) (j2 (j2
= -2E[Xn+I]- + 2E [Xn] -n n
(j2 (j2 = -2f.1- + 2f.1- = O
n n
cov (Xn+l , (Xn+l - Xn)2) = COV (Xn+I,X~+1 - 2XnX n+1 + X~)
luego
= COV (Xn+l , X~+l) - 2cov (Xn+l , XnXn+l )
+ COV (Xn+I,X~) = - 2 f.1(j 2 + 2f.1(j2 = O
n 1 O (- S2) - O + O = . COV X n +l , n+l - (n + 1)2 (n + 1)2 o
Teorema 1.4.21. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población para la cual no se asume un modelo de probabilidad específico, entonces
1 n n
S~=<L/ .. 1\LL)Xi -Xj )2. i=l j=l
Demostración. De manera similar al punto de partida de la demostración del teorema 1.4.3,
n n
L(Xi - X j )2 = L [(Xi - X n ) - (Xj - Xn)]2. i=l i=l
n Desarrollando el cuadrado allí indicado y como ¿ (Xi - X n) = O, en
i=l tonces
n n
" 2" -2 -2 ~(Xi - Xj) = ~(Xi - X n) + n(Xj - X n ) i=l i=l

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 51
luego
n n n n
j=l i=l i=l j=l n
En consecuencia,
Teorema 1.5.2. Siendo X 1,n, X 2,n, . .. ,Xn,n las estadísticas de orden o la muestra ordenada de una población con función de distribución Fx(x), entonces para k = 1,2, ... ,n
FXk,n(y) = :t (~) [Fx(y)]j[l- Fx(y)]n- j . j=k J
Demostración. Fijando un valor particular y, se construye la variable aleatoria dicotómica Zi = l( -oo,y] (Xi), i = 1, 2, ... , n.
Como P[Zi = 1] = P[Xi ::; y] = Fx(y), entonces cada una de las variables independientes Zl, Z2, . .. ,Zn tiene distribución de Bernoulli con parámetro Fx(y).
n Adicionalmente, ¿ Zi rv Bin(n, Fx(Y)) dada la independencia citada
i=l n
de las variables Zl, Z2, ... ,Zn. ¿ Zi representa al número de observa-i=l
ciones muestrales menores o iguales al valor específico y.
Como el evento {X k,n ::; y} es equivalente al evento t~ Zi 2: k }, en
tonces la función de distribución de la k-ésima estadística de orden corresponde a
Fx ,," (y) ~ p IXk,n :S yl ~ p [t, Zi 2: k 1
= :t (~) [Fx(y)]j [1 - Fx(y)t-j
. j=k J
o

52 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Teorema 1.5.4. Siendo Xl, X 2 , .. . , X n una muestra aleatoria de una población con función de distribución continua Fx(x), la función de densidad de la k-ésima estadística de orden, k = 1,2, ... ,n, es
fXk,n(y) = (1 ,\~;~_ l\,[FX(y)]k-l[l- FX(y)t-kfx(y).
La función conjunta de densidad de la j-ésima estadística de orden y la k-ésima estadística de orden fXj,n,Xk,n (x, y) es
Cn,j,k[Fx (x )]3-1 [Fx(Y) - Fx(x )]k-j-l [1- Fx (y)t- k fx(y)fx (x )I(x,oo) (y)
para 1 :S j < k :S n, con Cn,j,k = n!j[(j - l)!(k - j - l)!(n - k)!]. La función conjunta de densidad de las estadísticas de orden es
!X1,n,X
2,n, ... ,Xn,n (Y1, Y2,"" Yn) = {n! fI !X(Yi) t=l
O
Y1 < Y2 < ... < Yn
en otros casos
Demostración. La primera afirmación del teorema se refiere a la función de densidad de la estadística Xk,n, función que corresponde a la derivada, respecto a los valores particulares de Xk,n, de su función de distribución FXk,n (y). Entonces
f () = ~F () = lim FXk,Jy + h) - FXk,Jy) xk,n y ay Xk,n y h-+O h
= lim p [y :S Xk,n :S y + h] h-+O h
• • y y+h
Por medio de la distribución multinomial se calcula la probabilidad del evento A(h) = {y :S Xk,n :S y + h}, descrito como
A(h) :"(k - 1) observaciones de la muestra son menores de y, una
pertenece al intervalo [y, y + h] Y las restantes (n - k)
observaciones son mayores que y + h ".

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 53
Al reemplazar Fx(v) por F(v), se tiene:
, P[A(h)] = (k _ l)!~;(n _ k)! [F(y)]k-l [F(y + h) - F(y)] [1 - F(y)t-k
y haciendo 6. = lim P[A(h)] h-+O h '
6. = n! [F( )]k-l [1 _ F( )t-k lim F(y + h) - F(y) (k - l)!(n - k)! Y Y h-+O h
(k -1)7~n _ k)! [FX(y)]k-l [1 - Fx(y)t-k
fx(Y) = fXk,n (y).
La segunda parte del teorema que enuncia la función conjunta de densidad de las estadísticas de orden j y k, fXj,n,Xk,n (x, y) se demuestra de manera similar.
x x+h Xj,n
Tomando 6. = fXj,n,xk,Jx, y) y FXj,n,xk,n (u, v) = F(u, v), entonces
6. = lim h-+O,t-+O
lim h-+O,t-+O
F(x + h, y + t) - F(x, y + t) - F(x + h, y) + F(x, y) ht
p [x S Xj,n S X + h, y S Xk,n S Y + t] ht
La probabilidad del evento A(h, t) = {x S Xj,n S x+h, y S Xk,n S y+t} igualmente se calcula por medio de la distribución multinomial.

54 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
Este evento está descrito como
A(h, t) : "(j - 1) observaciones pertenecen al intervalo h, una
observación pertenece al intervalo h, una observación
pertenece al intervalo 14 , (n - k) de las observaciones
pertenecen al intervalo h y las restantes (k - j - 1)
pertenecen al intervalo h ".
Para el cálculo de la probabilidad del evento A(h, t) es menester disponer de la relación de probabilidades de pertenencia de una unidad al intervalo correspondiente presentada en la tabla 1.1.
Luego
Intervalo Probabilidad I (-00, x] = h I Fx(x) = PI I
(x, x + h] = h I Fx(x + h) - Fx(x) = P2 I (x + h, y] = h I Fx(Y) - Fx(x + h) = P3 I (y,y+t]=14 I Fx(y+t)-Fx(y)=P41
(y+t,oo)=h I 1- Fx(y+t)=P5 I
Tabla 1.1:
[A(h )] n! (j-I) (k-j-I) (n-k) P ,t = (j _ l)!l!(k _ j _ l)!l!(n _ k)!PI P2P3 P4P5
Si Cn,j,k[Fx(x)jJ-I = B(x), Fx(v) = F(v), entonces D(h, t) es
[F(x+h) - F(x)][F(y) - F(x+h)]k-j-I[F(y+t) - F(y)][l- F(y+t)t-k
luego
l · A(h, t) B() l' D(h, t) 1m = x 1m
h--+O,t--+O ht h--+O,t--+O ht
donde lim D~,t) corresponde a h--+O,t--+O
lim [F(X + h) - F(X)] [F(y)-F(x+h)t-j-1 [F(Y + t) - F(Y)] [l-F(y+t)¡n-k h~O,t~O h t

1.7. DEMOSTRACIÓN DE LOS TEOREMAS 55
Esto es:
lim D~, t) = [jx(x)][Fx(y) _ Fx(x)]k-j-I[jX(Y)][l _ FX(y)]n-k h-+O,t-+O t
es decir, fXj,n,Xk,JX, y) es
Cn,j,k[Fx(x)Jl-I[Fx(Y) - FX(x)]k- j -l[l- Fx(y)t-k fx(y)fx(x)I(x,OCJ) (y)
para 1 ::; j < k ::; n, con Cn,j,k = n!j[(j - l)!(k - j - l)!(n - k)!]. La última parte es la generalización de los casos anteriores. Igualmente, con el apoyo de la distribución multinomial y teniendo en cuenta que la función conjunta de densidad f Xl,n,X2,n, ... ,Xn,n (YI, Y2,··· ,Yn) es
fácilmente se deduce que
n
fXl,n,X2,n, ... ,Xn,n (YI, Y2,' .. , Yn) = n! rr fX(Yi) para YI < Y2 < ... < Yn' i=l
o
Teorema 1.5.6. Sea Xl, X2, ... ,Xn, una muestra aleatoria de una población con función de distribución Fx(x) continua. Para p fijo, si xp
denota al único percentil lOOp poblacional, entonces
Demostración. Al igual que en una demostración anterior, se construye la variable aleatoria dicotómica Zi = I(-oo,x
p] (Xi), i = 1,2, ... , n. Como
Zi es una variable tal que Zi rv Ber(Fx(xp )), considerando los eventos
ellos son tales que P[A U B] = 1, por tanto
P [Xj,n ::; xp ::; Xk,n] = P[A n B] = prAl + P[B] - 1 = prAl - P[Be]

56 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
luego
p [Xj,n ~ X p ~ Xk,n] = P [Xj,n ~ X p ] - P [Xk,n ~ X p ].
Como el evento A (similarmente el evento B) puede transcribirse como A : "j o más observaciones son menores o iguales a x p ", entonces
P [Xj,n ~ x p ] = P [t Zi 2. j] = t (7)pl(1- p)n-l ~=l l=J
por tanto,
P [Xj,n ~ x p ~ Xk,n] = t (7)pl(1- pt-l - t (7)pl(1- p)n-l l=J l=k
y como j < k,
k-l ( ) P [Xj,n ~ xp ~ Xk,n] = L 7 pl(1- pt-l.
l=J o
Teorema 1.5.7. Siendo X 1 ,X2"",Xn una muestra aleatoria de una población con función de distribución Fx(x), entonces
p Fn(x) ---> Fx(x)
para un valor x dado.
Demostración. La función de distribución empírica puede ser reconocida como:
n
¿Zi i=l -
Fn(x) = -- = Zn n
siendo Zi = I(-oo,xj(Xi ), tal como se había convenido en la sección referente a la distribución de Fn(x). Desde este punto de vista, al entenderse que Zl, Z2, .. . , Zn es una muestra aleatoria de una población con distribución de Bernoulli de parámetro Fx(x), entonces el teorema de Khintchine garantiza que
- p p Zn -+ Fx(x), es decir que Fn(x) -+ Fx(x). o

1.8. EJERCICIOS 57
Teorema 1.5.8 La demostración puede consultarse en el texto Probability and Statistical Inference (Robert Bartoszynski y Magdalena Niewiadomska-Bugaj (1996) pp. 726 a 729).
Teorema 1.5.9. Siendo Xl, X 2 , .. . , X n una muestra aleatoria de una población con función de distribución Fx(x), la sucesión de variables aleatorias
{ y'n[Fn(x) - Fx(x)] }
JFx(x)[l - Fx(x)]
converge en distribución a una variable aleatoria con distribución Normal estándar.
Demostración. En los términos de la demostración del teorema 1.5.7 Y teniendo en cuenta que
E[Fn(x)] = Fx(x) y V[Fn(x)] = Fx(x)[l - Fx(x)] n
son finitos, entonces, a la luz del teorema del límite central (LindebergLévy) , la sucesión {Zn}, con
Zn = Fn(x) - Fx(x) = y'n[Fn((x) - Fx(x)] y'Fx(l-Fx(x)) JFx(l - Fx(x))
.¡n
converge en distribución a una variable aleatoria con distribución Normal estándar. D
1.8 Ejercicios
1. Demuestre que si la sucesión {Xn } converge en media cuadrática también converge en probabilidad.
2. Demuestre que el promedio basado en una muestra de tamaño n de una población con valor esperado ¡L y varianza (]'2, converge en media cuadrática a ¡L.
3. Si las variables aleatorias Xl, X 2, ... ,Xn constituyen una muestra aleatoria de una población con función de densidad,
fx(x) = 2x I(O,l) (x)
determine la distribución muestral del mínimo de la muestra.

58 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
4. Continúe realizando la demostración del teorema 1.4.3.
5. Si las variables aleatorias X I ,X2, ... ,Xn constituyen una muestra aleatoria de una población con distribución Exponencial de parámetro e, determine la distribución muestral del promedio de la muestra.
6. Si las variables aleatorias Xl, X2, ... ,Xn constituyen una muestra aleatoria de una población con distribución Exponencial de parámetro e, determine la distribución muestral del mínimo de la muestra.
7. Si las variables aleatorias Xl, X 2 , ... , X n constituyen una muestra aleatoria de una población con distribución Uniforme en el intervalo (O, 1), determine la distribución muestral del recorrido de la muestra.
8. Un dispositivo electrónico opera con base en el funcionamiento de n componentes conectados en serie que funcionan de manera independiente. Si el tiempo al fallar de cualquier componente se modela como una variable aleatoria con distribución Exponencial de parámetro e, determine el valor esperado y la varianza del tiempo de funcionamiento del dispositivo.
9. Una muestra de 36 botellas corresponde a la línea antigua de llenado A, que estando el proceso bajo control estadístico el contenido de una de ellas en mI se modela como una variable aleatoria con distribución Normal de valor esperado J-l y desviación estándar 12. Se considera otra muestra de 49 botellas de la nueva línea de llenado B, que de manera similar, estando el proceso bajo control estadístico, el contenido de una de ellas se modela como una variable aleatoria con distribución Normal de valor esperado J-l y desviación estándar 4. Determine la probabilidad de que los promedios muestrales difieran a lo sumo en 3 mI.
10. En el laboratorio de control de calidad de una compañía que produce elementos para cierto tipo de retroproyector, se encienden simultáneamente n bombillas. Utilizando el modelo Exponencial para describir el tiempo de vida de la bombilla, determine el valor esperado del tiempo de vida de la tercera bombilla en fallar.

1.8. EJERCICIOS 59
11. El examen de admisión de la Universidad Nacional de Colombia tiene un tiempo límite de dos horas y media y dentro de sus normas se establece que ningún aspirante puede retirarse del aula antes de haber transcurrido una hora de examen. Podría pensarse que el modelo para simbolizar el tiempo de permanencia del aspirante en el aula sería el modelo Exponencial doblemente truncado. Sin embargo, una buena elección la constituye el modelo Exponencial desplazado. Teniendo en cuenta que el tiempo medio de permanencia es de dos horas, ¿cuál es la probabilidad de que el docente que vigila el examen, en un aula con 25 aspirantes, no tenga que pronunciar la frase: "Por favor suspendan porque el tiempo de examen ha concluido"? La función de densidad de una variable aleatoria X con distribución Exponencial desplazada con parámetro O = (01, 02)', 01 E ~, 02 > 0, es
1 (-(X - Od) fx(x, O) = O2
exp O2
I(lJ¡,oo) (x).
12. Con base en el ejercicio 11, ¿cuál es el tiempo medio de permanencia en el aula del aspirante que se retira en primer lugar?
13. Según el ejercicio 11, ¿cómo cambia la respuesta al mismo y cómo cambia la respuesta al ejercicio 12, si se adopta el modelo de Pareto? La función de densidad de una variable aleatoria X con distribución de Pareto con parámetro O = (01 , O2 )', 01 > 0, O2 > 0, es
14. Si las variables aleatorias Xl, X 2 , .. . , X n constituyen una muestra aleatoria de una población con función de distribución absolutamente continua, ¿cuál es la probabilidad de que el máximo de la muestra exceda a la mediana poblacional?
15. Si las variables aleatorias Xl, X 2 , . .. ,Xn tienen la misma varianza y si la correlación entre cualquier par de variables diferentes tiene el mismo valor, demuestre que esa correlación tiene como cota inferior a - 1/ (n - 1).

60 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
16. Si las variables aleatorias Xl, X 2 , ... ,Xn constituyen una muestra aleatoria de una población con distribución de Bernoulli de parámetro e, determine la probabilidad de que Xl = 1, dado que
n ¿Xi =j,j=1,2, ... ,n. i=l
17. Si las variables aleatorias Xl, X2, ... ,Xn constituyen una muestra aleatoria de una población con distribución de Poisson con parámetro e, demuestre que para cualquier entero positivo k, con k :s; n, la distribución condicional de Xl, X 2 , ... , X n , dado que n ¿ Xi = k, corresponde a una distribución multinomial. i=l
18. Un procedimiento de control estadístico de calidad establece para cierto proceso de fabricación, la selección de manera aleatoria y sin remplazo de cinco amortiguadores de un lote de inspección que contiene seis de clase A y ocho de clase B, para ser examinados en el laboratorio. Si X 5 es la proporción muestral de amortiguadores de clase A, determine el valor esperado y la varianza de dicha estadística.
19. Si las variables aleatorias Xl, X 2 , ... , X n constituyen una muestra aleatoria de una población con distribución Binomial negativa de parámetros k y 7r, determine la distribución muestral correspon-
n diente a la estadística Tn = ¿ Xi.
i=l
20. Si las variables aleatorias Xl, X 2 , ... , X n constituyen una muestra aleatoria de una población con valor esperado ¡.t y varianza 4, determine el tamaño mínimo de la muestra para el cual la probabilidad de que el valor esperado y el promedio de la muestra no difieran en más de 0.1 sea superior a 0.95.
21. Con base en el ejercicio 20, ¿cuál debe ser el tamaño de la muestra, si la varianza fuese el doble?
22. La fracción de baldosas de cerámica con imperfectos producidas por una compañía es del 0.8% cuando el proceso está bajo control estadístico. Determine el tamaño de muestra mínimo para el cual la probabilidad de que la fracción con imperfectos y la proporción de baldosas con imperfectos en la muestra no difieran en más del 1 % sea superior a 0.95.

1.8. EJERCICIOS 61
23. Una norma particular de metrología determina que deben realizarse 36 mediciones de la emisión de ondas de un horno de microondas. El equipo debe estar calibrado de tal forma que la variabilidad en cada medición, cuantificada por medio de la desviación estándar, es de (7 unidades. Utilice la desigualdad de Chevyshev y el teorema del límite central en forma comparativa, para establecer el valor mínimo de la probabilidad de que el promedio de las mediciones difiera a lo sumo del verdadero valor promedio en K unidades. ¿Cuál es la razón de la diferencia de los resultados?
24. Según el ejercicio 23, también utilizando en forma comparativa la desigualdad de Chevyshev y el teorema del límite central, determine cuál debe ser el número de mediciones para que el valor mínimo de la probabilidad de que el promedio de las mediciones difiera a lo sumo del verdadero valor promedio en ~ unidades sea de 0.95. ¿Cuál es la razón de la diferencia de los resultados?
25. Un procedimiento de control estadístico de calidad ha establecido para la inspección del proceso de elaboración de láminas de madera aglomerada, un tamaño de muestra de 125 láminas. Si además se ha reconocido que el modelo de Poisson de parámetro 3 es un buen modelo para describir el número de defectos por lámina, determine la probabilidad de que el promedio de defectos por lámina en la muestra sea menor de 2.
26. Siendo dos minutos y cuarenta y cinco segundos el tiempo medio de transacción en un cajero electrónico y que el modelo Exponencial es un modelo admisible para representar el tiempo que utiliza un cliente en la transacción, determine la probabilidad de que se requieran más de 55 minutos para atender una cola de 16 clientes, pues la persona que ocupa el puesto 16 debe decidir si espera o no, en razón de que cuenta únicamente con los citados 55 minutos para realizar la diligencia.
27. Si las variables aleatorias Xl, X 2 , ... ,Xn constituyen una muestra aleatoria de una población con distribución de Bernoulli de parámetro e, ¿cuál es la distribución conjunta de Xl, X2, ... ,Xn y cuál
n es la distribución de la estadística ¿ Xi?
i=l
28. En el período preelectoral de la elección presidencial del 2002 en

62 CAPÍTULO 1. DISTRIBUCIONES MUESTRA LES
Colombia, los estimativos del favoritismo del candidato en definitiva elegido estuvieron persistentemente cerca del 52%. ¿Con cuál tamaño de muestra se hubiese podido predecir que no habría segunda vuelta, suponiendo como cierta la información que se disponía en ese momento y adoptando una probabilidad del 95%?
29. El tercer momento central es un elemento ligado a la descripción de la simetría de la función de densidad de una variable aleatoria. ¿ Qué puede afirmarse de la simetría de la función de densidad del promedio de una muestra de una población con distribución de Bernoulli de parámetro (), cuando el tamaño de la muestra crece?6 .
30. Determine el valor esperado y la varianza de la desviación estándar de una muestra aleatoria de una población con distribución normal de valor esperado 11 y varianza (J2.
31. Si las variables aleatorias Xl, X 2 , . .. , X n constituyen una muestra aleatoria de una población con función de densidad
1 !x(x) = ¡/{1,2, ... ,k}(X),
determine el valor esperado del semirrango de la muestra.
32. Si las variables aleatorias Xl, X 2 , ... , X n constituyen una muestra aleatoria de una población con valor esperado 11 y varianza finitos, muestre que las estadísticas
2 n • ¿iXi
n(n + 1) i=l
6 ~ .2X • ~ z . n(n + 1)(2n + 1) i=l t
convergen en probabilidad a 11.
33. Si las variables Xl, X 2 , •.. constituyen una sucesión de variables aleatorias, tales que P[Xi = iJ = P[Xi = -iJ = ~, entonces
n X. E[XiJ = 11 = O, i = 1,2, ... , demuestre que ¿ _t no converge
i=l n en probabilidad a 11 = O.
6Un coeficiente de simetría de la función de densidad de una variable aleatoria X, con momento central /-l3 y varianza (]"2, está definido como Q3 = /-l3/ (]"3.

1.8. EJERCICIOS 63
34. Si las variables aleatorias Xl, X 2, ... , X n constituyen una muestra aleatoria de una población con distribución Uniforme en el intervalo (O, e), demuestre que el máximo de la muestra converge en probabilidad a e.
35. Si las variables aleatorias Xl, X2, ... ,Xn constituyen una población con mediana e, demuestre que la mediana de la muestra converge en probabilidad a e.
36. Si las variables aleatorias Xl, X 2, . .. , X n constituyen una muestra aleatoria de una población con distribución Uniforme en el intervalo (0,1), determine el valor al cual la media geométrica de la muestra Gn converge en probabilidad
37. Si las variables aleatorias Xl, X 2, .. . , X n constituyen una muestra aleatoria de una población con distribución Exponencial con parámetro e, demuestre que la variable aleatoria
Qn = .¡n (ex n - 1) ~ Z rv N(O, 1).
38. La cantidad de café molido que se empaca en bolsas de 500 g mediante un proceso que, bajo control estadístico, puede modelarse como una variable aleatoria con valor esperado 500 y desviación estándar 10. Con base en una muestra de 100 bolsas, determine la probabilidad de que el promedio de la muestra esté entre 495 g y 504 g.
39. Si las variables aleatorias Xl, X2, .. . , X n constituyen una muestra aleatoria de una población con distribución de Bernoulli de parámetro e, demuestre que la estadística
converge en distribución a una variable aleatoria con distribución N ormal estándar.

64 CAPÍTULO 1. DISTRIBUCIONES MUESTRALES
40. Si las variables aleatorias Xl, X 2, . .. , X n constituyen una muestra aleatoria de una población con distribución de Poisson de parámetro (), demuestre que
exp (-Xn ) ~ P[XI = O].
41. Si las variables aleatorias Xl, X 2, ... ,Xn constituyen una muestra aleatoria de una población con función de densidad
fx(x) = xexp( -x) I(o,oo) (x),
determine el valor de la constante d, tal que P [Xn > d] = 0.95.
42. Si las variables aleatorias Xl, X2,"" X n constituyen una muestra aleatoria de una población con función de densidad
fx(x) = 12x2(1 - x) I(O,I) (x),
determine el tamaño de la muestra tal que P [f= Xi > gn] ::; 0.05. t=l
43. Si Xl, X 2, .. . , X n es una muestra aleatoria de una población con distribución Uniforme en el intervalo (O, ()), determine la función de distribución de la variable aleatoria Wn = n(() - Xn,n). ¿Cómo se distribuye la variable aleatoria a la cual la sucesión de variables aleatorias W I , W2 , •.. , Wn , .. . converge en distribución?

Capítulo 2
Estimación puntual de parámetros
En la primera sección del capítulo 1 se anotó que los modelos son elementos conexos con los quehaceres de la Ciencia. De índole diferente y con propósitos distintos, los modelos son artificios que cooperan en la descripción y explicación de la realidad al representarla de una manera muy peculiar, que posibilitan descripciones y explicaciones generales o minuciosas, según el propósito.
Entre otras funciones, el modelo subsume, en una especie de ideograma, una variedad de casos similares. Como modelo especial, el probabilístico, por su parte, simboliza mediante una expresión algebraica el comportamiento genérico de variables que aluden a mediciones, conteos, o valoraciones de unidades estadísticas; pero, igualmente, el modelo probabilístico puede entenderse como la representación del compendio de situaciones individuales, es decir, constituye una familia de modelos particulares de la misma naturaleza, los cuales pueden singularizarse determinando valores específicos de los parámetros, aquellas constantes que son elementos integrantes del modelo.
El vocablo puntual, que adjetiva la estimación motivo de este capítulo, tiene en castellano varias acepciones. El sentido que debe otorgársele dentro del contexto de la inferencia estadística es el de perteneciente o relativo al punto, por tratarse de la estimación de un parámetro por medio de un valor particular de una estadística, un punto del recorrido de ella, y también para distinguirla de la estimación por intervalo. Por ello, algunos traductores utilizan la expresión de estimación de punto.
65

66 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
En ese sentido, la estimación puntual de los parámetros puede interpretarse como la adopción de un modelo individual elegido dentro de una familia, para representar una realidad particular, elección fruto de la tasación de los respectivos parámetros por medio de un cálculo realizado con los valores observados de la muestra aleatoria, a través de la expresión que define la estadística facultada como estimador.
El objetivo de este capítulo es exponer algunos criterios que permiten estudiar el desempeño de estadísticas propuestas como estimadores, criterios que, como consecuencia, son algunos de los principios que facultan definitivamente a una estadística para desempeñarse como estimador. La estadística propuesta, o en examen, es habitualmente producto de la utilización de un método de construcción de estimadores. La primera parte del capítulo está dedicada a la presentación e ilustración de los métodos más corrientes en la construcción de estimadores; la segunda parte, substancial del capítulo, está dedicada al estudio de esos criterios evaluativos de un estimador.
Como ya ha venido insinuándose, se acude al concepto de variable aleatoria para representar una variable de interés que corresponde a la respuesta de cualquier unidad estadística. Al denotar se esta variable como X, su función de densidad 1, su función de distribución, su función generatriz de momentos y su función característica serán escritas casi siempre y de ahora en adelante como fx(x, O), Fx(x, O), Mx(t, O) Y IjJx(t, O), respectivamente, para enfatizar que las funciones asociadas al modelo asumido como modelo poblacional dependen, además de los valores para los cuales existen las mencionadas funciones, de las constantes inherentes al modelo dispuestas en el vector de k componentes O = (01 , O2 , ... , Ok)'. La finalidad de la estimación puntual de parámetros es estimar de la manera más eficiente los componentes del vector o la imagen de O bajo una función r( O) del mismo, a partir de la información disponible en la muestra.
Como preámbulo a la primera sección concerniente a los métodos tradicionales de construcción de estimadores, se presenta la definición inicial para la aprehensión de los elementos conceptuales integrantes del proceso de estimación estadística.
lEste texto, con el objetivo de simplificar el lenguaje, utiliza la expresión función de densidad para referirse tanto a la función de densidad de una variable aleatoria continua como a la función de masa, de probabilidad o de cuantía de una variable aleatoria discreta. El contexto de su utilización revelará el tipo de variable en referencia o se precisará cuando sea requerido.

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 67
Definición 2.0.1. Siendo X una variable aleatoria cuya función de densidad es fx(x, e), se denomina espacio del parámetro al conjunto de todos los posibles valores de los componentes del vector e, denotado como e e e IRk . -,--
Ejemplo 2.0.2. El modelo Uniforme es un modelo apto para emular variables que se distinguen por presentar frecuencias indiferentes para sus distintos valores. Considerando la variable aleatoria X con distribución Uniforme en el intervalo (O, e), es evidente, a partir de su función de densidad
1 fx(x, e) = (j I(o,li) (x),
que el cero es una frontera fija y que el parámetro e se desempeña como la frontera superior del recorrido de la variable, el cual asume un valor específico ante una situación también específica. En este caso, el parámetro e es un real positivo, por consiguiente, el espacio del parámetro es el conjunto
Ejemplo 2.0.3. El modelo gaussiano comentado y utilizado profusamente representa variables cuyas frecuencias, con marcada simetría, resaltan los valores intermedios y marginan los valores inferiores y superiores. Como se sabe, muchas son las variables factibles de ser abstraídas por este modelo. Considerando la variable aleatoria X con distribución Normal de valor esperado el y varianza e2 , el se desempeña como punto de simetría de su función de densidad
Y e2 regula su grado de apuntamiento como consecuencia de su dispersión. El modelo admite cualquier real como punto de simetría, mientras que exige un valor positivo para e2; por consiguiente, el espacio del parámetro es el conjunto e = {el, e2 1el E IR, e2 > O}, que gráficamente presenta la figura 2.1.
2.1 Métodos clásicos para construir estimadores
Previamente al desarrollo de las ideas básicas sobre los criterios capitales que permiten evaluar la aptitud de una estadística en su encargo como

68 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
(h ..
01
Figura 2.1: Espacio del parámetro para el modelo gaussiano.
estimador, se presentan tres métodos para producir estimadores: el de máxima verosimilitud, el de los momentos y el método por analogía. Una mención adicional a la estimación bayesiana cierra esta sección.
2.1.1 El método de máxima verosimilitud
Con la denominación de método de máxima verosimilitud, resultado de una amplia aceptación de la traducción por verosimilitud del término inglés likelihood, se conoce al método de construcción de estimadores más difundido y tal vez más utilizado. Aunque ya había sido concebido y empleado por Gauss, se debe realmente a Fisher, quien lo hizo público en la primera década del siglo XX. Por su fundamento y por producir estimadores que poseen propiedades especiales, las cuales se estudiarán más adelante, se convierte en un método con atractivos propios.
Definición 2.1.1. Siendo Xl, X 2 , ... , X n una sucesión de variables aleatorias idénticamente distribuidas pero no necesariamente independientes, la función conjunta de densidad de Xl, X 2 , ... , X n se conoce con el nombre de función de verosimilitud de Xl, X 2 , ... , X n .
Definición 2.1.2. Sea Xl, X 2 , . .. ,Xn una muestra aleatoria de una población con función de densidad fx(x, O), O E e, la función de verosimilitud de la muestra se denota y corresponde a
n
L(O; Xl, X2,···, Xn ) = rr fX(Xi, O). i=l

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 69
Recurriendo nuevamente a la primera sección del capítulo 1, para tener presente el sentido semántico que allí se aclaró, estimar significa la realización formal de un avalúo como proceso expreso, preciso y determinado que exige contar con información. Los valores particulares Xl, X2, ... , Xn , valores ya observados de las variables constituyentes de la muestra aleatoria, son el acervo de información con el cual se cuenta una vez haya concluido el acopio y registro de la misma en el estudio o investigación particular. En consecuencia, esos valores pueden asumirse como fijos en la función de verosimilitud y por eso en muchos textos se le considera como función de f) exclusivamente y suele expresarse como L(f)). Este texto utilizará en algunas oportunidades la expresión condensada L(O) o simplemente L a cambio de L(f); Xl, X2, .. . , x n ).
Definición 2.1.3. Siendo Xl, X 2, .. . , X n una muestra aleatoria de una población con función de densidad fx(x, f)), con f) E 8, se dice que el estimador T = t(XI , X2, ... , X n ) es el estimador máximo-verosímil de O (MLE de O; conservando las siglas inglesas de Maximum-Likelihood Estimator), si el valor particular de t = t(XI, X2, ... ,xn ) es tal que el supremum de L,
sup{L(f))If) E 8},
se consigue cuando f) = t, en cuyo caso t se denomina estimación máximo-verosímil de f).
El derrotero de la estimación máximo-verosímil puede percibirse inicialmente con el siguiente ejemplo.
Ejemplo 2.1.4. Como parte de una estrategia de mercadeo, una marca de pilas obsequia la persona que presente 10 pilas usadas impresas con el rótulo de promoción "Sello de oro", un paquete de cuatro pilas nuevas. Para imprimir en las pilas el rótulo se dispone de una máquina rotuladora que tiene tres niveles: alto, medio y bajo. La máquina estampa aleatoriamente el rótulo promocional en el nivel alto, medio y bajo, respectivamente, al 75%, 50% y 25% de las pilas. El comité ejecutivo de la empresa, basado en la información de las ventas, determina el nivel en que debe operar la rotuladora en un período determinado. Un comprador de un paquete desea estimar el nivel en el cual está operando la rotuladora. Para ello construye la tabla 2.1 basado en que el número de pilas rotuladas como "Sello de oro" en un paquete de cuatro se puede modelar como una variable aleatoria X distribuida binomialmente con

70 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
n = 4 Y probabilidad de éxito O. En este caso, el espacio del parámetro es e = {~, ~, ~}. Si el comprador sólo dispone de un paquete de cuatro pilas para inferir el nivel de la rotuladora, sus estimaciones máximo-verosímiles, derivadas de la citada tabla serán:
O 1 4: 1 "2 3 4:
1 - o equivalentemente nivel bajo, si x = O o si x = 1. 4 1 - o equivalentemente nivel medio, si x = 2. 2 -3 '4 o equivalentemente nivel alto, si x = 3 o si x = 4
x
O 1 2 3 4
0.316406 0.421875 0.210938 0.046875 0.003906
0.062500 0.250000 0.375000 0.250000 0.062500
0.003906 0.046875 0.210938 0.421875 0.316406
Tabla 2.1: Compilación de valores de una función de densidad Binomial con n = 4 Y probabilidad de éxito O.
justamente porque para un valor específico x, la estimación corresponde a aquella donde la probabilidad es máxima. El éxito de la promoción fue tal que una compañía de gaseosas acudió a la misma estrategia, obsequiando una canasta de 30 unidades a la persona que presente 75 tapas con la leyenda "Apaga gratis tu sed" . A diferencia de la anterior, la rotuladora de la compañía de gaseosas tiene la particularidad de que el nivel de estampación se puede ajustar a cualquier porcentaje. Igualmente, con base en el número de botellas cuyas tapas contienen la leyenda de la promoción en una canasta de 30 unidades, un comprador de una canasta desea estimar el nivel en el cual está operando la rotuladora. Para este caso ya no es posible construir una tabla como la 2.1, porque el espacio del parámetro es un conjunto infinito, e = {OIO < O < 1}.

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 71
Se podría construir una tabla similar con una selección de valores particulares de (). Entonces, denotando como X: número de botellas cuyas tapas contienen la leyenda promocional en una canasta de 30 unidades, los valores de la función
vistos como los componentes de una fila en una tabla similar a la 2.1, son los valores de una función de densidad para un valor específico de (). Una columna de una tabla construida con algunos valores de () estaría constituida por un conjunto de valores de funciones de densidad calculados con distintos valores del parámetro () y fijo el valor de x. Leída verticalmente esta tabla, mostraría el máximo del citado conjunto, la mayor probabilidad, indicativa de que su correspondiente valor de () es el valor más verosímil según las condiciones mencionadas. Como para efectos de esta estimación no existe la posibilidad de elegir valores particulares del parámetro, se acude al cálculo diferencial y de esta forma el valor de () para el cual L(()) sea máxima corresponde al valor más verosímil del nivel de estampación. Por ejemplo, si en una canasta se encuentran seis botellas cuyas tapas están marcadas con la leyenda promocional,
función cuya primera derivada es
derivada que es nula cuando () = t, y en ese punto la función L( ()) tiene máximo, lo cual significa que el valor más verosímil del nivel de estampación es del 20% cuando se dispone únicamente de la información relativa a una canasta que contiene seis unidades premiadas.
El anterior y los cuatro ejemplos siguientes, a la luz de la definición 2.1.3, mencionan el máximo de un conjunto o función, teniendo en cuenta que cuando un conjunto posee máximo, el cual pertenece al conjunto, el supremum de dicho conjunto es el mismo máximo.
Lema 2.1.5. Si t hace máxima a L(()), t igualmente hace máximo a lnL(()).

72 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Ejemplo 2.1.6. Se toma una muestra de tamaño tres de una población con distribución de Poisson de parámetro O, cuyos resultados son, Xl = 2, X2 = O, X3 = 5. Determinar la estimación máximo-verosímil de O.
_ ((Pe-O) ((}Oe-O) ((}5 e-O) _ (}7e-30 L((}) - -- -- -- --. 2! O! 5!
L'(O) = _1_ [706e-30 _ 307e-30] . 2!5!
L'(O) = O cuando O = O o cuando O = ~. Luego la estimación máximoverosímil de O es ~; el valor O = O no es un valor admisible por el modelo de Poisson porque
O E e = {OIO > O}.
Ejemplo 2.1. 7. Determinar el MLE de () a partir de una muestra aleatoria Xl, X 2 , ... ,Xn de una población con función de densidad
fx(x, O) = OX(1 - O)l-X I{O,l}(X), O E e = {OIO E (0,1)}
n
L(e; Xl, X2, ... , Xn ) = eX1 (1 - e)I-X1 eX2 (1 - e)I-X2 ... eXn (1 - e)l-xn II [{D,l} (Xi) i=l
n n n ¿: Xi n- ¿: Xi
= ei~1 (1 - e) i~1 II [{D,l} (Xi)
In L(O; x" X" ..• , x n ) ~ {[~ x,Jlno e} -~ x,Jln(! O) } !1 J{O,>}(x,)
o n n
!:) In L(O' ¿ Xi n - '" uO ,Xl, X2, ... X ) _ i=l Ú Xi , n _ - - 2=1 O n n
02 i~ Xi n - i~ Xi o02InL(O;Xl,X2, ... ,Xn)=-~- (1-0)2 <O
lo cual garantiza la existencia del máximo de ln( L( O; Xl, X2, ... ,xn )).
Luego In L( O) tiene máximo cuando
n ¿Xi i=l
O
n n- ¿ Xi
i=l
1-0

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 73
o, de otra manera, cuando
n Entonces, InL(O) tiene máximo en O = ~ ¿ Xi. Es decir, el estimador
i=l
máximo-verosímil de O es X n = Pn , llamado como ya se había anotado, proporción muestral.
Ejemplo 2.1.8. Determinar el MLE de O a partir de una muestra aleatoria Xl, X2, .. . , X n de una población con función de densidad
e-BOx
fx(x, O) = -,-I{Ü,1,2, ... }(x), O E e = {OIO > O} x.
con lo cual se garantiza la existencia del máximo de In L( O; Xl, X2, ... ,Xn ) n n
en O = ~ ¿ Xi, es decir, el MLE de O es ~ ¿ Xi. i=l i=l

74 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Ejemplo 2.1.9. Determinar el MLE de () a partir de una muestra aleatoria Xl, X2, . .. ,Xn de una población con función de densidad
fx(x, ()) = ()x()-II(o,l) (x), () E e = {()I() > O}.
Como en los casos anteriores, al hacer uso del cálculo diferencial, se deduce que el MLE de () es
n
In (TI Xi) . ~=l
Se evidencia el respaldo que el cálculo diferencial prestó para la construcción de los estimadores máximo-verosímiles en los ejemplos anteriores, tratándose de la herramienta matemática central del procedimiento, pues la consecución de estimadores de esta naturaleza es en sí uno de los denominados problemas de máximos y mínimos. Sin embargo, no siempre es pertinente la utilización de esta herramienta; por ejemplo, cuando la función de verosimilitud no sea diferenciable. Los siguientes ejemplos muestran una forma alternativa de encontrar un MLE.
Ejemplo 2.1.10. Determinar el MLE de () a partir de una muestra aleatoria Xl, X 2 , ... , X n de una población con función de densidad
fx(x, ()) = I[()-1,B+1l(x), () E e = {()I() E lR}
fx(x, ())
•
()_l 2
•
() ()+~ x
Figura 2.2: Gráfica de la función de densidad correspondiente al ejemplo 2.1.10

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES
n
L((); Xl, X2,···, Xn ) = rr I[B_~,o+~](Xi) i=l
75
Como L( ()) es distinta de cero cuando () - ~ :S Xi :S () + ~, i = 1,2, ... ,n, entonces
1 () - - < x· implica 2 - t
1 Y () + 2 2: Xi implica
1 () :S Xi + 2
1 (»x--
- t 2
Luego Xi - ~ :S () :S Xi + ~ para i = 1,2, ... ,n, particularmente
1 1 xn,n - 2 :S () :S Xl,n + 2·
De manera que la función de verosimilitud puede expresarse como
L( ())
L(()) = I[x _1 x +1](()). n,n 2' l,n 2
•
1 Xn,n - "2
•
1 Xl,n + "2 ()
Figura 2.3: Gráfica de la función de verosimilitud correspondiente al ejemplo 2.1.10
Como se deduce de la figura 2.3, cualquier valor entre Xn,n - ~ y Xl,n + ~ hace máxima la función de verosimilitud. Como el papel que desempeña el parámetro es la determinación de la posición de la función de densidad, que coincide con el centro del recorrido de la variable, es razonable asumir como MLE de () a
Xl,n +Xn,n
2

76 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Ejemplo 2.1.11. Determinar el MLE de e a partir de una muestra aleatoria Xl, X 2, ... , X n de una población con función de densidad
fx(x,e) = ~1(O,O)(X)' e E 8 = {ele> O}
(l)n n
L(e; Xl, X2,·· ., Xn ) = (j g 1(0,0) (Xi)'
Como L( e) es distinta de cero cuando O < Xi < e, en particular cuando xn,n < e, entonces
L(e;XI,X2, ... ,Xn) = (~)n 1(Xn,n,OO) (e).
L( e)
Xn,n e
Figura 2.4: Gráfica de la función de verosimilitud correspondiente al ejemplo 2.1.11
El estimador máximo-verosímil de e es Xn,n, porque el
sup(L( e)) = (x~,n) n.
Teorema 2.1.12 (Principio de invarianza de un MLE). Si las variables aleatorias Xl, X 2, ... , X n constituyen una muestra aleatoria de una población con función de densidad fx(x, e), Tn = t(XI , X 2, ... , X n )
un MLE de e, e E 8, 8 ~ ]R, Y si r(e) es una función uno a uno, entonces r(Tn ) es el estimador máximo-verosímil de la imagen de e bajo la función r.

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 77
De manera más general, este princIpIO de invarianza de los estimadores máximo-verosímiles se puede enunciar como lo establece el siguiente teorema.
. (1) (2) (k»)' Teorema 2.1.13. Szendo Tn = Tn ,Tn , ... , Tn un MLE de O,
donde T~j) = tj(Xl , X 2, .. . , X n ) para cualquier 1 :s: j :s: k, un esti-mador basado en una muestra aleatoria Xl, X2, ... , X n de una población
con función de densidad fx(x,O), 0= (Ol,02, ... ,Ok)" Si r(O) = (rl(O),r2(O), ... ,r¡(O)), 1 :s: l :s: k, entonces el MLE de la imagen de O bajo la función r es
Ejemplo 2.1.14 (Estimación en muestras censuradas). Para cerrar el estudio del método de máxima verosimilitud, se presenta una breve alusión a las muestras censuradas. En algunas aplicaciones como las relacionadas con los ensayos clínicos, con el análisis de sobrevivencia o con algunas investigaciones de laboratorio, el acopio de la información pertinente consiste en obtener el valor de la medición del tiempo de duración de algún evento vital o biológico de cada una de las n unidades estadísticas elegidas como tamaño de muestra, sólo que al finalizar el tiempo t establecido para el estudio, k < n de las unidades presentan valores en la duración inferiores a t, porque las (n-k) unidades restantes superaron el tiempo establecido, pero debido a la finalización del estudio no se conocen con exactitud sus valores. También se presentan situaciones en las cuales el estudio finaliza cuando únicamente k :s: n de las unidades estadísticas hayan concluido su observación, faltando las restantes (n - k) unidades. En cualquiera de las dos situaciones se habla de una muestra censurada.
Cuando t se ha establecido como un tiempo fijo, k representada por la variable K puede entenderse como una variable aleatoria y se habla en este caso de una muestra censurada del tipo 1. Si el número de unidades k necesario para concluir el estudio se fija de antemano y el tiempo correspondiente t representado por la variable T es considerado como una variable aleatoria, entonces la muestra recibe el nombre de muestra censurada del tipo 11.
Siendo X la variable aleatoria que representa la duración del evento vital o biológico de cualquier unidad estadística, el valor Xl,n representa la duración de la "t-widad con menor valor, X2,n representa la duración

78 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
de la unidad con el siguiente valor, y así sucesivamente hasta Xk,n que representa la duración de la última unidad con mayor duración inferior al tiempo t. Las restantes (n - k) unidades tienen una duración mayor al tiempo t, duración que no se puede establecer por la culminación del acopio la de información del estudio.
Considerando como objeto una muestra aleatoria censurada del tipo II, fijando los valores de k y n, como también asumiendo el modelo del tipo Exponencial para representar la duración del evento como la variable aleatoria X, con función de densidad
1 x
fx(x, B) = (/~9 1(0,00) (x),
se busca estimar el parámetro B, en estas condiciones. Para determinar un estimador máximo-verosímil del parámetro, la función de verosimilitud acorde con el tipo de muestra está constituida por el producto de dos factores:
n! k rr 1 ~ Xi,n
(n _ k)!. (je -0---
z=l
n Xk n
e~6 y rr i=k+l
El primer factor es la parte de la función de verosimilitud correspondiente a las k unidades con duración inferior al tiempo de corte; la presencia del coeficiente del producto de densidades radica en que hay (n~!k)! formas de tener k unidades de un total de n con tiempos inferiores al citado corte, por tratarse de k-uplas ordenadas sin repetición. El segundo factor corresponde a la probabilidad de que (n - k) unidades tengan una duración superior a Xk,n, debido a que P[X > xl = e~~. De esta manera, la función de verosimilitud de las n variables aleatorias es:
'
k n n. rr 1 Xi ,n xk,n
L(B; Xl, X2,··· ,Xn ) = 1__ '-\, (je~-o- rr e~-o- = L
n! L = (n - k)!
n! L = (n - k)!
i=l i=k+l
[ m k exp ( -~ t Xi,n) (exp ( - (n - :)Xk,n) ) 1
[ G)' exp ( -~ (t Xin + (n - k)Xk,n) ) 1

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 79
Procediendo de la manera usual puede deducirse que el MLE de e con base en una muestra aleatoria censurada del tipo 11, bajo este modelo Exponencial es:
k
¿ Xi,n + (n - k)Xk,n T
n = ~i=_l~ ______________ _
k
Por supuesto, si se asume otro modelo para describir la duración del evento vital o biológico, la determinación del correspondiente MLE dependerá del referido modelo, pero el bosquejo aquí presentado se mantiene.
Nota. La denominada función de verosimilitud en el ejemplo anterior referente a una estimación en una muestra censurada no es una función de verosimilitud estrictamente hablando. Es una función de cuasi verosimilitud, cuyo máximo reside en una estimación cuasi máximo-verosímil. Precisamente para denotar a un estimador de esta naturaleza, se utiliza la sigla QMLE (Quasi Maximum Likelihood Estimator). Incorrectas funciones de verosimilitud son propias de situaciones cuando la función de verosimilitud es supremamente complicada, cuando hay presencia de datos censurados, cuando se realizan algunos estudios basados en simulación o cuando se requiere excesivo cómputo estadístico para determinar una estimación máximo-verosímil y se acude a una función de cuasi verosimilitud para simplificarlo. En consecuencia, el estimador obtenido en el ejemplo 2.1.14 es realmente un QMLE.
2.1.2 El método de los momentos
Antes de la divulgación del método de máxima verosimilitud, SurglO el método más antiguo de construcción de estimadores, denominado el método de los momentos, propuesto y utilizado por Pearson a finales del siglo XIX. En casi todos los textos se describe como un método que deduce los estimadores por medio de un eje consistente en igualdades algebraicas de momentos muestrales con momentos poblacionales. Este texto, sin apartarse radicalmente del proceso tradicional, fundamenta el método y por tanto su procedimiento en la convergencia en probabilidad de los momentos muestrales a sus respectivos momentos poblacionales. Antes de exponer la idea del método es preciso referenciar dos teoremas que auxilian la fundamentación de método y su aplicación: el teorema 1.3.2 y el teorema que se enuncia a continuación.

80 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Teorema 2.1.15. Sea Xl, X 2 , ... ,Xn una muestra aleatoria de una población con función de densidad fx(x, O). Existiendo el momento J.l2r = E [X 2r
] , r = 1,2, ... ,
n 1 ~ ( - )r p -~ Xi-X n -tJ.lr·
n i=l
El método de los momentos consiste fundamentalmente en determinar las estadísticas unidimensionales que convergen en probabilidad a cada componente Oj del parámetro O, para j = 1,2, ... , k, a partir de un sistema de expresiones
M{ E. J.l~ I P I M 2 -t J.l2
M ' P I k -t J.lk·
Este sistema se fundamenta en los enunciados de los teoremas de Kintchine (1.4.6)y 1.4.7. En la determinación de las estadísticas en consideración, también se puede incluir en el sistema de expresiones el hecho que
P M r -t J.lr
como lo enuncia el teorema anterior.
Ejemplo 2.1.16. Siendo Xl, X 2 , .. . , X n una muestra aleatoria de una población con función de densidad
001
f ( O) - 2 01-1 -02 X ¡ () X x, - f(OI)X e (0,00) x ,
determinar los estimadores de los componentes 01 , O2 del correspondiente vector O = (01 ,02)" Como X '" Gama(Ol, 02),
E[X] = 01
O2 y
01 V[X] = O~
entonces, debido a la convergencia en probabilidad de los momentos muestrales
X P 01 n -t-
O2 y
1 n _ ~ (X. - X )2 E. 01 n ~ ~ n 02'
i=l 2

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES
y con el apoyo del corolario 1.3.3,
Por lo anterior,
Por otra parte,
También:
En consecuencia:
En síntesis,
Xn
luego ___ (}.:....!2~ __ E.. 1. n
*¿(Xi- X n)2 i=l
X n P --:c:n----- -+ O2 .
* ¿(Xi - Xn)2 i=l
luego (~)2 P 02 - -+ 2· X n
por tanto,
-2 __ n __ X_n'-'--__ E.. 0
1.
* ¿(Xi - Xn)2 i=l
( X~ Xn) n 'n
* i~(Xi - X n )2 * i~ (Xi - Xn)2
es el estimador por el método de los momentos de O = (01 , O2 )'.
81
El método de los momentos posee cierta flexibilidad en la construcción de estimadores, al admitir relativa libertad en la conformación del sistema de expresiones que son el punto de partida del método. En algunas oportunidades es posible acudir a otro momento para eludir un obstáculo no advertido. Muestra de ello es el siguiente ejemplo.

82 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Ejemplo 2.1.17. Sea Xl, X 2, . .. ,Xn una muestra aleatoria de una población Uniforme en el intervalo (-e, e). Determinar por el método de los momentos el estimador de e. Partiendo del hecho de que X n ~ O, al no contener información sobre e
e2
se explora en otra dirección. Como el segundo momento ordinario es :3
y por lo tanto
n
1 n _ "x2 p e2
n~ t--->-i=l 3
~ ~ X2 ~e. n~ t
i=l
Luego 1/ ~ L Xl es el estimador por el método de los momentos de e. i=l
Ejemplo 2.1.18. Si Xl, X 2, . .. ,Xn es una muestra aleatoria de una población Normal de valor esperado el y varianza e2
- p X n ---> el
1 ~ - 2 P - ~(Xi - X n ) ---> e2. n
i=l
(- 1 n - 2)
Luego X n , -:;¡ i~(Xi - X n ) es el estimador por el método de los mo-
mentos de e = (el, e2)'.
Ejemplo 2.1.19. Sea Xl, X2,'" ,Xn una muestra aleatoria de una población con función de densidad
fx(x, e) = ee-Bx 1(0,00) (x), e> o.
Determinar el estimador de la mediana poblacional por medio del método de los momentos.
- p 1 X n ---> e _1 __ ~ e. X n

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 83
Luego 1 es el estimador por el método de los momentos de e. Teniendo X n
. . ln(2) . en cuenta que la medIana poblaclOnal es -e-' su estImador por el
- - p ln(2) método de los momentos es X n ln(2) porque X n ln(2) ---+ -e-o
2.1.3 El método por analogía
La pretensión primaria al proponer un modelo es lograr la mayor fidelidad a los hechos, es decir, que haya concordancia entre los atributos de la realidad y los elementos del modelo que los representan. Los parámetros de un modelo probabilístico desempeñan funciones muy específicas, y es procedente, por tanto, que sus estimaciones estén en afinidad con ellos en el desempeño de funciones similares. Sugerido por Pleszczynska, el método por analogía, como su nombre lo indica, elige el estimador luego de indagar el papel que cumplen los componentes del parámetro dentro del modelo, derivando una estadística que de manera análoga realice la misma función dentro de la distribución empírica. Un par de ejemplos ilustran la manera como este método particular procede.
Ejemplo 2.1.20. Sea Xl, X 2 , . .. ,Xn una muestra aleatoria de una población con función de densidad
fx(x, e) = ee-()x 1(0,00) (x), e> O.
Determinar usando el método por analogía un estimador de e.
Como 1
E[X] = (j' entonces 1
e = E[X]'
El parámetro es el recíproco del valor esperado; su estimador debe del
sempeñar una función análoga. Por tanto, =- puede adoptarse como el X n
estimador de e usando el método por analogía.
Ejemplo 2.1.21. Sea Xl, X 2 , .. . , X n una muestra aleatoria de una población con función de densidad
1 fx(x,e) = (j1(o,()) (x).
El parámetro e determina el valor máximo de la variable aleatoria que representa a la población; Xn,n representa al valor máximo en cualquier muestra. Por tanto, Xn,n es el estimador de e usando el método por analogía.

84 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
2.1.4 Estimación bayesiana
El enfoque bayesiano en la estadística es un enfoque muy singular, pues se inspira en la concepción de la denominada probabilidad subjetiva que el investigador puede alterar a la luz de información o conocimiento adicional sobre la naturaleza del fenómeno en estudio. Coherentemente, la estimación bayesiana fundamenta su proceder sobre el principio de que información o conocimiento previo sobre algunos rasgos del parámetro son elementos contribuyentes en su estimación. Por ello, a diferencia de lo tratado hasta el momento, en el sentido de considerar una muestra aleatoria de una población con función de densidad fx(x, B), cuyo parámetro, un valor fijo que pertenece a un conjunto 8, el enfoque bayesiano considera una muestra aleatoria de una población con función de densidad fx(x, B), en la cual el parámetro e es entendido como un valor particular de una variable aleatoria 8, variable que tiene una función de densidad ge (B), cuyo parámetro es totalmente conocido. La función ge(B) recibe la denominación de función de densidad a priori de 8. Dependiendo de la naturaleza de e, la variable 8 es una variable aleatoria continua o discreta, según el caso.
Algunas situaciones en la práctica requieren un modelado especial y el enfoque bayesiano es propicio para tal fin. Por ejemplo, si una compañía recibe en su planta de producción materia prima cuyo nivel de calidad, medido en términos de la fracción disconforme de artículos, es variable de entrega a entrega, pero frecuentemente con valores bajos y muy raramente con valores altos, y si ese nivel de calidad es para un período de inspección de lotes, en el control de calidad de la materia prima, el valor del parámetro B de la función de densidad de una variable Y que contabiliza el número de artículos disconformes en una caja de 48 unidades, entonces para destacar esa índole de variabilidad y de marcada tendencia en la generación de valores bajos, el parámetro e puede modelarse como una variable aleatoria con distribución Beta, cuya función de densidad manifieste un fuerte sesgo a la derecha.
De la familia de densidades Beta, en esta explicación, se opta por una individual que preserve los rasgos esperados del parámetro
1 ge (e) = ni 1 \ ea
-1 (1 - e)b-1 1(0,1) (e)
densidad para la cual a y b son conocidos y para el caso b es suficientemente mayor que a para registrar el sesgo pretendido.

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 85
Adoptada la distribución a priori de e, se selecciona una muestra aleatoria Xl, X2, . .. ,Xn , de una población ya no con función de densidad fx(x, e) como hasta ahora ha venido concibiéndose, sino con función de densidad fx(xle), entendida ésta como una función de densidad condicional debido a que depende de los valores de la variable aleatoria e.
En el caso asociado en esta descripción, la muestra se selecciona de una población con función de densidad
La función de densidad condicional felxl,x2, ... ,Xn (eIXl, X2, ... , xn) se le conoce como la función de densidad a posteriori de e, función de densidad condicional que corresponde a
f Xl,X2, ... ,xnle=o(Xl, X2,·· ., xnle)ge(e)
fXl,X2, ... ,Xn (Xl, X2,···, Xn)
y debido a la independencia existente entre las variables aleatorias que conforman la muestra y la variable aleatoria que representa al parámetro e, la función de densidad a posteriori de e, conviniendo que e es una variable continua, puede expresarse como
Particularmente, al asumir el modelo de Bernoulli, como comportamiento poblacional, y el modelo Beta para el comportamiento del parámetro,
f3 C~ Xi + a, n + b - i~ Xi)
luego la distribución a posteriori de e es una distribución Beta. El hecho que la familia de densidades a la cual pertenece la función de densidad

86 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
a priori de e sea la misma de la función de densidad a posteriori de e, produce un hecho atractivo para la computación estadística, pues se puede simular la distribución a posteriori sin acudir directamente a los resultados del teorema de Bayes.
Pero no siempre se cuenta con esta ventaja. Si se asume la función de densidad a priori de e como Uniforme en el intervalo (O, 1) Y la función de densidad fx(xIO) = OX(1 - O)l-X I{O,I}(X), fácilmente puede comprobarse que la distribución a posteriori de e es Beta.
Definición 2.1.22. Sea Xl, X 2, ... ,Xn una muestra aleatoria de una población con función de densidad fx(x, O). Una familia D de densidades se dice que es conjugada para la función de densidad fx(x, O), o que es cerrada bajo muestreo respecto a la función de densidad fx(x, O), si la función de densidad a priori de e, ge(O) E D Y si
felxl,x2, ... ,xn (OIXI, X2,.· ., x n ) E D.
De lo anteriormente desarrollado se deriva que la familia de densidades Beta es conjugada para la función de densidad de un modelo de Bernoulli.
Definición 2.1.23. Sea Xl, X2, ... ,Xn una muestra aleatoria de una población con función de densidad fx(x, O), ge(O) la función de densidad a priori de e, y r(O) una función del parámetro O. El estimador bayesiano para la imagen de O bajo la función r, respecto a la función de densidad a priori ge (O) es aquel cuya estimación corresponde a
E [r( e) [XI, X2
, ••• ,Xnl ~ 1"=' r( e) [iD, f x (x.¡o) 1 ge( e)de
J~oo [iDI fX(XiIO)] ge(O)dO
Ejemplo 2.1.24. Como se afirmó, la familia de densidades Beta es conjugada para la función de densidad de un modelo de Bernoulli; entonces

2.1. MÉTODOS CLÁSICOS PARA CONSTRUIR ESTIMADORES 87
la estimación bayesiana de e corresponde a
[
n n 1 1 ¿ x;+a-l n- ¿ xi+b- 1 Jo e ei=l (1 - e) i=l de
E [eIX1, X2, ... ,Xnl = ( n n ) (3 ¿ Xi + a, n + b - ¿ Xi
i=l i=l
1 ¿ x;+a n- ¿ xi+b- 1
[
n n 1 Jo ei=l (1 - e) i=l de
(3 C~ Xi + a , n + b - i~ Xi)
n
¿Xi+ a i=l
En otros términos, el estimador bayesiano para e respecto a la función de densidad a priori de e, perteneciente a la familia Bernoulli de densidades, es
n
¿Xi+a 1: - _i=_l __ _ n- n+a+b
Puede comprobarse que si se hubiese asumido el modelo uniforme en el intervalo (0,1) como la distribución a priori de e, el estimador bayesiano correspondiente sería
n
¿Xi+ 1 T - _i=_l __ _
n - n+2
y la estimación bayesiana para la varianza de la población e(l - e), es decir la estimación bayesiana de la imagen de e bajo la función r(e) = e(l - e), asumiendo el mencionado modelo Uniforme en el intervalo (0,1) como la distribución a priori de e, se deriva en la forma

88 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
siguiente:
r10(1 [ f Xi n E [r(8)[X X Jo - O) Oi=l (1 - O)n-¿ Xi]
1, 2, ... ,Xnl = ,=1 dO
[
n 1 ¿ Xi n Jo Oi=l (1 - O)n-¿ Xi] ,=1 dO
1 ¿ x;+l n- ¿ Xi+ 1
[n n] Jo Oi=l (1 - O) i=l dO
(3 C~ Xi + 1 , n + 1 - i~ Xi)
[ t Xi + 1] [n + 1 - t Xi] 1=1 1=1
(n+3)(n+2)
Ejemplo 2.1.25. Sea Xl, X2, . .. , X n , una muestra aleatoria de una población con distribución Normal de valor esperado O y varianza (72
asumida como una constante conocida. La distribución a priori de 8 se establece como Normal de valor esperado f..lp y varianza (7~, por supuesto conocidos. Puede comprobarse que la familia de densidades gaussiana es conjugada para la función de densidad de un modelo gaussiano e igualmente que la distribución a posteriori de 8 es normal de valor esperado
y varianza
2- + 2 n(7pXn f..lp(7
n(72 + (72 P
(72(72 p
n(7~ + (72·
Nota. Como f..lp y (7~ son valores fijos y conocidos, en la medida que el tamaño de la muestra se incremente este estimador tiende al estimador máximo-verosímil para O.
Para finalizar, los estimadores bayesianos definidos en esta sección, realmente, son estimadores bayesianos cuyas estimaciones minimizan una función de pérdida particular llamada error cuadrático. Esto quiere decir que si se adopta otra función de pérdida, el estimador bayesiano puede ser de otra naturaleza.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 89
2.2 Criterios para examinar estimadores
Otorgar facultades a una estadística para que se desempeñe cabalmente como estimador es el resultado del cumplimiento por ésta de cada uno de los requisitos de un conjunto de requisitos deseables para un estimador idóneo; consiste en colocar en balanza los requisitos que la estadística cumple, sus capacidades, y aquellos rasgos que menoscaban en algún grado su misión, es decir, la evaluación del costo/beneficio de adoptar un estimador con algunas deficiencias frente a sus virtudes.
Se trata de un procedimiento análogo a un procedimiento de certificación de calidad que asegura que un producto, un proceso o un servicio, cumple los requisitos especificados, lo cual genera un factor imprescindible en la cimentación de la confianza en las relaciones cliente/proveedor. Facultar una estadística es en sí acreditar la calidad de un proceso, un proceso particular de inferencia, para que el usuario pueda aplicarlo con la confianza derivada de la certificación, a semejanza del uso que un cliente le da a un producto o servicio certificado.
Así como en una relación comercial el proveedor necesita disponer de evidencias que confirmen la aptitud del producto o la diligencia del servicio, para que su cliente pueda confiar en su destreza para satisfacer sus expectativas y necesidades, de un estimador es menester contar con una relación de sus solvencias para que su uso, sujeto al modelo adoptado, satisfaga la precisión y exactitud previstas en el proceso de estimación y tenga en cuenta las limitaciones y particularidades del entorno de su aplicación.
Contrario a lo que frecuentemente se presenta como propiedades de los estimadores, este texto las destaca como requisitos para facultar estadísticas en su desempeño como estimadores. Los requisitos indagan acerca del carácter del centro de gravedad de la distribución muestral de la estadística, sobre la naturaleza de su concentración, acerca de atributos especiales derivados de su construcción, sobre el efecto que pueda tener el tamaño de la muestra en su esencia y sobre otras condiciones de mayor abstracción.
Es usual en la certificación de estimadores adjetivar al estimador con el requisito que cumple. Por ejemplo, se designará como estimador insesgado al estimador que cumple el requisito del insesgamiento; estimador consistente, al estimador que satisface el requerimiento de la consistencia, etc. Igualmente, la estimación correspondiente, es decir el valor particular del estimador, se adjetiva de igual forma: estimación

90 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
insesgada, estimación consistente. Para dar paso a la exposición de estos requisitos o criterios para el
examen de una estadística, se describe en primer lugar lo relativo a la concentración de un estimador.
2.2.1 Concentración, un requisito de precisión
Definición 2.2.1. Sea Xl, X2, ... ,Xn una muestra aleatoria de una población con función de densidad fx(x, e), la función r(e) una función
/ (1) _ (2) _ ( del parametro e, y Tn - tl(Xl , X 2, .. ·, X n ), Tn - t2 Xl, X 2,···, X n )
dos estimadores para la imagen de e bajo la función r, función cuyo recorrido es un conjunto de números reales. Se dice que el estimador T~l) es más concentrado que el estimador T~2), si y sólo si
Pe [r(e) - >. < T~l) < r(e) + >.] 2: Pe [r(e) - >. < T~2) < r(e) + >.]
para cada>. > O Y cada e E 8.
En la definición anterior se utilizó el símbolo Pe en cambio del símbolo usual P, para acentuar que el cálculo de la probabilidad allí indicado se basa en un modelo asumido, modelo que lleva consigo al parámetro e como su componente connatural; quiere decir entonces que el citado cálculo alude a cualquier valor del parámetro, en su respectivo espacio, por supuesto. En este mismo sentido, al utilizar Ee Y Ve se hace referencia al valor esperado y a la varianza, respectivamente, de una variable aleatoria, según las consideraciones hechas de la dependencia del modelo asumido y de su parámetro inherente.
Definición 2.2.2. Sea Xl, X2, .. . , X n una muestra aleatoria de una población con función de densidad fx(x, e) y r(e) una función del parámetro. El estimador T~ = t*(Xl , X 2, ... ,Xn ) se denomina el estimador más concentrado para la imagen de e bajo r, si él es más concentrado que cualquier otro estimador para la imagen de e bajo la función r.
Definición 2.2.3. Dentro de la definición 2.2.1 el estimador T~l) se denomina estimador Pitman más concentrado que el estimador
T2) para la imagen de e bajo la función r, si y sólo si
Pe [IT2) - r(e)1 < IT~2) - r(e)l] 2: ~.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 91
Definición 2.2.4. El estimador T~ = t*(Xl , X 2 , ... ,Xn ) se denomina el estimador Pitman más concentrado para la imagen de O bajo la función r si él es Pitman más concentrado que cualquier otro estimador para imagen de O bajo r.
Definición 2.2.5. Sea Xl, X 2 , ... ,Xn una muestra aleatoria de una población con función de densidad fx(x, O), la función r(O) una función del parámetro O y Tn = t(Xl , X 2 , . .. , X n ) un estimador de la imagen de O bajo la función r. Una medida de concentración del estimador Tn es llamada error cuadrático medio MSE (Mean-Squared Error) definido como
El centro de gravedad de la función de densidad de una variable aleatoria es un punto de referencia destacado. Para una estadística, lo es en mayor medida al tornarse en ineludible el conocimiento, con el máximo detalle posible, de la índole de su valor esperado. En particular, saber si el centro de gravedad de la función de densidad de la estadística postulada coincide con el valor del parámetro o con la imagen del parámetro bajo una función determinada, según sea el caso, es una cualidad deseable dentro de los pormenores de la exactitud que se le exige y, por tanto, es un ingrediente necesario dentro del examen de idoneidad como estimador. Por ello cobra importancia el requisito de insesgamiento como uno de los elementos para facultar estadísticas, requisito que a continuación se presenta.
Definición 2.2.6. Dentro de las condiciones de la definición 2.2.5 un estimador Tn se dice que es un estimador insesgado para la imagen de O bajo la función r, si y sólo si
Ee[Tnl = r(O),
para todo O E 8.
Definición 2.2.7. Según las consideraciones de la definición 2.2.5, la diferencia
se denomina sesgo del estimador Tn para la imagen de O bajo r.

92 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
El error cuadrático medio de un estimador Tn puede expresarse como la suma de dos componentes: la varianza del estimador Tn Y el cuadrado del sesgo del mismo. En efecto,
MSETn(O) = Ee [(Tn - r(O))2]
= Ee {[(Tn - Ee[Tn]) + (Ee[Tnl- r(O))f}
= Ve[Tnl + B~[Tnl
porque (Ee[Tnl - r(O))Ee [Tn - Ee[Tnll = O. Por supuesto, si Tn es un estimador insesgado para la imagen de O bajo la función r, entonces Be [Tnl = O, Y por tanto
MSETn(O) = Ve[Tnl·
El requisito de insesgamiento puede cumplirse en muchos casos modificando ligeramente la estadística en consideración. En otras oportunidades, el sesgo pierde interés y no es obstáculo en el buen desempeño del estimador, porque en la medida que el tamaño de la muestra se incrementa el sesgo se disipa.
Definición 2.2.8. Con base en las consideraciones de la definición 2.2.5 al estimadorTn = t(XI ,X2, ... ,Xn) basado en una muestra aleatoria de un población con función de densidad fx(x, O) se le denomina estimador asintóticamente insesgado para la imagen de O bajo la función r, si
lim {Ee[Tnl - r(O)} = O n---+oo
para todo O E e.
Ejemplo 2.2.9. Sea Xl, X2, .. . , X n una muestra aleatoria de una población con función de densidad
1 fx(x,O) = 7/(o,e)(x), O> O.
El método por analogía sugiere el estimador Tn = Xn,n para O. Determinar el MSE de Xn,n.
nyn-l f xn,n (y) = -----¡¡n J(o,e) (y)
¡e n n O nd = __ _ Ee[Xn,nl = ° on Y y n + 1

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 93
n O Be[X ]=--0-0=---.
n,n n + 1 n + 1
Claramente, Xn,n es un estimador asintóticamente insesgado para O.
E [X2 ] = ~ re yn+l dy = _n_02 e n,n On Jo n + 2
2 V; [X ] - _n_02 _ n 02 _ n 02
e n,n - n+2 (n+1)2 - (n+1)2(n+2) .
Luego 202
MSEXn,n (O) = (n + 1)(n + 2)
Ejemplo 2.2.10. El MLE de a 2 basado en una muestra aleatoria Xl, X 2 , ... , X n , de una población gaussiana de valor esperado ¡.¡, y varianza a 2 es
Tn = .!. :t (Xi - Xn)2 , n i=l
estadística con un sesgo que puede pasarse por alto al contar con una muestra grande, porque Ee [Tn ] = n~ l a2 . Sin embargo es factible corregir esta ligera imperfección construyendo una estadística que cumpla el requisito de insesgamiento. Precisamente, la estadística
S2 = _1_ ~ (X. _ X ) 2 n n-1L.... t n
i=l
cuenta con una función de densidad cuyo centro de gravedad es justamente a 2 , como lo asegura de manera general el teorema 1.4.3. Independientemente del modelo asumido, el insesgamiento de S~ como estimador de la varianza poblacional es la razón por la cual S~ se adopta como varianza de la muestra.
Ejemplo 2.2.11. Si T~l) y T~2) son dos estimadores insesgados para
O cuyas varianzas son respectivamente ai y a~, y si T~i) rv N (O, al), entonces T~l) es más concentrado que T~2) para O, si y sólo si ai < a~. En efecto, como
P, [IT~i) ~ 01 < .xl = P, [ ~~ < T~i~i~ O < ~ 1 = p (~) - p ( - ~) = 2p (~) - 1

94 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
siendo <p(v) = J~oo vke-~z2 dz, entonces
Po [IT~l) - 01 < A] 2: Po [I T2) - 01 < A]
2<p (:1) - 1 2: 2<p (:2) - 1
<p (~) 2: <p (~)
desigualdad que se cumple cuando ~ 2: ~; en síntesis, cuando 0"1 < 0"2. 0"1 0"2
2.2.2 Consistencia, un requisito ligado al tamaño de la muestra
Definición 2.2.12. Sea Tn = t(Xl , X 2 , .. . , X n ) un estimador para la imagen de O bajo r, r una función de O, construido con base en una muestra aleatoria Xl, X 2 , .. . , X n de una población con función de densidad fx(x, O). Tn se denomina estimador consistente en error cuadrático medio para la imagen de O bajo la función r, si la sucesión de estadísticas {Tn } converge en media cuadrática a r( O), es decir, si
lim Eo [(Tn - r(0))2] = O, n-too
para todo O E e.
Definición 2.2.13. Según las consideraciones de la definición 2.2.12, Tn es un estimador consistente simple o consistente débil para la imagen de O bajo r, si la sucesión de estadísticas {Tn } converge en probabilidad a r( O), es decir, si
lim Po [r(O) - E < Tn < r(O) + El = 1, n-too
para todo O E e y E > O.
N ota. Un estimador que haya sido construido por el método de los momentos, naturalmente es un estimador consistente simple.
Como la consistencia de un estimador es una propiedad inherente a la convergencia, un estimador consistente en error cuadrático medio es un estimador consistente simple. Lo contrario no siempre es cierto.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 95
Definición 2.2.14. Sea T~ = t*(Xl , X 2, ... , X n ) una estadística basada en una muestra aleatoria Xl, X 2, . .. ,Xn de una población con función de densidad fx(x, O) estadística elegida como estimador para la imagen de O bajo una función r. T~ se denomina estimador BAN (Best Asymptotically Normal), si y sólo si:
1. La sucesión de variables aleatorias
{yn[T~ - r(O)]}
converge en distribución a una variable aleatoria con distribución Normal de valor esperado cero y varianza 0'*2 (O).
2. El estimador T~ es consistente simple para la imagen de O bajo la función r.
3. Siendo Tn cualquier otro estimador consistente simple para la imagen de O bajo la función r para el cual la sucesión
{yn[Tn - r(O)]}
converge en distribución a una variable aleatoria con distribución Normal de valor esperado cero y varianza 0'2 (O), se tiene que
Definición 2.2.15. Un estimadorTn para la imagen de O bajo la función r con las condiciones de la definición 2.2.14 se denomina estimador CAN (Gonsistent Asymptotically Normal), o Tn es GANE, sz
para todo O E e.
Definición 2.2.16. Siendo T2) y T2) dos estimadores GAN para la imagen de O bajo una función r, basados en una muestra aleatoria Xl, X 2, ... , X n de una población con función de densidad fx(x, O), cuyas
varianzas son respectivamente ai (O) y o'~ (O), se dice que TÁ1) es asintóticamente más concentrado que TÁ2) , si O'r (O) :S o'~ (O), para todo O E e.

96 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Teorema 2.2.17. Siendo Xl, X 2 , . •. ,Xn una muestra de una población con función de densidad fx(x, O), una función continua y positiva en el percentil xp con p un valor fijado de antemano, entonces la estadística de orden X[np]+l,n es un estimador CAN para el percentil xp con
(J2(0) = p~l-p) ; o dicho de otra manera nfx(xp,O)
J p(l ~ p/x(xp , O) [X[np]+l,n - xp] ~ Z rv N(O, 1).
2.2.3 Suficiencia, un requisito de retención de información
El concepto de suficiencia que no es tan intuitivo como el concepto de consistencia, insesgamiento o concentración, fue definido por Fisher en 1922. En una de sus afirmaciones expresaba que una estadística suficiente es "equivalente, para todos los propósitos de estimación, a los datos originales de los cuales fue derivada". Esta afirmación permite señalar entonces la importancia de una estadística suficiente y colegir que un buen estimador debe ser función de una estadística con esta propiedad.
La idea de suficiencia indaga sobre la pérdida de información, que para efectos de estimación del parámetro O supone la reducción de los valores observados Xl, X2, ... ,Xn en un solo dato: t n = t(Xl, X2,· .. , xn ),
que a la luz de la afirmación de Fisher, citada en el párrafo anterior, significa que una estadística suficiente conserva de alguna manera la información contenida en la muestra aleatoria, es decir, en las variables aleatorias que representan a los datos originales.
El concepto de suficiencia involucra las observaciones muestrales, observaciones que pueden considerarse como un elemento del espacio de las observaciones X subconjunto de lR.n definido como
X = {(Xl, X2, ... , Xn)IXI, X2, ... , Xn son valores observados de Xl, X 2, ... , Xn}.
El conocimiento de un valor particular t n de una estadística Tn no permite la identificación de cada uno de los valores muestrales Xl, x2, ... ,Xn , que lo produjeron, porque varios elementos del espacio de las observaciones X pueden tener como imagen el mismo valor t n , elementos éstos que conforman un subconjunto denominado contorno de la estadística Tn . Cualquier contorno de una estadística suficiente posee una propiedad especial: su comportamiento probabilístico no depende del parámetro O. Esta idea se abstrae y se formaliza en la siguiente definición.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 97
Definición 2.2.18. Una estadística Tn = t(Xl, X2, ... ,Xn ) se dice que es una estadística suficiente para e, basada en una muestra aleatoria Xl, X 2 , ... ,Xn de una población con función de densidad fx(x, e), si la distribución condicional de las variables aleatorias Xl, X 2 , .. . , X n dado Tn = t n , no depende de e para todo valor tn .
Ejemplo 2.2.19. Sea Xl, X 2 una muestra aleatoria de tamaño dos de una población con distribución de Bernoulli de parámetro e. T2 = Xl + X 2 es una estadística suficiente para e. Para los valores particulares de la estadística T2 = O Y T l = 2,
En el caso especial del valor T2 = 1, se tiene que
PO[T2 = 1] = PO[X l = 1, X 2 = O] + Po [Xl = O, X 2 = 1]
= e(l - e) + e(l - e)
= 2e(1 - e)
con lo cual
p. [X = 1 X = OITo = 1] = Po[X l = 1, X 2 = O] O 1 ,2 2 Po [T2 = 1]
e(l - e) 2e(1 - e) 1 -2
Po[Xl = O, X 2 = 1] Po[Xl = O, X 2 = 11 T2 = 1] = Po[T
2 = 1]
e(l - e) 2e(1 - e) 1 -
2
De esta manera se concluye que T2 = Xl + X 2 es una estadística suficiente para e, pues la distribución condicional de las variables Xl, X 2
dados valores particulares de la estadística T2 no depende de e. Por su parte, la estadística T~ = X 1X 2 no es una estadística suficiente

98 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
para O. La estadística produce dos valores: ° y 1. Entonces,
Pe[T~ = O] = Pe[XI = 0, X 2 = O] + Pe [Xl = 1, X 2 = O]
+ Pe [X l = 0, X 2 = 1]
= (1 - 0)2 + 2(1 - 0)0 = 1 - 02
Pe[T~ = 1] = 02.
Según la definición anterior, es preciso examinar la distribución condicional de Xl, X 2 dado T~ = t~, es decir, si las siguientes probabilidades dependen o no del parámetro O, para poder concluir sobre la suficiencia de la estadística.
, _ (1 - 0)2 = 1 - O Pe[XI = 0, X 2 = 0IT2 = O] - 1 _ 02 1 + O
, _ 0(1 - O) = ~O_ Pe[XI = 0, X 2 = 11T2 = O] - 1 _ 02 1 + O
, _ 0(1 - O) = _0_ Pe[XI = 1, X 2 = 0IT2 = O] - 1 _ 02 1 + O
Pe[XI = 1,X2 = 11T~ = 1] = 1
Con estos resultados puede deducirse que la estadística T~ = X I X 2 no es una estadística suficiente para O.
Determinar,con base en la definición 2.2.18 si una estadística específica es una estadística suficiente, no es una tarea fácil en la mayoría de las situaciones, porque sólo la construcción de la distribución condicional puede resultar dispendiosa. Menos complicado podría resultar el uso de la siguiente definición, apropiada más para señalar la no suficiencia que la suficiencia de una estadística particular. Por fortuna, el criterio de Fisher-Neyman es un instrumento seguro para la búsqueda o confirmación de estadísticas suficientes.
Definición 2.2.20. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con función de densidad f X (x, O). Una estadística Tn = t(XI ,X2 , ... ,Xn ) es una estadística suficiente para el parámetro O si y sólo si la distribución condicional de T~ = t'(XI , X 2 , .. . , X n ),
dado Tn = tn, no depende de O, siendo T~ cualquier estadística.
Teorema 2.2.21 (Criterio de factorización de Fisher-Neyman). Versión para estadísticas suficientes unidimensionales. S ea Xl, X 2, ... , X n

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 99
una muestra aleatoria de una población con función de densidad f x (x, e). Siendo Tn una estadística, Tn = t(Xl , X 2, ... , X n ), ella es suficiente para e, si y sólo si la función de verosimilitud de la muestra puede expresarse como el producto de dos factores:
siendo h una función no negativa que depende exclusivamente de Xl,
X2, ... ,Xn y la función g, no negativa, que depende de e y de Xl, X2, ... , Xn
a través de t(Xl,X2, ... ,Xn ).
El ejemplo 2.2.19 pretende ser inductor del concepto de la suficiencia de una estadística, ejemplo despojado de toda complicación de cálculo, para centrar la reflexión sobre el concepto a la luz de la definición 2.2.18. Por el contrario, el siguiente ejemplo, generalización del ejemplo 2.2.19, ilustra una forma mecánica de determinar estadísticas suficientes con el recurso del criterio de factorización de Fisher-Neyman.
Ejemplo 2.2.22. Sea Xl, X 2 , ... ,Xn una muestra aleatoria de una población con distribución de Bernoulli de parámetro e.
n Tn = ¿ Xi es una estadística suficiente para e. En efecto,
i=l
n
(1 ~ e )i~l Xi (1- e)n I1 I{o,l} (Xi) ~=~
~ [ e ~ B l' x, (1- e)n]11] I¡O,l} (Xil , v J v
h(Xl,X2, ... ,Xn ) g(t Xi,O) t=l
n Luego el criterio de Fisher-Neyman permite concluir que ¿ Xi es una
i=l estadística suficiente para e, porque g es una función no negativa que
n depende de e y de ¿ Xi Y h depende únicamente de Xl, X2,· .. ,Xn ·
i=l

100 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Definición 2.2.23. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad f x (x, O). Las estadísticas unidi-
. (1) (2) (m). d (i) ( ) menswnales Tn , Tn , ... , Tn ,szen O Tn = ti Xl, X2, ... , X n , para i = 1,2, ... , m, se denominan estadísticas conjuntamente suficientes para O, si y sólo si la distribución de Xl, X 2, . .. , X n, dado T~l), T2), ... , T~m), no depende de O.
Una colección de estadísticas conjuntamente suficientes corresponde a una estadística Tn de dimensión igual al número de estadísticas unidimensionales que conforman la colección, es decir, con los elementos de
la definición 2.2.23, Tn = (T~l), T~2) , ... , T~m»).
Teorema 2.2.24. Si las estadísticas T~l) t1(X1, X2, ... , X n),
T~2) = t2(X1, X2, . .. , X n ), . .. , T~m) = tm(X1, X2, ... , X n ) constituyen una colección de estadísticas conjuntamente suficientes, entonces cualquier transformación uno a uno de T2), T~2), ... , T~m) es también un conjunto de estadísticas suficientes.
Teorema 2.2.25 (Criterio de Factorización de Fisher-Neyman). Versión para estadísticas conjuntamente suficientes. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, O). Las estadísticas T~l) = t1(X1,X2, ... ,Xn),T~2) = t2(X1,X2, ... ,Xn ),
... ,T~m) = tm(X1, X 2, . .. ,Xn ) constituyen una colección de estadísticas conjuntamente suficientes para O, si y sólo si la función de verosimilitud de la muestra L(O; Xl, X2, . .. , Xn ) = L puede expresarse como
L = g(t1(X1, X2,···, x n ), .. ·, tm(X1, X2,···, x n ); 0)h(X1, X2,···, x n)
La función h es una función no negativa que depende de Xl, X2, ... , Xn exclusivamente y g una función no negativa que depende de O y de Xl, X2,· .. , Xn a través de t1, t2,·· ., tm .
Ejemplo 2.2.26. Sea Xl, X 2, .. . , X n una muestra aleatoria de una po-

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 101
blación Normal de valor esperado JL y varianza (j2, e = (JL, (j2)'.
n n h(XI, X2, ... ,Xn ) = 1. Luego ¿ Xi Y ¿ Xl son conjuntamente sufi-
i=l i=l
cientes para e = (JL, (j2)'. También son conjuntamente suficientes para e
Se anotaba en la parte introductoria del método de máxima verosimilitud, que los estimadores construidos con este procedimiento poseen propiedades especiales que los hacen atractivos. Sin destacarlas en sección alguna del texto, esas propiedades van surgiendo con el desarrollo del capítulo. En primer lugar, un MLE puede ser una estadística suficiente, teniendo en cuenta los enunciados de los teoremas 2.2.27 y 2.2.34.
Teorema 2.2.27. Si Tn es una estadística suficiente para e basada en una muestra aleatoria Xl, X 2 , ... ,Xn , de una población con función de densidad fx(x, e), y si T~ es un MLE para e, y es único, entonces T~ es función de Tn .
La estadística T~l) = t(Xl, X 2 , . .. ,Xn) = (Xl, X 2 , . .. ,Xn ) es, a la luz de la definición 2.2.18, una estadística suficiente, como lo es también T~2) = (X1,n, X 2,n, . .. ,Xn,n). Sin embargo, el propósito consiste en contar con una estadística que represente la condensación de n datos en uno solo, sin pérdida de información respecto al parámetro, valor singular correspondiente a un vector cuyo número de componentes sea inferior a n. La estadística suficiente con menor dimensión y con la máxima reducción de los datos representados por la muestra aleatoria, manteniendo intacta la suficiencia, es decir, sin pérdida de información sobre e, sugiere la noción de estadística suficiente minimal.

102 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Definición 2.2.28. Una estadística suficiente Tn se denomina suficiente minimal, si Tn es función de cualquier otra estadística suficiente.
Teorema 2.2.29. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, O), Y Tn = t(XI, X 2, . .. , X n ) una estadística. El cociente de verosimilitudes
L(01;XI,X2, ... ,xn )
L(OO;XI,X2, ... ,xn )
es función de t(XI, X2, ... , x n ), si y sólo si Tn es una estadística suficiente.
Teorema 2.2.30. Sean Xl, X 2, ... , X n y XL X~, ... , X~ dos muestras aleatorias de una población con función de densidad fx(x, O). La estadística Tn = t(X1 , X 2, ... , X n ) es una estadística suficiente minimal para el parámetro O, si ella tiene la propiedad tal que el cociente de verosimilitudes
L(O; Xl, X2,· .. , Xn )
L(O;x~,x~, ... ,X~)
no depende de O, si y sólo si t(XI,X2, ... ,Xn ) = t(x~,x~, ... ,X~).
Definición 2.2.31. Una colección de estadísticas conjuntamente suficientes se denomina minimal, si y sólo si ellas son función de cualquier otro conjunto de estadísticas suficientes.
Ejemplo 2.2.32. Determinar una estadística suficiente minimal para el parámetro O, cuando Xl, X2, .. . , X n es una muestra aleatoria de una población con distribución de Poisson.
n n
L(0;XI,X2, ... ,Xn )
L(O;x~,x~, ... ,x~)
TI x~! e-nllOnxn TI x~! i=l = on(xn -XI n) i=l . n_n TI Xi! e-nIlOnx'n TI Xi!
i=l i=l
Este cociente no depende de O, si y sólo si xn = x' n; es decir, X n es una estadística suficiente minimal para O.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 103
Ejemplo 2.2.33. La estadística (Xn , S~), la cual es suficiente para el parámetro e = (IL, ()2) como lo expone el ejemplo 2.2.26, es una estadística suficiente mini mal. La razón radica en que el cociente
~ = L(B;Xl,X2,'" ,xn) L(B;x~,x~, ... ,x~)
= exp [2~2 t(X~ - JL)2 - 2~2 t(Xi - JL)2]
= exp {2~2 [t(X~ - x' n? + n(x' n - JL)2 - t(Xi - xn)2 - n(xn - JL)2] }
= exp {2~2 [(n - l)s~ - (n - l)s;, + n(x' n - JL)2 - n(x - JL)2] }
Teorema 2.2.34. Sea Tn un MLE para e, estimador basado en una muestra aleatoria Xl, X 2 , ... , X n de una población con función de densidad fx(x, e). Si Tn es el único MLE para e, entonces Tn es función de una colección minimal de estadísticas conjuntamente suficientes. Si Tn no es el único MLE para e, entonces existe un estimador máximoverosímil T~ que es una función de una colección minimal de estadísticas conjuntamente suficientes.
Para propósitos diversos suele constituirse familias de densidades, que agrupan modelos probabilísticos que poseen alguna o algunas características comunes. La familia pearsoniana, por ejemplo, congrega densidades que satisfacen la ecuación diferencial
, x+a y = {3 + "(x + bx2 y
siendo y = fx(x) y a, {3, "(, b constantes. En otras oportunidades se construye una familia de densidades que se puede entender como un macromodelo puesto que incluye modelos probabilísticos tradicionales como sus casos particulares. Por ejemplo, la denominada distribución Gama generalizada, propuesta por Stacy, que incluye modelos particulares como la distribución Gama, la distribución Exponencial, la distribución Weibull e incluso la distribución Lognormal entendida como el caso en el cual k -+ oo. La función de densidad que identifica a esta distribución, a esta familia o a este macromodelo tiene como expresión

104 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
a f3 ( x ) f3k-1 [( x ) 13] ar(k) -; exp - -; 1(0,00) (x),
con x cualquier valor de la variable aleatoria, a, f3 y k constantes positivas.
Esta tendencia a la agrupación de modelos de probabilidad en familias tiene en cada caso propósitos específicos, como se había mencionado. Concretamente, en el estudio de la suficiencia y la completez tiene un singular interés una familia de densidades conocida corrientemente como la familia exponencial de densidades, que la definición 2.2.35 detalla.
Definición 2.2.35. Sea (Xl, X 2, . .. ,Xp )' un vector aleatorio. Se afirma que la función de densidad de (Xl, X 2, . .. ,Xp )' pertenece a la clase o familia p-dimensional de Koopman-Darmois k-paramétrica, que tiene la forma Koopman-Darmois o que pertenece a la clase o familia exponencial p-dimensional de densidades k-paramétrica, si la función de densidad fx 1 ,x2, ... ,xp (Xl, X2, .. . ,xp ) se puede expresar como
, exp [~dj(X1, X2, .. " xp)Cj(O) + arO) + b(X1, x2, .. , , Xp )] ,
- k . para todo B E e <;;; IR , para b, dI, d2, . .. , dk, funczones de Xl, X2,"" xp
ya, q, C2,"" Ck, funciones de B escogidas convenientemente.
Definición 2.2.36. Como caso especial en la definición 2.2.35, una función de densidad fx(x, B), B E e <;;; IR, pertenece a la familia exponencial unidimensional de densidades si la función de densidad fx(x, B) puede expresarse como
fx(x, B) = a(B)b(x)exp[c(B)d(x)],
para todo x, B E e con a, b, c, d funciones escogidas convenientemente.
Definición 2.2.37. También particularizando la definición 2.2.35, la función de densidad fx(x, B) pertenece a la familia exponencial de densidades k-param étri ca, si fx(x, B) puede expresarse como
fx(x, O) = a (0" O", ", Ok) b(x )exp {t Cj (0" O2,,,,, Ok) dj(x) } ,

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 105
para todo x, y todo O E e ~ JR.k, con a, b, Cj, dj funciones elegidas convenientemente.
En general, sin hacer mención al entero k que se refiere al número de componentes del vector O, ni al número p de variables aleatorias que constituyen el vector aleatorio, se habla simplemente de clase o familia Koopman-Darmois, clase o familia exponencial de densidades. La determinación de k y p será explícita o se podrá deducir del contexto.
Ejemplo 2.2.38. La función de densidad de una variable aleatoria con distribución Exponencial negativa pertenece a la familia exponencial de densidades. Efectivamente,
fx(x, O) = Oe-OXI(o,oo) (x) = [O]I(o,oo) (x)exp{[-O][x]}
donde a(O) = O, b(x) = I(o,oo) (x), c(O) = -O, d(x) = x.
Ejemplo 2.2.39. La función de densidad de una variable aleatoria con distribución de Poisson pertenece a la familia exponencial de densidades debido a que
OXe-O fx(x, O) = -,-I{O,1,2, ... }(x)
x.
= [e-O] [I{O,l'~i·}(X)] exp{[lnO][x]}
donde a(O) = e-O,b(x) = I{O,I,2, ... }(x)jx!,c(0) = InO,d(x) = x
Nota. Si fx(x, O) pertenece a la familia exponencial unidimensional de densidades y si Xl, X 2, ... ,Xn es una muestra aleatoria de una población con dicha función de densidad, la estadística
n
¿d(Xd i=l
es una estadística suficiente.
Esta afirmación puede sustentarse utilizando el criterio de factorización.

106 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Como fx(x, O) pertenece a la familia exponencial unidimensional de densidades,
fx(x, O) = a(O)b(x)exp{ c(O)d(x)}
L(x¡, X" ••• , X n; O) ~ an(O) Ú b(xi)exp { c(O) ~ d(Xi) }
g C~ d(Xi), ()) = an(())exp {c(()) i~ d(Xi)} y h(Xl, X2,···, xn) = i[Il b(Xi)'
k
La estadística ¿ d(Xi ) ha sido denominada por algunos autores como i=l
la estadística natural de la familia exponencial unidimensional e igual-mente por las razones de la nota anterior, para efectos de suficiencia, se le conoce como la estadística natural suficiente de la familia exponencial unidimensional. También al vector 0* = (q (0), C2 (0), ... , Ck (O))' se le denomina el parámetro natural de la distribución, y en general a la estadística
(n n n)' ~ d1(Xi ), ~ d2(Xi ), ... , ~ dk(Xi )
se le conoce como estadística natural k-dimensional para O.
Ejemplo 2.2.40. La función de densidad de una variable aleatoria X
1 fx(x,O) = n//1 /1 \xOl-1(1-x)02-1ICO,1)(X)
pertenece a la familia exponencial 2-paramétrica de densidades. En efecto,
!x(X,()) = [¡3(():,()2)] [1(0,1) (x)] exp{[()l -l][ln(x)] + [()2 -l][ln(l- x)]).
Nótese que en este caso a(O) = 1/(3(01,02), b(x) = I CO ,l) (x), q(Ol, 02) = 01 -1, C2(01, O2) = O2 - 1, d1(x) = lnx, d2(X) = In(l- x).
Nota. Igualmente, con el apoyo del criterio de factorización se deduce que si fx(x, O) pertenece a la familia exponencial k-paramétrica de densidades, las estadísticas
n n n
L d1(Xi ), L d2(Xi ), ... , L dk(Xi )
i=l i=l i=l

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 107
son conjuntamente suficientes para (). Además se puede demostrar que constituyen una colección minimal.
Antes de concluir lo concerniente a la suficiencia, es menester precisar el término equivalencia y su efecto en la suficiencia, debido a la existencia de estadísticas que para efectos de inferencia proporcionan la misma información. Igualmente, si la suficiencia se asocia con la idea de retención de información, lo contrario, no poseer información relativa al parámetro, es un atributo que de alguna manera debe señalarse.
Definición 2.2.41. Sea Xl, X 2, ... , X n , una muestra aleatoria de una población con función de densidad fx(x, ()). Siendo T~ y Tn dos estadísticas tales que T~ = t*(XI, X2, ... , X n) y Tn = t(XI, X2, ... , X n), se dice que las dos estadísticas son equivalentes si existe una función 9 uno a uno de tal manera que T~ = g(Tn ).
Teorema 2.2.42. Sea Xl, X2, . .. , X n , una muestra aleatoria de una población con función de densidad fx(x, ()). Siendo Tn = t(XI , X2, ... , X n )
y T~ = t*(X I , X 2, . .. , X n ) estadísticas equivalentes, si Tn es una estadística suficiente para (), también lo es T~.
Esta propiedad, que resalta el anterior teorema, se intuye fácilmente porque dado cualquier contorno de la estadística T~ él corresponde al mismo contorno de la estadística Tn . Esta propiedad permite construir buenos estimadores a partir de una estadística suficiente.
Finalmente, contrario a lo expresado en esta sección dedicada a la suficiencia, en el sentido de que una estadística suficiente contiene toda la información respecto al parámetro, existen estadísticas que no contienen dicha información. Entonces la idea contraria a la suficiencia puede formalizarse en la siguiente definición y una utilización particular de ella la precisa el teorema de Basu.
Definición 2.2.43. Sea Xl, X 2, ... , X n , una muestra aleatoria de una población con función de densidad fx(x, (). Tn = t(XI, X 2, .. . , X n ) se denomina estadística auxiliar para el parámetro (), si frn (t) es una función que no depende de (). Si específicamente E[Tnl es un valor que no depende de (), Tn se denomina estadística auxiliar de primer orden.
Teorema 2.2.44 (Teorema de Basu). Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, ()). Siendo

108 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
la estadística Tn = t(XI , X2, . .. , X n ) una estadística auxiliar para el parámetro e y la estadística T~ = t*(XI, X 2, .. . , X n ) una estadística suficiente para e, entonces Tn Y T~ son variables aleatorias estadísticamente independientes.
Ejemplo 2.2.45. Cuando se derivaba el estimador por el método de los momentos para el parámetro e bajo el modelo Uniforme en el intervalo (-e, e), ejemplo 2.1.17, página 82, el método encontró un obstáculo:
X n !!...." O. Allí se afirmó que X n no contenía información sobre e. Como Eo [X n] = O, entonces X n es una estadística auxiliar de primer orden.
Ejemplo 2.2.46. Siendo Xl, X2,.'" X n una muestra aleatoria de una
población Uniforme en el intervalo (O, e), las estadísticas TJI) = XI,n y X nn
TJ2) = Xn,n son variables aleatorias independientes. ' Como Xn,n es una estadística suficiente para e, de acuerdo con el teorema
de Basu sólo resta mostrar que TJI) es una estadística auxiliar. En efecto,
[Xl n ] FT$.l)(t) = P Xn',n::; t, 0< t < 1
= P [XI,n ::; tXn,nl
_ rO rty n(n - 1) (Ji _ ~)n-2
- Jo Jo e2 e e dx dy
= [1 - (1 - t)n-l] I(o,l)(t) + I[l,oo) (t).
Por tanto, la función de densidad correspondiente no depende de e. Entonces T2) y TJ2) son estadísticamente independientes.
2.2.4 Varianza mínima, un requisito de máxima precisión
La variabilidad es en esencia inherente a la estadística, su razón y su objeto. Poder conocer su comportamiento, cuantificarla y en muchos casos mantenerla bajo control son propósitos deseables y además viables. Los estimadores surgidos de esa condición de variabilidad heredan esa misma naturaleza, sólo que para éstos la precisión en su papel de estimar parámetros es reconocida a través de su variabilidad. Por ello la variabilidad, medida por medio de la varianza, se convierte en un criterio de examen de estadísticas, pues evidentemente es más preciso aquel estimador que tenga menor varianza, ya que tiene la capacidad de producir estimaciones más concentradas. Esta sección se enfoca hacia este requisito.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 109
Definición 2.2.47. Siendo Tn Y T~ dos estimadores insesgados para la imagen de e bajo la función r, r : e -----t e* ~ ~, estimadores basados en una muestra aleatoria Xl, X 2, ... , X n, de una población con función de densidad fx(x, e), se dice que Tn es un estimador uniformemente mejor que T~ si Ve [Tnl :::; Ve [T~l, para todo e E e.
Definición 2.2.48. Un estimador T~ = t*(Xl , X 2, .. . , X n) basado en una muestra aleatoria Xl, X 2, ... , X n de una población con función de densidad fx(x, e), r(e) una función de e, es insesgado de varianza uniformemente mínima UMVUE (Uniformly minimum-variance unbiased) para la imagen de e bajo la función r si y sólo si T~ es un estimador insesgado para la imagen de e bajo r y Ve [T~l :::; Ve [Tnl siendo Tn = t(Xl , X 2, ... , X n ) cualquier otro estimador insesgado para la imagen de e bajo la función r.
Teorema 2.2.49 (Teorema de Rao-Blackwell). Sean Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, e),
las estadísticas T2) = h(Xl ,X2, ... ,Xn),TÁ2) = t2(Xl ,X2, ... ,Xn),
... , TÁm) = tm(Xl , X2, ... , X n) estadísticas conjuntamente suficientes, r(e) una función de e, y siendo la estadística Vn = t(Xl ,X2, ... ,Xn) un estimador insesgado para la imagen de e bajo la función r y T~ = t*(Xl , X 2, ... , X n) un estimador tal que la estimación t~ se deter-mina como
* - E [TT IT(l) T(2) T(m)l tn - e Vn n , n , ... , n
entonces,
1. T~ es una estadística, función de estadísticas suficientes solamente.
2. Ee[T~l = r(e).
3. V¡¡[T~] :::; V¡¡[Vn].
Ejemplo 2.2.50. Sea Xl, X 2 , .. . , X n una muestra aleatoria de una población con distribución de Bernoulli de parámetro e. El proceso de Rao - Blackwell, brinda un camino de construcción de un estimador insesgado para e con una varianza menor a la varianza de un estimador insesgado elegido inicialmente.
A partir de Tn = Xl, como un estimador in sesgado para e y de
TÁl) = f: Xi una estadística suficiente, se determina la estimación i=l

110 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
t~ = Eo[TnIT2)l.
[
n 1 Po [Xl = O, i~ Xi = tI] Po Xl = 01 LXi = tI = n -
i=l Po [2: Xi = tI]
p. [Xl = 1
Luego
t=l
Po [Xl = 0, f: Xi = tI] t=2
Po [f: Xi = tI] ~=l
(1- O)(n~I)(O)tl(l_ 0)n-I-t1
n-tI
n
(~)(O)tl(l- o)n-tl
n 1 Po [Xl = 1, i~ Xi = tI] LXi = tI = -...::....--;:---n----=:-----"-
i=l Po [2: Xi = tI] t=l
Po [Xl = 1, f: Xi = tI - 1] t=2
Po [f: Xi = tI] t=l
0(n-l)ot1-1(1 - 0)n-I-t1+1 t tl-l l (~)Otl (1 - o)n-tl n
E. [Xl t Xi = t1 1 = O (n: t1 ) +J. (~) En consecuencia,
1 n
T* = - ""' Xi n n~ i=l
V[Tnl = 0(1 - O) > V[T~l = 0(1 - O) . n

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 111
Definición 2.2.51. Sea X una variable aleatoria cuya función de densi
dad fx(x, O) es tal que :0 In fx(x, O) existe para todo x, fx(x, O) > 0, y
para todo O E 8 <;;;; IR. La información de Fisher acerca del parámetro O en la variable aleatoria X, I (O) se define como
1(0) = E, {[:O In tx(X, O)]'} .
Nota. Si ~ In fx(x, O) existe para todo x tal que fx(x, O) > ° y para
todo O E 8 <;;;; lR, la información de Fisher acerca del parámetro O, en la variable aleatoria X, también puede definirse como
I(O) = -Ef) [::2 Infx(X,o)] .
1 (x_O)2
Ejemplo 2.2.52. Sea fx(x, O) = ícL e-~ con (J conocido. V 27W
ícL 1 2 Infx(x,O) = -In(J-lnv27f- -2(x-O)
2(J
8 (x-O) 80 In f x (x, O) = -----¡;¡-
1(0) = E, [ (X,,~ o)'] = :4 E, [(X - O)']
Vf)(X) 1 (J4 (J2 .
Definición 2.2.53. La información de Fisher acerca del parámetro O en la muestra aleatoria Xl, X2, ... , X n de una población con función de densidad fx(x, O) se define como
y es equivalente a nI (O), siendo I (O) la información de Fisher acerca del parámetro O en la población, cuya función de densidad es fx(x, O).

112 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Definición 2.2.54. Sea Xl, X2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, O) Y Tn = t(Xl , X2, . .. , X n )
una estadística. Se habla de un caso regular de estimación o de cumplimiento de condiciones de regularidad cuando el modelo escogido para representar el comportamiento de la población y la estadística en consideración cumplen las siguientes condiciones:
1. :0 lnfx(x,O) existe para todo x tal que fx(x,O) > O Y para todo
OE8~R
2. La información de Fisher acerca del parámetro O en la población 1 (O) es finita para todo O E 8.
3. Si la variable X que representa a la población es continua
:e j ... jITfX(Xi,e)dX1 .. . dxn = j ... j :e ITfX(xi,e)dx 1 .. . dx n ,
1=1 1=1
análogamente cuando X es discreta.
4. Si la variable X que representa a la población es continua
:0 J ... J t(Xl, X2,· .. , x n ) rr fX(Xi, O)dXl dX2· .. dXn
i=l
= J ... J t(Xl, X2,··· ,Xn) :0 rr fX(Xi, O)dXl dX2 ... dxn ,
1=1
análogamente cuando X es discreta.
Teorema 2.2.55 (Desigualdad de Cramer-Rao). Sea Xl, X 2, .. ·, X n una muestra aleatoria de una población con función de densidad f x (x, O), r(O) una función de O, Tn = t(X l , X2, ... , X n ) un estimador para la imagen de O bajo la función r y Be(Tn) el sesgo de Tn . Dentro de un caso regular de estimación,
Ee [(Tn - r(0))2] 2': (r'(O) + B~(Tn))2 nI(O)
con B~(Tn) = :oBe(Tn).

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 113
Dentro de un caso regular de estimación, si Tn es un estimador insesgado para la imagen de O bajo una función r, la desigualdad de CramerRao adquiere la versión particular
\7¡ (~ ) > (r'(0))2 B n - nI(O)
que corresponde a la versión más difundida entendida como la determinación de una cota para la varianza de cualquier estimador insesgado para la imagen de O bajo una función r, conocida precisamente como la cota de Cramer-Rao.
Corolario 2.2.56. La igualdad en el teorema 2.2.55 se da cuando
En este caso, Tn es un UMVUE para la imagen de O bajo la función r.
En la desigualdad de Schwarz E[(Xy)2] = E[X2]E[y2], cuando y = kX, siendo k una constante. Por tanto,
E [(~ _ (0))2J = [B~(Tn) + r'(0)]2 B n r nI(O) ,
cuando existe una constante tal que
8 n
80 In rr fx(xi, O) = k(tn - r(O)). i=l
En esta oportunidad se menciona la estimación máximo-verosímil en relación con la consistencia asintóticamente normal, como una propiedad particular que en casos especiales presentan los estimadores construidos mediante este procedimiento. El siguiente teorema da fe de ello.
Teorema 2.2.57. En un caso regular de estimación, si Tn es el estimador máximo-verosímil para la imagen de O bajo la función r, Tn es un estimador CAN de manera que
vÍn(Tn - r(O)) .!!... N (o, ItO)) .

114 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
1 n Ejemplo 2.2.58. Siendo Pn = - ¿ Xi el MLE para e en el caso de
n i=l una población de Bernoulli de parámetro e, Pn es un estimador CAN para e. Esto es
y'ii(Pn - e) ~ N(O, e(l - e)).
n Para el modelo de Bernoulli y la estadística ¿ Xi se cumplen las condi
i=l ciones de regularidad, entonces
fx(x, e) = e X (1- e)l-x 1{o,1} (x)
In f X (x, e) = x In e + (1 - x) In (1 - e)
a x 1- x ae lnfx(x,e) = 7i - 1- e·
Con estos elementos, la información de Fisher se puede obtener como sigue:
{(X 1-X)2} 1(e) = Ee e - 1 - e
1 Ee {((1- e)x - e(l- X))2}
1 { 2} Ve(X) = e2(1- e) 2E e (X - e) = e2(1- e)2
e(l - e) 1
e2(1 - e)2 e(l - e)·
Luego d y'ii(Pn - e) ----+ N(O, e(l - e)).
Definición 2.2.59. La eficiencia relativa de T2) = t2(XI , X 2 , ... ,Xn )
respecto a T2) = tl(XI , X 2, ... , X n ), estimadores insesgados para la imagen de e bajo una función r, basados en una muestra aleatoria Xl, X 2, . .. ,Xn de una población con función de densidad fx(x, e), corresponde al cociente
Ve [T2)]
Ve[T~2)]

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 115
Siendo la eficiencia relativa un elemento de comparación entre dos estimadores, pueden involucrarse elementos adicionales para enriquecer la mencionada comparación, como el tamaño de la muestra. Suponiendo
que T~l) y T;;) sean dos estimadores para la imagen de O bajo una
función r, tales que T2) '" N (r(o), (Ji~O)) y T;;) '" N (r(o), (J~O)) asumiendo que (Ji (O) < (J~ (O), la eficiencia relativa de T;;) respecto a
T~l) corresponde a (Ji(O)/n
d(O)/m·
En estos términos, T;;) será tan eficiente como T~l) en la medida que la . ... (Ji( O) n
cItada efiCIenCIa tenga un valor Igual a uno; caso en el cual (J~ (O) = m·
Teniendo en cuenta que (Ji (O) < (J~ (O), entonces !!-. < 1. Si en gracia m
·d ., 1 1 d 1 . t (Ji(O) 09· a esta conSI eraClOn e va or e COCIen e (J~(O) se asume en . , qUIere
decir que T;;) requiere una muestra de un tamaño cercano al 11.11 % mayor que el tamaño de la muestra n calculado con base en el estimador T~l) para tener igual desempeño, o igualmente que a T2) sólo le basta
contar con el 90% del tamaño de muestra calculado para T;;).
Definición 2.2.60. La eficiencia relativa asintótica de T~2) respecto
a T~l), siendo T2) y T~2) estimadores CAN, para la imagen de O bajo una función r, con varianzas (Ji (O) y (J~ (O) respectivamente, es el cociente
Definición 2.2.61. En un caso regular de estimación la eficiencia de un estimador Tn insesgado para la imagen de O bajo una función r se define como
Ef (T ) = (r'(O))2 / nI(O) e n Ve [Tn ] .
Definición 2.2.62. En un caso regular de estimación, si Tn un estimador insesgado para la imagen de O bajo una función r, Tn se denomina estimador eficiente o BR UE (best regular unbiased estimator) para la imagen de O bajo la función r, si Efe (Tn ) = 1.

116 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Nota. Todo BRUE es un UMVUE, mas no todo UMVUE es BRUE.
Definición 2.2.63. En un caso regular de estimación, la eficiencia asintótica de un estimador Tn insesgado para la imagen de e bajo una función r, se define como
lim Efe (Tn ). n--->oo
Ejemplo 2.2.64. Sea Xl, X2,'" ,Xn una muestra aleatoria de una población con función de densidad
( ) 1 _lx ( ) fx x, e = ee IJ 1(0,00) x .
Teniendo en cuenta que E[X] = e, V[X] = e2 , l(e) = ¡}Z, y que X n es MLE para e, entonces
E[Xn ] = e V[Xn ] = e2
n
de donde 1 e2
-1
- n¡p _ ~ = 1 Efe (X n ) = --0'2 - e2
n n
Luego X n es un BRUE y UMVUE para e.
2.2.5 Completez, un requisito de la distribución muestral
El requerimiento de completez es el menos intuitivo de los requisitos. Tomado del análisis funcional, en lo concerniente a un conjunto completo de elementos de un espacio de Hilbert, se adapta y configura una formalidad que puede clasificarse como un requisito referente a la familia de densidades correspondiente a la distribución muestral de la estadística en examen.
Definición 2.2.65. La familia de densidades {fx(x, e)le E 8} se dice que es una familia de densidades completa, si para todo e E 8, la condición
Ee[z(X)] = O
implica que Pe[z(X) = O] = 1 para todo x tal que fx(x, e) > o.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 117
Definición 2.2.66. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con función de densidad fx(x, e) y Tn = t(XI, X 2 ,.··, X n )
una estadística. Tn se dice que es una estadística completa para el parámetro e si la función de densidad fTn (t) pertenece a una familia de densidades completa.
Ejemplo 2.2.67. La familia de densidades
{fx(x, e) = (:) (1 - e)n-XeX I e E (0,1) }
es una familia de densidades completa, puesto que si
Eo[z(X)] = °
0= t z(j) (~) ej (1 - e)n-j j=o J
O ~ ~Z(j)(;) e ~ oY (i - 9)"
0= t z(j) (~)aj, j=O J
(a= l~e) luego
y la única forma de tener esta igualdad es cuando
z(O) = z(l) = ... = z(n) = ° Entonces, Eo[z(X)] = ° implica que z(j) = 0, para j = 0,1,2, ... , n. Por tanto, la familia de densidades Binomial es completa.
Ejemplo 2.2.68. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población con distribución de Bernoulli de parámetro e, la estadística
n

118 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
n es una estadística completa para e. En efecto, ¿ Xi rv Bin(n, e), como
i=l se confirmó que la familia de densidades Binomial es completa, entonces
n la estadística ¿ Xi es completa.
i=l
Ejemplo 2.2.69. Si Xl, X2, . .. ,Xn es una muestra aleatoria de una población Uniforme en el intervalo (O, e), Xn,n es una estadística completa para e. En efecto, como
fY 1 1 Fx(y) = Jo (jdx+I(O,CXJ)(Y) = (jyI(o,o)(y) + I(o,CXJ) (y),
la función de densidad del máximo de la muestra es
fXn,n (y) = n[Fx(y)]n-1 fx(Y)
[1 ] n-l 1
= n (jY (j I(o,o) (y)
n n-l ( ) = en y I(o,o) y ,
Partiendo de la condición
fO n Eo [z(Y)] = Jo z(y) en yn-Idy = °
n fO = en Jo z(y)yn-Idy = °
y utilizando el teorema fundamental del cálculo se obtiene que
z(e)en- l = 0, es decir z(e) = 0, para todo e > 0,
con lo cual se concluye que Xn,n es una estadística completa para e, porque Eo[z(X)] = ° implica que z(y) = ° para ° < y < e.
Ejemplo 2.2.70. La familia de densidades
{fx(x, e) = ~e-ix I(o,CXJ) (x) le> ° } es una familia completa,
fCXJ 1 1
Eo[z(X)] = ° = Jo (jz(t)e-{jtdt

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 119
expresión que corresponde a la transformada de Laplace de una función z(t) con B > O. Si esta transformación es cero para todo B > O, entonces z debe ser la función nula.
La familia exponencial de densidades ha mostrado un conjunto de propiedades interesantes. El siguiente teorema amplía ese conjunto incluyendo una propiedad adicional que integra la suficiencia y la completez en esta familia.
Teorema 2.2.71. Sea Xl, X2, ... , X n una muestra aleatoria de una población con función de densidad f x (x, B), función de densidad que pertenece a la familia exponencial de densidades, la estadística natural
n de la familia ¿ d(Xi ) es una estadística suficiente y completa para B.
i=l
El concepto de completez no dispone de la autonomía de otros requisitos en el proceso de facultar estadísticas. Por ello, a priori no es fácil intuir su sentido ni tampoco comprender su inclusión dentro de una lista de requisitos. La integración de la completez al conjunto de requerimientos responde a que su participación en la configuración de un UMVUE, participación expresa en el enunciado del teorema de Lehmann-Scheffé, es obligatoria para la sustentación de uno de los argumentos de la demostración del mismo; realmente su importancia radica en este hecho. Se puede afirmar que la completez es un requisito indirecto para el examen o mejoramiento de la precisión de un estimador.
Como exordio al valioso teorema de Lehmann-Scheffé y como argumento en su demostración se presenta el siguiente teorema.
Teorema 2.2.72. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, B), B E e, r(B) una función del parámetro B y Tn = t(X l , X2, . .. , X n ) un estimador insesgado para la imagen de B bajo la función r. Si Tn es una estadística completa para B, entonces Tn es el único estimador insesgado de la imagen de B bajo la función r.
Teorema 2.2.73 (Teorema de Lehmann-Scheffé). Sea Xl, X 2 , •.. , X n
una muestra aleatoria de una población con función de densidad f x (x, B)
y r una función de B. Si las estadísticas T2) = tI (Xl, X 2, . .. ,Xn ),
T~2) = t2(Xl , X 2, ... ,Xn ), . .. , T~m) = tm(Xl , X 2, ... , X n ) constituyen una colección de estadísticas conjuntamente suficientes y completas para
B . T* t*('7"'(l) '7"'(2) '7"'(m)) t· d· d l y SZ n = 1n. ,1n , ... ,1n es un es zma or znsesga o para a

120 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
imagen de e bajo la función r, entonces T~ es UMVUE para la imagen de e bajo la función r.
Ejemplo 2.2.74. Sea X 1 ,X2, ... ,Xn una muestra aleatoria de una población con distribución de Poisson de parámetro e, X n es UMVUE para e. Esta afirmación es cierta, teniendo en cuenta lo siguiente:
1. La familia de densidades a la cual pertenece la densidad de Poisson es una familia exponencial de densidades. Por tanto,
n
LXi i=l
es una estadística suficiente y completa para e, tal como lo garantiza el teorema 2.2.71.
n 2. X n es una función de la estadística ¿ Xi, esta última suficiente y
i=l completa para e.
3. X n es un estimador insesgado para e.
En virtud de estos resultados y con el auxilio del teorema del LehmannScheffé, X n es UMVUE para e. Por otra parte, si el interés se centra en estimar la imagen de e bajo la función r(e) = e-e, donde e-o = P[X = O], el proceso de determinar un estimador UMVUE para e-o requiere algunos pasos especiales.
1. I{o}(X1 ) es un estimador insesgado para e-o, porque
Eo [I{o}(X1 )] = 0.P[X1 2: 1] + 1.P[X1 = O] = e-o.
2. Ee [1 {O} (Xl) I i~ Xi] es una estimación insesgada función de i~ Xi,

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 121
conforme al teorema de Rao-Blackwel (2.2.49).
E, [I¡O¡(X¡) 1 ~Xi] ~ O· P, [Xl"" 11 ~Xi ~ t] + 1· p() [Xl = 01 tXi = t].
~=l
p() [Xl = O, t Xi = t] ~=2
p()[XI = OlP() [i~ Xi = t] p() [t Xi = t]
~=l
Como Xi "-' Poiss(B), entonces M Xi (t) = e()(et-l), i = 1,2, ... , n. n
Si y = ¿ Xi, My(t) = e(n-l)()(et-l), luego Y "-' Poiss((n - 1)()). i=2
n Si Z = ¿ Xi, Mz(t) = en()(et-l) , significa que Z "-' Poiss(nB);
i=l por tanto,
n
[n] ¿ Xi
Entonces E() I{o} (Xl) I i~ Xi = (n;;:l )i=l ,luego la estadística
n
( )
¿ Xi n: 1 i=l
es un estimador insesgado función de una estadística suficiente y completa; por tanto es UMVUE para e-().

122 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Ejemplo 2.2.75. Determinar un UMVUE para e cuando el modelo asumido para representar la población es un modelo Exponencial negativo
fx(x, e) = ee-(}x 1(0,00) (x).
n 1. fx(x, e) pertenece a la familia exponencial de densidades, LXi
i=l es una estadística suficiente y completa para e.
n 2. X n es una función de LXi, X n es un estimador insesgado para
i=l 1 -- 1 e; por tanto, X n es un UMVUE para e·
El estimador para e se intuye como ~ con c constante; entonces
LXi i=l
E(} [~l = e = e E [~] - roo 1 i~ Xi ' T - e Jo t h(t)dt,
n
T= LXi. i=l
Como la suma de variables aleatorias con distribución exponencial es una variable aleatoria con distribución Gama, se tiene que
E(}[~l LXi i=l
100 1 1 = c - __ entn-1e-(}tdt o t f(n)
= c -- entn- 2e-(}tdt 1 100 r(n) o ce roo
= f(n) Jo un-
2e-u du (utilizando la sustitución u = et)
cef(n - 1) ce n>l
r(n) n - 1
Un estimador insesgado para e es : - 1 , el cual es una estadística fun
LXi i=l
ción de una estadística suficiente y completa. Por ser insesgado para e, es UMVUE para el parámetro e.

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 123
Expuestos, de manera separada por razones académicas, los criterios más conocidos para facultar estadísticas como estimadores de parámetros, le resta entonces al lector, con el apoyo de los ejercicios propuestos y de los que encuentre en otros textos, la realización de una actividad de síntesis conceptual integradora de los requisitos exigibles a los estimadores, respaldada por los enunciados de los teoremas incluidos y por los argumentos que los garantizan, que se presentan en la sección 2.3.
2.2.6 Robustez, un requisito de estabilidad
Este capítulo cierra con una breve exposición de un requisito denominado robustez, término acuñado por Box, pero cuya idea ya había sido expresada mucho antes por Pearson. Este requisito, en ciertas oportunidades exigible a algunos estimadores y en forma general a algunos procedimientos estadísticos, adquiere un destacado interés cuando no existe plena afinidad entre el comportamiento global e individual de las observaciones de la muestra y el modelo postulado como modelo original de las observaciones, o cuando no hay coherencia total con los supuestos admitidos. Los requisitos presentados en el desarrollo de este capítulo de ninguna manera controvierten la afinidad o incompatibilidad entre las observaciones de la muestra y el modelo original. El modelo define un ambiente y bajo él, una estadística exhibe sus atributos y desatinos en la misión de ser un estimador del parámetro característico del modelo.
Definición 2.2.76. Un procedimiento o método estadístico se denomina robusto, si su desempeño es imperturbable a ligeras discordancias del modelo original o de los supuestos asumidos con la información acopiada. Particularmente, un estimador Tn basado en una muestra aleatoria Xl, X2, ... , X n , de una población con función de densidad fx(x, O), recibe la denominación de estimador robusto, si su desempeño permanece inalterado ante discrepancias con el modelo original.
Que el desempeño de un estimador o el de un método estadístico sean inalterables frente a ligeras discordancias con el modelo o con los supuestos, es decir que sean robustos, es en sí una propiedad deseable. Sin embargo es un criterio vago porque es imprecisa la expresión desempeño del estimador, como igualmente es impreciso el alejamiento del modelo o de los supuestos y como también lo es el no cumplimiento de los supuestos. El alejamiento de un modelo puede tener varias facetas: presencia de outliers, valores insólitos bajo el modelo original,

124 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
discrepancias en la forma de la densidad, como el apuntamiento y la simetría entre otras. El no cumplimiento de los supuestos, por su parte, podría ser taxativo: no se cumplen unas condiciones sobre las cuales un procedimiento estadístico se ha estructurado, ¿pero en qué medida no se cumplen los supuestos? Por ejemplo, la homoscedasticidad, más allá de la definición clara y precisa de igualdad de varianzas, ¿cuándo k poblaciones no tienen la misma variabilidad?
Suponiendo que se desea estimar el promedio poblacional, valor esperado de una variable aleatoria, que el estimador elegido es X n, basado en una muestra aleatoria Xl, X 2 , ... , X n , de una población con función de densidad fx(x, O), y que asumido el modelo original, X n posee propiedades inmejorables, propiedades válidas únicamente bajo la regencia del modelo adoptado, ante la presencia de discrepancias con el modelo puede menoscabarse su idoneidad, en cuyo caso se hablaría de la no robustez del estimador.
Las discrepancias con el modelo se pueden teorizar de variadas formas, una de ellas en forma particular a través de la contaminación.
Definición 2.2.77. Una variable aleatoria Xc se dice que es una variable aleatoria contaminada, si su función de densidad f Xc (x, O) es un combinación lineal de dos o más funciones de densidad,
k
fxc(x, O) = L EjfXj (x), j=l
k
siendo L Ej = l. j=l
Concretamente, si la función de densidad del modelo original es fx(x, O), y las discrepancias con el modelo motivan la consideración de una nueva función de densidad para la variable aleatoria X, de la forma
fxc(x, O) = (1 - E)fx(x, O) + Eg(X)
elegida g(x) de manera que sea la responsable de generar los valores insólitos, bajo el modelo original cuya función de densidad es fx(x, O), entonces X n es altamente sensible frente a las discrepancias citadas. Esa falta de robustez de la media de la muestra ha sido paliada por eliminación de los valores más extremos, o por la utilización de la mediana de la muestra, menos afectada por dichos valores.
En general, son varios los mecanismos de enfrentar la no robustez, sólo que dentro del contexto del capítulo se desea en un sentido destacar uno basado en la idea de excluir valores extremos, o de remplazarlos

2.2. CRITERIOS PARA EXAMINAR ESTIMADORES 125
para eliminar los outliers o amortiguar su efecto: los estimadores L y en otro sentido hacer una ligera mención de los estimadores M.
Definición 2.2.78. Sea Xl,n, X 2,n, ... ,Xn,n, una muestra ordenada de una población con función de densidad fx(x, e), e E e ~ ]R, e un parámetro de localización2 . Un estimador L para e es una estadística de la forma
n
Tn = "" en iXi n ~, , i=l
donde los coeficientes Cn,i, i = 1,2, ... ,n están determinados.
Son ejemplos de estimadores L, el promedio, el mínimo y el máximo de la muestra, pero deben destacarse, respondiendo a esta idea de exclusión o remplazo de valores extremos, los promedios recortados y los promedios "windsorizados".
Un a-promedio recortado es el promedio aritmético de las n - 2[na] estadísticas de orden centrales, con O < a < ~, es decir, se elimina la fracción a de las observaciones inferiores de la muestra e igualmente se elimina la fracción a de las observaciones superiores de la muestra, y con la restante fracción de observaciones 1 - 2a se determina el promedio aritmético que justamente se adjetiva como recortado. Su expresión corresponde a
n-[na] - 1 ""
r X n,a = n _ 2[na] ~ Xi,n. i=[na] +1
Un a-promedio windsorizado no elimina la fracción a de las observaciones inferiores ni de las observaciones superiores de la muestra, O < a < ~, sino que remplaza cada una de ellas por las estadísticas de orden X[na]+l,n y Xn-[na],n, respectivamente, y luego considera el promedio aritmético de estas n variables como lo indica su expresión
{
n-[na] } wXn,a = ~ [na]X[na]+l,n + L Xi,n + [na]Xn-[na],n .
i=[na]+l
Por otra parte, un estimador M para e, basado en una muestra aleatoria Xl, X 2 , .•. , X n, de una población con función de densidad fx(x, e),
2El concepto de parámetro de localización puede consultarse en la definición 3.2.7.

126 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
es un estimador que minimiza la suma
n
LH(Xi - t) i=l
siendo H una función predeterminada, o es un estimador que es solución de la ecuación
n
Lh(Xi - t) = 0, i=l
igualmente para una función h predeterminada. Entonces el estimador M está dependiendo de una elección de una función H o h según el fin. Como casos especiales se pueden construir estimadores M correspondientes a los estimadores máximo-verosímiles tomando
h(x, t) = - :t In fx(x, e) como también construir estimadores M corres
pondientes a los denominados estimadores de mínimos cuadrados tomando H(x, t) = (x - t)2, estimadores muy corrientes en los modelos lineales y en el diseño experimental.
Finalmente, es pertinente señalar que en la actualidad se utilizan procedimientos de mejoramiento de estimadores, procedimientos que requieren extenso uso de cómputo estadístico, conocidos como métodos de remuestreo, de los cuales se destacan el jackknifing y el boostraping, consistentes en pocas palabras en la utilización sistemática de todas las posibles submuestras obtenidas removiendo observaciones de la muestra original y calculando la estimación correspondiente.
2.3 Demostración de los teoremas
Teorema 2.1.12. Si las variables aleatorias X 1 ,X2, ... ,Xn constituyen una muestra aleatoria de una población con función de densidad fx(x, e), Tn = t(X1 , X 2, .. . , X n ) un MLE de e, e E e, e ~ ]R, y si r(e) es una función uno a uno, entonces r(Tn ) es el estimador máximoverosímil de la imagen de e bajo la función r.
Demostración. En primer lugar, asumiendo que la función r(e) = e* es una función uno a uno, con dominio e y recorrido e*, entonces e = r~l(e*). Como la función de verosimilitud L(e; Xl, X2, ... , x n ) tiene máximo en el punto e = tn, equivale a afirmar que ella tiene máximo en

2.3. DEMOSTRACIÓN DE LOS TEOREMAS 127
el punto r-I(O*) = tn, es decir, en 0* = r(tn). De esta manera, el MLE de 0* es r(Tn ).
En segundo lugar, si la función r( O) no es una función uno a uno, el principio de invarianza se mantiene. Como se afirmó, la función de verosimilitud tiene máximo en el punto 0= tn' Varios valores de O tienen como imagen a 0* = r(tn ), uno de ellos hace máxima a L(O; Xl, X2, .. . , x n )
precisamente O = tn' En conclusión, cualquiera sea el caso, el MLE de 0* = r(O) es r(Tn ). D
Teorema 2.1.15. Sea Xl, X2, .. . , X n una muestra aleatoria de una población con función de densidad fx(x, O). Existiendo el momento J.l2r = E [x2r] , r = 1,2, ... ,
n 1 '" ( - )r p - ~ Xi - X n --+ J.lr· n
i=l
Demostración. Como preparación a la demostración, hay que tener presente que el momento central de orden r, J.lr = E [(X - J.l Yl puede expresarse en términos de los momentos ordinarios, de menor orden. Utilizando el teorema binomial se logra dicho propósito.
Igualmente, el momento muestral central de orden r puede expresarse en términos de los momentos muestrales ordinarios de menor orden.
~ t (Xi - Xn)" ~ ~ t~ G)Xi(-XnY J
~ ~ [~t G)X!(-Xnr-'] = i)-Xnr-jG)~tX1
)=0 z=l
= t (~) (Mj)j (-Xnr-j
j=O J

128 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
Como el momento f.l2r existe, los momentos f.ls Y f.l~, s ::; 2r existen. Los teoremas 1.4.7 y 1.3.2, garantizan que
M r = t (~) (Mj)j (-xny-j p ) t (~) (f.lj)j (-f.ly-j. j=O J j=O J
D
Teorema 2.2.17 Este teorema coincide con el teorema 1.6.2, vista la estadística de orden X[npJ+l,n como estimador de x p.
Teorema 2.2.21. Sea Xl, X 2, .. . , X n una muestra aleatoria de una población con función de densidad fx(x, e). Siendo una estadística, Tn = t(XI , X 2, ... ,Xn ), ella es suficiente para e, si y sólo si la función de verosimilitud de la muestra puede expresarse como el producto de dos factores:
L(e; Xl, X2,· .. ,Xn ) = g(t(XI, X2,···, Xn ); e)h(XI, X2,··· ,Xn )
siendo h una función no negativa que depende exclusivamente de Xl, X2, ... , Xn y la función g, no negativa, que depende de e y de Xl, X2, .. ·, Xn a través de t(XI, X2,···, x n ).
Demostración. La demostración se realizará en dos sentidos. En primer lugar, se supone la suficiencia de la estadística para concluir que la función de verosimilitud se puede expresar como el producto de factores en la forma indicada; la segunda parte se desarrolla en sentido contrario.
Se considera únicamente el caso discreto, porque el caso continuo requiere consideraciones adicionales; sin embargo, las ideas y los argumentos utilizados son similares en los dos casos.
Antes de abordar la demostración, como Xl, X2, . .. , X n constituyen una muestra aleatoria,
Pe [Xl = Xl, X2 = X2,· .. ,Xn = xnl = fx(xI, e)fx(x2, e) ... fx(xn , e)
= L(e;XI,X2, ... ,xn ).
Para efectos de notación, al conjunto de valores (Xl, X2, ... , x n ) tales que t(XI, X2, .. . , x n ) = t, llamado un entorno de Tn , se denota como A(t),
con lo cual Pe [Tn = tl = ¿ L(e; Xl, X2,.··, Xn ). A(t)

2.3. DEMOSTRACIÓN DE LOS TEOREMAS 129
En primer término, como se había manifestado, se parte del supuesto de que Tn es una estadística suficiente para e es decir que
Pe [Xl = X1,X2 = X2, o o o ,Xn = xnlTn = t]
no depende de e, probabilidad que puede denotarse como h(X1, X2, o o o, xn), porque únicamente depende de los valores particulares Xl, X2, o o o, Xno Por otra parte, la probabilidad Pe [Tn = t] al depender del valor t y de e puede denotarse como g(t, e), con lo cual
L(B;XI,X2, o o o ,xn) = Po [Xl = XI,X2 = X2, o o o ,Xn = xn]
= Po [Xl = Xl, X 2 = X2, o o o, X n = xnlTn = t] Po[Tn = t] = h(XI,X2,000,Xn )g(t,B)0
En segundo término, partiendo del supuesto de que
L(e; Xl, X2, o o o , Xn) = g(t, e)h(X1, X2, o o o, Xn)
y considerando un valor particular t (obviamente si (Xl, X2, o o o, Xn) rj:. A(t) entonces Pe [Xl = Xl, X 2 = X2, o o o, X n = xnlTn = t] = O)
Pe [Xl = X1,X2 = X2, o o o ,Xn = xnlTn = t] = ~
~ = Pe[X1 = X1,X2 = X2, o o o ,Xn = Xn] Pe[Tn = t]
L(e; Xl, X2, o o o, Xn)
¿: L(e; Xl, X2, o o o, Xn) A(t)
g(t, e)h(X1, X2, o o o , Xn )
¿: h(X1,X2,0 oo,xn)g(t,e) A(t)
h(X1, X2, o o o , Xn)
¿: h(X1,X2,000 ,Xn) A(t)
g(t,e)h(X1,X2,000,Xn)
g(t,e) ¿: h(X1,X2,0 OO,Xn) A(t)
expresión que no depende del parámetro eo D
Teorema 2.2.250 Sea Xl, X2, o o o, X n una muestra aleatoria de una población con función de densidad fx(x, e)o El conjunto de estadísticas
(1) ) (2) Tn h(X1,X2,000,Xn , Tn t2(X1,X2,000,Xn),000,
T~m) = tm(X1, X2, o o o, X n) constituye una colección de estadísticas conjuntamente suficientes para e, si y sólo si la función de verosimilitud de la muestra L(e; Xl, X2, o o o, Xn) = L puede expresarse como

130 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
La función h es una función no negativa que depende de Xl, X2, ... , Xn
exclusivamente y g una función no negativa que depende de e y de
Xl, X2,···, Xn a través de tI, t2,· .. , tm ·
Demostración. La demostración de este teorema es muy similar a la del teorema que hace referencia al criterio de factorización de FisherNeyman, para el caso de una estadística suficiente unidimensional.
Para esta demostración se introducen algunos elementos como el vec-
tor T = (T2), T2) , ... , T~m»)', el conjunto A( t) que para este caso se re-fiere al conjunto de valores (XI,X2, ... ,Xn ), con tl(XI,X2, ... ,Xn ) = tI, t2(X1,X2, ... ,Xn ) = t2, ... ,tm(XI,X2, ... ,Xn ) = tm Y t corresponde al vector t = (tI, t2, ... , tm)', con lo cual
Po [T~l) =tl,T~2) =t2, ... ,T~m) =tm] =Po[T=t] = LL(B;Xl,X2' ... 'Xn ).
A(t)
El desarrollo de la demostración con base en estos elementos es el mismo que se realizó para el caso de una estadística suficiente unidimensional.
O
Teorema 2.2.27. Si Tn es una estadística suficiente para e basada en una muestra aleatoria Xl, X 2, ... , X n , de una población con función de densidad fx(x, e) y si T~ es un MLE para e, y es único, entonces T~ es función de Tn .
Demostración. Siendo Tn una estadística suficiente para e, entonces, según el criterio de factorización de Fisher-Neyman,
L(e; Xl, X2,· .. , Xn ) = g(t(XI, X2,··· , Xn )); e)h(XI, X2, ... , x n ).
En el caso de ser T~ = t*(XI , X 2, ... , X n ), el único MLE de e, entonces e = t* hace máxima a L y por supuesto a g(t(XI, X2, .. . , x n )), luego t* es una función de t(XI,X2, ... ,xn ). O
Teorema 2.2.49. Siendo Xl, X2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, e), r(e) una función de e, y
(1) (2) ( Tn tl(X1,X2, ... ,Xn ), Tn t2 X I ,X2, ... ,Xn ), ... ,
T~m) = tm(XI , X 2, . .. , X n ) estadísticas conjuntamente suficientes, y siendo la estadística Vn = t(XI , X 2, ... , X n ) un estimador insesgado para la imagen de e bajo la función r y T~ = t*(XI , X 2, . .. , X n ) un estimador tal que la estimación t~ se determina como
* - E [TT IT(l) T(2) T(m)] t n - () Vn n , n , ... , n

2.3. DEMOSTRACIÓN DE LOS TEOREMAS 131
entonces,
1. T~ es una estadística, función de estadísticas suficientes solamente.
2. Eo[T~] = r(B).
Demostración. Respecto al punto 1, afirmar que T~ es una estadística función de estadísticas suficientes solamente, es consecuencia del hecho de ser T~I), T~2), ... ,T~m) una colección de estadísticas conjuntamente suficientes; debido a su construcción T~, es una estadística suficiente por ser función únicamente de esa colección.
Respecto al punto 2, se considera sólo el caso en el cual la variable aleatoria que representa a la población es una variable continua; el caso discreto es similar. Como el objeto es concluir que Eo [Eo [VnIT~I), T~2), ... , T~m)]] = r(B), para facilitar la notación, la colección de estadísticas conjuntamente suficientes se dispone en el vector aleatorio T = (T~I), T~2), ... , T~m))', cuya función de densidad es fr(t), siendo t = (tI, t2, .. . , tn).
El valor esperado EO[VnIT] = c(t) es una función que depende únicamente de los valores particulares de t.
Eo [Eo [VnI T ]] = Eo [c(T)]
= 1: 1:···1: c(t)fr(t)dhdt2··· dtm
= 1: 1:···1: [1: VnfVn,T(Vn , t)dVn] dtIdt2··· dtm ,
porque J~oo VnfVn,T(Vn , t)dvn = C(t)fT(t); intercambiando apropiada-

132 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
mente el orden de integración se tiene que
E() [E()[VnI T ]] = i: Vn i:'" i: fVn,T(Vn, t)dt ldt2'" dtmdvn
= i: vnfvn (vn)dvn = E[Vn] = r( ()),
porque J~'" J~(x,fVn,T(Vn, t)dt ldt2" . dtm = fVn (vn). Para concluir el desarrollo de lo pertinente al punto 3, se parte de la conocida adición de un cero, así
V()[Vn] = E() [(Vn - r(O))2] = E() [(Vn - c(T) + c(T) - r(()))2]
= E() [(Vn - c(T))2] + E() [(c(T) - r(O))2]
= E() [(Vn - c(T))2] + V()[c(T)],
puesto que E()[c(T)] = r(O) y 2E() [(Vn - c(T))(c(T) - r(O))] = O. E() [(Vn - c(T))(c(T) - r(O))] = O, como se deduce a continuación.
E() [(Vn - c(T))(c(T) - r(()))] = E() [Vnc(T)]- r2(()) - E() [c2(T) + r2 (())]
= E() [c(T)(Vn - c(T))] = ~
~ = i: i: .. , i: i: c(t)(vn - c(t))fVn,T(Vn, t)dvndtldt2'" dtm
= i: i: .. , i: c(t) [¡: (vn - c(t))fVn,T(Vn, t)dVn] dtldt2'" dtm
i: (vn - c(t))fVn,T(Vn, t)dvn = i: VnfVn,T(Vn, t)dvn
- c(t) i: fVn,T(Vn, t)dvn
= C(t)fT(t) - C(t)fT(t) = O
Por tanto ~ = E() [c(T)(Vn - c(T))] = O. Regresando al paso en el cual se enunció que
V()[Vn] = E() [(Vn - c(T))2] + V()[c(T)]
y teniendo en cuenta que
E() [(Vn - c(T))2] ~ O,

2.3. DEMOSTRACIÓN DE LOS TEOREMAS 133
entonces Ve[c(T)] ::; Ve[Vn] o Ve [Ee [VnIT]] ::; Ve[Vn]. En síntesis,
D
Teorema 2.2.55. Sea Xl, X 2, . .. , X n una muestra aleatoria de una población con función de densidad fx(x, e), r(e) una función del parámetro e, Tn = t(XI , X 2, . .. , X n) un estimador para la imagen de e bajo la función r y Be(Tn) el sesgo de Tn. Dentro de un caso regular de estimación,
E [(T _ (e))2] > (r'(e) + B~(Tn))2 e n r - nI(e) ,
con B~(Tn) = :eBe(Tn).
Demostración. Esta demostración parte de la definición de sesgo y utiliza las condiciones de regularidad como argumentos para su desarrollo. Dado que Be(Tn) = Ee(Tn) - r(e),
B(}(Tn ) + r(B) = E(}(Tn )
= 1:1: ... 1: t(Xl,··· ,xn ) (gfX(Xi,B)) dXl···dxn ·
Tratándose de un caso regular de estimación, :eBe(Tn) + r'(e) = ~, siendo
8 n (8 n )(n ) puesto que 8e IJI f x (Xi, e) = 8e In i!:I f x (Xi, e) i!:JI f X (Xi, e) ,
porque d~ lng(x) = ~(~}, y por tanto, g'(x) = (d~ lng(x)) g(x). Antes de continuar, es necesario demostrar que

136 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
aleatoria X, con distribución de Pareto es
020~2 fx(x, O) = x02+l 1(01,00) (x),
los componentes del parámetro O = (01 , O2 ), son tales que 01 > 0, O2 > O. ¿Cuál es el MLE para O? Asumiendo conocido o fijo el valor de 01 , ¿cuál es el MLE para 02? ¿ Cuál es el estimador por el método de los momentos para 02? ¿Es procedente la construcción de un estimador por analogía para 02? De la misma manera, asumiendo conocido o fijo el valor de O2 ,
¿cuál es el MLE para 01? ¿Cuál es el estimador por el método de los momentos para 01? ¿Es factible determinar un estimador por analogía para 01?
3. El modelo Zeta, utilizado particularmente en lingüística, está construido con base en la función zeta de Riemann, función definida como
00 1 (( s) = L ~, con s > lo
j=l J
Una variable aleatoria X se dice que tiene distribución Zeta con parámetro O, O > 0, o que tiene distribución de Zipf (en honor a George Zipf), si su función de densidad es
1 fx(x, O) = xO((O) 1{1,2, ... }(x)
en cuyo caso E [Xk ] = (~(~)k), con O > k + 1, k = 1,2, ... Particularmente
((O -1) . E[X]= ((O) s10>2
V[X] = ((O - 2) _ [((O - 1)] 2
((O) ((O) si O > 3.
Explore la forma de estimar puntualmente el parámetro O.
4. El modelo de Poisson, muy conocido por sus múltiples aplicaciones, incluye una constante O que corresponde tanto al centro de gravedad de la función de densidad de una variable aleatoria regido por este modelo como la cuantificación de la dispersión de la

2.4. EJERCICIOS 137
misma. Dado que la función de densidad de una variable aleatoria X, con distribución de Poisson es
ex fx(x,e) = ,e-o
¡{0,1,2, ... }(x), x.
siendo e > o, ¿cuál es el MLE para e? ¿Cuál es el estimador por el método de los momentos para ()? ¿Cuál es el estimador por analogía para e?
5. El modelo gaussiano representa una gama amplia de situaciones y es el modelo capital en estadística. Es necesario diferenciar las formas como se deben estimar las dos constantes que participan en el modelo. Señalando que la función de densidad de una variable aleatoria X, con distribución gaussiana es
1 (x-01 )2
fx(x e) = e- 2°2
'y'27re2 '
los componentes del parámetro e = (el, ( 2 ) son tales que el E IR, e2 > O. ¿Cuál es el MLE para e? Para el caso particular en el que se asuma conocido o fijo el valor de el, ¿cuál es el MLE para e2? ¿Cuál es el estimador por el método de los momentos para e2? ¿Cuál es el estimador por analogía para e2? Del mismo modo, dado el caso en el que se asuma conocido o fijo el valor de e2 , ¿cuál es el MLE para el? ¿Cuál es el estimador por el método de los momentos para el? ¿ Cuál es el estimador por analogía para el?
6. El modelo Gama realmente es una familia de modelos. Las dos constantes que intervienen en la naturaleza del modelo, usualmente llamadas parámetro de forma y parámetro de escala, se pueden estimar de varias maneras. Recordando que la función de densidad de una variable aleatoria X, con distribución Gama es
f ( ll) _ eg1 01-1 -02 X ¡ ()
xX,U -r(edx e (0,00) x,
los componentes del parámetro e = (el, (2) son tales que el > o, e2 > O. ¿Cuál es el MLE para e? Cuando se asume conocido o fijo el valor de el, ¿cuál es el MLE

138 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
para fh? ¿ Cuál es el estimador por el método de los momentos para 02? ¿ Cuál es el estimador por analogía para 02? De manera similar, cuando se asume conocido o fijo el valor de 02, ¿cuál es el MLE para 01? ¿Cuál es el estimador por el método de los momentos para 01? ¿Cuál es el estimador por analogía para 01?
7. Una variable aleatoria X, con distribución de Gumbel tiene como función de distribución a
Fx(x, O) = exp ( - exp (x ~2 01) ) .
Los componentes del parámetro O = (01 , O2 ), son tales que 01 E ~,
O2 > O. Explore la forma de estimar puntualmente el parámetro O, teniendo en cuenta que E[X] = 01 + "(02 , siendo "( ~ 0.577216,
7r2 (J2 Y además V(X) = ~.
8. Una variable aleatoria X, con distribución de Laplace o con distribución Exponencial doble, tiene como función de densidad a
fx(x, O) = _1 _Ix-Oll 20
2 e °2
Los componentes del parámetro 0= (01 , O2 ) son tales que 01 E ~,
O2 > O. Explore la forma de estimar puntualmente el parámetro O, teniendo en cuenta que E[X] = 01 Y V[X] = 20~.
9. Determine una eficiencia especial de * f: (Xi - Xn)2 frente a S;, i=l
para estimar (J2 cuando se ha asumido un modelo Normal con valor esperado J..L y varianza (J2.
10. De los dos estimadores para (J2 del ejercicio 9 ¿cuál tiene mayor error cuadrático medio?
11. Igualmente, de los dos estimadores para (J2 del ejercicio 10, ¿cuál tiene menor varianza?
12. Un tramposo juega con una moneda de dos sellos, pero algunas veces para no despertar sospechas, utiliza una moneda equitativa. El objeto de este ejercicio es estimar cuál moneda está utilizando en

2.4. EJERCICIOS 139
un momento dado, a partir de los resultados de n lanzamientos de una misma moneda, es decir, estimar el parámetro () cuyo espacio es el conjunto e = {~, 1}. Compruebe que el MLE para () es
13. ¿El estimador Tn del ejercicio 12 es un estimador insesgado, o es un estimador asintóticamente insesgado para ()?
14. Determine el error cuadrático medio del estimador Tn del ejercicio anterior.
15. Si las variables aleatorias Xl, X 2 , . .. ,Xn son una muestra aleatoria de una población con distribución Uniforme en el intervalo (O, ()), determine la varianza del estimador por el método de los momentos para (), basado en la muestra aleatoria, y examine si es un estimador insesgado para ().
16. (Este ejercicio y los cinco siguientes hacen referencia al ejercicio 15 J. Determine la varianza del estimador máximo-verosímil para (), basado en la muestra aleatoria, y concluya si es un estimador consistente para ().
17. Construya un estimador insesgado para (), que sea función del máximo de la muestra, y determine su varianza. ¿Es consistente este estimador para ()?
18. Entre el estimador del ejercicio 17 y el estimador por el método de los momentos, ¿cuál elige?
19. ¿Es posible construir un estimador insesgado para () que sea función del mínimo de la muestra? Si es factible, identifíquelo y determine su varianza. ¿Es consistente este estimador para ()?
20. Considere los estimadores para () de la forma Tn = h(n)Xn,n, siendo h(n) una función exclusiva del tamaño de la muestra. Determine el estimador de esta clase que tenga el menor error cuadrático medio.
21. En síntesis, ¿cuál estimador elige como el más apto estimador para ()?

140 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
22. Siendo las variables aleatorias Xl, X2, .. . , X n una muestra aleatoria de una población con distribución de Laplace con (h = 1, ¿existe una estadística suficiente para (h?
23. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población con función de densidad
e fx(x,e) = X2 I[B,oo) (x), e> o
determine el MLE de e. Compruebe que este estimador es una estadística suficiente para e.
24. Si Xl, X 2 , ... ,Xn es una muestra aleatoria de una población con distribución de Poisson con parámetro A y e = P[Xi = O] = e-A, determine el MLE de e, mediante dos procedimientos: directamente y usando la propiedad de invarianza de los estimadores máximo-verosímiles.
25. Si las variables aleatorias Xl, X 2 , ... ,Xn constituyen una muestra aleatoria de una población con distribución de Bernoulli de parámetro e, determine el MLE para la varianza poblacional.
26. Si las variables aleatorias Xl, X 2 , ... ,Xn constituyen una muestra aleatoria de una población con distribución gaussiana de valor esperado el y varianza e2 , determine el MLE para er + e2 .
27. Determine la cota de Cramer-Rao para la varianza de los estimadores insesgados para e, basados en una muestra aleatoria de tamaño n de una población con distribución de Bernoulli de parámetro e.
28. Con base en el ejercicio 27, ¿existe un UMVUE para e?
29. Si las variables aleatorias Xl, X 2 , . .. ,Xn constituyen una muestra aleatoria de una población con distribución Binomial de valor esperado me y varianza me(1 - e), con m conocido, e E (0,1), obtenga el MLE, el estimador por el método de los momentos y el estimador por analogía para e. ¿Existe una estadística suficiente? Si es factible, determine el UMVUE para e.
30. Determine la cota de Cramer-Rao para la varianza de los estimadores insesgados para e, basados en una muestra aleatoria de

2.4. EJERCICIOS 141
tamaño n de una población con distribución de Poisson de parámetro (J.
31. Teniendo en cuenta el ejercicio 30, ¿existe un UMVUE para (J?
32. Si se asume el modelo gaussiano, ¿X n es un UMVUE para el promedio poblacional? ¿La varianza de S; es igual a la correspondiente cota de Cramer-Rao para los estimadores insesgados para la varianza poblacional?
33. Si se adopta el modelo gaussiano, y se asume que el promedio poblacional es conocido, ¿existe un UMVUE para la varianza poblacional? ¿Qué ocurriría si no se asume que el promedio poblacional es conocido?
34. Determine la cota de Cramer-Rao para la varianza de los estimadores insesgados para el parámetro de escala, basados en una muestra aleatoria de tamaño n de una población con distribución Gama. ¿Existe un UMVUE para el parámetro de escala?
35. Teniendo en cuenta una muestra aleatoria de tamaño n de una po
blación Uniforme en el intervalo (O, (J), calcule Eo { [:0 In Ix (x, O) r} y compárelo con la varianza del estimador insesgado para (J basado en el máximo de la muestra. ¿Se presenta alguna contradicción?
36. Si Xl, X2, .. . , X n es una sucesión de variables aleatorias incorrelacionadas tales que (j; = V[Xil y E [Xil = p" i = 1,2, ... , n,
n considere el estimador Tn = I: f3i X i, siendo f31, f32, . .. , f3n, cons-
i=l tantes determinadas. ¿Cuál condición deben cumplir estas cons-tantes para que el estimador Tn sea insesgado para p,? Determine la varianza de Tn en términos de f31,f32, .. ·,f3n y (j1,(j2, .. ·,(jn' Bajo la restricción del insesgamiento de Tn , use multiplicadores de Lagrange para comprobar que la varianza de Tn es mínima cuando
l ;;-z
f3j = ~ paraj = 1,2, ... ,n.
I:~ i=l J
Si (jI, (j2,"" (jn se asumen conocidas, una estadística como lo sugiere este ejercicio se denomina BL UE (Best Linear Unbiased Estimator) para p,.

142 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
37. Teniendo en cuenta lo expuesto en el ejercIcIO 36, si las variables aleatorias Xl, X 2, .. . , X n constituyen una muestra aleatoria de una población con valor esperado /.l y varianza (J2, ¿X n es BL UE para /.l? ¿Se requiere conocer el valor de (J?
38. Si Xl, X2, .. . , X n es una muestra aleatoria de una población con distribución Gama con parámetro O = (01 , O2 ) y siendo Gn la media geométrica muestral, ¿la estadística Tn = (Xn , Gn ) es una estadística suficiente para O? Si se asume conocido 01 , ¿existe un UMVUE para 02?
39. Si Xl, X 2, ... , X n es una muestra aleatoria de una población con distribución Beta con parámetro 0= (0 1 , O2 ), ¿existe una estadística suficiente para O?
40. Si Xl, X2, ... , X n es una muestra aleatoria de una población con distribución Uniforme en el intervalo (O, O), ¿existe una estadística suficiente para O?
41. Si Xl, X 2, ... ,Xn es una muestra aleatoria de una población con distribución Uniforme en el intervalo (O, 0+ 1), O > 0, compruebe que la estadística (Xl,n, Xn,n) es una estadística suficiente para O.
42. Muestre que si Tn es una estadística completa para O, y si T~ es otra estadística, ella es completa si Tn y T~ son estadísticas equivalentes.
43. La estadística
[n ~ 1 ~Xil- [n(n1_ 1) (~Xi)'l
basada en una muestra aleatoria Xl, X 2, ... , X n de una población con distribución de Bernoulli de parámetro O, ¿es UMVUE para 0(1 - O)?
44. Y = 100X es el contenido porcentual de calcio en cierto compuesto, que se puede modelar como una variable aleatoria tal que la función de densidad de la variable aleatoria X es
fx(x,O) = OxfJ-lICü,l) (x), O> O.

2.4. EJERCICIOS 143
Con base en n determinaciones independientes YI , Y2, ... , Yn , las cuales se pueden tratar como una muestra aleatoria, encuentre un MLE y un UMVUE para el contenido medio de calcio. ¿Existe alguna función de () tal que haya un estimador insesgado para la imagen de (), cuya varianza coincida con su correspondiente cota de Cramer-Rao?
45. El tiempo en la atención a un cliente en un banco se puede modelar como una variable aleatoria con distribución Exponencial de valor esperado ~. Con base en una muestra de n clientes atendidos, se desea estimar el tiempo mediano de atención. Obtenga un MLE y un UMVUE para este tiempo mediano.
46. El número de animales de cierta especie que se pueden encontrar dentro de un cuadrante (cuadrado ubicado cartográficamente en el área de investigación), se modela corrientemente como una variable aleatoria con distribución de Poisson de parámetro (). Existe un interés particular dentro de la descripción de la distribución espacial, por la probabilidad de encontrar a lo sumo un ejemplar de la especie, es decir, por la función r(()) = (1 +())e-o. Construya un MLE y un UMVUE para la imagen de () bajo la función r, basado en una muestra aleatoria Xl, X 2 , ... , X n , siendo Xi la variable aleatoria que representa al número de animales de la especie en el i-ésimo cuadrante elegido, i = 1,2, ... ,n.
47. Si Xl, X 2 , . .. , X n es una muestra aleatoria de una población con distribución gaussiana de valor esperado () y varianza (), ¿cuál estimador debe adoptarse en términos de insesgamiento, completez y suficiencia?
48. Si en el ejercicio 47 se establece que el valor esperado es () y la varianza ()2, bajo los mismos términos, ¿de cuál o cuáles estimadores se puede disponer?
49. Si las variables aleatorias Xl, X 2 , ... , X n constituyen una muestra aleatoria de una población con distribución Binomial de valor esperado m() y varianza m()(l - ()), con m conocido, () E (0,1), ¿es factible determinar un UMVUE para ()m?
50. Si Xl, X 2 , . .. , X n es una muestra aleatoria de una población con distribución Geométrica con parámetro (), es decir de una pobla-

144 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
ción con función de densidad
fx(x, O) = (1 - 0)X-101{1,2, ... }, O E (0,1),
establezca un UMVUE para O y un UMVUE para 1 -¡/ . 51. Para el análisis de la fatiga de un material se planea un ensayo
con una muestra de n probetas, el cual culmina cuando k de las n probetas hayan fallado. Determine el QMLE para O2 suponiendo conocido 01 , si el modelo adoptado para la descripción del tiempo de falla de la probeta es el modelo de Weibull, cuya función de densidad es
1 () 1 X O [ ( )
Ih] fx(x, O) = 0~1 X 1- exp - O
2 1(0,00) (x), 0= (01 , O2 ).
52. Compruebe que la familia de densidades Gama es conjugada para la función de densidad de un modelo de Poisson.
53. Con base en el ejercicio 52, determine el estimador bayesiano para el parámetro O de una distribución de Poisson.
54. ¿La familia de densidades Gama es cerrada bajo muestreo para la función de densidad de un modelo Exponencial?
55. Si Xl, X 2 , •.• , X n es una muestra aleatoria de una población con distribución Uniforme en el intervalo (-O, O), ¿son las estadísticas Xl,n Y Xn,n conjuntamente suficientes para O? ¿La familia a la cual pertenece la función de densidad de la población es una familia completa? ¿Es Tn = max( -Xl,n, Xn,n) un MLE para O?
56. Si Xl, X 2 , .. . , X n es una muestra aleatoria de una población con distribución Exponencial desplazada con parámetro O = (01 , O2 ),
determine una estadística suficiente para O.
57. Si Xl, X2, ... , X n es una muestra aleatoria de una población con función de densidad
1 x fx(x, O) = ee-(j 1(0,00) (x),

2.4. EJERCICIOS 145
muestre que n
y
son dos variables estadísticamente independientes.
58. Se repite un ensayo de Bernoulli, con probabilidad de éxito e, hasta que ocurren exactamente k éxitos. Si X es la variable aleatoria que contabiliza el número de ensayos necesarios para obtener los k éxitos, es decir que
¿la familia de densidades a la cual pertenece la función de densidad de la variable aleatoria X es una familia completa? ¿Es ~=i una estimación insesgada de e?
59. Si Xl, X 2 , ... , X n es una muestra aleatoria de una población con distri bución Uniforme en el intervalo (el - e2, el + (2) con el E IR Y e2 > O, muestre que las estadísticas XI,n, Xn,n son estadísticas conjuntamente suficientes para e = (el, ( 2 ).
60. Si Xl, X 2 , ..• , X n es una muestra aleatoria de una población con función de densidad
n ¿es L Xi una estadística suficiente y completa para e? Determine
i=l n
un estimador insesgado para e que sea una función de L Xi tal i=l
que él tenga la varianza mínima.
61. Compruebe que el MLE para e es una función de la media geométrica muestral, y que ésta es una estadística suficiente y completa para el parámetro e, basados en una muestra aleatoria Xl, X2, ... , X n , de una población con función de densidad
!x(x,e) = exo-II(o,l) (x), e> o.

146 CAPÍTULO 2. ESTIMACIÓN PUNTUAL DE PARÁMETROS
62. Si Xl, X2, . .. ,Xn es una muestra aleatoria de una población con distribución Uniforme discreta con parámetro e, es decir que su función de densidad es
1 fx(x, e) = 7¡!{1,2, ... ,O} (x), e> 0,
demuestre que el máximo de la muestra es una estadística suficiente y completa.
63. Con base en el ejercicio 62, determine un estimador insesgado de varianza mínima para e.
64. Si Xl, X 2 , . .. ,Xn es una muestra aleatoria de una población con función de densidad
fx(x,e) = e-(x-O)I(o,oo) (x), e E IR,
determine una estadística suficiente y completa y un UMVUE para e.

Capítulo 3
Estimación por intervalo de parámetros
Una estadística facultada para estimar un parámetro particular producirá estimaciones alrededor del valor específico del parámetro, porque cumplió el requisito de insesgamiento y esas estimaciones serán de la mayor precisión porque la estadística elegida posee la menor varianza. y seguramente tal estimador tiene en su haber otras cualidades primordiales que lo hacen apto para su labor, y de esa manera está certificada su competencia.
Esa certificación brinda el suficiente respaldo para que las estimaciones gocen de toda la confianza, y así sustituir esas constantes fundamentales del modelo por estimaciones válidas y sustentadas, de manera que sean la licencia para poner en marcha el modelo concebido y responder de manera técnica a las preguntas pertinentes del fenómeno modelado.
Pero no siempre el fin de la inferencia es estimar un parámetro de la forma como hasta este punto se ha considerado; en algunas aplicaciones, el propósito de la inferencia está en el sentido de llevar a cabo un avalúo de ese parámetro por medio de un intervalo, emitiendo ya no un único valor sino un rango de valores como estimación del parámetro. Algunas investigaciones encuentran en este procedimiento una mejor forma de estimación de parámetros, más útil y provechosa, frente a la declaración de un único valor; por ello corrientemente suelen dar a conocer el punto medio de un intervalo y sus extremos, para declarar, además de la estimación de un parámetro, una idea de variabilidad asociada a tal es-
147

148 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
timación, máxime cuando el punto medio corresponde a una estimación puntual de la mejor calidad.
Este proceder especial de estimación conlleva elementos conceptuales propios que este capítulo menciona en su primera parte; también cuenta con varios métodos para la construcción de esos intervalos de estimación, llamados intervalos confidenciales o intervalos de confianza, de los cuales este texto solamente tratará el método de la variable pivote. Para comenzar, se da paso a la primera fase dentro de la construcción conceptual de la estimación por intervalo de parámetros.
3.1 Conceptos preliminares
Definición 3.1.1. Un intervalo aleatorio es un intervalo tal que al menos uno de sus extremos es una variable aleatoria.
Definición 3.1.2. Sean X 1,X2",.,Xn una muestra aleatoria de una población con función de densidad fx(x, O), O E e y las estadísticas
(1) _ (2) _ ( ) Tn - t1(X1,X2, ... ,Xn ), Tn - t2 X 1,X2, ... ,Xn tales que
Po [T~1) < T~2)] = 1, r(O) una función cuyo recorrido es un conjunto
de números reales. El intervalo aleatorio (T~l), T~2)) se denomina in
tervalo confidencial para la imagen de O bajo r del 100(1 - a)% de confianza, si
Po [T2) < r(O) < T~2)] = 1 - a
probabilidad que no depende de O.
Definición 3.1.3. En la definición 3.1.2, T2) Y TJ2) reciben el nombre de límite confidencial inferior y límite confidencial superior, respectivamente, y el valor 1 - a nivel confidencial o confianza.
Definición 3.1.4. Bajo las consideraciones de la definición 3.1.2 el in
tervalo (t1, t2), intervalo particular del intervalo confidencial (TJ1), TJ2))
se denomina estimación por intervalo del 100(1 - a)% de confianza para la imagen de O bajo r.
Definición 3.1.5. Sea Xl, X2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, O), r(O) una función del parámetro, cuyo recorrido es un conjunto de números reales, con 8 < r(O) < f3

3.2. EL MÉTODO DE LA VARIABLE PIVOTE 149
yTJl) una estadística, TJl) = tl(Xl ,X2, ... ,Xn ). El intervalo aleatorio
(TJl),,B) es un intervalo confidencial unilateral del 100(1 - a)%
de confianza para la imagen de O bajo r, si Po [TJ!) < r(O)] = 1 - a, probabilidad que no depende de O.
También si TJ2) = t2(Xl , X2, ... , X n ) es una estadística, el interva
lo aleatorio (<5, T2)) es un intervalo confidencial unilateral del
100(1 - a)% de confianza para la imagen de O bajo r, si
Po [r(O) < T2)] = 1 - a, probabilidad que no depende de O.
Definición 3.1.6. TJ!) Y TJ2) en la definición 3.1.5 reciben respectivamente el nombre de límite confidencial inferior unilateral para r(O) y límite confidencial superior unilateral para r(O).
Teorema 3.1.7. Sea Xl, X 2, ... , X n una muestra aleatoria de una po
blación con función de densidad fx(x, O), Y TJi) = ti(Xl , X2,"" X n ),
i = 1,2, estadísticas tales que (TJ!), TJ2)) es un intervalo confidencial
para O. Si r( O) es una función estrictamente monótona con dominio e y recorrido un subconjunto de]R., (r ( TJ!)) ,r ( TJ2))) es un intervalo
confidencial para la imagen de O bajo r, cuando ésta es estrictamente cre
ciente y (r (T2)) , r (TJl))) es un intervalo confidencial para la imagen
de O bajo r, cuando la función r es estrictamente decreciente.
El concepto de intervalo confidencial es un caso particular de un concepto más general: la región confidencial.
Definición 3.1.8. Sea Xl, X2, ... ,Xn una muestra aleatoria de una población con función de densidad fx(x,O). Siendo A(Xl,X2, ... ,xn ) un subconjunto del espacio de las observaciones X, A(Xl , X2,"" X n ) se denomina región confidencial del 100(1 - a)% de confianza para el parámetro O, si Po [O E A(Xl , X2, ... ,Xn )] = 1 - a, probabilidad que no depende de O.
3.2 El método de la variable pivote
Como se mencionó en la introducción de este capítulo, la estimación por intervalo posee varios métodos para la construcción de intervalos confidenciales; sin embargo, el de mayor tradición y renombre es el método de la variable pivote, método que se describe en esta sección.

150 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
Definición 3.2.1. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con función de densidad fx(x, e). Sea Qx = q(B; Xl, X 2 ,.·., X n )
una función de las variables que conforman la muestra aleatoria y del parámetro e. Qx se denomina variable aleatoria pivote (variable pivote) para el parámetro e si la distribución de Qx no depende de e. Ejemplo 3.2.2. Si Xl, X 2 , •.. , X n es una muestra aleatoria de una población Normal de valor esperado e y varianza (7"2 conocida, entonces
y'n(Xn - e) (7"
es una variable pivote para e, porque además de depender de Xl, X 2 , ... ,
X n , a través de X n ,
y'n(Xn - e) rv N(O, 1). (7"
Ejemplo 3.2.3. Si Xl, X2, . .. , X n es una muestra aleatoria de una población Normal de valor esperado e y varianza (7"2, X n y S~, el promedio y varianza muestrales entonces
Qx = y'n(Xn - e) Sn
es una variable pivote para e. En efecto, Qx es una función de XI,X2, ... ,Xn a través de X n y Sn. Además:
1. y'n(Xn - e) rv N(O, 1). (7"
n ¿(Xi - Xn)2
2. (n - l)S~ (7"2
i=l (7"2 rv x2 (n - 1).
3. Debido a que X n y S~ son estadísticamente independientes,
y'nCXn - e) (7"
también lo son; entonces
y (n - l)S~
(7"2
.¡n(Xn-B) y'nCXn - e) rv t(n _ 1). O" " Q - 2
X - '(n-I)SR (n-I)O"

3.2. EL MÉTODO DE LA VARIABLE PIVOTE 151
El método de la variable pivote es el método más utilizado en la construcción de intervalos confidenciales. Consiste en partir del paso inicial, una vez definido el coeficiente 1 - a,
Po[a < Qx < b] = 1 - a
continuar con pasos intermedios que consisten en considerar eventos equivalentes hasta determinar el evento tal que
y como consecuencia el intervalo aleatorio (T~l), T~2)) será un intervalo confidencial del 100(1 - a)% para r(O).
Ejemplo 3.2.4. Determinar un intervalo confidencial para el parámetro O basado en una muestra aleatoria Xl, X 2 , .. . , X n , de una población con función de densidad
La variable aleatoria Yi = 20 Xi tiene distribución exponencial con parámetro !' hecho que se reconoce de la siguiente manera:
Por tanto,
Flj(Y) = Po[20Xi ::; y] = Po [Xi::; :0]
= FXi (:0) i = 1,2, ... , n.
r?o FYi (y) = Jo Oe-Oxidxi; luego
1 lbL flj (y) = O 20 e - 29
1 1
= "2 e- 2Y 1(0,00) (y).
Con base en este resultado se establece a
n n
Qx = ¿Yi = 20¿Xi i=l i=l
como una variable aleatoria pivote, variable que tiene distribución Ji -cuadrado de parámetro 2n, debido a lo siguiente:

152 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
1 [ 1 ] n para t < !' M}i (t) = O~t)' y por tanto, MQx (t) = (!~t) por ser
Y1 , Y2, ... ,Yn un conjunto de variables aleatorias independientes; esta función generatriz de momentos es propia de una variable aleatoria con distribución Ji-cuadrado con 2n grados de libertad.
Como la distribución de Qx no depende de e, ésta constituye una auténtica variable pivote, y con base en lo anterior, como punto de partida en la construcción del intervalo confidencial, se considera el evento aleatorio {a < Q x < b}. En consecuencia,
Po [a < 2e t Xi < b] = Po [na < e < nb ] = 1 - a.
i=l 2 ¿ Xi 2 ¿ Xi i=l i=l
Eligiendo los valores a, b, como a = X~ (2n) y b = xL~ (2n), el intervalo 2 2
aleatorio
( x~ (2n) xL% (2n)) n , n
2¿Xi 2¿Xi i=l i=l
es un intervalo confidencial del 100(1- a)% para el parámetro e, porque además de ser
[ x~ (2n) xL% (2n)]_ Po n < n - 1
2 ¿ Xi 2 ¿ Xi i=l i=l
el valor de 1 - a no está supeditado a ningún valor de e. Sobra anotar que la anterior elección de a y b es una escogencia
particular, y por supuesto puede adoptarse otra pareja de valores a, b. La pareja (a, b) puede ser única cuando se le plantean requerimientos al intervalo, como que su longitud sea mínima, en cuyo caso es menester llevar a cabo unos pasos adicionales a fin de determinar el intervalo que satisfaga esa condición.
El método de la variable pivote tiene tres condiciones esenciales: (1) la existencia misma de una variable pivote como tal; (2) la factibilidad
de deducir las estadísticas T~l) y T~2) a partir de la variable pivote, estadísticas que definen en últimas el intervalo confidencial; (3) lograr encontrar la variable pivote con una distribución, en lo posible conocida,

3.2. EL MÉTODO DE LA VARIABLE PIVOTE 153
que permita determinar sus percentiles. El siguiente ejemplo trata del establecimiento de una variable pivote general, para aquellos casos en los cuales la función de distribución tiene una expresión algebraica explícita.
Ejemplo 3.2.5 (Una variable pivote general). Partiendo del hecho que si X es una variable aleatoria con función de distribución Fx(x, ()) continua, entonces la variable aleatoria Y = Fx(X, ()) tiene distribución Uniforme en el intervalo (0,1), es posible construir una variable pivote de la manera siguiente.
Siendo Xl, X2, . .. , X n una muestra aleatoria de una población con función de distribución Fx(x, () continua,
porque
i = 1,2, ... , n
E¿ = -In Ui rv Exp(l),
FRi(r) = Pe[E¿ ~ r] = Pe[-lnUi ~ r] = Pe[lnUi > -r] = Pe[Ui > e-r ] = 1 - Pe[Ui ~ e-r ] = 1- FUi (e-r )
= 1 - e-r
luego E¿ rv Exp(l). Definiendo
n n
Qx = L Ri = L -lnFx(Xi , ()) rv Gama(n, 1) i=l i=l
porque
= E [etRléR2 ... etRn ]
= E [etR1 ] E [etR2 ] ... E [e tRn ]
dado que Ul, U2, ... , Un es una muestra aleatoria, Rl, R2,"" Rn son variables aleatorias independientes e idénticamente distribuidas; luego
t < 1,

154 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
entonces Qx rv Gama(n, 1). Por lo anterior, la variable
n n
Qx = ¿Ri = ¿ -lnFx(Xi,e) rv Gama(n, 1) i=l i=l
variable que puede utilizarse como una variable pivote para e, siempre y cuando la función de distribución de la población tenga una expresión que permita aplicar el método.
La deducción de una variable aleatoria pivote general se basó en que FX(Xi , e) para i = 1,2, ... , n, tiene distribución Uniforme en el intervalo (0,1). Para algunos casos particulares, por razones expeditivas, la variable aleatoria pivote se construye a partir de que igualmente 1 - Fx(Xi , e) rv U(O, 1).
U na sutil modificación a la variable aleatoria pivote general, regida por el modelo Gama, permite la construcción de otra variable aleatoria pivote, ésta bajo la distribución Ji-cuadrado, así
n
Q'X = -2 ¿ In Fx(Xi , e) rv x2 (2n). i=l
Porque, de la misma manera a lo expresado en el ejemplo 3.2.5, como FX(Xi , e) tiene distribución Uniforme (O, 1), -21n Fx(Xi , e) rv Exp (~),
n con lo cual la variable aleatoria I: -2 In FX(Xi , e) rv Gama (n, ~), es
i=l decir,
n
Q'X = -2 ¿ In Fx(Xi , e) rv x2(2n). i=l
Cualquiera de las variables aleatorias pivotes generales puede expresarse de forma alternativa, forma conveniente para algunos casos individuales, gracias a la propiedad fundamental de la función logaritmo, así
n n
Qx = -In II Fx(Xi , e) o Q'X = -21n II Fx(Xi , e). i=l i=l
Ejemplo 3.2.6. El desarrollo del ejemplo 3.2.4, produjo un intervalo confidencial para el parámetro e, basado en una muestra aleatoria Xl, X 2 , ... ,Xn , de una población con función de densidad
fx(x, e) = ee~Ox 1(0,00) (x).

3.2. EL MÉTODO DE LA VARIABLE PIVOTE 155
Como Fx(x,e) = (1- e-1h ) 1(0,00) (x),
(1 - Fx(x, e)) 1(0,00) (x) = e-ex 1(0,00) (x),
con lo cual e-exi rv U(O,l) e igualmente -In (e-exi) = eXi tiene distribución Exponencial con parámetro igual a uno, hecho que permite justificar el motivo para la adopción de la variable pivote:
n
Qx = 2e L Xi rv x2 (2n). i=l
A partir de esta variable es fácil determinar un intervalo confidencial para e. Para coadyuvar en el cumplimiento de la primera condición del método, la determinación de una variable pivote, la función que desempeña el parámetro en consideración, es algunas veces una vía para identificar dicha variable. Tales son los casos cuando el parámetro se identifica como parámetro de localización o cuando el parámetro se denomina como parámetro de escala.
Definición 3.2.7. Sea {fx(x, e)le E e ~ ]Rk} una familia de densidades. El componente ej de e se denomina componente de localización, si y sólo si la distribución de X - ej o de X + ej , según sea el caso, no depende de ej. Cuando e ~ ]R, el parámetro e se denomina parámetro de localización si y sólo si la distribución de X - e o de X + e no depende de e. Ejemplo 3.2.8. Si
entonces el es el componente de localización. En efecto, la variable aleatoria (X - el) rv N(O, ( 2 ), distribución que no depende del valor de
el·
Definición 3.2.9. Sea {fx(x, e)le E e ~ ]Rk} una familia de densidades. El componente ej de e se denomina componente de escala,
si y sólo si la distribución de (~) o de (Xe j ), según sea el caso, no
depende de ej. Cuando e ~ ]R, el parámetro e se denomina parámetro
de escala si y sólo si la distribución de (~) o de (Xe) no depende de
e.

156 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
Ejemplo 3.2.10. Si
Jx(x, e) = ee-ex 1(0,00) (x),
el parámetro e es un parámetro de escala dado que la distribución de Z = ex, no depende de e, porque
Fz(z) = Pe[Z :::; z] = Pe[eX :::; z]
= Pe [X :::; ~] = Fx (~) = 1 - e-z .
Luego Z '" Exp(l), distribución que no depende del valor que asuma el parámetro e.
Reconocer a un parámetro como de escala o como un parámetro de localización, es una vía para la identificación de una variable pivote como se había expresado anteriormente. Por consiguiente, si e es un parámetro de escala, según sea el caso, ~ o eXi es una variable aleatoria
n n pivote, y lo es también L ~ o e L Xi dependiendo de la situación. De
i=l i=l n n
manera similar, L (Xi - e) o L (Xi + e), según el caso, es una variable i=l i=l
pivote para el parámetro de localización e.
Teorema 3.2.11. Sea Xl, X2, ... , X n una muestra aleatoria de una población conjunción de densidad Jx(x,e), e E e ~ ]Rk, Y las estadísticas
Tn , T~l) Y T~2), estadísticas basadas en esta muestra aleatoria.
1. Si e es un parámetro de localización y si Tn es MLE de e, Tn - e o Tn + e es una variable aleatoria pivote.
T, 2. Si e es un parámetro de escala y si Tn es MLE de e, en o eTn es
una variable aleatoria pivote para e.
3. Si el es el componente de localización y T~l) un MLE de el y
además si e2 es el componente de escala y T~2) un MLE de e2,
(
T,(l) - e ) entonces n T~2) l es una variable aleatoria pivote para el, si
ésta no depende de los demás componentes de e, o si éstos son conocidos.

3.3. ESTIMACIÓN DE PROMEDIOS BAJO NORMALIDAD 157
Teorema 3.2.12. Bajo un caso regular de estimación, si el estimador Tn = t(XI , X2, ... , X n ) es insesgado para la imagen de O bajo una función r, cuya varianza coincide con la cota de Cramer-Rao, basado en una muestra aleatoria Xl, X 2 , ... , X n de una población con función de densidad f X (x, O), entonces la variable aleatoria
ynT(O) (7: - r( O)) r'(O) n
converge en distribución a una variable aleatoria con distribución Normal estándar.
Las dos secciones siguientes, dedicadas a los intervalos confidenciales bajo Normalidad, son fundamentalmente una relación de ejemplos del uso del método de la variable pivote, cuando se ha asumido el modelo gaussiano como regente del comportamiento probabilístico de la población. Estos intervalos comúnmente se describen en la mayoría de textos de estadística; su inclusión, además de ser una serie de ejemplos en la construcción de intervalos confidenciales, responde a que esos intervalos son de uso corriente.
3.3 Estimación de promedios bajo Normalidad
3.3.1 Intervalos confidenciales para el promedio de una población
Sea Xl, X 2 , ..• , X n una muestra aleatoria de una población con distribución Normal de valor esperado j.l y varianza (12. Se consideran dos casos, dependiendo de los supuestos que se hagan sobre la varianza poblacional. Caso 1 Un intervalo confidencial del 100(1 - a)% para j.l, de longitud mínima, cuando el valor de la varianza (12 es conocido, es
La variable pivote mencionada en el ejemplo 3.2.2, es la variable pivote que utiliza este primer caso,
Qx = fo(Xn - j.l) f"V N(O, 1). (1

158 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
El punto de partida del método, como se ha indicado de manera general, es entonces
PJ1- [a< Vn(X;-fL) <b] =(l-a)
que corresponde gráficamente al esquema que presenta la figura 3.1
fQx (q)
a b q
Figura 3.1: Esquema del punto de partida del método de la variable pivote para el caso 1.
1 - a = PJ1- [aa < Vn(Xn - fL) < ba]
[aa - ba]
= PJ1- Vn < (X n - fL) < Vn
[- aa - ba]
= PJ1- -Xn + Vn < -fL < -Xn + Vn
[- ba - aa]
= PJ1- X n - Vn < fL < X n - Vn .
Se ha determinado así un intervalo confidencial para fL,
(- ba- aa) X n - Vn,Xn - Vn
cuya longitud L¡ es factible hacerla mínima.
- aa (- ba) L¡ = X n - Vn - X n - Vn
a = Vn(b - a).

3.3. ESTIMACIÓN DE PROMEDIOS BAJO NORMALIDAD 159
Cualquier elección de la pareja (a, b) debe satisfacer para sus componentes la relación fundamental:
¡b fQx(q)dq = 1- a
o equivalentemente
Acatando esta relación entre a y b,
y derivando la relación fundamental en términos de b, se deduce que
Por tanto, fQx(b) 8 ~=--::---:- = - a fQx (a) 8b·
Sustituyendo esta última relación se tiene que
De esta manera,
o cuando a = b, pero esta última solución no es admisible porque no satisface la relación fundamental entre a y b. Gráficamente, la figura 3.2 muestra la elección apropiada de a y b para conseguir el intervalo confidencial con la exigencia de longitud mínima. Por consiguiente, el intervalo confidencial del 100(1 - a)% para ¡..¿ de longitud mínima bajo el supuesto de que la varianza 0-2 es conocida corresponde a

160 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
fQx (q)
a 2 ......
a (-Zl_2'. )
2
o
a /2
b (Zl_2'.) 2
q
Figura 3.2: Elección de los valores a y b que minimizan la longitud del intervalo confidencial correspondiente al caso 1.
Caso 2 Un intervalo confidencial del 100(1 - 0:)% para JL de longitud mínima, cuando la varianza de la población es desconocida, es
(- Sn - ) Sn) X n - t1_%(n - 1) yn' X n + t1_%(n - 1 yn .
Este intervalo atañe a situaciones más realistas, o por lo menos más corrientes que a la considerada por el caso 1. La variable aleatoria pivote para JL que genera este intervalo confidencial es
Qx = yn(Xn - JL) '"" t(n - 1) Sn
tal como fue mencionada en el ejemplo 3.2.3 de la página 150. A partir de ella y siguiendo prácticamente los mismos pasos y consideraciones del caso 1, se puede deducir el citado intervalo confidencial. Un buen estimador de la probabilidad de éxito 7f en un modelo de Bernoulli, también llamada proporción poblacional, es el promedio de la muestra que por su singularidad se le denomina proporción muestral y es denotado como Pn , como ya se había anotado. Este estimador derivado con base en el método de máxima verosimilitud goza de buenas propiedades que lo hacen óptimo. Con base en él es factible construir un intervalo confidencial para la proporción poblacional utilizando muestras grandes. El siguiente teorema apresta el fundamento de su construcción.

3.3. ESTIMACIÓN DE PROMEDIOS BAJO NORMALIDAD 161
Teorema 3.3.1. Sea Tn un MLE insesgado para e, cuya varianza coincide con la cota de Cramer-Rao y que cumple conjuntamente las condiciones de regularidad con el modelo probabilístico elegido, entonces para un tamaño de muestra suficientemente grande, un intervalo confidencial de aproximadamente 100(1 - a)% de confianza para e es
donde I(Tn ) es la información de Fisher evaluada en la estadística Tn .
3.3.2 Estimación de la proporción poblacional
Siendo Xl, X2, ... ,Xn una muestra aleatoria de una población con distribución de Bernoulli de parámetro 7r, un intervalo confidencial del 100(1 - a)% para 7r es
(Pn - Z1-, J Pn(J : Pn), Pn + Z1-'¡ J Pn(!: Po)) .
En efecto, teniendo en cuenta que
y utilizando el teorema 3.3.1, el intervalo confidencial para la proporción poblacional es
Es decir,
Como este intervalo requiere para su aplicación que el tamaño de la muestra sea grande, una recomendación práctica para su utilización, según varios autores, es confirmar que npn > 5 Y n(1 - Pn) > 5.

162 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
U n intervalo confidencial también utilizado en la estimación de 7f ,
citado en algunos textos, basado en la misma variable pivote VnI(O)(Pn - O) es
(
z2 V z2 a z2 V z2 a ) p. 1-~ P,,(l-P,,) + 1- 2 p. 1-~ P,,(1-P,,) + 1- 2
n + 2n n ~ n + 2n n ~ ------,2.="-- - Zl-"- 2 2 + Zl-"- 2
1+z1-~ 2 1+Z1-~ l+ z, --<t 2 l+ z, --<t n n n n
3.3.3 Intervalo confidencial para la diferencia de prome-dios basado en una muestra pareada
Cuando las variables aleatorias X, Y representan variables medidas en las mismas unidades y que cuantifican el mismo aspecto de la unidad estadística sólo que en circunstancias distintas y cuando la variable aleatoria Xi - Yi, i = 1,2, ... ,n representa una variable que tenga sentido, la muestra aleatoria (Xl, Yd, (X2 , Y2 ), . .. ,(Xn , Yn ) se denomina muestra pareada. Siendo la muestra pareada (Xl, Yl ), (X2 , Y2 ), . .. , (Xn , Yn ) una muestra aleatoria bivariada de una población con distribución Normal bivariada, cuya función conjunta de densidad f X,Y (x, y) es
Kexp {- 1 [(X-J.L1)2 _ (Y-J.L2)2 -2P(~) (Y-J.L2)]} 2(1 - p) 0"1 0"2 0"1 0"2
siendo la constante K = 1/(27fO"iO"2.J1="P), el intervalo confidencial del 100(1 - a)% de confianza para la diferencia de promedios
¡..td = ¡..ti - ¡..t2
con longitud mínima es
(- Sdn - Sdn) Dn - tl-~ (n - 1) fo ,Dn + tl-~ (n - 1) fo
siendo
• Di = Xi - Yi (D = X - Y)
• D rv N (¡..ti - ¡..t2, O"r + O"~ - 2PO"10"2)
2 1 n - 2 • Sd,n = n _ 1 i~(Di - Dn) ,
_ 1 n Dn = - ¿ Di.
n i=l

3.3. ESTIMACIÓN DE PROMEDIOS BAJO NORMALIDAD 163
La deducción de este intervalo confidencial corresponde a la de un intervalo confidencial del 100(1 - a)% de confianza para ¡..td = ¡..tI - ¡..t2
bajo Normalidad y asumiendo que la varianza O"i + O"§ - 2PO"l0"2 es desconocida. Por tanto, constituye un caso particular de un intervalo ya desarrollado.
3.3.4 Intervalos confidenciales para la diferencia de promedios en poblaciones independientes
Sean Xl, X 2 , .. . ,Xn una muestra aleatoria de tamaño n de una población Normal con valor esperado ¡..tI y varianza O"i, y YI, Y2, ... , Ym
una muestra aleatoria de tamaño m de una población Normal con valor esperado ¡..t2 y varianza O"§. Las dos poblaciones son estadísticamente independientes. Los casos que se consideran a continuación también corresponden a supuestos que se hacen sobre las varianzas poblacionales. Caso 1 U n intervalo confidencial del 100 (1 - a) % para la diferencia de promedios de dos poblaciones independientes, de longitud mínima, cuando O"i y O"§ son conocidas se desarrolla con base en los siguientes elementos:
- 0"2 ( 2) Y m rv N ¡..t2, m
A partir de esta variable pivote para (¡..tI - ¡..t2) puede generarse el intervalo confidencial correspondiente:
Caso 2 Un intervalo del 100(1 - a)% para la diferencia de promedios poblacionales correspondientes a dos poblaciones independientes, de longitud

164 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
mínima, bajo el supuesto de que las varianzas poblacionales son desconocidas pero iguales, se desarrolla teniendo en cuenta lo siguiente: Sea (JI = (j§ = (j2, entonces
(X -n-Y m) - (¡..t1 ¡..t2) ja' + a' ~ N(O, 1)
n m
n ¿(Xi - Xn)2 i=l 2 -=-----=---,,2-- '" X (n - 1)
(n - l)SI,n (j2 (j
m ¿ (Yj - y m)2 )=1
(j2 '" x2(m - 1). (m - l)S~,m
(j2
Como las poblaciones son estadísticamente independientes,
n m -2"" -2 ¿(Xi-Xn) +L.,(Yj-Ym)
_i=_l ____ ----,,;,.:-j=_l ____ 2( ) 2 "'X m+n-2 (j
(n - l)Sr,n + (m - l)S~,m '" x2(m + n _ 2) (j2
y a partir de estos resultados, la variable pivote para ¡..t1 - ¡..t2 será, por tanto,
(X -n-Y m)-(1l1 ¡.L2)
Q _ aJl+-L
X _ n m
(n-1)S? n+(m-1)S~ m
(m'+n-2)a2 '
(Xn - y m) - (¡..t1 - ¡..t2) '" t(n + m _ 2) Qx = J1 1
Sp,n+m n + m
(n - 1) Sr n + (m - 1) S~ m donde Si n+m = ( , , 'es el estimador de la varian-
, n+m-2 za común (j2. El intervalo confidencial para (¡..t1 - ¡..t2) basado en esta

3.4. ESTIMACIÓN DE VARIANZAS BAJO NORMALIDAD 165
variable pivote tiene como límite confidencial inferior a
- - gl (Xn - Y m)-tl_S!(n+m-2)Spn+m -+-2 ' n m
y como límite confidencial superior a
- - gl (Xn - y m) + tl_S!(n + m - 2)Spn+m - +-. 2 ' n m
Caso 3 Un intervalo confidencial del 100 (1 - a) % de confianza para la diferencia de los promedios de dos poblaciones independientes de longitud mínima, cuando las varianzas poblacionales se asumen distintas y desconocidas, está basado en la variable pivote
que tiene una distribución similar a la distribución t. Se puede decir que tiene distribución t aproximada con v grados de libertad.
Welch propone que los grados de libertad v deben ser el entero más cercano a
(~+~ )2 C~n f C~)2
n-l + m-l
De esta manera, el intervalo confidencial en consideración es
3.4 Estimación de varianzas bajo Normalidad
3.4.1 Intervalos confidenciales para la varianza de una población
Sea Xl, X2, ... , X n una muestra aleatoria de una población con distribución Normal de valor esperado J..l y varianza (Y2. Dependiendo del

166 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
supuesto asumido para 1-", se consideran dos casos: Caso 1 Un intervalo confidencial del 100(1- a)% para (]"2 cuando 1-" es conocido se basa en la siguiente variable pivote:
n ¿(Xi - 1-")2 i=l
(]"2 rv x2 (n).
Por tanto, la determinación del intervalo confidencial es como sigue. El punto de partida es
¿(Xi - 1-")2 i-l
[
n ] Pa2 a < - (]"2 < b = 1 - a
que corresponde gráficamente al esquema que presenta la figura 3.3. Equivalentemente
Pa2 [1 (]"2 1] b < i~(Xi - 1-")2 < ~
=1-a
es decir,
[
I=(Xi - 1-")2 I=(Xi - 1-")2] Pa2 ~=l b < (]"2 < ~=l a = 1-a.
La longitud del intervalo aleatorio
(i~ (x: -1'1' , i~ (X~ - 1')')

3.4. ESTIMACIÓN DE VARIANZAS BAJO NORMALIDAD 167
fQx (q)
a b q
Figura 3.3: Esquema del punto de partida del método de la variable pivote para el caso 1.
manifestado en este punto de la deducción puede minimizarse. La longitud mencionada,
está sujeta a la relación fundamental entre a y b,
Utilizando los recursos del cálculo diferencial,
De la relación fundamental entre a y b se deduce que
o 0= fQx (b) oa b - fQx (a)
fQx(a) = ~b. fQx (b) oa

168 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
a 1 1 a . Luego oa L¡ = 0, cuando a2 = b2 oa b, es decIr, cuando
1 1 fQx(a) a2 = b2 fQx(b)·
Concretamente, el intervalo confidencial tiene longitud mínima cuando
a2 fQx(a) = b2 fQx(b).
Establecidos los grados de libertad y en nivel confidencial (1 - a), es posible identificar los valores de a y b que cumplen la anterior condición, a través de métodos numéricos. Algunos autores han desarrollado tablas para este propósito, pero es fácil elaborar un programa de computador que los calcule. Esta limitación menor se elude en la medida que se cuente con una muestra grande.
Corrientemente, para muestras grandes se prefiere la elección de a y b como
a = x~(n) 2
b = xL~(n), 2
tal como lo ilustra la figura 3.4.
fQx(q)
a 2"
b (xi-% (n)) q
Figura 3.4: Elección corriente de los valores a y b para el intervalo confidencial correspondiente al caso 1.
En síntesis, el intervalo confidencial del 100(1 - a)% de confianza para

3.4. ESTIMACIÓN DE VARIANZAS BAJO NORMALIDAD 169
(J2 cuya longitud no es mínima, usado corrientemente es
Caso 2 Un intervalo confidencial del 100(1 - a)% de confianza para (J2 cuando j.l es desconocido es
intervalo que se puede construir a partir de la variable pivote para (J2:
n ¿(Xi - Xn)2
Qx = _i=_l_-----::-__ rv x2 (n -1) (J2
y cuya deducción es idéntica al caso l. El intervalo de longitud mínima, al igual que el anterior, debe ser aquel para el cual se cumpla que
3.4.2 Intervalos confidenciales para el cociente de varianzas de dos poblaciones independientes
Sean Xl, X 2 , . .. , X n una muestra aleatoria de tamaño n de una población Normal con valor esperado j.ll y varianza (Ji, y YI , Y2 , •.. , y m
una muestra aleatoria de tamaño m de una población Normal con valor esperado j.l2 y varianza (J~. Las dos poblaciones son estadísticamente independientes. Los casos que se consideran a continuación también corresponden a supuestos que se hacen sobre los promedios poblacionales. Caso 1 Un intervalo confidencial del 100(1 - a)% de confianza para el cociente
2
de varianzas ~ de dos poblaciones independientes, cuando j.ll y j.l2 son a 2

170 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
conocidos, es el siguiente:
( i~(Xi - f..ld2/n i~(Xi - f..ld
2/n 1
m f!fj (m, n), m ft-!fj (m, n) ¿ (Yj - f..l2)2/m ¿ (Yj - f..l2)2/m j=l j=l
En efecto, n m ¿ (Xi - f..ll)2 ¿ (Yj - f..l2)2 i= 1 2 ( ) j = 1 2 ( )
2 rvX n 2 rvX m. U 1 U2
Con base en estas variables y reiterando la independencia estadística de 2
las poblaciones se construye la siguiente variable pivote para ~: a 2
m m ¿ (Yj - f..l2)2 /(mu~) 2 ¿ (Yj - f..l2)2/m j=l U 1 j=l
Qx = n - 2" n rv F(m, n). ¿(Xi - f..ll)2/(nur) U2 ¿(Xi - f..ll)2/n i=l i=l
Al partir de
Pai,a~ [mi
2 ¿ (Yj - f..l2)2/m Ulj=l
a<- <b =l-a U2 n
2 i~(Xi - f..ll)2/n
que corresponde gráficamente al esquema que presenta la figura 3.5. surge un intervalo confidencial para el cociente de varianzas debido a que
[
n n 1 ¿(Xi - f..ll)2/n 2 ¿(Xi - f..ld 2/n i=l Ul i=l
Pa2 a2 a m < -2 < b m = 1 - a. l' 2 U
j~l (Yj - f..l2)2/m 2 j~l (Yj - f..l2)2 /m
Para simplificar los pasos posteriores en la construcción del intervalo confidencial en consideración, se establece la sustitución
n
¿(Xi - f..ld 2/n T = -'::i=:-::-=l'--___ _
m
¿ (Yj - f..l2)2 /m j=l

3.4. ESTIMACIÓN DE VARIANZAS BAJO NORMALIDAD 171
a b q
Figura 3.5: Esquema del punto de partida del método de la variable pivote para el caso 1.
Con ello
y la longitud del intervalo L¡ es
L¡ = bT - aT = T(b - a)
que se minimiza, como en casos anteriores, haciendo uso de los procedimientos respectivos del cálculo diferencial.
!!...-L¡ = T (!!...-b - 1) . oa oa
. o fQx (a) o (fQX (a) ) Como ya se ha establecIdo oa b = fQx (b) , luego oa L¡ = T fQx (b) - 1 ,
o entonces oaL¡ = O, cuando fQx(a) = fQx(b).
De manera similar al caso de los intervalos confidenciales de longitud mínima para las varianzas bajo normalidad, establecidos los grados de libertad y el nivel confidencial (1 - a), es posible identificar los valores de a y b que cumplen la condición anterior, como lo muestra la figura 3.6, por medio de métodos numéricos. De la misma manera, es fácil elaborar un programa de computador que los calcule. E igualmente esta limitación se soslaya en la medida que se cuente con muestras grandes.

172 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
fQx (q)
a b q
Figura 3.6: Elección de los valores a y b que minimizan la longitud del intervalo confidencial correspondiente al caso 1.
Para n y m grandes, corrientemente se utilizan los percentiles a = f2:(m,n), b = fl-2:(m,n), en cuyo caso el intervalo confidencial
2 2 0'2
para 3- del 100(1 - a)% de confianza es 0'2
(
n n ) ¿ (Xi - JLl)2 In ¿ (Xi - JLd 2 In i;;;l f2: (m, n), i~l h-2: (m, n) .
j~l (Yj - JL2)2/m 2 j~l (Yj - JL2)2/m 2
Caso 2 Un intervalo confidencial del 100(1 - a)% de confianzas para el cociente
2
de varianzas ~ de dos poblaciones independientes, cuando JLl y JL2 se 0'2
desconocen, es
(
n n ) ¿(Xi - Xn)2/(n -1) ¿(Xi - Xn)2/(n -1) i=l i=l b m a, m
j~/Yj - y m)2 I(m - 1) j~l (Yj - y m)2 I(m - 1)

3.5. EJEMPLOS NUMÉRICOS DE APLICACIÓN
2
intervalo confidencial basado en la variable pivote para ~ a 2
173
Para tamaños de muestra suficientemente grandes, un intervalo confia 2
dencial para 3 es a 2
( Sr n Sr n ) -' Fa(m-1 n-1) -' Fl a(m-1 n-1) . s2 2 ' , S2 -2 ' 2,m 2,m
3.5 Ejemplos numéricos de aplicación
Ejemplo 3.5.1. El servicio de asesoría estadística que la Universidad N acional presta a través del Departamento de Estadística realizó en 1997 un estudio de opinión sobre la justicia en Colombia y entre muchos de los interrogantes que el Consejo Superior de la Judicatura quería dilucidar con esta investigación era la percepción de los abogados, que se desempeñan en el área penal, frente al nuevo sistema acusatorio, fruto de la creación de la Fiscalía. Para ello diseñó una muestra en varias etapas y concretamente encontró que 315 abogados de los 509 entrevistados consideraron que el nuevo sistema acusatorio no es un instrumento en la lucha contra la impunidad. Con base en estos resultados se precisa estimar con una confianza del 95% el nivel de asentimiento del nuevo sistema acusatorio por los abogados penalistas, en ese momento. Siendo P509 = 315/509 = 0.61886 la proporción de interés en la muestra, y con la adopción de ZO.975 = 1.96 Y debido a que npn = 315 > 5 Y n(l - Pn) = 194 > 5, entonces se puede estimar con una confianza del 95% que entre el 57.66% y el 66.1% de los abogados que se desempeñan en asuntos del derecho penal, consideran que el nuevo sistema acusatorio no es un instrumento contra la impunidad, puesto que la estimación por

174 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
intervalo de la proporción en mención es
( vPn(1- Pn) + VPn(1- pn)) Pn - Z1_.9'. ,Pn Z1-.9'.
2 n 2 n
( 0.6188 * 0.3811
= 0.6188 - 1.96 509 ' 0.6188 + 1.96
= (0.5766,0.6610).
0.6188 * 0.3811) 509
Ejemplo 3.5.2. Antes de implementar los gráficos de control, para el monitoreo de un proceso industrial, es preciso desarrollar varias actividades, entre otras el llamado precontrol. El modelo Normal es una herramienta muy utilizada en esta etapa para estimar el promedio del proceso e igualmente para determinar sus cambios. Para controlar estadísticamente el proceso de fabricación de un tipo de fibra para la elaboración de alfombras, se analiza la información relativa a la resistencia a la tensión de trozos de fibra, en kilogramos, elegidos para la respectiva prueba en el laboratorio. En diez períodos de inspección con cinco trozos cada uno, se acopió la información con el propósito de estimar el promedio de resistencia de la fibra, información registrada en la tabla 3.1.
Período Resistencias observadas
1 78.4 79.9 78.9 78.3 77.5 2 75.9 75.1 75.1 79.9 77.1 3 78.9 78.4 78.1 78.3 77.8 4 75.9 79.5 79.1 77.9 77.5 5 78.1 79.9 77.9 77.8 79.9 6 77.1 79.7 76.9 78.4 79 7 77.9 79.5 78.9 78.5 78.9 8 78.9 79.8 78.6 78.2 77.6 9 78.5 79.5 79.9 78.4 77.7 10 78.6 79.9 78.6 77.4 77.5
Tabla 3.1: Datos relativos a la información acopiada del ejemplo 3.5.2.
Para cumplir la estimación mencionada, se consideran las 50 observaciones como una sola muestra particular de tamaño 50, que presenta un promedio de 78.3 kg y una desviación estándar de 1.184078 kg, con lo

3.6. TAMAÑO DE LA MUESTRA SIMPLE BAJO NORMALIDAD 175
cual se estima con una confianza del 95% que la resistencia media a la tensión está entre 77.96 kg Y 78.63 kg puesto que la estimación por intervalo del 95% de confianza para el promedio de resistencia, desconocida la varianza poblacional, es
( ~ ~) xn - t1-% (n - 1) Vii' xn + t 1-% (n - 1) Vii
( 1.184078 1.184078)
= 78.3 - 2.009574 V56 ,78.3 + 2.009574 V56
= (77.9634,78.6365).
3.6 Tamaño de la muestra simple bajo Normalidad
Esta sección es una presentación sucinta, dedicada al tamaño de la muestra. Este tema primordial y complejo es un tema extenso que abarca varios aspectos incluyendo el relativo a la determinación de la numerosidad de la muestra propiamente dicha. Si el lector continúa trabajando sobre conceptos del área de la estadística, tendrá la oportunidad de profundizar sobre este tema fundamental tanto en el diseño como en la ejecución de investigaciones auxiliadas por la estadística. Entonces, se trata de un modesto anticipo sin la menor pretensión de lo que significa la determinación del tamaño muestral.
Para estimar el parámetro J.L, promedio poblacional, se puede deducir el tamaño de una muestra a partir de la expresión de uno de sus intervalos confidenciales.
P¡.t [Xn - Zl-%::n < J.L < Xn + Zl-~ ::nJ = 1- a
PJ.L [-Zl-% ::n < J.L - X n < Zl-~ ::nJ = 1 - a
P¡.t [IXn - J.LI < Zl_~ ::nJ = 1 - a
P¡.t [IXn - J.LI < e] = 1 - a.
Fijando de antemano como medida de precisión de la estimación de J.L el valor Zl-Q ~ = e, el tamaño de muestra puede ser derivado inmediata-
2 yn

176 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
mente como
(ZI_Q.o") 2
n = __ 2_
e
En esta expreSlOn corriente del tamaño de una muestra simple, e se denomina error máximo admisible en la estimación de /1, o margen de error, y constituye una cota para la diferencia aleatoria IXn - /11. Con la denominación de confianza se hace referencia al valor 1 - a, y el valor de O" usualmente se estima por medio de una muestra llamada muestra piloto, en caso de no asumirlo conocido. Para estimar la diferencia de promedios entre dos poblaciones independientes, los tamaños de muestra pueden establecerse como
1- 2 2 2 (Z a)2 n = m = -e- (0"1 + 0"2)'
En el ejercicio 11 de este capítulo se deduce la expresión anterior.
n
~ (Zl-eU/2r
1 2 1 7f
Figura 3.7: Tamaño holgado de la muestra para estimar la proporción poblacional.
Para estimar la proporción poblacional 7f, el tamaño de muestra requerido es
(ZI a)2
n= :2 7f (1-7f)
cuyo tamaño más holgado puede adoptarse como
n = (ZI: % ) 2 (l) ,

3.7. ESTIMACIÓN BAYESIANA POR INTERVALO 177
pues al ser n una función de 7r, además de otras variables,
su máximo puede determinarse fácilmente en los siguientes términos:
g'(7r) = (Zl:~) 2 (1 _ 27r)
g"(7r) = -2 (Zl:~) 2 < O
1 g'(7r) = O cuando 7r = "2
como lo destaca la figura 3.7.
3.7 Estimación bayesiana por intervalo
El numeral 2.1.4 de la página 84 se dedicó a la presentación de algunas ideas globales de la estimación bayesiana. Precisamente se definió como función de densidad a posteriori de 8 a la función de densidad condicional
felxl,x2, ... ,xn (eIXl, X2,···, x n )
y ésta permite deducir directamente un intervalo para estimar el parámetro e.
Definición 3.7.1. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con función de densidad fx(xle), ge(e) la función de densidad a priori de 8, y felxl,x2, ... ,xn (eIXl, X2, .. . , x n ) la función de densidad a posteriori de 8. Sean ea ye l dos valores de la variable aleatoria 8 tales que
entonces el intervalo (ea, el) se denomina intervalo bayesiano para e de probabilidad 1 - a.
El intervalo (ea, el) se adopta como una estimación de e con probabilidad asociada 1 - a, cuya interpretación no es la misma que la de

178 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
una estimación por intervalo del 100(1 - a)% para el mismo parámetro. Es válido entonces decir, dentro del enfoque bayesiano, que la probabilidad de que el parámetro se encuentre entre los valores eo y el es 1 - a, mas sería una interpretación errónea si se tratase de una estimación por intervalo.
Ejemplo 3.7.2. Si X l ,X2, ... ,Xn es una muestra aleatoria de una población con distribución Normal de valor esperado e y varianza 0"2
asumida como una constante conocida, y si la distribución a priori de 8 se establece como Normal de valor esperado f.Lp y varianza O"ª, el ejemplo 2.1.25 de la página 88, menciona que la distribución a poste-
n0"2x + f.L 0"2 riori de 8 es Normal de valor esperado f.L* = p; ~ y varianza
nO"p + O"
2 0"20"2 0"* = P n0"0 + 0"2· Entonces
P [eo < 8 < el] = p * < Z < * = 1 - a. [ eo - f.L el - f.L ]
0"* 0"*
El intervalo bayesiano (eo, ed tiene longitud mínima escogiendo
eo - f.L* el - f.L* --- = -Zl-Q< Y = Zl-Q<·
0"* 2 0"* 2
De esta forma, el intervalo bayesiano de probabilidad 1 - a bajo las condiciones establecidas es
(
nO"ªxn + f.Lp 0"2 _ O"pO"Zl_%, nO"ªxn + f.L p 0"2 O"PO"Zl_~) 2 2 l' 2 2 + 1 .
nO" p + O" (n0"0 + 0"2) 2: nO" p + O" (nO"~ + 0"2) 2:
Tanto la estimación como los intervalos bayesianos tratados en este texto son menciones tangenciales de unos conceptos que pertenecen a un cuerpo conceptual propio dentro de la estadística: el análisis bayesiano o estadística bayesiana. El lector puede contar con una extensa bibliografía en el tema, si le interesa conocer a profundidad la filosofía y los métodos de este enfoque estadístico.
3.8 Demostración de los teoremas
Teorema 3.1. 7. Sea Xl, X 2 , ... , X n , una muestra aleatoria de una po
blación con función de densidad fx(x, e), y T~i) = ti(X l , X 2 , ... , X n ),

3.8. DEMOSTRACIÓN DE LOS TEOREMAS 179
i = L 2, estadísticas tales que (T2) , T~2») es un intervalo confidencial
para e. Si r(e) es una función estrictamente monótona con dominio e y recorrido un subconjunto de IR, (1' (T2») ,1' (T~2»)) es un intervalo
confidencial para la imagen de e bajo 1', cuando ésta es estrictamente cre
ciente y (1' ( Tr~2») ,1' ( T2»)) es un intervalo confidencial para la imagen
de e bajo l' cuando la función l' es estrictamente decreciente.
Demostración. Corno (T2), Tr~2») es un intervalo confidencial para e
es porque en particular Pe [T~l) < TrF)] = 1. Si r(e) es una función
estrictamente decreciente, entonces Pe [1' ( Tr~l») > l' (T~2»)] = 1 Y el
evento aleatorio {r ( T,~1») > 1'( e) > l' ( T~2») } es equivalente al evento
{ T2) < e < T~2)}; por tanto,
1- a = Pe [T2) < e < T~2)] = Pe [1' (T~2») < r(e) < l' (T2»)].
Como 1 - a no depende de e y Pe [1' (T~2») < l' (T~l»)] = 1, el in
tervalo aleatorio (1' ( Tr~2») ,1' ( T2»)) es un intervalo confidencial del
100(1 - a)% de confianza para la imagen de e bajo la función r.
De manera similar, el intervalo aleatorio (1' (T~ 1») ,1' (T~2»)) es un in
tervalo confidencial del 100(1- a)% para la imagen de e bajo la función 1', cuando ésta es una función estrictamente creciente. D
Teorema 3.2.12. Bajo un caso regular de estimación, si el estimador Tn = t(X1 , X 2 , . .. ,Xn ) es insesgado para la imagen de e bajo una función 1', cuya varianza coincide con la cota de Cramer-Rao, basado en una muestra aleatoria X 1,X2 , ... ,Xn de una población con función de densidad f X (x, e), entonces la variable aleatoria
JrllWJ (T - (e)) r/(e) n l'
converge en distribución a una variable aleatoria con distribución Normal estándar.
Demostración. Los argumentos de la demostración de este teorema se basan en ideas circundantes a la información de Fisher y en el teorema

180 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
del límite central. El elemento original consiste en considerar la variable aleatoria
8 H(X,O) = 80 [lnfx(X,O)].
Esta variable tiene valor esperado cero y varianza 1(0).
fOO 8 E[H(X, O)] = J-oo 80 [In fx(x, O)] fx(x, O) dx
8 foo 80fx(x, O)
= J-oo 1" I /1\ fx(x,O)dx
foo 8 = J-oo 80 fx (x, O) dx
8 foo 8 = 80 J-oo fx(x,O) dx = 80(1) = O
V[H(X, O) = E [H2 (X, O)] = 1(0)].
Creada de esta forma la variable aleatoria H(X, O), la sucesión de variables aleatorias H(X1 , O), H(X2 , O), ... ,H(Xn , O) constituye una muestra aleatoria de manera que aplicando la versión de Lindeberg-Feller del teorema del límite central, teorema 1.4.12, página 21,
y'n1(0)
n 8 i~ (j(j [lnfx(Xi, O)]
y'n1(0) ~ Z rv N(O, 1).
n ¿ H(Xi,O) i=l
Como se afirma que Tn es un estimador insesgado para la imagen de O bajo la función r, cuya varianza es la cota de Cramer-Rao, es porque existe una función K ( O, n) tal que
8 (n ) n 8 80 In g fx(Xi, O) = ~ 80 In fx(Xi, O) = K(O, n) [Tn - r(O)] ,
como lo asegura el corolario 2.2.56, página 113; esto es,
n
I: H(Xi, O) = K(O, n) [Tn - r(O)]. i=l

3.8. DEMOSTRACIÓN DE LOS TEOREMAS
Por tanto, 1 n
Tn = r(e) + K(e, n) t; H(Xi , e)
expresión de la cual se puede afirmar que
Entonces
i=l
nI(e) V[Tn] = K2(e, n)'
K(e, n) [Tn - r(e)]
J K2(e, n)V[Tn]
Tn - r(e)
JV[Tn]'
181
Como Tn es insesgado para la imagen de e bajo la función r, cuya varianza es la cota de Cramer-Rao,
(r'(e))2 V[Tn] = nI(e) ,
lo cual finalmente permite concluir que
Tn-r(e) (r'(II))2 nI(iJ)
JnI(e) d r'(e) [Tn - r(e)] --- Z rv N(O, 1). o
Teorema 3.3.1. Sea Tn un MLE insesgado para e, cuya varianza coincide con la cota de Cramer-Rao y que cumple conjuntamente las condiciones de regularidad con el modelo probabilístico elegido, entonces para un tamaño de muestra suficientemente grande, un intervalo confidencial de aproximadamente 100(1 - a)% de confianza para e es
donde I(Tn) es la información de Fisher evaluada en la estadística Tn .
Demostración. Más allá de ser una demostración, se presentan algunas consideraciones respecto a la misma. El hecho de que Tn sea MLE e insesgado para e, cuya varianza corresponde a la cota de Cramer-Rao, permite garantizar, según el teorema 3.2.12, que
Qx = JnI(e)(Tn - e)

182 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
converge en distribución a una variable aleatoria con distribución normal estándar; luego para un tamaño de muestra suficientemente grande, Qx se puede asumir como una variable aleatoria pivote para e. Entonces,
Pe [a < JnI(e)(Tn - e) < b] = Ón ~ 1 - a.
La probabilidad Ón es cercana a 1 - a, porque en la práctica n es finito, probabilidad que no depende de e y como la información de Fisher es una cantidad positiva
Ón = Pe [
a < T - e < -----=b=] JnI(e) n JnI(e)
=Pe [-~<B-Tn<-~] =Pe [
T- b <e<T- a] n JnI(e) n JnI(e)
El intervalo aleatorio que sugiere esta última expresión no es un intervalo confidencial para e, porque sus límites están dependiendo de e por medio de I(e). La elección de a y b puede ser hasta cierto punto arbitraria, sujeta a la relación entre a y b para garantizar el nivel de confianza Ón ,
pero pueden utilizarse los valores que generan el intervalo de longitud mínima como en los casos 1 y 2 tratados en el numeral 3.3.1. En concreto, una estimación aproximadamente del 100(1 - a)% de confianza para e puede realizarse mediante el intervalo confidencial
Tn - 2, Tn + 2 , (
Zl--'" Zl--'" )
JnI(Tn) JnI(Tn)
tal como lo afirman Bartoszynski y Niewiadomska-Bugaj. D
3.9 Ejercicios
1. Si Xl,n, X 2 ,n, ... ,Xn,n es una muestra aleatoria ordenada de una población con distribución Uniforme en el intervalo (O, e), y si
TAl) = X n n, TA2) = (l)n X n n son estadísticas, con e una cons-
, e'
tante, O < e < 1, demuestre que el intervalo (TAl), TA2») es un
intervalo confidencial para e y determine el valor esperado de la longitud del intervalo y su nivel confidencial.

:1.9. EJERCICIOS 183
2. Si las variables aleatorias Xl, X2, ... ,Xn constituyen una muestra aleatoria de una población con función de densidad
Ix(x, e) = e-(x-e) 1(e.00) (x),
¿es el intervalo aleatorio (Xl,n + ~ In a, Xl,n) un intervalo confidencial del 100(1 - a)% de confianza para e?
3. Explore la forma de estimar por intervalo el parámetro e, a partir de una muestra aleatoria Xl, X2, . .. ,Xn, de una población con distribución de Poisson de parámetro e.
4. Asumiendo que el es una cantidad conocida, proponga una forma de estimar por intervalo el parámetro e2 , a partir de una muestra aleatoria Xl, X2,' .. ,Xn , de una población con función de densidad
e-el
( ) _ 2 el -1 - i- ( ) Ix x, e - r(el
) x e 21(0,00) x .
5. Explore la forma de estimar por intervalo el parámetro e, y e2
a partir de una muestra aleatoria Xl, X2, .. . ,Xn , de una población con distribución Normal de valor esperado e y varianza ke2 ,
conocido el valor de k.
6. Considere el intervalo confidencial de longitud mínima para el valor esperado, desconocida la varianza, bajo el modelo gaussiano. ¿ Cómo varía el valor esperado de la longitud del intervalo cuando el tamaño de muestra se incrementa? Y además, ¿cuál es la relación entre el citado valor esperado y el nivel confidencial?
7. Consiga una forma de estimar por intervalo el coeficiente de variación (J/fL a partir de una muestra aleatoria X l ,X2,." ,Xn , de UIla población con distribución gaussiana de valor esperado fL y varianza (J2.
8. Suponiendo que (JI / (Ji = c, c una constante conocida, determine un intervalo confidencial para la diferencia fLl - fL2 con base en dos muestras aleatorias independientes de sus respectivas poblaciones cuyas distribuciones son asumidas como gaussianas de valores esperados fLl, fL2 Y varianzas (JI, (Ji, respectivamente.

184 CAPÍTULO 3. ESTIMACIÓN POR INTERVALO DE PARÁMETROS
9. Asumiendo 01 como una constante conocida, explore la forma de estimar por medio de un intervalo confidencial el parámetro O2 ,
basado en una muestra aleatoria Xl, X2, ... , X n , de una población con distribución de Pareto, es decir con función de densidad
020~2 fx(x, O) = x 02+l1(01,00)(x).
10. ¿Cuál de los dos intervalos confidenciales para la estimación de la proporción poblacional, presentados en el numeral 3.3.2, prefiere utilizar?
11. Deduzca la expresión para el tamaño de la muestra simple requerido en la estimación de la diferencia de promedios en poblaciones independientes bajo Normalidad.
12. El número de disconformidades de una baldosa de cerámica se modela para efectos de control de calidad, como una variable aleatoria con distribución de Poisson. La variabilidad propia del proceso de manufactura sugiere reconocer al parámetro como una variable aleatoria, para la cual se propone un modelo Exponencial de parámetro igual a uno. Determine un intervalo bayesiano para estimar la tasa de disconformidades por unidad, con base en una muestra aleatoria de tamaño n.
13. Deduzca un intervalo confidencial del 100(1 - a)% de confianza para O, basado en una muestra aleatoria censurada de una población con función de densidad, tal como la presenta el ejemplo 2.1.14, de la página 77.
14. Sea Xl,X2, ... ,Xn , una muestra aleatoria de una población con función de densidad Uniforme en el intervalo (O, O), fijo el valor e, ¿el intervalo aleatorio (Xn,n, c~Xn,n) es un intervalo confidencial de longitud mínima para O? Si el espacio del parámetro es 8 = {010 < O :S k}, k una constante conocida, determine el tamaño de muestra mínimo tal que la longitud del intervalo confidencial sea por lo menos lo.
15. Si Xl, X 2, ... , X n es una muestra aleatoria de una población con función de densidad Uniforme en el intervalo (O - ~,O + ~), determine un intervalo confidencial del 100(1 - a)% de confianza para O.

3.9. EJERCICIOS 185
16. Si Xl, X2, . .. , X n es una muestra aleatoria de una población con función de densidad
fx(x, e) = e exp( -ex)I(o,oo) (x),
determine un intervalo confidencial del 100(1 - a)% de confianza para P[X > 1].
17. Con base en el ejercicio 16, determine un intervalo confidencial del 100(1- a)% de confianza para e, basado únicamente en el mínimo de la muestra.
18. Si Xl, X 2 , . .. , X n es una muestra aleatoria de una población con función de densidad
2x fx(x, e) = e2I(O,B)(x), con e > o,
determine un intervalo confidencial del 100(1 - a)% de confianza para e.
19. Si Xl, X 2 , . .. ,Xn es una muestra aleatoria de una población con función de densidad
1 1 l fx(x, e) = (jX o- I(O,I) (x), con e > o,
determine un intervalo confidencial del 100(1 - a)% de confianza para e.
20. Si Xl, X 2 , . .. , X n es una muestra aleatoria de una población con función de densidad
fx(x,e) = eXB-II(o,l) (x), con e > o,
determine un intervalo bayesiano para e, si la distribución a priori de e es Gama con los componentes del parámetro especificados.

Capítulo 4
Juzgamiento de hipótesis
A este capítulo tradicionalmente se le ha llamado prueba de hipótesis, contraste de hipótesis, docimasia de hipótesis e incluso cotejo de hipótesis, como resultado de las traducciones del vocablo inglés test, o testing. Sin embargo, al volver a examinar las acepciones de cada uno de los términos utilizados se encuentra que no ofrecen la precisión semántica necesaria para enmarcar un sistema de conceptos substanciales dentro de la estructura conceptual de la inferencia estadística.
Prueba de hipótesis, tal vez la forma más cotidiana para referirse al contenido del capítulo, utiliza un término que dentro de sus muchas acepciones presenta algunas asociadas con el tema. "Prueba: razón, argumento, instrumento u otro medio con que se pretende mostrar y hacer patente la verdad o falsedad de algo. Ensayo o experimento que se hace de algo para saber cómo resultará en su forma definitiva. Indicio, señal o muestra que se da de algo" 1. Quizás uno de sus sinónimos que mejor resume su sentido es cateo. Pero decidir a favor o en contra de una aseveración que traduce una explicación apriorística de algún fenómeno particular de la realidad, cuya decisión se toma a la luz de la información de la muestra, no puede entenderse como un cateo.
Por otra parte, contraste de hipótesis tampoco es una acertada elección para la denominación del tema porque además de utilizar el vocablo contraste, muy propio en el planteamiento de hipótesis en los modelos lineales o en el diseño experimental, entre otros, término que podría introducir confusión, ninguna de sus acepciones ligadas al tema es sufi-
lReal Academia Española (2001). Diccionario de la lengua española. Vigésimasegunda edición. Madrid: Espasa Calpe S.A.
187

188 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
ciente para describir globalmente esta área del conocimiento estadístico. En efecto, "contrastar: ensayar o comprobar y fijar la ley, peso y valor de las monedas o de los objetos ... Comprobar la exactitud o autenticidad de algo. Mostrar notable diferencia, o condiciones opuestas, con otra, cuando se comparan ambas" (Op. cit), es un término más cercano para estimar o para destacar que a la toma de decisiones a partir de la información de la muestra.
Docimasia como "arte de ensayar los minerales para determinar la naturaleza y proporción de los metales que contienen" 2, Y de otras de sus acepciones, presenta más un sentido de análisis que un sentido de opción por algo a la luz de los hechos. Además, su origen etimológico de ensayar o probar, la colocaría como sinónimo de prueba, y no habría razones para adoptarla. Cotejo como acción y efecto de cotejar, siendo cotejar "confrontar algo con otra u otras cosas; compararlas teniéndolas a la vista" (Op. cit), consistiría igualmente en un simple sinónimo de contraste, que no introduce elementos adicionales para admitirlo como palabra nuclear.
Como juzgamiento es acción y efecto de juzgar, entendiendo que juzgar significa "deliberar acerca de la culpabilidad de alguien o de la razón que le asiste en un asunto y sentenciar lo procedente. Decidir en favor o en contra y especialmente pronunciar como juez una sentencia acerca de alguna cuestión o sobre alguno" ( Op. cit), además de tomarse como directriz a una de sus acepciones que condensa la finalidad de un procedimiento de toma de una decisión a favor o en contra de algo, juzgamiento por su parte es un vocablo que permite construir una analogía magistral entre un juicio que se realiza ante un juez y los elementos, pasos y conceptos en el acopio de información, su procesamiento y la decisión que se toma ante una afirmación relativa al fenómeno en estudio, que la inferencia estadística abstrae y estructura como una de sus partes fundamentales.
En consecuencia, este texto titula al presente capítulo como Juzgamiento de hipótesis, porque como se comprenderá, en la medida que vaya desarrollándose, se trata realmente de algo análogo a un juicio, particularmente a un juicio penal. Para iniciar la exposición de los conceptos propios del juzgamiento de hipótesis, se parte del concepto de hipótesis estadística.
2VOX. (1991). Gran diccionario general de la lengua española. Segunda Edición. Editorial Presencia para Colombia. Bogotá.

4.1. ELEMENTOS BÁSICOS 189
4.1 Elementos básicos
Definición 4.1.1. Una hipótesis estadística es una aseveración o conjetura acerca de la distribución de una población, afirmación que generalmente está asociada a un subconjunto del espacio del parámetro e correspondiente al modelo probabilístico que representa la citada población. Como notación, la aseveración se enuncia después de la abreviatura Ho o H¡. El juzgamiento de una hipótesis estadística es un proceso que culmina con una decisión de rechazar o de no rechazar una hipótesis con base en la información de una muestra aleatoria Xl, X 2 , .. . , X n de una población para la cual se ha asumido un modelo probabilístico cuya función de densidad es fx(x, O).
Definición 4.1.2. La hipótesis sobre la cual se estructura el proceso de juzgamiento se denomina hipótesis nul(]" se denota Ho y se enuncia como
Definición 4.1.3. La hipótesis elegida como contraste a la hipótesis nula se denomina hipótesis alterna, se denota H¡ y se enuncia como
e ce -1 -, e ne = 0. -1 -o
Definición 4.1.4. La díada de hipótesis nula y alterna constituye el sistema de hipótesis del proceso de juzgamiento de la hipótesis nula, sistema que se enuncia como
Ho : O E eo frente a
Hl : O E el·
Definición 4.1.5. Una hipótesis H : O E e', e' c e se denomina hipótesis simple si con dicha aseveración queda plenamente especificada la distribución de la población. En caso contrario se denomina hipótesis compuesta.
Ejemplo 4.1.6. El diseño de un producto establece un envase de 20 onzas fluidas; en consecuencia, el proceso de llenado debe adecuarse a ese requerimiento y deben planearse y ejecutarse los controles periódicos

190 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
para tomar las decisiones a que haya lugar sobre los ajustes a las máquinas y al proceso en general, una vez se obtenga y se procese la información pertinente durante los controles.
Para respaldar cualquier decisión con el apoyo de procedimientos estadísticos, una manera consistiría en idealizar el contenido del producto en el envase como una variable aleatoria y adoptar un modelo probabilístico como regente de su comportamiento. En particular, si se elige el modelo gaussiano como el más idóneo para representar el contenido mencionado, con valor esperado e y bajo el supuesto de varianza conocida, la declaración H : e = 20 indicativa de que el proceso de llenado está centrado de acuerdo con el requerimiento del diseño, corresponde a una hipótesis simple, puesto que conocida la varianza y admitido e = 20 como el valor esperado de la variable que representa el citado contenido, queda plenamente determinada la distribución de esa variable.
Por su parte, la afirmación de que el proceso de llenado tiende a rebosar el envase, traducida como H : e > 20, corresponde a una hipótesis compuesta, porque se trata de una afirmación que aunque lleva tácita la alusión a una variable con distribución gaussiana de varianza conocida, no identifica una distribución singular.
Continuando dentro de este contexto industrial, si en el instante de cierre del envase posterior al llenado, mediante la utilización de una fotocélula, se detectan envases con contenido inferior a 18.5 fl oz, éstos son trasladados a un proceso de reciclaje prácticamente sin costo alguno, mientras que los recipientes que contienen 18.5 fl oz o más, no activan señal alguna de la fotocélula, siendo la preocupación central por aquellos envases que contienen más de 20 fl oz, pues proporcionalmente al contenido adicional generan costos considerables. Para el seguimiento del proceso, en cada período de control se recoge la información correspondiente al contenido de 49 envases elegidos en forma aleatoria dentro del lote de producción, como parte del aprestamiento para el control estadístico de calidad del proceso, con la finalidad de decidir si deben realizarse ajustes a las máquinas o al proceso en general, o, por el contrario, para dar parte de la no presencia de factores perturbadores del proceso.
El sistema de hipótesis que origina el procedimiento que permite la toma de decisiones dentro de este proceso industrial particular, puede

formularse así
4.1. ELEMENTOS BÁSICOS
Ho: 0=20
frente a
H 1 : e > 20,
191
sistema entendido como el juzgamiento de la aseveración de que el proceso está controlado o equivalentemente que está centrado en 20 fl oz, declaración concretada en la hipótesis nula Ho Y enfrentada con una manifestación de una situación alternativa relacionada con la inconveniencia de producir unidades con contenido superior al establecido por el diseño del producto, representada por la hipótesis alterna H 1 .
Definición 4.1.7. El proceso de juzgamiento de la hipótesis nula conlleva un procedimiento, regla o norma que permite tomar la decisión a que haya lugar, denominado test. Como notación, el test se enuncia después de la letra T.
Definición 4.1.8. El test utilizado dentro del proceso de juzgamiento de la hipótesis nula Ho, tiene vinculado un subconjunto del espacio de las observaciones X. Este subconjunto denotado por CT,n está determinado por su respectivo test así:
T: "Rechazar la hipótesis Ho si (Xl,X2, ... ,Xn ) E CT,n".
El conjunto CT,n se denomina región crítica o región de rechazo del test para juzgar a Ho y el test así definido se denomina test no aleatorizado. El conjunto X - CT,n recibe el nombre de región de aceptación del test para juzgar a Ho.
Definición 4.1.9. Un test T recibe la denominación de test aleatorizado para el juzgamiento de la hipótesis nula Ho, si la función '1fJT calculada en los valores observados de una muestra aleatoria, con O < '1fJT(Xl, X2, .. . , xn ) < 1, determina la probabilidad de éxito de una variable aleatoria Y con distribución de Bernoulli, cuyos valores particulares se generan por un procedimiento aleatorio adicional, y está definido como
T: "Rechazar Ho si y = 1".
A la función '1fJT se le denomina función crítica del test aleatorizado T.

192 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Como los tests aleatorizados no son del interés de este texto, debe entenderse que dentro del contenido del presente capítulo el término test hace mención únicamente a los tests no aleatorizados.
Ejemplo 4.1.10. Un test propuesto para el juzgamiento de Ho dentro del sistema de hipótesis del ejemplo 4.1.6 es
T : "Rechazar Ho si X49 > 20.27, en caso contrario no rechazarla",
norma que permite optar por la exploración y remoción de causas extrañas al proceso responsables de la no adecuación a los requerimientos, si el contenido promedio en una muestra aleatoria particular de 49 envases supera las 20.27 fl oz. Por otra parte, permite no reportar novedad alguna en el desarrollo del proceso, cuando el señalado promedio es a lo sumo 20.27 fl oz. La región crítica asociada a este test es, por consiguiente,
CT ,49 = {(Xl, X2,···, X49)lx49 > 20.27}.
Cualquier decisión que se tome en el juzgamiento de una hipótesis estadística lleva consigo el riesgo de incurrir en una opción equivocada. Como en la analogía acogida, el juzgamiento de una persona en un tribunal o juzgado, es factible concluir el correspondiente proceso judicial con una decisión ajustada a las normas procesales y a la naturaleza de las pruebas, pero en realidad no acertada en cuanto a la verdad de los hechos, verdad que no siempre el juez puede conocer enteramente; por ello repetidamente se mencionan expresiones relativas a los inocentes que se encuentran purgando penas, o a los culpables que gozan de libertad plena. De manera similar a los errores en los cuales se puede incurrir en el juzgamiento de una persona, en el juzgamiento de hipótesis estadísticas se corren riesgos semejantes.
Así como un proceso judicial termina en forma normal, con la decisión de un juez o tribunal, el proceso de juzgamiento de una hipótesis nula culmina con una decisión: ya sea rechazar la hipótesis nula cuando hay evidencia estadística para hacerlo o al no contar con dicha evidencia para rechazar la hipótesis, la de optar por no rechazarla. En este sentido, cualquiera de las decisiones puede ocasionar una equivocación o error. Uno de ellos consiste en rechazar una hipótesis nula cuando la hipótesis es verdadera, el otro en no rechazar una hipótesis nula en el caso de ser falsa.
Cuando se traducen apartes de las explicaciones previas o provisionales de un fenómeno a afirmaciones de carácter estadístico, es decir,

4.1. ELEMENTOS BÁSICOS 193
cuando se formalizan hipótesis estadísticas, éstas heredan la veracidad o falsedad acorde con la explicación apriorística del fenómeno. Esa veracidad o falsedad inmanentes a la incertidumbre misma que motiva la realización de la investigación no son directamente el objetivo de su juzgamiento; el objetivo inmediato es la toma de una decisión frente a la afirmación que determina la hipótesis a la luz de la información contenida en los datos acopiados. En este sentido es pertinente precisar que cuando se utilizan expresiones como "bajo la hipótesis ... , siendo cierta la hipótesis ... " , debe entenderse que la afirmación de la frase precedente a alguna de las expresiones mencionadas, o a otra similar, está condicionada a la veracidad de la hipótesis en consideración, o al supuesto de que la afirmación fuese verdadera.
Como los errores en los cuales se puede incurrir cuando se toma la decisión están dependiendo de la real o supuesta veracidad de la hipótesis, la concisión y denominación de cada uno de estos errores se indica en la definición siguiente.
Definición 4.1.11. Dentro del proceso de juzgamiento de la hipótesis Ho se denomina error del tipo 1 a la decisión de rechazar Ho, siendo verdadera la hipótesis; asimismo, se designa como error del tipo 11 a la decisión de no rechazar la hipótesis nula siendo ella falsa. En resumen:
Decisión
Ro Rechazar Ro No rechazar Ro
Cierta Error del tipo 1 Correcta
Falsa Correcta Error del tipo JI
Definición 4.1.12. Sea Xl, X 2 , . .. ,Xn una muestra aleatoria de una población con función de densidad fx(x, ()) y sea además T un test no aleatorizado para el juzgamiento de la hipótesis nula Ho : () E 8 0 definido como
T: "Rechazar Ho si (XI,X2,'" ,xn) E CT,n".
La función
SZ (XI,X2,'" ,xn ) = x~ E CT,n
SZ x~ E C~,n siendo C~,n = X - CT,n

194 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
se denomina función crítica del test no aleatorizado T.
Si la hipótesis nula Ho : e = eo es una hipótesis simple, es decir la aseveración alude que la distribución de la variable representativa de la población está plenamente determinada, y si además dicha hipótesis se asume verdadera, entonces el error del tipo 1 puede calcularse como
P(Jo ['l/!T(X~) = 1] . Dicho de otra manera, calcular este error del tipo 1 corresponde al cálculo de la probabilidad de rechazar la hipótesis nula dado que el valor del parámetro es e = eo. Sin embargo, en una situación relativa a una hipótesis nula compuesta, que se refiere a una variedad de distribuciones, el error del tipo 1 no sería único, sería un conjunto de errores del tipo 1. El máximo del conjunto citado, la mayor probabilidad de rechazar la hipótesis nula siendo cierta, se adopta como uno de los elementos constituyentes en la construcción, en la caracterización o en la evaluación de un test. La siguiente definición hace referencia a ello.
Definición 4.1.13. El tamaño del test T, el tamaño de la región crítica CT,n, la probabilidad de error del tipo lo nivel del test T
se denota usualmente por a y está definido como
a = m~xP(J ['l/!T(X~) = 1] . (JE8 -o
Ejemplo 4.1.14. Sea Xl, X 2 , ... , X n una muestra aleatoria de tamaño 10 de una población con distribución de Bernoulli con parámetro e. Para juzgar la hipótesis nula Ho : e s; ~ dentro del sistema,
3 Ho : e s; "4
frente a
3 H 1 : e > "4
10 se propone el test, T "Rechazar Ho si ¿ Xi > 9". Entonces, puesto
i=l 10
que ¿ Xi rv Bin(10, e), i=l
P, [~Xi ~ 9] = C~)9' + G~)91O(l ~ 9)° = 109' ~ 9910

4.1. ELEMENTOS BÁSICOS 195
luego
[ 10 1 (3) 9 (3) 10 ma~ p(} LXi 2: 9 = ma~ (1009
- 9010) = 10 4" - 9 4"
(}E(O,:¡;] i=l (}E(O,:¡;]
= a ~ 0.244.
En otras palabras, el nivel del test se entiende como la mayor probabilidad de tomar una decisión incorrecta asumiendo verdadero cualquier valor del parámetro O asociado con la hipótesis nula, y aun cuando es un elemento que dentro del proceso de juzgamiento de hipótesis es controlable y elegible arbitrariamente, por supuesto debe corresponder a una probabilidad relativamente pequeña, es usual asumirlo como alguno de los tres niveles: a = 0.1, a = 0.05 y a = 0.01, niveles que generalmente se les conoce como niveles del 10%, 5% y 1%, respectivamente.
El error del tipo n, denotado frecuentemente por {3, es otro elemento constitutivo del proceso de juzgamiento de la hipótesis nula, tal vez habitualmente menos aludido que el error del tipo I, pero igualmente esencial. De manera afín al cálculo del error del tipo I, se puede generar una variedad de errores del tipo n correspondientes a cada situación particular indicativa de la falsedad de la hipótesis nula, un poco más complejo porque la probabilidad de no rechazar la hipótesis nula se calcula bajo la consideración de que la hipótesis nula es falsa. Entonces cabe preguntarse: ¿qué significa que Ho se considere falsa? Si 8 1 = ~, entonces H o es falsa cuando H 1 sea considerada cierta, en cuyo caso el sistema de hipótesis está conformado por hipótesis antitéticas; pero cuando 8 1 #- 8~, entonces el subconjunto de valores de 8 asociados con la falsedad de la hipótesis nula será 8 - 8 0 , conjunto que contiene a 8 1 , Este hecho pone de manifiesto que si Ho se asume como falsa no implica necesariamente que H1 sea verdadera, puntualización ésta que no se puede pasar por alto cuando se realiza el cálculo del error del tipo n.
¿ Cuál de los dos errores que se pueden cometer en el juzgamiento de hipótesis estadísticas es el más grave? La respuesta realmente es que en forma general no se puede evaluar su gravedad; cada caso particular permitirá valorar las implicaciones de una decisión errónea.
Por ejemplo, si el propósito es remplazar un medicamento existente por uno nuevo con base en el análisis de su eficacia, podría asumirse el modelo de Bernoulli para representar si la aplicación del medicamento en un tipo de paciente surte el efecto esperado o no, y evaluar la citada

196 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
eficacia por medio de una muestra de pacientes a los cuales se les administre el medicamento. De esta manera, si e denota la probabilidad de que el efecto de la aplicación del nuevo medicamento en un paciente sea el esperado y si el fármaco existente tiene una eficacia cuantificada en eo, puede establecerse el siguiente sistema de hipótesis:
Ho : e :S eo frente a
H 1 : e > eo.
La afirmación de que el nuevo medicamento es a lo sumo tan eficaz como el actual, traducida a lenguaje estadístico corresponde a la hipótesis nula en este sistema. Respecto a la decisión que debe tomarse, ésta se encuentra explícita en el párrafo anterior: mantener el medicamento vigente o remplazarlo por el nuevo medicamento.
Entonces, en esta situación particular, el error del tipo 1 consiste en colocar en el mercado un medicamento con menor o igual eficacia que el actual, mientras que el error del tipo n radica en abstenerse de colocar en el mercado un medicamento más eficaz que el vigente. La primera decisión implica pérdidas para el laboratorio productor, mientras que la segunda involucra pérdida de rentabilidad. Con la ayuda de la información financiera de la compañía farmacéutica, puede establecerse cuál decisión sería más costosa. Pero desde el punto de vista de salud pública, las decisiones pueden valorarse contrariamente. ¿Es más grave consumir un fármaco de menor calidad que no tener la posibilidad de utilizar uno altamente eficaz? Se obliga precisar con mayor detalle el contexto propio para valorar las implicaciones de la decisión: ¿se trata de un medicamento contra el resfriado común, o se trata de un medicamento para la cura de un determinado tipo de cáncer?
Como se deduce de lo anterior, no se puede hablar en términos absolutos cuál de los errores es más oneroso, mientras que para una situación específica sí existe mayor factibilidad de hacerlo. En caso de poder establecer la preponderancia de uno de los dos errores, algunos autores sugieren que se establezca el sistema de hipótesis orientado por la convención de que el error del tipo 1 es más serio que el error del tipo n. De esta manera se controla el error del tipo 1, o lo que es equivalente se regula el nivel del test, y el cálculo o la determinación del error del tipo n estaría sujeto a esta elección de a. Sin embargo, esta sugerencia es más una invitación a valorar la magnitud de los potenciales errores en

4.1. ELEMENTOS BÁSICOS 197
Probabilidad de error del tipo 11
Test (J = 19.9 (J = 20.1 (J = 20.2 (J = 20.3 (J = 20.4 (J = 20.5 (J = 20.6
7"1 0.9997 0.9437 0.7432 0.3897 0.1125 0.0159 0.0010
7"2 0.9993 0.9043 0.6456 0.2877 0.0677 0.0076 0.0004
7"3 0.9981 0.8477 0.5372 0.2005 0.0381 0.0034 0.0001
Tabla 4.1: Compilación de probabilidades de error del tipo II, para tres test particulares, según algunos supuestos valores de (j.
un caso determinado y no debe tenerse como principio inquebrantable.
Ejemplo 4.1.15. Retomando el ejemplo 4.1.10 y estableciendo el valor de la desviación estándar como 0.75 fl oz, tanto la probabilidad de error del tipo 1 como la probabilidad de error del tipo II, utilizando cada uno de los siguientes tests, pueden ser calculadas y comparadas para varios valores de ().
71 : "Rechazar Ha si X49 > 20.27, en caso contrario no rechazarla".
72 : "Rechazar Ha si X49 > 20.24, en caso contrario no rechazarla".
73 : "Rechazar Ha si X49 > 20.21, en caso contrario no rechazarla".
El nivel del primer test es a = 0.00587, porque
P2a [X 49 > 20.27J = 1 - <I> [v'49 (20.27 - 20)] = 1 - <I>(2.52) = 0.00587 0.75
De igual manera, los niveles de los test 72 y 73 son respectivamente del 1.255% y 2.5%.
Del contenido de la tabla 4.1 y de los niveles de los tests en consideración, se deduce la superioridad del tercer test. Si se pretende elegir un test con nivel inferior al 5%, los tests en comparación cumplen la exigencia y aunque con mayor error del tipo 1, el tercer test presenta persistentemente los menores valores de la probabilidad de error del tipo II dentro del rango de valores de () señalados en la tabla mencionada.
Los temas de próximas secciones están justamente relacionados con la construcción de los mejores tests, construcción basada en métodos

198 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
con alcances mucho más generales que lo logrado en el ejemplo inmediatamente anterior.
El buen uso de la estadística además de ser realizado según principios éticos, consiste en la elección y aplicación de los mejores procedimientos disponibles para el logro de los objetivos en una situación particular. La incertidumbre con la cual trabaja tanto el investigador, el analista estadístico como el usuario ocasional de la estadística, no justifica la utilización de cualquier herramienta para abordar la explicación, descripción de un fenómeno o para la toma de decisiones frente a él. Es preciso acudir a los cánones estadísticos para evaluar la condición de cada procedimiento elegible al utilizarlo.
Cada uno de los procedimientos de la inferencia estadística está recomendado por medio de una certificación relativa a su propósito. Los buenos estimadores son elegibles a la luz de los requisitos tratados en el segundo capítulo; las mejores estimaciones por intervalo se logran a través de intervalos confidenciales construidos con base en buenos estimadores puntuales pero esencialmente por su mínima longitud. La calidad de un test, por su parte, al configurarse como la estrategia fundamental para la toma de decisiones estadísticas, es examinada desde varios puntos de vista pero connaturalmente desde su capacidad de rechazar la hipótesis nula bajo presuntos escenarios relativos a valores del parámetro, perspectiva conocida como la potencia de un test. Siendo ésta la directriz de la construcción y evaluación del desempeño de un test, se tratará a partir de la siguiente definición inicial conocida como función de potencia.
Definición 4.1.16. Sea T un test no aleatorizado para el juzgamiento de Ha con función crítica 1PT(X~). La función de potencia denotada como 7rT (B) es una función con dominio 8 y recorrido el intervalo (0,1), definida como
7rT(B) = Po [1PT(X~) = 1] .
Definición 4.1.17. Siendo 8 1 = 8~ la función f3T(B) = 1 - 7rT(B), es llamada curva característica de operación o curva CO del test T.
Ejemplo 4.1.18. El tiempo que una persona requiere para comprar una tarjeta de ingreso en el sistema de Transmilenio en la estación de Alcalá durante el 2002, ha mostrado un comportamiento que sugiere el modelo Uniforme en el intervalo (O, B) para su descripción. Se afirma

4.1. ELEMENTOS BÁSICOS 199
que el tiempo máximo de permanencia en la fila está entre dos y tres minutos. Para evaluar la afirmación y tomar los correctivos del caso, se va a registrar el tiempo empleado por n personas que serán elegidas por medio de un procedimiento especial de muestreo en la rampa de ingreso, y se propone la utilización del test
T : "Rechazar Ho si xn,n :s; 1.9 o si xn,n > 2.9"
para el juzgamiento de la hipótesis nula Ho en el sistema
Ho: e E [2,3] frente a
H 1 : e rJ. [2,3].
La función de potencia del test propuesto es
7rT (e) = Pe[Xn,n :s; 1.9] + Pe [Xn,n > 2.9]
= Pe[Xn,n :s; 1.9] + 1 - Pe[Xn,n :s; 2.9]
= 1 + FXn,n (1.9, e) - FXn,n (2.9, e)
(1.9)n [(1.9)n (2.9)n] 7rT (O) = I(0,1.9] (O) + B I(1.9,2.9] (O) + 1 + B - B I(2.9,00) (O)
cuya representación gráfica se observa en la figura 4.1.
1 2 3 4 5
Figura 4.1: Gráfico de la función de potencia correspondiente al ejemplo 4.1.18.

200 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Idealmente, la función de potencia de un test T sería
nAO) = 1 - le (O) -o
o equivalentemente la curva CO ideal del test T se establecería como f3T(O) = 1 - le (O).
La funciónde potencia ideal para el ejemplo anterior tendría la forma que muestra la figura 4.2
'lrT(O)
1 •
1.9 2.9 O
Figura 4.2: Gráfico de la función de potencia ideal correspondiente al ejemplo 4.1.18.
Definición 4.1.19. El test T con función crítica 'lf\(X~) se dice que es un test insesgado para la hipótesis Ho si
mª-xPo ['ljJT(X~) = 1] :S miP- Po ['ljJT(X~) = 1] OES2o OES21
o dicho en otra forma si
mª-x 'lrT( O) :S miP- 'lrT( O). OES2o OES21
El tamaño de la muestra reveló sus efectos en la estimación de parámetros y ahora nuevamente se manifiesta como un elemento trascendental en la toma de decisiones basadas en información estadística. Como se señaló en el capítulo 2, la calidad y la cantidad de información con la cual se cuenta para llevar a cabo procesos de inferencia estadística son dos ejes esenciales sobre los cuales se sustentan los alcances de los procesos. Evidentemente, contar con una cantidad suficiente de información de excelente calidad, permite tomar decisiones acertadas sin mayores riesgos. El concepto de la consistencia de un test, presentado a través de la siguiente definición, es la formalización y compendio de esta evidencia.

4.2. TESTS MÁS POTENTES 201
Definición 4.1.20. Siendo Tn un test de nivel a, n = 1,2, ... , para la hipótesis nula Ho : O E 8 0 frente a la hipótesis alterna Hl : O E 8 1 = 8~, basado en una muestra aleatoria Xl, X 2 , .•. , X n , de una población con función de densidad fx(x, O), dicho test recibe la denominación de test consistente para Ho, si para cada O E 8 1 ,
lim Po ['l/JTn (X~ = 1)] = lo n-->oo
4.2 Tests más potentes
La función de potencia, además de describir perfectamente el comportamiento de un test ante cualquier valor del parámetro, como ya se mencionó, es la directriz de la construcción de tests. Esa construcción o evaluación fija la atención sobre el valor o valores particulares de la función de potencia para uno o varios valores específicos del parámetro, en especial para valores del parámetro asociados con la hipótesis alterna. Como precisión semántica, la expresión potencia del test se deja exclusivamente para referirse al valor de la función de potencia para un elemento particular del espacio del parámetro, así varios autores se refieran a ella como la probabilidad de rechazar Ho siendo Hl verdadera. En ese sentido, la siguiente sección inicia lo pertinente a la idea de test más potente.
Definición 4.2.1. Si dentro del proceso de juzgamiento de la hipótesis nula Ho, se considera a Ho Y Hl como hipótesis simples, conformando el sistema de hipótesis
Ho: O = 00
frente a
Hl : 0=01 ,
el test r* con nivel a se dice que es más potente para Ho que cualquier otro test T para Ho, con nivel menor o igual a a, si
1. 1fT ' (00) = a.
2. 1f T* (01) 2: 1fT (01).
Teniendo en cuenta un sistema de hipótesis como en el precisado en la definición 4.2.1, de inmediato se advierte que 1 - 1fT (Ol) es la

202 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
probabilidad de ocurrencia del error del tipo Il al utilizar el test T.
En estas condiciones, en un sistema de hipótesis simples, un test más potente de tamaño a es aquel que induce menor j3, tal como lo logra el resaltado test T* de la aludida definición.
Con el propósito de minimizar el error del tipo Il, manteniendo el control del error del tipo 1 viene a cooperar el teorema de Neyman y Pearson, que a continuación se presenta y permite deducir una forma de obtención de tests más potentes, es decir, revela un procedimiento para la construcción de tests con menores errores del tipo Il. Para aprestar su enunciado es menester contar con la siguiente definición.
Definición 4.2.2. Sea Xl, X2, . .. , X n una muestra aleatoria de una población con función de densidad fx(x, O). Si el sistema de hipótesis de juzgamiento de la hipótesis nula Ho es un sistema de hipótesis simples
un test definido como
Ho: 0=00
frente a
Hl : 0=01 ,
T: "Rechazar Ho si An < k"
recibe la denominación de test de razón simple de verosimilitudes siendo
n
L(Oo; Xl, X2,···, X n ) An = ) L(Ol; Xl, X2,· .. , X n
TI fX(Xi, 00) i=l
n
TI fX(Xi, Ot) i=l
Teorema 4.2.3 (Lema de Neyman Pearson). Sea Xl, X 2 , ... , X n
una muestra aleatoria de una población con función de densidad fx(x, O). Si el sistema de hipótesis es
Ho: 0=00
frente a
Hl : 0=01 ,

4.2. TESTS MÁS POTENTES 203
el test T cuya función crítica corresponde a n n
r' si k II fX(Xi, Od > II fX(Xi, ( 0 ) esto es, si k > An;
'lj!T(X~) = i=l i=l n n
0, sz k IIfx(xi,Od < IIfx(xi'Oo) es decir, si k < An; i=l i=l
es un test más potente para Ho, siendo k una constante positiva y 11"7(00 ) = 0:.
Ejemplo 4.2.4. Si Xl, X 2 , ... ,Xn es una muestra aleatoria de una población con distribución Normal de valor esperado ¡..t y varianza conocida (72, determinar un test más potente para Ho, en el sistema
H o : ¡..t = ¡..to
frente a
H1 : ¡..t = ¡..tI·
Conviniendo que ¡..tI > ¡..to,
El test de razón simple de verosimilitudes para Ho dentro del sistema establecido puede formularse como
que equivale a
T: "Rechazar Ho si :2 (¡..to - ¡..tI) t Xi - 2:2 (¡..t6 - ¡..tI) < In k". i=l
Simplificadamente equivale al test conseguido a partir de operaciones convenientes
n
T : "Rechazar Ho si LXi> e" . i=l

204 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
La constante c puede ser determinada una vez haya sido adoptado un valor específico de a; así
PJ.LO [t Xi > el = a = PJ.LO [Xn > ~] = 1 - <p (Vn (~ - /LO)) . ~l n u
Dicho en otros términos:
1 - " ~ <P ( Vn (~a - 1'0) )
Vn(~-JLo) luego n = Zl-a, de donde puede determinarse la constante e
u en mención.
Nótese que el test también puede enunciarse como
T: "Rechazar Ho si Vn (xn - /Lo) > Zl-a". U
La idea de la razón simple de verosimilitudes da pie para presuponer que ese concepto puede originar un concepto más general que abarque aquellas situaciones en las cuales el sistema de hipótesis incluya al menos una hipótesis compuesta. En efecto, la razón generalizada de verosimilitudes hace referencia a un sistema de hipótesis como el mencionado, pero con la especificidad de estar constituido por hipótesis antitéticas. La siguiente definición formaliza dicho concepto.
Definición 4.2.5. Sea Xl, X2, . .. , X n una muestra aleatoria de una población con función de densidad f x (x, B). Si el sistema de hipótesis en el juzgamiento de la hipótesis nula es
Ho : B E 8 0
frente a
Hl : B E 8 1 ,
con 8 1 = 8 - 8 0 , la razón generalizada de verosimilitudes corresponde al cociente
s~ L(B;Xl,X2, ... ,Xn )
, _ BES¿o An - ~~---- A( su!?L(B;Xl,X2,""Xn ) = Xl,X2,""Xn ),
BES¿

4.2. TESTS MÁS POTENTES 205
Acerca de An objeto de la definición 4.2.5 es conveniente puntualizar lo siguiente:
1. An es un valor particular de la variable aleatoria
2. An E (0,1].
3. El denominador de An es la función de verosimilitud evaluada en el estimador máximo verosímil de O.
El conocimiento de la distribución de An permite consecuentemente la formulación definitiva del test, pero esto no siempre sucede, y por ello en muchas oportunidades es necesario recurrir a tests equivalentes derivados del comportamiento de An. Sin embargo algunas veces la exploración de la citada distribución no es factible, pero se puede contar con un tamaño de muestra relativamente grande. Bajo ciertas condiciones, la variable aleatoria -21n(An ) puede manejarse como una variable aleatoria con distribución Ji-cuadrado, como lo indica el siguiente teorema, y de esta manera se puede establecer una forma especial del test.
Teorema 4.2.6. Bajo condiciones de regularidad, dentro del juzgamiento de la hipótesis nula, siendo L(Ol, O2, .. . , Ol, ul, U2, . .. ,UN) la función de verosimilitud de las variables aleatorias Ul, U2, ... , U N Y lo el número de componentes especificadas por la hipótesis nula, entonces la variable aleatoria -21n(AN) converge en distribución a una variable aleatoria con distribución Ji-cuadrado con v grados de libertad, v = l -lo.
Bajo estas condiciones, un test de razón generalizada de verosimilitudes puede presentarse en una forma especial correspondiente a
T: "Rechazar Ho si - 21n(AN) > XLa(v)".
Ejemplo 4.2.7. El juzgamicnto de la homoscedasticidad ha inducido el desarrollo de varios tests. Este ejemplo, como forma especial de juzgarla, es una ilustración del teorema 4.2.6. Se consideran k poblaciones independientes asumiendo para cada una de ellas el modelo gaussiano, de manera que la variable que representa a la población j tiene valor esperado ¡.tj y desviación estándar O"j,
j = 1,2, ... , k. Según estas consideraciones, X j1 , X j2 , . .. ,Xjnj representa la muestra aleatoria de tamaño nj, correspondiente a la población

206 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
J. La homoscedasticidad entendida como la característica de que un grupo de poblaciones tienen la misma dispersión, expresada en términos de sus varianzas, se puede traducir en la hipótesis nula que forma parte del siguiente sistema:
= .,.,.2 _ ,.,.2 _ _ ,.,.2 .l.l0 . vI - V2 - .•. - vk
frente a
H I : no todas las varianzas son iguales.
La función de verosimilitud
L = L (J-tl' J-t2,···, J-tk, ar, a~, ... , a~; Xl1, X12,···, Xl n1 ,···, Xkl, Xk2,···, Xknk)
de las N variables aleatorias X ll , XI2, ... , XI,nl' ... ' Xkl, X k2 , ... , X knk , n
incluye l = 2k componentes, donde N = ¿ nj; por otra parte denotanj=1
do por (J"2 el valor común desconocido de las varianzas de cada población,
8 0 = {(¡.tI, ¡.t2,···, ¡.tk, (J"2)I¡.tj E IR, (J"2 > O}
determinado por la hipótesis nula, incluye lo (k + 1) componentes, especificadas por ésta. Entonces
L = exp __ J J . rrk rrnj 1 {1 (X.i - ft")2}
j=1 i=1 V27i(J"j 2 (J"j
supL e
La determinación de AN = -o L requiere los siguientes elementos: sup
ª nj
• La estimación máximo-verosÍmil de ¡.tj es ;; ¿ Xji = Xj. J i=1
nj
• La estimación máximo-verosÍmil de (J"J es ;; ¿ (Xji - Xj)2. J i=1
• La estimación máximo-verosímil del valor común (J"2 bajo la hipók nj
tesis nula es lv ¿ ¿ (Xji - Xj)2. j=1 i=1

4.2. TESTS MÁS POTENTES 207
Con lo anterior
pero la determinación de la distribución de AN es una tarea muy intrincada. Por ello, si se cuenta con muestras relativamente grandes, -21n(AN ) converge en distribución a una variable aleatoria con distribución Ji-cuadrado con v = l - lo = 2k - (k + 1) = (k - 1) grados de libertad. Por tanto, se le puede tratar como tal y por consiguiente el test puede enunciarse como
T: "Rechazar Ho si
Definición 4.2.8. Conforme con la definición 4.2.5, un test T cuya función crítica corresponde a
sz k> An
sz k < An
recibe la denominación de test de razón generalizada de verosimilitudes de nivel a, siendo m~Po ["pT (X~) = 1] = a y k una constante
OE8 -o positiva.
La sigla LRT (likelihood ratio test) se utiliza frecuentemente como abreviatura para referirse a un test de razón de verosimilitudes, denominación ésta que cubre tanto a los tests de razón simple de verosimilitudes como a los tests de razón generalizada de verosimilitudes.
Ejemplo 4.2.9. Si Xl, X 2 , .•• , X n es una muestra aleatoria de una población con función de densidad fx(x, O) definida como
fx(x, O) = Oe-ox 1(0,00) (x),

208 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
determinar un test de razón generalizada de verosimilitudes para el juzgamiento de Ho en el sistema
Ho : () ~ ()o
frente a
H 1 : () > ()o·
n -B L: Xi
Como L(();X1,X2, ... ,Xn) = ()ne i=l y además
SUE.L(();X1,X2, ... ,xn) = (! )n e-n
BEª- X n
y con el apoyo de la figura 4.3
Luego
{
( 1 )n 1 =- e -n cuando =- ~ ()o
Xn Xn sup L(();X1,X2, ... ,Xn) = _ 1 O<B<Bo ()üe-Bonxn cuando =- > ()o
Xn
An ~ ¡ 08e-~onX" 1 cuando =- ~ ()o
Xn
1 cuando =- > ()o
Xn
Por tanto, el test de razón generalizada de verosimilitudes se puede enunciar como
o
1 ()ne-Bonxn T: "Rechazar Ho si =- > ()o y (o)n < k"
xn _1 e-n X n
T: "Rechazar Ho si xn()o < 1 y (()oxn)ne-n(Boxn-1) < k".
Remplazando ()oxn = y, nótese que yne-n(y-1) tiene máximo cuando y = 1 y dado que y < 1, yne-n(y-1) < k, si y sólo si y < ko, como se deriva de la figura 4.4. En consecuencia, el test puede enunciarse como
T : "Rechazar Ho si ()oxn < ko"

4.2. TESTS MÁS POTENTES 209
L(O)
L(O)
Figura 4.3: Determinación del supremum para O < 00, según la localización de 00, correspondiente al ejemplo 4.2.9.
El nivel de test puede determinarse ahora, de la siguiente manera:
n porque 00 I: Xi rv Gama(n, 1). A partir de este punto es posible re-
i=l definir el test, pues de la última igualdad se obtiene el valor de ko, siendo por supuesto nko el correspondiente percentil a.
Definición 4.2.10. Si dentro del proceso de juzgamiento de la hipótesis

210 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
yne -n(y-1)
1 k
ko 1 y
Figura 4.4: Representación gráfica de la equivalencia del test de razón generalizada de verosimilitudes con el test final del ejemplo 4.2.9.
nula Ho se considera el sistema de hipótesis
Ho: O E 8 0
frente a
H1 : O E 8 1
siendo 8 1 = 8 - 8 0 , el test T* se denomina test uniformemente más potente, UMP, para Ho con nivel ü si
1. sup 7rT * (O) = ü.
oEflo
2. 7r T* (O) 2': 7r T (O) para todo O E 8 1 y para todo test T con nivel menor o igual a ü.
Ejemplo 4.2.11. Determinar un UMP para Ho en el sistema de hipótesis
Ho: 0=00
frente a
H 1 : O > 00 ,
basado en una muestra aleatoria Xl, X 2 , ... , X n de una población con función de densidad
fx(x, O) = Oe-ox 1(0,00) (x).

4.2. TESTS MÁS POTENTES
En el sistema de hipótesis
Ho : e = eo frente a
HI : e = el
211
y conviniendo que el > eo, un test más potente para Ho puede obtenerse a partir del lema de Neyman Pearson (teorema 4.2.3, página 202). Siendo
n -()o ¿ Xi
e~e i=l
An = n
-()1 ¿ Xi
efe i=l
el test más potente para Ho en este último sistema está formulado como
(eo)n -(()O-()l) f Xi
T : "Rechazar Ho si el e i=l < k"
o
T: "Rechazar Ho si tXi < e ~ e In [(~l)n k] " i=l lOO
o de manera más simple, como
n
T : "Rechazar Ho si 2:= Xi < e". i=l
Este test es más potente para Ho en cualquier elección de el > eo, de manera que el test
n
T: "Rechazar Ho si 2:= Xi < e" i=l
es UMP para Ho en el sistema
Ho : e = eo frente a
HI : e > eo.

212 CAPÍTULO 4, JUZGAMIENTO DE HIPÓTESIS
Finalmente, para un nivel preestablecido del test, la constante c puede determinarse de la siguiente forma:
a = p., [t Xi < el = __ (rtn-le-Ootdt ¡e 1
O r(n) O
c es entonces el percentil a de una Gama(n, ( 0 ).
Definición 4.2.12. Una familia de densidades {Jx(x, O)}, O E e ~ IR se dice que tiene razón monótona de verosimilitudes, MLR, en la estadíst,ica T = t(Xl , X 2, ... , X n) si para dicha estadística, el cociente
L(Ol; Xl, X2,···, Xn ) L(02; Xl, X2,· .. , Xn )
es una función no creciente de t(Xl, X2, .. . , x n), para cada 01 < O2 o no decreciente de t(Xl, X2, ... , x n), para cada 01 < O2.
Ejemplo 4.2.13. La familia de densidades de Poisson tiene razón mo-n
nótona de verosimilitudes en 2:= Xi. En efecto, i=l
L(01;Xl,X2, ... ,xn )
L(02; Xl, X2, . .. , Xn) (01 ) 'f Xi O
2 ,=1 e-n(Ol-02)
n la cual es una función no creciente de 2:= Xi, puesto que 01 < O2 .
i=l
Teorema 4.2.14. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, O), O E e ~ IR Y la familia {Jx(x, O)} tiene MLR en la estadística T = t(Xl , X 2, ... , X n ).
1. Si la razón monótona de verosimilitudes es no decreciente y si ta es tal que
POo [t(Xl ,X2 , ... ,Xn ) < tal = a
entonces el test
T: "Rechazar Ho si t(Xl, X2,· .. , xn ) < ta"

4.2. TESTS MÁS POTENTES
es UMP para Ho, en el sistema
Ho : fJ :S fJo
frente a
Hl : fJ > fJo·
213
2. Si la razón monótona de verosimilitudes es no creciente y si ti-a es tal que
entonces el test
T: "Rechazar Ho si t(Xl, X2, ... , Xn) > ti-a"
es UMP para Ho, en el sistema
Ho : fJ :S fJo
frente a
Hl : fJ > fJo·
Teorema 4.2.15. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, fJ), fJ E e ~ IR, Y fx(x, fJ) perteneciente a la familia exponencial unidimensional de densidades.
n Siendo Tn = t(Xl ,X2 , ... ,Xn) = ¿ d(Xi ) la estadística natural de la
i=l familia exponencial, si c( fJ) es una función estrictamente monótona, en-tonces la familia de densidades {fx(x, fJ)} tiene MLR en la estadística Tn .
Teorema 4.2.16. Sea Xl, X 2, ... , X n una muestra aleatoria de una población con función de densidad fx(x, fJ), fJ E e ~ IR Y fx(x, fJ) pertenece a la familia exponencial unidimensional de densidades. Siendo
n la estadística natural de la familia Tn = t(X l , X2, ... , X n ) = ¿ d(Xi ),
i=l entonces
1. Si c(fJ) es una función monótona creciente de fJ y ti-a tal que

214
el test
CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
n
T: "Rechazar Ho si L d(xi) > h-a " i=l
es UMP para Ho en el sistema
o en el sistema
Ho : O :S 00
frente a
H1 : O > 00
Ho: 0=00
frente a
Hl : O > Oo.
2. Si c( O) es una función monótona decreciente de O y ta tal que
el test
POo [t d(Xil < tal ~ <>,
n
T: "Rechazar Ho si L d(xi) < ta" i=l
es UMP para Ho en el sistema
o en el sistema
Ho : O :S 00
frente a
Hl : O > 00
Ho: 0=00
frente a
H1 : O > Oo·
Antes de continuar en la siguiente seCClOn dedicada al estudio de algunos tests bajo normalidad, es necesario concluir la presentación de

4.2. TESTS MÁS POTENTES 215
los conceptos básicos del juzgamiento de hipótesis con una mención del denominado valor p.
Para hacer expedito un test, su forma final debe ser preferentemente muy sencilla. En lo posible, debe conocerse la distribución de la estadística que lo soporta y ser factible el cálculo de sus percentiles, precisamente para que la utilización del test sea fácil.
Igualmente, esa forma final, como la de muchos tests, debe estar en la forma estándar consistente en la comparación de un valor de una estadística con un percentil de la misma elegido conforme al nivel del test asumido, para conservar estable un modo común muy difundido y generalmente aceptado.
Muchos tests han sido construidos teniendo en cuenta estas sugerencias, y la realización de los cálculos respectivos y la determinación de los percentiles se logran mediante la utilización de alguno de los múltiples programas de cómputo estadístico que se encuentran en el mercado de software o a disposición en internet.
Justamente esos programas han incorporado dentro de sus cálculos y por ende dentro de la presentación de los resultados el denominado valor p. Este valor puede entenderse como una ayuda muy eficiente en la lectura de los resultados para el juzgamiento de una hipótesis, porque su valor condensa los elementos del test y hace más diligente la decisión.
Tratando al valor particular de la estadística explícito en el test como un percentil de la misma, la forma estándar que compara el valor de la estadística con algunos de sus percentiles, es decir, que compara valores de una variable aleatoria, puede vérsela de manera equivalente desde otro ángulo, la de comparar probabilidades: la probabilidad asociada al valor particular de la estadística tratado como un percentil y la probabilidad que representa el valor a.
Entonces, un test de nivel a puede transformarse a una manera equivalente utilizando el recurso del valor p, de la siguiente manera:
T : "Rechazar H o si el valor p es inferior a a" .
Esta probabilidad asociada al valor particular de la estadística, el valor p, corresponde a una función de la probabilidad de que la variable aleatoria que soporta el test sea menor que el valor específico obtenido de la información de la muestra particular. Un par de ejemplos ilustran mejor la idea del valor p.
Ejemplo 4.2.11. El test obtenido en el ejemplo 4.2.11, página 210,

216 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
puede modificarse finalmente como a continuación se indica y de allí originar el valor p correspondiente.
n Debido a que bajo la hipótesis nula 2: Xi rv Gama(n,Oo), entonces
i=l n
la variable que soporta el test Wc = 200 2: Xi tiene distribución Jii=l
cuadrado con 2n grados de libertad. Con estos elementos el test presenta su forma final
T: "Rechazar Ho si W c < x;(2n)".
El valor p en este caso es
lWC
1 (l)n n-l _!x p = P[Wc < wcJ = o r(n) 2 x e 2 dx.
Por supuesto, si W c < x~(2n) implica que p < a y como consecuencia el test puede expresarse equivalentemente como
T: "Rechazar Ho si p < a".
Ejemplo 4.2.18. La muestra de 49 envases que señala el ejemplo 4.1.6, página 189, también puede utilizarse para respaldar el control de las disconformidades en la fase de rotulación del envase, puesto que las normas internas de aseguramiento de la calidad admiten a lo sumo el 1 % como fracción disconforme en la fase de rotulación y exigen que el test escogido debe tener nivel inferior a 5%. Acudiendo al modelo de Bernoulli, conviniendo que el término éxito corresponde a la representación de un envase que revela alguna disconformidad en su rótulo (colocación incorrecta, rotura, decoloración o inexistencia) y denotando la probabilidad de éxito como 1r (fracción disconforme), el seguimiento estadístico de la fase de rotulación del proceso puede estar encauzado por el sistema de hipótesis
Ho : 1r :S 0.01
frente a
Hl : 1r > 0.01.
Como la familia de densidades de Bernoulli tiene razón monótona de n
verosimilitudes en la estadística Wc = 2: Xi (variable que registra i=l
el número de envases en la muestra rotulados no apropiadamente), y

4.2. TESTS MÁS POTENTES 217
W c P[Wc > W c ]
O 0.3888827605
1 0.0864105914
2 0.0130840050
3 0.0014801344
4 0.0001322100
Tabla 4.2: Algunos valores p en el juzgamiento sobre la fracción disconforme
n además la razón es no creciente en L Xi, entonces un test UMP para
i=l Ho en el sistema planteado es
T : "Rechazar Ho si W c > k" .
49 Teniendo en cuenta que bajo la hipótesis nula L Xi rv Bin( 49,0.01) Y
i=l que un test con nivel del 5% no es posible conseguirse, la tabla 4.2 per-mite dos finalidades: la especificación de a, siguiendo la recomendación de las normas internas, y la enumeración de algunos valores p.
El valor p en este caso corresponde a p = 1-P[Wc :s; wcl, y del contenido de la tabla anterior se deduce que a = 0.013084, porque 0.086410 no es admisible por las normas. Finalmente, el test correspondiente formulado específicamente para tomar decisiones en la fase de rotulación,
equivale a
49
T : "Rechazar Ho si LXi> 2" i=l
T : "Rechazar Ho si p < 0.013084".
Por tanto, si el monitor de un computador muestra el valor p = 0.0864106 significa que en la muestra se encontraron 2 envases disconformes y, por ende, no se toma correctivo alguno. Mientras que si p = 0.00013221 significa que en la muestra se encontraron 5 envases rotulados no apropiadamente y, por tanto, la decisión consiste en evaluar las posibles causas atribuibles a la perturbación y de tomar los correctivos a que haya lugar.

218 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
4.3 Juzgamiento de hipótesis sobre promedios bajo Normalidad
Utilizar el modelo gaussiano como asistente en la toma de decisiones es una práctica común no siempre realizada empleando las mejores premisas. La divulgación acentuada que hacen los textos sobre los tests bajo Normalidad da pie para que el lector cimiente la idea de que el juzgamiento de hipótesis se reduce únicamente a casos particulares regidos por el modelo gaussiano. La inclusión de dos secciones en este capítulo relativas a algunos tests bajo normalidad debe entenderse como aplicaciones muy especiales de conceptos previos en la construcción de tests bajo el modelo soberano de los modelos de probabilidad, y que su aplicación está sujeta a los resultados favorables a la normalidad dentro de un proceso de juzgamiento del ajuste al modelo, tema que será tratado posteriormente, o según argumentos sólidos de tamaño de muestra suficiente que justifican su utilización. Esta sección está dedicada al desarrollo de tests para el juzgamiento de hipótesis referentes a promedios poblacionales y la sección siguiente trata lo pertinente al juzgamiento de hipótesis sobre varianzas, bajo la adopción del modelo de Gauss.
4.3.1 Juzgamiento de la hipótesis nula Ho : 11 = 110
Siendo Xl, X2, ... , X n una muestra aleatoria de tamaño n con distribución Normal de valor esperado J.l y varianza (7"2, pueden fijarse tres sistemas de hipótesis en el juzgamiento de esta hipótesis particular:
• Sistema A:
• Sistema B:
Ho : J.l = J.lo frente a
HI : J.l < J.lo·
Ho : J.l = J.lo
frente a
HI : J.l > J.lo·

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 219
• Sistema C:
Ha : J.l = J.la frente a
Hl : J.l .¡. J.la·
1. Primer supuesto: CJ2 es una cantidad conocida. Considerando específicamente el sistema B, fx(x, B) puede expresarse como
De esta manera se deduce que fx(x, B) pertenece a la familia exponencial de densidades, estableciendo las funciones
1 1(0)2 1(x)2 B a(B) = f2= e- 2 ~ ,b(x) = e- 2 ~ ,c(B) = - , d(x) = x.
V.:.7rCJ CJ
En razón de que c( B) es monótona creciente, considerando la estadística
el test
n
t(X1 , X 2 ,···, X n ) = LXi, i=l
n
TB : "Rechazar Ha si LXi> k*" i=l
es UMP para Ha en el sistema B.

220 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
X n - /-lo entonces donde Zc = (J"/vn '
TB : "Rechazar Ho si Zc > Zl~a".
De manera similar, un test para Ho en el sistema A es
TA : "Rechazar Ho si Zc < za"
que gráficamente la figura 4.5 lo representa.
Rechazar H o ---.J o Z
Figura 4.5: Región crítica del test T A.
Bajo la misma SUpOSlClOn de que (J"2 es conocido, finalmente el juzgamiento de Ho : /-l = /-lo dentro del sistema e,
Ho: /-l = /-lo frente a
HI : /-ll- /-lo
está apoyado por un test que se deduce de la forma siguiente:
n - ¿(Xi - B) 1 i=l
L(B; Xl, X2,·· ., Xn ) = (V27i(J") exp 2(J"2 {
n 2}

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 221
Como
n
i=l
( l)n {- i~1(Xi-¡.tO)2} SUp L y!2;(J exp 2(J2
()=¡.to
.An = -~~~-L = -( -l-)-n--:-{ --i"f=--n 1 (-Xi _-xn-j2--Ó-}
y!2;(J exp 2(J2
n
i=l n n
i=l i=l
n
= ¿(Xi - Xn)2 + n(xn - /-LO)2 i=l
n
i=l
entonces
_ (_ n(xn - /-LO?) - exp 2. 20-
Por tanto, el test construido con base en la razón generalizada de verosimilitudes está determinado como
. (n(xn - /-Lo)2) Te : "Rechazar Ho SI exp - 20-2 < k"
pero
( n(xn - /-LO) 2
) exp - < k implica que 20-2

222 CAPÍTULO 4. JUZGA MIENTO DE HIPÓTESIS
y consecuentemente que IZel > k*. En definitiva se establece el test como
Te : "Rechazar H o si IZel > Zl~Q"· 2
que gráficamente está representado por la figura 4.6. La función
Q Q
2' /2
Rechazar H ° ----.J a L- Rechazar H o Z
Figura 4.6: Región crítica del test Te'
de potencia de este test se puede establecer fácilmente como
7rTC
(O) = <I> ( -Zl~% + Vn(0(J"- J.Lo)) + <I> ( -Zl~% - Vn(0(J"- J.Lo))
Gráficamente, esta función de potencia se presenta en la figura 4.7.
2. Segundo supuesto: (J"2 es una cantidad desconocida.
• Con referencia al sistema e, estrictamente hablando el sistema debería plantearse así:
De esta manera,
Ho: J.L = J.LO,(J"2 > a frente a
H1 : J.L i J.Lo, (J"2 > a.
80 = {(J.L,(J"2)1J.L = J.LO,(J"2 > a},8 = {(J.L,(J"2)1J.L E lR,(J"2 > a}

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 223
7rTJe) 1 ---------------------
¡..¿o e
Figura 4.7: Forma de la función de potencia del test Te para el juzgamiento de la hipótesis nula Ho : e = ¡..¿o bajo el modelo gaussiano asumiendo el supuesto de varianza conocida.
y por tanto
Por otra parte,
porque bajo 8 0 , la función de verosimilitud L tiene máximo

224 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
n cuando f..l = f..lo Y (72 = ~ ¿ (Xi - f..lO)2. En consecuencia,
i=l
An = (
n _ 2) ~ ¿(Xi - x n )
tE (Xi - f..lo)2 t=l
( f=(Xi- Xn)2 \~ t-l I
¡ 2 'S (Xi - xn), '"\""'n f-"U; J
,1
= (1 + ~(~n-¡.to)2 ) ~ ¿ (Xi- Xn)2 i=l
Entonces, el test de razón generalizada de verosimilitudes para la hipótesis en consideración en el sistema e,
Te : "Rechazar Ho si An < k"
puede formularse en términos de
n(xn - f..lO)2 n ¿ (x;-xn)2 i=l
n-l
puesto que cuando esta expresión crece el valor de An decrece. Ahora bien, como
Te = n(Xn - 110)2
f: (Xi -X,,)2 í=l
n-l
n(X,,-¡.to)2 ,¡n (Xn - 110) rv t(n-l) a
" - )2 Sn ¿ (Xi-X" i=l
u(n-l)
el test para el juzgamiento de Ho en el sistema e queda establecido como
Te : "Rechazar Ho si Itcl > d"
o más precisamente, cuando se especifica un valor de a, como
Te : "Rechazar Ho si Itcl > t1-Q. (n - 1)". 2

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 225
• En el sistema A se tiene que
Ho : /-l = /-lo frente a
Hl : /-l < /-lo,
de manera que el test para juzgar Ho corresponde a
TA : "Rechazar Ho si te < teAn - 1)" .
• En el sistema B,
Ho : /-l = /-lo frente a
Hl : /-l > /-lo,
el test para juzgar Ho está dado por
TB : "Rechazar Ho si te > tl-a(n - 1)".
La decisión que se tome mediante el test T A, bajo el primer supuesto, puede asumirse igualmente mediante su correspondiente valor p, valor que puede calcularse como
mientras que el valor p asociado al test TB se obtiene mediante la probabilidad
y finalmente para el caso del valor p ligado al test Te, se calcula mediante
p = 2(1 - <I>(lzel))
La razón de este cálculo lo sugiere la figura 4.8; ante una situación en la cual el valor particular Ze fuese tal que Zl-a < I Ze I < Zl-.9:, Y admi-
2
tiendo que p = 1 - <I>(ze), no se dispondría de una forma alternativa de decisión equivalente al test Te, puesto que claramente no habría evidencia estadística para rechazar la hipótesis nula por ser IZel < Zl_.9:, pero
2
por otra parte como p < a la decisión sería contraria. De esta manera,
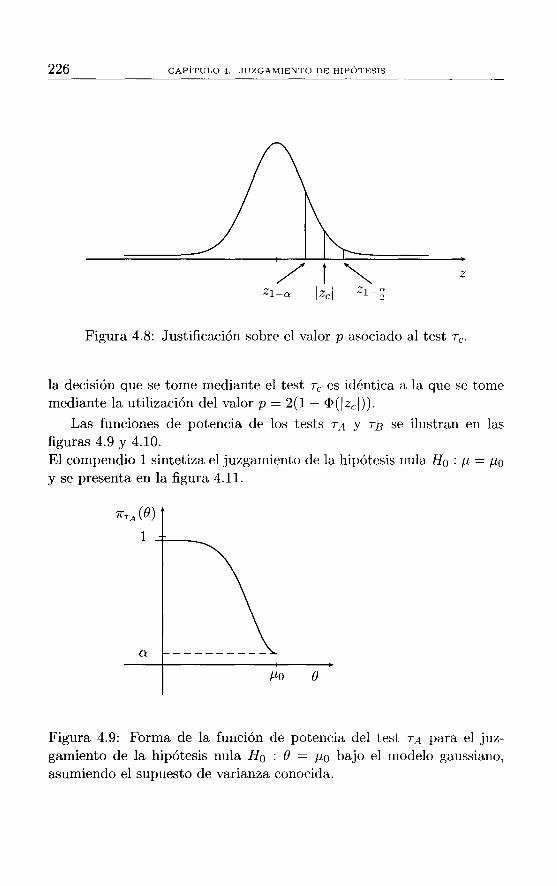
226 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
/1"" z Zl-a Izcl Zl-~
Figura 4.8: Justificación sobre el valor p asociado al test T c .
la decisión que se tome mediante el test Tc es idéntica a la que se tome mediante la utilización del valor p = 2(1 - 1f>(lzcl)).
Las funciones de potencia de los tests T A Y TB se ilustran en las figuras 4.9 y 4.10. El compendio 1 sintetiza el juzgamiento de la hipótesis nula Ho : J..l = J..lo y se presenta en la figura 4.11.
1T'TA (O)
1
a
J..lo O
Figura 4.9: Forma de la función de potencia del test TApara el juzgamiento de la hipótesis nula Ho : O = J..lo bajo el modelo gaussiano, asumiendo el supuesto de varianza conocida.

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 227
7rTB (B)
1 ---------------------
a ---------
f.lo B
Figura 4.10: Forma de la función de potencia del test TE para el juzgamiento de la hipótesis nula Ho : B = f.lo bajo el modelo gaussiano, asumiendo el supuesto de varianza conocida.
4.3.2 Juzgamiento de la hipótesis nula Ho : /11 - /12 = 60
Sea Xl, X2, . .. , X n una muestra aleatoria de tamaño n de una población con distribución Normal de valor esperado f.l1 y varianza O"I. De la misma forma, sea YI , Y2 , . .. , Ym una muestra aleatoria de tamaño m, de una población Normal de valor esperado f.l2 y varianza O"§. Siendo independientes las dos muestras, la hipótesis nula puede juzgarse frente a tres hipótesis alternas, en los siguientes términos:
• Sistema A:
• Sistema B:
H o : f.l1 - f.l2 = 60
frente a
Ha : f.ll - f.l2 < 60 .
Ho : f.l1 - f.l2 = 60
frente a
Ha : f.ll - f.l2 > 60 .

228 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Sistema A Ho:J-L=J-Lo
frente a H¡ :J-L<J-Lo
Tests
T A : "Rechazar Ho si t, < ta(n - 1)"
TB : "Rechazar Ho si te> tl-n(n - 1)"
Te : "Rechazar Ro si It,1 > t l _" (n - 1)"
J uzgamiento de
Ho :J'=J-Lo
Sistema B Ho:J-L=J-Lo
frente a H¡: J-L > J-Lo
Sistema e Ho:J-L=J-Lo
frente a
HI : J-Li J'o
Tests
T/\ : "Rechazar Ho si Zc < kn"
TH : "Hf>chazar Ro si Zr o > ZI n
T(' : "Rechazar lI,) si Iz,1 > ZI_ ~"
Figura 4.11: Compendio 1.
• Sistema C:
H o : J..ll - J..l2 = 60
frente a
Ha : J..ll - J..l2 =1= 60.
El propósito de expresar la diferencia de promedios poblacionales en términos de 60 tiene el fin de presentar de una manera más general el caso particular muy corriente en el cual la hipótesis nula establece que
60 = O.

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 229
l. Primer supuesto: aI, a§ son constantes conocidas. Considerando la variable aleatoria
es muy sencillo confirmar que se trata de una variable aleatoria con distribución Normal estándar, teniendo en cuenta que las muestras aleatorias son independientes; esta expresión por su condición es una variable pivote para la construcción de un intervalo confidencial para f..ll - f..l2. Se hace esta mención en razón a que existe cierta correspondencia entre la estimación por intervalo y
el juzgamiento de hipótesis. En efecto, si (TJ!) , T~2)) es un in
tervalo confidencial del 100(1 - 0:)% de confianza para el parámetro (J, un test razonable de nivelo: para el juzgamiento de la hipótesis nula Ho : (J = (Jo, frente a HI : (J =F (Jo descrito como
T : "Rechazar Ho si (Jo ~ (t~l), t~2)) ", es un test que da origen a
uno equivalente formulado en la forma característica. De los intervalos confidenciales unilaterales también se pueden deducir tests. Utilizando este recurso, se pueden derivar los test correspondientes así:
TA : "Rechazar Ho si Zc < za"·
TB : "Rechazar Ho si Zc > Zl-a".
Te: "Rechazar Ho si Izcl > ZI_.2'.". 2
2. Segundo supuesto: aI = a§ = a2 son constantes desconocidas (homoscedasticidad) . La función de verosimilitud de Xl, X2, .. . , X n , YI , Y2, . .. , Ym , depende particularmente de f..ll, f..l2 Y 0-
2 , dado que el supuesto de homoscedasticidad declara que las varianzas son iguales, su expresión es, entonces,

230 CAPÍTULO 4. JUZGA MIENTO DE HIPÓTESIS
Al acoger esta suposición de homoscedasticidad pero desconocidos los valores de las varianzas, los estimadores de f.Ll, f.L2 Y (72 son, respectivamente:
X n ,
Entonces,
supL = ()Eª
Y m , 1
m + n [(n - l)S?,n + (m - l)Si,m] .
n+m
2,,- (.t, (Xi - "n)' + j~, (Yj - l/m)')
m±n 2
n±rn e--2 -
En 8 0 , los estimadores máximo-verosímiles de f.L = f.Ll = f.L2 Y (72
cuando 150 = O son
1 ~ -
J.L= m+n (tXi+ i:Yj) = nXn+mYm
m+n i=l j=l
[
n m 1 - 2 - 2 mn - - 2 ~(Xi-Xn) +f;(Yj-Xm ) +m+n(Xn-Ym ) .
- 1 0'2 =--
m+n
De esta forma, el sup L corresponde a ()Eªo
m+n
27r {i~ (Xi - xn)2 + j~l (Yj - Ym)2 + :+r:., (Xn - Ym)2 }
con lo cual
nl+n -2-
An+m = [ 1
-mi" mn (- -)2
1 m+n X n - Ym + n m
i~ (Xi - xn)2 + j'fl (Yj - Ym)2
Teniendo en cuenta que
n+rn e--2-

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 231
n m
¿ (Xi - X n? + ¿ (Yj - y m)2
• _i=_I _____ -::--j=_I _____ rv X2 (n + m - 2) 0-2
Y dada la independencia de las dos variables aleatorias mencionadas,
Con este complemento, la razón generalizada de verosimilitudes se puede expresar en forma más simple como
A partir de ella, se pueden formular los tests en la forma siguiente:
Te : "Rechazar Ha si Itel > tI_S! (n + m - 2)". 2
TA : "Rechazar Ha si te < ta(n + m - 2)".
TB : "Rechazar Ha si te > tl-a(n + m - 2)".
Es importante hacer notar que la expresión simplificada de Te es
donde n m ¿(Xi - Xn)2 + ¿ (Yj - y m)2
8 2 = i=1 j=1
p n+m-2
El supuesto de homoscedasticidad, o-r = o-§, puede ser sustentado mediante argumentos tomados de la explicación teórica del

232 CAPÍTULO 4. JUZGA MIENTO DE HIPÓTESIS
fenómeno o de la información detallada fruto de un seguimiento permanente del mismo, que avalen la no existencia de razones para asegurar que una población es más variable que la otra. Cuando estos argumentos no están disponibles, o aun contando con ellos, el camino estadístico para la adopción de la homoscedasticidad o para descartarla es el juzgamiento de la hipótesis nula
2 2 Ho : 0"1 = 0"2'
cuya determinación de tests para tal propósito bajo Normalidad será tratada en el numeral 4.4.2.
Dentro de la construcción de tests bajo Normalidad, no poder asumir el supuesto de homoscedasticidad impide simplificar en forma mayúscula muchas etapas en la búsqueda de la distribución de una estadística que soporte el correspondiente test como no ocurre cuando se le asume; para el juzgamiento de la diferencia de promedios poblacionales, la adopción de la homoscedasticidad encauza la construcción del test sobre las ideas de Gosset para obtener un test fundamentado en la distribución de Student, en la forma como se dedujo en este punto relativo al segundo supuesto.
Esa imposibilidad de la adopción de la homoscedasticidad en el juzgamiento de la diferencia de promedios poblacionales, asumiendo el modelo gaussiano, genera un problema importante en la inferencia estadística y por consiguiente en la toma de decisiones en la práctica, denominado el problema de Behrens-Fisher, del cual se tiene una solución exacta, basada en análisis estadístico secuencial, solución que requiere un tipo de muestras seleccionadas en etapas, que este texto no aborda por no estar dentro del propósito del mismo. A continuación se presenta una solución aproximada al problema, la cual se cita en muchos libros de estadística.
3. Tercer supuesto: O"I =1= O"§ constantes desconocidas. (problema de Behrens-Fisher). Dentro de las soluciones, en la actualidad se destaca la solución de Welch. Esta solución utiliza la siguiente estadística:
T' = X n-Y m - 60 e JS2 S2
~ + 2,m n m

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 233
Esta estadística no tiene distribución t. Welch propone los siguientes tests:
TA : "Rechazar Ho si t~ < ta(f - 1)".
TE : "Rechazar Ho si t~ > tl-a(f - 1)".
Te : "Rechazar Ho si It~1 > tl-~ (f - 1)", 2
donde f = min { m, n}. Estos test pueden mejorarse en potencia, escogiendo f entre min{m, n} y (m + n - 2). La solución de Welch en este mejoramiento de potencia escoge a f como el entero más próximo a
C~n + s~n) 2
f= 2 2 2 2·
C~n) C~~m) -n---l - + ---'----m-_-lc;'--
El compendio 2, es una síntesis del juzgamiento de la hipótesis nula Ho : /11 - /12 = Jo, el cual se presenta en la figura 4.12.
Como conclusión esta sección 4.3 y como generalización del numeral 4.3.2, asumiendo el modelo de Gauss para cada una de las k poblaciones independientes, de manera que la variable que representa a la población j tiene valor esperado /1j y desviación estándar (J, j = 1,2, ... ,k, y siendo X j1 , X j 2, ... ,XJ1lJ , la muestra aleatoria de tamaño nJ correspondiente a la población j y bajo el supuesto de homoscedasticidad, el procedimiento de juzgamiento de la hipótesis nula que forma parte del sistema
Ho : /11 = /12 = ... = /1k
frente a
H 1 : no todos los promedios poblacionales son iguales,
se le conoce como análisis de varianza a una vía, procedimiento tratado inicialmente por Fisher en la segunda década del siglo XX. La denominación de este procedimiento estadístico como análisis de varianza, aparentemente sin vinculación con el sentido de la hipótesis planteada, proviene de la expresión de la estadística que fundamenta el test correspondiente, al tratarse de una separación de componentes de una

234 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
1 Sistema A
Ho : ¡.tI - J-l2 = Jo frente a
H I : 111-/1-2 <ou
Juzgamiento de
Ho : Ml -/12 = Jo
T
Sistema B Ro : Jll - J-L'l = 50
frente a H I : MI -f-L'2 >ou
I
1 Sistema e
Ho :JIl -J-!2 =c10 fr('Il1,t> a
Il] : ji1 - /12 i- 60
I
~ &
JI No
I (xn-l/m)-Jol ti - 'l
e - J'l" + ",,,, n Tn
1 Tests
T A : "Rechazar Hu si t~ < t,,(f -1)"
TB : "Rechazar Hu si t; > tl-a(f - 1)"
Te : "Rechazar Hu si It;1 > tl -1(f _1)"
Tests
TA : "Rechazar Ho si t, <t,,(n+m-2)"
TB : "Rf'chazar Ro si t,. > tl_,,(n + m - 2)"
Te : "R,('ehazar Ho ~.;i
It,1 > t l_ ,(n+m - 2)"
= (x" -l/m) -J"1 ~ y~+7,7
Tests
T A : "R{'chazar !Io si Z,. < z,,"
T 13 : •• R t-'chazar Ho si Z,. > 21 _(~ ..
Te : "R('cha7,ar lIo si Iz,1 > ZI_,"
Figura 4.12: Compendio 2.
varianza, concordante con el término análisis que significa "distinción y separación de las partes de un todo hasta llegar a conocer sus principios o elementos "3.
La función de verosimilitud
L = L (1-" 1 , 1-"2,·· ., I-"k, 0"2; Xll, X12,"" Xl n1 ," ., Xkl, Xk2,·· . ,Xknk)
de las n variables aleatorias Xll, X 12 ,···, X 1n1 ,·.·, X k1 , X k2 ,.··, X knk ,
siendo 0"2 el valor común desconocido de las varianzas de cada población
3 Real Academia Española (2001). Diccionario de la lengua española. Vigésimasegunda edición. Madrid: Espasa Calpe S.A.

4.3. JUZGAMIENTO DE HIPÓTESIS SOBRE PROMEDIOS BAJO NORMALIDAD 235
k adoptando la homoscedasticidad y n = ¿ nj, es específicamente
j=l
L = rr rr _1 exp {_~ (Xji -l1j)2}
j=l i=l vl2ii0- 2 o-
con la utilización de esta función se puede establecer que
nj
• La estimación máximo-verosímil de I1j es ~. ¿ Xji = Xj J i=l
k nj
• La estimación máximo-verosímil de 0-2 es * ¿ ¿ (Xji - Xj)2
j=l i=l
de tal manera que sup L =
ª Acorde con la hipótesis nula, denotando por 11 el valor común desco
nocido de los promedios de cada población, 8 0 = {(11, (72) 111 E lR, (72 > O}, de donde se pueden establecer los siguientes elementos:
• La estimación máximo-verosímil del valor común 11 bajo la hipó-nJ
tesis nula es * ¿ x ji = X. i=l
• La estimación máximo-verosímil de 0-2 bajo la hipótesis nula es k nj * ¿ ¿(Xji -x)2.
j=l i=l

236 CAPÍTULO 4. JUZGA MIENTO DE HIPÓTESIS
Por tanto, sup L
ªo [21ft I:(Xji-X)21-~ {_~}
j=l i=l exp 2' n
cuencia
supL
An = ªo -supL -
ª r
k n 1-~ j'fl i~ (Xji - x)2
k nj
~li~(XJl ~JJ J k nj
y en conse-
Algebraicamente, la expresión ¿ ¿ (x ji - x?, llamada suma total de j=l i=l
cuadrados, puede expresarse como la adición de dos cantidades,
k k nj
¿ nj(Xj - x)2 + ¿ ¿(Xji - Xj)2 j=l j=l i=l
conocidas estas últimas como suma de cuadrados entre grupos (en el lenguaje del diseño experimental, suma de cuadrados entre tratamientos) y suma de cuadrados de errores, respectivamente. Como estas cantidades son calculadas a partir de los valores observados de las muestras, la suma total de cuadrados es el numerador de una varianza muestral particular, varianza que se descompone entonces en dos partes: una varianza entre grupos o tratamientos o intervarianza y una varianza dentro de los grupos o intravarianza.
An =
Sustituyendo
k L nj(Xj-x)2 j=l
k-l k nj
L L (Xjí-Xj)2 j=l í=l
n-k
[
k k nj l-~ j'fl nj(Xj -x)2 + j'fli~(Xji -Xj)2
k nj
¿ ¿(Xji - Xj)2 j=l i=l
por fe, ( k-l )-~
entonces An = 1 + n _ kfe

4.4. JUZGAMIENTO DE HIPÓTESIS SOBRE VARIANZAS BAJO NORMALIDAD 237
Visto An de esta manera, los valores pequeños de la razón generalizada de verosimilitudes son causados por valores grandes de fe, y sólo resta entonces conocer la distribución de la variable Fe porque ya se manifiesta la forma del test equivalente al test original basado en An. En primer lugar, la independencia de las variables aleatorias
k k nj
L nj (X j - X)2 Y L L (Xji - X j )2 j=l j=l i=l
está garantizada por la independencia estadística entre las variables alea-. _ nj _ 2
tonas X j y ¿ (Xji - Xj) . i=l
En segundo lugar, bajo la hipótesis nula
y
k ¿ nj (X j - X)2
=-..j =_1---:0--,----___ '" X2 (k - 1) (J2(k - 1)
k nj 2 ¿ ¿ (Xji - Xj)
=-..j =_1_i_=--c1 ,-------- '" X2 (n - k).
(J2(n - k)
Por consiguiente, el cociente Fe tiene distribución F con (k-1) y (n-k) grados de libertad. Para concluir, el test original
T: "Rechazar Ha si An < e"
puede reformularse como:
T: "Rechazar Ha si fe > h-a((k - 1), (n - k))".
4.4 Juzgamiento de hipótesis sobre varianzas bajo Normalidad
4.4.1 Juzgamiento de la hipótesis nula Ha : a2 = a5. Según las condiciones establecidas en la sección 4.3.1, página 218, los tres sistemas que pueden plantearse son:

238
• Sistema A:
• Sistema B:
• Sistema C:
CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
H . 2 2 O .!J = !JO
frente a
H . 2 2 1 .!J < !Jo·
H .,.,.2 2 O . v = !Jo
frente a
H . 2 2 1 .!J > !Jo·
H .,.,.2 2 O . v = !Jo
frente a
H 1 : !J2 "# !J6.
1. Primer supuesto: f..L es una constante conocida. El juzgamiento de la hipótesis Ho bajo el sistema B, suponiendo f..L conocido, puede llevarse a cabo por medio de un test derivado de lo siguiente, con () = !J2. Como
n 2
)
n ~...!... '" (x~J.1) 1 20.L... ,
L( O; XI, X2, ••• ,Xn ) ~ (V21i'v'e e ,~, "
~...!... f: (Xí~J.1)2+1n( ~v'8) 20. 1 = e ,=
entonces considerando c( ()) = - 210 Y la pertenencia a la familia
exponencial de densidades, como c( ()) es creciente, por tanto
n
TB : "Rechazar Ho si ¿)Xi - f..L)2 > k". i=l
Este test es un test UMP para Ho en el sistema B, que equivale a
n ¿(Xi - f..L)2
"R h H· 2 i=l TB : ec azar O SI XC1 = - 2 !Jo
> x2 (n)" 1~n /
que gráficamente está representado por la figura 4.13.

4.4. JUZGAI\IIENTO DE HIPÓTESIS SOBRE VARIANZAS BAJO NORMALIDAD 239
Figura 4.13: Región crítica del test TB.
2. Segundo supuesto: f.1 es una constante desconocida. De modo similar, un test para Ha en el sistema B, cuando f.1 es desconocido es
n L (Xi - Xn)2
"Rechazar Ha si X~2 = _i=_l_----;c--__ > XLa(n - 1)". a5
Para los sistemas A y e, los tests son los siguientes:
TA : "Rechazar Ha si X~l < x;(n)";
TA : "Rechazar Ha si X~2 < x;(n - 1)",
según el supuesto que se adopte acerca de f.1. Igualmente,
Te: "Rechazar Ha si X~l < x;(n) o X~l > XJ(n)";
Te : "Rechazar Ha si X~2 < x;(n - 1) o X~2 > xJ(n - 1)")
que gráficamente están representados en la figura 4.14 donde a = E + (1 - eS). La escogencia de los percentiles X; y XJ es la misma que la de los percentiles que minimizan la longitud del intervalo confidencial para a 2 . La solución E = ~ yeS = 1- ~ debe evitarse para muestras pequenas.

240 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
E
Rechazar H o.---J L Rechazar Ho X2(V)
Figura 4.14: Región crítica del test Te, con v = n o v = n - 1 según el caso.
Nota. El teorema utilizado para la construcción del test bajo el Sistema E, permite utilizar el mismo test para juzgar Ha en el sistema siguiente:
rr 2 2 110 : (j ~ (jo
frente a
H . 2 2 1 . (j > (jo'
En el compendio 3, correspondiente a la figura 4.15, se resume el juzgamiento de la hipótesis nula Ha : (j2 = (j6'
4.4.2 J uzgamiento de homoscedasticidad
El juzgamiento de homoscedasticidad fue tratado en el ejemplo 4.2.7, página 205. Sin embargo, en el caso usual referente a dos poblaciones independientes, corresponde al juzgamiento de la hipótesis nula Ho : (ji = (j~. Para tal efecto, pueden establecerse tres sistemas de hipótesis:
• Sistema A:
Ha : (ji = (j~ frente a
H 1 : (ji < (j~.

4.4. JUZGAMIENTO DE HIPÓTESIS SOBRE VARIANZAS BAJO NORMALIDAD 241
n
Sistema A Hu: aL = a;}
frente a H¡ : aL < al~
L(:r, -In)' r--:-j
TA : "lV'('hazar Hu si \;, < \~(fl -- 1)"
TU : "Rpcha:;;ar /lo si ,;, > \~(n- 1)"
: "l{í·dlazar Ho si < \;(71 - 1) () si
> x¡(n - 1)"
n = (+ (1- J)
J uzgamiento de
Sistema B Ho : a 2 = a(~
frente a H¡ : (J2 > (T(~
Sistema e Ho: (72 = a5
frente a H¡ : ,,2 #,,~
f= (x, - J1.)2
X~l = =,~,-,1_",,~ __
Tests
T A : "Rechazar Ha si X~, < x;(n)"
Tn : "Rechazar Ho si X~, > x~(n)"
Te : "Rechazar Ho si X~, < x;(n) o si
X:, > x~(n)" a = f + (1 - o)
Figura 4.15: Compendio 3 .
• Sistema B:
• Sistema C:
Ho : (Ti = (T~ frente a
H 1 : (Ti > d·
lJ 2 2 110 : (TI = (T2
frente a
H 1 : (Ti 1= (T~.

242 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Los tests utilizados en el juzgamiento de H o, en cualquiera de los tres sistemas, están basados en el valor de la estadística
2
f -~ e - 2 8 2
donde Fe rv F(n - 1, m - 1) bajo las condiciones del numeral 4.3.2, página 227. Entonces, los respectivos tests pueden enunciarse como
TA : "Rechazar Ho si fe < fa(n - 1, m - 1)".
TB : "Rechazar Ho si fe > h-a(n - 1, m - 1)".
Te : "Rechazar Ho si fe < f,(n - 1, m - 1) o fe > fo(n - 1, m - 1)".
Lo mismo que en el caso anterior a = E + (1 - 5). La escogencia de los percentiles f,(n - 1, m - 1), fo(n - 1, m - 1) que incluye el test Te, es la misma que la de los percentiles de los intervalos confidenciales para el cociente de varianzas de dos poblaciones independientes desarrollados en el numeral 3.4.2, página 169. Si los tamaÍios de las muestras son relativamente grandes, se pueden usar E = ~ = 5.
4.5 Juzgamiento de proporciones
El juzgamiento de proporciones poblacionales es un tema muy común en los textos de estadística de todos los niveles, en razón de que muchas afirmaciones de la cotidianidad, de la actividad industrial, del desarrollo del comercio, de los quehaceres de la ciencia recurren a porcentajes y por tanto su empleo es muy amplio. El lenguaje común y el especializado han incorporado tasas y porcentajes con el sentido específico de su campo, para proporcionar un elemento descriptivo en la obtención de información o conocimiento sobre el tema en cuestión y su usanza se ha ampliado porque aritméticamente es simple y su comprensión muy generalizada.
Presentar algunas ideas en el juzgamiento de la cuantía de una proporción poblacional, o porcentaje como ordinalmente se le designa, cuantía que generalmente no es posible determinar para una población particular, constituye el propósito de esta sección. Se evitan algunos detalles considerados en secciones anteriores, pues en este punto ya deben ser familiares la estructura y las rutinas propias del juzgamiento de hipótesis, pero con base en las consideraciones que se realizan es posible construir con los detalles necesarios los distintos tests requeridos.

4..5. JUZGAMIENTO DE PROPORCIONES 243
Para comenzar, el modelo asumido es el modelo de Bernoulli de parámetro K. La familia de densidades de Bernoulli posee características especiales, en el sentido que los teoremas 4.2.14 y 4.2.15, páginas
n 212 y 213 respectivamente, legitiman a ¿ Xi como la estadística que
i=l fundamenta el juzgamiento de la hipótesis nula Ha : K = Ka en el sistema
Ha : K = Ka frente a
H 1 : K > Ka,
n por medio de un test establecido como T : "Rechazar Ha si ¿ Xi > k".
i=l n
Bajo la hipótesis nula ¿ Xi rv Bin(n, Ka), elegido un nivel del test i=l
a, y con el ánimo de determinar plenamente el valor de k, puede suceder que
P,,, [t,Xi 2 k+ 1] <" < P,,, [t,Xi 2 k] es decir, no se puede determinar un valor de k para el cual el nivel del test sea exactamente a. En esta situación hay dos soluciones: modificar el valor de a por un valor menor a' o establecer un test aleatorizado.
La primera solución es adoptar el nivel a' = P-rro [i~ Xi 2: k + 1] .
La segunda solución es establecer una función crítica:
n 1 si ¿ Xi 2: k + 1
i=l n
1jJ(x~) = r5 si ¿ Xi = k i=l
n O si ¿ Xi < k
i=l
La probabilidad de éxito r5 de la variable auxiliar en el test aleatorizado corresponde a:
a - P-rro [i~ Xi 2: k + 1] r5 = -~---~.:---=_--;=---=-----~
[ t Xi 2: k] - P-rro [t Xi 2: k + 1] l=l l=l
a - P-rro [i~ Xi 2: k + 1] P-rro [t Xi = k]
l=l

244 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
De manera que el tamaño del test será:
o· P" [t,Xi <k] a - Pno [i~ Xi ~ k + 1] [ n ]
+ n ] Pno l:= Xi = k P ['" X = k i=l no 0 ,.
i=l
+ 1 . P'o [t, Xi 2 k + 1]
= (a -P" [t,Xi 2 k+ 1]) +P.o [~Xi 2 k+ 1] = Q
Consideraciones similares pueden realizarse en el juzgamiento de la hipótesis nula Ho : 7r = 7ro en el sistema
Ho : 7r = 7ro
frente a
HI : 7r < 7ro,
n a través de un test establecido como T : "Rechazar Ho si LXi < k", Y
i=l para el juzgamiento de la referida hipótesis nula en el sistema
por intermedio de un test
Ho : 7r = 7ro
frente a
HI : 7r #- 7ro,
n n
T : "Rechazar Ho si l:= Xi < kl o si l:= Xi > k2".
i=l i=l
Recurriendo a otras consideraciones, referentes a tamaños de muestra grandes, las cuales encaminan el desarrollo de los tests más difundidos en el juzgamiento de un proporción poblacional, se presentan los rasgos generales de la deducción de los tests correspondientes.
Siendo Xl, X2, . .. ,Xn una muestra aleatoria de una población con n
distribución de Bernoulli de parámetro 7r, la estadística Pn = ~ LXi, i=l

4.5. JUZGAMIENTO DE PROPORCIONES 245
la proporción muestral, es un MLE insesgado para 7T, y siendo 1r(L1r) la correspondiente información de Fisher,
~ f¿ d
( ) (Pn - 7T) ---+ Z rv N(O, 1),
7T1-7T
con lo cual la hipótesis nula Ho : 7T = 7To puede juzgarse atendiendo a este resultado, según alguno de los siguientes sistemas:
• Sistema A:
• Sistema B:
• Sistema C:
Ho : 7T = 7To
frente a
H 1 : 7T < 7Too
Ho : 7T = 7To
frente a
H 1 : 7T > 7Too
Ho : 7T = 7To
frente a
H 1 : 7T =1= 7Too
Basados en la estadística
los tests respectivos pueden formularse como
TA : "Rechazar Ho si Zc < Za"o
TE : "Rechazar Ho si Zc > Zl-a" o
Te : "Rechazar Ho si Izcl < Zl--"'-" o
2
El requisito que algunos autores subrayan en la utilización correcta de estos tests consiste en garantizar que npn > 5 y que n(l - Pn) > 50

246 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Por último, cuando se desea juzgar la diferencia entre dos proporciones poblacionales correspondientes a dos poblaciones, se considera una muestra aleatoria Xl, X2, .. . , X n , de una población con distribución de Bernoulli de parámetro Irl, Y una muestra Yl , Y2 , ... , Yrn, de una población con distribución de Bernoulli de parámetro Ir2, siendo estas poblaciones estadísticamente independientes. Particularmente, si los tamaños de las muestras son relativamente grandes, los tests para el juzgamiento de la hipótesis nula Ho : Irl - Ir2 = 00, se basan en la estadística
(pÁl) - pj;)) - 00 Zc = ----¡:::==============
/ p(1) (l_P(l)) p(2) (1_P(2)) n n + = =
siendo p2) = ~ t Xi Y pj;) = ~ f }jo i=l j=l
Si algún sistema enuncia la hipótesis nula como Ho = IrI - Ir2 = 0, la estadística apropiada que fundamenta el respectivo test es
p(1) _ p(2)
Z n m
c= J P(l - P) (~ + ~)
siendo P 1")(1) + 1")(2) nrn mrm
entendida esta estadística como un esti-n+m
mador del valor común Ir = Irl = Ir2.
4.6 Ejemplos numéricos de aplicación
Ejemplo 4.6.1. El índice de Fishman es un indicador de la madurez esquelética de adolescentes y preadolescentes. Dentro del estudio epidemiológico de salud y mal oclusión dental realizado por la Facultad de Odontología de la Universidad Nacional de Colombia y la Caja de Compensación Familiar Colsubsidio, entre 1994 y 1996 Y basado en una muestra de 4.724 pacientes de su antigua clínica infantil, se comparó la edad cronológica de niños y niñas con igual maduración esquelética. Particularmente para un análisis puntual, se consideró una submuestra de 64 niñas con Índice igual a siete que registró un promedio de edad de 12.6 años con una desviación estándar de 1.21 años, y paralelamente una

4.6. EJEMPLOS NUMÉRICOS DE APLICACIÓN 247
submuestra de 51 mnos, con Índice igual a siete presentó un promedio de edad de 14.4 años con una desviación estándar de un año. Bajo el modelo gaussiano, que mostró ser apto para representar la edad cronológica en este nivel de maduración, ¿es razonable afirmar que el promedio de eelad en la cual los niños y las niñas alcanzan un Índice de maduración esquelética de siete, difiere según el género? En primer lugar, ¿es pertinente adoptar la homoscedasticidad? Dentro
2
de su juzgamiento, SI = 1.21, S2 = 1 Y fe = ~ = 1.4641 Y teniendo en S2
cuenta que Fe rv F(63, 50), la probabilidad P[Fe > 1.4641J = 0.0811587 es un valor que al asumir a = 0.05 permite adoptar la homoscedasticidad como supuesto de juzgamiento de Ha : MI = M2 (el promedio de edad en la cual los niños y las niñas alcanzan un Índice de maduración de siete es el mismo) dentro del sistema
Ha : MI = M2
frente a
HI : MI -¡ M2·
2 (n-l)s2 +(m-l)s2 . Entonces como Sp = ~~m-2 2,m, para este caso partIcular, la
t · ., 'el l' 2 63x(1.21)2+5axl 1 258746018 es lmaClOn cornun e a vananza es sp = 64+51-2 =. , y con este resultado
12.6 - 14.4 = -8.54731294.
(1.121938509)) l4 + II
En consecuencia como el valor p para este juzgamiento es 6.8511 x 10-14 ,
éste valor se constituye en evidencia estadística para rechazar la hipótesis nula Ha : MI = M2 dentro del sistema en consideración.
Si se pasa por alto la homoscedasticidad o si la decisión respecto a ella hubiese sido contraria, se acudiría a la solución de Welch para poder contar con los argumentos necesarios para sustentar la afirmación de igualdad de promedios poblacionales. Dado que
12.6 - 14.4 = -8.6928 ) 1.4641 + ..l.
64 51
su valor absoluto supera ampliamente al percentil 0.975 de una distribu-

248 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
ción t con 112 grados de libertad, 1.98137059, porque
f= (
82 82
) 2 ~+~
C~n ) 2 C~~m ) 2
-.-+--.
2
(~ + ir) = 112.83397. 2 ( 1 ) 2
( 1.4641 ) 51 64_ + 50 63
En consecuencia, bajo esta solución, también hay suficiente evidencia estadística para rechazar la hipótesis Ho : ¡'.11 = /-12, es decir, la información contenida en la muestra respalda cuantitativamente la afirmación motivada por este análisis puntual.
Ejemplo 4.6.2. El estrés afecta de manera importante la producción de leche en el ganado vacuno. Las causas que lo producen son de distinta naturaleza, pero una de ellas parece ser la temperatura del ambiente, pues las reses tienden a reducir la ingestión de alimento cuando la temperatura aumenta y por consiguiente se ve reducida la producción láctea. Para evaluar esta circunstancia, se construyeron establos con cubierta de material aislante del calor para ubicar durante un mes 47 vacas Holstein de las mismas características que 38 vacas mantenidas en los potreros, durante el mismo período, cuya protección solar fueron los árboles y arbustos presentes en el lugar. Del acopio de información de la producción de leche de cada una de las vacas, se tiene lo siguiente: El promedio de producción mensual de las 47 vacas aisladas del calor fue de 597 1 con una desviación estándar de 36 1, mientra..'l que el promedio de producción de leche del otro grupo de vacas fue de 360 1 con una desviación estándar de 45 1. ¿Independientemente de la producción lechera, modelada apropiadamente de forma Normal según el test de Lilliefors, se puede afirmar que, de todas maneras, la variabilidad de la producción es prácticamente igual en las dos condiciones de temperatura? Además de preguntarse si ante las condiciones de temperatura del ambiente se modifica la producción lechera, lo cual puede analizarse de manera similar al ejemplo anterior, el investigador centra su atención sobre la variabilidad de la producción. La hipótesis de que el efecto de la temperatura no altera la variabilidad de la producción, Ho : (}r = ()~, al manifestarse el sentido de aumento o disminución de la misma, se

juzga en el sistema
4.7. TAMAÑO DE LA MUESTRA
Ho: a~ = a~ frente a
Hl : a~ i= a~.
249
Entonces, fe = ~ = i!~l~ = 0.64. La solución corriente establece para
este caso que fO.025 (46, 37) = 0.54323124 Y que fO.975 (46, 37) = 1.8880067, con lo cual
fO.025 (46,37) < fe < fO.975 (46,37)
y de allí concluir que no hay la suficiente evidencia estadística para rechazar la homoscedasticidad, con lo cual se puede asegurar que bajo las dos condiciones de temperatura en las cuales permanecen las reses, la variabilidad no se modifica de una manera notable.
4.7 Tamaño de la muestra
El tamaño de la muestra tiene consecuencias ostensibles en la toma de decisiones, así como en la calidad de las estimaciones. Estimar un parámetro es una actividad que persigue fines distintos de los del juzgamiento de una afirmación acerca de él, y, por tanto, la disposición de lo necesario para el logro de los fines estrictamente no es la misma. Son dos procesos entroncados pero distintos en sus efectos o trascendencias. El tamaño de la muestra que se utiliza con la finalidad de estimar parámetros no necesariamente es el tamaño apto para el juzgamiento de hipótesis, o, contrariamente, un tamaño elegido para juzgar una hipótesis no propiamente es el tamaño adecuado para estimar el parámetro correspondiente.
El tamaño de la muestra es un tema que induce la reflexión en los teóricos y la indagación de su magnitud en los usuarios de la estadística; corresponde a un asunto de gran amplitud que contiene muchas singularidades y por supuesto no puede ser abordado por un texto que tiene otra mira. Reiterando lo expresado en el capítulo 3, sólo se presentan unas minúsculas consideraciones, sin mayor pretensión, sobre dos tamaños de muestra simple bajo la orientación del modelo gaussiano.
Como el tamaño de la muestra tiene efectos directos sobre los errores del tipo 1 y del tipo Il, la función de potencia asiste su determinación.

250 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Usualmente se suele asumir un valor de a deseado y a partir de él ajustar un tamaño muestral para obtener un pretendido valor de (3.
Particularmente, el juzgamiento de la hipótesis nula Ho : ¡..¿ = ¡..¿o en el sistema A, asumiendo Normalidad y varianza conocida, requiere un tamaño de muestra específico. Según las consideraciones anteriores, el test correspondiente de tamaño a, como se dedujo en la subsección 4.3.1, es
T : "Rechazar Ho si y'Ti(xn ~ ¡..¿o) < Z " O" a
que puede enunciarse igualmente como
O"Zü" T : "Rechazar Ho si xn < ¡..¿o + y'Ti .
Si ¡..¿ fuese igual a ¡..¿* (¡..¿* .¡. ¡..¿o), la probabilidad del error del tipo II sería, por consiguiente,
Por tanto,
[- O"za] (3=PJL* X n 2:¡..¿o+ y'Ti
_ [y'Ti CXn ~ ¡..¿*) > y'Ti(¡..¿o ~ ¡..¿*) + Zü] - PJL* ~ O" O"
y'Ti(¡..¿o ~ ¡..¿*) ~~--=-------.:-----.:.. + Za = Zl-¡3
O"
y como Za = ~Zl-a, entonces
de donde finalmente,
y'Ti(¡..¿o ~ ¡..¿*) ~ Zl-ü = zl-¡3 O"
n= [0"(Zl-a+ Zl_¡3)]2 ¡..¿o ~ ¡..¿*
tamaño idéntico al requerido para el juzgamiento de la hipótesis nula Ho : ¡..¿ = ¡..¿o en el sistema B. La determinación de ¡..¿* no es del todo arbitraria, como puede ser la de a o la de {3. Concretamente, la pretensión del menor riesgo en la decisión se materializa en la adopción de probabilidades pequeñas para los errores del tipo 1 y II; pero la elección de ¡..¿* que acompaña las reflexiones alrededor del error del tipo II, que

4.7. TAMAÑO DE LA MUESTRA 251
corresponda al valor de f3 deseado, debe responder a razones de índole de sensibilidad del test. Fijar el valor de /L* cercano a /Lo, permaneciendo constantes los valores de la desviación estándar y los percentiles señalados, tiene un efecto extraordinario en el tamaño de la muestra, pues lo magnifica sobremanera. En este sentido, la respuesta a la pregunta ¿qué tan sensible debe ser el test? es la única vía que proporciona los elementos y argumentos para la escogencia de /L*.
Otra situación particular la constituye el establecimiento del tamaño de muestra adecuado para juzgar la hipótesis nula Ho : /Ll - /L2 = Jo, en el sistema B. Al igual que el caso anterior se asume el modelo gaussiano y adicionalmente el conocimiento de las varianzas poblacionales (Ti y (T~.
El test TB desarrollado en el numeral 4.3.2, considerando m = n puede formularse de otra manera como
"R h H' (- -) ¡; V (Ti + (T~ " TB : ec azar o SI X n - Yn > uO + n Zl-a·
Si /Ll - /L2 fuese igual a 15*, la probabilidad del error del tipo II sería, en consecuencia,
f3 = Po*
Con lo cual se puede afirmar que
Jo - 15*
PfI2 2 + Zl-ü = Z(3, y debido a que Z(3 = -Zl-(3, entonces
al +a2 n
JO - 15* --;:== + Zl-a = -Zl-(3, luego
2 2 al +a2
n
15* - JO
PfI = Zl-a + Zl-(3,
2 2 al +a2
n
con lo cual se deduce que
Cada una de las dos muestras debe entonces contar con n unidades para cumplir cabalmente las exigencias relacionadas con las probabilidades

252 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
de los errores en la decisión. Esta expresión es igualmente válida para el cálculo del número de unidades estadísticas que deben seleccionarse en cada una de las dos poblaciones, para el caso del juzgamiento de la hipótesis nula Ho : /11 - /12 = 50, en el sistema A. La sensibilidad del test, como en el caso anterior, es la determinante del valor 5*.
4.8 J uzgamiento secuencial
Como formas especiales de juzgamiento de hipótesis, dentro de la temática conocida como análisis secuencial que incluye también estimación de parámetros, se encuentran procedimientos basados en tests llamados secuenciales surgidos de la idea de Wald, denominada originalmente como tests secuenciales de razón de probabilidad (SPRT Sequential Probabilit Y Ratio Test). Estas formas especiales de juzgamiento de hipótesis utilizan explícitamente tanto la probabilidad del error del tipo 1 como la probabilidad del error del tipo II fijando de antemano sus valores, de manera que el tamaño de la muestra no está predeterminado sino que ahora depende de Q y (3 y la decisión final está sujeta a decisiones previas tomadas en pasos consecutivos dentro del proceso. En términos generales, un test secuencial requiere menor número de observaciones muestrales que un test basado en una muestra aleatoria de tamaño fijo.
Como punto de partida en la construcción del concepto de juzgamiento secuencial de hipótesis, se presenta la siguiente definición inicial que detalla la idea de una clase particular de tests secuenciales, reconocida como tests secuenciales de razón de verosimilitudes.
Definición 4.8.1. Siendo Xl, X 2 , . .. , X j una muestra aleatoria de tamaño j de una población con función de densidad f x (x, e), fijando los valores ""o y ""1 tales que ""o < ""1, estableciendo el sistema de hipótesis
Ho : fx(x, e) = fx(x, eo)
frente a
H 1 : fx(x, e) = fx(x, et)
y denotando la razón de verosimilitudes Aj, para j = 1,2, ... , como
j
L(eO;X1,X2, ... ,Xj) Aj = L(fh;X1,X2, ... ,Xj)
TI fx(x, eo) i=l
j
TI fx(x, el) i=l

4.8. JUZGAMIENTO SECUENCIAL
al test descrito por
T : "Rechazar Ho en el paso j si Aj S /'\:0; no rechazar Ho si
Aj 2: /'\:L incluir la observación Xj+1 Y calcular la nueva
razón de verosimilitudes Aj+1 para continuar en el paso
j + 1 si /'\:0 < Aj < /'\:1 "
se le denomina test secuencial de razón de verosimilitudes.
253
La región crítica CT de un test secuencial T está conformada por la unión de las regiones CT,n a saber:
donde la región CT,n = {X~IAj E (/'\:0, /'\:1), An S /'\:0, j = 1,2, ... ,n - 1} describe el subconjunto del espacio de las observaciones, cuyos elementos facultan al test secuencial para rechazar la hipótesis nula en el sistema de hipótesis establecido.
La región de aceptación del test secuencial T, denotada por AT , de manera similar a su región crítica es
siendo AT,n = {X~IAj E (/'\:0, /'\:1), An 2: /'\:1, j = 1,2, ... , n - 1}. Corno se comentó al iniciar la sección 4.8, el juzgamiento secuencial
establece previamente los valores de a y (3 manejando así simultáneamente los errores del tipo 1 y del tipo II y la delimitación del tamaño de la muestra sujeta a esas determinaciones previas. En consecuencia,
a = f 1, f:r fx(xi, ()0) dX1 dX2 ... dXn n=l Cr,n i=l
(3 = f 1 f:r fx(xi, ()1) dx1 dX2 ... dxn .
n=l Ar,n i=l
Como a y (3 han sido establecidos de antemano, los conjuntos AT,n y CT,n no están totalmente especificados y requieren para su determinación los valores de las constantes /'\:0 y /'\:1, los cuales definen plenamente el test secuencial. Entonces, el paso siguiente consiste en la concreción de esos valores, para los cuales el teorema siguiente facilita una aproximación.

254 CAPÍTULO 4. JUZGAMIENTO DE HIPÓT~~SIS
Teorema 4.8.2. Definidos los tamaños de los errores o: y (3, los valores ""o y ""1, que definen un test secuencial T, pueden aproximarse mediante
o: ""o ~ 1 - J1
1-0: Y ""1 ~ -(3 .
Teorema 4.8.3. Definidos los tamaños de los errores a y (3, y aproxi-d 1 1 * Q * 1-Q t' t ma os os va ores ""o Y ""1, por ""o = 1-,6 Y ""1 = T' respec zvamen e,
los tamaños 0:* y (3* correspondientes a los valores por ""o y ""i son tales que
a * + (3* < o: + (3.
Ejemplo 4.8.4. Sea Xl, X 2 , . .. ,Xn una muestra aleatoria de tamaño n, n un valor no prefijado, de una población con distribución de Bernoulli de parámetro O. Un test secuencial T para el juzgamiento de la hipótesis Ho : 0=00 en el sistema de hipótesis simples
Ho: 0=00
jrentea
H1 : 0=01
habiendo definido previamente o: y (3, puede formularse en los siguientes términos. Definida la razón de verosimilitudes
j rr O~i(l - OO)l-xi A' - _i=_l _____ _
J - j rr O~i(l - 01)1-xi
J
[00 (1- Od] i~l x, [1 -Oo]j 01(1 - 00 ) 1 - 01
i=l
el test secuencial T rechaza Ho : O = 00 si Aj :s; ""o. Al utilizar la aproximación derivada anteriormente, el test rechaza Ho si Aj :s; 1~,6' es decir, si
j
[ 00(1-0d]i~lXi o: [1-01]j 01(1-00 ) :s; 1-(3 1-00
Asumiendo que 00 < 01, entonces i=~~ < 1 Y ~~g::::~:)l < 1, luego el test secuencial rechaza la hipótesis nula Ho : 0= 00 , si
1 [01(1 - 00 )] L:
j . > 1 [~] . [~] n O ( O ) X 2 - n + J In O 01-1. o: 1-1
2=1

Denotando por
al =
4.8. JUZGAMIENTO SECUENCIAL
In [~] In [e1 (1-eol ]
eo(l-eIl
y por
el test rechaza la hipótesis nula si
j
¿Xi:2: al + bj. i=l
255
Por otra parte, el test secuencial no rechaza la hipótesis nula, si Aj :2: '"'1; igualmente, al utilizar la aproximación derivada anteriormente, el test no rechaza Ho si Aj :2: 1ft, es decir, si
Denotando por
ao = -In (T) In [e1(1-eol] ,
eO(l- el)
el test no rechaza la hipótesis nula si
j
¿Xi :S ao + bj. i=l
En síntesis, el test secuencial se puede formular de manera simplificada como
j
T : "En el paso j rechazar Ho si ¿ Xi :2: al + bj; no rechazar Ho i=l
j
en el paso j si ¿ Xi :S 00 + bj ; incluir la observación Xj+1 para i=l
j+1
calcular el nuevo valor ¿ Xi Y continuar en el paso j + 1, si i=l
j
ao + bj < ¿ Xi < al + bj" . ;=1

256 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
De manera gráfica puede entenderse el test como lo muestra la figura 4.16.
j
i~ Xii ...
....... _ .. . -Rechazar Ho .. -
....... _ .. - ... _.- ....... .. - _ ..
...... Continuar .-..-...... N o rechazar H o _ .. -_.-
.. -1 2 3 4 5 6 7 8 9 10 J
Figura 4.16: Representación del test secuencial del ejemplo 4.8.4.
Ejemplo 4.8.5. Sea Xl, X 2 , . .. ,Xn una muestra aleatoria de tamaño n, n un valor no prefijado, de una población con distribución gaussiana de valor esperado f) y varianza (J2 conocida. Un test secuencial T para el juzgamiento de la hipótesis Ho : f) = ¡.Lo en el sistema de hipótesis simples
Ho : f) = ¡.Lo
frente a
HI : f) = ¡.Lo + C(J,
siendo e una constante conocida y definidos previamente O' y (3, puede formularse en los siguientes términos: En primer lugar,
Aj = cxp [2~2 (t,(Xi -"o - ca)' - t,(Xi -1,o)2) 1

4.8. JUZGAMIENTO SECUENCIAL 257
El test secuencial T rechaza Ha : () = ¡..ta, si Aj ::; /'\,a, que al utilizar la aproximación obtenida anteriormente, el test rechaza Ha si Aj ::; 1~,B'
es decir, si
a <--1-,6
o rechazar la hipótesis nula, si
2:j
(Xi - ¡..ta) 1 1 (1 -a) . e -'-----'----'- > - - n -- + J - . (J" - e ,6 2
i=1
En segundo lugar, el test secuencial no rechaza la hipótesis nula si Aj 2:: /'\,1; igualmente, al utilizar la aproximación obtenida anteriormente, el test no rechaza Ha si Aj 2:: l~a, es decir, si
2:j
(Xi - ¡..ta) 1 1 (1 -a) . e -'-----'----'- < - - n -- + J - . (J" -c ,6 2
i=l
Recapitulando, el test secuencial se puede formular de manera simplificada corno
, . . ~ (Xi - ¡..ta) 1 (a) . e T :"En el paso J rechazar Ha SI 6 2:: --In ~ + J-;
(J" e 1-jJ 2 i=1
j
no rechazarla si ~ (Xi - ¡..ta) ::; _~ In (1 - a) + j~; calcular el 6 (J" e ,6 2 }.=1
)+1
1 ~ (Xi - ¡..ta) t· 1 . 1 . va or 6 para con rnuar en e paso J + , SI (J"
;.=1
2:j
(Xi - ¡..tu) (1 (a) e 1 (1 - a) e) " -'-------'- E --In -- + j-, --In -- + j- . . (J" e 1-,6 2 e ,6 2 1=1
El tamaño de la muestra que siempre ha sido un interrogante mayúsculo, en el juzgarniento secuencial tiene un sentido singular. Corno la decisión de rechazar o no rechazar la hipótesis nula puede ser pronta, es decir tornada con muy pocas unidades observadas, pero también tardía después de haber observado un número considerable de unidades, el

258 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
interrogante cambia de ¿cuál será el número de unidades que se debe elegir? a ¿cuántas unidades en promedio se deben elegir?, puesto que el tamaño de la muestra final como no está predeterminado ya no es un número fijo sino variable porque depende de Aj, y precisamente para estos procedimientos de tipo secuencial se asume como una variable aleatoria, denotada como N.
En términos de la definición 4.8.1 se puede demostrar que tanto Eoo [N] como EOl [N] son finitos. Mediante la llamada ecuación de Wald es posible establecer aproximaciones a estos valores esperados del tamaño de muestra.
Teorema 4.8.6 (Ecuación de Wald). Si la sucesión Y1, Y2 ,···, Yr¿, ... , es una sucesión de variables aleatorias independientes e idénticamente distribuidas, tales que E[iYi 1] y E[Yi] = r¡ son finitos, y si N es una variable aleatoria cuyo recorrido es el conjunto de los naturales y cuyos valores n, dependen de las variables Y1 , Y2, ... , YrL' entonces
E [t Y¡ 1 ~ 1¡E[N].
E r t d 1 t't" 1 [fX(Xi,Ool] . 1 2 3 1 ' lec uan o a sus 1 uClOn Yi = n fX(Xi,O¡) ,Z = , , , ... , a razon j
de verosimilitudes Aj se puede expresar como Aj = L Yi. De esta ma-i=l
nera el test secuencial se puede enunciar como
j
T : "Rechazar Ha : e = ea, si LYi :::: In Ka, no rechazar Ha : e = ea, i=l
j
si LYi :::: In Kl, ... ; incluir la observación Yj+l para calcular la i=1
]+1
nueva razón de verosimilitudes LYi' para continuar en el paso i=1
j
j + 1, si In Ka < L Yi < In K 1" .
i=1
Como el tamaño de muestra no está prefijado, y sus valores considerados como observaciones de la variable aleatoria N, cuando el test secuencial

4.8. JUZGAMIENTO SECUENCIAL 259
conduce a rechazar la hipótesis nula, P [i~ Yi :S In ""o] = 1 Y i~ Yi tiende a tomar valores cercanos a In ""o y cuando el test conduce a no
rechazar la hipótesis nula P [i~ Yi 2': In ""1] = 1 Y i~ Yi tiende a tomar
valores cercanos a In ""l. Con estas consideraciones, Eeo [f Yi] ~ In ""o t=l
e igualmente EOl [i~ Yi] ~ In"" 1, entonces
siendo r la probabilidad de rechazar la hipótesis nula. Usando la ecuación de Wald, el tamaño de muestra esperado
E [f Yi] E[N] = i=l
r¡
de manera que su valor puede aproximarse como
Luego
E [N] ~ r In ""o + (1 - r) In "" 1 .
r¡
o: In ""o + (1 - 0:) In "" 1 o: In [ ~] + (1 - 0:) In [T ] 1. Eoo[N] ~ E [Y;] ~ E [Y;]
~ t ~ t
(1 - 13) In ""o + 13 In ""1 (1 - 13) In [~] + 13 In [T] 2. EOl [N] ~ E [Y;] ~ E [Y;] el t el t
Ejemplo 4.8.7. Sea Xl, X 2, ... ,Xn una muestra aleatoria de una población con distribución gaussiana de valor esperado () y varianza conocida a 2
. Determinar el tamaño de la muestra requerido para el juzgamiento de la hipótesis nula H o, en el sistema de hipótesis
Ho : () = 75
frente a
H 1 : () = 80,

260 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
con las siguientes condiciones: a = 0.01, j3 = 0.05, (]"2 = 25. Igualmente, determinar los tamaños de muestra esperados si el test que se va utilizar es un test secuencial. El test T: "Rechazar Ho si xn > c" es un test equivalente al test de razón simple de verosimilitudes. Entonces
PO=75 [Xn > cJ = 0.01 = PO=75 [yIn(X~ -75) > y1n(c5- 75)]
PO=80 [Xn < cJ = 0.05 = PO=80 [yIn(Xn - 80) < y1n(c - 80)] 55'
Luego
<I> ( y1n(c5- 75)) = 0.99 Y <I> ( y1n(c
5- 80)) = 0.05
es decir,
y1n(c - 75) y1n(c - 80) 5 = ZO.99 = 2.326347 Y 5 = ZO.05 = -1.64485348
de donde se deduce que yIn = 3.97120048, entonces n = 15.7704332, es decir, n = 16. En general, si el sistema de hipótesis se formula. como
siendo ¡..to < ¡..tI,
Ho: e = ¡..to
frente a
HI : e = ¡..tI,
[Ix (Xi, /LO)]., 1 [( 2 2) 2 ( )] Yi = In I ( ),2 = 1,2,3, ... , Yi = -----:2 ILo - P'1 - Xi ILo - IL] .
X Xi, /LI 2a
Luego
1 2 E¡.to [Yi] = 2(]"2 (¡..tI - ¡..to)
1 2 E¡.tl [Yi] = - 2(]"2 (¡..tI - /Lo) .
En el caso particular ¡..to = 75, ¡..tI = 80, (]"2 = 25, EO=75 [Yi] EO=80[Yi] = -~, a = 0.01, j3 = 0.05, entonces
Eoo [N] ~ 2 [a In (1 ~ j3) + (1 - a) In (1 ~ a)] = 5.8206 ~ 6
EOl[N] ~ -2 [(1- j3) In (1 ~ j3) + j31n (1 ~ a)] = 8.3538 ~ 9.
I 2'

4.9. JUZGAMIENTO DEL AJUSTE 261
En general, esta propiedad de necesitar un tamaño esperado de la muestra menor al tamaño de la muestra que requieren los tests que deben determinar previamente el tamaño citado, es una propiedad que caracteriza a los tests secuenciales.
Terminada esta breve presentación de la idea central de un test secuencial, se continúa con la siguiente sección dedicada al juzgamiento del ajuste.
4.9 Juzgamiento del ajuste
Al constituir distintas formas de teorizar y de aplicar conceptos, posiciones que no rivalizan dentro de una concepción unitaria de la estadística, algunas áreas de la estadística prescinden de los modelos de probabilidad mientras que otras, como la concepción bayesiana, extienden su tarea. Pero indiscutiblemente a la esencia misma de la inferencia estadística son inherentes los modelos probabilísticos; por ello en reiteradas ocasiones este texto se ha referido al modelo de probabilidad elegido, como la manera propia de representar el comportamiento de una variable y más específicamente para representarlo en la acepción de población.
Con la elección de un modelo se buscan o evalúan estadísticas para su certificación como estimadores, se construyen buenos intervalos confidenciales para alguna función del parámetro o para sus componentes, se apoya el juzgamiento de una hipótesis relativa precisamente al modelo elegido. Pero, en un caso particular, ¿cuál debe ser el modelo adecuado?
Por supuesto que hay innumerables distribuciones estadísticas que pueden servir de modelo para representar una población específica; pero por tratarse de una tarea de adopción de un paradigma lo más fiel a la realidad en estudio, la elección debe responder tanto a razones estadísticas como a argumentos no estadísticos. La tradición de un modelo para representar una variable puede ser un argumento importante, porque permite la comparación de resultados de distintas investigaciones o estudios, pero no siempre debe ser el único argumento. Indiscutiblemente, en los detalles del conocimiento del fenómeno dentro del cual se modela una variable se encuentran argumentos de mayor significación para señalar a un modelo en particular.
Pero al lado de razones propias de la naturaleza del fenómeno, hay instrumentos estadísticos que permiten valorar la aptitud del modelo

262 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
de ser emulado por la información disponible en la muestra. Se trata de un variado repertorio de procedimientos con la denominación de bondad del ajuste, construidos sobre diversos puntos de vista. El lector encontrará una profusa bibliografía acerca del ajuste a modelos probabilísticos, principalmente al modelo gaussiano, conocido como pruebas de Normalidad. Este texto solamente introduce las ideas pertinentes al tema por medio de los tests, de Pearson, como uno de los procedimientos más tradicionales para el examen de la calidad del ajuste y el test de Kolmogorov-Smirnov. Sin embargo es necesario mencionar la existencia de tests como los de Lilliefors, el test de Normalidad de AndersonDarling, pruebas especiales para el juzgamiento de la Normalidad como la de Shapiro-Wilk o la de Martínez-Iglewics, que poseen propiedades especiales y las hacen en cierta forma más demandadas, tests entre otros que el lector podrá estudiar y profundizar en un curso de estadística no paramétrica principalmente.
4.9.1 Juzgamiento del ajuste por medio del método de Pearson
Propuesta a principio del siglo XX por Pearson, es la forma pionera de los tests de juzgamientos del ajuste, aun cuando un concepto paralelo al tema venía desarrollándose en el siglo anterior: la estimación de una función de densidad.
Para dar inicio a las consideraciones del juzgamiento del ajuste, se fija una partición del recorrido de la variable que va a ser representada por la variable aleatoria X, asumida como modelo para la población, partición constituida por k clases disjuntas y se considera además una muestra aleatoria Xl, X2, .. . , X n , de tamaño n de una población cuya función de densidad no se conoce.
En términos muy concretos, la decisión frente a la elección de un modelo propuesto corresponde al juzgamiento de la hipótesis "el modelo candidato interpreta adecuadamente el comportamiento poblacional", que se traduce en la mayoría de las veces a través de la función de distribución como Ho : Fx(x) = Fo(x, e) para todo x, frente a alguna hipótesis alterna apropiada.
Siendo N j la variable que contabiliza el número de observaciones muestrales que pertenecen a la j-ésima clase ej, j = 1, 2, ... ,k, el vector aleatorio V = (Ni, N 2 , . .. ,Nk )' tiene distribución multinomial con parámetro

4.9. JUZGAMIENTO DEL AJUSTE 263
k
e = (1f1,1f2,'" ,1fk)', cuyos componentes son tales que ¿ 1fj = 1, Y j=l
k
por otra parte ¿ nj n, nj E {O, 1, ... , n}. En otras palabras, su j=l
función de densidad es:
, n __ n_'-II nj - k 1fj .
TI nj! i=l j=l
El j-ésimo componente del vector e, 1fj denota la probabilidad de que una observación muestral pertenezca a la clase j, probabilidad que se calcula por supuesto por medio del modelo en consideración. De esta manera, el sistema de hipótesis que incluye la hipótesis nula reformulada puede plantearse como
H O :1fj=1fJ, j=1,2, ... ,k
frente a
H 1 : 1fj # 1fJ, j = 1,2, ... ,k.
Entonces, el test de razón generalizada de verosimilitudes será
T: "Rechazar Ho si An = nn II :J < c ", k ( 0) nj
j=l J
que al contar con un tamaño de muestra suficientemente grande, en consonancia con el enunciado del teorema 4.2.6 página 205, puede enunciarse como
La idea de Pearson, anterior a la existencia de conceptos como la razón generalizada de verosimilitudes, es cotejar la frecuencia N j , denominada j-ésima frecuencia observada con la frecuencia n1fJ conocida como j-ésima frecuencia esperada, porque bajo la adopción del modelo,

264 CAPÍTULO 4. JUZGA MIENTO DE HIPÓTESIS
E[Nj ] = mrJ. Pearson sintetiza su idea en la estadística
k L (Nj - mrJ)2
j=l n1["° ' J
pues valores pequeños de ella se constituyen en argumentos a favor de la hipótesis nula, que en general se le entiende como ajuste, mientras que los valores grandes son evidencias estadísticas de no coherencia con el modelo, es decir, de no ajuste. La Estadística de Pearson converge en distribución a una variable aleatoria con distribución Ji-cuadrado con (k - 1) grados de libertad, luego la adopción del modelo se desecha si
k (N. _ n1["0)2 '"' J J 2 ~ n1["0 > x1-oJk - 1). J=l J
Ejemplo 4.9.1. Como preparación a la evaluación del ajuste al modelo Uniforme en el intervalo (0,1) de una variable que toma valores en el mismo intervalo, se establece una partición que por comodidad puede consistir de subintervalos de igual amplitud; es decir, el subintervalo
j-ésimo es (2if, fe), de manera que
i
° i k
1 1[".= dx=-J ~ k'
k
j = 1,2, ... ,k.
En segundo lugar se considera una muestra aleatoria Xl, X 2 , .. . ,Xn , de tamaño n de una población Uniforme en el intervalo (0,1), y a partir de ella se determina cada una de las variables N j , como se señaló anteriormente, con lo cual se establece la Estadística de Pearson. De manera particular, la proporción de la prima legal que el asalariado dedica a pagar obligaciones económicas contraídas anteriormente es una de las variables de interés para un estudio sociológico, de cuyos resultados se extrae la tabla 4.3, basada en los resultados de una entrevista a 950 empleados del sector manufacturero. Los teóricos sociales encargados de la conducción del estudio no encuentran razones especiales para afirmar que la proporción de la prima dedicada a cubrir obligaciones económicas contraídas tenga una distribución con algún sesgo o que tenga un apuntamiento especial; por tanto, encuentran razonable el uso del modelo Uniforme para describir rasgos de

4.9. .JUZGAMIENTO DEL AJUSTE 265
Porcentaje Número de dedicado Empleados
Más de hasta O 20 162
20 40 210 40 60 194 60 80 186 80 100 198
Total 950
Tabla 4.3: Distribución del número de empleados según el porcentaje de la prima que dedican al pago de sus obligaciones económicas adquiridas.
este aspecto de los empleados. La tabla 4.4 presenta tanto las frecuencias observadas y esperadas corno los sumandos para la determinación del valor de la Estadística de Pearson, derivados de la información precedente.
I j I Clase j I nj I n1rJ I 1 [0,0.2] 174 190 2 (0.2,0.4] 198 190 3 (0.4,0.6] 194 190 4 (0.6,0.8] 186 190 5 (0.8,1.0] 198 190
Total
(nj - npi~)2
npiC! 1
1.34736842 0.33684211 0.08421053 0.08421053 0.33684211 2.18947368
Tabla 4.4: Elementos para el cálculo del valor de la Estadística de Pearson correspondiente al ejemplo 4.9.1.
El valor 9.48778 corresponde al percentil 95 de una variable con distribución Ji-cuadrado con (k - 1) = 4 grados de libertad; por tanto, al ser el valor de la Estadística de Pearson menor que el mencionado percentil, se concluye que no hay evidencia estadística para rechazar el modelo uniforme para caracterizar con propiedad la proporción de la prima de los empleados dedicada a cubrir obligaciones económicas contraídas, decisión idéntica si se utiliza el valor p cuyo valor corresponde

266 CAPÍTULO 4. JUZGA MIENTO DE I1IPÓTgSIS
a 0.70095688.
Ejemplo 4.9.2. Igualmente como preparación a la evaluación del ajuste al modelo gaussiano con valor esperado J.L y varianza CJ2 totalmente especificados, de una variable de interés, se determina una partición de la recta real que por comodidad puede consistir de k subintervalos disjuntos de igual amplitud, exceptuándose el primero y el último. El subintervalo j-ésimo (xj -1' xj), con x~ = - 00 y x~ = 00, es un intervalo cuya probabilidad es
o _¡Xj 1 [1 (x - J.L) 2] d _ (X j - JI) (X j -1 - J.L) ]f. - -- exp -- -- x - ([> -- -([>
J x' vI21iCJ 2 CJ CJ CJ )-1
j = 1,2, ... , k, y seguidamente se considera una muestra aleatoria Xl, X 2 , . .. ,Xn , de tamaño n de una población cuya densidad se desconoce y a partir de ella se determina cada una de las variables Nj ,
como se ha señalado, para establecer la correspondiente estadística de Pearson. Específicamente, en un estudio neumológico, la CPT (capacidad pulmonar total) definida como el volumen máximo que los pulmones pueden alcanzar con el máximo esfuerzo, es una de las variables relevantes. En los adultos, la CPT tiene como promedio 5.800 mI, con una desviación estándar de 150 mI. De una muestra de 270 pacientes, sin antecedentes neumológicos, a los cuales se les realizó un examen para determinar la CPT, se ha resumido la información de esta variable en la tabla 4.5.
CPT(ml) Número de Pacientes
Menos de 5 400 12 de 5 400 a 5 500 46 de 5 500 a 5 700 78 de 5 700 a 5 850 80 de 5 850 a 6 000 39 de 6000 y más 15
Total 270
Tabla 4.5: Distribución del número de pacientes según la capacidad pulmonar total.

4.9. JUZGAMIENTO DEL AJUSTE 267
¿El modelo gaussiano de valor esperado 5.800 y desviación estándar de 150, será una elección acertada como modelo para representar la capacidad pulmonar total de pacientes que cumplen los criterios de inclusión definidos para el estudio? La tabla 4.6 presenta tanto las frecuencias observadas y esperadas como los sumandos para la determinación del valor de la Estadística de Pearson, derivados de la información precedente.
1 ( -00,5400] 2 2 (5400,5550] 15 3 (5550,5700] 60 4 (5700,5850] 102 5 (5850,6000] 71 6 (6000,00] 20
0.003830425 1.03421478 0.043959905 11.86917443 0.204702137 55.26957697 0.378066128 102.07785468 0.278230122 75.12213300 0.091211282 24.62704613
Total
(nj - npi~)2
npi~ 0.90188334 0.82584251 0.40486834
5.9680E - 05 0.22619140 0.86935135
3.22819633
Tabla 4.6: Elementos para el cálculo del valor de la Estadística de Pearson correspondiente al ejemplo 4.9.2.
El valor 11.0705 corresponde al percentil 95 de una variable con distribución Ji-cuadrado con (k - 1) = 5 grados de libertad; por tanto, al ser el valor de la estadística de Pearson menor que el mencionado percentil, se conduye que no hay evidencia estadística para rechazar el modelo gaussiano como modelo apto para caracterizar la CPT, decisión que equivale a utilizar el valor p cuyo valor es 0.66485144.
En estos ejemplos se proporcionaron explícitamente los valores de los componentes del parámetro. En el primer caso, (h = O y fh = 1; en el segundo, el = f.j = 5800 Y e2 = 0-
2 = (150)2. Sin embargo no siempre ocurre que el modelo en elección esté completamente especificado; muchas veces se candidatiza a la familia de modelos y no a un miembro particular de ella, lo cual implica la estimación de componentes del parámetro, bajo el modelo en consideración por supuesto, y de esta manera se afecta la distribución de la Estadística de Pearson, pues se reducen los grados de libertad en el número de componentes estimados. La demostración de esta afirmación está en concordancia con el teorema

268 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
4.2.6 Y está fuera de los alcances de este texto. Entonces, si en el ejemplo anterior no se hubiesen especificado los
valores de J..l = 5800 Y (J = 150, habría sido necesario estimar los dos componentes del parámetro, y como consecuencia los grados de libertad disminuirían de 5 a 3. Con esta modificación en los grados de libertad y la sustitución de J..l y (J por sus respectivas estimaciones, que para este caso son X270 = 5698.88 Y 8270 = 182.45, el procedimiento es el mismo que el seguido en los dos ejemplos anteriores.
4.9.2 Juzgamiento del ajuste por medio del método de Kolmogorov-Smirnov
Como se manifestó en el numeral anterior, la decisión frente a la elección de un modelo propuesto, equivale al juzgamiento de la hipótesis "el modelo candidato interpreta adecuadamente el comportamiento poblacional", traducida generalmente a través de la función de distribución. El método de Kolmogorov-Smirnov evalúa el ajuste a modelos que representen variables continuas y juzga la hipótesis nula Ho : Fx(x) = Fo(x, B) para todo x, dentro del sistema de hipótesis
Ho : Fx(x) = Fo(x, B) para todo x
frente a
H1 : Fx(x) .¡. Fo(x, B) para algún x.
A diferencia de la idea de Pearson que coteja las frecuencias observadas con las frecuencias esperadas, la idea de Kolmogorov, por su parte, coteja la función de distribución correspondiente al modelo postulado con la función de distribución empírica. A principio de la década del 30 del siglo pasado, Kolmogorov condensó su idea en la estadística
Dn = sup IFn(x) - Fo(x, B)I -oo<x<oo
que luego Smirnov, a finales del mencionado decenio, la hizo extensiva a otros propósitos, estadística cuya distribución depende directamente del tamaño de la muestra como lo garantiza el teorema de GlivenkoCantelli. Del mismo teorema se puede afirmar que valores pequeños de la estadística Dn son argumentos estadísticos a favor de la hipótesis nula, porque si la mayor diferencia entre la distribución propuesta y la función de distribución empírica es relativamente pequeña, las demás diferencias

4.9. JUZGAMIENTO DEL AJUSTE 269
también serán pequeñas y, por tanto, el modelo es pertinente; mientras que valores grandes de la estadística se constituyen en evidencias estadísticas para prescindir del modelo propuesto como representante del comportamiento poblacional. La distribución muestral de Dn tiene una expresión engorrosa, que el lector puede consultar en Nonparametric Statistical Inference (J. D. Gibbons (1971) pp. 77 a 81). El siguiente teorema presenta una aproximación cuando el tamaño de muestra es relativamente grande.
Teorema 4.9.3. Si Fo(x, fJ) es una función de distribución continua, entonces para cada v > O,
La función h( v) fue tabulada por Smirnov a mediados del siglo pasado y muchos programas de cómputo estadístico han incluido algoritmos para la determinación de los respectivos percentiles y el cálculo de los valores p, e igualmente algunos textos, principalmente los textos de estadística no paramétrica, incluyen tablas que permiten determinar los percentiles correspondientes.
En pocas palabras, cuando la calidad del ajuste no es satisfactoria se descarta el modelo propuesto, decisión que se adopta cuando dn > c. Utilizando la aproximación ofrecida por el teorema anterior, el tamaño del test puede establecerse mediante la expresión
Ejemplo 4.9.4. Para ilustrar la parte operativa del ajuste por el método de Kolmogorov-Smirnov, una muestra de 25 baldosas de cerámica de un lote de producción fueron seleccionadas para identificar el modelo apropiado para describir la variabilidad del grosor de la baldosa que ella alcanza al final del proceso de fabricación. Teniendo en cuenta información que acopia el Departamento de control de calidad, es razonable pensar que el grosor tiene un comportamiento uniforme entre 90 y 110 milímetros. La tabla 4.7 presenta los valores particulares de la muestra ordenados, la función empírica, la función de distribución correspondiente al modelo en consideración y las diferencias entre ellas. Como sup 1F25(X) - Fo(x, fJ)1 = 0.05 y el percentil 95 de la distribución

270 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
Valores ordenados F25 (X) Fo(x, 8) IF25 (X) - Fo(x, 8)1
91 0.04 0.05 0.01 92 0.08 0.10 0.02 93 0.12 0.15 0.03 94 0.20 0.20 0.00 94 0.20 0.20 0.00 95 0.28 0.25 0.03 95 0.28 0.25 0.03 96 0.32 0.30 0.02 97 0.36 0.35 0.01 98 0.40 0.40 0.00 99 0.44 0.45 0.01 100 0.48 0.50 0.02 101 0.52 0.55 0.03 102 0.56 0.60 0.04 103 0.60 0.65 0.05 104 0.72 0.70 0.02 104 0.72 0.70 0.02 104 0.72 0.70 0.02 106 0.76 0.80 0.04 107 0.84 0.85 0.01 107 0.84 0.85 0.01 108 0.88 0.90 0.02 109 0.96 0.95 0.01 109 0.96 0.95 0.01 110 1.00 1.00 0.00
Tabla 4.7: Valores muestrales ordenados del grosor de las baldosas y sus respectivos valores de las funciones de distribución.
de Dn es 0.238 (valor tomado de la tabla III de Applied Nonparametric Statistical M ethods (P. Sprent (1993)), no hay evidencia estadística para desechar el modelo uniforme en el intervalo (90,110) para describir las irregularidades, respecto al estándar, del grosor de la baldosa.
N ata. El juzgamiento del ajuste de una variable discreta mediante el

4.9. JUZGAMIENTO DEL AJUSTE 271
método de Pearson no tiene restricción alguna, sólo la que le es común a cualquier tipo de variable: tamaño de una muestra relativamente grande, para que sea legítimo el uso de los percentiles de una variable aleatoria con distribución Ji-cuadrado, o el cálculo de los valores p a través de ella, corno los puntos de referencia para tornar la decisión. El método de juzgamiento del ajuste mediante la estadística de K olmogorov-Smirnov se ha establecido sobre la consideración de que Fo(x, O) es continua. Sin embargo, algunos autores corno Noether han demostrado que se puede utilizar el procedimiento para ajuste de modelos discretos, pero que el nivel del test se altera.
Para finalizar este capítulo y por consiguiente al contenido del libro, una precisión acerca del vocablo modelo, que aparece por primera vez en este texto en la página 1 cuando se cita una frase del psicólogo Jerome Seymour Bruner, con la cual se encabeza el capítulo 1, Y que se menciona con frecuencia de manera explícita o tácita en todos los capítulos y que incluso también en estos últimos párrafos se hace alusión a él.
La mente humana puede construir modelos tan artificiosos y complejos como quiera, pues cuenta con herramientas que le permiten elaborar ilimitadamente mundos virtuales donde puede incorporar, a voluntad, propiedades, relaciones, normas, semánticas, en fin, un sinnúmero de elementos, agregados a voluntad o en coherencia con otros, para generar la dinámica propia de ese mundo virtual.
Pero tal vez no sea la mejor ruta el excesivo detalle y meticulosidad en la elaboración del modelo, tratándose de encontrar un paradigma que a manera de una réplica ofrezca alternativas de explicación de la realidad, de reproducción simplificada de los rasgos y características de ella. Aunque en el modelado de la realidad se incluyen elementos no reales y se excluyen realidades que se suponen o se demuestran que son superfiuas, en la descripción o explicación de un fenómeno ese proceso modelador debe estar inspirado en un principio de economía que permite simplificar al máximo los conceptos, elementos y relaciones del modelo.
Guillermo de Ockham, polémico filósofo del siglo XIV ya lo advertía con su famosa Ley de parsimonia que corrientemente se le conoce como Navaja de Ockham, que consiste en la inutilidad de multiplicar los elementos explicativos o descriptivos de algún fenómeno, enunciada como "Entia non sunt multiplicanda sine necessitate" que puede traducirse como, no hay que multiplicar las cosas sin necesidad, y entenderse en este texto como la intención sana de formular modelos y teorías que busquen

272 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
explicar los hechos utilizando el mínimo de presupuestos. Los modelos probabilísticos, como se ha afirmado a lo largo de este
texto, son modelos especiales que intentan reproducir un comportamiento exclusivo de variabilidad, modelos que incorporan expresiones matemáticas propias que lo identifican y lo caracterizan, expresiones que dependen principalmente de parámetros que habilitan la identificación de miembros de una familia particular de modelos. Como modelos que son, los modelos probabilísticos no están exentos de construirse de manera exagerada y compleja complicando posiblemente su manejo.
La sencillez del modelo despojado de lo superfluo, con parsimonia en sus parámetros, lo enaltece, lo hace atractivo, lo hace útil. Por ello la propuesta de modelos sencillos para representar una población particular, cuando los modelos usuales y tradicionales no colman las expectativas de los investigadores y analistas estadísticos en casos específicos, es un reto interesante para una mente inquieta que ve en la naturaleza la fuente de inspiración y el motivo de sus reflexiones estadísticas.
"La mayoría de las ideas fundamentales de la ciencia son esencialmente sencillas y por lo general pueden ser expresadas en un lenguaje comprensible para todos".
Albert Einstein

4.10. DEMOSTRACIÓN DE LOS TEOREMAS 273
4.10 Demostración de los teoremas
Teorema 4.2.3. Sea Xl, X 2 , . .. ,Xn una muestra aleatoria de una población con función de densidad f X (x, e). Si el sistema de hipótesis es
Ho: e = eo frente a
Hl : e = el,
el test T cuya función crítica corresponde a
n n
82
;=1 ;=1 n n
;.=1 ;=1
es un test más potente para Ho, siendo k una constante positiva y 7rr (eo) = 0:.
Demostración. Como preparación para la demostración, se tienen los siguientes elementos:
l. Paralelamente al test T, se considera cualquier test T' para el juzgamiento de la hipótesis nula, con función crítica CPr' (x~) y nivel 0:.
2. Además de la región crítica Cr,n asociada al test T, cuya función crítica es 1{!r (x~), se establecen los siguientes conjuntos, disyuntos entre sí y disyuntos con Cr,n,
D ~ {x;. k gfx(Xi,B¡) < gfX(Xi,BO)};
E ~ {x;. k gfX(Xi,B¡) ~ gfx(Xi,Bo)},
3. 1{!r(X~) puede considerarse una variable aleatoria con distribución de Bernoulli cuya probabilidad de éxito bajo eo es

274 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
4. El símbolo J corresponde a la integral múltiple sobre el conjunto A
A y dx~ representa a dX1 dX2 ... dx,.,.
El objeto de la demostración es simple: concluir que 7rT (e1) 2" 7rT /(e1 )
tal como lo estipula la definición 4.2.1 o en otros términos concluir que
Eel ['Ij!T(X~)J 2" Ee1 [<PT/(X~)J .
Para ello, la demostración gira alrededor de la diferencia:
~ = Ee1 ['Ij!T(X~)] - Ee1 [<PT/(X~)] = Ee ['Ij!T(X~) - <PT/(X~)]
= J ['Ij!T(X~) - <PT/(X~)] fr fx(xi, e1)dx~. X 2=1
Como X = GT ,,., U D U E,
~ = J ['Ij!T(X~) - <PT/(X~)J fr fx(xi, eddx~l e 2=1
T,n
+ J ['Ij!T(X~) - <PT/(X~)] fr fx(xi, el)dx~ D 2=1
+ J ['Ij!T(X~) - <PT/(X~)J fr fx(xi, e1)dx~1 E 2=1
cuando x~ E GT,n, 'lj!T(X~) = 1 Y cuando x~ E D, 'lj!T(X~) = O; entonces,
6.1 = J [1- CPT'(X~)J frfX(Xi,eddx~ +./ [-CPT,(x~)l frr'«(xi,eddx~ CT,n ,=1 D 7=1
+ ./ [~T(X~) - CPT'(X~)l frfX(Xi,eddx~. E ,=1
,., 11
Adicionalmente, cuando x~ E GT ,,.,, k TI fx(xi,ed > TI fx(xi,eo), y i=l i=l
con ello
k ./ [1- CPT'(X~)J frfX(Xi,eddx~ > ./ [1- CPT,(x~)l llfx(:1;i,eu)dx;¡. i=l i=1
cr,n Cr,n

4.10. DEMOSTRACIÓN DE LOS TEOREMAS 275
n n Igualmente, cuando x~ E D entonces -k TI fx(xi, el) > - TI fx(xi, ea),
i=l i=l por tanto,
k J [-<PTI(X~)J TI:fx(xi,eddx~ > J [-<PTI(X~)J TI:fx(xi,eo)dx~. D 2=! D 2=1
n n
Finalmente, cuando x~ E E, k TI fX(Xi, el) = TI fx(xi, ea), con lo cual i=l i=l
k J [1j)T(X~) - <PTI(X~)J TI: fx(xi, eddx~ E 2=1
= J [1/JT(X~) - <PTI(X~)J TI: fx(xi, eo)dx~. E 2=1
Teniendo en cuenta las desigualdades descritas,
kD.1> / [1- <PTI(x~)l frfX(Xi,eo)dx~ + / [-<PTI(x~)l frfX(Xi,eo)dx~ CT,n 1,=1 D 1,=1
+ / [l/)T(X~) - <PTI(X~)l frfX(Xi,eo)dx~ = D.2 ~' 1.=1
D.2 = / [l/)T(X~) - <PTI(X~)l gfX(Xi,eo)dX~ CT,n
+ / [l/)T(X~) - <PTI(X~)l frfX(Xi,eO)dx~ D 1=1
+ / [l/)T(X~) - <PTI(X~)l frfX(Xi,eo)dx~ E 1=1
= EOo ['l/)T(X~) - <PTI(X~)l·
Como los tests tienen el mismo nivel, ~2 = a-a = O Y como k~l > ~2, se puede afirmar que ~1 2: O; luego
conclusión que garantiza que el test T cuya región crítica es CT,n es un

276 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
test más potente para
Teorema 4.2.6
Ho : (J = (Jo
frente a
HI : (J = (JI. o
Su demostración puede consultarse en Mathematical Statistics (Wilks (1962), pp. 419 Y 420).
Teorema 4.2.14. Sea Xl, X 2, .. . , X n una muestra aleatoria de una población con función de densidad fx(x, (J), (J E e <:;;; IR Y la familia {Jx(x, (J)} tiene MLR en la estadística T = t(XI , X2,' .. ,Xn ).
1. Si la razón monótona de verosimilitudes es no decreciente y si ta es tal que
POo[t(XI , X 2,···, X n ) < tal = a
entonces el test
T: "Rechazar Ho si t(XI, X2,·· . , x n ) < ta"
es UMP para Ho, en el sistema
Ho : (J :S; (Jo
frente a
HI : (J > (Jo.
2. Si la razón monótona de verosimilitudes es no creciente y si tI-a es tal que
POO [t(XI ,X2, ... ,Xn ) > tI-al = a,
entonces el test
T: "Rechazar Ho si t(XI, X2,··· , x n ) > tI-a"
es UMP para Ho, en el sistema
Ho : (J :S; (Jo
frente a
HI : (J > (Jo·

4.10. DEMOSTRACIÓN DE LOS TEOREMAS 277
Demostración. Sean fh y e2 dos valores de e de manera que el ~ eo y e2 > eo, con ellos se formula un nuevo sistema de hipótesis simples como:
Hó : e = el frente a
H; : e = e2 .
El lema de Neyman-Pearson garantiza que el test
"R h H*· \ L(el ;Xl,X2, ... ,Xn ) " T : ec azar o SI An = < K,
L(e2 ;Xl,X2, ... ,Xn )
es un test más potente para Hó en el nuevo sistema. Dado que la familia {Jx(x, en tiene MLR en la estadística T = t(Xl , X 2 , ... , X n ),
y suponiendo que el cociente de verosimilitudes es una función no creciente de t(Xl, X2, . .. , xn), afirmar que la razón de verosimilitudes An < K,
equivale a afirmar que t(Xl, X2, ... , x n ) > tI-e", como lo indica la figura 4.17. Por tanto, el test se puede formular de manera equivalente como
T : "Rechazar Hó si t(Xl, X2,·· ., x n ) > h-a".
Este test es UMP para Ho en el sistema
Ho : e ~ eo frente a
Hl : e > eo,
debido a que el test no depende de el ni de e2 , porque el test es más potente para cualquier elección de el, e2 E e, sujetos a que el ~ eo < e2. El otro numeral del enunciado del teorema se demuestra de igual manera.
O
Teorema 4.8.2. Definidos los tamaños de los errores a y {3, los valores K,o Y K,l, que definen un test secuencial T, pueden aproximarse mediante
a K,o ~--
1-{3 y
1-a K,l ~--{3 .
Demostración. Asumiendo que la hipótesis nula es cierta, entonces
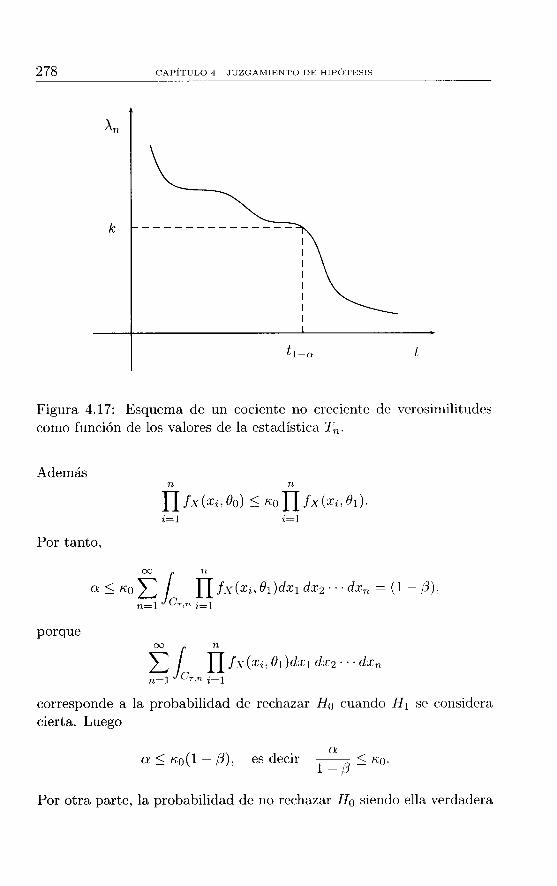
278 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
An
k
tI-a t
Figura 4.17: Esquema de un cociente no creciente de verosimilitudes como función de los valores de la estadística Tn .
Además n n rr fx(xi, 80 ) :s; ~o rr fx(xi, 8d·
i=1 i=1
Por tanto,
o: :s; ~o f ¡ TI: fx(xi, 81 ) dx I dX2' .. dXn = (1 - (3), n=1 CT,n i=1
porque
f ¡ TI: fx(xi, 81 ) dx l dX2'" dXn
n=1 CT,n i=1
corresponde a la probabilidad de rechazar Ho cuando Hl se considera cierta. Luego
o: :s; ~0(1- (3), es decir o:
1 - (3 :s; ~o·
Por otra parte, la probabilidad de no rechazar Ho siendo ella verdadera

4.10. DEMOSTRACIÓN DE LOS TEOREMAS
corresponde a
y como en los casos de no rechazo de la hipótesis nula,
n
i=1
entonces
Luego
n
i=1
es decir, 1-0
i'í:1 :s: -(3-'
279
i'í:o tiene entonces una cota inferior 1~¡3 y i'í:1 tiene una cota superior 1~Q, cotas que se pueden asumir como aproximaciones a i'í:o Y i'í:1, respectivamen~. O
Teorema 4.8.3. Dtfinidos los tamaños de los errores o y (3, y aproxi-d l l * o. * 1-0. t' t ma os os va ores i'í:o Y i'í:1, por i'í:o = 1-13 Y i'í:1 = T' respec zvamen e,
los tamaños 0* y (3* correspondientes a los valores por i'í:o y i'í:Í son tales que
0* + (3* < o + (3.
Demostración. Sean e;, C;,n' A;, A;,n las regiones críticas y de aceptación correspondientes a los niveles 0* y (3* derivados de los valores i'í:o
y i'í:i·
0* = f Ir. rr !X(Xi, Bo)dx l dX2'" dXn n-1 Gr,n i~1
:s: 1 ~ (3 f fe. rr !X(Xi, BI)dx1 dX2 ... dxn . n=1 T,n z=1
De acuerdo con uno de los pasos de la demostración del teorema 4.8.2,
_0_ f r rr !X(Xi, B1)dx1 dX2'" dXn = _0_(1 - (3*). 1 - (3 ) G' . 1 - (3
n=1 T,n z=1

280 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
De modo similar,
1 - a* = f 1 * fr fX(Xi, OO)dXl dX2·· . dXn
n=l A.,.,n i=l
lOOr n
~ ~aLJA* rrfX(Xi,01)dxldx2···dxn. n=l "',n t=l
A su vez,
1-a~ r rrn 1-a *
-(3-~ J) * fX(Xi, Oddx l dX2··· dXn = --{3 n=l A.,.,n i=l {3
Concretamente de lo anterior,
a* ::; 1 ~ {3(1 - (3*) y (1 _ a*) ~ 1 - a {3 .
Con base en estas desigualdades es fácil comprobar que
a* + {3* ::; a + {3.
4.11 Ejercicios
D
1. Adoptando el modelo Uniforme en el intervalo (O, O) para representar el comportamiento de una población, para la cual se conjetura además que el valor del parámetro no excede 00 , se determina el siguiente sistema de hipótesis
Ha : O ::; 00
frente a
Hl : O > Oo.
Formalice un test con nivel a para el juzgamiento de Ha dentro de este sistema de hipótesis, basado en una muestra aleatoria de tamaño n de esta población.
2. Con base en las consideraciones del ejercicio 1, formalice un test con nivel a para el juzgamiento de Ha dentro del sistema de hipótesis
Ha: 0=00
frente a
Hl : O -# Oo·

4.11. EJERCICIOS 281
3. Establezca una expresión algebraica para la función de potencia del test determinado en el ejercicio 1.
4. Al adoptar la distribución de Poisson con parámetro O para modelar una población particular, conviene proveer un test que permita decidir sobre la hipótesis nula Ho dentro del sistema
Ho: O = 00
jrentea
Hl : O =1- Oo·
Para tal efecto, determine un test con nivel a basado en una muestra aleatoria de tamaño n de la citada población.
5. La distribución de Cauchy es un modelo muy singular debido a sus particularidades de no existencia de sus momentos. ¿La familia de densidades de Cauchy es una familia que tiene MLR en alguna estadística 7
6. Considere la distribución particular de Cauchy
1 jx(x) = 7f[l+(x_O)2],XER
¿Bajo el siguiente sistema de hipótesis es posible determinar un UMP de nivel a para el juzgamiento de Ho basado en una muestra aleatoria de tamaño n
Ho: O = O
jrentea
Hl : O > 07
7. El modelo Exponencial desplazado, mencionado en los ejercicios del primer capítulo y en un ejemplo de este capítulo tiene diversas aplicaciones. En particular, regido por este modelo resulta algunas veces interesante evaluar el hecho de si para un caso individual el desplazamiento es un elemento significativo dentro del modelado, es decir, si es preciso introducir un componente del parámetro para indicar el desplazamiento, o por el contrario es inocuo hacerlo y

282 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
de esta manera simplificar el modelo elegido. En el lenguaje del juzgamiento de hipótesis corresponde al sistema
Ho : el = o jrentea
H 1 : el > o.
Teniendo presente que el parámetro e = (el, e2) reserva el primer componente para referirse precisamente al desplazamiento, construya un test de nivel a para este propósito.
8. Una modalidad característica de procedimientos en el control estadístico de la calidad se ha denominado muestreo para la aceptación de lotes, dentro de la cual se menciona un procedimiento particular correspondiente al juzgamiento de la hipótesis Ho dentro del sistema
Ho: e < eo jrentea
H 1 : e 2 eo,
parámetro cuyo espacio corresponde al intervalo (0,1) y que representa la denominada fracción no conforme de materia prima, de productos en proceso o de productos terminados, según el objetivo y momento de su aplicación, que dentro del modelo de Bernoulli corresponde a la probabilidad de éxito. Determine un test de nivel cercano a a y su función de potencia. Bosqueje la curva de operación OC.
9. Desarrolle un test para el juzgamiento de la homoscedasticidad como el presentado en el numeral 4.4.2, página 240, asumiendo que J-l1 y J-l2 son valores conocidos.
10. ¿Cambiará radicalmente el test para homoscedasticidad en dos poblaciones Normales, si se asume que J-l1 y J-l2 son desconocidos pero iguales?
11. Determine una expresión para el cálculo del tamaño de muestra apropiado para el juzgamiento de la hipótesis nula Ho : 1f = 1fo en

el sistema
4.11. EJERCICIOS
Ha : 7r = 7ro
frente a
HI : 7r > 7ro,
283
por medio de un test construido considerando un tamaño de muestra grande, siendo 7r la probabilidad de éxito o proporción poblacional.
12. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con función de densidad fx(x, e) = e(l - x)e-II(o,I)(X), con e > O. Este modelo se propone como emulador del comportamiento de la fracción no conforme de la materia prima que recibe cierta compañía para utilizarlo como la distribución a priori de 8. Pero previo a ello y dentro del análisis de su ajuste se desea contar con un test que juzgue la hipótesis nula Ha : e ::; ea dentro del sistema de hipótesis
Ha : e ::; ea
frente a
HI : e > ea.
Determine un test para tal fin.
13. Sea Xl, X 2 , ... , X n una muestra aleatoria de una población con función de densidad Uniforme en el intervalo (O, e). Fijando el valor k, si (Xn.n, k~,Xn,n) es un intervalo confidencial para el parámetro e, entonces use este hecho para derivar de allí un test para juzgar la hipótesis nula Ha : e = ea dentro del sistema de hipótesis
Ha : e = ea frente a
HI : e -¡. ea.
Si no es así, desarrolle un test utilizando otros medios para el juzgamiento de la hipótesis nula en el citado sistema.
14. Si Xl, X2, ... , X n es una muestra aleatoria de una población con función de densidad Uniforme en el intervalo (e, e + 1), con

284 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
() E lR, determine un test para el juzgamiento de la hipótesis nula Ho : () = O dentro del sistema de hipótesis
Ho : () = O
frente a
HI : () > O.
15. Si Xl, X 2 , . .. ,Xn es una muestra aleatoria de una población con función de densidad fx(x,()) = ()exp(-()x)I(o,oo)(x), determine la función de potencia de un test para el juzgamiento de la hipótesis nula Ho : () = 1 dentro del sistema de hipótesis
Ho : () = 1
frente a
HI : () -=1- 1.
16. Determine la función de potencia del test correspondiente al juzgamiento de la hipótesis nula Ho : J..lI - J..l2 ::; 60 dentro del sistema de hipótesis
Ho : J..lI - J..l2 ::; 60
frente a
HI : J..lI - J..l2 > 60,
bajo Normalidad, y con base en dos muestras seleccionadas de dos poblaciones independientes y homoscedásticas. Exprese esa función de potencia en términos de 60.
17. Si (Xl, YI ), (X2 , Y2 ), . .. , (Xn , Yn ) es una muestra aleatoria de una población Normal bivariada, determine un test para el juzgamiento de la hipótesis nula Ho : p = O dentro del sistema de hipótesis
Ho: p = O
frente a
HI : P -=1- o.
18. La contaminación de los ríos es un desastre para la humanidad. El río Bogotá recibe en casi todo su recorrido desechos que trastornan

4.11. EJERCICIOS 285
extraordinariamente la vida del río. Si una autoridad de salud pública tiene que evaluar el nivel de contaminación del río en un punto especial y tomar decisiones al respecto, y particularmente sobre el contenido promedio de plomo J..L, que no debe exceder J..Lo partes por millón por litro de agua, decisión que debe tomarse a través de un test estadístico basado en una muestra de tamaño n, lleve a cabo una reflexión sobre los valores del error del tipo 1 que deben adoptarse.
19. Muestre que la función de potencia del test Te, correspondiente al sistema e para el juzgamiento de la hipótesis nula Ho : () = J..Lo bajo Normalidad y adoptando el primer supuesto, presentada en la sección 4.3.1, página 218, cumple las siguientes propiedades:
a. 1f Te (()) es simétrica respecto a J..Lo.
b. 1fTJ()) es decreciente en el intervalo (-00, J..Lo) Y creciente en el intervalo (J..LO, 00 ).
c. lim 1fTc (()) = 1 Y lim 1fTJ()) = 1. (}->-oo (}->oo
d. 1fTe (J..Lo) = a.
20. Desarrolle un test de nivel a para el juzgamiento de la hipótesis nula Ho : () <:::: J..Lo frente a la hipótesis alterna H1 : () > J..Lo bajo Normalidad y conocido el valor de (J. Muestre que la función de potencia del test es
función que cumple las siguientes propiedades:
a. 1fT (()) es creciente.
b. lim 1fT (()) = O Y lim 1fT (()) = 1. (}->-oo (}->oo
C. 1fT (J..Lo) = a.
21. Muestre que la expresión algebraica que permite el cálculo del valor p al utilizar el test Te en el juzgamiento de la hipótesis nula Ho : J..L = J..Lo frente a la hipótesis alterna Hl : J..L i- J..Lo, bajo N ormalidad asumiendo el segundo supuesto, es

286 CAPÍTULO 4. JUZGAMIENTO DE HIPÓTESIS
siendo F(n-I)(X) la función de distribución de una variable aleatoria X, con distribución t con (n - 1) grados de libertad.
22. Muestre que la expresión algebraica de la función de potencia al utilizar el test Te para juzgar la hipótesis nula Ho : a2 = a5 frente a la hipótesis alterna H 1 : (]"2 i= (]"5, bajo Normalidad asumiendo desconocido el valor del promedio poblacional y eligiendo los valores E = Ó = ~ es
2 (a5xL9.(n -1)) (a5X~(n -1)) 'lfTC(a) = 1-F(n-I) ~2 +F(n-I) 2a2
siendo F(n-I) (x) la función de distribución de una variable aleatoria X, con distribución Ji-cuadrado con (n -1) grados de libertad. Deduzca las propiedades de esta función de potencia.
23. Respecto al ejercicio 22, determine la expresión para el cálculo del correspondiente valor p.
24. Muestre que la expresión algebraica de la función de potencia, al utilizar el test T para juzgar la hipótesis nula Ho : a2 'S a5 frente a la hipótesis alterna Ho : a2 > a5, bajo Normalidad asumiendo desconocido el valor promedio poblacional es
2 ao 2 (
2 ) 'lfT(a ) = 1 - F(n-.I) a2X1 - O,(n - 1)
siendo F(n-I) (x) la función de distribución de una variable aleatoria X, con distribución Ji-cuadrado con (n - 1) grados de libertad. Deduzca las propiedades de esta función de potencia.
25. Respecto al ejercicio 24, determine la expresión para el cálculo del correspondiente valor p.
26. Se cuenta con recursos económicos únicamente para seleccionar N = n + m unidades estadísticas para el juzgamiento de la hipótesis nula Ho : J-LI = J-L2 concerniente a la "comparación de los promedios poblacionales" de dos poblaciones independientes regidas por el modelo gaussiano y conocidos los valores de ar y a~, frente a la hipótesis alterna HI : J-LI i= J-L2. ¿Cómo deben elegirse los tamaños de las muestras n y m para mantener las características del test desarrollado para el mencionado juzgamiento?

4.11. EJERCICIOS 287
27. Desarrolle un test para el juzgamiento de la hipótesis nula Ho : til = 2ti2 bajo la regencia del modelo gaussiano correspondiente a dos poblaciones independientes de las cuales se conocen los valores de (TI y (T§, frente a la hipótesis alterna Hl : f1l i= 2f12.
28. ¿Existe algún impedimento en el desarrollo de un test para el juzgamiento de una hipótesis nula más general, que la del ejercicio 27, Ho : f1l = Cf12, siendo C > O una constante conocida?
29. Determine un test secuencial para el juzgamiento de la hipótesis nula Ho : e = eo, en el sistema de hipótesis simples
Ho: e = eo frente a
Hl : e = el,
basado en una muestra aleatoria de una población con distribución de Poisson de parámetro e.
30. Si Xl, X2, . .. , X n es una muestra aleatoria de una población con distribución Beta con el = e2 = e, determine un test más potente para el juzgamiento de la hipótesis nula Ho : e = 1, dentro del sistema de hipótesis
Ho: e = 1
frente a
Hl : e = 2.
31. Dentro del sistema de hipótesis del ejercicio 30, determine un test más potente para juzgar la hipótesis nula Ho : e = 1 si el modelo asumido es un modelo cuya función de densidad es
fx(x,e) = eXB-lI(o,l)(X), e> O.
32. Teniendo en cuenta el ejercicio 31, muestre que el test uniforme más potente para juzgar la hipótesis nula dentro del sistema
Ho: e = 1
frente a
Hl : e < 1
está basado en una estadística suficiente para e.

288 CAPÍTULO 4. JUZGA MIENTO DE HIPÓTESIS
33. En un estudio de opinión se realizaron 6.348 llamadas telefónicas y la firma encuestadora informa que el 25% de las llamadas fueron fallidas y, por tanto, los resultados se refieren a las entrevistas realizadas a personas mayores de 18 años correspondiente al restante porcentaje. El auditor estadístico considera que el porcentaje de no respuesta está muy elevado, y propone juzgar la afirmación de la compañía por medio de una muestra seleccionada de los registros de las llamadas realizadas por los entrevistadores para comprobar la no respuesta. Puede entonces asumirse el modelo Bernoulli con parámetro (), y juzgar la hipótesis nula Ho : () = ~, dentro del sistema de hipótesis
1 Ho : () = -
4 frente a
1 HI : () < :;¡-.
Determine un test que permita el juzgamiento de esta hipótesis.
34. Si Xl, X 2 , . .. ,Xn es una muestra aleatoria de una población con distribución gaussiana de valor esperado cero y varianza (), ¿existe un test uniforme más potente para juzgar la hipótesis nula Ho : () = ()o, frente a la hipótesis alterna HI : () "1= ()o?

Bibliografía
[1] Arthanari, T. S. and Yadolah Dodge (1981). Mathematical Programming in statistics. New York: John Wiley.
[2] Ash B. Robert (1970). Basic Probability Theory. New York: John Wiley & Sons, Inc.
[3] Barndorff-Nielsen (1978). Ole Information and Exponential Families: in Statistical Theory. New York: John Wiley.
[4] Barnett, Victor David (1975) Comparative Statistical Inference. London : Jo1m Wiley.
[5] Bartoszynski, Robert and Niewiadomska-Bugaj, Magdalena (1996). Probability and Statistical Inference. New York: John Wiley.
[6] Beard, Robert Eric; Pentikainen, T. and Pesonen E. (1984) Risk Theory: the Stochastics Basis of Insurance. 3rd ed. London: Chapman and Hall.
[7] Berger, James O. (1985). Statistical Decision Theory and Bayesian Analysis. second ed. New York: Springer-Verlag.
[8] Bernardo, José Miguel and Smith, Andrain F. M. (1994). Bayesian Theory. New York: John Wiley.
[9] Brunk, H. D. (1965). An Introduction to Mathematical Statistics. 2nd ed. Waltham, Mass: Blaisdell.
[10] Cramer, Harald (1960). Métodos matemáticos de estadística. Madrid: Aguilar.
289

290 BIBLIOGRAFÍA
[11] Cramer, Harald (1972). Elementos de la teoría de probabilidades y algunas de sus aplicaciones. Traducción de Anselmo Calleja. 6a ed. Madrid: Aguilar.
[12] Daykin, Chris D.; Pentikainen, T. and Pesonen M. (1944). Pmctical Risk Theory for Actuaries. New York: Chapman and Hall.
[13] De Groot, Morris (1988). Probabilidad y estadística. Wilmington: Addison-Wesley Iberoamericana.
[14] Dorea, Chang Chung Yu (1995). Teoria assintotica das estatisticas. Rio de Janeiro: Instituto de Matematica Pura e Aplicada.
[15] Dudewics Edward J. and Mishra Satya N. (1998). Modem Mathematical Statistics. New York: John Willey.
[16] Edwards, Anthony William Fairbank (1972). Likelihood: an Account of the Statistical Concept of Likelihood and its Application to Scientific Inference. Cambridge: Cambridge University Press.
[17] Ekeblad, Frederick A. (1962). The Statistical Method in Business, Applications of Probability and Inference of Business and Other Problems. New York: John Wiley.
[18] EIlis, Richard B. (1975). Statisticallnference: Basic Concepts. Englewood Cliffs: Prentice-Hall.
[19] Feller, William (1968). An Introduction to Probability Theory and its Applications. 3rd ed. New York: John Wiley.
[20] Fisz, Marek (1967). Probability Theory and Mathematical Statistics. 3a ed. New York: John Wiley.
[21] Freund, John E. (1962). Mathematical Statistics. Englewood Cliffs: Prentice-Hall.
[22] Freeman, Harold (1963). Introduction to Statistical Inference. Reading, Mass.: Addison-Wesley.
[23] Guenther, William C. (1965). Concepts of Statistical Inference. New York: McGraw-Hill.
[24] Gmurman, Vladimir Efimovich (1974). Teoría de las probabilidades y estadística matemática. Traducción de Akp Grdian. Moscú: Mir.

BIBLIOGRAFÍA 291
[25] Gmurman, Vladimir Efimovich (1975). Problemas de la teoría de las probabilidades y de estadística matemática. Traducción de Akp Grdian. Moscú: Mir.
[26] Hacking, Ian (1987). The Emergence of Probability: a Philosophical Study of Early Ideas about Probability, Induction and Statistical Infercncc. Cambridge: Cambridge University Press.
[27] Hettmansperger, Thomas P. (1984). Statistical Inference Based on Ranks. New York: John Wiley.
[28] Hoel Paul G. (1954). Introduction to Mathematical Statistics. 2nd
ed. New York: John Wiley.
[29] Hogg, Robert V. and Craig, Allen T. (1995). Introduction to Mathematical Statistics. 5a ed. Prentice Hall.
[30] Keeping E. S. (1962). Introduction to Statistical Inference. New York: D. Van Nostrand.
[31] Larson, Harold J. (1974). Introduction to Probability Theory and Statistical Inference. New York: John Wiley.
[32] Lehmann, Erich Leo (1983). Theory of Point Estimation. New York: John Wilcy.
[33] Mood, Alexaneler McFarlane; Graybill, Franklin A. anel Boes, Duane C. (1974). Introd7Lction to the Theory of Statistics. 3rd eel. International eel. Sigapore: McGraw-Hill.
[34] Muirhead, Robb John (1982). Aspects of M7Lltivariate Statistical Theory. New York: John Wiley.
[35] Parzen, Emanucl (1971). Modern Probability Theory and its Applications. New York: John Wiley.
[36] Randles, Ronald H. and Wolfe, Douglas A. (1979). Introduction to the Theory of Nonpammetric Statistics. New York: John Wiley.
[37] Rohatgi, Vijak K. (1984). Statistical Inference. New York: John Wiley.
[38] SerfEng, Robert J. (1980). Approximation Theorems of Mathematical Statistic8. New York: John Wiley.

292 BIBLIOGRAFÍA
[39] Tanner, Martin Abba (1993). Tools for Statistical lnference: Methods for the Exploration of Posterior Distributions and Likelihood Functions. 2nd ed. New York: Springer-Verlag.
[40] Tennant-Smith. J. (1986). Estadística: teoría, problemas y aplicaciones en BASle. Traducción de Manuel Urrutia Avisrror. Madrid: Anaya Multimedia.
[41] Thomasian, Aram J. (1969). The Structure of Probability Theory with Applications. New York: McGraw-Hill.
[42] Tucker, Howard G. (1967). An lntroduction to Probability and Mathematical Statistics. New York: Academic Press.
[43] Weatherburn, C. E. (1962). A First Course in Mathematical Statistics. 2nd ed. Cambridge: Cambridge University Press.
[44] Wilks, S. S. (1950). Mathematical Statistics. Princeton: Princeton U niversity Press.
[45] Zacks, Shelemyahu (1971). The Theory of Statistical lnference. New York: Wiley.

, Indice de Materias
análisis de varianza a una vía, 233
Basu teorema de, 107
Behrens-Fisher problema de, 232
bondad del ajuste, 262
caso regular de estimación, 112
completez, 116 componente
de escala, 155 de localización, 155
concentración, 90 condiciones de regularidad
cumplimiento de, 112 confianza, 148 consistencia, 94 contorno, 96 convergenCIa
casi segura, 13 con probabilidad uno, 13 débil, 14 en distribución, 15 en media cuadrática, 14 en medida, 14 en momento de orden r, 14 en probabilidad, 13
293
en valor esperado, 14 estocástica, 14
cota de Cramer-Rao, 113
Cramer-Rao cota de, 113 desigualdad de, 112
criterios de exclusión, 6 de inclusión, 6
curva característica de operación,
198 CO del test, 198
desigualdad de Cramer-Rao, 112
distribución Beta, 135 de Cauchy, 281 de Gumbel, 138 de la función de distribución
empírica, 30 de la mediana muestral, 29 de Laplace, 138 de las estadísticas de orden,
27 de Pareto, 59, 136, 184 de Poisson, 137 de Zipf, 136 del rango, 29

294 ÍNDICE DE MATERIAS
del semirrango, 29 exponencial desplazada, 59 exponencial doble, 138 Gama, 137 gaussiana, 137 muestral, 12 normal bivariada, 162 original
de las observaciones, 12 reducida, 12 U niforme discreta, 146 Zeta, 136
eficiencia asintótica, 116 de un estimador, 115 relativa, 114
asintótica, 115 equivalencia, 107 error
cuadrático medio, 91 del tipo 1, 193 del tipo 11, 193 máximo admisible, 176
espacio de las observaciones, 96 del parámetro, 67
estadística, 9 auxiliar, 107
de primer orden, 107 completa, 11 7 contorno de la, 96 de orden, 25, 26 de Pearson, 264, 266 natural, 106
k-dimensional, 106 suficiente, 106
suficiente, 97, 98 minimal, 102
estadísticas conjuntamente suficientes, 100 equivalentes, 107
estimación, 10, 11 bayesiana, 84
por intervalo, 177 cuasi máximo-verosímil, 79 de la proporción poblacional,
161 en muestras censuradas, 77 máximo-verosímil, 69 por intervalo, 148
estimador, 11 asin tóticamen te
más concentrado, 95 asintóticamente insesgado, 92 BAN,95 bayesiano, 86 BLUE, 141 BRUE, 115 CAN,95 CANE,95 consistente
débil, 94 en error cuadrático medio,
94 simple, 94
de mínimos cuadrados, 126 eficiencia de un, 115 eficiente, 115 el más concentrado, 90 insesgado, 91 insesgado de varianza uniforme-
mente mínima, 109 L,125 M,125 más concentrado, 90 máximo-verosímil, 69

ÍNDICE DE MATERIAS 295
MLE,69 Pitman
el más concentrado, 91 más concentrado, 90
QMLE,79 robusto, 123 UMVUE,109 uniformemente
mejor, 109 estimar, 10
familia de densidades
cerrada bajo muestreo, 86 completa, 116 conjugada, 86
de densidades pearsoniana, 103
exponencial
Fisher
de densidades k-paramétrica, 104
p-dimensional de densidades, 104
unidimensional de densidades, 104
información de, 111 Fisher -N eyman
criterio de factorización de, 98, 100
función crítica
del test aleatorizado, 191 del test no aleatorizado, 194
de cuasi verosimilitud, 79 de densidad
a posteriori, 85 a priori, 84
de distribución
empírica, 26 muestral, 26
de potencia, 198 de verosimilitud, 68
de la muestra, 68
G livenko-Cantelli teorema de, 30
hipótesis alterna, 189 compuesta, 189 estadística, 189
juzgamiento de una, 189 nula, 189 simple, 189 sistema de, 189
homoscedasticidad, 229, 231 juzgamiento de la, 240
información de Fisher, 111
intervalo aleatorio, 148 bayesiano, 177 confidencial, 148
unilateral, 149
juzgamiento del ajuste, 261
método de Kolmogorov-Smirno1
268 método de Pearson, 262
secuencial, 252
Khintchine, teorema de, 19 Kolmogorov-Smirnov
juzgamiento del ajuste, método de, 268
Koopman-Darmois

296 ÍNDICE DE MATERIAS
familia o clase p-dimensional, 104
Lehmann-Scheffé teorema de, 119
Lévy, teorema de, 15 Ley
débil de los grandes números, 19
fuerte de los grandes números, 20
límite central
Lindeberg-Feller, teorema del,21
Lindeberg-Lévy, teorema del, 21
confidencial inferior, 148 inferior unilateral, 149 superior, 148 superior unilateral, 149
máximo de la muestra, 26
mediana muestral, 26 poblacional, 34
método de la variable pivote, 149 de los momentos, 79 de máxima verosimilitud, 68 por analogía, 83
mínimo de la muestra, 26
modelo, 7, 65, 271 Beta, 135 de Pareto, 59, 135 de Poisson, 136
exponencial desplazado, 59 Gama, 137 gaussiano, 137 original, 12 probabilístico, 65 reducido, 12 Zeta, 136
momentos de estadísticas de orden, 31 muestrales
centrales, 12 ordinarios, 12
muestra, 6 aleatoria, 7
bivariada, 162 ordenada, 26
censurada, 77 del tipo 1, 77 del tipo II, 77 estimación en, 77
pareada, 162 piloto, 176 proporción en la, 22 simple
tamaño de la, 175 tamaño, 8 tamaño de la, 249
N eyman Pearson lema de, 202
nivel confidencial, 148 del test, 194
Normal bivariada, 162
parámetro, 9 de escala, 155 de localización, 155

ÍNDICE DE MATERIAS 297
natural, 106 Pearson
estadística de, 264, 266 juzgamiento del ajuste, método
de, 262 población, 6 principio
de invarianza de un MLE, 76
probabilidad de error del tipo 1, 194
procedimiento robusto, 123
promedio de la muestra, 12 muestral, 12 poblacional, 18, 37 recortado, 125 windsordizado, 125
proporción muestral, 22, 73 poblacional, 22, 160
estimación de la, 161 pruebas de Normalidad, 262
rango muestral, 26 Rao- Blackwell, teorema de, 109 razón
generalizada de verosimilitudes, 204
MLR, 212 monótona rk verosimilitudes
212 '
región confidencial, 149 crítica, 191
tamaüo de la, 194 de aceptación, 191 de rechazo, 191
robustez, 123
semirrango muestral, 26 sesgo del estimador, 91 suficiencia, 96
tamaüo de la muestra, 8, 249 de la muestra simple, 175 de la región crítica, 194 del test, 194 muestral, 8
test, 191 aleatorizado, 191
función crítica del, 191 consistente, 201 curva CO del, 198 de razón generalizada de ve
rosimilitudes, 207 de razón simple de verosimi-
litudes, 202 insesgado, 200 LRT, 207 más potente, 201 nivel del, 194 no aleatorizado, 191
función crítica del, 194 secuencial
de razón de verosimilitu-des, 253
tamaño del, 194 UMP, 210 uniformemente más potente,
210
unidades estadísticas, 6
valor p, 215 variable
pivote, 150

298
general, 153 método de la, 149
variable aleatoria contaminada, 124 pivote, 150
varianza mínima, 108 muestral, 12 poblacional, 18, 37
Wald, ecuación de, 258 Welch, solución de, 232
ÍNDICE DE MATERIAS

Inferencia estadística SE TERMINÓ DE IMPRIMIR
EN BOGOTÁ EL MES DE
JULIO DE 2004 EN LAS
PRENSAS EDITORIALES DE
UNIBIBLOS, UNIVERSIDAD
NACIONAL DE COLOMBIA

