understanding expert ratings of essay quality: coh-metrix analyses
TRANSCRIPT

170 Int. J. Cont. Engineering Education and Life-Long Learning, Vol. 21, Nos. 2/3, 2011
Copyright © 2011 Inderscience Enterprises Ltd.
Understanding expert ratings of essay quality: Coh-Metrix analyses of first and second language writing
Scott A. Crossley* Department of Applied Linguistics, Georgia State University, 34 Peachtree St. Suite 1200, One Park Tower Building, Atlanta, GA 30303, USA E-mail: [email protected]
Danielle S. McNamara Psychology/Institute for Intelligent Systems, University of Memphis, Memphis, TN 38152, USA E-mail: [email protected]
Abstract: This article reviews recent studies in which human judgements of essay quality are assessed using Coh-Metrix, an automated text analysis tool. The goal of these studies is to better understand the relationship between linguistic features of essays and human judgements of writing quality. Coh-Metrix reports on a wide range of linguistic features, affording analyses of writing at various levels of text structure, including surface, text-base, and situation model levels. Recent studies have examined linguistic features of essay quality related to co-reference, connectives, syntactic complexity, lexical diversity, spatiality, temporality, and lexical characteristics. These studies have analysed essays written by both first language and second language writers. The results support the notion that human judgements of essay quality are best predicted by linguistic indices that correlate with measures of language sophistication such as lexical diversity, word frequency, and syntactic complexity. In contrast, human judgements of essay quality are not strongly predicted by linguistic indices related to cohesion. Overall, the studies portray high quality writing as containing more complex language that may not facilitate text comprehension.
Keywords: writing assessment; cohesion; essay quality; lexical development; syntactic development; computational linguistics.
Reference to this paper should be made as follows: Crossley, S.A. and McNamara, D.S. (2011) ‘Understanding expert ratings of essay quality: Coh-Metrix analyses of first and second language writing’, Int. J. Continuing Engineering Education and Life-Long Learning, Vol. 21, Nos. 2/3, pp.170–191.
Biographical notes: Scott A. Crossley is an Assistant Professor at Georgia State University. His interests include computational linguistics, corpus linguistics, and second language acquisition. He has published articles in second language lexical acquisition, multi-dimensional analysis, discourse processing, speech act classification, cognitive science, and text linguistics.

Understanding expert ratings of essay quality 171
Danielle S. McNamara is a Professor at the University of Memphis and the Director of the Institute for Intelligent Systems. Her work involves the theoretical study of cognitive processes as well as the application of cognitive principles to educational practice. Her current research ranges a variety of topics including text comprehension, writing strategies, building tutoring technologies, and developing natural language algorithms.
1 Introduction
The quality of a writing sample rests in the judgements made by the reader. In most cases, trained readers assess writing quality and the value they assign to that writing can have important consequences to the writer. Such consequences are especially evident in the values attributed to writing samples used in student evaluations (i.e., class assignments) and high stakes testing such as the scholastic aptitude test (SAT), the test of English as Foreign language (TOEFL), and the graduate record examination (GRE).
Our goal is to better understand how the linguistic features present in writing samples help explain human judgements of text quality for both first language (L1) and second language (L2) writers of English. We focus not only on holistic essay scores, but also on human scores of analytic text features (e.g., strength of thesis statement, continuity, reader orientation, relevance, conclusion strength, and mechanics). Understanding the textual features that underlie text quality can assist in understanding the linguistic processes involved in essay rating as well as help improve the type of feedback that writers receive (be it through teacher consultation or computer mediated feedback).
In this paper, we report on a series of studies that compare computational indices taken from the computational tool Coh-Metrix (Graesser et al., 2004; Graesser and McNamara, in press; McNamara and Graesser, in press) to human judgements of text quality. The automated indices reported by Coh-Metrix relate to broadly to lexical sophistication, syntactic complexity, and text cohesion. The results from these studies indicate that human judgements of text quality are best predicted by linguistic indices that correlate with measures of language sophistication such as lexical diversity, word frequency, and syntactic complexity. By contrast, human judgements of text quality are not strongly predicted by linguistic indices related to cohesion or models of text comprehension; however, human analytic scores of coherence are important predictors of overall essay quality. Broadly speaking, the studies reported in this paper portray high quality writing as containing more complex language that may not facilitate reading rate or text comprehension.
1.1 Writing development
Writing development is an important element of a student’s educational career and a major component of high-stakes tests, which require higher order writing skills (Jenkins et al., 2004). Students who fail to develop appropriate writing skills in school may not be able to articulate ideas, argue opinions, and synthesise multiple perspectives, all skills essential to communicating persuasively with others, including peers, teachers,

172 S.A. Crossley and D.S. McNamara
co-workers, and the community at large (Connor, 1987; Crowhurst, 1990; National Commission on Writing, 2004).
The majority of research that focuses on writing skills generally investigates cognitive and behavioural processes that occur during writing such as planning, translating, reviewing, and revising (Abbott et al., 2010). That is to say, most writing assessment research centres on the process of writing and not the product of writing (Abbott and Berninger, 1993). As an exception, the written product is of greater interest for researchers who focus on neurodevelopmental or linguistic processes (Berninger et al., 1991). Neurodevelopmental processes include the coding of orthographic information, finger movements, and the production of letters (Abbott et al., 2010). Linguistic processes include linguistic knowledge at the word, syntactic, and discourse levels (Berninger et al., 1992).
Neurodevelopmental processes are generally acquired by the end of childhood (Abbott et al., 2010), whereas linguistic processes continue to develop at most stages of writing development (Berninger et al., 1992). While children are acquiring neurodevelopmental processes, they also begin to master basic grammar, sentence structure, and even discourse devices. For instance, studies have shown that as early as the second grade, writers begin developing more cohesive writing through the use of linguistic connections such as referential pronouns and connectives (King and Rentel, 1979). The increased use of such cohesive cues related to local coherence continues until around the eighth grade (McCutchen and Perfetti, 1982). Such trends demonstrate that eighth grade essays contain more local coherence (i.e., connectives) between sentences than sixth grade essays (McCutchen, 1986). At a later stage, generally in older children who are able to write more coherent texts, we see the development of more complex syntactic constructions (McCutchen and Perfetti, 1982) and the use of cognitive strategies such as planning and revising (Abbott et al., 2010; Berninger et al., 1991). Development in sentence level processing and the use of cognitive strategies continue to be important factors in writing development until college and after (Berninger et al., 2010).
Studies examining L2 writers also provide important information about writing development and its related linguistic processes. Unlike writing research in L1 writers, a considerable amount of research has been conducted on the role of linguistic features in L2 writing proficiency. This research has traditionally investigated the potential for linguistic features such as lexical diversity, word repetition, word frequency, and cohesive devices to distinguish differences among L2 writing proficiency levels (e.g., Connor, 1990; Engber, 1995; Ferris, 1994; Frase et al., 1999; Jarvis, 2002; Jarvis et al., 2003; Reid, 1986, 1990; Reppen, 1994). However, the dependency on such surface level variables has made it difficult to coherently understand the linguistic features that characterise L2 writing (Jarvis et al., 2003).
Lexically, studies looking at linguistic development in L2 writers have demonstrated that higher rated essays contain more words with more letters or syllables (Frase et al., 1999; Grant and Ginther, 2000; Reid, 1986, 1990; Reppen, 1994). Syntactically, L2 essays that are rated as higher quality include more surface code measures such as subordination (Grant and Ginther, 2000) and instances of passive voice (Connor, 1990; Ferris, 1994; Grant and Ginther, 2000). Additionally, such essays contain more instances of nominalisations, prepositions (Connor, 1990), pronouns (Reid, 1992) and fewer present tense forms (Reppen, 1994). From a cohesion perspective, most studies have examined the production of explicit devices such as connectives. Jin (2001), for example, found that advanced Chinese graduate students writing in English produced more

Understanding expert ratings of essay quality 173
connectives than did intermediate Chinese graduate students. Similarly, Connor (1990) found that higher proficiency L2 writers used more connectives. Overall, studies examining differences in L2 writing proficiency demonstrate that linguistic variables related to cohesion and linguistic sophistication can be used to distinguish high and low proficiency essays.
1.2 Text comprehension
An important element of writing is the relationship between text production and text comprehension. Since our interest lies in investigating the effects of linguistic features on reader judgements of quality, it is important to discuss how linguistic features interact with text comprehension. Successful text comprehension is a multilevel process that depends first and foremost on word identification (i.e., decoding; Perfetti et al., 2005b). Texts with less frequent words and a greater variety of words are more difficult to process, especially for less skilled readers and, thus, increase comprehension challenges for the reader. For instance, words that are less frequent and thereby less likely to be encountered by readers, have longer eye fixation times, and are more difficult to decode (Just and Carpenter, 1987). In contrast, frequent words are processed more quickly and better understood (Haberlandt and Graesser, 1985). Once the reader has identified a word (or a group of words) and its meaning, the reader must link that word to previous words in order to develop deeper level concepts. The process of linking words together into meaningful phrases and constituents is known as syntactic parsing. Once words are parsed together into units, the reader can begin to determine relations between the words and organise the words into concepts (Just and Carpenter, 1987; Raynor and Pollatsek, 1994). If the syntax of a sentence is complex, higher demands are placed on working memory processing, especially for less skilled readers (Just and Carpenter, 1992). These higher demands occur because less skilled readers cannot immediately construct the appropriate syntactic structures (Raynor and Pollatsek, 1994). However, skilled readers process complex syntax and less frequent words more quickly than less skilled readers, and assumedly are more familiar with a greater range of syntactic structures and words (Just and Carpenter, 1992; Raynor and Pollatsek, 1994).
Once the reader has developed meaningful phrases, connections need to be made between these discourse constituents at the sentence level, paragraph level, and text level in order to develop a coherent mental representation of the text (Graesser et al., 2003). These connections are generally strengthened by the presence of cohesive devices that maintain links among textual elements and develop coherence in the mind of the readers. It has generally been thought that essay quality is highly related to cohesion in that cohesive devices in essays help build coherent textual representations. This is reflected in the literature about writing (e.g., Collins, 1998; DeVillez, 2003), as well as textbooks that teach students how to write (Golightly and Sanders, 1997). However, there have been few studies that have empirically investigated the role of cohesive devices and, by proxy, coherence, in essays. Cohesive devices include local linguistic elements (defined as explicit markers of coherence) taken from Halliday and Hasan’s (1976) research on cohesion (e.g., reference, substitution, ellipsis, conjunction, repetition, and anaphora) as well as more global measures (implicit markers of coherence) such as causal relationships (Graesser et al., 2004) and semantic similarity (Foltz, 2007). These linguistic features are important in connecting ideas to other ideas in order to develop a continuous theme as well as connect ideas with topics (Gumperz et al., 1984; Graesser et al., 2004). Previous

174 S.A. Crossley and D.S. McNamara
studies have demonstrated that the presence of such cohesive devices in text improves text comprehension (Gernsbacher, 1990), especially for low-knowledge readers (McNamara et al., 1996). However, whether these cohesive devices facilitate comprehension also depends on the needs of the reader. Indeed, there seems to be an advantage for low cohesion texts in aiding text comprehension for high-knowledge readers (McNamara, 2001; McNamara et al., 1996; O’Reilly and McNamara, 2007). This ‘reverse cohesion effect’ is premised on the notion that high-knowledge readers, unlike low-knowledge readers, can successfully make the inferences needed to bridge the conceptual gaps that are in low-cohesion text. In fact, high-knowledge readers may benefit from low cohesion texts because gaps in cohesion force the reader to make connections in text that are not explicitly available (McNamara, 2001; O’Reilly and McNamara, 2007). Thus, cohesion cues may be unnecessary, and potentially distracting when the material covered in a text is familiar to the reader. In general, then, cohesion may play an important role in facilitating coherence and, as a result, text comprehension, for low knowledge readers, but cohesion may be inversely related to text comprehension for high knowledge readers.
We are left, then, with conflicting perspectives on the role of linguistic features and the evaluation of essay quality on the part of expert raters. On one hand, features of writing associated with language sophistication may surpass features of writing that facilitate processing, such as higher cohesion and less complex linguistic features. If so, then higher judgements of essays quality on the part of expert readers would be characterised by more complex sentences, less frequent words, and fewer cohesive devices. The opposite of this perspective involves increased cohesion and less linguistic sophistication facilitating the reading process and, as a result, increasing judgements of essay quality. If this hypothesis held true, then the opposite pattern would be expected (that essay quality will improve as text cohesion and linguistic features related to text comprehension increase).
1.3 Automatic free-text assessment
Recent advances in various disciplines such as computational linguistics, discourse processing, and information retrieval have made it possible to computationally investigate measures of text and language comprehension that are important for understanding the textual effects of cohesion and linguistic sophistication. Together, these advances allow for the analysis of many surface and deep level factors of lexical sophistication, syntactic complexity, and text cohesion to be automated, affording accurate and detailed analyses of language to take place. The tool that perhaps best represents the synthesis of these advances is Coh-Metrix (Graesser et al., 2004; Graesser and McNamara, in press; McNamara and Graesser, in press). Coh-Metrix measures text difficulty and cohesion through the integration of lexicons, pattern classifiers, part-of-speech taggers, syntactic parsers, shallow semantic interpreters, and other components that have been developed in the field of computational linguistics (Jurafsky and Martin, 2008). Coh-Metrix analyses text on several dimensions of lexical cohesion including co-referential cohesion, causal cohesion, density of connectives, temporal cohesion, spatial cohesion, and latent semantic analysis (LSA). Coh-Metrix also reports on a variety of lexical indices related to sophistication such as psycholinguistic information about words (word concreteness, imagability, meaningfulness, and familiarity scores from the MRC psycholinguistic database; Coltheart, 1981), semantic

Understanding expert ratings of essay quality 175
features of words along with semantic relations between words (word polysemy and hypernymy values taken from WordNet; Miller et al., 1990), word frequency indices (taken from the CELEX database), and a variety of lexical diversity indices (McCarthy and Jarvis, 2010). Coh-Metrix also provides indices related to syntax using a parser based on Charniak (2000). A brief overview of the Coh-Metrix indices commonly used in studies regarding text quality and text comprehension is given below.
1.4 Cohesion indices in Coh-Metrix
• Causal cohesion. Causal cohesion is measured in Coh-Metrix by calculating the ratio of causal verbs to causal particles. The causal verb count is based on the number of main causal verbs identified through WordNet (Fellbaum, 1998; Miller et al., 1990). Causal cohesion is relevant to texts that depend on causal relations between events and actions. Causal cohesion also helps to create relationships between sentences or clauses (Pearson, 1974–1975).
• Connectives. Coh-Metrix assesses connectives on two dimensions. The first dimension contrasts positive versus negative connectives, whereas the second dimension is associated with particular classes of cohesion identified by Halliday and Hasan (1976) and Louwerse (2001). These connectives are associated with positive additive (also, moreover), negative additive (however, but), positive temporal (after, before), negative temporal (until), and causal (because, so) measures. Connectives play an important role in the creation of cohesive links between ideas and clauses (Crismore et al., 1993; Longo, 1994) and provide clues about text organisation (van de Kopple, 1985).
• Logical operators. The logical operators measured in Coh-Metrix include variants of or, and, not, and if-then combinations, all of which have been shown to relate directly to the density and abstractness of a text and correlate to higher demands on working memory (Costerman and Fayol, 1997).
• Lexical overlap. Coh-Metrix considers four forms of lexical overlap between sentences: noun overlap, argument overlap, stem overlap, and content word overlap. Noun overlap measures how often a common noun of the same form is shared between two sentences. Argument overlap measures how often two sentences share nouns with common stems (including pronouns), while stem overlap measures how often a noun in one sentence shares a common stem with other word types in another sentence (not including pronouns). Content word overlap refers to how often content words are shared between sentences (including pronouns). Lexical overlap has been shown to aid in text comprehension (Douglas, 1981; Kintsch and van Dijk, 1978; Rashotte and Torgesen, 1985).
• Semantic co-referentiality. Coh-Metrix measures semantic co-referentiality using LSA, a mathematical and statistical technique for representing deeper world knowledge based on large corpora of texts. LSA uses a general form of factor analysis to condense a large corpus of texts down to 300–500 dimensions. These dimensions represent how often a word occurs within a document (defined at the sentence level, the paragraph level, or in larger sections of texts) and each word, sentence, or text is represented by a weighted vector. The relationships between the

176 S.A. Crossley and D.S. McNamara
vectors form the basis for representing semantic similarity between words, an important indicator of cohesion (Landauer et al., 2007).
• Anaphoric reference. Coh-Metrix measures anaphoric links between sentences by comparing pronouns to previous references. For instance, if the current sentence contains a pronoun, Coh-Metrix calculates if previous sentences contain noun and pronoun references that agree in number (singular/plural), gender (male/female), and person (human/non-human) with the given pronoun. Anaphoric references are important indicators of text cohesion (Halliday and Hasan, 1976).
1.5 Lexical indices in Coh-Metrix
• Hypernymy. Coh-Metrix uses WordNet to report word hypernymy (i.e., word specificity). Coh-Metrix reports WordNet hypernymy values for all content words, nouns, and verbs on a normalised scale with 1 being the highest hypernym value and all related hyponym values increasing after that. Thus, a lower value reflects an overall use of less specific words, while a higher value reflects an overall use of more specific words.
• Polysemy. Coh-Metrix measures word polysemy (the number of senses a word has) through the WordNet computational, lexical database (Fellbaum, 1998). Coh-Metrix reports the mean WordNet polysemy values for all content words in a text. Word polysemy is indicative of text ambiguity.
• Lexical diversity. Lexical diversity indices generally measure the number of types (i.e., unique words occurring in the text) divided by tokens (i.e., all instances of words), forming an index that ranges from 0 to 1, where a higher number indicates greater diversity. Traditional indices of lexical diversity are highly correlated with text length and are not reliable across a corpus of texts where the token counts differ markedly. To address this problem, a wide range of more sophisticated approaches to measuring lexical diversity have been developed. Those reported by Coh-Metrix include the Measure of Textual Lexical Diversity (MTLD) (McCarthy and Jarvis, 2010) and D (Malvern et al., 2004). Lexical diversity indices relate to the number of words a writer knows.
• Word frequency. Word frequency indices measure how often particular words occur in the English language. The indices reported by Coh-Metrix are taken from CELEX (Baayen et al., 1995), a 17.9 million-word corpus. Word frequency is an important indicator of lexical knowledge.
• Word information measures. Coh-Metrix calculates word information indices from the MRC psycholinguistic database (Wilson, 1988). These indices include concreteness, familiarity, imagability, and meaningfulness. Words that reference an object, material, or person generally receive a higher concreteness score than an abstract word. More familiar words are more readily recognised, but not necessarily more frequent (compare eat to while). A highly imageable word such as cat evokes images easily and is thus scored more highly than a word such as however, which produces a mental image with difficulty. Words with high meaningfulness scores are highly associated with other words (e.g., people), whereas a low meaningfulness

Understanding expert ratings of essay quality 177
score indicates that the word is weakly associated with other words. All of these indices are important indicators of word knowledge.
1.6 Syntactic indices in Coh-Metrix
• Syntactic complexity. Syntactic complexity is measured by Coh-Metrix by calculating the mean number of words before the main verb, the mean number of high-level constituents (sentences and embedded sentence constituents) per word, and the average number of modifiers per noun phrase. Sentences with difficult syntactic constructions include the use of embedded constituents and are often structurally dense, syntactically ambiguous, or ungrammatical (Graesser et al., 2004). As a consequence, they are more difficult to process and comprehend (Perfetti et al., 2005a).
• Syntactic similarity. Coh-Metrix assesses syntactic similarity by measuring the uniformity and consistency of the syntactic constructions in the text. This index not only looks at syntactic similarity at the phrasal level, but also takes account of the parts of speech involved. More uniform syntactic constructions result in less complex syntax that is easier for the reader to process (Crossley et al., 2008).
2 Coh-Metrix and judgements of essay quality
The power of Coh-Metrix has afforded numerous recent investigations into the role of linguistic features and writing quality as function of expert reader evaluations. These investigations have generally examined argumentative essays written by native speakers and non-native speakers (NNSs) of English. The studies help to explain the role linguistic features play in text comprehension by high knowledge readers and how the presence of linguistic features affects holistic and analytic judgements of texts. Below, we provide an overview of these investigations and summarise their implications for judgements of writing quality and text comprehension.
2.1 Human judgements of essay quality (native speakers of English)
An initial study was conducted to investigate the linguistic features of text that were important in explaining essay quality as a function of human ratings (McNamara et al., 2010) for native speakers of English. Of particular interest in this study was an examination of the role cohesive devices and indices related to linguistic sophistication have in explaining human ratings of essay quality. McNamara et al. (2010) collected a corpus of 120, un-timed argumentative essays written by college freshmen at a large university. They had expert raters (college composition instructors with at least three years of teaching experience) evaluate the essays using a holistic scoring rubric taken from the SAT. McNamara et al. were interested in two aspects of quality. The first aspect was categorical quality (could Coh-Metrix indices successfully distinguish between high and low proficiency essays). The second aspect of quality was continuous (could Coh-Metrix indices predict variance in the essay grades). For the first type of quality, the essays were divided into high and low groupings based on a median split and a discriminant function analysis based on the Coh-Metrix indices was used to categorise

178 S.A. Crossley and D.S. McNamara
essays as high or low. For the second aspect of quality, McNamara et al. conducted a regression analysis using essay rating as the dependent variable and Coh-Metrix indices as the predictor variables to determine which linguistic features measured by Coh-Metrix were most predictive of essay ratings and accounted for the largest amount of variance associated with essay quality.
For both analyses, McNamara et al. (2010) used scores from a variety Coh-Metrix indices. The indices considered were from six classes: text information (e.g., number of words, number of paragraphs), co-reference (e.g., word and semantic overlap), connectives (e.g., positive logical connectives, logical operators, negative temporal connectives), syntactic complexity (e.g., number of words before the main verb, number of modifiers per noun phrase), lexical diversity (e.g., MTLD, M, D), word characteristics (e.g., word frequency, word hypernymy, word polysemy, word concreteness, word imagability). The initial analyses (ANOVAs and correlations) indicated that none of the co-reference or connective indices showed significant differences as a function of essay quality, nor were they significantly correlated with the essay scores. These results indicated that Coh-Metrix indices of cohesion (as measured by co-reference and the use of connectives) did not distinguish between the high and low quality essays.
However, the analysis did show that three linguistic indices related to lexical sophistication and syntactic complexity were predictive of essay quality. These indices were the number of words before the main verb, MTLD, and CELEX logarithm frequency including all words. Descriptive and ANOVA statistics for these variables are located in Table 1. Table 1 Descriptive and ANOVA statistics for the low and high proficiency essays reported in
McNamara et al. (2010)
Variables Low proficiency High proficiency F(1.78) 2ph
Syntactic complexity 4.06 (0.92) 4.89 (1.24) 11.87* 0.13 Lexical diversity 72.64 (10.89) 78.71 (13.19) 5.07** 0.06 Word frequency 3.17 (0.08) 3.13 (0.09) 4.64** 0.06
Note: *p < .001 and **p < .05.
When these three indices were included in a discriminant function analysis, the resulting algorithm correctly classified 52 of the 80 essays in a training set (df = 1, n = 80) χ2 = 7.16, p < .01) and 28 of the 40 essays in a test set (df = 1, n = 40) χ2 = 6.20, p < .05). Thus, these three variables were able to accurately classify 67% of the essays as being either low or high quality essays. A stepwise regression analysis also showed that the indices significantly predicted essay ratings, F(1, 118) = 15.85, p < .001, r = .47, r2 = .22, adjusted r2 = .20. CELEX word frequency was a significant predictor (t = –3.43, p < .001) and accounted for 7.9% of the variance. The number of words before the main verb was also a significant predictor (t = 3.84, p < .001) and accounted for 11.8% additional variance. MTLD was not a significant predictor (t = .19, p > .05), but accounted for 2.5% of the variance (see Table 7 for additional information).
Overall, the McNamara et al. (2010) study indicated that human judgements of essay quality are best predicted at the linguistic level by linguistic indices related to lexical sophistication (i.e., word frequency and lexical diversity) and syntactic complexity (i.e., the number of words before the main verb). Indices related to cohesion were not significant predictors of human judgements of essay quality.

Understanding expert ratings of essay quality 179
2.2 Human judgements of essay quality (non-native speakers of English)
The McNamara et al. (2010) study indicated that native speakers of English acting as expert raters likely relied on linguistic indices to inform their judgements of essay quality. Of interest are also the relationships between linguistic features and judgements of essay quality in reference to NNSs of English as reported by Crossley and McNamara (in press). A contrast between NSs and NNSs provides the opportunity to investigate if the findings reported by McNamara et al. (2010) generalise to other types of expert readers (i.e., NNSs).
Crossley and McNamara (2010) used a corpus of argumentative essays written by high school students taking the Hong Kong advanced level examination (HKALE). The essays were administered to senior high school students and were designed to assess students’ ability to understand and use English at the college level. The writing examination lasted for one hour and 15 minutes during which participants were expected to write a 500-word essay. The essays were graded by trained raters from the Hong Kong Examinations and Assessment Authority. The samples selected represented six of the seven grade levels assigned to HKALE (the grade of unclassifiable was left out). Thus, the grades ranged from A to F (including the grade of E). In this study, Crossley and McNamara controlled for the effects of text length by selecting only essays that had text lengths between 485 and 555 words. Table 2 Correlation between Coh-Metrix variables and essay grades from Crossley and
McNamara (in press)
Variable r value p value
D lexical diversity 0.426 < .001 Word familiarity –0.400 < .001 CELEX content word frequency –0.336 < .001 Content word overlap –0.279 < .001 LSA given/new –0.265 < .001 Incidence of positive logical connectives –0.227 < .001 Word concreteness –0.209 < .001 Word imagability –0.180 < .001 Word meaningfulness –0.176 < .001 Aspect repetition –0.163 < .050 LSA sentence to sentence –0.150 < .001 Number of motion verbs 0.124 < .050 Logical operators 0.122 < .050 Verb hypernymy 0.121 < .050
To determine which Coh-Metrix variables to use in the analysis, Crossley and McNamara (in press) conducted Pearson correlations comparing the human essay ratings to the reported Coh-Metrix indices. The selected variables, by strength of r value were D (lexical diversity), word familiarity, CELEX content word frequency, content word overlap, LSA given/new, incidence of positive logical connectors, word concreteness, word imagability, word meaningfulness, aspect repetition, LSA sentence to sentence score, number of motion verbs, logical operators, and verb hypernymy. No indices of

180 S.A. Crossley and D.S. McNamara
syntactic complexity significantly correlated to the human scores of essay quality. All indices of cohesion, except logical operators, which demonstrated a small effect size, were negatively correlated to human judgements of quality. This indicates that increased cohesion was characteristic of essays scored lower by NNSs. Results from the reported correlations are provided in Table 2.
Crossley and McNamara (in press) computed a linear regression analysis using the 12 selected variables to account for the variance in the raters’ evaluations for the 344 essays in the corpus. The regression yielded a significant model, F(5, 338) = 28.278, p < .001, r = .543, r2 = .295. Five variables were significant predictors in the regression: D (lexical diversity), word familiarity, CELEX content word frequency, word meaningfulness, and aspect repetition. Descriptive statistics for these five variables are provided in Table 3. The model for the test set yielded r = .454, r2 = .206. The model for the entire dataset yielded r = .509, r2 = .259. The results from the entire dataset model demonstrate that the combination of the five variables accounted for 26% of the variance in the evaluation of the 514 essays that comprised their L2 writing corpus. Table 3 Descriptive statistics (means and standard deviations) for variables from Crossley and
McNamara’s (in press) regression analysis
Assigned grade/rating Coh-Metrix index
A B C D E F
Lexical diversity D 109.667 (30.793)
82.881 (22.465)
83.048 (20.882)
77.172 (21.600)
71.50 (22.934)
60.307 (20.789)
CELEX content word frequency
1.116 (0.221)
1.180 (0.212)
1.237 (0.205)
1.277 (0.228)
1.329 (0.232)
1.356 (0.230)
Word meaningfulness 615.588 (44.612)
633.497 (41.203)
637.823 (44.998)
637.413 (40.788)
644.928 (42.990)
643.936 (43.242)
Average of word familiarity
592.453 (2.649)
594.727 (2.668)
594.493 (2.489)
594.670 (2.754)
596.201 (2.807)
596.796 (2.968)
Aspect repetition 0.921 (0.077)
0.923 (0.087)
0.945 (0.056)
0.948 (0.062)
0.950 (0.074)
0.954 (0.063)
Note: Standard deviations are in parentheses
The results of this analysis support the findings of McNamara et al. (2010) in that greater linguistic sophistication (in the form of greater lexical diversity, fewer familiar words, more infrequent words, and fewer meaningful words) characterised essays rated as higher quality by the expert L2 readers. Different from the McNamara et al. (2010) study was the inclusion of an index related to text cohesion (aspect repetition). However, this variable correlated negatively with human scores of essay quality indicating that the more cohesive essays, in terms of aspect repetition, were rated as lower quality.
2.3 Writing development as a function of grade level (L1 writers)
In addition to examining connections between essay scores and linguistic features in L2 texts, Crossley et al. (2010a) also conducted an analysis that examined differences in the production of linguistic features as a function of grade level. The purpose of this study was to examine linguistic differences in the writing samples of adolescents and young adult students at different grade levels to investigate whether writing styles changed in

Understanding expert ratings of essay quality 181
predictable patterns as writers developed proficiency. As in the previous studies, Crossley et al. were interested in linguistic development and conducted a variety of computational analyses using the computational tool Coh-Metrix on a corpus of scored essays. Unlike the McNamara et al. (2010) study, this analysis surveyed essays collected from three different groups of learners (ninth grade writers, 11th grade writers, and college freshman writers). The primary goals of the study were to connect increased writing proficiency with increased grade level, to test the model reported by McNamara et al. to predict the variance in the essays scores, and to examine linguistic differences among the essays as a function of grade level to investigate whether linguistic features other than those reported by McNamara et al. were important indicators of essay quality across grade levels.
All of the essays collected for this study were timed argumentative essays (25 minutes) and were written in response to prompts used in the SAT writing section. The ninth grade writers and college freshman were given a choice between two prompts. The 11th grade writers all wrote on the same prompt. There was no overlap in prompts within the groups. Crossley et al. (2010a) collected 62 essays from 62 ninth grade writers, 70 essays from 70 11th grade writers, and 70 essays from 70 college freshmen. The essays were collected from three different geographic areas. The ninth grade essays were collected from a suburban school district in upstate New York. The 11th grade essays were collected from a suburban school in Washington, DC. The college freshman essays were collected from students attending Mississippi State University. Thus, the Crossley et al. corpus differed from the corpus analysed in McNamara et al. (2010) because the essays were timed; the prompts were general knowledge; and students of varying grade levels wrote the essays. As in the McNamara et al. (2010) study, expert raters scored each essay using a holistic rubric used in SAT essay scoring.
Crossley et al. (2010a) first assessed differences in the quality of the essays among the grade levels by conducting an ANOVA comparing the human scores of essay quality. The ANOVA showed significant differences in human assessments of essay quality between the three levels of writers, F(2, 201) = 80.056, p < .001, h2 = .446. Essays written by ninth grade students received the lowest score (M = 1.653; SD = 0.766) followed by 11th grade essays (M = 2.979; SD = 1.133) and essays written by college freshmen (M = 3.757, SD = 0.924). To ensure that prompt differences did not affect holistic scoring, Crossley et al. also conducted t-tests between the holistic scores for each essay at the ninth grade and freshman level based on the essay prompt. These analyses demonstrated no significant differences between the holistic scores of the essays as a function of prompt. Overall, these analyses support the hypothesis that writing quality increases as a function of grade level.
Crossley et al. (2010a) next used the regression model reported by McNamara et al. (2010) to predict the amount of variance in the essays scores. The model yielded r = .442 and r2 = .196. Thus, the McNamara et al. (2010) model explained 20% of the variance found in the human scores of essay quality for the between grade levels corpus. This finding is similar to the findings of McNamara et al.’s study in which the model explained 22% of the variance in the test set of essays.
The primary goal of Crossley et al. (2010a) was to assess the strength of Coh-Metrix indices to classify essays based on grade level. To select indices from Coh-Metrix, ANOVAs were conducted to compare differences in various features as a function of grade level. The indices that reported the largest effect sizes were number of words, number of paragraphs, word concreteness, CELEX word frequency for all words, incidence of positive logical connectives, D (lexical diversity) average number of

182 S.A. Crossley and D.S. McNamara
modifiers per noun phrase (syntactic complexity), content word overlap, and average word polysemy. Descriptive and ANOVA statistics for these variables are located in Table 4. Ninth grade essays were characterised by less lexical sophistication and syntactic complexity, but greater cohesion (e.g., greater incidence of connectives and greater word overlap).
Table 4 Descriptive and ANOVA statistics for among grade levels analysis
9th grade
11th grade
College freshman f value p value 2
ph
Number of words 178.614 (83.339)
287.745 (92.623)
384.205 (117.251)
47.844 < .001 0.420
CELEX Word frequency all words 3.239 (0.087)
3.207 (0.104)
3.124 (0.083)
18.254 < .001 0.217
Incidence of positive logical connectives
45.267 (21.582)
25.912 (12.299)
30.113 (13.136)
17.844 < .001 0.213
Word concreteness content words 327.539 (17.930)
340.119 (18.820)
350.712 (18.148)
17.653 < .001 0.211
Lexical diversity D 55.114 (21.690)
73.234 (25.927)
86.318 (27.179)
17.207 < .001 0.207
Modifiers per noun phrase 0.583 (0.160)
0.690 (0.173)
0.764 (0.132)
14.922 < .001 0.184
Content word overlap 0.166 (0.071)
0.148 (0.046)
0.107 (0.045)
13.025 < .001 0.165
Word polysemy 4.562 (0.612)
4.402 (0.547)
4.074 (0.386)
9.891 < .001 0.130
Number of paragraphs 2.318 (1.459)
3.809 (1.227)
4.909 (4.724)
8.768 < .001 0.117
Source: Crossley et al. (2010a)
These indices were then used as variables in a discriminant function analysis (DFA) to classify the essays based on grade level. The DFA correctly allocated 95 of the 135 essays in a training set (df = 4, n = 135) χ2 = 95.325, p < .001) for an accuracy of 70.4%. The DFA correctly allocated 51 of the 67 essays (df = 4, n = 67) χ2 = 58.104, p < .001) in a test set for an accuracy of 76.1%. The results provide strong evidence that the linguistic features of writing can be used to classify essays in terms of the grade level of the writer.
Overall, this study demonstrated that linguistic differences at the text level, at the word level, at the syntactic level, and at the level of cohesion distinguish essays written at the ninth grade, 11th grade, and college level. The differences in grade level also reflect human judgements of essay quality in that significant score differences existed between the grade levels. Like the McNamara et al. (2010) and Crossley and McNamara (in press) studies, indices related to lexical sophistication and syntactic complexity were important predictors of writer development and essay quality as seen in increased sophistication and complexity as a function of grade level. Like the Crossley and McNamara (in press) study, this study also demonstrated that cohesive devices were important indicators of

Understanding expert ratings of essay quality 183
writing development and essay quality; however, an increased use of cohesive devices was characteristic of writing at lower grade levels.
2.4 Analytic evaluations of essay quality
The previous studies we have discussed (McNamara et al., 2010; Crossley and McNamara, in press; Crossley et al., 2010a) all support the notion that cohesive devices have either little predictive power in assessing essay quality or are negative predictors of essay quality. A key assumption of these analyses was that the cohesive devices measured by Coh-Metrix had links to the building of coherent textual representations in the minds of readers. While these analyses seem to indicate that the cohesive devices measured by Coh-Metrix are not predictive of essay quality, they merely suggest that coherence is not an important factor of essay scoring. In order to assess the role of coherence in human scoring of essays, Crossley and McNamara (2010) investigated the potential for analytical scores of essay quality (e.g., essay cohesion, essay coherence, essay structure, strength of thesis, conclusion type) to predict holistic essays scores. Such an analysis permitted an examination of links between holistic essay scores and analytic factors to determine the importance of these features in predicting essay quality.
In their study, Crossley and McNamara (2010) examined the same corpus used in McNamara et al. (2010). However, in their follow up study, they looked at not only the holistic scores of the essays, but also the analytic scores. So, instead of relying solely on computational indices to model overall essay quality, they instead concentrated on the investigation of human judgements of individual text features in relation to overall text quality. Included in the individual text features evaluated by human experts were two measures of coherence (a full list of the analytic features used in the analysis can be found in Table 5). They also examined if computational indices of cohesion could model human ratings of coherence. As in the McNamara et al. (2010) study, two expert raters with master’s degrees in English and at least three years experience teaching composition classes at a large university rated 184 essays using both a holistic and analytic rubric. A Pearson correlation for each rubric evaluation was conducted between the raters’ responses. If the correlations between the raters did not exceed r = .50 (which was significant at p < .05) on all items, the ratings were reexamined until scores reached the r = .50 threshold. Raters followed similar protocol for the holistic score, but were expected to reach an r >= .70. After the raters had reached an inter-rater reliability of at least r = .50 (r = .70 for the holistic score), each rater then evaluated the 184 essays that comprise the corpus used in this study. Once final ratings were collected, differences between the raters were calculated. If the difference in ratings on survey feature were less than 2, an average score was computed. If the difference was greater than 2, a third expert rater adjudicated the final rating.
Crossley and McNamara (2010) then used a regression analysis to examine the predictive ability of the analytic scores to explain the variance in the holistic scores in a training set. Five variables were significant predictors in the regression: reader orientation (t = 6.668, p < .001) conclusion type (t = 5.068, p < .001), evidential sentences (t = 3.495, p < .001), topic sentences (t = 3.180, p < .010), and appropriate registers (t = –1.419, p < .050). Three variables were not significant predictors: relevance (t = 1.841, p > .050), continuity (t = 1.760, p > .050), and grammar, spelling, and punctuation (t = 1.486, p > .050). The latter variables were left out of the subsequent analysis.

184 S.A. Crossley and D.S. McNamara
Table 5 Analytic ratings used in Crossley and McNamara (2010)
Structure Clarity of division into introductions, argumentation, and conclusion. Continuity Strength of connection of ideas and themes within and between the
essays’ paragraphs (cohesion). Introduction Presence of a clear, introductory sentence. Thesis statement Strength of the thesis statement and its attached arguments. Reader orientation Overall coherence and ease of understanding. Topic sentences Presence of identifiable topic sentences in argumentative paragraphs. Evidential sentences
Use of evidential sentences in the argumentative paragraphs that support the topic sentence or paragraph purpose.
Relevance Degree to which argumentation in the paper contained only relevant information.
Appropriate registers
Degree to which the vocabulary in the essays followed the expected register.
Grammar, spelling, and punctuation
Accuracy of grammar, spelling, and punctuation.
Conclusion Clarity of the conclusion Conclusion type Identifiable conclusion type. Conclusion summary
Presence of summary within the conclusion including arguments and the thesis of the essay.
Closing Clarity of closing statements within the essay.
The linear regression using the five variables yielded a significant model, F(5, 117) = 89.693, p < .001, r = .891, r2 = .793, demonstrating that the combination of the five variables accounted for 79% of the variance in the human evaluations of essay quality for the 123 essays examined in the training set. The model for the test set yielded r = .922, r2 = .850. The results from the test set model demonstrated that the combination of the five variables accounted for 85% of the variance in the evaluation of the 61 essays comprising the test set.
This analysis indicated that text coherence was the most informative predictor of human judgements of essay quality, explaining 65% of the variance in the training set. Crossley and McNamara (2010) then attempted to identify if the cohesive devices reported by Coh-Metrix correlated with human judgements of coherence. Crossley and McNamara examined only those indices that had theoretical correlates with cohesion. These included indices related to semantic co-reference, causal cohesion, spatial cohesion, temporal cohesion, connectives and logical operators, anaphoric resolution, word overlap, and lexical diversity. Among these variables, only a few demonstrated significant correlations with the human ratings of coherence; however, the majority of these indices correlated negatively to the human ratings indicating an inverse relation between the selected cohesion variables and the human judgements of coherence. These indices included the proportion of anaphoric references between sentences, the incidence of causal verbs and particles, positive temporal connectives, causative subordinators, noun overlap, and stem overlap. The one index that demonstrated positive correlations, subordinating conjunctions, also had strong links to syntactic complexity. All other selected variables (i.e., indices related to semantic co-reference, logical operators, lexical diversity, spatial cohesion, and temporal cohesion) did not yield significant correlations

Understanding expert ratings of essay quality 185
with the human judgements of coherence. The indices with the highest correlations from this analysis are presented in Table 6 along with their r and p values. Table 6 Correlations between human ratings of coherence and Coh-Metrix indices of cohesion
as reported in Crossley and McNamara (2010)
Variable r value p value Anaphoric reference –0.349 < .001 Ratio of causal particles and verbs –0.259 < .010 Incidence of positive temporal connectives –0.237 < .010 Subordinating conjunctions 0.240 < .010 Causative subordinators –0.211 < .050 Content word overlap –0.187 < .050
Unlike the previous studies discussed in this paper, the Crossley and McNamara (2010) study indicates that human ratings of coherence are an important indicators of holistic evaluations of essay proficiency. However, how human raters construct a coherent mental representation does not correlate with the cohesive devices reported by Coh-Metrix.
3 Discussions
The findings from these studies indicate that argumentative essays judged to be of higher quality by expert human raters are more linguistically sophisticated, but at the same time contain fewer cohesive devices to facilitate text comprehension. Thus, higher quality essays may be more difficult to process, but demonstrate a greater mastery of language skills. From a processing perspective, higher rated essays contain fewer cohesive devices. From a sophistication perspective, higher rated essays contain more complex syntax and more rare words that do not promote meaningful connections and words that are less familiar and imageable. However, these differences do not seem to negatively affect the building of coherent mental representations on the part of expert raters, whose ratings of coherence strongly predict essay quality regardless of the absence of cohesion devices.
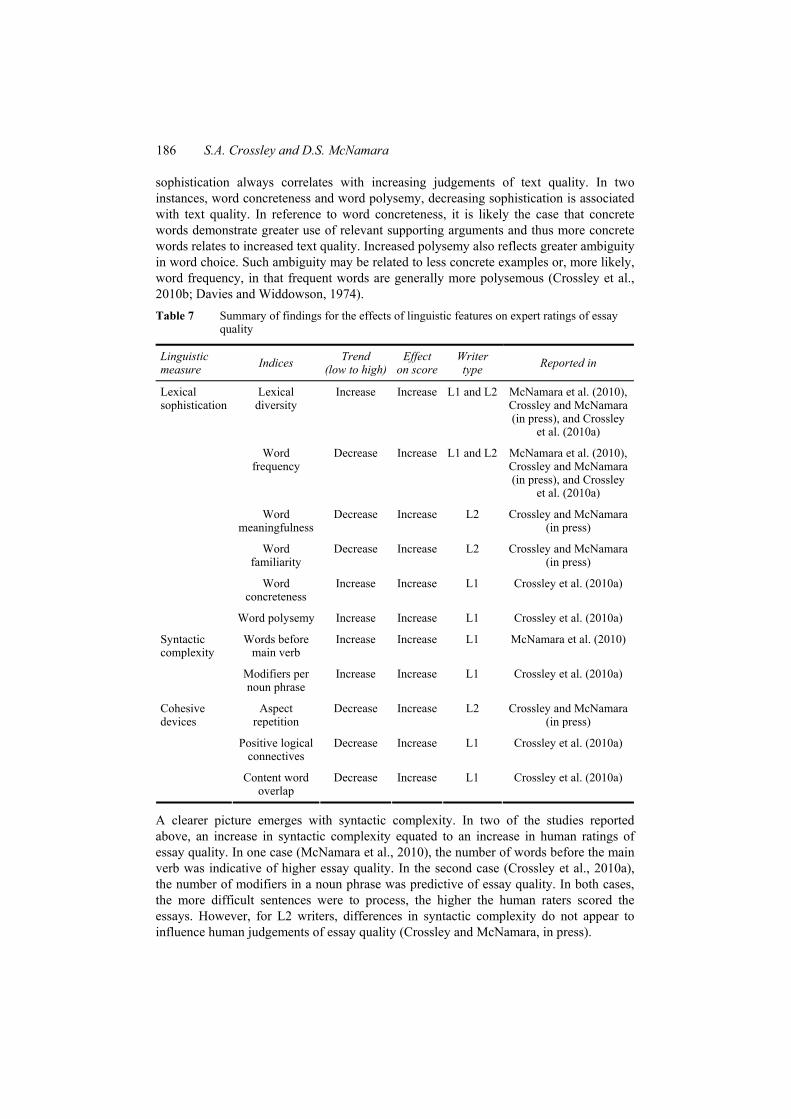
Thus, when we revisit our earlier hypotheses that lexical and syntactic features of a text could either interact with cohesive devices such that lower sophistication and higher cohesion could predict increasing human quality scores or that linguistic sophistication could surpass the need for cohesion, we are left with evidence that the latter is true. We see, conversely, that text quality generally results from linguistic complexity at the lexical and syntactic level and that a lower incidence of cohesion devices promotes increased essay scores or has no effect on score. A short overview of these differences is provided in Table 7.
As we see, human judgements of text quality generally increase as lexical sophistication increases. Such an effect is most prevalent in indices of lexical diversity and word frequency. In the three studies summarised in this paper, increasing lexical diversity is associated with increasing essay scores. The same is true for word frequency in that decreasing word frequency is associated with increasing scores. Similar trends are reported for word familiarity and word meaningfulness (decreasing values equate to increasing scores). In these instances, more sophisticated lexical features identify with increasing evaluations of essay quality. It is not the case, however, that increasing lexical
186 S.A. Crossley and D.S. McNamara
sophistication always correlates with increasing judgements of text quality. In two instances, word concreteness and word polysemy, decreasing sophistication is associated with text quality. In reference to word concreteness, it is likely the case that concrete words demonstrate greater use of relevant supporting arguments and thus more concrete words relates to increased text quality. Increased polysemy also reflects greater ambiguity in word choice. Such ambiguity may be related to less concrete examples or, more likely, word frequency, in that frequent words are generally more polysemous (Crossley et al., 2010b; Davies and Widdowson, 1974). Table 7 Summary of findings for the effects of linguistic features on expert ratings of essay
quality
Linguistic measure Indices Trend
(low to high)Effect
on scoreWriter type Reported in
Lexical diversity
Increase Increase L1 and L2 McNamara et al. (2010), Crossley and McNamara (in press), and Crossley
et al. (2010a)
Word frequency
Decrease Increase L1 and L2 McNamara et al. (2010), Crossley and McNamara (in press), and Crossley
et al. (2010a)
Word meaningfulness
Decrease Increase L2 Crossley and McNamara (in press)
Word familiarity
Decrease Increase L2 Crossley and McNamara (in press)
Word concreteness
Increase Increase L1 Crossley et al. (2010a)
Lexical sophistication
Word polysemy Increase Increase L1 Crossley et al. (2010a)
Words before main verb
Increase Increase L1 McNamara et al. (2010) Syntactic complexity
Modifiers per noun phrase
Increase Increase L1 Crossley et al. (2010a)
Aspect repetition
Decrease Increase L2 Crossley and McNamara (in press)
Positive logical connectives
Decrease Increase L1 Crossley et al. (2010a)
Cohesive devices
Content word overlap
Decrease Increase L1 Crossley et al. (2010a)
A clearer picture emerges with syntactic complexity. In two of the studies reported above, an increase in syntactic complexity equated to an increase in human ratings of essay quality. In one case (McNamara et al., 2010), the number of words before the main verb was indicative of higher essay quality. In the second case (Crossley et al., 2010a), the number of modifiers in a noun phrase was predictive of essay quality. In both cases, the more difficult sentences were to process, the higher the human raters scored the essays. However, for L2 writers, differences in syntactic complexity do not appear to influence human judgements of essay quality (Crossley and McNamara, in press).

Understanding expert ratings of essay quality 187
A different story emerges when we examine the use of cohesive devices on the part of writers and their effect on human judgements of text quality. Generally, when text contains more cohesion, they are scored lower. For instance, Crossley and McNamara (in press) found that writers who used the same aspect more often in text were given a lower score than those writers that did not repeat aspect to the same degree. Similarly, Crossley et al. (2010a) found that a greater incidence of positive logical connectors and content word overlap was indicative of lower level writers. McNamara et al. (2010), however, reported no effect on text quality as a result of cohesion. Overall, these studies support the notion that increased cohesion is not related to increased text quality and that, in many cases, an increase in cohesion is a negative predictor of text quality.
It is important to note however that increased linguistic sophistication and decreasing cohesion does not seem to affect text coherence for the expert raters in these studies. In fact, those essays scored the highest which contained higher levels of linguistic sophistication and lower levels of cohesion are also judged as most coherent by the raters. Not only are essays containing high levels of linguistic sophistication and low levels of cohesion judge to be coherent, but these judgements of coherences are the strongest predictors of holistic scores surpassing structural concerns, relevance of arguments, mechanics, register use, and the strength of introductions and conclusions. We hypothesise, then, that it is not a matter of cohesive devices producing coherent text for high level readers, but rather that texts with low cohesion allow high level readers to interact with the text in ways high cohesive texts do not. Such an effect is likely the result of the knowledge base available to expert raters. Expert raters are likely high-knowledge readers and, thus, can successfully make the inferences necessary to bridge the conceptual gaps that characterise low cohesion essays. Low cohesion might even benefit high-knowledge readers because conceptual gaps force the reader to make implicit connections explicit. Such gaps in the text oblige high-knowledge readers to interact with the text even when the text content may be familiar to them (Crossley and McNamara, 2010; McNamara, 2001; O’Reilly and McNamara, 2007).
4 Conclusions
This study has demonstrated the value of using automatic text evaluation to assess expert ratings of essay quality. Overall, we find that the use of the text evaluation tool Coh-Metrix can help us better understand the interplay between linguistic features and human judgements of essay quality. This interplay is complicated by the likelihood that expert raters are high knowledge readers and thus an increase in cohesive devices in the text may not lead to a more coherent representation of the text. However, it may be the case that our indices of cohesion measure only fundamentally basic elements of cohesion. New indices that take into consideration contextual factors such as the writing prompt may need to be developed. It may also be the case the cohesion is a property of cooperation among paragraph types (introduction, body, and conclusion paragraphs) and does not solely reside in isolation at the sentence, paragraph, or text level. Thus, new indices that measure links between paragraph types may prove beneficial. It may also be the case that the effects of text cohesion are important in assessing writing quality for low or middle knowledge readers or that cohesion cues are important in judgements of writing quality in genres outside of argumentative essays. Future studies should consider such factors and how they may interact.

188 S.A. Crossley and D.S. McNamara
Acknowledgements
This research was supported in part by the Institute for Education Sciences (IES R305A080589 and IES R305G20018-02). Ideas expressed in this material are those of the authors and do not necessarily reflect the views of the IES.
References Abbott, R. and Berninger, V.W. (1993) ‘Structural equation modeling of relationships among
developmental skills and writing skills in primary- and intermediate-grade writers’, Journal of Educational Psychology, Vol. 85, pp.478–508.
Abbott, R., Berninger, V.W. and Fayol, M. (2010) ‘Longitudinal relationships of levels of language in writing and between writing and reading in grades 1 to 7’, Journal of Educational Psychology, Vol. 102, pp.281–298.
Baayen, R.H., Piepenbrock, R. and Gulikers, L. (1995) The CELEX lexical database (release 2) [CD-ROM], University of Pennsylvania, Linguistic Data Consortium, Philadelphia, PA.
Berninger, V., Mizokawa, D. and Bragg, R. (1991) ‘Theory-based diagnosis and remediation of writing disabilities’, Journal of School Psychology, Vol. 29, pp.57–79.
Berninger, V., Yates, C., Cartwright, A., Rutberg, J., Remy, E. and Abbott, R. (1992) ‘Lower-level developmental skills in beginning writing’, Reading and Writing: An Interdisciplinary Journal, Vol. 4, pp.257–280.
Berninger, V.W., Abbott, R.D., Nagy, W. and Carlisle, J. (2010) ‘Growth in phonological, orthographic, and morphological awareness in grades 1 to 6’, Journal of Psycholinguistic Research, Vol. 39, pp.141–163.
Charniak, E. (2000) ‘A maximum-entropy-inspired parser’, Proceedings of the First Conference on North American Chapter of the Association for Computational Linguistics, Morgan Kaufman Publishers, San Francisco, CA, pp.132–139.
Collins, J.L. (1998) Strategies for Struggling Writers, Guilford Publications, New York, NY. Coltheart, M. (1981) ‘The MRC psycholinguistic database’, Quarterly Journal of Experimental
Psychology, Vol. 33, pp.497–505. Connor, U. (1987) ‘Research frontiers in writing analysis’, TESOL Quarterly, Vol. 21, pp.677–696. Connor, U. (1990) ‘Linguistic/rhetorical measures for international persuasive student writing’,
Research in the Teaching of English, Vol. 24, pp.67–87. Costerman, J. and Fayol, M. (1997) Processing Interclausal Relationships: Studies in Production
and Comprehension of Text, Lawrence Erlbaum, Hillsdale, NJ. Crismore, A., Markkanen, R. and Steffensen, M.S. (1993) ‘Metadiscourse in persuasive writing: a
study of texts written by American and Finnish university students’, Written Communication, Vol. 10, pp.39–71.
Crossley, S.A. and McNamara, D.S. (2010) ‘Cohesion, coherence, and expert evaluations of writing proficiency’, in Catrambone, R. and Ohlsson, S. (Eds.): Proceedings of the 32nd Annual Conference of the Cognitive Science Society, pp.984–989, Cognitive Science Society, Austin, TX.
Crossley, S.A. and McNamara, D.S. (in press) ‘Predicting second language writing proficiency: the role of cohesion, readability, and lexical difficulty’, Journal of Research in Reading.
Crossley, S.A., Greenfield, J. and McNamara, D.S. (2008) ‘Assessing text readability using cognitively based indices’, TESOL Quarterly, Vol. 42, pp.475–493.
Crossley, S.A., McNamara, D.S., Weston, J. and McLain Sullivan, S.T. (2010a) ‘The development of writing proficiency as a function of grade level: a linguistic analysis’, Technical report, The University of Memphis, available at http://w-pal.memphis.edu/main/publications.html.

Understanding expert ratings of essay quality 189
Crossley, S.A., Salsbury, T. and McNamara, D.S. (2010b) ‘The development of polysemy and frequency use in English second language speakers’, Language Learning, Vol. 60, pp.573–605.
Crowhurst, M. (1990) ‘Reading/writing relationships: an intervention study’, Canadian Journal of Education, Vol. 15, pp.155–172.
Davies, A. and Widdowson, H.G. (1974) ‘Reading and writing’, in Allen, J.B.P. and Corder, S.P. (Eds.): The Edinburgh Course in Applied Linguistics: Techniques in Applied Linguistics, pp.155–201, Oxford University Press, London, England.
DeVillez, R. (2003) Writing: Step by Step, Kendall/Hunt Publishing Company, Dubuque, IA. Douglas, D. (1981) ‘An exploratory study of bilingual reading proficiency’, in Hudelson, S. (Ed.):
Learning to Read in Different Languages, pp.33–102, Center for Applied Linguistics, Washington, DC.
Engber, C. (1995) ‘The relationship of lexical proficiency to the quality of ESL compositions’, Journal of Second Language Writing, Vol. 4, pp.139–155.
Fellbaum, C. (1998) WordNet: An Electronic Lexical Database, MIT Press, Cambridge, MA. Ferris, D. (1994) ‘Lexical and syntactic features of ESL writing by students at different levels of L2
proficiency’, TESOL Quarterly, Vol. 28, pp.14–20. Foltz, P. (2007) ‘Discourse coherence and LSA’, in Landauer, T., McNamara, D.S., Dennis, S. and
Kintsch, W. (Eds.): Handbook of Latent Semantic Analysis, pp.167–184, Lawrence Erlbaum Associates, Mahwah, NJ.
Frase, L.T., Faletti, J., Ginther, A. and Grant, L. (1999) Computer Analysis of the TOEFL Test of Written English, ETS, Princeton, NJ.
Gernsbacher, M.A. (1990) Language Comprehension as Structure Building, Earlbaum, Hillsdale, NJ.
Golightly, K.B. and Sanders, G. (Eds.) (1997) Writing and Reading in the Disciplines, Pearson, Boston, MA.
Graesser, A.C. and McNamara, D.S. (in press) ‘Computational analyses of multilevel discourse comprehension’, Topics in Cognitive Science.
Graesser, A.C., McNamara, D.S. and Louwerse, M.M. (2003) ‘What do readers need to learn in order to process coherence relations in narrative and expository text’, in Sweet, A.P. and Snow, C.E. (Eds.): Rethinking Reading Comprehension, pp.82–98, Guilford Publications, New York, NY.
Graesser, A.C., McNamara, D.S., Louwerse, M. and Cai, Z. (2004) ‘Coh-Metrix: analysis of text on cohesion and language’, Behavior Research Methods, Instruments, & Computers, Vol. 36, pp.193–202.
Grant, L. and Ginther, A. (2000) ‘Using computer-tagged linguistic features to describe L2 writing differences’, Journal of Second Language Writing, Vol. 9, pp.123–145.
Gumperz, J.J., Kaltman, H. and O’Connor, M.C. (1984) ‘Cohesion in spoken and written discourse: ethnic style and the transition to literacy’, in Tannen, D. (Ed.): Coherence in Spoken and Written Discourse, pp.3–20, Ablex, Norwood, NJ.
Haberlandt, K. and Graesser, A.C. (1985) ‘Component processes in text comprehension and some of their interactions’, Journal of Experimental Psychology: General, Vol. 114, pp.357–374.
Halliday, M.A.K. and Hasan, R. (1976) Cohesion in English, Longman, London, England. Jarvis, S. (2002) ‘Topic continuity in L2 English article use’, Studies in Second Language
Acquisition, Vol. 24, pp.387–418. Jarvis, S., Grant, L., Bikowski, D. and Ferris, D. (2003) ‘Exploring multiple profiles of highly rated
learner compositions’, Journal of Second Language Writing, Vol. 12, pp.377–403. Jenkins, J., Johnson, E. and Hileman, J. (2004) ‘When is reading also writing: sources of individual
differences on the new reading performance assessments’, Scientific Studies in Reading, Vol. 8, pp.125–151.

190 S.A. Crossley and D.S. McNamara
Jin, W. (2001) ‘A quantitative study of cohesion in Chinese graduate students’ writing: variations across genres and proficiency levels’, Paper presented at the Symposium on Second Language Writing, September, Purdue University, West Lafayette, Indiana.
Jurafsky, D. and Martin, J.H. (2008) Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, Prentice Hall, Upper Saddle River, NJ.
Just, M.A. and Carpenter, P.A. (1987) The Psychology of Reading and Language Comprehension, Allyn and Bacon, Boston, MA.
Just, M.A. and Carpenter, P.A. (1992) ‘A capacity theory of comprehension: individual differences in working memory’, Psychological Review, Vol. 99, pp.122–149.
King, M. and Rentel, V. (1979) ‘Toward a theory of early writing development’, Research in the Teaching of English, Vol. 13, pp.243–253.
Kintsch, W. and van Dijk, T.A. (1978) ‘Toward a model of text comprehension and production’, Psychological Review, Vol. 85, pp.363–394.
Landauer, T., McNamara, D.S., Dennis, S. and Kintsch, W. (Eds.) (2007) Handbook of Latent Semantic Analysis, Erlbaum, Mahwah, NJ.
Longo, B. (1994) ‘Current research in technical communication: the role of metadiscourse in persuasion’, Technical Communication, Vol. 41, pp.348–352.
Louwerse, M.M. (2001) ‘An analytic and cognitive parameterization of coherence relations’, Cognitive Linguistics, Vol. 12, pp.291–315.
Malvern, D.D., Richards, B., Chipere, N. and Duran, P. (2004) Lexical Diversity and Language Development: Quantification and Assessment, Palgrave Macmillan, Houndmills, Basingstoke, Hampshire.
McCarthy, P.M. and Jarvis, S. (2010) ‘MTLD, vocd-D, and HD-D: a validation study of sophisticated approaches to lexical diversity assessment’, Behavior Research Methods, Vol. 42, pp.381–392.
McCutchen, D. (1986) ‘Domain knowledge and linguistic knowledge in the development of writing ability’, Journal of Memory and Language, Vol. 25, pp.431–444.
McCutchen, D. and Perfetti, C. (1982) ‘Coherence and connectedness in the development of discourse production’, Text, Vol. 2, pp.113–139.
McNamara, D.S. (2001) ‘Reading both high-coherence and low-coherence texts: effects of text sequence and prior knowledge’, Canadian Journal of Experimental Psychology, Vol. 55, pp.51–62.
McNamara, D.S. and Graesser, A.C. (in press) ‘Coh-Metrix: an automated tool for theoretical and applied natural language processing’, in McCarthy, P.M. and Boonthum, C. (Eds.): Applied Natural Language Processing and Content Analysis: Identification, Investigation, and Resolution, IGI Global, Hershey, PA.
McNamara, D.S., Crossley, S.A. and McCarthy, P.M. (2010) ‘Linguistic features of writing quality’, Written Communication, Vol. 27, pp.57–86.
McNamara, D.S., Kintsch, E., Songer, N.B. and Kintsch, W. (1996) ‘Are good texts always better? Text coherence, background knowledge, and levels of understanding in learning from text’, Cognition and Instruction, Vol. 14, pp.1–43.
Miller, G.A., Beckwith, R., Fellbaum, C., Gross, D. and Miller, K. (1990) Five Papers on WordNet, Princeton University Cognitive Science Laboratory.
National Commission on Writing (2004) Writing: A Ticket to Work or a Ticket Out, College Board. O’Reilly, T. and McNamara, D.S. (2007) ‘Reversing the reverse cohesion effect: good texts can be
better for strategic, high-knowledge readers’, Discourse Processes, Vol. 43, pp.121–152. Pearson, P.D. (1974–1975) ‘The effects of grammatical complexity on children’s comprehension,
recall, and conception of certain semantic’, Reading Research Quarterly, Vol. 10, pp.155–192.

Understanding expert ratings of essay quality 191
Perfetti, C.A., Landi, N. and Oakhill, J. (2005a) ‘The acquisition of reading comprehension skill’, in Snowling, M.J. and Hulme, C. (Eds.): The Science of Reading: A Handbook, pp.227–247, Blackwell, Oxford.
Perfetti, C.A., Wlotko, E.W. and Hart, L.A. (2005b) ‘Word learning and individual differences in word learning reflected in event-related potentials’, Journal of Experimental Psychology: Learning Memory and Cognition, Vol. 31, pp.1281–1292.
Rashotte, C.A. and Torgesen, J.K. (1985) ‘Repeated reading and reading fluency in learning disabled children’, Reading Research Quarterly, Vol. 20, pp.180–188.
Raynor, A. and Pollatsek, K. (1994) The Psychology of Reading, Prentice Hall, Cliffs, NJ. Reid, J. (1986) ‘Using the writer’s workbench in composition teaching and testing’, in
Stansfield, C.W. (Ed.): Technology and Language Testing, pp.167–187, TESOL, Washington, DC.
Reid, J. (1990) ‘Responding to different topic types: a quantitative analysis from a contrastive rhetoric perspective’, in Kroll, B. (Ed.): Second Language Writing: Research Insights for the Classroom, pp.191–210, Cambridge University Press, Cambridge.
Reid, J. (1992) ‘A computer text analysis of four cohesion devices in English discourse by native and non-native writers’, Journal of Second Language Writing, Vol. 1, pp.79–107.
Reppen, R. (1994) ‘A genre-based approach to content writing instruction’, TESOL Journal, Vol. 4, pp.32–35.
van de Kopple, W. (1985) ‘Some exploratory discourse on metadiscourse’, College Composition and Communication, Vol. 36, pp.82–93.
Wilson, M.D. (1988) ‘The MRC psycholinguistic database: machine readable dictionary, version 2’, Behavior Research Methods, Instruments, and Computers, Vol. 20, pp.6–11.