una medición del efecto de los programas productivos...
TRANSCRIPT

Una medición del efecto de los programas productivos sobre el empleo y
los ingresos de los jóvenes en México
Eduardo Calderón Cuevas1
Candidato a Doctor en Economía Aplicada por la UAB
Resumen:
Este documento explora los efectos de un conjunto de programas públicos sobre el empleo
y los ingresos de los jóvenes en México. Para aislar el efecto de las intervenciones se
construye un grupo de control óptimo a través de un modelo de pareamiento por propensión
a partir de la propuesta de Rosenbaum y Rubin (1983).
Para la estimación de los efectos se miden los resultados mediante diferencias simples, y
para controlar la existencia de sesgos atribuibles a variables no observadas se utilizan los
estimadores de dobles diferencias propuestos por Heckman, Ichimura y Todd (1997) y
Heckman, Ichimura, Smith y Todd (1998).
Para las estimaciones empíricas se utiliza la información de una encuesta con tres
observaciones longitudinales en grupos de tratamiento y control, en los años 2010 a 2012.
Los resultados indican efectos positivos de los programas analizados sobre la participación
laboral de los jóvenes, pero no sobre los ingresos.
1 Para cualquier observación por favor escribir al correo: [email protected]

2
I. Introducción
En México existe un conjunto de programas sociales que busca atender distintos aspectos
del desarrollo, mediante la construcción de mecanismos de protección social orientados a la
protección de la población ante riesgos, y la promoción del desarrollo en materia de salud,
educación, nutrición o la mejora de las viviendas y la infraestructura social.
En materia de empleo, existen diversos programas que buscan incidir sobre la participación
económica y los ingresos laborales de la población.2 Cada uno de estos programas de
generación de empleo, ingresos y proyectos productivos (PEPP) atiende una o más
problemáticas relacionadas con la participación laboral, la generación de ingresos o la
productividad. Tales como, promover el desarrollo de capacidades o habilidades, facilitar
la vinculación entre la oferta y la demanda laboral, o el acceso a financiamiento productivo,
entre otros.
Una forma de caracterizar los programas que operan en México para atender las
problemáticas relacionadas con el empleo y la generación de ingresos laborales es en
función de sus componentes: políticas para las PyMEs;3 políticas activas de empleo
(PAEs);4 o políticas basadas en la comunidad
5 (ver en el anexo la clasificación de Orozco y
Salgado 2010).
Además de las posibles variaciones en los efectos de los programas debido a la
heterogeneidad de sus componentes y mecanismos de operación, los resultados pueden
tener implicaciones desiguales entre distintos estratos o grupos de la población. Ya sea en
función del sexo, la escolaridad, la edad o el lugar de residencia de la población
beneficiaria, entre otros.
Como parte del sistema de rendición de cuentas en México se han realizado una serie de
evaluaciones a los programas sociales6. Específicamente, las relativas a los programas que
buscan incidir sobre el empleo y la generación de ingresos (CONEVAL, 2008, 2008b,
2009, 2009b, 2010, 2010b, 2011, 2013, 2014)7. Estas evaluaciones han analizado el diseño
de los programas en relación con los problemas que buscan atender, así como su
2 Se utiliza el concepto “empleo” para hacer referencia a toda forma de trabajo de mercado, ya sea formal o informal, asalariado o no, autoempleo, etc.
3 Dirigidas a empresas pequeñas y medianas, persiguen un amplio rango intervenciones: sistemas simplificados de impuestos; régimen laboral
diferenciado; acceso a crédito; subsidios; servicios de capacitación empresarial, innovación o certificación.
4 Que pueden incluir: facilitar la vinculación entre oferentes y demandantes de empleos (asistencia en la búsqueda); capacitación para el trabajo, ya sea en
clases o in situ; empleos subsidiados, ya sea en el sector público o en el privado.
5 Pueden incluir mejoras a la infraestructura física, social, económica, organizacional o ambiental de una localidad o área geográfica realizadas por
ciudadanos, grupos comunitarios, y/o autoridades locales. Tales como: instalación o mejora de infraestructura básica; remoción de riesgos ambientales;
provisión de incentivos para el mantenimiento y administración comunitaria; construcción o rehabilitación de instalaciones comunitarias (de salud,
educación, etc.); mejora en las viviendas o el acceso a los servicios de cuidados, educación y de otros programas de protección relacionados con temas de
adicciones o seguridad; o mejora de oportunidades de generación de ingresos a través de capacitación y micro-créditos.
6 Sistema de Información sobre Evaluaciones de Programas Sociales, CONEVAL. http://www.coneval.org.mx/Evaluacion/Paginas/InformeEvaluacion.aspx
Consultado en abril 2017.

3
desempeño, gestión y vinculación, complementariedad o potencial duplicidad con otros
programas públicos. En algunos programas se ha buscado medir efectos sobre los ingresos
utilizando encuestas ad hoc. Este tipo de evaluaciones se ha basado en diseños que
únicamente permiten medir diferencias simples en el tiempo, pues no disponen de grupos
de comparación para controlar los efectos atribuibles a los programas. Los resultados
obtenidos se basan en el conjunto total de la población beneficiaria de los programas, sin
distinción de los efectos por grupos etarios.
El objetivo de este documento es identificar el efecto del conjunto de programas que capta
la Encuesta Nacional de Evaluación de Programas Productivos y de Empleo con
Perspectiva de Género (ENEPPEG) sobre la participación laboral y los ingresos de los
jóvenes menores de 30 años de edad. Con ello se logra un importante resultado, que
consiste en contar con estimaciones de estos efectos para este grupo específico de
población, a partir de realizar ajustes econométricos para obtener una medición insesgada
del efecto atribuible a los programas.
En la sección II de este documento se describen los métodos de pareamiento por propensión
documentados en la literatura y la metodología que se utiliza para el análisis de los efectos
de los programas en los indicadores de oferta laboral e ingresos de los jóvenes. La sección
III contiene una descripción de los datos de la ENEPPEG, que es la fuente de información
que se utiliza para la estimación. En la sección IV se muestra la estimación empírica del
modelo de pareamiento por propensión y las pruebas de ajuste que justifican su utilización.
La sección V contiene los resultados del análisis y el efecto sobre los indicadores de oferta
laboral e ingresos de los jóvenes considerando distintas aproximaciones metodológicas. Por
último, se presentan las conclusiones del estudio.

4
II. Metodología
En el estudio de los efectos de intervenciones o tratamientos sobre un conjunto de la
población, comúnmente se presenta una dificultad para establecer comparaciones en
relación a un grupo de control. Esto se debe a que la población dentro de un grupo de
tratamiento por lo general presenta un sesgo de selección (véase Heckman 1974; Barnow,
Cain y Goldberger 1980; Rosembaum y Rubin 1983).
En los experimentos sociales que buscan medir el efecto de un programa, el sesgo de
selección puede provenir de diversas fuentes, como por ejemplo el criterio de focalización
de los programas, las tasas de aceptación de los mismos por parte de la población elegible o
inclusive la forma en que los programas se difunden entre la población, o la capacidad de
las organizaciones e instituciones locales para acercar los apoyos de los programas a la
población.
La técnica por excelencia utilizada por la investigación científica para evitar este tipo de
sesgos en los grupos de tratamiento es el diseño experimental de intervenciones. Sin
embargo, en el caso de experimentos sociales esta posibilidad enfrenta diversas
restricciones que comúnmente hacen inviable contar con datos provenientes de muestras
completamente aleatorizadas.
Por otra parte, inclusive en casos en donde se cuenta con información proveniente de un
diseño experimental completamente aleatorizado, el seguimiento longitudinal de casos
puede presentar sesgos de selección debido a la pérdida de sujetos de estudio que provoca
atrición en la muestra de evaluación utilizada. La atrición puede deberse a que los
individuos bajo estudio pueden cambiar de domicilio o a la negativa de ser entrevistados.
No obstante, existe un cúmulo importante de literatura para el análisis de datos
provenientes de intervenciones no aleatorizadas, basadas en la selección de personas
beneficiarias de un programa social (choice-based). Un método ampliamente utilizado se
basa en la construcción de grupos de control a partir de un conjunto de población que no
recibe los apoyos del programa o intervención, basados en la similitud de las características
de la población intervenida en una etapa pre-tratamiento.
Entre los métodos existentes, el más utilizado es el pareamiento por propensión (PPP, o
PSM por sus siglas en inglés, propensity score matching) propuesto por Rosembaum y
Rubin (1983), aunque existen otras metodologías disponibles. Iacus, King y Porro (2011a)
distinguen dos clases generales de métodos del pareamiento. En una primera clase
identifican a los métodos de igual porcentaje de reducción de sesgos (EPBR, por sus siglas
en inglés, Equal Percent Bias Reducing). En otra clase identifican los métodos de límite de
desequilibrio monotónico (MIB, por sus siglas en inglés, Matched Interface and
Boundary).
En los métodos EPBR es necesario que todos los casos dentro del conjunto de datos de
tratamiento sean pareados, en tanto que es posible que sólo conjunto de los datos de control
sean utilizados para el pareamiento. Estos métodos se enfocan en reducir los desbalances

5
sobre la media de los grupos de tratamiento y control, de las covariables utilizadas o sus
transformaciones.
En estos métodos el valor promedio de la diferencia o desbalance de las variables
pretratamiento dentro del conjunto de datos pareados es proporcional al desbalance dentro
de los grupos originales de tratamiento y control. Esta propiedad significa que el balanceo
que se logra en los promedios de alguna de las variables pretratamiento mejora el balanceo
en el resto de las variables. De acuerdo con Rosenbaum y Rubin (1985) hay tres
condiciones que debe cumplir el vector de covariables X cuando se utilizan este tipo de
métodos: i) X debe provenir de una población específica; ii) la distribución poblacional de
X debe ser simétrica y elipsoidal; y iii) el algoritmo de pareamiento es invariante a
transformaciones afines de X.
Los métodos de la clase MIB son una generalización hecha por Iacus et. al. (2011a) sobre
los métodos de la clase EPBR. En estos métodos no se hacen supuestos distribucionales
respecto de los datos. De hecho, no utilizan supuestos sobre los datos. Se enfocan en el
desbalance de los datos muestrales, y no sobre la reducción de los valores esperados del
desbalance; se centran en la reducción de los desbalances de cada variable a la vez, el lugar
de considerar el vector de promedios de las covariables; establecen a priori una distancia
máxima a alcanzar entre los promedios de cada variable para realizar el pareamiento y
permiten que el número de casos dentro del conjunto de datos de tratamiento, y dentro del
conjunto de datos de control, sea determinado por el método utilizado; utilizan una medida
general de desbalanceo en vez de la media; y, la distancia entre el conjunto de
observaciones pareadas de tratamiento y control, valuada a través de ese medida general de
desbalanceo o función tiene un límite superior definido por una función monotónica
creciente. La principal dificultad con esta clase de métodos es que por lo general pueden
producir un número muy pequeño de datos pareados, lo que disminuye radicalmente el
número de grados de libertad disponibles para la estimación de un modelo. Esto en la
práctica implica la imposibilidad de hacer inferencia a partir de los resultados obtenidos.
Entre la clase EPBR se encuentran el método de vecino más cercano mediante pareamiento
por propensión, que establece pares a partir de las probabilidades condicionales de
tratamiento; el método de vecino más cercano con distancia de Mahalanobis (Cochran y
Rubin 1973), que utiliza la menor distancia media entre casos de tratamiento y control; el
método de distancia de Mahalanobis con calibración del PSM, que combina los dos
métodos previos (Althauser y Rubin 1971); el método de pareamiento óptimo (Rosenbaum
2002:311, Iacus et. al. 2011b); el método de calibración con ortogonalización, en donde dos
observaciones de cada uno de los grupos de tratamiento y control son pares respecto a una
covariable determinada si su diferencia absoluta es menor que un escalar, o caliper
(Caliendo et. al. 2012:4), este método es un caso particular del PSM (Cochran 1972). En la
clase MBI se encuentran el método de calibración sin ortogonalización o el método de
pareamiento exacto.
Además de los distintos métodos de pareamiento, existen refinamientos técnicos para
mejorar la precisión de los estimadores que se obtienen a partir del PSM, como los
aplicados por Heckman, Ichimura y Todd (1997). Estos refinamientos se describen en las
secciones II.2 y II.3.

6
Con base en Heckman et.al. (1997 y 1998a), Todd (1999) describe los distintos estimadores
que pueden obtenerse a partir de adoptar distintos métodos y supuestos para el pareamiento.
Esta autora hace dos clasificaciones generales de los estimadores que se obtienen a través
del pareamiento: estimadores CS (por sus siglas en inglés, cross-sectional) obtenidos a
partir de datos transversales, que se obtienen de comparar los indicadores de resultado entre
los grupos de tratamiento y control en un momento posterior al inicio del programa que se
evalúa; y estimadores DID (por sus siglas en inglés, diference-in difference) o de dobles
diferencias, que se obtienen de comparar el cambio en el indicador de resultados en el
grupo de control respecto de un momento en el tiempo previo al inicio del programa que se
evalúa, con el respectivo cambio en el indicador dentro del grupo de control. Es decir, los
estimadores DID contemplan la información disponible cuando se cuenta con una línea de
base.
El método y tipo de estimador que se seleccione en un estudio puede ser más pertinente
dependiendo del tipo de información y de las características de los datos con que se cuenta.
Los métodos de pareamiento se desarrollaron simultáneamente desde dos aproximaciones
distintas, la econometría y la evaluación. El trabajo de Barnow, Cain y Goldberger (1981)
es una de las primeras aproximaciones en la literatura que se enfoca a identificar la
convergencia entre los métodos de análisis de sesgos de selección en el contexto de las
evaluaciones y en el contexto del análisis econométrico de la economía laboral, basado en
las aportaciones de Heckman (1974, 1976, 1979); Maddala (1976); y Maddala y Lee
(1976).
Barnow y sus coautores (1981) plantean que la preocupación por los sesgos de selección se
debe a que implican la existencia de alguna característica del grupo de tratamiento o de
control que está asociada simultáneamente a la asignación del tratamiento y a la variable de
resultado. De esta forma establecen la analogía entre la presencia de un sesgo de selección
y un error de especificación, comúnmente denominado como el problema de variables
omitidas en los estudios econométricos. La consecuencia en este caso es que el sesgo de
selección puede conducir a que se atribuya erróneamente un efecto de causalidad entre el
tratamiento y el resultado que se desea medir. Estos autores formulan un modelo de
evaluación para establecer la correspondencia entre la medición de efectos de tratamiento
en el contexto de la evaluación y del análisis econométrico. Mediante el que se modela el
proceso de selección, en el caso econométrico, o de asignación, en el caso de la evaluación.
Por su parte, Heckman y Robb (1986:102) señalan que el problema de selección basado en
variables observables que utiliza el PSM es tan solo un caso particular del problema general
de sesgo de selección que plantean los modelos econométricos. Y que el sesgo de selección,
a su vez, origina un problema de inferencia causal. En su estudio establecen las condiciones
bajo las cuales la probabilidad condicional utilizada por el PSM se desempeña
adecuadamente para la corrección de sesgos de selección. Específicamente, señalan que
esto sucede cuando, dado el conjunto de características que determinan la probabilidad de
selección o de participación en el tratamiento, la distribución de las variables observadas
que determinan la participación y la variable de resultado es independiente de las variables

7
no observadas. Es decir, cuando únicamente existe selección sobre las variables observadas,
de la misma forma que lo plantearon Rosenbaum y Rubin (1983). De hecho, Heckman,
Ichimura y Todd (1997) afirman que, de las tres potenciales fuentes de sesgos de selección,
el pareamiento potencial puede eliminar dos: el proveniente de soportes no traslapados,
mediante la identificación de un área común de soporte; y el proveniente de distintas
ponderaciones en la función de densidad de los datos, mediante la reponderación de los no
participantes del tratamiento a partir del pareamiento. Sin embargo, el PSM no elimina los
sesgos que puedan provenir de variables no observadas.
No obstante, Heckman y Robb (1986) señalan que más allá del planteamiento hecho por
Rosenbaum y Rubin (1983), el pareamiento por propensión puede ser utilizado cuando
existe selección en las variables no observables, pero no la existe en las observables
(Heckman 1980). Sin embargo, aclaran que esto requiere de supuestos distintos a los que
plantean Rosenbaum y Rubin (1983).
Heckman y Robb (1986) también identifican los aspectos adicionales que debe contener
una función de control para corregir este tipo de sesgos en tres posibles conjuntos de datos:
transversales post tratamiento; transversales repetidos y longitudinales. Aunque en su texto
hacen hincapié en la necesidad de que se profundice en la literatura las pruebas formales de
las propiedades de los estimadores de los métodos de pareamiento, estudios más recientes
como el del mismo Heckman en colaboración con Ichimura y Todd (1997) y el de Todd e
Ichimura (2006) hacen uso de los métodos de pareamiento introduciendo mejoras técnicas a
la propuesta de Rosenbaum y Rubin (1983).
En resumen, aunque metodológicamente el análisis econométrico y el análisis en el
contexto de la evaluación son equivalentes, ambos utilizan supuestos distintos que hacen al
segundo un caso particular del planteamiento desarrollado en el contexto del análisis
econométrico (Heckman y Robb, 1986; Heckman, Ichimura, Smith y Todd,1998). Una de
las principales diferencias que hacen distintas estas aproximaciones radica en lo siguiente.
Dentro de los análisis econométricos la corrección de sesgo se realiza en función de
variables proxy que determinan la probabilidad de observación del resultado. Dichas
variables están definidas en el mismo momento en el tiempo que el resultado que se desea
medir; en este caso la variable de resultado no es observada en el grupo de control. Un
ejemplo de este tipo de información es el análisis del mercado laboral femenino, en donde
la selección está dada por la participación en el mercado laboral, y los salarios o ingresos
por trabajo no son observados para las mujeres que no se encuentran trabajando.
A diferencia de los métodos econométricos ejemplificados, en el contexto de la evaluación
de programas, los métodos de pareamiento basan el sesgo de selección en un conjunto de
variables observadas en un momento en el tiempo previo al inicio del tratamiento cuyo
efecto se desea medir. Adicionalmente, en este caso la variable de resultado sí es observada
tanto en el grupo de tratamiento, como en el grupo de control (véase Barnow et.al. 1980).
No obstante, solo es observada en función de la asignación al tratamiento, por lo que se
observa en forma condicional. Esto significa que no es posible observar el resultado sin
tratamiento para una observación que pertenece al grupo de tratamiento. En analogía con el
ejemplo del análisis del mercado laboral femenino, para el análisis de los ingresos laborales
en el contexto de la evaluación de programas sí se cuenta con datos en las observaciones

8
tanto de tratamiento, como de control. Lo que no se observa es el ingreso de una persona
que trabaja bajo el supuesto de que no estuviera inserta en el mercado laboral.
Estas diferencias entre la corrección econométrica de sesgos de selección y el pareamiento
en el contexto de la evaluación de programas derivan en la existencia de supuestos
adicionales en el método de pareamiento. En particular, el supuesto de traslape y el
supuesto de estabilidad (SUTVA, por sus siglas del inglés, stable unit treatment value
assumption), si bien ambas aproximaciones comparten el supuesto de independencia
condicional (Caliendo et. al. 2005; King 2016). Todos estos supuestos se describen en la
sección II.1 para el método de PSM.
Heckman et. al. (1998a) también señalan que la solución propuesta por Rosenbaum y Rubin
(1983) al problema de dimensionalidad es impráctica debido a que su teorema supone que
la probabilidad de selección es conocida y utiliza varios supuestos de independencia. Estos
últimos autores proponen utilizar la probabilidad de selección en lugar del conjunto de
variables X para reducir el problema de multidimensionalidad del pareamiento a una única
dimensión. Heckman y sus coautores generan una teoría de distribución asintótica del
estimador de probabilidad para resolver adecuadamente el problema. De esta forma
introducen el concepto de estimación de un área común de soporte para el pareamiento.
II.1 Pareamiento por propensión (PPP)
El pareamiento por propensión y la corrección de sesgos de selección en los análisis
econométricos pueden utilizar métodos paramétricos o no paramétricos para estimar la
probabilidad condicional de participar en el programa que se analiza. En los primeros se
utiliza comúnmente un modelo logit o probit, mientras que en los segundos la literatura
documenta el uso de estimadores kernel y estimadores lineales de regresión local (LLR, por
sus siglas en inglés, linear local regression) para suavizar los datos (véase Todd 1999).
El método consiste en reducir a una dimensión el problema de condicionamiento a partir de
la información de múltiples dimensiones expresada en un vector de covariables X.
Rosenbaum y Rubin (1983) plantean la posibilidad de obtener estimadores insesgados para
medir los efectos atribuibles a un tratamiento o intervención no completamente
aleatorizado.
La técnica se basa en la comparación entre la variable de respuesta a un tratamiento en
relación a la respuesta a un tratamiento alternativo (que bien puede ser un control o,
dicho de otra forma, la ausencia de tratamiento) para un individuo . Utilizando la
información de estos grupos puede obtenerse una estimación del efecto de causalidad
atribuible al tratamiento, ya sea en términos de una diferencia o de una razón de resultados.
Estas comparaciones se establecen a partir de obtener los valores esperados de las variables
de respuesta en las muestras de tratamiento y de control tomando en cuenta algunas
consideraciones. denota el tratamiento asignado a la observación , que es una variable
dicotómica que asume valores 0 y 1 si el individuo no recibe el tratamiento o si lo recibe,
respectivamente es un vector de covariables observadas en un momento previo al
tratamiento o pre-tratamiento, que se utiliza para estimar una función de balanceo. De

9
acuerdo con Rosenbaum y Rubin (1983), las diferencias en los valores esperados
condicionales, o promedios, entre observaciones de tratamiento y control para distintos
valores de la función de balanceo construida a partir del vector de covariables son
estimadores insesgados del efecto de tratamiento para dicho valor. Dadas las propiedades
de la función de balanceo el pareamiento de casos produce un estimador insesgado del
efecto de tratamiento promedio (ATE, por sus siglas en inglés).
En la técnica de PPP, el puntaje de propensión es una función de balanceo particular
definida como la probabilidad condicional de dado , es decir . Es decir,
la probabilidad de participar en un programa o intervención dado un conjunto de
características observadas (Caliendo et.al. 2005).8
El principio que rige el PPP es el de ortogonalidad entre y dada una función de
balanceo o puntaje dependiente de . En su versión más ordinaria esta función es un
puntaje de propensión . El puntaje de propensión en el PPP se estima comúnmente
utilizando un modelo logit, pero también es común en la literatura la utilización de un
modelo probit.
El modelo de Roy-Rubin define el efecto del tratamiento para el individuo como,
… (1)
Como en la práctica el resultado para el individuo en ausencia del tratamiento, es decir, el
resultado contrafactual no es observado, la técnica de estimación de PPP se basa en obtener
el efecto promedio del tratamiento (ATE, average treatment effects) sobre la población, que
se define como,
… (2)
Y el efecto sobre la población tratada (ATT, average treatment effect on the treated) se
define como:
… (3)
La elección de un sustituto apropiado de la media contrafactual no observada requiere que
se cumplan las siguientes condiciones (Caliendo et. al. 2005; King y Nielsen 2016):
1) el supuesto de traslape, que implica la existencia de un área de soporte común o traslape,
lo significa que no existe predictibilidad perfecta del tratamiento dado , es decir, que los
individuos con los mismos valores de tienen una probabilidad definida de participar o no
en el tratamiento (Caliendo et. al. 2005 citando a Rosenbaum y Rubin, 1983, y a Heckman,
Lalonde y Smith, 1999),9
8 Otra técnica utilizada es el pareamiento por covarianza (CVM, por sus siglas en inglés).
9También denominado ignorabilidad en Rosenbaum y Rubin (1983).

10
2) el supuesto de estabilidad, SUTVA, que implica que para poder efectuar la estimación
del efecto promedio de tratamiento se requiere que el efecto de tratamiento de cada
individuo sea independiente de la participación en el tratamiento de otros individuos
(Caliendo et. al. 2012:3; King y Nielsen 2016:3, con base en Rubin 1980; VanderWeele y
Hernan 2012),
3) el supuesto de independencia condicional, que significa que dado el conjunto de
covariables que no están afectadas por el tratamiento, los resultados potenciales Y(0) y
Y(1) son independientes de la asignación del tratamiento. Es decir, de acuerdo con
Caliendo et. al. (2012:4), que la selección se basa únicamente en características observadas
y que todas las variables que tienen influencia simultáneamente en la asignación al
tratamiento y los resultados potenciales Y, son observadas.
De esta forma, el estimador del efecto promedio sobre los tratados en el PPP se define
como la diferencia promedio entre los resultados de tratamiento y sus contrafactuales
dentro del área de soporte,
… (4)
Hay dos criterios básicos que rigen la selección de : evitar la omisión de variables
relevantes que pueden generar sesgos importantes en la estimación econométricas; e incluir
únicamente variables que pueden influir simultáneamente las decisiones de participación y
la variable de resultado. Por supuesto, las observaciones de no deben estar afectadas aún
por el tratamiento o intervención, o bien debe tratarse de variables que son fijas en el
tiempo (Caliendo et.al. 2005).
La especificación del modelo se puede valorar a través de diversos criterios, como la
maximización de la tasa de predicción correcta; la significancia estadística del modelo
respecto de un modelo básico (o nulo, si solo incluye la constante); la combinación de la
maximización de la tasa de predicción y la significancia estadística; la validación cruzada
excluyendo conjuntos de variables y comparando los errores cuadrados medios y la calidad
del matching.
A pesar de la amplia utilización del PSM, su aplicación no se encuentra libre de críticas.
Heckman, Ichimura y Todd (1998a) identifican que la utilización del PSM no
necesariamente es mejor en el sentido de que no reduce la varianza del estimador
resultante. Estos autores hacen cuatro críticas a este tipo de metodología: i) señalan que
utiliza supuestos estadísticos más fuertes de los necesarios, que son inconsistentes con
algunos modelos de participación en programas, lo que genera que aun cuando se cumpla el
supuesto de independencia condicional para un conjunto de variables X, ello no significa
que se verifique para otro conjunto X; ii) se requiere establecer la teoría de distribución
para las variables continuas; iii) no cuenta con un marco de referencia sobre la
separabilidad de las variables observadas y no observadas, o restricciones que permitan
aislar las variables que determinan el resultado esperado versus las que determinan la
participación en el programa; y iv) el PSM requiere de muchos datos para evitar tener
celdas vacías (curse of dimensionality).

11
King 2016 muestra un análisis comparativo de los métodos de Mahalanobis Distance
Matching (MDM) y Coarsened Exact Matching (CEM) con el PSM.
II.2 Estimación Kernel
El método de estimación de Kernel es una generalización del PSM propuesta por Heckman,
Ichimura y Todd (1998a) que consiste básicamente en utilizar la muestra completa de
control asignando ponderaciones menores a las observaciones más alejadas o menos
semejantes a las observaciones de tratamiento. Para ello se lleva a cabo un procedimiento
de suavizamiento. En este caso el parámetro de interés es el efecto de tratamiento sobre los
tratados.
El sesgo de selección derivado de aproximar el valor esperado del resultado dada la
ausencia de tratamiento para un individuo que participa en la intervención o programa está
dado por,
II.3 Modelos de diferencias
La estimación del efecto de un tratamiento con datos longitudinales para los que se dispone
de información en una línea de base aporta precisión adicional a la medición. Todd (1999)
señala que, a diferencia de los estimadores CS, los estimadores DID permiten considerar
diferencias no observadas entre los grupos de tratamiento y control que son invariantes en
el tiempo. Su descripción de las bondades y debilidades de los estimadores que discuten
Heckman et.al. (1997 y 1998a) considera las diferencias en los estimadores CS y DID, así
como sus respectivas versiones basadas en el método kernel y el método de estimación
lineal local.
Idealmente, la recolección de datos sobre las variables de resultado en un momento previo
al inicio de la intervención permite ajustar las diferencias atribuibles al diseño del
experimento, ya sea que se trate o no de una intervención totalmente aleatorizada o de un
diseño cuasi-experimental.
A las diferencias entre resultados de tratamiento en dos momentos en el tiempo y se
les conoce como primeras diferencias o diferencias simples. En este tipo de diferencias no
es posible aislar el efecto de la tendencia secular. Se definen como,
… (5)
En tanto, las diferencias que incorporan dos observaciones en el tiempo para grupos de
tratamiento y control se conocen como dobles diferencias o diferencia en diferencias, y se
definen como la diferencia de las primeras diferencias entre ambos grupos de la siguiente
manera,

12
… (6)
El estimador de dobles diferencias permite aislar las tendencias seculares y ajustar por las
diferencias observadas previas al tratamiento.
Heckman, Ichimura y Todd (1997 y 1998a) aplican una combinación de diferencias en
diferencias como extensión al modelo tradicional de pareamiento por propensión, a partir
de establecer condiciones generales para el pareamiento. Con ello pretenden disminuir el
sesgo de selección que se logra a través de los métodos de parea miento, pero que sin
embargo no logra eliminarse. En su estudio calcula la probabilidad de pertenencia el
tratamiento y utilizan dichas probabilidades para ajustar el método de pareamiento. Su
método considera cinco aspectos: a) incorporen restricciones a las ecuaciones de
participación y de resultado del programa evaluado; b) presentan una simplificación de las
condiciones requeridas que justifican el pareamiento por propensión como una técnica
adecuada; c) incorporan información a priori sobre la forma funcional para la estimación de
las ecuaciones; d) extienden el pareamiento a un contexto longitudinal para obtener un
estimado por generalizado bajo supuestos más débiles en comparación con el pareamiento;
e) presentan una teoría de distribución asintomática del estimador si necesidad de establecer
supuestos sobre la distribución de los datos utilizados.
La aproximación de estos autores respecto de la literatura de evaluación previa a su estudio
incorpora tres factores importantes adicionales al supuesto de similitud distribución al de
las variables no observadas entre grupos de tratamiento y control. Estos factores son:
similitud distribución al de las variables observadas, que resuelven a través de métodos de
remuestreo; la aplicación de cuestionarios idénticos a cada uno de los grupos para la
medición tanto de las variables de control como de las variables de resultado; y la similitud
del entorno económico entre ambos grupos.
III. Datos
La Encuesta Nacional de Evaluación de Programas Productivos y de Empleo con
Perspectiva de Género (ENEPPEG) desarrollada por INMUJERES y PNUD tiene una
estructura longitudinal para el seguimiento de las y los beneficiarios de diversos programas
orientados a la inclusión productiva.
Esta encuesta se diseñó para realizar comparaciones entre grupos de tratamiento y control a
través de técnicas de pareamiento por propensión. Lo cual, a diferencia de otras encuestas,
permite aislar tendencias seculares en los datos para identificar los efectos de los
programas. Contiene información sobre 11 programas de empleo y proyectos productivos
(PEPP).10
Programa
10 Se enlistan los nombres de los programas tal como se denominaban en el 2010, año a partir del cual se construyó el marco de muestreo de la encuesta. Si
bien para el año 2016, algunos de estos programas han cambiado de nombre o se han fusionado entre sí o con algunos otros programas.

13
Programa
Programa de Empleo Temporal (PET): SCT, SEDESOL, SEMARNAT
Programa de la Mujer en el Sector Agrario (PROMUSAG-SRA)
Fondo para el Apoyo a Proyectos Productivos en Núcleos Agrarios (FAPPA- SRA)
Programa de Organización Productiva para Mujeres Indígenas (POPMI- CDI)
Programa de Opciones Productivas (SEDESOL)
Programa de Soporte al Sector Agropecuario (SAGARPA)
Programa de Conservación y Restauración de Ecosistemas Forestales (Proárbol- CONAFOR)
Fondo de Microfinanciamiento a Mujeres Rurales (FOMMUR- SE)
Programa Nacional de Financiamiento al Microempresario (PRONAFIM- SE)
Fondo Nacional de Apoyos para Empresas en Solidaridad (FONAES- SE) 11
Programa de Apoyo al Empleo (PAE- STPS)
Su marco de muestreo fueron los padrones de beneficiarios de los programas sociales para
el año 2010. La muestra estadística de la encuesta fue diseñada con representatividad
nacional y por sexo para la población beneficiaria de los programas. Durante 2011 y 2012
recolectó datos retrospectivos para 2010 y datos relativos a un periodo de referencia para
2011 y 2012, a nivel de personas, hogares, viviendas y entorno.
La muestra total de la ENEPPEG comprende 5,913 entrevistas a población beneficiaria, o
grupo de tratamiento o intervención; y dos muestras para la población de control. Estas
últimas se levantaron mediante dos distintas metodologías: en las mismas localidades
seleccionadas para la muestra de tratamiento y en localidades donde no hubo presencia de
alguno de los programas a evaluar. Las muestras de control comprenden un total de 3,699
entrevistas, 2,112 pertenecen al primer grupo de localidades, y 1,587 al segundo grupo. El
levantamiento se desarrolló en un total de 378 localidades ubicadas a lo largo del territorio
nacional (INMUJERES-PNUD, 2012).12
En el caso de la población joven, se utilizó un
total de 1,329 casos de tratamiento y 917 casos de control.
Contiene datos sobre las características socioeconómicas de los hogares y sus integrantes
(incluida la identificación de población indígena); las viviendas; la posesión de activos de
los integrantes del hogar (por sexo); ingresos por trabajo, transferencias privadas y apoyos
de programas públicos; apoyos de programas sociales (en el año previo a la entrevista); y
uso del tiempo. Particularmente, en relación con los PEPP y los objetivos a los que se
orientan, cuenta con información sobre los siguientes indicadores: i) participación
económica 2010 (mes de referencia de la entrevista 2011), 2011 y 2012 (trabajo durante el
mes previo a la entrevista); ii) ocupación 2010, 2011, 2012; iii) características de la unidad
económica en la que trabajan 2010, 2011, 2012; iv) razones de no trabajo 2010, 2011,
2012; iv) tiempo destinado a trabajar 2010 (semana típica), 2011 y 2012 (semana previa a
la entrevista); v) ingresos por trabajo 2010, 2011, 2012; vi) adquisición de herramientas de
trabajo 2011 (año previo), 2012; vii) aversión al riesgo 2011; viii) barreras a la
11 Este programa se denominaba en el año 2012 “Fondo Nacional de Apoyos para Empresas en Solidaridad (FONAES)” y era operado por la Secretaría
de Economía (SE). Cambió de denominación en el año 2013, bajo el nombre “Programa de Fomento a la Economía Social” según se especifica el
Presupuesto de egresos de la federación 2012 y 2013, en el apartado de Programas presupuestarios en clasificación económica. A partir de 2016 es el
principal programa a cargo del INAES, que ha sido re sectorizado de la SE a la Secretaría de Desarrollo Social (SEDESOL) según se establece en el
Presupuesto de egresos de la federación 2016 y sus anexos.
12 INMUJERES-PNUD (2012).

14
participación productiva 2011, 2012; ix) cohesión social, redes 2011; x) género, autonomía
y toma de decisiones, 2011; xi) operación de programas: requisitos, difusión y acceso,
utilización de recursos del programa, tipos de apoyo, capacitación, inserción productiva y
tipo de actividad, continuidad de la actividad productiva, razones de abandono de la
actividad productiva, monto del apoyo, repago, aportación colateral y préstamos, ingresos
obtenidos, ventas, gastos y uso de ganancias, 2010, 2011.
IV. Estimación y ajuste
A pesar que se conoce por diseño que la muestra que compone la ENEPPEG no proviene
de una asignación aleatorizada a partir de un diseño experimental, se obtendrán las
estadísticas descriptivas y pruebas de hipótesis con el fin de ilustrar los sesgos potenciales
de comparación y, en su caso, la pertinencia de utilizar la técnica de PPP.
Las variables en pueden no incluir todas las variables utilizadas para la asignación del
tratamiento, ya sea porque se desconocen o no se encuentran a disposición en los datos que
se analizan.13
De forma que es necesario elegir de entre las variables de que se dispone. El
Cuadro 2 muestra los promedios estimados de un conjunto de variables pre-tratamiento o
cuasi-fijas. Las diferencias observadas en los promedios señalan importantes sesgos entre
las características de los grupos de tratamiento y de control originales. A excepción de las
variables que caracterizan la propiedad de la vivienda, la disponibilidad de cuarto para
cocinar, la disponibilidad de agua y drenaje, el resto de las variables presentan diferencias
estadísticamente significativas al nivel del 99%.
Es decir, existen sesgos que de no corregirse generarían un estimador sesgado del efecto de
tratamiento. De ahí la pertinencia de utilizar el PPP para construir un grupo de control
óptimo. En la sección de resultados se ejemplificarán los sesgos potenciales.
En la estimación del PPP se utiliza el modelo logit que se muestra en el
13 En el caso particular que analizamos dado que los criterios de asignación de apoyos de los diferentes programas son heterogéneos y no siempre están
claramente definidos esto es evidente.

15
Cuadro 3. Se consideran los conjuntos de datos de potenciales controles tanto en
localidades en donde operan los programas, como en localidades en donde no hubo
intervención de estos programas. La especificación del modelo es simple, no incluye
interacciones entre las variables ni segmentaciones de la población por grupos dado que el
tamaño de la muestra es relativamente pequeño para el número de celdas que generan las
distintas categorías de las variables explicativas del modelo.
Con esta especificación, el modelo cumple las propiedades de balanceo e independencia
condicional de acuerdo con la rutina desarrollada por Becker e Ichino (2002), así como la
generación de un área común de soporte. Es decir, que los resultados obtenidos en las
variables sobre las que se pretenda medir el efecto del tratamiento son independientes de la
asignación misma del tratamiento una vez que se condiciona sobre el modelo de PPP; y que
individuos distintos, , con los mismos valores de tienen una probabilidad positiva
de pertenecer a cualquiera de los grupos de tratamiento o control.
La significancia estadística del modelo de PPP utilizado se verifica mediante una prueba de
diferencia de log-verosimilitud respecto de un modelo nulo (Cuadro 5). Adicionalmente se
probó la significancia del modelo de PPP respecto de un modelo que excluye el conjunto de
variables que no resultaron significativas. En ambos casos el modelo PPP resultó en una
mejor especificación.
En la gráfica 2 se observa la distribución del pscore del modelo PPP para los grupos de
tratamiento y control en relación a los bloques que define el modelo. Se puede observar la
concentración de los casos en los bloques 1 a 3, con mayor densidad de casos en el bloque
tres para el grupo de tratamiento y relativamente pocos casos de control en los bloques 4 a
7 en relación a la densidad de tratamiento. Esto sugiere que la utilización de un pareamiento
por estratos o bloques puede ser adecuada, pero el calculo del estimador kernel aporta
precisión al considerar la muestra completa de controles con distintos ponderadores para el
cálculo de efectos cuando el pscore es mayor a 0.2. Al observarse menor densidad de casos
en el grupo de control en la parte superior de la distribución, el estimador kernel constituye
una mejor opción para el calculo de efectos dado que ocupa más casos muestrales.
El Gráfica 2. Distribución del pscore por bloques, según tratamiento y control

16
Cuadro 6 muestra las tasas de predicción del modelo nulo y el del PPP. El modelo nulo
carece de posibilidades de predicción, dado que los indicadores de sensibilidad y
especificidad se ubican en los extremos 0 ó 100. En tanto que la sensibilidad del modelo de
PPP es 64.26% y su especificidad 64.72%, con una tasa de predicción total de 64.7%.
Aunque la tasa es relativamente reducida, las limitaciones en la disponibilidad de
covariables pretratamiento y la necesidad de balancear el modelo no permiten lograr un
mejor ajuste.
V. Resultados
Los coeficientes del modelo de PPP del Cuadro 7 indican que el desbalance original de los
datos se asocia con una menor probabilidad de encontrarse en el grupo de tratamiento para
los hombres; y quienes cuentan con al menos un grado escolar de secundaria o tienen más
escolaridad. Por el contrario, quienes tienen mayor probabilidad son las personas que
hablan alguna lengua indígena. El resto de las variables resultan no significativas, pero se
decidió mantenerlas en el modelo para fines de comparación de la estimación de efectos del
tratamiento con la totalidad de la población de todos los grupos de edad.
En el Cuadro 8 se muestran los promedios y la diferencia de medias en los grupos de
tratamiento y control originales para las dos variables en las que se medirá el efecto del
tratamiento: la participación laboral y el ingreso laboral mensual. En ambos casos se
muestra el promedio para el año 2010, que es el momento pre-tratamiento, y el 2011 y
2012, uno y dos años después de la intervención de los programas. Todas las diferencias
resultan estadísticamente significativas, a excepción de las correspondientes a la
05
10
15
0 .2 .4 .6 0 .2 .4 .6
0 1
De
nsi
ty
PSMGraphs by 1 tratamiento
0: control 1: tratamiento
PSM según tratamiento y control

17
participación laboral 2011 y 2012. De no realizarse la corrección a partir del estimador de
dobles diferencias, los efectos derivados de comparar el grupo de tratamiento y control en
el año 2011 y 2012 podrían indicar la inexistencia de efectos sobre la participación laboral
de los jóvenes y el decrecimiento estadísticamente significativo del ingreso laboral.
Aún con el sesgo original que se observa en el año 2010, la construcción de un grupo de
control apropiado utilizando el score o puntaje generado a partir del modelo de PPP
estimado produce un efecto de tratamiento sobre los tratados ATT estadísticamente
significativo, equivalente a 8.4% sobre la probabilidad de encontrarse empleado en el año
2011. Y de 12.9% en el 2012 (Cuadro 9).
Sin embargo, la información disponible en la ENEPPEG permite un refinamiento adicional
en la estimación de los efectos de los programas, ya que proporciona datos sobre las
variables de impacto en un momento pre-tratamiento. Metodológicamente esto significa la
posibilidad de generar indicadores de dobles diferencias, que proporcionan información
más robusta, pues permite la corrección del sesgo pre-tratamiento al utilizar la condición de
participación laboral y los ingresos en el año 2010.
Para calcular el efecto a partir de un estimador de dobles diferencias se utilizan las
diferencias pre y post tratamiento que se muestran en el Cuadro 8, tanto para la
participación laboral, como para los ingresos. Las diferencias pre-tratamiento son
estadísticamente significativas en ambos casos, correspondientes a -11% en el caso de la
particiáción laboral, y -1,103 pesos en el caso del ingreso. Estas diferencias pueden
producir ajustes al estimador final de efecto. Por lo que utilizar el estimador de dobles
diferencias aporta precisión a la medición del efecto.
A partir de los estimadores de dobles diferencias que se muestran en el Cuadro 9, el efecto
sobre la participación laboral se estima en 14% y es significativo para el año 2012. Como
se señaló, si no se utilizara la información pre-tratamiento, el efecto calculado a partir de un
estimador simple se habría estimado en 12.9%. En el caso del ingreso el efecto es negativo
y de mucho mayor magnitud al utilizar el estimador de dobles diferencias, pero no resulta
significativo.
Estas variaciones reflejan la relevancia del PPP y de la aplicación de la metodología de
dobles diferencias, que pudieron aplicarse gracias a la existencia de datos pre-tratamiento
sobre distintas covariables y las variables de impacto. El efecto sobre la participación
laboral final es estadísticamente significativo y representa tres veces el efecto que se habría
estimado de haber preservado el grupo de control original sin considerar el valor de la línea
de base. En tanto, el efecto sobre los ingresos resulta no significativo, en contraste con el
estimador original.
Las implicaciones que tienen los refinamientos metodológicos son especialmente
importantes porque los resultados de la estimación de efectos de uno o más programas
sociales pueden conducir a conclusiones incorrectas y decisiones erróneas sobre la
pertinencia de mantener, transformar o eliminar un programa. En el caso que nos ocupa,
haber soslayado los aspectos metodológicos habría llevado a concluir que los programas no
tuvieron efectos significativos sobre el empleo y tuvieron efectos negativos y

18
estadísticamente significativos sobre los ingresos. En contraste, la conclusión es que tienen
un efecto significativo de 14% sobre la participación laboral, pero no tienen efectos
significativos sobre los ingresos al nivel de significancia considerado, si bien podrían ser
potencialmente negativos a otros niveles de significancia.

19
VI. Conclusiones
La aplicación de metodologías apropiadas en la evaluación de programas sociales es
indispensable para proveer información precisa para la toma de decisiones y el uso eficiente
de los recursos. Las variaciones atribuibles a la aplicación de distintas metodologías, el
cambio en la magnitud de los efectos estimados y su significancia pueden conducir a
conclusiones contradictorias. Esto obliga a considerar las metodologías de recolección de
datos y estimación que han demostrado ser más efectivas en la literatura sobre el tema.
La utilización del PPP es una alternativa que presenta ventajas sustantivas en el caso que se
analiza, debido a que el tratamiento no proviene de un diseño aleatorizado. Su aplicación
permitió la corrección de la estimación de efectos de tratamiento inducida por sesgos de
selección. La combinación del PPP con la aplicación de dobles diferencias condujo a contar
con estimadores más robustos basados en información pre y post tratamiento.
Existen diversas limitaciones en los datos y la técnica utilizada. Aunque las primeras no
pueden ser subsanadas en este conjunto de datos, proveen evidencia para mejorar la calidad
de la evaluación en futuras investigaciones. Las segundas pueden ser exploradas a partir de
modelos econométricos más complejos diseñados para el análisis de tratamientos múltiples
si se cuenta con muestras de tamaño suficiente. No obstante, debido a la disponibilidad de
una muestra pequeña de datos para este grupo de edad, la finalidad del análisis realizado
fue únicamente estimar el efecto conjunto de diversas intervenciones gubernamentales, más
que la comparación de efectos entre tratamientos múltiples.
Los resultados obtenidos reflejan la existencia de efectos positivos sobre la participación
laboral de los jóvenes en un periodo de dos años posterior al inicio del tratamiento. Pero no
se registran resultados a un año de iniciado. El efecto de los programas sobre el ingreso
laboral no resultó significativo en ningún caso.

20
VII. Referencias
Althauser, R. P., y Rubin, D. (1971). “Measurement error and regression to the mean in
matched samples”. Social Forces, 50,206-214
Becker, Sascha O. y Andrea Ichino (2002) “Estimation of average treatment effects based
on propensity scores” The Stata Journal Volume 2 Number 4: pp. 358-377.
Barnow, B., Cain, G. y Goldberger, A. (1981). “Issues in the analysis of selectivity bias”,
Evaluation studies, 5, E. W Stromsdorfer/G. Farkus (eds).
CONEVAL (2009) “Seguimiento a aspectos susceptibles de mejora derivados de las
evaluaciones externas Fondo de Apoyo para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2008/Secretar%C3%ADa%2
0de%20la%20Reforma%20Agraria/DT_SRA_NUCLEOS.pdf
CONEVAL. López Cervantes, C (2013) “Ficha de Monitoreo 2013 Fondo de Apoyo para
Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/Informes/Evaluacion/Ficha_Monitoreo_Evaluacion_20
13/SAGARPA/08_S089.pdf
CONEVAL. Soto, J M. (2014) “Ficha de Monitoreo 2014 Fondo de Apoyo para Proyectos
Productivos (FAPPA)”
http://www.coneval.org.mx/Evaluacion/Documents/EVALUACIONES/FMyE_201
4_2015/SAGARPA/S089/S089_FMyE.pdf
CONEVAL. Soto, J M. (2014) “Ficha de Monitoreo 2014 Programa de Apoyo para la
Productividad de la Mujer Emprendedora (PROMETE)”
http://www.coneval.org.mx/Evaluacion/Documents/EVALUACIONES/FMyE_201
4_2015/SAGARPA/S088/S088_FMyE.pdf
CONEVAL/ Academia Mexicana de Auditoría Integral y al Desempeño, A.C. Lozano
Dubernard, G (2008) “Informe Completo de la Evaluación Específica de
Desempeño 2008 Fondo de Apoyo para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/coneval/eval_mon/3898.pdf

21
CONEVAL/ Academia Mexicana de Auditoría Integral y al Desempeño, A.C. Lozano
Dubernard, G (2008) “Informe Ejecutivo de la Evaluación Específica de
Desempeño 2008 Fondo de Apoyo para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/coneval/eval_mon/3897.pdf
CONEVAL/ CIESAS, Gallart N, M A. (2013) “Informe Completo de la Evaluación
Específica de Desempeño 2012 – 2013 Fondo de Apoyo para Proyectos Productivos
(FAPPA)”
http://www.coneval.org.mx/Informes/Evaluacion/Especificas_Desempeno2012/SE
DATU/15_S089/15_S089_Completo.pdf
CONEVAL/ CIESAS, Gallart N, M A. (2013) “Informe Ejecutivo de la Evaluación
Específica de Desempeño 2012 – 2013 Fondo de Apoyo para Proyectos Productivos
(FAPPA)”
http://www.coneval.org.mx/Informes/Evaluacion/Especificas_Desempeno2012/SE
DATU/15_S089/15_S089_Ejecutivo.pdf
CONEVAL/ Colegio de Postgraduados, Jaramillo Villanueva, J L. (2010) “Informe
Completo de la Evaluación Específica de Desempeño 2009 – 2010 Fondo de Apoyo
para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/coneval/EVALUACIONES/especificas_de
sempeno/dependencias/SRA/SRA2A.pdf
CONEVAL/ Colegio de Postgraduados, Jaramillo Villanueva, J L. (2010) “Informe
Ejecutivo de la Evaluación Específica de Desempeño 2009 – 2010 Fondo de Apoyo
para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/coneval/EVALUACIONES/especificas_de
sempeno/dependencias/SRA/SRA2B.pdf
CONEVAL/ Colegio de Postgraduados, Jaramillo Villanueva, J L. (2011) “Informe
Completo de la Evaluación Específica de Desempeño 2010 – 2011 Fondo de Apoyo
para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/coneval/EVALUACIONES/EVALUACIO

22
NES_PROGRAMAS_POLITICAS_DS/EED_2010-
2011/SRA/FAPPA/Completo.pdf
CONEVAL/ Colegio de Postgraduados, Jaramillo Villanueva, J L. (2011) “Informe
Ejecutivo de la Evaluación Específica de Desempeño 2010 – 2011 Fondo de Apoyo
para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/coneval/EVALUACIONES/EVALUACIO
NES_PROGRAMAS_POLITICAS_DS/EED_2010-
2011/SRA/FAPPA/Ejecutivo.pdf
CONEVAL/ Consultores en Innovación Desarrollo y Estrategia Aplicada S.C. Soto, J M.
(2015) “Informe Completo de la Evaluación Específica de Desempeño 2014 – 2015
Fondo de Apoyo para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/Evaluacion/Documents/EVALUACIONES/EED_2014
_2015/SAGARPA/S089_FAPPA/S089_FAPPA_IC.pdf
CONEVAL/ Consultores en Innovación Desarrollo y Estrategia Aplicada S.C. Soto, J M.
(2015) “Informe Ejecutivo de la Evaluación Específica de Desempeño 2014 – 2015
Fondo de Apoyo para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/Evaluacion/Documents/EVALUACIONES/EED_2014
_2015/SAGARPA/S089_FAPPA/S089_FAPPA_IE.pdf
CONEVAL/AUC. Zepeda del Valle, J.M. Lara Reyes, U. (2009) “Evaluación Externa
Complementaria para medir los Indicadores de Fin y Propósito. Programa fondo
para el apoyo a proyectos productivos en núcleos agrarios (FAPPA 2008)”
Universidad Autónoma de Chapingo
http://www.coneval.org.mx/Informes/Evaluacion/Complementarias/Complementari
as_2009/SRA/compl_09_sra_FAPPA.pdf
CONEVAL/SEDATU (2013) “Ficha de Monitoreo 2012 – 2013 Fondo para el Apoyo a
Proyectos Productivos en Núcleos Agrarios (FAPPA)”
http://www.coneval.org.mx/Informes/Evaluacion/Ficha_Monitoreo_2012/SEDATU
/15_S089_FM.pdf

23
CONEVAL/SEDATU (2013) “Seguimiento a aspectos susceptibles de mejora clasificados
como específicos, derivados de informes y evaluaciones externas 2012 – 2013
Fondo para el Apoyo a Proyectos Productivos en Núcleos Agrarios (FAPPA)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2012/SEDATU/S089_FAPP
A/S089_DT.pdf
CONEVAL/SRA (2009) “Seguimiento a aspectos susceptibles de mejora derivados de las
evaluaciones externas 2007 Programa de la Mujer en el Sector Agrario
(PROMUSAG)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2008/Secretar%C3%ADa%2
0de%20la%20Reforma%20Agraria/DT_SRA_PROMUSAG.pdf
CONEVAL/SRA (2010) “seguimiento a aspectos susceptibles de mejora derivados de las
evaluaciones externas Fondo de Apoyo para Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2009/SRA/DT_S089_FAPP
A.pdf
CONEVAL/SRA (2010) “Seguimiento a aspectos susceptibles de mejora derivados de las
evaluaciones externas. Programa de la Mujer en el Sector Agrario (PROMUSAG)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2009/SRA/DT_S088_PROM
USAG.pdf
CONEVAL/SRA (2011) “Seguimiento a aspectos susceptibles de mejora clasificados como
específicos, derivados de informes y evaluaciones externas Programa de la Mujer en
el Sector Agrario (PROMUSAG)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2010/SRA/PROMUSAG_DT
CONEVAL/SRA (2012) “Evaluación de Consistencia y Resultados 2011-2012 Fondo de
Apoyo para Proyectos Productivos (FAPPA)”
http://web.coneval.gob.mx/Informes/Evaluacion/Consistencia/2011_2012/No_contr
atadas_por_CONEVAL/SRA/S_089_FAPPA/S_089_FAPPA.zip

24
CONEVAL/SRA (2012) “Seguimiento a aspectos susceptibles de mejora clasificados como
específicos, derivados de informes y evaluaciones externas Fondo de Apoyo para
Proyectos Productivos (FAPPA)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2011/SRA/DT_FAPPA.pdf
CONEVAL/SRA (2012) “Seguimiento a aspectos susceptibles de mejora clasificados como
específicos, derivados de informes y evaluaciones externas Programa de la Mujer en
el Sector Agrario (PROMUSAG)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2011/SRA/DT_PROMUSAG
CONEVAL/SRA (2013) “Seguimiento a aspectos susceptibles de mejora clasificados como
específicos, derivados de informes y evaluaciones externas Programa de la Mujer en
el Sector Agrario (PROMUSAG)”
http://www.coneval.org.mx/rw/resource/Mecanismos_2012/SEDATU/S088_PROM
USAG/S088_DT.pdf
Caliendo, M. y Sabine Kopeinig (2005). “Some Practical Guidance for the Implementation
of Propensity Score Matching”. IZA Discussion Paper No. 1588
Cochran, W., (1972), “Observational Studies,” in Statistical Papers in Honor of George W.
Snedecor, ed. T.A. Bancroft, 1972, Iowa State University Press, pp. 77-90, reprinted
in Observational Studies, 2015.
Hahn, Jinyong, Petra Todd y Wilbert Van der Klaauw, 1999. "Evaluating the Effect of an
Antidiscrimination Law Using a Regression-Discontinuity Design," NBER
Working Papers 7131, National Bureau of Economic Research, Inc.
Heckman J. J. (1974), “Shadow Wages, Market Wages and Labor Supply”, Econometrica
42, 679–693.
Heckman J. J. (1976), “The Common Structure of Statistical Models of Truncation, Sample
Selection and Limited Dependent Variables and a Simple Estimator for Such
Models”, Annals of Economic and Social Measurement 5, 475–492.

25
Heckman J. J. (1979), “Sample Selection Bias as a Specification Error”, Econometrica 47,
153–161
Heckman, J., Ichimura, H. y Petra Todd (1997). “Matching as an econometric evaluation
estimator: Evidence from evaluating a job training program”. Review of Economic
Studies 64 (4), 605–654.
Heckman, J., Ichimura, H. y Petra Todd (1998a). “Matching as an econometric evaluation
estimator”. Review of Economic Studies 65 (2), 261–294.
Heckman, J., Ichimura, J. Smith y Petra Todd (1998) “Characterizing Selection Bias Using
Experimental Data”. Econometrica, Vol. 66, No. 5. (Sep., 1998), pp. 1017-1098.
Heckman, J. J., Lalonde, R. J., y Smith, J. A. (1999). Capítulo 31 “The economics and
econometrics of active labor market programs”. Handbook of Labor Economics, 3
Part(1), 1865-2097.
Heckman, J.J. y R. Robb. (1986)“Alternative methods for solving the problem of selection
bias in evaluating the impact of treatments on outcomes.” En: Wainer, H., Editor.
Drawing Inferences from Self-Selected Samples. New York: Springer-Verlag;
Mahwah, NJ: Lawrence Erlbaum Associates; pp. 63-107.Reprinted in 2000.
Iacus, S., King, G., y Porro, G. (2011a). “Causal Inference without Balance Checking:
Coarsened Exact Matching”. Political Analysis, 20(1), pp. 1-24. Cambridge
University Press.
_______________________ (2011b). “Multivariate Matching Methods That Are
Monotonic Imbalance Bounding”. American Statistical Association Journal of the
American Statistical Association March 2011, Vol. 106, No. 493, Theory and
Methods.
Ichimura, Hidehiko y Petra E. Todd, (2006). "Implementing Nonparametric and
Semiparametric Estimators," CIRJE F-Series CIRJE-F-452, CIRJE, Faculty of
Economics, University of Tokyo.

26
Imbens y Wooldridge (2007). “What’s New in Econometrics?”, NBER, Summer 2007
Lecture 10 notes. <http://www.nber.org/WNE/lect_10_diffindiffs.pdf>
INMUJERES-PNUD (2012). “Resultados de la evaluación estratégica con perspectiva de
género de los programas de empleo y proyectos productivos” Cuadernos de trabajo
sobre género N° 34, INMUJERES.
<http://www.gob.mx/inmujeres/documentos/cuadernos-de-trabajo-sobre-genero>
King, Gary y Richard Nielsen. Working Paper. “Why Propensity Scores Should Not Be
Used for Matching”. Accedido electrónicamente en http://j.mp/2ovYGsW
Maddala, G.S. y L. Lee, 1976. “Recursive Models with Qualitative Endogenous Variables”.
Annals of Economic and Social Measurement. 5: 525 - 545.
Orozco, M. y Carlos Salgado (2010). Documento conceptual sobre el proyecto
“Levantamiento de información y evaluación de los programas de trabajo,
proyectos productivos y de enfoque social, desde una perspectiva de género”.
Mimeo
Orozco, M. (2016). Caracterización de la Encuesta Nacional de Evaluación de Programas
Productivos y de Empleo con Perspectiva de Género (ENEPPEG). Mimeo
Rosenbaum, P. R. (2002), Observational Studies (2nd ed.), New York: Springer.
Rosenbaum, P. R. y Donald B. Rubin, 1983. "The Central Role of the Propensity Score in
Observational Studies for Causal Effects". Biometrika, Vol. 70, No. 1. (Apr., 1983),
pp. 41-55
Rosenbaum, Paul R. y Donald B. Rubin, 1985. "Constructing a Control Group Using
Multivariate Matched Sampling Methods that Incorporate the Propensity Score".
The American Statistician, Vol. 39. No. 1. (February, 1985), pp. 33-38.
Smith, J. y Petra Todd (2000). “Does Matching Overcome Lalonde’s Critique of
Nonexperimental Estimators?” PIER Working Paper 01-035.

27
Zaiontz, Charles (2013-2016). Real statistics using excel. <http://www.real-statistics.com/
>

28
VIII. Anexo
Cuadro 1. Programas de generación de empleo e ingresos según su tipo
Políticas Activas
de Empleo
Impulso a
PyME’s
Basadas en la
Comunidad
Programa de Empleo Temporal (PET-
SCT, SEDESOL, SEMARNAT)
X X X
Programa de la Mujer en el Sector Agrario
(PROMUSAG-SRA)
X
Fondo para el Apoyo a Proyectos Productivos
en Núcleos Agrarios (FAPPA- SRA)
X
Programa de Organización Productiva para
Mujeres Indígenas (POPMI- CDI)
X
Programa de Opciones Productivas
(SEDESOL)
X X
Programa de Soporte al Sector Agropecuario
(SAGARPA)
X
Programa de Conservación y Restauración de
Ecosistemas Forestales (Proárbol-
CONAFOR)
X X
Fondo de Microfinanciamiento a Mujeres
Rurales (FOMMUR- SE)
X
Programa Nacional de Financiamiento al
Microempresario (PRONAFIM- SE)
X
Fondo Nacional de Apoyos para Empresas en
Solidaridad (FONAES- SE)
X
Programa de Apoyo al Empleo (PAE- STPS) X
Estancias Infantiles (SEDESOL) X X
Fuente: extraído de Orozco y Salgado (2010)
Cuadro 2. Estadísticas descriptivas de las variables para el PPP.
Tratamiento Control Diferencia
Variable n Promedio n Promedio dif p
1 tratamiento 1,356 1.00 926 0.00 1.00
1 hombre 1,356 0.46 926 0.66 -0.20 0.000
edad 1,356 24.64 926 23.72 0.91 0.000
edad al cuadrado 1,356 617.54 926 575.01 42.53 0.000
1 lengua indígena 1,354 0.22 925 0.11 0.11 0.000
1 vivienda rentada 2010 1,356 0.12 924 0.21 -0.09 0.000
1 vivienda prestada 2010 1,356 0.24 924 0.19 0.04 0.011
1 vivienda propia pero la están
pagando 2010 1,356 0.02 924 0.01 0.01 0.046
1 vivienda propia 2010 1,356 0.60 924 0.56 0.04 0.042
1 vivienda intestada o en litigio 2010 1,356 0.00 924 0.00 0.00 0.150
otra 2010 1,356 0.02 924 0.03 -0.01 0.041
1 vivienda rentada 2011 1,355 0.12 924 0.21 -0.09 0.000

29
Tratamiento Control Diferencia
Variable n Promedio n Promedio dif p
1 vivienda prestada 2011 1,355 0.23 924 0.19 0.04 0.015
1 vivienda propia pero la están
pagando 2011 1,355 0.02 924 0.01 0.01 0.012
1 vivienda propia 2011 1,355 0.61 924 0.56 0.04 0.036
1 vivienda intestada o en litigio 2011 1,355 0.00 924 0.00 0.00 0.150
otra 2011 1,355 0.02 924 0.03 -0.01 0.061
1 hay lugar para cocinar en la vivienda
2010 1,355 0.95 926 0.93 0.02 0.038
1 hay lugar para cocinar en la vivienda
2011 1,354 0.95 926 0.92 0.03 0.001
1 estufa en el hogar 1,356 0.46 926 0.64 -0.18 0.000
1 agua de la red pública dentro de la
vivienda 2010 1,354 0.69 925 0.80 -0.11 0.000
1 agua de la red pública fuera de la
vivienda 2010 1,354 0.15 925 0.09 0.05 0.000
1 agua de la red pública de otra
vivienda 2010 1,354 0.01 925 0.01 0.00 0.621
1 agua de la llave pública o hidrante
2010 1,354 0.02 925 0.01 0.01 0.037
1 agua de pipa 2010 1,354 0.01 925 0.00 0.00 0.596
1 agua de pozo 2010 1,354 0.12 925 0.07 0.05 0.000
1 agua de río, arroyo, lago u otro 2010 1,354 0.02 925 0.02 0.00 0.778
1 agua de la red pública dentro de la
vivienda 2011 1,353 0.69 924 0.80 -0.11 0.000
1 agua de la red pública fuera de la
vivienda 2011 1,353 0.14 924 0.10 0.05 0.000
1 agua de la red pública de otra
vivienda 2011 1,353 0.01 924 0.01 0.00 0.622
1 agua de la llave pública o hidrante
2011 1,353 0.02 924 0.01 0.01 0.039
1 agua de pipa 2011 1,353 0.00 924 0.00 0.00 0.864
1 agua de pozo 2011 1,353 0.12 924 0.07 0.05 0.000
1 agua de río, arroyo, lago u otro 2011 1,353 0.02 924 0.02 0.00 0.876
1 drenaje de red pública 2010 1,355 0.62 926 0.77 -0.15 0.000
1 drenaje de fosa séptica 2010 1,355 0.27 926 0.17 0.11 0.000
1 drenaje de tubería que da a una
barranca o grieta 2010 1,355 0.01 926 0.00 0.00 0.178
1 drenaje de tubería que da a un lago,
río o mar 2010 1,355 0.01 926 0.01 0.00 0.847
sin drenaje 2010 1,355 0.08 926 0.05 0.04 0.000
1 drenaje de red pública 2011 1,353 0.62 926 0.77 -0.15 0.000
1 drenaje de fosa séptica 2011 1,353 0.27 926 0.17 0.11 0.000
1 drenaje de tubería que da a una
barranca o grieta 2011 1,353 0.01 926 0.01 0.00 0.451
1 drenaje de tubería que da a un lago,
río o mar 2011 1,353 0.01 926 0.01 0.00 0.849
1 sin drenaje 2011 1,353 0.08 926 0.05 0.04 0.000
1 sin escolaridad 1,331 0.05 920 0.01 0.05 0.000

30
Tratamiento Control Diferencia
Variable n Promedio n Promedio dif p
1 preescolar 1,331 0.01 920 0.00 0.01 0.003
1 algún grado de primaria 1,331 0.21 920 0.13 0.08 0.000
1 algún grado de secundaria 1,331 0.32 920 0.38 -0.05 0.009
1 algún grado de media superior 1,331 0.28 920 0.34 -0.06 0.002
1 algún gradeo de normal, profesional
o más 1,331 0.13 920 0.15 -0.02 0.121
hacinamiento 2010 1,349 2.57 921 2.21 0.36 0.000
hacinamiento 2011 1,352 2.55 922 2.16 0.38 0.000
número de niños de 0 a 5 en el hogar 1,356 0.77 926 0.62 0.15 0.000
número de niños de 6 a 12 en el hogar 1,356 0.52 926 0.39 0.12 0.000
número de personas de 65 y más en el
hogar 1,356 0.10 926 0.05 0.05 0.000
Grado de marginación 1,356 7.63 0
7.63
1 muy alta marginación 2005 1,356 0.07 926 0.02 0.04 0.000
1 alta marginación 2005 1,356 0.30 926 0.13 0.17 0.000
1 media marginación 2005 1,356 0.12 926 0.09 0.03 0.010
1 baja marginación 2005 1,356 0.17 926 0.16 0.01 0.531
1 muy baja marginación 2005 1,356 0.34 926 0.60 -0.26 0.000
Fuente: elaboración propia con base en la ENEPPEG 2011.
Nota:Datos ponderados. Puebas de significancia calculadas con n muestrales.

31
Cuadro 3. Modelo logit, PPP
Estimation of the propensity score
(sum of wgt is 2.1682e+03)
Iteration 0: log pseudolikelihood = -400.13195
Iteration 1: log pseudolikelihood = -383.81839
Iteration 2: log pseudolikelihood = -378.2934
Iteration 3: log pseudolikelihood = -378.20558
Iteration 4: log pseudolikelihood = -378.20549
Logistic regression Number of obs = 2246
Wald chi2(7) = 57.17
Prob > chi2 = 0.0000
Log pseudolikelihood = -378.20549 Pseudo R2 = 0.0548
Robust
tratcon Coef. Std. Err. z P>z [95% Conf. Interval]
1 hombre -0.9453754 0.1895005 -4.99 0 -1.31679 -0.5739613
edad 0.3505632 0.4355321 0.8 0.421 -0.5030641 1.20419
edad al cuadrado -0.0055453 0.0092226 -0.6 0.548 -0.0236212 0.0125306
1 lengua indígena 0.7403715 0.2630109 2.81 0.005 0.2248797 1.255863
1 vivienda propia 2010 0.2012219 0.1927023 1.04 0.296 -0.1764676 0.5789114
1 sin escolaridad 1.73865 0.5761723 3.02 0.003 0.6093734 2.867927
número de niños de 0 a 5 en el hogar -0.0060964 0.120468 -0.05 0.96 -0.2422094 0.2300165
_cons -7.997888 5.031864 -1.59 0.112 -17.86016 1.864384
Cuadro 4. Modelo nulo
Iteration 0: log likelihood = -1256863.8
Iteration 1: log likelihood = -1256863.8
Logistic regression
Number of obs = 7,054,963
LR chi2(0) = 0.00
Prob > chi2 = .
Log likelihood = -1256863.8 Pseudo R2 = 0.0000
------------------------------------------------------------------------------
tratcon | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_cons | -3.096432 .0018507 -1673.11 0.000 -3.10006 -3.092805
------------------------------------------------------------------------------

32
Gráfica 1. Sensibilidad y especificidad del modelo PPP
Nota: Sensibilidad es la probabilidad de clasificación como tratamiento dado que en efecto es un tratamiento. Especificidad es la probabilidad de
clasificación como control dado que es control.

33
Cuadro 5. Pruebas de diferencia de log-verosimilitud
Modelo PPP vs modelo nulo
Likelihood-ratio test LR chi2(7) = 171340.32
(Assumption: m0 nested in m1) Prob > chi2 = 0.0000
Akaike's information criterion and Bayesian information criterion
Model Obs ll(null) ll(model) df AIC BIC
m0 7161524 -1273660 -1273660 1 2547323 2547336
m1 7054963 -1256864 -1187990 8 2375996 2376106
Note: N=Obs used in calculating BIC; see [R] BIC note.
Gráfica 2. Distribución del pscore por bloques, según tratamiento y control
Cuadro 6. Tasa de predicción del modelo PPP
Modelo nulo
Classified + if predicted Pr(D) >= .5
True D defined as tratcon != 0
Sensitivity Pr( +| D) 0.00%
Specificity Pr( -|~D) 100.00%
05
10
15
0 .2 .4 .6 0 .2 .4 .6
0 1
De
nsi
ty
PSMGraphs by 1 tratamiento
0: control 1: tratamiento
PSM según tratamiento y control
34
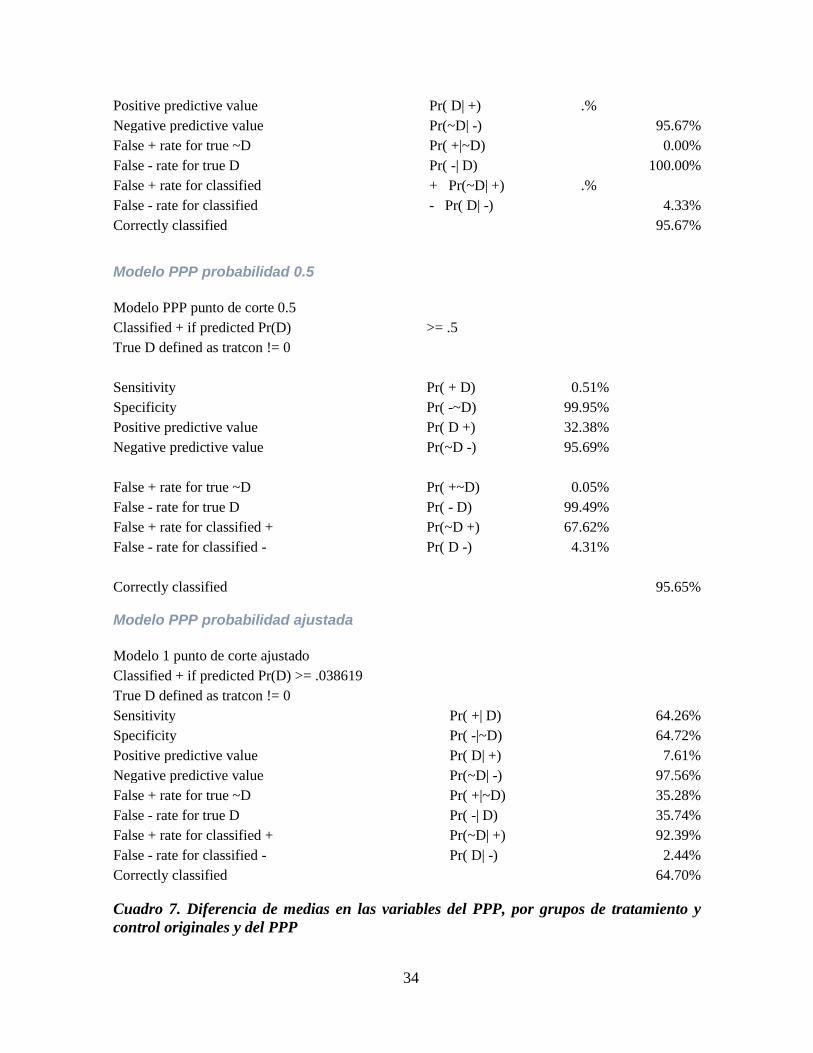
Positive predictive value Pr( D| +) .%
Negative predictive value Pr(~D| -) 95.67%
False + rate for true ~D Pr( +|~D) 0.00%
False - rate for true D Pr( -| D) 100.00%
False + rate for classified + Pr(~D| +) .%
False - rate for classified - Pr( D| -) 4.33%
Correctly classified 95.67%
Modelo PPP probabilidad 0.5
Modelo PPP punto de corte 0.5 Classified + if predicted Pr(D) >= .5
True D defined as tratcon != 0
Sensitivity Pr( + D) 0.51% Specificity Pr( -~D) 99.95% Positive predictive value Pr( D +) 32.38% Negative predictive value Pr(~D -) 95.69%
False + rate for true ~D Pr( +~D) 0.05% False - rate for true D Pr( - D) 99.49% False + rate for classified + Pr(~D +) 67.62% False - rate for classified - Pr( D -) 4.31%
Correctly classified
95.65%
Modelo PPP probabilidad ajustada
Modelo 1 punto de corte ajustado
Classified + if predicted Pr(D) >= .038619
True D defined as tratcon != 0
Sensitivity Pr( +| D) 64.26%
Specificity Pr( -|~D) 64.72%
Positive predictive value Pr( D| +) 7.61%
Negative predictive value Pr(~D| -) 97.56%
False + rate for true ~D Pr( +|~D) 35.28%
False - rate for true D Pr( -| D) 35.74%
False + rate for classified + Pr(~D| +) 92.39%
False - rate for classified - Pr( D| -) 2.44%
Correctly classified 64.70%
Cuadro 7. Diferencia de medias en las variables del PPP, por grupos de tratamiento y
control originales y del PPP

35
Variable Tratamiento Control Diferencia
estandarizada
Tratamiento del
PPP
Control del
PPP
Diferencia
estandarizada
1 hombre 0.54 0.73 -0.423 0.54 0.73 -0.414
edad 24.51 24.22 0.092 24.51 24.23 0.089
edad al cuadrado 610.56 596.28 0.095 610.39 596.53 0.092
1 lengua indígena 0.21 0.17 0.107 0.2 0.17 0.093
1 vivienda propia 2010 0.6 0.58 0.057 0.61 0.58 0.056 1 hay lugar para cocinar en
la vivienda 2010 0.93 0.94 -0.035 0.93 0.94 -0.038
1 sin escolaridad 0.03 0.01 0.149 0.01 0 0.096 número de niños de 0 a 5 en
el hogar 0.64 0.72 -0.112 0.64 0.72 -0.111
1 muy alta marginación 2005 0.06 0.06 -0.019 0.05 0.06 -0.038
1 alta marginación 2005 0.32 0.38 -0.131 0.32 0.38 -0.126
1 media marginación 2005 0.13 0.17 -0.124 0.13 0.17 -0.12
1 baja marginación 2005 0.15 0.17 -0.048 0.15 0.17 -0.05 1 muy baja marginación
2005 0.34 0.22 0.289 0.35 0.22 0.293

36
Cuadro 8. Diferencia de medias en las variables de impacto para los grupos de
tratamiento y control originales
Variable n Promedio n Promedio Diferencia T-C Sign
Participación laboral 2010 1,329 0.59 917 0.70 -0.11 ***
Participación laboral 2011 1,329 0.70 917 0.71 -0.02 NS
Participación laboral 2012 1,238 0.82 765 0.80 0.02 NS
Ingreso 2010 714 3,767 528 4,870 -1103.64 ***
Ingreso 2011 858 3,129 545 3,867 -737.48 ***
Ingreso 2012 777 5,005 434 6,018 -1012.23 **
Cuadro 9. Efecto sobre los tratados ATT
Diferencias T-C
Trabajo n tratamiento n control ATT Error estándar t
2010 1329 917 -0.011 0.022 -0.496
2011 1329 917 0.084 0.019 4.475
2012 1329 917 0.129 0.021 6.138
Ingreso
2010 1329 917 219.638 351.809 0.624
2011 1329 917 -217.358 223.163 -0.974
2012 1329 917 -60.656 394.907 -0.154
Horas de trabajo remunerado
2010 1329 917 -3.762 1.096 -3.432
2011 1329 917 -3.131 0.825 -3.797
2012 1329 917 -1.888 0.865 -2.182
Horas de trabajo doméstico no remunerado
2011 1329 917 3.314 2.059 1.609
2012 1329 917 -2.316 2.872 -0.807
Horas de cuidados
2011 1329 917 0.415 2.051 0.202
2012 1329 917 -2.192 3.322 -0.660
Dif (T1-C1) ATT
error estándar=s/raíz(n)
DS (T1-T0)
t=x1-x2/raiz(s1**2/n1+s2**2/n2)
DD (T1-T0)-(C1-C0) o (T1-C1)-(T0-C0)
t=x1-x2/raiz(error estandar1**2+error estándar2**2)

37
Dobles diferencias
Trabajo
DD t Sign al 0.01
2011-2010
0.095 0.462 NS
2012-2011
0.045 1.589 NS
2012-2010
0.14 4.603 ***
Ingresos
2011-2010
-436.996 -1.049 NS
2012-2011
156.7 0.345 NS
2012-2010
-280.294 -0.529 NS
Fuente: elaboración propia con base en la ENEPPEG (2011).