un estudio empírico de micro algoritmos inspirados en la...
TRANSCRIPT

Laboratorio Nacional de Informática Avanzada
Centro de Enseñanza LANIA
Un Estudio Empírico de Micro Algoritmos
Inspirados en la Naturaleza en la Minimización de
Inestabilidad Cíclica en Ambientes Inteligentes.
T E S I S
Que presentaLucía Yunuén Juárez López
Para obtener el grado deMaestra en Computación Aplicada
Directores de TesisDr. Efrén Mezura Montes
Dr. Víctor Manuel Zamudio Rodríguez
Dra. Cora Beatriz Excelente Toledo
Xalapa, Veracruz, México Febrero de 2015


Resumen
En esta tesis se presenta un estudio empírico para el problema de la inestabilidadcíclica en ambientes inteligentes con entrada y salida dinámica de agentes. La inesta-bilidad cíclica se caracteriza por crear ciclos indebidos que se ejecutan inde�nidamenteen el sistema los cuales pueden crear fallas generales. Estos ciclos se pueden generarcuando entra o sale un agente debido a la regla de comportamiento inherente a cadauno (compuerta lógica AND y OR) y las relaciones de dependencia que tenga con otrosagentes del sistema.
Para tratar la inestabilidad cíclica se utilizaron tres micro algoritmos inspirados enla naturaleza, micro Algoritmo Genético (µ-GA), micro Evolución Diferencial (µ-DE)y micro Optimización mediante Cúmulo de Partículas (µ-PSO) con las variantes depeso de inercia (w) y factor de estrechamiento (k). Debido a que este tipo de meta-heurísticas requieren de la evaluación de una función objetivo se consideró el Promediode Cambios en el Sistema (ACS por las siglas en inglés de Average Change of theSystem), conocido en la literatura especializada, como medida de desempeño de lainestabilidad cíclica, por lo que los micro algoritmos de optimización se orientaron enla minimización del ACS.
Los valores obtenidos de las ejecuciones de los micro algoritmos se sometieron a pruebasestadísticas no paramétricas de la prueba de suma de rangos con signo de Wilcoxon yla prueba de Friedman. Estos resultados rechazan la hipótesis planteada para este tra-bajo, donde se consideraba que la micro Optimización mediante Cúmulo de Partículas(µ-PSO) obtendría las mejores soluciones en el problema de la inestabilidad cíclica enambientes inteligentes con entrada y salida dinámica de agentes. Además, con base enlos resultados obtenidos podemos decir que el micro Algoritmo Genético (µ-GA) ob-tuvo un mejor desempeño en general, pero no existen diferencias signi�cativas contrala micro Evolución Diferencia (µ-DE) la cual obtuvo mejores valores en la desviaciónestándar.
i

Agradecimientos
La realización de esta tesis marca una etapa importante en mi vida y quiero expresarun profundo agradecimiento a quienes con su ayuda, impulso, estímulo y fé me alen-taron a lograrlo.
A Dios por darme fortaleza en el camino (Abuelita†, Becker†, Ing. Gaspar†, Aarony tia Tina).
Quiero agradecer a mi mamá, a mi papá, a 'dadita' por ser parte de este viaje es-trecho que ha ampliado horizontes junto con Rocío y mis sobrinos. A Lila y 'Pelusita'Juárez por la paz y compañía que me conceden.
Le agradezco en especial al Dr. Efrén Mezura por su paciencia, conocimiento y granapoyo que como asesor y ser humano me brindó, al Dr. Horacio Tapia por su tiempoy guía, al Dr. Victor Zamudio por la dedicación y con�anza y al maestro AlejandroSosa por la disposición y atención otorgada siempre.
A la Dra. Cora, a Marco de apoyo escolar, al MC. Juan Manuel y al MC. MiguelAngel por la disponibilidad de apoyarme constantemente en la realización de estatesis. A todos mis profesores de LANIA por ser un ejemplo profesional y personal decalidad y a mis compañeros de maestría que con su espíritu de competitividad for-maron un mejor grupo.
A mis amigas y amigos cuyo cariño no disminuye con la distancia ni el tiempo.
Agradezco a Conacyt por el apoyo y beca otogada para realizar mis estudios en laMaestría en Computación Aplicada del Programa Nacional de Posgrados de Calidadcuya oportunidad tuve la fortuna de ser bene�ciaria.
ii

Cada vez que un hombre se propone aprendertiene que esforzarse como el que más, y los límitesde su aprendizaje están determinados por su propia
naturaleza [. . . ] por más temible que sea el aprendizaje,es más terrible la idea de un hombre sin conocimiento.
Carlos Castañeda
iii

Contenido
Resumen i
Agradecimientos ii
Introducción 1Planteamiento del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . 2Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
Objetivo General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2Hipótesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2Justi�cación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3Contribuciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1 El problema de inestabilidad cíclica en Ambientes Inteligentes 41.1 Ambientes Inteligentes . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.1 Inestabilidad en ambientes inteligentes (AmI) . . . . . . . . . . 41.2 Inestabilidad cíclica en agentes inteligentes . . . . . . . . . . . . . . . . 51.3 Teoría base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.1 Grafo dirigido . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.3.2 Matriz de adyacencia . . . . . . . . . . . . . . . . . . . . . . . . 51.3.3 Matriz de incidencia . . . . . . . . . . . . . . . . . . . . . . . . 61.3.4 Interaction Network . . . . . . . . . . . . . . . . . . . . . . . . 71.3.5 Ejemplo ilustrativo . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4 Medida de desempeño . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.5 Trabajos relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.5.1 Instability Prevention System (INPRES) e IntelligentLocking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.5.2 Algoritmo c-INPRES . . . . . . . . . . . . . . . . . . . . . . . . 91.5.3 Algoritmos inspirados en la naturaleza aplicados para
minimizar la inestabilidad cíclica . . . . . . . . . . . . . . . . . 9
2 Modelo de simulación 102.1 Comportamiento dinámico . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.1 Estado del agente . . . . . . . . . . . . . . . . . . . . . . . . . . 112.1.2 Compuertas AND y OR . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Medida de desempeño . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.1 Promedio de Cambios en el sistema . . . . . . . . . . . . . . . . 122.2.2 Bloqueo de agentes . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Escenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
iv

CONTENIDO
3 Algoritmos inspirados en la naturaleza 15
3.1 Cómputo inteligente . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Algoritmo Genético . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2.1 Micro Algoritmo Genético . . . . . . . . . . . . . . . . . . . . . 16
3.3 Evolución Diferencial . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.1 Evolución Diferencial Binaria . . . . . . . . . . . . . . . . . . . 19
3.3.2 Micro Evolución Diferencial . . . . . . . . . . . . . . . . . . . . 20
3.4 Optimización mediante Cúmulo de Partículas . . . . . . . . . . . . . . 21
3.4.1 Peso de inercia . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4.2 Factor de estrechamiento . . . . . . . . . . . . . . . . . . . . . . 22
3.4.3 PSO Binario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4.4 Micro Optimización mediante Cúmulo de Partículas . . . . . . . 23
4 Comparativo empírico 25
4.1 Calibración de parámetros . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1.1 Parámetros calibrados de los micro algoritmos . . . . . . . . . . 26
4.1.2 Pruebas estadísticas no paramétricas . . . . . . . . . . . . . . . 27
4.1.3 Prueba de suma de rangos con signo de Wilcoxon . . . . . . . . 27
4.1.4 Prueba de Friedman . . . . . . . . . . . . . . . . . . . . . . . . 28
5 Muestra de resultados 30
5.1 Escenarios de prueba . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.2 Muestra de resultados para la Probabilidad de Compuerta OR 10 condiferente Probabilidad de Conexión . . . . . . . . . . . . . . . . . . . . 31
5.2.1 Comparativo de diferencias signi�cativas con µ-DE para la Prob-abilidad de Compuerta OR 10 . . . . . . . . . . . . . . . . . . . 34
5.3 Muestra de resultados para la Probabilidad de Compuerta OR 90 condiferente Probabilidad de Conexión . . . . . . . . . . . . . . . . . . . . 37
5.3.1 Comparativo de diferencias signi�cativas con µ-DE para la Prob-abilidad de Compuerta OR 90 . . . . . . . . . . . . . . . . . . . 40
5.4 Análisis de resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
6 Conclusiones y trabajo futuro 45
Anexos 47
A Estadísticas para la Probabilidad de Compuerta OR 10 48
A.1 Probabilidad de Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . 49
A.2 Probabilidad de Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . 50
A.3 Probabilidad de Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . 51
B Grá�cas de caja para la Probabilidad de Compuerta OR 10 52
B.1 Probabilidad de Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . 52
B.2 Probabilidad de Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . 54
B.3 Probabilidad de Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . 56
v

CONTENIDO
C Grá�cas de medianas para la Probabilidad de Compuerta OR 10 58C.1 Probabilidad de Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . 58C.2 Probabilidad de Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . 60C.3 Probabilidad de Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . 62
D Estadísticas para la Probabilidad de Compuerta OR 90 64D.1 Probabilidad de Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . 65D.2 Probabilidad de Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . 66D.3 Probabilidad de Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . 67
E Grá�cas de caja para la Probabilidad de Compuerta OR 90 68E.1 Probabilidad de Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . 68E.2 Probabilidad de Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . 70E.3 Probabilidad de Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . 72
F Grá�cas de medianas para la Probabilidad de Compuerta OR 90 74F.1 Probabilidad de Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . 74F.2 Probabilidad de Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . 76F.3 Probabilidad de Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . 78
vi

Lista de Figuras
1.1 Ejemplo de grafo dirigido . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2 Dígrafo con 5 nodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 Interaction Network muestra dependencias entre 5 componentes . . . . 8
2.1 Interaction Network entre 4 agentes con 1 ciclo. . . . . . . . . . . . . . 13
3.1 Representación de la cruza de 2 puntos en los Algorítmos Genéticos . . 173.2 Representación de la mutación uniforme en los Algorítmos Genéticos . 173.3 Representación del operador de mutación en la Evolución Diferencia . . 193.4 Representación del operador de cruza en la Evolución Diferencia . . . . 20
4.1 Esquema de �ujo de información en irace . . . . . . . . . . . . . . . . . 26
5.1 Grá�ca de caja para �P. Compuerta OR 10; P. Bloqueo 15; P. Conexión20�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.2 Grá�ca de medianas para �P. Compuerta OR 10; P. Bloqueo 15; P.Conexión 20�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.3 Grá�ca de caja para �P. Compuerta OR 10; P. Bloqueo 30; P. Conexión40�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.4 Grá�ca de medianas para para �P. Compuerta OR 10; P. Bloqueo 30;P. Conexión 40�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.5 Grá�ca de caja para �P. Compuerta OR 90; P. Bloqueo 0; P. Conexión30�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.6 Grá�ca de medianas para �P. Compuerta OR 90; P. Bloqueo 0; P. Conex-ión 30�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.7 Grá�ca de caja para �P. Compuerta OR 90; P. Bloqueo 15; P. Conexión90�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.8 Grá�ca de medianas para �P. Compuerta OR 90; P. Bloqueo 15; P.Conexión 90�. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
vii

Lista de Tablas
2.1 Tabla de variables de control de los escenarios de estudio. . . . . . . . . 102.2 Tabla de compuertas lógicas AND y OR . . . . . . . . . . . . . . . . . 122.3 Tabla de compuerta binaria. . . . . . . . . . . . . . . . . . . . . . . . . 122.4 Evolución de estados de agentes basados en reglas. . . . . . . . . . . . . 132.5 Tabla de variables para generar los escenarios de estudio. . . . . . . . . 142.6 Resultados del Promedio de Cambios en el Sistema con Probabilidad de
Compuerta OR-AND de 100-0 hasta 50-50 . . . . . . . . . . . . . . . . 142.7 Resultados del Promedio de Cambios en el Sistema con Probabilidad de
Compuerta OR-AND de 50-50 hasta 0-100 . . . . . . . . . . . . . . . . 14
4.1 Tabla de parámetros calibrados de los micro algoritmos . . . . . . . . . 26
5.1 Parámetros para la creación de escenarios de prueba . . . . . . . . . . . 315.2 Valores de los parámetros para la creación de los escenarios de prueba . 315.3 Estadísticas para �P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 20�. 325.4 Estadísticas para �P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 40�. 335.5 Friedman para Probabilidad de Compuerta OR 10 y Probabilidad de
Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.6 Friedman para Probabilidad de Compuerta OR 10 y Probabilidad de
Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.7 Friedman para Probabilidad de Compuerta OR 10 y Probabilidad de
Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.8 Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 0 . . 365.9 Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 15 . . 365.10 Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 30 . . 375.11 Concentrado de diferencias signi�cativas para Probabilidad de Com-
puerta OR 10 con respecto a la µ-DE. . . . . . . . . . . . . . . . . . . 375.12 Estadísticas para �P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 30�. 385.13 Estadísticas para �P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 90�. 395.14 Friedman para Probabilidad de Compuerta OR 90 y Probabilidad de
Bloqueo 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.15 Friedman para Probabilidad de Compuerta OR 90 y Probabilidad de
Bloqueo 15 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.16 Friedman para Probabilidad de Compuerta OR 90 y Probabilidad de
Bloqueo 30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.17 Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 0 . . 425.18 Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 15 . . 425.19 Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 30 . . 42
viii

LISTA DE TABLAS
5.20 Concentrado de diferencias signi�cativas para Probabilidad de Com-puerta OR 90 con respecto a la µ-DE. . . . . . . . . . . . . . . . . . . 43
5.21 Comparativo de diferencias signi�cativas entre µ-DE y µ-GA para laProbabilidad OR 10. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.22 Comparativo de diferencias signi�cativas entre µ-DE y µ-GA para laProbabilidad OR 90. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
ix

Índice de algoritmos
1 Pseudocódigo µ-GA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182 Pseudocódigo µ-DE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213 Pseudocódigo µ-PSO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
x

Introducción
Actualmente los sistemas computacionales se vuelven gradualmente más complejosy difíciles de controlar con los métodos de programación tradicionales. Además con-sumen más recursos computacionales como el tiempo de ejecución, funciones complejas,volumen y variedad de datos de entrada y salida, etc. [17].
Este tipo de problemas se pueden tratar dentro de un sistema inteligente mediante eluso de agentes, los cuales son piezas de software capaces de tener un comportamientoautónomo dentro del sistema y se comunican entre sí para solucionar un problemaglobal. No obstante, los sistemas de ambientes inteligentes, que están compuestos porequipo de control y agentes inteligentes como se de�ne en la sección 1.1 también tieneninconvenientes, como es el caso donde los agentes pueden caer en ciclos indeseados ensu ambiente o con otro agente generando un problema denominado inestabilidad cíclica[18][23][12].
A pesar de que la inestabilidad cíclica es un problema presente, no existen muchasherramientas que la estudien. Una de ellas es el Promedio de Oscilaciones Acumuladas(ACO), desarrollado para medir la amplitud de oscilaciones en un sistema inteligentepor medio de algoritmos meta-heurísticos, el cual, aparte de minimizar la amplitud deoscilaciones, disminuye el número de agentes bloqueados. Además identi�ca vectoresde agentes que previenen la oscilación del sistema en un problema estático, es decir,con un número �nito de agentes [12].
Existe evidencia que indica que es posible minimizar este problema con algoritmosevolutivos y de inteligencia colectiva [7][12][20] y reducir el número de agentes afec-tados por esta condición en un ambiente con un número �nito de agentes [12]. Sinembargo los resultados correspondientes a los algoritmos PSO (Optimización medianteCúmulo de Partículas) y µ-PSO, (micro Optimización mediante Cúmulo de Partículas)no muestran una gran diferencia de agentes no bloqueados [12][20], los cuales estánrelacionadas con la investigación de la inestabilidad cíclica en ambientes inteligentesy con resultados obtenidos en ambientes dinámicos [20]. Por ende, surge el interés deexplorar con mayor detalle a las versiones micro de este tipo de algoritmos.
Con base en estas observaciones se propone realizar un estudio con tres micro algorit-mos inspirados en la naturaleza en el problema de inestabilidad cíclica en un ambientedinámico, donde los agentes entren y salgan constantemente del sistema para analizarcon mayor profundidad el desempeño de este tipo de micro algoritmos en este dominioen particular.
1

ÍNDICE DE ALGORITMOS
Planteamiento del problema
La inestabilidad cíclica es un problema caracterizado por la presencia de oscilacionescausadas por la interacción de las reglas que gobiernan a los agentes inteligentes en unsistema [12] los cuales han sido tratados con algoritmos inspirados en la naturaleza enotros trabajos [7][12][20].
Cabe mencionar que en la literatura especializada los micro algoritmos inspiradosen la naturaleza están diseñados usualmente para trabajar con poblaciones pequeñasy por esta característica generalmente el costo computacional es menor debido a queel número de evaluaciones requeridas para alcanzar la cercanía a una solución compe-titiva se reduce [7].
La intención de este trabajo es resolver instancias del problema de inestabilidad cíclicausando tres micro algoritmos de optimización, un micro Algoritmo Genético (µ-GA),una micro Evolución Diferencial (µ-DE) y una micro Optimización mediante Cúmulode Partículas (µ-PSO), de manera que se logre disminuir la amplitud de las oscilacio-nes, donde podemos considerar como el mejor de los casos a un sistema estable, esdecir, que minimice la inestabilidad cíclica del sistema.
Objetivos
Objetivo General
Comparar el desempeño de tres micro algoritmos inspirados en la naturaleza; microAlgoritmo Genético (µ-GA), micro Evolución Diferencial (µ-DE) y micro Optimizaciónmediante Cúmulo de Partículas (µ-PSO) al resolver instancias del problema de ines-tabilidad cíclica en ambientes inteligentes considerando el caso dinámico con entraday salida de agentes al sistema.
Hipótesis
La micro Optimización mediante Cúmulo de Partículas (µ-PSO) presenta un desem-peño más competitivo en instancias dinámicas en el problema de inestabilidad cíclicaen ambientes inteligentes con respecto a los otros dos micro algoritmos desarrolladosconsiderando el Promedio de Cambios en el Sistema (ACS) como medida de desem-peño del sistema.
2

ÍNDICE DE ALGORITMOS
Justi�cación
Los resultados obtenidos en investigaciones anteriores [12][20] revelan que el uso dealgoritmos inspirados en la naturaleza pueden disminuir el problema de inestabilidadcíclica en ambientes inteligentes. Además que entre los algoritmos PSO y µ-PSO elnúmero de agentes bloqueados no varía demasiado y los resultados del µ-PSO alcanzavalores competitivos contra los otros algoritmos tradicionales utilizados [7].
Por lo mencionado anteriormente, se busca veri�car si es posible obtener una respuestaaceptable, es decir, resultados de minimización en el número de agentes bloqueadosen el sistema [7] utilizando micro algoritmos en un ambiente dinámico y midiendo elcomportamiento oscilatorio del sistema con la función del Promedio de Cambios en elSistema (ASC).
Contribuciones
Las contribuciones de este trabajo son:
• El primer estudio empírico de micro algoritmos bio-inspirados para minimizar lainestabilidad cíclica en ambientes con entrada y salida de agentes.
• Proveer de soluciones computacionalmente menos costosas que puedan trabajaren línea en un ambiente inteligente real.
3

Capítulo 1
El problema de inestabilidad cíclica enAmbientes Inteligentes
1.1 Ambientes Inteligentes
Actualmente la inclusión de la tecnología en nuestra vida diaria es cada vez más imper-ceptible y utilizada en diversas áreas para asistir a las personas y proporcionar serviciospersonalizados. Esta �ltración de la tecnología en los diferentes campos favorece lavisión futura de un ambiente inteligente donde equipos eléctricos y electrónicos, sis-temas computacionales y personas interactúan entre sí. El uso efectivo de los ambientesinteligentes requieren de la integración de sensores, agentes inteligentes y otros com-ponentes. Para �nes prácticos se entenderá como agente inteligente a un componentedel sistema que interactúa autónomamente y tiene un comportamiento basado en re-glas, los cuales pueden trabajar en conjunto dentro de un Sistema Multi-Agente pararesolver problemas que superan sus capacidades y conocimientos particulares ya quecada agente tiene información y capacidades individuales [20][24].
Además, los ambientes inteligentes favorecen conceptos como la casa inteligente dondeelementos como la calefacción, la televisión, teléfonos o cualquier otro objeto puedemantener una conexión digital de una manera inteligente y sensorial [21].
1.1.1 Inestabilidad en ambientes inteligentes (AmI)
La implementación de los sistemas inteligentes conectados unos a otros aumentan laposibilidad de fallas pues existe una complejidad inherente al software que gobiernaestos sistemas debido a la integración de todos los diferentes componentes, la conec-tividad mutua entre ellos y la complejidad de comunicación. Dada la naturaleza delas interacciones que existen, se pueden generar posibles fallas de comunicación y fun-cionalidad creando un comportamiento errático e inestable que puede causar un fallogeneral del sistema o fallas como el deadlock o abrazo mortal, al que se puede de�nircomo un ciclo en espera que ocurre cuando dos o más procesos esperan inde�nida-mente un evento que solo puede ser completado por uno de los procesos involucrados,haciendo imposible completar la tarea. Otra posible falla es la inestabilidad cíclica queocurre cuando un ciclo se ejecuta inde�nidamente debido a que llega siempre a unacondición lógica de VERDAD que conlleva a su activación. En otras palabras, deadlock es
4

1.2. INESTABILIDAD CÍCLICA EN AGENTES INTELIGENTES
la versión estática e inestabilidad cíclica es la versión dinámica de un ciclo en un ambientede agentes inteligentes [22] [23] [11] [2].
1.2 Inestabilidad cíclica en agentes inteligentes
Para estudiar el problema de inestabilidad cíclica en agentes inteligentes, se considera a unagente inteligente como un componente del sistema autónomo y con un comportamientobasado en reglas. Dado que cada agente tiene su propia regla de comportamiento, al interac-tuar con otros agentes del sistema se puede generar inestabilidad cíclica. Por ejemplo, en unsistema con agentes inteligentes basados en un conjunto de reglas booleanas, los cuales tienenun estado binario On (encendido) y O� (apagado), la inestabilidad cíclica es una conductaerrática provocada por la oscilación de los estados de los agentes del sistema, alternando elestado de uno o varios agentes entre On y O� periódicamente y se puede decir que el estadogeneral del sistema es inestable [25][24][20].
1.3 Teoría base
Una solución inicial para el problema de inestabilidad cíclica fue desarrollada en el sistemaINPRES que identi�ca e�cazmente el problema y origina técnicas e�caces de representacióncon dígrafos con el framework Interaction Network. Además representa la interdependenciaentre los agentes del sistema con la Matriz de Incidencia y otros conceptos [22] utilizadospara este trabajo, los cuales se explican brevemente en esta sección.
1.3.1 Grafo dirigido
Un grafo dirigido G, también conocido como dígrafo, como se muestra en la �gura 1.1, con-siste en un conjunto V de vértices o nodos y un conjunto E de aristas o arcos donde elgrafo G es denotado como G = (V,E) en el que cada arista e ∈ E está asociada con un parordenado de vértices (v, w) el cual se puede representar como e = (v, w), o por simplicidad vw.
En un dígrafo, se dice que un par de vértices v y w son incidentes cuando se asocian por unaarista e, asimismo se consideran vértices adyacentes [22] [10].
1.3.2 Matriz de adyacencia
Es posible representar un grafo dirigido utilizando una matriz donde se pueden observar lasconexiones con dirección entre los nodos. Dado un sistema con n nodos, la matriz de adya-cencia M = mij se de�ne por la ecuación 1.1.
mij =
{1 si (vi, vj)0 en otro caso
(1.1)
5

CAPÍTULO 1. EL PROBLEMA DE INESTABILIDAD CÍCLICA EN AMBIENTES INTELIGENTES
Figura 1.1: Ejemplo de grafo dirigido [10].
Por ejemplo, considerando el dígrafo de la �gura 1.2, la matriz de adyacencia correspon-diente se representa con la matriz 1.2.
Figura 1.2: Dígrafo con 5 nodos [22].
M =
0 1 0 0 00 0 1 0 11 0 0 0 00 0 1 0 00 0 0 0 0
Matriz de adyacencia (1.2)
1.3.3 Matriz de incidencia
La matriz de incidencia es la transpuesta de la matriz de adyacenciaMT la cual representa lasdependencias con dirección entre los nodos. Por ejemplo, la matriz de incidencia del dígrafode la �gura 1.2 es la transpuesta de la matriz M y se representa con la matriz 1.3.
MT =
0 0 1 0 01 0 0 0 00 1 0 1 00 0 0 0 00 1 0 0 0
(1.3)
Matriz de incidencia
6

1.3. TEORÍA BASE
1.3.4 Interaction Network
Interaction Network (IN) es un framework desarrollado para capturar las relaciones de inter-dependencia funcionales entre las reglas de comportamiento de los agentes. IN usa un nivelde abstracción de dichas dependencias y forma una representación grá�ca basada en la teoríadel grafo [22].
Propiedades de Interaction Network
Interaction Network tiene dos propiedades inherentes de la relación que surge entre los agentesy sus reglas de dependencia:
• La presencia de múltiples aristas, por ejemplo, dos aristas conectadas a los dos mismosnodos no es posible debido a que la dependencia funcional sería la misma.
• Los ciclos de longitud 1 o bucles no se contemplan en Interaction Network. La pre-sencia de un bucle se permitirá sólo si el usuario explícita y deliberadamente deseacon�gurarlo como parte del sistema.
Debido a estas dos propiedades, un Interaction Network es un grafo dirigido simple [22].
Representación en Interaction Network
Interaction Network es un dígrafo (V,E) donde un vértice v ∈ V es un agente autónomo A y(vi, vj) ∈ E si las funciones booleanas ϕj , ψj del agente autónomo Aj depende del estado sidel agente Aj .
Cada agente tiene 2 estados booleanos s ∈ 0, 1, donde 0 signi�ca O� (apagado) y 1 sig-ni�ca On (encendido).
Si tenemos n agentes autónomos A1, A2, . . . , An el estado del sistema es S = s1, s2, . . . , sn.Cada agente Ai tiene una regla de comportamiento basada en las 2 reglas de comportamientode la ecuación 1.4a y 1.4b.
Si ϕj entonces si = 1 (1.4a)
Si ψj entonces si = 0 (1.4b)
Donde:
ϕj , ψj : si → {0, 1} para i = 1, 2, ..., n
Es posible que un agente no tenga relaciones de dependencia funcionales con otros agentes,en este caso, el agente conservará su estado inicial y cambiará solo si se generan dependenciasdurante la ejecución del sistema [20].
7

CAPÍTULO 1. EL PROBLEMA DE INESTABILIDAD CÍCLICA EN AMBIENTES INTELIGENTES
1.3.5 Ejemplo ilustrativo
Consideremos un sistema con los siguientes 5 componentes: Editor de Texto (Word), EquipoMP3, Sensor de luz, Lámpara, Sensor de sofá y Sofá, donde la aplicación del Editor de Textodepende del estado del sensor del Sofá y el estado de la Lámpara; el estado de la Lámparadepende del estado del Sensor de Luz y del estado del Equipo MP3; y el estado del EquipoMP3 depende del estado de Editor de Texto. En este caso existe un ciclo en las dependen-cias como se muestra en la �gura 1.3 indicado en línea de trazos, donde el Equipo MP3, laLámpara y el Editor de Texto son parte del ciclo.
Figura 1.3: Interaction Network muestra dependencias entre 5 componentes [22].
1.4 Medida de desempeño
En la literatura especializada existen varias formas de medir la conducta del problema deinestabilidad cíclica, entre las más destacadas se encuentra el bloqueo de agentes o función delocking [22][25], el Promedio de la Oscilación Acumulativa (ACO) y el Promedio de Cambiosen el Sistema (ACS por las siglas en inglés de Average Change of the System) [12][20].
Para este trabajo se considera el Promedio de Cambios en el Sistema (ACS) como medidamás propia para identi�car el desempeño en el problema de inestabilidad cíclica en agentesnómadas dinámicos [20], la cual se especi�ca en la sección 2.2.
1.5 Trabajos relacionados
1.5.1 Instability Prevention System (INPRES) e IntelligentLocking
INPRES es una estrategia que identi�ca los ciclos presentes en la red y los rompe bloqueandoun miembro de cada ciclo presente. Requiere de un análisis previo de las propiedades de latopología y ha sido probado exitosamente en sistemas de baja densidad de interconexiones yreglas estáticas (no en equipos nómadas). Sin embargo cuando el número de agentes aumentay tienen alta dependencia entre ellos o cuando los agentes son nómadas, la solución propuestapor INPRES no es práctica debido al costo computacional que representa analizar toda latopología del sistema y tiende a bloquearlo afectando su correcta funcionalidad [25][12].
8

1.5. TRABAJOS RELACIONADOS
1.5.2 Algoritmo c-INPRES
El algoritmo c-INPRES re�na el análisis de Interaction Network e introduce opciones de blo-queo con un peso unitario en cada agente obteniendo el costo mínimo para reducir el númerode agentes bloqueados. También calcula el número promedio de ciclos por nodo, denominadodensidad del sistema, sin embargo cuando la densidad aumenta hay una tendencia natural deauto-bloqueo generando un ambiente más accidentado donde en algún punto algunos nodosno podrán cambiar su estado volviendo al sistema no funcional. Debido a que c-INPRESestá basado en el análisis de las reglas de acoplamiento de los agentes requiere de un grannúmero de cálculos, aumentando aún más el costo computacional, lo que da inicio al usode estrategias de optimización combinatoria o algoritmos metaheurísticos para minimizar lasoscilaciones y estabilizar con éxito sistemas complejos [5][13][25].
1.5.3 Algoritmos inspirados en la naturaleza aplicados paraminimizar la inestabilidad cíclica
Debido a que las soluciones que requieren análisis de la topología pueden ser computacional-mente costosas hacen muy limitada su aplicación en escenarios de tiempo real, lo que propiciael uso de algoritmos inspirados en la naturaleza o bio-inspirados para tratar el problema dela inestabilidad cíclica trasladándolo a un problema de optimización inteligente dentro detécnicas de búsqueda exhaustiva y búsquedas metaheurísticas que no requieren del análisisde la topología del sistema, lo que representa una gran ventaja computacional [12].
Trabajos relacionados con el juego de la vida [8] y la minimización de inestabilidad cíclicaen sistemas con agentes nómadas de entrada dinámica [20] determinaron que los algoritmosbio-inspirados son competentes para alcanzar una solución que minimice el número de agentesbloqueados en ambientes inteligentes y el Promedio de Cambios en el Sistema dando lugaral estudio de la minimización de la inestabilidad cíclica para casos de agentes nómadas deentrada y salida utilizando un porcentaje de agentes bloqueados en el sistema para su esta-bilización [12].
9

Capítulo 2
Modelo de simulación
Usualmente el comportamiento inteligente en un sistema está basado en un conjunto de re-glas formadas por sus agentes autónomos [21] dentro de un ambiente de�nido. Dichos agentespueden verse afectados por errores como cualquier otro sistema de cómputo. Entre los pro-blemas que afectan a los ambientes inteligentes multiagente basados en reglas se encuentra lainestabilidad cíclica, caracterizada por manifestar �uctuaciones inesperadas provocadas poruna interacción no planeada entre los mismos agentes y las reglas que los gobiernan [23][21].Para poder reproducir el problema de manera sintética se presenta un modelo de simulaciónque representa agentes con reglas basadas en las compuertas AND y OR y con un compor-tamiento dinámico de entrada y salida en el ambiente.
El modelo de simulación cuenta con variables de control para establecer los escenearios deestudio en el ambiente del sistema mostradas en la tabla 2.1.
Variable Descripción
N agentes Número de agentes del sistemaMax entrada Número máximo de agentes que entran al sistema por iteración.Max salida Número máximo de agentes que salen del sistema por iteración.P. Compuerta Probabilidad de compuerta OR-AND asignada.P. Conexión Probabilidad de conexión entre agentes (dinámica).P. Bloqueo Porcentaje de agentes bloqueados.
Tabla 2.1: Tabla de variables de control de los escenarios de estudio.
2.1 Comportamiento dinámico
El número de agentes que ingresan o abandonan el sistema se genera aleatoriamente con res-pecto al número máximo de entrada (max entrada) y salida (max salida) simulando �latidos�del sistema hasta alcanzar el número de agentes deseados (N agentes).
10

2.1. COMPORTAMIENTO DINÁMICO
En el proceso de entrada, cada agente se crea con una compuerta lógica determinada poruna probabilidad entre AND y OR (P. Compuerta), un estado (encendido/apagado) asignadoaleatoriamente y asume un comportamiento social para generar relaciones con otros agentesexistentes en el ambiente y viceversa. Estas relaciones se manipulan con una probabilidadde conexión global en el sistema (P. Conexión) diferente a la probabilidad de asignación decompuerta lógica antes mencionada.
La salida de un agente libera las relaciones y dependencias que haya tenido durante suintervención en el sistema y después el agente se elimina del ambiente [20].
2.1.1 Estado del agente
El estado de un agente o nodo se identi�ca por dos valores que representan encendido (On) yapagado (O�) que puede cambiar debido a las condiciones del ambiente. Entonces el estado�nal del agente dependerá de su tipo de compuerta y la interacción con los agentes con quientenga dependencias.
Estos cambios de estado nos ayudan a reconocer el comportamiento del ambiente, pues sise modi�ca constantemente entre On y O� en un periodo de�nido podemos identi�car ines-tabilidad cíclica y determinar si el sistema es estable o no.
2.1.2 Compuertas AND y OR
La compuerta lógica AND u OR asignada a un agente representa su regla de comportamientoy puede cambiar el estado del agente basándose en la lógica booleana correspondiente, verecuaciones 2.1 y 2.2.
x1 ∧ x2 ={
1 si x1 = 1 y x2 = 10 de otra manera
(2.1)Lógica booleana AND.
x1 ∨ x2 ={
1 si x1 = 1 o x2 = 10 de otra manera
(2.2)Lógica booleana OR.
Por ejemplo, cuando una compuerta AND recibe entradas x1 y x2 produce una salida deno-tada por AND y una compuerta OR produce una salida denotada por OR como se indicaen la tabla 2.2.
En los casos donde el agente sólo tiene una relación de dependencia, la compuerta lógicase considera una compuerta binaria que devuelve el mismo valor obtenido, ya que no puedecalcular el resultado con la compuerta lógica como se muestra en la tabla 2.3.
11

CAPÍTULO 2. MODELO DE SIMULACIÓN
x1 x2 AND OR1 1 1 11 0 0 10 1 0 10 0 0 0
Tabla 2.2: Tabla de compuertas lógicas AND y OR [20][10].
x1 Binaria1 10 0
Tabla 2.3: Tabla de compuerta binaria.
2.2 Medida de desempeño
2.2.1 Promedio de Cambios en el sistema
El Promedio de Cambios en el Sistema (ACS) se considera como función objetivo en el pro-blema de optimización para la minimización de inestabilidad cíclica. El ACS se calcula conla ecuación 2.3.
o =
∑n−1i=1 xin− 1
{1 si S(t) 6= S(t+ 1)0 en otro caso
(2.3)
Donde:
o : Promedio de Cambios en el Sistema.n : Generaciones del ciclo de vida para si.S(t) : Estado del sistema en el tiempo t.S(t+ 1) : Estado del sistema en el tiempo t+ 1.
Representación
Un ejemplo ilustrativo se puede ver en la �gura 2.1 que representa una Interaction Networkentre 4 agentes, el cual presenta inestabilidad cíclica en los nodos 1, 2 y 3. La matriz deincidencia correspondiente se representa con la matriz 2.4. En la tabla 2.4 se representa laevolución de los estados de cada agente mostrando el comportamiento cíclico en las itera-ciones inicial y la número 3. En este caso el cálculo del valor del Promedio de Cambios en elSistema es 1.0 ya que el estado S(t) siempre es diferente al estado S(t+ 1).
12

2.3. ESCENARIOS
Figura 2.1: Interaction Network entre 4 agentes con 1 ciclo.
M =
0 1 0 00 0 1 01 0 0 00 0 1 0
(2.4)
Matriz de incidencia entre 4 agentes con 1 ciclo
EstadosIteración 1 2 3 4Inicial 0 1 0 1
1 0 0 1 12 1 0 0 13 0 1 0 1
Tabla 2.4: Evolución de estados de agentes basados en reglas.
2.2.2 Bloqueo de agentes
El boqueo se realiza con una probabilidad de bloqueo (P. Bloqueo) y se aplica sobre el totalde agentes que existan en el sistema. Esta estrategia tiene como función bloquear el estadode uno o varios agentes dentro del sistema, no permitiendo cambiar de estado a pesar de quesus reglas generen uno diferente, al mantenerlo de esta forma durante un periodo de tiempodado se trata de estabilizar el comportamiento de los agentes y el ambiente [8]. Debido aque un excesivo número de agentes bloqueados en un sistema complejo puede volverlo nofuncional se considera una variable notable en el desempeño del problema de inestabilidadcíclica para estabilizar el sistema.
2.3 Escenarios
Los escenarios de estudio se de�nieron con una probabilidad de compuerta (P. Compuerta)OR 10 y 90. Además se consideraron las variables de la tabla 2.5 para generar el ambienteinteligente que sirve como escenario de estudio.
13

CAPÍTULO 2. MODELO DE SIMULACIÓN
Variable ValorN agentes 50Max entrada 20Max salida 10P. Conexion 10, 20, 30, 40, 50, 60, 70, 80 y 90P. Bloqueo 10, 15 y 30
Tabla 2.5: Tabla de variables para generar los escenarios de estudio.
En las tablas 2.6 y 2.7 se puede apreciar que cuando la probabilidad de AND y OR están en90-10 y 10-90 respectivamente, existen cambios en el sistema en todas las probabilidades deconexión en comparación a las otras probabilidades de conexión. Podemos decir de maneraempírica que la probabilidad de compuerta afecta el comportamiento del sistema sin importarque los nodos tengan una probabilidad de conexión baja o alta, aunque este tema requieremayor investigación al respecto.
N agentes = 50 ; Max entrada = 20 ; Max salida = 10
P. Compuerta OR 100 90 80 70 60 50P. Conexión Media Mediana Media Mediana Media Mediana Media Mediana Media Mediana Media Mediana5 0.0286195 0.030303 0.1026936 0.040404 0.1138047 0.0505051 0.0838384 0.0505051 0.2127946 0.0606061 0.0824916 0.050505110 0.0191919 0.020202 0.037037 0.030303 0.0740741 0.040404 0.0713805 0.040404 0.0646465 0.030303 0.0346801 0.03030320 0.0131313 0.010101 0.0282828 0.020202 0.0272727 0.020202 0.016835 0.010101 0.0148148 0.010101 0.0148148 0.01010130 0.010101 0.010101 0.0245791 0.020202 0.0151515 0.010101 0.0111111 0.010101 0.0107744 0.010101 0.0104377 0.01010140 0.010101 0.010101 0.016835 0.010101 0.0117845 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.01010150 0.010101 0.010101 0.013468 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.01010160 0.010101 0.010101 0.0124579 0.010101 0.0104377 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.01010170 0.010101 0.010101 0.013468 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.01010180 0.010101 0.010101 0.0124579 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.01010190 0.010101 0.010101 0.0121212 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101100 0.010101 0.010101 0.0107744 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101
Tabla 2.6: Resultados del Promedio de Cambios en el Sistema con Probabilidad deCompuerta OR-AND de 100-0 hasta 50-50
N agentes = 50 ; Max entrada = 20 ; Max salida = 10
P. Compuerta OR 40 30 20 10 0P. Conexión Media Mediana Media Mediana Media Mediana Media Mediana Media Mediana5 0.1575758 0.0606061 0.0942761 0.0606061 0.056229 0.0505051 0.0700337 0.030303 0.0616162 0.03030310 0.0670034 0.030303 0.1350168 0.030303 0.0420875 0.040404 0.0350168 0.030303 0.0205387 0.02020220 0.0148148 0.010101 0.0171717 0.020202 0.0245791 0.020202 0.0299663 0.030303 0.013468 0.01010130 0.0111111 0.010101 0.0111111 0.010101 0.0148148 0.010101 0.0265993 0.020202 0.010101 0.01010140 0.010101 0.010101 0.010101 0.010101 0.0114478 0.010101 0.020202 0.010101 0.010101 0.01010150 0.010101 0.010101 0.010101 0.010101 0.0104377 0.010101 0.0161616 0.010101 0.010101 0.01010160 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.0144781 0.010101 0.010101 0.01010170 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.0144781 0.010101 0.010101 0.01010180 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.0114478 0.010101 0.010101 0.01010190 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.0107744 0.010101 0.010101 0.010101100 0.010101 0.010101 0.010101 0.010101 0.010101 0.010101 0.0114478 0.010101 0.010101 0.010101
Tabla 2.7: Resultados del Promedio de Cambios en el Sistema con Probabilidad deCompuerta OR-AND de 50-50 hasta 0-100
14

Capítulo 3
Algoritmos inspirados en la naturaleza
Para resolver problemas de optimización complejos existen técnicas no tradicionales conocidascomo métodos meta-heurísticos que garantizan una solución aceptable en un tiempo razona-ble. Dentro de estos métodos existe un grupo de algoritmos que basan su comportamientointeligente en fenómenos de la naturaleza conocidos como algoritmos bio-inspirados [4]. Eneste capítulo se muestra brevemente la conducta de los algoritmo inspirados en la naturalezautilizados en el problema de la minimización de la inestabilidad cíclica en ambientes inteli-gentes, los cuales son el micro Algoritmo Genético (µ-GA), la micro Evolución Diferencial(µ-DE) con representación de cadena binaria y la micro Optimización mediante Cúmulo dePartículas (µ-PSO) con representación binaria. Los algoritmos bio-inspirados o inspiradosen la naturaleza pertenecen a una sub-rama de la Inteligencia Arti�cial llamada CómputoInteligente (CI) de�nida en la sección 3.1. En la sección 3.2 se describen brevemente losAlgoritmos Genéticos, la versión del micro Algoritmo Genético (µ-GA) y sus operadores, enla sección 3.3 se presenta la Evolución Diferencial (DE) y la versión micro Evolución Diferen-cial (µ-DE) con representación de cadena binaria y �nalmente en la sección 3.4 se muestrala Optimización mediante Cúmulo de Partículas (PSO), la representación binaria (binPSO),las variantes con peso de inercia (w) y factor de estrechamiento (k) y la versión de la microOptimización mediante Cúmulo de Partículas (µ-PSO).
3.1 Cómputo inteligente
El Cómputo Inteligente (CI) es una sub-rama de la Inteligencia Arti�cial dedicada al es-tudio de mecanismos adaptables para generar o facilitar un comportamiento inteligente enambientes complejos y cambiantes. El CI consta de varios paradigmas, que tienen su origenen modelos biológicos, como Redes Neuronales Arti�ciales, Cómputo Evolutivo, InteligenciaColectiva, Sistemas Inmunes Arti�ciales y Sistemas Difusos. Los algoritmos utilizados parael desarrollo de este trabajo pertenecen a los paradigmas de Cómputo Evolutivo que com-prende los Algoritmos Genéticos (GA por sus siglas en inglés) y la Evolución Diferencial (DE)y el paradigma de Inteligencia Colectiva que incluye el algoritmo de Optimización medianteCúmulo de Partículas (PSO) [6].
El Cómputo Evolutivo (EC) usa un modelo computacional del proceso de la evolución naturalutilizando conceptos de selección, reproducción y supervivencia del más apto. Los AlgoritmosGenéticos (GA), popularizados por John H. Holland en los años 60s [6][19], son algoritmosque utilizan una población de individuos representados por cadenas que simbolizan genotipos,
15

CAPÍTULO 3. ALGORITMOS INSPIRADOS EN LA NATURALEZA
para los GA los operadores más signi�cativos son la selección y la recombinación mediante unoperador de cruza. La Evolución Diferencial (DE), desarrollada por Storn y Price en 1995, esuna estrategia de búsqueda que utiliza una población de individuos representados por vectoresy el cálculo de la diferencia de dichos vectores para explorar el espacio de búsqueda dondela información de la distancia y la dirección de la población actual son utilizadas como guía.Con respecto a la reproducción DE, aplica operadores de mutación y cruza para producir unnuevo vector [6].
La Inteligencia Colectiva (IC) supone un grupo de individuos con un comportamiento socialal intercambiar información en la búsqueda de una solución. Dentro de la IC, la Optimizaciónmediante Cúmulo de Partículas (PSO), propuesto por Kennedy y Eberhart, es un algoritmode búsqueda basado en la simulación del comportamiento social entre las aves de una par-vada. En el algoritmo PSO los individuos de la población son conocidos como partículas quevan cambiando de posición dependiendo de su propia experiencia y la de su grupo [6][15].
Los Algoritmos Evolutivos y de Inteligencia Colectiva se basan en un conjunto de solucionesllamada población (entre 50 y 200 aproximadamente) para explorar áreas del espacio debúsqueda, requiriendo generalmente una cantidad considerable de tiempo y recursos com-putacionales. Los micro algoritmos evolutivos son versiones de los algoritmos evolutivostradicionales diseñados para trabajar con poblaciones muy pequeñas que utilizan usualmenteelitismo y un mecanismo de reinicio para evitar convergencia nominal, la cual ocurre cuandotodos los individuos de la población se vuelven muy similares. Aún con la reducción deltamaño de la población, los micro algoritmos han demostrado un rendimiento competitivo enla solución de problemas de optimización [7].
3.2 Algoritmo Genético
Los Algoritmos Genéticos (GA) representan un modelo basado en la simulación de la evolucióngenética de acuerdo al principio Darwiniano de reproducción y supervivencia del más apto.El GA trabaja con una población de individuos llamados cromosomas que tienen relacionadauna aptitud de�nida por la función objetivo. Para generar una nueva población el algoritmorealiza una selección de individuos considerados padres, al aplicar operadores genéticos adichos padres se generan nuevos individuos llamados hijos. Los operadores genéticos emplea-dos son: la cruza como operador principal, mutación que introduce nuevo material genéticoy elitismo que se re�ere a la supervivencia del mejor individuo en la nueva generación [19][6].
3.2.1 Micro Algoritmo Genético
Un micro Algoritmo Genético (µ-GA) se re�eren a un Algoritmo Genético con una poblaciónmuy pequeña y un proceso de reinicialización para evitar que las soluciones tengan una con-vergencia prematura. Existen varios mecanismos de selección, tipos de cruza y mutación quealteran la composición de los individuos para crear una nueva generación [19][6]. En el casodel µ-GA los operadores utilizados son:
16

3.2. ALGORITMO GENÉTICO
• Selección por torneo binario determinista. La selección de padres por torneo binariorealiza cierto número de competencias entre los individuos, barajando inicialmente losindividuos de la población escoge 2 individuos y selecciona al ganador con base en suaptitud calculada con la función objetivo.
• Cruza de dos puntos. En este método se considera un porcentaje de cruza para re-combinar a los individuos padre, después se seleccionan dos puntos aleatoriamente dela cadena binaria y se intercambian las secciones entre estos dos puntos para generarnuevos hijos como se muestra en la �gura 3.1.
• Mutación uniforme. Para aplicar esta técnica se considera un porcentaje de mutaciónconstante durante el proceso evolutivo. La mutación uniforme evalúa en cada bit delindividuo la probabilidad de cambiar el valor binario de la posición seleccionada comose muestra en la �gura 3.2.
• Elitismo. Selecciona el mejor individuo y pasa intacto a la siguiente generación.
Figura 3.1: Representación de la cruza de 2 puntos en los Algorítmos Genéticos[6].
Figura 3.2: Representación de la mutación uniforme en los Algorítmos Genéticos[6].
17

CAPÍTULO 3. ALGORITMOS INSPIRADOS EN LA NATURALEZA
Pseudocódigo de µ-GA
En el micro Algoritmo Genético (µ-GA) la población inicial P se constituye de M individuos(donde M es un valor entero pequeño) y cada individuo se compone de una cadena binariagenerada inicialmente con valores aleatorios. Durante su ejecución el µ-GA aplica genera-cionalmente los operadores genéticos para generar las nuevas poblaciones hasta alcanzar lacondición de paro del algoritmo dada por un número máximo de evaluaciones. El detalle deµ-GA se puede observar en el algoritmo 1.
Algoritmo 1: Pseudocódigo µ-GA
Data: P ∈ [4, 8] (tamaño de la población); pcruza ∈ R.Result: mejor individuo de la población
1 Generar la población inicial P de tamaño M ;2 i = 0;3 repeat
4 Calcular aptitudes con la función objetivo;5 Aplicar selección por torneo binario;6 if (rndreal (0.0, 1.0) < pcruza) then7 Aplicar cruza;8 end if
9 Aplicar mutación;10 Aplicar elitismo;11 Generar nueva población;
12 until condición de paro;
Pseudocódigo µ-Algoritmo Genético (µ-GA) [19].
3.3 Evolución Diferencial
La Evolución Diferencial (DE) es actualmente una de las meta-heurísticas más popularespara resolver problemas de optimización en espacios continuos. DE utiliza un operador demutación simple basado en la diferencia entre pares de soluciones llamados vectores con elobjetivo de encontrar una búsqueda direccionada basada en la distribución de las solucionesde la población actual [16]. En la DE cada individuo xi(t) de la población, también llamadovector padre, produce un nuevo vector llamado vector trial Ui seleccionando tres vectores di-ferentes de la población (r1, r2 y r3) y aplicando el operador de mutación F como se muestraen la fórmula 3.1. Después aplica un operador de cruza CR para generar un descendientecon una recombinación discreta de los elementos entre el vector resultado de la mutación (omutante) y el vector padre xi(t) implementando la fórmula 3.2 [6].
Uij = xgr1,j + F (xgr2,j − xgr3,j) (3.1)
xij(t+ 1) =
{Uij = xgr1,j + F (xgr2,j − x
gr3,j) si rndreal(0,1) < CR o j = jrand
Uij = xg1,j en otro caso(3.2)
18

3.3. EVOLUCIÓN DIFERENCIAL
Donde:
i : Es el i-ésimo vector de la población, dado i = 1, 2..M , siendo M el tamaño de lapoblación.
j : Es el j-esimo elemento del vector xi(t), dado j = 1, 2..N siendo N la dimensión delas variables.
g : Generación actual.r1, r2 y r3 : Tres vectores aleatorios de la población.F : Operador de mutación ∈ R.CR : Operador de cruza ∈ R.Ui(t) : Es el vector trial.N : Es el conjunto de elementos o variables del problema.
Dicho descendiente compite con el padre y el mejor de ellos permanecerá para la siguientegeneración, mientras que el otro será desechado [6]. Una manera grá�ca de ver el operadorde mutación se muestra en la �gura 3.3 donde los vectores xr1 , xr2 y xr3 generan un nuevovector escalado con el factor F (F (xr2 − xr3)) el cual compite con el vector padre xi dandocomo resultado el vector Ui. En la �gura 3.4 se muestra el operador de cruza donde el vectorxgi (siendo g la generación actual) se cruza con el vector Ug
i recien obtenido utilizando el
factor de cruza CR y dando como resultado el vector xg+1i que pasa a la siguiente generación.
Figura 3.3: Representación del operador de mutación en la Evolución Diferencia[6].
3.3.1 Evolución Diferencial Binaria
La Evolución Diferencial Binaria (binDE) utiliza vectores con valores de punto �otante paragenerar una solución de cadena binaria. Los valores de punto �otante en los individuos de-
19

CAPÍTULO 3. ALGORITMOS INSPIRADOS EN LA NATURALEZA
Figura 3.4: Representación del operador de cruza en la Evolución Diferencia[6].
terminan una probabilidad en cada componente del vector y cada probabilidad establece siel valor binario correspondiente es 0 o 1 calculado con la función sigmoide (ecuación 3.3) y lafórmula de la ecuación 3.4. Después con el vector binario obtenido se determina la aptitudde la función objetivo cuyo valor es relacionado al vector de punto �otante correspondiente[6].
f(x) =1
1 + e−x(3.3)
yij =
{0 si f(xij(t)) ≥ 0.51 si f(xij(t)) < 0.5
(3.4)
3.3.2 Micro Evolución Diferencial
La micro Evolución Diferencial (µ-DE) es una versión modi�cada del algoritmo tradicional.El µ-DE maneja poblaciones muy pequeñas de individuos lo que puede provocar que el al-goritmo tenga una convergencia prematura, para compensar esta característica el algoritmoimplementa un método de elitismo y un mecanismo de reinicio [7]. El algoritmo 2 muestrala implementación de la micro Evolución Diferencial (µ-DE).
Pseudocódigo de µ-DE
Primeramente se crea una población inicial P de tamaño M cuyos elementos se forman conN valores aleatorios. La implementación de la µ-DE se ejecuta hasta alcanzar la condiciónde paro y posee una generación de reemplazo GR que se evalúa durante la ejecución paraconservar las mejores soluciones de esa generación y reemplazar un número de solucionesNR con nuevos elementos. El proceso, como en la Evolución Diferencial, genera un vector
20

3.4. OPTIMIZACIÓN MEDIANTE CÚMULO DE PARTÍCULAS
trial considerando el operador de mutación con el parámetro F y el operador de cruza con elparámetro CR, y generar así un descendiente que compita con el padre para ir conformandouna nueva población [7][20].
Algoritmo 2: Pseudocódigo µ-DE
Data: P ∈ [2, 6] (tamaño de la población); CR ∈ R (Operador de cruza); F ∈ R;NR ∈ N (número de soluciones a reemplazar); GR ∈ N (generación dereemplazo).
Result: mejor vector encontrado
1 Set G =MaxFes/P ; cont = 1;2 for (g=1 a G) do
3 if (cont == GR) then
4 Reinicializar a los NR peores individuos;5 Set cont = 1;
6 end if
7 Set r1 6= r2 6= r3 6= i, r1, r2, r3 ∈ [1, P ], jrand ∈ [i,D] rand ;8 if (rndreal(0, 1) < CR o j == jrand, j = 1, ..., D, i = 1, ..., P ) then9 Uij = xgr1,j + F (xgr2,j − x
gr3,j) ;
10 else
11 Uij = xg1,j ;
12 end if
13 if (f(xgi ) > f(Ugi )) then
14 xg+1i = Ug
i ;15 else
16 xg+1i = xgi ;
17 end if
18 Set cont = cont + 1;
19 end for
Pseudocódigo µ-Evolución Diferencial (µ-DE) [7].
3.4 Optimización mediante Cúmulo de Partículas
El concepto original de Cúmulo de Partículas se basa en la simulación de vuelo de una par-vada y el comportamiento individual y social de las aves que lo conforman. En el algoritmo deOptimización mediante Cúmulo de Partículas (PSO) los elementos se denominan partículas,al conjunto de partículas se le llama parvada y a la partícula con la mejor aptitud (valor asig-nado con la función objetivo) es considerada líder de la parvada. En el PSO cada partícularepresenta una posible solución que durante un vuelo o generación ajusta su posición en elespacio de búsqueda aplicando un vector de velocidad. La velocidad de una partícula secalcula con la ecuación 3.5 y re�eja su propia experiencia (la mejor posición conocida por lapartícula), llamada pbest, y la experiencia de su grupo (líder de la parvada), llamada gbest
[15][6].
vi(t+ 1) = vi(t) + c1r1(xpbesti − xi) + c2r2(xgBest − xi) (3.5)
21

CAPÍTULO 3. ALGORITMOS INSPIRADOS EN LA NATURALEZA
Donde:
vi(t+ 1) : Es el nuevo vector de velocidad.vi(t) : Es el vector de velocidad actual.i : Es la i-ésima partícula de la parvada.c1 y c2 : Son constantes de aceleración para controlar la in�uencia del conocimiento
personal de la partícula y conocimiento social respectivamente.r1 y r2 : Números reales entre 0 y 1 generados con una distribución uniforme.
Después de obtener el vector de velocidad, la nueva posición de la partícula se ajusta agre-gando la velocidad a la posición actual con la fórmula de vuelo expresada en la ecuación 3.6[15].
xi(t+ 1) = xi(t) + vi(t+ 1) (3.6)
Donde:
xi(t+ 1) : Es la nueva posición de la partícula.xi(t) : Es la posición actual de la partícula.vi(t+ 1) : Es la velocidad actual de la partícula.
3.4.1 Peso de inercia
Existen variaciones en el cálculo de la velocidad de la partícula para mejorar la velocidadde convergencia y la calidad de las soluciones encontradas. El peso de la inercia w fue in-troducido por Shi y Eberhart como un mecanismo de control de exploración y explotación,básicamente controla cuanta memoria de la dirección del vuelo anterior in�uye en la nuevavelocidad con la fórmula 3.7 [6].
vi(t+ 1) = wvi(t) + c1r1(xpbesti − xi) + c2r2(xgBest − xi) (3.7)
Donde w representa el peso de la inercia que escala el valor de la velocidad actual vi(t) de lapartícula i [15].
3.4.2 Factor de estrechamiento
Con el objetivo de no reprimir la velocidad y alentar la convergencia, el factor de estrechamientok controla la exploración y explotación que realiza la parvada con la fórmula 3.8. A diferenciadel peso de la inercia, el factor de estrechamiento afecta todos los valores involucrados en laactualización de la velocidad [15].
22

3.4. OPTIMIZACIÓN MEDIANTE CÚMULO DE PARTÍCULAS
vi(t+ 1) = k[vi(t) + c1r1(xpbesti − xi) + c2r2(xgBest − xi)] (3.8)
3.4.3 PSO Binario
Originalmente el PSO binario (binPSO) fue desarrollado para operar en espacios binariosde búsqueda pero también se puede aplicar a valores reales haciendo una transformación delos valores donde cada elemento de la partícula puede tomar un valor binario 0 o 1. En elbinPSO las velocidades y las trayectorias de las partículas son a menudo de�nidas en términosde probabilidades en el rango [0, 1]. La normalización de velocidades se realiza aplicando lafunción sigmoide (fórmula 3.9), donde vij(t) es el valor de la velocidad actual y utilizando lafórmula de la ecuación 3.10 se actualiza el cambio en la posición xij considerando un valoraleatorio r3j [6].
vij(t+ 1) = sig(vij(t)) =1
1 + e−vij(t)(3.9)
xij(t+ 1) =
{1 si r3j(t)) < sig(vij(t+ 1)0 en otro caso
(3.10)
3.4.4 Micro Optimización mediante Cúmulo de Partículas
La micro Optimización mediante Cúmulo de Partículas (µ-PSO) utiliza un tamaño de cúmulomuy pequeño que normalmente acelera la pérdida de diversidad. Para compensar esta carac-terística se aplica un proceso de reinicialización para mantener variedad de partículas en lapoblación. También en la versión µ-PSO se utiliza un operador de mutación para aumentarla capacidad de búsqueda del algoritmo [3]. Los detalles se observan en el Algoritmo 3.
23

CAPÍTULO 3. ALGORITMOS INSPIRADOS EN LA NATURALEZA
Pseudocódigo de µ-PSO
Algoritmo 3: Pseudocódigo µ-PSO
Data: P ∈ [2, 6] (tamaño de la población); NR ∈ N (número de soluciones areemplazar); GR ∈ N (generación de reemplazo); PM ∈ [0.0, 1.0](operador de mutación); c1 y c2 ∈ R
Result: gBest (mejor partícula encontrada)
1 Inicializar partículas con posiciones y velocidades aleatorias en D dimensiones.;2 Set G =MaxFes/P ; cont = 1;3 for (g=1 a G) do
4 if (cont == GR) then
5 Reinicializar las NR peores partículas;6 Set cont = 1;
7 end if
8 Recalcular la posición del mejor global gbest;9 Seleccionar la mejor posición personal;10 for (cada xgi , i = 1, . . . , P ) do11 Recalcular la velocidad de la partícula;12 Recalcular la posición de la partícula;
13 end for
14 Aplicar mutación a cada partícula con probabilidad PM ;15 Set cont = cont + 1;
16 end for
Pseudocódigo µ-Optimización mediante Cúmulo de Partículas (µ-PSO) [7][20].
El µ-PSO crea un cúmulo inicial P de tamaño M (un valor pequeño) cuyos elementos se for-man con N valores aleatorios. Con los valores GR, generación de reemplazo, y NR, númerode partículas a reemplazar, se generan nuevos elementos para evitar la convergencia pre-matura. El µ-PSO calcula las mejores opciones de su propia experiencia y la de su parvadapara después calcular la nueva velocidad y posición de cada partícula. Después aplica mu-tación PM y continúa el ciclo hasta la condición de paro dando como solución el gBest, querepresenta la mejor partícula encontrada [7][20].
24

Capítulo 4
Comparativo empírico
Para realizar la comparación de los resultados obtenidos con los micro algoritmos inspiradosen naturaleza aplicados al problema de minimización de la inestabilidad cíclica en ambientesinteligentes, cada micro algoritmo se sometió previamente a un ajuste de parámetros. Ademásde de�nir un mismo número de evaluaciones con el �n de realizar las comparaciones los másequitativamente posible. En la sección 4.1 se especi�can los parámetros calibrados para elmicro Algoritmo Genético (µ-GA), micro Evolución Diferencia (µ-DE) y micro Optimizaciónmediante Cúmulo de Partículas (µ-PSO) con peso de inercia w y factor de estrechamientok respectivamente. Es importante mencionar que para todos los algoritmos comparados larepresentación de soluciones fue con cadenas binarias donde el tamaño lo de�ne el númeromáximos de agentes que puedan estar en el ambiente. Un uno signi�ca que el agente está enel ambiente y un cero signi�ca lo contrario.
En la sección 4.1.2 se mencionan brevemente los métodos estadísticos no paramétricos utiliza-dos para determinar el comportamiento de los micro algoritmos cuyos resultados y muestrasestadísticas se presentan en el capítulo 5.
4.1 Calibración de parámetros
Los algoritmos de optimización, como los algoritmos evolutivos, tienen un conjunto de pa-rámetros con�gurables que deben ser ajustados al problema debido a que no hay una con-�guración óptima única para cada posible aplicación del algoritmo. El rendimiento en unproblema determinado depende de la con�guración particular de estos parámetros [14]. Conel propósito de con�gurar automáticamente los algoritmos de optimización se utilizó la her-ramienta de con�guración automática de parámetros irace package de R statistics. Dichaherramienta se empleó para encontrar la con�guración más apropiada para los escenarios deprueba del problema de inestabilidad cíclica en ambiente inteligentes.
La herramienta irace, presentada por Dubois-Lacoste, López-Ibáñez y Stützle, utiliza méto-dos de con�guración automática con un mecanismo que veri�ca la convergencia prematura encada bloque de candidatos evaluados. Esta herramienta utiliza tipos de parámetros categóri-cos, que representan valores discretos y parámetros numéricos. Irace usualmente se describecomo un escenario de �con�guración fuera de línea� debido a que se ejecuta en varias faseshasta encontrar los mejores candidatos como se muestra en la �gura 4.1 [14].
25

CAPÍTULO 4. COMPARATIVO EMPÍRICO
Figura 4.1: Esquema de �ujo de información en irace [14].
La herramienta irace requiere de la descripción del espacio de los parámetros y con�guraciónpara de�nir el tipo de dato, el rango comprendido y restricciones de cada uno. Un conjuntode instancias propone ejemplos representativos que sirven para buscar una con�guración ex-plícita. Dados estos datos la con�guración de irace realiza ciclos de ejecuciones con ayudade un programa auxiliar llamado hookRun, responsable de aplicar la con�guración particulara una instancia y regresar el valor correspondiente para obtener �nalmente con�guracionescandidatas y con�guraciones cuasi-óptimas de los parámetros [14].
4.1.1 Parámetros calibrados de los micro algoritmos
Con el propósito de comparar los algoritmos inspirados en la naturaleza utilizados en el pro-blema de inestabilidad cíclica en ambientes inteligentes se consideró el mismo número deevaluaciones de llamadas a la función objetivo para todos los casos. Las pruebas se realiza-ron con un micro Algoritmo Genético (µ-GA), micro Evolución Diferencia (µ-DE) y microOptimización mediante Cúmulo de Partículas (µ-PSO) con peso de inercia w y factor de es-trechamiento k respectivamente. La ejecución de los algoritmos se realizaron iterativamentehasta alcanzar una condición de paro, que para todos los casos es el máximo número deevaluaciones. La tabla 4.1 muestra los parámetros que se ajustaron con irace en cada microalgoritmo.
Parámetro µ-DE µ-PSO (w) µ-PSO (k) µ-GA Descripción
M 4 6 3 8 Número de individuos de la población/partículasen el cúmulo
CR 0.602 � � � Probabilidad de recombinaciónF 0.112 � � � Factor de escalaw � 0.721 � � Peso de la inerciak � � 0.781 � Factor de estrechamientoc1 � 1.153 1.934 � Coe�ciente de aceleración del aprendizaje personalc2 � 1.291 1.119 � Coe�ciente de aceleración del aprendizaje socialPM � 0.707 0.965 � Probabilidad de mutaciónNR 2 2 2 � Número de partículas a reemplazarGR 97 85 80 � Generación de reemplazo
pcruza � � � 0.884 Probabilidad de cruza
Tabla 4.1: Tabla de parámetros calibrados de los micro algoritmos
26

4.1. CALIBRACIÓN DE PARÁMETROS
4.1.2 Pruebas estadísticas no paramétricas
Actualmente las pruebas estadísticas son cada vez más utilizadas para corroborar resultadosen los algoritmos de cómputo inteligente. Se utilizan para realizar un análisis de los datosobtenidos y como apoyo para poder decidir si un algoritmo se considera mejor que otro.Dentro de las pruebas estadísticas, los métodos no paramétricos son útiles para analizar ex-perimentos cuya distribución de resultados no se ajusta a la Normal, como es el caso de losalgoritmos de cómputo inteligente, donde las distribuciones de las muestras suelen carecerde tal ajuste. Además, para tratar este tipo de problemas se debe supone una hipótesisdonde dos distribuciones poblacionales son idénticas y las pruebas estadísticas no paramétri-cas son métodos para detectar diferencias poblacionales cuando las suposiciones no se satis-facen [26][9].
Los métodos no paramétricos no asumen ajuste a la Normal de la distribución de los datos. Elprocedimiento plantea una hipótesis nula, una hipótesis alternativa y especi�cando un valorsigni�cativo de comparación llamado p-value con un valor de signi�cancia alfa de 0.05. Paraeste trabajo se realiza una comparación por pares con la prueba de suma de rangos con signode Wilcoxon, y para realizar una comparación múltiple se utiliza la prueba de Friedman [9].
Primeramente, en los métodos estadísticos no paramétricos se de�ne una hipótesis nula citadacomo H0 la cual supone que las distribuciones de las poblaciones a comparar son idénticas,es decir, la hipótesis nula es verdadera cuando ambas poblaciones están distribuidas nor-malmente con la misma media y la misma varianza. La hipótesis alternativa, Ha, es ver-dadera cuando las distribuciones de localización son diferentes, es decir, que la distribuciónse desplaza una cantidad desconocida hacia la derecha o la izquierda. El valor p-value dainformación de la prueba estadística determinando si la diferencia es signi�cativa o no, entremás pequeño es el valor de p-value, la evidencia para desechar H0 es más sólida [26][9].
4.1.3 Prueba de suma de rangos con signo de Wilcoxon
La prueba estadística de suma de rangos con signo de Wilcoxon, utilizada para comparar dospoblaciones basadas en muestras aleatorias independientes, fue propuesta por Frank Wilcoxonen 1945. Esta prueba trabaja con observaciones pareadas de la forma (Xi, Yi) y se calculanlas diferencias (Di) para cada uno de los p pares, de�niendo la diferencia como di = Xi − Yi.Para llevar a cabo la prueba de Wilcoxon se de�nen la hipótesis nula H0 y la hipótesis alter-nativa Ha.
• H0: Las distribuciones poblacionales para las X y Y son idénticas.
• Ha: Las dos distribuciones poblacionales di�eren en localización.
Después se obtienen las diferencias donde aquellas que son iguales a cero se eliminan y elnúmero de pares p, se reduce de conformidad, entonces se clasi�can las muestras en orden de
27

CAPÍTULO 4. COMPARATIVO EMPÍRICO
magnitud creando rangos y asignando valores a cada uno, un 1 al más pequeño, 2 al segundomás pequeño y así sucesivamente hasta p (la más grande). Si dos o más diferencias estánempatadas para el mismo rango entonces el promedio de las clasi�caciones que se hubieranasignado a estas diferencias se asigna a cada miembro del grupo empatado. Entonces secalculan la suma de rangos para las diferencias negativas y positivas utilizando las fórmulas4.1 y 4.2 [26].
R+ =∑di>0
rank(di) +1
2
∑di=0
rank(di) (4.1)
R− =∑di<0
rank(di) +1
2
∑di=0
rank(di) (4.2)
Para este método el valor más pequeño se utiliza como estadístico de la prueba y sirve paraprobar la hipótesis nula, la cual dice que los dos histogramas de frecuencias relativas pobla-cionales son idénticos. En consecuencia, rechazaremos la hipótesis nula si el p-value es menora la 1 menos la con�anza de la prueba (100%− 95% = 5% por ejemplo) y cuanto menor seael valor, mayor será el valor de evidencia a favor del rechazo de la hipótesis nula, con lo quese puede concluir que hay diferencias en las distribuciones de X y Y [26][9].
4.1.4 Prueba de Friedman
La prueba estadística de Friedman, inventada por Milton Friedman en 1937, está diseñadapara probar la hipótesis nula donde las distribuciones de probabilidad de las k muestras sonidénticas contra la alternativa de que al menos dos de las distribuciones di�eren en distribu-ción [26].
• H0: Las muestras vienen de la misma población
• Ha: Las muestras no vienen de la misma población.
El procedimiento de la prueba de Friedman supone b bloques aleatorizados para comparar elrendimiento de varias muestras, los b bloques se suponen para el experimento y sirven paracomparar las localizaciones de las distribuciones de las respuestas correspondientes a cadauna de las k muestras [26].
El primer paso para calcular la prueba estadística es convertir los resultados originales enrangos utilizando los siguientes pasos:
• Reunir los resultados observados de cada algoritmo.
• Por cada problema i, crear rangos desde 1 (el más pequeño del bloque) a k (el másgrande del bloque), los cuales se denotan como rji (1 ≤ j ≤ k)
28

4.1. CALIBRACIÓN DE PARÁMETROS
• Por cada algoritmo j, promediar los rangos obtenidos para obtener al �nal el rangoRj con la fórmula 4.3. Si dos o más observaciones del mismo bloque están empatadaspara el mismo rango, entonces el promedio de los rangos se asigna a cada miembro delgrupo empatado.
Rj =1
b
∑i
rji (4.3)
Después de clasi�car en rangos y realizar la suma de los mismos, la prueba de Friedman enpráctica se puede de�nir con la fórmula 4.4.
Fr =12
bk(k + 1)
k∑i=1
R2j − 3b(k + 1) (4.4)
Si la hipótesis nula es verdadera y las distribuciones de probabilidad de las respuesta de lasmuestras no di�eren en localización, esperamos que los valores Rj sean aproximadamenteiguales y el valor resultante Fr sea pequeño.
Si la hipótesis alternativa fuera verdadera se esperaría que esto llevara a diferencias entrelos valores Rj y grandes valores de Fr correspondientes [26][9].
29

Capítulo 5
Muestra de resultados
Para las pruebas realizadas se consideró como medida de desempeño el Promedio de Cambiosen el Sistema, ACS (ver sección 2.2), cuyo valor máximo es 1.0 que representa un sistematotalmente inestable. Dado que el propósito es reducir el Promedio de Cambios en el Sistema,se puede decir que estamos tratando un problema de minimización con los micro algoritmosinspirados en la naturaleza: micro Algoritmo Genético (µ-GA), micro Evolución Diferencia(µ-DE) y micro Optimización mediante Cúmulo de Partículas (µ-PSO) con peso de inercia wy factor de estrechamiento k (los parámetros de los micro algoritmos se listan en la tabla 4.1),los cuales buscan minimizar el valor del Promedio de Cambios en el Sistema considerandocomo mejores resultados a los valores más cercanos a 0. Estos resultados fueron comparadosempíricamente con las pruebas no paramétricas de suma de rangos con signo de Wilcoxon yFriedman (ver capítulo 4).
Los escenarios utilizados en las pruebas para la minimización de la inestabilidad cíclica enambientes inteligentes dinámicos se especi�can en la sección 5.1. Para cada escenario deprueba se realizaron 30 ejecuciones. Además, como condición de paro en cada micro algo-ritmo se consideraron 30,000 evaluaciones.
La muestra de los resultados obtenidos para la probabilidad de Compuerta OR 10 se puedenver en la sección 5.2 y en la sección 5.3 se encuentra la muestra de los resultados obtenidospara la probabilidad de Compuerta OR 90. Posteriormente en la sección 5.4 se realiza unanálisis de los resultados obtenidos.
5.1 Escenarios de prueba
En el modelo de simulación del problema de la inestabilidad cíclica en ambientes inteligentes(ver capítulo 2) los agentes tienen un comportamiento dinámico de entrada y salida en elambiente. A esta acción la llamaremos evento ya que identi�ca un cambio en el ambiente.Cada evento en el sistema es aleatorio, por lo que en un momento determinado puede ocurriro no. Además, un evento puede alterar el Promedio de Cambios en el Sistema dependiendode los parámetros del agente que provoca el evento, es decir, su compuerta lógica (OR/AND)y su conexión con otros agentes.
30

5.2. MUESTRA DE RESULTADOS PARA LA PROBABILIDAD DE COMPUERTA OR 10 CON DIFERENTE PROBABILIDAD DECONEXIÓN
Para la creación de los escenarios de prueba se manejaron los parámetros de compor-tamiento listados en la tabla 5.1.
Parámetro Nombre Descripción
P. Compuerta OR Probabilidad de compuerta OR Determina si la regla de comportamiento delagente es una compuerta OR o una compuerta AND.
P. Bloqueo Probabilidad de bloqueo Determina si el estado del agente, On/O�, puede sermodi�cado por la regla de comportamiento o es �jo.
P. Conexión Probabilidad de conexión Determina la conducta social del ambiente para crearrelaciones y dependencias entre los agentes.
Tabla 5.1: Parámetros para la creación de escenarios de prueba
Los experimentos se determinaron con las probabilidades de�nidas en la tabla 5.2, cuya com-binación proporciona 54 escenarios de prueba.
Parámetro Valor
P. Compuerta OR 10 y 90P. Bloqueo 0, 15 y 30P. Conexión 10, 20, 30, 40, 50, 60, 70 , 80 y 90
Tabla 5.2: Valores de los parámetros para la creación de los escenarios de prueba
5.2 Muestra de resultados para la Probabilidad de
Compuerta OR 10 con diferente Probabilidad de
Conexión
En las pruebas para la Probabilidad de Compuerta OR 10 se realizaron los experimentospara la Probabilidad de Bloqueo 0, 15 y 30. Además de utilizar la Probabilidad de Conexión10, 20, 30, 40, 50, 60, 70, 80 y 90. Por ejemplo, la tabla 5.3 muestra las estadísticas del casode estudio �P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 20�. La grá�ca de caja 5.1representa la distribución de los datos de cada micro algoritmo, donde el punto superiorindica el peor valor obtenido, el punto inferior el mejor valor, la cruz indica la media, lacaja representa la distribución del 50% de los resultados y la línea horizontal es la mediana.Además, la longitud de la caja representa la desviación estándar de los datos [27].
31

CAPÍTULO 5. MUESTRA DE RESULTADOS
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.01071693 0.00897868 0.00656566 0.003003Media 0.01639788 0.03214203 0.02260612 0.01730944Mediana 0.0166913 0.02825126 0.01791727 0.01635827Peor 0.02236652 0.09395323 0.05255082 0.06135428Desv. Est. 0.00244704 0.02095797 0.01248671 0.00966096
Tabla 5.3: Estadísticas para �P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 20�.
Figura 5.1: Grá�ca de caja para �P. Compuerta OR 10; P. Bloqueo 15; P. Conexión20�.
Podemos observar que los micro algoritmos utilizados obtuvieron valores del Promedio deCambios en el Sistema (ACS) cercanos a 0. Para el ejemplo utilizado, el µ-GA se considerael mejor resultado.
La grá�ca de la �gura 5.2 muestra el comportamiento de la corrida ubicada en el valorde la mediana del número de ejecuciones independientes realizadas para cada micro algo-ritmo. Durante la corrida se generon eventos de entrada y salida de agentes en el ambientehasta alcanzar el máximo número de agentes (50). Por cada evento se realiza el proceso deminimización del Promedio de Cambios en el Sistema. Podemos notar que todos los microalgoritmos durante la corrida de la mediana tuvieron un comportamiento esperado en cadaevento, pero el µ-GA y el µ-DE muestran un valor más bajo del ACS.
32

5.2. MUESTRA DE RESULTADOS PARA LA PROBABILIDAD DE COMPUERTA OR 10 CON DIFERENTE PROBABILIDAD DECONEXIÓN
Figura 5.2: Grá�ca de medianas para �P. Compuerta OR 10; P. Bloqueo 15; P. Conex-ión 20�.
Otro ejemplo se muestra en la tabla 5.4 que contiene las estadísticas del caso de estudio�P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 40� representada en la grá�ca de cajamostrada en la �gura 5.3.
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.00956938 0.0094697 0.00766284 0.00566642Media 0.01096231 0.01753692 0.01300088 0.01090181Mediana 0.01065449 0.01223918 0.0103981 0.01019201Peor 0.01822574 0.03755504 0.02637486 0.02462986Desv. Est. 0.001497 0.00861575 0.00575499 0.00350506
Tabla 5.4: Estadísticas para �P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 40�.
Figura 5.3: Grá�ca de caja para �P. Compuerta OR 10; P. Bloqueo 30; P. Conexión40�.
33

CAPÍTULO 5. MUESTRA DE RESULTADOS
De igual forma se puede observar que los micro algoritmos utilizados obtienen valores cer-canos a 0 pero los algoritmos µ-DE y µ-GA sobresalen de las variantes del µ-PSO (peso deinercia w y factor de estrechamiento k). La grá�ca 5.4 muestra el comportamiento de lasmedianas donde podemos observar que en los diferentes eventos que hay en el ambiente laµ-DE y el µ-GA tiene un comportamiento esperado, es decir, en todo momento mantienenbaja la inestabilidad.
Figura 5.4: Grá�ca de medianas para para �P. Compuerta OR 10; P. Bloqueo 30; P.Conexión 40�.
En los casos de muestra se puede observar que los valores más competitivos para el mejorvalor obtenido, la media y la mediana los obtiene el µ-GA pero la mejor desviación estándarla obtiene el µ-DE, sin considerar aún que los valores son relativamente cercanos, por lo queen la sección 5.2.1 se muestran las diferencias signi�cativas entre los micro algoritmos utiliza-dos.
En general, en todas las pruebas realizadas para la Probabilidad de Compuerta OR 10 seobservó un comportamiento similar a las muestras presentadas en este capítulo, donde losmicro algoritmos µ-DE y µ-GA destacan sobre los resultados obtenidos con la µ-PSO conpeso de inercia w y factor de estrechamiento k.
Para ver el resto de las estadísticas para la Probabilidad de Compuerta OR 10 ver el AnexoA que contiene las Probabilidades de Bloqueo 0, 15 y 30 y las diferentes Probabilidades deConexión 10, 20, 30, 40, 50, 60, 70, 80 y 90. En el Anexo B se pueden consultar el resto de lasgrá�cas de caja para la Probabilidad de Compuerta OR 10 y el Anexo C contiene las grá�casde comportamiento por evento de las medianas correspondientes.
5.2.1 Comparativo de diferencias signi�cativas con µ-DE parala Probabilidad de Compuerta OR 10
Para poder comparar los resultados obtenidos con los micro algoritmos inspirados en la na-turaleza se realizaron las pruebas estadísticas de suma de rangos con signo de Wilcoxon yFriedman. El método estadístico de Friedman, utilizado para la comparación de múltiplesalgoritmos, indica que hay diferencias signi�cativas en los resultados de al menos un microalgoritmo, excepto en un caso con Probabilidad de Bloqueo 30. La tabla 5.5 muestra los
34

5.2. MUESTRA DE RESULTADOS PARA LA PROBABILIDAD DE COMPUERTA OR 10 CON DIFERENTE PROBABILIDAD DECONEXIÓN
resultados de Friedman para la Probabilidad de Compuerta OR 10 y Probabilidad de Blo-queo 0 para los diferentes valores de la Probabilidad de Conexión. En la tabla 5.6 se puedenver los resultados de Friedman igualmente para la Probabilidad de Compuerta OR 10 conlas diferentes Probabilidad de Conexión pero con Probabilidad de Bloqueo 15 y la tabla 5.7contiene los resultados de Friedman para la Probabilidad de Bloqueo 30.
P. Conexión p-valor
10 < 0.0001√
20 0.03207√
30 < 0.0001√
40 < 0.0001√
50 < 0.0001√
60 < 0.0001√
70 < 0.0001√
80 < 0.0001√
90 < 0.0001√
Tabla 5.5: Friedman para Probabilidad de Compuerta OR 10 y Probabilidad de Blo-queo 0
P. Conexión p-valor
10 0.00061√
20 < 0.0001√
30 < 0.0001√
40 < 0.0001√
50 < 0.0001√
60 < 0.0001√
70 < 0.0001√
80 < 0.0001√
90 < 0.0001√
Tabla 5.6: Friedman para Probabilidad de Compuerta OR 10 y Probabilidad de Blo-queo 15
Para obtener las diferencias signi�cativas entre los diferentes micro algoritmos inspiradosen la naturaleza se aplicó el método estadístico de suma de rangos con signo de Wilcoxon,utilizado para la comparación por pares. Debido a que los resultados de la µ-DE sobresalíanvisualmente, se realizó un concentrado de dichas diferencias signi�cativas para compararlascontra el µ-PSO con peso de inercia w, µ-PSO con factor de estrechamiento k y el µ-GA.Para indicar que la µ-DE obtuvo mejores resultados se manejó el símbolo +, el símbolo �
35

CAPÍTULO 5. MUESTRA DE RESULTADOS
P. Conexión p-valor
10 < 0.0001√
20 0.00011√
30 < 0.0001√
40 < 0.0001√
50 < 0.0001√
60 < 0.0001√
70 0.01961√
80 0.05604 x90 0.00076
√
Tabla 5.7: Friedman para Probabilidad de Compuerta OR 10 y Probabilidad de Blo-queo 30
indica que obtuvo peores resultados contra el micro algoritmos de comparación y el símbolo ≈indica que no hubo diferencias signi�cativas como se muestra en las tablas 5.8, 5.9 y 5.10. Enla tabla 5.8 se muestra el concentrado para Probabilidad de Bloqueo 0, la tabla 5.9 contieneel concentrado para Probabilidad de Bloqueo 15 y la tabla 5.10 muestra el concentrado paraProbabilidad de Bloqueo 30.
P. Bloqueo 0
P. Conexión 10 20 30 40 50 60 70 80 90µ-PSO (w) + ≈ + + + + + + +µ-PSO (k) ≈ ≈ ≈ + ≈ + ≈ ≈ ≈µ-GA ≈ - + ≈ ≈ - ≈ ≈ -
Tabla 5.8: Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 0
P. Bloqueo 15
P. Conexión 10 20 30 40 50 60 70 80 90µ-PSO (w) + + + + + + + + +µ-PSO (k) ≈ + + + ≈ + + + ≈µ-GA - ≈ - - ≈ ≈ ≈ ≈ ≈
Tabla 5.9: Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 15
36

5.3. MUESTRA DE RESULTADOS PARA LA PROBABILIDAD DE COMPUERTA OR 90 CON DIFERENTE PROBABILIDAD DECONEXIÓN
P. Bloqueo 30
P. Conexión 10 20 30 40 50 60 70 80 90µ-PSO (w) ≈ + + + ≈ + + ≈ +µ-PSO (k) ≈ + + ≈ ≈ ≈ + ≈ +µ-GA - ≈ + - + ≈ + ≈ ≈
Tabla 5.10: Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 30
Al realizar el conteo del concentrado de diferencias signi�cativas listado en la tabla 5.11podemos observar que de 81 comparaciones para la Probabilidad de Compuerta OR 10, conProbabilidad de Bloqueo 0, 15, 30 y los diferentes valores para la Probabilidad de Conexión,en casi la mitad de ellos la micro Evolución Diferencial (µ-DE) obtuvo mejores resultados,pero la otra mitad se consideran casos sin diferencias signi�cativas y en 7 casos obtuvo peoresresultados contra el micro Algoritmo Genético (µ-GA).
P. Compuerta OR 10
P. Bloqueo 0 15 30 TOTAL+ 11 15 13 39≈ 13 9 12 34- 3 3 2 8
Tabla 5.11: Concentrado de diferencias signi�cativas para Probabilidad de CompuertaOR 10 con respecto a la µ-DE.
Considerando las diferencias signi�cativas ahora para los casos de muestra �P. Compuerta OR10; P. Bloqueo 15; P. Conexión 20�, la µ-DE obtiene mejores resultados pero sin diferenciassigni�cativas contra el µ-GA y para el caso �P. Compuerta OR 10; P. Bloqueo 30; P. Conexión40� el µ-GA obtuvo mejores resultados pero la µ-DE obtuvo un mejor valor en la desviaciónestándar. Estos dos casos de muestra representan el comportamiento en general de los casosde prueba para la Probabilidad de Compuerta OR 10.
5.3 Muestra de resultados para la Probabilidad de
Compuerta OR 90 con diferente Probabilidad de
Conexión
En las pruebas para la Probabilidad de Compuerta OR 90 se realizaron los experimentospara la Probabilidad de Bloqueo 0, 15 y 30. Además de utilizar la Probabilidad de Conexión10, 20, 30, 40, 50, 60, 70, 80 y 90. Para el caso de estudio �P. Compuerta OR 90; P. Bloqueo0; P. Conexión 30� la tabla 5.12 muestra las estadísticas de los resultados los cuales estánrepresentados en la grá�ca de caja 5.5.
37

CAPÍTULO 5. MUESTRA DE RESULTADOS
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.0140802 0.00991395 0.00993809 0.00387205Media 0.02063028 0.02746484 0.02580332 0.018308Mediana 0.01966089 0.01706252 0.0245741 0.01705737Peor 0.04101622 0.11551412 0.07456003 0.03478446Desv. Est. 0.00579386 0.02453069 0.0146977 0.00697398
Tabla 5.12: Estadísticas para �P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 30�.
Figura 5.5: Grá�ca de caja para �P. Compuerta OR 90; P. Bloqueo 0; P. Conexión30�.
Se puede observar que el micro Algoritmo Genético (µ-GA) obtuvo mejores resultados perola micro Evolución Diferencial (µ-DE) tiene una mejor desviación estándar. En la grá�ca 5.6podemos notar el comportamiento de los micro algoritmos durante los eventos de la ejecu-ción ubicada en el valor de la mediana correspondiente. En todos los casos se puede apreciarque los micro algoritmos utilizados obtienen valores del Promedio de Cambios en el Sistemacercanos a 0.
38

5.3. MUESTRA DE RESULTADOS PARA LA PROBABILIDAD DE COMPUERTA OR 90 CON DIFERENTE PROBABILIDAD DECONEXIÓN
Figura 5.6: Grá�ca de medianas para �P. Compuerta OR 90; P. Bloqueo 0; P. Conexión30�.
Para el otro caso de muestra �P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 90�, latabla 5.13 muestra las estadísticas de los resultados representados en la grá�ca de caja 5.7.
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.00986334 0.00697888 0.00636803 0.00461133Media 0.01048641 0.01898882 0.01706087 0.01350739Mediana 0.01036683 0.01112246 0.01069519 0.01010101Peor 0.01154401 0.05135866 0.04336468 0.02716823Desv. Est. 0.00042262 0.01205568 0.00921988 0.00685573
Tabla 5.13: Estadísticas para �P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 90�.
Figura 5.7: Grá�ca de caja para �P. Compuerta OR 90; P. Bloqueo 15; P. Conexión90�.
39
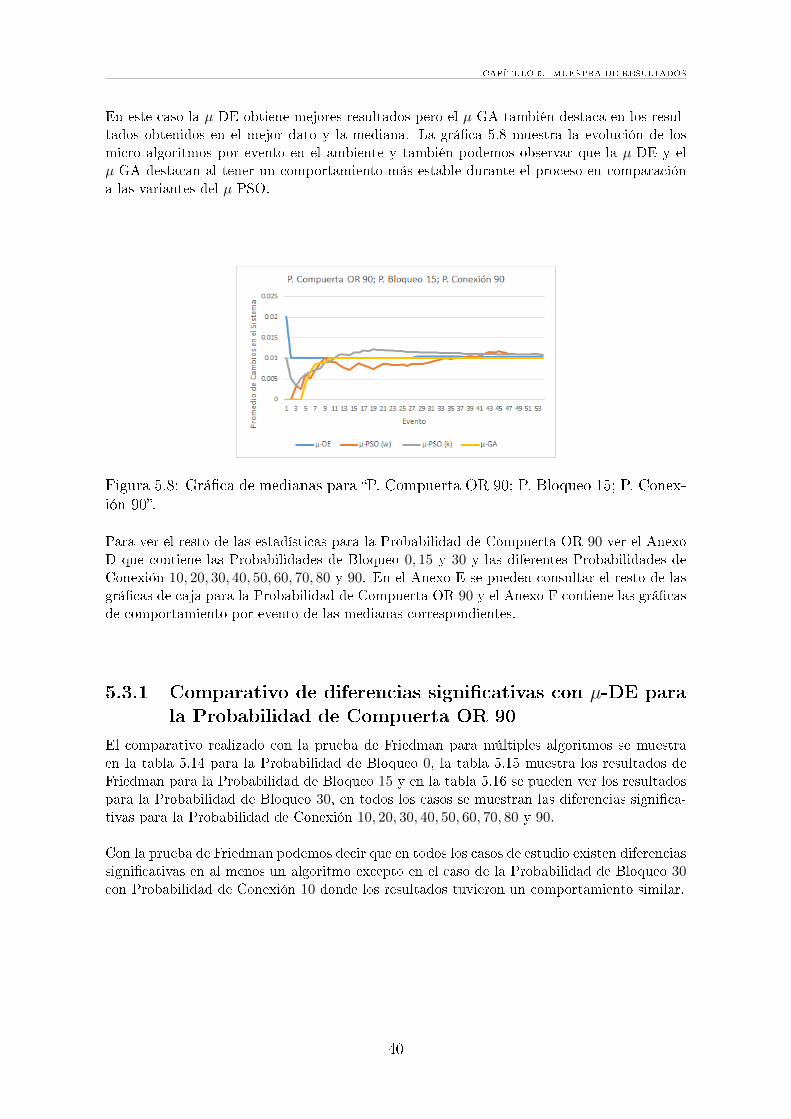
CAPÍTULO 5. MUESTRA DE RESULTADOS
En este caso la µ-DE obtiene mejores resultados pero el µ-GA también destaca en los resul-tados obtenidos en el mejor dato y la mediana. La grá�ca 5.8 muestra la evolución de losmicro algoritmos por evento en el ambiente y también podemos observar que la µ-DE y elµ-GA destacan al tener un comportamiento más estable durante el proceso en comparacióna las variantes del µ-PSO.
Figura 5.8: Grá�ca de medianas para �P. Compuerta OR 90; P. Bloqueo 15; P. Conex-ión 90�.
Para ver el resto de las estadísticas para la Probabilidad de Compuerta OR 90 ver el AnexoD que contiene las Probabilidades de Bloqueo 0, 15 y 30 y las diferentes Probabilidades deConexión 10, 20, 30, 40, 50, 60, 70, 80 y 90. En el Anexo E se pueden consultar el resto de lasgrá�cas de caja para la Probabilidad de Compuerta OR 90 y el Anexo F contiene las grá�casde comportamiento por evento de las medianas correspondientes.
5.3.1 Comparativo de diferencias signi�cativas con µ-DE parala Probabilidad de Compuerta OR 90
El comparativo realizado con la prueba de Friedman para múltiples algoritmos se muestraen la tabla 5.14 para la Probabilidad de Bloqueo 0, la tabla 5.15 muestra los resultados deFriedman para la Probabilidad de Bloqueo 15 y en la tabla 5.16 se pueden ver los resultadospara la Probabilidad de Bloqueo 30, en todos los casos se muestran las diferencias signi�ca-tivas para la Probabilidad de Conexión 10, 20, 30, 40, 50, 60, 70, 80 y 90.
Con la prueba de Friedman podemos decir que en todos los casos de estudio existen diferenciassigni�cativas en al menos un algoritmo excepto en el caso de la Probabilidad de Bloqueo 30con Probabilidad de Conexión 10 donde los resultados tuvieron un comportamiento similar.
40

5.3. MUESTRA DE RESULTADOS PARA LA PROBABILIDAD DE COMPUERTA OR 90 CON DIFERENTE PROBABILIDAD DECONEXIÓN
P. Conexión p-valor
10 < 0.0001√
20 0.00319√
30 < 0.0001√
40 < 0.0001√
50 < 0.0001√
60 < 0.0001√
70 < 0.0001√
80 < 0.0001√
90 < 0.0001√
Tabla 5.14: Friedman para Probabilidad de Compuerta OR 90 y Probabilidad deBloqueo 0
P. Conexión p-valor
10 < 0.0001√
20 < 0.0001√
30 < 0.0001√
40 < 0.0001√
50 < 0.0001√
60 < 0.0001√
70 < 0.0001√
80 < 0.0001√
90 < 0.0001√
Tabla 5.15: Friedman para Probabilidad de Compuerta OR 90 y Probabilidad deBloqueo 15
P. Conexión p-valor
10 0.91448 x20 < 0.0001
√
30 < 0.0001√
40 < 0.0001√
50 < 0.0001√
60 < 0.0001√
70 < 0.0001√
80 0.00011√
90 0.0058√
Tabla 5.16: Friedman para Probabilidad de Compuerta OR 90 y Probabilidad deBloqueo 30
41

CAPÍTULO 5. MUESTRA DE RESULTADOS
Para la prueba de suma de rangos con signo de Wilcoxon también se creó un concentradode diferencias signi�cativas entre la µ-DE contra el µ-PSO con peso de inercia w, µ-PSOcon factor de estrechamiento k y el µ-GA. En el concentrado se utiliza el símbolo + dondela µ-DE obtiene mejores resultados, el símbolo � para indicar que obtuvo peores resultadosy el símbolo ≈ indica que no hubo diferencias signi�cativas contra el micro algoritmos decomparación. La tabla 5.17 muestra el concentrado para Probabilidad de Bloqueo 0, la tabla5.18 contiene el concentrado para Probabilidad de Bloqueo 15 y la tabla 5.19 muestra elconcentrado para Probabilidad de Bloqueo 30.
P. Bloqueo 0
P. Conexión 10 20 30 40 50 60 70 80 90µ-PSO (w) + ≈ ≈ + + + + + +µ-PSO (k) ≈ ≈ + ≈ ≈ + + + ≈µ-GA + - - - ≈ ≈ ≈ ≈ +
Tabla 5.17: Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 0
P. Bloqueo 15
P. Conexión 10 20 30 40 50 60 70 80 90µ-PSO (w) ≈ + + + + + + + +µ-PSO (k) ≈ ≈ + ≈ + + + ≈ +µ-GA + ≈ - - + ≈ ≈ ≈ ≈
Tabla 5.18: Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 15
P. Bloqueo 30
P. Conexión 10 20 30 40 50 60 70 80 90µ-PSO (w) + + + + + + + + ≈µ-PSO (k) + + + + + ≈ ≈ + +µ-GA + ≈ ≈ - ≈ ≈ ≈ ≈ +
Tabla 5.19: Diferencias signi�cativas para µ-DE con Probabilidad de Bloqueo 30
De las 81 comparaciones realizadas para la Probabilidad de Compuerta OR 90, con Pro-babilidad de Bloqueo 0, 15 y 30 y los diferentes valores para la Probabilidad de Conexión,en más de la mitad la micro Evolución Diferencial (µ-DE) obtuvo mejores resultados, sinembargo, 30 comparaciones no tienen diferencias signi�cativas y en 6 casos obtuvo peoresresultados contra el micro Algoritmo Genético (µ-GA) como se puede apreciar en la tabla5.20.
42

5.4. ANÁLISIS DE RESULTADOS
P. Compuerta OR 90
P. Bloqueo 0 15 30 TOTAL+ 13 15 17 45≈ 11 10 9 30- 3 2 1 6
Tabla 5.20: Concentrado de diferencias signi�cativas para Probabilidad de CompuertaOR 90 con respecto a la µ-DE.
5.4 Análisis de resultados
Analizando los resultados podemos concluir que para ambas Probabilidades de CompuertaOR, 10 y 90, los resultados de la micro Evolución Diferencial (µ-DE) y el micro AlgoritmoGenético (µ-GA) sobresalen sobre la micro Optimización mediante Cúmulo de Partículas (µ-PSO) tanto con peso de inercia w y factor de estrechamiento k. Debido a ésto se realizó unconteo de diferencias signi�cativas entre la µ-DE y el µ-GA. En la tabla 5.21 se muestra elconteo para la Probabilidad de Compuerta OR 10 y en la tabla 5.22 para la Probabilidad deCompuerta OR 90 donde el símbolo + indica que la µ-DE obtuvo mejores resultados que elµ-GA, el símbolo � indica que obtuvo peores resultados y el símbolo ≈ se re�ere a que nohubo diferencias signi�cativas.
P. Compuerta OR 10
P. Bloqueo 0 15 30 TOTAL+ 1 0 3 4≈ 5 6 4 15- 3 3 2 8
Tabla 5.21: Comparativo de diferencias signi�cativas entre µ-DE y µ-GA para laProbabilidad OR 10.
P. Compuerta OR 90
P. Bloqueo 0 15 30 TOTAL+ 2 2 2 6≈ 4 5 6 15- 3 2 1 6
Tabla 5.22: Comparativo de diferencias signi�cativas entre µ-DE y µ-GA para laProbabilidad OR 90.
43

CAPÍTULO 5. MUESTRA DE RESULTADOS
Podemos observar en el conteo de diferencias de la Probabilidad de Compuerta OR 10 que elµ-GA tiene un mejor desempeño que el µ-DE, pero se puede apreciar que en la mayoría delos casos de estudio no existen diferencias signi�cativas entre µ-DE y µ-GA. En la Probabi-lidad de Compuerta OR 90 tanto la µ-DE como el µ-GA tienen el mismo número de casoscon mejor desempeño pero de igual forma en la mayoría de los casos no hay evidencia dediferencias signi�cativas entre ellos, lo que signi�ca que ambos micro algoritmos son igual dee�cientes al minimizar la inestabilidad cíclica. Sin embargo, la desviación estándar de µ-DEes en general menor a la desviación estándar de µ-GA, por lo que podemos decir que µ-DEmostró ligeramente una mayor robustez.
La literatura especializada [20] indica que el algoritmo de Optimización mediante Cúmulode Partículas (PSO) y su versión micro (µ-PSO) obtuvieron resultados similares en la min-imización de la inestabilidad cíclica en ambientes dinámicos con entrada de agentes. Sinembargo, los resultados obtenidos en este trabajo muestran que otros µ-algoritmos evolutivoscomo la µ-DE y el µ-GA pueden proveer un mejor y más consistente desempeño.
44

Capítulo 6
Conclusiones y trabajo futuro
El objetivo principal de este trabajo fue comparar el desempeño de tres micro algoritmos ins-pirados en la naturaleza en el problema de la inestabilidad cíclica en ambientes inteligentescon entrada y salida dinámica de agentes autónomos. La inestabilidad cíclica es un com-portamiento errático en el sistema causado por ciclos no deseados creados por las reglas decomportamiento propias de los agentes y las relaciones de dependencia que generan con otrosagentes en el sistema. En el sistema de simulación para formar los escenarios de prueba, laregla de comportamiento de cada agente está basada en las compuertas lógicas AND y OR, ylas relaciones de dependencia se crean dinámicamente durante los eventos de entrada o salidade agentes en el ambiente.
Para tratar el problema de la inestabilidad cíclica se desarrollaron los micro algoritmos ins-pirados en la naturaleza: micro Algoritmo Genético (µ-GA), micro Evolución Diferencial(µ-DE) y micro Optimización mediante Cúmulo de Partículas (µ-PSO) con las variantes depeso de inercia (w) y factor de estrechamiento (k). Para medir la inestabilidad cíclica seutilizó el Promedio de Cambios en el Sistema (ACS), tomada de la literatura especializada,como función objetivo para la minimización requerida en los algoritmos de optimización men-cionados.
Los resultados obtenidos en los experimentos realizados con los micro algoritmos para la mini-mización de la inestabilidad cíclica fueron sometidos a las pruebas estadísticas no paramétricasconocidas como la prueba de suma de rangos con signo de Wilcoxon y la prueba de Friedman.Los resultados de las pruebas fueron consistentes para todas las instancias o escenarios deprueba.
Con base en estos resultados podemos decir que en general el micro Algoritmo Genético(µ-GA) obtuvo un mejor desempeño en la minimización de la inestabilidad cíclica, pero noexisten diferencias signi�cativas contra la micro Evolución Diferencia (µ-DE), por lo quepodemos concluir que ambos son e�cientes para este problema. Sin embargo, la µ-DE en lamayoría de los casos tiene un menor valor en la desviación estándar, es decir, mostró unaconsistencia ligeramente mejor.
También podemos rechazar la hipótesis presentada que pretendía demostrar que la microOptimización mediante Cúmulo de Partículas (µ-PSO) presentaba un desempeño más com-petitivo en las instancias de la inestabilidad cíclica estudiadas, utilizando como medida dedesempeño el Promedio de Cambios en el Sistema.
45

CAPÍTULO 6. CONCLUSIONES Y TRABAJO FUTURO
Cabe mencionar que para este estudio se desarrollaron las versiones generales de micro Al-goritmo Genético (µ-GA), micro Evolución Diferencial (µ -DE) y micro Optimización me-diante Cúmulo de Partículas (µ-PSO) con las variantes de peso de inercia (w) y factor deestrechamiento (k) por lo que es necesario realizar pruebas con otras variantes de los al-goritmos mencionados. Además, en las pruebas realizadas no se consideraron agentes conprioridad los cuales no se podrían desactivar, por ejemplo en un ambiente que tenga comoagente una alarma de seguridad. Tampoco se consideró ruido por acciones externas, porejemplo la interacción humana. Los casos antes mencionados requieren de más trabajo fu-turo para su estudio.
Este trabajo se realizó en un simulador de escenarios de prueba para ambientes inteligentesy los resultados obtenidos demuestran que los micro algoritmos inspirados en la naturalezason e�cientes para la minimización de la inestabilidad cíclica, por lo que los trabajos futurospodrían desarrollarse en ambientes reales.
46

Anexos
47

Anexo A
Estadísticas para la Probabilidad deCompuerta OR 10
48

A.1. PROBABILIDAD DE BLOQUEO 0
A.1 Probabilidad de Bloqueo 0
P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 10 P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 20
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.015713 0.010101 0.006588 0.007427 Mejor 0.010711 0.007533 0.006018 0.003157Media 0.020784 0.035174 0.020267 0.022295 Media 0.022175 0.039651 0.027974 0.019488Mediana 0.020104 0.025974 0.013685 0.019108 Mediana 0.020596 0.016739 0.015904 0.017783Peor 0.034792 0.088334 0.083126 0.074242 Peor 0.043305 0.121493 0.104631 0.046317Desv. Est. 0.003986 0.021042 0.01514 0.01336 Desv. Est. 0.007391 0.035342 0.02378 0.00889
P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 30 P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 40
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.012235 0.007805 0.007215 0.00777 Mejor 0.009804 0.00947 0.005471 0.005908Media 0.019339 0.036341 0.026873 0.020995 Media 0.018322 0.029511 0.022266 0.017195Mediana 0.017621 0.033333 0.014735 0.018568 Mediana 0.017057 0.029442 0.021142 0.017661Peor 0.029516 0.16803 0.183601 0.045625 Peor 0.033498 0.063208 0.045732 0.035038Desv. Est. 0.004769 0.032094 0.032576 0.007914 Desv. Est. 0.005611 0.016122 0.011953 0.00778
P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 50 P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 60
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009981 0.007443 0.008054 0.006216 Mejor 0.009276 0.007925 0.008369 0.005772Media 0.016909 0.035002 0.019827 0.016265 Media 0.015953 0.031106 0.021204 0.01321Mediana 0.015429 0.019131 0.013147 0.015152 Mediana 0.015595 0.028283 0.021044 0.012191Peor 0.032078 0.133915 0.071088 0.041246 Peor 0.032828 0.104798 0.056105 0.0284Desv. Est. 0.005188 0.03459 0.015062 0.007542 Desv. Est. 0.004892 0.022182 0.01184 0.00537
P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 70 P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 80
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009596 0.009753 0.007905 0.003974 Mejor 0.009223 0.009215 0.007805 0.001263Media 0.014089 0.032826 0.016569 0.015629 Media 0.012937 0.02673 0.020332 0.012874Mediana 0.012597 0.024705 0.011983 0.014749 Mediana 0.012599 0.016009 0.0114 0.010732Peor 0.021812 0.097643 0.042312 0.034545 Peor 0.021131 0.078249 0.068528 0.031583Desv. Est. 0.003539 0.022701 0.008952 0.008075 Desv. Est. 0.002784 0.021631 0.016229 0.007141
P. Compuerta OR 10; P. Bloqueo 0; P. Conexión 90
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.010101 0.006465 0.00726 0.004209Media 0.012623 0.02647 0.017732 0.017552Mediana 0.01221 0.019936 0.011328 0.017063Peor 0.019712 0.087651 0.046667 0.034407Desv. Est. 0.002506 0.01949 0.011756 0.007966
49
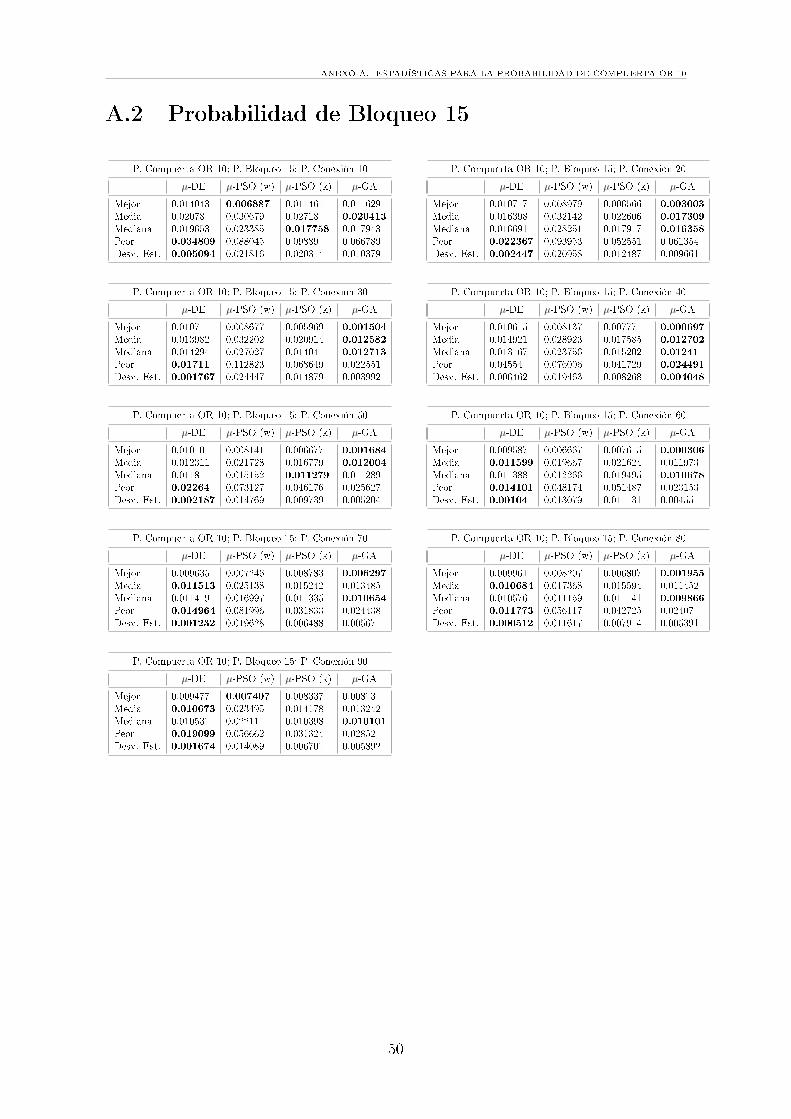
ANEXO A. ESTADÍSTICAS PARA LA PROBABILIDAD DE COMPUERTA OR 10
A.2 Probabilidad de Bloqueo 15
P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 10 P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 20
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.014043 0.006887 0.011461 0.011629 Mejor 0.010717 0.008979 0.006566 0.003003Media 0.02078 0.030679 0.02718 0.020413 Media 0.016398 0.032142 0.022606 0.017309Mediana 0.019653 0.023385 0.017758 0.017943 Mediana 0.016691 0.028251 0.017917 0.016358Peor 0.034809 0.088045 0.09889 0.066789 Peor 0.022367 0.093953 0.052551 0.061354Desv. Est. 0.005094 0.021816 0.020314 0.010379 Desv. Est. 0.002447 0.020958 0.012487 0.009661
P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 30 P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 40
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.01071 0.008677 0.005969 0.001504 Mejor 0.010615 0.008137 0.00777 0.000697Media 0.013982 0.032202 0.020914 0.012582 Media 0.014921 0.028923 0.017585 0.012702Mediana 0.014294 0.027027 0.01404 0.012713 Mediana 0.013167 0.023756 0.015202 0.01241Peor 0.01711 0.112823 0.068649 0.022551 Peor 0.04554 0.076006 0.041729 0.024491Desv. Est. 0.001767 0.024447 0.014879 0.003992 Desv. Est. 0.006462 0.019463 0.008268 0.004048
P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 50 P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 60
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.010101 0.008141 0.006677 0.001684 Mejor 0.009587 0.006667 0.007615 0.000306Media 0.012311 0.021728 0.016779 0.012004 Media 0.011599 0.019667 0.021624 0.011973Mediana 0.0118 0.015152 0.011279 0.011289 Mediana 0.011388 0.012266 0.019495 0.010678Peor 0.02264 0.073127 0.046176 0.025627 Peor 0.014101 0.048174 0.051487 0.023153Desv. Est. 0.002187 0.014769 0.009739 0.005204 Desv. Est. 0.00104 0.013079 0.011131 0.00455
P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 70 P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 80
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009635 0.007246 0.008783 0.006297 Mejor 0.009961 0.008207 0.006807 0.001955Media 0.011513 0.025138 0.015242 0.013485 Media 0.010684 0.017368 0.015594 0.011452Mediana 0.011419 0.016997 0.011335 0.010654 Mediana 0.010576 0.011159 0.011141 0.009866Peor 0.014964 0.081996 0.031833 0.024438 Peor 0.011773 0.056117 0.042725 0.02407Desv. Est. 0.001232 0.019628 0.006488 0.00567 Desv. Est. 0.000512 0.011617 0.007914 0.005391
P. Compuerta OR 10; P. Bloqueo 15; P. Conexión 90
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009477 0.007407 0.008337 0.00813Media 0.010673 0.023495 0.014178 0.013242Mediana 0.010531 0.02211 0.010398 0.010101Peor 0.019099 0.056662 0.031324 0.02852Desv. Est. 0.001674 0.014089 0.006701 0.005892
50
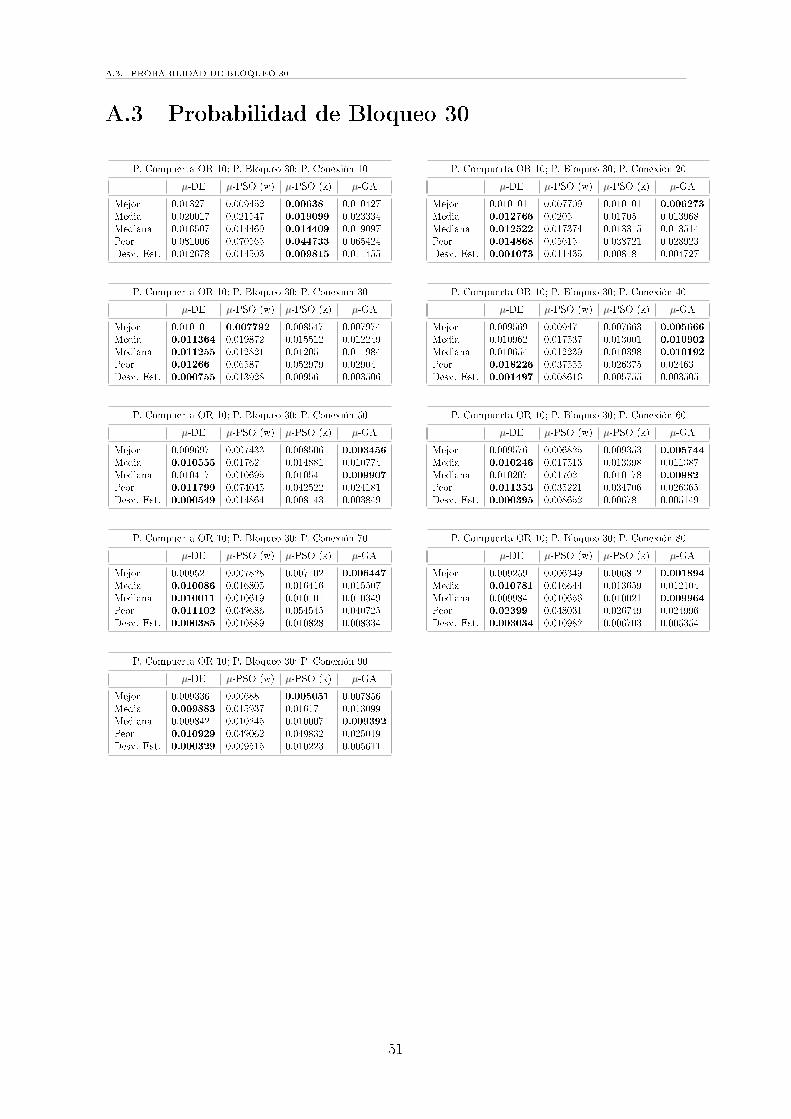
A.3. PROBABILIDAD DE BLOQUEO 30
A.3 Probabilidad de Bloqueo 30
P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 10 P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 20
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.01327 0.009452 0.00638 0.010427 Mejor 0.010101 0.007709 0.010101 0.006273Media 0.020017 0.021547 0.019099 0.023334 Media 0.012766 0.0205 0.01705 0.013968Mediana 0.016507 0.014469 0.014409 0.019097 Mediana 0.012522 0.017374 0.013315 0.013514Peor 0.081006 0.070565 0.044733 0.065424 Peor 0.014868 0.05615 0.038721 0.028923Desv. Est. 0.012678 0.014503 0.009815 0.011455 Desv. Est. 0.001073 0.011435 0.00818 0.004727
P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 30 P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 40
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.010101 0.007792 0.008547 0.007974 Mejor 0.009569 0.00947 0.007663 0.005666Media 0.011364 0.019872 0.015512 0.012249 Media 0.010962 0.017537 0.013001 0.010902Mediana 0.011255 0.012821 0.01205 0.011984 Mediana 0.010654 0.012239 0.010398 0.010192Peor 0.01266 0.06587 0.052979 0.02904 Peor 0.018226 0.037555 0.026375 0.02463Desv. Est. 0.000755 0.013928 0.009561 0.003506 Desv. Est. 0.001497 0.008616 0.005755 0.003505
P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 50 P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 60
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009697 0.007433 0.008506 0.003456 Mejor 0.009576 0.006825 0.009353 0.005744Media 0.010555 0.01762 0.014881 0.010774 Media 0.010246 0.017513 0.013398 0.011387Mediana 0.010417 0.010695 0.01054 0.009907 Mediana 0.010207 0.01702 0.010178 0.00982Peor 0.011799 0.074045 0.042522 0.024181 Peor 0.011353 0.035221 0.034706 0.026365Desv. Est. 0.000549 0.014864 0.008143 0.003849 Desv. Est. 0.000395 0.008652 0.00678 0.005149
P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 70 P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 80
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.00952 0.007828 0.007102 0.006447 Mejor 0.009259 0.006349 0.006812 0.001894Media 0.010086 0.016805 0.016416 0.015507 Media 0.010781 0.016644 0.013659 0.012104Mediana 0.010011 0.010619 0.010101 0.010349 Mediana 0.009984 0.010656 0.010021 0.009964Peor 0.011102 0.049686 0.054545 0.040725 Peor 0.02399 0.048031 0.026749 0.024996Desv. Est. 0.000385 0.010889 0.010828 0.008334 Desv. Est. 0.003034 0.010982 0.006703 0.005354
P. Compuerta OR 10; P. Bloqueo 30; P. Conexión 90
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009336 0.00688 0.005051 0.007856Media 0.009883 0.015937 0.01617 0.013099Mediana 0.009842 0.010245 0.010007 0.009392Peor 0.010929 0.049062 0.049832 0.025019Desv. Est. 0.000329 0.009515 0.010223 0.005611
51

Anexo B
Grá�cas de caja para la Probabilidadde Compuerta OR 10
B.1 Probabilidad de Bloqueo 0
52

B.1. PROBABILIDAD DE BLOQUEO 0
53
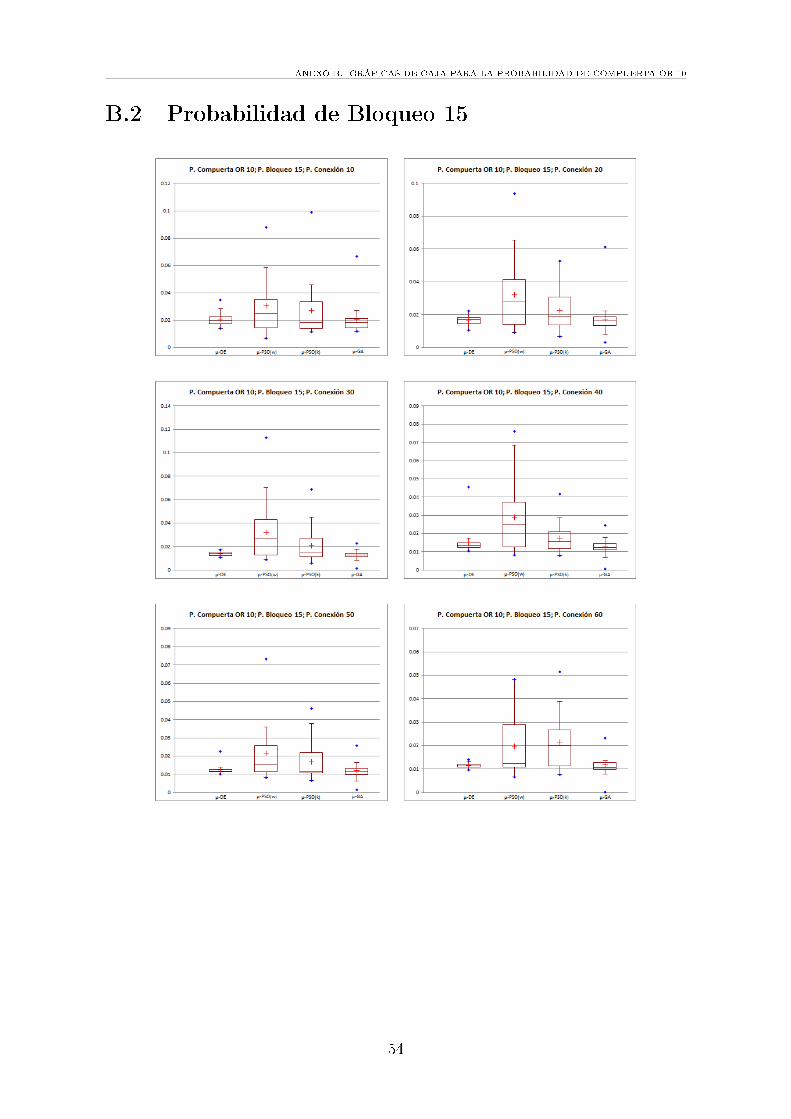
ANEXO B. GRÁFICAS DE CAJA PARA LA PROBABILIDAD DE COMPUERTA OR 10
B.2 Probabilidad de Bloqueo 15
54

B.2. PROBABILIDAD DE BLOQUEO 15
55

ANEXO B. GRÁFICAS DE CAJA PARA LA PROBABILIDAD DE COMPUERTA OR 10
B.3 Probabilidad de Bloqueo 30
56

B.3. PROBABILIDAD DE BLOQUEO 30
57

Anexo C
Grá�cas de medianas para laProbabilidad de Compuerta OR 10
C.1 Probabilidad de Bloqueo 0
58

C.1. PROBABILIDAD DE BLOQUEO 0
59

ANEXO C. GRÁFICAS DE MEDIANAS PARA LA PROBABILIDAD DE COMPUERTA OR 10
C.2 Probabilidad de Bloqueo 15
60

C.2. PROBABILIDAD DE BLOQUEO 15
61

ANEXO C. GRÁFICAS DE MEDIANAS PARA LA PROBABILIDAD DE COMPUERTA OR 10
C.3 Probabilidad de Bloqueo 30
62

C.3. PROBABILIDAD DE BLOQUEO 30
63

Anexo D
Estadísticas para la Probabilidad deCompuerta OR 90
64

D.1. PROBABILIDAD DE BLOQUEO 0
D.1 Probabilidad de Bloqueo 0
P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 10 P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 20
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.01332 0.008137 0.005582 0.011019 Mejor 0.012626 0.009635 0.006544 0.007663Media 0.020461 0.031377 0.0218 0.026591 Media 0.02169 0.027684 0.023374 0.018831Mediana 0.019594 0.025395 0.016211 0.024144 Mediana 0.02173 0.017347 0.015567 0.016758Peor 0.032846 0.118763 0.074285 0.078245 Peor 0.032667 0.09673 0.06658 0.030456Desv. Est. 0.00389 0.023165 0.013534 0.013828 Desv. Est. 0.004597 0.021207 0.01646 0.005868
P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 30 P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 40
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.01408 0.009914 0.009938 0.003872 Mejor 0.01126 0.009515 0.005744 0.001616Media 0.02063 0.027465 0.025803 0.018308 Media 0.018481 0.030925 0.019646 0.015726Mediana 0.019661 0.017063 0.024574 0.017057 Mediana 0.018047 0.024367 0.011223 0.015512Peor 0.041016 0.115514 0.07456 0.034784 Peor 0.032449 0.085593 0.080957 0.027645Desv. Est. 0.005794 0.024531 0.014698 0.006974 Desv. Est. 0.005131 0.019624 0.016321 0.006051
P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 50 P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 60
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.010468 0.0105 0.007696 0.004681 Mejor 0.009881 0.009293 0.009171 0.006018Media 0.018198 0.036803 0.021931 0.018215 Media 0.014191 0.038406 0.021612 0.016058Mediana 0.017327 0.02399 0.016835 0.017424 Mediana 0.013949 0.018519 0.019117 0.011909Peor 0.028608 0.151515 0.089466 0.03555 Peor 0.020875 0.226869 0.047138 0.037589Desv. Est. 0.004605 0.031103 0.016298 0.007966 Desv. Est. 0.002808 0.050233 0.011452 0.008452
P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 70 P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 80
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009548 0.008547 0.008821 0.007148 Mejor 0.010009 0.007522 0.007328 0.000337Media 0.014369 0.025857 0.022574 0.015053 Media 0.01344 0.034239 0.020308 0.015096Mediana 0.012498 0.024006 0.019376 0.013034 Mediana 0.012536 0.021243 0.018063 0.013062Peor 0.021977 0.056595 0.074151 0.042027 Peor 0.018959 0.114899 0.072278 0.029972Desv. Est. 0.003696 0.014078 0.015189 0.007379 Desv. Est. 0.002339 0.034013 0.013475 0.007003
P. Compuerta OR 90; P. Bloqueo 0; P. Conexión 90
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009419 0.006921 0.00639 0.006173Media 0.011615 0.026867 0.018139 0.01704Mediana 0.011033 0.019402 0.010307 0.017216Peor 0.018568 0.116092 0.095286 0.030105Desv. Est. 0.001957 0.022855 0.018203 0.007069
65

ANEXO D. ESTADÍSTICAS PARA LA PROBABILIDAD DE COMPUERTA OR 90
D.2 Probabilidad de Bloqueo 15
P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 10 P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 20
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.013284 0.010101 0.005691 0.003247 Mejor 0.011177 0.009948 0.005908 0.009038Media 0.01889 0.028 0.02031 0.025305 Media 0.01629 0.028154 0.017723 0.016969Mediana 0.018398 0.018419 0.014475 0.018519 Mediana 0.016262 0.024343 0.012929 0.015848Peor 0.027257 0.125786 0.055922 0.066017 Peor 0.024722 0.069234 0.052247 0.043098Desv. Est. 0.003138 0.023363 0.012512 0.014059 Desv. Est. 0.002869 0.015592 0.011536 0.006636
P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 30 P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 40
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009808 0.00991 0.008376 0.006958 Mejor 0.010101 0.00913 0.007215 0.006428Media 0.014649 0.027371 0.020187 0.013876 Media 0.013358 0.02858 0.015748 0.012543Mediana 0.013963 0.019059 0.016574 0.013468 Mediana 0.012942 0.020333 0.012864 0.012311Peor 0.034264 0.073232 0.061669 0.026236 Peor 0.02385 0.13104 0.050323 0.026263Desv. Est. 0.004291 0.017758 0.011183 0.003975 Desv. Est. 0.002405 0.025823 0.008449 0.004591
P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 50 P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 60
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009921 0.008114 0.006944 0.006605 Mejor 0.009893 0.009139 0.00528 0.00667Media 0.012394 0.028616 0.018146 0.012775 Media 0.011887 0.025863 0.017881 0.012492Mediana 0.012254 0.019879 0.012391 0.011419 Mediana 0.011655 0.017728 0.012432 0.010871Peor 0.014469 0.086667 0.043191 0.031987 Peor 0.014646 0.083198 0.039792 0.02852Desv. Est. 0.001106 0.023712 0.010274 0.00563 Desv. Est. 0.001331 0.019314 0.009402 0.005459
P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 70 P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 80
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009976 0.008506 0.008152 0.006025 Mejor 0.009828 0.007334 0.006313 0.007433Media 0.011308 0.026984 0.018378 0.01296 Media 0.010704 0.022414 0.014612 0.013791Mediana 0.011149 0.018023 0.011865 0.010267 Mediana 0.010626 0.016751 0.010422 0.010101Peor 0.012884 0.116162 0.071639 0.026297 Peor 0.011972 0.082645 0.052381 0.02705Desv. Est. 0.000858 0.023271 0.012822 0.005957 Desv. Est. 0.000593 0.018063 0.009657 0.006427
P. Compuerta OR 90; P. Bloqueo 15; P. Conexión 90
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009863 0.006979 0.006368 0.004611Media 0.010486 0.018989 0.017061 0.013507Mediana 0.010367 0.011122 0.010695 0.010101Peor 0.011544 0.051359 0.043365 0.027168Desv. Est. 0.000423 0.012056 0.00922 0.006856
66

D.3. PROBABILIDAD DE BLOQUEO 30
D.3 Probabilidad de Bloqueo 30
P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 10 P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 20
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.012121 0.008724 0.008359 0.008754 Mejor 0.010392 0.008764 0.009583 0.005245Media 0.017269 0.028788 0.024866 0.02008 Media 0.015341 0.01863 0.021925 0.013745Mediana 0.016523 0.014854 0.015311 0.016867 Mediana 0.012903 0.014329 0.013584 0.013131Peor 0.033792 0.128716 0.090332 0.048822 Peor 0.053278 0.042522 0.105089 0.036988Desv. Est. 0.004722 0.024049 0.018298 0.009991 Desv. Est. 0.008489 0.009274 0.022947 0.005298
P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 30 P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 40
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.010195 0.008605 0.008359 0.00551 Mejor 0.009759 0.008616 0.008305 0.005261Media 0.011759 0.018147 0.016179 0.012348 Media 0.010915 0.020451 0.017082 0.010629Mediana 0.011544 0.013608 0.012672 0.011544 Mediana 0.01089 0.020106 0.011111 0.010382Peor 0.014141 0.039689 0.034007 0.023661 Peor 0.012393 0.041832 0.054943 0.024213Desv. Est. 0.001001 0.009048 0.007857 0.004271 Desv. Est. 0.000696 0.009899 0.011192 0.002887
P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 50 P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 60
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009416 0.007504 0.008353 0.00463 Mejor 0.009232 0.007623 0.007071 0.004821Media 0.010335 0.018329 0.016877 0.011186 Media 0.010373 0.016634 0.013324 0.011523Mediana 0.010363 0.012441 0.011141 0.010267 Mediana 0.010208 0.010623 0.010101 0.009832Peor 0.011307 0.065756 0.040246 0.026612 Peor 0.011754 0.048757 0.026653 0.023623Desv. Est. 0.000402 0.012186 0.008944 0.00419 Desv. Est. 0.000536 0.010965 0.005799 0.005338
P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 70 P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 80
µ-DE µ-PSO (w) µ-PSO (k) µ-GA µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009667 0.007456 0.007362 0.007491 Mejor 0.009366 0.006734 0.007514 0.000481Media 0.010215 0.017915 0.012837 0.012165 Media 0.009996 0.01689 0.018211 0.012214Mediana 0.010101 0.011095 0.009901 0.009812 Mediana 0.009989 0.010926 0.010207 0.009749Peor 0.011375 0.053219 0.028226 0.026194 Peor 0.010536 0.054834 0.042057 0.030303Desv. Est. 0.000392 0.011452 0.005837 0.005271 Desv. Est. 0.000228 0.011034 0.010775 0.005968
P. Compuerta OR 90; P. Bloqueo 30; P. Conexión 90
µ-DE µ-PSO (w) µ-PSO (k) µ-GA
Mejor 0.009416 0.006652 0.007576 0.000389Media 0.009862 0.014568 0.016546 0.015415Mediana 0.009804 0.009727 0.009982 0.0162Peor 0.010713 0.044519 0.037782 0.032375Desv. Est. 0.000299 0.009735 0.009224 0.007399
67

Anexo E
Grá�cas de caja para la Probabilidadde Compuerta OR 90
E.1 Probabilidad de Bloqueo 0
68

E.1. PROBABILIDAD DE BLOQUEO 0
69

ANEXO E. GRÁFICAS DE CAJA PARA LA PROBABILIDAD DE COMPUERTA OR 90
E.2 Probabilidad de Bloqueo 15
70

E.2. PROBABILIDAD DE BLOQUEO 15
71

ANEXO E. GRÁFICAS DE CAJA PARA LA PROBABILIDAD DE COMPUERTA OR 90
E.3 Probabilidad de Bloqueo 30
72

E.3. PROBABILIDAD DE BLOQUEO 30
73

Anexo F
Grá�cas de medianas para laProbabilidad de Compuerta OR 90
F.1 Probabilidad de Bloqueo 0
74

F.1. PROBABILIDAD DE BLOQUEO 0
75

ANEXO F. GRÁFICAS DE MEDIANAS PARA LA PROBABILIDAD DE COMPUERTA OR 90
F.2 Probabilidad de Bloqueo 15
76

F.2. PROBABILIDAD DE BLOQUEO 15
77

ANEXO F. GRÁFICAS DE MEDIANAS PARA LA PROBABILIDAD DE COMPUERTA OR 90
F.3 Probabilidad de Bloqueo 30
78

F.3. PROBABILIDAD DE BLOQUEO 30
79

Bibliografía
[1] Alejandro Sosa, Víctor Zamudio, Rosario Baltazar, Carlos Lino, Miguel Angel Casillas yMarco Sotelo. Algoritmos peso y de aplicados a la minimización de inestabilidad cíclicade sistemas con agentes nómadas. Programación Matemática y Software, 5(1):108 � 120,Noviembre 2013.
[2] Alejandro Sosa, Víctor Zamudio, Rosario Baltazar, Vic Callaghan and Efrén Mezura.Genetic algorithms and di�erential evolution algorithms applied to cyclic instabilityproblem in intelligent environments with nomadics agents. Workshop Proceedings of
the 9th International Conference on Intelligent Environments, 17:222 � 231, 2013.DOI:10.3233/978-1-61499-286-8-222.
[3] Juan Carlos Fuentes Cabrera. Un nuevo algoritmo de optimización basado en opti-mización mediante cúmulos de partículas utilizando tamaños de poblacion muy pe-queños. Master's thesis, Maestría en Ciencias en la Especialidad de Ingeniería Eléctrica: Centro de Investigación y de Estudios Avanzados del Instituto Politécnico Nacional,Marzo 2008.
[4] Efrén Mezura-Montes, Omar Cetina-Domínguez and Betania Hernández-Ocaña. Nuevasheurísticas inspiradas en la naturaleza para optimización numérica. Mecatrónica, pages249�272, 2010.
[5] Emmanuel Amaro, Juan Manuel Lopez, Victor Zamudio, Rosario Baltazar, Miguel AngelCasillas and Vic Callaghan. Innovative locking: E�ciently removing instabilitites inmulti agent systems. In Proceedings of The Seventh IEEE International Conference on
Intelligent Environments, volume 25-28, pages 135�141, Nottingham, United Kingdom,July 2011.
[6] Andries P. Engelbrecht. Computational Intelligence: An Introduction. Wiley, secondedition edition, 2007.
[7] Francisco Viveros-Jiménez,Efrén Mezura-Montes and Alexander Gelbukh. Empiricalanalysis of a micro-evolutionary algorithm for numerical optimization. International
Journal of Physical Sciences, (8):1235�1258, February 2012. doi:10.5897/IJPS11.303.
[8] Leoncio Romero González. Aplicación de locking por medio de técnicas de inteligenciaarti�cial en ambientes de cómputo pervasivo con alta inestabilidad. Master's thesis,Intituto Tecnológico de León, División de Estudios de Postgrado e Investigación, Agosto2012.
[9] Daniel Molina Joaquín Derrac, Salvador García and Francisco Herrera. A practicaltutorial on the use of nonparametric statistical tests as a methodology for comparingevolutionary and swarm intelligence algorithms. Swarm and Evolutionary Computation,pages 3�18, March 2011. doi:10.1016/j.swevo.2011.02.002.
80

BIBLIOGRAFÍA
[10] Richard Johnsonbaugh. Matemáticas Discretas. Pearson Educación, Prentice Hall, sextaedición edition, 2005.
[11] Juan C. Augusto, Vic Callaghan, Diane Cook, Achilles Kameas y Ichiro Satoh. Intelli-gent environments: a manifesto. Human-centric Computing and Information Sciences,3:12, 2013. doi:10.1186/2192-1962-3-12. http://www.hcis-journal.com/content/pdf/2192-1962-3-12.pdf.
[12] Leoncio A. Romero, Víctor Zamudio, Rosario Baltazar, Efrén Mezura Montes, MarcoSotelo and Vic Callaghan. A comparison between metaheuristics as strategies for min-imizing cyclic instability in ambient intelligence. Sensors (Basel), 12(8), August 2012.http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3472871/.
[13] Leoncio A. Romero, Víctor Zamudio, Rosario Baltazar, Marco Sotelo, Carlos Lino, EfrénMezura Montes and Vic Callaghan. A comparative study of intelligent bio-inspired algo-rithms applied to minimizing cyclic instability in intelligent environments. In Intelligent
Environments (Workshops), volume 13 of Ambient Intelligence and Smart Environments,pages 130�141. IOS Press, June 2012.
[14] Manuel López-Ibáñez, Jérémie Dubois-Lacoste, Thomas Stützle and Mauro Birattari.The irace package: Iterated racing for automatic algorithm con�guration. Iridia Tech-
nical Report Series, (TR/IRIDIA/2011-004), January 2011.
[15] Efrén Mezura-Montes and JorgeIsacc Flores-Mendoza. Improved particle swarm opti-mization in constrained numerical search spaces. In Raymond Chiong, editor, Nature-Inspired Algorithms for Optimisation, volume 193 of Studies in Computational Intelli-
gence, pages 299�332. Springer Berlin Heidelberg, 2009.
[16] Efrén Mezura-Montes, Margarita Reyes-Sierra, and CarlosA.Coello Coello. Multi-objective optimization using di�erential evolution: A survey of the state-of-the-art. InUdayK. Chakraborty, editor, Advances in Di�erential Evolution, volume 143 of Studiesin Computational Intelligence, pages 173�196. Springer Berlin Heidelberg, 2008.
[17] Miguel Mascaró Portell, Pere A. Palmer Rodríguez y Antoni Jaume Capó. Análisis delcoste computacional. http://dmi.uib.es/~mascport/tp/perweb/tema1.html.
[18] Miranda Mowbray y Matthew M. Williamson. Resilience for autonomous agents.Internet Systems and Storage Laboratory,, October 2003. http://www.hpl.hp.com/
techreports/2003/HPL-2003-210.pdf.
[19] Gregorio Toscano Pulido. Optimización multiobjetivo usando un micro algoritmogenético. Master's thesis, Maestría en Inteligencia Arti�cial: Universidad Veracruzana,Septiembre 2001.
[20] Alejandro Sosa Sales. Estrategias de estabilización en ambientes inteligentes dinámicosmediante técnicas de inteligencia arti�cial. Master's thesis, Intituto Tecnológico de León,División de Estudios de Postgrado e Investigación, Septiembre 2013.
[21] Vic Callaghan, Victor Zamudio and Jeannette S. Y. Chin. Understanding interactionsin the smart home. PerAda Magazine, April 2009. DOI:10.2417/2200904.1625.
[22] Victor Manuel Zamudio Rodriguez. Understanding and Preventing Periodic Behaviour
in Ambient Intelligence. PhD thesis, University of Essex, Department of Computing andElectronics Systems, October 2008.
81

BIBLIOGRAFÍA
[23] Victor Zamudio and Vic Callaghan. Facilitating the ambient intelligence vision: a theo-rem, representation and solution for instability in rule-based multi-agent systems. SpecialSection on Agent Based System Challenges for Ubiquitous and Pervasive Computing., 4,May 2008.
[24] Victor Zamudio and Vic Callaghan. Understanding and avoiding interaction based in-stability in pervasive computing environments. International Journal of Pervasive Com-puting and Communications, 5:163�186, 2009. doi:10.1108/17427370910976043.
[25] Victor Zamudio, Rosario Baltazar, Miguel Casillas and Vic Callaghan. c-inpres:Coupling analysis towards locking optimization in ambient intelligence. The 6th In-
ternational Conference on Intelligent Environments IE10, pages 68�73, July 2010.doi:10.1109/IE.2010.20.
[26] William Mendenhall III Richard L. Schea�er. Wackerly, Deniss D. Estadística
Matemática con aplicaciones. Cengage Learning, séptima edition, 2010.
[27] Barbara M. Beaver. William Mendenhall, Robert J. Beaver. Introducción a la probabili-
dad y estadística. Cengage Learning, décimo tercera edition, 2006.
82