uc berkeley mlbase$ - massachusetts institute of...
TRANSCRIPT

Denny Britz, John Duchi, Michael J. Franklin, Rean Griffith, Joseph Gonzalez, Michael I. Jordan, Tim Kraska, Xinghao Pan, Virginia Smith,
Evan Sparks, Ameet Talwalkar, Andre Wibisono
MLbase
UC Berkeley
<www.mlbase.org>

MoMvaMon

CollecMng Data Is Easier Than Ever Before

My Personal MoMvaMon: Proof

The Problem
Build a Classifier for X
What you want to do What you have to do • Learn the internals of ML
classifica=on algorithms, sampling, feature selec=on, X-‐valida=on,….
• Poten=ally learn Spark/Hadoop/… • Implement 3-‐4 algorithms • Implement grid-‐search to find the
right algorithm parameters • Implement valida=on algorithms • Experiment with different sampling-‐
sizes, algorithms, features • ….
and in the end
Ask For Help

Do We All Need To Be ML-‐Experts

A DeclaraMve Approach to ML
SQL Result
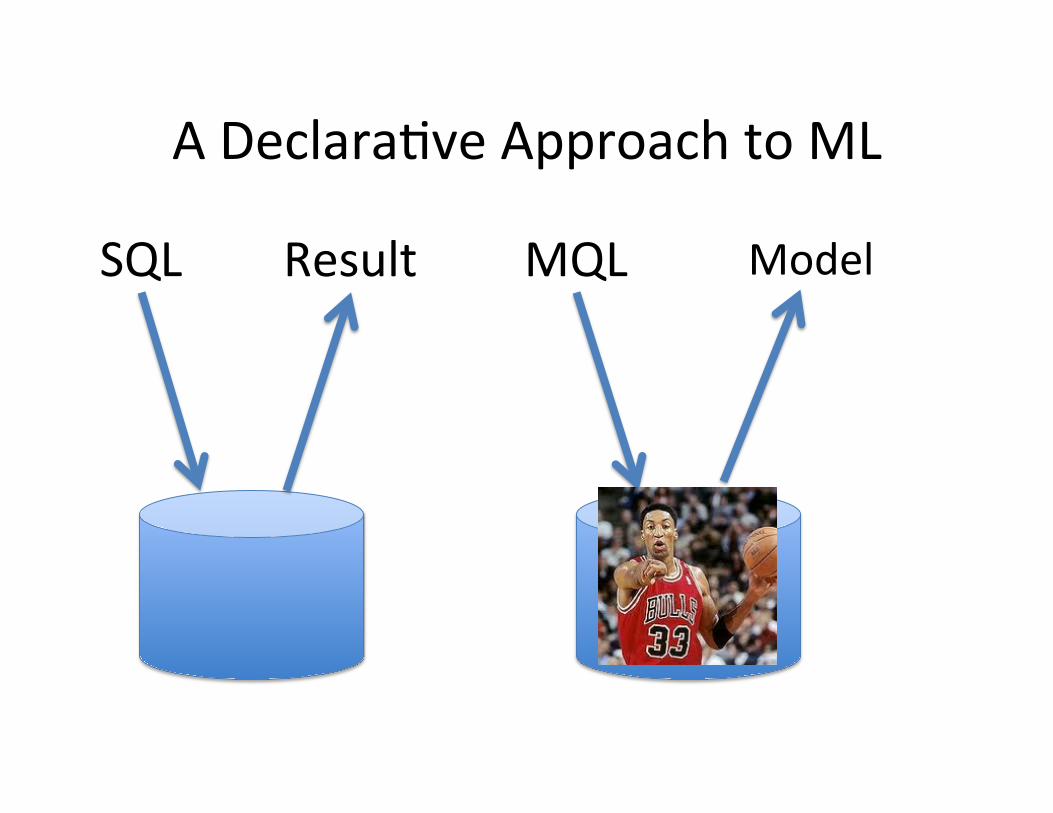
A DeclaraMve Approach to ML
SQL Result MQL Model

Use Cases
var X = load("als_clinical", 2 to 10) var y = load("als_clinical", 1) var (fn-‐model, summary) = top(doClassify(X, y), 5min)
var G = loadGraph("twi`er_network") var hubs-‐nodes = findTopKDegreeNodes(G, k = 1000) var text-‐features = textFeaturize(load("twi`er_tweet_data")) var T-‐hub = join(hub-‐nodes, "u-‐id", text-‐features, "u-‐id") findTopFeatures(T-‐hub)
Supervised ClassificaMon: ALS PredicMon
Unsupervised Feature ExtracMon: Twi`er

ML Developer
Meta-Data
Statistics
User
Declarative ML Task
ML Contract + Code
Master Server
….
result (e.g., fn-model & summary)
COML(Optimizer)
Parser
Executor/Monitoring
Binders of Algorithms
Runtime Runtime Runtime Runtime
LLP
PLP
Master
MLbase Architecture
Binders full of algorithms allows to add more operators
Result No single correct answer – instead approximaMon and conMnuous refinement
Sta=s=cs about algorithms and data
Adap=ve Op=mizer esMmates run-‐Mme and quality improvement
Distributed Run=me build for fast (in-‐memory) iteraMon

Binders Full of Algorithms

Binders Full of Algorithms
Implementa=on Using high-‐level pa`erns provided by MLbase
Contract • Type (e.g., classificaMon) • Parameters • RunMme (e.g., O(n)) • Input-‐SpecificaMon • Output-‐SpecificaMon • …
+
ML Developer

Common to state-‐of-‐the-‐art algorithms • SVMs, LogisMc Regression, Naïve Bayes, LogitBoost, Linear Regression, Ridge Regression, LASSO, Matrix FactorizaMon via SGD, DFC, K-‐Means, DP-‐Means
• More to come • Standalone implementaMons on Spark (soon!)
Today: Half-‐Full Binders

var X = load("als_clinical",2 to 10) var y = load("als_clinical", 1) var (fn-‐model, summary) = top(doClassify(X, y), 10min)
(1) MQL
OpMmizaMon (2) Generic Logical Plan
grid-search
configure model
train model
down-sample
model/data interpretation
(X', y')
load (als_clinical)
SVM Adaboost
RBF linear stumps
regularization rounds
technique
kernel
params
...
...
...
(fn-model, summary)
down-sample
(X, y)
originalfeaturization ...normalizedbin
(X, y)
fn-model
cross-validate
top-1
fn-model
summary

var X = load("als_clinical",2 to 10) var y = load("als_clinical", 1) var (fn-‐model, summary) = top(doClassify(X, y), 10min)
(1) MQL
OpMmizaMon (2) Generic Logical Plan
grid-search
configure model
train model
down-sample
model/data interpretation
(X', y')
load (als_clinical)
SVM Adaboost
RBF linear stumps
regularization rounds
technique
kernel
params
...
...
...
(fn-model, summary)
down-sample
(X, y)
originalfeaturization ...normalizedbin
(X, y)
fn-model
cross-validate
top-1
fn-model
summary

var X = load("als_clinical",2 to 10) var y = load("als_clinical", 1) var (fn-‐model, summary) = top(doClassify(X, y), 10min)
(1) MQL
OpMmizaMon (2) Generic Logical Plan
grid-search
configure model
train model
down-sample
model/data interpretation
(X', y')
load (als_clinical)
SVM Adaboost
RBF linear stumps
regularization rounds
technique
kernel
params
...
...
...
(fn-model, summary)
down-sample
(X, y)
originalfeaturization ...normalizedbin
(X, y)
fn-model
cross-validate
top-1
fn-model
summary
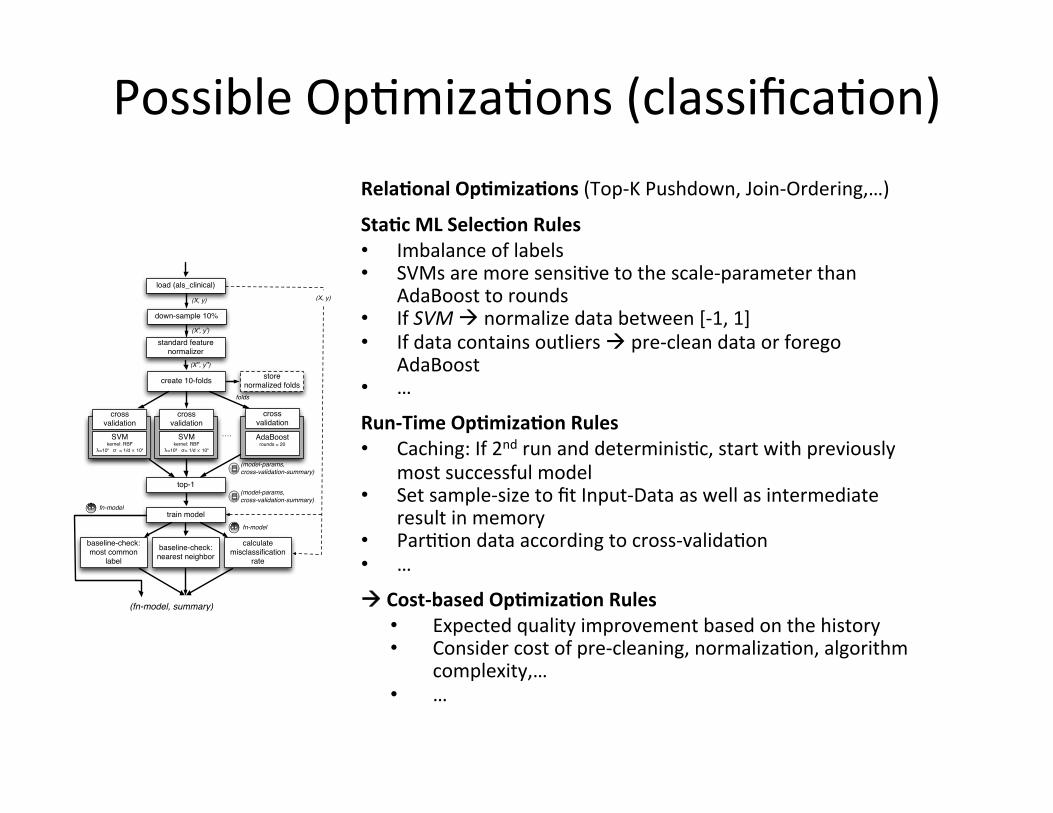
Possible OpMmizaMons (classificaMon)
standard feature normalizer
create 10-folds
cross validation
folds
(X'', y'')
SVMkernel: RBF
λ=10⁶ σ = 1/d ⨉ 10⁶
(model-params, cross-validation-summary)
top-1
train model
calculate misclassification
rate
(fn-model, summary)
(X, y)
….
cross validation
SVMkernel: RBF
λ=10³ σ= 1/d ⨉ 10⁶
cross validation
AdaBoostrounds = 20
baseline-check: nearest neighbor
baseline-check: most common
label
(model-params, cross-validation-summary)
fn-model
load (als_clinical)
down-sample 10%
(X, y)
(X', y')
store normalized folds
fn-model
Rela=onal Op=miza=ons (Top-‐K Pushdown, Join-‐Ordering,…)
Sta=c ML Selec=on Rules • Imbalance of labels • SVMs are more sensiMve to the scale-‐parameter than
AdaBoost to rounds • If SVM à normalize data between [-‐1, 1] • If data contains outliers à pre-‐clean data or forego
AdaBoost • …
Run-‐Time Op=miza=on Rules • Caching: If 2nd run and determinisMc, start with previously
most successful model • Set sample-‐size to fit Input-‐Data as well as intermediate
result in memory • ParMMon data according to cross-‐validaMon • …
Cost-‐based Op=miza=on Rules • Expected quality improvement based on the history • Consider cost of pre-‐cleaning, normalizaMon, algorithm
complexity,… • …

Why OpMmize?
SVM AdaBoostoriginal scaled
a1a 82.93 82.93 82.87australian 85.22 85.51 86.23
breast 70.13 97.22 96.48diabetes 76.44 77.61 76.17fourclass 100.00 99.77 91.19splice 88.00 87.60 91.20
Figure 3: Classifier accuracy using SVM with an RBF kernel and using AdaBoost
3.6.3 Preliminary Results
To demonstrate the possible advantages of an optimizer just for selecting among di↵erent MLalgorithms even without considering the system aspect, we implemented a prototype using twoalgorithms: SVM and AdaBoost. For both algorithms, we used publicly available implementations:LIBSVM [33] for SVM and the ML AdaBoost Toolbox [1] for AdaBoost. We evaluated the op-timizer for a classification task similar to the one in Figure 2 with 6 datasets from the LIBSVMwebsite: ‘a1a’, ‘australian’, ‘breast-cancer’, ‘diabetes’, ‘fourclass’, and ‘splice’. To better visualizethe impact of finding the best ML model, we performed a full grid search over a fixed set of algo-rithm parameters, i.e., number of rounds (r) for AdaBoost and regularization (�) and RBF scale(�) parameters for SVM. Specifically, we tested r = {25, 50, 100, 200}, � = {10�6
, 10�3, 1, 103, 106},
and � = 1d ⇥ {10�6
, 10�3, 1, 103, 106}, where d is the number of features in the dataset. For each
algorithm, set of features and parameter settings, we performed 5-fold cross validation, and reportthe average results across the held-out fold.
Table 3 shows the best accuracy after tuning the parameters using grid search for the di↵erentdatasets and algorithms, with and without scaling the features (the best combination is marked inbold). The results show first that there is no dominant combination for all datasets. SometimesAdaBoost outperforms SVM, sometimes scaling the features helps, sometimes it does not.
Next we turn to understanding the search problem for the parameters themselves, depicted inFigures 4(a) and 4(b). Figure 4(a) shows, for fixed regularization �, the impact of the � parameterin the RBF kernel on the accuracy, whereas Figure 4(b) visualizes the accuracy for varying thenumber of rounds r for AdaBoost. As shown in Figure 4(a), the choice of � in the SVM problemclearly has a huge impact on quality; automatically selecting � is important. On the other hand,for the same datasets, it appears that the number of rounds in AdaBoost is not quite as significantonce r � 25 (shown in Figure 4(b)). Hence, an optimizer might decide to initially use AdaBoost -without scaling and with a fixed round parameter - in order to quickly provide the user with a firstclassifier. Afterwards, the system might explore SVMs with scaled features to improve the model,before extending the search space to the remaining combinations.
The general accuracy of algorithms is just one of the aspects an optimizer may take into account.Statistics about the dataset itself, di↵erent data layouts, algorithm speed and parallel executionstrategies (as described in the next section) are just a few additional dimensions the optimizer mayexploit to improve the learning process. In this project, we will evaluate these freedoms of choiceand build the foundation for cost-based (query) optimization for machine learning.
10

Why OpMmize?
0%#10%#20%#30%#40%#50%#60%#70%#80%#90%#100%#
a1a# australian# breast# diabetes# fourclass# splice#
Accuracy'
10^=6#
10^=3#
1#
10^3#
10^6#
(a) Impact of di↵erent � =
1d ⇥{10�6, 10�3, 1, 103, 106}
on the SVM accuracy with an RBF kernel and � = 10
�6
on LIBSVM data-sets
0%#
10%#
20%#
30%#
40%#
50%#
60%#
70%#
80%#
90%#
100%#
a1a# australian# breast# diabetes# fourclass# splice#
Accuracy' 25#
50#
100#
200#
(b) Impact of r = {25, 50, 100, 200} on AdaBoost on
LIBSVM data-sets
Figure 4: Parameter Impact
4 Related Work
COML is not the first system trying to make machine learning more accessible, but it is the first tofree users from algorithm choices and to automatically optimize for distributed execution. Probablymost related to COML are Weka [4], MADLib [47], and Mahout [3]. Weka is a collection of MLtools for data mining that simplifies their usage by providing a simple UI. Weka, however, requiresexpert knowledge to choose and configure the ML algorithm and is a single node system. On thedatabase and distributed side, Mahout’s goal is to build a scalable ML library on top of Hadoop,while MADLib provides an ML library for relational database systems. Neither system addressesthe (di�cult but necessary) challenge of optimizing the learning algorithms.
Google Predict [2] is Google’s proprietary web-service for prediction problems, but restricts themaximum training data-size to 250MB. In [18], the authors make the case that databases shouldnatively support predictive models and present a first prototype called Longview. We extend thisvision by supporting all kinds of ML algorithms, not just predictive models. Furthermore, thefocus of this project is on the optimization for ML instead of the language integration within therelational model.
Recently, there have been e↵orts to build distributed run-times for more advanced analytical tasks.For example, Hyracks [27], HaLoop [32] and AMPLab’s Spark [72, 6] have special iterative in-memory operations to better support ML algorithms. As mentioned earlier, the goal of this projectis not on inventing a new run-time for machine learning; instead we will use Spark.
SystemML [46] proposes an R-like language and shows how it can be optimized and compiled downto MapReduce. However, SystemML tries to support ML experts to develop e�cient distributedalgorithms and does not aim at simplifying the use of ML, for example, by automatically tuning thetraining step. Still, the ideas of SystemML are compelling and we might leverage them as part of ourphysical plan optimization. In [41], the authors show how many ML algorithms can be expressed asa relational-friendly convex-optimization problem, whereas the authors of [70] present techniquesto optimize inference algorithms in a probabilistic DBMS. We leverage these techniques in ourrun-time, but our system aims beyond a single machine and extends the presented optimizationtechniques.
This project builds on the strong foundation of declarative languages and query optimization.
11
0%#10%#20%#30%#40%#50%#60%#70%#80%#90%#100%#
a1a# australian# breast# diabetes# fourclass# splice#
Accuracy'
10^=6#
10^=3#
1#
10^3#
10^6#
(a) Impact of di↵erent � =
1d ⇥{10�6, 10�3, 1, 103, 106}
on the SVM accuracy with an RBF kernel and � = 10
�6
on LIBSVM data-sets
0%#
10%#
20%#
30%#
40%#
50%#
60%#
70%#
80%#
90%#
100%#
a1a# australian# breast# diabetes# fourclass# splice#
Accuracy' 25#
50#
100#
200#
(b) Impact of r = {25, 50, 100, 200} on AdaBoost on
LIBSVM data-sets
Figure 4: Parameter Impact
4 Related Work
COML is not the first system trying to make machine learning more accessible, but it is the first tofree users from algorithm choices and to automatically optimize for distributed execution. Probablymost related to COML are Weka [4], MADLib [47], and Mahout [3]. Weka is a collection of MLtools for data mining that simplifies their usage by providing a simple UI. Weka, however, requiresexpert knowledge to choose and configure the ML algorithm and is a single node system. On thedatabase and distributed side, Mahout’s goal is to build a scalable ML library on top of Hadoop,while MADLib provides an ML library for relational database systems. Neither system addressesthe (di�cult but necessary) challenge of optimizing the learning algorithms.
Google Predict [2] is Google’s proprietary web-service for prediction problems, but restricts themaximum training data-size to 250MB. In [18], the authors make the case that databases shouldnatively support predictive models and present a first prototype called Longview. We extend thisvision by supporting all kinds of ML algorithms, not just predictive models. Furthermore, thefocus of this project is on the optimization for ML instead of the language integration within therelational model.
Recently, there have been e↵orts to build distributed run-times for more advanced analytical tasks.For example, Hyracks [27], HaLoop [32] and AMPLab’s Spark [72, 6] have special iterative in-memory operations to better support ML algorithms. As mentioned earlier, the goal of this projectis not on inventing a new run-time for machine learning; instead we will use Spark.
SystemML [46] proposes an R-like language and shows how it can be optimized and compiled downto MapReduce. However, SystemML tries to support ML experts to develop e�cient distributedalgorithms and does not aim at simplifying the use of ML, for example, by automatically tuning thetraining step. Still, the ideas of SystemML are compelling and we might leverage them as part of ourphysical plan optimization. In [41], the authors show how many ML algorithms can be expressed asa relational-friendly convex-optimization problem, whereas the authors of [70] present techniquesto optimize inference algorithms in a probabilistic DBMS. We leverage these techniques in ourrun-time, but our system aims beyond a single machine and extends the presented optimizationtechniques.
This project builds on the strong foundation of declarative languages and query optimization.
11
SVM
AdaBoost regularizaMon
Scale-‐factor
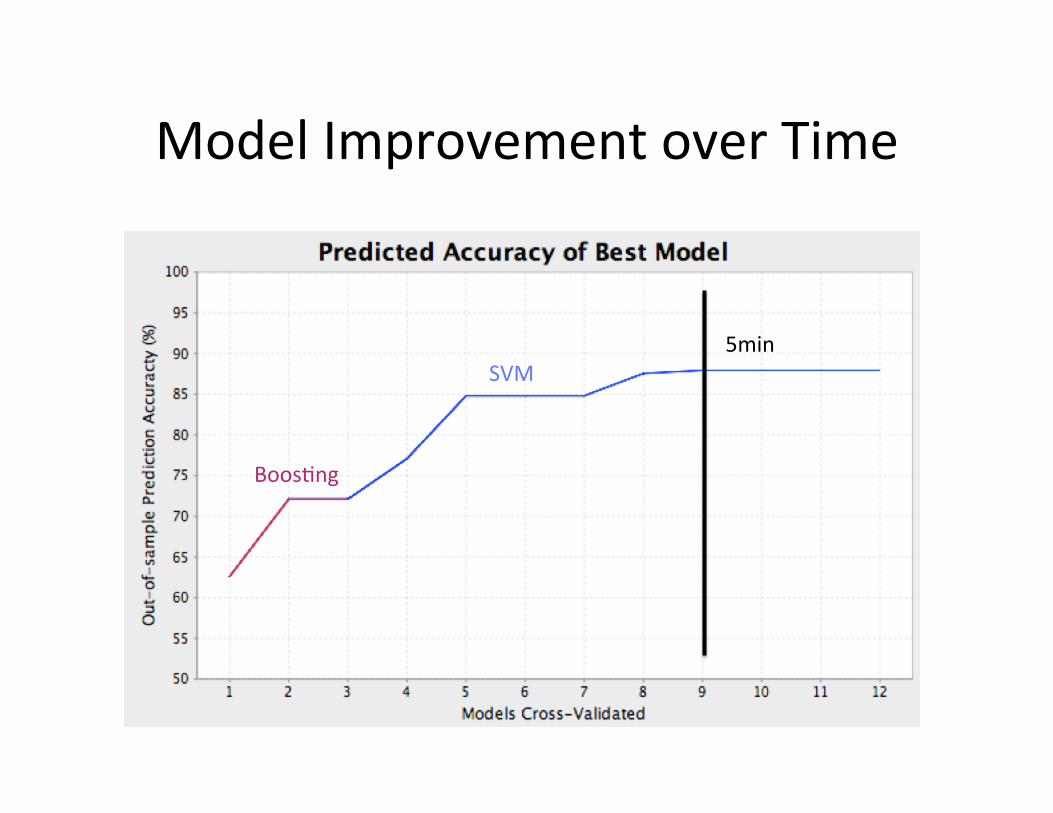
Model Improvement over Time
5min
BoosMng
SVM

Summary • MLbase is a first declaraMve machine-‐learning system
• It simplifies ML in the same way as databases simplify data management
• MLBase is currently under heavy-‐development, but a first prototype is up and running: – 1st iniMal language for classificaMon, clustering, and matrix
factorizaMon – Rule-‐based opMmizer – Distributed algorithms for: k-‐means clustering, LogitBoost, various
matrix factorizaMon algorithms and support vector machines. – Spark and GraphLab on Spark as the run-‐Mme
• We plan to release a first prototype by this summer
[email protected] <www.mlbase.org>