tutorial
DESCRIPTION
TutorialTRANSCRIPT

A crosstabulation displays the number of cases in each category defined by two or more grouping variables.
For example, we can display the number of sales employees in each division in each office location.
Crosstabulations are useful for summarizing categorical variables -- variables with a limited number of distinct categories.
1

The chi-square measures test the hypothesis that the row and column variables in a crosstabulation are independent
H0: Variable A and Variable B are independent. Ha: Variable A and Variable B are not independent.
A low significance value (typically below 0.05) indicates that there may be some relationship between the two variables.
2

While the chi-square measures may indicate that there is a relationship between two variables, they do not indicate the strength or direction of the relationship.
The nominal directional measures indicate both the strength and significance of the relationship between the row and column variables of a crosstabulation.
3

The value of each statistic can range from 0 to 1 and indicates the proportional reduction in error in predicting the value of one variable based on the value of the other variable.
For example, a test statistic value of 0.021 indicates that you have only reduced the error rate by 2.1% over what you could expect by random chance.
4

In this example, the low significance values for both tau and the uncertainty coefficient indicate that there is a relationship between the two variables...
But the low values for both test statistics indicate that the relationship between the two variables is a fairly weak one.
5

The nominal directional measures are appropriate when both variables are nominal, categorical variables.
Somers' d is an ordinal directional measure that indicates the significance, strength and direction of the relationship between the row and column variables of a crosstabulation.
6

A low significance value (typically less than 0.05) indicates that there is a relationship between the two variables.
The value of the statistic can range from -1 to 1.
Negative values indicate a negative relationship, and positive values indicate a positive relationship
7

In this example, the low significance values for Somers' d indicate that there is a relationship between the two variables...
But the low values for the test statistic indicate that the relationship between the two variables is a fairly weak one.
8

Somers' d is appropriate when both variables are ordinal, categorical variables.
The nominal symmetric measures indicate both the strength and significance of the relationship between the row and column variables of a crosstabulation.
9
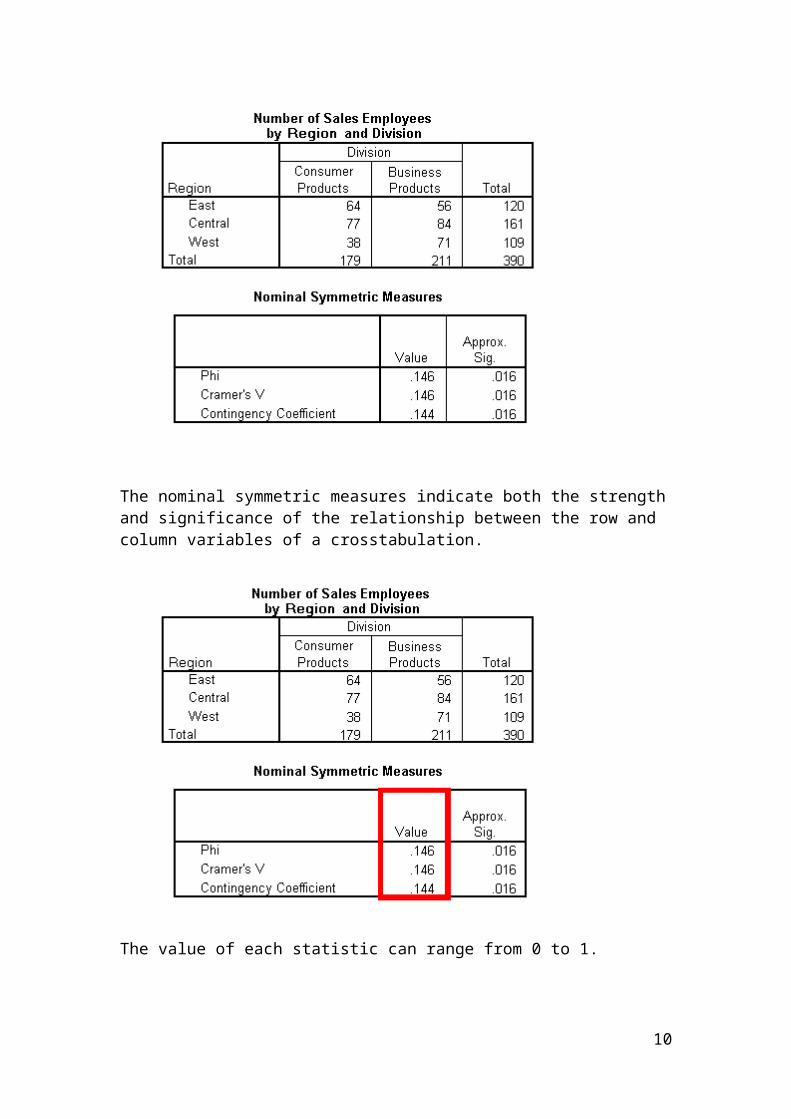
The value of each statistic can range from 0 to 1.
Phi is only appropriate for 2x2 tables.
10
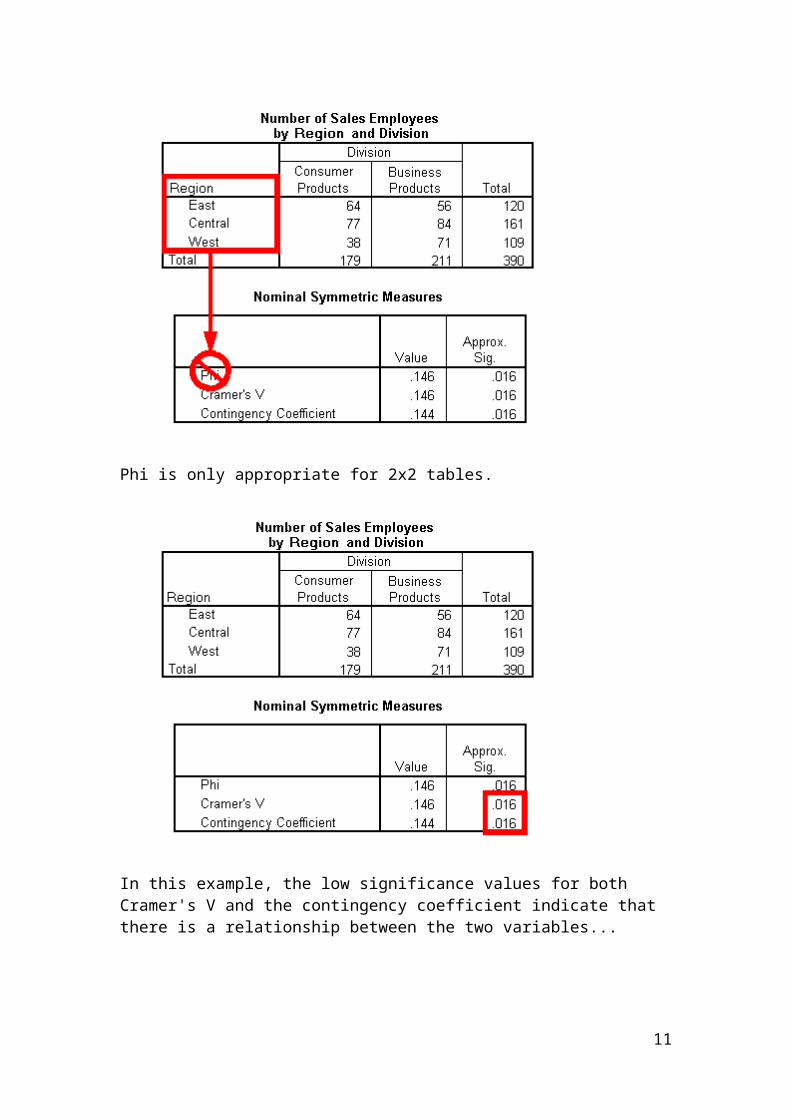
In this example, the low significance values for both Cramer's V and the contingency coefficient indicate that there is a relationship between the two variables...
But the low values for the test statistics indicate that the relationship between the two variables is a fairly weak one.
11
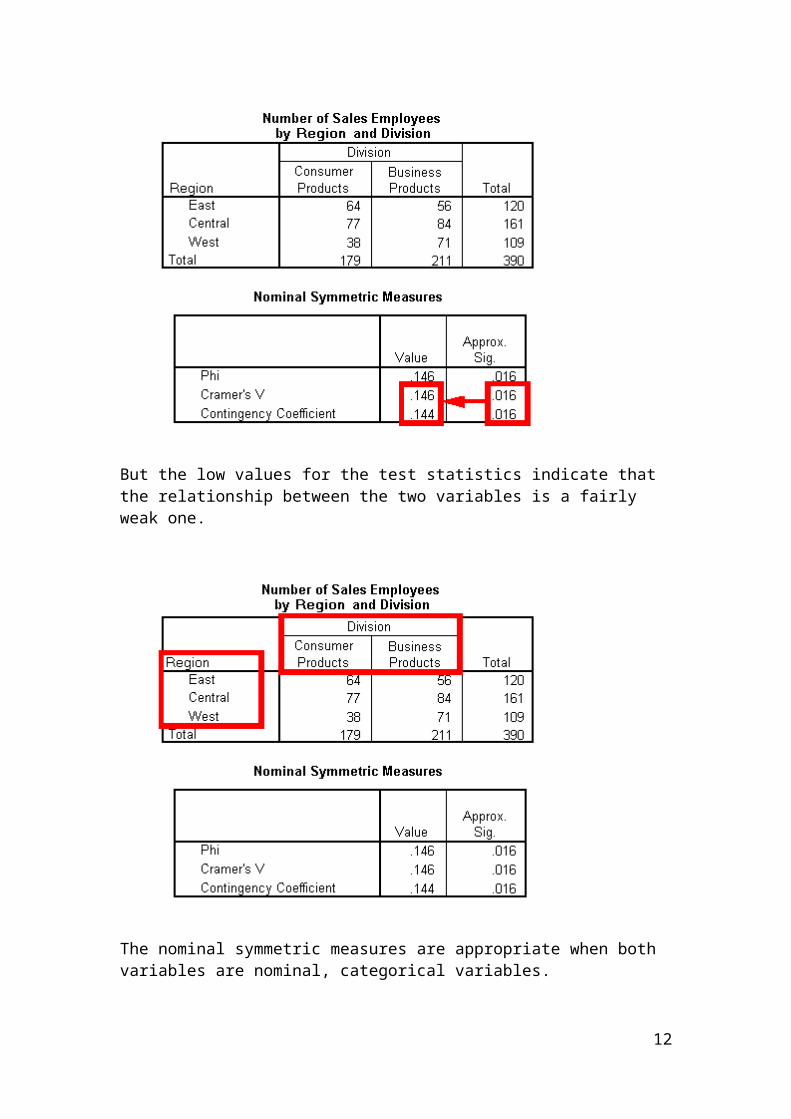
The nominal symmetric measures are appropriate when both variables are nominal, categorical variables.
The ordinal symmetric measures indicate the significance, strength and direction of the relationship between the row and column variables of a crosstabulation.
12

A low significance value (typically less than 0.05) indicates that there is a relationship between the two variables.
If there is (approx. Sig) < 0.05 than there is a relation
The values of the test statistics can range from -1 to 1.Negative values indicate a negative relationship, and positive values indicate a positive relationship. In order to decide whether the variables are uncorrelated, we test the null hypothesis that τB = 0. The alternative hypothesis is that the variables are correlated, and τB is non-zero.H0: τB = 0. Ha: τB ≠ 0.
13

If there is (approx. Sig) < 0.05 than there is a relation. Then
If Kendall’s tau > 0 then
Respondents from vertical categories (at end of arrow) and here High are more likely to be (at the end of horizontal arrow) and here High.
If there is (approx. Sig) < 0.05 than there is a relation. Then
If Kendall’s tau < 0 then
Respondents from vertical categories (at end of arrow) and here High are more likely to be (at the end of horizontal arrow) and here Low
14

In this example, the low significance values indicate that there is a relationship between the two variables...
But the low values for the test statistics indicate that the relationship between the two variables is a fairly weak one.
15

The ordinal symmetric measures are appropriate when both variables are ordinal, categorical variables.
The relative risk estimate is a measure of association between the presence or absence of a factor and the occurrence of an event.
For example, you could examine the relationship between smoking and lung cancer.
16

In this hypothetical example, the relative risk of lung cancer is more than twice as high among smokers than among non-smokers.
And the 95% confidence interval for the relative risk ratio does not include 1, indicating that there is a significant difference in the occurrence of lung cancer between smokers and non-smokers.
17

The Breslow-Day and Tarone's statistics test the homogeneity of the odds ratio across categories of the layer variable.
A low significance value (typically below 0.05) indicates that the odds ratio varies across categories of the layer variable
The Cochran's and Mantel-Haenszel statistics are designed to test for independence between a binary factor variable and a binary response variable. The statistics are adjusted for covariate patterns defined by one or more control variables.
low significance value (typically below 0.05) indicates that there may be some relationship between the two variables.
While the measures may indicate that there is a relationship between two variables, they do not indicate the strength or direction of the relationship.
18

This is essentially a t-test for the value of the common odds ratio.
19

The estimate and natural log of the estimate of the common odds ratio are normally distributed for sufficiently large data sets.
A low significance value (typically below 0.05) indicates that the hypothesized value of the common odds ratio is probably incorrect.
20

21