treatment and analysis of data – applied statistics ...lennart/statistics3.pdf · quantiles...
TRANSCRIPT

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 1
Treatment and analysis of data – Applied statisticsLecture 3: Sampling and descriptive statistics
Topics covered:
Parameters and statistics
Sample mean and sample standard deviation
Order statistics and quantiles
Confidence intervals and confidence levels
Error bars and box plots
Histograms
Cumulative and percentile plots
Probability plots
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 2
Population, parameters, sample and statistics
Sample space (in probability theory) ≡ population (in statistics)
A (random) sample isdrawn from the population
population described by certain parameters such as μ and σ
statistics such asm and s
sampling(data collection)
inference
data analysis
data

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 3
Parameters and statistics
A parameter is a quantity that describes a population (e.g. the population mean μand population standard deviation σ).
Data are obtained by sampling the population (e.g., x1, x2, ..., xn).
Any function of the data is called a statistic. Examples of statistics:
n - the number of data points
min(x1, x2, ..., xn) - the smallest data value
x1 + n1/3 - not a very useful statistic
m = (x1 + x2 + ... + xn)/n - the sample mean
s = [ Σi (xi–m)2 / (n–1) ]1/2 - the sample standard deviation
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 4
Descriptive statistics
Simple calculations on the data allow to condense them in a form useful e.g. in order to
• summarize results in a way that is quickly grasped
• assess the quality of the data
• compare different sets of data
• explore what kind of information the data may contain
• support a statement (make a conclusion more convincing)
When the data represent a more or less unknown distribution, the most important statistics may be
some measure of location, such as the sample mean or median
some measure of scale (or scatter, or precision), such as the sample standard deviation or interquartile range
This is often supported by graphics which give much more complete information on distributions. (A graph is also a statistic.)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 5
Sample mean and sample standard deviation
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 6
Be careful to distinguish between:
• the sample standard deviation
which measures the dispersion among the values x1, x2, ..., xn around the sample mean value m, and
• the standard deviation of the sample mean, which is usually estimated as
and which may be quoted as the standard error (1σ uncertainty) of m.
E.g.: "the mean value and dispersion of the data are 12.3 ± 2.5" is ambiguous!
Important comment
( )∑=
−−
=n
ii mx
ns
1
2
11
( ) ( )∑=
−−
==n
ii mx
nnnsmD
1
2
11
][

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 7
Alternative measures of location and scale
The sample mean and sample standard deviation are very sensitive to outliers or stongly deviating points. In manual data analysis one can often cope interactively with these cases, but for automatic analysis it is better to use a more robust method.
In such cases, or when the distribution is known or suspected to be non-gaussian, there are many other useful measures of location and scale.
Instead of the sample mean m we may use the sample median xmed (see below).
Instead of the sample standard deviation (= RMS deviation from the sample mean), we may use the mean absolute deviation from the mean:
Often the sample median is used instead of the sample mean when calculating the MAD. In fact, for any fixed sample the median minimizes the MAD, so it is logical to use the median and MAD together.
∑=
−=n
ii mx
n 1
1MAD
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 8
Order statistics

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 9
Sample quantiles
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 10
Quantiles for the normal (Gaussian) distribution
value
frequency
68% of the area is within ±1σ
32% of the area is outside ±1σ
4.6% of the area is outside ±2σ
0.3% of the area is outside ±3σ
−1σ +1σ +2σ +3σ0−2σ−3σ

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 11
frequency
value
25 75 95500.5 5 99.5 percentile
0 0.67 1.65 2.57-2.57 -1.65 -0.67 standard deviations
Confidence intervals and levels – normal case (1)
Alternatively, the precision can be specified as a confidence interval, with an associated confidence level (CL):
x = 3.7 ± 2.5 (90% CL) or 1.2 < x < 6.2 (90% CL)
x > 1.2 (95% CL) [one-sided confidence interval]
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 12
Confidence intervals and levels – normal case (2)
Confidence Level two-sided confidence interval (for normal distr.)
50% [ −0.67σ, +0.67σ ]
68% [ −1.00σ, +1.00σ ]
90% [ −1.65σ, +1.65σ ]
95% [ −1.96σ, +1.96σ ]
99% [ −2.58σ, +2.58σ ]
99.9% [ −3.29σ, +3.29σ ]
Caution: older astronomical literature (< 1960) often uses “probable error” (p.e.), which corresponds to 50% CL or ±0.67σ.
Thus: (standard error) = 1.5 × (probable error)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 13
Actual errors rarely follow the normal distribution:
usually points beyond ±3σ are much more frequent than expected for a normal distribution (0.3%)
the distribution is often skew, especially in the tails
sometimes the distribution is completely different, e.g. exponential
Although the standard deviation is applicable to many non-normal cases, it could be misleading without further specification of the distribution.
For instance, given only the information
x = 3.7 ± 1.5 (s.e.)
one might conclude that x > 8.2 is very unlikely (0.15%). However, if x has a log-normal distribution, the probability is in fact 2 – 3%.
Deviations from the normal distribution
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 14
Quantiles (fractiles), percentiles, quartiles, etc
Other names for quantiles at certain q-values:
Q(0.5) = median (or 50th percentile)
Q(0.25) = lower quartile (or 25th percentile)
Q(0.75) = upper quartile (or 75th percentile)
Q(0.1) = first decile, Q(0.2) = second decile, etc [not so often used]
The interquartile range IQR = Q(0.75) – Q(0.25) is sometimes used as a measure of precision (equal to 1.35σ for a normal distribution).
Half the "intersextile range" (not a standard term), [Q(5/6) – Q(1/6)]/2 = 0.97σ for a normal distribution, and is useful as a robust assessment of the dispersion.
NOTE: The terms quantile, fractile, and percentile are used almost synonymously in the literature, while median, quartile, decile etc have very specific meanings.

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 15
Error bars and box plots
Error bars usually indicate ±1σ (i.e. the confidence interval at 68% CL). If not, the exact meaning must definitely be stated in the figure caption.
Box plots (or box-whisker plots):
medianlower quartile
upper quartile
lowest “non-outlier”
highest “non-outlier”
“outliers” (>1.5×IQR from median)
“outlier”
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 16
Histograms
One-dimensional sample distributions are often shown as histograms. A histogram displays the number of data points per bin, versus the position of the bin (or the density of data points, if unequal bin sizes are used).
E.g., define the sequence x0, x1, ..., xn which are the boundaries of n bins.Equal bins of size Δx are obtained as xi = x0 + i Δx, i = 1, 2, ..., n.
Let hi be the number of data points with xi–1 ≤ x < xi . (Note position of <)In the histogram, hi (or sometimes hi /Δxi ) is plotted as a bar from xi–1 to xi .
Things to consider when constructing a histogram:
Which bin size to use? - compromise between resolution and noise. In any case, be careful to specify the bin size if it is not clear from the graph!
Where to start (x0)? - often arbitrary!
What to do with points outside x0, xn (if any)?
A difficulty with histograms is that they look radically different depending on the choices you make!

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 17
Different histograms of the same data... (1)
These histograms (of the same 200 points) differ only in the choice of starting value x0
bin size = 2 bin size = 2
bin size = 2 bin size = 2
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 18
Different histograms of the same data... (2)
These histograms (of the same 200 points) differ in bin size as well. It is better to make thebins too narrow than too wide: the eye can smooth out the noise but cannot recover lost resolution! Note that the uncertainty of any histogram value hi. is of order ±√hi.
bin size = 2
bin size = 0.5
bin size = 1
bin size = 1

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 19
Cumulative plots
An alternative to histogram is to plot the cumulative fraction, analoguous to the cumulative distribution function (cdf):
theoretical distributions empirical data
cumulative distribution function ⇔ cumulative fraction
probability density function ⇔ histogram
The cumulative fraction is a step function that increments by 1/n for each data point, starting from 0 and ending at 1.
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 20
Cumulative plot, example
Cumulative fraction plot for the same 200 data points as in the histograms. The two modes can be seen as the steeper parts of the curve around 10 and 15.
n = 200
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 21
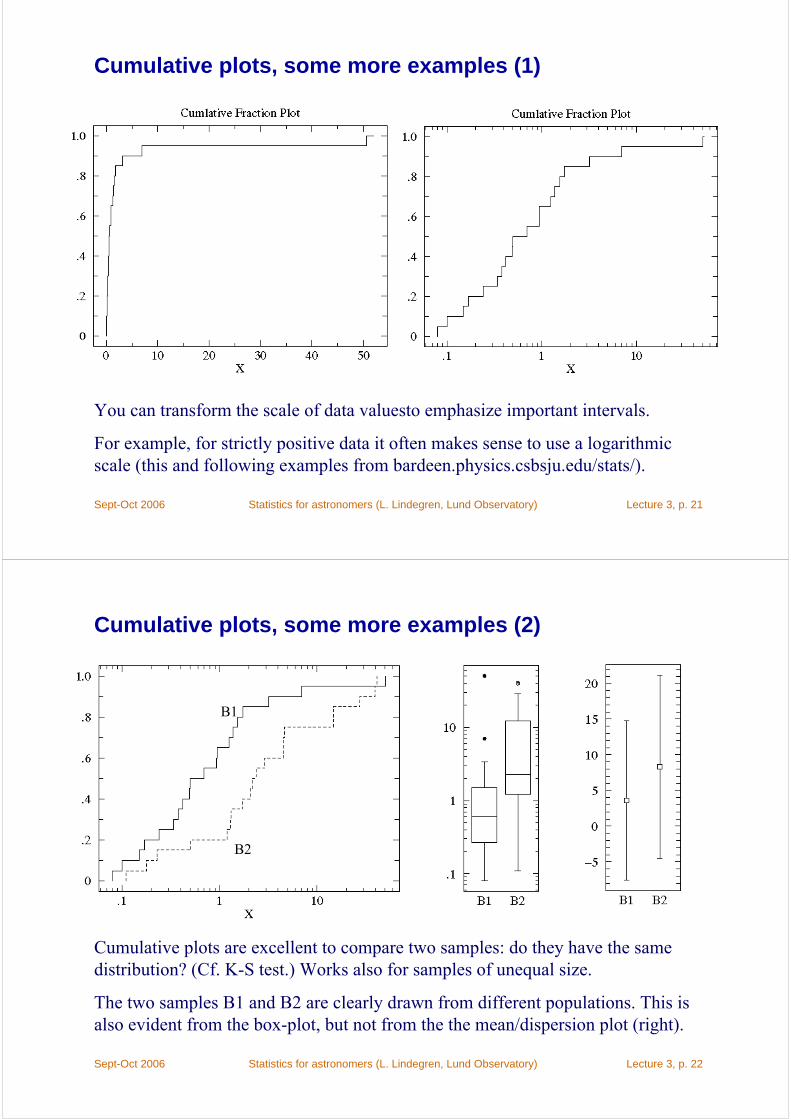
Cumulative plots, some more examples (1)
You can transform the scale of data valuesto emphasize important intervals.
For example, for strictly positive data it often makes sense to use a logarithmic scale (this and following examples from bardeen.physics.csbsju.edu/stats/).
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 22
Cumulative plots, some more examples (2)
Cumulative plots are excellent to compare two samples: do they have the same distribution? (Cf. K-S test.) Works also for samples of unequal size.
The two samples B1 and B2 are clearly drawn from different populations. This is also evident from the box-plot, but not from the the mean/dispersion plot (right).
B1
B2

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 23
Percentile plots
The ragged appearance of the cumulative plot can be disturbing to the eye, especially for small n.
It may then be better to use a percentile plot (red line), which simply connects the n points with x(i) as abscissa and p = i/(n+1) as ordinate. This is actually a better estimate of the cumulative distribution function than the cumulative fraction plot.
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 24
Percentile plot, example
Percentile plot for the same 200 data points as in the histograms and as in the cumulative fraction plot (slide 20).
n = 200

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 25
Transformed percentiles...
Sometimes it's useful to transform the percentile scale to bring out more clearly the important parts of the distribution.
In this example (a sample drawn from from χ32) we are concerned about the tail of
large values, which is difficult to see in the standard percentile plot (left). By plotting 1 – p instead of p and using a logarithmic scale, the tail is emphasized.
n = 200 n = 200
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 26
Probability plots
As n → ∞ the percentile plot converges to the cdf F(x).
To see if the data follow a given distribution F(x), we could make a percentile plot with F–1(i/(n+1)) on the y-axis instead of i/(n+1). If the data follow F(x) we should then get (approximately) a straight line. This is a probability plot.
The nice thing about probability plots is that any linear transformation axi+b of the data will just shift and change the slope of the curve, but a straight line (for example) remains straight.
The most common type of this plot is the normal probability plot, using the standard normal cdf
The abscissae are x(i) and the ordinates are Φ–1(i/(n+1)) for i = 1, 2, ..., n.
∫∞−
⎟⎟⎠
⎞⎜⎜⎝
⎛−=Φ
x
ttx d2
exp2
1)(
2
π

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 27
The inverse standard normal cdf
To make normal probability plots you need to be able to compute the inverse standard normal cdf Φ–1(p) for any 0 < p < 1. Routines for this are are available in most numerical/statistical packages (can be found e.g. in Numerical Recipes).
If not readily available, use the following approximation which is always good enough for probability plots (maximum error is 0.003; Abramowitz & Stegun, Handbook of Mathematical Functions):
where
The values Φ–1(p) are sometimes called the normal scores.
⎪⎪
⎩
⎪⎪
⎨
⎧
<≤−Φ−
≤<−++
+
=Φ−
−
15.0if)1(
5.00if04481.099229.01
27061.030753.2
)(1
2
1
pp
pttt
t
p
pt ln2−=
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 28
Percentile vs. probability plot (1)
Percentile plot for 50 random numbers from a normal distribution with mean = 2 and s.d. = 5.
Note that you can use the percentile plot to estimate quantiles, e.g. the median and the first/last sextiles.
n = 50
0.5
median ≈ 1
5/6
5th sextile ≈ 7
1/61st sextile ≈ -3
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 29
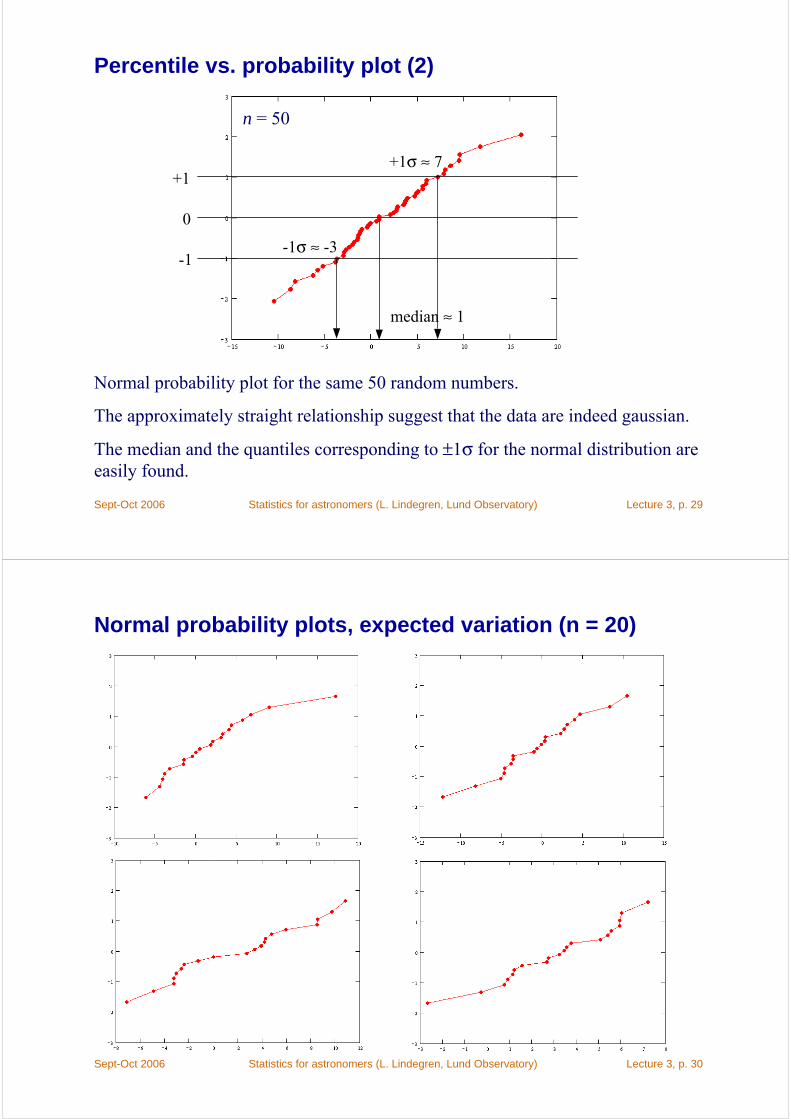
Percentile vs. probability plot (2)
Normal probability plot for the same 50 random numbers.
The approximately straight relationship suggest that the data are indeed gaussian.
The median and the quantiles corresponding to ±1σ for the normal distribution are easily found.
n = 50
0
median ≈ 1
+1+1σ ≈ 7
-1-1σ ≈ -3
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 30
Normal probability plots, expected variation (n = 20)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 31
Normal probability plots, expected variation (n = 200)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 32
Normal probability plot for a non-normal sample
Normal probability plot for the bimodal sample earlier plotted in the histograms (slides 17-18).
n = 200
bin size = 0.5

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 33
Normal probability plot for a non-normal sample
Typical normal probability plot for a sample that is nearly gaussian, but with some outliers
n = 200
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 34
Normal probability plot for a non-normal sample
Normal probability plot for a sample drawn from the Cauchy distribution with location α = 2 and scale β = 5.
n = 200

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 35
Cauchy probability plot for the Cauchy sample
Cauchy probability plot for the same sample as in the previous slide. The inverse cdf for the standard Cauchy distribution is F–1( p) = tan [( p – 0.5) π].
n = 200
Probability plots may notbe very useful for extreme distributions like Caucy!
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 36
Related to probability plots...
100
101
102
20th Century’s 100 largest disasters worldwide
US Power outages (10M of customers,1985-1997)
Natural ($100B)
Technological ($10B)
Slope = -1(α=1)
10-2
10-1
100

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 37
A histogram plot from Hipparcos data analysis
Normalised differences between the FAST and NDAC parallax estimates for successive solutions (12, 18, 30, 37 months of data). n = 40,000 - 100,000.
ESA SP-1200Vol. 3, Fig. 16.28
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 3, p. 38
The same data in a normal probability plot
Normalised differences between the FAST and NDAC parallax estimates for successive solutions (12, 18, 30, 37 months of data). n = 40,000 - 100,000.
ESA SP-1200Vol. 3, Fig. 16.29
Real data aresometimessurprisinglyGaussian!