three dimensional fast fourier transform cuda...
TRANSCRIPT

Three Dimensional Fast Fourier TransformCUDA Implementation
Kumar Aatish, Boyan Zhang

Contents
1 Introduction 2
1.1 Discrete Fourier Transform (DFT) . . . . . . . . . . . . . . . . . . . . . . 2
2 Three dimensional FFT Algorithms 3
2.1 Basis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 In-Order Decimation in Time FFT . . . . . . . . . . . . . . . . . . . . . . 9
3 CUDA Implementation 11
3.1 Threadblock Geometry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2 Twiddle Multiplication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Transpose Kernel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4 Experiment Result 17
4.1 Occupancy calculation and analysis . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Benchmarking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5 Scope for further improvements 19
5.1 Algorithmic Improvements . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.1.1 CUDA FFT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.1.2 Transpose Kernel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2 Kepler Architecture Specific Improvements . . . . . . . . . . . . . . . . . 20
5.2.1 Register Per Thread . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2.2 Shuffle Instruction . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
A Occupancy Calculation for Different Thread Block Heights 20
1

1 Introduction
1.1 Discrete Fourier Transform (DFT)
One dimensional Discrete Fourier Transform (DFT) and Inverse Discrete Fourier Trans-
form (IDFT) are given below[Discrete Fourier Transform]:
x(k) =
N−1∑n=0
x(n)W knN , 0 ≤ n ≤ N − 1, (1)
x(n) =1
N
N−1∑k=0
x(n)W−knN , 0 ≤ k ≤ N − 1, (2)
where
W knN = e−i 2πkn
N (3)
In above discrete transform, the input is N-tuple complex vector x(n), output is vector
with same length.
X = Wx (4)
If a complex function h(n1, n2) defined over the two-dimensional grid n1 ∈ [0, N − 1],
n2 ∈ [0, N − 1]. We can define two-dimensional DFT as a complex function H(k1, k2),
defined over the same grid.
H(k1, k2) =
N2−1∑n2=0
N1−1∑n1=0
e−2πik2n2
N2−2πik1n1
N1 h(n1, n2) (5)
Correspondingly, it is inverse transform can be re-addressed in such form:
H(n1, n2) =1
N1N2
N2−1∑k2=0
N1−1∑k1=0
e−2πik2n2
N2−2πik1n1
N1 h(k1, k2) (6)
Since the Fourier Transform or Discrete Fourier Transform is separable, two dimensional
DFT can be decomposed to two one dimensional DFTs. Thus the computation of two
dimensional DFT can achieved by applying one dimensional DFT to all rows of two
dimensional complex matrix and then to all columns (or vice versa). Higher dimensional
DFT can be generalized from above process, which hints similar computation solution
along each transform dimension.[Separability of 2D Fourier Transform]
2

2 Three dimensional FFT Algorithms
As explained in the previous section, a 3 dimensional DFT can be expressed as 3 DFTs
on a 3 dimensional data along each dimension. Each of these 1 dimensional DFTs can be
computed efficiently owing to the properties of the transform. This class of algorithms
is known as the Fast Fourier Transform (FFT). We introduce the one dimensional FFT
algorithm in this section, which will be used in our GPU implementation.
2.1 Basis
The DFT of a vector of size N can be rewritten as a sum of two smaller DFTs, each of size
N/2, operating on the odd and even elements of the vector (Fig 1). This is know as the
Danielson-Lancsoz Lemma [G. C. Danielson and C. Lanczos] and is the basis of FFT. .
So-called fast fourier transform (FFT) algorithm reduces the complexity to O(NlogN).
Danielson-Lancsoz Lemma:
X(k) =
N2−1∑
n=0
x(2n)e−i2π×(2n)k
N +
N2−1∑
n=0
x(2n + 1)e−i2π×(2n+1)k
N
=
N2−1∑
n=0
x(2n)e−i 2πnkN
2 +
N2−1∑
n=0
x(2n + 1)e−i 2πnkN
2
= DFTN2
[x0, x1, . . . , xN−2] + WKN DFTN
2[x1, x3, . . . , xN−1]
If N is a power of 2, this divide and conquer strategy can be used to recursively break
down the transform of size N into log2(N) transforms of length 1 leading to performance
increase (O(Nlog2N)) over a nave matrix multiplication of a vector with the DFT matrix
(O(N2)).
The exact method of decomposing the larger problem into smaller problems can vary
widely. A number of algorithms have been proposed over the years, the most famous
of which is the Cooley-Tukey Algorithm[Cooley, J. W. and Tukey, O. W.] which has two
variations called the Decimation in Time (DIT) and Decimation in Frequency (DIF).
3
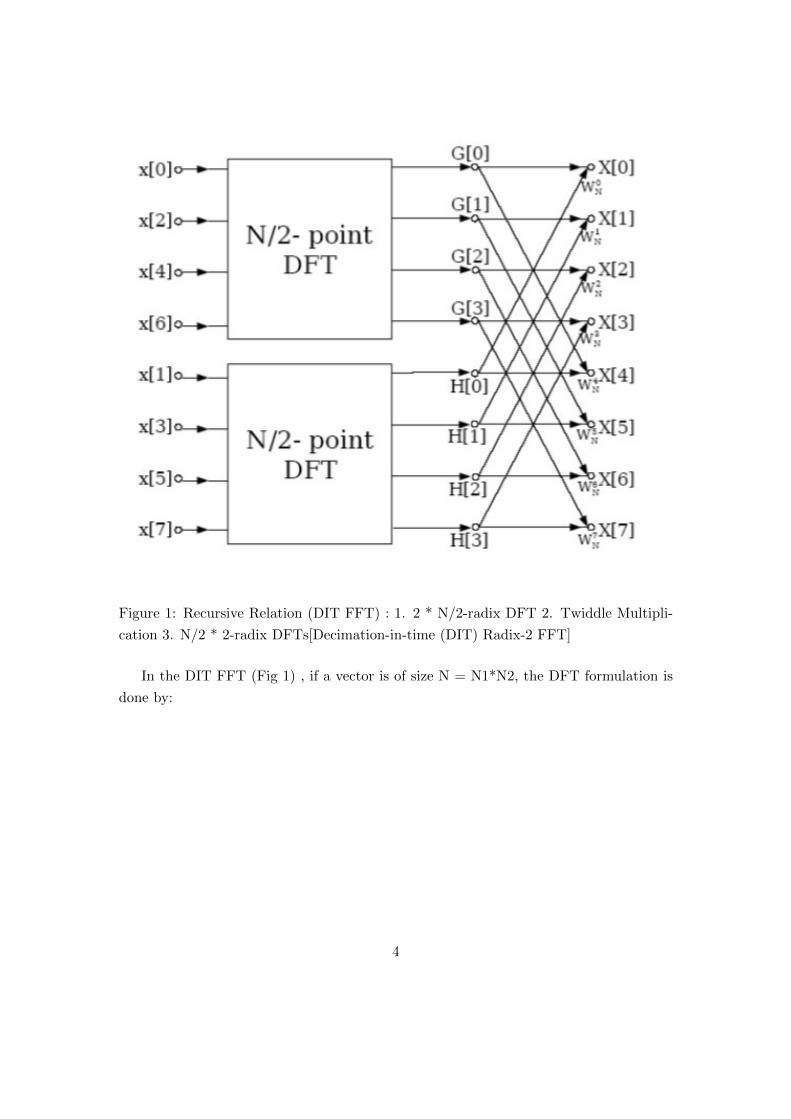
Figure 1: Recursive Relation (DIT FFT) : 1. 2 * N/2-radix DFT 2. Twiddle Multipli-
cation 3. N/2 * 2-radix DFTs[Decimation-in-time (DIT) Radix-2 FFT]
In the DIT FFT (Fig 1) , if a vector is of size N = N1*N2, the DFT formulation is
done by:
4

Figure 2: Recursive Relation (DIF FFT) : 1. N/2 * 2-radix DFTs 2. Twiddle Multipli-
cation 3. 2 * N/2-radix DFT[Decimation-in-time (DIT) Radix-2 FFT]
• Performing N1 DFTs of size N2 called Radix−N2 FFT.
• Multiplication by complex roots of unity called twiddle factors.
• Performing N2 DFTs of size N1 called Radix−N1 FFT.
The DIF FFT, the DFT formulation is:
• Performing N2 DFTs of size N1 called Radix−N1 FFT.
• Multiplication by complex roots of unity called twiddle factors.
• Performing N1 DFTs of size N2 called Radix−N2 FFT.
In this paper, we implement the DIT FFT for length 128, although, according to our
hypothesis, an equivalent DIF FFT would not differ in performance. By using this 128
5

element FFT, we can further construct FFT algorithms for different sizes by utilizing
the recursive property of FFTs. However, such an exercise is not under the scope of our
project.
In the DIT scheme, we apply 2 FFT each of size N/2 which can be further broken
down into more FFTs recursively. After applying each such recursive relation, we get a
computation structure which is popularly referred to as a Butterfly.
W (N,N
2) = −1 (7)
Therefore, W (N, k) can be expressed as
−W (N, k − N
2),N
2≤ k ≤ N − 1 (8)
Since we can express half of the twiddle factors in terms of the other half, we haveN2 twiddle multiplication at each stage, excluding multiplications by -1. For an input
(G(i), H(i)) the function B(G(i), H(i)) = (G + W iN ∗H(i), G−W i
N ∗H(i)).
Figure 3: Butterfly [Signal Flow Graphs of Cooley-Tukey FFTs]
It should be noted that while breaking down the FFT of size N into two FFTs of sizeN2 , the even and odd inputs are mapped out of order to the output. Decomposing this
problem further to FFTs of the smallest size possible would lead to an interesting order
of input corresponding to the output. Upon inspection, we can see (Fig 4) that an input
having an index k, had a corresponding output with index as bitreverse (k, log2(N)), i.e.
the bit reversal done in log2(N) bits.
6

Figure 4: Radix-2 DIT FFT on vector with length 8
[Decimation-in-time (DIT) Radix-2 FFT]
Input Output
0 000 000 0
1 001 100 4
2 010 010 2
3 011 110 6
4 100 001 1
5 101 101 5
6 110 011 3
7 111 111 7
This pattern can be explained by the fact that applying an FFT of length N2 would
require reshuffle of input indices into even − odd relative to the new transform length
after the decomposition, e.g. N2 after the first decomposition. This would be the same as
7

sorting with length N(2p−1) with respect to the p−1th bit first and then by the remaining
bits in the pth decomposition.
Input Output
0 000 000 0
2 010 100 1
4 100 010 2
6 110 110 3
1 001 001 4
3 011 101 5
5 101 011 6
7 111 111 7
Input Output
0 000 000 0
4 100 100 1
2 010 010 2
6 110 110 3
1 001 001 4
5 101 101 5
3 011 011 6
7 111 111 7
Input Output
0 000 000 0
4 100 100 1
2 010 010 2
6 110 110 3
1 001 001 4
5 101 101 5
3 011 011 6
7 111 111 7
After the complete decomposition of the problem is achieved, we would be left with an
FFT of length 2 and the number of decompositions done would be log2(N). Thus we
can do the FFT in log2(N) time steps, and each such step is referred to as Stages in this
paper.
8

2.2 In-Order Decimation in Time FFT
A DIT FFT does not necessarily imply an out of order input and an in order output.
We can reshuffle the input order at the expense of ordering of the output. For example,
in Fig 5, for the case of FFT length = 16, the reshuffled butterfly diagram has in-
order input and out-of-order output. For the development of our GPU algorithm, this
approach would be more conducive for coalesced memory access.
As mentioned before, it is easy to observe that after every stage, there are alwaysN2 twiddle multiplications. This is due to the fact that every decomposition stage p,
there are N2p twiddle factors introduced by 2p−1 DFTs. As the recursive relation leads
to smaller transform lengths, the range of twiddle factors introduced at each step varies.
It is because of this reason that the difference between a DIT and DIF implementation
of FFT is the range of twiddle factors WQ used to multiply the intermediate values
with before every stage. Fortunately, the values that the twiddle factors take can be
determined, although the relationship between the twiddle factors and the input index
is not so obvious.
9

Figure 5: DIT FFT, In-order input, out-of-order output. Every stage has N/2 twiddle
factors [Decimation-in-time (DIT) Radix-2 FFT]
Stage k input index range(Q)
1 0-3, 4-7 4-7, 12-15 0 4
2 0-1, 2-3, 4-5, 6-7 2-3, 6-7, 10-11, 14-15 0, 4, 2, 6
3 0, 1, 2, 3, 4, 5, 6, 7 1, 3, 5, 7, 9, 11, 13, 15 0, 4, 2, 6, 1, 5, 3, 7
At every stage, the Stride is defined to be N(2p) and each such stage consists of 2p−1
sets of butterflies. Depending upon whether the input element index falls on the lower
half or the upper half of a butterfly set, elements are either added to or subtracted
10

from elements across a stride. More precisely, the following pseudocode demonstrate the
ADDSUB step of each stage:
i f ( ( t i d & STRIDE(p ) ) == STRIDE(p ) )
{va l [ i ] = va l [ i − STRIDE(p ) ] − va l [ i ] ;
}e l s e
{va l [ i ] = va l [ i + STRIDE(p ) ] + va l [ i ] ;
}
After the ADDSUB step, the MUL TWIDDLE step takes place for all stages except the
last one
i f ( ( t i d & STRIDE(p+1)) == STRIDE(p+1))
{va l [ i ] = va l [ i ]∗TWIDDLE KERNEL( i , p , N) ;
}
Our implementation, does not make function calls to generate twiddle factors but are
instead hard coded. A general relation between the kth twiddle factor and its value Q can
be expressed as bitreverse(FLOOR[k/(N/2p)], log2(N)−1).[Computing FFT Twiddle Factors]
This idea has been applied to our implemented case of length 128 and a detailed
relation between input index and Q is given in the next section.
3 CUDA Implementation
Our implementation does an FFT transform in the row major dimension of a given three
dimensional matrix at a time. Thus, the complete 3D FFT is a set of 1D FFT kernels
and transpose kernels which bring a desired coordinate axis to the row major format
to enable coalesced global reads. The implemented kernel performs a single precision
1D FFT and uses the fast math functions for calculating the sin and cos of the phases
corresponding to twiddle factors.
The GPU used is the C2050 Fermi GPU on the DIRAC cluster on the Carver system
provided by the National Energy Research Scientific Computing Center. The NVIDIA
Tesla C2050 has 448 parallel CUDA processor cores with 3 GB of memory.
11

3.1 Threadblock Geometry
The threadblock geometry and global data mapping onto the block can be done in more
ways than one.
Figure 6: Serial Configuration of thread block mapping
(Fig 6) shows that each CUDA thread within a thread block manages entire row
vector transform. this configuration does not meet memory usage requirement for large
input data size because of limitation of local storage space (registers per thread). More-
over, reads from global memory are not coalesced.
12

Figure 7: Serial Configuration of thread block mapping
(Fig 7) shows a different mapping approach of thread block structure. Threads within
one thread block are working on a single row vector. Required communication among
different threads only happens within each thread block.
13

Figure 8: Serial Configuration of thread block mapping
(Fig 8) is a modified configuration for that showed in (Fig 7)., a single row of threads
are grouped within one thread block responsible for calculating the transform of more
than one row of data. If we assume length of transform vector is 128, upto 4 rows can
be grouped within one thread block. For the optimal number, a trade-off may be made
between multiprocessor computing ability and resource.
We have implemented the third alternative that transforms more than one row of
data by a single row of threads resulting in higher Instruction Level Parallelism. Each
such threadblock is assigned a shared memory block of height H and row size TLEN =
128. Since, we are dealing with complex numbers two identical shared memory blocks
are maintained for both real and imaginary components of the data.
The real and imaginary component of the data is loaded onto the shared memory
from the global and is also read into the registers. After this step each of the 7 stages
of the FFT are computed. Each of these stages consists of the ADDSUB step, that is,
every thread reading data element of a thread either STRIDE(p) ahead and add the
value to its own value, or read from a thread STRIDE(p) behind and subtract its own
value from this value.
The next stride value STRIDE(p+1) decides which of these elements get multiplied
by the twiddle factor. Those threads that satisfy the condition are allowed to multiply
14

their data with the twiddle factor, after which the resultant data is written back to the
shared memory to be used by the threadblock. This sequence of steps continues till the
FFT is completed. The last stage however, does not involve multiplication by twiddle
factor and only consists of the ADDSUB step after which the values of each thread is first
written to the bit reversed column in the shared memory. The data is then read back
to the registers of every thread in a contiguous pattern and then written to the global
memory in a coalesced fashion. Although an increased H would apparently increase
the instruction level parallelism there are limits to the range of H as it can cause lower
occupancy due to limitation of shared memory resource. Apart from shared memory, an
increased H would also cause an increased register pressure and could lead to register
spilling leading to inefficient execution and lowered performance. Even if we somehow
limit the row size so that H * TLEN is lesser than 32 KB (Available register memory), a
severe limitation of the Fermi architecture is that it only allows 63 registers per thread.
Due to these concerns, we experimentally determined the optimal height H for which
the 1D FFT kernel would be most efficient. These experiments are dealt with in the
Experimental Results section.
3.2 Twiddle Multiplication
As explained in the Algorithms section, the relationship between the kth twiddle factor
and the twiddle factor value Q is given by bitreverse(FLOOR[k/(N/2p)], log2(N)− 1).
Since our implementation maps elements of the transformed vector along the thread-
block, the thread index maps directly to the input index.
For our case, N = 128, log2(N)− 1 = 6 For p = 1,
Figure 9: Twiddle factors for stage 1
For p = 2,
15

Figure 10: Twiddle factors for stage 2
A general pattern emerges from these two tables. For any given thread id in the pth
stage, the most significant p bits are reversed in log2(N) − 1 bits and remaining bits
are ignored. For e.g., for stage 5, if the thread id corresponding to a particular data
item, which is to be multiplied with a twiddle factor is of the type ABCDEXY, then the
value of Q, which is to be multiplied with the data item, is EDCBA0. For each of the
stages for N = 128, different bit reversal techniques were used to maximize performance.
More often that not, unnecessary operations were removed from a generalized 6 bit, bit
reversal.
3.3 Transpose Kernel
Our 1D FFT kernel is designed to work in the row major dimension. Due to this, after
performing a 1D FFT, we must transpose the global data so that the 1D FFT kernel can
work in a different data dimension. Since the 3D FFT would also encompass transpose
operations, it is imperative that an efficient transpose kernel is developed. CUDA SDK
provides a great example for starting with two dimensional square matrix transpose
[Optimizing Matrix Transpose in CUDA]. The optimized kernel removes uncoalesced
memory accessing and shared memory bank conflicts. We modified transpose kernel to
adapt to our requirement for three dimensional transpose.
Considering the stride between sequence elements is large, performance tends to
degrade for higher dimensions. Global transpose is involved with significant amount
of global memory operation, consequently, optimized transpose operation is critical for
achieving better overall performance. Before performing the 1D FFT, the data dimension
in which the transform is desired is brought down to the lowest dimension. After this
process is completed for all the data dimensions, the data is transposed back to the
original data dimensions. In totality, the 1D FFT kernel is called thrice interspersed
with 4 transpose kernels.
16

4 Experiment Result
4.1 Occupancy calculation and analysis
Appendix A lists figures result of occupancy testing for multiprocessor warp occupancy
under different thread block height configurations. It can be shown that when H =
16, local shared memory usage serves as limiting factor for warp occupancy rate. Each
thread block is assigned 16KB shared memory block. On Dirac GPUs with 2.0 compute
capability [Node and GPU Configuration], each multiprocessor has only 48KB shared
memory space available. Applying this calculation to the case when H = 8, we found
that the concurrent executing threadblock on each multiprocessor is 6 which is less than
physical limits for active thread block. The optimal height H is 4, although it deliv-
ers same occupancy rate with smaller height size, but better local memory bandwidth
utilization benefits memory accessing latency hiding. However, occupancy calculation
also shows possibility for further improvement, each threadblock can have more threads
without touching/reaching register and shared memory usage critical points. Based on
discussion above, we expect implementation scheme such as assigning 2xTLEN threads
for one thread block will deliver better performance, although without implementation
and test result to support the hypothesis.
Figure 11: FFT 1D Implementation Vs. CUFFT 1D
17

Figure 12: FFT 1D Implementation Vs. CUFFT 3D
Figure 13: FFT 3D Execution Time (ms)
4.2 Benchmarking
Two testing schemes are utilized for benchmarking our kernel with CUFFT library per-
formance.
• 1D CUFFT plan (1D in place transform) over three dimensional data
18

• 3D CUFFT plan (3D in place transform) over three dimensional data
5 Scope for further improvements
5.1 Algorithmic Improvements
5.1.1 CUDA FFT
The algorithm employed in this project can be improved further by utilizing register
memory for FFT transform. Recall that the optimum height of a global data chunk
belonging to a thread block is 4. Before starting a 1D FFT along the row major direction,
suppose in a thread block every thread having global Y index tid y were to load the data
row with index bitreverse(tid y). This would be followed by a 1D FFT in the row major
direction. Since the Height is 4, every thread has 4 elements in the Y direction, but since
we have loaded rows corresponding to bitreverse(tid y), , each thread would be able to
finish the first two stages of the FFT in the Y direction using register memory without
synchronization getting into the picture. This would be followed by 2 transposes so that
the Y data dimension becomes row major and Z data dimension becomes column major,
however its indices would be bitreversed. This would be followed by 1D FFT in the
row major order. Since we have read the rows in the bitreverse order in the last 1D
FFT, currently, the input to the 1D FFT would be out of order, the data would already
be in the third stage of the 1D FFT computation and the final output data would be
in-order. This would be followed by the same sequence of instructions till the 3D FFT
is computed.
5.1.2 Transpose Kernel
Current implementation of the 3D FFT involves calls to two transpose kernels after the
third 1D FFT is completed. These two calls individually exchange the data dimensions
XY and YZ to undo the effect of transpose required by the 1D FFT kernels. It is possible
to merge these two transpose kernels to transpose X, Y and Z dimensions simultaneously.
Since each transpose kernel spends non-trivial time calculating its new index, instruction
level parallelism can be utilized to hide the memory latency.
19

5.2 Kepler Architecture Specific Improvements
5.2.1 Register Per Thread
One of the prime reasons why the Height of data chunk assigned to a thread block could
not be increased is due to register pressure. It would be possible to increase this Height
in Kepler GK110 since the maximum number of registers per thread possible has been
raised to 255 as compared to 63 in Fermi. An increased Height could mean an improved
performance since it would allow even more stages of computation of column major
FFT (as explained in the previous subsection) to be computed by a single thread using
register memory only.
5.2.2 Shuffle Instruction
It is quite possible that the shared memory usage of the 1D FFT Kernel be drastically
reduced because of the shuffle instruction. Shuffle Instruction enables data exchange
within threads of a warp, hence shared memory usage would go down as a result. For
out of order input and in-order output, this would be especially more beneficial because
the first few stages would eliminated the need for inter warp communication.
A Occupancy Calculation for Different Thread Block Heights
H = 1
20

Figure 14: Threads Per Block Vs. SM Warp Occupancy
Figure 15: Registers Per Thread Vs. SM Warp Occupancy
21

Figure 16: Shared Memory Usage Vs. SM Warp Occupancy
H = 2
Figure 17: Threads Per Block Vs. SM Warp Occupancy
22

Figure 18: Registers Per Block Vs. SM Warp Occupancy
Figure 19: Shared Memory Usage Vs. SM Warp Occupancy
23

H = 4
Figure 20: Threads Per Block Vs. SM Warp Occupancy
24

Figure 21: Registers Per Block Vs. SM Warp Occupancy
H = 8
25

Figure 22: Threads Per Block Vs. SM Warp Occupancy
Figure 23: Registers Per Block Vs. SM Warp Occupancy
26

Figure 24: Shared Memory Usage Vs. SM Warp Occupancy
H = 16
27

Figure 25: Threads Per Block Vs. SM Warp Occupancy
Figure 26: Registers Per Block Vs. SM Warp Occupancy
28

References
[Discrete Fourier Transform] http://en.wikipedia.org/wiki/Discrete Fourier transform
[Separability of 2D Fourier Transform] www.cs.unm.edu/ williams/cs530/ft2d.pdf
[The Cooley-Tukey Fast Fourier Transform Algorithm] http://cnx.org/content/m16334/latest/#uid8
[Node and GPU Configuration] http://www.nersc.gov/users/computational-
systems/dirac/node-and-gpu-configuration/
[Optimizing Matrix Transpose in CUDA]
[G. C. Danielson and C. Lanczos] ”Some improvements in practical Fourier analysis and
their application to X-ray scattering from liquids”, J. Franklin Inst. 233, 365 (1942)
[Cooley, J. W. and Tukey, O. W.] ”An Algorithm for the Machine Calculation of Com-
plex Fourier Series.” Math. Comput. 19, 297-301, 1965.
[Computing FFT Twiddle Factors] http://www.dsprelated.com/showarticle/107.php
[Decimation-in-time (DIT) Radix-2 FFT] http://cnx.org/content/m12016/latest/
[Signal Flow Graphs of Cooley-Tukey FFTs] http://cnx.org/content/m16352/latest/
29