the fast frontend to hadoop - big data la
TRANSCRIPT

Managing the Fast Data Pipeline
from Ingest to Export
John Hugg, Ryan Betts Founding Engineer(s)

Why A Fast Frontend?What is a fast frontend?

HDFS
Consumers
Transformers
Data Source Flume
Kafka
Whatever
Data Source
Data Source
BIG DATA
Ingestion Batch

HDFS
Consumers
Transformers
Data Source Flume
Kafka
Whatever
Data Source
Data Source
BIG DATA
Ingestion Batch
What do the green things have in common?
Movers. Not shakers.

HDFS
Consumers
Transformers
Data Source Flume
Kafka
Whatever
Data Source
Data Source
BIG DATA
Ingestion Batch
Ingestion Engine
Fast Data

HDFS
Consumers
Transformers
Data Source Flume
Kafka
Whatever
Data Source
Data Source
BIG DATA
Ingestion Batch
Ingestion Engine
Fast Data
What’s the value proposition?
Better data in HDFSFilter, Aggregate, Enrich
Lower latency to understanding what is
going on
Serve directly from the ingestion engine

Overview• What’s in that Orange Box (Ingestion Engine)
• Kafka Patterns
• Filter, De-Dup, Aggregation, Enrich - Value Proposition #1
• Understand Faster - Value Proposition #2
• Serving Layer - Value Proposition #3
• How wrong could my answers be?

HDFS
Consumers
Transformers
Data Source Flume
Kafka
Whatever
Data Source
Data Source
BIG DATA
Ingestion Batch
Ingestion Engine
Fast Data
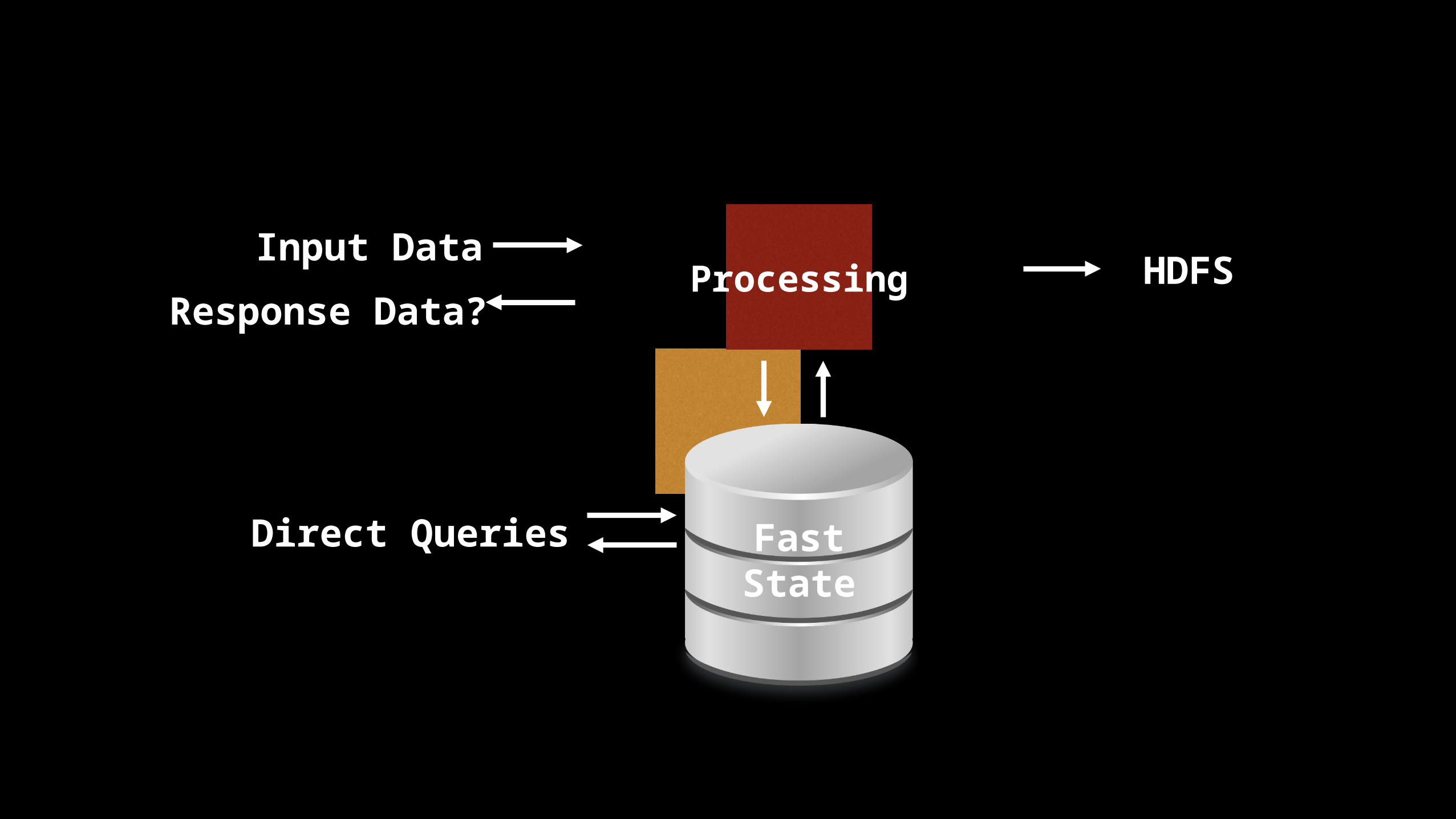
ProcessingInput Data
Direct Queries
HDFSResponse Data?
FastState

ProcessingInput Data
Direct Queries
HDFSResponse Data?
FastState
Super Important!

ProcessingInput Data
Direct Queries
HDFSResponse Data?
FastState
Let’s Get Real!
What tools do people use?
or or…

What is Kafka?• Almost a persistent message queue, but not quite.
• A distributed and partitioned log.
• Clients read linearly, but start wherever they want.
• Scalable. Persistent.
Start of Time Next Append HereApp A read to here App B read to here

Filter / De-DupAggregate
Enrich / De-Normalize
These Features = Money

Filter• De-Duplification at ingest time is an obvious value here.
Example: sensor networks
• Otherwise, people like to dump everything into HDFS and sort it out later.
• Should you do that? I don’t know.
• Easy thing is to filter bad data that meets some criteria for rejection stored in the ingestion engine.Too old. Missing values. Test data. Spam.
• With a good ingestion engine (cough), this stuff is not expensive.
Value Proposition #1

Aggregation (Counting) Example
• Raw event stream at 100k events per second.
• Send 1 aggregated row per second for hadoop.
• Aggregate can pick from COUNT, MIN, MAX, AVG, SUM, MEDIAN, etc…
• Can delay sending aggregates to HDFS to allow for late arriving events for the window.
• If this fits what you’re doing, this has the potential to speed up Impala, Hive, etc… by several orders of magnitude.
Value Proposition #1

Enrich: Call Center Example
• Event comes in that an call center agent was connected to a caller
• How long did was the caller on hold?
• User has an SLA for hold times.
• Send to HDFS a record of the hold time, including the start, end, and duration.
Value Proposition #1

Enrich: Finance Example• Message from the exchange that order 21756 was
executed?
• What is order 21756?
• Ingestion engine has a table of outstanding orders.
• Send to HDFS a record that the order for 100 shares of Microsoft by trader Joe using his algorithm “greedisgood” were executed. Include the timestamp the order was placed, the timestamp of execution and the price.
Value Proposition #1

Schema-On-Read

Schema On Read

Schema On Ingest
Should I organize by color, type,
size?
It matters, but don’t punt because it’s
nontrivial.
All Lego pros organize pieces. HDFS is the
same thing.
Don’t get me started on secondary indexes.

Schema On Read: Not Even Once
• Old Story: Dump everything into HDFS. Process it when you read it into something-schema-y.
• Turns out this is slooooooooowwwwwww.Might as well run Ruby.
• New Story: Organize data with types and reasonable schema on ingest.

Understanding
Value Proposition #2

What forms of Understanding?
• Dashboards with aggregations
• Queries that support filtering or enrichment at ingest
• Queries that make decisions on ingestRouting, Responding, Alerting, Transacting
• Queries that look for certain conditionsLike SQL triggers, but way more powerful
• Actual deep analytical queries*
Value Proposition #2

ExamplesDashboards with aggregations
Show me outstanding positions by trader by algorithm on a webpage that refreshes every second
Queries that support filtering or enrichment at ingest
FInd me all events related to this eventIf last event in a chain, push denormalized, enriched data to
HDFS
Queries that make decisions on ingest
Click event arrives. Which ad did we show? Was it fraudulent? Was it a robot? Which customer account to debit?
Queries that look for certain conditions
Is this router under attack? or…Are my SLAs not being met? If so, what’s the contractual cost?
Actual deep analytical queries*
How many purple hats were sold on Tuesdays in 2015 when it rained?
Value Proposition #2

But How?• Just use VoltDB (I know. I know.)
• Just write down the logic in Java code.
• Nothing is trivial, but some things are easier.
• Two main reasons VoltDB does this stuff better:
• Strong integration of state and processing (ACID txns).
• Straightforward development. Java + SQL.
• Sadly, the things that might be comparably not-terrible are not publicly available.
Value Proposition #2

• Logical Schema• Queryable• Concurrency• No hard stuff…
Stored Procedure
Java / SQL
Input Data
SQLJDBC/ODBC/Rest
CLI/Drivers
HDFSOLAP
CSV
SMSResponse Data
State

• Logical Schema• Queryable• Concurrency• No hard stuff…
What about this meaty bit here?
Stored Procedure
Java / SQL
• Fully integrated processing & state.
• State access is global.
• Standard SQL with extensions like “upsert” and JSON support.
• Fully consistent, ACID“Program like you’re alone in the world”
• Synchronous intra-cluster HA.Disk durability & memory speed.

• Logical Schema• Queryable• Concurrency• No hard stuff…
What about this meaty bit here?
Stored Procedure
Java / SQL
• Native AggregationsFully SQL-Integrated as Live Materialized Views
• Easy counts, ranks, sorts
• Leverage existing Java libraries (like HyperLogLog, but also JSON, gzip, Avro, protobufs, etc…)
Serving Layer• You can’t easily get real time responses with high
concurrency from HDFS.
• You can’t query Kafka or Flume or anything like that.
• So this one is a no-brainer. Query the Fast Data front end.
• I work for a vendor who sells a Fast Data front end that uses SQL and I’m going to tell you that SQL and standards like JDBC are pretty awesome for this purpose.
• You should be skeptical when a vendor tells your their tech choices are the right ones. Except this one time. SQL.
Value Proposition #3

SQL?• You should be skeptical when a vendor tells your their tech choices are
the right ones.
• Except this one time.
• SQL is winning:• Google has moved back to SQL.• Facebook uses tons of SQL. • Cassandra has CQL.• Impala, Presto, SparkSQL - Lots of new love.• Couchbase recently introduced N1QL and is pretending they never said
anything bad about SQL ever and actually SQL is great and you should use it.
Value Proposition #3

How wrong could this data be?

Delivery Guarantees
• At Least Once
• At Most Once
• None of the Above
• Exactly Once

At most once delivery
• Send all events once.
• On failure, you might lose some.
• How many are lost?

At least once delivery
• When the status of an event is unclear, send it again.
• This is not always easy. Event sources need to be robust.

Exactly once delivery
• Option 1: No side effects. Strong consistency is used to track incrementing offsets. Processing is atomic.
• Option 2: Use at-least-once, but make everything idempotent.
• Some people will tell you that option 2 isn’t exactly once. This argument is exausting. The result is the same, so who cares.

None of the Above• Extremely common.
• Kafka high level consumer - offsets roughly track work, but not exactly.
• “We use Storm in at-least once mode, unless it gets busy or jammed, then we let it drop events to keep up.”- Heavy Storm User
• Users who think they have at least once, might have this.

Partial Failure
• This is why ACID exists, folks.
• A in ACID mean “Atomic”
• Atomic means it happens or it doesn’t.
• C, I & D don’t hurt either.
• What even are side effects?
• Come back to this.

Atomic Fail: Romeo & Juliet
ACID Transaction:Operation 1: Fake your deathOperation 2: Tell Romeo

Reality is More Mundane
• Call center example: When a hold ends…Remove outstanding hold record.Add new completed hold record.Mark agent as busy.Update total hold time aggregates.
• Financial example: When order executes:Remove from outstanding orders.Update position on Microsoft.Update aggregates for trader, algorithm, time window
But still costly to screw up

Side Effects• Clearest example is writing to Cassandra from within Storm to handle an
event.Storm can’t control Cassandra the way it needs to.
• If the Storm code fails, the Cassandra write is still there?
• If the Storm code is retried, the Cassandra write happens twice?
• If the Cassandra write fails, how does Storm retry?
• If processing a Spark Streaming Micro-batch fails, then it can be re-processed, because of the integration between HDFS and SS.Spark Streaming trades latency and makes state restrictions to avoid side effects.
Anytime doing something in one system involves doing
something in another.

Conclusion - Thanks
• There is a lot of awesomeness to be had with a Fast Data frontend to Hadoop/HDFS.
• VoltDB is really good at this stuff and other available systems are much less good.
• As a vendor, you shouldn’t blindly trust me.
• So try it out. Ask questions. Engage. Explore.
http://chat.voltdb.com
[email protected]@ryanbetts
[email protected]@johnhugg