the charm++ programming model and namd abhinav s bhatele department of computer science university...
TRANSCRIPT

The Charm++ Programming Model and NAMD
Abhinav S BhateleDepartment of Computer Science
University of Illinois at Urbana-Champaign
http://charm.cs.uiuc.eduE-mail: [email protected]
Abhinav S Bhatele 2Feb 13th, 2009
University of IllinoisUrbana-Champaign,Illinois, USA

Abhinav S Bhatele 3
Processor Virtualization
User View System View
Programmer: Decomposes the computation into objects
Runtime: Maps the computation on to the processors
Feb 13th, 2009

Abhinav S Bhatele 4
Benefits of the Charm++ Model
• Software Engineering– Number of VPs independent of physical processors– Different sets of VPs for different computations
• Dynamic Mapping– Load balancing– Change the set of processors used
• Message-driven execution– Compositionality– Predictability
Feb 13th, 2009

Abhinav S Bhatele 5
Charm++ and CSE Applications
Feb 13th, 2009
Gordon Bell Award, SC 2002
Fine-grained CPAIMD
Cosmological Simulations

Abhinav S Bhatele 6
Adaptive MPI (AMPI)
Feb 13th, 2009
MPI “Processes” - Implemented as virtual “processes” (light-weight user level migratable threads)

Abhinav S Bhatele 7
Load Balancing
• Based on Principle of Persistence• Runtime instrumentation– Measures communication volume and computation
time• Measurement based load balancers– Use the instrumented data-base periodically to
make new decisions– Many alternative strategies can use the database
• Centralized vs distributed• Greedy improvements vs complete reassignments• Taking communication into account
Feb 13th, 2009

Abhinav S Bhatele 8
NAMD
Feb 13th, 2009
• NAnoscale Molecular Dynamics• Simulates the life of bio-molecules• Simulation window broken down into a large
number of time steps (typically 1 fs each)• Forces on each atom calculated every step• Positions and velocities updated and atoms
migrated to their new positions
Abhinav S Bhatele 9
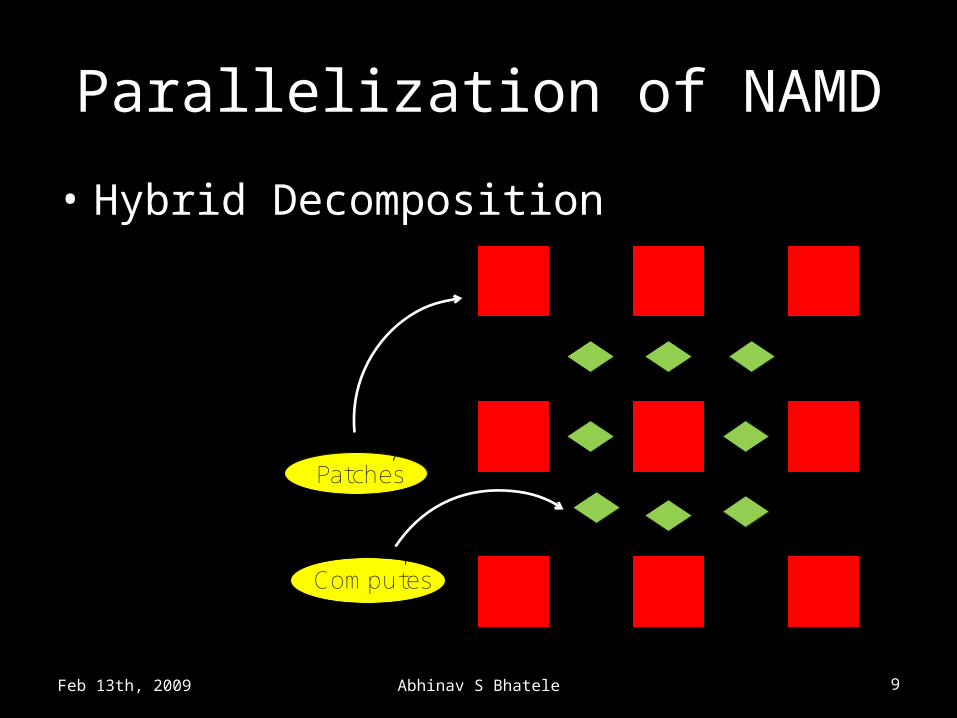
Parallelization of NAMD
• Hybrid Decomposition
Feb 13th, 2009
Patches
Computes

Abhinav S Bhatele 10
Control Flow
Feb 13th, 2009
BondedComputes
Non- bondedComputes
Patch Integration
Patch Integration
Reductions
MulticastPoint to Point
Point to Point
PME

Abhinav S Bhatele 11Feb 13th, 2009
Non-bonded Work
Bonded Work Integration
PME
Communication
BondedComputes
Non- bondedComputes
Patch Integration
Patch Integration
Reductions
MulticastPoint to Point
Point to Point
PME

Abhinav S Bhatele 12
Optimizations on MareNostrum
• Fixes to the CVS version– Crash due to a xlc compiler bug
• Performance analysis– Using Projections performance analysis tool
• Performance tuning– Configuration parameters for NAMD to enable
high parallelization
Feb 13th, 2009

Abhinav S Bhatele 13
Performance Tuning
• Increasing the number of objects– twoAway{X, Y, Z} options
• Choice of PME implementation– Slab (1D) vs. Pencil (2D) decomposition
• Offloading processors doing PME • Use of spanning tree for communication
Feb 13th, 2009

Abhinav S Bhatele 14
DD on MareNostrum
4 8 16 32 64 128 256 512 10240
10
20
30
40
50
60
NAMD CVS OptNAMD CVSNAMD Aug 19
No. of cores
Perf
orm
ance
(ns/
day)
Feb 13th, 2009

Abhinav S Bhatele 15
DD with Slab PME
Feb 13th, 2009
Abhinav S Bhatele 16
DD with Pencil PME
Feb 13th, 2009

Abhinav S Bhatele 17
Problem?
Feb 13th, 2009
1.2 ms

Abhinav S Bhatele 18Feb 13th, 2009
Abhinav S Bhatele 19
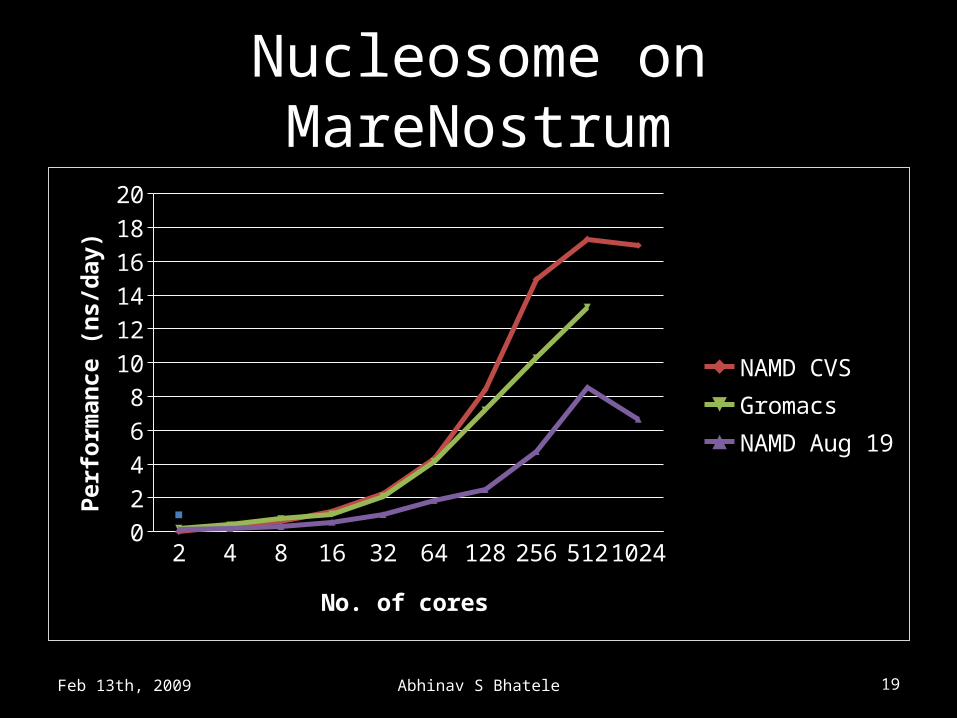
Nucleosome on MareNostrum
2 4 8 16 32 64 128 256 512 102402468
101214161820
NAMD CVSGromacsNAMD Aug 19
No. of cores
Perf
orm
ance
(ns/
day)
Feb 13th, 2009

Abhinav S Bhatele 20
Membrane on MareNostrum
32 64 128 256 512 10240
1
2
3
4
5
6
7
8
9
NAMD CVS OptNAMD CVSNAMD Aug 19Gromacs
No. of cores
Perf
orm
ance
(ns/
day)
Feb 13th, 2009

Abhinav S Bhatele 21
Similar Problem?
Feb 13th, 2009
16 ms
Bandwidth on Myrinet: 250 MB/sExpected Latency for 6-10 KB messages < 0.1 ms

Abhinav S Bhatele 22
Optimizations on the Xe Cluster
• Getting the CVS version running (over mpi)• Trying a development version of charm– Runs directly over Infiniband (ibverbs)– Currently unstable
Feb 13th, 2009

Abhinav S Bhatele 23
DD on Xeon Cluster
2 4 8 16 320
2
4
6
8
10
12
14
NAMD InfinibandNAMD MPINAMD MayDesmond
No. of cores
Perf
orm
ance
(ns/
day)
Feb 13th, 2009

Thank You!