the 10-milion-words spoken dutch corpus and its potential use in experimental phonetics
DESCRIPTION
The 10-milion-words Spoken Dutch Corpus and its potential use in experimental phonetics. Louis C.W. Pols Institute of Phonetic Sciences University of Amsterdam. 100 Years of Experimental Phonetics in Russia St.-Petersburg State Univ., Febr. 1-4, 2001. Amsterdam city center. Herengracht 338. - PowerPoint PPT PresentationTRANSCRIPT

The 10-milion-words Spoken Dutch Corpus and its potential use in experimental phonetics
Louis C.W. Pols
Institute of Phonetic Sciences
University of Amsterdam
100 Years of Experimental Phonetics in RussiaSt.-Petersburg State Univ., Febr. 1-4, 2001
2
Herengracht 338
Amsterdam city center

3
Overview
• Introduction
• Corpus design, recording, digitization
• Orthographic transcription
• Part-of-speech tagging, lemmatization and syntactic annotation
• Phonetic transcription
• Prosodic transcription
• Exploration
• Potential phonetic benefit

4
Introduction
• appropriate topic given long Russian tradition• Dutch-Flemish initiative• 10 Mƒ, 10 M words (about 1000 hrs of speech)• start June 1998, 5 yrs, 7 releases (audio + ann.)• many speaking styles, also over telephone, only
adult speakers, ABN variants but no dialect• for linguistics and speech/language technology• rights with NTU (http://www.taalunie.nl)
5
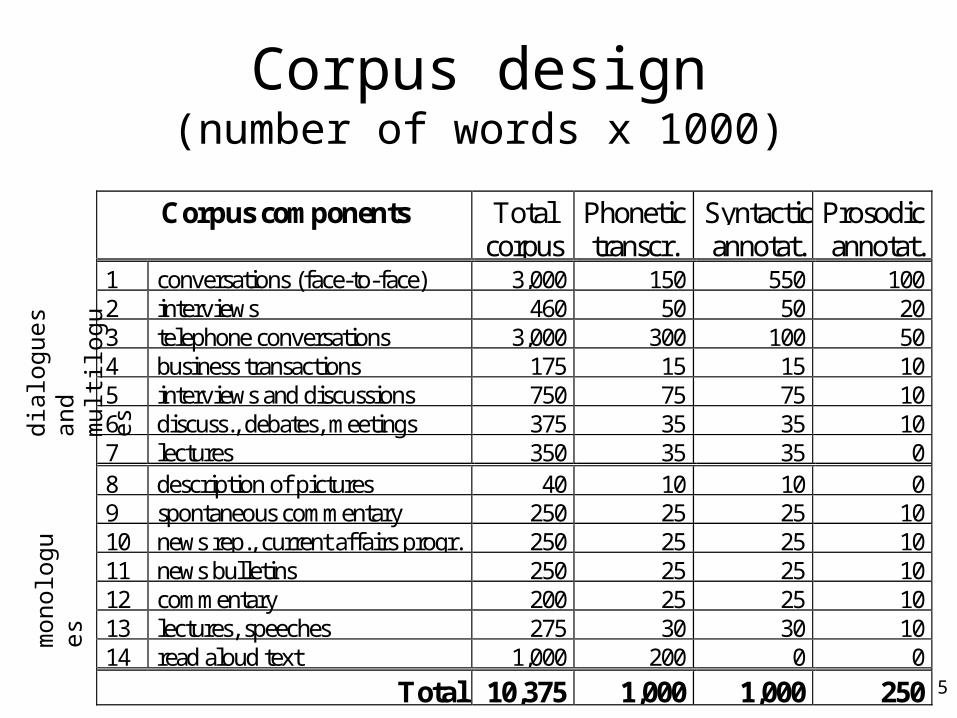
Corpus design(number of words x 1000)
Corpus components Totalcorpus
Phonetictranscr.
Syntacticannotat.
Prosodicannotat.
1 conversations (face-to-face) 3,000 150 550 1002 interviews 460 50 50 203 telephone conversations 3,000 300 100 504 business transactions 175 15 15 105 interviews and discussions 750 75 75 106 discuss., debates, meetings 375 35 35 107 lectures 350 35 35 08 description of pictures 40 10 10 09 spontaneous commentary 250 25 25 1010 news rep., current affairs progr. 250 25 25 1011 news bulletins 250 25 25 1012 commentary 200 25 25 1013 lectures, speeches 275 30 30 1014 read aloud text 1,000 200 0 0
Total 10,375 1,000 1,000 250
dial
ogue
s an
d m
ulti
logu
esm
onol
ogue
s

6
Recording, digitization
• mono or stereo using portable DAT-recorders
• 16 kHz and 16 bit (telephone recordings at 8 kHz and 8 bit)
• .WAV format in PRAAT
• meta data about recording and speaker
• 7 audio releases on CD-ROM, or DVD (future?)
• annotations updated with each release

7
Orthographic transcription (1)
• by trained students, checked by expert
• according to fixed protocol; no text interpretations
• transcr. aligned at few sec. chunks; multiple tiers
• few punctuations; capitals for names only
• standard spelling conventions, checked vs. lexicon
• special mark-up symbols: – *d dialect words; *z regionally accented words– *t interjection; *a truncated wrd; *u mispronunciation– *v foreign words; *n new words; *x hardly intelligible– ggg speaker sounds; xxx unintelligible word(part)(s)
8
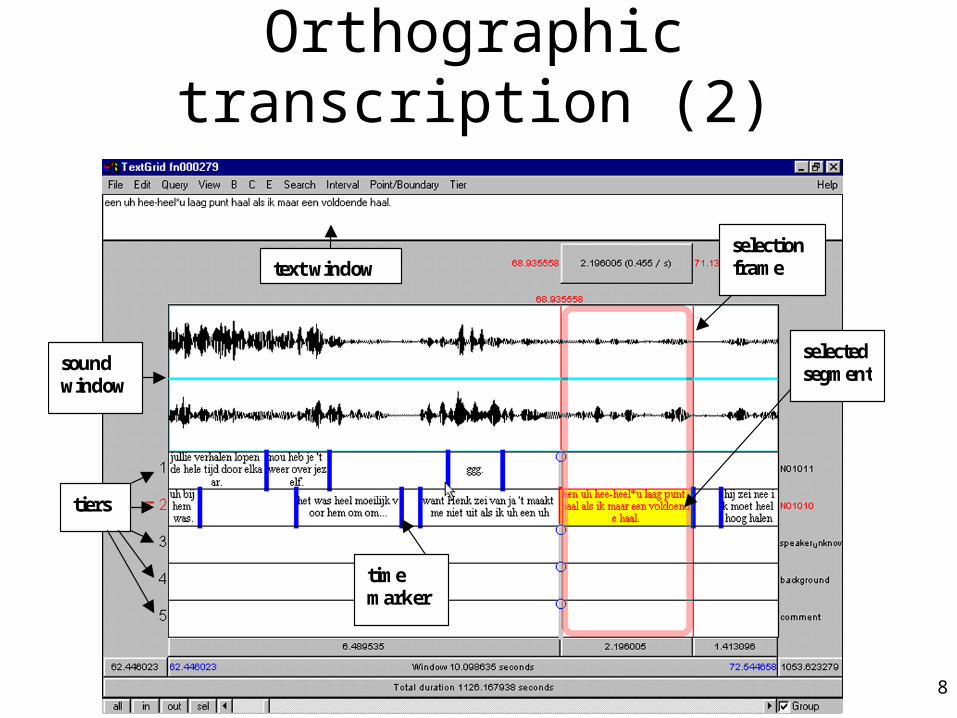
Orthographic transcription (2)
text window
soundwindow
tiers
selectedsegment
timemarker
selectionframe

9
Part-of-speech tagging
• all words in the text automatically tagged
• discontinuous verbs not recognized at this level
• Dutch tag set with 10 major word classes(noun, adjective, verb, pronoun, article, numeral, preposition, adverb, conjunction, and interjection)
• additional morpho-syntactic features per class(e.g., singular, dimunitive and neuter for nouns)
• resulting in some 300 tags
• self-learning automatic tagger (given context)

10
Lemmatization
• all words autom. paired with base form (lemma)• verbs infinitive (gedaan doen) other
forms stem (vijfde vijf) truncated forms full forms (z’n zijn)
• base form must be an independently existing form(hersenen hersen; meisje meis)
• discontinuous verbs and split prepositions are not recognized at this level (op...bellen; van...uit)
• one and only one baseform per word(vliegen verb vliegen, or noun vlieg, depending POS)

11
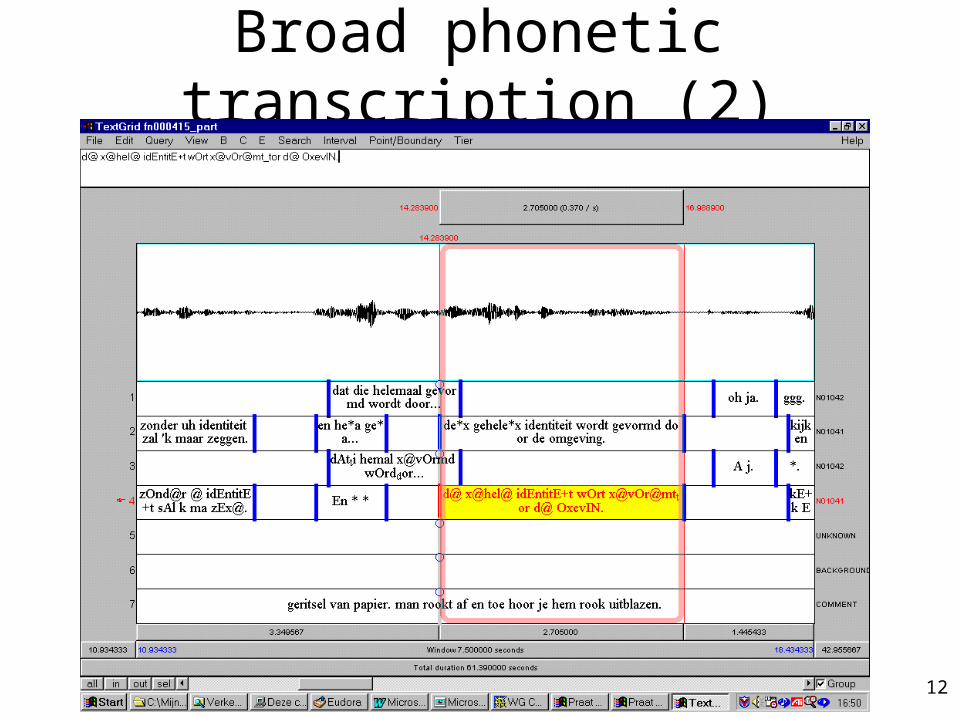
Broad phonetic transcription (1)
• on 10% of the data (mainly dialogues)
• hand correction of automatic phonetic transcription
• across-word assimilation, levels of reduction?
• use of extended SAMPA
• within PRAAT
• word level respecteddie ik wel vind dat ze kloppen di k wEl fInt_tAt s@ klOp@
• no hand segmentation at phoneme level
12
Broad phonetic transcription (2)

13
Signal coupling, word alignment• the phonetically transcribed part (1 M words) will
be automatically aligned at word level• using ASR techniques (forced alignment)• this word alignment will be hand corrected
– pauses and noises will also be aligned– geminate plosives are aligned separately, others shared
(komt terug kom t erug; is zeker isseker)– inserted phonemes are shared with neighbouring words
(toen belde n ie naar huis belden nie
• all the rest may be automatically aligned only• few seconds chunks are always accessible

14
Syntactic annotation
• 10% will be semi-automatically annotated
• procedure still under developed
• interactive annotation software from NEGRA project (Saarbrücken) will be used
• taking into account idiosyncracies of speech, such as hesitations, false starts, clause extensions
• functional information (dependency labels)
• category information (in form of node labels)

15
Prosodic annotation
• manually, on 250K words subset only
• procedure still under development
• prosodic markers in orthography
• 1) prosodic boundarieslong silences ()phrase boundaries ()other discontinuities, like (filled) pauses (%)
• 2) prominence (^ before vowel in prominent syllable)
sp. A: n^ee Jan heeft n^egen % medailles z^even medailles.
sp. B: z^even

16
Exploration software
• COREX tool under developed (Max Planck Inst.)
• both locally and internet-based (Java)
• 1) browser
• 2) viewer for orthography and annotations, plus waveform display and audio player (time synchr.)
• 3) search module, also on meta data

17
Potential phonetic benefit• huge database, many speakers/styles,‘real’ speech
• easily accessible via orthography, plus audio
• partly accessible via phonetic transcription
• no segmentation at phoneme level (automatic?)
• automatic segmentation at word level
• after COREX search: own additions possible
• f.i. spectro-temporal analyses via PRAAT scripts
• f.i. svarabhakti vowel, final n-deletion, assimilation
• f.i. vowel reduction, turn-taking behavior, etc.

18
More information
• see references in paper
• see websites mentioned in paper
• second release Oct. 2000
• new releases every half year
• feedback from users group (workshops)• useful for proposed INTAS project
“Spontaneous speech of typologically unrelated languages (Russian, Finnish and Dutch): Comparison of phonetic properties” (De Silva, 2000)