text mining for biomedicine: techniques & tools
TRANSCRIPT

Text Mining for Biomedicine: Techniques & tools
Sophia Ananiadou
School of Computer ScienceNational Centre for Text Mining

Outline
•
Challenges / objectives of TM in biomedicine•
Terminology processing –
Term extraction, term variation, named entity recognition
•
Resources for TM in biomedicine•
Information Extraction approaches
•
Biological Annotation and Event Recognition•
Biomedical text mining services and systems @ NaCTeM –
TerMine, AcroMine, FACTA–
Medie, InfoPubMed, KLEIO, PathText

Material
•
Further background on TM for BiologyAnaniadou, S. & McNaught, J. (eds) (2006) Text Mining for Biology and Biomedicine. Boston, MA: Artech
House
•
Numerous papers on line from bibliography•
See BLIMP http://blimp.cs.queensu.ca/–
Biomedical Literature (and text) mining publications

Text Mining in biomedicine
•
Why biomedicine?– Consider just MEDLINE: 17,000,000 references,
40,000 added per month–
Dynamic nature of the domain: new terms (genes, proteins, chemical compounds, drugs) constantly created
–
Impossible to manage such an information overload

Text mining aims
•
Extract and discover knowledge hidden in text•
Aid domain experts by automatically:– identifying concepts– extracting facts/relations – discovering implicit links– generating hypotheses (based on integration of
heterogeneous knowledge sources)

Need for text mining•
Increased availability of full text –
Information overload
–
Information retrieval insufficient solution•
Bio-databases, controlled vocabularies and bio-
ontologies
encode only small fraction of information
•
Most information is in textual form –
unstructured data
•
Automated aids are needed

FromFrom
TextText
toto
KnowledgeKnowledge: : tackling the data deluge through text miningtackling the data deluge through text mining
Unstructured Text(implicit knowledge)
Structured content(explicit knowledge)
Informationextraction
Semanticmetadata
Knowledge Discovery
InformationRetrieval
AdvancedInformation
Retrieval

Information deluge
•
Bio-databases, controlled vocabularies and bio- ontologies
encode only small fraction of
information•
Linking
text to databases and ontologies
–
Curators struggling to process scientific literature–
Discovery of facts and events crucial for gaining insights in biosciences: need for text mining
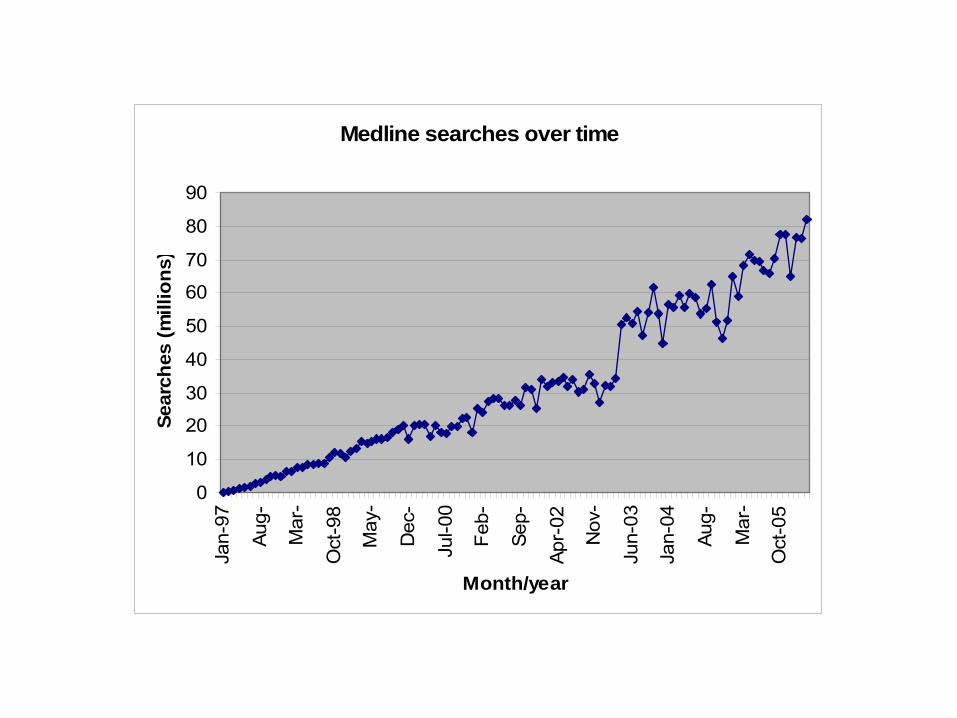
Medline searches over time
0
10
20
30
40
50
60
70
80
90Ja
n-97
Aug-
Mar
-
Oct
-98
May
-
Dec
-
Jul-0
0
Feb-
Sep-
Apr-
02
Nov
-
Jun-
03
Jan-
04
Aug-
Mar
-
Oct
-05
Month/year
Sear
ches
(mill
ions
)

A solution: Text Mining www.nactem.ac.uk
•
Location: Manchester Interdisciplinary Biocentre
(MIB) www.mib.ac.uk
•
First publicly funded text mining centre in the world..
•
Focus: biology, medicine, social sciences…

We don’t just press a button…•
TM involves–
Many components (converters, analysers, miners, visualisers, ...)
–
Many resources (grammars, ontologies, lexicons, terminologies, thesauri, CVs)
–
Many combinations of components and resources for different applications
–
Many different user requirements and scenarios, training needs
•
The best solutions are customised

What NaCTeM is building:
•
Resources: ontologies, lexicons, terminologies, thesauri, grammars, annotated corpora–
BOOTStrep project http://www.nactem.ac.uk/bootstrep.php
•
Tools: tokenisers, taggers, chunkers, parsers, NE recognisers, semantic analysers
•
NaCTeM is also providing services•
Our related bio-text mining projects–
REFINE Representing Evidence For Interacting Network Elements –
ONDEX (data integration, workflows, text mining)–
PathText
(from text to pathways)

Individual tools for user data•
Splitters, taggers, chunkers, parsers, NER, term extractors
•
Modes of useDemonstrators: for small-scale online useBatch mode: upload data, get email with link to download site when job doneWeb Services
•
Some services are compositions of tools

Aims
•
Text mining: discover & extract unstructured knowledge hidden in text–
Hearst (1999)
•
Text mining aids to construct hypotheses
from associations derived from text
– protein-protein interactions –associations of genes –
phenotypes
–functional relationships among genes

Impact of text mining
•
Extraction of named entities (genes, proteins, metabolites, etc)
•
Discovery of concepts allows semantic annotation
of documents
–
Improves information access by going beyond index terms, enabling semantic querying
•
Construction of concept networks
from text–
Allows clustering, classification of documents
–
Visualisation of concept maps

Impact of TM
•
Extraction of relationships (events and facts) for knowledge discovery–
Information extraction, more sophisticated annotation of texts (event annotation)
–
Beyond named entities: facts, events–
Enables even more advanced semantic querying

Hypothesis generation from literature
•
Swanson experiments (1986) influenced conceptual biology–
rapid ‘mining’
of candidate hypotheses from the literature –
migraine and magnesium deficiency (Swanson, 1988)–
indomethacin and Alzheimer’s disease (Swanson and Smalheiser 1994),
–
Curcuma longa and retinal diseases, Crohn's disease and disorders related to the spinal cord (Srinivasan and Libbus 2004).
–
(Weeber M, Rein et al. 2003) thalidomide for treating a series of diseases such as acute pancreatitis, chronic hepatitis C.

Text mining steps
•
Information Retrieval
yields all relevant texts–
Gathers, selects, filters documents that may prove useful–
Finds what is known
•
Information Extraction
extracts facts & events of interest to user–
Finds relevant concepts, facts about concepts
–
Finds only what we are looking for
•
Data Mining
discovers unsuspected associations–
Combines & links facts and events–
Discovers new knowledge, finds new associations

Structured Knowledge
FromFrom
TextText
toto
KnowledgeKnowledge: : NLP and NLP and KnowledgeKnowledge
ExtractionExtraction
Lexicons and ontologies
Knowledge Extraction
Tools
TextAnnotation Tools

Challenge: the resource bottleneck
•
Lack of large-scale, richly annotated corpora–
Support training of ML algorithms
–
Development of computational grammars–
Evaluation of text mining components
•
Lack of knowledge resources: lexica, terminologies, ontologies.

Text semantic annotation
•
annotation of events
and involved named entities–
Example: “Regulation of Transcription events”
–
BOOTSTrep project http://www.nactem.ac.uk/bootstrep.php
•
two different types of annotation levels •
linguistic annotation levels
•
biological annotation level, in charge of marking the biological knowledge contained in the text
•
Linking text with biological knowledge

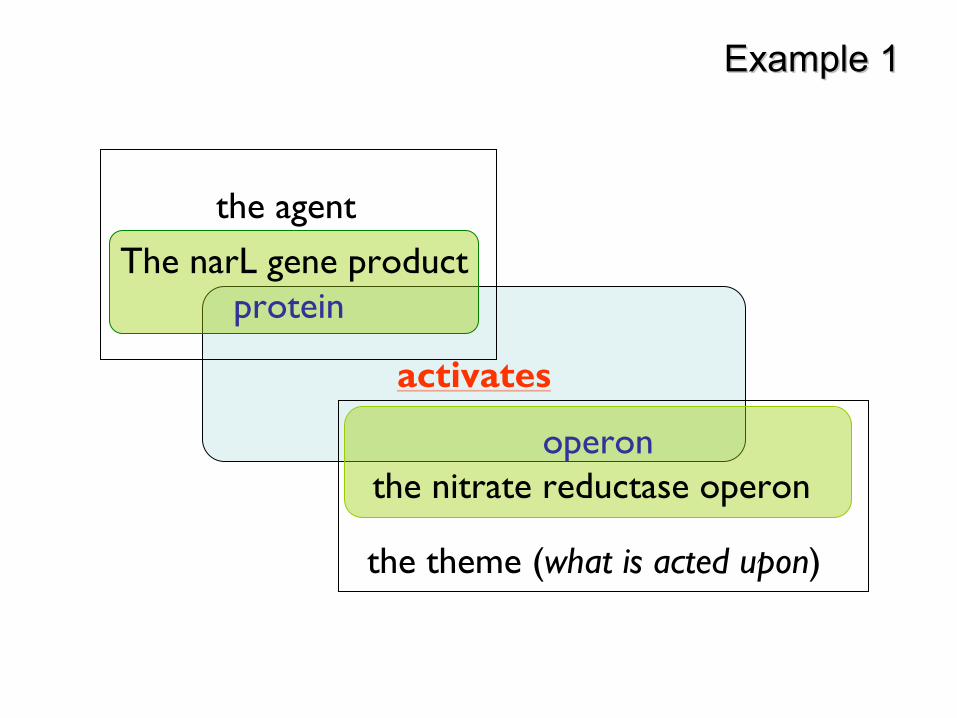
Events and variablesEvents and variables
•
Biological events can be centred on:–
verbs, e.g. activate, –
nouns with verb-like meanings (nominalised verbs), e.g. transcription
•
Different parts of sentence correspond to different types of variables in the event e.g.–
What caused event •
The narL gene product activates the nitrate reductase
operon–
What was affected by event•
Analysis of mutants …–
Where event took place•
These fusions were formed on plasmid cloning vectors
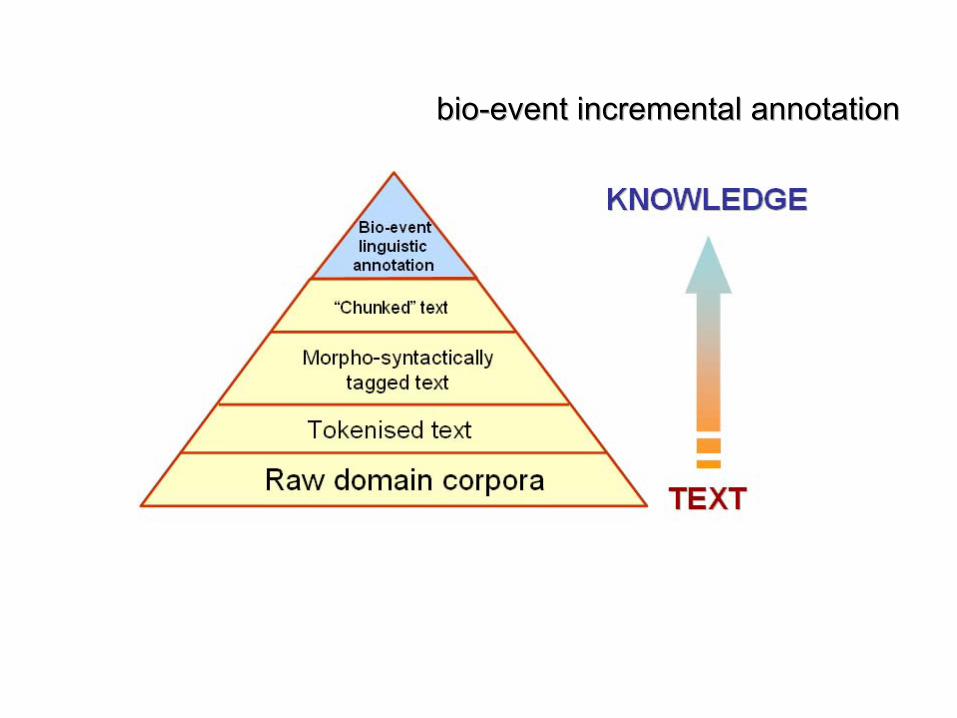
biobio--event incremental annotationevent incremental annotation
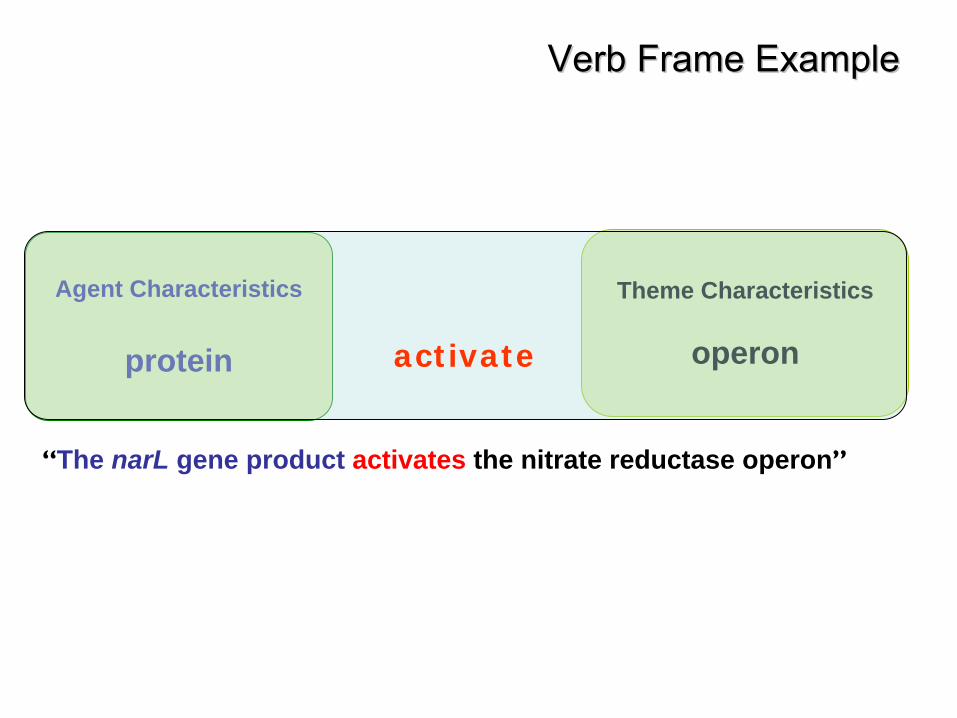
“The narL gene product activates the nitrate reductase operon”
Theme Characteristics
operon
Verb Frame ExampleVerb Frame Example
Agent Characteristics
protein activate

Role Name Description Phrase Type(s) Clues
AGENT Drives or instigates event
Entity or event Typically subject of verb,Follows by in passives
The narL gene product activates the nitrate reductase
operon
THEME Affected by or results from event
Entity or event Typically object of verb, subject in passives
recA protein was induced by UV radiation
MANNER Method or way in which event is carried out
Event (process),adverb, direction, in vitro, in vivo etc
by, through, via, using
cpxA
gene increases the levels of csgA
transcription by dephosphorylation of CpxR

Role Name Description Phrase Type(s) CluesINSTRUMENT Used to carry out
event Entity with,with the aid of,
via, by, through, using
EnvZ functions through OmpR to control porin gene expression in Escherichia coli K-12
LOCATION Location of event Entity in, on, near, etc
Phosphorylation
of OmpR
by the osmosensor
EnvZ
modulates expression of the ompF
and ompC
genes in Escherichia coliSOURCE Start point of event Entity fromA transducing
lambda phage carrying glpD''lacZ, glpR, and malT
was isolated from a strain harbouring
a glpD''lacZ
fusion
DESTINATION End point of event Entity to, into
Transcription of gntT
is activated by binding of the cyclic AMP (cAMP)-cAMP
receptor protein (CRP) complex to a CRP binding site

Role Name Description Phrase Type(s) Clues
TEMPORAL Situates event in time or with respect to another event
Normally an event or time interval
during, before or after
The Alp protease activity is detected in cells after introduction of plasmids carrying the alpA
gene
DESCRIPTIVE Descriptive information about other entity
Entity as
It is likely that HyfR
acts as a formate-dependent regulator of the hyf
operon
CONDITION Environmental conditions or changes in conditions
Entity, event or adverb
in the presence of, in response to.
Strains carrying a mutation in the crp
structural gene fail to repress ODC and ADC activities in response to increased cAMP
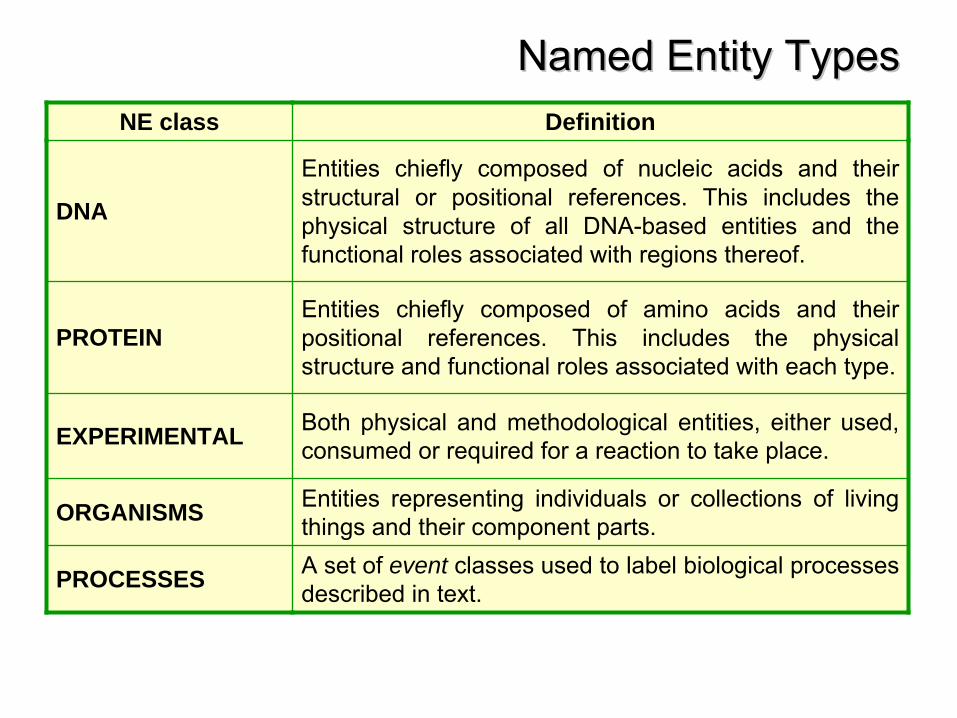
Named Entity TypesNamed Entity TypesNE class Definition
DNA
Entities chiefly composed of nucleic acids and their structural or positional references. This includes the physical structure of all DNA-based entities and the functional roles associated with regions thereof.
PROTEINEntities chiefly composed of amino acids and their positional references. This includes the physical structure and functional roles associated with each type.
EXPERIMENTAL Both physical and methodological entities, either used, consumed or required for a reaction to take place.
ORGANISMS Entities representing individuals or collections of living things and their component parts.
PROCESSES A set of event classes used to label biological processes described in text.
activates
Example 1Example 1
operonthe nitrate reductase
operon
The narL
gene productprotein
the agent
the theme (what is acted upon)

Linguistically Annotated Corpora
•
GENIA–
Domain•
Mesh term: Human, Blood Cells, and Transcription Factors. –
Annotation: POS, named entity, parse tree•
Penn BioIE–
Domain •
the molecular genetics of oncology•
the inhibition of enzymes of the CYP450 class. –
Annotation: POS, named entity, parse tree•
Yapex
•
GENETAG
a corpus of 20K MEDLINE®
sentences for gene/protein NER

Annotation of GENIA corpus –
Term&POS
Term (entity) annotation 2000+400 abstracts
Term (entity) annotation 2000+400 abstracts
Part-of-speech annotation
2,000 abstracts
Part-of-speech annotation
2,000 abstracts

The GENIA annotation
•
Linguistic annotation–
Reveals linguistic structures behind the text•
Part-of-speech annotation–
annotates for the syntactic category of each word.•
Syntactic Tree annotation–
annotates for the syntactic structure of sentences.
•
Semantic annotation–
Reveals knowledge pieces delivered by the text.•
Term annotation–
annotates domain-specific terms•
Event annotation–
annotates events on biological entities.Ontology-driven
annotation

Annotation ToolAnnotation Tool
•
WordFreak http://wordfreak.sourceforge.net/•
Java-based linguistic annotation tool developed at University of Pennsylvania
•
Extensible to new tasks and domains•
Customised visualisation and annotation specification–
Allows annotation process to be made as simple as possible

WordFreakWordFreak
ToolTool

Resources

What about existing resources?
•
Ontologies
important for knowledge discovery–
They form the link between terms in texts and biological databases
–
Can be used to add meaning, semantic annotation of texts
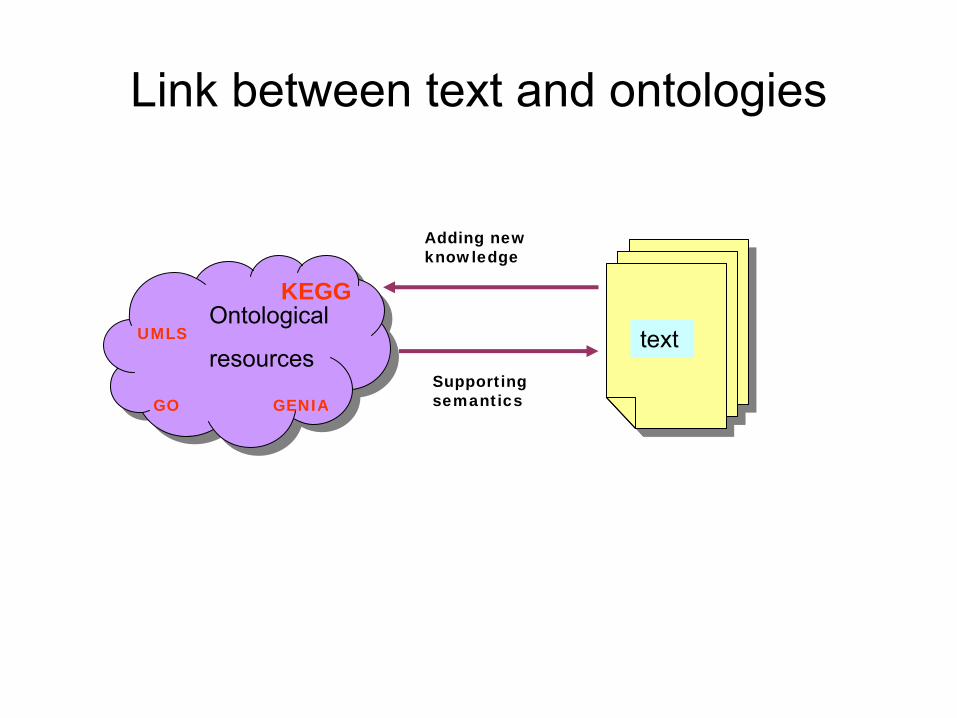
Link between text and ontologies
Ontological
resourcestext
GO
UMLS
GENIASupporting semantics
Adding new knowledge
KEGG

Ontological
resourcestext
GO
UMLS
GENIASupporting semantics
Adding new knowledge
KEGG
Databases
SemanticInterpretation of data
Mathematical Models
SemanticInterpretation of models in Systems Biology
Bridging the Gap– Integrating data, text and knowledge

Resources for Bio-Text Mining
•
Lexical / terminological resources–
SPECIALIST lexicon, Metathesaurus
(UMLS)
–
Lists of terms / lexical entries (hierarchical relations)•
Ontological resources–
Metathesaurus, Semantic Network, GO, SNOMED CT, etc
–
Encode relations among entitiesBodenreider, O. “Lexical, Terminological, and Ontological Resources for Biological Text Mining”, Chapter 3, Text Mining for Biology and Biomedicine, pp.43-66

SPECIALIST lexicon
–
UMLS specialist lexicon http://SPECIALIST.nlm.nih.gov
•
Each lexical entry contains morphological (e.g. cauterize, cauterizes, cauterized, cauterizing), syntactic (e.g. complementation patterns for verbs, nouns, adjectives), orthographic information (e.g. esophagus – oesophagus)
•
General language lexicon with many biomedical terms (over 180,000 records)
•
Lexical programs include variation (spelling), base form, inflection, acronyms

Lexicon record
{base=Kaposi's sarcomaspelling_variant=Kaposi sarcoma entry=E0003576cat=nounvariants=uncountvariants=regvariants=glreg}
Kaposi’s sarcoma
Kaposi’s sarcomas
Kaposi’s sarcomata
Kaposi sarcoma
Kaposi sarcomas
Kaposi sarcomata
The SPECIALIST Lexicon and Lexical Tools Allen C. Browne, Guy Divita, and Chris Lu PhD 2002 NLM Associates Presentation, 12/03/2002, Bethesda, MD

Normalisation (lexical tools)
Hodgkin DiseaseHODGKIN DISEASEHodgkin’s DiseaseHodgkin’s diseaseDisease, Hodgkin ...
disease hodgkinnormalise

Steps of Norm Remove genitive
Hodgkin’s DiseasesReplace punctuation with spaces
Hodgkin DiseasesRemove stop words
Hodgkin DiseasesLowercase
hodgkin
diseasesUninflect
each wordhodgkin
diseaseWord order sort
disease hodgkin
Lexical tools of the UMLS http://lexsrv3.nlm.nih.gov/SPECIALIST/index.html

The Gene Ontology (GO)
• Controlled vocabulary for the annotation of gene products
http://www.geneontology.org/19,468 terms. 95.3% with definitions
10391 biological_process1681 cellular_component
7396 molecular_function

Gene Ontology
•
GOA database (http://www.ebi.ac.uk/GOA/) assigns gene products to the Gene Ontology
•
GO terms follow certain conventions of creation, have synonyms such as:–
ornithine cycle is an exact synonym of urea cycle
–
cell division is a broad synonym of cytokinesis–
cytochrome bc1 complex is a related synonym of ubiquinol-cytochrome-c reductase activity

GO terms, definitions and ontologies in OBO
id: GO:0000002 name: mitochondrial genome maintenance namespace: biological_processdef: "The maintenance of the structure and integrity of the
mitochondrial genome.“
[GOC:ai] is_a: GO:0007005 ! mitochondrion organization and biogenesis

Metathesaurus
•
organised by concept–
5M names, 1M concepts, 16M relations
•
built from 134 electronic versions of many different thesauri, classifications, code sets, and lists of controlled terms
•
"source vocabularies“•
common representation

Are the existing knowledge resources sufficient for TM?
No!Why?
Limited lexical & terminological coverage of biological sub-domainsResources focused on human specialists
GO, UMLS, UniProt
ontology concept names frequently confused with terms

Naming conventions
3.
Update and curation
of resources–
FlyBase
gene name coverage 31% (abstracts) to
84% (full texts)
4.
Naming conventions and representation in heterogeneous resources
–
Term formation guidelines from formal bodies e.g. HUGO, IPI not uniformly used
–
Problems with integration of resourcesdystrophin used for 18 gene products “Dystrophin (muscular dystrophy, Duchenne and Becker
types), included DXS143, DXS164, DXS206, …” HUGO

Term variation
5.
Terminological variation and complexity of names–
High correlation between degree of term variation and dynamic nature of biomedicine
–
Variation occurs in controlled vocabularies and texts but discrepancy between the two
–
Exact match methods fail to associate term occurrences in texts with databases

What’s in a name?
Terms, named entities in biology

What’s in a name?
•
Breast cancer 1 (BRCA1)•
p53
•
Ribosomal protein S27•
Heat shock protein 110
•
Mitogen
activated protein kinase
15•
Mitogen
activated protein kinase
kinase
kinase
5
From K. Cohen, NAACL 2007

Worst gene names
•
sema
domain, seven thrombospondin
repeats (type 1 and type 1-like), transmembrane
domain
(TM) and short cytoplasmic
domain, (semaphorin) 5A
K. Cohen NAACL 2007

Worst gene names
•
sema
domain, seven thrombospondin
repeats (type 1 and type 1-like), transmembrane
domain
(TM) and short cytoplasmic
domain, (semaphorin) 5A
K. Cohen NAACL 2007

Worst gene names
•
sema
domain, seven thrombospondin
repeats (type 1 and type 1-like), transmembrane
domain
(TM) and short cytoplasmic
domain, (semaphorin) 5A
•
SEMA5A
K. Cohen NAACL 2007

Worst gene names
•
sema
domain, seven thrombospondin
repeats (type 1 and type 1-like), transmembrane
domain (TM) and short
cytoplasmic
domain, (semaphorin) 5A •
SEMA5A
•
Tyrosine kinase with immunoglobulin and epidermal growth factor homology domains
•
tie
K. Cohen NAACL 2007

Term ambiguity
Neurofibromatosis 2
[disease]
NF2 Neurofibromin
2 [protein]
Neurofibromatosis 2 gene [gene]
O. Bodenreider, MIE 2005 tutorial
http://www.nactem.ac.uk/

Term ambiguity
–
Gene terms may be also common English words•
BAD human gene encoding BCL-2 family of proteins (bad news, bad prediction)
–
Gene names are often used to denote gene products (proteins)
•
suppressor of sable is used ambiguously to refer to either genes
and proteins
–
Existing resources lack information that can support term disambiguation
–
Difficult to establish equivalences between termforms and concepts

Homologues
•
Cycline-dependent kinase
inhibitor
first introduced to represent a protein family p27–
But it is used interchangeably with p27
or p27kip1, as
the name of the individual protein
and not as the name of the protein family (Morgan 2003).
•
NFKB2
denotes the name of a family of 2 individual proteins with separate IDs in Swiss-
Prot. –
These proteins are homologues belonging to different species, homo sapiens & chicken.

Terms
–
Term: linguistic realisation of specialised concepts, e.g. genes, proteins, diseases
–
Terminology: collection of terms structured (hierarchy) denoting relationships among concepts, part-whole, is-a, specific, generic, etc.
–
Terms link text and ontologies–
Mapping is not trivial (main challenge)

Term variation and ambiguity
Term1 Term2
Term3 TEXT
Term1 Term2
Term3 TEXT
Concept1 concept2
concept3 ONTOLOGY
Concept1 concept2
concept3 ONTOLOGY
Term ambiguity
Term variation

Term mining steps
Term recognition
Term classification
Term mapping
Tp53
Gene
Genome Database,
IARC TP53 Mutation Database

Term recognition techniques
•
ATR
extracts terms (variants) from a collection of document
•
Distinguishes terms vs
non-terms•
In NER
the steps of recognition and
classification
are merged, a classified terminological instance is a named entity
•
The tasks of ATR and NER share techniques but their ultimate goals are different–
ATR for resource building, lexica & ontologies
–
NER first step of IE, text mining

Overview papers
1. S. Ananiadou & G. Nenadic (2006) Automatic Terminology Management in Biomedicine, Text Mining for Biology and Biomedicine, pp. 67- 97.
2. M. Krauthammer & G. Nenadic (2004) Term identification in the biomedical literature, JBI 37 (2004) 512-526
3. J.C. Park & J. Kim (2006) Named Entity Recognition, Text Mining for Biology and Biomedicine, pp. 121-142
Detailed bibliography in Bio-Text Mining 1. BLIMPhttp://blimp.cs.queensu.ca/2. http://www.ccs.neu.edu/home/futrelle/bionlp/Book on BioText Mining1. S. Ananiadou & J. McNaught (eds) (2006) Text Mining for Biology and
Biomedicine, Artech House.
Other Bio-Text Mining tutorialsKevin Cohen (NAACL 2007 tutorial) U. Colorado
Main ATR approaches
ATR
Dictionary based
Rule based
Machine learning

Dictionary NER (1)
•
Use terminological resources to locate term occurrences in text–
NCBI http://www.ncbi.nlm.nih.gov/
–
EBI http://www.ebi.ac.uk/–
neologisms, variations, ambiguity problematic for simple dictionary look-up
–
Ambiguous words e.g. an, for, can …–
spelling variants, punctuation, word order variations
•
estrogen oestrogen•
NF kappa B / NF kB

Dictionary NER (3)
–
Tsuruoka & Tsujii (2003) suggest a probabilistic generator of spelling variants, edit distance operations (delete, substitute, insert)•
Terms with ED ≤
1 considered spelling
variants•
Used a dictionary of protein terms
–
Support query expansion–
Augment dictionaries with variation
Rule NER (2)
Rule based
PROPER, Fukuda,1998 Yapex, Franzen 2002

Rule based (1)
•
Use orthographic, morpho-syntactic features of terms –
Rules that make use of internal term formation patterns (tagging, morphological analysers) e.g. affixes, combining forms
–
Do not take into account contextual features–
Dictionaries of constituents e.g. affixes, neoclassical forms included
•
Portability to different domains?

Rule-based
•
Fukuda (1998) used lexical, orthographic features for protein name recognition e.g. upper case character, numerals etc.
•
PROPER: core
and feature
elements–
Core: meaning bearing elements–
Feature: function elements
SAP kinasecore feature
Core elements extended to feature based on concatenation rules (based on POS tags)

Rule-based
•
Inspired by PROPER, Yapex
uses Swiss-Prot to add core term elements
http://www.sics.se/humle/projects/prothalt/yapex.cgi•
Hou
(2003) used Yapex
with context information (collocations) appearing with protein names
•
Rule based approaches construct rule and patterns manually or automatically
•
Difficult to tune to different domains

Machine learning systems
•
Learn features from training data for term recognition and classification
•
Most ML systems combine recognition and classification
Challenges–
Feature selection and optimisation
–
Availability of training data –
detection of term boundaries
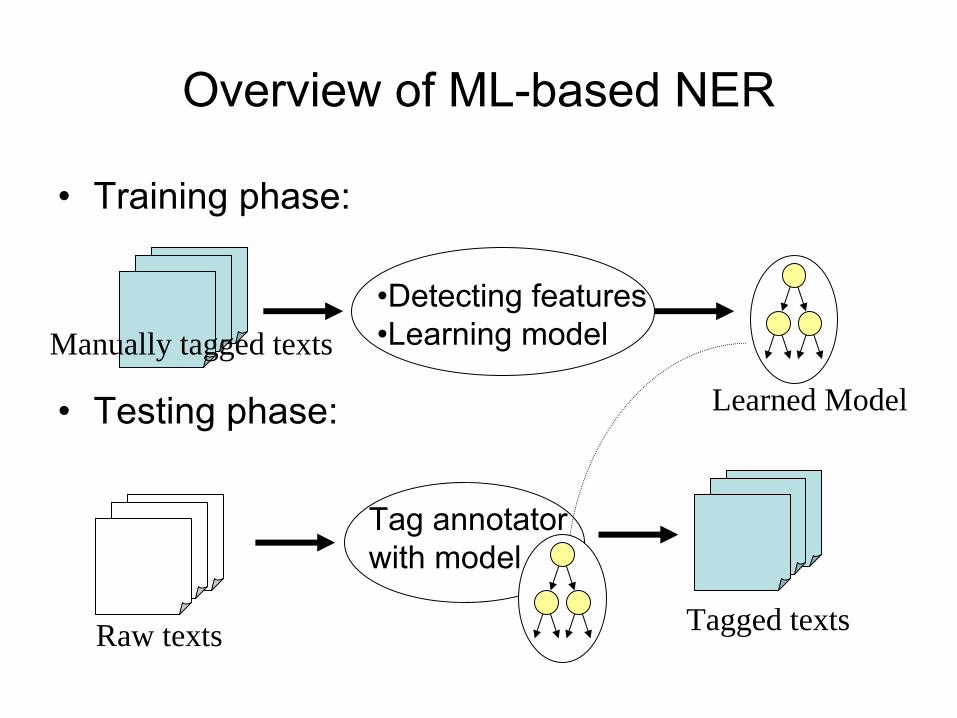
Overview of ML-based NER
•
Training phase:
•
Testing phase:
Manually tagged texts•Detecting features•Learning model
Learned Model
Tagged texts
Tag annotatorwith model
Raw texts

ML (1)
•
Nobata et al.(1999) used Decision Tree for NER•
Decision tree: one of the methods to classify a case using training data–
Node: specifies some condition with a subtree
–
Leaf: indicates a class•
Features:–
Part-of-speech information
–
Orthographic information–
Term lists

Example of a decision tree
Is the current wordin the Protein term list?
YesNo
What is thenext word’s POS?
NounVerb …
Does the previous wordhave figures?
YesNo
PROTEINUnknown RNADNA
Each node has one condition:
Each leaf has one class:
……

ML (2)
•
Collier (2000) used HMM, orthographic features for term recognition–
HMM looks for most likely sequence of classes corresponding to a word sequence e.g. interleukin-2 protein/DNA
–
To find similarities between known words (training set) and unknown words, use character features
Feature ExamplesDigitNumber
[2]protein[3]DNA
GreekLetter
[alpha]proteinTwoCaps
[RelB]protein[TAR]RNA

ML (2)
•
Use of GENIA resources as training data–
Results depend on training data
•
Morgan (2004) used FlyBase
to construct automatically training corpus–
Pattern matching for gene name recognition, noisy corpus annotated
–
HMM was trained on that corpus for gene name recognition

Support Vector Machines (1)
•
Kazama
trained multi-class SVMs
on Genia corpus
•
Corpus annotated with B-I-O tags–
B tags denote words at beginning of term
–
I tags inside term–
O tags outside term
–
B-protein-tag
: word in the beginning of a protein name

SVMs
for NER (2)
•
Yamamoto used a combination of features for protein name recognition:–
Morphological, lexical, boundary, syntactic (head noun), domain specific (if term exists in biomedical database).
•
Lee use different features for recognition and classification.
•
orthographic, prefix, suffix•
Contextual information

81
Challenges of D-NER
1. IL-2-mediated activation of2. IL-2 receptor activates3. IL2-mediated activation of4. Interleukin 2-mediated activation of•
We use a 3-stage strategy:
1.
Use character based tagging which integrates tagging process with dictionary consultation process
2.
Use CRF to treat broader term formation patterns3.
Term normalisation in lexicon which treats all spelling variants
and maps extracted terms to semantic UniProt
ID

82
Dictionary based NER
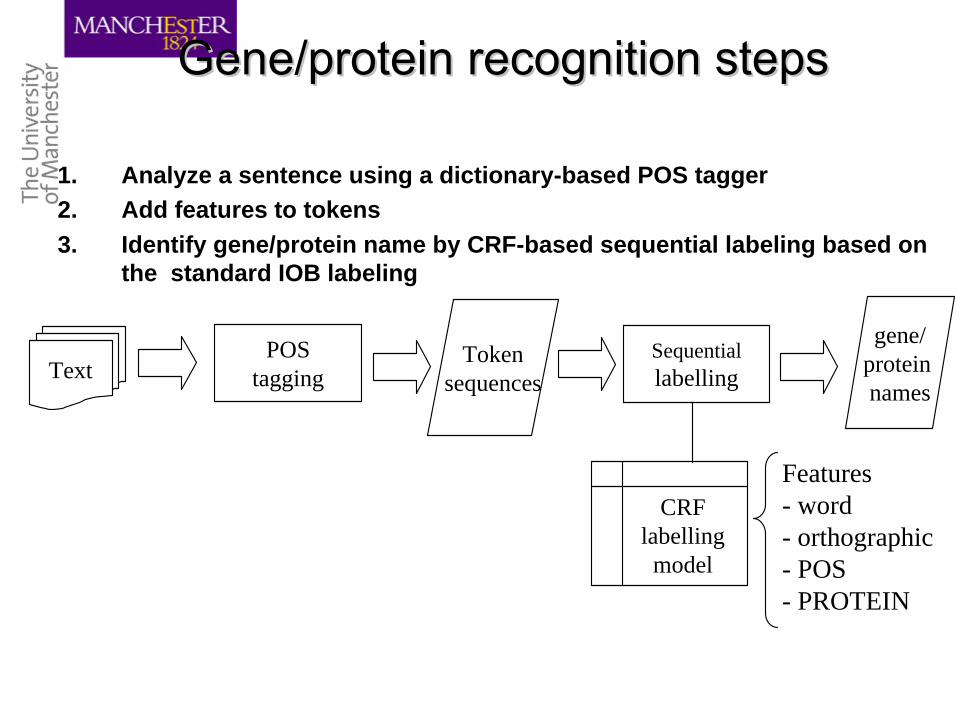
TextPOS
taggingToken
sequencesSequentiallabelling
gene/protein names
CRFlabellingmodel
Features- word- orthographic- POS- PROTEIN
Gene/protein recognition stepsGene/protein recognition steps
1. Analyze a sentence using a dictionary-based POS tagger2. Add features to tokens3. Identify gene/protein name by CRF-based sequential labeling based on
the standard IOB labeling

84
Features used for Features used for CRFsCRFs
•
CRFs
find the best sequence of labels based on–
state feature: features for each token–
edge feature: features between two adjacent tokens•
State (token) feature used–
Word: surface word form of the token–
Orthographic –
POS: the POS of the token–
PROTEIN: whether the token is a known protein name•
Edge feature used–
All combinations of state features of two adjacent tokens

Hybrid approaches
•
Combine rules, statistics, resources
Hybrid ATR / NER
ABGene (Tanabe & Wilbur)
ARBITER (Rindflesch)
C/NC-value (Frantzi & Ananiadou)

Hybrid (1)
•
ABGene: protein and gene name tagger–
Combines ML, transformation rules, dictionaries with statistics
–
Protein tagger trained on MEDLINE abstracts by adapting Brill’s tagger
–
Transformation rules for recognition of gene, protein names
–
Used GO, LocusLink
list of genes, proteins for false negative tags

Hybrid (2)
–
ARBITER (Access and Retrieve Binding Terms) uses •
UMLS Metathesaurus
and GenBank
to
map NPs (binding terms)•
morphological features
•
lexical information (head noun)–
EDGAR recognises gene, cell, drug names using co-occurrences of cell,
clone,
expression

Hybrid (3)
•
C/NC value (Frantzi & Ananiadou, 1999)•
C-value
•
Linguistic filters •
total frequency of occurrence of string in corpus
•
frequency of string as part of longer candidate terms (nested terms)
•
number of these longer candidate terms•
length of string
–
Output: automatically ranked terms (TerMine)

C-value
•
C-
value measure
extracts multi-word, nested terms
[adenoid [cystic [basal [cell carcinoma]]]]cystic basal cell carcinoma
ulcerated basal cell carcinomarecurrent basal cell carcinoma
basal cell carcinoma

Term variation
•
variation recognition as part of ATR (Nenadic, Ananiadou)
•
recognise term forms and link them into equivalence classes
•
important if ATR is based on statistics (e.g. frequency of occurrence)–
corpus-based measures are distributed across different variants
–
conflation of various surface representations of a given term should improve ATR

Simple variation
•
orthographic–
hyphens, slashes (amino acid and amino-acid)
–
lower/upper cases (NF-KB and NF-kb)–
spelling variations (tumour and tumor)
–
transliterations (oestrogen and estrogen)•
morphological–
inflectional phenomena (plural, possessives)
•
lexical–
genuine synonyms (carcinoma and cancer)


Biomedical IE/IR Systems
•
iHOP–
http://www.ihop-net.org/UniPub/iHOP/•
EBIMed–
http://www.ebi.ac.uk/Rebholz-srv/ebimed/index.jsp•
GoPubMed–
http://www.gopubmed.org/•
PubFinder–
http://www.glycosciences.de/tools/PubFinder•
Textpresso–
http://www.textpresso.org/

Acronyms
•
Very productive type of term variation •
Acronym variation (synonymy)–
NF kappa B/ NF kB
/ nuclear factor kappa B
•
Acronym ambiguity (polysemy) even in controlled vocabularies
GR glucocorticoid
receptorglutathione reductase

Acronym recognition
•
Swartz, A. & Hearst, M. (2003) A simple algorithm for identifying abbreviation definitions in biomedical text, PSB 2003,8, 451-462
•
Adar, E. (2004) SaRAD: a simple and robust abbreviation dictionary, Bioinformatics, 20(4) 527-533
•
Chang, J.T. & Schutze, H. (2006) Abbreviations in biomedical text, Text Mining for Biology and Biomedicine, pp.99-119, Artech
•
Tsuruoka, Y., Ananiadou, S. & Tsujii, J. (2005) A Machine learning approach to automatic acronym generation, ISMB, BioLink SIG, 25-31
•
Okazaki, N. & S.Ananiadou (2006) Acronym recognition based on term identification, Bioinformatics

The importance of acronym recognition
•
Acronyms are among the most productive type of term variation–
64, 242 new acronyms are introduced in 2004 [Chang and Schütze 06]
•
Acronyms are used more frequently than full terms–
5,477 documents could be retrieved by using the acronym JNK while only 3,773 documents could be retrieved by using its full term, c-jun
N-terminal kinase
[Wren et al. 05]
•
No rules or exact patterns for the creation of acronyms from their full form

Recognition
•
Extracting pairs of short and long forms<acronym, long form>
–
Distinguishing acronyms from parenthetical expressions
–
Search for parentheses in text; single or more words; e.g. Ab (antibody)
–
Limit context around ( ); limit number of words according to number of letters in acronym

Letter matching
–
Alignment: find all matches between letters of acronyms and their long forms and calculate likelihood (Chang & Schütze)
•
Solves problem of acronyms containing letters not occurring in LF
•
Choose best alignment based on features, e.g. position of letter etc.
•
Finding optimal weight for each feature challenge
http://abbreviation.stanford.edu/
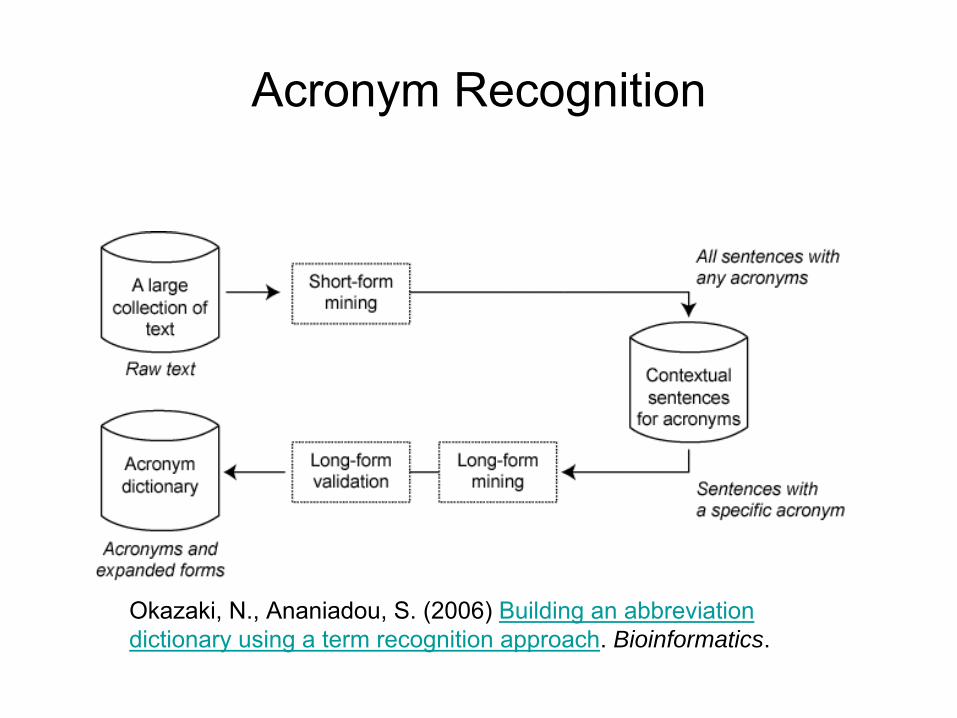
Acronym Recognition
Okazaki, N., Ananiadou, S. (2006) Building an abbreviation dictionary using a term recognition approach. Bioinformatics.

A simple algorithm – Schwartz and Hearst (2003)
•
Uses parenthetical expressions as a marker of a short form
… long-form ‘(‘short-form ‘)’ …•
All letters and digits in a short form must appear in the corresponding long form in the same order
– We used hidden markov model (HMM) to …
– Early repolarization (ER) is an enigma.

Problems of letter-matching approach
•
Highly dependent on the expressions in the target text–
o acquired immuno deficiency syndrome (AIDS)–
x acquired syndrome (AIDS)–
x a patient with human immunodeficiency syndrome (AIDS)–
? magnetic resonance imaging unit (MRI)–
! beta 2 adrenergic receptor (ADRB2)–
! gamma interferon (IFN-GAMMA)(These examples are obtained from actual MEDLINE abstracts)
•
Naive with respect to term variations

AcroMine’s
approach
•
Extract a word or word sequence:–
Co-occurring frequently with an acronym (e.g., TTF-1)• 1, factor 1, transcription factor 1, thyroid transcription
factor 1–
Does not co-occur with other surrounding words• thyroid transcription factor 1
•
Not necessarily based on letter-matching–
Note that this is a difficult case for the letter-matching algorithm•
Prune unlikely candidates–
Nested candidates: transcription factor 1–
Expansions: expression of thyroid transcription factor 1–
Insertions: thyroid specific transcription factor 1

Short-form mining
•
Enumerate all short forms in a target text–
Using parentheses as a clue: … ‘(‘short-form ‘)’ …–
Validation rules for identifying acronyms [Schwartz and Hearst 03]
•
It consists of at most two words•
Its length is between two to ten characters•
It contains at least an alphabetic letter•
The first character is alphanumeric
The present system consists of a hidden Markov model (HMM) based automatic speech recognizer (ASR), with a keyword spotting system to capture the machine sensitive words (registered in a dictionary) from the running utterances.
The contextual sentence of HMM and ASR.
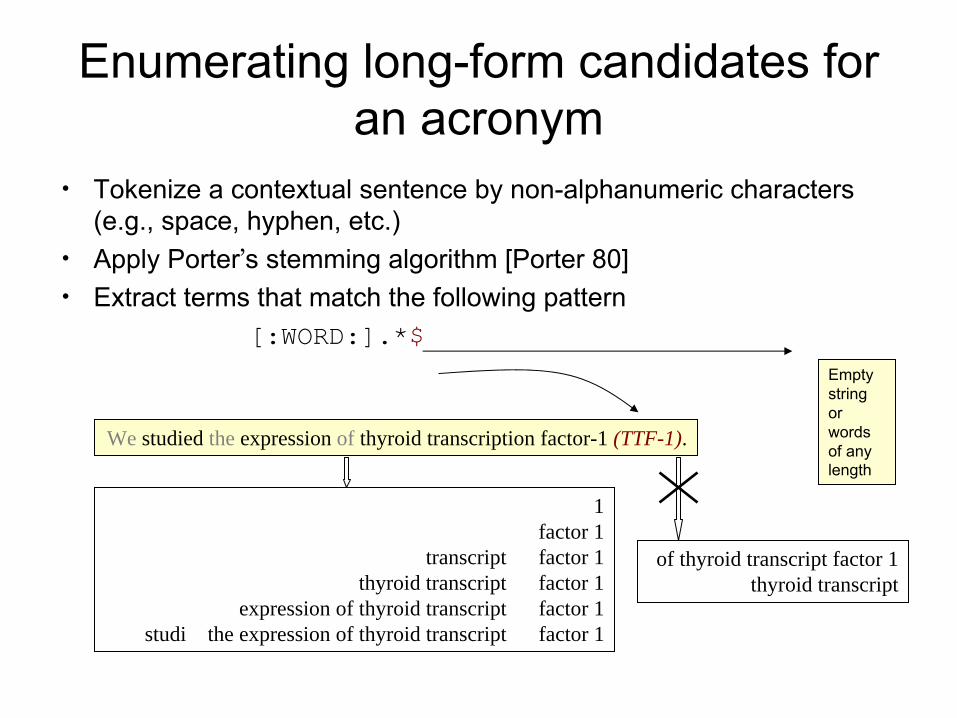
Enumerating long-form candidates for an acronym
•
Tokenize a contextual sentence by non-alphanumeric characters (e.g., space, hyphen, etc.)
•
Apply Porter’s stemming algorithm [Porter 80]•
Extract terms that match the following pattern[:WORD:].*$
We studied the expression of thyroid transcription factor-1 (TTF-1).
1 factor 1
transcript factor 1thyroid transcript factor 1
expression of thyroid transcript factor 1studi the expression of thyroid transcript factor 1
of thyroid transcript factor 1thyroid transcript
Empty string or words of any length

Expansions for TTF-1
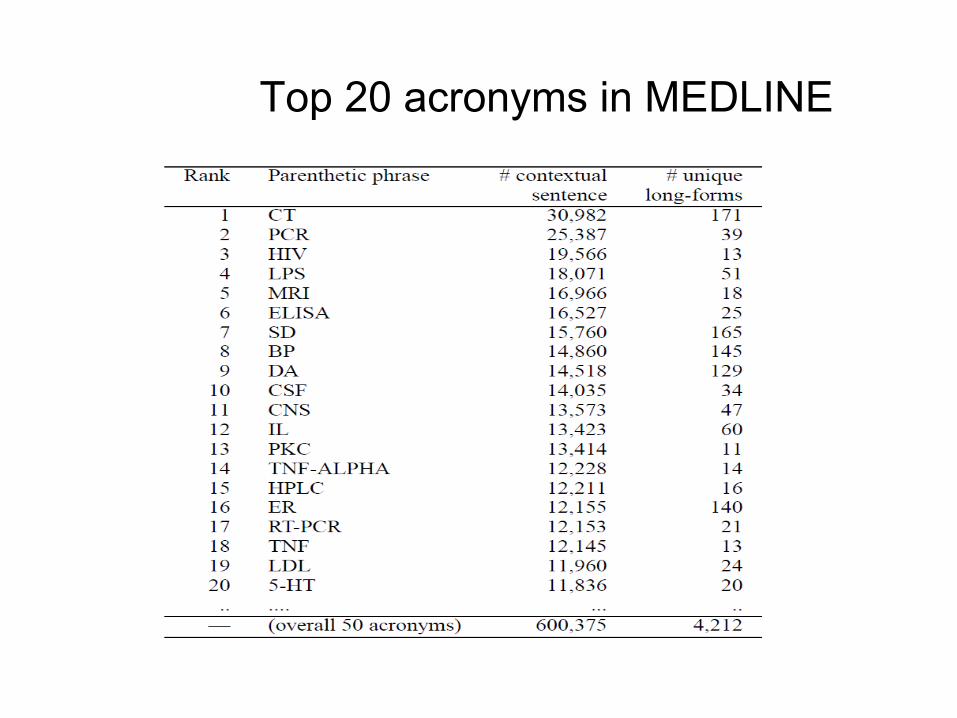
Top 20 acronyms in MEDLINE
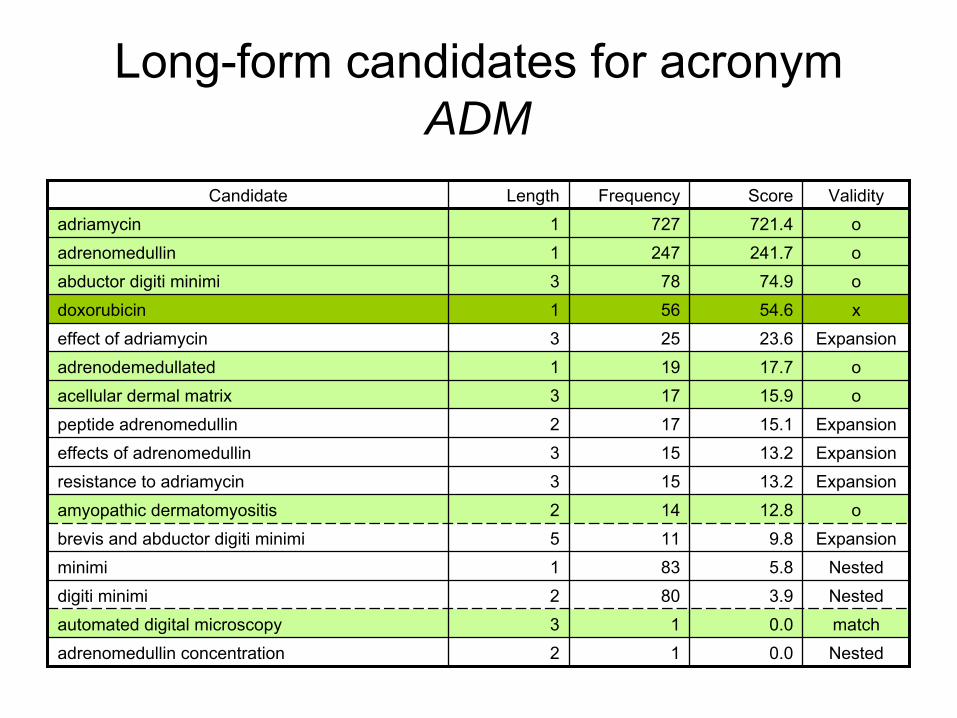
Long-form candidates for acronym ADM
Candidate Length Frequency Score Validityadriamycin 1 727 721.4 oadrenomedullin 1 247 241.7 oabductor digiti
minimi 3 78 74.9 odoxorubicin 1 56 54.6 xeffect of adriamycin 3 25 23.6 Expansionadrenodemedullated 1 19 17.7 oacellular
dermal matrix 3 17 15.9 opeptide adrenomedullin 2 17 15.1 Expansioneffects of adrenomedullin 3 15 13.2 Expansionresistance to adriamycin 3 15 13.2 Expansionamyopathic
dermatomyositis 2 14 12.8 obrevis
and abductor digiti
minimi 5 11 9.8 Expansionminimi 1 83 5.8 Nesteddigiti
minimi 2 80 3.9 Nestedautomated digital microscopy 3 1 0.0 matchadrenomedullin
concentration 2 1 0.0 Nested

Long-form extraction
•
Long-form candidates are sorted with their scores in a descending order
•
A long-form candidate is considered valid if:–
It has a score greater than 2.0
–
The words in the long form can be rearranged so that all alphanumeric letters appear in the same order as the short form
–
It is not nested or expansion of the previously chosen long forms
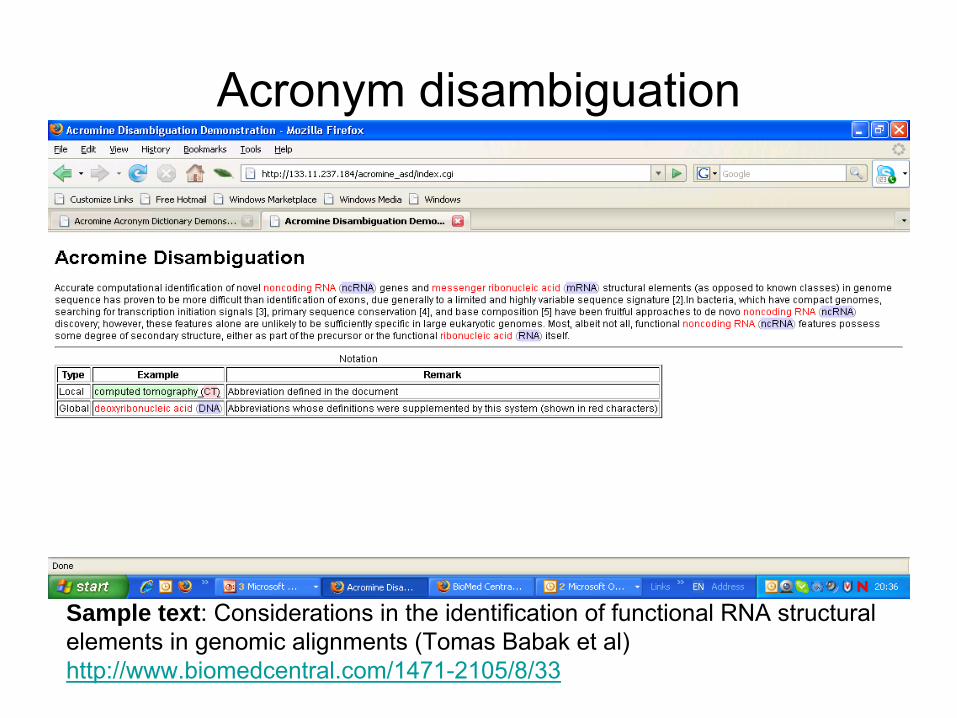
Acronym disambiguation
Sample text: Considerations in the identification of functional RNA structural elements in genomic alignments (Tomas Babak
et al)http://www.biomedcentral.com/1471-2105/8/33

KLEIO
•
Semantically enriched information retrieval system for biology
•
Offers textual and metadata searches across MEDLINE
•
Provides enhanced searching functionality by leveraging terminology management technologies
http://nactem4.mc.man.ac.uk:8080/Kleio

KLEIO architecture

Text mining modules
1.
Acronym recognition and disambiguation2.
Normalisation
of biology terms
3.
Named entity recognition for gene/protein names
4.
Indexing of terms

1. Acronym recognition and disambiguation
•
Recognises
acronyms and their definitions from Medline
•
Disambiguates isolated acronyms using their context
•
Maps acronyms into corresponding definitions
Okazaki, N. and Ananiadou, S. (2006) Building an Abbreviation Dictionary using a Term Recognition Approach, in Bioinformatics
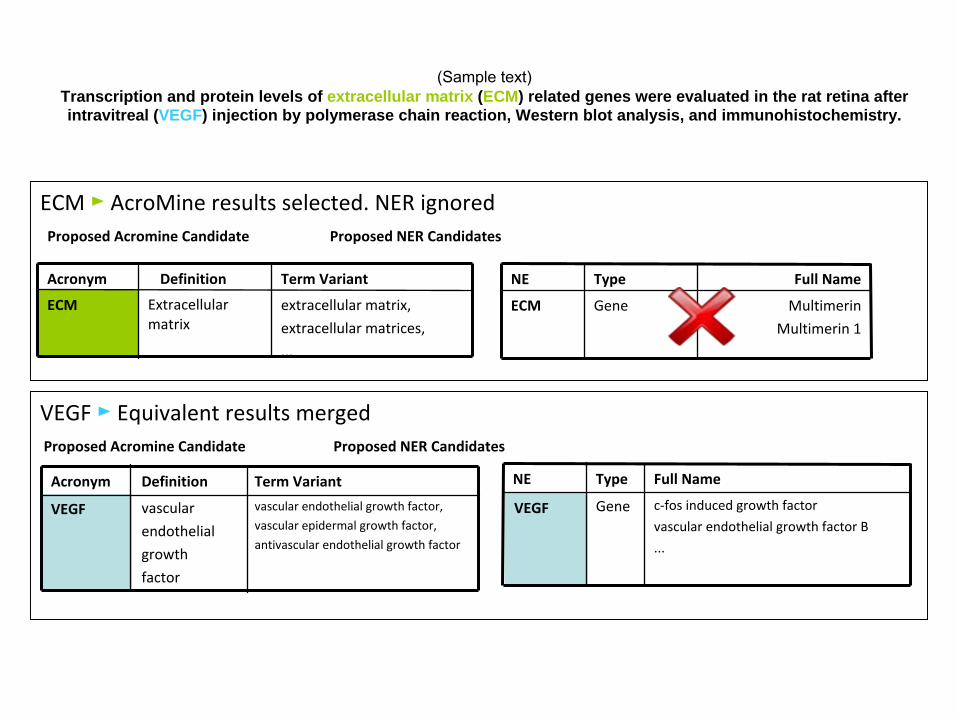
VEGF ►
Equivalent results mergedProposed Acromine
Candidate Proposed NER Candidates
ECM ►
AcroMine
results selected. NER ignoredProposed Acromine
Candidate Proposed NER Candidates
(Sample text)
Transcription and protein levels of extracellular matrix (ECM) related genes were evaluated in the rat retina after intravitreal (VEGF) injection by polymerase chain reaction, Western blot analysis, and immunohistochemistry.
extracellular matrix,
extracellular matrices,
...
Extracellular
matrixECM
Term VariantDefinitionAcronym
Multimerin
Multimerin
1
GeneECM
Full NameTypeNE
vascular endothelial growth factor,
vascular epidermal growth factor,
antivascular
endothelial growth factor
vascular
endothelial
growth
factor
VEGF
Term VariantDefinitionAcronym
c‐fos
induced growth factor
vascular endothelial growth factor B
...
GeneVEGF
Full NameTypeNE

2.Normalisation of biology terms
•
Based on a combination of exact and soft string matching methods
•
Permit efficient look-up and to discover ambiguous and variant terms in the resources
•
Using existing resources to learn term variation patterns automatically

3. Named entity recognition for gene/protein names
•
Allow users to specify the entity type they want to retrieve (e.g. gene/protein)
•
Combination of conditional random fields and maximum entropy models to filter out false positives
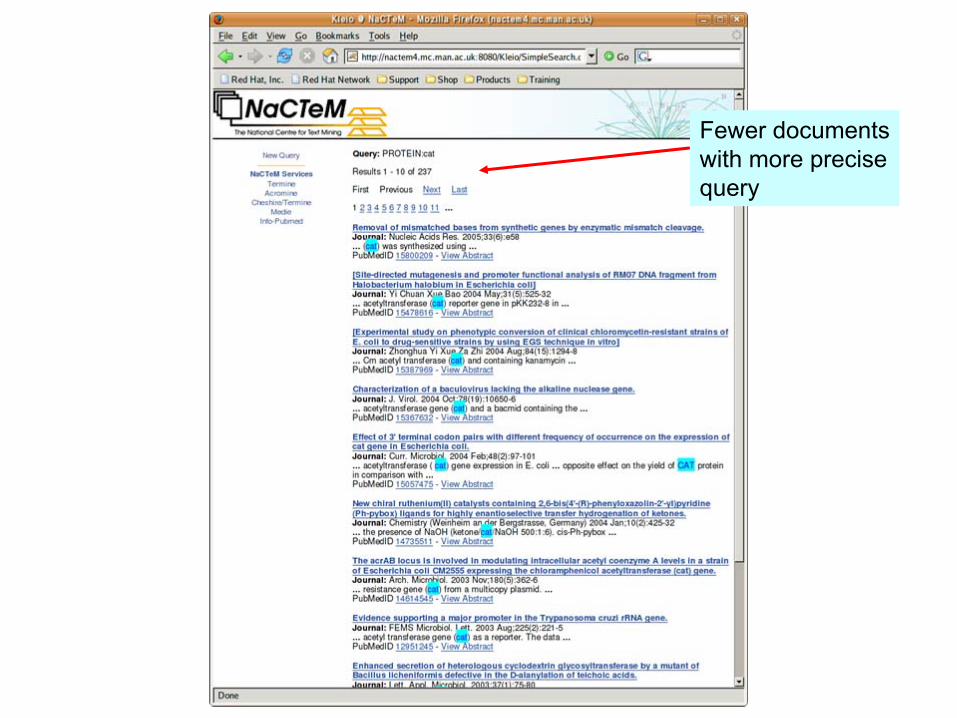
Fewer documentswith more precisequery

122
Mining associations from MEDLINE
•
FACTA: Finding Associated Concepts with Text Analysis –
What diseases are related to a particular chemical?–
What proteins are related to a particular disease?–
etc.
•
EBIMed
http://www.ebi.ac.uk/Rebholz-srv/ebimed/index.jsp•
PubMatrix
http://pubmatrix.grc.nia.nih.gov/
:•
FACTA http://text0.mib.man.ac.uk/software/facta/–
Quick and interactive

123
Query

124
Click!
125
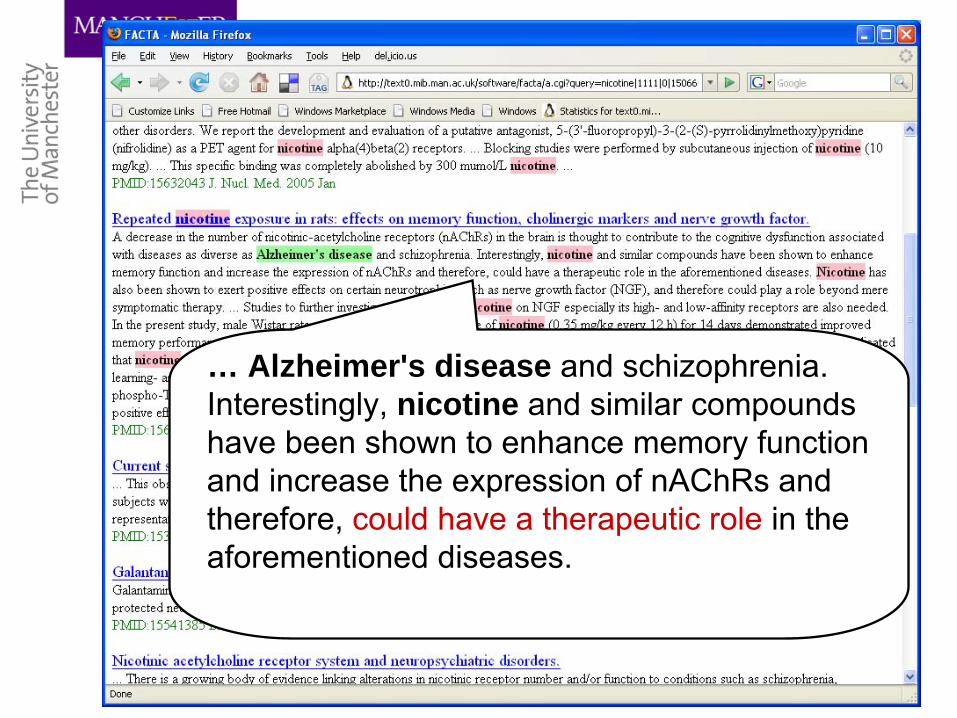
… Alzheimer's disease and schizophrenia. Interestingly, nicotine and similar compounds have been shown to enhance memory function and increase the expression of nAChRs
and
therefore, could have a therapeutic role
in the aforementioned diseases.

Biological Annotation and Event Recognition
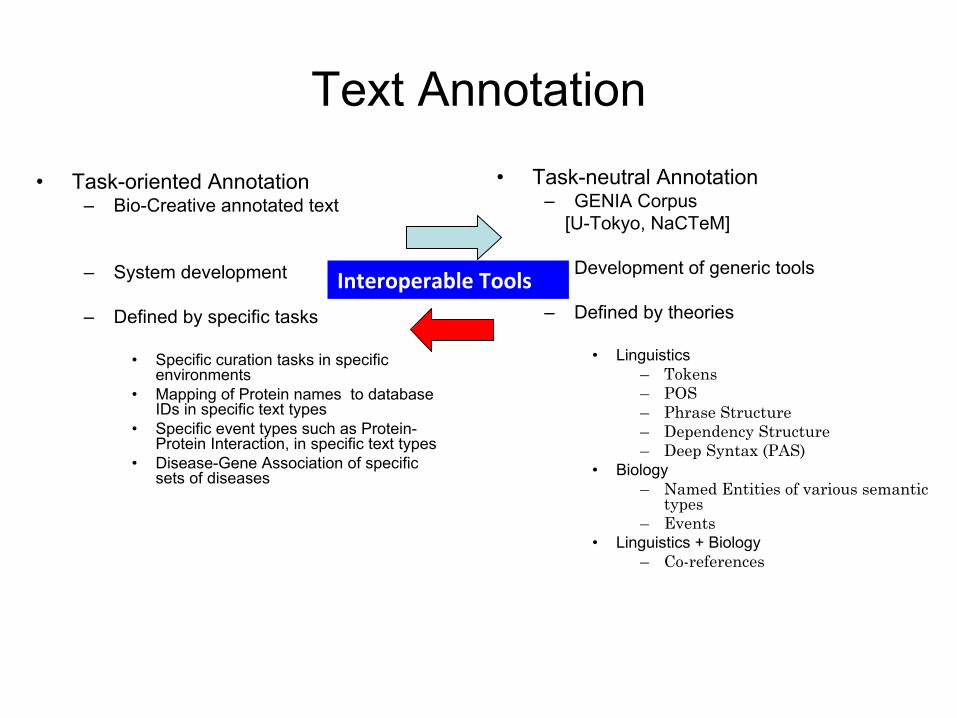
Text Annotation
•
Task-oriented Annotation–
Bio-Creative annotated text
–
System development
–
Defined by specific tasks
•
Specific curation
tasks in specific environments
•
Mapping of Protein names to database IDs in specific text types
•
Specific event types such as Protein-
Protein Interaction, in specific text types •
Disease-Gene Association of specific sets of diseases
•
Task-neutral Annotation–
GENIA Corpus[U-Tokyo, NaCTeM]
–
Development of generic tools
–
Defined by theories
•
Linguistics–
Tokens–
POS–
Phrase Structure–
Dependency Structure–
Deep Syntax (PAS)•
Biology–
Named Entities of various semantic types
–
Events•
Linguistics + Biology–
Co-references
Interoperable Tools

Text Annotation
•
Task-oriented Annotation–
Bio-Creative annotated text
–
System development
–
Defined by specific tasks
•
Specific curation
tasks in specific environments
•
Mapping of Protein names to database IDs in specific text types
•
Specific event types such as Protein-
Protein Interaction, in specific text types •
Disease-Gene Association of specific sets of diseases
•
Task-neutral Annotation–
GENIA Corpus[U-Tokyo, NaCTeM]
–
Development of generic tools
–
Defined by theories
•
Linguistics–
Tokens–
POS–
Phrase Structure–
Dependency Structure–
Deep Syntax (PAS)•
Biology–
Named Entities of various semantic types
–
Events•
Linguistics + Biology–
Co-references
Interoperable Tools

Annotation of GENIA corpus –
Annotation Tool

Annotation of GENIA corpus –
Term&POS
Term (entity) annotation 2000+400 abstracts
Term (entity) annotation 2000+400 abstracts

Annotation of GENIA corpus –
Term&POS
Part-of- speech
annotation 2,000
abstracts
Part-of- speech
annotation 2,000
abstracts

Annotation of GENIA corpus –
Term&POS
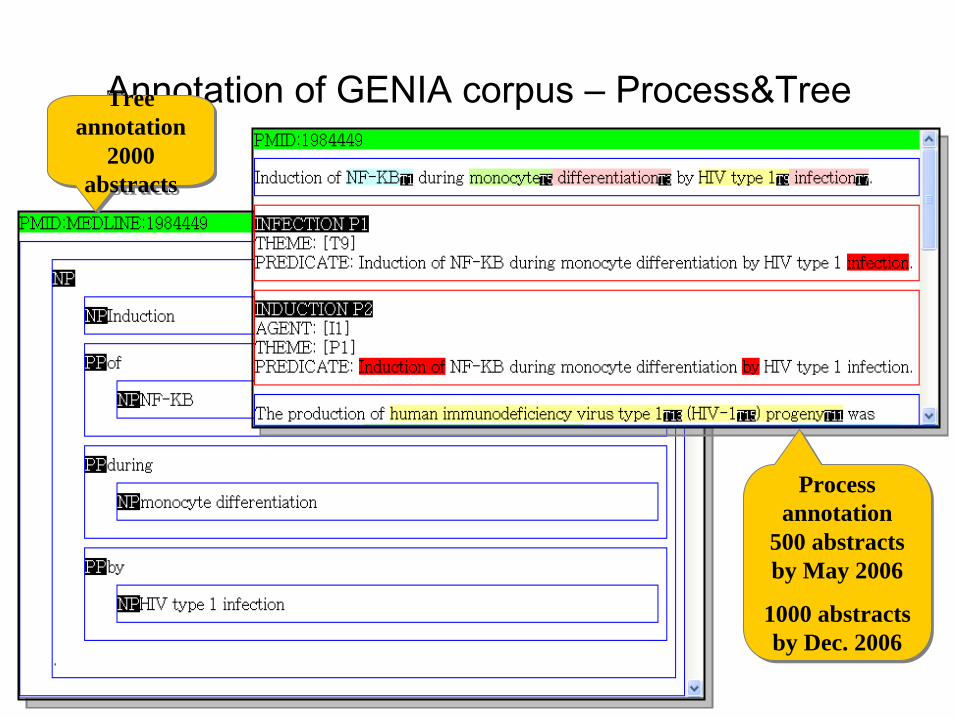
Annotation of GENIA corpus –
Process&TreeTree annotation
2000 abstracts
Tree annotation
2000 abstracts
Process annotation
500 abstracts by May 2006
1000 abstracts by Dec. 2006
Process annotation
500 abstracts by May 2006
1000 abstracts by Dec. 2006

Example of Co-references (Institute of Infocomm
Research, Singapore)
<s>Consistent with <COREF ID=“35” REF=“34” MIN=“t1/2” TYPE=“IDENT”> this short t1/2 </COREF>, accumuration of <COREF ID=“19” REF=“8” TYPE=“IDENT”> 1,25(OH)2D3 recepter RNA </COREF> increased in <COREF ID=“36”> cells </COREF> as <COREF ID=“37” REF=“36” TYPE=“PRON”> their </COREF> protein synthesis was inhibited.</s>
IDs are assigned to all NPs and they are used for representingco-referential relationships
•Pronouns•Relative clauses•Noun phrases with/without definite determiners•Appositions

Adaptation of Tools for the Biology Domain

Why Linguistic Annotation?
•
Tool Development and Adaptation
–
Training, Development, Test
–
New Research: Domain Adaptation
Crucial for the success of Text Mining in Specific Domain

Tool1: POS Tagger
•
General-Purpose POS taggers, trained by WSJ–
Brill’s tagger, TnT
tagger, MX POST, etc. –
97%
•
General-Purpose POS taggers do not work well for MEDLINE abstracts
The peri-kappa B site mediates human immunodeficiencyDT NN NN
NN
VBZ JJ NN
virus type 2 enhancer activation in monocytes …NN NN
CD NN NN
IN NNS

Errors seen in TnT
tagger (Brants
2000)A chromosomal translocation in …DT JJ NN IN
… and membrane potential after mitogen binding.CC NN NN IN NN JJ
… two factors, which bind to the same kappa B enhancers…CD NNS WDT NN TO DT JJ NN NN NNS
… by analysing the Ag amino acid sequence.IN VBG DT VBG JJ NN NN
… to contain more T-cell determinants than …TO VB RBR JJ NNS INStimulation of interferon beta gene transcription in vitro by
NN IN JJ JJ NN NN IN NN IN

Performance of GENIA Tagger
Training corpus WSJ GENIA
WSJ 97.0 84.3
GENIA 75.2 98.1
WSJ+GENIA 96.9 98.1
Training corpus WSJ GENIA
WSJ 96.7 84.3
GENIA 80.1 97.9
WSJ+GENIA 96.5 97.5
• GENIA tagger (Ref.) TnT tagger
No degradation of the taggertrained by the mixed corpus
Some degradations (0.2 ~ 0.4) were observed, compared withthe taggers trained by “pure”corpora

Semantic structure
CRP mesurement
does
NP13
VP17
VP15
So
NP1
DT2
A
VP16
AV19
not
VP21
VP22
exclude
NP25
NP24
AJ26
deep
NP28
NP29
vein
NP31
thrombosis
serum
NP4
AJ5
normal
NP7
NP8 NP10
NP11
ARG1
ARG1
MOD
MOD
ARG1
ARG2
ARG1
ARG1
ARG2
ARG1
MOD
Predicate
argument
relations
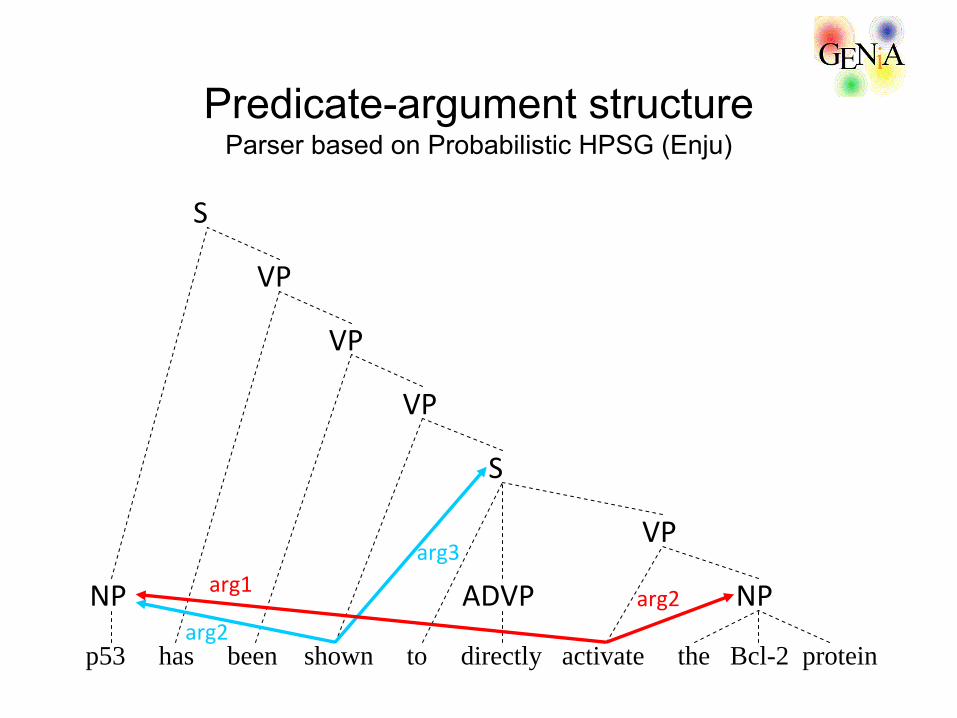
Predicate-argument structure Parser based on Probabilistic HPSG (Enju)
S
p53 has been shown to directly activate the Bcl-2 protein
NP
VP
ADVP
S
VP
VP
VP
NP arg1arg2
arg2
arg3

Event Annotation

GENIA event annotation•
Target of GENIA event annotation–
Corpus
•
Part of GENIA corpus which is taken from PubMed
using the MeSH
terms, Human, Blood Cells and Transcription Factors.
–
Ontology•
From the Gene ontology, concepts required for describing NFkB
pathway have been selected (34 terms).•
3 additional concepts have been defined–
Gene_expression–
Artificial_process–
Correlation

GENIA event annotation –
Stat (1/2)
•
Annotation–
5 annotators + 1 manager with biology background.–
using XConc
Annotation tool
•
1,000
abstracts have been annotated–
# of sentences: 8,981
–
# of sentences with events: 8,265•
92.0%–
# of events: 34,065
•
Avg. 4.15 events/sentence

GENIA event annotation –
Stat (2/2)
•
Correlation–
meaning ‘some’
relation between events.
•
Artificial_process–
Artificially performed processes.–
Transfection, treatment, …•
Gene_expression–
Transcription + Translation
(758)
(1,740)
(6/2,297)(2,269)
(22)(170)(261)
(407)
(1)
(485)
(6/1,330)
(1,149/6,755)
(730)(117/4,876)
(69/152)(26)(57)
(0)(2,958)(31/668)
(22/62)
(40)(164)(71/411)
(3)(1)
(9)(321)
(6)(0)
(46/52)(6)
(929)(4,229/19,940)
(4,567)(11,144)
(476/1,043)(277)(290)
(59/29,127)

GENIA Event Annotation -
example
LinkCauseLinkCause
–
For an identified event in the given sentence,•
classify the type of events and record the text span giving the clue of it (ClueType).•
identify the theme of the events and record the text span linking the theme to the
event (LinkTheme).•
identify the cause of the events and record the text span linking the cause to the
event (LinkCause).•
record the environment (location, time) of the events (ClueLoc, ClueTime).
LinkThem e
LinkThem e
ClueLocClueLoc
ClueTypeClueType
ClueTypeClueType
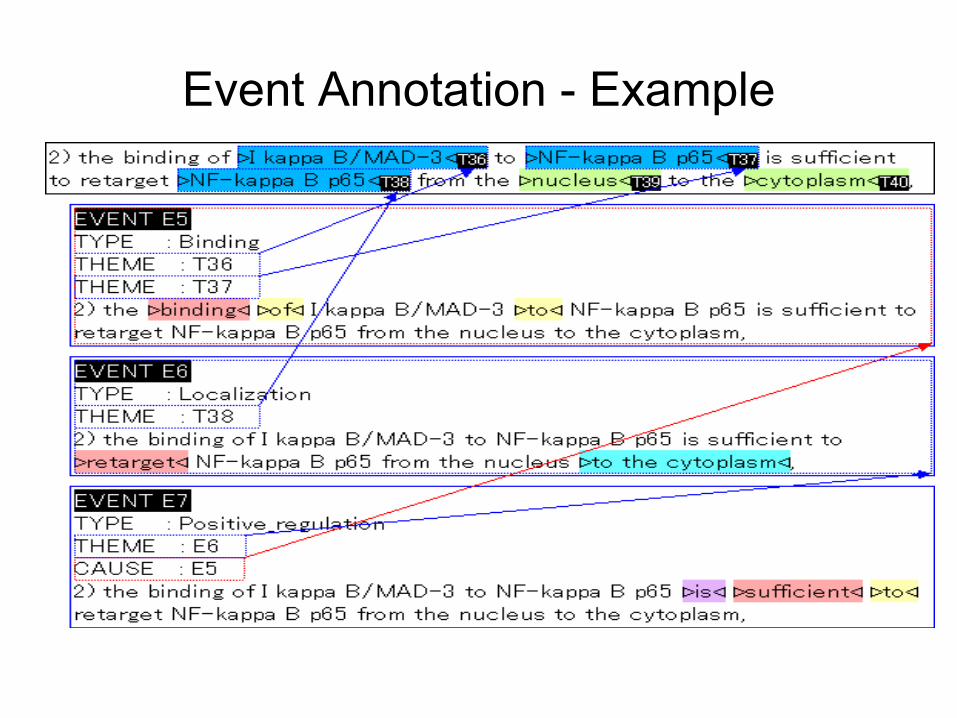
Event Annotation -
Example

Localization•
Theme patterns observed (730)–
Protein
608–
Lipid
31–
Atom
29–
Other_organic_compound
14–
DNA 12–
Virus 5–
Carbohydrate
5–
RNA
4–
Inorganic
4–
Peptide
3
•
ClueLoc–
NONE
241
–
nuclear
140
–
to the nucleus 12
–
into the nucleus
11
–
Cytoplasmic
8
–
in the cytoplasm
7
–
macrophages
5
–
nuclear … in t lymphocytes
4
–
monocytes
4
–
in the nucleus 4
–
in the cytosol
4
–
in colostrum
4
–
from the cytoplasm to the nucleus 4

Localization•
Keywords and Locations–
translocation (166)•
nuclear108•
NONE
38•
…–
secretion (100)•
NONE
57•
name_of_cells
43–
release (80)•
NONE
51•
name_of_cells
19•
…–
localization (30)•
nuclear25•
intracellular
3–
uptake (24)•
NONE 14•
name_of_cells
20
•
Keywords and Themes–
translocation (166)•
Protein161•
Virus
4•
RNA
1–
secretion (100)•
Protein 98•
Lipid
1•
Peptide
1–
release (80)•
Protein
67•
Other_organic_compoun
6•
Lipid
3–
localization (30)•
Protein30–
uptake (24)•
Lipid
15•
Carbohydrate 5•
Protein
4

Event Recognition
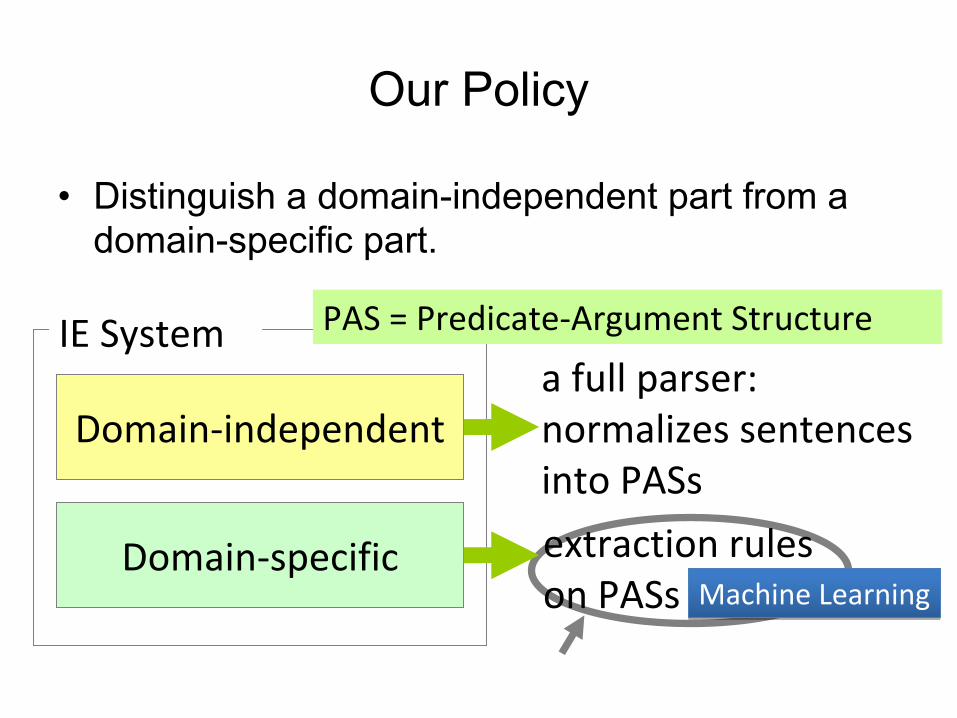
Our Policy
•
Distinguish a domain-independent part from a domain-specific part.
Domain‐independent
Domain‐specific
IE Systema full parser:normalizes sentences
into PASs
extraction rules on PASs
PAS = Predicate‐Argument Structure
Machine LearningMachine Learning

An Advantage of Using Full Parsing
•
Normalization of syntactic variations into PASs
We can construct more general extraction rules. Less extraction rules
less training corpus
Entity1 activates Entity2 Entity2 is activated by Entity1 Entity1 cooperate to activate Entity2 Entity1 play key roles by activating Entity2
activateARG1 Entity1ARG2 Entity2

Target Domain/Task
•
Extraction of protein-protein interactions from MEDLINE abstracts
•
A source corpus of extraction rules: Aimed [Bunescu
et al., 2004]
–
MEDLINE abstracts obtained from the Database of Interacting Proteins (DIP)
–
Tagged protein names and interactions of them
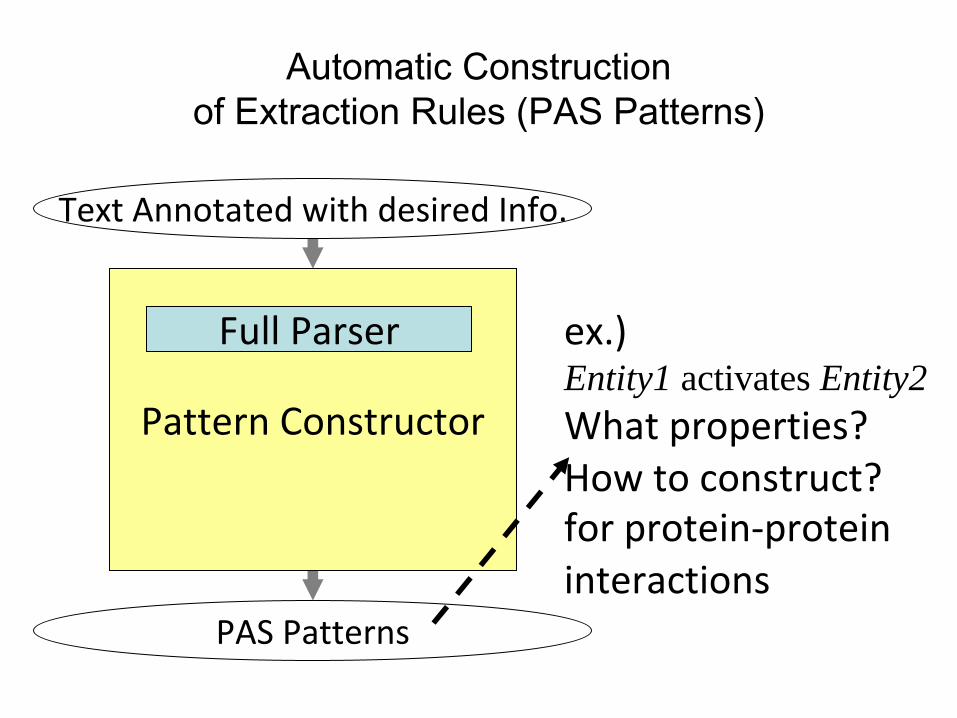
Automatic Construction of Extraction Rules (PAS Patterns)
Pattern Extraction
PAS Patterns
Pattern Division
Pattern Filtering
Pattern Constructor
Full Parser ex.)Entity1 activates Entity2What properties?
How to construct?for protein‐protein
interactions
Text Annotated with desired Info.

Required Patterns
Classes(1) Entity-Verb(-Preposition)-Entity(2) Other Patterns with a Single Verb(3) Patterns with More than One Verb(4) Noun Patterns(5) Adjective Patterns

(1) Entity-Verb(-Preposition)-Entity
This demonstrates that Entity1 recognizes Entity2.We found Entity1, interacted with Entity2.
•
Straightforward•
Easy to extract

(2) Other Patterns with a Single Verb
(2a) With Nouns Unable to Be OmittedEntity1 formed complexes with Entity2.
(2b) With Nouns Able to Be OmittedEntity1 protein interacts with Entity2.
•
Can be divided into verbal components and nominal components
•
In (2b), every combination of verbal and nominal components can be used as a pattern

(3) Patterns with More than One Verb
Entity1 recognizes one FGFR isoform known as Entity2.Entity1 contains this site as well as a region that restricts interaction with Entity2.
•
Combinations of general verbs and domain- specific verbs --
Can be divided?
Not Dividing Now

(4) Noun Patterns (1/2)
(4a) Coordinates with Nouns of Interacting SubstancesEntity1 receptor ( Entity2 )
(4b) Nouns Representing Interactioninteraction of Entity1 with Entity2
(4c) Nouns and Modifiers Representing InteractionEntity1 binding domain on Entity2

(4) Noun Patterns (2/2)
(4c) Nouns and Modifiers Representing InteractionEntity1 binding domain on Entity2
•
Difficult Problems:–
Distinction of these modifiers from general modifiers
–
Decision on whether modifiers are needed for proper patternsspecific Entity1 ligand ( Entity2 )
Not Supporting Now

(5) Adjective Patterns
dimeric Entity1Entity1 is a homodimeric protein.
•
Similar with (4c)
Not Supporting Now

Class of Required Patterns
Supported Patterns at the present(1) Entity-Verb(-Preposition)-Entity(2) Other Patterns with Only 1 Verb(3) Patterns with More than 1 Verb(4) Noun Patterns
(Partially)(5) Adjective Patterns

Automatic Construction of Extraction Rules (PAS Patterns)
Text Annotated with desired Info.
Pattern Extraction
PAS Patterns
Pattern Division
Pattern Filtering
Pattern Constructor

Automatic Construction of PAS Patterns
Text Annotated with desired Info.
Pattern Extraction
PAS Patterns
Pattern Division
Pattern Filtering
Generalization by parsing
Generalization by dividing into components
Raising accuracy by deleting inappropriate
patterns

Entity1 coreceptor interacts with non-polymorphic regions of the Entity2.
Pattern Extraction
Entity1MODARG 1 coreceptor
interactARG1 1
•
Convert a sentence annotated with desired information to PASs
by parsing.
•
Extract the smallest PAS set.
withARG1ARG2
2
2
3 region
ofARG1ARG2
3Entity2
, ,
,
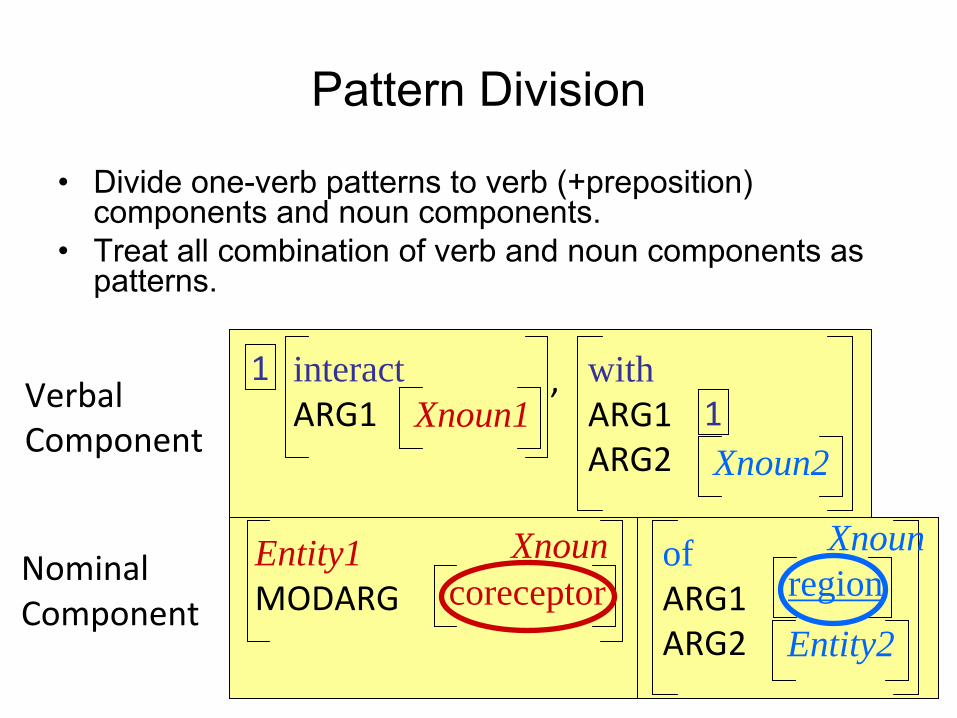
Pattern Division
•
Divide one-verb patterns to verb (+preposition) components and noun components.
•
Treat all combination of verb and noun components as patterns.
Entity1MODARG coreceptor
withARG1ARG2
1Xnoun2
ofARG1ARG2 Entity2
Xnoun1interactARG1
1 ,
Xnounregion
Xnoun
Verbal Component
Nominal Component

Application Systemswith Event Recognition
169
MEDIE
•
An interactive intelligent IR system retrieving events
•
Performs a semantic search •
System components–
GENIA tagger
–
Enju
(HPSG parser)–
Dictionary-based named entity recognition
Demo

170
Medie
system overview
InputTextbase
Deep parser
Entity Recognizer
Semantically-annotatedTextbase
RegionAlgebraSearch engine
Query Searchresults
Off-line
On-line

171

172
Info-PubMed
•
An interactive IE system and an efficient PubMed
search tool, helping users to find information about biomedical entities such as genes, proteins,and
the interactions
between them. •
System components–
MEDIE–
Extraction of protein-protein interactions –
Multi-window interface on a browserDemo
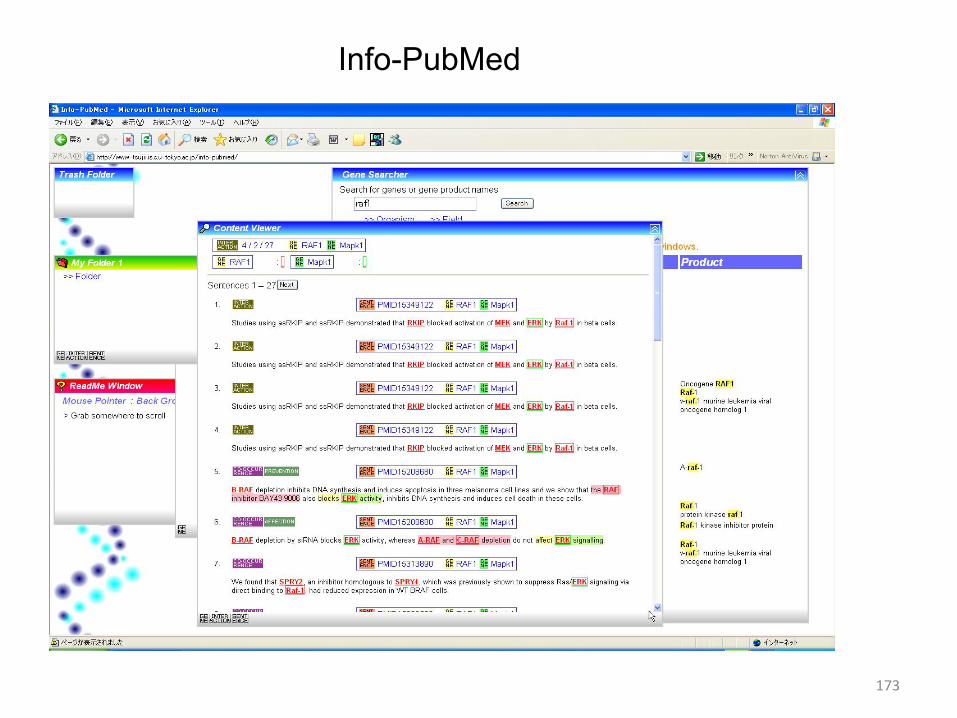
173
Info-PubMed

I
Information Extraction

IE in Biology
Pattern-matchingContext-free grammar approachesFull parsing approachesSublanguage driven IEOntology-driven IE
McNaught, J. & Black, W. (2006) Information Extraction, Text Mining for Biology & Biomedicine, Artech
house, pp.143-177

Pattern-matching IE
–
Usual limitations with non inclusion of semantic processing
–
Large amount of surface grammatical structures = too many patterns (Zipf’s
law)
–
Cannot explore syntactic generalisations (active, passive voice)
–
Systems extract phrases or entire sentences with matched patterns; restricted usefulness for subsequent mining

Pattern-matching systems (1)
BioIE uses patterns to extract sentences, protein families, structures, functions..
Presents user with relevant information, improvement from classic IR
BioRAT uses “deeper” analysis, tagging, apply RE over POS tags, stemming, gazettercategories etc
Templates apply to extract matching phrases, primitive filters (verbs are not proteins, etc)

Pattern matching systems (2)
RLIMS-P (Hu) protein phosphorylation by looking for enzymes, substrates, sites assigned to agent, theme, site roles of phosphorylation relationsPos tagger, trained on newswire, chunking, semantic typing of chunks, identification of relations using pattern-matching rules Semantic typing of NPs: using combination of clue words, suffixes, acronyms etcSemantically typed sentences matched with rulesPatterns target sentences containing phosphorylate

Full parsing approaches
•
Link Grammar applied for protein-protein interactions; general English grammar adapted to bio-text
•
Link Grammar finds all possible linkages according to its grammar•
Number of analyses reduced by random sampling, heuristics, processing constraints relaxed–
10,000 results permitted per sentence–
60% of protein interactions extracted–
Problems: missing possessive markers & determiners, coordination
of compound noun modifiers

Full parsing IE (2)
•
Not all parsing strategies suitable for bio-text mining•
Text type, abstracts, “ungrammaticality”
related with sublanguage characteristics?
•
Ambiguity and full parsing; fragmentary phrases (titles, headings, text in table cells, etc)
•
CADERIGE
project used Link grammar but on shallow parsing mode
•
Kim & Park (BioIE)
use combinatorial categorial
grammar, annotated with GO concepts, extract general biological interactions
•
1,300 patterns applied to find instances of patterns with keywords

Full parsing (3)
•
Keywords indicate basic biological interactions•
Patterns find potential arguments of the interaction keywords (verbs or nominalisations) –
Validated arguments mapped into GO concepts–
Difficult to generalise interaction keyword patterns•
BioIE’s
syntactic parsing performance improved after
adding subcategorisation
frames on verbal interaction keywords

Full parsing (4)
–
Daraselia(2004) use full parsing and domain specific filter to extract protein interactions
1.
All syntactic analyses discovered using CFG and variant of LFG
2.
Each alternative parse mapped to its corresponding semantic representation
3.
Output= set of semantic trees, lexemes linked by relations indicating thematic or attributive roles
4.
Apply custom-built, frame based ontology to filter representations of each sentence
5.
Preference mechanism controls construction of frame tree, high precision, low recall (21%)

Sublanguage-driven IE (1)
•
Language of a special community (e.g. biology) •
Particular set of constraints re GL•
Constraints operate at all linguistic levels–
Special vocabulary (terms) –
Specialised term formation rules–
Sublanguage syntactic patterns–
Sublanguage semantics•
These constraints give rise to the informational structure of the domain (Z. Harris)
•
See JBI 35(4) Special Issue on Sublanguage

GENIES system
•
Employs SL approach to extract biomolecular
interactions•
Uses hybrid syntactic-semantic rules –
Syntactic and semantic constraints referred to in one rule•
Able to cope with complex sentences•
Frame-based representation –
Embedded frames•
Domain specific ontology covers both entities and events

GENIES system
•
Default strategy: full parsing –
Robust due to sublanguage constraints–
Much ambiguity excluded•
If full parse fails, partial parsing invoked–
Maintains good level of recall•
Precision: 96%, Recall: 63%

Ontology-driven IE
•
Until recently most rule based IE have used neither linguistic lexica nor ontologies–
Reliance on gazetteers –
Small number of semantic categories•
Gazetteer approach not well suited in bioIE•
Ontology based
vs
ontology driven–
Passive use of ontologies, map discovered entity to concept–
Active use, ontology guides and constrains analysis, fewer rules•
Examples: PASTA, GenIE
not SL •
GENIES, SL and ontology driven

Summary: simple pattern matching
Over text stringsMany patterns required, no generalisation possible
Over POSSome generalisation but ignore sentence structure
POS tagging, chunking, semantic p-m, typingLimited generalisation, some account taken of structure, limitedconsideration of SL patterns

Summary: full parsing
Full parsing on its own, parsing done in combination with chunking, partial parsing, heuristics) to reduce ambiguity, filter out implausible readings
GL theories not appropriate Difficult to specialise for biotextMany analyses per sentenceMissing information due to sublanguage meaning

Summary: sublanguage approach
Exploits a rich SL lexiconDescribes SL verbs in detailSyntactic-semantic grammarCurrent systems would benefit from adopting ontology-driven approach

Ontology-driven
Uses event concept frames to guide processingIntegration of extracted informationCurrent systems would benefit from adopting also SL approach