técnicas de computación científicavicente/tcc/tcc.optsec.parte1.pdf · otros: familias intel...
TRANSCRIPT

Técnicas de Computación Científica
Parte I: Optimización Secuencial
FIM - 2011/12
Vicente Martín v0.4d

Arquitecturas Secuenciales
● Un sólo procesador con acceso a un único espacio de direcciones de memoria (física)– El espacio físico se puede dividir en varios espacios
lógicos de modo que varios procesos puedan compartir el procesador. El sistema operativo provee una imágen lineal de la memoria a cada proceso como si éste tuviese acceso exclusivo a la memoria física. (Memoria virtual)

Instrucciones y Filosofías de Diseño● CISC: Complex Instruction Set Computer. “cuanto más haga
una sola instrucción, mejor” eg.: VAX-11/780 (1978) 303 instrucciones, 16 modos de direccionamiento, formatos variables desde 2 a 57 bytes, 456KB de microcódigo en la CU. Otros: familias Intel 80386 y Motorola 68000.
● RISC: Reduced Instruction Set Computer. “simplifica, evita todo lo que no sea muy usado, hará más fácil el diseño y más rápido el HW” Cierto con el apoyo de buenos compiladores. eg.: IBM 801 (experimental, 1975), RISC I/II (Berkeley, 1985) origen de los SPARC , MIPS (Stanford, 1985). La gran mayoría de CPUs actuales de propósito general.
● VLIW: Very Long Instruction Word. “dale a la CPU palabras grandes con toda la información necesaria para utilizar completamente todo su HW directamente” El compilador tiene que ser muy listo para organizar estas palabras. La complejidad pasa del HW al SW. eg.: Transmeta (necesita capas de code morphing), CPUs para dispositivos empotrados, con HW de ayuda parcial al SW: EPIC (Itanium 1/2)

How an instruction is processed?● A group of n instructions are predecoded to the Instruction Cache.
– Each group is tagged with flow history bits.● Instructions within the group are tagged with kind of
instruction (essentially, Functional unit needed) and branch history bits (color the instructions).
● Predicting a bad branch results in a heavy penalty for CPUs with long pipelines: discarding the instructions/registers with a given color.
– Also, fetching of the wrong instructions could occur due to misprediction.
● Instructions are processed when HW available (funct. Unit, registers) and reordered to maximize HW use.
● Registers are not committed to memory till the associated instructions are accepted (retired)

How an instruction is processed? (II)– Some execution units can have several outstanding instructions
at a given point in time.● Specially true for memory operations in order to mask
latency.– When a branch is resolved, it must be communicated to other
execution units in order to free/invalidate resources/instructions.
– In the final stage the Completed Instruction Buffer holds all instructions executed till the Retire Unit makes sure that no previous instruction produced an exception, then it is retired (in program order)
● A modern CPU can have more than 200 instructions in flight at any given point in time.

Eg. CPU RISC moderna: IBM Power 4+
Esquema del pipeline. No se representan las unidades funcionales duplicadas. Cada unidad funcional tiene su propia cola, las instrucciones no se ejecutan necesariamente en orden. Puede mantener mas de 200 instruciones en ejecución simultánea, lo que haceque la lógica de control sea muy compleja.
Behling 01
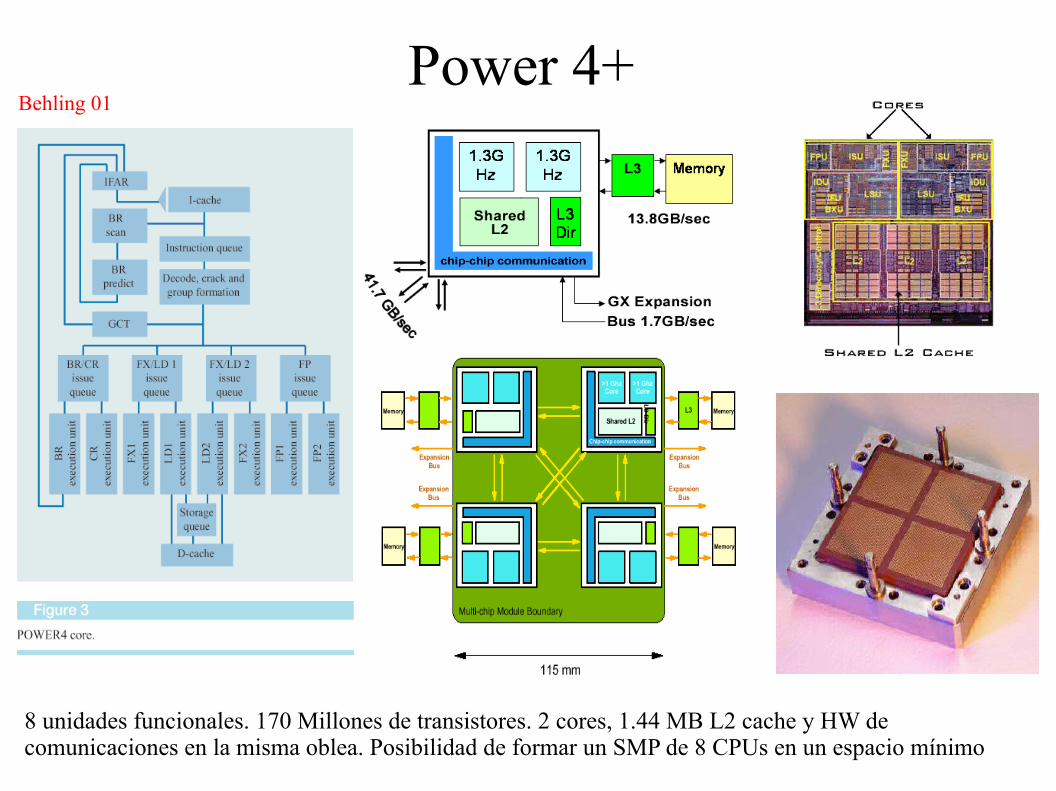
Power 4+
8 unidades funcionales. 170 Millones de transistores. 2 cores, 1.44 MB L2 cache y HW de comunicaciones en la misma oblea. Posibilidad de formar un SMP de 8 CPUs en un espacio mínimo
Behling 01

Itanium 2Cambio radical de la IA32. EPIC, parcialmente VLIW,core “simplificado”, rendimiento más dependiente delcompilador. Sin HW para “glueless” SMP. Cache L3 en la oblea (Madison: version con 6MB). 210 Millones de transistores (410?? Madison)
Steen 03
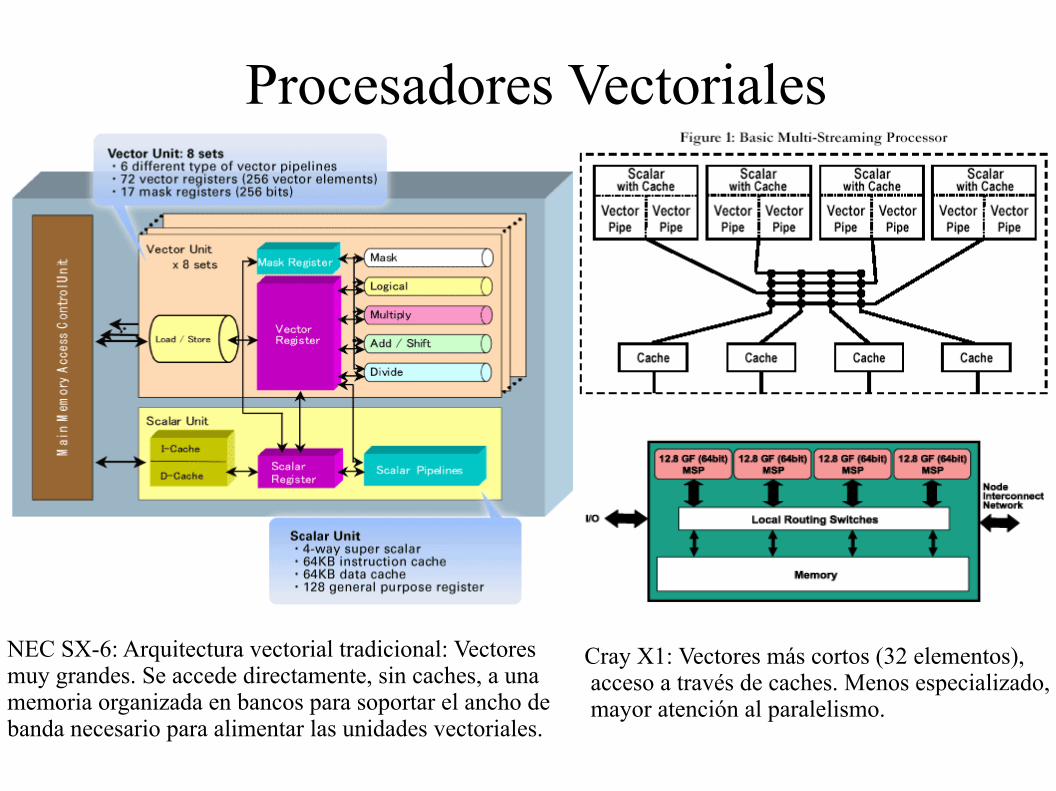
Procesadores Vectoriales
NEC SX-6: Arquitectura vectorial tradicional: Vectores muy grandes. Se accede directamente, sin caches, a una memoria organizada en bancos para soportar el ancho de banda necesario para alimentar las unidades vectoriales.
Cray X1: Vectores más cortos (32 elementos), acceso a través de caches. Menos especializado, mayor atención al paralelismo.

Parámetros de algunas CPUs TípicasReloj
L1-D
L2
L3
Bus/MemPpal.
Rendi-miento
Otros
Itanium-21500MHz
16KB, 64B/Linea, 4-w assoc. Latencia 1 ciclo. No FP.24 GB/sec (bus 128b)
256KB, 128B/Linea, 8-w assoc. Latencia 5/6 ciclos (Int/FP) 48 GB/sec (bus 256)
6MB, 128B/Linea 24-w assoc. Latencia 14 ciclos48 GB/sec (bus 256b)
6.4 GB/sec (bus 128b a 400MHz)
Pico Teorico: 6 GflopsLinpack: 1659/5400 MFlopsSpecFP2000: 2161
410?!! Mill. Transistores Sin logica adicional SMP.
Power 4+1700 MHz
32KB, 128B/Linea,2w asoc.Latencia 1 ciclo. 27.2 GB/sec (bus 128b)
1.41 MB, 3 bancos. 128B/linea4w o 8w. Latencia 8-10 ciclos. 156 GB/sec (32B+8B x 2cores)
Hasta 32MB, 8w asoc.512B/linea. 18.1 GB/sec(2x16B a 3:1) escalable.
6.4 GB/sec (128b a 400MHz)escalable
Pico Teorico: 6.8 GflopsLinpack:1486/3884 MFlopsSpecFP2000: 1642
2 cores/chip, montables en un grupo de 4 con bus de 60 GB/s
NEC SX-6500 Mhz
n/a
n/a
n/a
32 GB/sec (512ba 500 MHz)
Pico: 8 GflopsLinpack: 1161/7575 MFlopsSpecFP2000: no medido
primera CPU vectorial en un chip. Earth Simul. +5000 procesadores.

Latencias.
IBM Power4 a 1.3 GHz, Intel Itanium2 a 1 Ghz con 3 MB de L3 y NEC SX6. En azul claro las caches incluidas en el mismo chip que la CPU. En azul oscuro las externas. Los anchos de banda son la suma de los anchos de banda en lectura y escritura. En el Power4 las caches L2 y L3 son compartidos entre los dos cores (hay una version del chip con un solo core, para HPC que no comparte caches.
InSide, spring 2003

No todo es lo que parece Incluso en parámetros aparentemente fáciles de definir, como el ancho de banda, hay muchos detalles escondidos. Los fabricantes no suelen dejar claro a qué se refieren en las “macrocifras”... eg.: anchos de banda detallados del Power4:
Grassl 02

R. Kalla et al. “IBM Power5 Chip: A dual-core multithreaded processor” IEEE Micro, Mar-apr. 2004, pag. 40
Parece inviable seguir complicando lasCPUs incrementando el numero de unidadesfuncionales y el HW asociado para mantener-las llenas. Aumentar el numero de etapas encada unidad para llevarlas a mayores velocidades tambien complica el HW y empiezan a ser muy graves los problemas de disipación. El gap de velocidad entre la memoria y la CPU se incrementa. De momento las soluciones van por incluir soporte especifico para hilos de ejecución (SMT: Symmetric Multithreading), que incrementa las posibilidades de llenado de unidades funcionales y la tolerancia a la latencia en la memoria. Como el soporte parahilos tambien complica el HW se prefiere incluir más cores en un solo chip que añadir soporte para mas hilos. Un chip Power 5 es visto como 4 CPUs por el SO: 2 cores con dos hilos por core. Se añade además soporte para comunicaciones off-chip: multiproceso, I/O y se hace algo más rápida la jerarquia de memoria. Tendencias similares en AMD o Intel.

Optimización Secuencial● Nuestro objetivo es usar de la manera más eficiente posible el HW que, para un ordenador secuencial, consideraremos dividido en dosgrandes bloques:
➔ Memoria➔ CPU
y tendremos que hacernos alguna idea de si la eficiencia con la que se ejecuta un programa es razonable o no y los posibles motivos por los que el rendimiento no es óptimo.
En esta sección mostraremos algunas técnicas básicas, para que un programa se aproxime al rendimiento ideal en un sistema monoprocesador

● El procesador de un SMP con ocho “procesadores” (Pwr5: 16 hilos de ejecución, el SO los ve como si fueran 16 CPUs) Power 5, incluyendo la jerarquia de memoria hasta los 32MB de cache L3
● 32-way Power 4 System Showing 4 MCMs and L3 Cache

Power 6● Evolución de Power 4/5: mismas
ideas básicas.
● Aspectos destacados:
– Vuelven los incrementos notables de la velocidad de reloj (5 GHz)
– Baja disipación, con énfasis en fiabilidad.
– Base tecnológica del Power7, máquinas multipetaflops. (PERCS: Productive, Easy to Use, Reliable Computing System)
– Duplica la velocidad de los procesadores más rápidos (con el mismo número de cores, specfp2006, en el momento de su presentación: Agosto 07)
● Creación de “Virtual Vector Architecture” concatenando varios Power6 ● Soporte de aritmética decimal: IBM quiere servir con un sólo diseño de CPU a todas las series de ordenadores (incluyendo la zSeries de uso financiero). Se incluye también en “blades”.
(50 GB/s)


8 cores/chip4 FPUs/core1 vector unit
32 cores/Multichip module1 Tflop. 800 Watt power consumption1.28 Gflops/Watt (double than Current best Intel quadcore)
Optoelectronical comm-unications module. 1128 GB/sec
Blade, Water cooled
1200 Mill. Transistors.32KB L1 D, 256 KB L280 MB L3 (shared 8 cores)
Power 7
* Also a 16 cores version* Each core 4 ways SMT

Power 8
* First servers mid 2014 (e.g. 32 TB, 384 cores, 3082 threads). * First version 12 cores “only”: More memory, less cores... * Each core 8 ways SMT* On Chip PCI-express 3 controllers with coherent memory protocols to External accelerators (CAPI). Generic “upgradeable” memory contoller (integrated with L4)* Memory hierarchy to L4 cache* Expect ~3000 mill. Transistors.* 4 FPU, 2 VMX vector math units.* One cryptographic unit
~3000 Mill. Transistors.*64KB L1 D, L1 to L2 bus 64 bits(double Pwr7) 512 KB L2*Better prefetching.* 96 MB L3 (shared 12 cores, 8 MB/Core), segmented, better protocol* Up to 128 MB L4 cache * L4->L3 128 GB/s; L3->L4 96 GB/s* L2-> core 256 GB/s; core->L2 64 GB* 4 TB/sec L2 bandwidth (12 cores)* 3 TB/sec L3 bandwidth (12 cores)* Approx 2.5x Power7 performance.* 410 GB/s DRAM bandwidth
OpenPower licensing initiative

Intel.
● En el segmento de las CPUs para consumo masivo.
– Más cores: Quadcores por 600 €
– Más cuidado con la potencia disipada: mejor para clusters grandes.

Intel.● Sandy Bridge (tock: new microarchitecture)
– Ivy Bridge (tick: shrinking to 22 nm from 32 nm)
● Haswell (tock: 22nm, new microarchitecture, jul. 2013)
-...
Sandy Bridge:* L1 64 KB/core, 64 bytes line* L2 256 KB/Core* L3 up to 20 MB shared* 8 cores / 16 threads (2.270 Mill. transistors)* AVX 256 bits* Improved memory bus.* Includes graphics on chip.

AMD.
● “Bulldozer” chip.
– 32nm, Silicon on Insulator for low power consumption..
– Vector operations (aka multimedia extensions, SSE...)
- 4 modules to make an 8 core chip (2011).

Aproximaciones más radicales...
R. Krashinsky et al. “TheVector-Thread Architecture”IEEE Micro, Nov-Dec. 2004pag. 84.
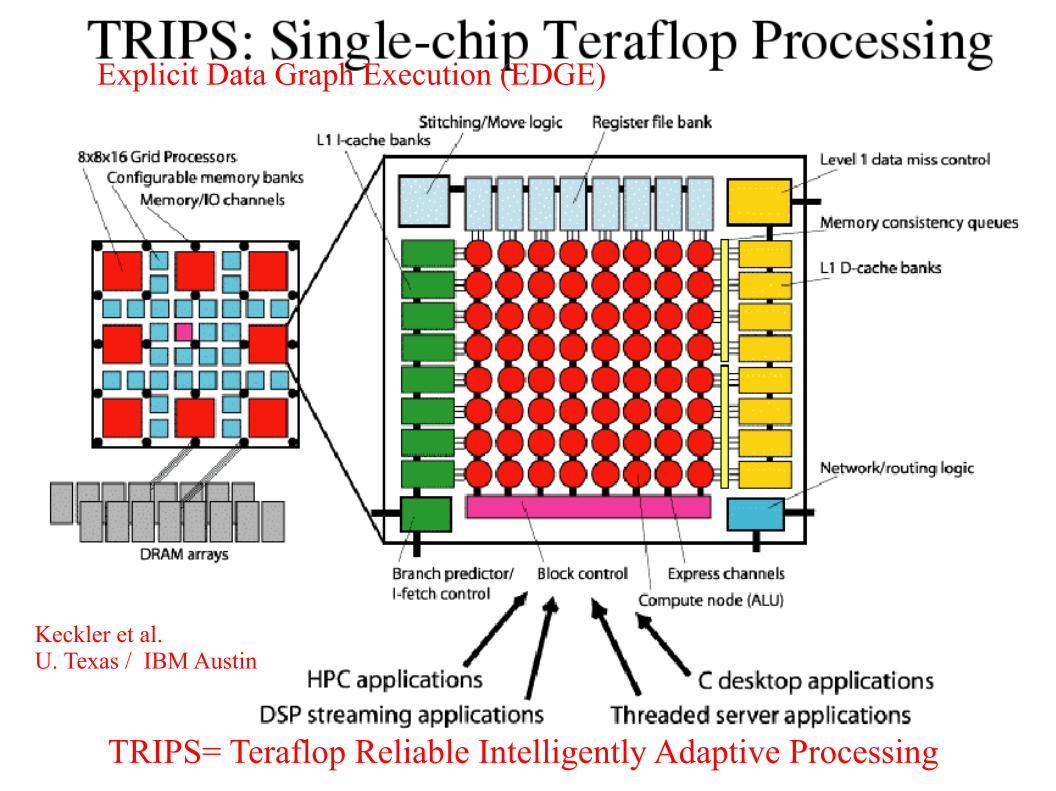
Keckler et al. U. Texas / IBM Austin
TRIPS= Teraflop Reliable Intelligently Adaptive Processing
Explicit Data Graph Execution (EDGE)



170 Million transistors


“Teraflops protoytpe processor with 80 cores”. Y. Hoskote et al. Hot Chips 07,



Intel MIC: Many Integrated CoresThe outcome of the previous project: Coprocessor, x64 instruction set, PCI-Express 3.0. Target for delivery: +50 cores, 22nm tech, second semester 2012.
Streamlined (eg.: no out of order) x64 core, 512 bits vector processor (16 SP Flops). Ring Interconnect keeps cache coherency. Estimated performance (per module) with 22nm tech. (64 cores) at 2 Ghz = 2 Tflops SP ( 1TFlop DP)
“Aubrey Isle” chip, 45 nm, 1,2 Ghz, 32 Cores,4 threads/core, 32 KB D + 32KB I L1 cache per core,shared 8MB L2 cache, 2 GB DDR5 Memory

Intel Many Integrated Core Architecture (MIC): Outcome
of several of the previous projects.
The Knights Ferry has 32 x86 cores on chip, each with 32KB L1 instruction cache, 32KB L1 data cache, and 256KB L2 cache. I will refer to them as 32 processors. Each processor has a vector unit, essentially a very wide (512 bits or 16 floats) SSE unit, allowing 16 single precision floating point operations in a single instruction. Double-precision compute throughput is half that of single-precision. The 32 data caches are kept coherent by a ring network, which is also the connection to the on-chip memory interface(s). Each processor supports a multithreading depth of four, enough to keep the processor busy while filling an L1 cache miss. The Knights Ferry is implemented on a PCI card, and has its own memory, connected to the host memory through PCI DMA operations. This interface may change in future editions, but Intel advertises the MIC as “an Intel Co-Processor Architecture.” This could be taken as acknowledgement that accelerators can play a legitimate role in the high performance market.(from PGI: Michael Wolfe.)



Contrast with the 2007 view that pushed the Cell: This is not going to last… (mainly because of heat dissipation due to stray currents through the insulator layer of VLSI ICs)

Selling in 2013: 2000-2500$

More Many Integrated Cores: AdaptevaFourth generation: 64 cores ,2D low overhead interconnect mesh. 28 nm tech. Floating point accelerator 100 Gflops SP using 2 Watts. 1GHz.
50 Gflops/W (compare with approx. 6 Gflops/W of Intel MIC -expected- or 10 Gflops/W of upcomig Kepler GPU. Targeted not only to HPC, but also embedded and mobile processor market. A restricted Developer's toolkit by now.


●Cores de propósito general. Cache distribuida.●5 Redes independientes (32 bits, full duplex): Sistema e I/O, Cache misses y DMA, Tile to Tile Mempry access, User level streaming y acceso escalar.

●Nicho de mercado, sistema de desarrollo, chip con 16-100 cores a la venta.

More Processor In Memory
● CPUs are far more complex than memory● Memory is built using a physical process much more simple Than CPUs:
● Three layer process for DRAM● >10 layers for CPUs
● By designing a much less complex CPU, the same technology than for DRAM can be used (TOMI architecture).
● CPU cores using 22.000 transistors only: No FPU, 32 bit integer HW, reduced set of instructions... embedded in a 1 Gbit DRAM● Much less expensive (1$ compared to 300$ of an Standard CPU)● Uses much less power (98 mW with 8 cores at 2.1 GhzCompared to 100 Watts of an ordinary Intel)
●Manufacturer (Venray technologies) claims: 16 CPUs (128 cores embedded in 16 GB DRAM) outperform by a factorOf 10 to an equivalent Intel cluster at 1/20 cost and 1/10 power.● SW development environment still poor.

IBM/Toshiba/Sony: CELL
Prototipo 4 GHz/ 256 GFlops (sp, no IEC539)/ 25 Gflops(dp, IEEE) / 80W. Destinado a productos de consumo (televisiones HD, PlayStation 3... , pero también se piensaen el para HPC) Un core de arquitectura PPC con cache + 8 procesadores SIMD (a la MMX o AltiVec) con HW simplificado (eg. sin predicción de branch) con 256KB de memoria privada (no cache, bajo control del programa). I/O de 76.8 GB, pero con limitaciones (division en 12 “lanes” con usos especificados para ellas)... hay que notar que también hay que hacer una inversión SW para sacar rendimiento a esto.

IBM Cell X8i

Texas Instruments: Now has an HPCDivision to market the new DigitalSignal Processors with floating point Units... originally developed for 4Gmobile networks.
●Up to 8 cores/chip in 40 nm process.●VLIW + High speed switch fabric (Teranet)●1.25 Ghz, 160 Gflops SP (DP = 3/8 x 160) 10 Watts,
● Better than any GPU... by now.●“Easy” to program:
● No host needed. Works like a CPU.● Standard development kit with C,
OpenMP, MPI●512KB-1MB L2 per core. 32 KB L1.
DSP

¿Problemas calientes?
http://www.phys.ncku.edu.tw/~htsu/humor/fry_egg.html
● Athlon XP 1500.● Disipador sustituido por una pila de monedas.● 11 Min. “time to completion”

Y hay más...

Y hay más...

Y más.
“Thermal Considerations in Cooling a Large Scale High Compute Density Data Center” C.D. Patel et al. Hewlett-Packard

Refrigeración líquida


El empaquetamiento y la baja disipación serán determinantes: IBM BlueGene/L
The BlueGene/L Team “An overview of theBlueGene/L Supercomputer”. Supercomputing2002 technical papers.http://sc-2002.org/program_tech.html
● Actual Nº 1 en el Top500.● 70.72 Tflops● 32768 procs. / 0.8 MW / 70 m2
C h i p( 2 p r o c e s s o r s )
C o m p u t e C a r d( 2 c h i p s , 2 x 1 x 1 )
N o d e B o a r d( 3 2 c h i p s , 4 x 4 x 2 )
1 6 C o m p u t e C a r d s
S y s t e m( 6 4 c a b i n e t s , 6 4 x 3 2 x 3 2 )
C a b i n e t( 3 2 N o d e b o a r d s , 8 x 8 x 1 6 )
2 . 8 / 5 . 6 G F / s4 M B
5 . 6 / 1 1 . 2 G F / s0 . 5 G B D D R
9 0 / 1 8 0 G F / s8 G B D D R
2 . 9 / 5 . 7 T F / s2 5 6 G B D D R
1 8 0 / 3 6 0 T F / s1 6 T B D D R
2 cores de PPC 440 + FP2 a0.7 GHz 4 flops/ciclo/core. Disipador de 15W
A comparar con el Earth Simulator, varios años en el Nº1 del Top500: 35.86 Tflops, 5120 procs. / 1.28 MW (solo los nodos de cómputo) / 3250 m2 (nodos de computo+red+almacenamiento pero sinsoporte adicional -planta para cableado, acondicionamiento, etc.- )

The modern version: IBM BlueGene Q
https://computing.llnl.gov/tutorials/bgq/
Sequoia. 20 Pflops, 5 PB RAM, #1 June 2012. 98 Knodes, 768 I/O Nodes,1.5 Mill. Cores. Water cooled. 2069 Mflops/watt. 5D torus.

The modern version: IBM BlueGene Q compute processor
https://computing.llnl.gov/tutorials/bgq/
* 16 user cores + 1 OS core + 1 reserve.* 1.6 Ghz* 1.470 Mill. Transistors.* 4 FPU, SMT4* 16 KB L1, 32 MB L2 (shared, 2MB slices, crossbar connected with the cores)* 43 GB/s to RAM
Compute card

Evoluciones.➔ En el campo de los vectoriales clásicos también se producen mejoras significativas:
● NEC SX-8: Esencialmente duplica al SX-6 - Pico de 16 Gflops/CPU (frente a 8 del SX-6)
- Ancho de banda de 64GB/s (frente a 32)- En un 25% menos de tamaño y con la mitad de consumo.
● NEC SX-9: (nov. 07)• 3.2 Ghz, 8 unidades vectoriales/chip con 2 FPU capaces de fma:
32x3.2~100 Gflops/chip.• 16 CPU + 1TB en un rack 42U por nodo. • Hasta 4TB/s de ancho de banda por nodo. 256 GB/s entre nodos• Máximo de 512 nodos.
➔ Itanium de momento apuesta por incrementar la velocidad de reloj y aumentar el tamaño de cache (6MB, 24 veces asociativa, de nivel 3 on chip) sin disparar el consumo (130W).

Otras Aproximaciones● Los viejos coprocesadores en nuevos trajes:
– FPGAs como coprocesadores especializados: Ej: generación de números aleatorios.
– GPUs
– Programables: A través de un API especializado en gráficos, no de propósito general.
– FPU 32 bits (no IEEE).Diseñadas para operaciones
muy paralelizables. “Ley de Moore” de 6-8 meses en lugar de cada 18.

➔Texture memory➔Fragment Processors
➔ 8 Vertex shaders con FPUs
➔ 24 Pixel shaders con FPUs
➔ 303 Millones de transistores


● No es trivial programar las GPUs para operaciones que no son gráficas : Hay que hacerlo a través de alguna API (se están desarrollando lenguajes: Brook, Sh). CUDA.
● Hay que usar la memoria eficientemente: Normalmente hay un espacio definido por el problema y un espacio de memoria hw (normalmente una textura 2D) y un paso de traducción intermedio.
Owens et al. “A Survey of General Purpose Computation on Graphics HW” Eurographics 05
Krüger et al. “Linear Algebra operators for GPU Implementation on Numerical Algorithms” SigGraph 03

Galoppo et al. “ LU-GPU: Efficient Algorithms for Solving Dense Linear Systems on Graphics HW”, IEEE/ACM Supercomputing 05

Galoppo et al. “ LU-GPU: Efficient Algorithms for Solving Dense Linear Systems on Graphics HW”, IEEE/ACM Supercomputing 05

“Parallel Processing with CUDA”, T.R. Halfill. Microprocessor Report, January 2008.



• 7.1 Billion transistors, double the previous iteration (GK104’ 3.54 Billion. )
• Each SMX unit contains 192 CUDA cores, 32 load/store units,
• 16 texture units, and 4 warp schedulers. There are 15 SMX

●El programador no crea explícitamente código para los hilos.● A HW thread manager controla los hilos automáticamente.●Los hilos son “ligeros” en tanto operan sobre conjuntos pequeños de datos, pero el soporte es completo: stack, PC, registros, memoria local.●Instrucciones de diferentes hilos pueden compartir el pipeline del procesador. El procesador ouede cambiar de hilo en un ciclo. Esta gestión es transparente para el programador.
saxpy_parallel debecompilarse para laGPU.
OTRAS HERRAMIENTAS: RAPIDMIND, soporte para GPUS de distintos fabricantes.
Dimension del “grid” de datos dado en“bloques” (nblocks) medidos en hilos (256). NVIDIA aconseja usar del orden De 5000 hilos para ocupar la GPU.

AMD Fusion: AMDx86 cores + ATIGraphics in one chip.
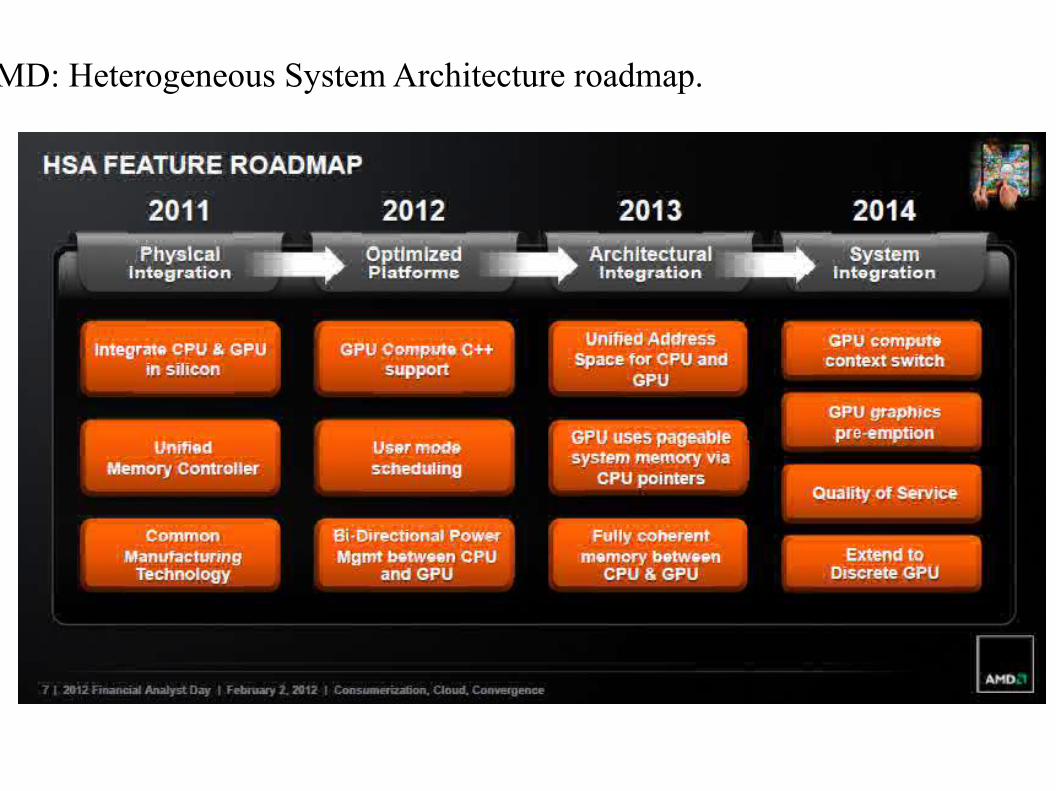
AMD: Heterogeneous System Architecture roadmap.

Texas Instruments: Now has an HPCDivision to market the new DigitalSignal Processors with floating point Units... originally developed for 4Gmobile networks.
Up to 8 cores/chip in 40 nm process. VLIW + High speed switch fabric (Teranet) 1.25 Ghz, 160 Gflops SP (DP = 3/8 x 160) 10 Watts,
Better than any GPU... by now.“Easy” to program:
No host needed. Works like a CPU. Standard development kit with C,
OpenMP, MPI512KB-1MB L2 per core. 32 KB L1.
DSP

FPGAs Field programmable Gate Arrays
• A set of programmable logic blocks with reconfigurable interconnections.• Field programmable using a Hardware Description Language (VHDL, Verilog)• Used typically for embedded processing.• There are very powerful models used forvery demanding applications:
• Avionics, radars• Image processing (medical scanners…• High speed communications• …
• They can be very fast, but it is not easyto program them.• In principle, not very suitable for GeneralPurpose computing• When used together with a computer, theyare mostly used as co-processors.• A section of the code is offloaded to the FPGA,executed there and results transferred back to the host (much as a GPU)
Example of programmable FPGA logic block (wikipedia).LUT= Look Up Table, FA=Full Adder, DFF= D-Type Flip Flop

FPGAs-2
Convey –HC2Hybrid Core computers.
• Blade-style compute nodes: • With communications.• Ready to build a cluster.
• Intel Xeon Processors tightly integrated with FPGAs (Application Engines in Convey jargon)• Sharing the memory with the host: just one addressing space per node.• With cache coherency.
• Hiding the programming of the FPGAs• Using “personalities” (many already prepackaged)
• Instructions sets that increment the IA32.• The user can also develop new personalities through SW (easy, but only when compared
to the traditional approach...)
• Fully integrated with the development SW: Compilers, debuggers, profilers…• The compiler generates a single stream of instructions from the source file.• Some instructions are executed by the Xeons, some by the FPGAs

Optimización Secuencial Nuestro objetivo es usar de la manera más eficiente posible el HW que, para un ordenador secuencial, consideraremos dividido en dosgrandes bloques:
Memoria CPU
y tendremos que hacernos alguna idea de si la eficiencia con la que se ejecuta un programa es razonable o no y los posibles motivos por los que el rendimiento no es óptimo.
En esta sección mostraremos algunas técnicas básicas, para que un programa se aproxime al rendimiento ideal en un sistema monoprocesador

Metodología
● Usar librerías de alto rendimiento siempre que sea posible.
– +30 años de inversión en librerías numéricas, no es para desperdiciarlo...
● Re/escritura de parte del código Análisis del comportamiento del programa: uso de memoria y CPU
– Las modificaciones dedicadas al rendimiento deben ser lo más inobstrusivas posible.
● Optimizaciones automáticas del compilador.
– Conoce tu compilador... viene con manuales.
Poner las cosas fáciles al compilador sin complicar mucho el código.

SECCIÓN I
Uso de Librerías

Librerías: Objetivos● Aumento de Productividad:
– Del programador:● Facilidad de uso / Interfaz cómodo: claridad y modularidad● Reutilización de componentes.● Mejora de la portabilidad.
– Del usuario:● Mayor velocidad.● Uso eficiente de los recursos computacionales.
... y, además, en nuestro caso, usuario y programador suelen coincidir.

BLAS: una Librería Tipo● Ejemplo clásico de librería matemática, muy eficiente,
muy usada y muy extendida.– Es una especificación de interfaz para operaciones básicas con
vectores y matrices -> Problemas regulares y altamente optimizables.
– Operaciones seleccionadas por ser muy comunes en la gran mayoría de aplicaciones en ciencia e ingeniería.
– La implementación real la realiza el fabricante del hardware -> Muy eficientes
– Habitualmente incluidas con las librerías que suministra el fabricante: ESSL de IBM, dxml de Digital/Compaq/HP, mathlib de SGI, etc. Implementaciones automáticas: ATLAS

BLAS (2)● Especificación inicial en 1977 (nivel 1). Ultimas
modificaciones en 2001 (nuevas rutinas, precisión extendida...)
● Forman la base de otras librerías de alto nivel, siendo esenciales para su eficiencia.
● Bindings para casi todos los lenguajes relevantes: F77/f90/95/HPF, C/C++
● Versiones secuencial, pBLAS: paralela, memoria distribuida. SparseBLAS para matrices dispersas.
– BLACS, misma filosofía para comunicaciones.
– BLAST, Basic Local Alignment Tool: Biología.

BLAS: Estructura● Rutinas distribuidas en niveles:
– Nivel 1: Operaciones vector-vector
– Nivel 2: Operaciones vector-matriz
– Nivel 3: Operaciones matriz-matriz
● Clave para la eficiencia: Manejar correctamente la jerarquía de memoria para tener todas las unidades funcionales llenas.
y yx
y yAx
A ABC

BLAS: Levels
BLAS Levels:� Level 1: vector-vector (i.e.: DAXPY)
� Level 2: matrix-vector (i.e.: DGEMV)
� Level 3: matrix-matrix (i.e.: DGEMM)
• Memory operations are slower: • Bring all that is needed from memory only once.• Use it for all that is needed and forget.
Level 3 BLAS for maximum performance.
Flops: 2n+1 Memory refs: 3n+1 Ratio: 2/3
Flops: 2n2 Memory refs: 2n2+ 3n Ratio: 2
Flops: 2n3 Memory refs: 4n2 Ratio: 2n

Matrix, vectors, flops and complexity
Use as a rough guide the leading order. Vector-vector (length n)
� Vector sum, multiplication by a scalar: ~ n flops.� Inner (outer products): ~2n (~n)
• Matrix-vector: y = Ax, A=mxn matrix.� ~2mn (n large)� ~2N, if A sparse with N nonzero elements� ~2p(n+m) if A is given as a factorization: A=UVT with
U=mxp and VT=pxn
• Matrix-matrix: C=AB, A mxn, B nxp
• ~2mnp (n large)
• ~m2n if C symmetric and p=m
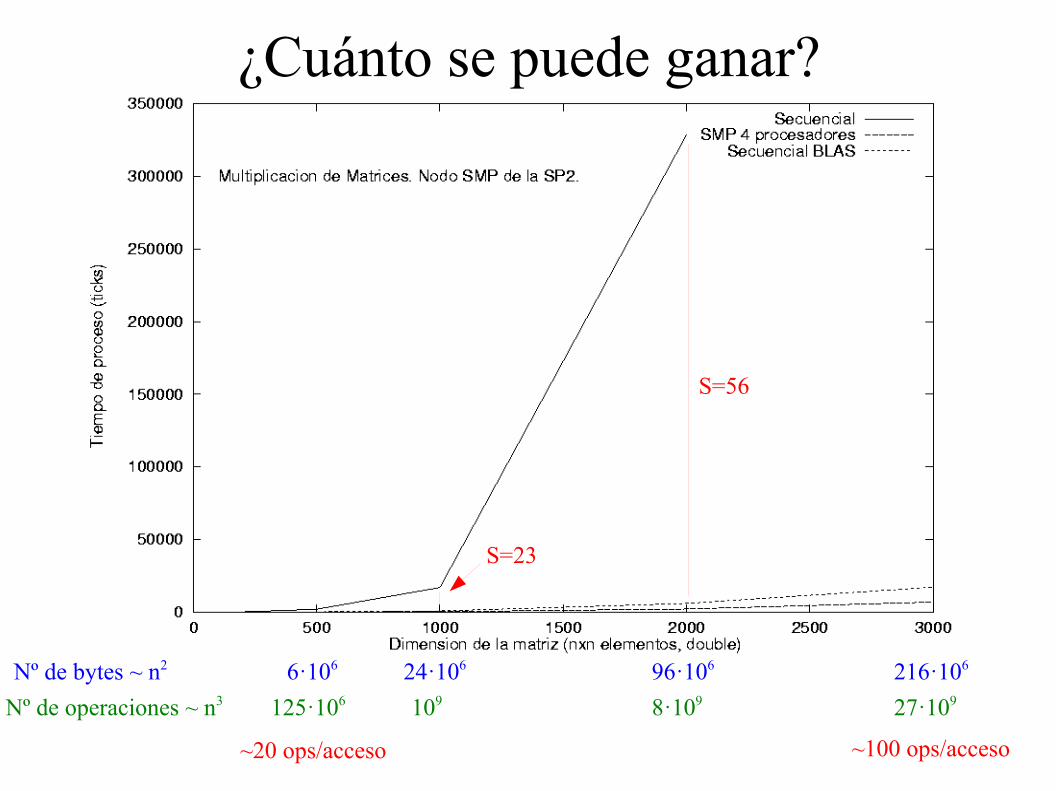
¿Cuánto se puede ganar?
S=23
S=56
Nº de bytes ~ n2 6·106 24·106 96·106 216·106
Nº de operaciones ~ n3 125·106 109 8·109 27·109
~20 ops/acceso ~100 ops/acceso

Ampliación de la parte inferior de la gráfica anterior.
Nº de bytes ~ n2 6·106 24·106 96·106 216·106
Nº de operaciones ~ n3 125·106 109 8·109 27·109
S=2.6
S=2.7S=2.9
S=2.5
S=23
S=20S=52
S=62
S=3.2
20 ops/acceso 100 ops/acceso

AEOS y SANS
● Automatic Empirical Optimization of Software – Given a well defined API with a good speed up
potential (eg: BLAS, LAPACK)● Automate the generation of optimally performing SW for a
given HW/SW platform, thus making it cheaper and more quickly available.
● Self Adapting Numerical Software.– Look for the most efficient method to solve a problem
in an automatic way.

● What you need to automatically optimize a library:– Isolate critical (where time is spend) routines (or pack the
critical pieces of code within a well defined I/O interface)– Implement a method to adapt theSW to different
environments: Code generation, parameterization (e.g.: block size for the different cache levels, unroling depth, etc.)
● Give an option to include highly optimized “hand written” code for a specific purpose/architecture that could have been developed by others.
– Robust time measurement, stable and able to give good results in different environments or in machines under heavy load.
– Build heuristics to find out a good implementation.

ATLAS● Automatically Tuned Linear Algebra Software.
– The most complete AEOS project.
– Assume a good C Compiler.
– Assume a memory hierarchy: At least registers and L1.
● Produces:
– BLAS level 3 (dense) based on an optimized GEMM (GEneral Matrix Matrix: matrices multiplicatio. All the rest are generated from GEMM)
– BLAS level 2 (dense) based on GENMV y GENR (multiplicación matrix vector multiply and vector update)
– BLAS level 1. Just a reference, without optimization..
– Some LAPACK routines: LU and
Cholesky decomposition. Note: Speed up is proportional to memory reuse. The Flops/Mem ops. ratio is much higher in Level 3 than in Level 1.

ATLAS: Ganancias y comparativa

SECCIÓN II
Optimización en el Subsistema de Memoria

CPU vs. memoria.
60 % per year
7% per year
How to deal with this?● Memory hierarchy(+cache +levels)● Prefetching, streaming(HW & SW)● Instruction reordering (Very detailed knowledge of the HW: memory subsystemand functional units)● Support for threads.
D. Klepacki, IBM.

Jerarquía de Memoria
*Las velocidades de transferencia citadasson picos basados en parametros HW, lasreales en una aplicación son mucho menores. Las cifras escritas pretenden más expresar la relación entre los distintos niveles que valores absolutos, ya que estos cambian con la tecnología y hay que actualizarlas.

Memoria y Sistema Operativo
El SO da a cada proceso de usuario una imagen lineal (contigua) de lamemoria. Estas imágenes se corresponden con páginas(bloques) de tamaño fijo(desde 4 KB a 16MB) quese corresponden con porciones de la memoriafísica que no tienen por que ser contiguas.La traducción de direcciones entre el espacio de usuario y el espaciofísico, real, la realiza el SO con ayudade tablas de páginas. Para hacer más rápido el proceso se usa HW específico que incluye caches con trozos de estas tablas (TLB)
Morris 98

Traducción de Memoria Virtual-Real
Morris 98
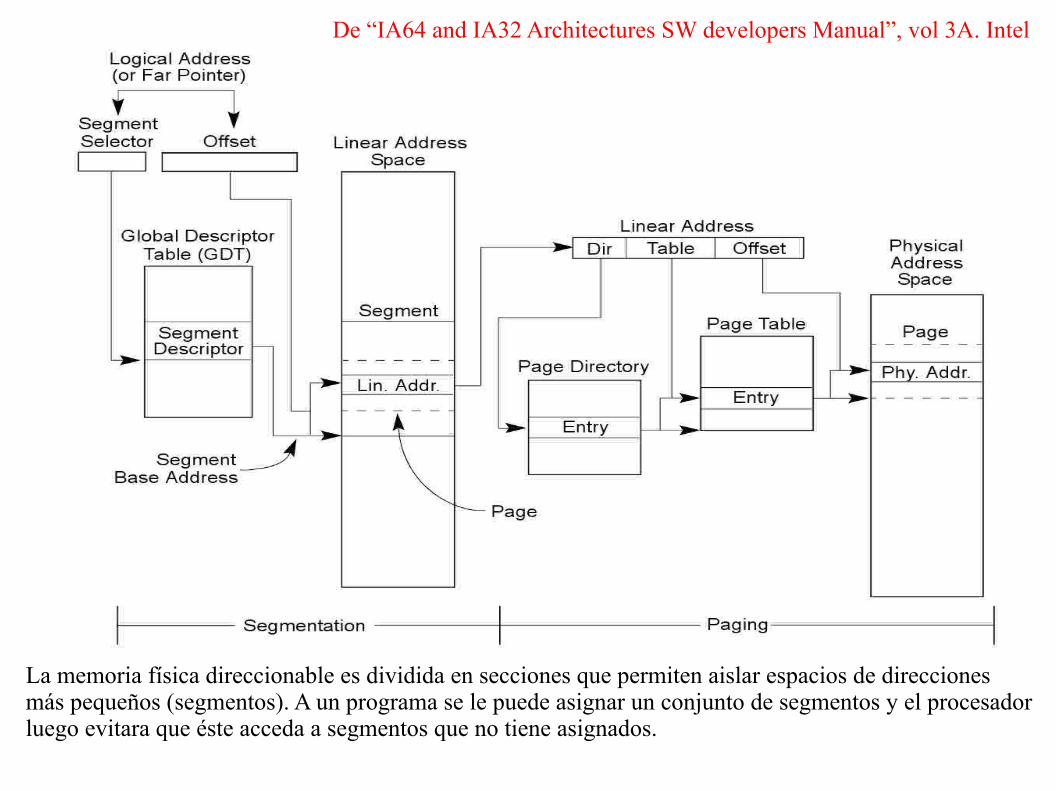
De “IA64 and IA32 Architectures SW developers Manual”, vol 3A. Intel
La memoria física direccionable es dividida en secciones que permiten aislar espacios de direcciones más pequeños (segmentos). A un programa se le puede asignar un conjunto de segmentos y el procesadorluego evitara que éste acceda a segmentos que no tiene asignados.

El Ciclo de la Memoria
Resulta evidente que fallos en la cache alargan notablemente el ciclo.
Morris 98

Uso de la Jerarquía de memoria:Funcionamiento de la cache.
If not in the cache,bring in a full line. Depending on associativity, each line can reference a limited set of addresses.

Uso de la Jerarquía de
MemoriaEjemplo: Cache 1
vez asociativa
La asociatividad indicael número de grupos distintosde bytes a los que puede apuntar una misma línea de la cache.

Uso de la Jerarquía de Memoria● Importancia del acceso a posiciones contiguas en
memoria:– Para no hacer fallos de cache: Un fallo puede costar
cualquier cosa entre 5 ciclos y cientos de ciclos... dependiendo si el dato está en L2, L3 y pudiendo llegar a miles si estamos en una máquina NUMA relativamente grande.
– Para utilizar todos los elementos de una linea y no hacer vaciados/llenados innecesarios de lineas de cache o agotar la asociatividad.
● En realidad un sistema sin cache funcionaría mejor... si pudiesemos permitirnoslo – (remember politically incorrect Seymour's Cray quote...)

K.Yelick, CS262, Yale.
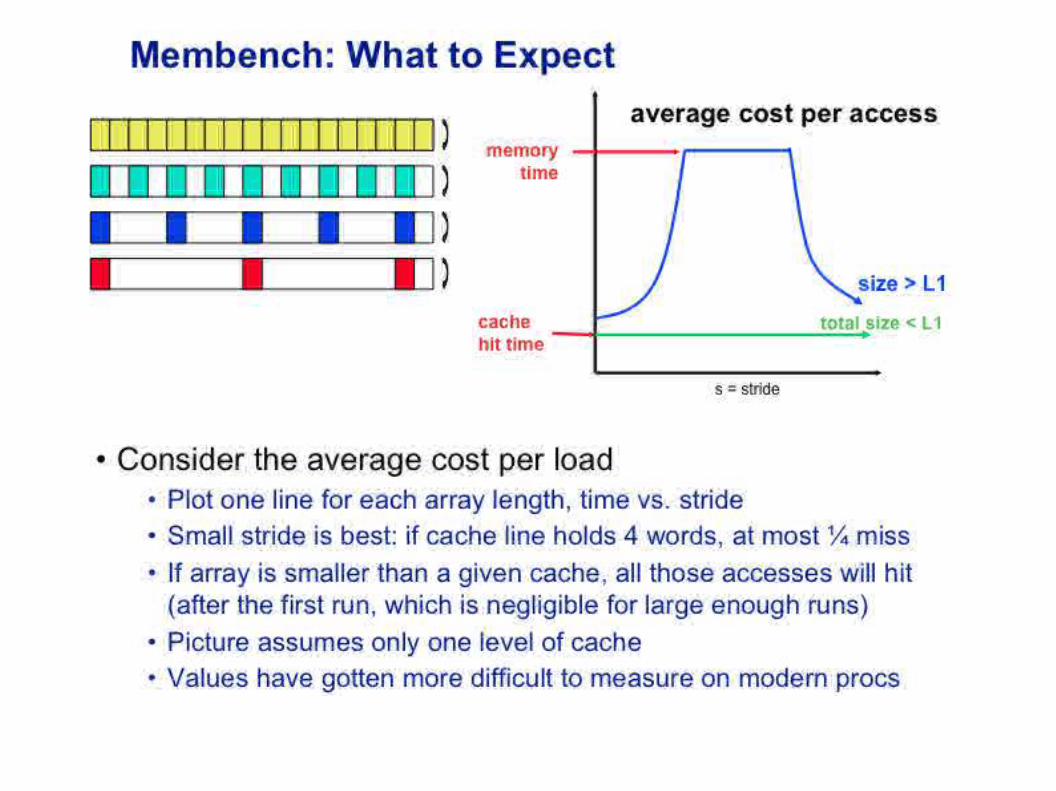

Una Jerarquía
Real
8 KB L1, 6.67 ns
256KB L2, 60ns
Main memory, 300ns
Paginasde 8KB
Lineas de 32 B
For (arraySize = 4KB; arraySize < 8MB; arraySize *= 2) for (stride = 1; stride <= arraySize/2; stride *=2) for (i = 0; i < arraySize: i*= stride) load A(i) (8 bytes)
For (arraySize = 4KB; arraySize < 8MB; arraySize *= 2) for (stride = 1; stride <= arraySize/2; stride *=2) for (i = 0; i < arraySize: i*= stride) load A(i) (8 bytes)
“Empirical Evaluationof the Cray T3D: A Compiler Perspective”R. Arpaci et al.
150 MHz (6.67 ns / ciclo)

Buen Estilo de Acceso a Memoria● En Fortran los elementos de una matriz se almacenan por
columnas (en C por filas): El elemento contiguo a B(1,1) es B(2,1) y asi hasta B(m,1). El contiguo a B(1,2) es B(2,2)... B(m,2)
● El siguiente ejemplo muestra cómo se usa esto en un programa. Ordenando los índice de modo que los accesos sean contiguos no se hacen fallos de cache y se utilizan todos los elementos que caben en una línea.

Test de Acceso a Memoria! Ejemplo de fallos de cache por ! mal acceso a memoria.
Integer, Parameter :: N=1024, M=1024 Real, Dimension (N,M) :: a,b Integer :: Inicio, Final, TicksPerSecond
Common /comun/a,b ! Buen acceso
Call System_Clock(Inicio,TicksPerSecond)
Do j=1, M
Do i=1, N
a(i,j) = b(i,j) + i End Do End Do
Call System_Clock(Final)
Print *,' Segundos :', &Float(Final-Inicio)/(Float(TicksPerSecond)) Print *,' Flops :', &(N*M)/(Float(Final-Inicio)/(Float(TicksPerSecond))) ! Mal acceso Call System_Clock(Inicio)
Do i=1, N
Do j=1, M
a(i,j) = b(i,j) + j End Do End Do
Call System_Clock(Final) Print *,' Segundos :', &Float(Final-Inicio)/(Float(TicksPerSecond))
End

Y todavía puede ser peor: Cache Trashing● El siguiente ejemplo es para una cache de 8KB dos veces asociativa.● Se definen tres vectores, cada uno ocupa completamete la cache. Se fuerza que el almacenamiento sea contiguo usando un bloque common● Seguidamente hacemos referencia a ellos usando los mismo índices. Las dimensiones se han elegido de modo que estemos requiriendo cada vez elementos de distinto vector a la misma línea de cache. Como la asociatividad es dos, no hay una tercera linea de cache disponible para apuntar al tercer elemento, así que la única posibilidad es vaciar una de las dos lineas, llenarla con los elementos del otro vector, usar uno solo y volverla a vaciar para volver a llenarla con los del otro... en este caso la jerarquia de memoria trabaja en contra nuestra.

Cache Trashing: Ejemplo! Ejemplo de fallos de cache por ! cache trashing. Se supone cache de 8 KB! y dos veces asociativo.
Integer, Parameter :: N=1024 Real(kind(1.0D0)), Dimension (N) :: a,b,c Integer :: Inicio, Final, TicksPerSecond, promedio
Common /comun/a,b,c ! Cache trashing Print *,' numero de vueltas en el bucle :' Read *, promedio Call System_Clock(Inicio,TicksPerSecond) ! para hacer promedios con una cierta credibilidad
Do j=1,promedio Do i=1, N a(i) = a(i) + b(i) + c(i) End Do ! a = a + b + c End Do
! Ejemplo de fallos de cache por ! cache trashing. Se supone cache de 8 KB! y dos veces asociativo.
Integer, Parameter :: N=1024 Real(kind(1.0D0)), Dimension (N) :: a,b,c Integer :: Inicio, Final, TicksPerSecond, promedio
Common /comun/a,b,c ! Cache trashing Print *,' numero de vueltas en el bucle :' Read *, promedio Call System_Clock(Inicio,TicksPerSecond) ! para hacer promedios con una cierta credibilidad
Do j=1,promedio Do i=1, N a(i) = a(i) + b(i) + c(i) End Do ! a = a + b + c End Do
Call System_Clock(Final) Print *,' Segundos :', &Float(Final-Inicio)/(Float(TicksPerSecond)) Print *,' Flops :', & (N*promedio)/(Float(Final-Inicio)/(Float(TicksPerSecond)))
Print *,' numero:' Read *, promedio Print *, a(promedio)
End
Call System_Clock(Final) Print *,' Segundos :', &Float(Final-Inicio)/(Float(TicksPerSecond)) Print *,' Flops :', & (N*promedio)/(Float(Final-Inicio)/(Float(TicksPerSecond)))
Print *,' numero:' Read *, promedio Print *, a(promedio)
End

... pero puede solucionarse: padding● Para evitar que se pidan posiciones de memoria
distintas a la misma línea de cache, bastará con desplazar uno de los vectores con direcciones asignadas a dicha línea por, al menos, un vector que ocupe una línea de cache.
● Algunos compiladores son capaces de reconocer este problema y resolverlo, aunque a veces hay que pedirlo explícitamente con alguna opción (bien específica o de optimización)

Array Padding: Ejemplo.
! Ejemplo de fallos de cache por ! cache trashing. Se supone cache de 8 KB! y dos veces asociativo. Lineas de 32 bytes.
Integer, Parameter :: N=1024 Real(kind(1.0D0)), Dimension (N) :: a,b,c Real(kind(1.0D0)), Dimension (4) :: ap, bp Integer :: Inicio, Final, TicksPerSecond, promedio
Common /comun/a,ap,b,bp,c ! Cache trashing Print *,' numero de vueltas en el bucle :' Read *, promedio
Call System_Clock(Inicio,TicksPerSecond) ! para hacer promedios con una cierta credibilidad! Do j=1,promedio Do i=1, N a(i) =a (i) + b(i) + c(i) End Do End Do
! Ejemplo de fallos de cache por ! cache trashing. Se supone cache de 8 KB! y dos veces asociativo. Lineas de 32 bytes.
Integer, Parameter :: N=1024 Real(kind(1.0D0)), Dimension (N) :: a,b,c Real(kind(1.0D0)), Dimension (4) :: ap, bp Integer :: Inicio, Final, TicksPerSecond, promedio
Common /comun/a,ap,b,bp,c ! Cache trashing Print *,' numero de vueltas en el bucle :' Read *, promedio
Call System_Clock(Inicio,TicksPerSecond) ! para hacer promedios con una cierta credibilidad! Do j=1,promedio Do i=1, N a(i) =a (i) + b(i) + c(i) End Do End Do
Call System_Clock(Final) Print *,' Segundos :', &Float(Final-Inicio)/(Float(TicksPerSecond)) Print *,' Flops :', &(N*promedio)/(Float(Final-Inicio)/(Float(TicksPerSecond)))
Print *,' numero:' Read *, promedio Print *, a(promedio)
End
Call System_Clock(Final) Print *,' Segundos :', &Float(Final-Inicio)/(Float(TicksPerSecond)) Print *,' Flops :', &(N*promedio)/(Float(Final-Inicio)/(Float(TicksPerSecond)))
Print *,' numero:' Read *, promedio Print *, a(promedio)
End

Otros Problemas: TLB
● Ya vimos que el TLB (Translation Lookaside Buffer) era una cache usada para gestionar la traducción de direcciones lógicas (virtuales) y físicas.
● Mantiene un trozo de la tabla de traducción con las correspondencias entre páginas virtuales y físicas.
● Fallos en el acceso a la TLB también penalizan el rendimiento, aunque tienden a permanecer más oculto que los fallos de cache

Translation Lookaside Buffer● Suele ser más difícil encontrar los parámetros de la TLB
que los de la cache.– Típicamente su tamaño va de 32 a 1024 entradas con
asociatividades que van desde completa hasta sólo 2.
– El tamaño de página va desde 512Bytes a 64KB, un tamaño típico es de 4KB.
● Más raramente se puede encontrar soporte para páginas muy grandes (16MB, Power4). En este caso suele ser necesario también modificar algún parámetro del sistema operativo.
● De nuevo la idea es mantener localidad espacial.– Problemas con la TLB suelen surgir con más probabilidad al
acceder a posiciones muy separadas entre sí y con potencias de 2.

Fallos de TLB: Ejemplo
! Bad TLB use. Integer, Parameter :: D=128, tlbpad=1 Real(Kind(1.0D0)), Dimension(D,D,D) ::a,b,c Real(Kind(1.0D0)), Dimension(D,D+tlbpad,D) :: da,db,dc Integer :: Inicio, Final, TicksPerSecond, Iter Common /comun/a,b,c Common /dcomun/da,db,dc Print *,' Indice del bucle :'Read *, nIter=n*n*n
Call CPU_Time(TiempoInicial) Do k=1,n Do j=1,n Do i=1,n a(i,j,k) = b(i,j,k)+c(i,j,k) End Do End Do End Do Call CPU_Time(TiempoFinal) Print *,' Iteraciones :',Iter Print *,' Segundos :', TiempoFinal-TiempoInicial Print *,' Flops :', Float(Iter)/(TiempoFinal-TiempoInicial)
! Bad TLB use. Integer, Parameter :: D=128, tlbpad=1 Real(Kind(1.0D0)), Dimension(D,D,D) ::a,b,c Real(Kind(1.0D0)), Dimension(D,D+tlbpad,D) :: da,db,dc Integer :: Inicio, Final, TicksPerSecond, Iter Common /comun/a,b,c Common /dcomun/da,db,dc Print *,' Indice del bucle :'Read *, nIter=n*n*n
Call CPU_Time(TiempoInicial) Do k=1,n Do j=1,n Do i=1,n a(i,j,k) = b(i,j,k)+c(i,j,k) End Do End Do End Do Call CPU_Time(TiempoFinal) Print *,' Iteraciones :',Iter Print *,' Segundos :', TiempoFinal-TiempoInicial Print *,' Flops :', Float(Iter)/(TiempoFinal-TiempoInicial)
Call CPU_Time(TiempoInicial) Do k=1,n Do j=1,n Do i=1,n da(i,j,k) = db(i,j,k)+dc(i,j,k) End Do End Do End Do Call CPU_Time(TiempoFinal)
Print *,' Iteraciones :',Iter Print *,' Segundos :', TiempoFinal-TiempoInicial Print *,' Flops :', &Float(Iter)/(TiempoFinal-TiempoInicial)
End
Call CPU_Time(TiempoInicial) Do k=1,n Do j=1,n Do i=1,n da(i,j,k) = db(i,j,k)+dc(i,j,k) End Do End Do End Do Call CPU_Time(TiempoFinal)
Print *,' Iteraciones :',Iter Print *,' Segundos :', TiempoFinal-TiempoInicial Print *,' Flops :', &Float(Iter)/(TiempoFinal-TiempoInicial)
End

Bloques.
● Una técnica habitual para mantener localidad de referencias es reformular el problema usando arrays divididos en bloques de tamaño elegido para usar eficientemente los diversos niveles de cache.
● En situaciones en las que es inevitable acceder a posiciones muy separadas entre sí esta técnica puede evitar la repetición innecesaria de fallos de cache/TLB.

Uso de Bloques: Program Blocked! Mejorando el rendimiento evitando fallos ! repetitivos de cache y TLB usando bloques. Integer, parameter :: N=2048, NB=32 Real(Kind(1.0D0)) :: A(N,N),B(N,N) Real(Kind(1.0D0)) :: Final, Inicial, Flops Integer :: I,J,K Flops=N*N*2 Do I=1,N Do J=1,N A(J,I)=rand()*J+I B(J,I)=rand()*I+J End Do End Do Call CPU_Time(Inicial) Do I=1,N Do J=1,N S=S+A(I,J)*B(J,I) End Do End Do Call CPU_Time(Final) Print *,'Segundos :',Final-Inicial Print *,'MFlops :', Flops/(Final-Inicial),'S :',S
Program Blocked! Mejorando el rendimiento evitando fallos ! repetitivos de cache y TLB usando bloques. Integer, parameter :: N=2048, NB=32 Real(Kind(1.0D0)) :: A(N,N),B(N,N) Real(Kind(1.0D0)) :: Final, Inicial, Flops Integer :: I,J,K Flops=N*N*2 Do I=1,N Do J=1,N A(J,I)=rand()*J+I B(J,I)=rand()*I+J End Do End Do Call CPU_Time(Inicial) Do I=1,N Do J=1,N S=S+A(I,J)*B(J,I) End Do End Do Call CPU_Time(Final) Print *,'Segundos :',Final-Inicial Print *,'MFlops :', Flops/(Final-Inicial),'S :',S
! Falta codigo aqui: Hacer flush Reiniciar A(I,J),B(I,J)
Call CPU_Time(Inicial) Do II=1,N,NB Do JJ=1,N,NB Do I=II,Min(N,II+NB-1) Do J=JJ,Min(N,JJ+NB-1) S=S+A(I,J)*B(J,I) End Do End Do End Do End Do Call CPU_Time(Final) Print *,'Segundos :',Final-Inicial Print *,'MFlops :', Flops/(Final-Inicial),'S :',S Stop End
! Falta codigo aqui: Hacer flush Reiniciar A(I,J),B(I,J)
Call CPU_Time(Inicial) Do II=1,N,NB Do JJ=1,N,NB Do I=II,Min(N,II+NB-1) Do J=JJ,Min(N,JJ+NB-1) S=S+A(I,J)*B(J,I) End Do End Do End Do End Do Call CPU_Time(Final) Print *,'Segundos :',Final-Inicial Print *,'MFlops :', Flops/(Final-Inicial),'S :',S Stop End

!C... Bucle triple Print *,'Iniciando mult. Bucle Triple (dos matrices mal acceso)' Call SYSTEM_CLOCK(InitialClock,TicksPerSecond)
Do i=1, NumColMat1 Do j=1, NumColMat2 Do k=1, NumColMat1 Res(i,j) = Res(i,j) + Mat1(i,k)*Mat2(k,j) End Do End DoEnd Do Call SYSTEM_CLOCK(FinalClock)ETime = (FinalClock - InitialClock) ETime = ETime/TicksPerSecond Print *,' Tiempo (segs.):',ETime
Probar tiempos de ejecución: Multiplicaciónde matrices con el bucle triple estándar.

!C... Bucle triple con hoisting. Print *, 'Iniciando mult. Bucle Triple con hoisting-2 de Mat2' Call SYSTEM_CLOCK(InitialClock,TicksPerSecond)
Do j=1, NumColMat2,2 Do k=1, NumColMat1,2
Mat2_00=Mat2(k,j) Mat2_10=Mat2(k+1,j) Mat2_01=Mat2(k,j+1) Mat2_11=Mat2(k+1,j+1) Do i=1, NumColMat1 Res(i,j) = Res(i,j)+Mat1(i,k)*Mat2_00+Mat1(i,k+1)*Mat2_10 Res(i,j+1)= Res(i,j+1)+Mat1(i,k)*Mat2_01+Mat1(i,k+1)*Mat2_11
End Do End DoEnd Do Call SYSTEM_CLOCK(FinalClock)ETime = (FinalClock - InitialClock)ETime = ETime/TicksPerSecond Print *,' Tiempo (segs.):',ETime
Multiplicación de matrices: Hoisting

Herramientas de Trazado (profiling)● Lo primero, antes de optimizar un programa, es saber donde
consume el tiempo.
● Para ello hay herramientas de trazado. Hay muchas, las más completas suelen ser de pago...
– Las típicas, gratuitas, que suelen estar incluidas en todos los SO tipo UNIX: prof, gprof. Son trazadores de bloques.
– También se pueden encontrar tcov, tprof, pixie. Son trazadores de línea.● Un trazador interrumpe continuamente la ejecución del programa. El
proceso de las interrupciones resulta muy costoso y puede degradar el rendimiento del SO. Para ejecutar alguna de estas herramientas es posible que el usuario deba pertenecer a algún grupo con privilegios especiales.
– Herramientas de dominio público y que son muy prometedoras: oprofile, PAPI.

Trazado de Programas● Uso de prof y gprof:
– Compilar el programa con los modificadores -p o -pg, respectivamente.
– Ejecutar el programa normalmente. Esto produce un archivo mon.out o gmon.out
– Procesar los archivos mon o gmon en conjunción con el programa original <prog> con la orden:
● prof <prog> mon.out● gprof <prog> gmon.out
– Se puede analizar simultáneamente varios gmon.out, adecuadamente renombrados, procedentes de varias ejecuciones
– Cuidado con las opciones de optimización (-O) y la inclusión de información simbólica (-g)

Ejemplos de prof y gprof Program exprof
! Ejemplo para uso de prof y gprof Integer :: i Call A Call B
End Program exprof
Subroutine A
Integer :: i
Call C
Do I=1,5000000
End DO
End Subroutine A
Program exprof
! Ejemplo para uso de prof y gprof Integer :: i Call A Call B
End Program exprof
Subroutine A
Integer :: i
Call C
Do I=1,5000000
End DO
End Subroutine A
Subroutine B
Integer :: i
Call C
Do I=1, 10000000 End DO
End Subroutine B
Subroutine C
Integer :: i
Do I=1, 5000000 End Do
End Subroutine C
Subroutine B
Integer :: i
Call C
Do I=1, 10000000 End DO
End Subroutine B
Subroutine C
Integer :: i
Do I=1, 5000000 End Do
End Subroutine C
$ f90 -p exprof.f90 -o ex $ ./ex$ prof ./ex mon.out
$ f90 -pg exprof.f90 -o exg$ ./exg$ gprof ./exg gmon.out
$ f90 -p exprof.f90 -o ex $ ./ex$ prof ./ex mon.out
$ f90 -pg exprof.f90 -o exg$ ./exg$ gprof ./exg gmon.out

Salida de prof
Name %Time Seconds Cumsecs #Calls msec/call.b 41.0 0.25 0.25 1 250..c 39.3 0.24 0.49 2 120..a 19.7 0.12 0.61 1 120..main 0.0 0.00 0.61 1 0..free 0.0 0.00 0.61 2 0..free_y 0.0 0.00 0.61 2 0..exit 0.0 0.00 0.61 1 0..monitor 0.0 0.00 0.61 1 0..moncontrol 0.0 0.00 0.61 1 0..catopen 0.0 0.00 0.61 1 0..setlocale 0.0 0.00 0.61 1 0..getenv 0.0 0.00 0.61 1 0.
Name %Time Seconds Cumsecs #Calls msec/call.b 41.0 0.25 0.25 1 250..c 39.3 0.24 0.49 2 120..a 19.7 0.12 0.61 1 120..main 0.0 0.00 0.61 1 0..free 0.0 0.00 0.61 2 0..free_y 0.0 0.00 0.61 2 0..exit 0.0 0.00 0.61 1 0..monitor 0.0 0.00 0.61 1 0..moncontrol 0.0 0.00 0.61 1 0..catopen 0.0 0.00 0.61 1 0..setlocale 0.0 0.00 0.61 1 0..getenv 0.0 0.00 0.61 1 0.

Salida de gprof(parcial)
called/total parents index %time self descendents called+self name index called/total children
0.00 0.48 1/1 .__start [2][1] 100.0 0.00 0.48 1 .main [1] 0.12 0.12 1/1 .a [4] 0.12 0.12 1/1 .b [5]
-----------------------------------------------
6.6s <spontaneous>[2] 100.0 0.00 0.48 .__start [2] 0.00 0.48 1/1 .main [1]
-----------------------------------------------
0.12 0.00 1/2 .a [4] 0.12 0.00 1/2 .b [5][3] 50.0 0.24 0.00 2 .c [3]
-----------------------------------------------
0.12 0.12 1/1 .main [1][4] 50.0 0.12 0.12 1 .a [4] 0.12 0.00 1/2 .c [3]
-----------------------------------------------
0.12 0.12 1/1 .main [1][5] 50.0 0.12 0.12 1 .b [5] 0.12 0.00 1/2 .c [3]
-----------------------------------------------
called/total parents index %time self descendents called+self name index called/total children
0.00 0.48 1/1 .__start [2][1] 100.0 0.00 0.48 1 .main [1] 0.12 0.12 1/1 .a [4] 0.12 0.12 1/1 .b [5]
-----------------------------------------------
6.6s <spontaneous>[2] 100.0 0.00 0.48 .__start [2] 0.00 0.48 1/1 .main [1]
-----------------------------------------------
0.12 0.00 1/2 .a [4] 0.12 0.00 1/2 .b [5][3] 50.0 0.24 0.00 2 .c [3]
-----------------------------------------------
0.12 0.12 1/1 .main [1][4] 50.0 0.12 0.12 1 .a [4] 0.12 0.00 1/2 .c [3]
-----------------------------------------------
0.12 0.12 1/1 .main [1][5] 50.0 0.12 0.12 1 .b [5] 0.12 0.00 1/2 .c [3]
-----------------------------------------------
Hacia arriba: Información relativa a esta rutina (b) procedente de sus padres
Hacia abajo: Información relativa a esta rutina (b) procedente de sus hijos
Información de la propia rutina.

Más sobre trazadores● prof y gprof son ejemplos de trazadores de bloques:
– Su instrumentación implica el generar puntos de entrada/salida en determinados bloques de código (e.g.: una subrutina) y contar las veces/tiempos que se pasa por estos puntos.
– O hacer estadísticas sobre el Program Counter. ● Los trazadores de bloques son mas intrusivos desde el punto de vista
del programa o del SO.
● Otros trazadores están basados en leer contadores especializados interconstruidos en el HW de la CPU.
● Algunos los llaman Performance Counters ... confusión con el PC.

● Contadores HW: Prácticamente todas las CPUs modernas tienen HW capaz de contar las veces que ocurren determinados eventos (ej.: fallos de cache L1, número de ciclos en modo usuario, etc.)– El número de eventos distintos que se pueden contar
individualmente son del orden del centenar.
– No todos se pueden contar a la vez (multiplexar)
– No existe un conjunto estándar que implementen todas las CPUs y estos pueden variar incluso entre versiones de la misma CPU.

● La infraestructura para usar estos contadores suele ser:– (casi) inexistente o propietaria.
– No portable.
– ... y no demasiado amigable.
– Suele pasar por instrumentalizar el ejecutable (al igual que con prof o gprof) o el código fuente y su salida es postprocesada (a veces con el mismo prof o gprof)
● PAPI: Performance API– Portable... dentro de los limites impuestos por la
diversidad del HW.
– Uso como librería: instrumentalizar el código fuente.

Ejemplos: perfex (SGI)$ perfex -a -y -o perfex.results.col.bueno col.buenoSummary for execution of col.bueno
Based on 250 MHz IP27 MIPS R10000 CPU CPU revision 3.x Typical Minimum Maximum Event Counter Name Counter Value Time (sec) Time (sec) Time (sec)=================================================================================================================== 0 Cycles...................................................... 100991312 0.403965 0.403965 0.40396516 Cycles...................................................... 100991312 0.403965 0.403965 0.40396514 ALU/FPU progress cycles..................................... 64784816 0.259139 0.259139 0.259139 2 Issued loads................................................ 42833760 0.171335 0.171335 0.17133518 Graduated loads............................................. 42319536 0.169278 0.169278 0.16927821 Graduated floating point instructions....................... 8940384 0.035762 0.017881 1.859600 3 Issued stores............................................... 8874944 0.035500 0.035500 0.03550019 Graduated stores............................................ 8868368 0.035473 0.035473 0.03547326 Secondary data cache misses................................. 89440 0.027011 0.017659 0.03005225 Primary data cache misses................................... 648544 0.023374 0.007316 0.023374 6 Decoded branches............................................ 4531936 0.018128 0.018128 0.01812822 Quadwords written back from primary data cache.............. 764704 0.011776 0.009605 0.013612 7 Quadwords written back from scache.......................... 183424 0.004696 0.003104 0.00469623 TLB misses.................................................. 1232 0.000336 0.000336 0.000336 9 Primary instruction cache misses............................ 960 0.000069 0.000022 0.00006924 Mispredicted branches....................................... 2192 0.000012 0.000006 0.00004610 Secondary instruction cache misses.......................... 16 0.000005 0.000003 0.00000530 Store/prefetch exclusive to clean block in scache........... 240 0.000001 0.000001 0.000001 1 Issued instructions......................................... 112601408 0.000000 0.000000 0.450406 4 Issued store conditionals................................... 0 0.000000 0.000000 0.000000 5 Failed store conditionals................................... 0 0.000000 0.000000 0.000000 8 Correctable scache data array ECC errors.................... 0 0.000000 0.000000 0.00000011 Instruction misprediction from scache way prediction table.. 64 0.000000 0.000000 0.00000012 External interventions...................................... 384 0.000000 0.000000 0.00000013 External invalidations...................................... 7120 0.000000 0.000000 0.00000015 Graduated instructions...................................... 117072976 0.000000 0.000000 0.46829217 Graduated instructions...................................... 116068032 0.000000 0.000000 0.46427220 Graduated store conditionals................................ 0 0.000000 0.000000 0.00000027 Data misprediction from scache way prediction table......... 199248 0.000000 0.000000 0.00079728 External intervention hits in scache........................ 384 0.000000 0.000000 0.00000029 External invalidation hits in scache........................ 2752 0.000000 0.000000 0.00000031 Store/prefetch exclusive to shared block in scache.......... 0 0.000000 0.000000 0.000000
(Contadores HW)
(Trazado de col.f: acceso por columnas en un array Fortran. Ejecutado en una SGI Origin 2000 del CEPBA: karnak)

Statistics=========================================================================================Graduated instructions/cycle................................................ 1.159238Graduated floating point instructions/cycle................................. 0.088526Graduated loads & stores/cycle.............................................. 0.506855Graduated loads & stores/floating point instruction......................... 5.725470Mispredicted branches/Decoded branches...................................... 0.000484Graduated loads/Issued loads................................................ 0.987995Graduated stores/Issued stores.............................................. 0.999259Data mispredict/Data scache hits............................................ 0.356370Instruction mispredict/Instruction scache hits.............................. 0.067797L1 Cache Line Reuse......................................................... 77.927419L2 Cache Line Reuse......................................................... 6.251163L1 Data Cache Hit Rate...................................................... 0.987330L2 Data Cache Hit Rate...................................................... 0.862091Time accessing memory/Total time............................................ 0.632410Time not making progress (probably waiting on memory) / Total time.......... 0.358511L1--L2 bandwidth used (MB/s, average per process)........................... 81.662153Memory bandwidth used (MB/s, average per process)........................... 35.604805MFLOPS (average per process)................................................ 22.131567
Continuación Ejemplo: perfex sobre col.f (buen acceso)

Ejemplo: perfex sobre col.f (mal acceso)
(Trazado de col.f: acceso por filas en un array Fortran. Ejecutado en una SGI Origin 2000 del CEPBA: karnak)$ perfex -a -y -o perfex.results.col.malo col.malo
Summary for execution of col.malo
Based on 250 MHz IP27 MIPS R10000 CPU CPU revision 3.x Typical Minimum Maximum Event Counter Name Counter Value Time (sec) Time (sec) Time (sec)=================================================================================================================== 0 Cycles...................................................... 2298683440 9.194734 9.194734 9.19473416 Cycles...................................................... 2298683440 9.194734 9.194734 9.19473426 Secondary data cache misses................................. 8256016 2.493317 1.630068 2.774021 7 Quadwords written back from scache.......................... 37466320 0.959138 0.633930 0.95913823 TLB misses.................................................. 2287792 0.623103 0.623103 0.62310325 Primary data cache misses................................... 8806480 0.317386 0.099337 0.31738614 ALU/FPU progress cycles..................................... 63715152 0.254861 0.254861 0.254861 2 Issued loads................................................ 63287104 0.253148 0.253148 0.25314818 Graduated loads............................................. 48516160 0.194065 0.194065 0.19406522 Quadwords written back from primary data cache.............. 7898480 0.121637 0.099205 0.140593 3 Issued stores............................................... 12914992 0.051660 0.051660 0.05166021 Graduated floating point instructions....................... 8792464 0.035170 0.017585 1.82883319 Graduated stores............................................ 8570928 0.034284 0.034284 0.034284 6 Decoded branches............................................ 3940832 0.015763 0.015763 0.01576310 Secondary instruction cache misses.......................... 1680 0.000507 0.000332 0.000564 9 Primary instruction cache misses............................ 3280 0.000236 0.000074 0.00023624 Mispredicted branches....................................... 2256 0.000013 0.000006 0.00004730 Store/prefetch exclusive to clean block in scache........... 288 0.000001 0.000001 0.00000131 Store/prefetch exclusive to shared block in scache.......... 112 0.000000 0.000000 0.000000 1 Issued instructions......................................... 166147584 0.000000 0.000000 0.664590 4 Issued store conditionals................................... 0 0.000000 0.000000 0.000000 5 Failed store conditionals................................... 0 0.000000 0.000000 0.000000 8 Correctable scache data array ECC errors.................... 0 0.000000 0.000000 0.00000011 Instruction misprediction from scache way prediction table.. 96 0.000000 0.000000 0.00000012 External interventions...................................... 392432 0.000000 0.000000 0.00000013 External invalidations...................................... 713680 0.000000 0.000000 0.00000015 Graduated instructions...................................... 142279568 0.000000 0.000000 0.56911817 Graduated instructions...................................... 143146464 0.000000 0.000000 0.57258620 Graduated store conditionals................................ 0 0.000000 0.000000 0.00000027 Data misprediction from scache way prediction table......... 112 0.000000 0.000000 0.00000028 External intervention hits in scache........................ 382528 0.000000 0.000000 0.00000029 External invalidation hits in scache........................ 226688 0.000000 0.000000 0.000000

Statistics=========================================================================================Graduated instructions/cycle................................................ 0.061896Graduated floating point instructions/cycle................................. 0.003825Graduated loads & stores/cycle.............................................. 0.024835Graduated loads & stores/floating point instruction......................... 6.492729Mispredicted branches/Decoded branches...................................... 0.000572Graduated loads/Issued loads................................................ 0.766604Graduated stores/Issued stores.............................................. 0.663642Data mispredict/Data scache hits............................................ 0.000203Instruction mispredict/Instruction scache hits.............................. 0.060000L1 Cache Line Reuse......................................................... 5.482396L2 Cache Line Reuse......................................................... 0.066674L1 Data Cache Hit Rate...................................................... 0.845736L2 Data Cache Hit Rate...................................................... 0.062507Time accessing memory/Total time............................................ 0.398288Time not making progress (probably waiting on memory) / Total time.......... 0.972282L1--L2 bandwidth used (MB/s, average per process)........................... 44.393133Memory bandwidth used (MB/s, average per process)........................... 180.128235MFLOPS (average per process)................................................ 0.956250
Continuación: perfex sobre col.f (mal acceso)
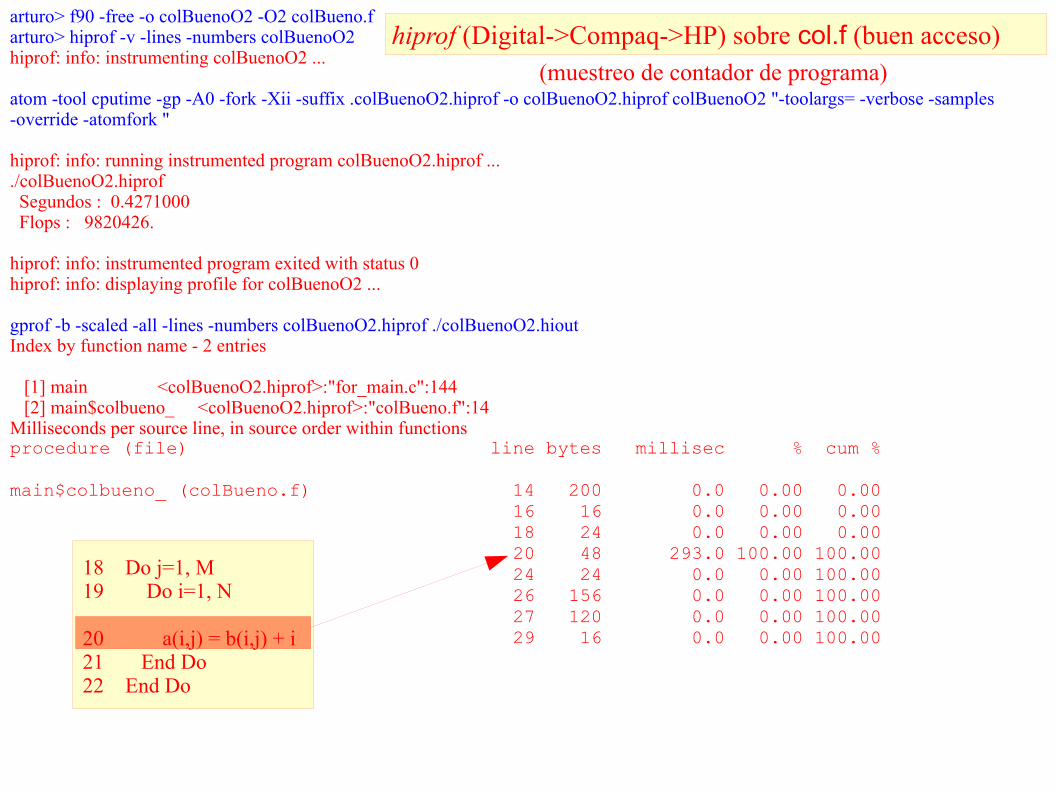
arturo> f90 -free -o colBuenoO2 -O2 colBueno.farturo> hiprof -v -lines -numbers colBuenoO2hiprof: info: instrumenting colBuenoO2 ...
atom -tool cputime -gp -A0 -fork -Xii -suffix .colBuenoO2.hiprof -o colBuenoO2.hiprof colBuenoO2 "-toolargs= -verbose -samples -override -atomfork "
hiprof: info: running instrumented program colBuenoO2.hiprof ..../colBuenoO2.hiprof Segundos : 0.4271000 Flops : 9820426.
hiprof: info: instrumented program exited with status 0hiprof: info: displaying profile for colBuenoO2 ...
gprof -b -scaled -all -lines -numbers colBuenoO2.hiprof ./colBuenoO2.hiout Index by function name - 2 entries
[1] main <colBuenoO2.hiprof>:"for_main.c":144 [2] main$colbueno_ <colBuenoO2.hiprof>:"colBueno.f":14Milliseconds per source line, in source order within functionsprocedure (file) line bytes millisec % cum %
main$colbueno_ (colBueno.f) 14 200 0.0 0.00 0.00 16 16 0.0 0.00 0.00 18 24 0.0 0.00 0.00 20 48 293.0 100.00 100.00 24 24 0.0 0.00 100.00 26 156 0.0 0.00 100.00 27 120 0.0 0.00 100.00 29 16 0.0 0.00 100.00
hiprof (Digital->Compaq->HP) sobre col.f (buen acceso)
18 Do j=1, M19 Do i=1, N
20 a(i,j) = b(i,j) + i21 End Do22 End Do
(muestreo de contador de programa)

arturo> f90 -free -o colBuenoO4 -O4 colBueno.farturo> hiprof -v -lines -numbers colBuenoO4hiprof: info: instrumenting colBuenoO4 ...
atom -tool cputime -gp -A0 -fork -Xii -suffix .colBuenoO4.hiprof -o colBuenoO4.hiprof colBuenoO4 "-toolargs= -verbose -samples -override -atomfork "
hiprof: info: running instrumented program colBuenoO4.hiprof ..../colBuenoO4.hiprof Segundos : 0.1757000 Flops : 2.3871964E+07
hiprof: info: instrumented program exited with status 0hiprof: info: displaying profile for colBuenoO4 ...
gprof -b -scaled -all -lines -numbers colBuenoO4.hiprof ./colBuenoO4.hiout Index by function name - 2 entries [1] main <colBuenoO4.hiprof>:"for_main.c":144 [2] main$colbueno_ <colBuenoO4.hiprof>:"colBueno.f":14Milliseconds per source line, in source order within functions
procedure (file) line bytes millisec % cum %
main$colbueno_ (colBueno.f) 14 200 0.0 0.00 0.00 16 16 0.0 0.00 0.00 18 120 0.0 0.00 0.00 20 2480 39.1 100.00 100.00 24 24 0.0 0.00 100.00 26 156 0.0 0.00 100.00 27 120 0.0 0.00 100.00 29 28 0.0 0.00 100.00
hiprof (Digital->Compaq->HP) sobre col.f (buen acceso)(continuación, optimización -O4)

hiprof (Digital->Compaq->HP) sobre col.f (mal acceso)
18 Do i=1, N19 Do j=1, M
20 a(i,j) = b(i,j) + i21 End Do22 End Do
arturo> f90 -free -o colMaloO2 -O2 colMalo.f arturo> hiprof -v -lines -numbers colMaloO2hiprof: info: instrumenting colMaloO2 ...
atom -tool cputime -gp -A0 -fork -Xii -suffix .colMaloO2.hiprof -o colMaloO2.hiprof colMaloO2 "-toolargs= -verbose -samples -override -atomfork "
hiprof: info: running instrumented program colMaloO2.hiprof ..../colMaloO2.hiprof Segundos : 1.695500 Flops : 2473786.
hiprof: info: instrumented program exited with status 0hiprof: info: displaying profile for colMaloO2 ...
gprof -b -scaled -all -lines -numbers colMaloO2.hiprof ./colMaloO2.hiout Index by function name - 2 entries [1] main <colMaloO2.hiprof>:"for_main.c":144 [2] main$colmalo_ <colMaloO2.hiprof>:"colMalo.f":14Milliseconds per source line, in source order within functions
procedure (file) line bytes millisec % cum %
main$colmalo_ (colMalo.f) 14 200 0.0 0.00 0.00 16 16 0.0 0.00 0.00 18 24 0.0 0.00 0.00 20 48 1502.9 100.00 100.00 24 24 0.0 0.00 100.00 26 156 0.0 0.00 100.00 27 120 0.0 0.00 100.00 29 16 0.0 0.00 100.00

arturo> f90 -free -o colMaloO4 -O4 colMalo.farturo> hiprof -v -lines -numbers colMaloO4hiprof: info: instrumenting colMaloO4 ...
atom -tool cputime -gp -A0 -fork -Xii -suffix .colMaloO4.hiprof -o colMaloO4.hiprof colMaloO4 "-toolargs= -verbose -samples -override -atomfork "
hiprof: info: running instrumented program colMaloO4.hiprof ..../colMaloO4.hiprof Segundos : 1.166900 Flops : 3594399.
hiprof: info: instrumented program exited with status 0hiprof: info: displaying profile for colMaloO4 ...
gprof -b -scaled -all -lines -numbers colMaloO4.hiprof ./colMaloO4.hiout Index by function name - 2 entries [1] main <colMaloO4.hiprof>:"for_main.c":144 [2] main$colmalo_ <colMaloO4.hiprof>:"colMalo.f":14Milliseconds per source line, in source order within functions
procedure (file) line bytes millisec % cum %
main$colmalo_ (colMalo.f) 14 208 0.0 0.00 0.00 16 16 0.0 0.00 0.00 18 56 1.0 0.09 0.09 20 972 1032.2 99.91 100.00 24 28 0.0 0.00 100.00 26 156 0.0 0.00 100.00 27 112 0.0 0.00 100.00 29 36 0.0 0.00 100.00
hiprof (Digital->Compaq->HP) sobre col.f (mal acceso)Optimización -O4

arturo> f90 -free -g1 -O2 colBueno.f -o colBuenoO2arturo> pixie -heavy -quit 3 colBuenoO2pixie: info: instrumenting colBuenoO2 ...pixie: info: running instrumented program colBuenoO2.pixie ...
Segundos : 0.3475000 Flops : 1.2069940E+07pixie: info: instrumented program exited with status 0pixie: info: displaying profile for colBuenoO2 ...----------------------------------------------------------------------------* -h[eavy] using basic-block counts; ** sorted in descending order by the number of instructions executed ** in each line; unexecuted lines are excluded *----------------------------------------------------------------------------procedure (file) line bytes instrs % cum %
main$colbueno_ (colBueno.f) 20 48 29364227 63.62 63.62main$colbueno_ (colBueno.f) 18 24 16781312 36.36 99.99main$colbueno_ (colBueno.f) 16 16 6145 0.01 100.00
arturo> f90 -free -g1 -O5 colBueno.f -o colBuenoO5arturo> pixie -heavy -quit 3 colBuenoO5pixie: info: instrumenting colBuenoO5 ...pixie: info: running instrumented program colBuenoO5.pixie ...
Segundos : 0.1796000 Flops : 2.3353586E+07pixie: info: instrumented program exited with status 0pixie: info: displaying profile for colBuenoO5 ...procedure (file) line bytes instrs % cum %
main$colbueno_ (colBueno.f) 20 1296 27922435 75.22 75.22main$colbueno_ (colBueno.f) 18 424 9191426 24.76 99.98main$colbueno_ (colBueno.f) 16 16 6145 0.02 99.99
pixie (program counter, Digital, Compaq. HP) sobre col.f (buen acceso)

pixie (program counter, Digital, Compaq. HP) sobre col.f (mal acceso)
arturo> f90 -free -g1 -O2 colMalo.f -o colMaloO2arturo> pixie -heavy -quit 3 colMaloO2pixie: info: instrumenting colMaloO2 ...pixie: info: running instrumented program colMaloO2.pixie ... Segundos : 3.088400 Flops : 1358083.pixie: info: instrumented program exited with status 0pixie: info: displaying profile for colMaloO2 ...----------------------------------------------------------------------------* -h[eavy] using basic-block counts; ** sorted in descending order by the number of instructions executed ** in each line; unexecuted lines are excluded *----------------------------------------------------------------------------procedure (file) line bytes instrs % cum %main$colmalo_ (colMalo.f) 20 48 29364227 63.62 63.62main$colmalo_ (colMalo.f) 18 24 16781312 36.36 99.99main$colmalo_ (colMalo.f) 16 16 6145 0.01 100.00
arturo> f90 -free -g1 -O5 colMalo.f -o colMaloO5arturo> pixie -heavy -quit 3 colMaloO5pixie: info: instrumenting colMaloO5 ...pixie: info: running instrumented program colMaloO5.pixie ... Segundos : 0.1728000 Flops : 2.4272592E+07pixie: info: instrumented program exited with status 0pixie: info: displaying profile for colMaloO5 ...procedure (file) line bytes instrs % cum %main$colmalo_ (colMalo.f) 20 724 14825478 92.58 92.58main$colmalo_ (colMalo.f) 16 48 1175552 7.34 99.92main$colmalo_ (colMalo.f) 18 28 10242 0.06 99.99

arturo> f90 -free -O2 colBueno.f -o cBO2arturo> uprofile -asm -quit 90cum% cycles cBO2 Segundos : 0.4343000 Flops : 9657619.Writing umon.outDisplaying profile for cBO2:----------------------------------------------------------------------------* -a[sm] using performance counters: ** cycles: 1 sample every 65535 Inst's (Exec Cycles) (0.000079 seconds) ** sorted in descending order by total time spent in each procedure; ** unexecuted procedures excluded *----------------------------------------------------------------------------Each sample covers 4.00 byte(s) for 0.0036% of 2.1789 seconds millisec % cum % address:line instructionmain$colbueno_ (colBueno.f) ...trozo fuera:linea 14..............
0.0 0.00 0.00 0x120001c6c:16 lda t1, 2048(zero) 0.0 0.00 0.00 0x120001c70:20 lda t2, 8192(zero) 0.0 0.00 0.00 0x120001c74:14 lda gp, 25692(gp) 0.0 0.00 0.00 0x120001c78:20 ldq t3, -32608(gp) 0.0 0.00 0.00 0x120001c7c:20 ldah t3, 256(t3) 0.2 0.01 0.01 0x120001c80:20 addq t3, t2, t5 0.2 0.01 0.02 0x120001c84:18 lda t4, 2048(zero) 0.1 0.00 0.02 0x120001c88:18 bis zero, 0x1, t6
0.0 0.00 0.02 0x120001c8c:20 lda t5, -8192(t5) 239.7 11.00 11.02 0x120001c90:20 lds $f1, 0(t5) 201.6 9.25 20.28 0x120001c94:20 ldah a1, -256(t5) 184.3 8.46 28.73 0x120001c98:18 lda t4, -1(t4) 215.5 9.89 38.62 0x120001c9c:18 lda t5, 4(t5) 244.2 11.21 49.83 0x120001ca0:20 stq t6, 16(sp) 195.5 8.97 58.80 0x120001ca4:18 addl t6, 0x1, t6 135.7 6.23 65.03 0x120001ca8:20 ldt $f0, 16(sp) 148.6 6.82 71.85 0x120001cac:20 cvtqs $f0,$f0 177.5 8.15 80.00 0x120001cb0:20 adds $f1,$f0,$f0 191.8 8.80 88.80 0x120001cb4:20 sts $f0, 0(a1) 240.3 11.03 99.83 0x120001cb8:18 bgt t4, 0x120001c90
uprof (contadores HW, Digital,Compaq, HP) sobrecol.f (buen acceso)
Instrucciones correspondientes a la línea 20.

arturo> f90 -free -O2 colMalo.f -o cMO2arturo> uprofile -asm -quit 90cum% cycles cMO2 Segundos : 3.350900 Flops : 1251695.Writing umon.outDisplaying profile for cMO2:----------------------------------------------------------------------------* -a[sm] using performance counters: ** cycles: 1 sample every 65535 Inst's (Exec Cycles) (0.000079 seconds) ** sorted in descending order by total time spent in each procedure; ** unexecuted procedures excluded *----------------------------------------------------------------------------Each sample covers 4.00 byte(s) for 0.0024% of 3.2743 seconds millisec % cum % address:line instructionmain$colmalo_ (colMalo.f) ... Trozo fuera : linea 14 ... 0.0 0.00 0.00 0x120001c6c:16 lda t1, 2048(zero) 0.0 0.00 0.00 0x120001c70:20 bis zero, 0x4, t2 0.0 0.00 0.00 0x120001c74:14 lda gp, 25692(gp) 0.0 0.00 0.00 0x120001c78:20 ldq t3, -32608(gp) 0.0 0.00 0.00 0x120001c7c:20 ldah t3, 256(t3) 0.2 0.00 0.00 0x120001c80:20 addq t3, t2, t5 0.0 0.00 0.00 0x120001c84:18 lda t4, 2048(zero) 0.1 0.00 0.01 0x120001c88:18 bis zero, 0x1, t6 0.2 0.00 0.01 0x120001c8c:20 lda t5, -4(t5) 198.2 6.05 6.06 0x120001c90:20 lds $f1, 0(t5) 216.0 6.60 12.66 0x120001c94:20 ldah a1, -256(t5) 237.2 7.24 19.90 0x120001c98:18 lda t4, -1(t4) 200.9 6.14 26.04 0x120001c9c:18 lda t5, 8192(t5) 207.6 6.34 32.38 0x120001ca0:20 stq t6, 16(sp) 272.1 8.31 40.69 0x120001ca4:18 addl t6, 0x1, t6 220.6 6.74 47.43 0x120001ca8:20 ldt $f0, 16(sp) 246.9 7.54 54.97 0x120001cac:20 cvtqs $f0,$f0 1012.8 30.93 85.90 0x120001cb0:20 adds $f1,$f0,$f0 199.4 6.09 91.99 0x120001cb4:20 sts $f0, 0(a1)
uprof (contadores HW, Digital,Compaq, HP) sobrecol.f (mal acceso)
Instrucciones correspondientes a la línea 20.

Estos son sólo los más comunes...
● Echar un vistazo a:– Oprofile (oprofile.sourceforge.net)
– PAPI: Performance Application Programming Interface (Uso estandarizado de los contadores de rendimiento HW de las CPU modernas. http://icl.cs.utk.edu/papi)
– Herramientas propietarias (e.g.: Vtune de Intel)

PAPI: Performance API● Built in two layers: a HW independent (portable) and a
dependent part (substrate). Becoming a de facto standard

– API definition, but also defines a set of standard events assumed useful for studying the performance of an application.
● This events can be extracted by translating the info obtained from several HW counters.
– Ej.: If you are interested in the total number of L2 cache misses, that is obtained as:
● “L2_LINES_IN” on Pentium 3● “L2_MISSES” on Itanium● The sum of “SYS_DC_REFILLS_TOT” and “SYS_IC_REFILLS”
on Athlon● PAPI calls it “PAPI_L2_TCM” and takes care of the proper mapping.
● Not all possible events are counted always. The set of possible events that can be tracked simultaneously depend on the CPU support for HW counters.
– PAPI allows for event multiplexing

– PAPI is used to build many applications that measure performance:
● Perfsuite● PapiEx● TAU: Tuning and Analysis Utilities● HPCToolkit● KOJAK● ...● Some utilities included: papi_avail, papi_clockres,
papi_command_line, papi_cost, papi_event_chooser, papi_mem_info, papi_native_avail
– And can be used as a stand alone library by instrumenting the program yourself.

– PAPI can access native events in a given CPU using its low level interface (define and manage event sets, timers, thread support...).
● Not all CPUs support the same native events (PAPI can query)● Native events and codes are CPU dependent.
– PAPI provides an abstraction of the native events by using a collection of preset events that are common and useful (and could be either directly given by a native event or by deriving it from several counters). They provide a translation between the PAPI standard name and the native name(s)
● PAPI high level: start, stop, read and accumulate counters for preset events.
● Around 100 preset events (defined in papiStdEventDefs.h check also http://icl.cs.utk.edu/projects/papi/presets.html)

PAPI example: simple use (high level)
include 'f90papi.h'
real real_time, cpu_time, mflops integer*8 fp_ins integer ierr
C Call PAPIF_flops to get things started. This will initialize PAPIC and start the counters running.
call PAPIF_flops(real_time, cpu_time, fp_ins, mflops, ierr)
C Do some computation
Do I=1, 10000000 a=i*2.0 End Do
C Read the values in the counters and print them out. Any call to C PAPIF_flops with fp_ins set to the value -1 will reinitializeC all counters to zero.
call PAPIF_flops(real_time, cpu_time, fp_ins, mflops, ierr)
write (*,100) real_time, cpu_time, fp_ins, mflops
100 format(' Real time (secs) :', f15.3, + /' CPU time (secs) :', f15.3, + /'Floating point instructions :', i15, + /' MFLOPS :', f15.3) End
include 'f90papi.h'
real real_time, cpu_time, mflops integer*8 fp_ins integer ierr
C Call PAPIF_flops to get things started. This will initialize PAPIC and start the counters running.
call PAPIF_flops(real_time, cpu_time, fp_ins, mflops, ierr)
C Do some computation
Do I=1, 10000000 a=i*2.0 End Do
C Read the values in the counters and print them out. Any call to C PAPIF_flops with fp_ins set to the value -1 will reinitializeC all counters to zero.
call PAPIF_flops(real_time, cpu_time, fp_ins, mflops, ierr)
write (*,100) real_time, cpu_time, fp_ins, mflops
100 format(' Real time (secs) :', f15.3, + /' CPU time (secs) :', f15.3, + /'Floating point instructions :', i15, + /' MFLOPS :', f15.3) End
Compilation line in ELMER (Power5, AIX 5L 64 bits):$ xlf -q64 -o mt mytest.f -I/usr/local/include -L/usr/local/lib/ -lpapi64 -lpmapi
bash-3.00$ ./mt Real time (secs) : .260 CPU time (secs) : .260Floating point instructions : 10000000 MFLOPS : 38.522
bash-3.00$ ./mt Real time (secs) : .260 CPU time (secs) : .260Floating point instructions : 10000000 MFLOPS : 38.522
Wall clock time since first call
Process time since first call
Mflops since last call
Floating point instructions since first call
NOTE: What is considered a flop or a fpins is CPU dependent. Some counters count floating point load/storeas a flop, some other not...

– Examples of some preset events:
For floating point operations
For L2 cache
Check event availability for a given CPUby issuing the command (utility included inthe PAPI distribution): papi_avail

HPC Toolkit

HPC Toolkit
● hpcstruct <prog>● hpcrun <prog>hpcrun -L para lista de eventos. hpcrun -t para generar traza para ver con hpctraceviewer● hpcprof -S <prog>.hpcstruct -I ./'*' hpctoolkit-co-measurements/● hpcviewer hpctoolkit-mmult-database

SECCIÓN III
Optimización en la CPU

Optimización de Uso de la CPU● En general el subsistema de memoria es menos
variable entre sistemas secuenciales que la CPU -> Optimizaciones sobre ésta son mejores candidatas a que el compilador lo haga por nosotros– No obstante, hay una serie de técnicas comunes a la
mayoría de las CPUs.
– Además, hay que tener una idea de la velocidad pico teórica para saber si es necesario optimizar o no y si el compilador esta haciendo bien su trabajo.

Estimaciones de Velocidad Máxima
● Nos centramos en operaciones de punto flotante. Para ilustrar el proceso– Seleccionamos kernels típicos y simples.
– Usaremos una CPU diseñada para cálculo científico y técnico conocida por su facilidad para ser optimizada: Power 2SC
● Buen ancho de banda a memoria.● Un solo nivel de cache.● Pipelines cortos.

Diagrama de una CPU Power2
● Observar el bus de 2x4x32 lineas que unen las caches de datos (DCU) con la unidad de punto flotante (FPU) y la memoria central.

Power2: Detalles.● Dos load/store en un sólo ciclo.
– Instrucciones load/store quad: 4 palabras de 32 bits son traidas/llevadas desde dos registros consecutivos a cuatro posiciones contiguas (en cache)
– Doble FPU con un pipeline de profundidad dos.● Fma (floating point multiply and add): 2 operaciones por ciclo
una vez lleno el pipeline● Instrucciones de división (15 ciclos) y raiz cuadrada (26)● Los registros de punto flotante (FPR) son accesibles por
instrucciones load aún cuando la FPU esté operando en el mismo registro (renombrado hardware de FPR)
– Instrucción bct (branch on count) con un registro especial (count register)

Estimación de Velocidad Máxima.● En un bucle simple es fácil:
– Ciclos de memoria: contar el número de escrituras/lecturas a/de memoria. Sumar uno por cada.
– Ciclos de cálculo: contar el número de operaciones.● Número de multiplicaciones y sumas emparejadas en fma y aquellas
desemparejadas. Suma un ciclo por cada pero contar dos operaciones por fma.
● Contar divisiones y raices cuadradas: sumar 16 por división y 26 por raiz.
● Como normalmente los ciclos de memoria y los de cálculo se solapan, el bucle tarda el mayor número de los dos calculados.

Bucles de Prueba● Nos centramos en kernels de punto flotante muy comunes
en programas técnicos y científicos con características distintas con respecto al subsistema de memoria y CPU.

Estimaciones para P2SC● En una CPU P2SC a 160 Mhz, el búcle de la raíz tendrá un pico de
160x10E6/26=6153846 ops. Con dos FPUs independientes: 12.307.692 o 12 Mflops/seg
● En un dAXpY hay una fma, dos lecturas y una escritura. Sólo se aprovechan en cálculo dos de cada tres ciclos: Bucle limitado por ancho de banda a memoria. 2 FPUs x 2 Flops x 2 ciclos /3 -> 8x160x10E6/3=426.6 Mflops/seg.
● En un producto escalar: dos lecturas, ninguna escritura y una fma. El número de ciclos de accesos a memoria y de operaciones es el mismo -> Bucle equilibrado, 4 flops por ciclo: 8x160x10E6 = 640 Mflops/seg.
● Suma de cuadrados: una lectura y una fma. 4 Flops/ciclo. 640 Mflops/seg. Bucle limitado por la FPU.

Optimizaciones (secuenciales)● Situación ideal: Que el compilador genere código
óptimo por nosotros.– Esto no siempre es así. Para obtener un rendimiento
razonable que se mantenga cuando cambiemos de HW/SW, hay que seguir unas normas sensatas.
● El mandato básico: Exponer suficiente paralelismo (a nivel de instrucción) y preparar suficientes datos para usar completamente las unidades funcionales de la CPU.

Algunas Normas Básicas● Acceder a la memoria de manera contigua.
● Evitar condicionales, I/O, llamadas a subrutinas en los bucles críticos. Considera inlining.
● No usar índices de matrices complicados.
● Usar escalares para los temporales.
● Evitar dimensionar matrices grandes en potencias de dos.
● Sustituir operaciones caras (división) por otras más baratas (multiplicación por recíproco)
● Evitar conversiones de tipo, especialmente las implícitas.
● Usar librerías de alto rendimiento (BLAS, MASS, fastv, etc.)
● Loop unrolling/fusion.

Para probar.
Program Loops! Rendimiento para diversos bucles y ! modificaciones de los mismos que ! ayudan a mejorar la velocidad. Implicit None Integer, parameter ::N=512, M=30720 Real(kind(1.0D0)), Dimension (N) :: x, Y Real(Kind(1.0D0)) :: ROps, InvROps Real :: Inicio, Final Integer :: Ops, i, j ! Raiz cuadrada Ops = N*M Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =sqrt(y(i)) End Do Call dummy(x,n) End Do Call CPU_Time(Final)
Print *,' ********** Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops Sqrt:', &Float(Ops)/(Final- Inicio)
Program Loops! Rendimiento para diversos bucles y ! modificaciones de los mismos que ! ayudan a mejorar la velocidad. Implicit None Integer, parameter ::N=512, M=30720 Real(kind(1.0D0)), Dimension (N) :: x, Y Real(Kind(1.0D0)) :: ROps, InvROps Real :: Inicio, Final Integer :: Ops, i, j ! Raiz cuadrada Ops = N*M Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =sqrt(y(i)) End Do Call dummy(x,n) End Do Call CPU_Time(Final)
Print *,' ********** Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops Sqrt:', &Float(Ops)/(Final- Inicio)
Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N,2 x(i) =sqrt(y(i)) x(i+1) = sqrt(y(i+1)) End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops Sqrt unroll x 2:', &Float(Ops)/(Final-Inicio)
! Division Ops = N*M ! ops es entera Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =y(i)/ops End Do Call dummy(x,n) End Do Call CPU_Time(Final)Print *,' Segundos :', Final-InicioPrint *,' Flops division + casting:', &Float(Ops)/(Final-Inicio)
Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N,2 x(i) =sqrt(y(i)) x(i+1) = sqrt(y(i+1)) End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops Sqrt unroll x 2:', &Float(Ops)/(Final-Inicio)
! Division Ops = N*M ! ops es entera Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =y(i)/ops End Do Call dummy(x,n) End Do Call CPU_Time(Final)Print *,' Segundos :', Final-InicioPrint *,' Flops division + casting:', &Float(Ops)/(Final-Inicio)
ROps = N*M !ROps es ahora real Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =y(i)/Rops End Do Call dummy(x,n) End Do Call CPU_Time(Final)
Print *,' Segundos :', Final-Inicio Print *,' Flops division reales:', & ROps/(Final-Inicio)
ROps = N*M !ROps es ahora real Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =y(i)/Rops End Do Call dummy(x,n) End Do Call CPU_Time(Final)
Print *,' Segundos :', Final-Inicio Print *,' Flops division reales:', & ROps/(Final-Inicio)
Sigue...

continuación...! Unrolled x2
ROps = N*M !ROps es ahora real Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N,2 x(i) = y(i)/Rops x(i+1) = y(i+1)/Rops End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops division reales unroll x 2:', &ROps/(Final-Inicio)
! Unrolled x4
ROps = N*M !ROps es ahora real Call Random_number(y) Call CPU_Time(Inicio)
! Unrolled x2
ROps = N*M !ROps es ahora real Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N,2 x(i) = y(i)/Rops x(i+1) = y(i+1)/Rops End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops division reales unroll x 2:', &ROps/(Final-Inicio)
! Unrolled x4
ROps = N*M !ROps es ahora real Call Random_number(y) Call CPU_Time(Inicio)
DO j=1, M Do i=1,N,4 x(i) = y(i)/Rops x(i+1) = y(i+1)/Rops x(i+2) = y(i+2)/Rops x(i+3) = y(i+3)/Rops End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops division reales unroll x 4:', & ROps/(Final-Inicio)
! sustitucion de division por !multiplicacion por inversa. invRops = 1.0D0/ROps Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =y(i)*InvRops End Do Call dummy(x,n) End Do
DO j=1, M Do i=1,N,4 x(i) = y(i)/Rops x(i+1) = y(i+1)/Rops x(i+2) = y(i+2)/Rops x(i+3) = y(i+3)/Rops End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops division reales unroll x 4:', & ROps/(Final-Inicio)
! sustitucion de division por !multiplicacion por inversa. invRops = 1.0D0/ROps Call Random_number(y) Call CPU_Time(Inicio) DO j=1, M Do i=1,N x(i) =y(i)*InvRops End Do Call dummy(x,n) End Do
Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops multiplicacion por inversa:', &ROps/(Final-Inicio) Call CPU_Time(Inicio) Call Random_number(y) DO j=1, M Do i=1,N,4 x(i) =y(i)*InvRops x(i+1) = y(i+1)*InvRops x(i+2) = y(i+2)*InvRops x(i+3) = y(i+3)*InvRops End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops multiplicacion por inversa',& 'unroll x 4:', ROps/(Final-Inicio) Stop End
Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops multiplicacion por inversa:', &ROps/(Final-Inicio) Call CPU_Time(Inicio) Call Random_number(y) DO j=1, M Do i=1,N,4 x(i) =y(i)*InvRops x(i+1) = y(i+1)*InvRops x(i+2) = y(i+2)*InvRops x(i+3) = y(i+3)*InvRops End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,&' Flops multiplicacion por inversa',& 'unroll x 4:', ROps/(Final-Inicio) Stop End

dAXpY● dAXpY: Double precision A times X plus y. Dos
lecturas, una escritura y una fma.● Implementación en un P2SC: Unroll x 4.
– Expone cuatro operaciones fma que mantienen los dos pipes de las dos FPU llenos.
– Usa cuatro cargas de quadwords obteniendo así en dos ciclos los ocho números que alimentan las cuatro fma.
– Un ciclo para escribir los cuatro resultados. El ancho de banda se usa completamente y eso impone el límite de (2/3)x4x160=426 MFlops/seg.

dAXpY Program dAXpY Integer, parameter ::N=256, M=30720, A=2.0D0 Real(kind(1.0D0)), Dimension (N) :: x, Y Real(Kind(1.0D0)) :: Inicio, Final, ROps Integer :: Ops, i, j Ops = 2*N*M Call CPU_Time(Inicio)
DO j=1, M Do i=1,N y(i) =y(i)+A*x(i) End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops dAXpY:', Float(Ops)/(Final-Inicio)
Program dAXpY Integer, parameter ::N=256, M=30720, A=2.0D0 Real(kind(1.0D0)), Dimension (N) :: x, Y Real(Kind(1.0D0)) :: Inicio, Final, ROps Integer :: Ops, i, j Ops = 2*N*M Call CPU_Time(Inicio)
DO j=1, M Do i=1,N y(i) =y(i)+A*x(i) End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops dAXpY:', Float(Ops)/(Final-Inicio)
! Unroll x 4 Call CPU_Time(Inicio)
DO j=1, M Do i=1,N,4 y(i) =y(i)+A*x(i) y(i+1) =y(i+1)+A*x(i+1) y(i+2) =y(i+2)+A*x(i+2) y(i+3) =y(i+3)+A*x(i+3) End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops dAXpY, unroll x 4:', &Float(Ops)/(Final-Inicio)
Stop End
Subroutine Dummy(x,n) integer :: n Real(Kind(1.0D0)) :: X(n) Return End
! Unroll x 4 Call CPU_Time(Inicio)
DO j=1, M Do i=1,N,4 y(i) =y(i)+A*x(i) y(i+1) =y(i+1)+A*x(i+1) y(i+2) =y(i+2)+A*x(i+2) y(i+3) =y(i+3)+A*x(i+3) End Do Call dummy(x,n) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops dAXpY, unroll x 4:', &Float(Ops)/(Final-Inicio)
Stop End
Subroutine Dummy(x,n) integer :: n Real(Kind(1.0D0)) :: X(n) Return End

Producto Escalar● Implementación en P2SC: Unroll x 4.
– De nuevo se exponen 4 fma.
– No hay ciclo de escritura.
– Problemas con el detalle fino:● Cuatro cargas de quadwords, cuatro fma y el branch del
final de bucle.● Son 9 instrucciones, el P2SC tiene una cola de 8: Se
necesita un ciclo adicional.
● De nuevo el rendimiento es (2/3)x4x160=426 MFlops/seg.

Producto escalar Program dDOT Integer, parameter ::N=512, M=30720 Real(kind(1.0D0)), Dimension (N) :: x, Y Real(Kind(1.0D0)) :: Inicio, Final Real(Kind(1.0D0)) :: S,S0,S1,S2,S3,S4,S5,S6,S7 Integer :: Ops, i, j Ops = 2*N*M Call CPU_Time(Inicio)
DO j=1, M Do i=1,N S =S+x(i)*y(i) End Do Call dummy(s) End Do Call CPU_Time(Final) Print *,' Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops dDOT:', Float(Ops)/(Final-Inicio)
Program dDOT Integer, parameter ::N=512, M=30720 Real(kind(1.0D0)), Dimension (N) :: x, Y Real(Kind(1.0D0)) :: Inicio, Final Real(Kind(1.0D0)) :: S,S0,S1,S2,S3,S4,S5,S6,S7 Integer :: Ops, i, j Ops = 2*N*M Call CPU_Time(Inicio)
DO j=1, M Do i=1,N S =S+x(i)*y(i) End Do Call dummy(s) End Do Call CPU_Time(Final) Print *,' Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops dDOT:', Float(Ops)/(Final-Inicio)
! Unroll x 4 Call CPU_Time(Inicio) DO j=1, M Do i=1,N,4 S0 =S0+y(i)*x(i) S1 =S1+y(i+1)*x(i+1) S2 =S2+y(i+2)*x(i+2) S3 =S3+y(i+3)*x(i+3) End Do S=S0+S1+S2+S3 Call dummy(s) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops dDOT, unroll x 4:',& Float(Ops)/(Final-Inicio)
Stop End
Subroutine Dummy(s) Real(Kind(1.0D0)) :: S Return End
! Unroll x 4 Call CPU_Time(Inicio) DO j=1, M Do i=1,N,4 S0 =S0+y(i)*x(i) S1 =S1+y(i+1)*x(i+1) S2 =S2+y(i+2)*x(i+2) S3 =S3+y(i+3)*x(i+3) End Do S=S0+S1+S2+S3 Call dummy(s) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops dDOT, unroll x 4:',& Float(Ops)/(Final-Inicio)
Stop End
Subroutine Dummy(s) Real(Kind(1.0D0)) :: S Return End

Suma de Cuadrados
● Implementación en un P2SC: Unroll x 4– Este bucle carga menos el subsistema de memoria.
– 4 fma pero sólo se necesitan dos cargas de quadwords.
– Ahora el branch figura en la séptima posición por lo que está dentro del buffer de decodificación, no hay penalización de un ciclo adicional.
● Se ejecuta en dos ciclos dando 4 operaciones por ciclo: 4x160=640 MFlops/Seg.

Suma de Cuadrados Program SSQ ! Suma de cuadrados Integer, parameter ::N=512, M=30720 Real(kind(1.0D0)), Dimension (N) :: x Real(Kind(1.0D0)) :: Inicio, Final Real(Kind(1.0D0)) :: S,S0,S1,S2,S3,S4,S5,S6,S7 Integer :: Ops, i, j Ops = 2*N*M Call CPU_Time(Inicio)
DO j=1, M Do i=1,N S =S+x(i)*x(i) End Do Call dummy(s) End Do Call CPU_Time(Final) Print *,' Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops SSQ:', Float(Ops)/(Final-Inicio)
Program SSQ ! Suma de cuadrados Integer, parameter ::N=512, M=30720 Real(kind(1.0D0)), Dimension (N) :: x Real(Kind(1.0D0)) :: Inicio, Final Real(Kind(1.0D0)) :: S,S0,S1,S2,S3,S4,S5,S6,S7 Integer :: Ops, i, j Ops = 2*N*M Call CPU_Time(Inicio)
DO j=1, M Do i=1,N S =S+x(i)*x(i) End Do Call dummy(s) End Do Call CPU_Time(Final) Print *,' Operaciones :', Ops Print *,' Segundos :', Final-Inicio Print *,' Flops SSQ:', Float(Ops)/(Final-Inicio)
! Unroll x 4 Call CPU_Time(Inicio) DO j=1, M Do i=1,N,4 S0 =S0+x(i)*x(i) S1 =S1+x(i+1)*x(i+1) S2 =S2+x(i+2)*x(i+2) S3 =S3+x(i+3)*x(i+3) End Do S=S0+S1+S2+S3 Call dummy(s) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops SSQ, unroll x 4:', &Float(Ops)/(Final-Inicio)
Stop End
Subroutine Dummy(s) Real(Kind(1.0D0)) :: S Return End
! Unroll x 4 Call CPU_Time(Inicio) DO j=1, M Do i=1,N,4 S0 =S0+x(i)*x(i) S1 =S1+x(i+1)*x(i+1) S2 =S2+x(i+2)*x(i+2) S3 =S3+x(i+3)*x(i+3) End Do S=S0+S1+S2+S3 Call dummy(s) End Do Call CPU_Time(Final) Print *,' Segundos :', Final-Inicio Print *,' Flops SSQ, unroll x 4:', &Float(Ops)/(Final-Inicio)
Stop End
Subroutine Dummy(s) Real(Kind(1.0D0)) :: S Return End

Predicción de Flujos● Para evitar los problemas que, a veces, producen las jerarquias de
cache, algunas CPUs disponen de un mecanismo de bypass de algunos niveles de cache: Flujos Hardware.
– Se monitorizan los fallos de L1 y se hace una predicción sobre la próxima línea a traer. Se mantiene un registro de con las últimas predicciones. Si se produce un fallo y este coincide con una predicción se activa uno de los flujos disponibles, que trae una linea de memoria directamente a un buffer de nivel L1. Una vez que el flujo está activado un acceso al buffer produce un refresco automático de éste con la siguiente predicción.
● Se necesitan varios flujos a memoria para llenar todo el ancho de banda L1/CPU.
● Los flujos normalmente están controlados por HW. Su activación depende del ordenamiento de los accesos y puede ser necesario usar variables de entorno y/o directivas de compilación.

Predicción de Flujos.Program streams ! uso de los streams en una CPU Power 3 Integer, parameter :: N=1024, promedio=4096 Real(kind(1.0D0)), Dimension(N) :: a1, a2, a3, a4, a5 ,a6 Real(Kind(1.0D0)) :: s,s1,s2,s3, Bytes, MBytes,Inicio, Final common /comun/a1,a2,a3,a4,a5,a6 Bytes = 48*N*promedio MBytes = Bytes/(1024.*1024.) Call CPU_Time(Inicio) Do j=1,promedio Do I=1,N S=S+a1(i)*a2(i)+a3(i)*a4(i)+a5(i)*a6(i) End Do Call Dummy(s,n) End Do Call CPU_Time(Final) Print *,'Total MB transferidos :', MBytes, ' en ', Final-Inicio,' segs.' Print *,'Velocidad de transferencia (MB/seg.)', MBytes/(Final-Inicio)
Program streams ! uso de los streams en una CPU Power 3 Integer, parameter :: N=1024, promedio=4096 Real(kind(1.0D0)), Dimension(N) :: a1, a2, a3, a4, a5 ,a6 Real(Kind(1.0D0)) :: s,s1,s2,s3, Bytes, MBytes,Inicio, Final common /comun/a1,a2,a3,a4,a5,a6 Bytes = 48*N*promedio MBytes = Bytes/(1024.*1024.) Call CPU_Time(Inicio) Do j=1,promedio Do I=1,N S=S+a1(i)*a2(i)+a3(i)*a4(i)+a5(i)*a6(i) End Do Call Dummy(s,n) End Do Call CPU_Time(Final) Print *,'Total MB transferidos :', MBytes, ' en ', Final-Inicio,' segs.' Print *,'Velocidad de transferencia (MB/seg.)', MBytes/(Final-Inicio)
Call CPU_Time(Inicio) Do j=1,promedio Do I=1,N S1=S1+a1(i)*a2(i) S2=S2+a3(i)*a4(i) S3=S3+a5(i)*a6(i) End Do S=S1+S2+S3 Call Dummy(s,n) End Do Call CPU_Time(Final) Print *,'Total MB transferidos :', MBytes, &' en ', Final-Inicio,' segs.' Print *,'Velocidad de transferencia (MB/seg.)',& MBytes/(Final-Inicio)
Stop End Subroutine Dummy(s,n) return end
Call CPU_Time(Inicio) Do j=1,promedio Do I=1,N S1=S1+a1(i)*a2(i) S2=S2+a3(i)*a4(i) S3=S3+a5(i)*a6(i) End Do S=S1+S2+S3 Call Dummy(s,n) End Do Call CPU_Time(Final) Print *,'Total MB transferidos :', MBytes, &' en ', Final-Inicio,' segs.' Print *,'Velocidad de transferencia (MB/seg.)',& MBytes/(Final-Inicio)
Stop End Subroutine Dummy(s,n) return end

El código Máquina.● Sólo en contadas ocasiones merece la pena escribir una rutina
en código máquina, sin embargo, para comprender por qué a veces el rendimiento se encuentra lejos del esperado, es útil entender qué hace el compilador en determinadas secciones.
● Todos los compiladores son capaces de producir un listado del código máquina en ensamblador. El ejemplo que sigue está obtenido para una CPU IBM Power.
● Es interesante saber que la mayoría de las CPU modernas pueden reestructurar el código en tiempo de ejecución: Las instrucciones no tienen por qué ejecutarse en el orden en que aparecen en el listado.

17 | DO j=1, M 18 | 19 | Do i=1,N 20 | 21 | y(i) =y(i)+A*x(i) 22 | End Do 23 | 24 | Call dummy(x,n) 25 | End Do 26 | 27 | Call CPU_Time(Final) .............. trozo fuera ........... 33 |! Unroll x 4 34 | 35 | Call CPU_Time(Inicio) 36 | 37 | DO j=1, M 38 | 39 | Do i=1,N,4 40 | 41 | y(i) =y(i)+A*x(i) 42 | y(i+1) =y(i+1)+A*x(i+1) 43 | y(i+2) =y(i+2)+A*x(i+2) 44 | y(i+3) =y(i+3)+A*x(i+3) 45 | 46 | End Do 47 | 48 | Call dummy(x,n) 49 | End Do
17 | DO j=1, M 18 | 19 | Do i=1,N 20 | 21 | y(i) =y(i)+A*x(i) 22 | End Do 23 | 24 | Call dummy(x,n) 25 | End Do 26 | 27 | Call CPU_Time(Final) .............. trozo fuera ........... 33 |! Unroll x 4 34 | 35 | Call CPU_Time(Inicio) 36 | 37 | DO j=1, M 38 | 39 | Do i=1,N,4 40 | 41 | y(i) =y(i)+A*x(i) 42 | y(i+1) =y(i+1)+A*x(i+1) 43 | y(i+2) =y(i+2)+A*x(i+2) 44 | y(i+3) =y(i+3)+A*x(i+3) 45 | 46 | End Do 47 | 48 | Call dummy(x,n) 49 | End Do
17| CL.0:19| 000034 cal 38600001 1 LI gr3=119| 000038 st 90612054 0 ST4A i(gr1,8276)=gr319| CL.2:21| 00003C l 80612054 1 L4A gr3=i(gr1,8276)21| 000040 rlinm 54631838 2 SLL4 gr3=gr3,321| 000044 cax 7C811A14 1 A gr4=gr1,gr321| 000048 lfd C8241038 0 LFL fp1=y(gr4,4152)21| 00004C cax 7C811A14 1 A gr4=gr1,gr321| 000050 lfd C8440038 0 LFL fp2=x(gr4,56)21| 000054 lfs C07F0000 1 LFS fp3=+CONSTANT_AR...21| 000058 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr21| 00005C cax 7C611A14 0 A gr3=gr1,gr321| 000060 stfd D8231038 0 STFL y(gr3,4152)=fp122| 000064 l 80612054 0 L4A gr3=i(gr1,8276)22| 000068 cal 38630001 2 AI gr3=gr3,122| 00006C cmpi 2C030200 0 C4 cr0=gr3,51222| 000070 st 90612054 1 ST4A i(gr1,8276)=gr322| 000074 bc 4081FFC8 0 BF CL.2,cr0,0x2/gt ,22| CL.3:24| 000078 cal 38610040 1 AI gr3=gr1,6424| 00007C cal 38800200 0 LI gr4=51224| 000080 st 90812060 1 ST4A #1(gr1,8288)=gr424| 000084 cal 38812060 0 AI gr4=gr1,828824| 000088 bl 4BFFFF79 0 CALL gr3=dummy,2,x",g...24| 00008C cror 4DEF7B82 025| 000090 l 80612058 1 L4A gr3=j(gr1,8280)25| 000094 cal 38630001 2 AI gr3=gr3,125| 000098 cmpi 2C037800 1 C4 cr0=gr3,3072025| 00009C st 90612058 0 ST4A j(gr1,8280)=gr325| 0000A0 bc 4081FF94 1 BF CL.0,cr0,0x2/gt ,25| CL.1:27| 0000A4 cal 38612048 1 AI gr3=gr1,826427| 0000A8 bl 4BFFFF59 0 CALL gr3=_xldctime,1,... ......... trozo fuera ...........
17| CL.0:19| 000034 cal 38600001 1 LI gr3=119| 000038 st 90612054 0 ST4A i(gr1,8276)=gr319| CL.2:21| 00003C l 80612054 1 L4A gr3=i(gr1,8276)21| 000040 rlinm 54631838 2 SLL4 gr3=gr3,321| 000044 cax 7C811A14 1 A gr4=gr1,gr321| 000048 lfd C8241038 0 LFL fp1=y(gr4,4152)21| 00004C cax 7C811A14 1 A gr4=gr1,gr321| 000050 lfd C8440038 0 LFL fp2=x(gr4,56)21| 000054 lfs C07F0000 1 LFS fp3=+CONSTANT_AR...21| 000058 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr21| 00005C cax 7C611A14 0 A gr3=gr1,gr321| 000060 stfd D8231038 0 STFL y(gr3,4152)=fp122| 000064 l 80612054 0 L4A gr3=i(gr1,8276)22| 000068 cal 38630001 2 AI gr3=gr3,122| 00006C cmpi 2C030200 0 C4 cr0=gr3,51222| 000070 st 90612054 1 ST4A i(gr1,8276)=gr322| 000074 bc 4081FFC8 0 BF CL.2,cr0,0x2/gt ,22| CL.3:24| 000078 cal 38610040 1 AI gr3=gr1,6424| 00007C cal 38800200 0 LI gr4=51224| 000080 st 90812060 1 ST4A #1(gr1,8288)=gr424| 000084 cal 38812060 0 AI gr4=gr1,828824| 000088 bl 4BFFFF79 0 CALL gr3=dummy,2,x",g...24| 00008C cror 4DEF7B82 025| 000090 l 80612058 1 L4A gr3=j(gr1,8280)25| 000094 cal 38630001 2 AI gr3=gr3,125| 000098 cmpi 2C037800 1 C4 cr0=gr3,3072025| 00009C st 90612058 0 ST4A j(gr1,8280)=gr325| 0000A0 bc 4081FF94 1 BF CL.0,cr0,0x2/gt ,25| CL.1:27| 0000A4 cal 38612048 1 AI gr3=gr1,826427| 0000A8 bl 4BFFFF59 0 CALL gr3=_xldctime,1,... ......... trozo fuera ...........

39| CL.6:41| 000264 l 80612054 1 L4A gr3=i(gr1,8276)41| 000268 rlinm 54631838 2 SLL4 gr3=gr3,341| 00026C cax 7C811A14 1 A gr4=gr1,gr341| 000270 lfd C8241038 0 LFL fp1=y(gr4,4152)41| 000274 cax 7C811A14 1 A gr4=gr1,gr341| 000278 lfd C8440038 0 LFL fp2=x(gr4,56)41| 00027C lfs C07F0000 1 LFS fp3=+CONSTANT_AREA(gr31,0)41| 000280 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr41| 000284 cax 7C611A14 0 A gr3=gr1,gr341| 000288 stfd D8231038 0 STFL y(gr3,4152)=fp142| 00028C l 80612054 0 L4A gr3=i(gr1,8276)42| 000290 rlinm 54631838 2 SLL4 gr3=gr3,342| 000294 cax 7C811A14 1 A gr4=gr1,gr342| 000298 lfd C8241040 1 LFL fp1=y(gr4,4160)42| 00029C cax 7C811A14 0 A gr4=gr1,gr342| 0002A0 lfd C8440040 1 LFL fp2=x(gr4,64)42| 0002A4 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr42| 0002A8 cax 7C611A14 0 A gr3=gr1,gr342| 0002AC stfd D8231040 0 STFL y(gr3,4160)=fp143| 0002B0 l 80612054 0 L4A gr3=i(gr1,8276)43| 0002B4 rlinm 54631838 2 SLL4 gr3=gr3,343| 0002B8 cax 7C811A14 1 A gr4=gr1,gr343| 0002BC lfd C8241048 1 LFL fp1=y(gr4,4168)43| 0002C0 cax 7C811A14 0 A gr4=gr1,gr343| 0002C4 lfd C8440048 1 LFL fp2=x(gr4,72)43| 0002C8 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr43| 0002CC cax 7C611A14 0 A gr3=gr1,gr343| 0002D0 stfd D8231048 0 STFL y(gr3,4168)=fp144| 0002D4 l 80612054 0 L4A gr3=i(gr1,8276)44| 0002D8 rlinm 54631838 2 SLL4 gr3=gr3,344| 0002DC cax 7C811A14 1 A gr4=gr1,gr344| 0002E0 lfd C8241050 1 LFL fp1=y(gr4,4176)44| 0002E4 cax 7C811A14 0 A gr4=gr1,gr344| 0002E8 lfd C8440050 1 LFL fp2=x(gr4,80)44| 0002EC fma FC2208FA 1 FMA fp1=fp1-fp3,fcr44| 0002F0 cax 7C611A14 0 A gr3=gr1,gr344| 0002F4 stfd D8231050 0 STFL y(gr3,4176)=fp146| 0002F8 l 80612054 0 L4A gr3=i(gr1,8276)46| 0002FC cal 38630004 2 AI gr3=gr3,446| 000300 cmpi 2C030200 0 C4 cr0=gr3,51246| 000304 st 90612054 1 ST4A i(gr1,8276)=gr346| 000308 bc 4081FF5C 0 BF CL.6,cr0,0x2/gt ,46| CL.7:
39| CL.6:41| 000264 l 80612054 1 L4A gr3=i(gr1,8276)41| 000268 rlinm 54631838 2 SLL4 gr3=gr3,341| 00026C cax 7C811A14 1 A gr4=gr1,gr341| 000270 lfd C8241038 0 LFL fp1=y(gr4,4152)41| 000274 cax 7C811A14 1 A gr4=gr1,gr341| 000278 lfd C8440038 0 LFL fp2=x(gr4,56)41| 00027C lfs C07F0000 1 LFS fp3=+CONSTANT_AREA(gr31,0)41| 000280 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr41| 000284 cax 7C611A14 0 A gr3=gr1,gr341| 000288 stfd D8231038 0 STFL y(gr3,4152)=fp142| 00028C l 80612054 0 L4A gr3=i(gr1,8276)42| 000290 rlinm 54631838 2 SLL4 gr3=gr3,342| 000294 cax 7C811A14 1 A gr4=gr1,gr342| 000298 lfd C8241040 1 LFL fp1=y(gr4,4160)42| 00029C cax 7C811A14 0 A gr4=gr1,gr342| 0002A0 lfd C8440040 1 LFL fp2=x(gr4,64)42| 0002A4 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr42| 0002A8 cax 7C611A14 0 A gr3=gr1,gr342| 0002AC stfd D8231040 0 STFL y(gr3,4160)=fp143| 0002B0 l 80612054 0 L4A gr3=i(gr1,8276)43| 0002B4 rlinm 54631838 2 SLL4 gr3=gr3,343| 0002B8 cax 7C811A14 1 A gr4=gr1,gr343| 0002BC lfd C8241048 1 LFL fp1=y(gr4,4168)43| 0002C0 cax 7C811A14 0 A gr4=gr1,gr343| 0002C4 lfd C8440048 1 LFL fp2=x(gr4,72)43| 0002C8 fma FC2208FA 1 FMA fp1=fp1-fp3,fcr43| 0002CC cax 7C611A14 0 A gr3=gr1,gr343| 0002D0 stfd D8231048 0 STFL y(gr3,4168)=fp144| 0002D4 l 80612054 0 L4A gr3=i(gr1,8276)44| 0002D8 rlinm 54631838 2 SLL4 gr3=gr3,344| 0002DC cax 7C811A14 1 A gr4=gr1,gr344| 0002E0 lfd C8241050 1 LFL fp1=y(gr4,4176)44| 0002E4 cax 7C811A14 0 A gr4=gr1,gr344| 0002E8 lfd C8440050 1 LFL fp2=x(gr4,80)44| 0002EC fma FC2208FA 1 FMA fp1=fp1-fp3,fcr44| 0002F0 cax 7C611A14 0 A gr3=gr1,gr344| 0002F4 stfd D8231050 0 STFL y(gr3,4176)=fp146| 0002F8 l 80612054 0 L4A gr3=i(gr1,8276)46| 0002FC cal 38630004 2 AI gr3=gr3,446| 000300 cmpi 2C030200 0 C4 cr0=gr3,51246| 000304 st 90612054 1 ST4A i(gr1,8276)=gr346| 000308 bc 4081FF5C 0 BF CL.6,cr0,0x2/gt ,46| CL.7:
33 |! Unroll x 4 34 | 35 | Call CPU_Time(Inicio) 36 | 37 | DO j=1, M 38 | 39 | Do i=1,N,4 40 | 41 | y(i) =y(i)+A*x(i) 42 | y(i+1) =y(i+1)+A*x(i+1) 43 | y(i+2) =y(i+2)+A*x(i+2) 44 | y(i+3) =y(i+3)+A*x(i+3) 45 | 46 | End Do 47 | 48 | Call dummy(x,n) 49 | End Do
33 |! Unroll x 4 34 | 35 | Call CPU_Time(Inicio) 36 | 37 | DO j=1, M 38 | 39 | Do i=1,N,4 40 | 41 | y(i) =y(i)+A*x(i) 42 | y(i+1) =y(i+1)+A*x(i+1) 43 | y(i+2) =y(i+2)+A*x(i+2) 44 | y(i+3) =y(i+3)+A*x(i+3) 45 | 46 | End Do 47 | 48 | Call dummy(x,n) 49 | End Do

37| CL.21: 0| 000240 mtspr 7EC903A6 1 LCTR ctr=gr22 0| 000244 cal 386100E0 0 AI gr3=gr1,224 41| 000248 lfq E0031010 1 LFQ fp0,fp1=x(gr3,4112) 41| 00024C lfq E0430010 0 LFQ fp2,fp3=y(gr3,16) 41| 000250 fma FC00173A 1 FMA fp0=fp2,fp0,fp28,fcr 42| 000254 fma FC211F3A 0 FMA fp1=fp3,fp1,fp28,fcr 0| 000258 bc 43400030 0 BCF ctr=CL.90,taken=0%(0,100) 39| CL.23: 43| 00025C lfq E0831020 1 LFQ fp4,fp5=x(gr3,4128) 43| 000260 lfq E0430020 0 LFQ fp2,fp3=y(gr3,32) 43| 000264 fma FC44173A 1 FMA fp2=fp2,fp4,fp28,fcr 44| 000268 fma FC651F3A 0 FMA fp3=fp3,fp5,fp28,fcr 42| 00026C stfq F0030010 0 STFQ y(gr3,16)=fp0,fp1 41| 000270 lfq E0830030 0 LFQ fp4,fp5=y(gr3,48) 41| 000274 lfq E0031030 1 LFQ fp0,fp1=x(gr3,4144) 41| 000278 fma FC00273A 0 FMA fp0=fp4,fp0,fp28,fcr 44| 00027C stfqu F4430020 0 STFQU gr3,y(gr3,32)=fp2,fp3 42| 000280 fma FC212F3A 0 FMA fp1=fp5,fp1,fp28,fcr 0| 000284 bc 4320FFD8 0 BCT ctr=CL.23,taken=100%(100,0) 0| CL.90: 43| 000288 lfq E0831020 1 LFQ fp4,fp5=x(gr3,4128) 43| 00028C lfq E0430020 0 LFQ fp2,fp3=y(gr3,32) 43| 000290 fma FC44173A 1 FMA fp2=fp2,fp4,fp28,fcr 44| 000294 fma FC651F3A 0 FMA fp3=fp3,fp5,fp28,fcr 42| 000298 stfq F0030010 0 STFQ y(gr3,16)=fp0,fp1 48| 00029C st 93A10048 0 ST4A T_20(gr1,72)=gr29 48| 0002A0 cal 38810048 1 AI gr4=gr1,72,ca" 44| 0002A4 stfdu DC430020 0 STFDU gr3,y(gr3,32)=fp2 44| 0002A8 stfd D8630008 1 STFL y(gr3,8)=fp3 48| 0002AC cal 386110F0 0 AI gr3=gr1,4336,ca" 48| 0002B0 bl 4BFFFD51 0 CALL dummy,2,x",gr3,T_20",gr4,dummy",fcr",gr1,cr[01567]",gr0",gr3"-gr12",fp0"-fp13",mq",lr",fcr",xer",fsr",ca",ctr" 48| 0002B4 oril 60000000 1
37| CL.21: 0| 000240 mtspr 7EC903A6 1 LCTR ctr=gr22 0| 000244 cal 386100E0 0 AI gr3=gr1,224 41| 000248 lfq E0031010 1 LFQ fp0,fp1=x(gr3,4112) 41| 00024C lfq E0430010 0 LFQ fp2,fp3=y(gr3,16) 41| 000250 fma FC00173A 1 FMA fp0=fp2,fp0,fp28,fcr 42| 000254 fma FC211F3A 0 FMA fp1=fp3,fp1,fp28,fcr 0| 000258 bc 43400030 0 BCF ctr=CL.90,taken=0%(0,100) 39| CL.23: 43| 00025C lfq E0831020 1 LFQ fp4,fp5=x(gr3,4128) 43| 000260 lfq E0430020 0 LFQ fp2,fp3=y(gr3,32) 43| 000264 fma FC44173A 1 FMA fp2=fp2,fp4,fp28,fcr 44| 000268 fma FC651F3A 0 FMA fp3=fp3,fp5,fp28,fcr 42| 00026C stfq F0030010 0 STFQ y(gr3,16)=fp0,fp1 41| 000270 lfq E0830030 0 LFQ fp4,fp5=y(gr3,48) 41| 000274 lfq E0031030 1 LFQ fp0,fp1=x(gr3,4144) 41| 000278 fma FC00273A 0 FMA fp0=fp4,fp0,fp28,fcr 44| 00027C stfqu F4430020 0 STFQU gr3,y(gr3,32)=fp2,fp3 42| 000280 fma FC212F3A 0 FMA fp1=fp5,fp1,fp28,fcr 0| 000284 bc 4320FFD8 0 BCT ctr=CL.23,taken=100%(100,0) 0| CL.90: 43| 000288 lfq E0831020 1 LFQ fp4,fp5=x(gr3,4128) 43| 00028C lfq E0430020 0 LFQ fp2,fp3=y(gr3,32) 43| 000290 fma FC44173A 1 FMA fp2=fp2,fp4,fp28,fcr 44| 000294 fma FC651F3A 0 FMA fp3=fp3,fp5,fp28,fcr 42| 000298 stfq F0030010 0 STFQ y(gr3,16)=fp0,fp1 48| 00029C st 93A10048 0 ST4A T_20(gr1,72)=gr29 48| 0002A0 cal 38810048 1 AI gr4=gr1,72,ca" 44| 0002A4 stfdu DC430020 0 STFDU gr3,y(gr3,32)=fp2 44| 0002A8 stfd D8630008 1 STFL y(gr3,8)=fp3 48| 0002AC cal 386110F0 0 AI gr3=gr1,4336,ca" 48| 0002B0 bl 4BFFFD51 0 CALL dummy,2,x",gr3,T_20",gr4,dummy",fcr",gr1,cr[01567]",gr0",gr3"-gr12",fp0"-fp13",mq",lr",fcr",xer",fsr",ca",ctr" 48| 0002B4 oril 60000000 1
33 |! Unroll x 4 34 | 35 | Call CPU_Time(Inicio) 36 | 37 | DO j=1, M 38 | 39 | Do i=1,N,4 40 | 41 | y(i) =y(i)+A*x(i) 42 | y(i+1) =y(i+1)+A*x(i+1) 43 | y(i+2) =y(i+2)+A*x(i+2) 44 | y(i+3) =y(i+3)+A*x(i+3) 45 | 46 | End Do 47 | 48 | Call dummy(x,n) 49 | End Do
33 |! Unroll x 4 34 | 35 | Call CPU_Time(Inicio) 36 | 37 | DO j=1, M 38 | 39 | Do i=1,N,4 40 | 41 | y(i) =y(i)+A*x(i) 42 | y(i+1) =y(i+1)+A*x(i+1) 43 | y(i+2) =y(i+2)+A*x(i+2) 44 | y(i+3) =y(i+3)+A*x(i+3) 45 | 46 | End Do 47 | 48 | Call dummy(x,n) 49 | End Do
Compiled with-O2 -qarch=pwr2

El Compilador● Las optimizaciones que hemos visto sirven para alcanzar un
rendimiento razonable, de manera portable, con un esfuerzo modesto: El compilador deberá ser capaz de generar código máquina eficiente a partir del programa fuente usando opciones de compilación moderadamente agresivas.
● El nivel de transformaciones que aplicará el compilador al código fuente es controlable a través de las opciones de compilación.
– Hay preprocesadores (KAP,VAST) capaces de alterar el código fuente, optimizándolo para un conjunto HW/SW dado.
– Algunas opciones pueden ser peligrosas. Mayores niveles de agresividad en la optimización no producen necesariamente ejecutables más óptimos. Programas escritos usando las normas básicas vistas producirán ejecutables de calidad más constante al cambiar el entorno HW/SW.

El Compilador● Opciones genéricas de optimización: Típicamente -Ox Donde x es el
nivel de optimización. Según cada fabricante dispara optimizaciones más o menos agresivas. Cuidado con los niveles más altos.
● Opciones de ajuste de la arquitectura: Controlan la CPU a la que va destinado el programa así como detalles de otras partes de la arquitectura (Ej: tamaño o asociatividad de la cache)
● Opciones -qarch, -qtune, -qcache en el xlf de IBM.● Opciones para hacer análisis interprocedural y optimizaciones
basadas en ejecuciones reales
● Opciones -qipa -Q en xlf● Opciones de control del comportamiento de punto flotante.
● -qfloat, -qhslt en xlf.

¿Qué suele ser capaz de hacer el compilador?● Eliminar subexpresiones comunes. Sustituir código como
en por
– Menos operaciones, promociones a registros (y/o menor número de registros usados)
– Puede ocurrir con arrays, pero no con llamadas de funciones (excepto si son puras).
– Cuando la eliminación de expresiones comunes requiere la reordenación de operaciones el resultado puede no ser identico, ya que las operaciones en punto flotante no son conmutativas.
● No todos los compiladores lo harán o lo harán sólo en los niveles más altos de optimización.
● No todos los lenguajes lo permiten en su definición (Fortran si, Java no - ... en principio, ver cualificador nostrictfp-)
S1 = a + b + cS2 = a + b - c
T = a + bS1 = T + cS2 = T - c

● Reducción de “intensidad” (strength). Sustitución de expresiones aritméticas por otras similares pero más rápidas: x**2 por x*x
● Extracción de código invariante. Sacando fuera del bucle las partes que se recalculan dentro pero sin depender de la variable de iteración: por
● Propagación y evaluación de constantes. por
● Simplificación de variables de inducción. por
Do i=1,n
a(i) = r*s*a(i)End Do
Do i=1,n
a(i) = r*s*a(i)End Do
T= r*sDo i=1,n a(i) = t*a(i)End Do
T= r*sDo i=1,n a(i) = t*a(i)End Do
Pi = 3.141592D0s2a= Sin(2*Pi*a)
Pi = 3.141592D0s2a= Sin(2*Pi*a) s2a= Sin(6.283184*a)s2a= Sin(6.283184*a)
Dimension a(4,1000)Do i=1,1000 x=x+a(1,i)End Do
Dimension a(4,1000)Do i=1,1000 x=x+a(1,i)End Do
Dimension a(4*1000)iadd = 1Do i=1,1000 x=x+a(iadd) iadd = iadd + 4End Do
Dimension a(4*1000)iadd = 1Do i=1,1000 x=x+a(iadd) iadd = iadd + 4End Do

● Ordenamiento de instrucciones y registros para eliminación de dependencias y aprovechamiento del pipeline.
por
● Combinaciones de las anteriores
por
x=1+c*a(i)s = s+xy=2+c*b(i) t = t+y
x=1+c*a(i)s = s+xy=2+c*b(i) t = t+y
x=1+c*a(i)y=2+c*b(i) s = s+xt = t+y
x=1+c*a(i)y=2+c*b(i) s = s+xt = t+y
x= a + b/cy= e + f/c
x= a + b/cy= e + f/c d= 1/c
x= a + b*dy= e + f*d
d= 1/cx= a + b*dy= e + f*d

Optimización Automática● Hay optimizaciones que siempre estarán más allá de las
capacidades de un compilador... aunque sólo sea por que el usuario no está dispuesto a soportar tiempos de compilación de días.
● La optimización manual fina, más allá de las técnica vistas, es excesivamente costosa, en términos de tiempo y conocimiento.
– El HW: CPU, memoria y SW: SO, compiladores, entorno de ejecución, evolucionan muy rápidamente. Resulta inviable pensar que los fabricantes inviertan tanto esfuerzo de manera continuada en proveer librerías muy optimizadas excepto para los casos más significativos.
– Además... cuando por fin se tienen librerías optimizadas, el HW ha quedado obsoleto, de aquí la importancia de los sistemas automáticos (AEOS, SANS, ...)

SECCIÓN III
Evaluación (Benchmarking)

Evaluación (benchmarking)● Obtener una idea acerca del rendimiento que se
puede obtener de una máquina dada en un problema concreto.
● Realizar pruebas que puedan asesorar sobre todos los posibles aspectos HW/SW (bajo nivel) puede ser muy prolijo y de difícil interpretación.– La evaluación de aspectos aislados del comportamiento
muchas veces sólo tiene sentido cuando se está diseñando un subsistema específico, lo que raramente tiene interés para el usuario final.

Filosofías de Benchmarking
● Pruebas de una sola aplicación simple pero muy utilizada: LINPACK
● Pruebas de comportamiento modelo esquematizado de varias aplicaciones: Livermore Loops, evaluaciones sintéticas.
● Pruebas de comportamiento de subsistemas: Genesis bajo nivel, cachebench.
● Pruebas de aplicación completa: SPEC, NAS.

Descripción de algunos Métodos● LINPACK: Resolución de un sistema de ecuaciones
100x100, 1000x1000 o hasta la capacidad de la máquina. Se cita el mejor resultado en Mflops. La mayor carga viene de los dAXpY.– LINPACK base: Se resuelve via descomposición LU un
sistema 100x100. No está permitido modificar el programa original, solo se puede modificar su compilación via las opciones del compilador.
– LINPACK pico: Se resuelve un sistema 1000x1000 dado utilizando un método cualquiera (en cualquier lenguaje)pero con una precisión especificada (~2E-53). Como conteo de operaciones se usa el de la descomposición LU.

– LINPACK paralelo (MPL): Igual que en el 1000x1000, pero el sistema de ecuaciones lineales es de tamaño libre. Además de la velocidad máxima, las magnitudes significativas son el tamaño del problema para el que se alcanza la velocidad máxima y el tamaño para el que se alcanza la mitad de la velocidad máxima.

● A pesar de ser una evaluación antigua y limitada, se sigue citando y publicando nuevos resultados, siendo la base de listas tan conocidas como el Top500, que usa el MPL.
● Hay que ser cuidadoso al considerar su relevancia en la evaluación de una máquina. El 100x100 apenas evalua el subsistema de memoria, ya que en la actualidad cabe en casi cualquier cache. La velocidad viene limitada por el ratio FPU/acceso a la cache. El 1000x1000 se desarrolló para ser más sensible a esto, pero las caches siguen aumentando. En cualquier caso siempre se trata de un problema de álgebra lineal densa: Accesos muy regulares.

Linpack Test
Note: First Page on 1-jun-2012List is the same

Linpack 100x100

Linpack 100x100

Linpack 100x100

Linpack Test (Losúltimos)
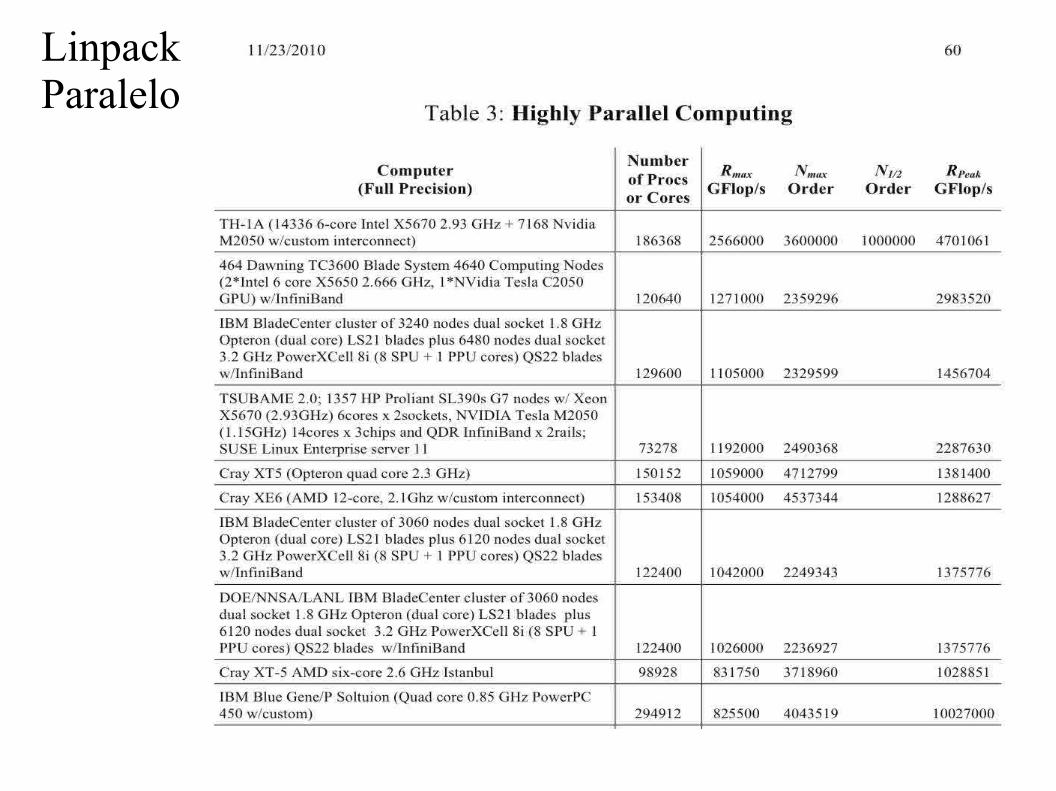
LinpackParalelo

Top500● Basado en MPL. Ampliamente usado para reconocertendencias sobre procesadores, fabricantes, arquitecturas,ámbitos de uso, etc.
Tu P4 a 3 GHz

Top 500
Junio 2008: Por primeravez se lista también el consumo (asociado directamente al cálculo,no se cuenta aire acondicionado, UPS,sistemas de discos nonecesarios para correrel benchmark, etc.)

Top 500
Nov. 2012

Top 500
Nov. 2011

Green 500
Jun. 2011

Green 500
Nov. 2012

Aside: Data Intensive Computing is rapidly establishing as a new paradigm. The design of supercomputers for DIC is different and benchmarks will be also different. Linpack is not only biased and limited for current compute intensive workloads, but is clearly inadequate for DIC machines.

Power consumption brief (jul-08).● Average Power consumption of a TOP10 system is 1.32 Mwatt and average
power efficiency is 248 Mflop/s/Watt.
● Average Power consumption of a TOP500 system is 257 kwatt and average power efficiency is 122 Mflop/s/Watt.
● Most energy efficient supercomputers are based on:
● IBM QS22 Cell processor blades up to 488 Mflop/s/Watt,
● IBM BlueGene/P systems up to 371 Mflop/s/Watt
● Intel Harpertown quad-core blades are catching up fast:
● IBM BladeCenter HS21with low-power processors (L5420) up to 265 Mflop/s/Watt
● SGI Altix ICE 8200EX Xeon nodes (E5472) with high efficient Linpack up to 240 Mflop/s/Watt
● Hewlett-Packard Cluster Platform 3000 BL2x220 with double density blades up to 227 Mflop/s/Watt
● These systems are already ahead of BlueGene/L (up to 210 Mflop/s/Watt).

● Quad-core processor based systems have taken over the TOP500 quite rapidly. Already 283 systems are using them. 203 dual-core processors. 11 systems single core. 3 systems use IBMs Cell processor with 9 cores.
● The entry level to the list moved up to the 9.0 Tflop/s mark, compared to 5.9 Tflop/s six months ago.
● The last system on the list would have been listed at position 200 in the previous TOP500 just six months ago. This is the largest turnover rate in the 16 years of the history of the TOP500 project.
● Total combined performance has grown to 11.7 Pflop/s, compared to 6.97 Pflop/s six months ago.
● The entry point for the top 100 increased in six months from 12.97 Tflop/s to 18.8 Tflop/s
● The average concurrency level in the TOP500 is 4,850 cores per system up from 3,290 six month ago.
A few highlights (oct.-08):
Take a look at: http://www.top500.org/lists/2008/06/highlights/general


Livermore Loops
● Intento de extender la validez de Linpack a otros problemas (todos del área técnica o científica)– Se seleccionaron un conjunto de núcleos
computacionales (básicamente bucles) de aplicaciones representativas de cálculo intensivo: Dinámica de fluidos, Montecarlo, etc.
● Estas pruebas apenas se citan ya, aunque fueron la base de evaluaciones sintéticas.

● Pruebas sintéticas: ejecutar una mezcla de operaciones típica que se aproxime al comportamiento promedio de un programa dado.– Dhrystones: Programas con predominio de cálculo con
enteros.
– Whetstones: Predominio de punto flotante.● Estas evaluaciones no se desarrollaron conjuntamente. Sujetas
a muchas críticas por la dificultad de decidir el tipo y la cantidad de operaciones de un programa “promedio”. Dhrystones era muy sensibles a optimizaciones del compilador, eliminación de código muerto. Whetstone menos sensible y más variado que Linpack, pero sufrio tantas variantes que finalmente no se sabia lo estaba ejecutando cada vendedor que lo citaba.

SPEC● Standard Performance Evaluation Corporation. (IBM, Intel,
SGI, Compaq, Siemens, etc.)
– “stablish, maintain and endorse a standardized set of relevant benchmarks that can be applied to the newest generation of high performance computers”
– Son el estándar de facto, al menos en arquitecturas secuenciales. El conjunto de evaluaciones SPEC se compran a la organización. Cualquiera puede publicar los resultados, pero hay que someterse a normas muy estrictas.
– Nos interesan las CPU2006, pero hay otras evaluaciones: ● Para computacion de alto rendimiento: SPEC OMP2001, MPI2007.
Para www: SPEC web99. Para Java: SPEC jvm98, jbb2000. Para correo electrónico: SPECMail. Para consumo: SPECpower_ssj2008...

● Los componentes de la organización proponen y aprueban conjuntamente las pruebas de evaluación , que son aplicaciones completas. – Pruebas y resultados se hacen públicos en www.spec.org El número
final citado es la media geométrica -pesa más el más desfavorable-

– El objetivo es medir el rendimiento en cálculo intensivo. Miden principalmente:
● La CPU.● La arquitectura de memoria.● Los compiladores.
– La primera versión fue SPEC89, posteriormente SPEC92, SPEC95, SPEC2000 y ahora SPEC2006. Los números citados pueden no ser comparables entre distintas versiones. En SPEC2006 la diferencia, además del cambio de algunas aplicaciones, es el tamaño de las mismas (memory footprint target ~ 900MB)
– Los test están divididos en una parte de enteros (SPEC CINT) y otra de coma flotante (SPEC CFP). Para cada parte hay también evaluaciones de rendimiento final (throughput)

● SPEC CFP2006: 17 benchmarks. 4 en C++, 3 en C, 6 en Fortran, y 4 mezclan C y Fortran.
Componentesde la parte enpunto flotante de SPEC: CFP2006

● SPEC CINT2006: 12 benchmarks: 9 en C y 3 en C++.
Componentes de laparte entera del SPEC: CINT2006

Criterios de elección de las aplicaciones:● Citando literalmente a SPEC:
– Portability to a variety of CPU architectures (32- and 64-bit including AMD64, Intel IA32, Itanium, PA-RISC, PowerPC, SPARC, etc.)
– Portability to various operating systems, particularly UNIX and Windows
– Nearly all of the time is spent compute bound
– Little time spent in IO and system services
– Benchmarks should run in about 1GB RAM without swapping or paging

Criterios de elección de las aplicaciones(II)
– No more than five percent of benchmarking time should be spent processing code not provided by SPEC
– Well-known applications or application areas
– Available workloads that represent real problems

SPEC CPU2006: Perfiles de memoria.

SPEC CPU2006: Perfiles de memoria.

SPEC: Resultados.● Se citan tres tipos de resultados:
– Máximo: citados habitualmente sin identificador adicional. Se obtienen usando cualquier cualificador de compilación deseado.
– Base: Sólo se pueden usar determinados cualificadores. Se citan como SPECint_base2006 o SPECfp_base2006.
● Se dan referidos a una escala en la que una Sun Ultra Sparc II a 300MHz tiene resultado 1 para todas las evaluaciones. En esta máquina una copia del benchmark tarda unos 12 días en terminar. Máquinas modernas tardan entre uno y dos días.– Rate: Medida de rendimiento final. Capacidad de ejecución simultánea
de tantas tareas como sea posible. El ordenador es alimentado con varias copias del test SPEC (Típicamente una por CPU). SPECint_rate2006, SPECfp_rate2006

● Hoja típicade resultados SPEC (1/4)

● Hoja típicade resultadosSPEC (2/4)Compilersettings.

● Hoja típicade resultadosSPEC (3/4)Compilersettings.

● Hoja típicade resultadosSPEC (4/4)Compilersettings.

Viejo SPEC CPU2000: Ejemplo de Resultados

SPEC MPI2007● Sharing many ideas from SPEC CPU benchmarks:
– Uses complete applications written in Fortran, C and C++– No code modification, controlled environment. Run “as is”
(aided by a closed kit that can be slightly taylored to make the benchmark run and to give the needed input: compiler flags, environment variables, etc.)
– The results are expected to give an idea of the performance for “commercialy systems” available to others, not just an experimental non-production SW/HW set.
– It tests the performance of CPUs vs # of nodes vs Communication interconnect vs. memory architecture vs. SW environment (compiler, OS, file system...)...

HPC Challenge● Extensión del Linpack MPL.
– Incluye el mismo HPL usado en el Top500.– Incluye otros benchmarks que miden, sobre todo, el
subsistema de memoria:● STREAMS: Benchmark sintético. Mide ancho de banda
sostenible a memoria y ratio de computación en un kernel vectorial simple.
● PTRANS: Parallel Matrix Transpose. Mide la capacidad de la red que conecta dos procesadores dados.
● b_eff: Test de bajo nivel para medir la latencia y ancho de banda en diversos tipos de acceso
● RandomAccess: Actualización de posiciones de memoria obtenidas de manera aleatoria.

HPC Challenge: Ejemplo de resultados

Dejamos Fuera...● Hay otras muchas evaluaciones, no es un tema resuelto
en el sentido en que no hay consensos unánimes.– Evaluaciones con aplicaciones específicas: Rendimiento de
Gaussian (química cuántica), BLAST (Basic Local Alignment Tool, biología)
– Evaluaciones interesantes en otros campos: Proceso de transacciones (TPA, TPB, TPC). Servidores web (SPEC web), motores java (SPEC jvm), etc.
– Máquinas paralelas: NAS, PARKBENCH, Genesis, SPEC hpc, SPEC omp

No hay sustituto para los propios.● Las pruebas vistas nos pueden dar una idea general y
ayudarnos a la hora de reducir el posible rango de elecciones.
● Pero no nos darán una figura precisa sobre cómo irán las cosas con nuestra aplicación. Podemos intentar un benchmark propio:– Dimensionar correctamente la configuración, especialmente
en cuanto a requisitos de memoria.
– Probar la aplicación en el mismo entorno que se usará en producción: librerías, compiladores (usar bien las optimizaciones)
– Si se usará en tiempo compartido: medidas de throughput.

Y la velocidad no es todo...● Otras métricas:
– TCO (Total Cost of Ownership)/rendimiento: Topper.● Coste de Adquisición + Coste de operación.
– Coste de operación:● Administración● Potencia consumida (refrigeración incluida)● Tiempo de mantenimiento● Espacio ocupado
● TCO es difícil de cuantificar...
– Eficiencia de consumo: Rendimiento/Consumo
– Eficiencia en espacio: Rendimiento/espacio● Fáciles de cuantificar.

W. Feng http://sss.lanl.gov

Topper.

● The green grid: The Place to go for info related to datacenterenergy measurement and management.
http://www.thegreengrid.org/

●Freecooling directo: Inyección de aire desde el exterior.●Freecooling indirecto: refrigeración por expansión.

Power Efficiency Metrics for IT
• www.thegreengrid.org Seeking a standard set of measurements to be globally adopted by the IT industry.
• Agreed among HW & SW IT producers and consumers, also manufacturers of IT associated equipment (cooling, power, building…)
• IBM, Intel, Microsoft, eBay, Oracle, APD, Emerson, AEG, Google, BT…
• PuE: Power usage Effectiveness. CuE: Carbon usage Effectiveness
• DciE: DataCenter Infrastructure Efficiency


Bibliografía● BLAS/ATLAS/AEOS /SANS
– http://www.netlib.org/blas Y http://www.netlib.org/blast
– C. Lawson et al. Basic Linear Algebra Subprograms for Fortran Usage. ACM Transactions On Mathematical Software (TOMS) 5(1979)308
– J. Dongarra et al. An Extended Set of Fortran Basic Linear Algebra Subprograms. ACM-TOMS 14(1988)1
– J. Dongarra et al. A Set of Level 3 Basic Linear Algebra Subprograms. ACM TOMS 16(1990)1
– L.S. Blackford et al. An updated Set of BLAS. ACM-TOMS 28(2002)135
– Varios autores. Basic Linear Algebra Subprograms Technical (BLAST) Forum Standard. http://www.netlib.org/blas/blast.forum/blas-report.pdf

–ATLAS. http://math-atlas.sourceforge.net–R.C. Whaley and J. Dongarra. Automatically Tuned Linear Algebra Software. Supercomputing 98. http://www.cs.utk.edu/~rwhaley/papers/atlas_sc98.ps –R.C. Whaley et al. Automatic Empirical Optimization of Software and the ATLAS project. Parallel Computing 27(2001)3–B. Kågström et al. GEMM-Based Level 3 BLAS: High Performance implementations and performance evaluation benchmark. ACM-TOMS 24(1998)268–The Innovative Computing Laboratory, UTK. http://icl.cs.utk.edu/sans●Arquitecturas/Chips: –B. Wilkinson. Computer Architecture, Design and Performance. Prentice Hall 1996.–Communications of the ACM vol. 35, No. 8 1992 (monográfico)–R. W. Hockney y R.C. Jesshope. Parallel Computers II, Adam Hilger 1988.

– I. Foster, C. Kesselman (Eds.) The GRID: Blueprint for a New Computing Infrastructure. Morgan Kaufmann Publishers. (El capítulo 2 está en http://www.globus.org/research/papers/chapter2.pdf
– The Globus Project. http://www.globus.org
– UK Grid Support. http://www.grid-support.ac.uk
– R. Thompson. Grid Networking. http://www.owenwalcher.com/grid_networking.htm
– D. Jones y S. Smith. Operating Systems. Central Queensland University, 1997. http://infocom.cqu.edu.au
– G. Wellein et al. Itanium1/Itanium2 First Experiences. HPC Services Regionales Rechenzentrum Erlangen, 2003.
– J. Morris. Computer Architecture. 1998. http://ciips.ee.uwa.edu.au/~morris/Courses/CA406
– Cray X1 System Overview (S-2346-22), en http://www.cray.com
– C. Dulong. The IA-64 Architecture at Work. IEEE Computer. Julio 1998, pag. 24

– M. Schlansker y B. R. Rau. EPIC: Explicitly Parallel Instruction Computing. IEEE Computer. Feb. 2000, pag. 37
– C. Grassl. Optimization and Tuning on Power4 Systems. IBM Advanced Computing Technology Center, 2002.
– A.J. van der Steen. Overview of Recent Supercomputers (13th edition, 2003) . Netherlands National Computing Facilities Foundation, 2004.
– M.S. Schmalz. Organization of Computer Systems. University of FL 2001. http://www.cise.ufl.edu/~mszz/CompOrg/
– J. Laudon y D. Lenoski. The SGI Origin: A cc-NUMA Highly Scalable Server. Silicon Graphics Inc. 1998.
– J. Ammon. Hypercube Connectivity within cc-NUMA Architecture. Silicon Graphics Inc. 1998.
– General Purpose Computation Using Graphics Hardware: http://www.gpgu.org
– Owens et al. “A Survey of General Purpose Computation on Graphics Hardware”, Eurographics 05, State of the Art Reports.

– Pyush Chaudhary. IBM HPC systems update. SCICOMP 14, Mayo 2008
–

● Optimización:
– B. Alpern y L. Carter, SIAM Short Course on Performance Optimization. http://www.research.ibm.com/perfprog
– K.R. Wadleigh, I.L. Crawford. Software Optimization for High Performance Computing. Hewlett-Packard Professional Books, Prentice Hall PTR (2000)
– Cursos en U. Cornell Theory Center http://www.tc.cornell.edu/Services/Edu/Topics y Edinburgh Parallel Computer Centre http://www.epc.ed.ac.uk/computing
– Andersson et al. RS/6000 Scientific and Technical Computing: Power3 Introduction and Tuning Guide. IBM Redbooks. 1998. http://www.redbooks.ibm.com
– S. Behling et al. The Power4 Processor Introduction and Tuning Guide. IBM Redbooks. 2001. http://www.redbooks.ibm.com

– M. Barrios et al. Scientific Applications in RS/6000 SP Environments. IBM Redbooks 1999.
– S. Goedecker y A. Hoisie. Performance Optimization of Numerically Intensive Codes. SIAM 2001.
– C. Halloy y K. Wong. Maximizing Megaflops. Joint Institute for Computational Science, 2001. http://www.jics.utk.edu/SEPSCOR/Module2/index.htm
● Evaluación (Benchmarking):
– SPEC. http://www.spec.org
– J. Dongarra. Performance of Various Computers Using Standard Linear Algebra. (Linpack Test) http://www.netlib.org/benchmark/paper.ps
– Top500. http://www.top500.org
– HPC Challenge. http://icl.cs.utk.edu/hpcc

– W. Feng, M. Warren y E. Weigle. The Bladed Beowulf: A Cost-Effective Alternative to Traditional Beowulfs. Proceedings of IEEE Cluster 2002. También Los Alamos Unclassified Report 02-2582