task scheduling on computational grids using gravitational search algorithm
TRANSCRIPT

Cluster ComputDOI 10.1007/s10586-013-0338-8
Task scheduling on computational Grids using GravitationalSearch Algorithm
Amirreza Zarrabi · Khairulmizam Samsudin
Received: 28 August 2013 / Revised: 12 November 2013 / Accepted: 1 December 2013© Springer Science+Business Media New York 2013
Abstract Grid computing uses distributed interconnectedcomputers and resources collectively to achieve higher per-formance computing and resource sharing. Task schedul-ing is one of the core steps to efficiently exploit the capa-bilities of Grid environment. Recently, heuristic algorithmshave been successfully applied to solve task scheduling oncomputational Grids. In this paper, Gravitational Search Al-gorithm (GSA), as one of the latest population-based meta-heuristic algorithms, is used for task scheduling on compu-tational Grids. The proposed method employs GSA to findthe best solution with the minimum makespan and flowtime.We evaluate this approach with Genetic Algorithm (GA)and Particle Swarm Optimization (PSO) method. The resultsdemonstrate that the benefit of the GSA is its speed of con-vergence and the capability to obtain feasible schedules.
Keywords Grid task scheduling · Gravitational SearchAlgorithm · Makespan · Flowtime
1 Introduction
Scientific problems are becoming more and more compli-cated. They need huge amount of computing resources thatcannot be sufficiently presented in single workstation oreven distributed and parallel systems. Grid computing is
A. Zarrabi (B) · K. SamsudinDepartment of Computer and Communication SystemsEngineering, Faculty of Engineering, University Putra Malaysia,43400 UPM Serdang, Selangor, Malaysiae-mail: [email protected]
K. Samsudine-mail: [email protected]
a form of distributed computing but it introduces the in-volvement of collaborative teams and resource sharing [35].It provides an abstraction layer over resources that allowhomogeneous access to heterogeneous distributed resourceswith sharing policies that define logical grouping and shar-ing arrangement.
The Grid scheduling is defined as the process of com-position of a problem into a multiple tasks and allocationof them to available resources [2]. The Grid environment isdynamic in which resources join and leave the Grid in anunpredictable way [29]. In such environments assigning re-sources to tasks (match) and specifying the order of execu-tion on the resources (schedule) plays a key role to increasethe performance of Grid.
Scheduling is a crucial mechanism in the majority of Gridsystems. Several approaches are proposed in the literatureaiming to design schedulers capable of efficient planning oftasks to computational resources, including ad hoc methodssuch as batch mode and immediate mode scheduler [37, 38].Irrespective to their simplicity, there are two main drawbackassociated with these methods [39]:
– These methods fail to produce high quality planning oftasks to Grid resources.
– These methods can handle one objective at a time.
Metaheuristic methods have proven to be efficient in solvingcomputationally hard problems such as combinatorial opti-mization. There are many reasons that explain the strengthof metaheuristic approaches for designing efficient Gridschedulers [36]:
– In highly dynamic Grid environment it is impossible todefine the optimality of task planning. Therefore, thegood quality planning of tasks would suffice rather thansearching for optimal solution.

Cluster Comput
– Grid scheduling is a problem with multi-objective naturewhich tries to optimize many performance metric param-eters simultaneously.
Recently several metaheuristics were introduced such as sin-gle solution metaheuristic methods, e.g. Simulated Anneal-ing (SA) [21] and Tabu Search (TS) [17], which are used inGrid scheduling problem as reported by YarKhan and Don-garra [43] and Xhafa et al. [41].
Particularly, population-based techniques involving na-ture inspired metaheuristics have become the new focus ofscheduling research due to the ability to explore both globaland local optimal solutions [23]. Gravitational Search Al-gorithm (GSA) [26] is a newly developed population-basedmetaheuristic inspired from the law of gravity and mass in-teractions which is confirmed to have merit in the field of op-timization according to the comparative study between GSAand a small number of well-known algorithms.
It is desirable to explore new metaheuristics for devel-oping good scheduling mechanism because of complexityand practical importance of task scheduling in Grid environ-ment. In this paper, we propose an approach based on GSAfor Grid task scheduling where makespan and flowtime areminimized. The rest of the paper is organized as follows.Section 2 presents the related work about population-basedmetaheuristics task scheduling in Grids. Section 3 deals withsome theoretical foundations related to formulation and per-formance metrics. Section 4 describes GSA algorithm in de-tail. Sections 5 and 6, describes the proposed GSA basedalgorithm. Experimental results are presented in Sect. 7 andsome conclusions and future works are provided towards theend.
2 Related works
The literature is inundated with many Grid scheduling de-signs which deploy different methods and try to optimizevarious aspects of Grid environment. As there is no spe-cific algorithm to obtain the best solution for all optimiza-tion problems, there is always a tendency to apply newlydeveloped algorithm to previous well-known optimizationproblems.
The use of Genetic Algorithm (GA) [18] in scheduling,which applies evolutionary strategies to allow for the fastexploration of the search space of schedules, enables goodsolutions to be found quickly. Page and Naughton [25] pre-sented dynamic scheduling strategy using GA in which tasksare allowed to arrive for processing at arbitrary intervalsin a variable computing resource environment. Carretero etal. [8] used GA based schedulers for computational gridswhere different operators are implemented and empiricallystudied. Xhafa et al. [39] focused on tuning of the StruggleGA to alleviate the computational burden of that method.
Martino and Mililotti [13] proposed GA for finding a suboptimal solution to the task scheduling problem in Grid en-vironments. Moreover, Grid scheduling problem based onGA has been addressed in [7, 11, 12, 16, 22, 30].
Ant Colony Optimization (ACO) [15] imitates the behav-ior of real ant colonies in nature to search for food and toconnect to each other by pheromone laid on paths traveled.Bandieramonte et al. [5] proposed an ACO based schedul-ing algorithm for Grids which is based on a different in-terpretation of pheromone trails. Chang et al. [9] presentedBalanced ACO (BACO) which modify the global and localpheromone update functions in ACO algorithm in order tobalance the load for each Grid resource. Kant et al. [19] in-troduced scheduling model based on ACO which consistsof two types of ants namely red ants for resource estima-tion and black ants for resource allocation decision. It aimsat optimizing the task scheduling strategy and improving theresource utilization rate. Several other studies have been try-ing to apply ACO for solving Grid scheduling problem suchas [10, 24, 42].
Particle Swarm Optimization (PSO) [20] is an optimiza-tion technique inspired by a swarm of birds in their preyingactivity. Liu et al. [23] introduced a PSO based approach forscheduling tasks on Grids which is based on fuzzy matri-ces to represent the position and velocity of the particles inPSO. Sadasivam and Rajendran [32] proposed a task group-ing method using PSO to reduce the communication over-head and enhance task completion time. Tao et al. [34] pre-sented Rotary Chaotic PSO (RCPSO) for trustworthy Gridscheduling where trustworthiness refers to reliability, secu-rity, availability, and reputation.
Additionally, combination of multiple metaheuristics hasbeen proved to be effective for many problems by outper-forming single methods [33]. Xhafa et al. [40] combines GAand TS methods where GA runs as the main algorithm andcalls TS procedure to improve individuals of the population.Similarly, Ritchie and Levine [28] combined ACO with TSfor the problem.
3 Formulation and performance metrics
A model of execution times of the tasks on different ma-chines is required to formalize and evaluate the performanceof scheduling methods. One such model proposed by Ali etal. [3] consists of an estimated time to complete (ETC) ma-trix. An ETC matrix is n × m in which n is the number oftasks and m is the number of machines. The entry (i, j) isthe expected execution time of task t i on a machine mj . TheETC matrix demonstrates two characteristics, including:
– Machine Heterogeneity: It is the variance of executiontimes of all machines for a given task and represented byvariation along the ETC matrix row.

Cluster Comput
– Task Heterogeneity: It is the variance of execution timesfor all tasks in a given machine and represented by varia-tion along the ETC matrix column.
ETC matrix is categorized based on relationships amongtask computational requirements and machine capabilities.For every pair of machines mi and mj , ETC matrix is saidto be consistent if mi executes a task faster than mj then mi
executes all the tasks faster than mj while in an inconsistentETC matrix machine mi may be faster than machine mj forsome tasks and slower for others. In more realistic environ-ment the ETC matrix is partially-consistent. That is, It isinconsistent having a consistent submatrix of a predefinedsize.
There are many optimization criteria to evaluate the per-formance of Grid scheduling algorithm. Two of the mostextensively studied metrics are makespan and flowtime.Makespan is the time when Grid finishes the latest task whileflowtime represents the average response time of the Grid.
Considering ETC(i, j) as the estimated time to completefor task i on machine j , then Eq. (1) represents the time thatmachine j finishes all the tasks assigned to it.
completion(j) =∑
i∈tasks
ETC(i, j) (1)
Accordingly, the makespan and flowtime can be esti-mated using Eqs. (2) and (3) respectively.
makespan = max{completion(j)
}, j ∈ machines (2)
flowtime =m∑
j=1
completion(j) (3)
Minimizing makespan instructs the average task to finishquickly, at the expense of the largest task taking a long time,while minimizing flowtime, asks that no task takes too long,at the expense of most tasks taking a long time. Minimiza-tion of makespan will result in maximization of flowtime[23]. Therefore, the scheduling problem is an multivariateoptimization problem where tasks are being assigned to aset of machines so as to optimize these metrics.
Dealing with many conflicting optimization criteria at thesame time should be addressed through Pareto optimizationtheory [31]. The Weighted Aggregation is the most commonapproach for coping with multivariate optimization prob-lems where all criteria are summed to a weighted combina-tion F = ∑k
i=1 wi × f (x) where wi, i = 1, . . . , k are posi-tive weights.
The weights can be dynamically adapted during the op-timization to obtain an optimal set. However, in the Gridscheduling problem, rather than knowing many Pareto op-timal points in solution space, we could be interested inknowing a schedule having a tradeoff among the consid-ered criteria and which could be computed very quickly
[36]. Therefore, fixed weights are used to obtain a singlePareto optimal point per optimization run as in Eq. (4) withλ ∈ (0,1) to determine the effectiveness of parameters usedin this equation.
fitness = λ × makespan + (1 − λ) × flowtime
m(4)
λ = 0 means that flowtime is only considered in fitness eval-uation while λ = 1 means that makespan is only consideredin fitness evaluation.
4 Gravitational Search Algorithm
Gravitational Search Algorithm (GSA) [26] is based on theinteraction of particles in the universe and the magnitudeof gravitational force between them which depends on theirmasses and the distance between them. This is formulatedby Newtonian gravity law as:
F = GM1M2
R2(5)
where F is the magnitude of gravitational force between thefirst and second particles (typically in N), G is the gravita-tional constant with a value of 6.67259 × 1011 (typically inN(m2/kg2)), M1 and M2 are the masses of first and sec-ond particles, respectively (typically in kg), and R is thestraight-line distance between the two particles (typicallyin m). However, Rashedi et al. [26] reported that experi-ments show better results with the use of R instead of R2.
Based on Newton’s second law, when a force is applied toa particle, it accelerates and the magnitude of acceleration isdirectly proportional to the force and inversely proportionalto the mass of the particle which is based on the equationgiven below:
a = F
M(6)
where F and M are the gravitational force and mass of agiven particle, respectively.
The GSA applies this physical phenomenon when search-ing a problem space in solving optimization problems. Ev-ery particle (i.e. agent) represents a solution which has twospecifications, including: mass and position. These agentsmove in the search space based on the forces applied tothem from other agents. Based on Eqs. (5) and (6), the heav-ier a mass, the slower it moves. Masses are updated usinga fitness function so better solutions gain mass and worsesolutions lose mass. On the other hand, heavier masses havehigher attraction forces and pull other agents towards them-selves.

Cluster Comput
To describe the GSA, consider a system with N agents inwhich the position of the ith mass is defined as follows:
Xi = (x1i , . . . , xd
i , . . . , xni
), i = 1,2, . . . ,N (7)
where xdi is the position of the ith mass in the d th dimension
and n is the total number of dimensions in the search space.As mentioned earlier, the positions of the masses correspondto the solutions of the problem. The force acting on mass i
from mass j in dimension d at a specific time t is calculatedby:
Fdij (t) = G(t)
Mi(t) × Mj(t)
Rij (t) + ε
(xdj (t) − xd
i (t))
(8)
where G is the gravitational constant at the time t , Mi andMj are respectively the masses of agents i and j , and xd
i andxdj is the position of agents i and j in the d th dimension, re-
spectively. Rij is the Euclidean distance between two agents,and ε is very small constant to avoid division by zero.
The total force acting on agent i in the d th dimension isa randomly weighted sum of the forces applied from otheragents in the d th dimension.
Fdi (t) =
∑
j∈Kbest
randjFdij (t) (9)
where randi is a uniformly distributed random number inthe range of [0,1], and Kbest is the set of first K0 agentswith the best fitness value and biggest mass other than i.Initially, K0 is set to total number of agents and is decreasedlinearly to 1.
The law of motion dictates that the acceleration of theagent i in dimension d at time t is:
adi (t) = Fd
i (t)
Mi(t)(10)
where adi (0) = 0.
The next velocity of an agent is calculated as a fractionof its current velocity added to its acceleration and conse-quently its position is updated as follow:
vdi (t + 1) = randi × vd
i (t) + adi (t) (11)
xdi (t + 1) = xd
i (t) + vdi (t + 1) (12)
where vdi (0) = 0, randi is a uniformly distributed random
number in the range of [0,1] and gives a randomized char-acteristic to the search.
As mentioned before, masses are updated based on theirfitness and agents which represent better solutions shouldhave heavier masses. Agent mass is updated by followingequation:
Mi(t) = mi(t)∑Nj=1 mj(t)
(13)
Create an initial population with N agentsrepeat
for each agent i = 1,2, . . . ,N doif best > f (Xi) then
best = f (Xi)
endif worst < f (Xi) then
worst = f (Xi)
endendfor each agent i = 1,2, . . . ,N do
Update gravitational constant G
Calculate mass using Eq. (13)Update Xi using Eqs. (10), (11), and (12)
enduntil stopping condition is met or system age expire
Fig. 1 Concepts of Gravitational Search Algorithm
where:
mi(t) = fiti (t) − worst(t)
best(t) − worst(t)(14)
where fiti (t) represents the fitness value of the agent i attime t and best(t) and worst(t) are the best and worst fitnessvalue of all agents respectively. They are defined as follows:
best(t) = min{fiti (t)
}, ∀i ∈ {1,2, . . . ,N} (15)
worst(t) = max{fiti (t)
}, ∀i ∈ {1,2, . . . ,N} (16)
In the beginning, the position and the velocity are ran-domly initialized. The concepts of GSA is shown in Fig. 1where f (Xi) evaluates the fitness function.
Note that the gravitational constant G is initialized in thebeginning (t = 0) to G0 and in order to control the searchaccuracy is decreased towards zero at the last iteration (i.e.the end of system age).
Rashedi et al. [27] introduced binary version of GSA(BGSA) which differs from GSA in the position updatingmethod (i.e. Eq. (12)). The position of an agent in every di-mension takes only 0 or 1 and is updated so that the currentbit value is changed with a probability that is proportional tothe velocity as follow:
xdi (t + 1) =
{∼ xd
i (t) rand < S(vdi (t + 1))
xdi (t) rand ≥ S(vd
i (t + 1))(17)
where S is a probability function within interval [0,1] sothat for small |vd
i |, the probability of changing xdi is near
zero and for large |vdi |, the probability of changing xd
i ishigh.
5 Solution in Gravitational Search Algorithm
The proposed algorithm is based on GSA where the candi-date solutions have to present a sequence of tasks in avail-

Cluster Comput
able Grid machines. Therefore, the preliminary step is to de-termine the representation of solutions that aims at findingan appropriate mapping between problem solution and GSAagents.
Solutions are encoded in a m × n matrix in which m isthe number of machines and n is the number of tasks whereelement Xk(i, j) shows whether task j is allocated to a ma-chine i for agent k, e.g. in the following sample matrix,X1(4,4) = 1 and X1(4,5) = 1 specify that task t4 and t5are performed in m4 in agent 1.
X1 =
⎡
⎢⎢⎢⎢⎢⎢⎢⎣
t1 t2 t3 t4 t5 ··· tn
m1 1 0 0 0 0 · · · 0m2 0 0 1 0 0 · · · 0m3 0 1 0 0 0 · · · 0m4 0 0 0 1 1 · · · 0...
......
......
.... . .
...
mm 0 0 0 0 0 · · · 0
⎤
⎥⎥⎥⎥⎥⎥⎥⎦
Assuming tasks could be assigned to single machinewith no preemption [44], only one element in each columnis 1. Each machine could preform multiple tasks, e.g. ma-chine m4 performs two tasks sequentially. Similar encodingmethod is applied to V , F and a. They determine the totalvelocity, force, and the acceleration of a given agent, respec-tively.
This encoding enforces using Eq. (17) for updating po-sition of agents in every dimension. However, as mentionedeach task can only be allocated to single machine, Eq. (18)could be exploited to update position of agent k so that thereis single 1 in each column.
Xk(i, j) =
⎧⎪⎨
⎪⎩
1 Vk(i, j) = max{Vk(q, j)},∀q ∈ {1,2, . . . ,m}
0 otherwise
(18)
This specifies that value 1 is assigned to an element ineach column of Xk whose respective element in Vk has themaximum value in its corresponding column. For multipleelements with maximum value, one element is randomly se-lected and 1 assigned to its corresponding element in the Xk .
Finally, the gravitational constant G is considered as alinear decreasing function as follows:
G(t) = G0 ×(
1 − t
T
)(19)
where G0 is a constant and set to 100 and T is the totalnumber of iterations.
6 Grid scheduling using GSA
Based on the above description, in our proposed algorithmthe following steps should be done:
Step 1: Initialize N agents to represent possible problemsolutions. Normally, the initial agents are generated ran-domly but introducing a few good agents would be helpfulin reduction of makespan and flowtime. We used min-minheuristic [14] to generate one agent and the others are gen-erated randomly from a uniform distribution.
Step 2: Calculate the fitness function in Eq. (4) with λ =0.7 (i.e. represents makespan as primary objective) for allagents and keep the best one, which have the least value forfitness function, as a final candidate solution and also keepthe worst one to use for calculating the individual masses.
Step 3: Calculate the masses of agents based on fitnessfunction and worst value from step 2.
Mk = f (Xk) − worst∑N
i=1 f (Xi) − N × worst, k = 1,2, . . . ,N (20)
Step 4: Use Eqs. (8), (9), and (10) to calculate the outcomeof subset of forces that act on selected agent and calculatethe acceleration matrix of agent.
ak(i, j) =∑
q∈Kbest
G× randqMq
R + ε
(Xq(i, j)−Xk(i, j)
)(21)
where G is replaced to Eq. (19) and t is changed accordingto the current iteration. R is Hamming distance which isequal to the number of ones in Xq ⊕ Xk .
Step 5: Use Eq. (18) to update agents while the velocitymatrix is calculated using following equation.
Vk(i, j) = rand × Vk(i, j) + ak(i, j) (22)
Elements in velocity matrix are limited in range [−Vmax,
Vmax] in order to achieve a good converge rate. Based onour experiments, Vmax is set to be 10.
Step 6: If the termination criteria are satisfied display thebest agent as a final solution and stop otherwise go tostep 2.
7 Implementation and experimental results
We compared the performance of GSA Grid scheduling withGenetic Algorithm (GA) and Particle Swarm Optimization(PSO) approach. All methods have been implemented usingMatlab 8.01 on a AMD Athlon™ II X2 270 Processor, 4 GBRAM computer. The experimental results are averages of20 runs of simulation.
7.1 Benchmark environment
The benchmark environment in this paper is inspired fromBraun et al. [6] which was used widely in previous works toevaluate proposed scheduling algorithms.

Cluster Comput
for i from 1 to n
B(i) = U(1, ϕb)
for j from 1 to m
ETC(i, j) = B(i) × U(1, ϕr )
endend
Fig. 2 Range based matrix generation method
In the simulation experiments, ETC matrix can be de-rived from probability distributions with a given degree ofheterogeneity. In this paper we use range based ETC matrixgeneration method which was used in some previous works(e.g. [4, 6, 8, 39]) for simulating heterogeneous computingsystems.
Let U(a,b) be a sample from a uniform distribution witha range from a to b. The range based ETC matrix genera-tion method is defined in Fig. 2 with ϕb and ϕr representingtask and machine heterogeneity respectively. Bigger valuesexpress higher heterogeneities.
In more realistic environment the variation of task re-quirements surpasses the variation of machines capability.Therefore, for high task and machine heterogeneity ϕb andϕr are selected as 105 and 102 respectively. Low task andmachine heterogeneity are considered to be the same so thatϕb = ϕr = 10.
Incompatibilities among task t i and machine mj (e.g. ifspecific resource is not available on that machine) is ex-pressed by setting the (i, j) entry of ETC matrix to infinity.Other restrictions such as inter-task communications can besimulated using penalties to ETC matrix values.
We assume that there are no inter-task communicationsor task preemption and each task can run on all machines.According to characteristics of ETC matrix, there would be12 (2×2×3) instances of ETC matrix (i.e. 12 different Gridenvironment). Carretero et al. [8] labeled them as x–yy–zz
where:
– x represent type of inconsistency (c for consistent, i forinconsistent and, p for partially-consistent),
– yy shows tasks heterogeneity,– and zz represents machines heterogeneity.
Sample This is a low task heterogeneity (ϕb = 10), lowmachine heterogeneity (ϕr = 10) matrix which is producedby the range based ETC matrix generation method, i.e.i–lo–lo. The generated matrix is inconsistent and the con-sistent matrix is obtained by sorting each row of this matrixindependently.
Inconsistent⎡
⎢⎢⎢⎢⎢⎢⎣
16 6 5 28 45 43 3145 7 8 25 23 10 420 17 23 83 18 20 716 37 23 14 25 35 413 28 17 14 25 25 2044 56 11 13 8 15 27
⎤
⎥⎥⎥⎥⎥⎥⎦
Consistent⎡
⎢⎢⎢⎢⎢⎢⎣
5 6 16 28 31 43 454 7 8 10 23 25 457 17 18 20 20 23 834 14 16 23 25 35 37
13 14 17 20 25 25 288 11 13 15 27 44 56
⎤
⎥⎥⎥⎥⎥⎥⎦
For the partially-consistent matrices, the row elements incolumn positions {0,2,4, . . .} of every row are sorted, whilethe row elements in column positions {1,3,5, . . .} remainunchanged.
Parameters for GA, PSO, and GSA Algorithms have di-rect effect on their performance and fine tuning should beperformed to select the best values and operations. Specificparameters of the considered algorithms are described in Ta-ble 1 (see Figs. 3 and 4 for usage of each parameter). Similar
Table 1 Parameter settings forGA, PSO, and GSA algorithms Algorithm Parameter name Value/type
GeneticAlgorithm (GA)
Size of the population 50
Selection operator S Tournament (k = 7)
Crossover operator C Cycle crossover
Mutation operator M Inversion mutation
Replacement operator R Generational replacement
Probability of crossover Pc 0.8
Probability of mutation Pm 0.02
Particle SwarmOptimization (PSO)
Size of the population 50
Coefficient c1 1.6
Coefficient c2 1.6
Inertia weight w 1
Gravitational Search Algorithm(GSA)
Size of the population 50
Gravitational constant G0 100

Cluster Comput
Create an initial population with N agentsrepeat
for each agent k = 1,2, . . . ,N doif f (pbestk) > f (Xk) then
pbestk = Xk
endif f (pbestk) < f (gbest) then
gbest = pbestkend
endfor each agent k = 1,2, . . . ,N do
Vk = w × c1r1(pbestk − Xk) + c2r2(gbest − Xk)
endUpdate all agents using Eq. (18)
until stopping condition is met or system age expire
Fig. 3 PSO pseudo code for Grid task scheduling
Create an initial population with N individualsrepeat
Generate intermediate population (IP) using S
Use C to generate offspring of IP with probability Pc
Perform random mutation using M with probability Pm
Create new population using R from offspringuntil stopping condition is met or system age expire
Fig. 4 GA template for Grid task scheduling
approach reported in Sect. 5 is used to encode solutions inPSO algorithm.
In GA solutions are represented using permutation-based method so that each chromosome is a vector ofn + m − 1 genes. The gene n < x � n + m − 1 shows ma-chine boundaries, e.g. for Grid with 9 task and 5 machine[13,9,6,10,8,2,1,12,11,7,3,5,4] indicates that m1 hasno task assigned (no entry before 13), t9 and t6 are run onm2 (9 and 6 between 13 and 10), t8, t2 and t1 are run on m3
(8, 2 and 1 between 10 and 12), no task was assigned to m4
(no entry between 12 and 11).One of the main benefits of GSA is dependency on lim-
ited number of configuration settings which make it moreadaptive to Grid environments (e.g. Carretero et al. [8] ad-dressed the issue of identifying which GA operators workbest under certain Grid environment).
7.2 Experimental results
In our experiments, we compare algorithms in single Gridenvironment to evaluate performance and speed of conver-gence. Finally, various Grid environments are tested to as-sess the ability to obtain feasible schedules and scalability.
We begin with a small scale task scheduling problem in-volving 5 machines and 9 tasks, i.e. G1 (m = 5, n = 9). Therespective ETC matrix is demonstrated in Table 2a. The av-erage fitness value of GSA, GA, and PSO algorithms areillustrated in Fig. 6a. The speed of convergence for GSAand PSO are almost similar as after around 30 iteration theyexperienced minimal changes in fitness value. Nevertheless,
Table 2 Sample optimal task scheduling with GSA
Tasks Machines
m1 m2 m3 m4 m5
t1 21 30 6 12 15
t2 4 8 12 4 40
t3 8 6 1 4 2
t4 18 8 14 10 16
t5 16 2 14 12 18
t6 15 15 5 10 35
t7 27 27 9 36 9
t8 9 27 45 45 45
t9 15 30 5 35 10
(a) A low task and machine heterogeneity ETC matrix
Machines Tasks
t1 t2 t3 t4 t5 t6 t7 t8 t9
m1 0 0 0 0 0 0 0 1 0
m2 0 0 0 1 1 0 0 0 0
m3 1 0 1 0 0 0 0 0 1
m4 0 1 0 0 0 1 0 0 0
m5 0 0 0 0 0 0 1 0 0
(b) An optimal solution for G1 task scheduling problem
Fig. 5 The scheduling solution for Table 2b
GSA provides better results compared to other algorithms.An optimal scheduling result using GSA is represented inTable 2b and Fig. 5 (0.7 × (4 + 10) + 0.3 × 54
5 ). The av-erage best-so-far values and the standard deviations for 20trials are presented in Table 3. Additionally, we comparedthese algorithms for different problem sizes: G2 (m = 5, n =100), G3 (m = 10, n = 100), and G4 (m = 50, n = 100). Ina single Grid environment, the problem size could diverselyaffect the performance of GA and PSO task scheduling al-gorithms. This dependency is evident as there is a large gapbetween GA and PSO average fitness values and GSA inFigs. 6b, 6c, and 6d while they are in almost similar rangein Fig. 6a.
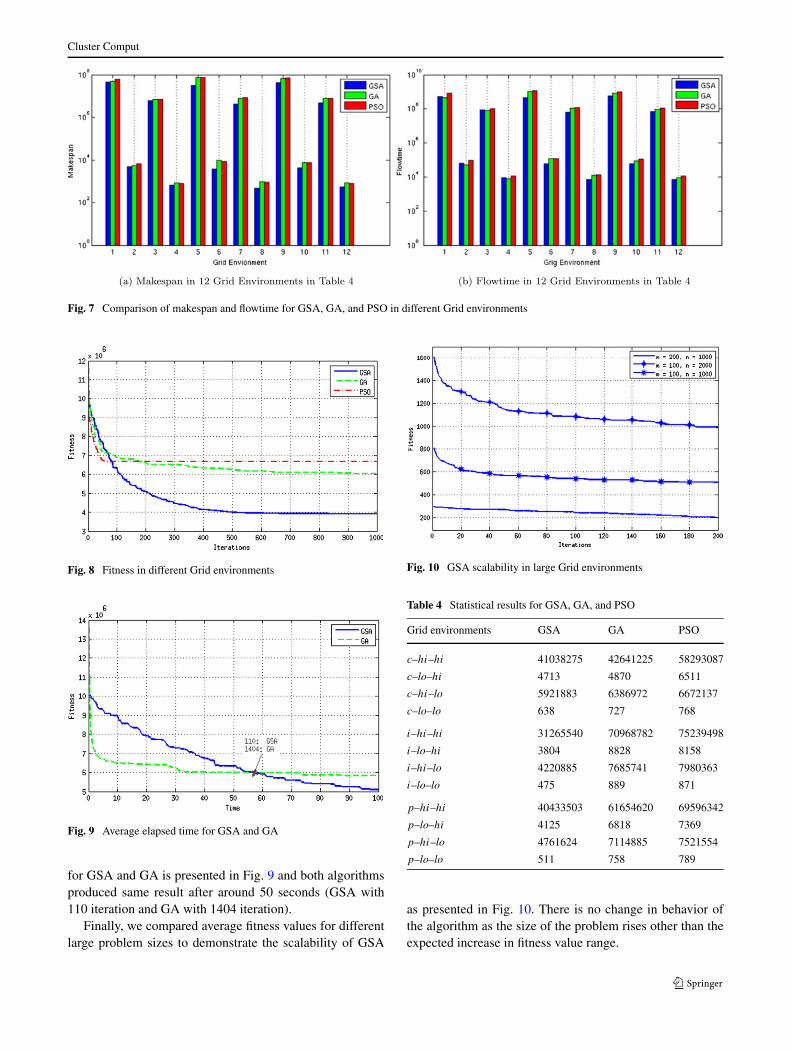
The fitness statistical results are compared in Table 4for G (m = 16, n = 512) in different environments. As canbe seen GSA can achieve best results in all cases. AlsoFig. 7 illustrates the makespan and flowtime for all 12different Grid environments in Table 4. As can be seen

Cluster Comput
Fig. 6 Fitness for GSA, GA, and PSO task scheduling in single Grid environment and multiple Grid sizes
Table 3 Performance comparison for GSA, GA, and PSO task scheduling with m machines and n tasks
Algorithm Item G1 (m = 5, n = 9) G2 (m = 5, n = 100) G3 (m = 10, n = 100) G4 (m = 50, n = 100)
GSA Average best-so-far 12.4050 261.7840 127.2595 50.0869
Standard deviation ±0.2500 ±6.1987 ±6.4652 ±6.8063
GA Average best-so-far 12.6200 343.2290 219.1415 80.1202
Standard deviation ±0.3518 ±17.6352 ±9.3658 ±4.1839
PSO Average best-so-far 13.8790 394.8700 243.7095 84.0497
Standard deviation ±1.5898 ±21.7180 ±16.3009 ±6.6847
from Fig. 7a our proposed method is capable of achiev-ing best results for makespan in all environments whileGA and PSO can obtain almost similar results in mostcases. We also realized that GA is able to produce bet-ter results for flowtime compared to GSA in consistent en-vironments. However, we set the makespan as main ob-jective (λ = 0.7) which leads to better fitness values asshown in Table 4. The average fitness for task schedul-ing in different Grid environment is depicted in Fig. 8.It is clear that GSA is capable of producing more feasi-
ble schedules compared to others after around 100 itera-tion.
Run time is an important factor when dealing with differ-ent scheduling algorithms in Grid environment. Obviously,GSA is heavier in term of time consumption because ofEqs. (20) and (21) compared to GA and PSO. This complex-ity can be ignored due to the GSA capability of generatingoptimal schedule in fewer number of iterations comparedto GA and PSO, e.g. Abraham et al. [1] used m × n × 50for total iteration in PSO and GA. The average elapsed time
Cluster Comput
Fig. 7 Comparison of makespan and flowtime for GSA, GA, and PSO in different Grid environments
Fig. 8 Fitness in different Grid environments
Fig. 9 Average elapsed time for GSA and GA
for GSA and GA is presented in Fig. 9 and both algorithmsproduced same result after around 50 seconds (GSA with110 iteration and GA with 1404 iteration).
Finally, we compared average fitness values for differentlarge problem sizes to demonstrate the scalability of GSA
Fig. 10 GSA scalability in large Grid environments
Table 4 Statistical results for GSA, GA, and PSO
Grid environments GSA GA PSO
c–hi–hi 41038275 42641225 58293087
c–lo–hi 4713 4870 6511
c–hi–lo 5921883 6386972 6672137
c–lo–lo 638 727 768
i–hi–hi 31265540 70968782 75239498
i–lo–hi 3804 8828 8158
i–hi–lo 4220885 7685741 7980363
i–lo–lo 475 889 871
p–hi–hi 40433503 61654620 69596342
p–lo–hi 4125 6818 7369
p–hi–lo 4761624 7114885 7521554
p–lo–lo 511 758 789
as presented in Fig. 10. There is no change in behavior ofthe algorithm as the size of the problem rises other than theexpected increase in fitness value range.

Cluster Comput
8 Conclusions
In this paper, we studied the task scheduling problem oncomputational Grids. We consider nature inspired meta-heuristics such as Genetic Algorithm (GA) and ParticleSwarm Optimization (PSO) methods. We proposed a taskscheduling approach using Gravitational Search Algorithm(GSA) to minimize makespan and flowtime simultaneously.It is compared with GA and PSO through carrying out ex-haustive simulation tests and different Grid environments.Empirical results revealed that the proposed approach canbe applied for task scheduling. Most important conclusionsof this work are:
– The experimental study reveals that the benefit of theGSA is its speed of convergence and the capability to ob-tain feasible schedules.
– Task scheduling using GSA is dependent on limited num-ber of configuration settings and can run adaptively withdifferent Grid environment and size.
Our future work concentrates on use of GSA in dynamicscheduling.
References
1. Abraham, A., Liu, H., Zhang, W., Chang, T.-G.: Scheduling jobson computational grids using fuzzy particle swarm algorithm. In:Knowledge-Based Intelligent Information and Engineering Sys-tems, pp. 500–507. Springer, Berlin (2006)
2. Akbari Torkestani, J.: A new approach to the job schedulingproblem in computational grids. Clust. Comput. 15(3), 201–210(2012)
3. Ali, S., Siegel, H.J., Maheswaran, M., Hensgen, D., Ali, S.: Repre-senting task and machine heterogeneities for heterogeneous com-puting systems. Tamkang J. Sci. Eng. 3(3), 195–208 (2000)
4. Ali, S., Braun, T.D., Siegel, H.J., Maciejewski, A.A., Beck, N.,Bölöni, L., Maheswaran, M., Reuther, A.I., Robertson, J.P., Theys,M.D., et al.: Characterizing resource allocation heuristics for het-erogeneous computing systems. Adv. Comput. 63, 91–128 (2005)
5. Bandieramonte, M., Di Stefano, A., Morana, G.: An ACO inspiredstrategy to improve jobs scheduling in a grid environment. In:Algorithms and Architectures for Parallel Processing, pp. 30–41.Springer, Berlin (2008)
6. Braun, T.D., Siegel, H.J., Beck, N., Bölöni, L.L., Maheswaran,M., Reuther, A.I., Robertson, J.P., Theys, M.D., Yao, B., Hensgen,D., et al.: A comparison of eleven static heuristics for mapping aclass of independent tasks onto heterogeneous distributed comput-ing systems. J. Parallel Distrib. Comput. 61(6), 810–837 (2001)
7. Carretero, J., Xhafa, F.: Use of genetic algorithms for schedulingjobs in large scale grid applications. Technol. Econ. Dev. Econ.12(1), 11–17 (2006)
8. Carretero, J., Xhafa, F., Abraham, A.: Genetic algorithm basedschedulers for grid computing systems. Int. J. Innov. Comput. Inf.Control 3(6), 1–19 (2007)
9. Chang, R.-S., Chang, J.-S., Lin, P.-S.: An ant algorithm for bal-anced job scheduling in grids. Future Gener. Comput. Syst. 25(1),20–27 (2009)
10. Chen, W.-N., Zhang, J.: An ant colony optimization approach toa grid workflow scheduling problem with various QoS require-ments. IEEE Trans. Syst. Man Cybern., Part C, Appl. Rev. 39(1),29–43 (2009)
11. de Mello, R.F., Andrade Filho, J.A., Senger, L.J., Yang, L.T.:Grid job scheduling using route with genetic algorithm support.Telecommun. Syst. 38(3–4), 147–160 (2008)
12. Di Martino, V., Mililotti, M.: Scheduling in a grid computing en-vironment using genetic algorithms. In: IPDPS (2002)
13. Di Martino, V., Mililotti, M.: Sub optimal scheduling in a gridusing genetic algorithms. Parallel Comput. 30(5), 553–565 (2004)
14. Dong, F., Akl, S.G.: Scheduling algorithms for grid computing:state of the art and open problems. School of Computing, QueensUniversity, Kingston, Ontario (2006)
15. Dorigo, M.: Optimization, learning and natural algorithms. Ph.D.thesis, Politecnico di Milano, Italy (1992)
16. Gao, Y., Rong, H., Huang, J.Z.: Adaptive grid job scheduling withgenetic algorithms. Future Gener. Comput. Syst. 21(1), 151–161(2005)
17. Glover, F.: Future paths for integer programming and links to arti-ficial intelligence. Comput. Oper. Res. 13(5), 533–549 (1986)
18. Goldberg, D.E.: Genetic Algorithms in Search, Optimization, andMachine Learning (1989)
19. Kant, A., Sharma, A., Agarwal, S., Chandra, S.: An ACO approachto job scheduling in grid environment. In: Swarm, Evolutionary,and Memetic Computing, pp. 286–295. Springer, Berlin (2010)
20. Kennedy, J., Eberhart, R.: Particle swarm optimization. In: Pro-ceedings of the IEEE International Conference on Neural Net-works, 1995, vol. 4, pp. 1942–1948. IEEE Press, New York(1995)
21. Kirkpatrick, S., Gelatt, D. Jr., Vecchi, M.P.: Optimization by sim-ulated annealing. Science 220(4598), 671–680 (1983)
22. Liu, D., Cao, Y.: A chaotic genetic algorithm for fuzzy grid jobscheduling. In: 2006 International Conference on ComputationalIntelligence and Security, vol. 1, pp. 320–323. IEEE Press, NewYork (2006)
23. Liu, H., Abraham, A., Hassanien, A.E.: Scheduling jobs on com-putational grids using a fuzzy particle swarm optimization algo-rithm. Future Gener. Comput. Syst. 26(8), 1336–1343 (2010)
24. Lorpunmanee, S., Noor Sap, M., Hanan Abdullah, A., Chompoo-inwai, C.: An ant colony optimization for dynamic job schedulingin grid environment. Int. J. Comput. Inf. Sci. Eng. 1(4), 207–214(2007)
25. Page, A.J., Naughton, T.J.: Framework for task scheduling in het-erogeneous distributed computing using genetic algorithms. Artif.Intell. Rev. 24(3–4), 415–429 (2005)
26. Rashedi, E., Nezamabadi-Pour, H., Saryazdi, S.: GSA: a gravita-tional search algorithm. Inf. Sci. 179(13), 2232–2248 (2009)
27. Rashedi, E., Nezamabadi-Pour, H., Saryazdi, S.: BGSA: bi-nary gravitational search algorithm. Nat. Comput. 9(3), 727–745(2010)
28. Ritchie, G., Levine, J.: A Hybrid Ant Algorithm for Schedul-ing Independent Jobs in Heterogeneous Computing Environments(2004)
29. Siddiqui, M., Fahringer, T.: Grid Resource Management: On-demand Provisioning, Advance Reservation, and Capacity Plan-ning of Grid Resources. Springer, Berlin (2010). LNCS sublibrary.SL 1. Theoretical computer science and general issues. ISBN9783642115783
30. Song, S., Hwang, K., Kwok, Y.-K.: Risk-resilient heuristics andgenetic algorithms for security-assured grid job scheduling. IEEETrans. Comput. 55(6), 703–719 (2006)
31. Steuer, R.E.: Multiple Criteria Optimization: Theory, Computa-tion, and Application. Wiley, New York (1986)
32. Sudha Sadasivam, G., Viji Rajendran, V.: An efficient approach totask scheduling in computational grids. Int. J. Comput. Sci. Appl.6(1), 53–69 (2009)

Cluster Comput
33. Talbi, E.-G.: A taxonomy of hybrid metaheuristics. J. Heuristics8(5), 541–564 (2002)
34. Tao, Q., Chang, H.-y., Yi, Y., Gu, C.-q., Li, W.-j.: A rotary chaoticPSO algorithm for trustworthy scheduling of a grid workflow.Comput. Oper. Res. 38(5), 824–836 (2011)
35. Wilkinson, B.: Grid Computing: Techniques and Applications.Chapman & Hall/CRC Press/Taylor & Francis, London/Boca Ra-ton/London (2011). ISBN 9781420069549
36. Xhafa, F., Abraham, A.: Computational models and heuristicmethods for grid scheduling problems. Future Gener. Comput.Syst. 26(4), 608–621 (2010)
37. Xhafa, F., Barolli, L., Durresi, A.: Batch mode scheduling in gridsystems. Int. J. Web Grid Serv. 3(1), 19–37 (2007)
38. Xhafa, F., Carretero, J., Barolli, L., Durresi, A.: Immediate modescheduling in grid systems. Int. J. Web Grid Serv. 3(2), 219–236(2007)
39. Xhafa, F., Duran, B., Abraham, A., Dahal, K.P.: Tuning strug-gle strategy in genetic algorithms for scheduling in computationalgrids. In: Computer Information Systems and Industrial Manage-ment Applications, pp. 275–280. IEEE Press, New York (2008)
40. Xhafa, F., Gonzalez, J.A., Dahal, K.P., Abraham, A.: A GA (TS)hybrid algorithm for scheduling in computational grids. In: Hy-brid Artificial Intelligence Systems, pp. 285–292. Springer, Berlin(2009)
41. Xhafa, F., Carretero, J., Dorronsoro, B., Alba, E.: A tabu searchalgorithm for scheduling independent jobs in computational grids.Comput. Inform. 28(2), 237–250 (2012)
42. Yan, H., Shen, X.-Q., Li, X., Wu, M.-H.: An improved ant algo-rithm for job scheduling in grid computing. In: Proceedings of2005 International Conference on Machine Learning and Cyber-netics, vol. 5, pp. 2957–2961. IEEE Press, New York (2005)
43. YarKhan, A., Dongarra, J.J.: Experiments with scheduling usingsimulated annealing in a grid environment. In: Grid Computing—GRID 2002, pp. 232–242. Springer, Berlin (2002)
44. Zarrabi, A., Samsudin, K., Wan Adnan, W.A.: Linux supportfor fast transparent general purpose checkpoint/restart of multi-threaded processes in loadable kernel module. J. Grid Comput.11(2), 187–210 (2013)
Amirreza Zarrabi received his mas-ter’s degree in Computer Communi-cation and Networks from Univer-sity Putra Malaysia. His researchinterests are in computer architec-ture, device modelling, embeddedsystems, operating systems, systemsecurity, and distributed computing.Currently he is working on acceler-ated live trading framework basedon GPU architecture as a researchengineer in an international invest-ment solution provider company inKuala Lumpur.
Khairulmizam Samsudin receivedhis PhD in Electrical and Electron-ics Engineering from the Universityof Glasgow. He specializes in com-puter architecture and embeddedsystems. He is currently the Direc-tor for Information and Communi-cation Development Center (iDEC),University Putra Malaysia. His re-search interest covers fundamentaland applied aspect of computer sys-tems. Areas of active interest in-clude: computer architecture, op-erating system, computer security,swarm mobile-robot and biologi-cally inspired computing.