tales from the front: an architecture for multi-data center scalable applications for things that...
TRANSCRIPT

Tales From The Front:
Dan FlavinDataStax2015-12-08
An Architecture For Scalable Multi-Data Center Applications for Things That Count Using Cassandra

2
This Session Says What?The Example Use Case is an Inventory Access Pattern Using
CassandraSame Patterns Apply To Other Distributed, Highly Current Applications
What We're Going To Cover in 30 Minutes• Quick review of Cassandra functionality that applies to this use case• Common Data Center and application architectures for highly
available inventory applications, and why the were designed that way
• Cassandra implementations vis-a-vis infrastructure capabilities– The impedance mismatch: compromises made to fit into IT infrastructures
designed and implemented with an old mindset*.
* just because an infrastructre made sense for the software architectures a decade ago doesn't mean it's still a good idea

Things That Count
How Did We Get HERE?
More Users, More ProblemsA Common Use - Inventory

4
Scaling and Availability
• We all want applications and services that are scalable and highly available
• Scaling our app tier is usually pretty painless, especially with cloud infrastructure– App tier tends to be stateless
while accessing a single stateful database infrastructure

5
Ways We Scale our Relational DatabasesSELECT array_agg(players), player_teamsFROM ( SELECT DISTINCT t1.t1player AS players, t1.player_teams FROM ( SELECT p.playerid AS t1id, concat(p.playerid, ':', p.playername, ' ') AS t1player, array_agg (pl.teamid ORDER BY pl.teamid) AS player_teams FROM player p LEFT JOIN plays pl ON p.playerid = pl.playerid GROUP BY p.playerid, p.playername ) t1 INNER JOIN ( SELECT p.playerid AS t2id, array_agg (pl.teamid ORDER BY pl.teamid) AS player_teams FROM player p LEFT JOIN plays pl ON p.playerid = pl.playerid GROUP BY p.playerid, p.playername ) t2 ON t1.player_teams = t2.player_teams AND t1.t1id <> t2.t2id) innerQueryGROUP BY player_teams
Scaling Up
SELECT * FROM denormalized_view
Denormalization

6
Ways we Scale our Relational Databases
Client
Users Data
Primary
Replica 1
Replica 2
FailoverProcess
MonitorFailover
Write RequestsRead Requests
Replication Lag
Router
A-F G-M N-T U-Z Replication Lag
Sharding and Replication (and probably Denormalization*)
Monitor the
Failover Monitor
* a.k.a. Demoralization – you lose your technology moral ground when you mix sharding, normalization / denormalization / failure survivability / flexibility and humanity
Screaming Man

7
Distributed Systems ≠Sharded or Bolt-on Replication Systems
ScalabilityÞ Distributed Systems, Distributed Data, all distributed
amongst "nodes" (a.k.a. computers)Þ No node is critical path or chokepoint
AvailabilityÞ Requests will always be responded to
Partition ToleranceÞ Component failure(s) do not bring whole
system down
ConsistencyÞ All nodes see the data at the same
time
Nodes are unitsof performance andavailability (a.k.a. incremental scalability)
The CAP Theorem describes distributed systems choices ConsistencyAvailabilityPartition Tolerance
Cassandra values AP where the balance between consistency and latency is tunable.

8
What is Cassandra?
• A Linearly Scaling and Fault Tolerant Distributed Database
• Fully Distributed– Data spread over many nodes– All nodes participate in a cluster– All nodes are equal– No SPOF (shared nothing)– Run on commodity hardware

9
What is Cassandra?
Linearly Scaling– Have More Data? Add more nodes.– Need More Throughput? Add more nodes.
Fault Tolerant– Nodes Down != Database Down– Datacenter Down != Database Down
10
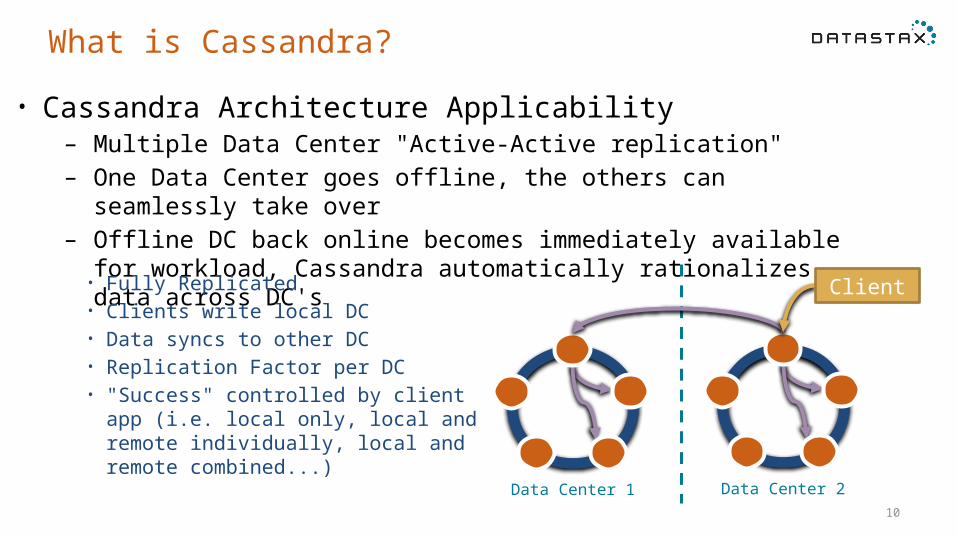
What is Cassandra?• Cassandra Architecture Applicability
– Multiple Data Center "Active-Active replication" – One Data Center goes offline, the others can seamlessly take
over– Offline DC back online becomes immediately available for
workload, Cassandra automatically rationalizes data across DC's• Fully Replicated• Clients write local DC• Data syncs to other DC• Replication Factor per DC• "Success" controlled by client app
(i.e. local only, local and remote individually, local and remote combined...)
Data Center 1 Data Center 2
Client

11
Replication Factor - How many nodes get the same data
Node 1 A
CD
Write Data Identified by a Primary Key A • Each node will get a range of keys
identified by a hash of a table's Primary Key
• On insert key A is hashed to determine nodes data is written to
Replication Factor=3
How? Replication Factor (server-side) Schema Configuration Implements setting how many copies of the
data on different nodes should exist for CAP• also good for Cassandra performance of some
operations (different topic)
Key To CAP System Implementation: Data is Spread Across Many Nodes
Client
Node 2 BAD
Node 3 CAB
Node 4 DBC
CQL: insert A into table... hash() Write to primary node 1, and simultaneously to nodes 2 & 3 (RF = 3)

12
Consistency Level (CL) and Speed• How many replicas we need to hear from can affect how
quickly we can read and write data in Cassandra
Client
BAD
CAB
ACD
DBC
5 µs ack300 µs ack
12 µs ack12 µs ack
Read A(CL=QUORUM)
• Same concept applies across Data Centers

13
Consistency Level and Data Consistency• Replicas may disagree
– Column values are timestamped– In Cassandra, Last Write Wins (LWW)
• Often use Lightweight Transactions– Allows for serialization / test-and-set
Client
BAD
CAB
ACD
DBC
A=2Newer
A=1Older
A=2
Read A(CL=QUORUM)
A good primer on consistency levels w/o LWT's: Christos from Netflix: “Eventual Consistency != Hopeful Consistency”https://www.youtube.com/watch?v=lwIA8tsDXXE
14
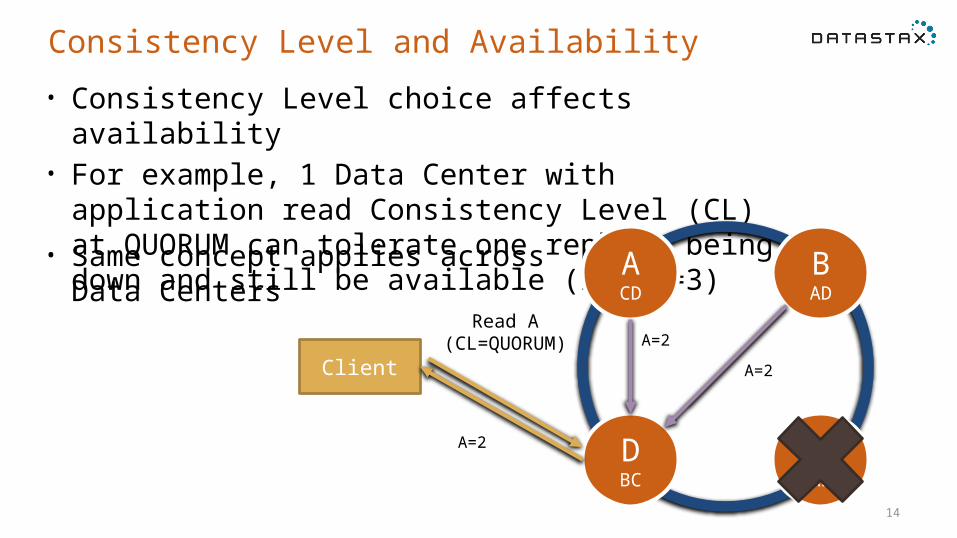
Consistency Level and Availability• Consistency Level choice affects availability• For example, 1 Data Center with application read
Consistency Level (CL) at QUORUM can tolerate one replica being down and still be available (in RF=3)
Client
BAD
CAB
ACD
DBC
A=2A=2
A=2
Read A(CL=QUORUM)
• Same concept applies across Data Centers

15
Consistency Levels (CL's)• Applies to both Reads and Writes (i.e. is set on each query)• Controlled at the Client API Level (% controlled by RF). Examples include:
– ONE – one replica from any DC– LOCAL_ONE – one replica from local DC– QUORUM – 51% of replicas from any DC– LOCAL_QUORUM – 51% of replicas from local DC– EACH_QUORUM – 51% of replicas from multiple DC's – ALL – all replicas– TWO...
• The client code has, and can control a hierarchy of automatic failure levels– i.e. one Data Center down with QUORUM, use LOCAL_QUORUM
• Cassandra will keep things consistent when the failed Data Center is back online • Will there potentially be a speed cost? Of course there might be, but your database never went down now did it?
– CL fallback patterns are usually set once when connection is made in the application using Cassandra
Other Constructs• BATCH – All statements succeed or fail• Light Weight Transactions (LWT) – Test and Set
Consistency Level Choices- Reacting when machines, data centers, networks, etc. go down (if you notice)

16
Primary Key and Replication Factor"Write Identified by Primary Key A" means what? What "Primay Key A" looks like in CQL
Replication Factor (per DC)

17
Review of Replication Factor (RF) and Consistency Level (CL)What matters for this discussion
• The KEY is the thing that is an enabler for distributed systems & CAP implementation– Along with Replication Factor determines what nodes (nodes can
live in different Data Centers) data will be written to and read from.
– Consistency Level controlled in application for the scenario that makes sense. A simple app may never notice node failures.• Unless... ... something in the infrastructure breaks
– Then the application gets to decide what to do » Ha! Like you even have those options with other
technologies» Is another topic completely out of scope here

18
Back to the Topic: Inventory Supply and Demand
• Cassandra Architecture Applicability– Linear scalability / de-scalability to handle heavy workload periods – Predictable performance– No Single Point of Failure
• Node(s)• Data Center(s)
– Flexible Deployment Options• On-Premise • Cloud• Hybrid Cloud / On-Premise
– Looks like one big old database to the client with visibility into it's working parts when needed
19
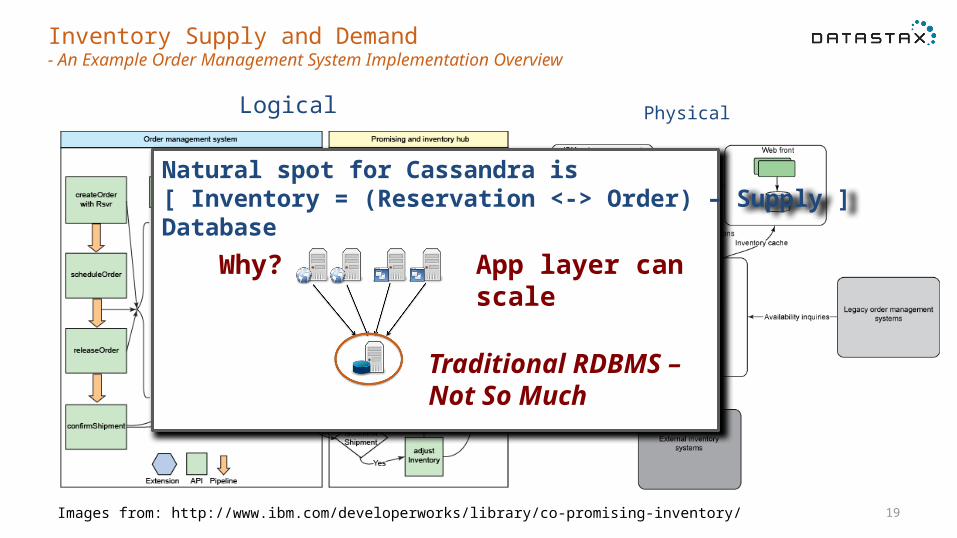
Inventory Supply and Demand- An Example Order Management System Implementation Overview
Logical
Images from: http://www.ibm.com/developerworks/library/co-promising-inventory/
Physical
Natural spot for Cassandra is [ Inventory = (Reservation <-> Order) – Supply ]Database
App layer can scale
Why?
Traditional RDBMS – Not So Much

20
CL's, RF's, and LWT's. Oh My!• Consistency Levels
– QUORUM (LOCAL_QUORUM)– ONE (LOCAL_ONE)
• Reduce or Remove– BATCH statements– Lightweight Transactions (LWT)
Other CL's, LWT's, and BATCH are not bad...– They put more work on the Cassandra cluster(s)– Potentially add more scenarios to deal with in the client application
Why put more work on the clusters if you can avoid with a circumspect design?

21
Inventory = Supply – Demand
Demand Mgmt Process /API's [ id'd by (sku, loc_id) ]
Available Inventory
Supply Mgmt Process /API's [ id'd by (sku, loc_id) ]
Application Layer

22
Traditional Multi Data Center Infrastructure
+ https://docs.oracle.com/middleware/1221/wls/WLCAG/weblogic_ca_archs.htm#WLCAG138 * http://www.ibm.com/developerworks/bpm/bpmjournal/1308_zhang/1308_zhang.html
What do we notice here? • Resilient (often
stateless) Web / App layer
• Primary / Failover DB (high transaction load can force this because active-active is too heavy)
• All active database access is managed in one Data Center
+ *
Inventory txn's id'd by (sku, loc_id) can flow from applications in either Data Center- multiple transactions for same item come through either DC, but db access only in 1 DC
Client Client
Stateless Application Processing Layer (Demand and Supply logic and queues, web layer, etc.)

23
Does Tradition Kill The Future?Pattern #1- Almost No Change To Infrastructure
Primary active -secondary failover DB's isolated in Data Centers Inventory database interaction (sku, loc_id) can come from the application layer in either Data Center with only . • 100% of data in both Data Centers
– Cassandra's active-active data synchronization between clusters
– more sophisticated than replication, but you can think of it that way if it makes things easier
DC1 DC2

24
Does Traditional Active / Failover DC Architecture Kill The Future?
Obviously inefficient usage! But works fine• Each operation will use DC1 as the primary Data Center• Lightweight Transactions typically used
– Same item id'd by (sku, loc_id) can be simultaneously updated by two different application paths
– Not necessarily evil, just more work for the database to do• Consistency Level
– For the scared neophytes• QUORUM, EACH_QUORUM, or SERIAL client gets success ack from nodes in both DC's (RF
= 3 x 2 DC's = 4 nodes respond)– Consistency Level for Cassandra's people
• LOCAL_QUORUM or LOCAL_SERIAL client gets success ack from nodes in DC1 (RF = 3 x 1 DC = 2 nodes respond). Cassandra will simultaneously update DC2, but client app does not wait
• Application Data Center FAILOVER for Cassandra is AutomaticDC1 DC2
Cassandra's active-active is way, way past primary-secondary RDBMS failover architecture of isolated in Data Centers. Stuck with old Data Center failover
scenario (but no RDBMS)
... and yes. Cassandra efficiently and elegantly deals with WAN Data Center latencies
• Pattern #1- Almost no change w/ a primary – secondary C* DB

25
Reality Check Before Next Section (uhh... nodes and DC's talk, right?)- How many Angels can blink while dancing on the head of a pin?
• It takes longer to think about it than it does to do it.– Cassandra operations are happening in units of micro- and milli- seconds [
(10-6) and (10-3) seconds ] / network typically in micro- to low milli-seconds• Reference Points
– The average human eye blink takes 350,000 microseconds (just over 1/3 of one second).
– The average human finger click takes 150,000 microseconds (just over 1/7 of one second).
– A camera flash illuminates for 1000 microseconds• Netflix AWS Inter-Region Test*
– "1 million records in one region of a multi-region cluster. We then initiated a read, 500ms later, in the other region, of the records that were just written in the initial region, while keeping a production level of load on the cluster"
• Consider Where Latency Bottlenecks Happen (slowest ship...)+Comparison of Typical Latency Effects
* http://www.slideshare.net/planetcassandra/c-summit-2013-netflix-open-source-tools-and-benchmarks-for-cassandra+ https://www.cisco.com/application/pdf/en/us/guest/netsol/ns407/c654/ccmigration_09186a008091d542.pdf
DC1 DC2

26
DC1 DC2
Does Traditional Active / Failover DC Architecture Kill The Future?
Works fine, but not super-efficient• Either Data Center can service requests (even from the same
client)• Lightweight Transactions typically used
– Same item id'd by (sku, loc_id) can be simultaneously updated by two different application paths
– Potential conflict across 2 Data Centers– Not the ultimate evil
• More work for the database to do across Data Centers• DC failure scenarios have more work to fully recover
• Cassandra will ensure 100% of the data is in both Data Centers
• Typical Consistency Level – QUORUM, SERIAL, EACH_QUORUM client gets success ack from nodes in
both DC's (RF = 3 x 2 DC's = 4 nodes respond)• Application Data Center FAILOVER for Cassandra is Automatic
• Pattern #2- Client requests access two active Cassandra Data Centers

27
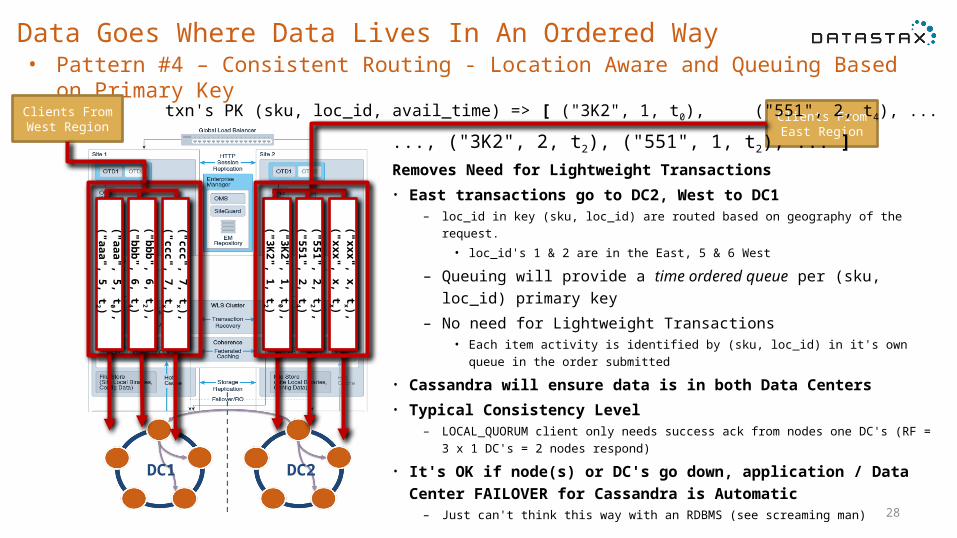
Time to drop the notion of a "Failover Data Database"• Pattern #3- Consistent Routing – i.e. Location Aware
Clients From East Region
Removes Cross-Region LWT Contention• East transactions go to DC2, West to DC1
– loc_id in key (sku, loc_id) are routed based on geography of the request.• loc_id's 1 & 2 are in the East, 5 & 6 West
– Potential LWT contention only per Data Center (sku, loc_id)– Does not have to be geographic, just consistent routing to a data
center by a piece of data that is in primary key (loc_id in this case). • Cassandra will ensure data is in both Data Centers• Typical Consistency Level
– LOCAL_QUORUM client gets success ack from nodes in one DC's (RF = 3 x 1 DC's = 2 nodes respond)
• Application Data Center FAILOVER for Cassandra is Automatic
DC1 DC2
Clients From West Region
txn's PK (sku, loc_id, avail_time) => [ ("3K2", 1, t0), ("551", 2, t4), ... ..., ("3K2", 2, t2), ("551", 1, t2), ... ]
[ ("3K2", 1, t0 ), ("551", 2, t4 ), ..., ("3K2", 2, t2 ), ("551", 1, t2 ), ... ]
[ ("aaa", 5, t0 ), ("bbb", 6, t4 ), ..., ("aaa", 6, t2 ), ("bbb", 5, t2 ), ... ]
28
Data Goes Where Data Lives In An Ordered Way
DC1 DC2
• Pattern #4 – Consistent Routing - Location Aware and Queuing Based on Primary Key
Clients From West Region
Clients From East Region
Removes Need for Lightweight Transactions• East transactions go to DC2, West to DC1
– loc_id in key (sku, loc_id) are routed based on geography of the request.• loc_id's 1 & 2 are in the East, 5 & 6 West
– Queuing will provide a time ordered queue per (sku, loc_id) primary key
– No need for Lightweight Transactions• Each item activity is identified by (sku, loc_id) in it's own queue in the
order submitted• Cassandra will ensure data is in both Data Centers• Typical Consistency Level
– LOCAL_QUORUM client only needs success ack from nodes one DC's (RF = 3 x 1 DC's = 2 nodes respond)
• It's OK if node(s) or DC's go down, application / Data Center FAILOVER for Cassandra is Automatic – Just can't think this way with an RDBMS (see screaming man)
txn's PK (sku, loc_id, avail_time) => [ ("3K2", 1, t0), ("551", 2, t4), ... ..., ("3K2", 2, t2), ("551", 1, t2), ... ]
("3K2", 1, t0 ), ("3K2",
1, t2 )
("551", 2, t2 ), ("551",
2, t4 )
("xxx", x, tx ), ("xxx",
x, tx )
("aaa", 5, t0 ), ("aaa",
5, t2 )
("bbb", 6, t2 ), ("bbb",
6, t4 )
("ccc", 7, tx ), ("ccc",
7, tx )

29
Blog Outlining An Implementation• http://www.datastax.com/dev/blog/scalable-inventory-example• Includes a logging table for immediate and historical queries and
analysis– Good use case for DataStax Enterprise Spark and Solr integration

30
Last Thoughts• None of the architecture patterns discussed
are bad, just some more efficient than others
• Cassandra gives you design choices on how to work with your Data Center architectures, not the other way around
• Cassandra can always scale!• Did not discuss different patterns as logic
for things such as safety stock is applied

Last Question – Why Not Active-Active RDBMS?• Limitations of technology
often force Pattern #1, the active / failover RDBMS in separate Data Centers
• Operationally this means compromising:– Speed– Always-on– Scalability
• Which can mean Screaming Man – is not good for your sanity or
career (imho)

32
References and Interesting Related Stuffhttp://www.datastax.com/dev/blog/scalable-inventory-examplehttp://www.nextplatform.com/2015/09/23/making-cassandra-do-azure-but-not-windows/http://highscalability.com/blog/2015/1/26/paper-immutability-changes-everything-by-pat-helland.htmlhttp://www.slideshare.net/planetcassandra/azure-datastax-enterprise-powers-office-365-per-user-storeLife beyond Distributed Transactions: an Apostate’s Opinion: http://www-db.cs.wisc.edu/cidr/cidr2007/papers/cidr07p15.pdfhttp://blogs.msdn.com/b/pathelland/archive/2007/07/23/normalization-is-for-sissies.aspxhttp://www.oracle.com/technetwork/database/availability/fmw11gsoamultidc-aa-1998491.pdfhttps://msdn.microsoft.com/en-us/library/azure/dn251004.aspxhttp://www.datastax.com/dev/blog/scalable-inventory-examplehttps://docs.oracle.com/middleware/1221/wls/WLCAG/weblogic_ca_archs.htm#WLCAG138 http://www.ibm.com/developerworks/bpm/bpmjournal/1308_zhang/1308_zhang.htmlThank You!