tachyon memory centric, fault tolerance storage for cluster framworks
TRANSCRIPT

Tachyon: memory centric, fault tolerance storage for cluster framworks
presented by Viet-Trung Tran

Memory is King
• RAM throughput increasing exponentially
• Disk throughput increasing slowly
Memory-locality key to interactive response time

Memory as cache
• Improve READ• Cannot help much with write
• Replication for fault tolerance• Network bandwidth and latency are much worse than that of memory
• Write throughput is limited by disk I/O• Required at least one copy on disk
• Inter-job data sharing cost dominates pipeline end-to-end latency• 34% jobs output as large as input (Cloudera survey)

Different jobs share data
Slow writes to disk
Spark Task
Spark mem block manager
block 1
block 3
Spark Task
Spark mem block manager
block 3
block 1
HDFS / Amazon S3block 1
block 3
block 2
block 4
storage engine & execution enginesame process(slow writes)
4

Different frameworks share data
Spark Task
Spark mem block manager
block 1
block 3
Hadoop MR
YARN
HDFS / Amazon S3block 1
block 3
block 2
block 4
storage engine & execution enginesame process(slow writes)
5
Slow writes to disk
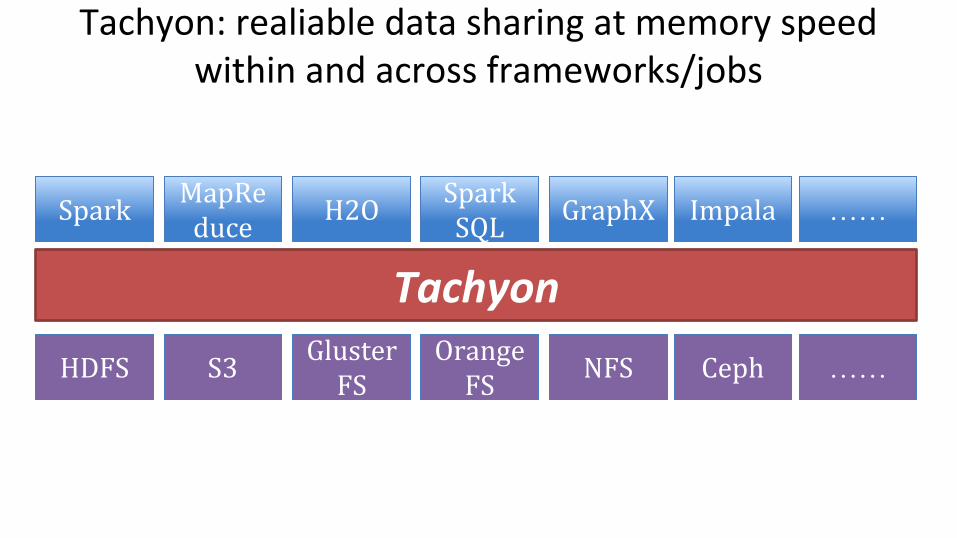
Tachyon: realiable data sharing at memory speed within and across frameworks/jobs
Tachyon
SparkMapRe
duceSparkSQL
H2O GraphX Impala
HDFS S3Gluster
FSOrange
FSNFS Ceph ……
……

Challenges
How to achieve reliability data sharing without replication?

Target workload properties
• Immutable data• Deterministic jobs• Locality based scheduling• All data vs working set• Program size vs data size

System architecture
Consists of two layer
• Lineage
• Deliver high throughput I/O
• Capture sequence of jobs/tasks that create output
• Persistence
• Asynchronous checkpoints
Facts
• One data copy in memory
• Recomputation for fault-tolerance

Memory-Centric Storage Architecture
10
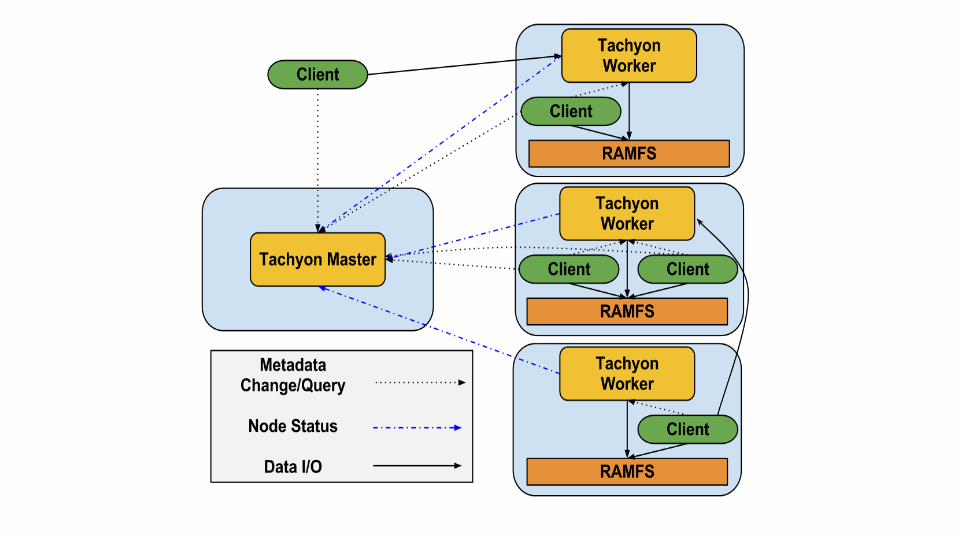

Master Node
• Similar to HDFS and GPS• Passive standby model
• BUT also contains a workflow manager• Track lineage information• Compute checkpoint order• Interact with cluster resource manager to allocate resources for re-
computations

Lineage

More complex lineage

Lineage metadata
• Binary program
• Configuration
• Input Files List
• Output Files List
• Dependency Type
• Narrow (filter, map)
• Wide (suffle, join)

Fault-recovery by recomputations
• Challenge• Bounding the recomputation cost for a long running storage
• Asynchronous checkpointing• Allocate resources for recomputations
• Make sure recomputation tasks get enough resources• Do not impact system performance (task priorities)
• Assumption• Input files are immutable• job executions are deterministic
• Client side caching to mitigate read hotspots

Asynchronous checkpointing
• Goals• Bounded recomputation time• Checkpointing hot files• Avoid checkpointing temp files
• Edge algoritim • Modeling relationships of files with a DAG
• Vertices are files • Edge from A to B if B is generated by a job that read A

Edge algorithm
• Checkpoint leaves• Checkpointing hot files
• Most file access are less than 3 ( yahoo survey for big data workload)• Thus, access more than twice get checkpointed
• Dealing with large dataset• 96% active job sizes fit in the cluster memory• synchronously write dataset above a defined threshold to disk• Most of the files in memory checkpointed can be evicted from memory
to make room

Resource allocation
• Depend on the scheduling policy of the running cluster• Requirements
• Priority compatibility• Resource sharing • Avoid cascading recomputation
• Best ordering recomputation• Most common policies
• priority based• weighted fair sharing

Priority based scheduler
•

Fair sharing based scheduler

Evaluation
• 110x faster than MemHDFS• 4x faster in realistic jobs• 3,8x faster in case of failure• Recover from master failure within 1 second• reduce replication caused network traffic up to 50%• recomputation impact is less than 1,6%