tabla de contenido - cenidet.edu.mx juan carlos... · 1 capítulo 1 introducción hoy en día...
TRANSCRIPT

i
Tabla de Contenido Página
Lista de Tablas ............................................................................................................ iv
Lista de Figuras...........................................................................................................vi
1. Introducción........................................................................................................... 1 1.1 Motivaciones ..................................................................................................... 3
1.2 Trabajos Relacionados ...................................................................................... 3
1.3 Descripción del Problema .................................................................................. 7
1.4 Objetivos ............................................................................................................ 9
1.5 Hipótesis de Investigación ............................................................................... 10
1.6 Justificación y Beneficios ................................................................................. 10
1.7 Aportaciones .................................................................................................... 12
1.8 Alcances y Limitaciones................................................................................... 13
1.9 Aplicaciones..................................................................................................... 15
2. Marco Teórico...................................................................................................... 17 2.1 Introducción ..................................................................................................... 17
2.2 Procesamiento de Lenguaje Natural PLN........................................................ 18
2.3 Interfaces de Lenguaje Natural para Bases de Datos ILNBDs ........................ 22
2.4 Sistema Administrador de Bases de Datos SABD........................................... 23
2.5 Structured Query Language SQL..................................................................... 23
3. Metodología de Solución .................................................................................... 26 3.1 Metodología de Solución.................................................................................. 27
3.2 Formalización de la Tipificación de Problemas en Consultas .......................... 34
3.3 Implementación de procesos de diálogo.......................................................... 44
3.4 Diseño Conceptual de la Interfaz con un Administrador de Diálogo ................ 47
4. Experimentación ................................................................................................. 50 4.1 La Base de Datos ATIS.................................................................................... 51
4.2 Experimento 1. Prueba del desempeño de la interfaz comercial English
Query con un corpus de preguntas con economía de palabras............................. 52
4.3 Experimentos 2 Prueba del desempeño de la interfaz comercial ELF con un
corpus de preguntas con economía de palabras ................................................... 54

ii
4.4 Experimento 3 Evaluación del desempeño de la ILNBD desarrollada en
CENIDET con un Administrador de Diálogo .......................................................... 55
4.5 Experimento 4 Evaluación del desempeño de la interfaz ELF con un corpus
con consultas con economía de palabras de la BD ATIS ...................................... 56
4.6 Experimentos 5.1, 5.2 Evaluación del desempeño de la ILNBD desarrollada
en CENIDET con un corpus con consultas con economía de palabras de la BD
ATIS....................................................................................................................... 57
4.7 Cálculo del número de ciclos de diálogo en la ILNBD desarrollada en
CENIDET ............................................................................................................... 60
4.8 Conclusiones ................................................................................................... 65
5. Conclusiones y Trabajos Futuros...................................................................... 69 5.1 Conclusiones ................................................................................................... 69
5.2 Trabajos Futuros.............................................................................................. 70
Referencias .............................................................................................................. 73 Anexos ..................................................................................................................... 78
Anexo A. Características de la ILNBD desarrollada en CENIDET......................... 78
Anexo B. Gramática de elementos considerados de SQL 1 para la tipificación de
problemas en consultas ......................................................................................... 82
B.1 Subconsultas ................................................................................................... 84
Anexo C. Ejemplo de configuración de la interfaz English Query (EQ).................. 86
Anexo D. Muestra de 102 consultas del corpus de la BD ATIS ............................. 89
Anexo E. Ejemplos de consultas con la interfaz desarrollada en CENIDET
incluyendo un administrador de diálogo................................................................. 93
Anexo F. Ejemplos de seis tipos de problemas en consultas ejecutadas por la
interfaz desarrollada en CENIDET....................................................................... 102
Anexo G. Información de la ILNBD desarrollada en CENIDET............................ 106
Anexo H. Instalación de la ILNBD........................................................................ 111
Anexo I. Diagrama de clases de la ILNBD desarrollada en CENIDET con
traductor............................................................................................................... 118
Anexo J. Resultados publicados.......................................................................... 119
Anexo K. Problemas en la ILNBD desarrollada en CENIDET.............................. 120

iii
Anexo L. Esquema de la BD ATIS....................................................................... 122

iv
Lista de Tablas
Página Tabla 1.2.1 Estado del arte de ILNBDs con independencia de dominio que
emplean un administrador de diálogo ......................................................................... 4
Tabla 3.1.2 Porcentaje de consultas clasificadas para las BDs Northwind, ATIS y
Pubs .......................................................................................................................... 32
Tabla 3.2.1 Tipificación de problemas compuestos considerando
combinaciones de problemas básicos....................................................................... 42
Tabla 3.2.2 Tipificación de problemas considerada para el
administrador de diálogo ........................................................................................... 42
Tabla 4.2.1 Resultados de la ejecución de consultas que involucran seis tipos de
problemas utilizando EQ ........................................................................................... 53
Tabla 4.3.1 Resultados de la ejecución de consultas que involucran seis tipos de
problemas utilizando ELF.......................................................................................... 54
Tabla 4.4.1 Resultados para seis tipos de problemas en consultas
del corpus de la BD Northwind .................................................................................. 55
Tabla 4.5.1 Resultados para cinco tipos de problemas con el corpus
de la BD ATIS y la interfaz ELF................................................................................. 56
Tabla 4.6.1 Resultados para cinco tipos de problemas con el corpus
de la BD ATIS y la ILNBD desarrollada en CENIDET ............................................... 58
Tabla 4.6.2 Resultados para cinco tipos de problemas con una muestra
del corpus de la BD ATIS y la ILNBD desarrollada en CENIDET
con estudiantes de maestría ..................................................................................... 59
Tabla 4.6.3 Resultados para cinco tipos de problemas con una muestra del
corpus de la BD ATIS y la ILNBD desarrollada en CENIDET con estudiantes de
licenciatura en informática......................................................................................... 60
Tabla 4.7.1 Resultados del número de ciclos de diálogo para cinco tipos de
problemas con una muestra del corpus de la BD ATIS y la ILNBD desarrollada en
CENIDET con estudiantes de licenciatura en informática y maestría en ciencias..... 61

v
Tabla 4.7.2 Aplicación del número de procesos de diálogo de acuerdo al tipo de
problemas en consultas en una ILNBD..................................................................... 62
Tabla D.1 Corpus de consultas de la BD ATIS.......................................................... 89
Tabla F.1 Ejemplos de seis tipos de problemas en consultas
para la BD Northwind ..........................................................................................................102

vi
Lista de Figuras
Página Figura 2.2.1 Arquitectura general de un sistema de diálogo.................................. 20
Figura 2.3.1 Flujo en una ILNBD [36]..................................................................... 22
Figura 3.2.1 Conjunto de consultas consideradas y problemas de omisión de
información ............................................................................................................ 34
Figura 3.2.2 Conjunto de consultas consideradas y problemas y de omisión de
información (básicos y compuestos)...................................................................... 36
Figura 3.2.3 Tipos de problemas básicos de omisión de información.................... 41
Figura 3.4.1 Esquema conceptual de la ILNBD desarrollada en CENIDET con un
administrador de diálogo........................................................................................ 48
Figura 4.8.1 Respuesta de ELF a la consulta:
What is the arrival time in Los Angeles? ................................................................ 65
Figura A.1 Arquitectura general de la ILNBD [1, 29]. ............................................. 79
Figura E.1 Selección de BD y consulta con el tipo de problema 3.1...................... 93
Figura E.2 Diálogo de aclaración. .......................................................................... 94
Figura E.3 Pantalla de solicitud de información faltante para “producto”. .............. 95
Figura E.4 Resultado de la consulta: ¿cuál es el precio del producto chang?....... 96
Figura E.5 Consulta con el tipo de problema 4.1 ................................................... 97
Figura E.6 Pantalla de solicitud de información faltante para “fecha” .................... 98
Figura E.7 Pantalla de solicitud de información faltante para “empleado” ............. 99
Figura E.8 Pantalla de solicitud de información faltante para “empleado” ........... 100
Figura E.9 Resultado a la consulta: Dame la fecha de contratación de Margaret
Peacock. .............................................................................................................. 101
Figura G.1 Fragmento de la información de la BD db2.mdb................................ 106
Figura G.2 Fragmento de la información de la BD Bitácora................................. 106
Figura G.3 Fragmento de la información de la tabla ConsultaLN de la BD
baseconsultas ...................................................................................................... 107
Figura G.4 Fragmento de la información de la tabla “specific” de la BD
domespec ............................................................................................................ 107

vii
Figura G.5 Fragmento de la información de la tabla “dom” de la BD dominio ..... 108
Figura G.6 Fragmento de la tabla “lexico” de la BD “lexicon” .............................. 108
Figura G.7 Fragmento de la tabla “sustantivos”de la BD “lexicon”....................... 109
Figura G.8 Fragmento de la tabla “MetadatosValores” de la BD metadatos........ 109
Figura G.9 Fragmento de la tabla “Metadatos” de la BD metadatos.................... 110
Figura H.1 Acceso a propiedades de entorno...................................................... 111
Figura H.2 Acceso a variables de entorno ........................................................... 112
Figura H.3 Creación de nueva variable de entorno.............................................. 113
Figura H.4 Agregar nueva variable de entorno .................................................... 114
Figura H.5 Acceso a “path” del sistema ............................................................... 115
Figura H.6 Modificación de “path” del sistema..................................................... 115
Figura H.7 Ruta para iniciar servidor de aplicaciones.......................................... 116
Figura I.1 Diagrama de clases de la interfaz desarrollada en CENIDET con
administrador de diálogo...................................................................................... 118
Figura L.1 Esquema de la BD ATIS ..................................................................... 122

1
Capítulo 1
Introducción Hoy en día utilizar una computadora y ejecutar aplicaciones o programas a
través de ésta es una tarea cotidiana y normal para muchas personas. Sin embargo,
las aplicaciones no siempre son fáciles de operar. La necesidad de obtener
información de una forma rápida y precisa demanda la existencia de aplicaciones
que no requieran de conocimientos especiales para poder operarlas de una forma
sencilla, sin complicaciones. El uso de lenguaje natural hablado y escrito ha dado
lugar a dos áreas de investigación que hasta la fecha siguen proponiendo nuevas
soluciones. Esta investigación se centra en la segunda de estas áreas: el lenguaje
natural escrito, específicamente, interfaces de lenguaje natural para bases de datos
(ILNBDs).
Una ILNBD permite al usuario acceder a información almacenada en una base de
datos mediante una solicitud en lenguaje natural. Las ILNBDs surgen como una
alternativa a varios problemas que se presentan en los sistemas y medios para
acceder a la información.

Introducción
2
Métodos y medios para acceder a información almacenada en bases de datos han
existido con anterioridad a la aparición de las ILNBDs. Sin embargo, las
características observadas en éstos se presentan como ventajas en unos y
desventajas en otros y viceversa. Por ejemplo, SQL es un lenguaje que presenta una
alta capacidad de formulación de consultas, pero para aplicarlo es necesario un
curso de capacitación, por lo que su aplicación no es fácil. Por otro lado, los sistemas
que permiten facilidad de operación como las interfaces gráficas, están limitadas en
su capacidad para formular consultas, algunos ejemplos de estos sistemas son: una
herramienta de consulta intuitiva para usuarios casuales de la red Internet basada en
consultas del tipo QBE (Query by Example) y una herramienta basada en consultas
del tipo QBE para múltiples BDs en Internet [49].
El desarrollo de sistemas de información involucra la creación de herramientas que al
final pueden ser operadas por un experto u operador del sistema, es decir, un
usuario que ha recibido una capacitación para operar el sistema. De tal forma que, si
otro usuario, un usuario inexperto, requiere operar el sistema, éste deberá recibir la
misma capacitación que el usuario experto. Los sistemas de información no
consideran a usuarios eventuales o inexpertos, especialmente altos ejecutivos de la
organización. A raíz de esta problemática surgen las interfaces de lenguaje natural
(ILN), las cuales permiten al usuario inexperto o experto consultar la información,
utilizando para ello lenguaje natural. Las ILNBDs se basan en las ILNs, ofreciendo
una nueva vertiente para acceder a la información estructurada en bases de datos.
Las ILNBDs han cambiado el enfoque para desarrollar sistemas de información y
permiten a toda clase de usuarios obtener con mayor facilidad la información que
éstos buscan. Sin embargo, en esta área aún existen problemas que hasta la fecha
las metodologías empleadas en las ILNBDs no han podido solucionar de una manera
total. Por lo tanto, es objetivo de este trabajo de tesis continuar con esfuerzos previos
a través de una ILNBD [1, 20] desarrollada en CENIDET. En este trabajo nos
enfocamos al diseño de procesos de diálogo con el fin de resolver uno de los

Introducción
3
problemas más importantes en lenguaje natural escrito y hablado: la economía de
palabras. En este proyecto, este problema se analiza de una manera sistemática
que nunca había sido tratado antes en trabajos previos sobre ILNBDs.
1.1 Motivaciones
Hasta la fecha se han desarrollado muchos trabajos sobre ILNBDs. Cada trabajo ha
propuesto soluciones a distintos problemas. Sin embargo, no todos los problemas
han sido resueltos de una forma satisfactoria. El proceso de traducción de una
consulta de lenguaje natural a un lenguaje de consulta de BDs como SQL es un
problema que no ha sido resuelto en su totalidad. En este proceso uno de los
problemas identificados es el problema de la economía de palabras, que puede
entenderse como la omisión de palabras importantes al formular una consulta en
lenguaje natural. Generalmente, escribimos de la misma forma en que nos
expresamos: omitiendo palabras al referirnos a objetos, personas, lugares, etc. que
suponemos que los que nos escuchan entienden. Aunque cada desarrollador de
ILNBDs ha enfrentado el problema de economía de palabras y ha tenido que tratar
de alguna manera con éste, una investigación exhaustiva sobre la literatura sobre
ILNBDs ha revelado que este problema no ha sido claramente identificado, y mucho
menos sistemáticamente tratado. Este trabajo es una continuación de la interfaz
desarrollada en CENIDET [1, 20], a la cual agregamos un administrador de diálogo,
que permite mejorar el porcentaje de consultas contestadas por la interfaz, basado
en una tipificación de problemas en consultas que proponemos como una alternativa
de solución sistemática al problema de economía de palabras.
1.2 Trabajos Relacionados
Desde los años 60s y hasta la fecha se han desarrollado muchos y diversos trabajos
sobre ILNBDs. Para propósitos de este trabajo consideramos sólo las interfaces más
recientes y la ausencia/presencia de dos características: independencia de dominio y

Introducción
4
administración de diálogo (AD). Las principales ILNBDs dependientes del dominio sin
AD son: ILNES [3], VILIB [4], Kid [5] y CISCO [6]. PLANES [7] es una interfaz
dependiente del dominio que incluye un AD. Las más importantes interfaces
independientes del dominio sin AD son: English Query [8], PRECISE [9], ELF [10],
Edite [11], SystemX [12] y MASQUE/SQL [13]; mientras que, las principales ILNBDs
independientes del dominio con AD son: Rendezvous [14], STEP [15], TAMIC [16] y
CoBase [17]. Otras interfaces comerciales independientes del dominio que incluyen
un administrador de diálogo son: BBN’s PARLANCE [18] e InBase [19].
Además de los trabajos mencionados anteriormente, en la tabla 1.2.1 se muestran
las interfaces con características similares al trabajo de investigación que se
presenta en esta tesis.
Tabla 1.2.1 Estado del arte de ILNBDs con independencia de dominio que emplean un administrador de diálogo
Sistema Descripción
EUFID [24] System Development Corporation
(1983)
Se enfoca en el manejo de tablas para definir un dominio; utiliza un diccionario para la consulta de la BD; presenta características de seguridad; utiliza diálogos de aclaración como medio de respuesta al usuario.
IR-NLI [25] Udine University
(1988)
Se enfoca a técnicas de recuperación de información; utiliza un dominio específico de conocimiento de la BD y un dominio lingüístico para entender solicitudes del usuario; emplea un módulo de razonamiento para capturar metas del usuario mediante mecanismos de inducción e inferencia; utiliza diálogos de aclaración como medio de respuesta al usuario.
CLARE [26] Cambridge Regional College
(1994)
Se enfoca a técnicas de procesamiento de lenguaje natural (PLN); utiliza los componentes: dominio léxico, lenguaje de PLN, definición de equivalencias y definición de relaciones funcionales para definir un dominio específico; utiliza un lenguaje de razonamiento (TRL); utiliza diálogos de aclaración como medio de respuesta al usuario.
CoBase [17] UCLA (1996)
Se enfoca en el manejo de estructuras de datos; crea tipos abstractos de jerarquías (THAs) para modelar la base de conocimientos; mediante los THAs define operaciones de especialización, generalización y asociación; emplea CoSQL una extensión a SQL; utiliza resultados en SQL como medio de respuesta al usuario.
TAMIC [16] Instituto per la Recerca Scientifica e
Tecnologica (1996)
Se basa en un enfoque semántico multinivel; utiliza un diccionario técnico para consulta de la BD; emplea el analizador WEDNESDAY y otros componentes desarrollados en el mismo instituto (IRST); utiliza diálogos de aclaración como medio de respuesta al usuario.
InBase [19] Russian Research Institute
(2003)
Se enfoca en el manejo de patrones semánticos para consultar la BD; emplea Q-language un lenguaje similar a OQL (Object Query Language); emplea Q-Gen un generador de lenguaje natural; utiliza diálogos de aclaración como medio de respuesta al usuario.

Introducción
5
Tabla 1.2.1 Estado del arte de ILNBDs con independencia de dominio que emplean un administrador de diálogo (continúa)
Sistema Descripción
STEP [15] Umea University
(2004)
Se enfoca en un esquema de tuplas de cálculo relacional; utiliza un diccionario de sinónimos de la BD; emplea SPASS un probador de teoremas para consultas; utiliza diálogos de aclaración como medio de respuesta al usuario.
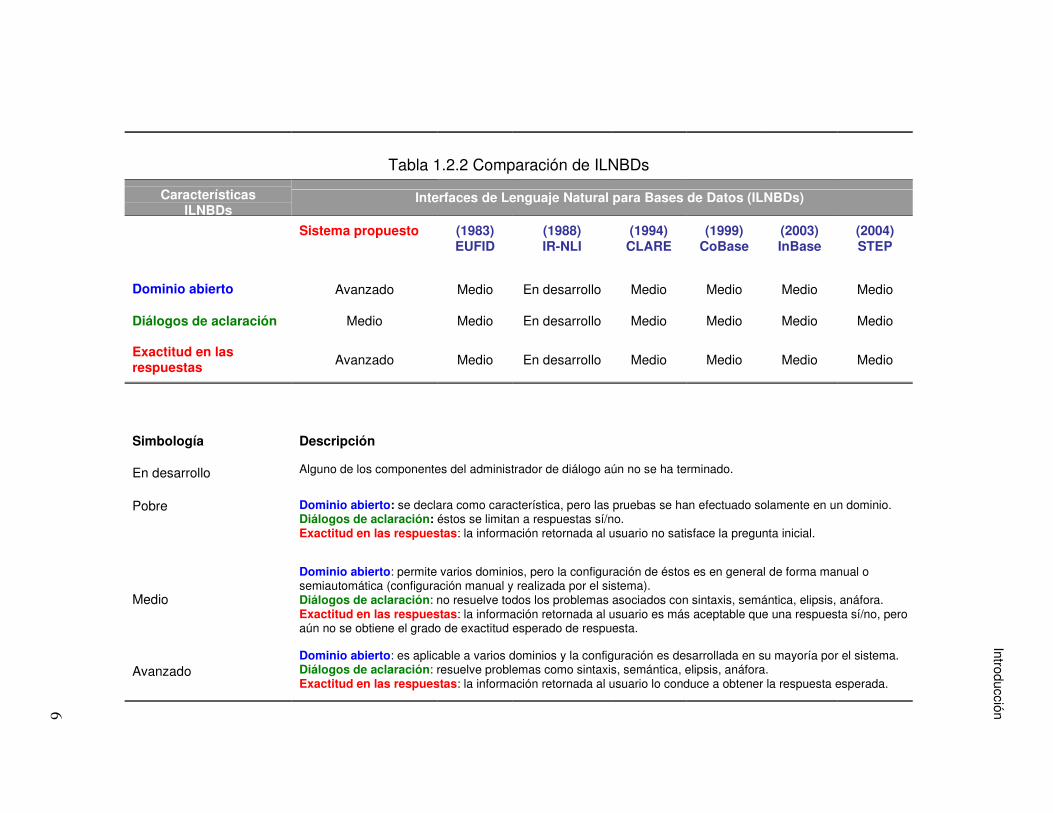
En la tabla 1.2.2 se muestra una comparación de las interfaces anteriores (tabla
1.2.1) con el administrador de diálogo implementado a la interfaz desarrollada en
CENIDET [1, 20]. A diferencia de los trabajos que se muestran en la tabla 1.2.2, la
interfaz desarrollada en CENIDET, en cuanto al dominio, permite la configuración de
diversos dominios de una forma más automatizada y menos tediosa. En lo que
respecta a diálogos de aclaración, los procesos de diálogo implementados en la
interfaz desarrollada en CENIDET están diseñados a partir de una tipificación de
problemas en consultas (capítulo 3), que permiten al usuario obtener la información
que está buscando. Es importante destacar que los procesos de diálogo
implementados en la interfaz desarrollada en CENIDET son independientes del
dominio, es decir, la lógica de implementación de éstos no requiere de cambios para
diferentes dominios. En cuanto a la característica de exactitud en las respuestas, las
respuestas obtenidas a través de los procesos de diálogo implementados son más
exactas. Los procesos de diálogo, como se mencionó anteriormente, permiten
obtener la información que el usuario está buscando y no “adivinan” la información
que el usuario busca. Todo lo anterior en conjunto permite que la interfaz
desarrollada en CENIDET tenga un porcentaje de acierto en las respuestas mayor
que sin un administrador de diálogo.
Introducción
6
(2004) STEP
Medio
Medio
Medio
(2003) InBase
Medio
Medio
Medio
(1999) CoBase
Medio
Medio
Medio
(1994) CLARE
Medio
Medio
Medio
(1988) IR-NLI
En desarrollo
En desarrollo
En desarrollo
(1983) EUFID
Medio
Medio
Medio
Interfaces de Lenguaje Natural para Bases de Datos (ILNBDs)
Sistema propuesto
Avanzado
Medio
Avanzado
Descripción
Alguno de los componentes del administrador de diálogo aún no se ha terminado.
Dominio abierto: se declara como característica, pero las pruebas se han efectuado solamente en un dominio. Diálogos de aclaración: éstos se limitan a respuestas sí/no. Exactitud en las respuestas: la información retornada al usuario no satisface la pregunta inicial.
Dominio abierto: permite varios dominios, pero la configuración de éstos es en general de forma manual o semiautomática (configuración manual y realizada por el sistema). Diálogos de aclaración: no resuelve todos los problemas asociados con sintaxis, semántica, elipsis, anáfora. Exactitud en las respuestas: la información retornada al usuario es más aceptable que una respuesta sí/no, pero aún no se obtiene el grado de exactitud esperado de respuesta.
Dominio abierto: es aplicable a varios dominios y la configuración es desarrollada en su mayoría por el sistema. Diálogos de aclaración: resuelve problemas como sintaxis, semántica, elipsis, anáfora. Exactitud en las respuestas: la información retornada al usuario lo conduce a obtener la respuesta esperada.
Tabla 1.2.2 Comparación de ILNBDs Características
ILNBDs
Dominio abierto
Diálogos de aclaración
Exactitud en las respuestas
Simbología
En desarrollo
Pobre
Medio
Avanzado

Introducción
7
1.3 Descripción del Problema
Una tendencia en el desarrollo de sistemas de información es la de permitir al
usuario comunicarse con el sistema empleando para ello lenguaje natural, ya sea en
forma oral o escrita. Las interfaces de lenguaje natural para bases de datos (ILNBDs)
constituyen una de las tecnologías que emplean el procesamiento y generación de
lenguaje natural. Éstas, en general, permiten al usuario comunicarse con un sistema
de información de una forma más amigable y natural.
Sin embargo, las ILNBDs (sección 1.2) desarrolladas hasta la fecha presentan varios
problemas en los cuales radica la dificultad de este proyecto de tesis. Estos
problemas son: la dificultad de traducción de la consulta en lenguaje natural a un
lenguaje de consulta de bases de datos y la independencia del dominio.
Los métodos y técnicas de traducción utilizados en la mayoría de las ILNBDs
consideran sólo partes de la oración (consulta) para obtener el equivalente en un
lenguaje de consulta de bases de datos, ignorando o descartando con esto algunos
elementos que son necesarios para efectuar una traducción de manera confiable y
precisa. Algunos ejemplos de ILNBDs que consideran sólo partes de la consulta son:
ELF [10] que es una interfaz que no se basa en gramáticas independientes de
contexto para efectuar la traducción de la consulta, la gramática en que se basa ELF
está orientada al lenguaje natural más que a un lenguaje de programación;
CoBase[27] utiliza un método de aproximación a resultados (relaxation), STEP [15]
se enfoca en un esquema de tuplas del cálculo relacional, KRISP [45] relaciona
(mapping) oraciones en lenguaje natural a su representación formal utilizando un
clasificador (string-kernel-based).
El proceso de traducción de la consulta en lenguaje natural a su equivalente a un
lenguaje de consulta de bases de datos involucra problemas como: la ambigüedad,

Introducción
8
información implícita por el ahorro de palabras (economía de palabras), consultas
mal formuladas, etc.
Este trabajo de tesis se enfoca al problema de la economía de palabras, el cual, si
bien ha sido enfrentado por los desarrolladores e investigadores de trabajos
anteriores en ILNBDs, éste no ha sido claramente identificado y mucho menos
sistemáticamente tratado; de hecho, en algunas interfaces el problema ha sido
evadido pasando éste al administrador del sistema de la BD, o quien está a cargo de
la configuración de la interfaz para adaptarla a una BD específica. Por ejemplo, en la
siguiente consulta “how many mammals are there”, los documentos de ELF [3]
sugieren que el administrador configure ELF para que pueda convertir la consulta
“how many mammals are there” a “how many animals are mammals”.
La economía de palabras consiste en la omisión de palabras importantes al redactar
o expresar una consulta en lenguaje natural. En una situación de conversación no se
habla con textos, es decir, no se habla con párrafos, capítulos, o documentos; se
habla con réplicas cortas, y la mayoría de la información omitida es clara en el
contexto previo [28]. La economía de palabras puede ocasionar una interpretación
errónea de una consulta, y por lo tanto, una traducción incorrecta de ésta.
Considérese el siguiente ejemplo: “listar las calificaciones para Jorge Salas”. Aunque
muchos estudiantes de maestría en Ciencias de la Computación podrían traducir
esta consulta a SQL dado el esquema de la BD, ésta podría ser difícil de contestar
por una ILNBD con independencia de dominio. El problema es que la consulta no
especifica la siguiente información: la tabla (cursos tomados) donde se almacenan
las calificaciones obtenidas, la tabla “estudiantes” y la columna “nombre” donde se
almacenan los nombres de los estudiantes. Si la consulta especificara esta
información, entonces podría leerse como sigue: “listar las calificaciones de los
cursos tomados por el estudiante cuyo nombre es Jorge Salas”.

Introducción
9
En este trabajo proponemos un nuevo enfoque para el proceso de traducción de una
consulta en lenguaje natural, el cual trata sistemáticamente el problema de la
economía de palabras. Utilizamos la ILNBD desarrollada en CENIDET [1, 20], y
diseñamos procesos de diálogo, los cuales fueron implementados e integrados a la
ILNBD para aclarar las consultas que presentan el problema de economía de
palabras.
1.4 Objetivos
Para resolver el problema propuesto en este tema de tesis, se plantea la siguiente
directriz u objetivo general (OG):
OG.1) Mejorar el desempeño de una ILNBD [1, 20] mediante el diseño de procesos
de diálogo buscando que éstos permitan al usuario obtener los resultados
esperados.
Para alcanzar el objetivo general (OG.1), se requiere cumplir con los siguientes
objetivos específicos (OE):
OE.1) Diseñar una nueva clasificación de consultas (ver capítulo 3), que incluya:
1) Consultas con información faltante:
• Consultas con información implícita.
2) Consultas mal formuladas.
3) Consultas ilógicas para la semántica de la base de datos.
OE.2) Diseñar los procesos de diálogo correspondientes al inciso (1) de los
problemas presentados en el OE.1 considerado la independencia de dominio.
OE.3) Los procesos de diálogo permitirán al usuario, mediante ciclos pregunta-
respuesta, obtener la información solicitada de forma eficaz.
OE.4) Los procesos de diálogo que se implementen serán incorporados a la ILNBD
desarrollada en CENIDET [1, 20], para verificar que aumenta el porcentaje de
acierto en las consultas.

Introducción
10
1.5 Hipótesis de Investigación
A continuación se describen las hipótesis de investigación como parte del proceso de
solución a la problemática planteada en este proyecto de investigación:
H.1) Es posible mejorar el desempeño de una ILNBD [1, 20] mediante la
incorporación de un proceso de diálogo.
H.2) Es posible que un proceso de diálogo pueda ser fácilmente configurado para
cualquier dominio en una ILNBD [1, 20].
Para demostrar las hipótesis anteriores se requiere de la siguiente hipótesis de
trabajo:
H.3) Es posible clasificar las consultas en base a características comunes, de tal
manera que para cada clase se pueda desarrollar un proceso de diálogo
independiente del dominio, que sea aplicable a todas las consultas de cada
clase.
1.6 Justificación y Beneficios
En el desarrollo de un sistema de información, generalmente se considera que, una
vez completado éste, se requiera de un proceso de capacitación para operarlo. Entre
más grande y complejo sea el sistema, será mayor la capacitación necesaria para
operarlo. En general, en este proceso se considera un solo tipo de usuario: el usuario
experto u operador del sistema (desarrolladores, capturistas, secretarias, etc.),
ignorando a otro tipo de usuarios, los usuarios casuales o inexpertos (ejecutivos de
jerarquía alta y media). De aquí que, hoy en día, debido a la gran dinámica de las
organizaciones, se requiera que los sistemas de información puedan ser utilizados de
manera fácil, rápida y amigable tanto por usuarios expertos como inexpertos. Las
ILNBDs constituyen una solución que cubre estas necesidades.

Introducción
11
Otras características cubiertas por las ILNBDs son la facilidad de operación y el
poder de consulta, características que no existían combinadas en un solo sistema
antes de la aparición de las ILNBDs. Uno de los métodos utilizados para acceder a la
información de una base de datos consiste en utilizar un lenguaje de consulta para
bases de datos como SQL, el cual posee un alto poder de consulta; pero para lograr
usar éste se requiere de capacitación, la cual no es accesible a todos los usuarios ni
tampoco todos los usuarios pueden ser candidatos, en cuanto habilidades, para
recibirla. Otro método de acceso es el empleo de interfaces gráficas, las cuales
ofrecen facilidad de operación, pero en cuanto al poder de consulta están limitadas a
ciertas funciones, de tal forma que un usuario no puede efectuar todas las
operaciones que desee. En tales circunstancias, el usuario tiene que elegir entre
poder de consulta o facilidad de operación. Las ILNBDs permiten combinar ambas
características en una sola interfaz.
Las ILNBDs constituyen una tendencia en el desarrollo de sistemas de información.
Con éstas se llegaron a resolver varios de los problemas encontrados en sistemas
anteriores. Sin embargo, hasta la fecha las ILNBDs existentes siguen presentando
problemas importantes, tales como errores en la traducción de la consulta y la
dificultad para ofrecer independencia de dominio. Las consultas mal interpretadas
pueden originar resultados incorrectos y confusos al usuario, causando que éste
pueda tomar decisiones incorrectas de vital importancia para la toma de decisiones.
Idealmente, una interfaz de lenguaje natural confiable debe responder siempre con
los resultados esperados.
El proceso de traducción de la consulta es uno de los principales problemas en las
ILNBDs. Traducir una consulta en lenguaje natural a su equivalente en un lenguaje
de consultas de bases de datos, como por ejemplo SQL, es un proceso que involucra
problemas como: ambigüedad, contexto de la información, economía de palabras,
etc.

Introducción
12
En este trabajo de tesis se pretende que, mediante la incorporación de un
administrador de diálogo a una ILNBD [1, 20] con independencia de dominio, el
usuario pueda obtener la respuesta esperada mediante ciclos pregunta-respuesta.
Los beneficios que se esperan obtener con este trabajo de investigación son los
siguientes:
1. En general, se espera facilitar la consulta a bases de datos. La incorporación
de procesos de diálogo permitirá al usuario, mediante ciclos de pregunta-
respuesta, obtener los resultados esperados. Este proceso se efectúa de
forma transparente para el usuario, es decir, éste no requiere conocer algún
lenguaje artificial o participar en el proceso de traducción de la consulta.
2. Específicamente, los procesos de diálogo permiten incrementar el porcentaje
de respuestas correctas y confiables al usuario, reduciendo el margen de error
al obtener información no requerida por el usuario. Además, los procesos de
diálogo poseen independencia de dominio y son generales (pueden ser
aplicables a diversos lenguajes como: inglés, francés, italiano, etc.),
características que los trabajos desarrollados hasta la fecha no presentan de
manera directa y transparente.
1.7 Aportaciones
Como resultados de este trabajo de investigación se obtuvieron una tipificación de
problemas en consultas, la cual trata de forma sistemática el problema de la
economía de palabras, y se formalizó la tipificación obtenida (capítulo 3). La
tipificación posee dos características importantes:
(1) Es independiente del dominio, lo que significa que ésta puede aplicarse a las
consultas de cualquier base de datos.

Introducción
13
(2) Es general, lo cual permite que ésta se pueda implementar en diversos
lenguajes como inglés, francés, italiano, etc.
Utilizando la teoría de conjuntos identificamos varios tipos de problemas recurrentes
en el universo de consultas para cualquier BD y logramos definir una solución, que
enmarca los problemas generales, en una tipificación de problemas en consultas
(partición del problema), la cual puede ser aplicable a las consultas de cualquier BD.
La tipificación propuesta (capítulo 3) constituye un enfoque de solución que no se
había presentado antes en ningún trabajo existente relacionado con ILNBDs. Con la
formalización damos soporte a la tipificación presentada en el capítulo 3.
1.8 Alcances y Limitaciones
Entre los alcances que se plantearon al inicio de este trabajo de investigación se
encuentran los siguientes:
a) Se debía diseñar una nueva clasificación de tipos de problemas en consultas,
como se muestra en el capítulo 3.
b) Se debían diseñar procesos de diálogo con propósitos de prueba, para los
tipos de consulta mencionados en la sección 1.4.
c) Los procesos de diálogo deberían funcionar para la ILNBD [1, 20], los cuales
debían poseer la característica de independencia de dominio.
d) Los procesos de diálogo diseñados deberían incrementar el porcentaje de
respuestas satisfactorias.
Entre las limitaciones de este trabajo se encuentran las siguientes:
a) El idioma soportado por el administrador de diálogo es únicamente español.
b) El medio de comunicación del proceso de diálogo es en lenguaje escrito.
c) Sólo se maneja un subconjunto de las consultas de SQL de la versión ISO/IEC
9075:1989(E) (SQL 1). Entre las funciones que no se implementaron se

Introducción
14
encuentran: Group by, Having, Order by, Desc, Asc y todas las funciones que
se relacionen con operaciones de inserción, borrado o actualización de
información.
d) No se trató el problema de la ambigüedad.
e) En cuanto a consultas mal formuladas, no se implementaron procesos de
diálogo, pero sí se detectan y se indican al usuario los diferentes tipos de
problemas.
Además se consideran las limitaciones que posee la ILNBD desarrollada en
CENIDET [1, 20]:
f) Debido a que en SQL una consulta se puede expresar de diferentes maneras,
no se considera el problema de transformar una consulta a su equivalente
optimizada.
g) No proporciona información que no esté explícita en la BD, ya que tendría que
ver con bases de datos deductivas.
h) No se manejan consultas temporales.
i) Las consultas deben ser léxica y sintácticamente correctas. El usuario debe
considerar esta condición para obtener una respuesta satisfactoria.
j) La información solicitada en la consulta a la base de datos debe expresarse
antes que la condición.
k) Las consultas pueden ser en forma interrogativa e imperativa.
l) Si la consulta incluye un valor numérico o tipo fecha, debe tener
explícitamente uno o más sustantivos que hagan referencia a la columna que
almacena el valor en la base de datos.
m) Si la consulta contiene un valor compuesto por dos o más palabras, el cual
corresponde a una columna de la base de datos, debe estar escrito entre
comillas dobles para poder encontrar su ubicación en la base de datos. Por
ejemplo: nombres de personas (“Juan Pérez Fernández”), domicilios, etc.
n) El formato para representar fechas debe ser: dd/mm/aaaa.

Introducción
15
o) En cuanto al tamaño de las BDs, el traductor está limitado por la cantidad de
memoria RAM que se tenga en la máquina donde se esté ejecutando éste; ya
que emplea un grafo donde se incluyen los nombres de las tablas de la BD y
sus relaciones. Además de lo anterior, el traductor presenta problemas en su
proceso de traducción con bases de datos más grandes y complejas en su
diseño.
1.9 Aplicaciones
El objetivo de una ILNBD es facilitar el acceso a información de una BD a todo tipo
de usuarios (inexpertos y expertos). El campo de aplicación de una ILNBD puede ser
muy variado. Algunos ejemplos de áreas de aplicación son: administración pública
(TAMIC [16]), bases de datos geográfica (STEP [15]), reservación de vuelos
(PLANES [7]), desarrollo de ILNBDs (English Query [8]), acceso a BDs de Microsoft
Access (ELF [10]), multimedia kiosks (Edite [11]), bases de datos estadísticas y
ambientales (System X [12]), acceso a BDs en Prolog (MASQUE/SQL [13]),
imágenes médicas (CoBase [17]), acceso a BDs de la marina de E.U. (BBN’s
PARLANCE [18]), etc.
Los alcances y limitaciones que posea una ILNBD serán definidos por la empresa u
organización que haga uso de ésta. Se debe considerar que una ILNBD es un
mecanismo de ayuda para facilitar el acceso a la información de una BD, razón por la
cual este tipo de sistemas no sustituye en su totalidad a un sistema de información
de una empresa u organización donde se consideran aspectos como tipos de usuario,
permisos, etc.
En el caso de la interfaz desarrollada en CENIDET [1, 20], no se consideraron
restricciones en cuanto al acceso a información. Ésta sólo permite acceder a
información, no permite modificar ni eliminar información de las BDs a consultar. La
interfaz desarrollada en CENIDET, como se menciona al inicio de esta sección,

Introducción
16
permite a usuarios inexpertos y expertos acceder a la información de una BD. Sin
embargo, es importante aclarar que el contexto que el usuario tenga con respecto a
la información que desea acceder influye en el uso, no sólo de esta interfaz sino en
general en el uso de ILNBDs. Un usuario sin idea de la información que desea
obtener es probable que formule consultas con un alto porcentaje de información
implícita en éstas, lo que ocasionará que la interfaz ejecute más procesos de diálogo,
y que el usuario, debido a esto, en algún momento pierda el interés en el uso de este
tipo de sistemas.

17
Capítulo 2
Marco Teórico
En este capítulo se definen conceptos y las áreas de investigación que abarca
este trabajo de tesis.
2.1 Introducción
A medida que una organización crece (llámese empresa, institución, universidad,
etc.), la tarea de acceder y recuperar la información se vuelve una actividad de
primordial importancia para tomar decisiones o decidir un curso de acción. Estas
entidades requieren de sistemas que puedan facilitarles recuperar información de la
manera más rápida, fácil y eficaz. Sin embargo, la operación de algunos de estos
sistemas muchas veces requiere de conocimientos previos y capacitación por parte
del usuario para poder operarlos de manera eficaz. Aunado a este problema, la
información a recuperar puede estar almacenada de muy diversas formas, y el
acceso y recuperación de ésta mediante los sistemas puede llegar a ser una tarea no
muy fácil, y los resultados obtenidos muchas veces pueden no satisfacer las

Marco Teórico
18
necesidades del usuario. En este ámbito el uso de interfaces, en la utilización de
estos sistemas para acceder a la información, permite a los usuarios entablar una
comunicación más amigable con el sistema.
La información en dispositivos electrónicos puede ser almacenada de muy diversas
formas, y los sistemas que acceden a la información utilizan diversos métodos o
técnicas para efectuar el acceso a ésta. Considerando lo anterior, esta investigación
se enfoca en el acceso a la información estructurada en bases de datos, utilizando
para ello una interfaz de lenguaje natural para bases de datos (ILNBD) en español
desarrollada en CENIDET [1, 20], y tiene como objetivo principal el diseño de
métodos de diálogo para su implementación en un administrador de diálogo con el fin
de mejorar el desempeño de la ILNBD en español, permitiendo al usuario obtener los
resultados esperados mediante ciclos pregunta-respuesta.
A continuación se detallan las disciplinas y tecnologías relevantes para el desarrollo
de este trabajo de investigación.
2.2 Procesamiento de Lenguaje Natural PLN
Lenguaje
Conjunto de sonidos articulados con que el hombre manifiesta lo que piensa o siente
[38].
Cuando se habla de lenguajes se pueden diferenciar dos clases muy bien definidas
[39]:
a) Los lenguajes naturales como el español, inglés, francés, etc.
b) Los lenguajes formales como los lenguajes de programación, el lenguaje de la
lógica matemática, etc.

Marco Teórico
19
Lenguaje formal
Un lenguaje formal es un lenguaje artificial creado por el hombre, el cual está
formado por símbolos y fórmulas y tiene como objetivo fundamental formalizar la
programación de computadoras o representar simbólicamente un conocimiento [39].
Lenguaje Natural
Lenguaje hablado o escrito por humanos, opuesto a un lenguaje de programación
utilizado para programar o comunicarse con computadoras [40].
Existen dos campos en el estudio del entendimiento del lenguaje natural [41]:
• Entendimiento del lenguaje escrito, que utiliza el conocimiento léxico, sintáctico y
semántico del lenguaje, unido a la información o conocimiento del dominio.
• Entendimiento del lenguaje oral, que comprende todo lo del campo anterior junto
con toda la fonología.
Las técnicas usadas en la comprensión de lenguaje natural derivan de la inteligencia
artificial. Para entender una oración simple, hay que considerar tres aspectos:
• Comprender el significado de cada palabra de la oración.
• Comprender la estructura de la oración o frase.
• Tener conocimiento del contexto en que se pronuncia.
Otra de las consideraciones en la comprensión del lenguaje natural escrito, además
del entendimiento de las palabras por separado, es “entender la estructura de la
oración”, que también es difícil. Este tema se puede dividir en tres análisis diferentes:
• Análisis sintáctico de la oración.
• Análisis semántico.
• Análisis interpretativo.

Marco Teórico
20
Procesamiento de Lenguaje Natural
El procesamiento de lenguaje natural (PLN o NLP en inglés) es un conjunto de
técnicas computacionales para analizar y representar naturalmente textos en uno o
más niveles de análisis lingüísticos, con el fin de llevar a cabo el procesamiento del
lenguaje como un humano para un rango de tareas y aplicaciones [42].
Diálogo
Un diálogo se puede describir como la interacción entre dos partes, en la cual la
información es transferida entre las partes mediante un número de turnos
secuenciales (un turno se refiere a la transferencia ininterrumpida de información de
una parte a la otra) [43].
Sistema de diálogo
Un sistema de diálogo es un sistema hombre máquina, en el cual el usuario puede
solicitar información acerca de un dominio específico. La interacción puede ser
conducida por la máquina, significando que el sistema guía al usuario, a menudo
efectuando preguntas simples y específicas [44] (figura 2.2.1).
Figura 2.2.1 Arquitectura general de un sistema de diálogo
Intérprete
Generador
Administrador de Diálogo
Historia del diálogo
Administrador de Dominio del
Conocimiento
Modelo de Sistema de
Tareas
Modelo de Diálogo
Modelo de Dominio de
Tareas
Módulo de Conocimiento 1
Módulo de Conocimiento 2
Módulo de Conocimiento n

Marco Teórico
21
Administrador de diálogo
El rol de un administrador de diálogo difiere ligeramente entre las diferentes
arquitecturas de sistemas de diálogo, pero su principal responsabilidad es controlar
el flujo del diálogo, decidiendo cómo debe responder el sistema a las expresiones del
usuario. Esto se consigue inspeccionando y especificando contextualmente la
estructura de información producida por un módulo de interpretación. Si falta alguna
información o una solicitud es ambigua, el administrador de diálogo genera preguntas
de aclaración al usuario [45].
Un administrador de diálogo puede utilizar un modelo de diálogo, un modelo de
tareas y una historia del diálogo [45]:
a) El modelo de diálogo mantiene una descripción genérica de cómo se
construye el diálogo; por ejemplo, para decidir qué acción tomar en una cierta
situación. Éste se utiliza para controlar la interacción, lo cual involucra
determinar: a) qué es lo que el sistema debe hacer enseguida, y b) decidir qué
acción comunicativa es apropiada en un estado de diálogo dado.
b) El modelo de sistema de tareas define cómo se ejecutan las tareas del
sistema.
c) La historia del diálogo almacena el foco de atención y contiene información
acerca de objetos, propiedades y relaciones, así como otra información del
diálogo tal como información de actos del habla e información de tareas del
sistema.
Los administradores de diálogo se pueden implementar utilizando alguna de las
siguientes tecnologías: transición de estados finitos, estados de información, planes y
formularios [46].

Marco Teórico
22
2.3 Interfaces de Lenguaje Natural para Bases de Datos ILNBDs
Una ILNBD es un sistema que permite al usuario acceder a la información
almacenada en una base de datos formulando una solicitud en lenguaje natural [35].
La arquitectura general de una ILNBD se muestra en la figura 2.3.1.
Figura 2.3.1 Flujo en una ILNBD [36]
El resultado obtenido por la interfaz varía de acuerdo a los objetivos y la
implementación de ésta; por ejemplo, algunas interfaces pueden retornar una
respuesta en lenguaje natural, utilizar formularios para presentar la información, etc.
En este trabajo de investigación los resultados corresponderán a los retornados por
la ejecución de una instrucción en el lenguaje SQL, como se observa en el siguiente
ejemplo:
Consulta en lenguaje natural: Obtener el número de vuelo y la hora de
partida y llegada de Atlanta a Boston
Consulta en SQL:
Select flight.flight_number, flight.departure_time, flight.arrival_time
From flight
Where flight.from_airport = 'ATL' and flight.to_airport = 'BOS'
Resultado:
Flight number Departure time Arrival time
296 6:36 10:00
314 6:41 08:55
140 7:55 10:19
Usuario
Interfaz
de LN
Consulta en LN
Resultado
BD
Consulta en SQL
Resultado de BD

Marco Teórico
23
El resultado de la consulta muestra la información organizada en columnas (Flight
number, Departure time, Arrival time) y renglones (registros encontrados).
2.4 Sistema Administrador de Bases de Datos SABD
Un SABD consiste en una colección de datos interrelacionados y un conjunto de
programas para acceder a dichos datos. La colección de datos, normalmente
denominada base de datos (BD), contiene información relevante para una
organización. El objetivo principal de un SABD es proporcionar una forma de
almacenar y recuperar la información de una base de datos de manera que sea tanto
práctica como eficiente [37].
2.5 Structured Query Language SQL
SQL (Lenguaje de consultas estructurado) fue desarrollado por IBM, originalmente
denominado Sequel, como parte del proyecto System R a principios de 1970. Hoy en
día numerosos productos son compatibles con el lenguaje SQL, y se ha establecido
como el lenguaje estándar para las bases de datos relacionales. La versión más
reciente publicada por la ANSI (American National Standards Institute) es SQL:2003.
SQL es una combinación de constructores del álgebra relacional y del cálculo
relacional. Usando SQL es posible, además de definir la estructura de los datos,
modificar los datos de la base de datos y especificar restricciones de seguridad [37].
El lenguaje SQL tiene varios componentes:
• Lenguaje de definición de datos (LDD). Proporciona comandos para la
definición de esquemas de relación, borrado de relaciones y modificación de
los esquemas de relación.

Marco Teórico
24
• Lenguaje de manipulación de datos (LMD). Es un lenguaje de consultas
basado tanto en el álgebra relacional como en el cálculo relacional de tuplas.
También contiene comandos para insertar, borrar y modificar tuplas.
• Integridad. El LDD incluye comandos para especificar las restricciones de
integridad que deben cumplir los datos almacenados en la base de datos. Las
actualizaciones que violan las restricciones de integridad se rechazan.
• Definición de vistas. El LDD incluye comandos para la definición de vistas.
• Control de transacciones. Incluye comandos para especificar el comienzo y fin
de las transacciones.
• SQL intercalado y SQL dinámico. SQL intercalado y SQL dinámico definen
cómo se pueden incorporar instrucciones de SQL en lenguajes de
programación de propósito general como C, C++, Java, PL/I, Cobol, Pascal y
Fortran.
• Autorización. El LDD incluye comandos para especificar los derechos de
acceso de los usuarios a las relaciones y a las vistas.
SQL:1999 es conocido también como SQL3. Éste ha sido caracterizado como SQL
orientado a objetos y es la base para varios sistemas administradores de BDs
orientadas a objetos (entre éstos se incluyen ORACLE8 de Oracle, Universal Server
de Informix, DB2 Universal Database de IBM y Cloundscape de Cloundscape, entre
otros). Las características de SQL:1999 se pueden dividir en características
relacionales (características que se relacionan al modelo de datos y de roles
tradicionales de SQL) y características orientadas a objetos. Las características
relacionales se dividen en cinco grupos: nuevos tipos de datos, nuevos predicados,
mejoras semánticas, seguridad adicional y bases de datos activas (a través de
triggers). En cuanto a las características orientadas a objetos, SQL:1999 mejoró la
capacidad denominada “SQL-invoked routines” agregando una tercera clase de
rutina conocida como métodos. Entre otras características se encuentran: tipos
estructurados definidos por el usuario y tipos REF (asociado siempre con un tipo
estructurado) [53].

Marco Teórico
25
Muchos sistemas de bases de datos soportan la mayor parte de la norma SQL-92 y
parte de los nuevos constructores de SQL:1999 y SQL:2003, aunque actualmente
ninguno soporta todos los constructores nuevos [37]. El traductor de la interfaz
desarrollada en CENIDET [1, 20] considera una parte de la gramática de SQL1 en su
proceso de traducción (anexo B).

26
Capítulo 3
Metodología de Solución Ya que este trabajo de investigación es una continuación de la interfaz
desarrollada en CENIDET [1, 20, 29], antes de plantear la metodología de solución,
es necesario explicar de manera general el funcionamiento de esta interfaz.
La interfaz desarrollada en CENIDET utiliza un método para la traducción de
consultas en español a SQL, lo cual permite a los usuarios realizar consultas a una
base de datos sin necesidad de tediosas configuraciones. El manejo de la
independencia del dominio es la característica principal de esta interfaz, y para
lograrlo utiliza un preprocesador que genera automáticamente un diccionario de
dominio y una técnica de traducción que utiliza sustantivos, preposiciones y
conjunciones, ya que estas últimas mantienen el significado en cualquier contexto y
no necesitan ser configuradas para un dominio particular. Las preposiciones y
conjunciones son representadas como operaciones usando la teoría de conjuntos.
Además, utiliza un grafo etiquetado y una taxonomía de la instrucción SELECT para
construir la consulta en SQL. Sin embargo, esta interfaz no permite al usuario un
diálogo de aclaración cuando la consulta no puede ser traducida, lo cual limita su

Metodología de Solución
27
capacidad para obtener un mayor porcentaje de aciertos en las consultas traducidas.
Una explicación más detallada de sus características se presenta en el anexo A.
3.1 Metodología de Solución
La metodología planteada para la solución de este problema parte de la propuesta de
implementar procesos de diálogo independientes del dominio para un administrador
de diálogo en una ILNBD [1, 29]. Esta propuesta implica que los procesos de diálogo
en el administrador de diálogo deberían funcionar para cualquiera de las bases de
datos relacionales existentes y por existir (considerando los alcances y limitaciones
de la ILNBD [1, 29], ver capítulo 1). Aunado a lo anterior, se tiene el hecho de que el
número de consultas que puede efectuarse a una base de datos en particular puede
llegar a ser muy grande; y por lo tanto, si se suman las consultas de todas las bases
de datos relacionales habidas y por haber, el número total resultaría astronómico.
Partiendo del razonamiento anterior, no sería factible (por razones de tiempo) tomar
cada una de las bases de datos relacionales existentes y tratar de implementar
procesos de diálogo para cada una de éstas. Para ilustrar el problema considérese el
caso de un sistema denominado BirdQuest. Esta interfaz fue desarrollada para un
sitio web donde la gente mira programas de televisión de la naturaleza y puede hacer
consultas relacionadas al programa, en este caso para aves nórdicas [43]. Un
ejemplo de diálogo de esta interfaz es el siguiente:
User: Information about Crows System: Birdquest can give information about the following properties for crows: call, habitat, appearance, feed,
breeding. Please specify what you´re interested in. User: I am interested in Call System: Call is vague, BirdQuest can give information about the following aspects of call: general, warning,
song. Please specify what you´re interested in. User: General, please. System: BirdQuest found the following information about general call for the crow: “The crows croak, krah (sic), krah (sic), is well known”

Metodología de Solución
28
En este punto es oportuno aclarar que BirdQuest, como muchas otras, es una ILNBD
dependiente del dominio. Al observar el ejemplo de diálogo de BirdQuest, surge la
siguiente pregunta: ¿se podrá adaptar el proceso de diálogo de BirdQuest para que
pueda aplicarse a otras BDs (v.g., control escolar, historiales clínicos)? Al analizar el
proceso de diálogo de BirdQuest, se observa que es muy dependiente del dominio;
así que la respuesta a la pregunta es no.
En tales circunstancias, surge otra pregunta: ¿será posible diseñar un proceso de
diálogo que pueda usarse con cualquier BD? Ya que el proceso de diálogo en
cuestión debería poder aplicarse a cualquier BD, incluso aquéllas que uno
desconozca, de esta pregunta se derivan las siguientes: ¿será posible diseñar un
proceso de diálogo para una BD desconocida? y ¿cómo podrá diseñarse tal
proceso? Planteadas de esta forma, las preguntas son muy difíciles; así que es
conveniente aplicar la técnica de “divide y vencerás” para atacar el problema.
Considerando que el universo de posibles consultas es extremadamente grande, se
puede plantear la siguiente pregunta: ¿será cada consulta tan diferente de las demás
que requiera un proceso de diálogo particular? Si la respuesta a esta pregunta es
afirmativa, entonces el problema no tiene solución práctica. Sin embargo, una
respuesta negativa a esta pregunta implicaría que existen varias o muchas consultas
que son semejantes en algún sentido, de tal manera que un solo proceso de diálogo
podría aplicarse para aclarar las consultas del grupo. En tales circunstancias, surgen
las siguientes preguntas: ¿puede dividirse el universo de consultas en grupos, tales
que las consultas de cada grupo sean semejantes, de tal suerte que pueda
aplicárseles un solo proceso de diálogo? Y si la respuesta a esta pregunta fuera
afirmativa, ¿en cuántos grupos con estas características puede dividirse el universo
de consultas?
Si la respuesta a esta última pregunta fuera que el número de grupos es muy grande,
digamos 1,000, entonces, aunque el problema sería tratable, de todos modos sería
muy tedioso resolverlo, porque habría que diseñar 1,000 procesos de diálogo

Metodología de Solución
29
diferentes. Por lo tanto, lo deseable sería encontrar una división del universo de
consultas que tuviera un número relativamente pequeño de grupos.
Finalmente, podemos plantear nuestra interrogante de investigación de la siguiente
manera: ¿es posible dividir el universo de consultas en un número relativamente
pequeño de grupos, tales que las consultas de cada grupo sean semejantes, de tal
suerte que pueda aplicárseles un solo proceso de diálogo?
En el resto de este capítulo se presenta el proceso que se siguió para determinar un
conjunto de tipos de consultas que satisfaga los requisitos expresados en esta última
interrogante.
I.- Inicialmente se adoptó la clasificación de consultas propuesta en la ILNBD [20],
agregando a esta clasificación la consideración de dividir la consulta en sus cláusulas
Select y Where, con lo cual se extendió la clasificación original a cincuenta y dos.
Usando esta clasificación, se distribuyeron las consultas de un corpus (BD
Northwind) entre cada una de las clases. Con el estudio de la nueva clasificación, se
observó que en ésta era difícil identificar características comunes que permitieran
diseñar procesos de diálogo generales, con la desventaja potencial de que la
clasificación podía seguir aumentando al analizar nuevos corpus de consultas o
generar nuevas consultas.
II.- En base al resultado anterior se concluyó que el uso de esta tipificación no era el
camino adecuado para conseguir los objetivos propuestos, por lo cual se idearon una
serie de principios para crear una tipificación de problemas en consultas. Para crear
la tipificación analizamos los corpus de tres bases de datos: Northwind (198
consultas en español, detalladas en [20]), Pubs (70 consultas en español, detalladas
en [20]), y ATIS [21] (benchmark de 2884 consultas en inglés); y seguimos los
siguientes principios:
1. Para que cada consulta razonablemente formulada en lenguaje natural pueda
ser traducida a SQL, debe siempre incluir una frase que se relacione a la

Metodología de Solución
30
cláusula Select de SQL, y usualmente incluir una frase que se relacione a la
cláusula Where de SQL. En nuestro análisis tales frases se denominan
cláusula Select y cláusula Where.
2. La economía de palabras en la formulación de una consulta solamente
involucra dos casos generales: omisión de nombres de columnas y omisión de
nombres de tablas.
3. La situación en la cual un nombre de columna o tabla es omitido difiere,
dependiendo de si esto ocurre en la cláusula Select o en la cláusula Where.
4. Un nombre de columna (o tabla) omitido puede referirse a un nombre de
columna (o tabla) o a varios nombres de columnas (o tablas). La primera
situación se considera como unívoca [30] y la segunda multívoca.
5. Aunque cualquier consulta en SQL siempre incluye una cláusula From, ésta
puede ignorarse para nuestros propósitos, ya que todos los nombres de tablas
incluidos en la cláusula From están siempre incluidos en las cláusulas Select y
Where, de esta forma la cláusula From puede generarse automáticamente a
partir de las cláusulas Select y Where.
Considerando los análisis previos obtuvimos una tipificación de problemas en
consultas, la cual se muestra en la tabla 3.1.1. Es importante notar que, de acuerdo a
esta tipificación, una consulta dada puede involucrar más de un problema, y por lo
tanto ésta puede ser clasificada en dos o más tipos.
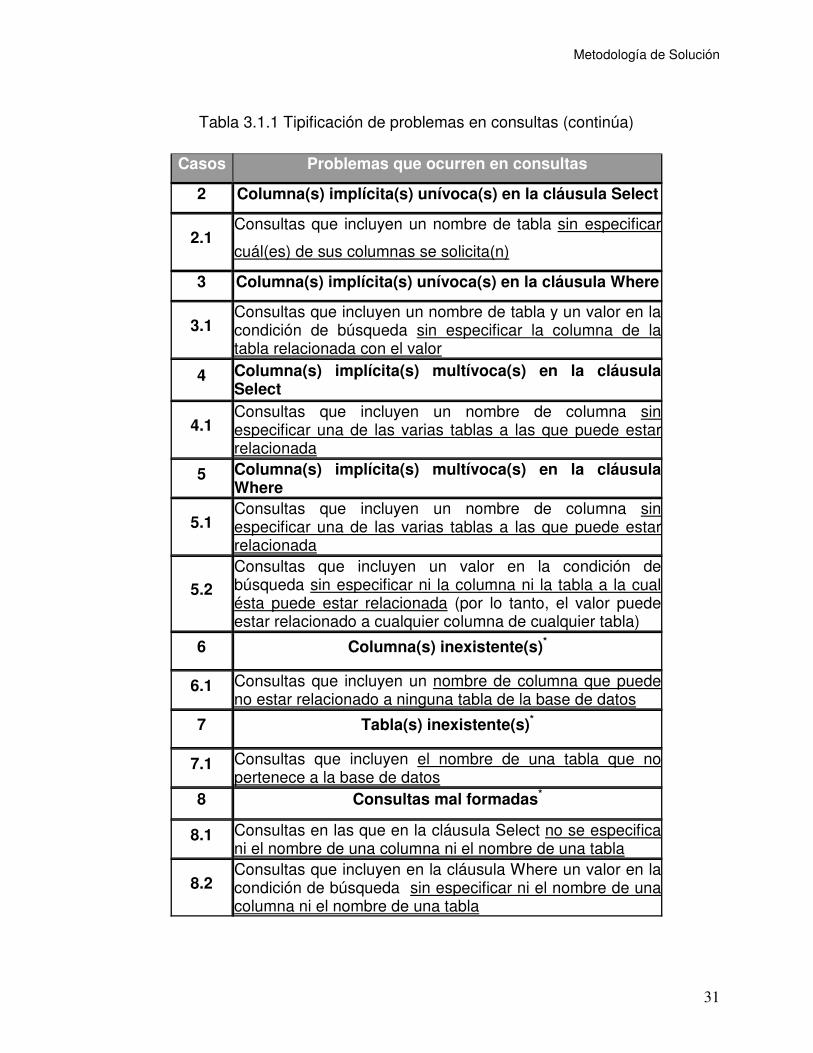
Tabla 3.1.1 Tipificación de problemas en consultas
Casos Problemas que ocurren en consultas
1 Columnas y tablas explícitas*
1.1 Consultas que incluyen las cláusulas Select y Where y explícitamente incluyen los nombres de columnas y tablas (por lo cual no requiere aclaración de información)
1.2 Consultas que incluyen sólo la cláusula Select y explícitamente incluyen los nombres de columnas y tablas (por lo tanto no, se requiere aclaración de información)
Metodología de Solución
31
Tabla 3.1.1 Tipificación de problemas en consultas (continúa)
Casos Problemas que ocurren en consultas
2 Columna(s) implícita(s) unívoca(s) en la cláusula Select
2.1 Consultas que incluyen un nombre de tabla sin especificar
cuál(es) de sus columnas se solicita(n)
3 Columna(s) implícita(s) unívoca(s) en la cláusula Where
3.1 Consultas que incluyen un nombre de tabla y un valor en la condición de búsqueda sin especificar la columna de la tabla relacionada con el valor
4 Columna(s) implícita(s) multívoca(s) en la cláusula Select
4.1 Consultas que incluyen un nombre de columna sin especificar una de las varias tablas a las que puede estar relacionada
5 Columna(s) implícita(s) multívoca(s) en la cláusula Where
5.1 Consultas que incluyen un nombre de columna sin especificar una de las varias tablas a las que puede estar relacionada
5.2
Consultas que incluyen un valor en la condición de búsqueda sin especificar ni la columna ni la tabla a la cual ésta puede estar relacionada (por lo tanto, el valor puede estar relacionado a cualquier columna de cualquier tabla)
6 Columna(s) inexistente(s)*
6.1 Consultas que incluyen un nombre de columna que puede no estar relacionado a ninguna tabla de la base de datos
7 Tabla(s) inexistente(s)*
7.1 Consultas que incluyen el nombre de una tabla que no pertenece a la base de datos
8 Consultas mal formadas*
8.1 Consultas en las que en la cláusula Select no se especifica ni el nombre de una columna ni el nombre de una tabla
8.2 Consultas que incluyen en la cláusula Where un valor en la condición de búsqueda sin especificar ni el nombre de una columna ni el nombre de una tabla

Metodología de Solución
32
Tabla 3.1.1 Tipificación de problemas en consultas (continúa)
Casos Problemas que ocurren en consultas
8 Consultas mal formuladas
8.3 Consultas que incluyen en la cláusula Where el nombre de una columna y/o el nombre de una tabla sin especificar un valor en la condición de búsqueda
* En el manejador de diálogo no se incluyó el tratamiento de los casos 1, 6, 7 y 8. Para los casos 6 y 7 se indican los problemas aunque no se implementan procesos de diálogo.
Con la tipificación anterior se clasificaron los corpus de consultas de las BDs:
Northwind, Pubs y ATIS (tabla 3.1.2). En este punto, es oportuno destacar que, en la
literatura revisada sobre el tema de ILNBDs (ver lista de referencias y sección 1.2),
no se ha encontrado que una clasificación de esta naturaleza haya sido usada
o propuesta, por algún otro investigador.
Tabla 3.1.2 Porcentaje de consultas clasificadas para las BDs Northwind, ATIS y Pubs
Base de Datos % Clasificadas % No clasificadas Total consultas Northwind 84.00 16.00 198
ATIS 55.07 44.93 2884 Pubs 82.00 18.00 70
Considerando el análisis del benchmark de ATIS en el cual se clasificaron un poco
más del 50% de las consultas, consideramos que esta tipificación cubre la mayor
parte de los problemas básicos recurrentes en cuanto al problema de la economía de
palabras. Además es importante mencionar que del universo de consultas no
clasificadas del corpus de ATIS, algunas de éstas corresponden a consultas que no
entran dentro de los alcances de la ILNBD [1, 20] desarrollada en CENIDET.

Metodología de Solución
33
Varias de estas “consultas” no pueden ser consideradas como tales; por ejemplo
tenemos las siguientes:
1. Eastern, okay.
2. Eliminate American Airlines.
3. Explain E Q P.
4. First class.
5. Give me help on abbreviations.
6. I am in Boston.
7. I need to consider the flights.
Además se tienen conversaciones, lo cual involucra manejo de discurso, lo cual
queda fuera de los alcances de la interfaz desarrollada en CENIDET. Un ejemplo es
el siguiente:
User: Name all the airports. User: Name them. User: Now give me a listing of all flights from Dallas to Atlanta. User: Now give me a listing of all flights returning from Denver to Dallas. User: Now list all the ground transportation to and from Boston airport. User: Now show me all of the flights from D F W to Oakland after five o'clock. User: Number of seats on D8S.
Como puede observarse en este fragmento de diálogo, sólo se incluye el diálogo del
usuario, las respuesta proporcionadas por el sistema no se presentan, lo cual
complica más el problema de economía de palabras.
Por último cabe destacar que esta tipificación posee dos características importantes:
(1) Es general, lo que permite que sea aplicable a diversos lenguajes como:
inglés, francés, italiano, etc.
(2) Es independiente del dominio, ya que puede ser aplicada a diversas bases de
datos.

Metodología de Solución
34
3.2 Formalización de la Tipificación de Problemas en Consultas
En esta sección se presenta una demostración formal de la idoneidad de la
tipificación (tabla 3.1.1) propuesta en este trabajo de investigación.
Una consulta en lenguaje natural será traducida a su equivalente a un lenguaje de
consultas de BDs SQL. Para lo cual utilizaremos la versión SQL1 ISO/IEC
9075:1989(E) [31] (ver Anexo B).
Para desarrollar la formalización de la tipificación de problemas en consultas, es
conveniente definir primero algunos términos:
C: = {c1, c2, ..., cm}, conjunto de todas las consultas que satisfacen las restricciones
de la sección anterior.
CP: = {cP1, cP2, ..., cPn}, conjunto de las consultas que pertenecen a C y que poseen
problemas de omisión de información.
PC: = {pC1, pC2, ..., pCp}, conjunto de todos los problemas compuestos de omisión de
información que existen en las consultas que pertenecen a CP. Un problema
compuesto es aquél que involucra la omisión de uno o más ítems de información
en una consulta.
Figura 3.2.1 Conjunto de consultas consideradas y problemas de omisión de información
La Figura 3.2.1 muestra las relaciones existentes entre los elementos de C, CP y PC.
La flecha que apunta de PC a CP significa que para cada problema compuesto pCi de
C
CP
PC
m 1
1
m

Metodología de Solución
35
PC existe una o muchas consultas de CP en donde se presenta el problema pCi;
mientras que la flecha que apunta de CP a PC significa que en cada consulta cPi de
CP ocurre uno o varios problemas de PC.
El problema de investigación consiste en determinar los problemas de omisión de
información que constituyen el conjunto PC, y encontrar una clasificación (es decir,
partición) de PC tal que posea las siguientes características:
1. Independencia de dominio; es decir, que sea aplicable a las consultas de
cualquier base de datos y que no cambie con diferentes bases de datos.
2. Completitud; es decir, que cualquier problema de omisión de información de
que adolezca una consulta en el conjunto CP, esté considerado en el conjunto
PC; en otras palabras, que no exista ningún problema que no esté considerado
en PC. Esta característica es indispensable para garantizar que no quede
excluído ningún problema que pueda presentarse en alguna consulta del
conjunto CP.
3. Disyunción; es decir, que cualquier problema de omisión de información que
tenga una consulta en el conjunto CP, sólo pueda estar asociado a un y sólo un
tipo en PC. Ésta es una característica deseable con el fin de que, para
cualquier problema que se presente en alguna consulta del conjunto CP,
quede claro a qué tipo pertenece y, por tanto, el proceso aplicable para
resolver el problema.
Formalmente, lo anterior puede expresarse de la siguiente manera, dado PC,
encontrar una partición TC = {tC1, tC2, ..., tCr}, tal que tCi ⊂ PC para i = 1, 2, ..., r, PC =
tC1 ∪ tC2 ∪ ... ∪ tCr, y tCi ∩ tCj = ∅ para todo i, j (donde i≠j). En este punto, es
conveniente aclarar que un elemento de la partición tCi es un conjunto que está
constituído por todos los problemas compuestos que son semejantes de alguna
manera, y por tanto, conviene identificarlos como un tipo.

Metodología de Solución
36
Debido a la complejidad de encontrar una partición de PC que satisfaga las
condiciones mencionadas, es conveniente definir el siguiente concepto:
PB: = {pB1, pB2, ..., pBq}, conjunto de todos los problemas básicos de omisión de
información que existen en las consultas que pertenecen a CP. Un problema
básico se define como aquél que involucra la omisión de un ítem de información
en una consulta.
La Figura 3.2.2 muestra las relaciones existentes entre los elementos de PB y PC. La
flecha que apunta de PB a PC significa que para cada problema básico pBi de PB
existe uno o varios problemas compuestos de PC en donde se presenta el problema
pBi; mientras que la flecha que apunta de PC a PB significa que en cada problema
compuesto pCi de PC ocurre uno o varios problemas de PB.
Figura 3.2.2 Conjunto de consultas consideradas y problemas de omisión de información (básicos y compuestos)
La estrategia consiste en determinar una partición TB del conjunto de problemas
básicos que sea completa y disjunta, la cual facilite encontrar una partición TC que
C
CP
PC
m
1
1
m
PB
m
m
1
1

Metodología de Solución
37
tenga las características antes mencionadas. Entonces, dado PB, el problema
consiste en encontrar una partición TB = {tB1, tB2, ..., tBs}, tal que tBi ⊂ PB para i = 1, 2,
..., s, PB = tB1 ∪ tB2 ∪ ... ∪ tBs, y ti ∩ tj = ∅ para todo i, j (donde i≠j).
Existen muchas particiones posibles TB que satisfacen las condiciones anteriores; así
que para encontrar una partición adecuada, se determinará primero una partición
TB ', con dos subconjuntos que satisfagan las condiciones de completitud y
disyunción; después para cada uno de estos subconjuntos se encontrará una
partición completa y disjunta, de tal suerte que estos nuevos subconjuntos
constituyan una nueva partición TB'' de PB. Este proceso se repetirá hasta obtener
una partición adecuada, la cual tenga las características deseadas de completitud y
disyunción.
Primeramente nótese que una consulta consta de tres cláusulas: Select, From y
Where. Es conveniente observar que en la cláusula From sólo se pueden especificar
tablas, y afortunadamente, éstas quedan automáticamente determinadas por las
tablas que aparezcan en las cláusulas Select y Where. Debido a esto, la cláusula
From puede ser ignorada en el resto de esta demostración, y sólo se considerarán
las cláusulas Select y Where.
Considerando lo anterior, entonces se puede diseñar una partición TB' = {PS, PW},
donde PS denota el conjunto de problemas básicos de omisión de información en la
cláusula Select, y PW denota el conjunto de problemas básicos de omisión de
información en la cláusula Where. La consulta mostrar los proveedores cuya ciudad
es Nueva Orleans es un ejemplo de omisión de información en la cláusula Select, ya
que no se especifica de qué columna(s) de la tabla proveedores se desea
información; en este caso se puede suponer que se desea información de los
nombres o los identificadores de proveedores. La consulta mostrar el descuento para
el almacén 8042 constituye un ejemplo de omisión de información en la cláusula

Metodología de Solución
38
Where, ya que no se especifica la columna de la tabla almacén a la que corresponde
el valor 8042; en este caso se supone que la columna faltante es identificador.
Finalmente, considérese la consulta mostrar el descuento para el identificador 8042,
en la que falta especificar la tabla almacén, lo cual se puede considerar como una
omisión de información tanto en la cláusula Select como en la cláusula Where. Para
simplificar este análisis, este caso se considera como dos problemas básicos:
omisión de información en la cláusula Select y omisión de información en la cláusula
Where.
Del análisis anterior resulta evidente que la partición TB' es completa, ya que
considera todas las secciones posibles de una consulta en las que puede ocurrir una
omisión de información: cláusula Select y cláusula Where. Además, considerando la
última aclaración del párrafo anterior, resulta evidente que no existe un problema
básico que pueda pertenecer a ambos conjuntos (PS y PW) y, por tanto, éstos son
disjuntos.
Continuando con la búsqueda de una partición adecuada, considérese primero el
conjunto PS (problemas básicos de omisión de información en la cláusula Select). En
este punto es conveniente notar que las omisiones de información en la cláusula
Select solamente pueden referirse a los únicos dos elementos que pueden existir en
dicha cláusula: tablas y columnas. Por consiguiente, para diseñar una partición se
deben tomar en cuenta el problema de omisión de información de una tabla y el
problema de omisión de información de una columna.
Considerando lo anterior, entonces se puede diseñar una partición TS'' = {PST, PSC},
donde PST denota el conjunto de problemas básicos de omisión de información de
una tabla en la cláusula Select, y PSC denota el conjunto de problemas básicos de
omisión de información de una columna en la cláusula Select.

Metodología de Solución
39
Se considera como omisión de información de tabla cuando no se especifica
explícitamente una tabla. Esta definición se puede ilustrar con la siguiente consulta:
mostrar el descuento para el identificador 8042, la cual constituye un ejemplo en el
que la tabla almacén ha sido omitida. Por consiguiente, esta consulta tiene un
problema básico que pertenece al conjunto PST.
Además, se considera como omisión de información de columna cuando no se
especifica explícitamente una columna como en la siguiente consulta: mostrar los
proveedores cuya ciudad es Nueva Orleáns, en la que la columna nombre ha sido
omitida, y por consiguiente, esta consulta adolece de un problema básico que
pertenece al conjunto PSC.
Finalmente, puede ocurrir el caso en el que no se mencione ni una columna ni la
tabla a la que pertenece la columna; lo cual queda ejemplificado por la siguiente
consulta: muestra Pittsburgh a Baltimore económica. Entonces, de acuerdo con estas
definiciones, esta última consulta tiene dos problemas básicos: uno que pertenece al
conjunto PSC y otro que pertenece a PST.
Del análisis anterior resulta evidente que la partición TS'' es completa, ya que
considera todos los elementos posibles (tablas y columnas) cuya información puede
estar omitida en la cláusula Select. Además, de acuerdo al párrafo anterior los
conjuntos PST y PSC no poseen elementos comunes, y por lo tanto, son disjuntos.
Continuando con la búsqueda de una partición adecuada, considérese ahora el
conjunto PW (problemas básicos de omisión de información en la cláusula Where). En
este caso las omisiones de información en la cláusula Where solamente pueden
referirse a los únicos tres elementos que pueden existir en dicha cláusula: tablas,
columnas y valores de la condición de búsqueda. Por consiguiente, para diseñar una
partición se deben tomar en cuenta el problema de omisión de información de una

Metodología de Solución
40
tabla, el problema de omisión de información de una columna, y el problema de
omisión de un valor.
Tomando en cuenta lo anterior, se puede diseñar una partición TW'' = {PWT, PWC,
PWV}, donde PWT denota el conjunto de problemas básicos de omisión de información
de una tabla en la cláusula Where, PWC denota el conjunto de problemas básicos de
omisión de información de una columna en la cláusula Where, y PWV denota el
conjunto de problemas básicos de omisión de información de un valor en la cláusula
Where.
La consulta mostrar el descuento para el identificador 8042 constituye un ejemplo de
omisión de información de tabla (almacén) en la cláusula Where, y por lo tanto, esta
consulta tiene un problema básico que pertenece al conjunto PWT. En cambio, la
consulta mostrar el descuento para el almacén 8042 constituye un ejemplo de
omisión de información de columna (identificador) en la cláusula Where, y por
consiguiente esta consulta tiene un problema básico que pertenece al conjunto PWC.
Por último, la consulta mostrar el descuento para el almacén con identificador es un
ejemplo de omisión de información de valor (8042) en la cláusula Where, y por lo
tanto, esta consulta tiene un problema básico que pertenece al conjunto PWV. Cuando
en la cláusula Where de una consulta falta la información de dos o más elementos
(tabla, columna y valor), entonces cada omisión se considera como un problema
básico diferente.
Del análisis anterior resulta evidente que la partición TW'' es completa, ya que
considera todos los elementos posibles (tablas, columnas y valores) cuya
información puede estar omitida en la cláusula Where. Además, de acuerdo al
párrafo anterior los conjuntos PWT, PWC y PWV no poseen elementos comunes, y por
lo tanto, son disjuntos.

Metodología de Solución
41
Como resultado del análisis anterior, se puede establecer la siguiente partición de PB
en todos los tipos de problemas básicos:
TB'' = {PST, PSC, PWT, PWC, PWV}
la cual posee las características de completitud y disyunción. En la Figura 3.2.3 se
muestra gráficamente la partición TB''.
Figura 3.2.3 Tipos de problemas básicos de omisión de información
Como se ha mencionado varias veces, en una misma consulta se pueden presentar
varios problemas básicos simultáneamente; así que, tomando esto en consideración,
en la Tabla 3.2.1 se muestran todas las posibles combinaciones de problemas
básicos que se pueden dar en la cláusula Select y todas las combinaciones posibles
de problemas básicos en la cláusula Where. Las combinaciones de problemas
básicos se han agrupado de tal manera que puedan ser tratadas uniformemente por
un proceso de diálogo para aclaración de la información omitida. En la última
columna de la tabla se indica el tipo de problema correspondiente a cada
combinación según la tipificación que se muestra en la Tabla 3.2.2, la cual fue la que
se consideró para la implementación del administrador de diálogo.
En la Tabla 3.2.1 se ha incluído el símbolo "××××" para denotar el caso de que en la
consulta se especifique una columna o una tabla que no exista en la base de datos.
Select
Tabla Columna Valor
PWC PWV Where PWT
PST PSC
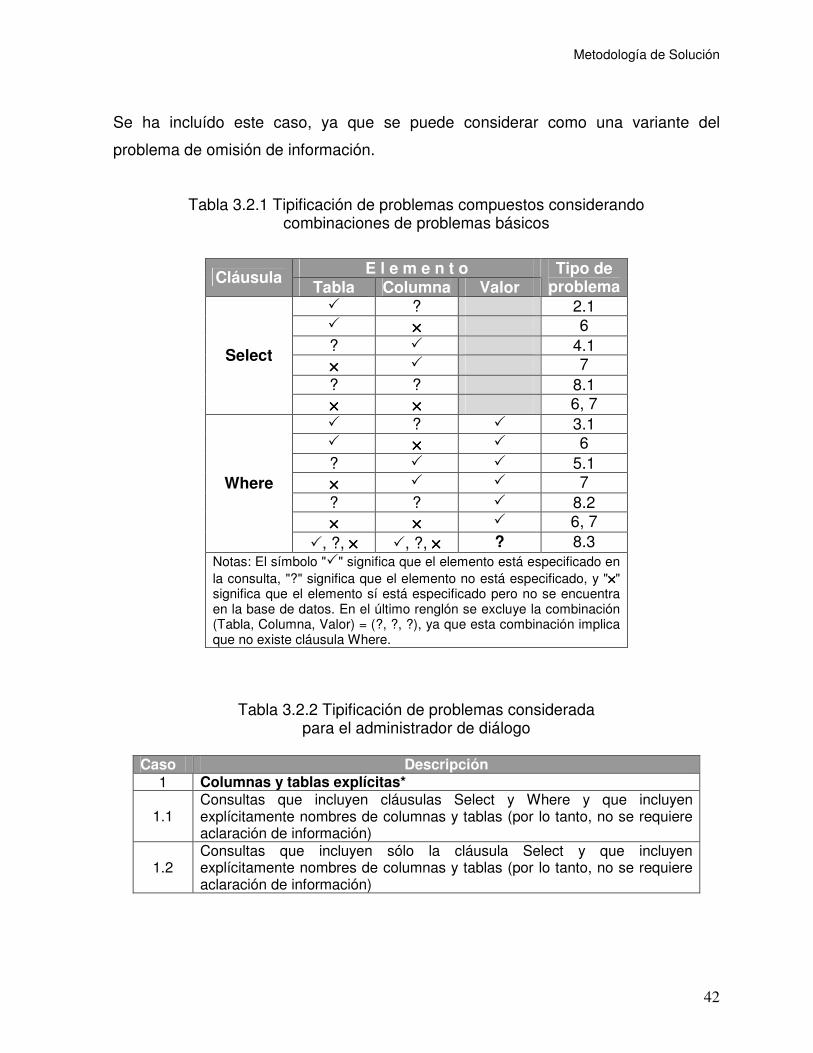
Metodología de Solución
42
Se ha incluído este caso, ya que se puede considerar como una variante del
problema de omisión de información.
Tabla 3.2.1 Tipificación de problemas compuestos considerando combinaciones de problemas básicos
E l e m e n t o Cláusula
Tabla Columna Valor Tipo de
problema � ? 2.1 � ×××× 6 ? � 4.1 ×××× � 7 ? ? 8.1
Select
×××× ×××× 6, 7 � ? � 3.1 � ×××× � 6 ? � � 5.1 ×××× � � 7 ? ? � 8.2 ×××× ×××× � 6, 7
Where
�, ?, ×××× �, ?, ×××× ? 8.3 Notas: El símbolo "�" significa que el elemento está especificado en la consulta, "?" significa que el elemento no está especificado, y "××××" significa que el elemento sí está especificado pero no se encuentra en la base de datos. En el último renglón se excluye la combinación (Tabla, Columna, Valor) = (?, ?, ?), ya que esta combinación implica que no existe cláusula Where.
Tabla 3.2.2 Tipificación de problemas considerada para el administrador de diálogo
Caso Descripción
1 Columnas y tablas explícitas*
1.1 Consultas que incluyen cláusulas Select y Where y que incluyen explícitamente nombres de columnas y tablas (por lo tanto, no se requiere aclaración de información)
1.2 Consultas que incluyen sólo la cláusula Select y que incluyen explícitamente nombres de columnas y tablas (por lo tanto, no se requiere aclaración de información)

Metodología de Solución
43
Tabla 3.2.2. Tipificación de problemas considerada para el administrador de diálogo (continúa)
Caso Descripción 2 Columna implícita unívoca en la cláusula Select
2.1 Consultas que incluyen un nombre de tabla sin especificar cuál(es) de sus columnas se solicita(n)
3 Columna implícita unívoca en la cláusula Where
3.1 Consultas que incluyen un nombre de tabla y un valor en la condición de búsqueda sin especificar la columna de tabla relacionada con el valor
4 Columna implícita multívoca en la cláusula Select
4.1 Consultas que incluyen el nombre de una columna sin especificar una de las varias tablas a las que puede estar relacionada
5 Columna implícita multívoca en la cláusula Where
5.1 Consultas que incluyen el nombre de una columna sin especificar una de las varias tablas a las que puede estar relacionada
5.2
Consultas que incluyen un valor en la condición de búsqueda sin especificar ni la columna ni la tabla a la que puede estar relacionado (por lo tanto, el valor puede estar relacionado a cualquier columna de cualquier tabla)
6 Columna inexistente*
6.1 Consultas que incluyen el nombre de una columna que no puede ser relacionado a ninguna tabla de la base de datos
7 Tabla inexistente*
7.1 Consultas que incluyen el nombre de una tabla que no pertenece a la base de datos
8 Consultas mal formadas*
8.1 Consultas en las que en la cláusula Select no se especifica ni el nombre de una columna ni el nombre de una tabla
8.2 Consultas que incluyen en la cláusula Where un valor en la condición de búsqueda sin especificar ni el nombre de una columna ni el nombre de una tabla
8.3 Consultas que incluyen en la cláusula Where el nombre de una columna y/o el nombre de una tabla sin especificar un valor en la condición de búsqueda
* En el manejador de diálogo no se incluyó el tratamiento de los casos 1, 6, 7 y 8.
Entre más información de columnas, tablas y valores se omita en una consulta, más
difícil resulta entender ésta y, por lo tanto, traducirla correctamente a SQL, aun para
un ser humano. Por ejemplo, considérese la siguiente consulta sin el problema de
omisión de información: mostrar el descuento para el almacén cuyo identificador es
8042; si en esta consulta se omitiera el valor 8042, entonces quedaría de la siguiente

Metodología de Solución
44
manera: mostrar el descuento para el almacén cuyo identificador, la cual es un
ejemplo de consulta del tipo 8.3, y resulta evidente que es una consulta incompleta
que no puede ser traducida. A éste y a otros tipos de consultas, se les ha agrupado
en un tipo general de consultas denominadas "mal formadas", las cuales
comprenden los grupos 8.1, 8.2 y 8.3. En la práctica el tipo de problema 8.3 no
ocurre en las consultas formuladas en lenguaje natural, y cabe mencionar que este
caso no se ha encontrado en ninguno de los corpus de consultas estudiados:
Northwind, Pubs y ATIS.
3.3 Implementación de procesos de diálogo
Considerando la tipificación de la tabla 3.1, a continuación se muestra la
implementación de los procesos de diálogo correspondientes a los problemas de la
tabla 3.1. En el anexo D se muestran ejemplos de la ejecución de procesos de
diálogo en la ILNBD desarrollada en CENIDET [1, 20].
3.3.1 Algoritmo 2.1 Consultas que incluyen un nombre de tabla sin especificar
cuál(es) de sus columnas se solicitan.
1. Identificación del nombre de la tabla.
2. Búsqueda en la BD del nombre de la tabla identificada y de las columnas de la
tabla identificada.
3. Despliegue al usuario de una pantalla de diálogo, en la cual se presenten una
pregunta y los nombres de columnas que pueden corresponder a la
información faltante identificada para aclarar la consulta, en forma de opciones
(lista tipo checkbox).
4. Modificación de la consulta original agregando la nueva información
proporcionada.
5. Ejecución de la consulta modificada.

Metodología de Solución
45
3.3.2 Algoritmo 3.1 Consultas que incluyen un nombre de tabla y un valor en la
condición de búsqueda sin especificar la columna de la tabla relacionada con
el valor.
1. Identificación del nombre de la tabla y el tipo de dato (cadena, entero, fecha,
etc.) del valor proporcionado en la condición.
2. Búsqueda en la BD del nombre de la tabla identificada y de las columnas de la
tabla identificada que correspondan al tipo de dato identificado.
3. Despliegue al usuario de una pantalla de diálogo, en la cual se presenten una
pregunta y los nombres de columnas que pueden corresponder a la
información faltante identificada para aclarar la consulta, en forma de opciones
(lista tipo checkbox).
4. Modificación de la consulta original agregando la nueva información
proporcionada.
5. Ejecución de la consulta modificada.
3.3.3 Algoritmo 4.1 Consultas que incluyen un nombre de columna sin
especificar una de las varias tablas a las que puede estar relacionada.
1. Identificación del nombre de la columna.
2. Búsqueda en la BD de las tablas que contengan el nombre de la columna
especificada en la consulta.
3. Despliegue al usuario de una pantalla de diálogo, en la cual se muestren una
pregunta y los nombres de las tablas (lista tipo checkbox) que contengan el
nombre de la columna especificada en la consulta.
4. Modificación de la consulta original agregando la nueva información
proporcionada.
5. Ejecución de la consulta modificada.
3.3.4 Algoritmo 5.1 Consultas que incluyen un nombre de columna sin
especificar una de las varias tablas a las que puede estar relacionada
1. Identificación del nombre de la columna.

Metodología de Solución
46
2. Búsqueda en la BD de las tablas que contengan el nombre de la columna
identificada.
3. Despliegue al usuario de una pantalla de diálogo, en la cual se presenten una
pregunta y los nombres de tablas que pueden corresponder a la información
faltante identificada para aclarar la consulta, en forma de opciones (lista tipo
radio button).
4. Modificación de la consulta original agregando la nueva información
proporcionada.
5. Ejecución de la consulta modificada.
3.3.5 Algoritmo 5.2 Consultas que incluyen un valor en la condición de
búsqueda sin especificar ni la columna ni la tabla a la cual ésta puede estar
relacionada (por lo tanto, el valor puede estar relacionado a cualquier columna
de cualquier tabla).
1. Identificación del valor proporcionado.
2. Búsqueda en la BD de todas las tablas que componen la BD.
3. Despliegue al usuario de una pantalla de diálogo, en la cual se presenten una
pregunta y los nombres de todas las tablas que componen la BD que puedan
corresponder a la información faltante identificada para aclarar la consulta, en
forma de opciones (lista tipo radio button).
4. Modificación de la consulta original agregando la nueva información
proporcionada.
5. Ejecución de la consulta modificada.
Como puede observarse en los algoritmos anteriores, los procesos de diálogo están
diseñados para obtener la información faltante en forma precisa, es decir, nuestros
algoritmos no “adivinan” lo que el usuario está buscando. Los algoritmos parten de la
información que el usuario proporciona en la consulta y con ésta buscan la
información faltante necesaria para completar la consulta. Además, heredan las
características de generalidad e independencia del dominio de la tipificación de

Metodología de Solución
47
problemas en consultas (tabla 3.1.1). Los algoritmos son aplicados tantas veces
como información faltante exista en la consulta, y éstos se complementan. Por
ejemplo, en el caso del algoritmo 5.2, éste parte del valor proporcionado por el
usuario en la consulta y presenta al usuario todas las tablas de la BD consultada, una
vez que el usuario selecciona una tabla, la consulta es completada con esta
información, pero enseguida se tiene ahora el problema de tener un nombre de tabla
y un valor con lo cual la consulta adquiere ahora el patrón del problema 3.1;
consecuentemente, para resolver este problema se ejecuta el algoritmo para este
caso, y así sucesivamente hasta completar la consulta.
3.4 Diseño Conceptual de la Interfaz con un Administrador de Diálogo
En la figura 3.4.1 se observa el diseño conceptual de la ILNBD [1, 20] con la inclusión
de un administrador de diálogo.
La interfaz original se encuentra encerrada en el rectángulo de línea segmentada;
mientras que el administrador de diálogo se encuentra encerrado en el rectángulo de
línea punteada.
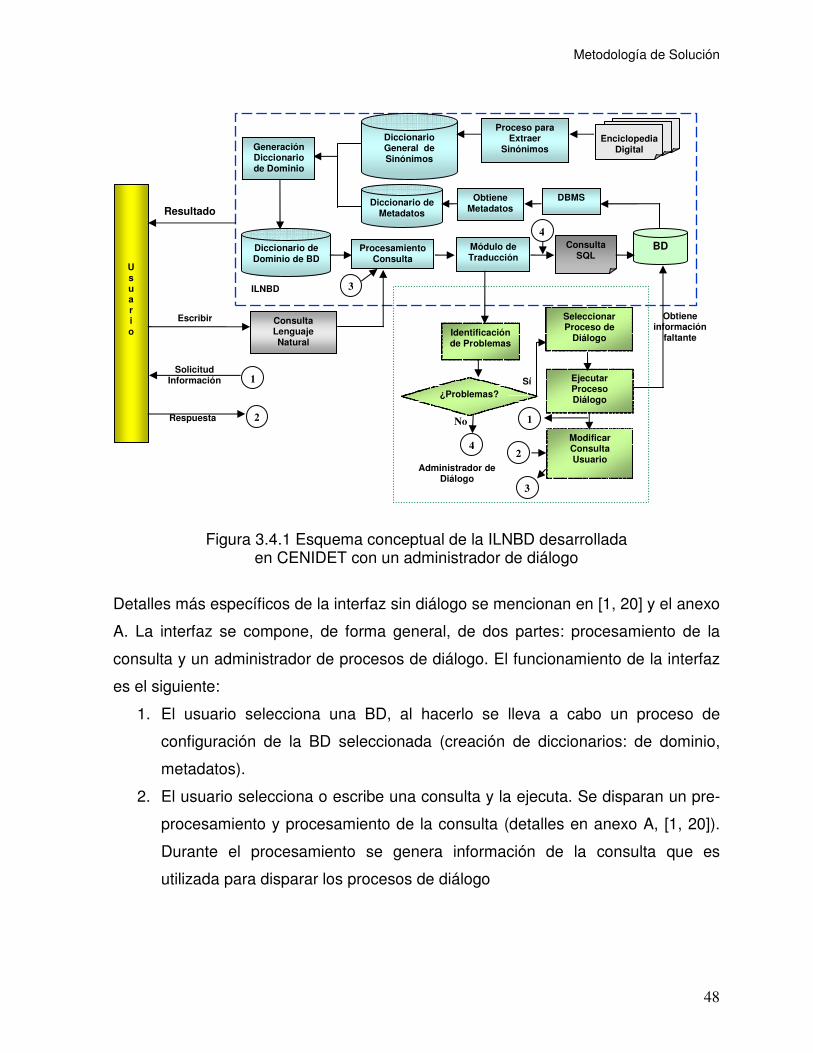
Metodología de Solución
48
Figura 3.4.1 Esquema conceptual de la ILNBD desarrollada en CENIDET con un administrador de diálogo
Detalles más específicos de la interfaz sin diálogo se mencionan en [1, 20] y el anexo
A. La interfaz se compone, de forma general, de dos partes: procesamiento de la
consulta y un administrador de procesos de diálogo. El funcionamiento de la interfaz
es el siguiente:
1. El usuario selecciona una BD, al hacerlo se lleva a cabo un proceso de
configuración de la BD seleccionada (creación de diccionarios: de dominio,
metadatos).
2. El usuario selecciona o escribe una consulta y la ejecuta. Se disparan un pre-
procesamiento y procesamiento de la consulta (detalles en anexo A, [1, 20]).
Durante el procesamiento se genera información de la consulta que es
utilizada para disparar los procesos de diálogo
Diccionario General de Sinónimos
U s u a r i o
Obtiene información
faltante
Enciclopedia Digital
Proceso para Extraer
Sinónimos
BD
Obtiene Metadatos
Diccionario de Metadatos
Diccionario de Dominio de BD
DBMS
Generación Diccionario de Dominio
Procesamiento Consulta
Módulo de Traducción
Consulta SQL
ILNBD
Consulta Lenguaje Natural
Identificación de Problemas
Seleccionar Proceso de
Diálogo
Resultado
Ejecutar Proceso Diálogo
Solicitud Información
¿Problemas?
No
Sí
Respuesta
Modificar Consulta Usuario
2
3
1
1
2
3
Escribir
4
4
Administrador de Diálogo

Metodología de Solución
49
3. Con la información generada durante el proceso de traducción, se identifica si
la consulta presenta problemas de economía de palabras (módulo
“Identificación de Problemas“).
a. Si existen problemas, se ejecuta el módulo “Seleccionar Procesos de
Diálogo”, y pasa al punto 4.
b. Si no existen problemas, continúa el flujo normal de la interfaz y la
consulta se traduce a su equivalente en lenguaje SQL.
4. Se ejecuta el proceso de diálogo en base al problema identificado. El proceso
de diálogo obtendrá información de la BD relacionada con la información
faltante. Al dispararse el proceso de diálogo, se generan ventanas para
interactuar con el usuario y solicitar información (flujo 1). Con la información
proporcionada por el usuario (flujo 2), la consulta es modificada y vuelta a
procesar (flujo 3). Regresa al punto 3 (este proceso se repetirá hasta que la
consulta no presente problemas de economía de palabras).
Es oportuno aclarar que el traductor de la ILNBD [1, 20] está limitado para contestar
consultas. Así que, considerando que los procesos de diálogo están enfocados a
resolver exclusivamente los problemas básicos de economía de palabras, para
obtener mejores resultados con el traductor es conveniente seguir las indicaciones
que se mencionan en el anexo A. El traductor presenta algunos problemas en el
proceso de traducción de la consulta que aún se tienen que resolver. Sin embargo,
con las modificaciones que se han hecho a éste, se espera que el usuario, en caso
de error o no traducción, obtenga una respuesta que le indique el estatus de su
consulta (en caso de error) o por qué no fue traducida.

50
Capítulo 4
Experimentación
Las pruebas para este trabajo de investigación se desarrollaron utilizando las
bases de datos: Northwind (198 consultas en español) y ATIS (benchmark de 2884
consultas en inglés). Además se utilizaron las interfaces comerciales English Query
[8] y ELF [10]. Cabe aclarar que estas interfaces no disponen de un administrador de
diálogo. Éstas se configuran automáticamente al asociarlas a una base de datos, y
también cuentan con opciones para configuración en forma manual por el usuario.
Por lo anterior, el objetivo de las pruebas no fue comparar estas interfaces con la
interfaz desarrollada en CENIDET [1, 20], ya que no es válido comparar sistemas
que tienen características diferentes y se aplican a idiomas diferentes (español e
inglés). Sin embargo, el desempeño de English Query y ELF puede servir como
punto de referencia para apreciar la mejoría que se puede obtener con el uso de un
administrador de diálogo.

Experimentación
51
Antes de presentar los experimentos desarrollados en la sección 4.1 se presenta
información de la BD ATIS, con la cual obtuvimos resultados impresionantes en
pruebas efectuadas a ELF y a la interfaz desarrollada en CENIDET.
4.1 La Base de Datos ATIS
ATIS contiene información del dominio de servicios de información de viajes aéreos.
ATIS es un corpus de consultas en lenguaje natural coleccionadas bajo el patrocinio
del programa de desarrollo de tecnología Advanced Research Projects Agency
Spoken Language System (ARPA-SLS). El corpus de ATIS fue diseñado por ARPA-
SLS y por el grupo Multi Site Atis Data COllection Working (MADCOW), y fue
coleccionado en cinco localidades a través de Estados Unidos [51]:
• BBN Systems & Technologies, Cambridge, MA.
• Carnegie Mellon University, Pittsburgh, PA.
• MIT Laboratory for Computer Science, Boston, MA.
• National Institute of Standards and Technology, Gaithersburg, MD.
• SRI International, Menlo Park, CA.
Existen diversos corpus desarrollados en dicho proyecto. Para los experimentos
desarrollados utilizamos la tercera versión de registros de lenguaje natural hablado
en el dominio de ATIS. Las consultas espontáneas originales para este corpus fueron
expresadas oralmente, sin scripts u otras restricciones, a un sistema de simulación
computarizado de una BD que incluye una versión simplificada de la Guía Oficial de
Aerolíneas (OAG) [51].
La BD ATIS fue diseñada para modelar tanto como fuera posible el mundo real. En
particular, se intentó modelar de una manera directa el contenido del documento
escrito por la OAG. La BD ATIS contiene información de vuelos, tarifas, aerolíneas,
ciudades, aeropuertos y servicios de transporte terrestre, y se compone de
veinticinco tablas [52]. El esquema de la BD se muestra en el anexo L.

Experimentación
52
4.2 Experimento 1. Prueba del desempeño de la interfaz comercial English Query con un corpus de consultas con economía de palabras
Este experimento tuvo como objetivo evaluar el desempeño de una ILNBD con un
conjunto de consultas que involucran el problema de economía de palabras. Para
este experimento utilizamos la interfaz comercial English Query (EQ) [8], la cual fue
probada con un subconjunto de 154 consultas, que involucran los tipos de problemas
indicados en la tabla 4.2.1 (algunas de estas consultas involucran dos o más tipos de
problemas, por lo tanto, son contadas más de una vez), de las 198 consultas del
corpus de la BD Northwind (detallado en [20]). Las consultas fueron traducidas al
inglés, y una muestra de 12 consultas representativas para los problemas indicados
en la tabla 4.2.1 fue obtenida del corpus total. Estas consultas fueron utilizadas para
configurar la interfaz EQ y adaptarla a la BD Northwind (un ejemplo de la
configuración obtenida por un usuario se muestra en el anexo C). Después de lo
anterior, ocho estudiantes de maestría en Ciencias de la Computación fueron
invitados a configurar EQ con la muestra de consultas, con lo cual se obtuvieron
ocho configuraciones. Finalmente, 154 consultas se utilizaron como entrada para
cada una de las configuraciones de la interfaz EQ, y los resultados correspondientes
se muestran en la tabla 4.2.1.

Experimentación
53
Tabla 4.2.1 Resultados de la ejecución de consultas que involucran seis tipos de problemas utilizando EQ
Tipos de problemas
Configurador Resultados 3.1 4.1 5.1 5.2 6.1 7.1
Total %
Correctas 7 5 1 13 1 0 27 18 Estudiante 1 Incorrectas/No
contestadas 33 29 19 32 10 4 127 82
Correctas 7 6 0 13 1 0 27 18 Estudiante 2 Incorrectas/No
contestadas 33 28 20 32 10 4 127 82
Correctas 9 4 0 11 1 0 25 16 Estudiante 3 Incorrectas/No
contestadas 31 30 20 34 10 4 129 84
Correctas 9 5 0 12 1 0 27 18 Estudiante 4 Incorrectas/No
contestadas 31 29 20 33 10 4 127 82
Correctas 8 5 0 12 1 0 26 17 Estudiante 5 Incorrectas/No
contestadas 32 29 20 33 10 4 128 83
Correctas 7 5 0 13 1 0 26 17 Estudiante 6 Incorrectas/No
contestadas 33 29 20 32 10 4 128 83
Correctas 7 6 0 12 1 0 26 17 Estudiante 7 Incorrectas/No
contestadas 33 28 20 33 10 4 128 83
Correctas 7 4 1 8 1 0 21 14 Estudiante 8 Incorrectas/No
contestadas 33 30 19 37 10 4 133 86
Correctas 7.6 5.0 0.3 11.8 1.0 0.0 25.6 16.9 Promedio Incorrectas/No
contestadas 32.4 29.0 19.7 33.2 10.0 .4.0. 128.4 83.1
Los resultados de la tabla 4.2.1 muestran que el porcentaje promedio de consultas
correctamente contestadas fue del 16.9%, lo cual comparado con los resultados
reportados por otros trabajos independientes (53%-83% [9], 58% [22]), implica una
reducción del 36%-66%, la cual podría ser atribuida a la dificultad de nuestro corpus
de consultas con economía de palabras. Esto revela la dificultad que tiene EQ para
contestar el tipo de consultas que son el tema de estudio de esta investigación. Los
resultados de este experimento nos sirven como una forma de medir el desempeño
de esta interfaz con un corpus con problemas de economía de palabras.

Experimentación
54
4.3 Experimento 2. Prueba del desempeño de la interfaz comercial ELF con un corpus de consultas con economía de palabras
Este experimento es similar al previo, excepto que en este caso ELF [2] (mencionada
en la literatura como una de las mejores ILNBDs) fue utilizada con el corpus de 154
consultas previamente mencionado. En este experimento se utilizaron dos
configuraciones para ELF: de forma automática (generada por ELF), y de forma
manual (por el usuario). Notas: este experimento fue de naturaleza exploratoria, y
con el fin de economizar tiempo, el usuario fue el propio autor de esta tesis.
Tabla 4.3.1 Resultados de la ejecución de consultas que involucran seis tipos de problemas utilizando ELF
Tipos de problemas Configuración
ELF Resultados
3.1 4.1 5.1 5.2 6.1 7.1 Total %
Correctas 18 26 11 38 7 3 103 67 Incorrectas/No contestadas
22 8 9 7 4 1 51 33 Automática
Total 40 34 20 45 11 4 154 100 Correctas 25 28 13 39 7 4 116 75 Incorrectas/No contestadas
15 6 7 6 4 0 38 25 Modificada
Total 40 34 20 45 11 4 154 100
De acuerdo con la tabla 4.3.1 el promedio de éxito fue del 75%, comparado con
resultados de otros trabajos (81% [22], 50%-80% [23]), implica una reducción del
desempeño del 6%, lo cual puede ser atribuido al problema de economía de palabras.
Al igual que con el experimento anterior, con los resultados de este experimento se
mide el desempeño de esta interfaz con un corpus con problemas de economía de
palabras.

Experimentación
55
4.4 Experimento 3. Evaluación del desempeño de la ILNBD desarrollada en CENIDET con un Administrador de Diálogo
Este experimento evaluó la mejoría del desempeño de una ILNBD [1, 20] con un
administrador de diálogo (AD) con respecto a la misma interfaz sin éste. Para tal
efecto se utilizaron dos versiones de la interfaz: sin AD y con AD (el cual incluyó
diálogos para los tipos de problemas indicados en la tabla 4.3.1). El corpus de 154
consultas, de la BD Northwind, fue utilizado para las dos versiones de la interfaz, y
los resultados correspondientes se muestran en la tabla 4.4.1. Estos resultados
muestran un incremento del 35% en el número de consultas correctamente
contestadas por la interfaz desarrollada en CENIDET [1, 20] cuando se incluye un AD.
Con los resultados de este experimento se comprueba el logro del objetivo general
de este trabajo de tesis OG.1 y los objetivos específicos OE.3 y el OE.4, y además
de la hipótesis H.1.
En el anexo E se muestran pantallas de ejemplos de la ILNBD [1, 20] desarrollada en
CENIDET con administrador de diálogo. En el anexo F se muestran algunos de los
resultados obtenidos por la interfaz correspondientes a la tabla 4.4.1.
Tabla 4.4.1 Resultados para seis tipos de problemas en consultas del corpus de la BD Northwind
Tipos de problemas ILNBD Resultados
3.1 4.1 5.1 5.2 6.1 7.1 Total %
Correctas 22 17 8 30 0 0 77 50 Incorrectas/ No contestadas
18 17 12 15 11 4 77 50 Sin diálogo
Total 40 34 20 45 11 4 154 100 Correctas 36 29 16 38 9 3 131 85 Incorrectas/ No contestadas
4 5 4 7 2 1 23 15 Con diálogo
Total 40 34 20 45 11 4 154 100 Mejora en el promedio de éxito: 35

Experimentación
56
4.5 Experimento 4. Evaluación del desempeño de la interfaz ELF con un corpus de consultas con economía de palabras de la BD ATIS
Al igual que en el experimento 4.3, el objetivo de este experimento fue evaluar
nuevamente el desempeño de la interfaz ELF, pero en este caso utilizando el
benchmark de la BD ATIS (2884 consultas en inglés). Para este caso se obtuvo una
muestra de 20 consultas representativas (correspondientes a los tipos de problemas
indicados en las tabla 4.5.1), y se invitó a participar inicialmente a 30 estudiantes de
maestría en Ciencias de la Computación con especialidades en Ingeniería de
Software y Sistemas Distribuidos.
El teorema del límite central [32] establece que la distribución normal estándar ofrece
una buena aproximación a una distribución con una desviación estándar desconocida
para muestras de tamaño 30 o más. Con el resultado de las configuraciones se
probó la interfaz ELF con un corpus de 102 consultas del total de 2884 (anexo D).
Sin embargo, durante el desarrollo de las pruebas, la interfaz ELF manifestó un
comportamiento con nula variación, es decir, independientemente de las
configuraciones, la interfaz se comporta de la misma forma: para cada tipo de
problema se obtienen los mismos números de consultas contestadas, no contestadas
e incorrectas. Cuando se presenta esta situación no se necesita una muestra de
tamaño 30, y por lo tanto, se decidió reducir el número de estudiantes a 20. Los
resultados se muestran en la tabla 4.5.1.
Tabla 4.5.1 Resultados para cinco tipos de problemas con el corpus de la BD ATIS y la interfaz ELF
Tipos de Problemas Configurador Resultados
2.1 3.1 4.1 5.2 6.1 Total %
Correctas 1 2 1 3 0 7 7
Incorrectas 7 9 2 11 9 38 37
No contestadas 10 19 7 11 10 57 56
20
estudiantes
de maestría Total 18 30 10 25 19 102 100

Experimentación
57
Como se puede observar en la tabla 4.5.1, el promedio obtenido de consultas
contestadas correctas es muy bajo. Aunque la interfaz ELF permite reconocer
patrones cuando se configura, para este tipo de problemas el desempeño de la
interfaz es impresionantemente bajo.
4.6 Experimentos 5.1, 5.2. Evaluación del desempeño de la ILNBD desarrollada en CENIDET con un corpus de consultas con economía de palabras de la BD ATIS
Experimento 5.1
En este experimento se evaluó el desempeño de la ILNBD [1, 20] desarrollada en
CENIDET con el corpus de 102 consultas del experimento 4.5 de la BD ATIS
(detalles en el anexo D). Para este experimento se tradujeron las consultas de inglés
a español y se ejecutaron en la interfaz con y sin diálogo. Los resultados se muestran
en la tabla 4.6.1. Como se puede observar, el porcentaje obtenido de consultas
contestadas correctamente es del 40% con diálogo, lo cual muestra una mejora del
30% comparado con el traductor sin diálogo y una mejora del 33% comparado con el
7% obtenido por ELF en el experimento 4 de la sección 4.5.
Cabe aclarar que el porcentaje de las consultas que no se contestaron o se
contestaron incorrectamente para este experimento se debe principalmente a errores
del traductor de la interfaz utilizada, ya que en muchos de los casos no traducidos los
procesos de diálogo son ejecutados correctamente pero la traducción es incorrecta.
Aunado a los problemas anteriores, la BD ATIS presenta problemas en su diseño, lo
cual usualmente no se presenta en BD diseñadas ad hoc, lo cual puede afectar el
desempeño de cualquier interfaz en general.
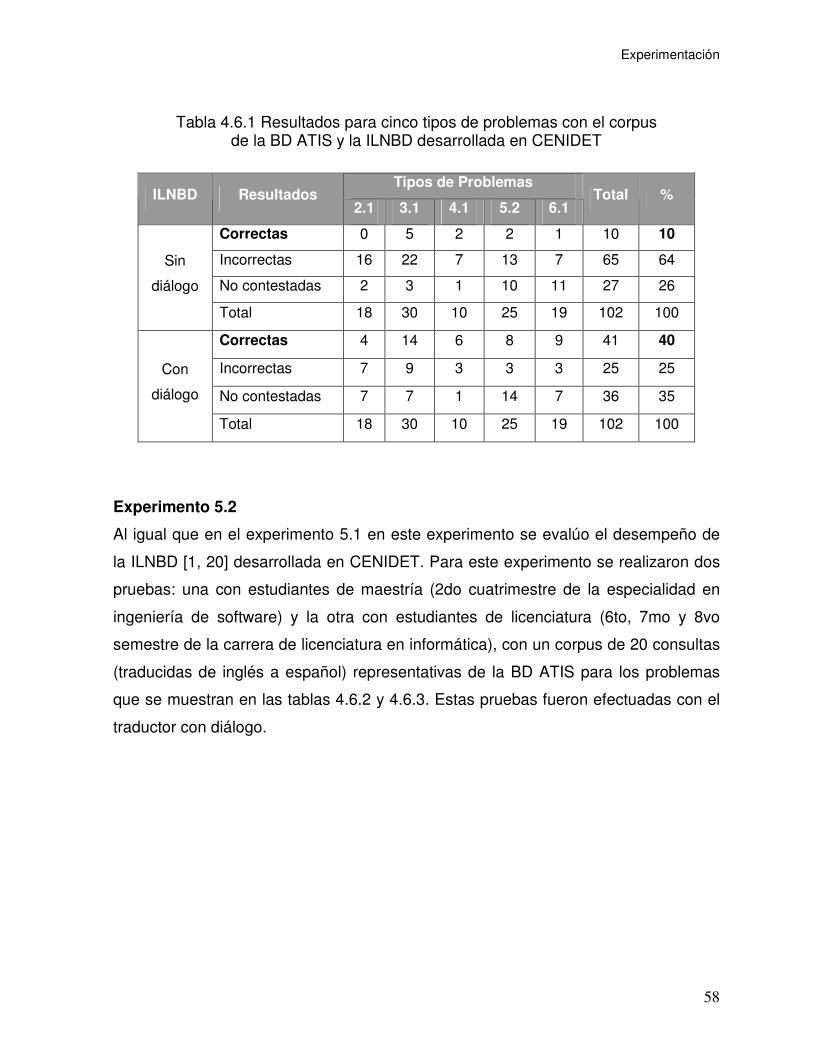
Experimentación
58
Tabla 4.6.1 Resultados para cinco tipos de problemas con el corpus de la BD ATIS y la ILNBD desarrollada en CENIDET
Experimento 5.2
Al igual que en el experimento 5.1 en este experimento se evalúo el desempeño de
la ILNBD [1, 20] desarrollada en CENIDET. Para este experimento se realizaron dos
pruebas: una con estudiantes de maestría (2do cuatrimestre de la especialidad en
ingeniería de software) y la otra con estudiantes de licenciatura (6to, 7mo y 8vo
semestre de la carrera de licenciatura en informática), con un corpus de 20 consultas
(traducidas de inglés a español) representativas de la BD ATIS para los problemas
que se muestran en las tablas 4.6.2 y 4.6.3. Estas pruebas fueron efectuadas con el
traductor con diálogo.
Tipos de Problemas ILNBD Resultados
2.1 3.1 4.1 5.2 6.1 Total %
Correctas 0 5 2 2 1 10 10
Incorrectas 16 22 7 13 7 65 64
No contestadas 2 3 1 10 11 27 26
Sin
diálogo
Total 18 30 10 25 19 102 100
Correctas 4 14 6 8 9 41 40
Incorrectas 7 9 3 3 3 25 25
No contestadas 7 7 1 14 7 36 35
Con
diálogo
Total 18 30 10 25 19 102 100

Experimentación
59
Tabla 4.6.2 Resultados para cinco tipos de problemas con una muestra del corpus de la BD ATIS y la ILNBD desarrollada en CENIDET
con estudiantes de maestría
Tipos de problemas Configurador Resultados
2.1 3.1 4.1 5.2 6.1 Total %
Correctas 3 5 2 4 4 18 90 Estudiante 1 Incorrectas 1 0 1 0 0 2 10 Correctas 2 5 2 4 4 17 85 Estudiante 2 Incorrectas 2 0 1 0 0 3 15 Correctas 2 4 3 4 4 17 85 Estudiante 3 Incorrectas 2 1 0 0 0 3 15 Correctas 2 5 3 4 4 18 90 Estudiante 4 Incorrectas 2 0 0 0 0 2 10 Correctas 3 5 3 4 4 19 95 Estudiante 5 Incorrectas 1 0 0 0 0 1 5 Correctas 2.4 5.8 2.6 4 4 18.8 89
Promedio Incorrectas 1 0.12 0.4 0 0 1.52 11
Como puede observarse, en los resultados obtenidos los porcentajes promedio de
acierto van del 79% (para estudiantes de licenciatura) al 89% (para estudiantes de
maestría). Estos resultados, al igual que en el experimento 5.1, muestran una mejora
comparados con los resultados obtenidos con las interfaces comerciales. Es
importante aclarar que la diferencia de incremento en porcentajes de los resultados
de los experimentos 5.1 y 5.2 se debe en parte a que el número de consultas
utilizadas en ambos experimentos difiere considerablemente: en el experimento 5.1
se utilizaron 102 consultas mientras en el experimento 5.2 se utilizaron 20. Además,
la dificultad de las consultas para el experimento 5.2 era menor que la del
experimento 5.1.
Además, se puede observar que el grado de preparación de los usuarios influye
perceptiblemente en cuanto a los resultados obtenidos. Se menciona el grado de
preparación ya que a estos usuarios se les proporcionó un esquema de la BD ATIS,
debido a que ninguno de estos usuarios tenía conocimiento del contexto de la
información, factor que influye de manera importante en el proceso de aclaración de
la información implícita en las consultas.
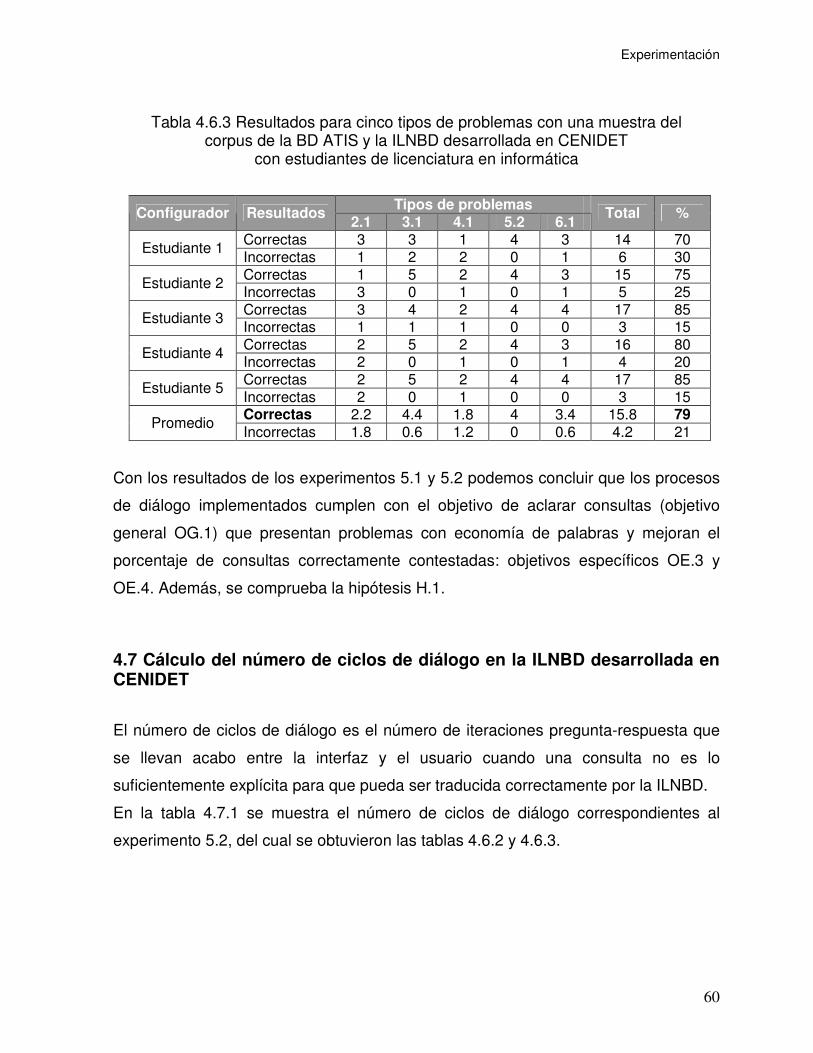
Experimentación
60
Tabla 4.6.3 Resultados para cinco tipos de problemas con una muestra del corpus de la BD ATIS y la ILNBD desarrollada en CENIDET
con estudiantes de licenciatura en informática
Tipos de problemas Configurador Resultados
2.1 3.1 4.1 5.2 6.1 Total %
Correctas 3 3 1 4 3 14 70 Estudiante 1 Incorrectas 1 2 2 0 1 6 30 Correctas 1 5 2 4 3 15 75 Estudiante 2 Incorrectas 3 0 1 0 1 5 25 Correctas 3 4 2 4 4 17 85 Estudiante 3 Incorrectas 1 1 1 0 0 3 15 Correctas 2 5 2 4 3 16 80 Estudiante 4 Incorrectas 2 0 1 0 1 4 20 Correctas 2 5 2 4 4 17 85 Estudiante 5 Incorrectas 2 0 1 0 0 3 15 Correctas 2.2 4.4 1.8 4 3.4 15.8 79
Promedio Incorrectas 1.8 0.6 1.2 0 0.6 4.2 21
Con los resultados de los experimentos 5.1 y 5.2 podemos concluir que los procesos
de diálogo implementados cumplen con el objetivo de aclarar consultas (objetivo
general OG.1) que presentan problemas con economía de palabras y mejoran el
porcentaje de consultas correctamente contestadas: objetivos específicos OE.3 y
OE.4. Además, se comprueba la hipótesis H.1.
4.7 Cálculo del número de ciclos de diálogo en la ILNBD desarrollada en CENIDET
El número de ciclos de diálogo es el número de iteraciones pregunta-respuesta que
se llevan acabo entre la interfaz y el usuario cuando una consulta no es lo
suficientemente explícita para que pueda ser traducida correctamente por la ILNBD.
En la tabla 4.7.1 se muestra el número de ciclos de diálogo correspondientes al
experimento 5.2, del cual se obtuvieron las tablas 4.6.2 y 4.6.3.
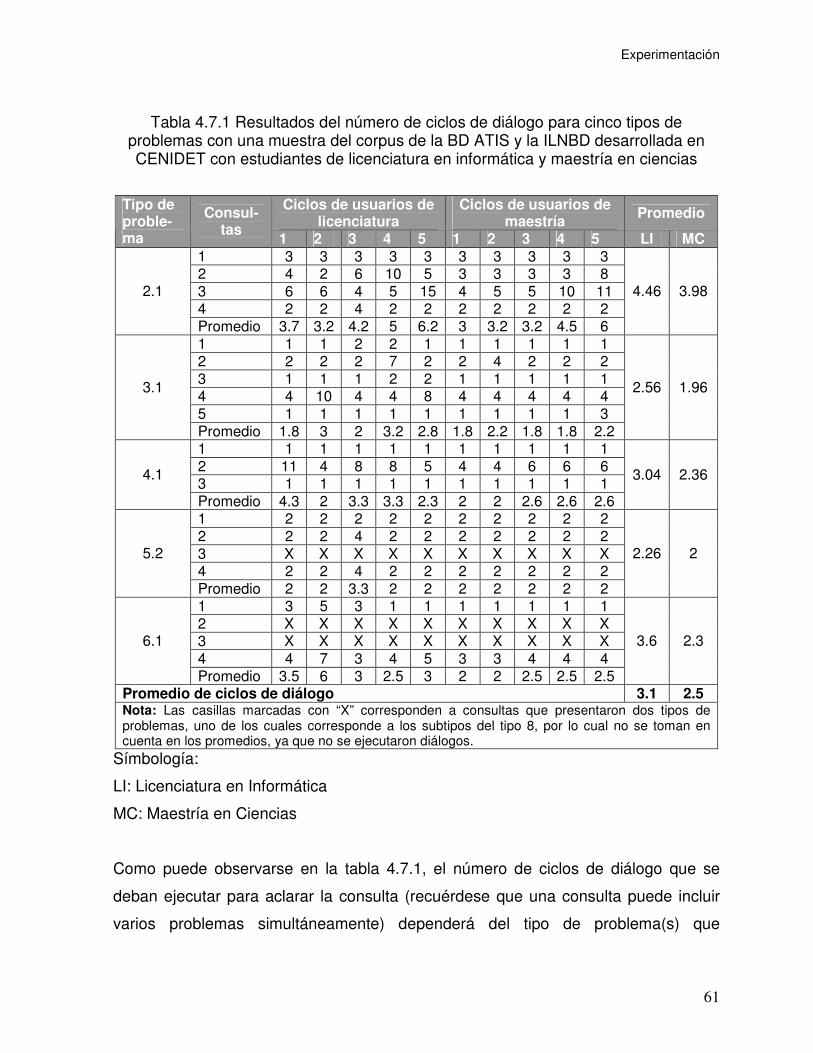
Experimentación
61
Tabla 4.7.1 Resultados del número de ciclos de diálogo para cinco tipos de problemas con una muestra del corpus de la BD ATIS y la ILNBD desarrollada en CENIDET con estudiantes de licenciatura en informática y maestría en ciencias
Ciclos de usuarios de licenciatura
Ciclos de usuarios de maestría
Promedio Tipo de proble-ma
Consul-tas
1 2 3 4 5 1 2 3 4 5 LI MC 1 3 3 3 3 3 3 3 3 3 3 2 4 2 6 10 5 3 3 3 3 8 3 6 6 4 5 15 4 5 5 10 11 4 2 2 4 2 2 2 2 2 2 2
2.1
Promedio 3.7 3.2 4.2 5 6.2 3 3.2 3.2 4.5 6
4.46 3.98
1 1 1 2 2 1 1 1 1 1 1 2 2 2 2 7 2 2 4 2 2 2 3 1 1 1 2 2 1 1 1 1 1 4 4 10 4 4 8 4 4 4 4 4 5 1 1 1 1 1 1 1 1 1 3
3.1
Promedio 1.8 3 2 3.2 2.8 1.8 2.2 1.8 1.8 2.2
2.56 1.96
1 1 1 1 1 1 1 1 1 1 1 2 11 4 8 8 5 4 4 6 6 6 3 1 1 1 1 1 1 1 1 1 1
4.1
Promedio 4.3 2 3.3 3.3 2.3 2 2 2.6 2.6 2.6
3.04 2.36
1 2 2 2 2 2 2 2 2 2 2 2 2 2 4 2 2 2 2 2 2 2 3 X X X X X X X X X X 4 2 2 4 2 2 2 2 2 2 2
5.2
Promedio 2 2 3.3 2 2 2 2 2 2 2
2.26 2
1 3 5 3 1 1 1 1 1 1 1 2 X X X X X X X X X X 3 X X X X X X X X X X 4 4 7 3 4 5 3 3 4 4 4
6.1
Promedio 3.5 6 3 2.5 3 2 2 2.5 2.5 2.5
3.6 2.3
Promedio de ciclos de diálogo 3.1 2.5 Nota: Las casillas marcadas con “X” corresponden a consultas que presentaron dos tipos de problemas, uno de los cuales corresponde a los subtipos del tipo 8, por lo cual no se toman en cuenta en los promedios, ya que no se ejecutaron diálogos.
Símbología:
LI: Licenciatura en Informática
MC: Maestría en Ciencias
Como puede observarse en la tabla 4.7.1, el número de ciclos de diálogo que se
deban ejecutar para aclarar la consulta (recuérdese que una consulta puede incluir
varios problemas simultáneamente) dependerá del tipo de problema(s) que

Experimentación
62
aparezcan en la consulta. Un factor importante que también influye
considerablemente en el número de ciclos de diálogo a ejecutarse es el relacionado
con qué tan familiarizado esté un usuario con el contexto de la información que
desea obtener.
Basándonos en la tipificación de problemas en consultas, definimos fórmulas para
determinar el número mínimo de ciclos de diálogo que debe ejecutar la interfaz para
cada tipo de problema. Estas fórmulas se resumen en la tabla 4.7.2.
Tabla 4.7.2 Aplicación del número de ciclos de diálogo de acuerdo al tipo de problemas en consultas en una ILNBD
Tipo de
problema Descripción Fórmula
No. ciclos en el
mejor de los casos
2.1 Consultas que incluyen un nombre de tabla sin especificar cuál(es) de sus columnas se solicita(n)
No. ciclos = 1 1
3.1
Consultas que incluyen un nombre de tabla y un valor en la condición de búsqueda sin especificar la columna de tabla relacionada con el valor
No. ciclos = número de valores en la condición de búsqueda
1
4.1
Consultas que incluyen el nombre de una columna sin especificar una de las varias tablas a las que puede estar relacionada
No. ciclos = número de tablas donde se encuentre la descripción de la columna
1
5.1
Consultas que incluyen el nombre de una columna sin especificar una de las varias tablas a las que puede estar relacionada
No. ciclos = número de tablas donde se encuentre la descripción de la columna
1
5.2
Consultas que incluyen un valor en la condición de búsqueda sin especificar ni la columna ni la tabla a la que puede estar relacionado (por lo tanto, el valor puede estar relacionado a cualquier columna de cualquier tabla)
No. ciclos = número de tablas de la BD + columna + número de valores en la condición de búsqueda
3

Experimentación
63
Las ILNBDs facilitan el acceso a información a usuarios inexpertos desde el punto de
vista de que el usuario no requiera conocer cómo acceder a la información, pero no
necesariamente a usuarios que, aparte del problema de cómo acceder a la
información, también desconozcan en absoluto el contexto de la información de la
BD o lo que desean obtener de la BD. Por lo tanto, la tabla 4.7.2 representa una
aproximación teórica del número de ciclos de diálogo que un usuario podría realizar
para obtener la información buscada, de acuerdo al tipo de problemas presentes en
la consulta a ejecutar. Por ejemplo, un usuario que acceda a información de una BD
que almacena información de aves nórdicas sin nunca antes haber investigado al
respecto, tendrá más dificultad para efectuar consultas que un usuario que se dedica
a investigar tales aves o tiene conocimientos al respecto.
Algunos ejemplos de la aplicación de la formulas se muestran a continuación:
1. Consulta: “Dame los proveedores de México”.
Problemas: 2.1 (no se especifica qué se desea obtener de la tabla
“proveedores”) y 3.1 (se especifica una tabla “proveedores” y un valor “México”
pero no se especifica a qué columna de la tabla “proveedores” corresponde el
valor “México”).
Solución: el número de diálogos generados es dos.
Al resolver el problema 2.1, primer proceso de diálogo, la consulta podría quedar
como “Dame los nombres de los proveedores de México”. Posteriormente se
ejecutaría el segundo proceso de diálogo para resolver el problema 3.1, con el
cual el usuario tendría que elegir de las columnas desplegadas en pantalla para la
tabla “proveedores” cuál de éstas corresponde al valor “México”.
Consulta final: “Dame los nombres de los proveedores de la ciudad igual a
México”.
2. Consulta: "Dame la dirección de Nancy Davolio".

Experimentación
64
Problemas: inicialmente 4.1 (especifica una columna “dirección”, pero no indica a
qué tabla pertenece). Para esta consulta, que corresponde al corpus de la BD
Northwind, se tienen 3 tablas (Empleados, Clientes y Proveedores) donde se
encuentra la columna “dirección”. Para este caso cabe hacer mención del
comentario antes hecho, si un usuario no está contextualizado con la información
tendría que ejecutar más procesos de diálogo que un usuario que sabe en forma
más precisa qué información desea obtener.
Solución: en el mejor de los casos se tendrían que ejecutar tres procesos de
diálogo. Con el primero el usuario seleccionaría la tabla “Empleado”, con lo cual la
consulta quedaría como “Dame la dirección del Empleado Nancy Davolio”, y
ahora la consulta presentaría el problema 3.1 (presencia de una tabla “Empleado”
y dos valores: “Nancy” y “Davolio”) lo cual origina dos procesos de diálogo, ya que
se tienen dos valores.
En el peor de los casos, y conociendo el mejor de los casos, el usuario tendría
que ejecutar hasta nueve procesos de diálogo: 1 diálogo por cada tabla más 2
diálogos en cada tabla seleccionada, nos da 3 diálogos en total para cada tabla.
Consulta final: “Dame la dirección del Empleado con nombre igual a Nancy y
apellido igual a Davolio”.
Con los ejemplos anteriores nos podemos dar una idea de lo que implica que un
usuario conozca o desconozca el contexto de la información que desea obtener. Es
natural que un usuario no contextualizado con la información terminará por enfadarse
o perderá el interés al utilizar este tipo de sistemas. Sin embargo, el número de ciclos
de diálogo que se disparan en la ILNBD [1, 20] pueden reducirse más. Por ejemplo,
para el caso 2 podría cargarse en una estructura dinámica aparte de las tablas, las
columnas pertenecientes a las tablas, y en el momento que el usuario seleccione una
tabla se desplieguen al instante que columnas se desean obtener, con lo cual se
podría ahorrar un ciclo de diálogo en el mejor de los casos.

Experimentación
65
4.8 Conclusiones
Los resultados obtenidos con los experimentos llevados a cabo son en algunos de
los casos impresionantes, tal como se observa en los experimentos de las secciones
4.2 y 4.3 con la BD Northwind y las interfaces English Query y ELF, y en la sección
4.5 con la BD ATIS y la interfaz ELF. En estos experimentos el porcentaje de
consultas contestadas es sorprendentemente bajo. Por ejemplo, considérese el
experimento 4.5 en el que a la interfaz ELF [2] (considerada en la literatura como una
de las mejores ILNBDs comerciales existentes) aplicada a consultas del corpus de la
BD ATIS (constituido por consultas apegadas a la realidad), se observa que
prácticamente ELF no considera en sus alcances resolver el problema de la
economía de palabras. Por ejemplo, con una consulta incluida en este experimento
(“What is the arrival time in Los Angeles?” ), ELF sugiere: “Ask me something I can
answer“ (figura 4.8.1).
Figura 4.8.1 Respuesta de ELF a la consulta: What is the arrival time in Los Angeles?
Los resultados obtenidos de las pruebas a las interfaces comerciales EQ y ELF
sirvieron para comparar y medir la dificultad del problema de economía de palabras.
Con los resultados obtenidos con la interfaz desarrollada en CENIDET y las BDs
Northwind y ATIS se cumple el objetivo general OG.1 de este trabajo de
investigación, ya que en estas pruebas se comprobó que fue posible mejorar el

Experimentación
66
desempeño de la interfaz. Así mismo, se cumplieron los objetivos específicos OE.3 y
OE.4 (se implementaron los procesos de diálogo a la interfaz desarrollada en
CENIDET, los cuales mediante ciclos pregunta-respuesta ayudaron al proceso de
aclarar consultas con economía de problemas).
Con la formalización de la tipificación de problemas en consultas se logró alcanzar el
objetivo específico OE.1.
El cumplimiento del objetivo específico OE.2 se demuestra con los procesos de
diálogo descritos, los cuales no requirieron de ningún cambio al traductor para ser
aplicados en diversos dominios usando la ILNBD desarrollada en CENIDET.
Además del cumplimiento del objetivo general y los objetivos específicos, se
cumplieron las hipótesis:
H.1) Es posible mejorar el desempeño de una ILNBD [1, 20] mediante la
incorporación de un proceso de diálogo. Se demuestra con los experimentos
realizados a la interfaz desarrollada en CENIDET.
H.2) Es posible que un proceso de diálogo pueda ser fácilmente configurado para
cualquier dominio en una ILNBD [1, 20]. Se demuestra con los procesos de
diálogo descritos en la sección 3, los cuales no necesitan más información de la
que se usa para configurar el traductor de lenguaje natural a SQL.
H.3) Es posible clasificar las consultas en base a características comunes, de tal
manera que para cada clase se pueda desarrollar un proceso de diálogo
independiente del dominio, que sea aplicable a todas las consultas de cada
clase. Se demuestra con los procesos de diálogo descritos en la sección 3, los
cuales no requirieron de ningún cambio al probarse con diversos dominios en la
interfaz desarrollada en CENIDET.

Experimentación
67
Los resultados obtenidos con estos experimentos van más allá de lo que
originalmente se había comprometido en la propuesta de tesis, ya que se
implementaron, no sólo algunos, sino todos los procesos de diálogo de la tipificación
de problemas (tabla 3.1.1) a la interfaz desarrollada en CENIDET, que se definieron
en los alcances propuestos, con lo cual se logró mejorar el porcentaje de consultas
correctamente contestadas. La tipificación propuesta de problemas en consultas
constituye un enfoque completamente innovador para atacar el problema de la
economía de palabras, un problema difícil y complejo de resolver como lo revelan los
resultados obtenidos en los experimentos con interfaces comerciales.
En general la ILNBD desarrollada en CENIDET [1, 20] presenta varios problemas en
sus procesos de traducción: análisis léxico, sintáctico y semántico, y en la técnica de
traducción para identificar las partes de una oración: cláusulas Select y Where. Estos
problemas ocasionan que la interfaz no tenga un buen desempeño cuando se
analizan BDs más grandes y complejas en su diseño. Varios problemas se
presentaron en las pruebas realizadas con la BD ATIS que, aunque no es una BD
muy grande, posee cierta complejidad en su diseño. Algunos ejemplos de problemas
encontrados en el proceso de traducción se describen en el anexo K.
Es conveniente mencionar que el desempeño de las ILNBDs en general no depende
del número de renglones de las tablas, pero disminuye cuando la complejidad de la
BD (número de columnas y tablas) aumenta, lo cual queda de manifiesto con los
resultados de las pruebas del experimento 4 (pruebas de ELF con la BD ATIS, tabla
4.5.1) en comparación con los del experimento 2 (pruebas de ELF con la BD
Northwind, tabla 4.3.1). Este mismo fenómeno también ocurre con la ILNBD de este
proyecto, pero se debe en mayor medida a deficiencias del traductor que al módulo
de diálogo.
El objetivo de una ILNBD es facilitar el acceso a información de una BD a usuarios
inexpertos, es decir, usuarios que no conocen de lenguajes de consulta a BDs o que

Experimentación
68
no conocen la operación o el manejo de un sistema de información. Un punto
importante que aclarar acerca de esta afirmación es que un usuario puede
desconocer o ignorar cómo acceder a la información, pero no necesariamente
ignorar o desconocer el contexto de la información. Un usuario no contextualizado
con la información de una BD tendrá más problemas para formular consultas y
obtener la información que busca en una BD. Esta característica en un usuario es
muy importante, ya que puede afectar el desempeño de cualquier ILNBD en general.

69
Capítulo 5
Conclusiones y Trabajos Futuros
En este capítulo se presentan las conclusiones de este trabajo de
investigación, el cual aborda el problema de la economía de palabras y presenta
soluciones a este problema mediante una tipificación de problemas y el diseño de
procesos de diálogo a partir de la tipificación. Además, se mencionan las
aportaciones principales de este trabajo y algunos trabajos futuros para mejorar aún
más los resultados obtenidos.
5.1 Conclusiones
El problema de economía de palabras es un problema sumamente complejo, como
se pudo observar en los resultados de los experimentos realizados. Éstos revelaron
una reducción del desempeño de 36%-66% en la interfaz English Query cuando se
probó con un corpus de consultas con economía de palabras. Otros resultados
experimentales, alentadores, mostraron que la inclusión de un administrador de
diálogo basado en nuestra tipificación a una ILNBD [1, 20] puede incrementar su

Conclusiones y Trabajos Futuros
70
desempeño (porcentaje de consultas correctamente contestadas) en un rango del 30
al 35% (experimentos 3 y 5).
La tipificación de problemas en consultas propuesta constituye un enfoque
completamente innovador respecto a los trabajos previos sobre ILNBDs, y el
problema de economía de palabras se abordó de una forma sistemática como se
refleja en la tipificación. Dos características destacables de la tipificación propuesta
son: generalidad, la cual permite que pueda ser aplicada a diversos lenguajes: inglés,
francés, italiano, etc., y la independencia del dominio, lo cual implica que puede ser
aplicada a diferentes bases de datos. La implementación de procesos de diálogo
basados en esta tipificación heredan por ende sus características, además de que su
implementación no es compleja. Los procesos de diálogo conducen al usuario a
obtener la información que está buscado, y a diferencia de los trabajos de otros
investigadores, nuestros procesos no “adivinan” sino que buscan “entender” lo que el
usuario expresa.
Aún existen otros tipos de problemas que resolver, por lo cual podemos establecer
que la tipificación propuesta no es definitiva, ésta puede seguir creciendo según se
analicen nuevos problemas.
Para finalizar podemos concluir que los objetivos propuestos se lograron, las
hipótesis propuestas se comprobaron y los resultados que esperábamos obtener
fueron más allá, en cuanto a la complejidad del problema, de lo que habíamos
vislumbrado en la propuesta de tesis. Todo lo anterior, resultado de este nuevo
enfoque propuesto.
5.2 Trabajos Futuros
En cuanto a la ILNBD [1, 20] utilizada se propone:

Conclusiones y Trabajos Futuros
71
1) Mejorar la técnica de traducción utilizada.
2) Incrementar el tipo de problemas a resolver.
3) Mejorar la interfaz gráfica propuesta.
4) Implementar la interfaz como una aplicación Web para propósitos de prueba y
retroalimentación que contribuyan a nuevas mejoras.
5) Efectuar pruebas con estudiantes de áreas ajenas a la computación con el
propósito de mejorar la interfaz.
6) Adaptar la interfaz para trabajar con diversos manejadores de BDs como:
PostgreSQL, Oracle, DB2, etc.
7) Considerar el manejo de valores compuestos sin necesidad de encerrar éstos
entre comillas.
8) Incorporar al traductor el manejo de consultas temporales.
9) Incorporar al traductor un analizador sintáctico para corregir consultas
escritas con errores sintácticos.
10) Incorporar al traductor el manejo de más instrucciones en SQL como: MAX,
MIN, etc. y permitir operaciones con fechas.
11) Implementar una ILNBD para manejar BD orientadas a objetos.
12) Implementar el manejo del discurso en el proceso de traducción.
En cuanto a la tipificación propuesta:
(1) Incluir tipos adicionales de problemas a resolver, tales como: consultas mal
formuladas, el problema de la ambigüedad, consultas ilógicas para la
semántica de la BD.
(2) Probar la tipificación con otras ILNBDs.
(3) Mejorar los procesos de diálogo, es decir, que éstos permitan más interacción
entre la ILNBD y el usuario.
(4) Analizar otros corpus de consultas para BDs de igual o mayor complejidad a la
de ATIS (principalmente corpus reales).

Conclusiones y Trabajos Futuros
72
En general en cuanto a los insumos a una ILNBD como lo son las BDs, existen
diversos problemas a tratar, uno de éstos es el concerniente al diseño de la BD, el
cual es un problema complejo que, no sólo involucra conocer y aplicar reglas de
diseño de BDs, sino que también es necesario utilizar los conocimientos de
administradores de BDs con experiencia. En cuanto al lenguaje de consulta de BDs
SQL, existen varias instrucciones para las que no es fácil implementar procesos de
traducción y diálogo, como por ejemplo: GROUP BY, HAVING, ORDER BY, etc.

73
Referencias
1. PAZOS R.A., GONZALEZ J., GELBUKH A., SIDOROV G. A Domain Independent
Natural Language Interface to Databases Capable of Processing Complex
Queries. LNCS: pp.833-842, Springer, 2005.
2. ELF SOFTWARE. Access ELF FAQ (Frequently Asked Questions),
http://www.elfsoft.com/help/accelf/ HowDoI.htm, 2002.
3. ROCHER G. Traducción de Queries en Prolog a SQL. BS thesis, Universidad de
las Américas, Puebla, México, 1999.
4. VILIB Virtual Library, http://www.islp.uni-koeln.de/aktuell/vilib/, 1999.
5. CHAE J., LEE S. Frame Based Decomposition Method for Korean Language
Query Processing. Computer Processing of Oriental Languages, 1998.
6. Procesamiento de Lenguaje Natural, http://gplsi.dlsi.ua.es/gplsi/areas.htm, 1998.
7. WALT D. An English Language Question Answering System for a Large
Relational Database. Communications of the ACM, 1978.
8. Microsoft Tech-Net, “Chapter 32 English Query Best Practices”,
http://www.microsoft.com/technet/prodtechnol/sql/2000/reskit/part9/c3261.mspx?
mfr=true, 2008.
9. POPESCU A., ETZIONI O., KAUTZ H. Towards a Theory of Natural Language
Interfaces to Databases, In Proc. IUI-2003, Miami, USA, 2003.
10. ELF Software, “ELF Software Documentation Series”, http://www.elfsoft.com/
help/accelf/Overview.htm, 2002.
11. REIS P., MATIAS J., MAMEDE N. A Natural Language Interface to Databases a
New Dimension for an Approach, 1997.
12. CERCONE N., McFETRIDGE P., POPOWISH F., FASS D., GROENEBOER C.,
HALL G. The System X, Natural Language Interface: Design, Implementation and
Evaluation, Centre for System Science, Simon Fraser University, British, Columbia,
1993.

Referencias
74
13. ANDROUTSOPOULUS I., RITCHIE G., THANISH P. MASQUE/SQL, An Efficient
and Portable Language Query Interface for Relational Databases, Department of
Artificial Intelligence, University of Edinburgh, 1993.
14. MINOCK M. A STEP Towards Realizing Codd´s Vision of Rendezvous with the
Casual User. Proc. 33rd International Conference on Very Large Databases (VLDB
2007), Demonstration Session, Vienna, Austria, 2007.
15. MINOCK M. Natural Language Access to Relational Databases through STEP.
Technical report, Department of Computer Science, Umea University, 2004.
16. BAGNASCO C., BRESCIANI P., MAGNINI B., STRAPPARAVA C. Natural
Language Interpretation for Public Administration Database Querying in the
TAMIC Demonstrator. In the Proc. Second International Workshop on Applications
of Natural Language to Information Systems, 1996.
17. W. CHU, YANG H., CHIANG K., MINOCK M., CHOW G., LARSON C. Cobase: A
Scalable and Extensible Cooperative Information System. Journal of Intelligent
Information System, vol. 6, pp. 253-259, 1996.
18. OTT N. Aspects of the Automatic Generation of SQL Statements in a Natural
Language Query Interface, Information Systems, 17(2): 147-159, 1992.
19. BOLDASOV M., SOKOLOVA G. QGen – Generation Module for the Register
Restricted InBASE System. Computational Linguistics and Intelligent Text
Processing, 4th International Conference, vol. 2588, pp. 465-476, 2003.
20. GONZALEZ, B. Traductor de Lenguaje Natural Español a SQL para un Sistema
de Consultas a Bases de Datos. PhD dissertation, Centro Nacional de
Investigación y Desarrollo Tecnológico, Cuernavaca, México, 2005.
21. DARPA Air Travel Information System (ATIS0), http://www.ldc.upenn.edu/
Catalog/readme_files/atis/sdtd/ trn_prmp.html, 1990.
22. BOOTHRA R. Natural Language Interfaces: Comparing English Language Front
End and English Query. MS thesis, Virginia Commonwealth University, 2004.
23. CONLON S., CONLON J., JAMES T. The Economics of Natural Language
Interfaces: Natural Language Processing Technology as a Scarce Resource,

Referencias
75
Decision Support Systems, Vol 38:141-159, Elsevier Science Publishers, The
Netherlands, 2004.
24. TEMPLETON, M., BURGER G. Problems in Natural Language Interfaces to
DBMS, Proceedings Conference on Applied Natural Language Processing, 1983.
25. BRAJNIK, G., GUIDA, G. IR-NLI II: Applying Man-Machine Interaction and
Artificial Intelligence Concepts to Information Retrieval, Proceedings of the
Eleventh Annual International ACM SIGIR Conference on Research and
Development in Information Retrieval, Interfaces (2), pp. 387-399, 1988.
26. ALSHAWI, H., CARTER, D., CROUCH, R., PULMAN, S., RAYNER, M., SMITH, A.
“CLARE: A Contextual Reasoning and Cooperative Response Framework for the
Core Language Engine”, Report CRC-028 (273 pages), 1994.
27. W., WESLEY, MERZBACHER, M., BERKOVICH, L. The Design and
Implementation of CoBase, Proceedings of ACM SIGMOD , 1993.
28. GELBUKH, A., SIDOROV, G. Procesamiento Automático del Español con
Enfoque en Recursos Léxicos Grandes, IPN , ISBN 970-36-0264-9, 2006.
29. GONZÁLEZ, B., PAZOS, R., CRUZ, C., FRAIRE, H., AGUILAR de L., y PÉREZ, O.
Issues in Translating from Natural Language to SQL in a Domain-Independent
Natural Language Interface to Databases, MICAI2006 , pp.922-931, 2006.
30. Diccionario de la lengua española, “Real Academia Española”, http://
buscon.rae.es/drael/SrvltConsulta?TIPO_BUS=3&LEMA=unívoco, vigésima se-
gunda edición, 2007.
31. International Standard ISO/IEC 9075:1989 (E). Information processing systems-
Database Language SQL with integrity enhacement, Second edition, 1989.
32. MENDENHALL, SCHEAFFER, WACKERLY, D. Estadística Matemática con
Aplicaciones, Grupo Editorial Iberoamérica, sexta edición, 2002.
33. PAZOS R., SANTAOLAYA S., ROJAS, P., PÉREZ, O. Shedding Light on a
Troublesome Issue in NLIBDs: Word Economy in Query Formulation, TSD 2008,
pp. 641-648, 2008.

Referencias
76
34. PAZOS R., SANTAOLAYA S., ROJAS, P., MARTÍNEZ, F., PÉREZ, O, CRUZ, R.
Domain Independent Dialog Processes for Solving the Word-Economy Problem in
a NLIDB, ACS 2008, Polish Journal of Environmental Studies, 2008.
35. ANDROUTSOPOULUS, I., GRAEME, D. Database Interfaces ”, In R. Dale, H.
Moisl, y H. Somers(Eds), Handbook of Natural Language Processing, chapter 9,
pp.209-240, Marcel Dekker Inc, 2000.
36. InBase, “Project InBase. Welcome”, http://www.inbase.artint.ru/english/default-
eng.asp, 2000.
37. S SILBERSCHATZ, KORTH, y SUDARSHAN, Fundamentos de Bases de Datos,
5ta edición, McGraw- Hill, 2006.
38. Real Academia Española, “Diccionario de la lengua española”,
http://buscon.rae.es/draeI/SrvltConsulta?TIPO_BUS=3&LEMA=lenguaje.
39. Monogragias.com, “Procesamiento de lenguaje natural en la inteligencia artificial”,
http://www.monografias.com/trabajos17/lenguaje-natural/lenguaje-natural.shtml#
LENGUAJE, 1997.
40. The Free Dictionary by Farlex, “TheFreeDictionary”, http://
encyclopedia2.thefreedictionary.com/natural+language.
41. ANDRADE, G. Supresión de Ambigüedades Léxicas en Galena mediante
Métodos Estadísticos, Tesis de Licenciatura, Universidade Da Coruña, 1997.
42. D., LIDDY. Natural Language Processing for Information Retrieval & Knowledge
Discovery, School of Information Studies, Syracuse University, 2001.
43. R., NIESLER y C. ROUX. “Natural Language Understanding in the DACST-AST
Dialogue System”, Proceedings of the 12th Annual Symposium of the Pattern
Recognition Association of South Africa (PRASA 2001), pp 134-137, 2001.
44. Electronic and Information Systems, “Research Groups Electronic and Information
Systems”, http://www.elis.rug.ac.be/ELISgroups/speech/cost249/report/chapters/
chapter6.pdf, 2006.
45. ROHIT, K., MOONEY, R. Using String-Kernels for Learning Semantic Parsers,
COLING/ACL-2006, pp. 913-920, 2006.

Referencias
77
46. FLYCHT-ERIKSSON, A., JÖNSSON. Dialogue and Domain Knowledge
Management in Dialogue Systems, Proceedings of the First SIGdial Workshop on
Discourse and Dialogue, 2002.
47. CAMA project Home Page, “Tran Manh, Research Engineer, Research CAMA”,
http://diuf.unifr.ch/people/thangt/dialog-research-guideline.pdf, 2003.
48. A., JÖNSSON, MERKEL, M. Some Issues in Dialogue-Based Question-Answering,
New Directions in Question Answering, AAAI Press, pp. 45-48, 2003.
49. RASGADO, F. Herramienta para Consultas Basadas en ejemplos (QBE) para una
Base de Datos en Internet. Tesis de Maestría, Centro Nacional de Investigación y
Desarrollo Tecnológico, Cuernavaca, Mexico, 1999.
50. MAY, A. Herramienta para Consultas Basadas en ejemplos (QBE) para
MultiBases de Datos en Internet. Tesis de Maestría, Centro Nacional de
Investigación y Desarrollo Tecnológico, Cuernavaca, Mexico, 2000.
51. Linguistic Data Consortium, “The LDC Corpus Catalog“, http://
www.ldc.upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC95S26, 1992-2008.
52. HEMPHILL, C., GODFREY, J., DODDINGTON, G. The ATIS spoken language
systems pilot corpus, Proceedings of the workshop on Speech and Natural
Language, pp. 96-101, 1990.
53. EISENBERG, A., MELTON, J. SQL:1999, formerly known as SQL3, ACM
SIGMOD, v.28, pp. 131-138, 1999.
54. Microsoft TechNet, “Biblioteca”, http://technet.microsoft.com/es-es/library/
ms189575.aspx.

78
Anexos
Anexo A. Características de la ILNBD desarrollada en CENIDET
La ILNBD [1, 20] fue diseñada para traducir consultas en lenguaje natural español a
SQL.
Las características de esta interfaz son las siguientes [29]:
• Es independiente de dominio y el proceso de configuración es automático. Para
lograr esto se basa en la creación de varios diccionarios: diccionario de
sinónimos, diccionario de metadatos de la base de datos y un diccionario del
dominio de la base de datos.
• Durante el proceso de traducción la ILNBD [1, 20] no requiere de la intervención
del usuario.
• Ejecuta un análisis de sustantivos, fechas y valores numéricos para determinar
las columnas y tablas involucradas en la consulta, y un tratamiento de la
preposición “de” y la conjunción “y” utilizando teoría de conjuntos.

Anexos
79
• La técnica de traducción implementada utiliza un algoritmo que construye un
grafo relacional de la base de datos para encontrar relaciones implícitas
involucradas en la consulta.
A continuación se describe de manera general el funcionamiento de los módulos que
constituyen esta interfaz, y se muestra en la figura A.1 la arquitectura general [29]:
� Procesamiento de la consulta. El procesador analiza cada palabra de la oración
y se obtiene información léxica y sintáctica (mediante el parser), e información
semántica (mediante interacción con el diccionario de dominio). La salida de este
módulo consiste en una consulta etiquetada. La consulta se divide en palabras, y
para cada palabra se incluye información de los siguientes tipos: léxica (forma de
la palabra, sinónimos y antónimos), morfosintáctica (categorías gramaticales de
acuerdo a su función en la oración) y semántica (significado de la palabra con
respecto a la base de datos).
Figura A.1 Arquitectura general de la ILNBD [1, 29]
� Módulo de traducción. Este módulo recibe la consulta etiquetada y la procesa
en tres fases: Fase 1: Identificación de las frases select y where. Se identifican las frases select
y where, para definir las columnas y tablas referidas por estas frases que incluyen al
menos un sustantivo (y posiblemente preposiciones, conjunciones, artículos,
Consulta en LN
Consulta en SQL
BD Diccionario de Dominio
Construcción del Diccionario
de Dominio
Procesamiento de la Consulta
Módulo de Traducción

Anexos
80
adjetivos, etc.). Se supone que la frase que define la cláusula select siempre precede
a la cláusula where. En español las palabras que separan estas frases son: cuyo,
que, con, de, donde, en, dentro de, tal que, etc.
Fase 2: Identificación de tablas y columnas. Para localizar las columnas y tablas
referidas por los sustantivos en las frases select y where, la preposición de y la
conjunción y que relacionan a los sustantivos, se representan por operaciones
utilizando la teoría de conjuntos, debido al rol que juegan en la consulta.
Si existe una frase select/where que incluya dos sustantivos p y q relacionados por la
preposición de (of), entonces la frase se refiere a elementos comunes (columnas o
tablas) referidas por p y q. Formalmente, S(p prep_de q) = S(p) ∩ S(q), donde S(x)
es el conjunto de columnas o tablas referidas por la frase x.
La conjunción y expresa la noción de adición o acumulación, tal que si hay una frase
select que involucre dos sustantivos p y q relacionados por la conjunción y, entonces
la frase se refiere a todos los elementos referidos por p y q. Formalmente, S(p conj_y
q) = S(p) ∪ S(q)
Antes de pasar a la fase 3 y continuando con el proceso de determinación de tablas y
columnas, se efectúa un proceso de marcado de tablas y columnas observando una
serie de condiciones previamente definidas [20].
La salida de esta fase es la interpretación semántica de las frases select y where (por
ejemplo, las columnas y tablas referidas por estas frases), la cual se utiliza en la fase
3 para traducirla a su expresión correspondiente en SQL.
Fase 3: Construcción del grafo relacional. El módulo de traducción tiene una
estructura de grafo que representa el esquema de la base de datos, donde se
incluyen las relaciones entre tablas. Las columnas, tablas y condiciones de búsqueda
obtenidas en las fases previas se marcan en el grafo, y desde esta estructura se
construye un subgrafo que representa la consulta del usuario.

Anexos
81
La construcción del grafo se lleva a cabo mediante los siguientes pasos [20]:
1. Considerando que la base de datos debe ser relacional y debe estar
modelada de acuerdo al modelo relacional o entidad-relación, se construye
un grafo no dirigido con base en el modelo relacional de la base de datos.
Cada nodo representa una tabla y sus arcos una relación referencial entre
tablas.
2. Se marcan los nodos de las tablas permanentemente marcadas en la Fase
2.
3. Se marca el arco incidente a los nodos que representan dos tablas para
cada condición de selección simple, donde la frase where involucre
columnas de estas tablas.
4. Si todas las condiciones de selección se enuncian explícitamente en la
consulta, entonces el subgrafo consistente de todos los nodos y arcos
marcados es un grafo conectado. De aquí se pude obtener la traducción a
SQL.
5. Un subgrafo desconectado significa que existen condiciones de selección
implícitas en la consulta, o que la consulta está formulada incorrectamente.
Además de lo anterior y como parte de la solución planteada en esta interfaz, se
diseñó la clasificación de las consultas en varios tipos [30], los cuales se listan a
continuación:
(1) Información de tablas y columnas explícita.
(2) Información de tablas explícita e información implícita de columnas.
(3) Información de tablas implícita e información explícita de columnas.
(4) Información implícita de tablas y columnas.
(5) Que involucra funciones especiales.
(6) Imposibles o difíciles de contestar.
En [20] se pueden encontrar más detalles de la implementación de la ILNBD.

Anexos
82
Anexo B. Gramática de elementos considerados de SQL 1 para la tipificación de problemas en consultas Basándonos en algunos de los elementos la versión SQL1 ISO/IEC 9075:1989(E),
una consulta tendría la siguiente forma básica (nota: los elementos subrayados no
son considerados ya que no forman parte de los alcances del traductor desarrollado
en CENIDET [1, 20, 29]):
<query specification> ::=
SELECT [ALL | DISTINCT] <select list> <table
expression>
<select list> ::= <value expression> , [{<value expression}…] | *
<value expression> es una secuencia en la cual cada <value expression> es una
<column specification>
<select list> ‘*’ es equivalente a la secuencia <value expression>
<column specification> ::= [<qualifier>.] | [<column name>]
<qualifier> ::= <table name> | <correlation name>
<table expression> ::=<from clause>[<where clause>] [group by clause] [having
clause]
<where clause> ::=WHERE <search condition>
<search condition> ::= <boolean term> | <search condition> OR <boolean term>
<search condition> ::= <boolean term> | <search condition> OR <boolean term>
<boolean term> ::= <boolean factor> | <boolean term> AND <boolean factor>
<boolean factor> ::= [NOT] <boolean primary>

Anexos
83
<boolean primary> ::= <predicate> | (<search condition>)
<predicate> ::= <comparison predicate>
| <between predicate>
| <in predicate>
| <like predicate>
| <null predicate>
| <quantified predicate>
| <exists predicate>
<comparison predicate> ::= <value expression> <comp op>{<value expression> |
<subquery>}
<comp op> ::= < >| < | > | <= | >=
<between predicate> ::=<value expression> [ NOT ] BETWEEN <value expression>
AND <value expression>}
<like predicate> ::=<column specification> [NOT] LIKE <pattern> [ESCAPE
<escape character>]
<pattern> ::= <value specification>
<escape character> ::=<value specification>
Notación:
1. [ ] indican elementos opcionales.
2. { } agrupan secuencias de elementos.
3. < > se utilizan para definer reglas de producción en notación BNF.

Anexos
84
4. ::= operador de definición. Se utiliza en una regla de producción para separar
los elementos definidos por la regla de su definición, donde el símbolo no-
terminal de la izquierda es sustituido por los símbolos de la derecha.
B.1 Subconsultas
Una subconsulta es una consulta anidada en una instrucción SELECT, INSERT,
UPDATE, DELETE, o bien en otra subconsulta [54]. La sintaxis que se define en la
versión SQL1 ISO/IEC 9075:1989(E) es la siguiente:
<subquery> ::= (SELECT | ALL | DISTINCT | <result specification>
<table expression>)
<result specification> ::= <value expression> | *
De acuerdo con la sintaxis anterior, las subconsultas como tal, no se manejan en el
traductor desarrollado en CENIDET [20]. Algunas subconsultas pueden
representarse también mediante diferentes tipos de la instrucción “join”. La
instrucción “join” no forma parte de la versión de SQL1. Sin embargo, para la versión
SQL1 se maneja una forma de “join interno”, el cual consiste en la selección de
información de dos o más tablas, las cuales son definidas en la cláusula “from”
separadas por comas. Un ejemplo de “join interno” se observa en la siguiente
consulta sql:
Select Empleado.Nombre, Ordenes.Producto From Empleados, Ordenes Where Empleado.Empleado_Id = Ordenes.Empleado_Id
Como puede observarse en la consulta sql anterior, en la cláusula “From” se tienen
dos tablas separadas por comas, y en la cláusula “Where” se utiliza el nombre de las
tablas y sus identificadores para poder efectuar una unión (join) entre las dos tablas y
obtener la información solicitada en la cláusula “Select”. Esta forma de “join” es la
forma más sencilla y la más comúnmente utilizada. En el caso del traductor

Anexos
85
desarrollado en CENIDET se considera este tipo de “join interno” para el manejo de
subconsultas.

Anexos
86
Anexo C. Ejemplo de configuración de la interfaz English Query (EQ)
Ejemplo de un fragmento de archivo xml generado por EQ para la BD Northwind,
resultado de las pruebas desarrolladas en la sección 4.2. Las etiquetas en este
fragmento establecen las relaciones que existen entre las tablas de la BD Northwind.
<?xml version="1.0" encoding="ISO-8859-1" ?> - <MODULE ID="MODULE:User4" VERSION="1.2"> - <SEMANTICS> - <RELATIONSHIP ID="RELATIONSHIP:categories_have_category_descriptions"> <JOINTABLE TABLE="TABLE:dbo.Categories" /> <ROLE ID="ROLE:categories_have_category_descriptions.category" HREF="ENTITY:category" /> <ROLE ID="ROLE:categories_have_category_descriptions.category_description" HREF="ENTITY:category_description" /> - <PHRASINGS> - <TRAITPHRASING ID="PHRASING:categories_have_category_descriptions.categories..20have..20category_descriptions"> <SUBJECT ROLEREF="ROLE:categories_have_category_descriptions.category" /> <OBJECT ROLEREF="ROLE:categories_have_category_descriptions.category_description" /> </TRAITPHRASING> </PHRASINGS> </RELATIONSHIP> - <RELATIONSHIP ID="RELATIONSHIP:categories_have_category_ids"> <JOINTABLE TABLE="TABLE:dbo.Categories" /> <ROLE ID="ROLE:categories_have_category_ids.category" HREF="ENTITY:category" /> <ROLE ID="ROLE:categories_have_category_ids.category_id" HREF="ENTITY:category_id" /> - <PHRASINGS> - <TRAITPHRASING ID="PHRASING:categories_have_category_ids.categories..20have..20category_ids"> <SUBJECT ROLEREF="ROLE:categories_have_category_ids.category" /> <OBJECT ROLEREF="ROLE:categories_have_category_ids.category_id" /> </TRAITPHRASING> </PHRASINGS> </RELATIONSHIP> - <RELATIONSHIP ID="RELATIONSHIP:categories_have_category_names"> <JOINTABLE TABLE="TABLE:dbo.Categories" /> <ROLE ID="ROLE:categories_have_category_names.category" HREF="ENTITY:category" /> <ROLE ID="ROLE:categories_have_category_names.category_name" HREF="ENTITY:category_name" /> - <PHRASINGS> - <TRAITPHRASING ID="PHRASING:categories_have_category_names.categories..20have..20category_names"> <SUBJECT ROLEREF="ROLE:categories_have_category_names.category" /> <OBJECT ROLEREF="ROLE:categories_have_category_names.category_name" />
</TRAITPHRASING> </PHRASINGS> </RELATIONSHIP>

Anexos
87
+ <RELATIONSHIP ID="RELATIONSHIP:category_names_are_adjectives_describing_category_descriptions"> + <RELATIONSHIP ID="RELATIONSHIP:customer_company_names_have_customer_contact_names"> + <RELATIONSHIP ID="RELATIONSHIP:customer_customer_demos_have_customer_customer_demo_customer_ids"> + <RELATIONSHIP ID="RELATIONSHIP:customer_customer_demos_have_customer_demographics"> + <RELATIONSHIP ID="RELATIONSHIP:customer_demographics_have_customer_demographic_customer_descs"> + <RELATIONSHIP ID="RELATIONSHIP:customer_demographics_have_customer_demographic_customer_type_ids"> + <RELATIONSHIP ID="RELATIONSHIP:customer_ids_are_the_unique_ids_of_customers"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_addresses"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_cities"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_company_names"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_contact_names"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_countries"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_faxes"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_phones"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_postal_codes"> + <RELATIONSHIP ID="RELATIONSHIP:customers_have_customer_regions"> + <RELATIONSHIP ID="RELATIONSHIP:employee_names_are_the_names_of_employees"> + <RELATIONSHIP ID="RELATIONSHIP:employee_territories_have_employee_territory_territory_ids"> + <RELATIONSHIP ID="RELATIONSHIP:employee_territories_have_employees"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_addresses"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_birth_dates"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_cities"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_countries"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_extensions"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_hire_dates"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_home_phones"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_ids"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_notes"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_photo_paths"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_postal_codes"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_regions"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_reports_tos"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_title_of_courtesies"> + <RELATIONSHIP ID="RELATIONSHIP:employees_have_employee_titles"> + <RELATIONSHIP ID="RELATIONSHIP:order_details_have_order_detail_discounts"> + <RELATIONSHIP ID="RELATIONSHIP:order_details_have_order_detail_order_ids"> + <RELATIONSHIP ID="RELATIONSHIP:order_details_have_order_detail_quantities"> + <RELATIONSHIP ID="RELATIONSHIP:order_details_have_order_detail_unit_prices"> + <RELATIONSHIP ID="RELATIONSHIP:order_details_have_products"> + <RELATIONSHIP ID="RELATIONSHIP:order_ids_are_the_unique_ids_of_orders"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_customer_ids"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_dates"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_employee_ids"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_freights"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_required_dates"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_addresses"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_cities">

Anexos
88
+ <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_countries"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_names"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_postal_codes"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_regions"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_ship_vias"> + <RELATIONSHIP ID="RELATIONSHIP:orders_have_order_shipped_dates"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_category_ids"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_ids"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_quantity_per_units"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_reorder_levels"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_supplier_ids"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_unit_prices"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_units_in_stocks"> + <RELATIONSHIP ID="RELATIONSHIP:products_have_product_units_on_orders"> + <RELATIONSHIP ID="RELATIONSHIP:region_ids_are_the_unique_ids_of_regions"> + <RELATIONSHIP ID="RELATIONSHIP:regions_have_region_descriptions"> + <RELATIONSHIP ID="RELATIONSHIP:shipper_ids_are_the_unique_ids_of_shippers"> + <RELATIONSHIP ID="RELATIONSHIP:shippers_have_shipper_company_names"> + <RELATIONSHIP ID="RELATIONSHIP:shippers_have_shipper_phones"> + <RELATIONSHIP ID="RELATIONSHIP:supplier_ids_are_the_unique_ids_of_suppliers"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_addresses"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_cities"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_company_names"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_contact_names"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_contact_titles"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_countries"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_faxes"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_home_pages"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_phones"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_postal_codes"> + <RELATIONSHIP ID="RELATIONSHIP:suppliers_have_supplier_regions"> + <RELATIONSHIP ID="RELATIONSHIP:territories_have_territory_descriptions"> + <RELATIONSHIP ID="RELATIONSHIP:territories_have_territory_region_ids"> + <RELATIONSHIP ID="RELATIONSHIP:territory_ids_are_the_unique_ids_of_territories"> </SEMANTICS>
</MODULE>

Anexos
89
Anexo D. Muestra de 102 consultas del corpus de la BD ATIS El siguiente corpus (Tabla D.1) corresponde a las consultas que fueron utilizadas
para la evaluación de la sección 4.5
Tabla D.1 Corpus de consultas de la BD ATIS
Tipo de Problema
Consulta
2.1 Consultas que incluyen un nombre de tabla sin especificar cuál(es) de sus columnas se solicita(n).
1 All flights from ATL to SFO on Delta first class
2 Show me all the one-way flights from DFW to BOS
3 Tell me the fare for number 18 one-way
4 Listing of all flights from ATL to BOS
5 Find me a list of transportation from downtown OOAK to SSFO downtown
6 Flights between SFO and Dallas between 12:00 and 5:00
7 Give a flight coach economy class
8 List fares for all flights leaving after 12:00 from BOS to BWI
9 List flights from ATL to Washington, D.C. on Delta Airlines
10 List meals served on DL 589 from PHL to Dallas
11 Give me the flights from SFO to DEN
12 Show me the Delta flights from DFW to DEN
13 Show fares United flight 880 from SFO to DEN on 06/01/1990
14 Show flights from DEN to SFO on 06/07/1990
15 What airlines fly from DEN to BOS on a 733
16 What ground transportation is available from SFO airport into the city?
17 What are the fares for flight 96?
18 Give me a economy class flight from DFW to BWI one-way
3.1 Consultas que incluyen un nombre de tabla y un valor en la condición de búsqueda sin especificar la columna de la tabla relacionada con el valor
1 Get me a date on flight 294 leaving ATL to Washington 2 What kind of airplane is US 1581. 3 What kind of ground transportation is available from the airport to downtown
BWI?
4 What kind of plane is flight 301? 5 Show the cost for flight 71 from ATL to SFO leaving on 08/14/1990 6 Show distance between airport BWI and city Baltimore 7 Show me all the type aircraft that flies from DFW to BOS 8 Show me departing flights from DFW to ATL 9 Show me departing flights from SFO to DFW arriving in DFW by 13:00

Anexos
90
Tabla D.1 Corpus de consultas de la BD ATIS (continúa)
Tipo de Problema
Consulta
3.1 Consultas que incluyen un nombre de tabla y un valor en la condición de búsqueda sin especificar la columna de la tabla relacionada con el valor
10 What day is 6? 11 What is the fare code for flight 351? 12 What is the name of the airport at DEN? 13 What kind of a plane is J31? 14 What kind of aircraft is Delta 314? 15 What restriction is VU? 16 What time zone is in Atlanta? 17 What type fare is QS? 18 Where does flight 1083 stop? 19 What types of aircraft fly from ATL to SFO? 20 What types of ground transportation are in ATL? 21 What's the price of ground transportation in DEN? 22 What's the type of aircraft for flight 5140? 23 What's the flight number for the 10:39 flight? 24 What meals are served on first class flights from BOS to DFW? 25 What time does flight 102136 leave Atlanta Hartsfield to Dallas? 26 What state is Dallas in? 27 What is the capacity of aircraft equipment 733? 28 List the type of aircraft for flights from PHL to ATL on 05/07/1990 29 Give me the types of ground transportation in ATL 30 How much is the Q fare for the flights from BOS to DFW?
4.1 Consultas que incluyen un nombre de columna sin especificar una de las varias tablas a las que puede estar relacionada
1 What is cost from DFW to ATL? 2 What is cost of flight 102166? 3 What is restriction AP/80? 4 What is the code for SFO? 5 What is the cost of 1006? 6 What type of meal is on American Airlines flight 288? 7 Which cities have taxis? 8 Show me departure time 9 What is the arrival time in Los Angeles? 10 When does Midway 589 leave PHL?
5.2
Consultas que incluyen un valor en la condicón de búsqueda sin especificar la columna ni la tabla a la cual ésta puede estar relacionada (por lo tanto, el valor puede estar relacionado a cualquier columna de cualquier tabla)
1 Give me First class Delta Airlines DFW to PHL 2 Give me a list of the cities served by Delta 3 How many engines does an M80 have? 4 How many passengers are on a 727? 5 How many passengers does a Boeing 733 carry?

Anexos
91
Tabla D.1Corpus de consultas de la BD ATIS (continúa)
Tipo de Problema
Consulta
5.2
Consultas que incluyen un valor en la condicón de búsqueda sin especificar la columna ni la tabla a la cual ésta puede estar relacionada (por lo tanto, el valor puede estar relacionado a cualquier columna de cualquier tabla)
6 How many seats are on an M80? 7 How much is a first class ticket from BOS to SFO? 8 How much is the coach fare on American Airlines flight 155? 9 Give me a limousine from Logan to Boston? 10 List number of seats on D9S 11 Show kind of aircraft for Continental 1631 12 How much is Delta flight 539 13 Show me a list of taxi services in Philadelphia 14 Show the meal plan from PHL to BOS 15 Show the names of cities served by both Midway and Eastern 16 What kind of plane is United flight number 438 departing Denver at 10:29 for
Dallas/Fort Worth? 17 What cities does Lufthansa Airlines fly from? 18 What cities does Midway Airlines fly to? 19 What days does DL 111 fly? 20 What is arrival time Delta 605? 21 What is the distance between Atlanta and Peachtree City? 22 What is the round-trip cost of DL 234? 23 What is the weight of a D10? 24 What is the speed of a 767? 25 Which carriers go to Boston?
6.1 Consultas que incluyen un nombre de columna que puede no estar relacionado a ninguna tabla de la base de datos
1 Book Continental 1215 from BOS to DEN 2 Give a description of the aircraft for Delta flight 16. 3 How long will it take to fly from Oakland to Boston? 4 How much does a coach flight from Baltimore to Philadelphia cost? 5 What is the price of flight 460 6 Cost of flight 1028 7 Flight schedule for Boston on 05/30/1990 8 Flights exiting Fort Worth and entering Dallas 9 How far is BWI from Washington, D.C.? 10 How fast can the Concorde fly? 11 I want to travel from DFW to SFO 12 I'd like to book a ticket for Delta flight 219 13 List the cost for limousines 14 List the movies that are available on all United Airlines flights 15 List the physical characteristic of a Douglas DC10 16 Show the size of the jets

Anexos
92
Tabla D.1 Corpus de consultas de la BD ATIS (continúa)
Tipo de Problema
Consulta
6.1 Consultas que incluyen un nombre de columna que puede no estar relacionado a cualquier tabla de la base de datos
17 What is equipment MD80? 18 What is the menu for flight 368? 19 What are the car rental agencies in Atlanta?
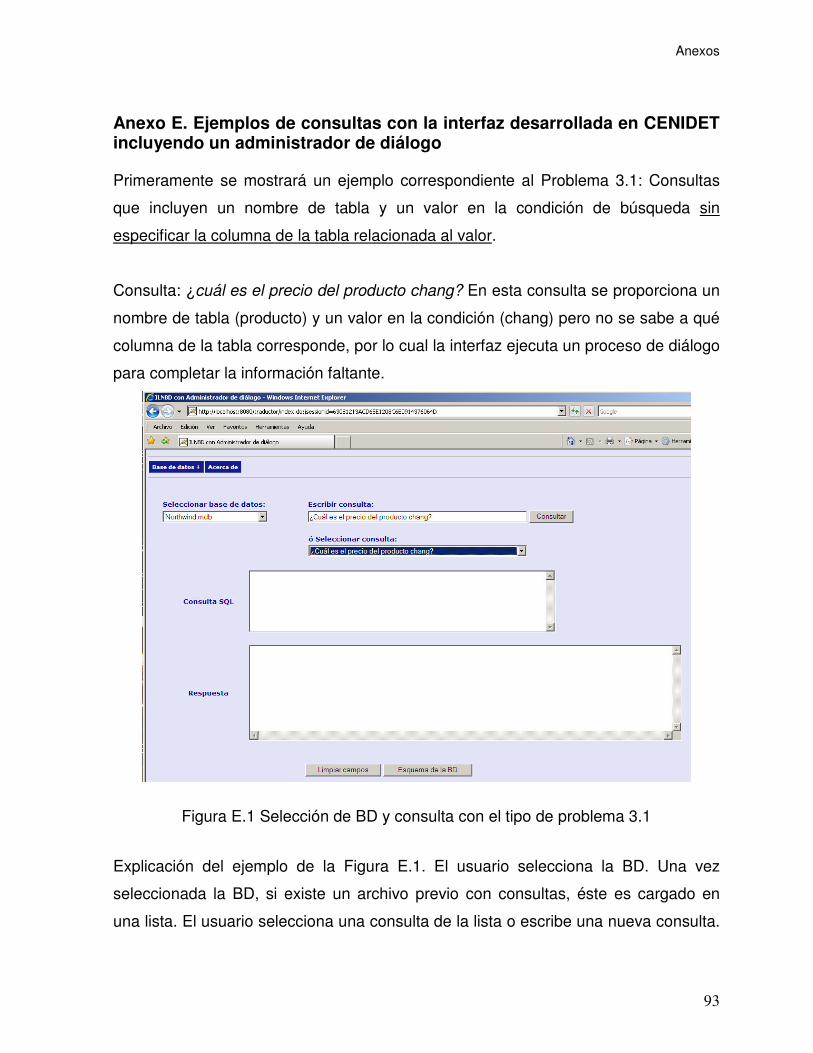
Anexos
93
Anexo E. Ejemplos de consultas con la interfaz desarrollada en CENIDET incluyendo un administrador de diálogo Primeramente se mostrará un ejemplo correspondiente al Problema 3.1: Consultas
que incluyen un nombre de tabla y un valor en la condición de búsqueda sin
especificar la columna de la tabla relacionada al valor.
Consulta: ¿cuál es el precio del producto chang? En esta consulta se proporciona un
nombre de tabla (producto) y un valor en la condición (chang) pero no se sabe a qué
columna de la tabla corresponde, por lo cual la interfaz ejecuta un proceso de diálogo
para completar la información faltante.
Figura E.1 Selección de BD y consulta con el tipo de problema 3.1
Explicación del ejemplo de la Figura E.1. El usuario selecciona la BD. Una vez
seleccionada la BD, si existe un archivo previo con consultas, éste es cargado en
una lista. El usuario selecciona una consulta de la lista o escribe una nueva consulta.
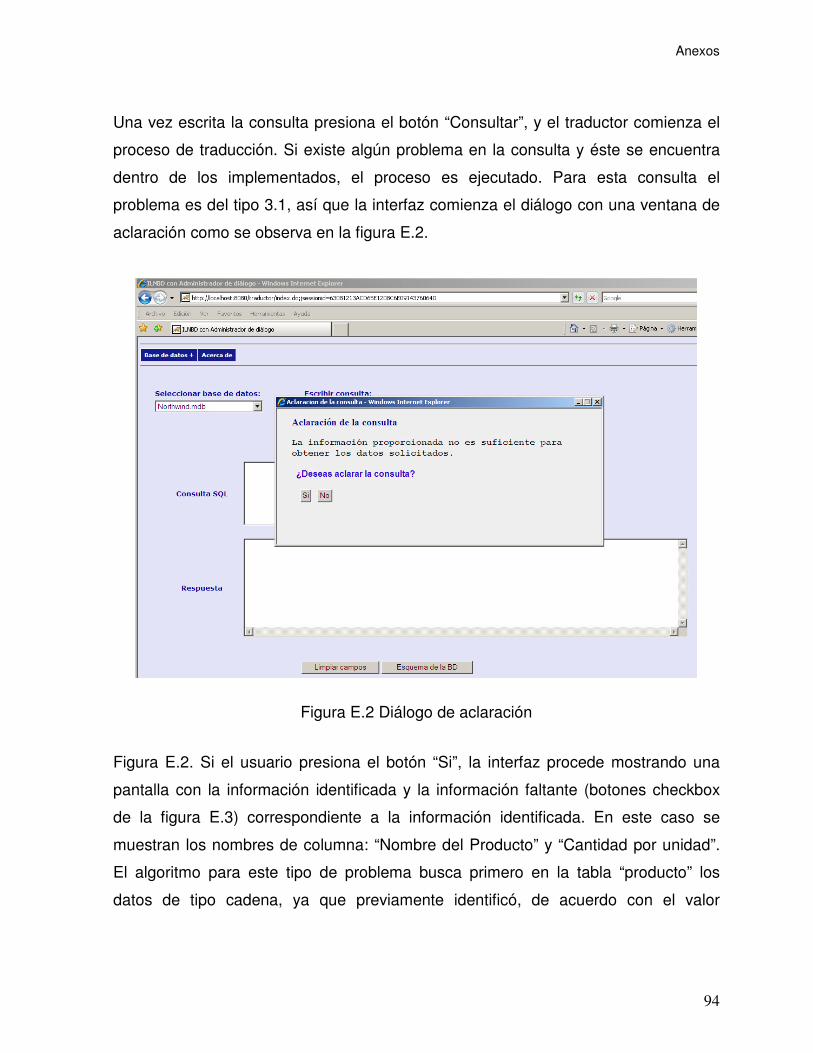
Anexos
94
Una vez escrita la consulta presiona el botón “Consultar”, y el traductor comienza el
proceso de traducción. Si existe algún problema en la consulta y éste se encuentra
dentro de los implementados, el proceso es ejecutado. Para esta consulta el
problema es del tipo 3.1, así que la interfaz comienza el diálogo con una ventana de
aclaración como se observa en la figura E.2.
Figura E.2 Diálogo de aclaración
Figura E.2. Si el usuario presiona el botón “Si”, la interfaz procede mostrando una
pantalla con la información identificada y la información faltante (botones checkbox
de la figura E.3) correspondiente a la información identificada. En este caso se
muestran los nombres de columna: “Nombre del Producto” y “Cantidad por unidad”.
El algoritmo para este tipo de problema busca primero en la tabla “producto” los
datos de tipo cadena, ya que previamente identificó, de acuerdo con el valor

Anexos
95
proporcionado por el usuario, que el tipo de dato del valor “chang” es de tipo cadena
(tipo string en Java).
Durante las pruebas efectuadas observamos que el diseño de una BD varía de
acuerdo al Administrador de la BD y principalmente a las necesidades del cliente, por
ejemplo en la siguiente consulta: “Dame los datos del proveedor 235” lo que para
nosotros puede representar o entenderse como un número como “235”, este dato
representado en una columna de una BD puede ser tanto un dato tipo numérico
como un dato tipo cadena. Por lo tanto, el algoritmo para este tipo de problema
identifica primero todos los tipos de dato correspondiente al valor proporcionado (en
este caso numéricos), y después agrega columnas restantes que podrían
corresponder al valor proporcionado (en este caso tipo cadena).
Si la información faltante se encuentra en las opciones, el usuario selecciona ésta y
presiona el botón “Aceptar” (Figura E.3).
Figura E.3 Pantalla de solicitud de información faltante para “producto”
Con la información seleccionada la interfaz modifica la consulta y ejecuta
nuevamente ésta. El proceso se repetirá hasta que la consulta no tenga ningún
problema (dentro de los identificados e implementados en la tipificación de la sección
3.1). Para este caso la respuesta se observa en la figura E.4.
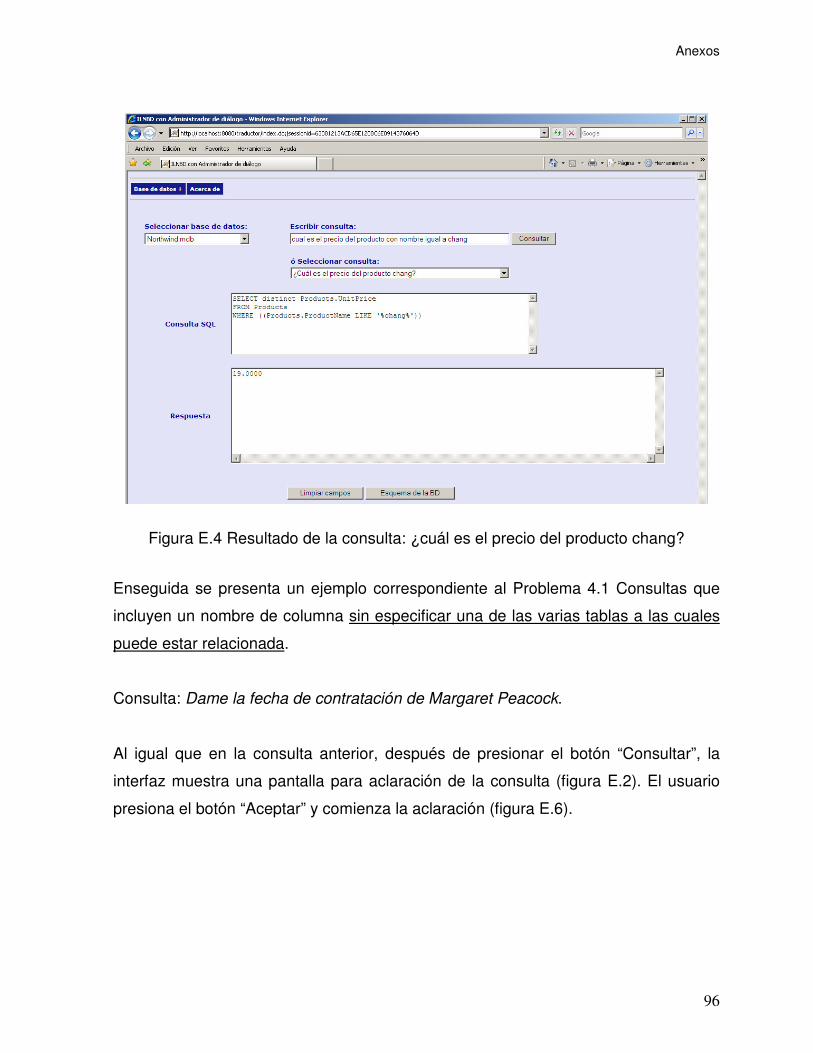
Anexos
96
Figura E.4 Resultado de la consulta: ¿cuál es el precio del producto chang?
Enseguida se presenta un ejemplo correspondiente al Problema 4.1 Consultas que
incluyen un nombre de columna sin especificar una de las varias tablas a las cuales
puede estar relacionada.
Consulta: Dame la fecha de contratación de Margaret Peacock.
Al igual que en la consulta anterior, después de presionar el botón “Consultar”, la
interfaz muestra una pantalla para aclaración de la consulta (figura E.2). El usuario
presiona el botón “Aceptar” y comienza la aclaración (figura E.6).
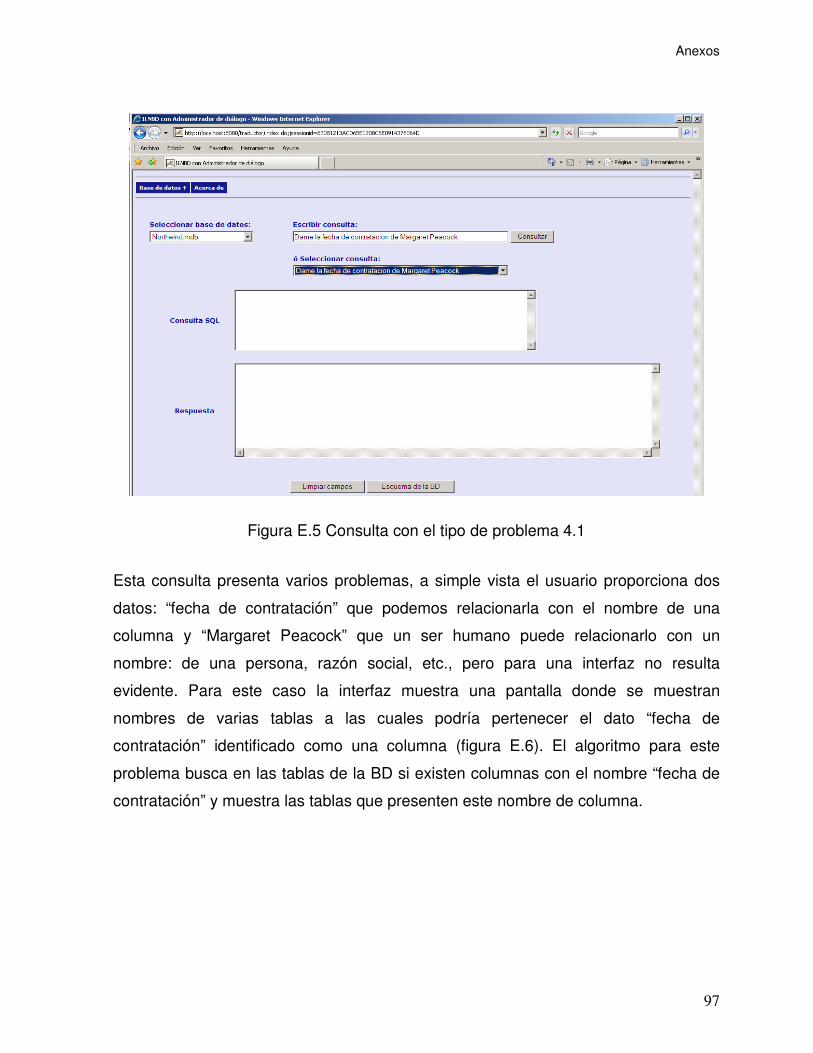
Anexos
97
Figura E.5 Consulta con el tipo de problema 4.1
Esta consulta presenta varios problemas, a simple vista el usuario proporciona dos
datos: “fecha de contratación” que podemos relacionarla con el nombre de una
columna y “Margaret Peacock” que un ser humano puede relacionarlo con un
nombre: de una persona, razón social, etc., pero para una interfaz no resulta
evidente. Para este caso la interfaz muestra una pantalla donde se muestran
nombres de varias tablas a las cuales podría pertenecer el dato “fecha de
contratación” identificado como una columna (figura E.6). El algoritmo para este
problema busca en las tablas de la BD si existen columnas con el nombre “fecha de
contratación” y muestra las tablas que presenten este nombre de columna.

Anexos
98
Figura E.6 Pantalla de solicitud de información faltante para “fecha”
Una vez proporcionada la información, la consulta es modificada a: Dame la fecha de
contratación del Empleado Margaret Peacock. La consulta es ejecutada nuevamente
pero ahora presenta el tipo de problema 3.1, por lo cual se repite el mismo proceso
como en el caso de la consulta anterior. En tales circunstancias se presenta la
pantalla de la figura E.2 y posteriormente la pantalla de la figura E.7.
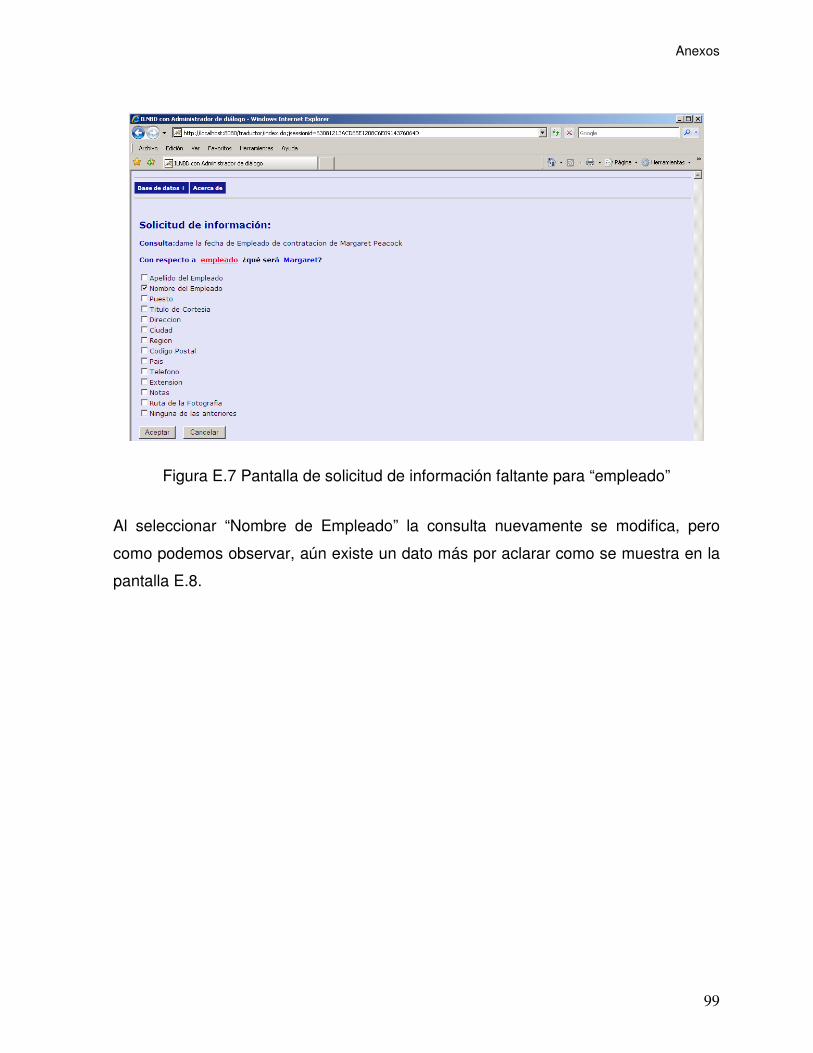
Anexos
99
Figura E.7 Pantalla de solicitud de información faltante para “empleado”
Al seleccionar “Nombre de Empleado” la consulta nuevamente se modifica, pero
como podemos observar, aún existe un dato más por aclarar como se muestra en la
pantalla E.8.

Anexos
100
Figura E.8 Pantalla de solicitud de información faltante para “empleado”
El resultado final se observa en la figura E.9. Al aplicar los procesos de diálogo
implementados no todas las consultas pueden ser resueltas. Esto tiene que ver con
el proceso de traducción de la interfaz utilizada [1, 20] y no precisamente con los
procesos de diálogo implementados, aunque éstos pueden ser mejorados.

Anexos
101
Figura E.9 Resultado a la consulta: Dame la fecha de contratación de Margaret Peacock
Las pantallas mostradas anteriormente son Java Server Pages (JSPs). Parte de la
información mostrada en éstas se forma dinámicamente con los resultados obtenidos
de la BD consultada.

Anexos
102
Anexo F. Ejemplos de seis tipos de problemas en consultas ejecutadas por la interfaz desarrollada en CENIDET
En la tabla F.1 se muestran ejemplos del corpus de consultas correspondientes a la
BD Northwind. Estas consultas fueron ejecutadas en la interfaz desarrollada en
CENIDET aplicando procesos de diálogo. En la columna “Resultado” se muestra la
conversión de la consulta de LN a SQL una vez aplicado el proceso de diálogo
correspondiente.
Tabla F.1 Ejemplos de seis tipos de problemas en consultas
para la BD Northwind
Problema Consulta Resultado
3.1 Consultas que incluyen un nombre de tabla y un valor en la condición de búsqueda sin especificar la columna de la tabla relacionada al valor
¿Cuál es el precio del producto ¿? chang?
SELECT Products.UnitPrice FROM Products WHERE ((Products.ProductName LIKE 'chang'))
Muéstrame las órdenes que se hayan realizado el ¿? 16/07/1996
SELECT Orders.OrderDate, Orders.OrderID FROM Orders WHERE ((Orders.OrderDate = #1996/07/16# OR Orders.RequiredDate = #1996/07/16# OR Orders.ShippedDate = #1996/07/16#))
Muestra el nombre del contacto que tiene el producto ¿? Chai
SELECT Customers.ContactName, Suppliers.ContactName, Products.ProductID, Products.ProductName FROM Products WHERE ((Products.ProductName LIKE 'Chai'))
Dame la fecha de envío de la orden ¿? 10277
SELECT Orders.ShippedDate FROM Orders WHERE ((Orders.ShippedDate = '10277'))
Listar el nombre del producto que cueste ¿? 10
SELECT Products.ProductName FROM Products WHERE ((Products.ProductName LIKE 'cueste' OR Products.QuantityPerUnit LIKE 'cueste') OR (Products.ProductName = '10'))

Anexos
103
Tabla F.1 Ejemplos de seis tipos de problemas en consultas para la BD Northwind (continúa)
Problema Consulta Resultado
4.1 Consultas que incluyen un nombre de columna sin especificar una de las varias tablas a las cuales puede estar relacionada
Dame la dirección ¿? de Around the Horn
SELECT Customers.Address, Employees.Address, Suppliers.Address, Employees.PhotoPath, Orders.ShipAddress FROM Customers, Employees, Orders, Suppliers, Products, OrderDetails WHERE ((Customers.ContactTitle LIKE '%de%' OR Customers.Address LIKE '%de%' OR Employees.Title LIKE '%de%' OR Orders.ShipAddress LIKE '%de%' OR Suppliers.ContactTitle LIKE '%de%' OR Suppliers.Address LIKE '%de%') OR (Customers.CustomerID LIKE '%the%' OR Customers.CompanyName LIKE '%the%' OR Customers.ContactName LIKE '%the%' OR Orders.CustomerID LIKE '%the%' OR Orders.ShipName LIKE '%the%' OR Suppliers.HomePage LIKE '%the%') OR (Customers.CompanyName LIKE '%Horn%' OR Orders.ShipName LIKE '%Horn%')) AND Suppliers.SupplierID = Products.SupplierID AND Products.ProductID = OrderDetails.ProductID AND OrderDetails.OrderID = Orders.OrderID AND Employees.EmployeeID = Orders.EmployeeID
Cuál es el nombre de la compañía que tiene fecha de envío 12/07/1996
SELECT Customers.CompanyName, Shippers.CompanyName, Suppliers.CompanyName, Orders.OrderID, Orders.OrderDate FROM Orders WHERE ((Orders.ShippedDate = #1996/07/12#))
5.1 Consultas que incluyen un nombre de columna sin especificar una de las varias tablas a las cuales puede estar relacionada
Dame el nombre de la compañía con el identificador 1
SELECT Customers.CompanyName, Shippers.CompanyName, Suppliers.CompanyName FROM Customers, Shippers, Suppliers, Products, OrderDetails, Orders WHERE ((Customers.CustomerID = '1' OR Shippers.ShipperID = 1 OR Suppliers.SupplierID = 1)) AND Suppliers.SupplierID = Products.SupplierID AND Products.ProductID = OrderDetails.ProductID AND OrderDetails.OrderID = Orders.OrderID AND Orders.ShipVia = Shippers.ShipperID
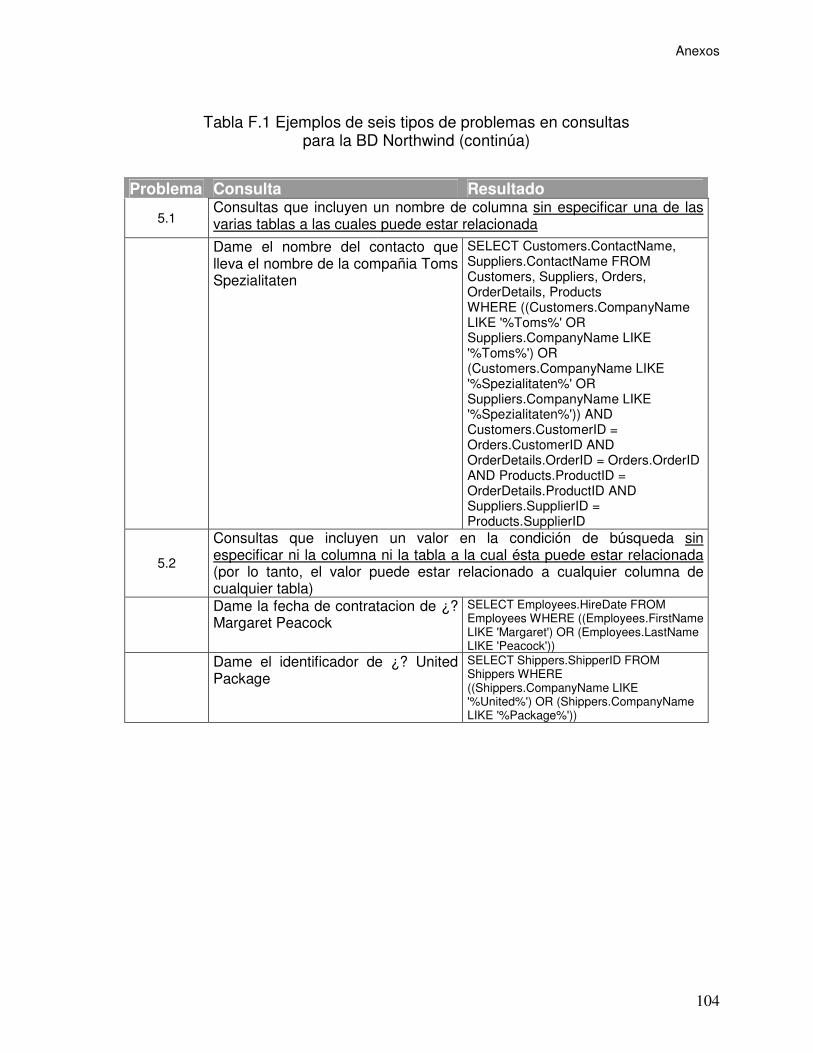
Anexos
104
Tabla F.1 Ejemplos de seis tipos de problemas en consultas para la BD Northwind (continúa)
Problema Consulta Resultado
5.1 Consultas que incluyen un nombre de columna sin especificar una de las varias tablas a las cuales puede estar relacionada
Dame el nombre del contacto que lleva el nombre de la compañia Toms Spezialitaten
SELECT Customers.ContactName, Suppliers.ContactName FROM Customers, Suppliers, Orders, OrderDetails, Products WHERE ((Customers.CompanyName LIKE '%Toms%' OR Suppliers.CompanyName LIKE '%Toms%') OR (Customers.CompanyName LIKE '%Spezialitaten%' OR Suppliers.CompanyName LIKE '%Spezialitaten%')) AND Customers.CustomerID = Orders.CustomerID AND OrderDetails.OrderID = Orders.OrderID AND Products.ProductID = OrderDetails.ProductID AND Suppliers.SupplierID = Products.SupplierID
5.2
Consultas que incluyen un valor en la condición de búsqueda sin especificar ni la columna ni la tabla a la cual ésta puede estar relacionada (por lo tanto, el valor puede estar relacionado a cualquier columna de cualquier tabla)
Dame la fecha de contratacion de ¿? Margaret Peacock
SELECT Employees.HireDate FROM Employees WHERE ((Employees.FirstName LIKE 'Margaret') OR (Employees.LastName LIKE 'Peacock'))
Dame el identificador de ¿? United Package
SELECT Shippers.ShipperID FROM Shippers WHERE ((Shippers.CompanyName LIKE '%United%') OR (Shippers.CompanyName LIKE '%Package%'))

Anexos
105
Tabla F.1 Ejemplos de seis tipos de problemas en consultas para la BD Northwind (continúa)
Problema Consulta Resultado
6.1 Consultas que incluyen un nombre de columna que puede no estar relacionado a cualquier tabla de la base de datos
Muestra los surtidores de ¿? Nueva Orleans
SELECT Suppliers.SupplierID, Customers.CustomerID, Customers.CustomerID, Orders.OrderID, Orders.OrderDate FROM Customers, Orders, Suppliers, Products, OrderDetails WHERE ((Customers.Region LIKE '%nueva%' OR Orders.ShipRegion LIKE '%nueva%') OR (Suppliers.CompanyName LIKE '%Orleans%' OR Suppliers.City LIKE '%Orleans%')) AND Suppliers.SupplierID = Products.SupplierID AND Products.ProductID = OrderDetails.ProductID AND OrderDetails.OrderID = Orders.OrderID
Detalles de la orden 10250 La palabra detalle no existe como COLUMNA ni como TABLA de la Base de Datos seleccionada. Modifique su consulta por favor.
7.1 Consultas que incluyen el nombre de una tabla que no pertenece a la base de datos
Dame la dirección de la taquería Antonio Moreno
No hay respuesta
En ésta se muestran algunos ejemplos de consultas con problemas de información
implícita. En la columna “Resultado” se observan algunas consultas subrayadas,
éstas son consultas que no tradujo en forma correcta la interfaz. Como se menciona
en otros capítulos, la ILNBD utilizada presenta algunos problemas en su proceso de
traducción.
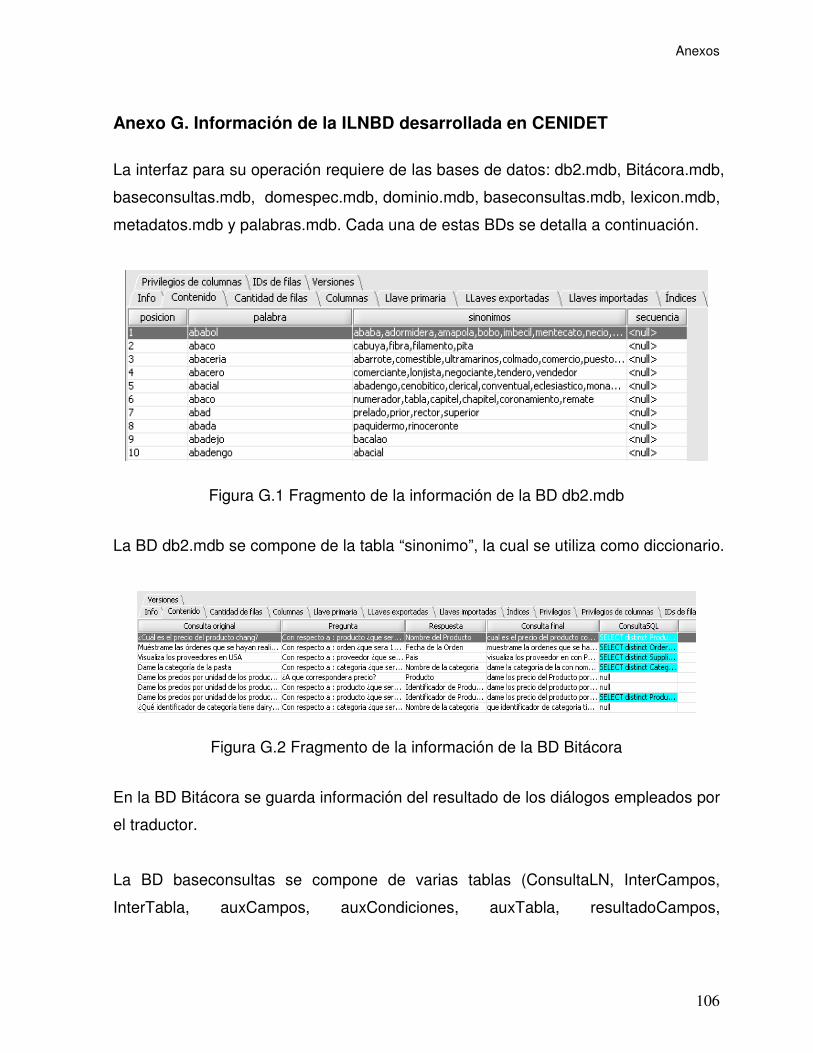
Anexos
106
Anexo G. Información de la ILNBD desarrollada en CENIDET
La interfaz para su operación requiere de las bases de datos: db2.mdb, Bitácora.mdb,
baseconsultas.mdb, domespec.mdb, dominio.mdb, baseconsultas.mdb, lexicon.mdb,
metadatos.mdb y palabras.mdb. Cada una de estas BDs se detalla a continuación.
Figura G.1 Fragmento de la información de la BD db2.mdb
La BD db2.mdb se compone de la tabla “sinonimo”, la cual se utiliza como diccionario.
Figura G.2 Fragmento de la información de la BD Bitácora
En la BD Bitácora se guarda información del resultado de los diálogos empleados por
el traductor.
La BD baseconsultas se compone de varias tablas (ConsultaLN, InterCampos,
InterTabla, auxCampos, auxCondiciones, auxTabla, resultadoCampos,
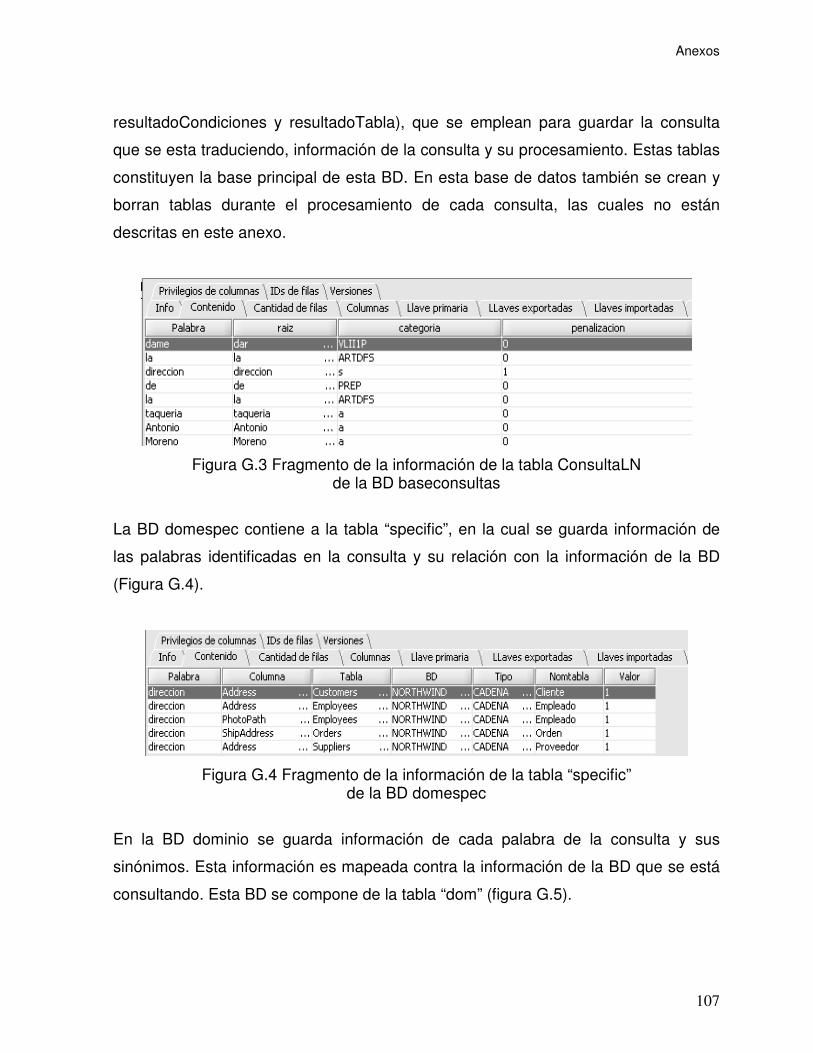
Anexos
107
resultadoCondiciones y resultadoTabla), que se emplean para guardar la consulta
que se esta traduciendo, información de la consulta y su procesamiento. Estas tablas
constituyen la base principal de esta BD. En esta base de datos también se crean y
borran tablas durante el procesamiento de cada consulta, las cuales no están
descritas en este anexo.
Figura G.3 Fragmento de la información de la tabla ConsultaLN de la BD baseconsultas
La BD domespec contiene a la tabla “specific”, en la cual se guarda información de
las palabras identificadas en la consulta y su relación con la información de la BD
(Figura G.4).
Figura G.4 Fragmento de la información de la tabla “specific” de la BD domespec
En la BD dominio se guarda información de cada palabra de la consulta y sus
sinónimos. Esta información es mapeada contra la información de la BD que se está
consultando. Esta BD se compone de la tabla “dom” (figura G.5).

Anexos
108
Figura G.5 Fragmento de la información de la tabla “dom” de la BD dominio
La BD “lexicon” se compone de las tablas: “lexico” y “sustantivos”, en las cuales se
guarda información léxica de palabras.
Figura G.6 Fragmento de la tabla “lexico” de la BD “lexicon”

Anexos
109
Figura G.7 Fragmento de la tabla “sustantivos” de la BD “lexicon”
La BD “metadatos” se compone de las tablas: “MetadatosValores” y “Metadatos”, en
las cuales se guarda información de la BD consultada.
Figura G.8 Fragmento de la tabla “MetadatosValores” de la BD metadatos
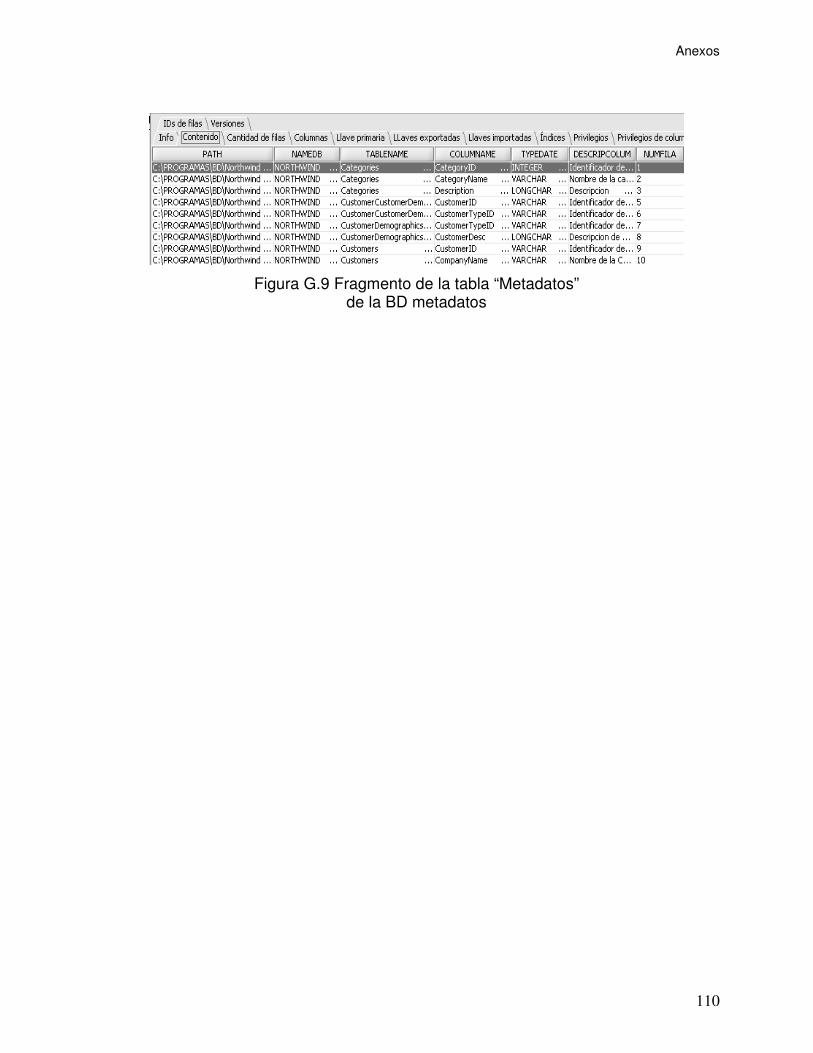
Anexos
110
Figura G.9 Fragmento de la tabla “Metadatos” de la BD metadatos

Anexos
111
Anexo H. Instalación de la ILNBD
Para instalar la ILNBD con administrador de diálogo se deben seguir los siguientes
pasos:
1. Instalación del software general.
• Desempaquetar el servidor de aplicaciones tomcat:
C:\java\apache-tomcat-6.0.13.zip
• Instalar el jdk de java:
C:\jdk-1_5_0_11-windows-i586-p.exe
• Instalar el jre de java:
C:\jre-1_5_0_11-windows-i586-p.exe
2. Instalación de variables de ambiente
• Crear la variable de ambiente JAVA_HOME:
(1) Acceder a mi PC y presionar botón derecho para acceder al menú de
propiedades:
Figura H.1 Acceso a propiedades de entorno
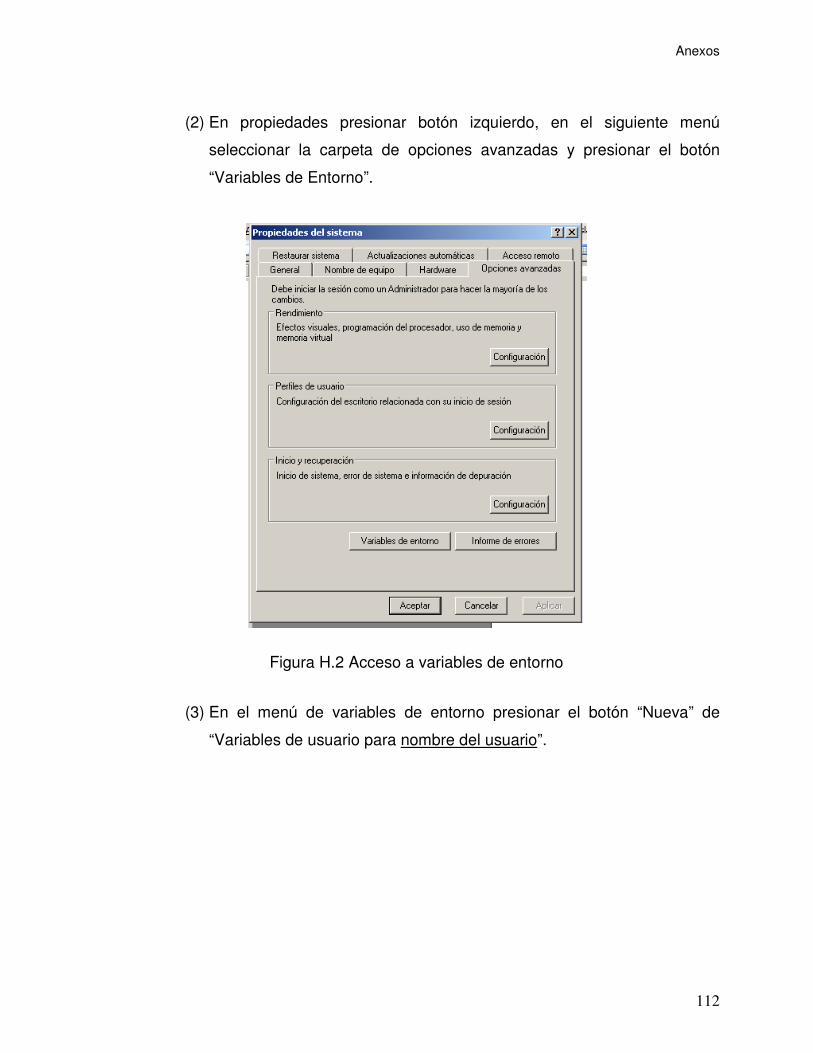
Anexos
112
(2) En propiedades presionar botón izquierdo, en el siguiente menú
seleccionar la carpeta de opciones avanzadas y presionar el botón
“Variables de Entorno”.
Figura H.2 Acceso a variables de entorno
(3) En el menú de variables de entorno presionar el botón “Nueva” de
“Variables de usuario para nombre del usuario”.
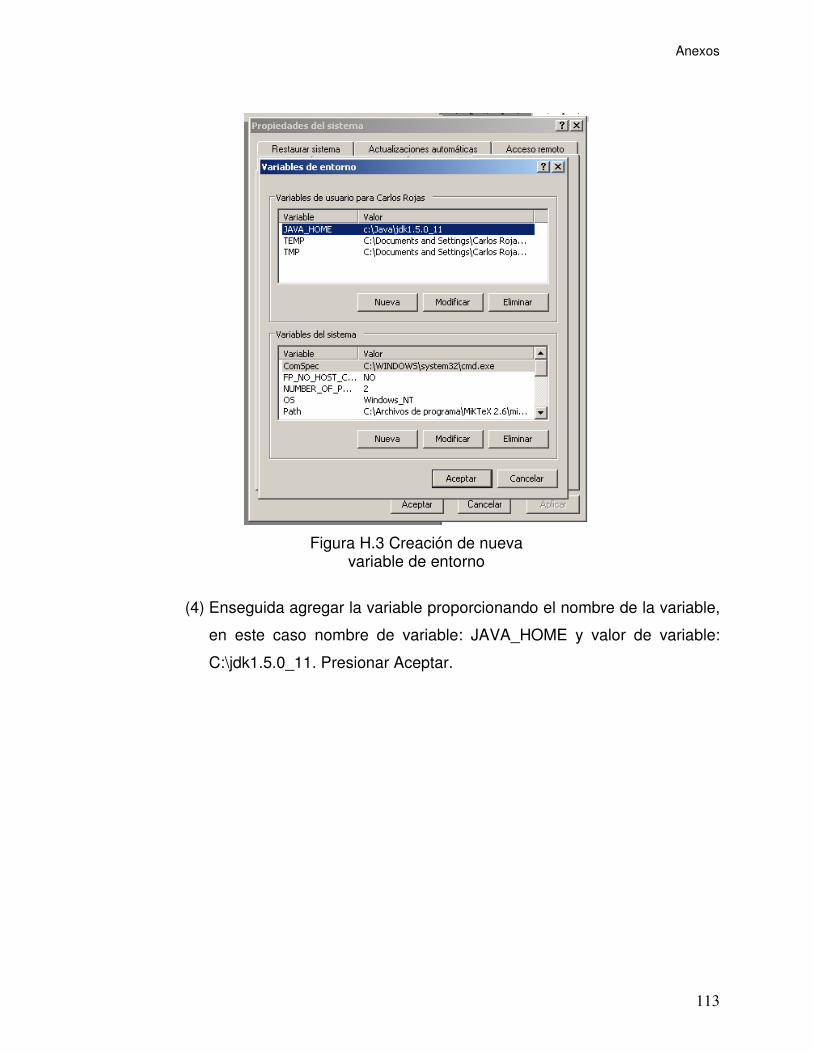
Anexos
113
Figura H.3 Creación de nueva variable de entorno
(4) Enseguida agregar la variable proporcionando el nombre de la variable,
en este caso nombre de variable: JAVA_HOME y valor de variable:
C:\jdk1.5.0_11. Presionar Aceptar.

Anexos
114
Figura H.4 Agregar nueva variable de entorno
(5) En el menú inferior seleccionar la variable del sistema “Path” y
presionar el botón “Modificar”.
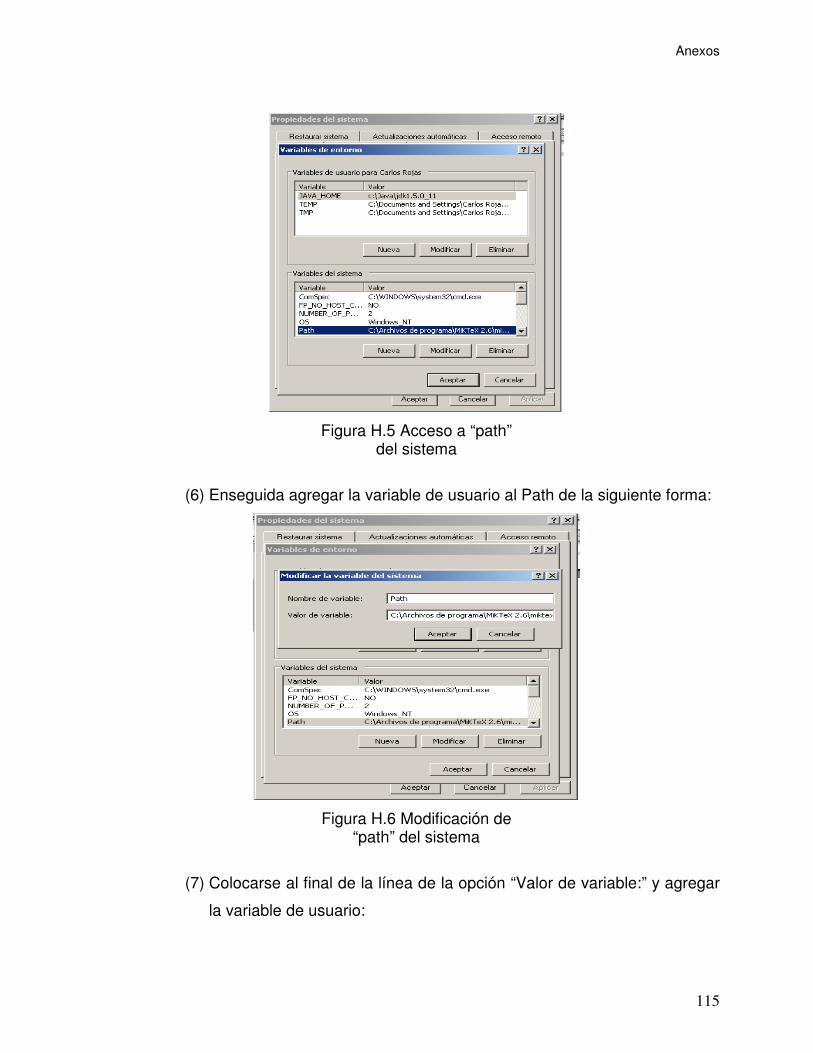
Anexos
115
Figura H.5 Acceso a “path” del sistema
(6) Enseguida agregar la variable de usuario al Path de la siguiente forma:
Figura H.6 Modificación de “path” del sistema
(7) Colocarse al final de la línea de la opción “Valor de variable:” y agregar
la variable de usuario:

Anexos
116
;%JAVA_HOME%\jre\bin;%JAVA_HOME%\jre\lib.
Presionar Aceptar y reiniciar el sistema para que tome estos valores.
3. Dar de alta orígenes de datos.
Utilizando “Herramientas administrativas” del panel de control de Windows,
ejecutar el programa “Orígenes de datos ODBC” y dar de alta las BDs
siguientes: bdatis, Bitacora, consultas, contar, diccionario, domcon, domespec,
dominio, grafo, lexicon, metadatos, northwind, palabra, Pubs y sinonimo.
4. Instalación de la herramienta.
• Una vez instalado el software y las variables de ambiente (en caso de instalar
las que s e requieran), la instalación del proyecto consistirá en desempaquetar
el archivo traductor.jar dentro de la carpeta siguiente:
C:\Java\apache-tomcat-6.0.13\webapps.
• Crear la carpeta “Traductor” en el directorio raíz: C:\Traductor.
5. Ejecutar el programa.
• Iniciar el servidor de aplicaciones desde una ventana del sistema:
Figura H.7 Ruta para iniciar servidor de aplicaciones

Anexos
117
Teclear startup para iniciar y presiona enter.
• Para cerrar el servidor de aplicaciones, teclear shutdown desde el mismo
directorio de la ventana anterior: c:\Java\apache-tomcat-6.0.13\bin>shutdown.
• Abrir un navegador y teclear la dirección: http://localhost:8080/traductor.

Anexos
118
Anexo I. Diagrama de clases de la ILNBD desarrollada en CENIDET con traductor
Figura I.1 Diagrama de clases de la interfaz desarrollada en CENIDET con administrador de diálogo

Anexos
119
Anexo J. Resultados publicados
Con los resultados de este trabajo de investigación se publicaron los artículos:
•••• PAZOS R., SANTAOLAYA S., ROJAS, P., PÉREZ, O. Shedding Light on a
Troublesome Issue in NLIBDs: Word Economy in Query Formulation, Lecture
Notes in Computer Science, Vol. 5246, pp. 641-648, 2008.
•••• PAZOS R., SANTAOLAYA S., ROJAS, P., MARTÍNEZ, F., PÉREZ, O, CRUZ,
R. Domain Independent Dialog Processes for Solving the Word-Economy
Problem in a NLIDB, ACS 2008, Polish Journal of Environmental Studies, 2008.

Anexos
120
Anexo K. Problemas en la ILNBD desarrollada en CENIDET
A continuación se presentan algunos problemas en la ILNBD desarrollada en
CENIDET.
Consulta Problemas
Muéstrame los vuelos de DFW a DEN en Delta
Interpreta la palabra “DEN” como “dar”.
Listar el nombre del producto que cueste 10
Traduce la consulta en forma errónea: SELECT Products.ProductName FROM
Products WHERE
((Products.QuantityPerUnit LIKE
'%cueste%') AND (Products.UnitPrice =
10)). ¿Cuáles son los nombres de las compañías que estén situadas en Mexico DF?
Traduce la consulta en forma errónea: SELECT Customers.CompanyName FROM
Customers WHERE ((Customers.Country
LIKE 'Mexico') OR (Customers.Region
LIKE 'DF')). Muestra la descripción del producto Aniseed Syrup Dame la fecha de cumpleaños de ¿? Andrew Fuller
En el proceso de traducción no se identifican campos, por lo cual las consultas no pueden ser traducidas.
Consulta Problemas
Dame la clase de comida que dan en los vuelos con destino a Baltimore y Tempoal y "Poza Rica
No existe la palabra comida en la BD lexicon, existe la palabra comer en la tabla lexico. Esto ocasiona que esta palabra no sea identificada como columna o tabla y el proceso de traducción en consultas con esta palabra ocasiona problemas.
Dame la aplicación del mínimo de permanencia igual a “3”.
Problemas en la identificación de sinónimos. Cambia la palabra “mínimo” por “pequeño”, lo cual ocasiona que cambie la semántica de la consulta y se convierte a “Dame la aplicación del pequeño de permanencia igual a 3.

Anexos
121
Debe revisarse cuidadosamente el proceso para describir el nombre de las columnas
al español en las tablas de la BD analizada. Cuando una columna incluye en su
nombre una palabra que puede ser catalogada como tabla o columna, el proceso de
traducción se complica. Por ejemplo, en la tabla Vuelos (Flight) de la BD ATIS
existen las columnas to_airport y from_airport, entonces al crear las descripciones en
español se tienen “aeropuerto origen” y “aeropuerto destino”; además, la palabra
“aeropuerto” existe también en la BD como una tabla, lo cual ocasiona que el
traductor encuentre problemas al procesar una consulta que incluya estos datos.
Por ejemplo, en la consulta “Dame los vuelos de ATL a SFO”, al traducir la consulta,
ésta quedaría como “Dame los vuelos del aeropuerto origen ATL al aeropuerto
destino SFO”. El proceso de traducción analiza cada palabra y la etiqueta como
tabla, columna, valor, preposición o conjunción. Al etiquetar esta consulta, en el
proceso de traducción, el traductor asocia el valor “ATL” a la tabla “Aeropuerto” en
lugar de la tabla “Vuelos”. Este problema puede ser resuelto por la interfaz con
procesos de diálogo. Sin embargo, el número de procesos de diálogo que se
generan es mayor comparado con la consulta formulada en la forma “Dame los
vuelos con origen ATL y destino SFO”, es decir, las descripciones de las columnas
“”to_airport” y “from_airport” en la tabla Vuelos deberían ser descritas como “origen” y
“destino”, para que el traductor no tenga problemas o genere más diálogos.
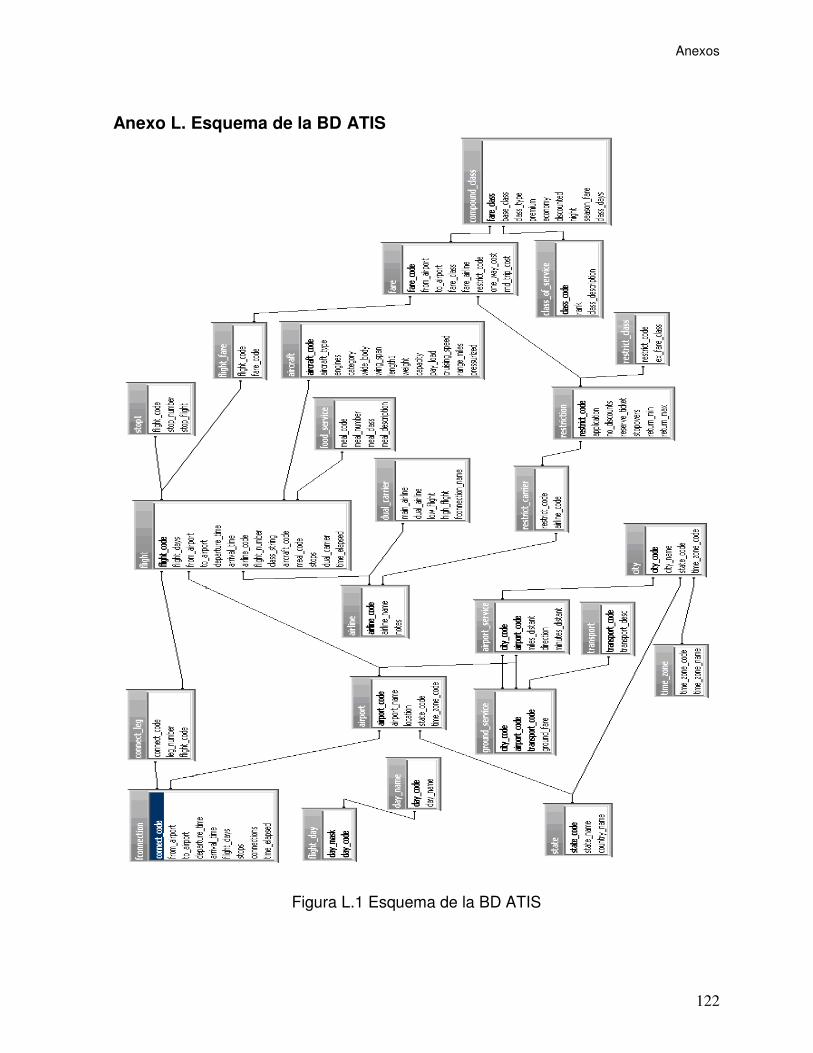
Anexos
122
Anexo L. Esquema de la BD ATIS
Figura L.1 Esquema de la BD ATIS