t he f orgotten f ill factor optimize performance minimize maintenance reduce problems
TRANSCRIPT

THE FORGOTTEN FILL FACTOROptimize Performance
Minimize Maintenance
Reduce Problems

ABOUT ME
SQL Server MCT Member of the Belgian Microsoft Extended
Expert Team

PURPOSE OF THIS SESSION

WHAT IS A FILLFACTOR
Optional INT value
Specifies empty pages in an Index
Server-wide default is 0

VISUAL
Good Fill Factor Bad Fill Factor

IMPACT ON PERFORMANCE

ADVISE OR HELP?
The result of this is: Try and Error “Forget” it “Default” it “Maintain” it No/Bad Indexes
Some exception examples: Very good whitepaper by Ken Lassesen Good blog post by Pinal Dave

WHY SHOULD WE CARE?
Increased Read Times Increased Write Times Increased CPU usage Index becomes useless Full Table Scans Index Maintenance comes under pressure Bad balance between main resources ! Compression Increases the problem !

NOW LETS START THE DIVE TO LEVEL 400

LET’S FOCUS ON READ TIME
Serial Read times: 0,5 ms Random Read times: Between 3,5 and 15 ms 1 non serial read, delays read speed with
13% 98 * 0,5 + 2*3,5 = 56 ms vs. 50 ms.
(98 serial reads, move to the disjoint one + move back)
• Less important with SSD’s!
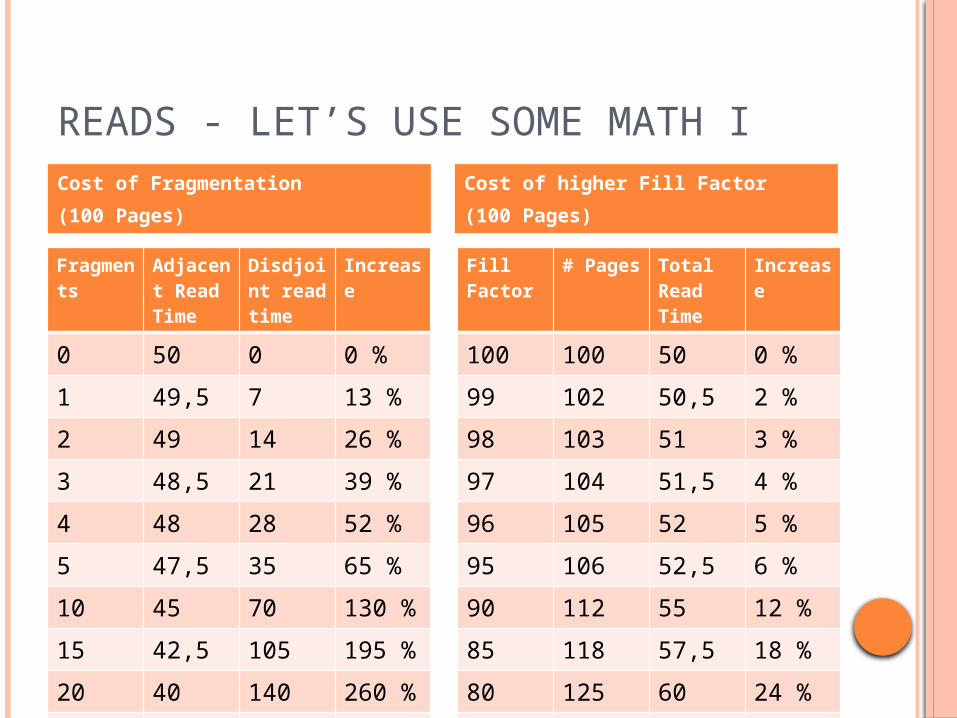
READS - LET’S USE SOME MATH I
Fragments
Adjacent Read Time
Disdjoint read time
Increase
0 50 0 0 %
1 49,5 7 13 %
2 49 14 26 %
3 48,5 21 39 %
4 48 28 52 %
5 47,5 35 65 %
10 45 70 130 %
15 42,5 105 195 %
20 40 140 260 %
40 30 280 520 %
Fill Factor
# Pages
Total Read Time
Increase
100 100 50 0 %
99 102 50,5 2 %
98 103 51 3 %
97 104 51,5 4 %
96 105 52 5 %
95 106 52,5 6 %
90 112 55 12 %
85 118 57,5 18 %
80 125 60 24 %
60 150 70 48 %
Cost of Fragmentation
(100 Pages)
Cost of higher Fill Factor
(100 Pages)

LET’S FOCUS ON WRITE TIMES
Similar behavior – Depends on Buffer Time to write to one extent : 0,3 ms Sequential write is 70% faster then Random
in Throughput Impact is even bigger on SSD’s The larger the subset, the bigger the impact
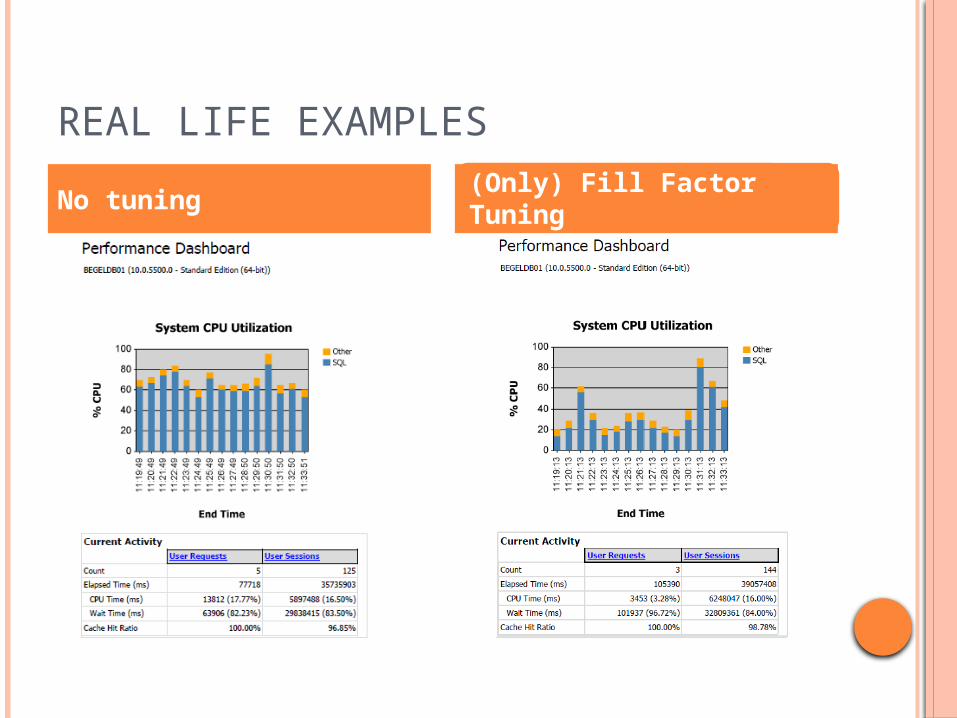
REAL LIFE EXAMPLES
No tuning (Only) Fill Factor Tuning(Only) Fill Factor Tuning

LET’S START THE CALCULATIONS

PREREQUISITES
We will focus on Read times Focus on OLTP Databases All other parameters will benefit as well
But increase is more difficult to calculate Is to dependent from incalculable parameters
Focus Highest possible Fill factor Lowest possible Fragmentation Highest possible Page fill ratio Acceptable Maintenance

NARROW DOWN THE PROBLEM INDEXES
Only tables that are large enough (> 8MB) Skip all Indexes where first Key is
Monotonically increasing Focus on:
Default Fill Factor High Fragmentation Average Fragmentation, High Page fill Low Fragmentation, Low Page fill Fill Factor < 100, Read Only Partition

IDENTIFY YOUR INDEX KEYS PER TYPE

THE EASY ONES…SINGLE KEY INDEXES - MONOTONIC
Monotonic Increasing Keys Identity Timestamp Rowversion
Careful with Date
Only if not assigned by code, but assigned by function
Rows containing extendable data types If these fields are updated and become larger, a
page split will occur
Fill Factor should always be 100% Empty pages will never be used

THE OTHERS…WILL HAVE FRAGMENTATION
And will need maintenance!

FIRST ACTIONS (READ AS QUICK-FIX)
Use Table Partitioning where possible Enterprise & Not every partition needs the same fill factor
single_partition_rebuild_index_option Offline!
Use filegroup/Database growth as initial guess Backup’s will give you an initial figure
You will need exact figures later on though
Narrow down to the problem Indexes Write a sys. Query to find:
Schema Name; Table Name; Index Name Key size, Index Size Fragmentation, Page Space Usage Current Fill Factor ! Partition !

CALCULATE POSSIBLE FILL FACTORS
What’s needed Key Size
How FLOOR(8060 / Key Size) = # Possible values
Calculates the array with possible FF Values Example
Int key (4 bytes) => 2015 possible FF values Only 100 are available for usage

KEY INDEXES – (SEMI)-SEQUENTIAL
Because they sometimes behave predictable We can still use statistics
Calculate possible fill factors Estimate the fragmentation likeliness Plot the possible fill factors vs. the Fragmentation
likeliness Achieve low fragmentation without wasting to much
space.

KEY INDEXES – (SEMI)-SEQUENTIAL
Sequential, but non unique Semi-Sequential, but unique Semi-Sequential, Non unique Key Features
High Selectivity. Gets inserted out of order with small derivations.
Or has multiple entries for the same key. Behaves predictable (Gaussian)

CALCULATE MAX POSSIBILITY OF FRAGMENTATION
Non unique sequential Sample the Key values
Select Count(Key),Key From Table Group by Key Order by Count(Key) Desc
Returns the maximum possible occurrence (Collisons)
Unique Semi-sequential Do we have a sequential Key? Use it to find the max out of sequence key values
(Read Fragmentation) Else
Do we have the out of sequence probability ratio? Can be used as initial growth ratio
Treat it as random

SIMPEL SEQUENTIAL CALCULATIONS
(8060)/([KeySize]) = #Entries/page Be carefull with
nullable datatypes Expandable Datatypes
[KeySize]*[MaxOccurence] = MaxEntriesPerKey
([KeySize]*[MaxOccurence])*(1-MaxFragmentation)=BestEntriesKey

INDEXES – RANDOM / CHAOS
Now it gets interesting We need Index data, to tune the index itself Key Indicators (no points for guessing)
The current fill factor Capability to cope with randomness & growth
Current Index Page fill ratio Current page usage Effectiveness of growth prediction
Current index Fragmentation level Indication of the real randomness & Growth
Current Table Growth ratio / Maintenance interval Amount of Rows as this influences the growth ratio Data type of the first column of the Index
Example GUID vs. Int

CALCULATE MAX SUPPORTED GROWTH RATIO FOR A SPECIFIC FILL FACTOR

DEMO TIMELET’S GO INTERACTIVE

NEVER FORGET
Page fill ratio Indication of effectiveness
Fill Factor improves Insert speeds But
Is badly used if the forseen space isn’t used! If badly used will
Increase read times Increase storage usage Decrease performance
Optimise for insert Be carefull with rebuilds
Partition Optimise for read

TIME FOR DECOMPRESSION