systap&/&bigdata®& -...
TRANSCRIPT

bigdata® Presented to CSHALS 2/27/2014
SYSTAP / bigdata®
Open Source High Performance Highly Available
1 http://www.bigdata.com/blog

bigdata® Presented to CSHALS 2/27/2014
SYSTAP, LLC
Customers
• OEMs and VARs • Government • TelecommunicaHons • Health Care • Network Storage • Finance • Design and Manufacturing • CollaboraHon & KM Portals
Products and Services
• Bigdata® RDF database – Dual license (GPLv2, commercial) – Training – Support – Custom Services
• Advanced Research Projects
Small Business, Founded 2006 100% Employee Owned

bigdata® Presented to CSHALS 2/27/2014
3 http://www.bigdata.com/blog
The data – it’s about the data

bigdata® Presented to CSHALS 2/27/2014
4 http://www.bigdata.com/blog
Bigdata 1.3 • Fast, scalable, open source, standards compliant database
-‐ Single machine to 50B+ triples or quads -‐ Plus a dedicated statement level metadata mode (RDR – see web site)
-‐ Scales horizontally on a cluster -‐ SPARQL 1.1 Query, Property Paths, Update, Federated Query, etc. -‐ NaHve RDFS+ inference. -‐ Vectored query engine.
-‐ High Availability -‐ RDF Graph Mining

bigdata® Presented to CSHALS 2/27/2014
Related “Graph” Technologies
SYSTAP™, LLC © 2006-2013 All Rights Reserved
5 http://www.bigdata.com/blog
Redpoint repositions existing technology. MPGraph compares favorably with high end hardware solutions from YARC, Oracle, and SAP, but is open source and uses commodity hardware.
Pair up bigdata and MPGraph
STTR

bigdata® Presented to CSHALS 2/27/2014
New Products and Services
Redpoint Graph Database • Larger market, same tech.
– 2x faster than neo4j. – Graph Traversal APIs – Efficient Link Ajributes
• Open Source (SubscripHons) • Highly Available
MPGraph • GPU graph mining library
– 5-‐500x faster than graphlab – 50,000x faster than graphdbs.
• Open Source • DARPA funding • DisrupHve technology
– Early adopters – Huge ROIs
SYSTAP™, LLC © 2006-2013 All Rights Reserved
6 http://www.bigdata.com/blog

bigdata® Presented to CSHALS 2/27/2014
SYSTAP™, LLC © 2006-2012 All Rights Reserved
7 http://www.bigdata.com/blog
Manufacturing Product Data is Heterogeneous …and difficult to find, re-‐use, and share
Autodesk PLM360

bigdata® Presented to CSHALS 2/27/2014
Road Map • Column-‐wise
– Faster load and query. – Increased data density and scaling. – IntegraHon point with GPU (shared data).
• MulH-‐node GPU – 2D decomposiHon (DARPA STTR)
• Performance opHmizaHon for scale-‐out – Reducing latency and increasing throughput – IntegraHon point for SPARQL acceleraHon and 2D GPU cluster.
• SPARQL on GPU – Query at 3 billion edges/second – Same underlying library, but horizontal scaling is NOT 2D.
SYSTAP™, LLC © 2006-2013 All Rights Reserved
8 http://www.bigdata.com/blog

bigdata® Presented to CSHALS 2/27/2014
Hadoop / bigdata® pipeline
SYSTAP™, LLC © 2006-2013 All Rights Reserved
9 http://www.bigdata.com/blog
Inference Cloud
HA Query Cloud
Durable Queue
Map/Reduce Layer
Durable Queue
+/- stmts
+/- stmts
BD Journals on PFS / HDFS
Linear scaling on query throughput
Scalable inference workload
Can be used for custom quads-mode inference strategies

bigdata® Presented to CSHALS 2/27/2014
High Availability • Shared nothing architecture
– Same data on each node – Coordinate only at commit
• Scaling – 50 billion+ triples or quads – Query throughput scales linearly
• Self healing – AutomaHc failover – AutomaHc resync amer disconnect – Online single node disaster recovery
• Online Backup – Online snapshots (full backups) – HA Logs (incremental backups)
• Point in Hme recovery (offline)
SYSTAP™, LLC © 2006-2013 All Rights Reserved
10 http://www.bigdata.com/blog
HAService
Quorum k=3
size=3
follower
leader
HAService
HAService

bigdata® Presented to CSHALS 2/27/2014
Self-‐Healing
HAService
Quorum k=3
size=2
follower
leader
HAService
HAService
join
synchronize
Service can fail for a variety of reasons: • JVM down • Machine down • Network parHHon • Zookeeper Hmeout • Discovery failure • Wrong commit point • Severe clock skew
(delta)
• Goal is to guarantee eventual consistency without allowing intermediate illegal states.
• Persistent state of the service must remain self-‐consistent
bigdata® Presented to CSHALS 2/27/2014
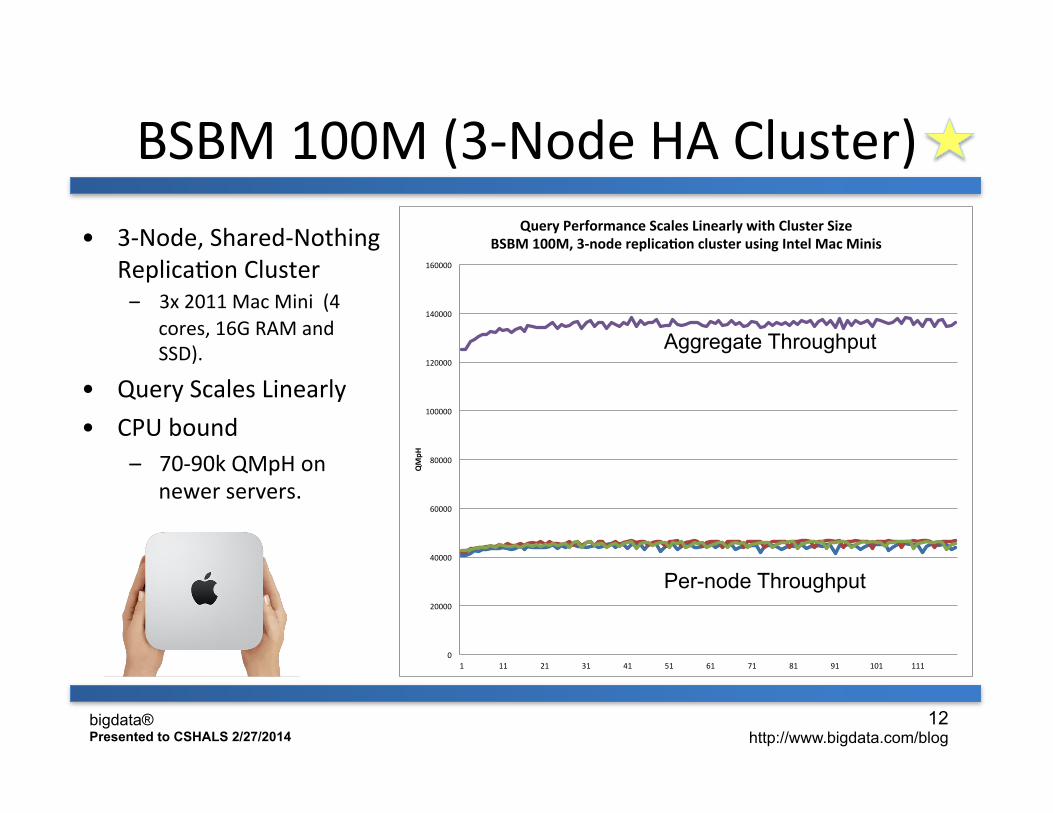
BSBM 100M (3-‐Node HA Cluster)
12 http://www.bigdata.com/blog
0"
20000"
40000"
60000"
80000"
100000"
120000"
140000"
160000"
1" 11" 21" 31" 41" 51" 61" 71" 81" 91" 101" 111"
QMpH
%
Query%Performance%Scales%Linearly%with%Cluster%Size%BSBM%100M,%3@node%replicaBon%cluster%using%Intel%Mac%Minis%• 3-‐Node, Shared-‐Nothing
ReplicaHon Cluster – 3x 2011 Mac Mini (4
cores, 16G RAM and SSD).
• Query Scales Linearly • CPU bound
– 70-‐90k QMpH on newer servers.
Aggregate Throughput
Per-node Throughput
bigdata® Presented to CSHALS 2/27/2014
● ●
●
●
●
● ●
●
●● ●
● ●●●● ● ●
● ●
●
●● ●
●●
●
●
●●
●●●
●
●●
●
●
101
102
103
2002 2004 2006 2008 2010 2012Date
GFL
OPS
Precision● SP
DP
Vendor●
●
●
●
AMD (GPU)
NVIDIA (GPU)
Intel (CPU)
Intel Xeon Phi
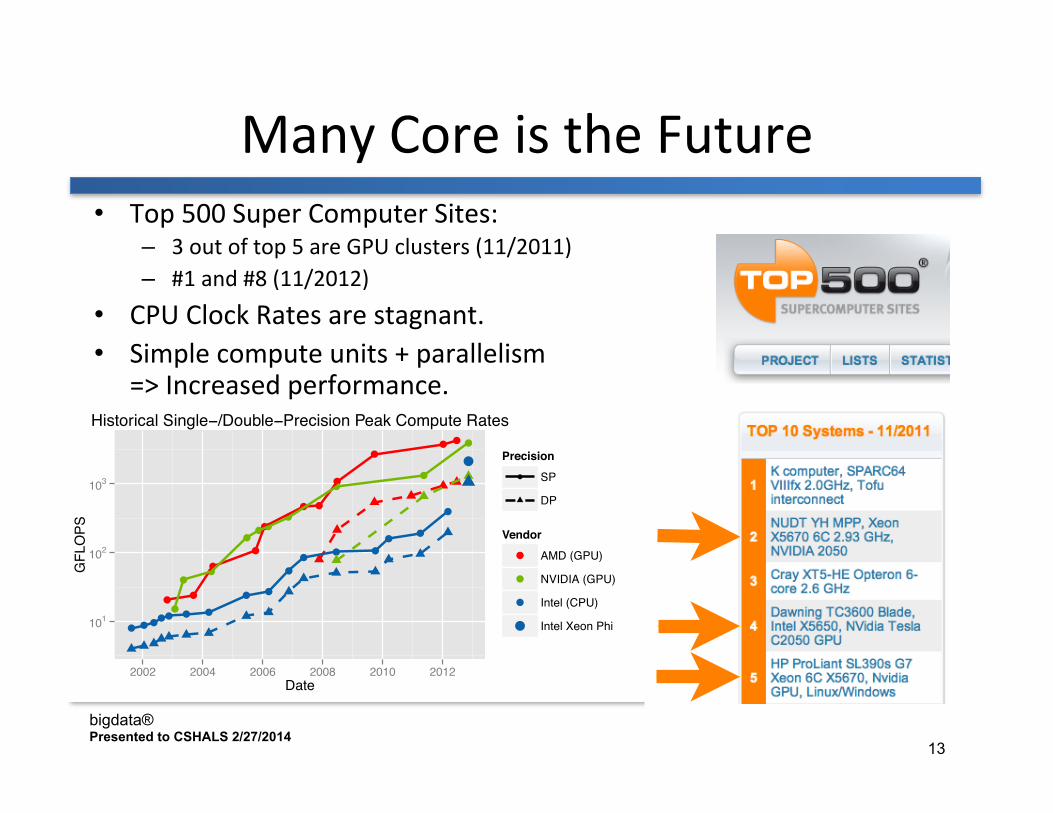
Historical Single−/Double−Precision Peak Compute Rates
Latest Top500
• Why?
• FLOPS/m2
• FLOPS/$
• FLOPS/W
Many Core is the Future • Top 500 Super Computer Sites:
– 3 out of top 5 are GPU clusters (11/2011) – #1 and #8 (11/2012)
• CPU Clock Rates are stagnant. • Simple compute units + parallelism
=> Increased performance.
13

bigdata® Presented to CSHALS 2/27/2014
14
GPUs – A Game Changer for Graph AnalyHcs?
0 500
1000 1500 2000 2500 3000 3500
1 10 100 1000 10000 100000
Millio
n Tr
aver
sed
Edge
s per
Se
cond
Average Traversal Depth
NVIDIA Tesla C2050 Multicore per socket Sequential
• Graphs are everywhere in data, also a powerful data model for federaHon
• GPUs may be the technology that finally delivers real-‐Hme analyHcs on large graphs
• 10x speedup over CPU • 10x DRAM bandwidth
• This is a hard problem • Data dependent parallelism • Non-‐locality • PCIe bus is bojleneck
• Significant speed up over CPU on BFS • 3 billion edges per second on one GPU
(see chart). • Roadmap
• GPU accelerated vertex-‐centric graph mining plazorm.
• GPU accelerated graph query
0
1 1 2
1
1
2
2 2
2
1
3
2
3
2
1 2
2
Breadth-First Search on Graphs 10x Speedup on GPUs

bigdata® Presented to CSHALS 2/27/2014
GAS – a Graph-‐Parallel AbstracHon
• Graph-‐Parallel Vertex-‐Centric API ala GraphLab • “Think like a vertex”
• Gather: collect informaHon about my neighborhood
• Apply: update my value
• Scajer: signal adjacent verHces • Can write all sorts of graph algorithms this way
– BFS, SSSP, (Personalized) PageRank, Connected Component, Triangle CounHng, Max Flow, (Approximate) Betweenness-‐Centrality, k-‐means clustering, Loopy Belief PropagaHon, etc.

bigdata® Presented to CSHALS 2/27/2014
Graph Mining on GPU Clusters
SYSTAP™, LLC © 2006-2012 All Rights Reserved
16 http://www.bigdata.com/blog
• 2D parHHoning (aka vertex cuts) – Compute grid defined over virtual nodes. – Patches assigned to virtual nodes based on source
and target idenHfier of the edge.
• Minimizes the communicaHon volume. – All messages in row or col of grid.
• One hop in-‐edge neighborhood is a column. • One hop out-‐edge neighborhood is a row. • For the diagonal only, the source and target
verHces are in the same patch.
• Batch parallel Gather in row, Scajer in column. – ComputaHon decomposed and
distributed using binary (albian) operator (sum, min, max, etc.)
– Local aggregates combined at caller. in-‐edges
out-‐edges
target vertex ids
Sou
rce
verte
x id
s

bigdata® Presented to CSHALS 2/27/2014
Similar models, different problems • Graph query and graph analyHcs (traversal/mining)
– Related data models – Very different computaHonal requirements
• Many technologies are a bad match or limited soluHon – Key-‐value stores (bigtable, Accumulo, Cassandra, HBase) – Map-‐reduce
• AnH-‐pajern – Dump all data into “big bucket”
• Storage and computaHon pajerns must be correctly matched for high performance.
• High performance requires – Query: Locality (1D parHHoning, mulHple indices, query opHmizaHon, and
execuHon constrained joins to read as lijle data as possible). – AnalyHcs: Parallelism, memory bandwidth, 2D parHHoning.
SYSTAP™, LLC © 2006-2013 All Rights Reserved
17 http://www.bigdata.com/blog

bigdata® Presented to CSHALS 2/27/2014
QuesHons? Bryan Thompson SYSTAP, LLC [email protected] 202/462-‐9888
SYSTAP™, LLC © 2006-2013 All Rights Reserved
18 http://www.bigdata.com/blog

bigdata® Presented to CSHALS 2/27/2014
Unifying Architecture (example)
SYSTAP™, LLC © 2006-2012 All Rights Reserved
19 http://www.bigdata.com/blog
Unified Data Model
Streams
Unstructured
Semi-structured
Structured
Heterogeneous Data Sources as Input
Federate
Aggregate
Resource Centric (Linked Data)
Discover
Unified Compute and Storage Model
Data Bus
Update Query Database (SSD)
- Business Logic - Web Clients - Peer Systems
Graph Mining (GPUs)
- Aggregated –or– federated - High-level Query (SPARQL)
- Graph traversal / mining - “Think like a vertex”
Data Cache
- Key Value Stores