synthetic data generation for statistical testing
TRANSCRIPT

.lusoftware verification & validationVVS .lu
software verification & validationVVS
Synthetic Data Generation for Statistical Testing
Ghanem Soltana, Mehrdad Sabetzadeh, and Lionel C. Briand
SnT Centre for Security, Reliability and Trust University of Luxembourg, Luxembourg
ASE 2017

Context and motivation
2

Context
3
• Collaboration withthe Government of Luxembourg
-CTIE: Government’s IT Centre
• New tax system under development: operationalization of the administrative procedures envisaged by the tax law
• System needs to be reliable

4
Reliability requirements
• Most data-centric systems, such as administration and financial systems, are subject to reliability requirements
- Example of a reliability requirement for the tax system: the probabilitythat a failure occurs in tax return calculation shall not exceed 10-3

5
Usage-based statistical testing
• Testing driven by the expected usage of a system
• Mimic system behavior in realistic circumstances
• Aimed at assessing system reliability and prioritizing failures that are more likely to occur during operation
• Uses operational profiles to characterize current or anticipated system usage
-For example, an operation profile can be a set of operations and their associated probabilities of occurrence

6
Systemunder test
Input to
Test data
Observed behavior/ results
Detect and analyze failures
Does system meet its reliability
requirements? ✗
Statistical testing for data-centric systems
When possible, it is more practical to
use real data

7
Motivation for generating synthetic data
• Real data might have gaps and structural mismatches (when compared to the data that will be processed by the system)
• Access to real data might be restricted
• Real data might be non-existent!

Test data
Synthetic test data requirements
Real Synthetic
8
• Child care tax deduction example
• Test data should be “statistically representative” (realistic circumstances)
Should be representative of the actual or anticipated
system usage

• Child care tax deduction example
• Such data help reasoning about robustness rather than reliability
Test data
Must be logically and structurally well-formed
to detect meaningful failures
Synthetic test data requirements
Real Synthetic
9
{Logically invalid
- receives_child_allowance = trueT1: ResidentTaxPayer
C1: Child
- receives_child_allowance = falseT1: ResidentTaxPayer
C1: Child
- receives_child_allowance = trueT1: ResidentTaxPayer
- receives_child_allowance = falseT1: ResidentTaxPayer

10
Objective
Test data for statistical testing of data-centric systems
Valid Representative
How to automatically generate test datathat meet both requirements at the same
time in a scalable manner?

11
Data generation at a glance
• Validity
• Representativeness
Exhaustive search Metaheuristic-search - Constraint programming [Cabot et al., JSS 2014]- Alloy[Sen et al., ICMT 2019]
- Alternating Variable Method (AVM)[Ali et al., TSE 2013][Ali et al., ESE 2016]
Heuristics Sampling - Rule-based[Hartmann et al., SmartGridComm 2014]- Model-based[Soltana et al., SoSyM 2016]
- Boltzmann's random sampling[Mougenot et al., ECMDA-FA 2009]

ApproachApproach
12

13
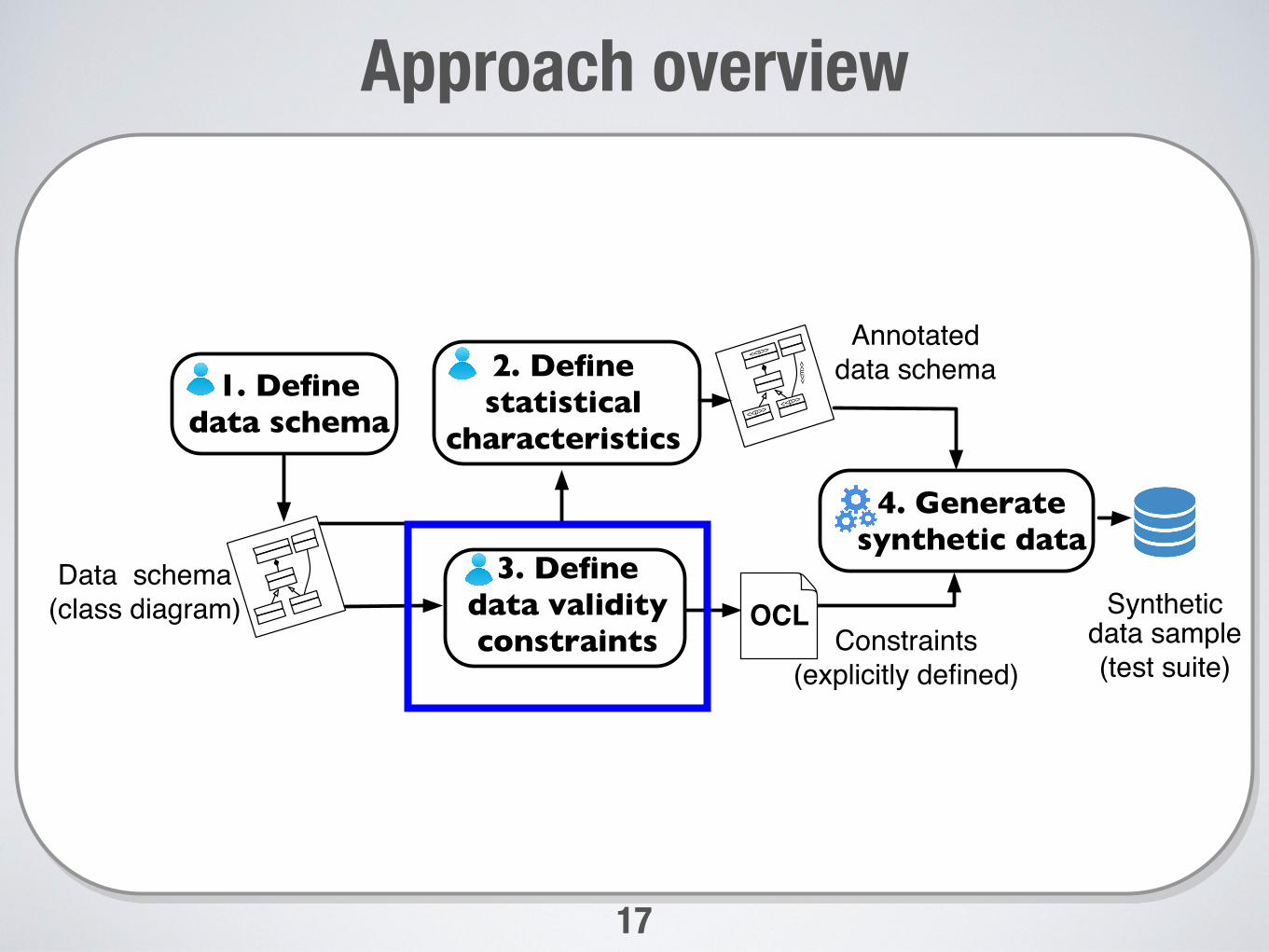
Approach overview
Synthetic data sample(test suite)
Data schema(class diagram)
2. Definestatistical
characteristics
Annotateddata schema
<<s>>
<<p>>
<<p>>
<<m
>>
3. Define data validity constraints Constraints
(explicitly defined)
4. Generate synthetic data
OCL
1. Define data schema

14
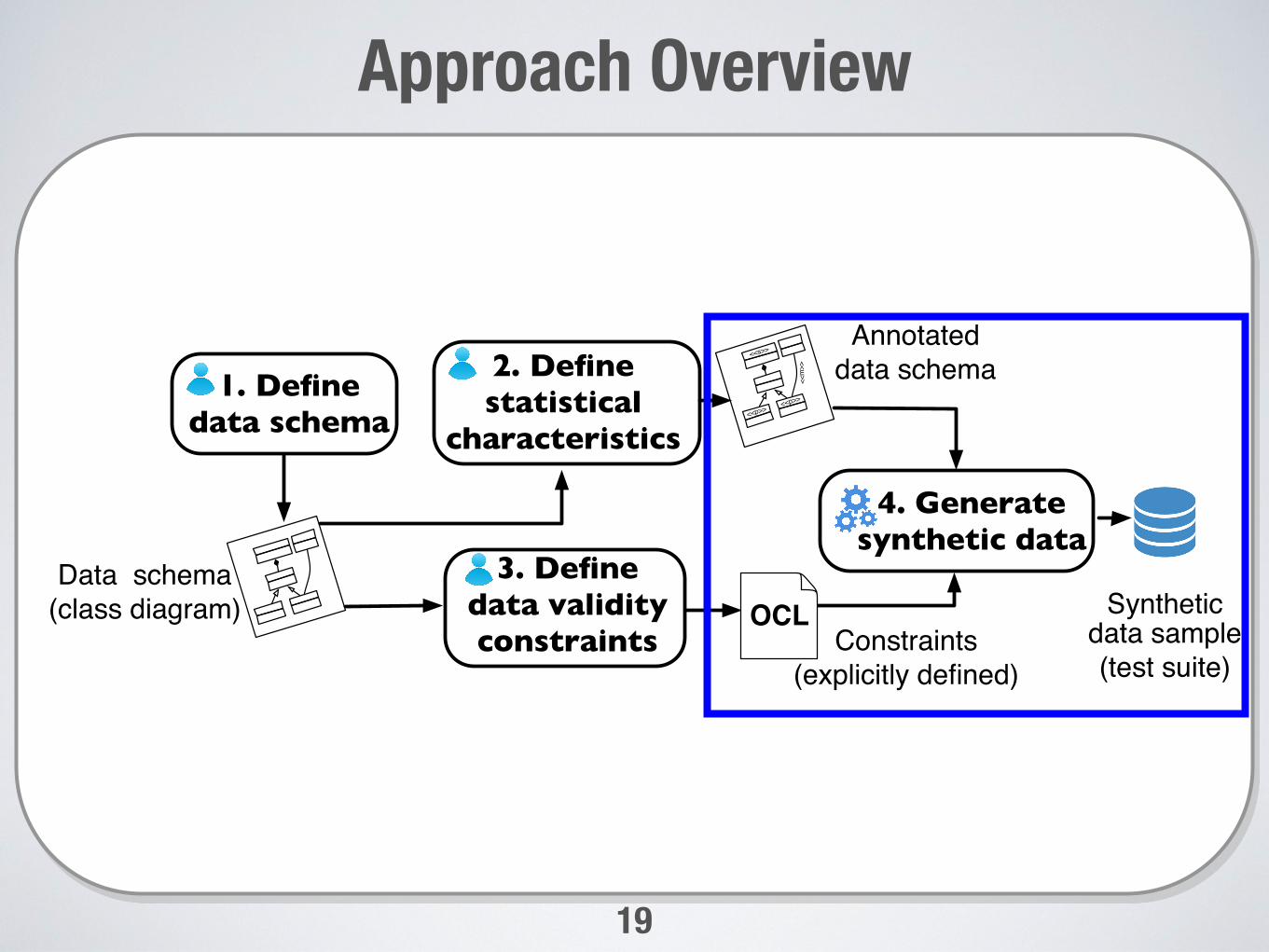
Approach overview
Synthetic data sample(test suite)
Data schema(class diagram)
2. Definestatistical
characteristics
Annotateddata schema
<<s>>
<<p>>
<<p>>
<<m
>>
3. Define data validity constraints Constraints
(explicitly defined)
4. Generate synthetic data
OCL
1. Define data schema

15
The statistical characteristics of the data
[Soltana et al., SoSyM 2016]
• We use a UML profile for defining the statistical characteristics of the data
• The profile is composed of a set of statistical annotations (stereotypes)
UML profiles are a standard mechanism to extend UML models with additional modeling concepts

Relative frequencies
60% of income types are Employment, 20% are Pension, and the remaining 20% are Other
Income
Employment
«probabilistic type»{frequency: 0.6}
Pension
«probabilistic type»{frequency: 0.2}
Other
«probabilistic type»{frequency: 0.2}
(abstract)
[Soltana et al., SoSyM 2016]
16
17
Approach overview
Synthetic data sample(test suite)
Data schema(class diagram)
2. Definestatistical
characteristics
Annotateddata schema
<<s>>
<<p>>
<<p>>
<<m
>>
3. Define data validity constraints Constraints
(explicitly defined)
4. Generate synthetic data
OCL
1. Define data schema

18
Define data validity constraints
• We use OCL to define data validity constraints
• Some of the constraints are derived from the class diagram and its annotations
• The remaining constraints are explicitly defined by users
context Physical_Person inv implicit_annotations:
self.birth_year <= 2017 and self.birth_year >= 1917
context Physical_Person inv explicite1:
self.children->forAll(c| c.birth_year > self.birth_year + 16)
19
Approach Overview
Synthetic data sample(test suite)
Data schema(class diagram)
2. Definestatistical
characteristics
Annotateddata schema
<<s>>
<<p>>
<<p>>
<<m
>>
3. Define data validity constraints Constraints
(explicitly defined)
4. Generate synthetic data
OCL
1. Define data schema

20
Our strategy for generating data for statistical testing
Phase 1: Enforce all OCL validity constraints
All validity constraints OCL
Data schema annotated with
statistical distributions
<<s>>
<<p>>
<<p>>
<<m
>>
Valid data sample
Final data sample
Phase 2: Attempt to improve representativeness while
maintaining validity

21
Phase 1: generate logically valid test data
Create seed sample
Create valid sample
Seed sample with potential
logical anomalies
Valid data sample
All validity constraints OCL
Uses our heuristic data generator for producing
representative (but invalid) data sample
Uses a customized search-based OCL
solver
• The valid sample might not end up too far away from being representative, in turn making it easier to fix deviations from representativeness in phase 2

22
Phase 2: generate valid and representative test dataValid data
sample All validity constraints
Generate corrective constraints
Proposetweaked
instance model
Corrective constraints
Tweaked instance model
Final data sample
(for each instance model in the sample)
OCL
Uses the same search-based
OCL solverProvides cues, via “soft” OCL
constraints, on how an instance model should be tweaked so that
the representativeness of the whole data sample is improved
23
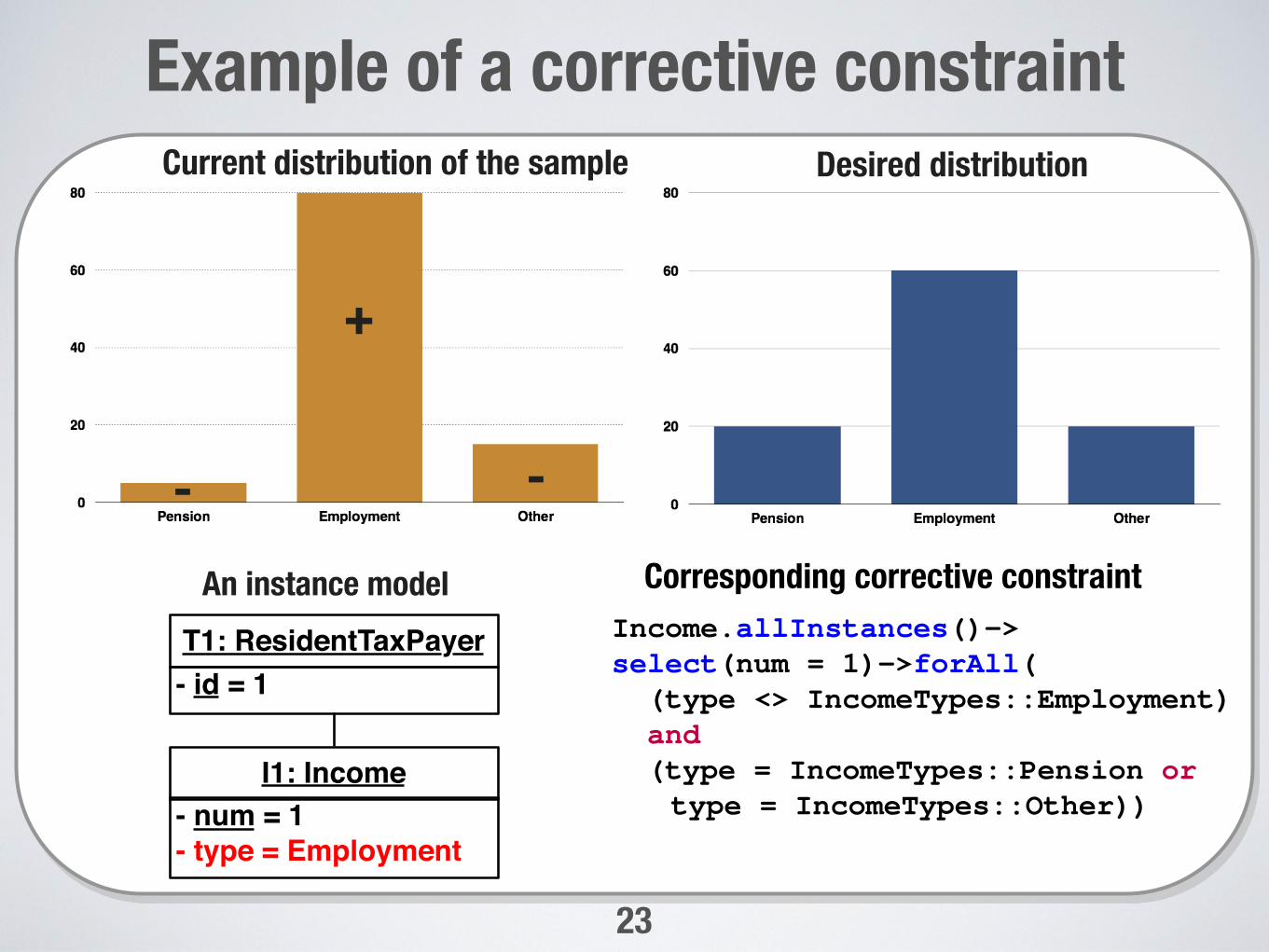
Example of a corrective constraint
-
+
-
Current distribution of the sample Desired distribution
An instance modelIncome.allInstances()->select(num = 1)->forAll(
(type <> IncomeTypes::Employment)and(type = IncomeTypes::Pension ortype = IncomeTypes::Other))
Corresponding corrective constraint
- id = 1T1: ResidentTaxPayer
I1: Income- num = 1- type = Employment
24
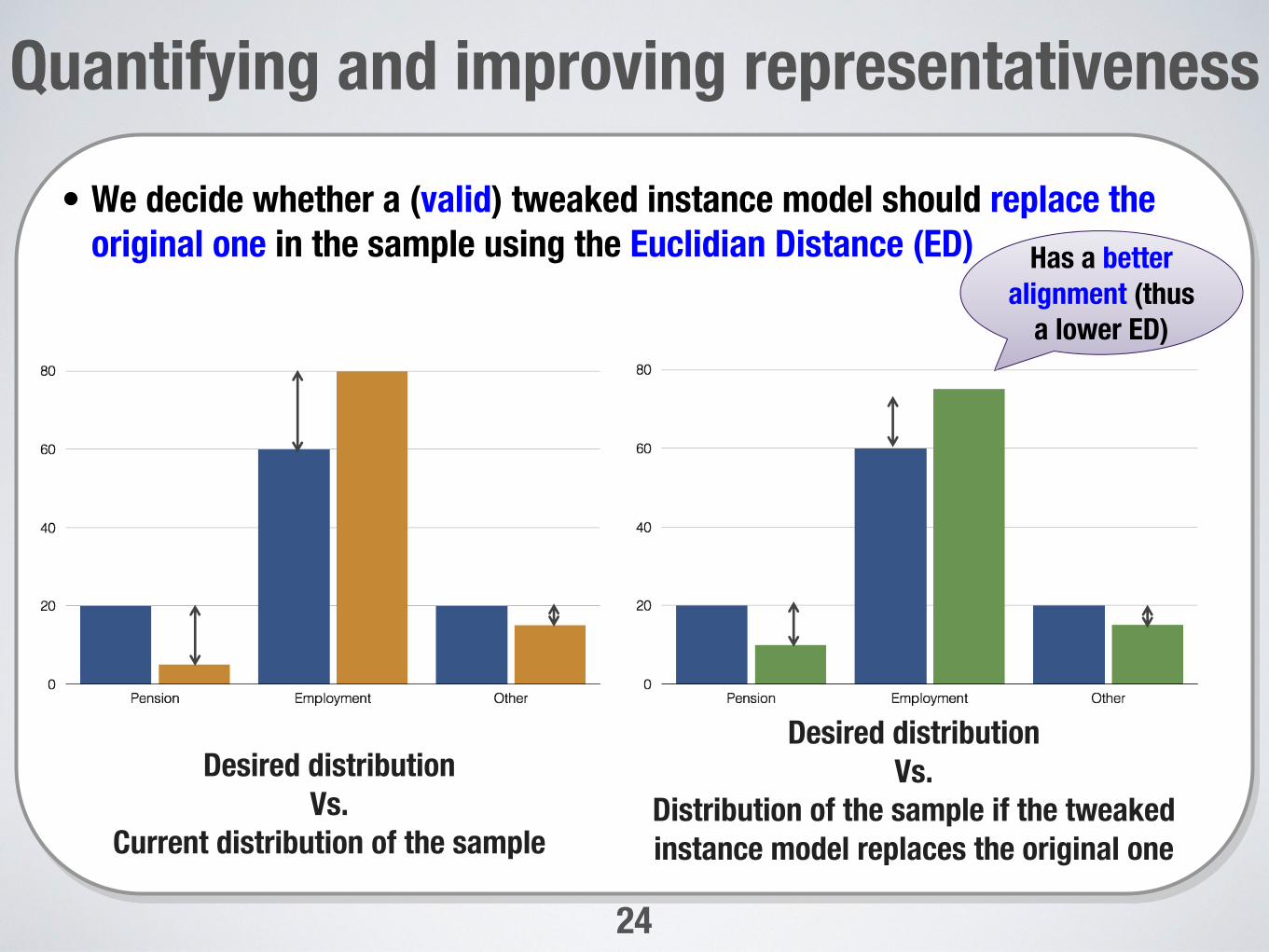
Quantifying and improving representativeness • We decide whether a (valid) tweaked instance model should replace the
original one in the sample using the Euclidian Distance (ED)
Desired distributionVs.
Current distribution of the sample
Desired distributionVs.
Distribution of the sample if the tweaked instance model replaces the original one
Has a better alignment (thus
a lower ED)

Case studyEvaluation
25

26
Case study
• Statistical testing of reliability requirements of a re-designed tax management system in Luxembourg
• Using actual data is not option:
- Actual data is sensitive and of a personal nature, sharing the data with third-parties poses complications
- There are structural mismatches between the data schema used by the system under test and the actual historical data
27
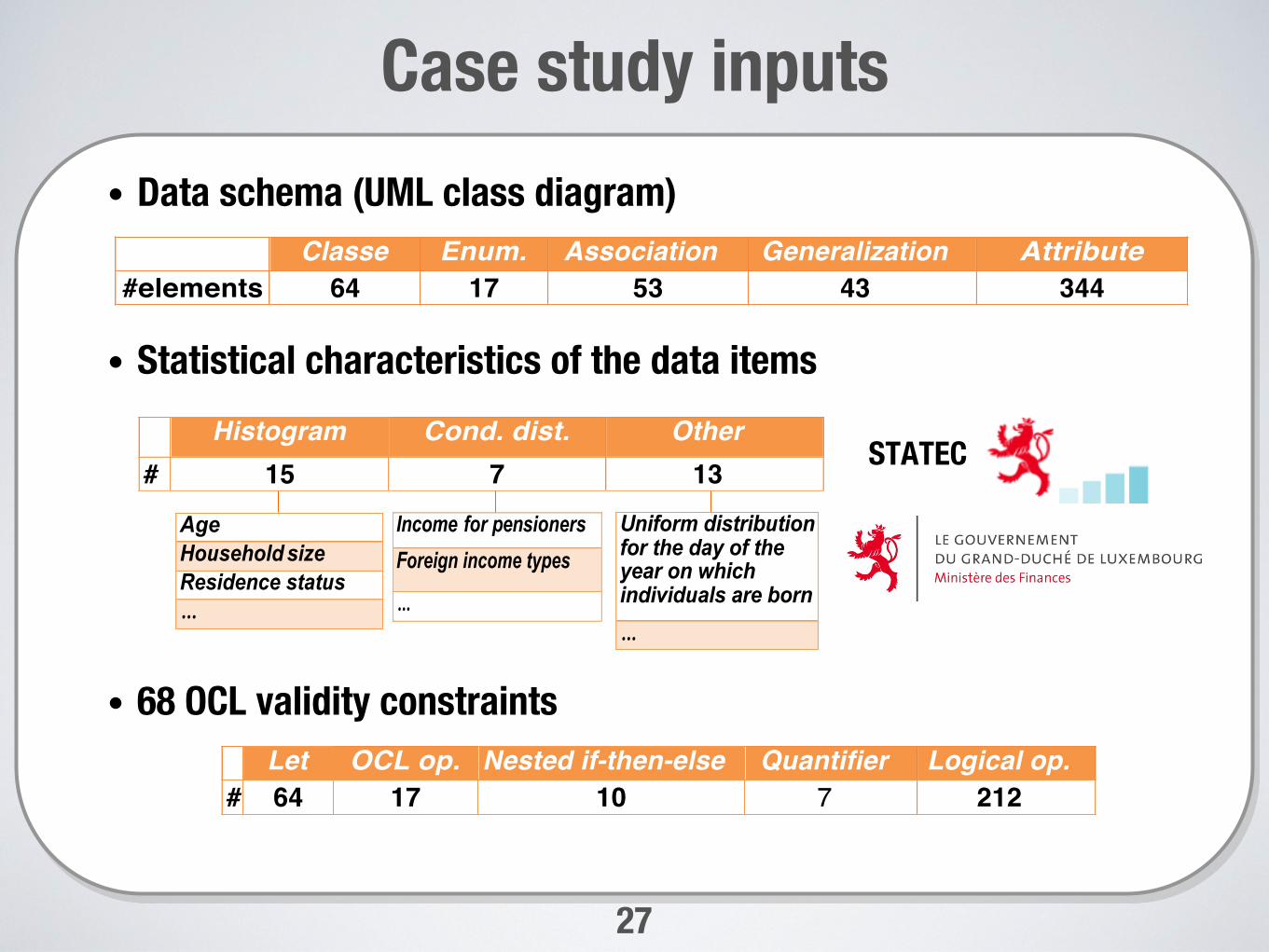
Case study inputs• Data schema (UML class diagram)
• Statistical characteristics of the data items
• 68 OCL validity constraints
Classe Enum. Association Generalization Attribute #elements 64 17 53 43 344
Histogram Cond. dist. Other # 15
7 13
Age Household size Residence status …
Income for pensioners Foreign income types
…
STATEC
Uniform distribution for the day of the year on which individuals are born
…
Let OCL op. Nested if-then-else Quantifier Logical op. # 64 17 10 7 212

28
Research questions
• RQ1: Does our synthetic data generator run in practical time?
• RQ2: Can our approach generate data samples that are both valid and statistically representative?

29
RQ1: execution time of the data generator
• We report on the average execution time (5 times) of our data generator for building data samples of different sizes, ranging from 100 to 1000
• Our data generator could produce data samples with up to 1000 instance models (representing tax cases) in less than 10 hours
- Execution time for generating initial (invalid) solutions is negligible
- Constraint solving accounts on average for 85% of the execution time
- Generating corrective constraints accounts on average for 14% of the execution time

30
RQ1: execution time of the data generator
This execution time is practical in our context since:
• Data generation can be performed overnight.
• For more complex systems, parallelization of search during constraint solving can be considered.
• Test data generation can be initiated well in advance of the testing phase, and as soon as the data profile for the system under test has stabilized.

31
Research questions
• RQ1: Does our synthetic data generator run in practical time?
• RQ2: Can our approach generate data samples that are both valid and statistically representative?

32
RQ2: quality of the generated data• Average (5 times) distances between the statistical distributions in a given
sample and the corresponding desired distributions• Three distance metrics: Euclidean, Manhattan and Canberra metrics
Data samples created by our data generator are valid, and at the same time, surpassing the state-of-the-art in terms of representativeness
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
100 200 300 400 500 600 700 800 900 1000
Eucl
idea
n di
stan
ce
Number of instance models in the sample
Distance for (invalid) seed sample
Distance for final valid sample

33
Summary
• A model-based data generator for supporting statistical testing ofdata-centric systems
• The data generator produces high-quality test data in a practical time:
- Produced test data samples are representative of with the actual or anticipated system usage
- Produced test data samples are structurally and logically valid
- The generator is able to produce up to 1000 instance models (here, tax cases) in less than 10 hours

.lusoftware verification & validationVVS .lu
software verification & validationVVS
Synthetic Data Generation for Statistical Testing
Ghanem [email protected] available at http://people.svv.lu/tools/SDG/
SnT Centre for Security, Reliability and Trust University of Luxembourg, Luxembourg
ASE 2017