survey on graph query processing on graph databasedimitris/6311/l15-graphq-fan.pdf · survey on...
TRANSCRIPT

Survey on Graph Query Processing on
Graph Database
Presented by FAN Zhe

Outline
� Introduction of Graph and Graph Database.
� Background of Subgraph Isomorphism.
� Background of Subgraph Query Processing.
� Background of Similarity Graph Query Processing.
� Background of Supergraph Query Processing.� Background of Supergraph Query Processing.

� Graph is powerful.
� Graph is everywhere.
� Graph is complex.
� While the size and volume of graph is increasing.
� Trade off. Easier for model, harder for analysis.
What is Graph
� Trade off. Easier for model, harder for analysis.
Chemical bonds Internet DNA Daily-life Objects

Two Scenarios of Graph Database
Bio-informatics Social Network
Graph Database is a database that contains millions of graphs.

Definition of Graph
A graph g is defined as a 4-tuple, g = (V,E,L, l), where V is the set of vertices, E is
the set of edges, L is the set of labels and l is a labelling function that maps each
vertex or edge to a label in L. We define the size of a graph g as size(g) = |E(g)|.
We restrict our discussion on undirected, labelled connected graphs.

1 Subgraph Isomorphism [Ullmann, J.ACM’76], [Cordella, PAMI’04], [QuickSI, VLDB’08]
2 Subgraph Query
2.1 One large graph [GraphGrep, ICPR’02], [TALE, ICDE’08], [GADDI, EDBT’09], [SAPPER, VLDB’10]
2.2 Numbers of small graphs[GraphGrep, ICPR’02], [gIndex, SIGMOD’04], [FG-index, SIGMOD’07], [C-
Tree, ICDE’06], [QuickSI, VLDB’08], [GBLENDER, SIGMOD’10], [iGraph, VLDB’10]
3 Similarity Graph Query (subgraph query is not always available in all cases)
3.1 One large graph [GraphGrep, ICPR’02], [TALE, ICDE’08], [GADDI, EDBT’09], [SAPPER, VLDB’10]
3.2 Numbers of small graphs [C-Tree, ICDE’06], [Grafil, SIGMOD’05]
Graph Query Processing Problem in Current Research Field
3.2 Numbers of small graphs [C-Tree, ICDE’06], [Grafil, SIGMOD’05]
4 Supergraph Query (containment graph query) [cIndex, VLDB’07], [GPTree, 09’EDBT],
5 Reachability Problem …
6 Shortest path Problem …
7 Spatial Data Problem …

Outline
� Introduction of Graph and Graph Database.
� Background of Subgraph Isomorphism.
� Background of Subgraph Query Processing.
� Background of Similarity Graph Query Processing.
� Background of Supergraph Query Processing.� Background of Supergraph Query Processing.

Definition of Subgraph Isomorphism
A
B C
A
B C
A
1
2 3
1
2 3
4
g g’
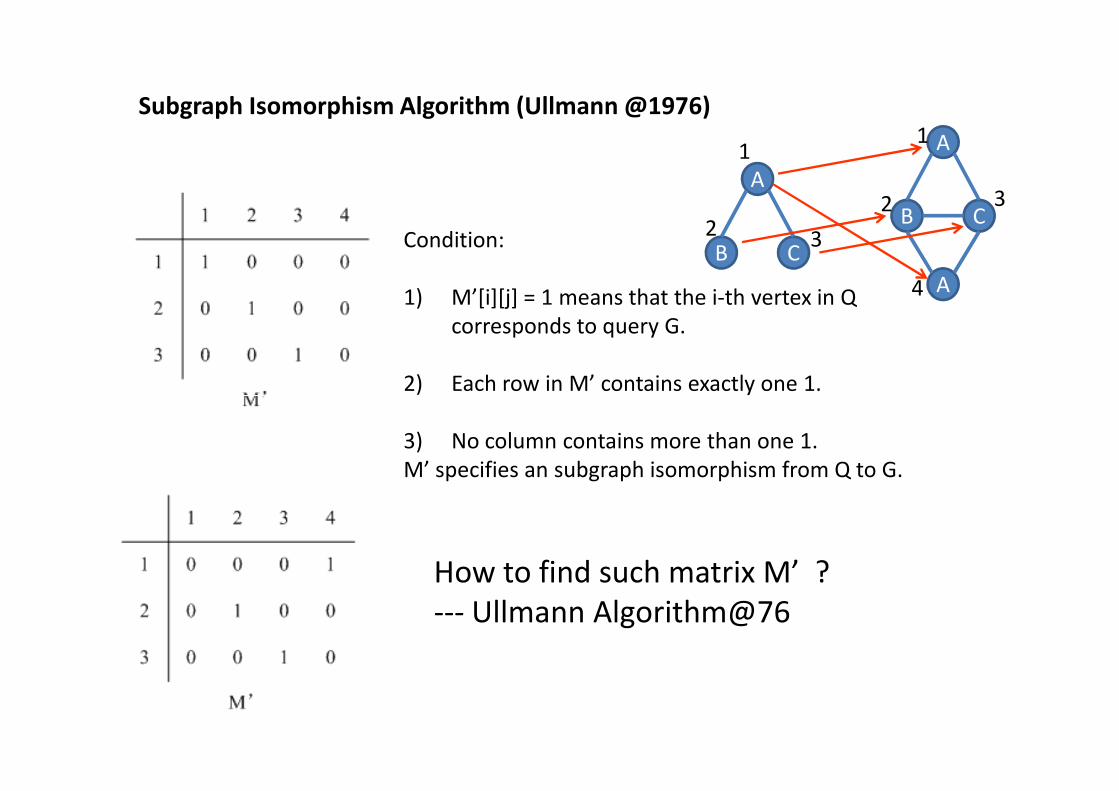
Condition:
1) M’[i][j] = 1 means that the i-th vertex in Q
corresponds to query G.
2) Each row in M’ contains exactly one 1.
Subgraph Isomorphism Algorithm (Ullmann @1976)
A
B C
A
B C
A
1
23
1
2 3
4
2) Each row in M’ contains exactly one 1.
3) No column contains more than one 1.
M’ specifies an subgraph isomorphism from Q to G.
How to find such matrix M’ ?
--- Ullmann Algorithm@76
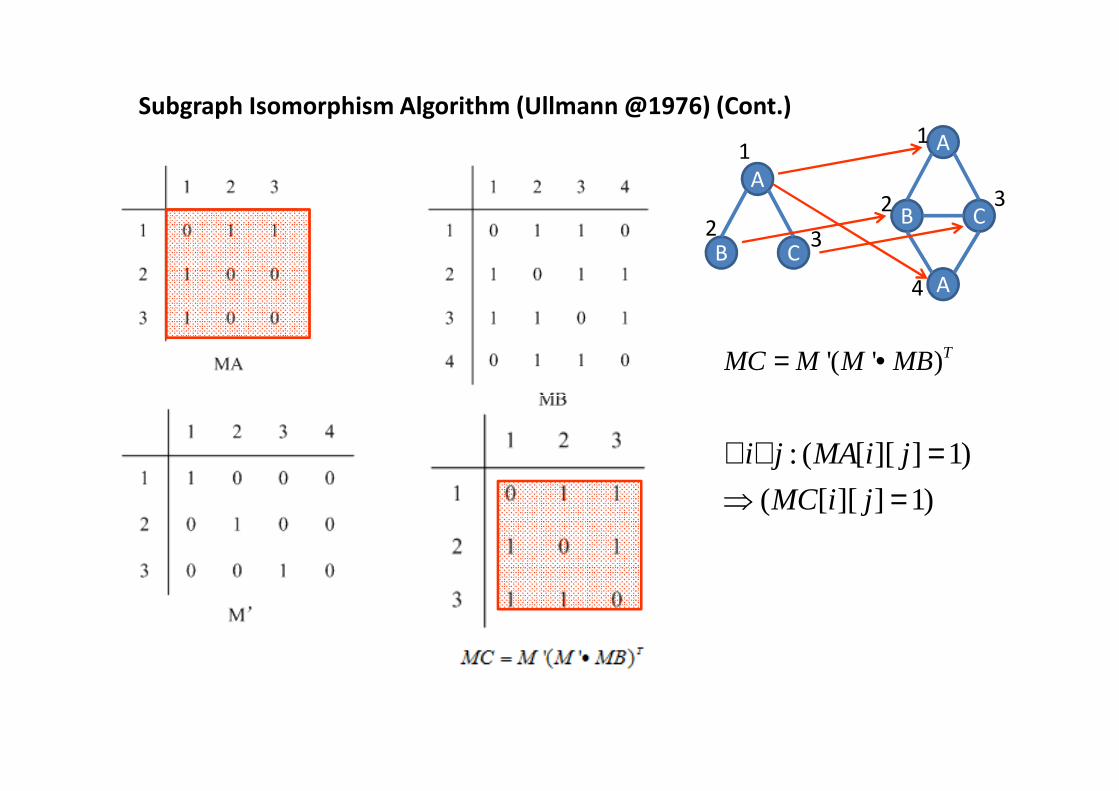
Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
A
B C
A
B C
A
1
23
1
2 3
4
'( ' )TMC M M MB= •
: ( [ ][ ] 1)
( [ ][ ] 1)
i j MA i j
MC i j
∀ ∀ =⇒ =

Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
'( ' )TMC M M MB= •
A
B C
A
B C
A
1
23
1
2 3
4
: ( [ ][ ] 1)
( [ ][ ] 1)
i j MA i j
MC i j
∀ ∀ =⇒ =

• Given two graphs Q and G, their corresponding matrixes are MAn×n=[aij] and MBm×m =
[bij].
• Goal: 1) Find matrix M’ n×m such that
• 2) or report no such marix M’.
: ( [ ][ ] 1)
( [ ][ ] 1)
i j MA i j
MC i j
∀ ∀ =⇒ =
'( ' )TMC M M MB= •
Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
• 2) or report no such marix M’.

Step 1. Set up matrix Mn×m , such that M[i][j]=1, if 1) the i-th vertex in Q has the same
label as the j-th vertex in G; and 2) the i-th vertex has smaller vertex degree than
the j-th vertex in G.
A1
Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
A
B C
A
B C
A
1
2 3
1
2 3
4

• Step 2. Matrixes M’ are generated by systematically changing to 0 all but one of
the 1’s in each of the rows of M, subject to the definition condition that no column
of a matrix M’ may contain more than one 1. (the maximal depth is |MA|).
1 0 0 1 1 0 0 0
Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
1 0 0 1
0 1 0 0
0 0 1 0
1 0 0 0
0 1 0 0
0 0 1 0
1 0 0 0
0 1 0 0
0 0 1 0
1 0 0 0
0 1 0 0
0 0 1 0

• Step 3. Verify matrix M’ by the following equation
: ( [ ][ ] 1)
( [ ][ ] 1)
i j MA i j
MC i j
∀ ∀ =⇒ =
'( ' )TMC M M MB= •
Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
Iterate the above steps and enumerate all possible matrixes M’ .
In the worst case, there are O(|MB|!) possible matrixes. (subgraph isomorphism is a
classical NP-hard problem)

Subgraph Isomorphism Algorithm (Ullmann @1976) (Cont.)
Some Optimizations of Ullmann’s algorithm, if interested, please check the
original research paper.
QuickSI: VLDB 08’
A good survey about graph matching algorithms: 《THIRTY YEARS OF GRAPH
MATCHING IN PATTERN RECOGNITION》@IJPR04
C++ library For Graph Isomorphism: VFLib library
…

Outline
� Introduction of Graph and Graph Database.
� Background of Subgraph Isomorphism.
� Background of Subgraph Query Processing.
� Background of Similarity Graph Query Processing.
� Background of Supergraph Query Processing.� Background of Supergraph Query Processing.

Problem definition
� Given a graph database D and a graph query q.
� Find all graphs g in D s.t. q is a subgraph of g.
Subgraph Query
N
N+
NH
N
O
N
HO
N
N
S
OH
N
N
O
O
OH
ONN
Sample database
Complexity: exactly NP-complete!
OHO
N
S
HOO
O
O
(a) (b) (c)
NN
Query graph

Application of Subgraph Query
�Protein interaction analysis
�Motif discovery in 3D protein structures
�Drug design
�Schema matching
�Graph similarity search
�Correlation discovery in graph databases

• Sequential scan is not scalable
– Disk I/O
– Subgraph isomorphism testing
• An indexing mechanism is needed
– DayLight: Daylight.com (commercial)
– GraphGrep: Dennis Shasha etc. PODS'02
Challenges of Subgraph Query
– GraphGrep: Dennis Shasha etc. PODS'02
– gIndex:
– FG-index:
– C-Tree:
– SwiftIndex:
– iGraph:
– …

Feature-based approach
gIndex, SIGMOD’04
Fgindex, SIGMOD’07
Non-Feature-based approach
GraphGrep, PODS’02
Representative Works on Subgraph Query
GraphGrep, PODS’02
QuickSI, VLDB’08
C-Tree, ICDE’06
GString, ICDE’07
GCoding, EDBT’08

GraphGrep (shasha et al. @PODS 02)
• Fingerprinting: to filter the database
• A subgraph matching algorithm
Basic Idea
Use small components of the query graph and the database graphs to filter the
database and to do the matching

GraphGrep (shasha et al. @PODS 02) (Cont.)

GraphGrep (shasha et al. @PODS 02) (Cont.)

gIndex (Yan et al. @SIGMOD 04)
Graph (G)Query graph (Q)
If graph G contains query
graph Q, G should contain any
substructure of Q
Substructure
Remarks
� Index substructures of a query graph to prune
graphs that do not contain these substructures

gIndex (Yan et al. @SIGMOD 04) (Cont.)
• Two steps in processing graph queries
Step 1. Index Construction
� Enumerate structures in the graph database,
build an inverted index between structures and
graphs
Framework
graphs
Step 2. Query Processing
� Enumerate structures in the query graph
� Calculate the candidate graphs containing these
structures
� Prune the false positive answers by performing
subgraph isomorphism test

gIndex (Yan et al. @SIGMOD 04) (Cont.)
Two Approaches:
� Path-based indexing
� Subgraph-based indexing

OHO
N
N+
NH
N
O
N
HO
ON
O
N N
N
S
OH
S
HOO
O
N
N
O
O
Sample database
(a) (b) (c)
gIndex (Yan et al. @SIGMOD 04) (Cont.)
Path-Based Approach
Paths
0-length: C, O, N, S
1-length: C-C, C-O, C-N, C-S, N-N, S-O
2-length: C-C-C, C-O-C, C-N-C, ...
3-length: ...
Built an inverted index between paths and graphs

gIndex (Yan et al. @SIGMOD 04) (Cont.)
Path-Based Approach (Cont.)
NN
Query graph
0-length: SC={a, b, c}, SN={a, b, c}0-length: SC={a, b, c}, SN={a, b, c}
1-length: SC-C={a, b, c}, SC-N={a, b, c}
2-length: SC-N-C = {a, b}, …
…
Intersect these sets, we obtain the candidate
answers - graph (a) and graph (b) - which may
contain this query graph.

gIndex (Yan et al. @SIGMOD 04) (Cont.)
Problem of Path-Based Approach
OHO
N
N+
NH
N
O
N
HO
ON
O
N N
N
S
OH
S
HOO
O
N
N
O
O
Sample database
(a) (b) (c)
Query graphGraph (c) contains this query graph.
However, if we only index paths: C, C-C,
C-C-C, C-C-C-C, we can not prune graph
(a) and (b).

• Paths are simple, structural information is lost
• There are too many paths
gIndex propose
gIndex (Yan et al. @SIGMOD 04) (Cont.)
Problem of Path-Based Approach
• Use structures instead of paths
• Use discriminative structures

gIndex: Indexing Graphs by Data Mining
• Identify frequent structures in the database, the frequent
structures are subgraphs that appear quite often in the graph
database
• Prune redundant frequent structures to maintain a small set
gIndex (Yan et al. @SIGMOD 04) (Cont.)
• Prune redundant frequent structures to maintain a small set
of discriminative structures
• Create an inverted index between discriminative frequent
structures and graphs in the database

Frequent Structures
OHO
N
N+
NH
N
O
N
HO
N
N
S
OH
S
HOO
O
N
N
O
O
OH
ON
O
N
(a) (b) (c)
Sample database
gIndex (Yan et al. @SIGMOD 04) (Cont.)
NNN
N
O
Frequent structures with support 2
(a) (b)

Frequent Structures (cont.)
• Efficient frequent graph mining algorithms are available
Apriori:
– AGM/AcGM: Inokuchi et al (PKDD’00)
– FSG, Kuramochi et al (ICDM’01)
gIndex (Yan et al. @SIGMOD 04) (Cont.)
– FSG, Kuramochi et al (ICDM’01)
– Vanetik et al (ICDM’02)
Pattern-growth:
– MoFa, Borgelt et al (ICDM’02)
– gSpan: Yan and Han (ICDM’02)
– …

Frequent Structures: Threshold Issue
• How to set up the minimum support threshold?
– If it is too low, it may generate too many frequent graphs
– If it is too high, it may miss important structures
gIndex (Yan et al. @SIGMOD 04) (Cont.)
• Should we enforce a uniform threshold for the different size
of structures?
Size-increasing support threshold

Frequent Structures: Threshold Issue
0
5
10
15
20
supp
ort(
%)
Θ
θ
gIndex (Yan et al. @SIGMOD 04) (Cont.)
• Intuition: large structures with low support will likely be
indexed well by their substructures that have the similar
support
• Size-increasing support threshold
– The support threshold increases when the indexed
structures become larger
0 5 100
fragment size (edges)

Frequent Structures: Volume Issue
• The number of frequent structures may exceed the number of
graphs in the database when the support is low
– 1,000 graphs may generate 1,000,000 frequent structures
• It is time and memory expensive to compute and index all
gIndex (Yan et al. @SIGMOD 04) (Cont.)
• It is time and memory expensive to compute and index all
frequent structures
discriminative structures

OHO
N
N+
NH
N
O
N
HO
ON
O
N N
N
S
OH
S
HOO
O
N
N
O
O
Sample database
(a) (b) (c)
Redundant Structures
gIndex (Yan et al. @SIGMOD 04) (Cont.)
• All graphs contain structures: C, C-C, C-C-C
• Why bother indexing these redundant frequent structures?
– Remove these redundant structures
– Only index structures that provide more information than
existing structures
(a) (b) (c)

Discriminative Structures
• Pinpoint the most useful frequent structures
– Given a set of sturctures and a new
structure , we measure the extra indexing power
provided by ,
xnfff K,, 21
x
gIndex (Yan et al. @SIGMOD 04) (Cont.)
provided by ,
When is small enough, is a discriminative
structure and should be included in the index
• Index discriminative frequent structures only
– Reduce the index size by an order of magnitude
– Achieve good performance
( ) .,,, 21 xffffxP in ⊂K
x
xP

gIndex - Construction
• First generates all frequent fragments while taking out
redundant ones
• Translates fragments into sequences and holds them in a
prefix tree
gIndex (Yan et al. @SIGMOD 04) (Cont.)
prefix tree
– Each fragment has an id list: the ids of the graphs
containing the fragment
– Graph Sequentialization (DFS Code)
• Labeled edge is a 5-tuple (I,j,li, l(I,j),lj)
• Described in another paper

gIndex - Construction
• gIndex Tree
– each fragment can be mapped to an edge sequence (DFS
code), insert the edge sequences of discriminative
fragments in a prefix tree called the gIndex Tree
gIndex (Yan et al. @SIGMOD 04) (Cont.)
fragments in a prefix tree called the gIndex Tree

gIndex - Search
gIndex (Yan et al. @SIGMOD 04) (Cont.)
Filtering AnswersQuery Verification

Query Response Time
( )testingmisomorphisioqindex TTCT _+×+
gIndex (Yan et al. @SIGMOD 04) (Cont.)
Cost Analysis
Query indexing time
Size of candidate answer set
Disk I/O time
Isomorphism testing time
Remark: make |Cq| as small as possible

gIndex - Search
• Optimization
• Apriori Pruning
– If a fragment is not in the gIndex tree, we need not check
gIndex (Yan et al. @SIGMOD 04) (Cont.)
– If a fragment is not in the gIndex tree, we need not check
its super-graphs

gIndex (Yan et al. @SIGMOD 04) (Cont.)

gIndex (Yan et al. @SIGMOD 04) (Cont.)

FGindex (Cheng et al. @SIGMOD 07)
� First work propose the concept of verification-free
� Basic idea:
• If the query is frequent feature, then no need to verify the
candidate
• If the query is not frequent feature, the cost is the same to
gIndex.
� Problem is if the query graph is large, the probability of being frequent
feature would be low.
gIndex.

Closure-Tree (He and Singh. @ICDE 04)

Closure-Tree (He and Singh. @ICDE 04) (Cont.)

iGraph (@VLDB 10)
In terms of the experiments and
conclusions. We have known that:
[iGraph, VLDB 10] is a common framework that implement most of the
above representative index, it uses the same subgraph isomorphism algorithm
and a common storage engine that guarantees real disk I/Os by bypassing the
OS file system cache.
conclusions. We have known that:
1. There is no single winner for all
the above techniques on subgraph
query processing.
2. Feature-based index, like gIndex
and FGindex, have the best pruning
power, which leads to lowest I/O cost
and small candidate set.

Outline
� Introduction of Graph and Graph Database.
� Background of Subgraph Isomorphism.
� Background of Subgraph Query Processing.
� Background of Similarity Graph Query Processing.
� Background of Supergraph Query Processing.� Background of Supergraph Query Processing.

� Given a graph database and a query graph Q,
� Find graphs containing Q exactly
(Precise Matching, gIndex, SIGMOD’04)
Precise vs. Approximate Search in Graphs
� Find graphs containing Q approximately
(Approximate Matching, Grafil)

1. Maximal Common Subgraph
(MCS):
Given two graphs Q and G, assume
that S is subgraph isomorphism to
both Q and G. S is called a common
subgraph of Q and G.
Evaluating Graph Similarity
A E
MCS
The MCS between Q and G is the
common subgraph with the largest
number of edges (|E(S)|).
B C
F
A B
C
Q G

Evaluating Graph Similarity (Cont.)
The minimal edit distance between Q and G is the minimal number of edit
operations (insertion, deletion, or relabeling ) in the optimal alignments that
make Q reach G.
2. Minimal Graph Edit Distance
A E
B C
F
B C
A
Q G

• Compute the similarity between the graphs in the database
and the query graph directly (costly)
– sequential scan
– subgraph similarity computation
Solution 1

• Form a set of subgraph queries from the original query graph
and use the exact subgraph search (costly)
– If we allow 3 edges to be missed in a 20-edge query graph,
it may generate 1,140 subgraphs.
Solution 2

• Precise Search
– Use frequent patterns as indexing features
– Select features in the database space based on their
selectivity
– Build the index
Solution 3
• Approximate Search
– Hard to build indices covering similar subgraphs –
explosive number of subgraphs in databases
– Idea: (1) keep the index structure
(2) select features in the query space

• Structure-based similarity measure
– The largest overlapping part of two graphs
Substructure Similarity Measure
– Relaxation: the number of edges that can be relabeled or deleted (relaxation of the query graph)
QG

OHO
N
N+
NH
N
O
N
HO
ON
O
N N
N
S
OH
S
HOO
O
N
N
O
O
Graph Database
(a) (b) (c)
Structural Features
Structural Features (small fragments)
• atom
• bond • subgraph
• path

• Feature-based similarity measure
– Each graph is represented as a feature vector
X = {x1, x2, …, xn}
– The similarity is defined by the distance of their
corresponding vectors
Substructure Similarity Measure
– Easy to index
– Very fast
– Rough measure

Structure-based similarity
• Accurate measure
• Slow
Can we transform structure-based to feature-based?
Substructure Similarity Measure
Feature-based similarity
• Rough measure
• Fast
Can we transform structure-based to feature-based?

Graph (G1)
Query (Q)
� If graph G contains the
major part of a query graph
Q, G should share a number
of common features with Q
Grafil (Yan et al. @SIGMOD 05)
Substructure
� Given a relaxation ratio,
calculate the maximal number
of features that can be missed !
At least one of them
should be contained
Graph (G2)

• An occurrence table between feature and graph
G1 G2 G3 G4 G5
f1 0 1 0 1 1
f2 0 1 0 2 1
Feature-Graph Matrix
Grafil (Yan et al. @SIGMOD 05) (Cont. )
f2 0 1 0 2 1
f3 1 0 1 1 1
f4 0 0 1 0 1
Assume a query graph has 4 features and only 1 feature to miss
due to the relaxation threshold

• Three steps in processing approximate graph queries
Step 1. Index Construction
� Select small structures as features in a graph
Query Processing Framework
Grafil (Yan et al. @SIGMOD 05) (Cont. )
� Select small structures as features in a graph
database, and build the feature-graph matrix
between the features and the graphs in the
database.

Step 2. Feature Miss Estimation
� Determine the indexed features belonging to the
query graph
� Calculate the upper bound of the number of features
Grafil (Yan et al. @SIGMOD 05) (Cont. )
Query Processing Framework
� Calculate the upper bound of the number of features
that can be missed for an approximate matching,
denoted by J
� On the query graph, not the graph database

Step 3. Query Processing
� Use the feature-graph matrix to calculate the
difference in the number of features between
graph G and query Q, FG – FQ
Grafil (Yan et al. @SIGMOD 05) (Cont. )
Query Processing Framework
graph G and query Q, FG – FQ
� If FG – FQ > J, discard G. The remaining graphs
constitute a candidate answer set

• If we allow k edges to be relaxed, the main idea is to transform edge misses k to
feature misses m.
• Classic set k-cover problem, NP-complete
� k: the number of missing edges in q.
� m: max number of features covered by k edges.
Selection of Upper Bound
Grafil (Yan et al. @SIGMOD 05) (Cont. )

Grafil (Yan et al. @SIGMOD 05) (Cont. )
Usage of the feature misses m
m = 4

Outline
� Introduction of Graph and Graph Database.
� Background of Subgraph Isomorphism.
� Background of Subgraph Query Processing.
� Background of Similarity Graph Query Processing.
� Background of Supergraph Query Processing.� Background of Supergraph Query Processing.

Supergraph Query Processing
� Counterpart of subgraph query processing.
� Problem statement:
� Given a graph database D and a graph query q.
� Find all graphs g in D s.t. q is a supergraph of g.

Challenges
� Problem complexity: NP-Complete.
� Same as subgraph query.
� Existing feature-based indexes for subgraph queries are not applicable:
� Inclusion logic for subgraph query
� If f ⊆ q and f ⊈ g, then q ⊈ g
� Exclusion logic for supergraph query
� If f ⊈ q and f ⊆ g, then q ⊉ g
Representative work
� cIndex (Chen et al., @VLDB ‘07).
� Feature-based approach.
� GPTree (Zhang et al., @EDBT ‘07)
� Feature-based approach.
� Fast sub-iso approach.

References
� [Shasha et al., PODS’02] Shasha, D., Wang, J.T.L., Giugno, R.: Algorithmics and
applications of tree and graph searching. In: PODS. (2002) 39–52
� [Yan et al., SIGMOD’04] Yan, X., Yu, P.S., Han, J.: Graph indexing based on discriminative
frequent structure analysis. In: SIGMOD. (2004) 335–346
� [He and Singh, ICDE’06] He, H., Singh, A.K.: Closure-tree: An index structure for graph
queries. In: ICDE. (2006) 38
� [Cheng et al., SIGMOD’07] Cheng, J., Ke, Y., Ng, W., Lu, A.: Fg-index: towards verification-
free query processing on graph databases. In: SIGMOD. (2007) 857–872free query processing on graph databases. In: SIGMOD. (2007) 857–872
� [Cheng et al., TODS’09] Cheng, J., Ke, Y., Ng, W.: Effective query processing on graph
databases. ACM Trans. Database Syst. 34(1) (2009)
� [Jiang et al., ICDE’07] Jiang, H., Wang, H., Yu, P.S., Zhou, S.: Gstring: A novel approach for
efficient search in graph databases. In: ICDE. (2007) 566–575
� [Zhang et al., ICDE’07] Zhang, S., Hu, M., Yang, J.: Treepi: A novel graph indexing method.
In: ICDE. (2007) 966–975
� [Williams et al., ICDE’07] Williams, D.W., Huan, J., Wang, W.: Graph database indexing
using structured graph decomposition. In: ICDE. (2007) 976–985

� [Zhao et al., VLDB’07] Zhao, P., Yu, J.X., Yu, P.S.: Graph indexing: Tree + delta >= graph. In:
VLDB. (2007) 938–949
� [Zou et al., EDBT’08] Zou, L., Chen, L., Yu, J.X., Lu, Y.: A novel spectral coding in a large
graph database. In: EDBT. (2008) 181–192
� [Shang et al., VLDB’08] Shang, H., Zhang, Y., Lin, X., Yu, J.X.: Taming verification hardness:
An efficient algorithm for testing subgraph isomorphism. In: VLDB. (2008) 364– 375
� [Chen et al., VLDB’07] Chen, C., Yan, X., Yu, P.S., Han, J., Zhang, D.Q., Gu, X.: Towards
graph containment search and indexing. In: VLDB. (2007) 926–937
References
graph containment search and indexing. In: VLDB. (2007) 926–937
� [Zhang et al., EDBT’09] Zhang, S., Li, J., Gao, H., Zou, Z.: A novel approach for efficient
supergraph query processing on graph databases. In: EDBT. (2009) 204–215
� [Raymond et al., CJ’02] Raymond, J.W., Gardiner, E.J., Willett, P.: RASCAL: calculation of
graph similarity using maximum common edge subgraphs. Comput. J. 45(6) (2002) 631– 644
� [Yan et al., SIGMOD’05] Yan, X., Yu, P.S., Han, J.: Substructure similarity search in graph
databases. In: SIGMOD Conference. (2005) 766–777
� [Faloutsos and Tong, ICDE’09] Faloutsos, C., Tong, H.: Large graph mining: patterns, tools
and case studies. In: ICDE (2009) tutorial

� [Shang et al., ICDE’10] Shang, H., Zhu, K., Lin, X., Zhang, Y., Ichise, R.: Similarity Search on
Supergraph Containment . In: ICDE. (2010)
� [Ke et al., KDD’07] Ke, Y., Cheng, J., Ng, W.: Correlation search in graph databases. In: KDD.
(2007) 390–399
� [Ke et al., SDM’09] Ke, Y., Cheng, J., Yu, J.X.: Top-k correlative graph mining. In: SDM.
(2009) 1038–1049
� [Ke et al. ICDM’09] Ke, Y., Cheng, J., Yu, J.X.: Efficient discovery of frequent correlated
subgraph pairs. In: ICDM. (2009) 239–248
References
subgraph pairs. In: ICDM. (2009) 239–248

Thank you !