supervised learning in r regression - amazon s3 · datacamp supervised learning in r: regression...
TRANSCRIPT

DataCamp SupervisedLearninginR:Regression
Logisticregressiontopredictprobabilities
SUPERVISEDLEARNINGINR:REGRESSION
NinaZumelandJohnMountWin-VectorLLC

DataCamp SupervisedLearninginR:Regression
PredictingProbabilitiesPredictingwhetheraneventoccurs(yes/no):classificationPredictingtheprobabilitythataneventoccurs:regressionLinearregression:predictsvaluesin[−∞,∞]Probabilities:limitedto[0,1]interval
Sowe'llcallitnon-linear

DataCamp SupervisedLearninginR:Regression
Example:PredictingDuchenneMuscularDystrophy(DMD)
outcome:has_dmd
inputs:CK,H

DataCamp SupervisedLearninginR:Regression
ALinearRegressionModel
outcome:has_dmd∈{0,1}
0:FALSE1:TRUE
Modelpredictsvaluesoutsidetherange[0:1]
>model<-lm(has_dmd~CK+H,+data=train)
>test$pred<-predict(+model,+newdata=test+)

DataCamp SupervisedLearninginR:Regression
LogisticRegression
log( ) = β + β x + β x + ...
GeneralizedlinearmodelAssumesinputsadditive,linearinlog-odds:log(p/(1 − p))
family:describeserrordistributionofthemodellogisticregression:family=binomial
1 − p
p0 1 1 2 2
glm(formula,data,family=binomial)
DataCamp SupervisedLearninginR:Regression
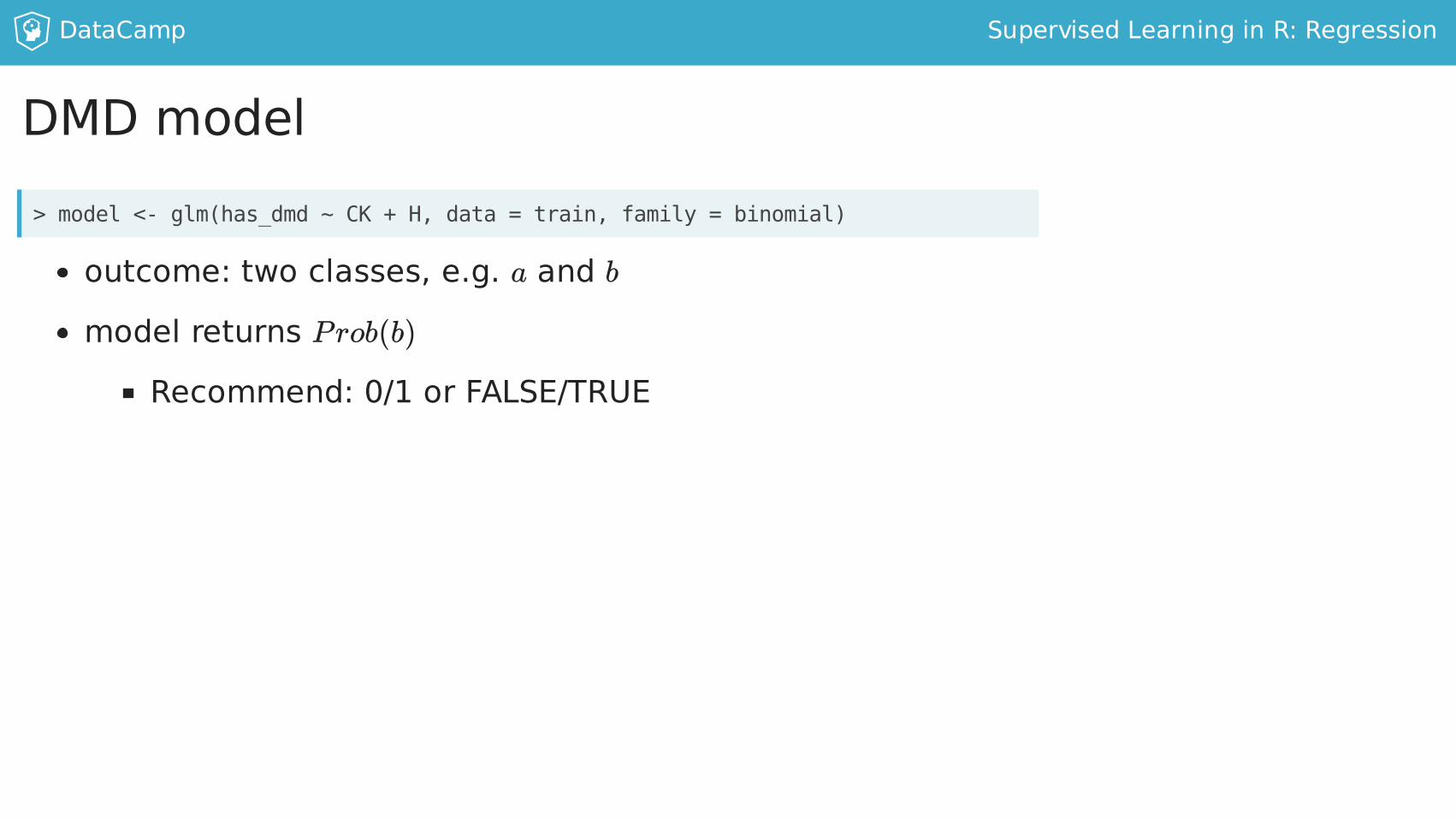
DMDmodel
outcome:twoclasses,e.g.aandbmodelreturnsP rob(b)
Recommend:0/1orFALSE/TRUE
>model<-glm(has_dmd~CK+H,data=train,family=binomial)

DataCamp SupervisedLearninginR:Regression
InterpretingLogisticRegressionModels>model
##Call:glm(formula=has_dmd~CK+H,family=binomial,data=train)####Coefficients:##(Intercept)CKH##-16.220460.071280.12552####DegreesofFreedom:86Total(i.e.Null);84Residual##NullDeviance:110.8##ResidualDeviance:45.16AIC:51.16

DataCamp SupervisedLearninginR:Regression
Predictingwithaglm()model
newdata:bydefault,trainingdata
Togetprobabilities:usetype="response"
Bydefault:returnslog-odds
predict(model,newdata,type="response")
DataCamp SupervisedLearninginR:Regression
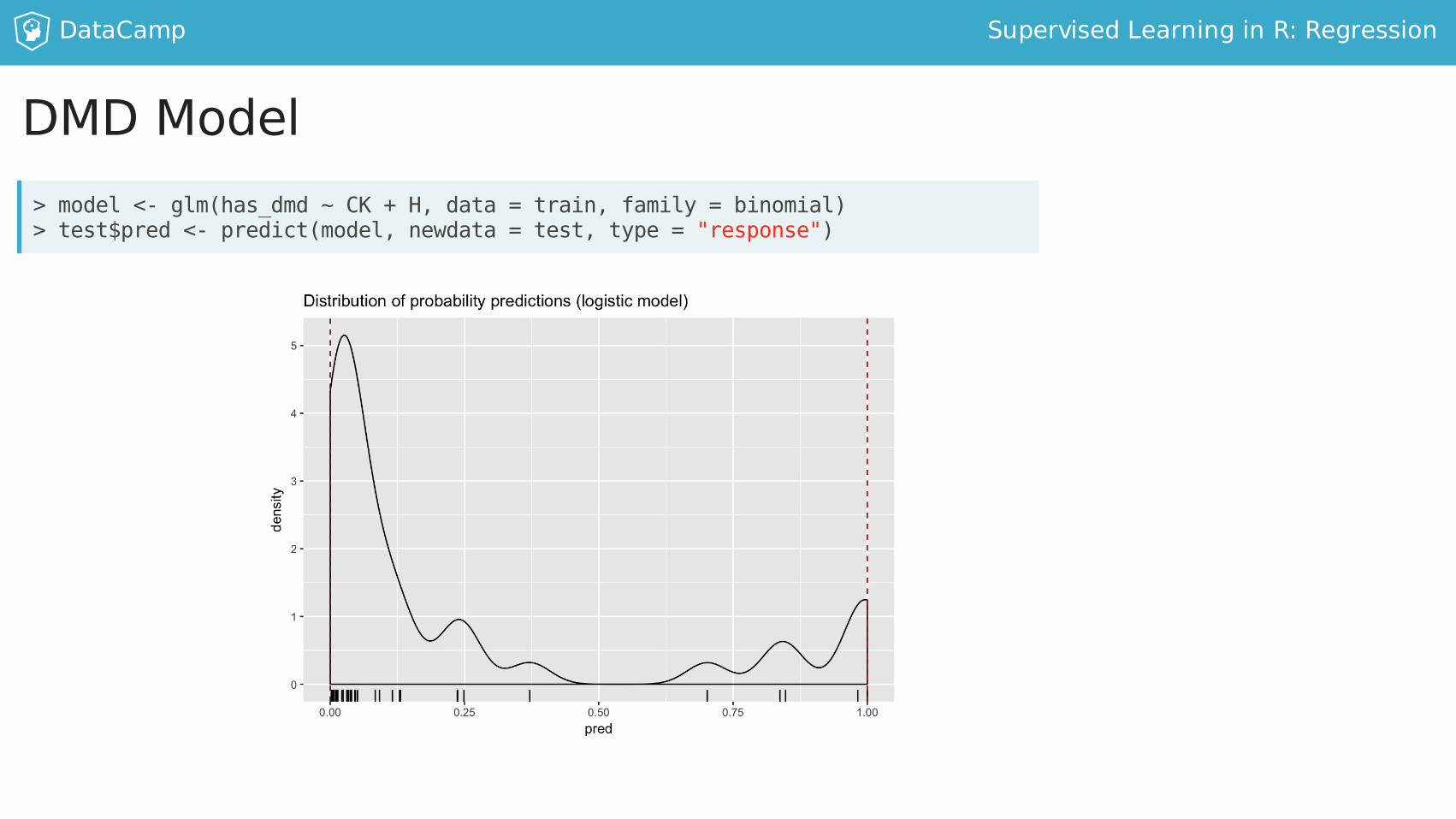
DMDModel>model<-glm(has_dmd~CK+H,data=train,family=binomial)>test$pred<-predict(model,newdata=test,type="response")

DataCamp SupervisedLearninginR:Regression
Evaluatingalogisticregressionmodel:pseudo-R2
R = 1 −
pseudoR = 1 −
Deviance:analogoustovariance(RSS)Nulldeviance:SimilartoSS
pseudoR^2:Devianceexplained
2
SST ot
RSS
2
null.deviance
deviance
T ot
DataCamp SupervisedLearninginR:Regression
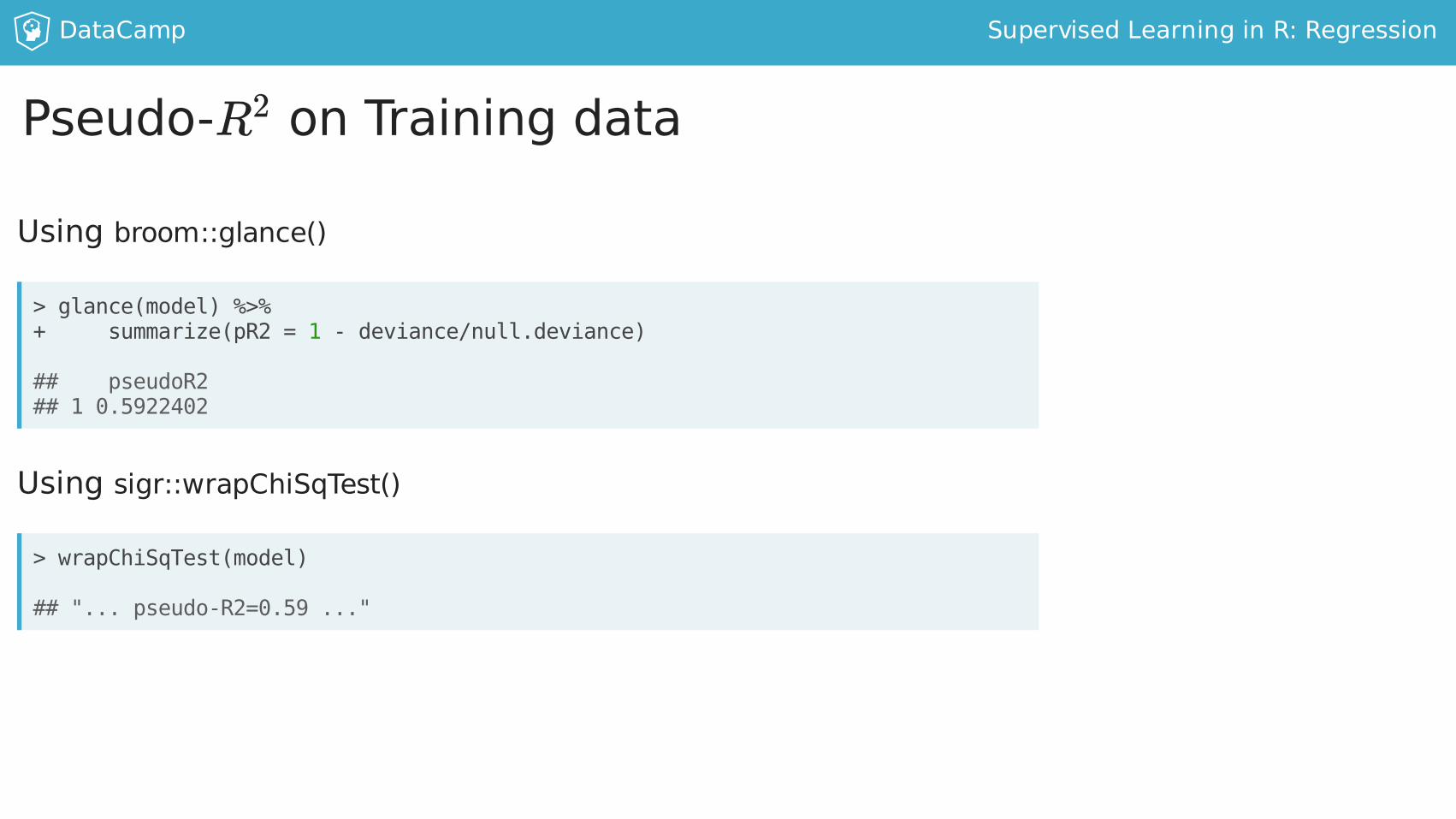
Pseudo-R onTrainingdata2
Usingbroom::glance()
Usingsigr::wrapChiSqTest()
>glance(model)%>%+summarize(pR2=1-deviance/null.deviance)
##pseudoR2##10.5922402
>wrapChiSqTest(model)
##"...pseudo-R2=0.59..."

DataCamp SupervisedLearninginR:Regression
Pseudo-R onTestdata2
Arguments:
dataframepredictioncolumnnameoutcomecolumnnametargetvalue(targetevent)
#Testdata>test%>%+mutate(pred=predict(model,newdata=test,type="response"))%>%+wrapChiSqTest("pred","has_dmd",TRUE)

DataCamp SupervisedLearninginR:Regression
TheGainCurvePlot>GainCurvePlot(test,"pred","has_dmd","DMDmodelontest")
DataCamp SupervisedLearninginR:Regression
Let'spractice!
SUPERVISEDLEARNINGINR:REGRESSION

DataCamp SupervisedLearninginR:Regression
Poissonandquasipoisson
regressiontopredictcounts
SUPERVISEDLEARNINGINR:REGRESSION
NinaZumelandJohnMountWin-Vector,LLC

DataCamp SupervisedLearninginR:Regression
PredictingCountsLinearregression:predictsvaluesin[−∞, ∞]
Counts:integersinrange[0, ∞]

DataCamp SupervisedLearninginR:Regression
Poisson/QuasipoissonRegression
family:eitherpoissonorquasipoisson
inputsadditiveandlinearinlog(count)
glm(formula,data,family)

DataCamp SupervisedLearninginR:Regression
Poisson/QuasipoissonRegression
family:eitherpoissonorquasipoisson
inputsadditiveandlinearinlog(count)outcome:integer
counts:e.g.numberoftrafficticketsadrivergetsrates:e.g.numberofwebsitehits/day
prediction:expectedrateorintensity(notintegral)expected#traffictickets;expectedhits/day
glm(formula,data,family)

DataCamp SupervisedLearninginR:Regression
Poissonvs.QuasipoissonPoissonassumesthatmean(y)=var(y)
Ifvar(y)muchdifferentfrommean(y)-quasipoisson
GenerallyrequiresalargesamplesizeIfrates/counts>>0-regularregressionisfine
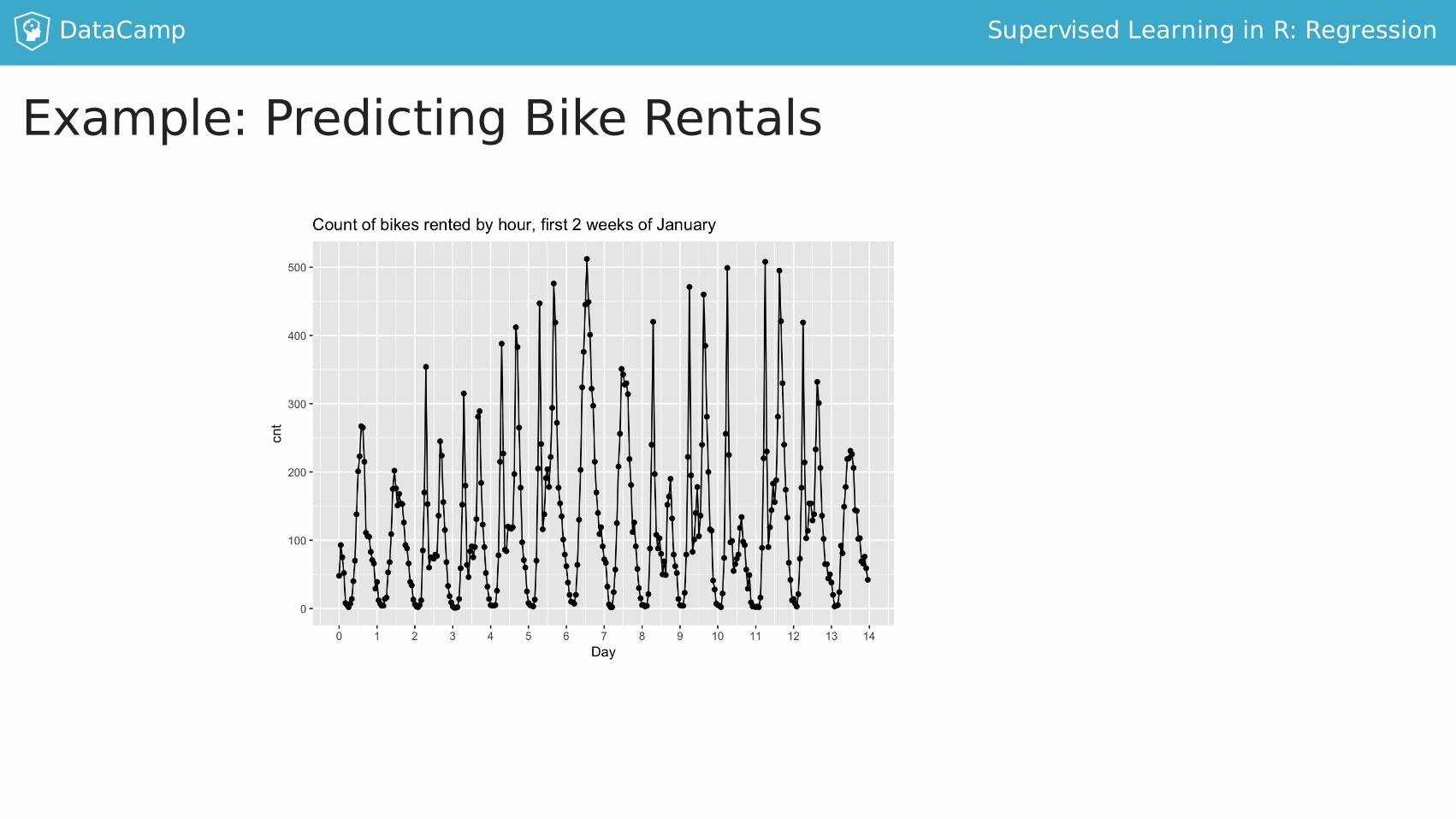
DataCamp SupervisedLearninginR:Regression
Example:PredictingBikeRentals

DataCamp SupervisedLearninginR:Regression
Fitthemodel
Sincevar(cnt)>>mean(cnt)→usequasipoisson
>bikesJan%>%+summarize(mean=mean(cnt),var=var(cnt))
##meanvar##1130.558714351.25
>fmla<-cnt~hr+holiday+workingday++weathersit+temp+atemp+hum+windspeed
>model<-glm(fmla,data=bikesJan,family=quasipoisson)

DataCamp SupervisedLearninginR:Regression
Checkmodelfit
pseudoR = 1 −2
null.deviance
deviance
>glance(model)%>%+summarize(pseudoR2=1-deviance/null.deviance)
##pseudoR2##10.7654358

DataCamp SupervisedLearninginR:Regression
Predictingfromthemodel>predict(model,newdata=bikesFeb,type="response")

DataCamp SupervisedLearninginR:Regression
Evaluatethemodel
YoucanevaluatecountmodelsbyRMSE
>bikesFeb%>%+mutate(residual=pred-cnt)%>%+summarize(rmse=sqrt(mean(residual^2)))
##rmse##169.32869
>sd(bikesFeb$cnt)[1]134.2865
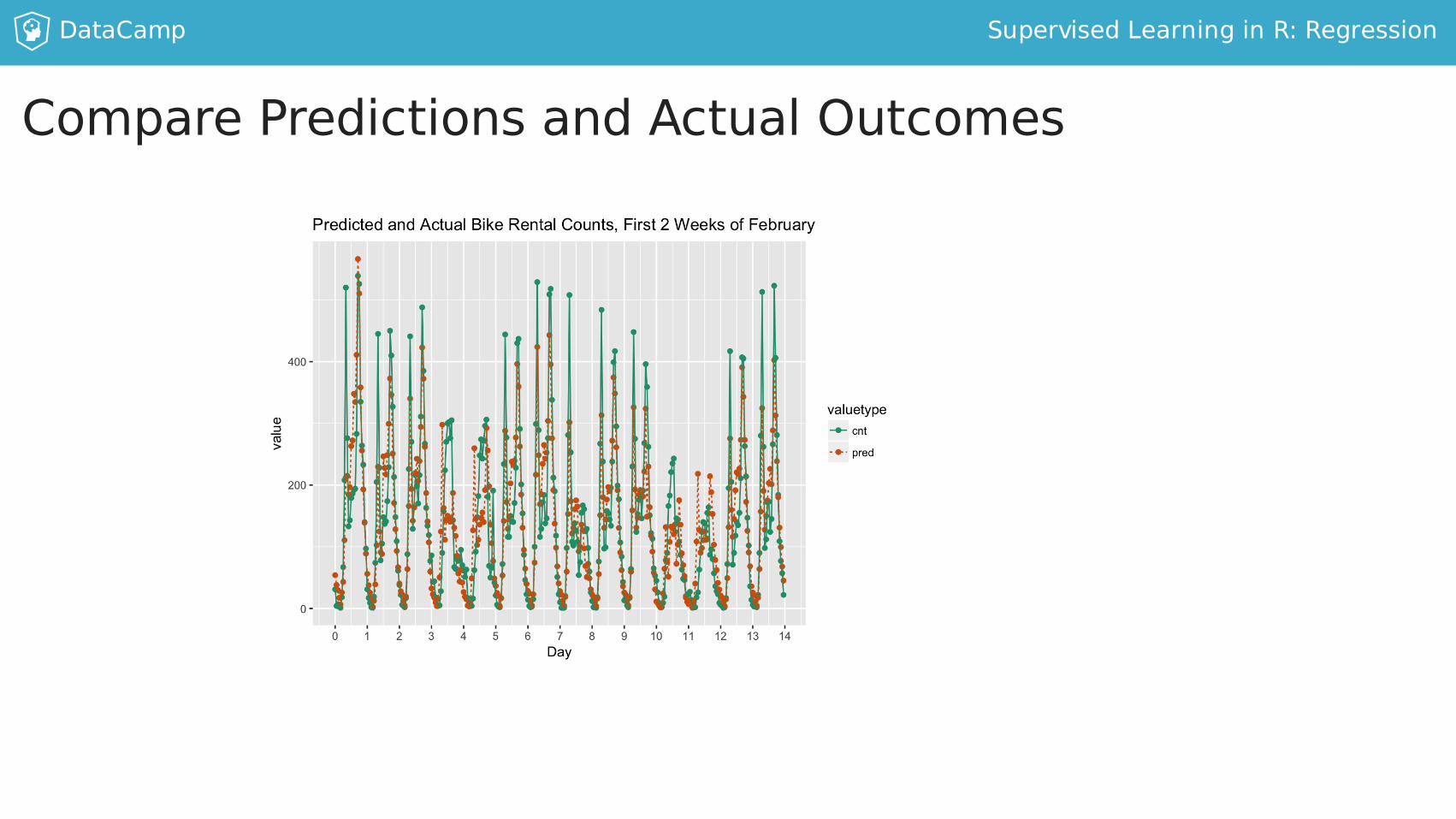
DataCamp SupervisedLearninginR:Regression
ComparePredictionsandActualOutcomes

DataCamp SupervisedLearninginR:Regression
Let'spractice!
SUPERVISEDLEARNINGINR:REGRESSION

DataCamp SupervisedLearninginR:Regression
GAMtolearnnon-lineartransformations
SUPERVISEDLEARNINGINR:REGRESSION
NinaZumelandJohnMountWin-Vector,LLC

DataCamp SupervisedLearninginR:Regression
GeneralizedAdditiveModels(GAMs)
y ∼ b0 + s1(x1) + s2(x2) + ....

DataCamp SupervisedLearninginR:Regression
LearningNon-linearRelationships

DataCamp SupervisedLearninginR:Regression
gam()inthemgcvpackage
family:
gaussian(default):"regular"regressionbinomial:probabilitiespoisson/quasipoisson:counts
Bestforlargerdatasets
gam(formula,family,data)

DataCamp SupervisedLearninginR:Regression
Thes()function
s()designatesthatvariableshouldbenon-linear
Uses()withcontinuousvariables
Morethanabout10uniquevalues
>anx~s(hassles)
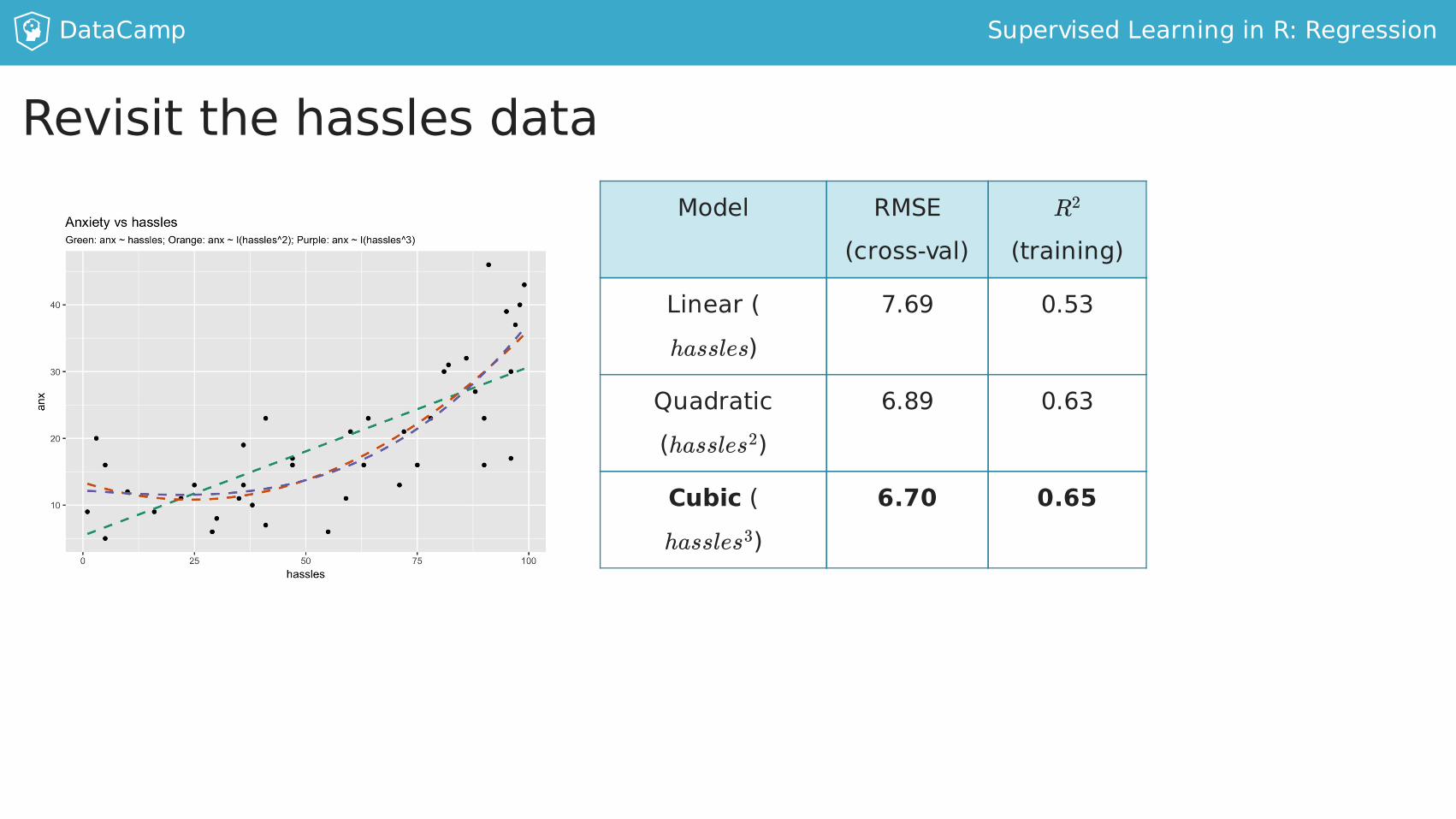
DataCamp SupervisedLearninginR:Regression
RevisitthehasslesdataModel RMSE
(cross-val)R
(training)
Linear(hassles)
7.69 0.53
Quadratic(hassles )
6.89 0.63
Cubic(hassles )
6.70 0.65
2
2
3
DataCamp SupervisedLearninginR:Regression
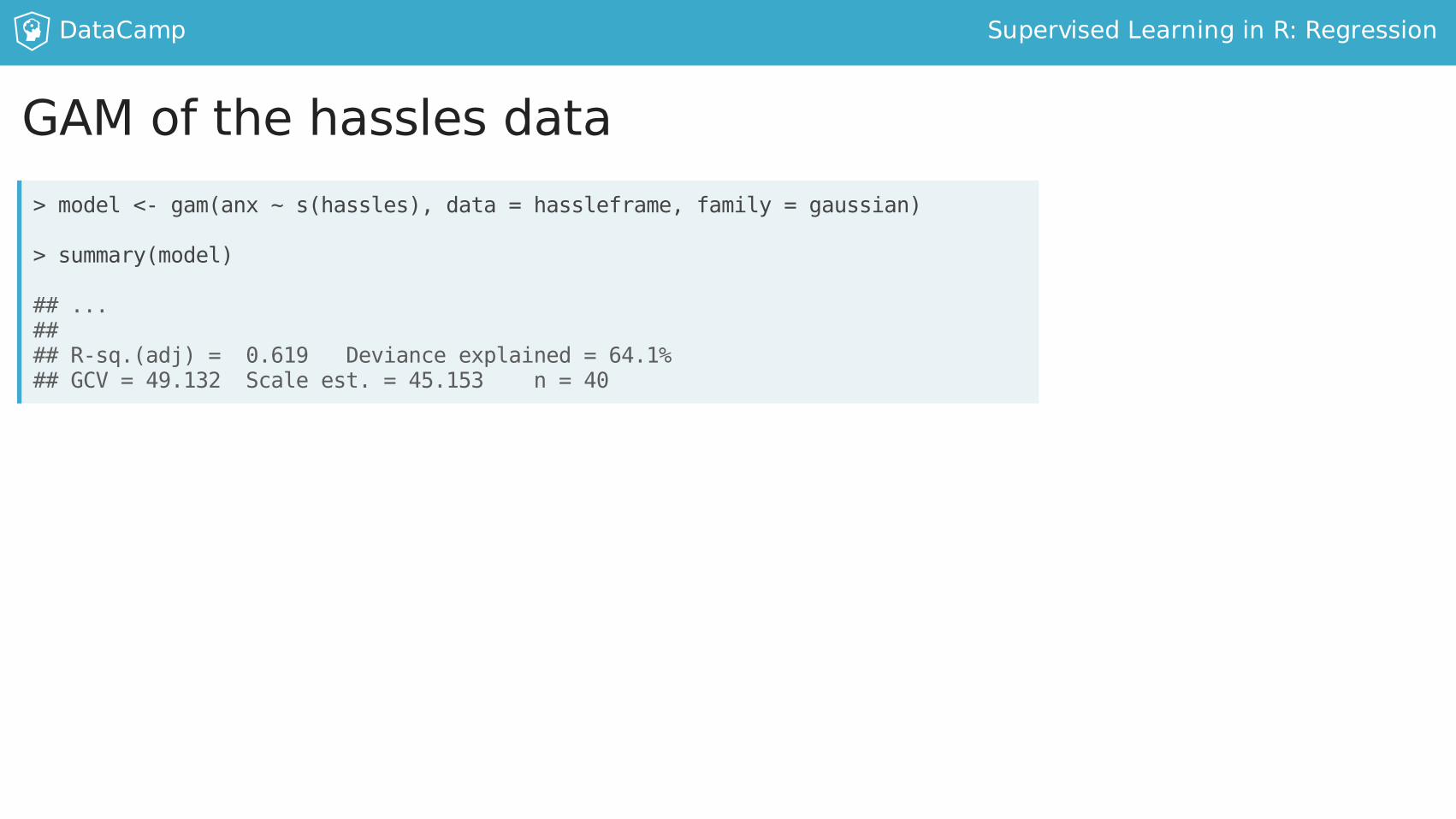
GAMofthehasslesdata>model<-gam(anx~s(hassles),data=hassleframe,family=gaussian)
>summary(model)
##...####R-sq.(adj)=0.619Devianceexplained=64.1%##GCV=49.132Scaleest.=45.153n=40
DataCamp SupervisedLearninginR:Regression
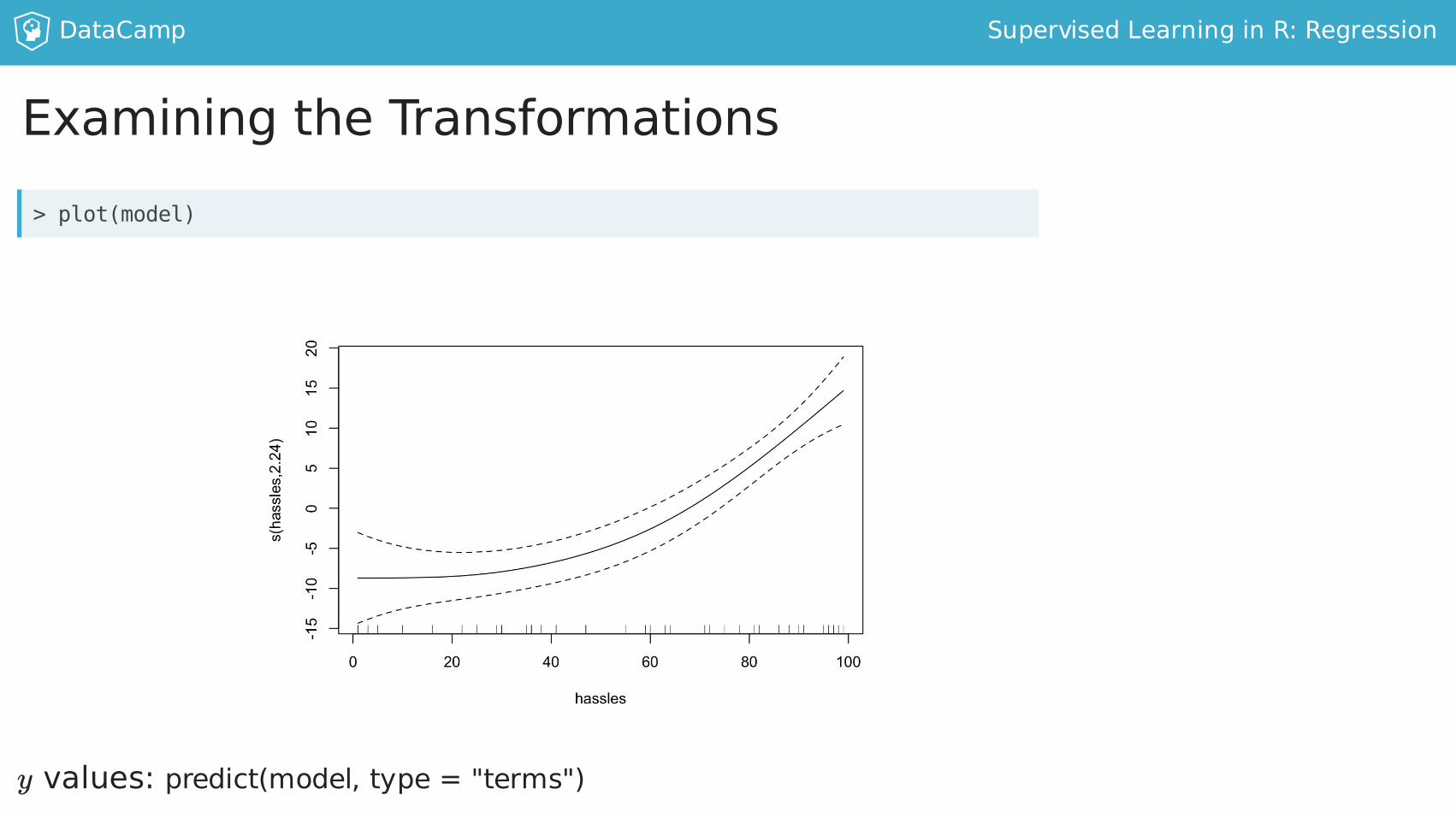
ExaminingtheTransformations
yvalues:predict(model,type="terms")
>plot(model)

DataCamp SupervisedLearninginR:Regression
PredictingwiththeModel>predict(model,newdata=hassleframe,type="response")

DataCamp SupervisedLearninginR:Regression
Comparingout-of-sampleperformance
Knowingthecorrecttransformationisbest,butGAMisusefulwhentransformationisn'tknown
Model RMSE(cross-val) R (training)
Linear(hassles) 7.69 0.53
Quadratic(hassles ) 6.89 0.63
Cubic(hassles ) 6.70 0.65
GAM 7.06 0.64
Smalldataset→noisierGAM
2
2
3
DataCamp SupervisedLearninginR:Regression
Let'spractice!
SUPERVISEDLEARNINGINR:REGRESSION