streamsets and spark
TRANSCRIPT


StreamSets Data Collector
Open source software for the rapid development and
reliably operation of complex data flows.
➢ Efficiency➢ Control➢ Agility

Inside an SDC

● Origins read data into the pipeline○ Kafka, Kinesis S3, JDBC, CDC, Local FS, Tail file, HDFS, MapR FS○ Automagically parse common data formats into Records - no coding required!
● Processors operate on Records making changes, adding, removing records or fields○ Field remover, renamer, flattener, masker, JSON/XML/Log parser, HTTP client..○ Scripting: Jython, Groovy, JavaScript○ Spark!
● Destinations write data out to external systems○ HDFS, MapR FS, S3, JDBC, Kafka, Kinesis, Mongo, HBase, Redis...○ Automagically convert Records into common data formats
● Executors run when events are sent to them by a linked stage○ Executors can be used to trigger an external action, like a Hive query (Impala refresh etc.)○ Any stage can send events - like when a file is closed, or table read is completed
Stages
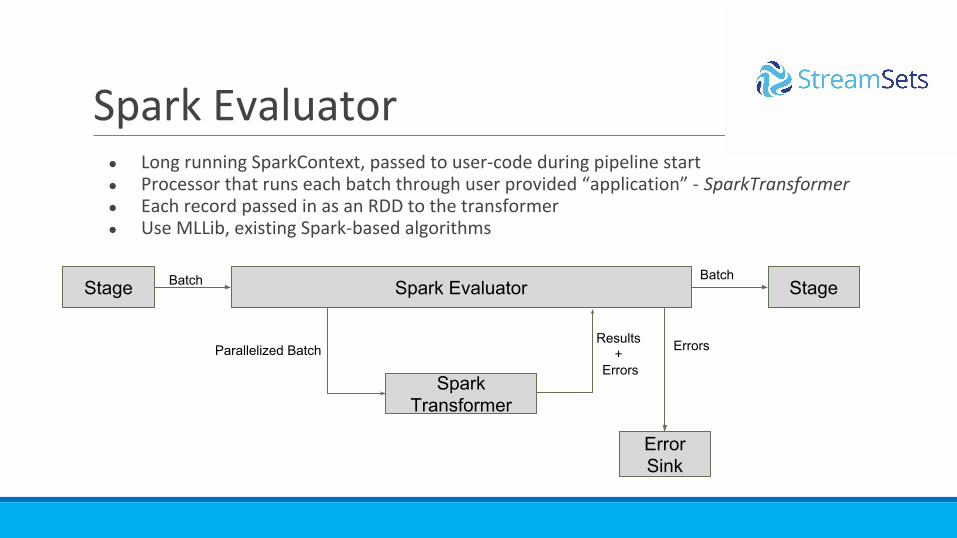
● Long running SparkContext, passed to user-code during pipeline start● Processor that runs each batch through user provided “application” - SparkTransformer● Each record passed in as an RDD to the transformer● Use MLLib, existing Spark-based algorithms
Spark Evaluator
Stage Spark Evaluator
Spark Transformer
Parallelized BatchResults
+ Errors
Error Sink
Errors
StageBatchBatch

● Transformer returns:
○ Result records that need to go to the next stage
○ Error records that can’t be processed
● Results are passed through to the rest of the pipeline
● Already available for CDH Spark in SDC 2.2.0.0
● MapR Spark support coming in 2.5.0.0
Spark Evaluator

Demo!

Cluster Pipelines on Spark
● Container on Spark● Leverage Direct Kafka DStream● Spark used only for Kafka partitioning
Cluster PipelineKafka DStream
Partition PipelineQueuePartition PipelineQueuePartition PipelineQueue
t1
Partition PipelineQueuePartition PipelineQueuePartition PipelineQueue
t2

Spark Evaluator in a Cluster World
● Able to see all the data coming in from Kafka as a single unit per batch
● Complex processing per batch, that can trigger shuffles
● Compare with Spark Streaming
● Update models in real time based on streaming data
● Maintain simple (non-distributed) state
● Can be used as a base for custom functions like count, windowing etc.
● Run Spark-processed data through our own processors and use our existing stages!

● Pipeline design will be exactly the same as standalone● RDD passed to SparkTransformer points to data across the cluster ● Each RDD partition represents data on each worker pipeline
Cluster Mode Spark Evaluator
Cluster PipelineKafka DStream
Kafka RDD
Spark Processor
Spark Processor
Spark Processor
RDD<Record>
Partition
Partition
Partition
SparkTransformer
Partition
Partition
Partition
RDD<Record>
Stage
Stage
Stage
Every Batch

SDC on Spark - ConnectivitySources
● Kafka
Destinations
● HDFS
● HBase
● S3
● Kudu
● MapR DB
● Cassandra
● ElasticSearch
● Kafka
● MapR Streams
● Kinesis● etc, etc, etc!

● When an event is received, kick off a Spark application
● Ability to provide an application jar, and specific configuration
● Supports YARN and Databricks cloud support.
● YARN
○ Client and Cluster mode
○ Parameters can be based on the event data like file name
● Databricks Cloud
○ Define job beforehand
○ Kick off the job on event
○ Parameters can be based on the event data like file name
Spark Executor

Questions?