stochastic models for semi- structured document … filedocument restructuration experiments...
TRANSCRIPT

Stochastic models for semi-structured document mining
P. GallinariCollaboration with
G. Wisniewski – L. Denoyer – F. Maes
LIP6
University Pierre – Marie Curie - Fr

2006-04-27 - LIPN - P. Gallinari 2
Outline
Context Generative tree models 3 problems
Classification Clustering Document mapping
Experiments Conclusion and future work
XML Document Mining Challenge

2006-04-27 - LIPN - P. Gallinari 3
Context - Machine learning in thestructured domain
Model, Classify, cluster structured data Domains: Chemistry, biology, XML, etc Models: discriminant e.g. kernels, generative e.g.
tree densities
Predict structured outputs Domains: natural language parsing, taxonomies, etc Models: relational learning, large margin extensions
Learn to associate structured representationsaka Tree mapping Domains: databases, semi-structured data

2006-04-27 - LIPN - P. Gallinari 4
Context- Machine learning in thestructured domain
Structure only vs Structure + content Central complexity issue
Representation space (#words, #tags,#relations)
Search space for structured outputs -idem
Large corporaneeds simple and approximate
methods

2006-04-27 - LIPN - P. Gallinari 5
Context-XML semi-structureddocuments
<fig>
<fgc>
<sec>
<p>
<bdy>
<article>
<st>
<hdr>
text
text
text

2006-04-27 - LIPN - P. Gallinari 6
Outline
Context Generative tree models 3 problems
Classification Clustering Document restructuration
Experiments Conclusion and future work
XML Document Mining Challenge

2006-04-27 - LIPN - P. Gallinari 7
Document model
),/()/(
)/,()/(
Θ==Θ==
Θ===Θ=ddd
dd
sStTPsSP
tTsSPdDP
Structuralprobability
Contentprobability
),( dd tsd =
s
t

2006-04-27 - LIPN - P. Gallinari 8
Document Model: Structure
Belief Networks
Paragraphe Paragraphe
Section Section
Titre
Titre
Document
Corps
Titre du document
Titre de la section
Cette section contient deuxparagraphes
Premier paragraphe Second paragraphe
La deuxième section necontient pas de paragraphes
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe
⇒
∏=
=//
1
)()(d
i
di
d sPsP∏=
=//
1
)))((/()(d
i
id
id
d nparentlabelsPsP( )∏=
=//
1
))(()),((/)(d
i
di
di
di
d nprécédentlabelnparentlabelsPsP
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe

2006-04-27 - LIPN - P. Gallinari 9
Document Model: Content
Model for each node
1st order dependency
Use of a local generative model for eachlabel
),....,( //1 dddd ttt =
∏=
=//
1
),/(),/(d
i
id
iddd stPstP θθ
)/(),/( idd si
did
i tPstP θθ =

2006-04-27 - LIPN - P. Gallinari 10
Final network Document
Intro SectionSection
Paragraphe
Paragraphe Paragraphe
T1= « Ce documentest un exemple dedocument structuré
arborescent »
T2= « Ceci est lapremière section du
document »
T3= « Le premierparagraphe »
T4= «Le secondparagraphe »
T5= «La secondesection »
T6= «Le troisièmeparagraphe »
)/( DocumentIntroP )/( DocumentSectionP)/( DocumentSectionP
)/( SectionParagrapheP
)/( SectionParagrapheP
)/( SectionParagrapheP)/1( IntroTP
)/2( SectionTP
)/3( ParagrapheTP
)/5( SectionTP
)/4( ParagrapheTP )/6( ParagrapheTP
( ))/6()/5()/4(*
)/3()/2()/1(*
)/arg()?/()/()( 3
ParagrapheTPSectionTPParagrapheTP
ParagrapheTPSectionTPIntroTP
SectionraphePPDocumentSectionPDocumentIntroPdP =

2006-04-27 - LIPN - P. Gallinari 11
Different learning techniques
Likelihoodmaximization
Discriminant learning
Logistic function Error minimization
contenustructure
Dd
d
i
ts
di
di
Dd
sd
Dd
LL
stPsP
dPL
TRAIN
di
TRAIN
TRAIN
+=
Θ+
Θ=
Θ=
∑ ∑∑
∑
∈ =∈
∈
//
1
),/(log)/(log
)/(log
∑=
−
−
+
=
+
=
n
ic
ixpaix
cixpaix
e
e
xcP
cxP
cxP
1 )(,
)(,log
)/(
)/(log
1
11
1)/(
θ
θ

2006-04-27 - LIPN - P. Gallinari 12
Fisher Kernel
Fisher Score :
HypothesisHypothesis : : The gradient of the log-likelihood isinformative about how much a feature « participate »to the generation of an example.
Fisher Kernel : K(X,Y)=K(Ux,Uy)
)/(log θθ XPUX ∇=

2006-04-27 - LIPN - P. Gallinari 13
Use with the model
( ) ∑ ∑Λ∈ =
ΘΘΘ
Θ∇+Θ∇=Θ+Θ∇=
l lsi
tdi
di
sdtddsdd
di
tlstPsPstPsPU/
),/(log)/(log),/(log)/(log
???
?
?
???
?
?
???
?
?
???
?
???
???
?
?
???
?
?????? ??
??
?
?
??
//1 //
),/(log,...,),/(log),/(log
lsi
tdi
di
lsi
tdi
di
sdd
di
tl
di
tl stPstPsPU
Sous-vecteurcorrespondantau gradient surle modèle destructure
Sous-vecteurcorrespondant augradient pour lesnœuds de label l1
Sous-vecteurcorrespondant augradient pour lesnœuds de label // ?l
),/(log tdd stP ?? ?

2006-04-27 - LIPN - P. Gallinari 14
Remark
Fisher kernels: very large number ofparameters On INEX :
With flat models : 200 000 parameters With structure models : 20 millions
parameters

2006-04-27 - LIPN - P. Gallinari 15
Conclusion about this faimily ofgenerative models
Natural setting for modeling semistructured multimedia documents Structural probability (Belief network) Content probability (local generative model)
Learning with maximum likelihood, orcross-entropy
Discriminant learning and Fisher Kernel

2006-04-27 - LIPN - P. Gallinari 16
Outline
Context Generative tree models 3 problems
Classification Clustering Document restructuration
Experiments Conclusion and future work
XML Document Mining Challenge

2006-04-27 - LIPN - P. Gallinari 17
Classification One model for each category
3 XML corpora + 1 multimedia corpus INEX : 12 000 articles from IEEE
18 journals WebKB : Web pages (8K pages)
course, department, …7 topics WIPO : XML Documents of patents
categories of patents NetProtect (European project) : 100 000 web pages
pornographic or not
2006-04-27 - LIPN - P. Gallinari 18
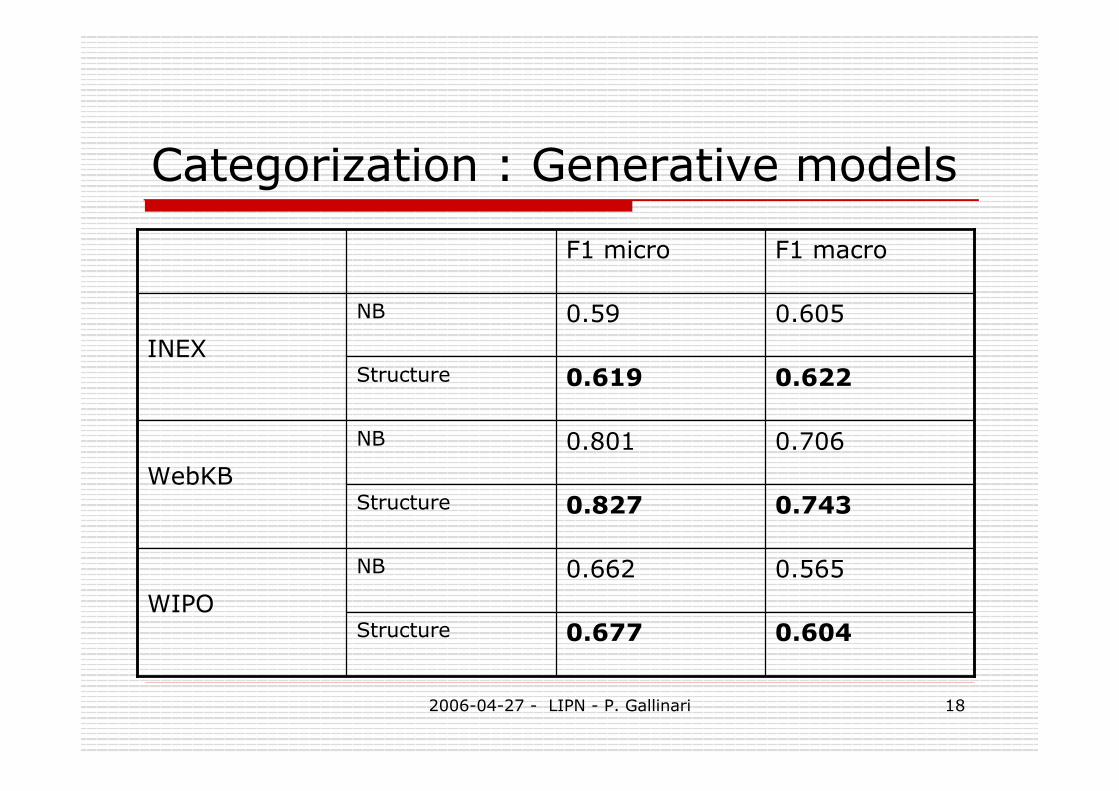
Categorization : Generative models
0.6040.677Structure
0.5650.662NB
WIPO
0.7430.827Structure
0.7060.801NB
WebKB
0.6220.619Structure
0.6050.59NB
INEX
F1 macroF1 micro

2006-04-27 - LIPN - P. Gallinari 19
0.6000.575Discriminant learning
0.6680.661Fisher kernel
0.5640.534SVM TF-IDF
0.6220.619Structure model
0.6050.59NB
F1 macroF1 micro
INEX
0.7150.862Fisher Kernel
0.710.822SVM TF-IDF
0.6040.677Structure model
0.5650.662NB
F1 macroF1 micro
WIPO
0.7920.868Discriminant learning
0.7380.823Fisher Kernel
0.6510.737SVM TF-IDF
0.7430.827Structure model
0.7060.801NB
F1 macroF1 micro
WebKB
Discriminant models

2006-04-27 - LIPN - P. Gallinari 20
Multimedia model
94.7[94.2 ;95.1]
93.6[93.1 ;94]
Structuremodeltext andpictures
82.7[81.9 ;83.4]
83[82.2 ;83.7]
Structuremodelwithpictures
92.9[92.3 ;93.3]
92.5[91.9 ;93]
Structuremodelwith text
88.4[87.7 ;89]
89.9[89.2 ;90.4]
NB
Microaveragerecall
Macroaveragerecall
Director Ang Lee Takes Risks with MeanGreen 'Hulk'
LOS ANGELES (Reuters) -Taiwan-born director Ang Lee,perhaps best known for hisOscar-winning "Crouching Tiger,Hidden Dragon," is taking a bigrisk with the splashy summerpopcorn flick …...
For loyal comic book fans who may think Lee's "Hulk" will be too touchy-feely, think again." This is a drama, a family drama," said Lee, "but with big action." His slumping shoulderstwitch and he laughs…..
FAMILY DRAMA, BIG ACTION

2006-04-27 - LIPN - P. Gallinari 21
Classification : conclusion
Structure model is able to handlestructure and content information
Both structure and content carry classinformation
Multimedia categorization Not in this talk :
Categorization of parts of documents Categorization of trees (structure only)

2006-04-27 - LIPN - P. Gallinari 22
Outline
Context Generative tree models 3 problems
Classification Clustering Document restructuration
Experiments Conclusion and future work
XML Document Mining Challenge

2006-04-27 - LIPN - P. Gallinari 23
Clustering
The usual goal is to find groups ofsimilar documents (in a thematic sense)
The task is different for structureddocuments : What means “similar documents” :
Same structure ? Same content ? Both
Open question

2006-04-27 - LIPN - P. Gallinari 24
Clustering
)/(*)/(//
1∑=
Θ=ΘC
ic
dc ii
sPdP α
Mixture model :
EM algorithm (CEM) Use on the structure (only) using INEX
corpus

2006-04-27 - LIPN - P. Gallinari 25
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe
Intro;Section;Section
Paragraphe;Paragraphe
)/()/;()/;;()( SectionParagraphePSectionParagrapheParagraphePDocumentSectionSectionIntroPsP d ?
? ???
//
1
))(()),((/)(
d
i
d
i
d
i
d
i
dnprécédentlabelnparentlabelsPsP ?
?
?
//
1
))(_/()(
d
i
id
id
dnlabelparentsPsP ?
?
?
//
1
)()(
d
i
di
d sPsP
Different models

2006-04-27 - LIPN - P. Gallinari 26
The grammar model
A
CA
A
B
AEE
A
A C
A C B C
E E A
B
Arbre 1
Arbre 2 Arbre 3
1
1)/,(
2
2)/,,(
5
2)/(
5
3)/,(
=
=
=
=
CCBP
BAEEP
ABP
ACAP

2006-04-27 - LIPN - P. Gallinari 27
Grammar model and DTD
A
CA
A
B
AEE
A
A C
A C B C
E E A
B
Arbre 1
Arbre 2 Arbre 3
1
1)/,(
2
2)/,,(
5
2)/(
5
3)/,(
=
=
=
=
CCBP
BAEEP
ABP
ACAP
]1[
]1[
]5
2[
]5
3[
BCC
EEAB
BA
CAA
→
→
→
→
BCC
EEAB
BA
CAA
→
→
→
→
< !DOCTYPE A [<!ELEMENT A (A,C)><!ELEMENT A (B) ><!ELEMENT B (E,E,A)><!ELEMENT C (B,C)>]>

2006-04-27 - LIPN - P. Gallinari 28
Clustering results
70
75
80
85
90
95
5 10 15 18 20 25 30 35 40
Nombre de clusters
En
tro
pie
mic
ro m
oyen
ne (
en
%)
Naive Bayes
Parent
Parent et GrandParent
Parent et Frere
Grammaire

2006-04-27 - LIPN - P. Gallinari 29
Example of DTDs

2006-04-27 - LIPN - P. Gallinari 30
Clustering : conclusions
Mixture model of belief networks Different models Grammar model is better
Able to compute a kind of DTD
Ill defined problem: clustering of XMLdocuments ?

2006-04-27 - LIPN - P. Gallinari 31
Outline
Context Generative tree models 3 problems
Classification Clustering Document restructuration
Experiments Conclusion and future work
XML Document Mining Challenge

2006-04-27 - LIPN - P. Gallinari 32
Structural heterogeneity<Restaurant><Nom>L’olivier</Nom><Description> Ce joli restaurant localisé près du
métro Jaurès, au 19 duboulevard de la vilette, perdudans le 19ème arrondissement deParis propose une cuisineitalienne, notamment des pâtesfraîches au 3 fromages.
</Description></Restaurant>
<Restaurant><Nom>La cantine</Nom><Adresse> 65 rue des pyrénées, Paris, 19ème,
FRANCE</Adresse><Spécialités> Canard à l’orange, Lapin au miel</Spécialités></Restaurant>
<Restaurant><Nom>Tokyo Bar</Nom><Adresse> <Ville>Paris</Ville> <Arrd>19</Arrd> <Rue>Bolivar</Rue> <Num>127</Num></Adresse><Plat>Sushi</Plat><Plat>Sashimi</Plat></Restaurant>
Problem: Query heterogeneous XML databasesor collections, Storage, etc
Needs to know the correspondence betweenthe structured representations

2006-04-27 - LIPN - P. Gallinari 33
Document mapping problem
Problem Learn from examples how to
map heterogeneous sourcesonto a predefined targetschema
Preserve the documentsemantic
Sources: semistructured,HTML, PDF, flat text, etc
Labeled tree mapping problem
<Restaurant><Nom>Lacantine</Nom><Adresse>
<Ville>Paris</Ville>
<Arrd>19</Arrd>
<Rue>pyrénées</Rue>
<Num>65</Num></Adresse><Plat> Canard à l’orange</Plat><Plat> Lapin au miel</Plat></Restaurant>
<Restaurant><Nom>Lacantine</Nom><Adresse> 65 rue despyrénées, Paris,19ème, FRANCE</Adresse><Spécialités> Canard àl’orange, Lapinau miel</Spécialités></Restaurant>

2006-04-27 - LIPN - P. Gallinari 34
Document mapping problem
Central issue: Complexity Large collections Large feature space: 103 to 106
Large search space (exponential)
Approach Learn generative models of XML target
documents from a training set Decoding of unknown sources according to
the learned model

2006-04-27 - LIPN - P. Gallinari 35
Learning the correspondencevia examples
Why using ML for structure matching ? Multiple sources: variability, documents do
not follow the schema, collection growth, etc Web sources: DTDs, Schema are often
unknown or do not exist

2006-04-27 - LIPN - P. Gallinari 36
Learning correspondence
Data centered view (Doan et al.) Multiple independent classifier combination Centralized (mediator) or P2P 1:1 or m:n transformations
Document centered view Document conversion (Xerox)
rendering format (HTML, PDF, etc) -> XMLpredefined DTD format
Information retrieval (LIP6) Content and structure queries (e.g. INEX)
2006-04-27 - LIPN - P. Gallinari 37
Problem formulation
GivenST a target formatdsin(d) an input documentFind the most probable target document
)'(maxarg)(
'din
TT S
SdS ddPd
∈=
Decoding Learnedtransformation model

2006-04-27 - LIPN - P. Gallinari 38
General restructuration model
sd
td'
sd'
td
?
),,/(),/(argmax '''
'1 ΘΘ= ddddd
dtstPssPd
2006-04-27 - LIPN - P. Gallinari 39
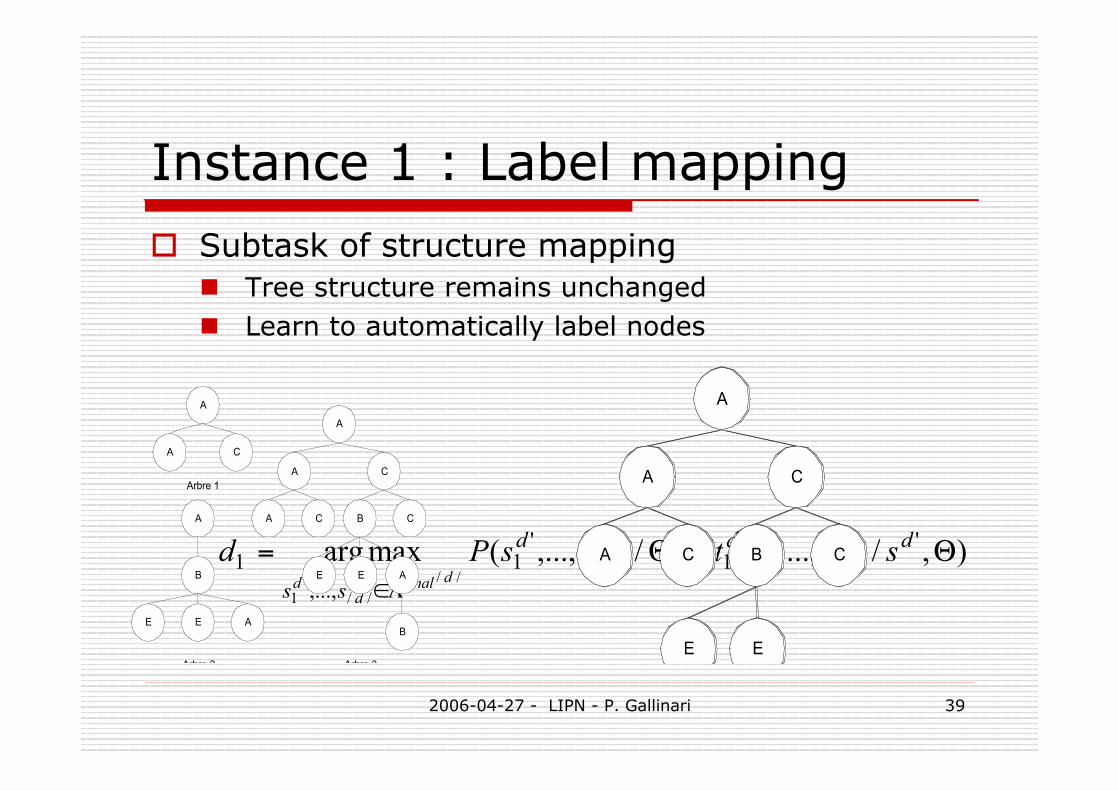
Instance 1 : Label mapping
Subtask of structure mapping Tree structure remains unchanged Learn to automatically label nodes
),/,.......,()/,...,(maxarg ''//
'1
'//
'1
,...,1
//'//
'1
ΘΘ=Λ∈
ddd
ddd
d
ss
sttPssPddfinald
dd
A
CA
A
B
AEE
A
A C
A C B C
E E A
B
Arbre 1
Arbre 2 Arbre 3
?
? ?
? ? ? ?
? ?
A
A C
A C B C
E E

2006-04-27 - LIPN - P. Gallinari 40
Document structure modelDocument
Title Section Section
Paragraph Paragraph
Italic
Paragraph FootNote
Title,Section,Section
Paragraph,Paragraph Paragraph,FootNote
∏=
dn
ntagngschildrentaPsPin nodes all
)),(|)(()|( θθ

2006-04-27 - LIPN - P. Gallinari 41
PCFG model
A
CA
A
B
AEE
A
A C
A C B C
E E A
B
Arbre 1
Arbre 2 Arbre 3
1
1)/,(
2
2)/,,(
5
2)/(
5
3)/,(
=
=
=
=
CCBP
BAEEP
ABP
ACAP
]1[
]1[
]5
2[
]5
3[
BCC
EEAB
BA
CAA
→
→
→
→
2006-04-27 - LIPN - P. Gallinari 42
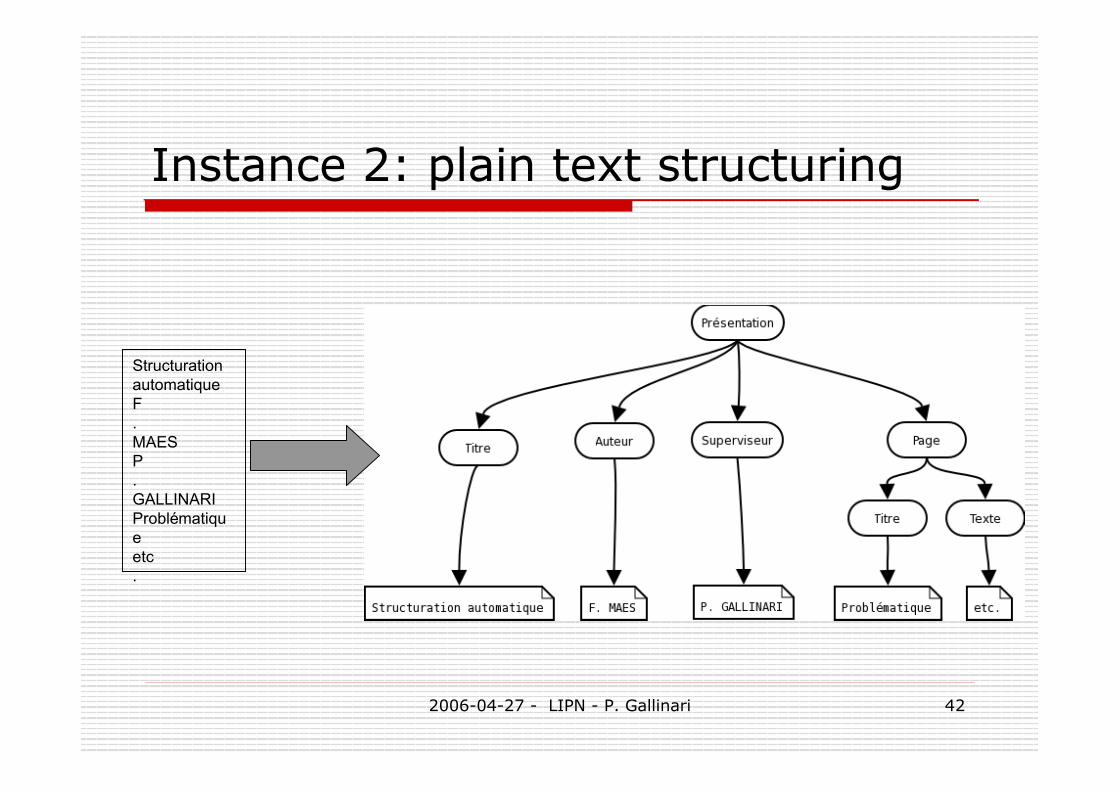
Instance 2: plain text structuring
StructurationautomatiqueF.MAESP.GALLINARIProblématiqueetc.

2006-04-27 - LIPN - P. Gallinari 43
Stochastic model
d = (c, s) s = (se, si)

2006-04-27 - LIPN - P. Gallinari 44
Sub-optimal approach
Segmentation and structuration are performedsequentially
Segmentation Structure Extraction

2006-04-27 - LIPN - P. Gallinari 45
Models Segmentation: HMM
Structure
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe

2006-04-27 - LIPN - P. Gallinari 46
Instance 3 : HTML to XML
Hypothesis Input document
HTML tags mostly for visualization Remove tags Keep only the segmentation (leaves)
Transformation Leaves are the same in the HTML and XML
document Target document model: node label depends
only on its local context Context = content, left sibling, father
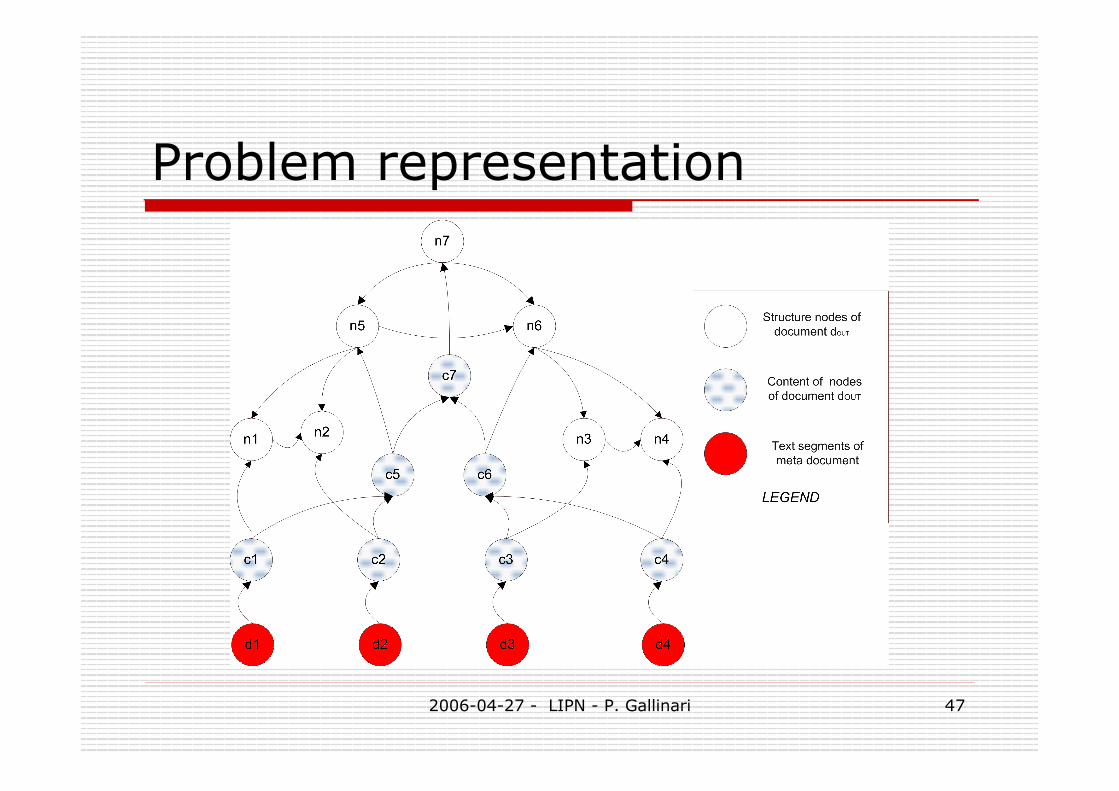
2006-04-27 - LIPN - P. Gallinari 47
Problem representation

2006-04-27 - LIPN - P. Gallinari 48
Model and training
Probability of target tree
Document model : max-entropy conditionalmodel learned from a training set of target docs
∏==
iniiiidT
dTdSinT
nfathernsibcnPdddP
dddPddP
))(),(,(),...,(
),...,()(
1
1)(
Document
Intro SectionSection
Paragraphe Paragraphe Paragraphe

2006-04-27 - LIPN - P. Gallinari 49
Decoding
Solve
Exact Dynamic Programming decoding O(|Leaf nodes|3.|tags|)
Approximate solution with LASO (Hal Daume ICML 2005) O(|Leaf nodes|.|tags||tree nodes|)
)'(maxarg)(
'din
TT S
SdS ddPd
∈=

2006-04-27 - LIPN - P. Gallinari 50
Experiments
INEX corpus: IEEE collection (XML) :
12 000 documents (training : 7 800 , Test : 4 200) ≈ 5 000 000 content nodes 139 tags Mean document depth ≈ 7 vocabulary : ≈ 22 000 mots
test corpus : Transaction On …series Unlabeled documents (tags removed)

2006-04-27 - LIPN - P. Gallinari 51
Instance 1 : Label mapping -results
9,5%65,30%49,70%27,80%139tags
79,3%86,50%72,90%58%5 tags
naïvemodel
Struct +Content
StructureContent

2006-04-27 - LIPN - P. Gallinari 52
Instance 1 : IR adapted measure
5 Tags
0102030405060708090100
0 10 20 30 40 50 60 70 80 90 100
% of nodes
% o
f d
oc
um
en
ts
139 Tags
0102030405060708090
100
0 10 20 30 40 50 60 70 80 90 100
% of nodes
% o
f d
oc
um
en
ts
Content with all nodes
Structure
Structure and Content
Content without emptynodes

2006-04-27 - LIPN - P. Gallinari 53
Instance 2: plain text structuringResults
22,8%24,6%91,5%HMM + TMM
31,2%75,7%92,8 %Exact + TMM
Structuration(internalnodes)
Segmentation(leafs)
labelingModels
Extreme structuration instance Exact + TMM: degraded version of HTML documents
structuration

2006-04-27 - LIPN - P. Gallinari 54
Instance 3 HTML to XML
IEEE collection / INEX corpus 12 K documents,
Average: 500 leaf nodes, 200 int nodes, 139 tags
Movie DB 10 K movie descriptions (IMDB)
Average: 100 leaf nodes, 35 int. nodes, 28 tags Shakespeare 39 plays
Few doc, but: Average: 4100 leaf nodes, 850 int nodes, 21 tags
Mini-Shakespeare Randomly chosen 60 scenes from the plays
85 leaf nodes, 20 int. nodes, 7 tags

2006-04-27 - LIPN - P. Gallinari 55
Performances

2006-04-27 - LIPN - P. Gallinari 56

2006-04-27 - LIPN - P. Gallinari 57
Conclusion
Document restructuration is a newproblem
Tree transformation problem of highcomplexity (content + structure)
Many different instances Approach based on generative models of
target documents

2006-04-27 - LIPN - P. Gallinari 58
XML Document Mining Challenge2006 Challenge
INEX-Delos and Pascal networks of excellence Three tasks
Classification Clustering Document mapping
3 XML corpora IEEE collection IMDB (Movie descriptions) Wikipedia in 4 languages Dead line : june 2006
Web site : http://xmlmining.lip6.fr Email : [email protected]