startup.ml: using neon for nlp and localization applications
TRANSCRIPT

Developing deep learning models with neon
Arjun Bansal
startup.ml November 7, 2015

Outline
2
• Intro to Deep Learning
• Nervana platform
• Neon
• Building a sentiment analysis model (hands-on)
• Building a model that learns to play video games (demo)
• Nervana Cloud

INTRO TO DEEP LEARNING
3

4
What is deep learning?
A method for extracting features at
multiple levels of abstraction
• Features are discovered from data
• Performance improves with more data
• Network can express complex transformations
• High degree of representational power
WHAT IS DEEP LEARNING?
DATA & DEEP LEARNING
MORE THAN AN ALGORITHM - A FUNDAMENTALLY DISTINCT COMPUTE PARADIGM
A method of extracting features at multiple levels of abstraction• Unsupervised learning can find structure in
unlabeled datasets• Supervised learning optimizes solutions for a
particular application• Performance improves with more training data
11

5
Convolutional neural networks
Filter + Non-Linearity
Pooling
Filter + Non-Linearity
Fully connected layers
…
“how can I help you?”
cat
Low level features
Mid level features
Object parts, phonemes
Objects, words
*Hinton et al., LeCun, Zeiler, Fergus
Filter + Non-Linearity
Pooling

6
Improved accuracyError rate1
0%!
5%!
10%!
15%!
20%!
25%!
30%!
2010! 2011! 2012! 2013! 2014! 2015!
Source: ImageNet1: ImageNet top 5 error rate

7
Improved accuracyError rate1
Deep learning techniques
0%!
5%!
10%!
15%!
20%!
25%!
30%!
2010! 2011! 2012! 2013! 2014! 2015!
Source: ImageNet1: ImageNet top 5 error rate

8
Improved accuracyError rate1
Deep learning techniques
0%!
5%!
10%!
15%!
20%!
25%!
30%!
2010! 2011! 2012! 2013! 2014! 2015!
human performance
Source: ImageNet1: ImageNet top 5 error rate

9
Scene Parsing
*Yann LeCun https://www.youtube.com/watch?v=ZJMtDRbqH40

10
Speech Translation
*Skype https://www.youtube.com/watch?v=eu9kMIeS0wQ

11
Understanding Images
*Karpathy http://cs.stanford.edu/people/karpathy/deepimagesent/

12
Types of models
Model Application
Convolutional Neural Network
(CNN)
Object localization and classification in
images
Restricted Boltzmann Machines
(RBM)
Drug targeting, Collaborative Filtering,
Imputing missing interactions
Recurrent Neural Networks
(RNN)
Forecasting or predictions for timeseries
and sequence datasets
Multilayer Perceptrons
(MLP)Arbitrary input-output problems
Deep Q Networks
(DQN)
Reinforcement Learning problems,
State-Action learning, decision-making

13
Recurrent neural networks
input
hidden
output
• MLP

13
Recurrent neural networks
input
hidden
output
input
recurrent
output
• MLP• Add recurrent
connections
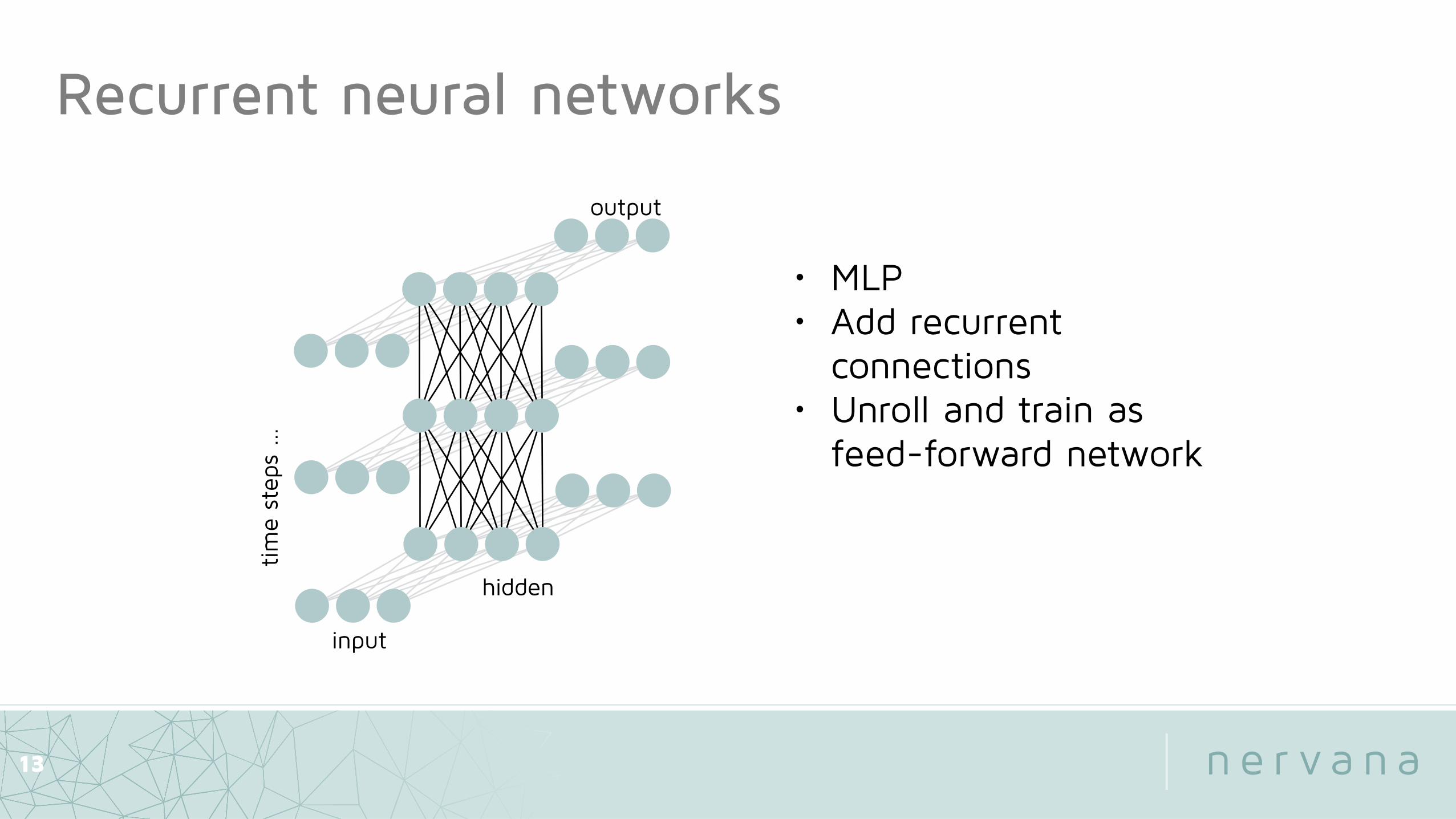
13
Recurrent neural networks
input
hidden
output
input
recurrent
output
• MLP• Add recurrent
connections• Unroll and train as
feed-forward network
input
hidden
output
tim
e s
teps
…

14
Long short term memoryNetwork activations determine states of input, forget, output gate:
f g i o
φ
* *
*
+
ct-1
ct ht
ht-1

14
Long short term memoryNetwork activations determine states of input, forget, output gate:• Open input, open output,
closed forget: LSTM network acts like a standard RNN
f g i o
φ
* *
*
+
ct-1
ct ht
ht-1
f g i o
φ
0 1
1
+
ct-1
ct ht
ht-1

14
Long short term memoryNetwork activations determine states of input, forget, output gate:• Open input, open output,
closed forget: LSTM network acts like a standard RNN
• Closing input, opening forget: Memory cell recalls previous state, new input is ignored
f g i o
φ
* *
*
+
ct-1
ct ht
ht-1
f g i o
φ
0 1
1
+
ct-1
ct ht
ht-1
f g i o
φ
1 0
1
+
ct-1
ct ht
ht-1

14
Long short term memoryNetwork activations determine states of input, forget, output gate:• Open input, open output,
closed forget: LSTM network acts like a standard RNN
• Closing input, opening forget: Memory cell recalls previous state, new input is ignored
• Closing output: Internal state is stored for the next time step without producing any output
f g i o
φ
* *
*
+
ct-1
ct ht
ht-1
f g i o
φ
0 1
1
+
ct-1
ct ht
ht-1
f g i o
φ
1 0
1
+
ct-1
ct ht
ht-1
f g i o
φ
1 0
0
+
ct-1
ct
ht-1
ht

15
LSTM networks
memory forget gate cell input input gate forget gate
LSTM weights:
• Requires less tuning than RNN, with same or better performance
• neon implementation hides internal complexity from the user
• LSTMs perform state of the art on sequence and time series data
• machine translation• video recognition• speech recognition• caption generation

NERVANA PLATFORM
16

17
Scalable deep learning is hard and expensive
Pre-process training
data
Augment
data
Design
model
Perform
hyperparameter
search
•Team of data scientists with deep learning expertise
•Enormous compute (CPUs /GPUs) and engineering resources
http://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf
18
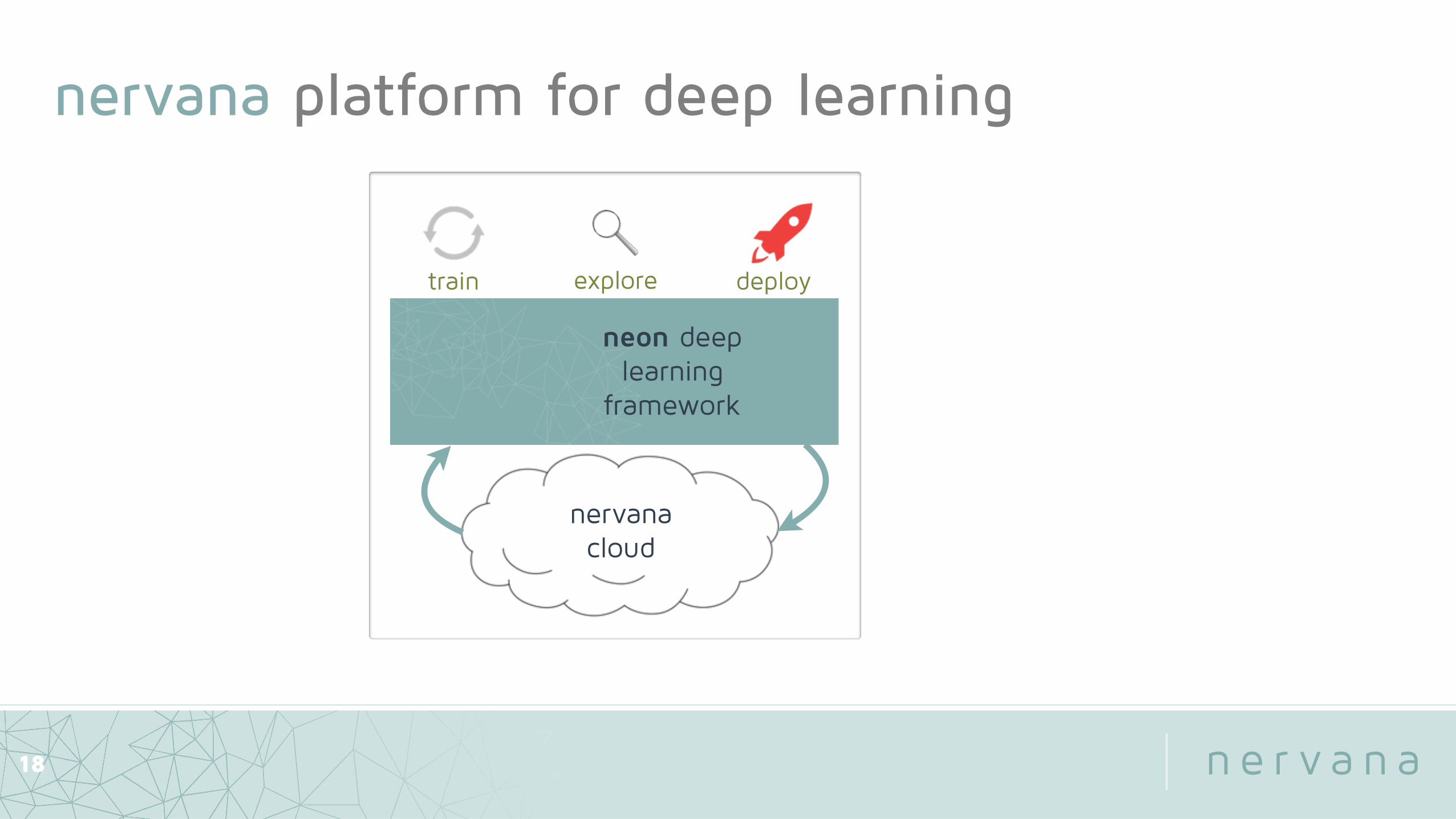
nervana platform for deep learning
neon deep learning
framework
train deploy
nervana cloud
explore

18
nervana platform for deep learning
neon deep learning
framework
train deploy
nervana cloud
exploreAWS
VM
S3 S3
Web
VM VM
VM VM VM
S3

18
nervana platform for deep learning
neon deep learning
framework
train deploy
nervana cloud
explore
GPUs
CPUs
nervana engine
AWS
VM
S3 S3
Web
VM VM
VM VM VM
S3

20
Deep learning as a core technology
DL
Image classification
Image localization
Speech recognition
Video indexing Sentiment
analysis
Machine Translation
Nervana Platform

21
Core technology
• Unprecedented compute density
21
Core technology
• Unprecedented compute density
• Scalable distributed architecture

21
Core technology
• Unprecedented compute density
• Scalable distributed architecture
• Learning and inference

• Architecture optimized for
algorithm
21
Core technology
• Unprecedented compute density
• Scalable distributed architecture
• Learning and inference

22
Verticals
Pharma Oil&Gas AgricultureMedical
$Finance Internet Govt

NEON
23

neon: nervana python deep learning library
24
• User-friendly, extensible, abstracts parallelism & data caching
• Support for many deep learning models
• Interface to nervana cloud
• Supports multiple backends
• Currently optimized for Maxwell GPU at assembler level
• Basic automatic differentiation
• Open source (Apache 2.0)
nervana engine
GPU cluster
CPU cluster { }See github for details

High level design
25
BackendsNervanaCPU, NervanaGPU NervanaEngine (internal)
DatasetsImages: ImageNet, CIFAR-10, MNIST
Captions: flickr8k, flickr30k, COCO; Text: Penn Treebank, hutter-prize, IMDB, Amazon
Initializers Constant, Uniform, Gaussian, Glorot Uniform
Learning rulesGradient Descent with Momentum
RMSProp, AdaDelta, Adam, Adagrad
Activations Rectified Linear, Softmax, Tanh, Logistic
LayersLinear, Convolution, Pooling, Deconvolution, Dropout
Recurrent, Long Short-Term Memory, Gated Recurrent Unit, Recurrent Sum, LookupTable
Costs Binary Cross Entropy, Multiclass Cross Entropy, Sum of Squares Error
Metrics Misclassification, TopKMisclassification, Accuracy
• Modular components
• Extensible, OO design
• Documentation
• neon.nervanasys.com

Proprietary and confidential. Do not distribute.
Using neon
26
Start with basic model:
# create training settrain_set = DataIterator(X, y)
# define modelinit_norm = Gaussian(loc=0.0, scale=0.01) layers = [ Affine(nout=100, init=init_norm, activation=Rectlin()), Affine(nout=10, init=init_norm, activation=Logistic(shortcut=True)) ] model = Model(layers=layers)cost = GeneralizedCost(CrossEntropyBinary())optimizer = GradientDescentMomentum(0.1, momentum_coef=0.9)
# fit modelmodel.fit(train_set, optimizer=optimizer, cost=cost)
mlp.py
Multilayer Perceptron
x
y

Proprietary and confidential. Do not distribute.
Using neon
27
Define data, model:
# create training settrain_set = DataIteratorSequence(X, y)
# define modelinit = Uniform(low=-0.08, high=0.08) layers = [ LSTM(hidden, init, Logistic(), Tanh()), Dropout(keep=0.5), Affine(features, init, bias=init, activation=Identity()) ] model = Model(layers=layers)cost = GeneralizedCost(SumSquared())optimizer = RMSProp()
# fit modelmodel.fit(train_set, optimizer=optimizer, cost=cost)
rnn.py
. . .xtkxt1 xt2
yt2yt1 ytk
Recurrent neural net

Proprietary and confidential. Do not distribute.
Speed is important
28
iteration = innovation
VGG-B ImageNet training
Trai
n t
ime (
hours
)
0
275
550
825
1,100
CPU Single GPU NervanaGPU Multi NervanaGPU
64
450
1,000
25,000
25,000*25000
*estimate
28
*

Proprietary and confidential. Do not distribute.
1 Soumith Chintala, github.com/soumith/convnet-benchmarks
Benchmarks for convnets1
29
Benchmarks compiled by Facebook. Smaller is better.

Proprietary and confidential. Do not distribute.
1 Soumith Chintala, github.com/soumith/convnet-benchmarks
Benchmarks for convnets (updated1)
30
Benchmarks compiled by Facebook. Smaller is better.

Proprietary and confidential. Do not distribute.
31
VGG-D speed comparison
RuntimesVGG-D
NEON[NervanaGPU]
Caffe[CuDNN v3]
NEONSpeed Up
fprop 363 ms 581 ms 1.6x
bprop 762 ms 1472 ms 1.9x
full forward/backward pass
1125 ms 2053 ms 1.8x
Proprietary and confidential. Do not distribute.
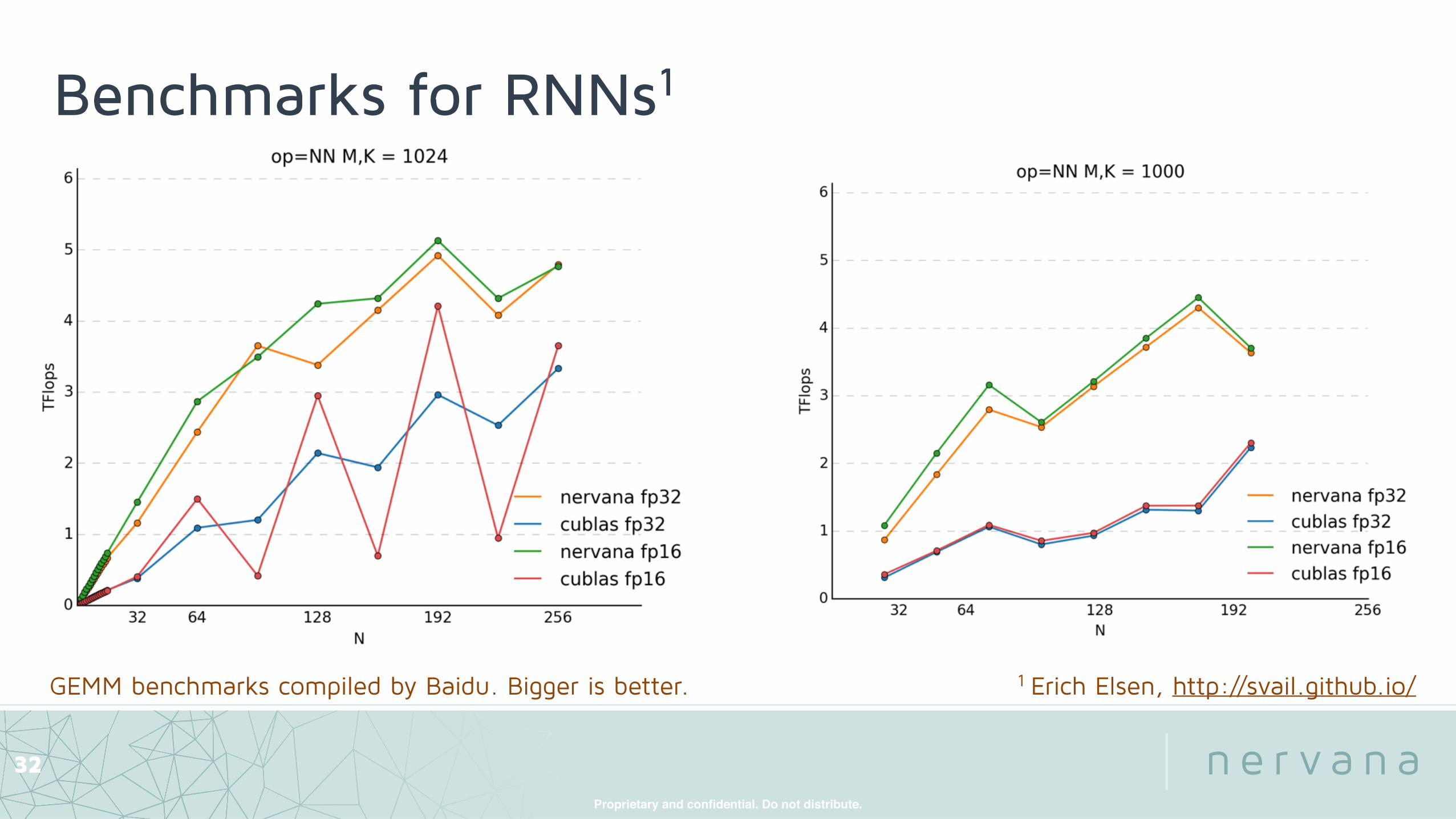
Benchmarks for RNNs1
32
GEMM benchmarks compiled by Baidu. Bigger is better. 1 Erich Elsen, http://svail.github.io/

33
Optimized data loading
• Goal: ensure neon
never blocks
waiting for data • C++ multi-
threaded • Double buffered,
pooled resources
LibraryWrapper
DataLoader DataLoader DecodeThreads
start
IOThreads
destroythreadpoolstop
next
...
next
createthreadpool
createthreadpool
destroythreadpool
readmacrobatchfile
decode
decode
decode
macrobatchbuffers
minibatchbuffers(pinned)
rawfilebuffers

HANDS ON EXERCISE
34

Sentiment analysis using LSTMs
35
• Analyze text and map it to a numerical rating (1-5)
• Movie reviews (IMDB)
• Product reviews (Amazon, coming soon)

Data preprocessing
36
• Converting words to one-hot
• Top 50,000 words
• PAD, OOV, START tags
• Ids based on frequency
• Pre-defined sentence length
• Targets binarized to positive (>=7), negative (<7)

Embedding
37
• Learning to embed words from a sparse representation to a dense space
Mikolov et al. 2013a *http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/
W(woman)−W(man) ≃ W(aunt)−W(uncle) W(woman)−W(man) ≃ W(queen)−W(king)

Model architecture
38
http://deeplearning.net/tutorial/lstm.html See J.Li et al, EMNLP2015 - http://arxiv.org/pdf/1503.00185v5.pdf
This movie was awesomethe opposite of…
Embedding layer
LSTM layer (128)
Recurrent Sum +Dropout
Affine
positive negative
…

Backend
39
NervanaCPU, NervanaGPU NervanaEngine (internal)
# setup backend
be = gen_backend(backend=args.backend, batch_size=batch_size, rng_seed=args.rng_seed, device_id=args.device_id, default_dtype=args.datatype)
# invoking from command line with arguments
python examples/imdb_lstm.py -b cpu -e 2 -val 1 -r 0

Dataset
40
# make dataset
path = load_text('imdb', path=args.data_dir)
(X_train, y_train), (X_test, y_test), nclass = Text.pad_data( path, vocab_size=vocab_size,
sentence_length=sentence_length)
train_set = DataIterator(X_train, y_train, nclass=2)test_set = DataIterator(X_test, y_test, nclass=2)
Images: ImageNet, CIFAR-10, MNIST Captions: flickr8k, flickr30k, COCO
Text: Penn Treebank, hutter-prize, IMDB, Amazon reviews

Initializers
41
# weight initialization
init_emb = Uniform(low=-0.1/embedding_dim, high=0.1/embedding_dim)
init_glorot = GlorotUniform()
Constant, Uniform, Gaussian, Glorot Uniform

Architecture
42
# Layers and Activations
layers = [ LookupTable(vocab_size=vocab_size,
embedding_dim=embedding_dim, init=init_emb), LSTM(hidden_size, init_glorot, activation=Tanh(), gate_activation=Logistic(), reset_cells=True), RecurrentSum(), Dropout(keep=0.5), Affine(2, init_glorot, bias=init_glorot,
activation=Softmax())]
Rectified Linear, Softmax, Tanh, Logistic
Linear, Convolution, Pooling, Deconvolution, Dropout Recurrent, Long Short-Term Memory, Gated Recurrent Unit,
Recurrent Sum, LookupTable

Cost & Metrics
43
cost = GeneralizedCost(costfunc=CrossEntropyMulti(usebits=True))
metric = Accuracy()
model = Model(layers=layers)
Binary Cross Entropy, Multiclass Cross Entropy, Sum of Squares ErrorMisclassification, TopKMisclassification, Accuracy

Learning rules & Callbacks
44
optimizer = Adagrad(learning_rate=0.01, clip_gradients=clip_gradients)
# configure callbacks
callbacks = Callbacks(model, train_set, args, valid_set=test_set)
Gradient Descent with Momentum RMSProp, AdaDelta, Adam, Adagrad

Train model
45
model.fit(train_set, optimizer=optimizer, num_epochs=num_epochs, cost=cost, callbacks=callbacks)

Demo
46
• Training
• python train.py -e 2 -val 1 -r 0 -s model.pkl --serialize 1
• Inference
• python inference.py --train_fname model
• Exercise
• Use word2vec to initialize embeddings
git checkout tutorial

DEMO
47

Deep Reinforcement Learning*
48
• Learning video games from raw pixels and scores
• Developer contribution: Tambet Matiisen, University of Tartu, Estonia
• https://github.com/tambetm/simple_dqn
*Mnih et al., Nature (2015)

Deep Reinforcement Learning*
48
• Learning video games from raw pixels and scores
• Developer contribution: Tambet Matiisen, University of Tartu, Estonia
• https://github.com/tambetm/simple_dqn
*Mnih et al., Nature (2015)

Deep Reinforcement Learning
49
• Convnet to compute Q score for state, action pairs
• Replay memory (to remove correlations in observation sequence)
• Freezing network (to reduce correlation with target)
• Clipping scores between -1, +1 (same learning rate across games)
• Same network can play a range of games
Mnih et al., Nature (2015)

Algorithm
50
Mnih et al., Nature (2015)

Deep Reinforcement Learning
51
Mnih et al., Nature (2015)

Deep Reinforcement Learning
51
Mnih et al., Nature (2015)
Conv Layer
FC LayerConv Layer
Conv Layer
FC Layer Q*(s,a)

DQN code (deepqnetwork.py)
52
init_norm = Gaussian(loc=0.0, scale=0.01)layers = []
layers.append(Conv((8, 8, 32), strides=4, init=init_norm, activation=Rectlin()))
layers.append(Conv((4, 4, 64), strides=2, init=init_norm, activation=Rectlin()))
layers.append(Conv((3, 3, 64), strides=1, init=init_norm, activation=Rectlin()))
layers.append(Affine(nout=512, init=init_norm, activation=Rectlin()))
layers.append(Affine(nout = num_actions, init = init_norm))

Other parts of the code
53
• main.py: executable
• agent.py: Agent class (learning and playing)
• environment.py: wrapper for Arcade Learning Environment (ALE)
• replay_memory.py: replay memory class

Demo
54
• Training
• ./train.sh --minimal_action_set roms/breakout.bin
• ./train.sh --minimal_action_set roms/pong.bin
• Plot results
• ./plot.sh results/breakout.csv
• Play (observe the network learning)
• ./play.sh --minimal_action_set roms/pong/.bin --load_weights
snapshots/pong_<epoch>.pkl
• Record
• ./record.sh --minimal_action_set roms/pong.bin --load_weights snapshots/pong_<epoch>.pkl

NERVANA CLOUD
55

Proprietary and confidential. Do not distribute.
Using neon and nervana cloud
56
Running locally:
% python rnn.py # or neon rnn.yaml
Running in nervana cloud:
% ncloud submit rnn.py # or rnn.yaml
% ncloud show <model_id>
% ncloud list
% ncloud deploy <model_id>
% ncloud predict <model_id> <data> # or use REST api

Proprietary and confidential. Do not distribute.
Contact
57
@coffeephoenix
github.com/NervanaSystems/neon

Proprietary and confidential. Do not distribute.
\