standard web search engine architecture crawl the web create an inverted index check for duplicates,...
Post on 21-Dec-2015
244 views
TRANSCRIPT

Standard Web Search Engine Architecture
crawl theweb
create an inverted
index
Check for duplicates,store the
documents
Inverted index
Search engine servers
userquery
Show results To user
DocIds

More detailed architecture,
from Brin & Page 98.
Only covers the preprocessing in
detail, not the query serving.

Indexes for Web Search Engines
• Inverted indexes are still used, even though the web is so huge
• Most current web search systems partition the indexes across different machines– Each machine handles different parts of the data (Google
uses thousands of PC-class processors and keeps most things in main memory)
• Other systems duplicate the data across many machines– Queries are distributed among the machines
• Most do a combination of these

Search Engine QueryingIn this example, the data for the pages is partitioned across machines. Additionally, each partition is allocated multiple machines to handle the queries.
Each row can handle 120 queries per second
Each column can handle 7M pages
To handle more queries, add another row.
From description of the FAST search engine, by Knut Risvikhttp://www.infonortics.com/searchengines/sh00/risvik_files/frame.htm

Querying: Cascading Allocation of CPUs
• A variation on this that produces a cost-savings:– Put high-quality/common pages on many
machines– Put lower quality/less common pages on
fewer machines– Query goes to high quality machines first– If no hits found there, go to other machines

• Google maintains (probably) the worlds largest Linux cluster (over 15,000 servers)
• These are partitioned between index servers and page servers– Index servers resolve the queries (massively
parallel processing)– Page servers deliver the results of the queries
• Over 8 Billion web pages are indexed and served by Google

Search Engine Indexes
• Starting Points for Users include
• Manually compiled lists– Directories
• Page “popularity”– Frequently visited pages (in general)– Frequently visited pages as a result of a query
• Link “co-citation”– Which sites are linked to by other sites?

Starting Points: What is Really Being Used?
• Todays search engines combine these methods in various ways– Integration of Directories
• Today most web search engines integrate categories into the results listings
• Lycos, MSN, Google
– Link analysis• Google uses it; others are also using it• Words on the links seems to be especially useful
– Page popularity• Many use DirectHit’s popularity rankings

Web Page Ranking
• Varies by search engine– Pretty messy in many cases– Details usually proprietary and fluctuating
• Combining subsets of:– Term frequencies– Term proximities– Term position (title, top of page, etc)– Term characteristics (boldface, capitalized, etc)– Link analysis information– Category information– Popularity information

Ranking: Hearst ‘96
• Proximity search can help get high-precision results if >1 term– Combine Boolean and passage-level
proximity– Proves significant improvements when
retrieving top 5, 10, 20, 30 documents– Results reproduced by Mitra et al. 98– Google uses something similar

Ranking: Link Analysis
• Assumptions:– If the pages pointing to this page are good,
then this is also a good page– The words on the links pointing to this page
are useful indicators of what this page is about
– References: Page et al. 98, Kleinberg 98

Ranking: Link Analysis
• Why does this work?– The official Toyota site will be linked to by lots
of other official (or high-quality) sites– The best Toyota fan-club site probably also
has many links pointing to it– Less high-quality sites do not have as many
high-quality sites linking to them

Ranking: PageRank
• Google uses the PageRank• We assume page A has pages T1...Tn which point
to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. d is usually set to 0.85. C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
• PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
• Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages' PageRanks will be one

PageRank
T2Pr=1Pr=1
T1Pr=.725Pr=.725
T6Pr=1Pr=1
T5Pr=1Pr=1
T4Pr=1Pr=1
T3Pr=1Pr=1
T7Pr=1Pr=1
T8T8Pr=2.46625Pr=2.46625
X1 X2
APr=4.2544375Pr=4.2544375
Note: these are not real PageRanks, since they include values >= 1

PageRank
• Similar to calculations used in scientific citation analysis (e.g., Garfield et al.) and social network analysis (e.g., Waserman et al.)
• Similar to other work on ranking (e.g., the hubs and authorities of Kleinberg et al.)
• How is Amazon similar to Google in terms of the basic insights and techniques of PageRank?
• How could PageRank be applied to other problems and domains?

Today
• Review– Web Crawling and Search Issues– Web Search Engines and Algorithms
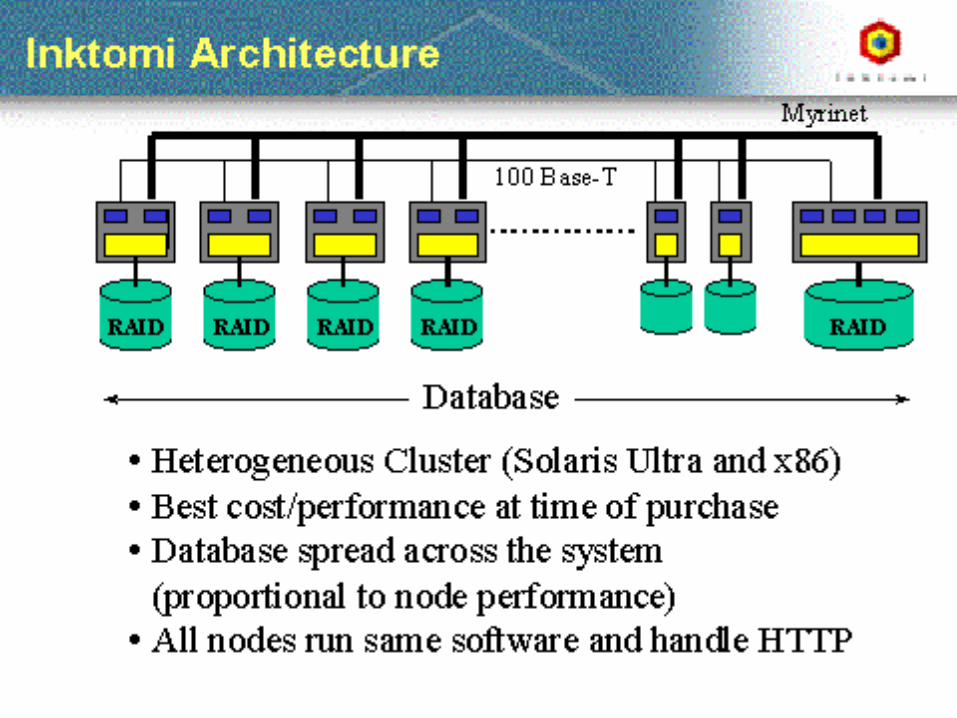
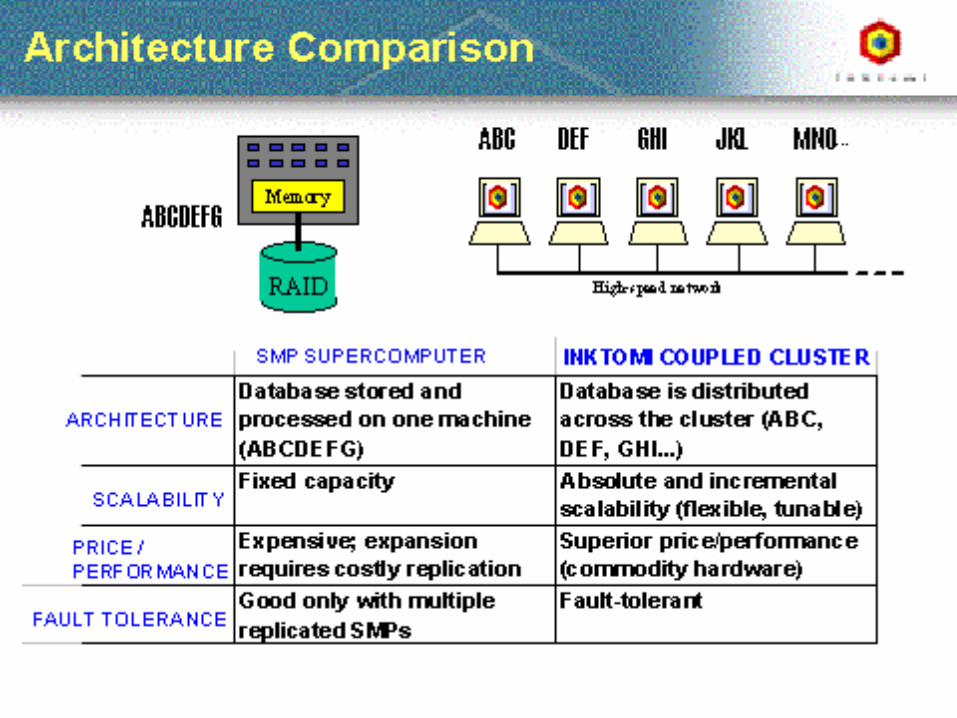
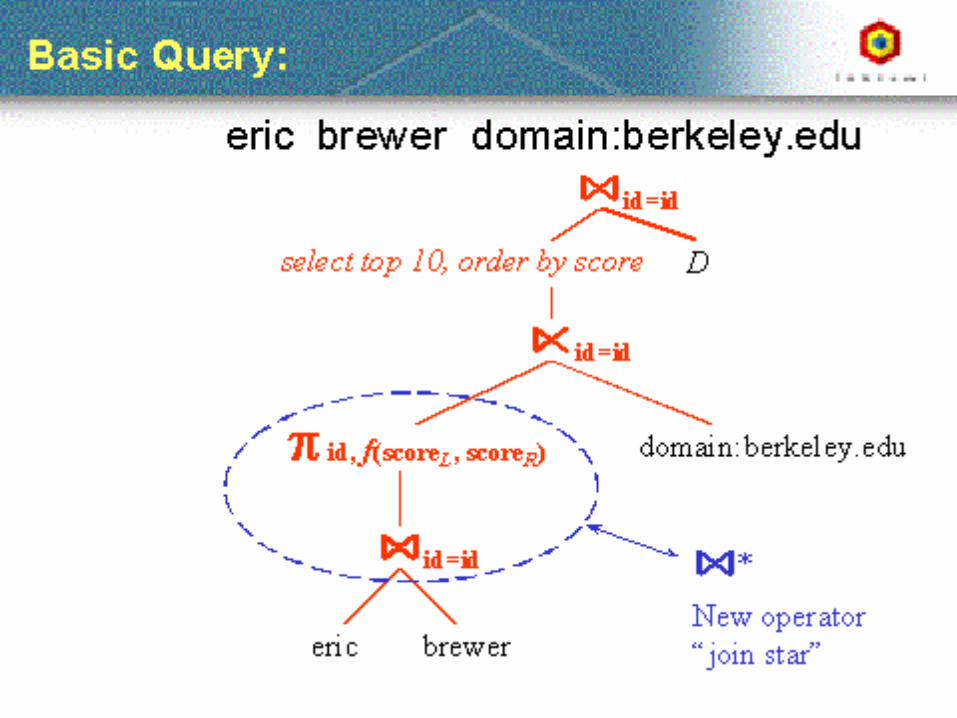
• Web Search Processing– Parallel Architectures (Inktomi – Eric Brewer)– Cheshire III Design
Credit for some of the slides in this lecture goes to Marti Hearst and Eric Brewer

















Digital Library Grid Initiatives:Cheshire3 and the Grid
Ray R. LarsonUniversity of California, Berkeley
School of Information Management and Systems
Rob SandersonUniversity of Liverpool
Dept. of Computer Science
Thanks to Dr. Eric Yen and Prof. Michael Buckland for parts of this presentation
Presentation from DLF Forum April 2005

Overview
• The Grid, Text Mining and Digital Libraries– Grid Architecture– Grid IR Issues
• Cheshire3: Bringing Search to Grid-Based Digital Libraries– Overview– Grid Experiments– Cheshire3 Architecture– Distributed Workflows

Grid
mid
dlew
are
Chem
i cal
Eng i
neer
i ng
Applications
ApplicationToolkits
GridServices
GridFabric
Clim
ate
Data
Grid
Rem
ote
Com
putin
g
Rem
ote
Visu
aliza
tion
Colla
bora
torie
s
High
ene
rgy
phy
sics
Cosm
olog
y
Astro
phys
ics
Com
bust
ion
.….
Porta
ls
Rem
ote
sens
ors
..…Protocols, authentication, policy, instrumentation,Resource management, discovery, events, etc.
Storage, networks, computers, display devices, etc.and their associated local services
Grid Architecture -- (Dr. Eric Yen, Academia Sinica, Taiwan.)

Chem
i cal
Eng i
neer
i ng
Applications
ApplicationToolkits
GridServices
GridFabric
Grid
mid
dlew
are
Clim
ate
Data
Grid
Rem
ote
Com
putin
g
Rem
ote
Visu
aliza
tion
Colla
bora
torie
s
High
ene
rgy
phy
sics
Cosm
olog
y
Astro
phys
ics
Com
bust
ion
Hum
anitie
sco
mpu
ting
Digi
tal
Libr
arie
s
…
Porta
ls
Rem
ote
sens
ors
Text
Min
ing
Met
adat
am
anag
emen
t
Sear
ch &
Retri
eval …
Protocols, authentication, policy, instrumentation,Resource management, discovery, events, etc.
Storage, networks, computers, display devices, etc.and their associated local services
Grid Architecture (ECAI/AS Grid Digital Library Workshop)
Bio-
Med
ical

Grid-Based Digital Libraries
• Large-scale distributed storage requirements and technologies
• Organizing distributed digital collections• Shared Metadata – standards and
requirements• Managing distributed digital collections• Security and access control• Collection Replication and backup• Distributed Information Retrieval issues
and algorithms

Grid IR Issues
• Want to preserve the same retrieval performance (precision/recall) while hopefully increasing efficiency (I.e. speed)
• Very large-scale distribution of resources is a challenge for sub-second retrieval
• Different from most other typical Grid processes, IR is potentially less computing intensive and more data intensive
• In many ways Grid IR replicates the process (and problems) of metasearch or distributed search

Cheshire3 Overview
• XML Information Retrieval Engine – 3rd Generation of the UC Berkeley Cheshire system,
as co-developed at the University of Liverpool.– Uses Python for flexibility and extensibility, but
imports C/C++ based libraries for processing speed– Standards based: XML, XSLT, CQL, SRW/U, Z39.50,
OAI to name a few.– Grid capable. Uses distributed configuration files,
workflow definitions and PVM (currently) to scale from one machine to thousands of parallel nodes.
– Free and Open Source Software. (GPL Licence)– http://www.cheshire3.org/ (under development!)

Cheshire3 Server Overview
API
INDEXING
T R RX E AS C NL O ST R F D O R M S
SEARCH
P HR AO NT DO LC EO RL
DB API
REMOTESYSTEMS
(any protocol)
XMLCONFIG
& MetadataINFO
INDEXES
LOCAL DB
STAFF UI
CONFIG
NETWORK
RESULTSETS
SCAN
USERINFOC
ONFIG&CONTROL
ACCESSINFO
AUTHENTICATION
CLUSTERING
Native calls
Z39.50SOAPOAI
JDBC
Fetch IDPut ID
OpenURL
APACHE
INTERFACE
SERVERCONTROL
UDDIWSRP
SRW
Normalization
ClientUser/
Clients
OGIS
Cheshire3 SERVER

Cheshire3 Grid Tests
• Running on an 30 processor cluster in Liverpool using PVM (parallel virtual machine)
• Using 16 processors with one “master” and 22 “slave” processes we were able to parse and index MARC data at about 13000 records per second
• On a similar setup 610 Mb of TEI data can be parsed and indexed in seconds

SRB and SDSC Experiments
• We are working with SDSC to include SRB support• We are planning to continue working with SDSC
and to run further evaluations using the TeraGrid server(s) through a “small” grant for 30000 CPU hours– SDSC's TeraGrid cluster currently consists of 256 IBM cluster nodes, each
with dual 1.5 GHz Intel® Itanium® 2 processors, for a peak performance of 3.1 teraflops. The nodes are equipped with four gigabytes (GBs) of physical memory per node. The cluster is running SuSE Linux and is using Myricom's Myrinet cluster interconnect network.
• Planned large-scale test collections include NSDL, the NARA repository, CiteSeer and the “million books” collections of the Internet Archive
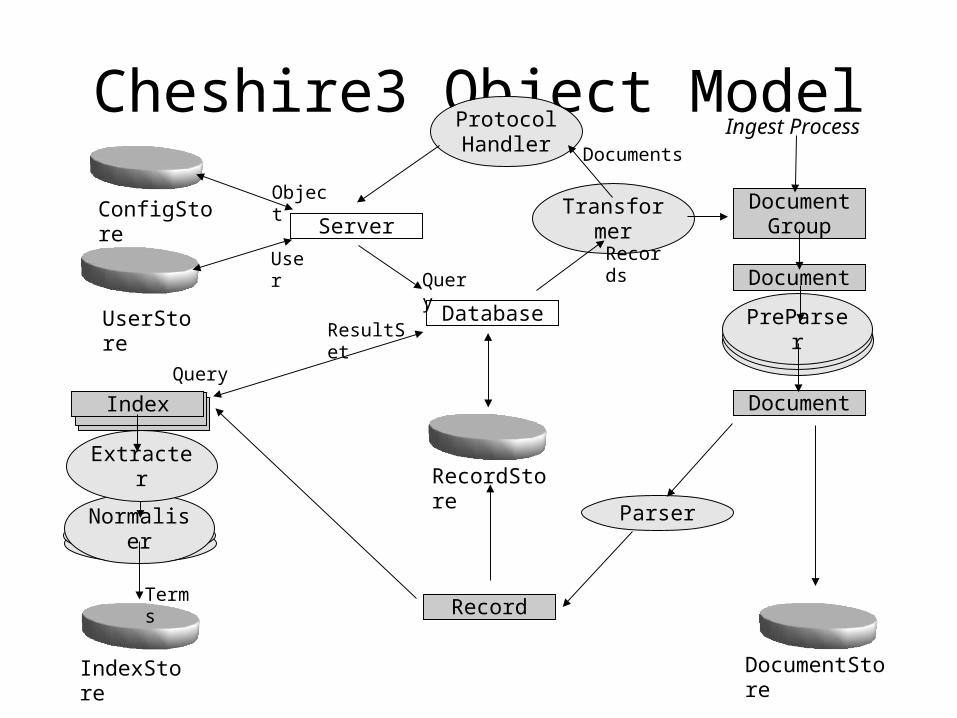
Cheshire3 Object Model
UserStore
User
ConfigStoreObject
Database
Query
Record
Transformer
Records
ProtocolHandler
Normaliser
IndexStore
Terms
ServerDocument
Group
Ingest ProcessDocuments
Index
RecordStore
Parser
Document
Query
ResultSet
DocumentStore
Document
PreParserPreParserPreParser
Extracter

Cheshire3 Data Objects
• DocumentGroup: – A collection of Document objects (e.g. from a file, directory, or external
search)
• Document:– A single item, in any format (e.g. PDF file, raw XML string, relational table)
• Record:– A single item, represented as parsed XML
• Query:– A search query, in the form of CQL (an abstract query language for
Information Retrieval)
• ResultSet:– An ordered list of pointers to records
• Index:– An ordered list of terms extracted from Records

Cheshire3 Process Objects
• PreParser: – Given a Document, transform it into another Document (e.g. PDF to
Text, Text to XML)
• Parser:– Given a Document as a raw XML string, return a parsed Record for the
item.
• Transformer:– Given a Record, transform it into a Document (e.g. via XSLT, from XML
to PDF, or XML to relational table)
• Extracter:– Extract terms of a given type from an XML sub-tree (e.g. extract Dates,
Keywords, Exact string value)
• Normaliser:– Given the results of an extracter, transform the terms, maintaining the
data structure (e.g. CaseNormaliser)

Cheshire3 Abstract Objects
• Server: – A logical collection of databases
• Database:– A logical collection of Documents, their Record
representations and Indexes of extracted terms.
• Workflow:– A 'meta-process' object that takes a workflow
definition in XML and converts it into executable code.

Workflow Objects
• Workflows are first class objects in Cheshire3 (though not represented in the model diagram)
• All Process and Abstract objects have individual XML configurations with a common base schema with extensions
• We can treat configurations as Records and store in regular RecordStores, allowing access via regular IR protocols.

Workflow References
• Workflows contain a series of instructions to perform, with reference to other Cheshire3 objects
• Reference is via pseudo-unique identifiers … Pseudo because they are unique within the current context (Server vs Database)
• Workflows are objects, so this enables server level workflows to call database specific workflows with the same identifier

Distributed Processing
• Each node in the cluster instantiates the configured architecture, potentially through a single ConfigStore.
• Master nodes then run a high level workflow to distribute the processing amongst Slave nodes by reference to a subsidiary workflow
• As object interaction is well defined in the model, the result of a workflow is equally well defined. This allows for the easy chaining of workflows, either locally or spread throughout the cluster.

Workflow Example1<subConfig id=“buildWorkflow”><objectType>workflow.SimpleWorkflow</objectType><workflow> <log>Starting Load</log> <object type=“recordStore” function=“begin_storing”/> <object type=“database” function=“begin_indexing”/> <for-each> <object type=“workflow” ref=“buildSingleWorkflow”> </for-each> <object type=“recordStore” function=“commit_storing”/> <object type=“database” function=“commit_indexing”/> <object type=“database” function=“commit_metadata”/></workflow></subConfig>

Workflow Example2<subConfig id=“buildSingleWorkflow”><objectType>workflow.SimpleWorkflow</objectType><workflow> <object type=“workflow” ref=“PreParserWorkflow”/> <try> <object type=“parser” ref=“NsSaxParser”/> </try> <except> <log>Unparsable Record</log> <raise/> </except> <object type=“recordStore” function=“create_record”/> <object type=“database” function=“add_record”/> <object type=“database” function=“index_record”/> <log>Loaded Record</log></workflow></subConfig>

Workflow Standards
• Cheshire3 workflows do not conform to any standard schema
• Intentional:– Workflows are specific to and dependent on the
Cheshire3 architecture– Replaces the distribution of lines of code for distributed
processing– Replaces many lines of code in general
• Needs to be easy to understand and create• GUI workflow builder coming (web and standalone)

External Integration
• Looking at integration with existing cross-service workflow systems, in particular Kepler/Ptolemy
• Possible integration at two levels:– Cheshire3 as a service (black box) ... Identify
a workflow to call.– Cheshire3 object as a service (duplicate
existing workflow function) … But recall the access speed issue.

Conclusions
• Scalable Grid-Based digital library services can be created and provide support for very large collections with improved efficiency
• The Cheshire3 IR and DL architecture can provide Grid (or single processor) services for next-generation DLs
• Available as open source via:http://cheshire3.sourceforge.net orhttp://www.cheshire3.org/


Plan for today
• Wrap up spam• Crawling• Connectivity servers

Link-based ranking
• Most search engines use hyperlink information for ranking
• Basic idea: Peer endorsement– Web page authors endorse their peers by linking to
them
• Prototypical link-based ranking algorithm: PageRank– Page is important if linked to (endorsed) by many
other pages– More so if other pages are themselves important– More later …

Link spam
• Link spam: Inflating the rank of a page by creating nepotistic links to it– From own sites: Link farms– From partner sites: Link exchanges– From unaffiliated sites (e.g. blogs, web forums, etc.)
• The more links, the better– Generate links automatically– Use scripts to post to blogs– Synthesize entire web sites (often infinite number of pages)– Synthesize many web sites (DNS spam; e.g. *.thrillingpage.info)
• The more important the linking page, the better– Buy expired highly-ranked domains– Post to high-quality blogs

Link farms and link exchanges

More spam techniques
• Cloaking–Serve fake content to search engine spider–DNS cloaking: Switch IP address.
Impersonate
Is this a SearchEngine spider?
Y
N
SPAM
RealDocCloaking

Tutorial onCloaking & Stealth
Technology
Tutorial onCloaking & Stealth
Technology

More spam techniques
• Doorway pages– Pages optimized for a single keyword that re-
direct to the real target page
• Robots– Fake query stream – rank checking programs
• “Curve-fit” ranking programs of search engines– Millions of submissions via Add-Url

Acid test
• Which SEO’s rank highly on the query seo?• Web search engines have policies on SEO
practices they tolerate/block– See pointers in Resources
• Adversarial IR: the unending (technical) battle between SEO’s and web search engines
• See for instance http://airweb.cse.lehigh.edu/

Crawling

Crawling Issues
• How to crawl? – Quality: “Best” pages first– Efficiency: Avoid duplication (or near duplication)– Etiquette: Robots.txt, Server load concerns
• How much to crawl? How much to index?– Coverage: How big is the Web? How much do we cover? – Relative Coverage: How much do competitors have?
• How often to crawl?– Freshness: How much has changed? – How much has really changed? (why is this a different question?)

Basic crawler operation
• Begin with known “seed” pages
• Fetch and parse them– Extract URLs they point to– Place the extracted URLs on a queue
• Fetch each URL on the queue and repeat

Simple picture – complications
• Web crawling isn’t feasible with one machine– All of the above steps distributed
• Even non-malicious pages pose challenges– Latency/bandwidth to remote servers vary– Robots.txt stipulations
• How “deep” should you crawl a site’s URL hierarchy?
– Site mirrors and duplicate pages
• Malicious pages– Spam pages (Lecture 1, plus others to be discussed)– Spider traps – incl dynamically generated
• Politeness – don’t hit a server too often

Robots.txt
• Protocol for giving spiders (“robots”) limited access to a website, originally from 1994– www.robotstxt.org/wc/norobots.html
• Website announces its request on what can(not) be crawled– For a URL, create a file URL/robots.txt– This file specifies access restrictions

Robots.txt example
• No robot should visit any URL starting with "/yoursite/temp/", except the robot called “searchengine":
User-agent: *
Disallow: /yoursite/temp/
User-agent: searchengine
Disallow:

Crawling and Corpus Construction
• Crawl order
• Distributed crawling
• Filtering duplicates
• Mirror detection
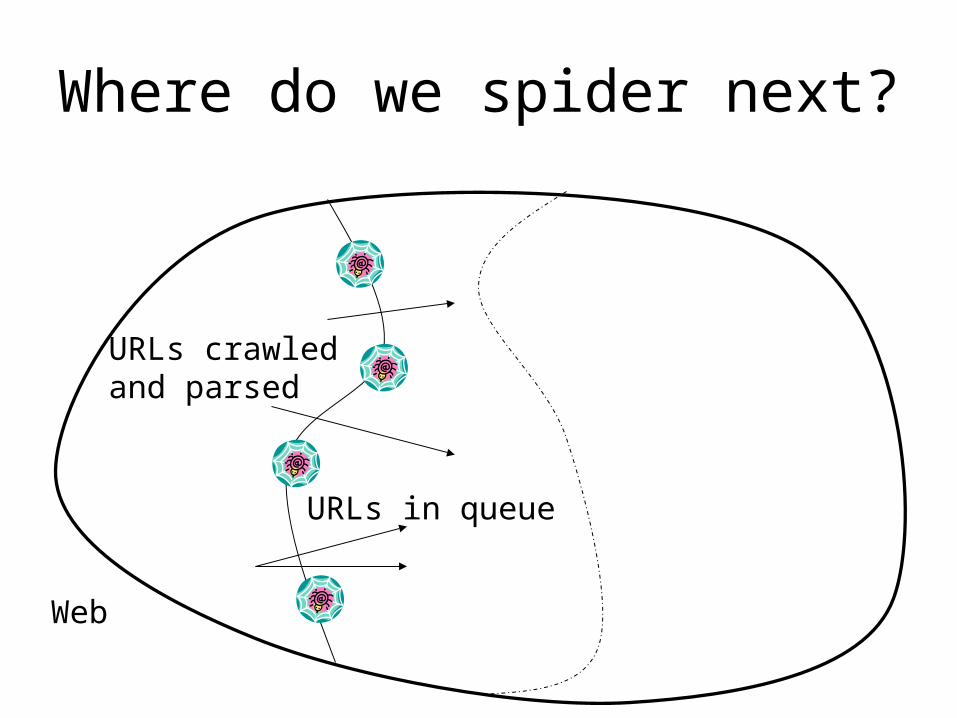
Where do we spider next?
Web
URLs crawledand parsed
URLs in queue

Crawl Order
• Want best pages first
• Potential quality measures:• Final In-degree • Final Pagerank
What’s this?

Crawl Order
• Want best pages first• Potential quality measures:
• Final In-degree • Final Pagerank
• Crawl heuristic:• Breadth First Search (BFS)• Partial Indegree• Partial Pagerank • Random walk
Measure of pagequality we’ll definelater in the course.
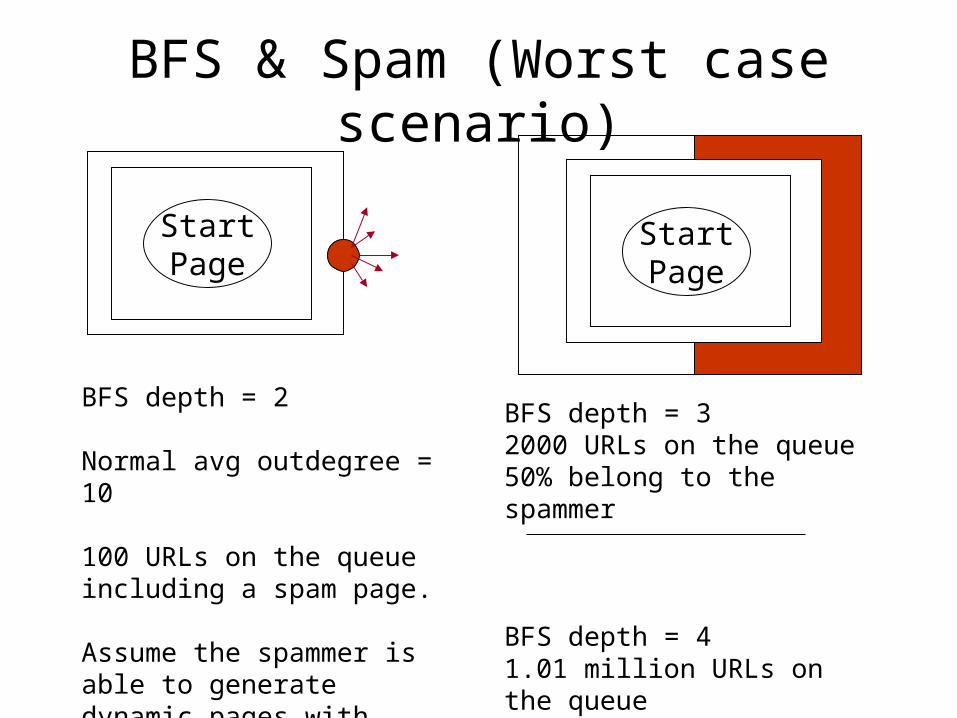
BFS & Spam (Worst case scenario)
BFS depth = 2
Normal avg outdegree = 10
100 URLs on the queue including a spam page.
Assume the spammer is able to generate dynamic pages with 1000 outlinks
StartPage
StartPage
BFS depth = 32000 URLs on the queue50% belong to the spammer
BFS depth = 41.01 million URLs on the queue99% belong to the spammer

Where do we spider next?
Web
URLs crawledand parsed
URLs in queue

Where do we spider next?
• Keep all spiders busy• Keep spiders from treading on each others’ toes
– Avoid fetching duplicates repeatedly
• Respect politeness/robots.txt• Avoid getting stuck in traps• Detect/minimize spam• Get the “best” pages
– What’s best?– Best for answering search queries

Where do we spider next?
• Complex scheduling optimization problem, subject to all the constraints listed– Plus operational constraints (e.g., keeping all
machines load-balanced)
• Scientific study – limited to specific aspects– Which ones?– What do we measure?
• What are the compromises in distributed crawling?

Parallel Crawlers
• We follow the treatment of Cho and Garcia-Molina:– http://www2002.org/CDROM/refereed/108/index.html
• Raises a number of questions in a clean setting, for further study
• Setting: we have a number of c-proc’s– c-proc = crawling process
• Goal: we wish to spider the best pages with minimum overhead– What do these mean?

Distributed model
• Crawlers may be running in diverse geographies – Europe, Asia, etc.– Periodically update a master index– Incremental update so this is “cheap”
• Compression, differential update etc.
– Focus on communication overhead during the crawl
• Also results in dispersed WAN load

c-proc’s crawling the web
URLs crawledURLs inqueues
Which c-procgets this URL?
Communication: by URLspassed between c-procs.

Measurements
• Overlap = (N-I)/I where– N = number of pages fetched– I = number of distinct pages fetched
• Coverage = I/U where– U = Total number of web pages
• Quality = sum over downloaded pages of their importance– Importance of a page = its in-degree
• Communication overhead =– Number of URLs c-proc’s exchange
x

Crawler variations
• c-procs are independent– Fetch pages oblivious to each other.
• Static assignment– Web pages partitioned statically a priori, e.g.,
by URL hash … more to follow
• Dynamic assignment– Central co-ordinator splits URLs among c-
procs

Static assignment
• Firewall mode: each c-proc only fetches URL within its partition – typically a domain– inter-partition links not followed
• Crossover mode: c-proc may following inter-partition links into another partition– possibility of duplicate fetching
• Exchange mode: c-procs periodically exchange URLs they discover in another partition

Experiments
• 40M URL graph – Stanford Webbase– Open Directory (dmoz.org) URLs as seeds
• Should be considered a small Web

Summary of findings
• Cho/Garcia-Molina detail many findings– We will review some here, both qualitatively
and quantitatively– You are expected to understand the reason
behind each qualitative finding in the paper– You are not expected to remember quantities
in their plots/studies

Firewall mode coverage
• The price of crawling in firewall mode

Crossover mode overlap
• Demanding coverage drives up overlap
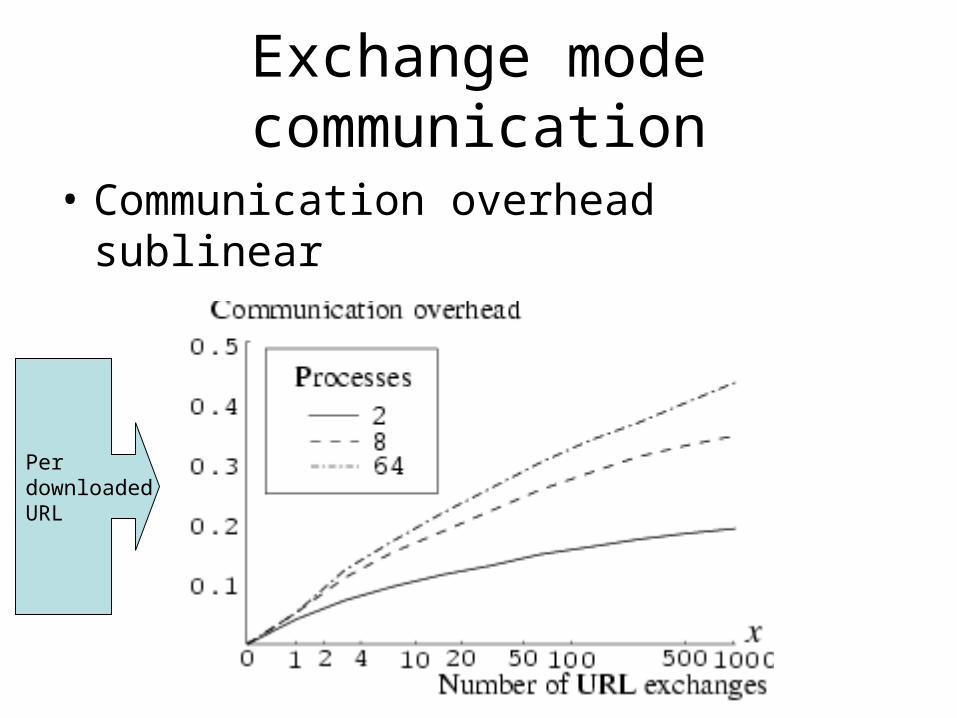
Exchange mode communication
• Communication overhead sublinear
PerdownloadedURL

Connectivity servers

Connectivity Server[CS1: Bhar98b, CS2 & 3: Rand01]
• Support for fast queries on the web graph– Which URLs point to a given URL?– Which URLs does a given URL point to?
Stores mappings in memory from• URL to outlinks, URL to inlinks
• Applications– Crawl control– Web graph analysis
• Connectivity, crawl optimization
– Link analysis• More on this later

Most recent published work
• Boldi and Vigna– http://www2004.org/proceedings/docs/1p595.pdf
• Webgraph – set of algorithms and a java implementation
• Fundamental goal – maintain node adjacency lists in memory– For this, compressing the adjacency lists is
the critical component

Adjacency lists
• The set of neighbors of a node• Assume each URL represented by an
integer• Properties exploited in compression:
– Similarity (between lists)– Locality (many links from a page go to “nearby”
pages)– Use gap encodings in sorted lists– Distribution of gap values

Storage
• Boldi/Vigna get down to an average of ~3 bits/link– (URL to URL edge)
– For a 118M node web graph
• How?
Why is this remarkable?

Main ideas of Boldi/Vigna
• Consider lexicographically ordered list of all URLs, e.g., – www.stanford.edu/alchemy– www.stanford.edu/biology– www.stanford.edu/biology/plant– www.stanford.edu/biology/plant/copyright– www.stanford.edu/biology/plant/people– www.stanford.edu/chemistry

Boldi/Vigna
• Each of these URLs has an adjacency list
• Main thesis: because of templates, the adjacency list of a node is similar to one of the 7 preceding URLs in the lexicographic ordering
• Express adjacency list in terms of one of these
• E.g., consider these adjacency lists– 1, 2, 4, 8, 16, 32, 64– 1, 4, 9, 16, 25, 36, 49, 64– 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144– 1, 4, 8, 16, 25, 36, 49, 64
Encode as (-2), remove 9, add 8
Why 7?

Resources
• www.robotstxt.org/wc/norobots.html• www2002.org/CDROM/refereed/108/index.ht
ml
• www2004.org/proceedings/docs/1p595.pdf
