stackstrom: if-this-than-that for devops automation
TRANSCRIPT

If-This-Then-That for DevOps Automation
@Stack_Storm http://github.com/StackStorm/st2
Dmitri Zimine @dzimine

Game Plan: Show and Tell
2
Demo
Where it applies
What is StackStorm


BS BINGO
DevOps Automation
Cross-Domain Integration
Event Driven
Orchestration ChatOps Serverless
Auto Remediation

StackStorm is like …
5
for DevOps

artefacts are code
IFTTT, for DevOps
6
cat /opt/stackstorm/packs/st2-demos/rules/demo.yaml --- name: "sensu_crit_to_slack" pack: "st2-demos" description: "Post all critical alerts to the demo enabled: true trigger: type: "sensu.event_handler" criteria: trigger.check.status: pattern: 2 type: "equals" trigger.check.name: pattern: "demo_.*" type: "matchregex" action: ref: "slack.post_message" parameters: message: > [ALERT]{{trigger.client.name}} {{trigger.check.output}} channel: "#demos"
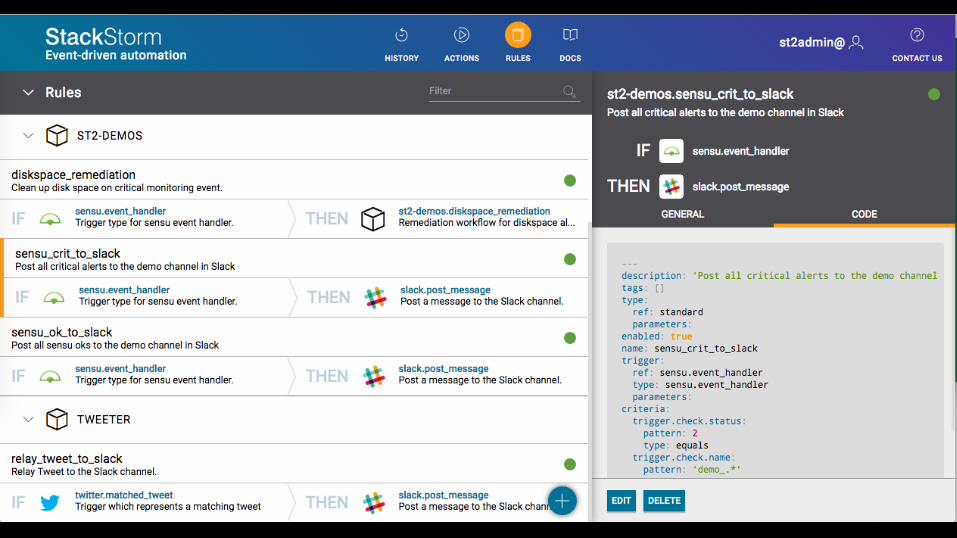
7

8
Trigger Action
Rule

Ingredients
9
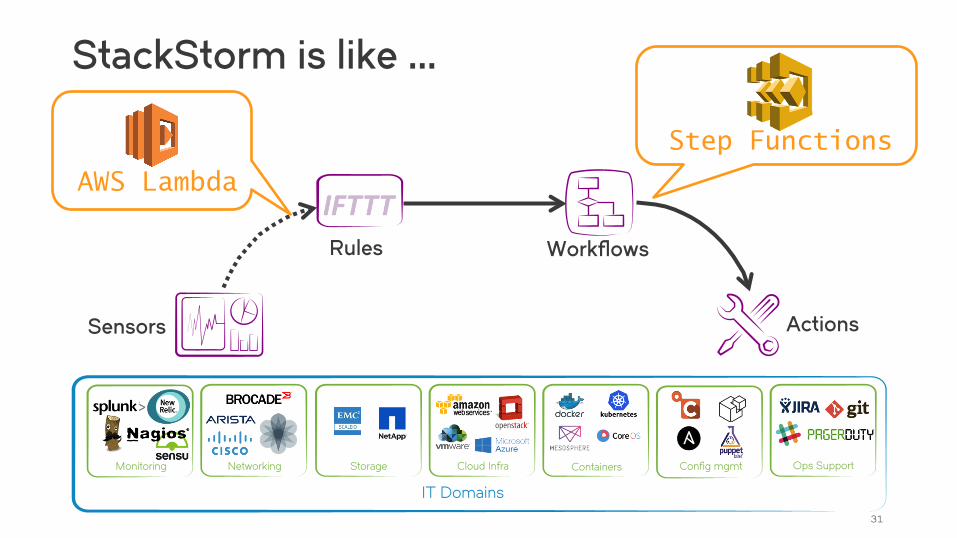
IT Domains
Config mgmt Storage Networking Containers Cloud Infra Monitoring
Actions Sensors
Workflows Rules
Ops Support
Trigger Call

Automation Example
10
Automation
Engineer Service
Monitoring Incident Management
Event: “low disk on web301”
Web301 is “low disk”
Resolve known cases, fast. Is it
/var/log? Clean up!
Unknown problem, need
a human
Wake up, buddy. Something real
is going on…

DEMO
11

What can be automated?
12

13
Got StackStorm !
Every automation looks like a nail

What is being automated with StackStorm • Security checks
– On malware detection in a VM, isolate network port on a switch
• App blue-green deployment – On Jenkins tests passed, bring new vm
claster, deploy and configure app, set loadbalancer to send % of traffic to new app, monitor, roll forward, or back out
• Networking – On BGP peer goes down: collect
troubleshooting data, post on slack & create JIRA ticket
– On Link aggregation member error, check load, if capacity of rest of LAG bundle enough, disable link with error
• OpenStack – orphan VM clean-up: On orphans
detected, shut down, email owner, keep for few days, delete
– VM evacuation on HW failures: On host RAID failure, get list of impacted VMs, email VM owners, evacuate VMs, create JIRA ticket for hardware replacement.
• Service remediation: – Cassandra “node down” recovery: On ring
node dying, deploy new node, configure, add to the ring.
– Remediating RabbitMQ, Galera cluster, MySQL, and more…
14

What SHOULD be automated? From: Practice of Cloud System Administration, by Thomas Limoncelli

16
Auto-Remediation
FB auto-remediates 98% alarms, can you?

Auto Remediation
17
FBAR (saving 13,680 hours/day)
Naoru
Nurse
Winston (powered by StackStorm)
Azure Automation
Mistral workflow service
StackStorm automation platform
ACT
OBSERVE
ORIENT
DECIDE

“Auto-Remediation & Automation at Facebook” @ Auto-Remediation Meetup SF https://www.meetup.com/Auto-Remediation-and-Event-Driven-Automation/events/236704012/
43 % Problem Fixed 51 % False positives 94 % Automated

“Sleep Better at Night: OpenStack Cloud Auto-Healing” @ OpenStack Summit Barcelona Mirantis: Auto-remediating 2,000 node OpenStack cluster at Symantec with StackStorm

Engineer Wakes up
Logs in and ACK
Checksrunbook
Studiesthe alert
Fixes theproblem
Runs diagnostics
PagerDuty Alert
2:02 AM 2:07 AM 2:15 AM 2:10 AM 2:30 AM2:20 AM 2:00 AM
On-call, Without Automation
Source: “Winston: Helping Netflix Engineers Sleep at Night” @ Qcon ‘16 SF https://goo.gl/lHzq4r

False Positive
Winston
2:00 AM
2:05 AM
2:05 AM
2:15 AM
AssistedDiagnostics
Fixed the problem
On-call With Winston
Source: “Winston: Helping Netflix Engineers Sleep at Night” @ Qcon ‘16 SF https://goo.gl/lHzq4r

22
Including legacy, business apps …
Integration

“Innovation at Dimension Data: Optimizing Operations with Event Driven Automation” https://stackstorm.com/2016/12/15/dimension-data-devops-beyond-deployment/

© 2016 BROCADE COMMUNICATIONS SYSTEMS, INC. 24
StackStorm Enterprise
eval license
automation • 5 cloud services
• Integrated with on-prem systems


26
IoT Fun stuff

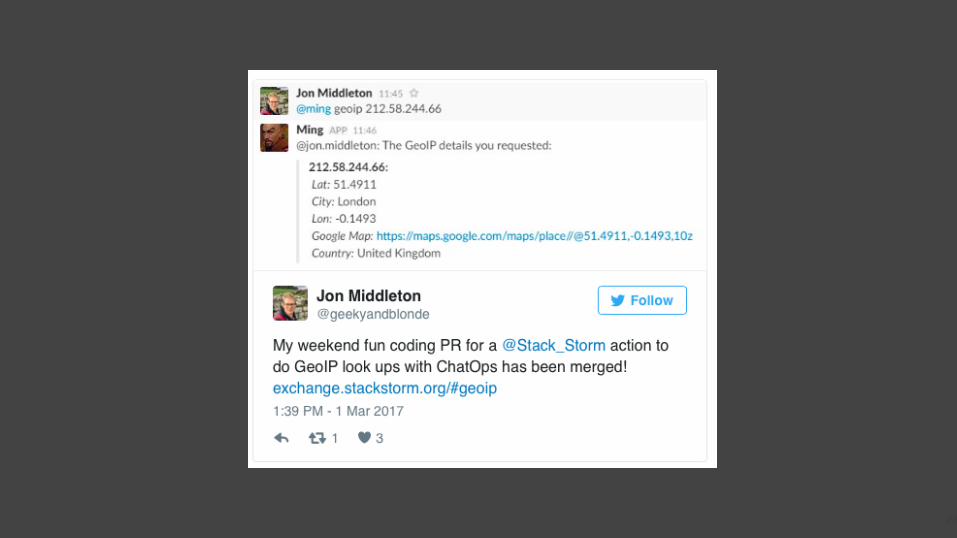
28

29
Serverless
Grab StackStorm & DIY

StackStorm is like …
30
AWS Lambda AWS Step Functions
OpenSource, for DIY Serverless
StackStorm is like …
31
Actions Sensors
Workflows Rules
IT Domains
Config mgmt Storage Networking Containers Cloud Infra Monitoring Ops Support
Step Functions
AWS Lambda

Serverless with Swarm for Genomic Annotation Computing Dmitri Zimine http://github.com/dzimine/serverless-swarm @dzimine
Image by Miki Yoshihito, Creative Commons license
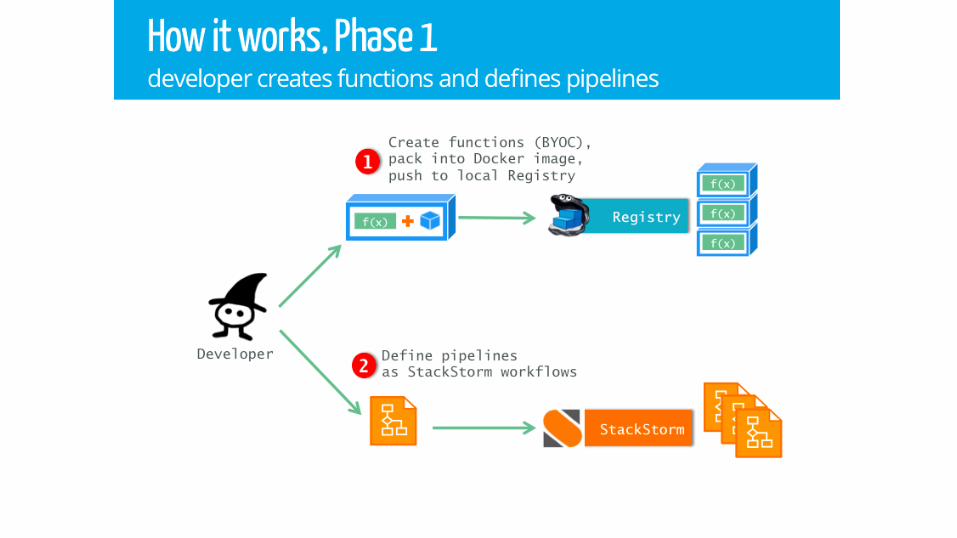



Why Not …
36
Why not Scripts?
37

Why not Scripts?
38
• Simple to define, reason, visualize
• Transparent – state is clear, execution is trackable: running, complete, failed steps
• Reliable – Workflows are long-running – Crash tolerance
– “Restart from point of failure”

© 2016 BROCADE COMMUNICATIONS SYSTEMS, INC.
39

Workflows Better in Operations
• Simple to define, reason, visualize
• Transparent – state is clear, execution is trackable: running, complete, failed steps
• Reliable – Workflows are long-running – Crash tolerance
– “Restart from point of failure”
© 2016 BROCADE COMMUNICATIONS SYSTEMS, INC. 40

Why not Legacy RunBook Automation?
41
DevOps!

Infrastructure As Code
Leverage social coding and collaboration
OpenSource
Designed for Devops

Infrastructure As Code
Leverage social coding and collaboration
OpenSource
Designed for Devops

44
Infrastructure as code
Case Study
• Service Catalog backed up by workflow
• Automate provisioning on VMW/OpenStack, 4 Data centers
• Before: CPO, operator updates via GUI, click and pray, x4
• After: StackStorm, dev -> code review -> staging -> QA-> prod

Infrastructure as code
45
The top predictor of IT performance?
Version control used by Ops, for Ops artifacts!

Ops Pattersns:
46
capture and share - as code!



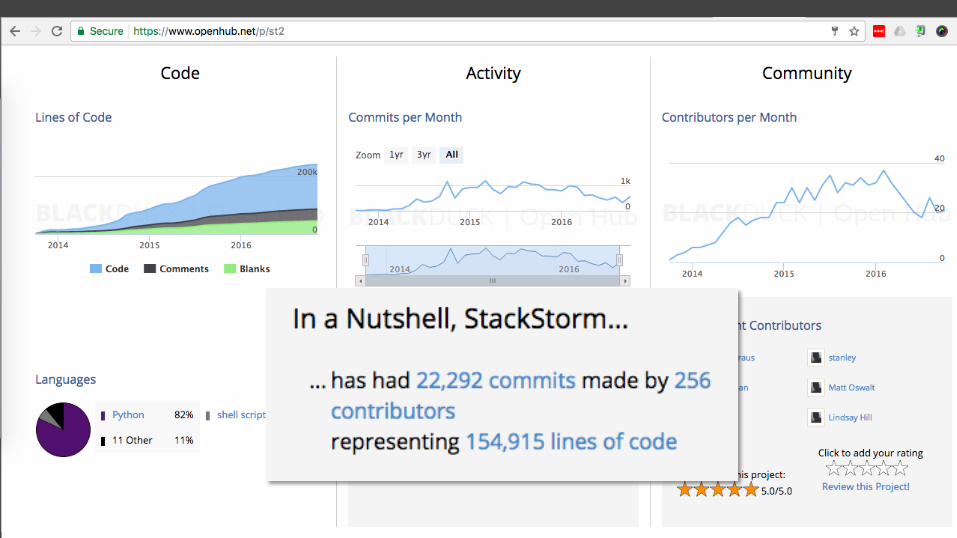
Infrastructure As Code
Leverage social coding and collaboration
OpenSource
Designed for Devops

StackStorm Exchange
© 2016 BROCADE COMMUNICATIONS SYSTEMS, INC. 52
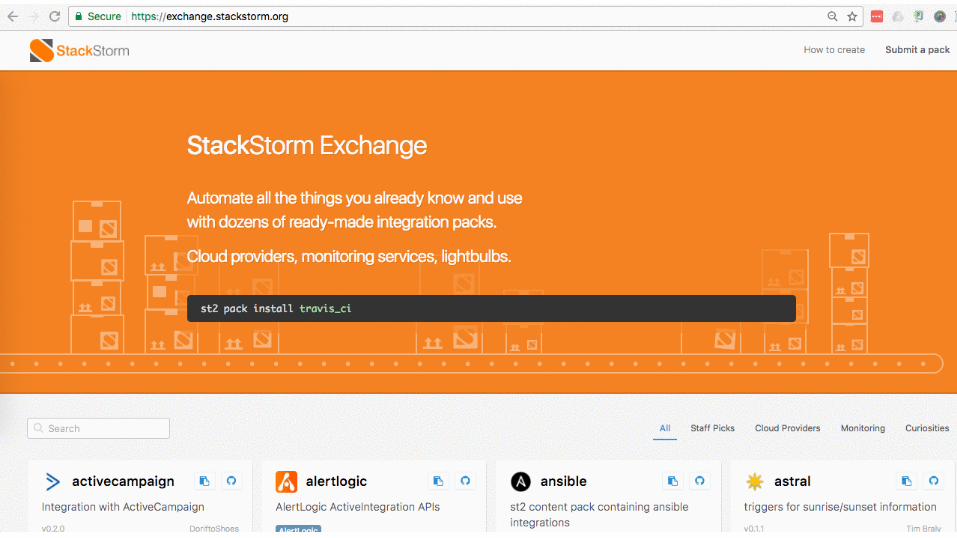
StackStorm Exchange
© 2016 BROCADE COMMUNICATIONS SYSTEMS, INC. 53

54

Take away:
55

• Use StackStorm. Try it, find automation, nail POC. Let us know, good & bad. curl -sSL https://stackstorm.com/packages/install.sh | bash -s docs.stackstorm.com/install
• Commit code. Become a “community maintainer” It is not hard (weekend hack?). We help & support.
• Spread the word Blog. Tweet. Talk. Mention. Bug. Github Star!
56
Contribute! Everything counts

Discussion
@Stack_Storm http://github.com/StackStorm/st2 Star 1,835
Dmitri Zimine @dzimine

Discussion
58