sppm: sparse privacy preserving mappings...this observation to develop sparse privacy-preserving...
TRANSCRIPT

SPPM: Sparse Privacy Preserving Mappings
Salman Salamatian * Nadia Fawaz † Branislav Kveton † Nina Taft †* Ecole Polytechnique Federale de Lausanne, 1015 Lausanne, Switzerland
† Technicolor, USA
Abstract
We study the problem of a user who has bothpublic and private data, and wants to re-lease the public data, e.g. to a recommenda-tion service, yet simultaneously wants to pro-tect his private data from being inferred viabig data analytics. This problem has previ-ously been formulated as a convex optimiza-tion problem with linear constraints wherethe objective is to minimize the mutual in-formation between the private and releaseddata. This attractive formulation faces achallenge in practice because when the un-derlying alphabet of the user profile is large,there are too many potential ways to distortthe original profile. We address this funda-mental scalability challenge. We propose togenerate sparse privacy-preserving mappingsby recasting the problem as a sequence of lin-ear programs and solving each of these in-crementally using an adaptation of Dantzig-Wolfe decomposition. We evaluate our ap-proach on several datasets and demonstratethat nearly optimal privacy-preserving map-pings can be learned quickly even at scale.
1 Introduction
Finding the right balance between privacy risks andbig data rewards is one of the biggest challenges fac-ing society today. Big data creates tremendous oppor-tunity, especially for all of the services that offer per-sonalized advice. Recommendation services are ram-pant today and offer advice on everything includingmovies, TV shows, restaurants, music, sleep, exercise,vacation, entertainment, shopping, and even friends.On one hand, people are willing to part with some oftheir personal data (e.g. movie watching history) forthe sake of these services. On the other hand, manyusers have some data about themselves they wouldprefer to keep private (e.g. their political affiliation,salary, pregnancy status, religion). Most individualshave both public and private data and hence they needto maintain a boundary between these different ele-
ments of their personal information. This is an enor-mous challenge because inference analysis on publiclyreleased data can often uncover private data [27, 6, 21].
A number of research efforts have explored the idea ofdistorting the released data [29, 26, 17, 7, 11, 3] to pre-serve user’s privacy. In some of these prior efforts,distortion aims at creating some confusion around userdata by making its value hard to distinguish from otherpossible values; in other efforts, distortion is designedto counter a particular inference threat (i.e. a specificclassifier or analysis). Recently [7] proposed a newframework for data distortion, based on informationtheory, that captures privacy leakage in terms of mu-tual information. Minimizing the mutual informationbetween a user’s private data and released data is at-tractive because it reduces the correlation between theprivate data and the publicly released data, and thusany inference analysis that tries to learn the privatedata from the public data is rendered weak, if not use-less. In other words, this approach is agnostic to thetype of inference analysis used in a given threat.
This promising framework, while theoretically sound,faces some challenges in terms of bridging the gapbetween theory and practicality. Distorting data, inthe context of recommendation systems, means alter-ing a user’s profile. The framework casts this privacyproblem as a convex optimization problem with lin-ear constraints, where the number of variables growsquadratically with the size of the underlying alphabetthat describes user’s profiles. In real world systems,the alphabet can be huge, thus the enormous numberof options for distorting user profiles presents a scala-bility challenge, that we address in this paper.
We make two contributions to handle scalability. First,by studying small scale problems, both analyticallyand empirically, we identify that mappings to dis-tort profiles are in fact naturally sparse. We leveragethis observation to develop sparse privacy-preservingmappings (SPPM). Second, we propose an algorithm,called SPPM that handles scalability through two in-sights. Although the underlying optimization problemhas linear constraints, its objective function is non-linear. We use the Frank-Wolfe algorithm that approx-imates the objective via a sequence of linear approx-imations that can be solved quickly. To do this, we
712

adapt the Dantzig-Wolfe decomposition to the struc-ture of our problem. Overall we reduce the numberof variables from quadratic to linear in the number ofuser profiles. To the best of our knowledge, this workis the first to apply large scale linear programming op-timization techniques to privacy problems.
A salient feature of our novel approach is that the dis-tortion applied to each user is personalized, meaningthat it is tailored for that user. Our solution doesnot require applying distortion to profiles in a uniformway, nor requires any monotonistic behavior such asmapping a profile to a far neighbor with decreasinglikelihood (such as in [19]. We will see that the flex-ibility our system allows for a better use of the dis-tortion budget where it is needed, and avoids wastingthis budget on unnecessary distortions.
Our third contribution is a detailed evaluation on threedatasets, in which we compare our solution to an opti-mal one (when feasible) and to a state-of-the-art solu-tion based on differential privacy (called the Exponen-tial Mechanism [19]). We find that our solutions areclose to optimal, and consistently outperform the ex-ponential mechanism (ExpMec) approach in that weachieve more privacy with less distortion. We showthat our methods scale well with respect to the num-ber of user profiles and their underlying alphabet.
Related Work. We consider the framework for pri-vacy against statistical inference in [7, 18, 24]. In [24],a method based on quantization was proposed to re-duce the number of optimization variables. It wasshown that the reduction in complexity does not affectthe privacy levels that can be achieved, but comes atthe expense of additional distortion. In [18], privacymappings in the class of parametric additive noise wereconsidered, which allow the number of optimizationvariables to be reduced to the number of noise parame-ters. However, this suboptimal solution is not suitablefor perfect privacy, as it requires a high distortion. Inthis paper, we propose to exploit the structure of theoptimization to achieve computational speed-ups thatwill allow scalability. To the best of our knowledge,this is the first paper that evaluates the privacy-utilityframework in [7] on such a large scale.
Our use of the information theoretic framework [7] re-lies on a local privacy setting, where users do not trustthe entity collecting data, thus each user holds hisdata locally, and passes it through a privacy-preservingmechanism before releasing it to the untrusted entity.Local privacy dates back to randomized response insurveys [28], and has been considered in privacy fordata mining and statistics [2, 12, 20, 16, 4, 7, 18, 9].Information theoretic privacy metrics have also beenconsidered in [23, 29, 12, 22, 25]. Finally, differen-tial privacy [10] is currently the prevalent notion ofprivacy in privacy research. In particular, the expo-
nential mechanism, to which we compare our privacymapping in Section 4.3, was introduced in [19].
The general problem of minimizing a convex functionunder convex constraints has been studied extensively,and is of crucial importance in many machine learn-ing tasks. The idea of a sparse approximate solutionsto those problems has also been studied in the litera-ture and is often called Sparse Greedy Approximation[8, 15, 14, 13, 30]. This type of algorithm has beenused with success in many applications such as Neu-ral Network [15], Matrix Factorization [14], SVM [13],Boosting [30], etc. We apply this approach to a newproblem and adapt it to efficiently handle our scala-bility challenges. Another common approach to mini-mizing a convex function is stochastic gradient descent[31]. This approach is preferable when the feasible sethas a simple form and is easy to project to. In ourcase, the feasible set is defined by many constraints,thus we opted for the Frank-Wolfe algorithm.
2 Problem Statement and Challenges
Privacy-Utility Framework: We consider the set-ting described in [7], where a user has two kinds ofdata: a vector of personal data A ∈ A that he wouldlike to remain private, e.g. his income level, his po-litical views, and a vector of data B ∈ B that he iswilling to release publicly in order to receive a use-ful service (such as releasing his media preferences toa recommender service to receive content recommen-dations). A and B are the sets from which A andB can assume values. We assume that the user pri-vate attributes A are linked to his data B by the jointprobability distribution pA,B. Thus, an adversary whowould observe B could infer some information aboutA. To reduce this inference threat, instead of releasingB, the user releases a distorted version of B, denotedB ∈ B, generated according to a conditional prob-abilistic mapping pB|B, called the privacy-preserving
mapping. Note that the set B may differ from B.This setting is reminiscent of the local privacy setting(e.g. randomized response, input perturbation) [28],where users do not trust the entity collecting data,thus each user holds his data locally, and passes itthrough a privacy-preserving mechanism before releas-ing it. The privacy mapping pB|B is designed to render
any statistical inference of A based on the observationof B harder, while preserving some utility to the re-leased data B, by limiting the distortion caused by themapping. Following the framework for privacy-utilityagainst statistical inference in [7], the inference threat
is modeled by the mutual information I(A; B) betweenthe private attributes A and the publicly released dataB, while the utility requirement is modeled by a con-straint on the average distortion EB,B[d(B, B)] ≤ ∆,
for some distortion metric d : B×B → R+, and ∆ ≥ 0.
713

In the case of perfect privacy (I(A; B) = 0), the pri-
vacy mapping pB|B renders the released data B statis-
tically independent from the private data A.
In general, a system that provides privacy protectiondoes not know in advance the inference algorithm thatthe adversary will run on released data. This frame-work is appealing because it works regardless of theinference algorithm used by an adversary. In addition,this framework allows for the use of any distortionmetric, either generic metrics such as Hamming, lp,or weighted norms, or specific utility metrics tailoredto a given learning algorithm that will run on the re-leased user data. The use of a generic distance in theutility constraint is relevant in several cases. First, thelearning algorithm that will run on the released datamay not be known in advance to the system providingprivacy protection, as it may be proprietary informa-tion that belongs to the service provider. Second, thereleased user data may be used by numerous analysestasks based on multiple different ML algorithms, inwhich case the utility constraint should not be limitedto one specific distortion metric.
Both the mutual information I(A; B) and the average
distortion EB,B[d(B, B)] depend on both the prior dis-tribution pA,B and the privacy mapping pB|B, since
A → B → B form a Markov chain. To stress thesedependencies, we will denote I(A; B) = J(pA,B, pB|B).
Consequently, given a prior pA,B linking the private at-tributes A and the data B, the privacy mapping pB|Bminimizing the inference threat subject to a distortionconstraint is obtained as the solution to the followingconvex optimization problem [7] 1
minimizepB|B∈Simplex
J(pA,B, pB|B)
s.t. EpB,B
[d(B, B)
]≤ ∆,
(1)
where Simplex denotes the probability simplex(∑
x p(x) = 1, p(x) ≥ 0 ∀x).
Sparsity of the privacy mapping: When apply-ing the aforementioned privacy-accuracy frameworkto large data, we encounter a challenge of scalabil-ity. Designing the privacy mapping requires charac-terizing the value of pB|B(b|b) for all possible pairs
(b, b) ∈ B × B, i.e. solving the convex optimization
problem over |B||B| variables. When B = B, and thesize of the alphabet |B| is large, solving the optimiza-tion over |B|2 variables may become intractable.
1Solving Optimization (1) for different values of ∆ al-lows to generate the whole privacy-utility curve, as inFig. 2. Any point on or above this curve is achievable.Using this curve, one can efficiently solve the related prob-lem of maximizing utility given a constraint on privacy: fora given privacy requirement, the curve gives the operatingpoint corresponding to the smallest loss in utility.
20 40 60 80 100 120
20
40
60
80
100
120
B
B20 40 60 80 100 120
20
40
60
80
100
120
B
B
Figure 1: Optimal mappings for Toy example
A natural question is whether B = B is a necessary as-sumption to achieve the optimal privacy-utility trade-off. In other words, does Optimization (1) need to besolved over |B|2 variables to achieve optimality? Thefollowing theoretical toy example motivates a sparserapproach to the design of the privacy mapping.
Example: Let A ∈ {0, 1}, and B ∈ {1, 2, . . . , 2m},and define the joint distribution pA,B such that p(A =0) = p(A = 1) = 1
2 , and for i ∈ {1, 2, . . . , 2m}, let
p(B = i|A = 0) = 12m−1 if i ≤ 2m−1, 0 otherwise, and
let p(B = i|A = 1) = 12m−1 if i > 2m−1, 0 otherwise.
For this example, the privacy threat is the worse itcould be, as observing B determines deterministicallythe value of the private random variable A (equiva-lently, I(A; B) = H(A) = 1). In Fig. 2, we consider
an l2 distortion measure d(B; B) = (B− B)2 and illus-trate the optimal mappings solving Problem ((1)) fordifferent distortion values. For small distortions, thered diagonal in Figure 2 shows that most points B = bare only mapped to themselves B = b. As we increasethe distortion level, each point B = b gets mapped toa larger number of points B = b.
This theoretical example, as well as experiments onreal world datasets such as the census data have shownthat the optimal privacy preserving mapping may turnout to be sparse, in the sense that the support ofpB|B(b|b) may be of much smaller size than B, and
may differ for different values of B = b. We proposeto exploit sparsity properties of the privacy mappingto speed up the computation, by picking the support ofpB|B(b|b), i.e. the set of points B = b to which B = b
can be mapped with a non-zero probability, in an it-erative greedy way. Although we a priori motivate thesparse approach using one theoretical example, andlimited empirical evidence from some datasets, our ex-perimental results demonstrate, a posteriori, that thesparse approach performs close to optimally on otherdatasets, and thus justifies empirically its relevance.
3 Sparse and Greedy Algorithm
Before we describe our algorithm, we rewrite Opti-mization (1) compactly. Let X be a n × n matrixof optimized variables, whose entries are defined as
714

xi,j = pB|B(bi | bj), and let xj be the j-th column
of X. To highlight the optimization aspect of ourproblem, we write the objective function J(pA,B, pB|B)
as a function f(X), with the understanding that fdepends on pA,B, which is not optimized, and onX, which is optimized. Similarly the distortion con-straint can be written as
∑nj=1 dT
jxj ≤ ∆, where each
dj = pB(bj)(d(b1, bj), d(b2, bj), . . . , d(bn, bj))T is
a vector of length n that represents the distortionmetric scaled by the probability of the correspond-ing symbol bj. The marginal of B is computed aspB(bj) =
∑a pA,B(a, bj). Finally, the simplex con-
strain can be written as 1nxj = 1 for all j, where 1n isan all-ones vector of length n. Given the new notation,our original problem (1) can be written compactly as:
minimizeX
f(X) (2)
subject to
n∑
j=1
dT
jxj ≤ ∆
1T
nxj = 1 ∀j = 1, . . . , n
X ≥ 0
where X ≥ 0 is an entry-wise inequality.
3.1 Franke-Wolfe Linearization
The optimization problem (1) has linear constraintsbut its objective function is non-linear. In this paper,we solve the problem as a sequence of linear programs,also known as the Frank-Wolfe method. Each iterationℓ of the method consists of three major steps. First,we compute the gradient ∇Xf(Xℓ−1) at the solutionfrom the previous step Xℓ−1. The gradient is a n ×n matrix C, where ci,j = ∂
∂xi,jf(Xℓ−1) is a partial
derivative of the objective function with respect to thevariable xi,j . Second, we find a feasible solution X′ inthe direction of the gradient. This problem is solvedas a linear program with the same constraint as theoriginal problem:
minimizeX
n∑
j=1
cT
jxj (3)
subject to
n∑
j=1
dT
jxj ≤ ∆
1T
nxj = 1 ∀j = 1, . . . , n
X ≥ 0
where cj is the j-th column of C. Finally, we find theminimum of f between Xℓ−1 and X′, Xℓ, and makeit the current solution. Since f is convex, this mini-mum can be found efficiently by ternary search. Theminimum is also feasible because the feasible region isconvex, and both X′ and Xℓ−1 are feasible.
Algorithm 1 SPPM: Sparse privacy preserving maps
Input: Starting point X0, number of steps L
for all ℓ = 1, 2, . . . , L doC← ∇Xf(Xℓ−1)V ← DWDFind a feasible solution X′ in the direction of thegradient C:
minimizeX
n∑
j=1
cT
jxj (4)
subject ton∑
j=1
dT
jxj ≤ ∆
1T
nxj = 1 ∀j = 1, . . . , n
X ≥ 0
xi,j = 0 ∀(i, j) /∈ V
Find the minimum of f between Xℓ−1 and X′:
γ∗ ← argminγ∈[0,1]
f((1− γ)Xℓ−1 + γX′) (5)
Xℓ ← (1 − γ∗)Xℓ−1 + γ∗X′
Output: Suboptimal feasible solution XL
3.2 Sparse Approximation
The linear program (3) has n2 variables and there-fore is hard to solve when n is large. In this section,we propose an incremental solution to this problem,which is defined only on a subset of active variablesV ⊆ {1, 2, . . . , n} × {1, 2, . . . , n}. The active variablesare the non-zero variables in the solution to the prob-lem (3). Therefore, solving (3) on active variables V isequivalent to restricting all inactive variables to zero.The corresponding linear program is shown in (4) inAlgorithm 1. This linear program has only |V| vari-ables. Now the challenge is in finding a good set ofactive variables V . This set should be small, and suchthat the solutions of (3) and (4) are close.
We grow the set V greedily using the dual linear pro-gram of (4). In particular, we incrementally solve thedual by adding most violated constraints, which corre-sponds to adding most beneficial variables in the pri-mal. The dual of (4) is (6) in Algorithm 2, where λ ∈ Ris a variable associated with the distortion constraintand µ ∈ Rn is vector of n variables associated with thesimplex constraints. Given a solution (λ∗, µ∗) to thedual, the most violated constraint for a given j is theone that minimizes:
ci,j − λ∗di,j − µ∗j . (8)
This quantity, called the reduced cost, has an intuitiveinterpretation. We choose an example i in the direc-
715

Algorithm 2 DWD: Dantzig-Wolfe decomposition
Initialize the set of active variables:V ← {(1, 1), (2, 2), . . . , (n, n)}
while the set V grows doSolve the master problem for λ∗ and µ∗:
maximizeλ,µ
λ∆ +n∑
j=1
µj (6)
subject to λ ≤ 0
λdi,j + µj ≤ ci,j ∀(i, j) ∈ V
for all j = 1, 2, . . . , n doFind the most violated constraint in the masterproblem for fixed j:
i∗ = argmini
[ci,j − λdi,j − µj ] (7)
if (ci∗,j − λdi∗,j − µj < 0) thenV ← V ∪ {(i∗, j)}
Output: Active variables V
tion of the steepest gradient of f(X), so ci,j is small;which is close to j, so di,j is close to zero (as λ∗ ≤ 0).The search for the most violated constraint leveragesthe problem structure. Therefore, our approach can beviewed as an instance of Dantzig-Wolfe decomposition.
The pseudocode of our search procedure is in Algo-rithm 2. This is an iterative algorithm, where eachiteration consists of three steps. First, we solve thereduced dual linear program (6) on active variables.Second, for each point j, we identify a point i∗ thatminimize the reduced cost. Finally, if the pair (i∗, j)corresponds to a violated constraint, we add it to theset of active variables V .
The pseudocode of our final solution is in Algorithm 1.We refer to Algorithm 1 as Sparse Privacy PreservingMappings (SPPM), because of the mappings learned bythe algorithm. Algorithm 2 is a subroutine of Algo-rithm 1, which identifies the set of active variables V .SPPM is parameterized by the number of iterations L.
3.3 Convergence
Algorithm SPPM is a gradient descent method. In eachiteration ℓ, we find a solution X′ in the direction of thegradient at the current solution Xℓ−1. Then we findthe minimum of f between Xℓ−1 and X′, and make itthe next solution Xℓ. By assumption, the initial so-lution X0 is feasible in the original problem (1). Thesolution X′ to the LP (4) is always feasible in (1), be-cause it satisfies all constraints in (1), and some addi-tional constraints xi,j = 0 on inactive variables. Afterthe first iteration of SPPM, X1 is a convex combina-
tion of X0 and X′. Since the feasible region is convex,and both X0 and X′ are feasible, X1 is also feasible.By induction, all solutions Xℓ are feasible.
The value of f(Xℓ) is guaranteed to monotonically de-crease with ℓ. When the method converges, f(Xℓ) =f(Xℓ−1). The convergence rate of the Frank-Wolfe al-gorithm is O(1/L) in the worst case [5].
3.4 Computational Efficiency
The computation time of our method is dominatedby the search for n2 violated constraints in Algo-rithm 2. To search efficiently, we implement the fol-lowing speedup in the computation of the gradientsci,j . The marginal and conditional distributions:
pB(b) =∑
a,b
pA,B(a, b)pB|B(b | b)
pB|A(b | a) =
∑b pA,B(a, b)pB|B(b | b)∑
b pA,B(a, b)
are precomputed, because these terms are common forall elements of C. Then each gradient is computed as:
∂
∂p(bi | bj)J(pa,b, pb|b) =
∑
a
p(a, bj) logp(bi | a)
p(bi)
+∑
a
p(a, b)
(p(bj | a)
p(bi | a)− p(a, bj)
p(bi)
).
Since all marginals and conditionals are precomputed,each gradient can be computed in O(|A|) time.
The space complexity of our method is O(|V|), becausewe operate only on active variables V .
We point out that the complexity of the algorithmis closely linked to the sparsity of the optimal solu-tion, which itself is related to the value of the distor-tion constraint ∆. This means that some distortionregimes may not be achievable with a given computa-tional budget. Therefore one has to reduce ∆ in orderto have a sparser solution. In practice however, we didnot run into problems, and were able to generate map-pings efficiently even when high distortion was neededto drive the mutual information close to 0.
4 Evaluation
4.1 Datasets
Census Dataset: The Census dataset is a sample ofthe United States population from 1994, and containsboth categoric and numerical features. Each entry inthe dataset contains features such as age, workclass,education, gender, and native country, as well as in-come category (smaller or larger than 50k per year).For our purposes, we consider the information to be
716
0 500 1000 15000
0.2
0.4
0.6
0.8
1
M
utu
alin
form
ation
inbits
L2 distance
SPPM: L = 50
SPPM: L = 100
SPPM: L = 500
CVX
0 0.1 0.2 0.3 0.40
0.1
0.2
0.3
0.4
0.5
Mutu
alin
form
ation
inbits
Hamming distance
SPPM: L = 100CVX
ExpMec
0 0.05 0.1 0.15 0.20
0.1
0.2
0.3
0.4
0.5
0.6
Mutu
alin
form
ation
inbits
Hamming distance
SPPM: L = 100
ExpMec
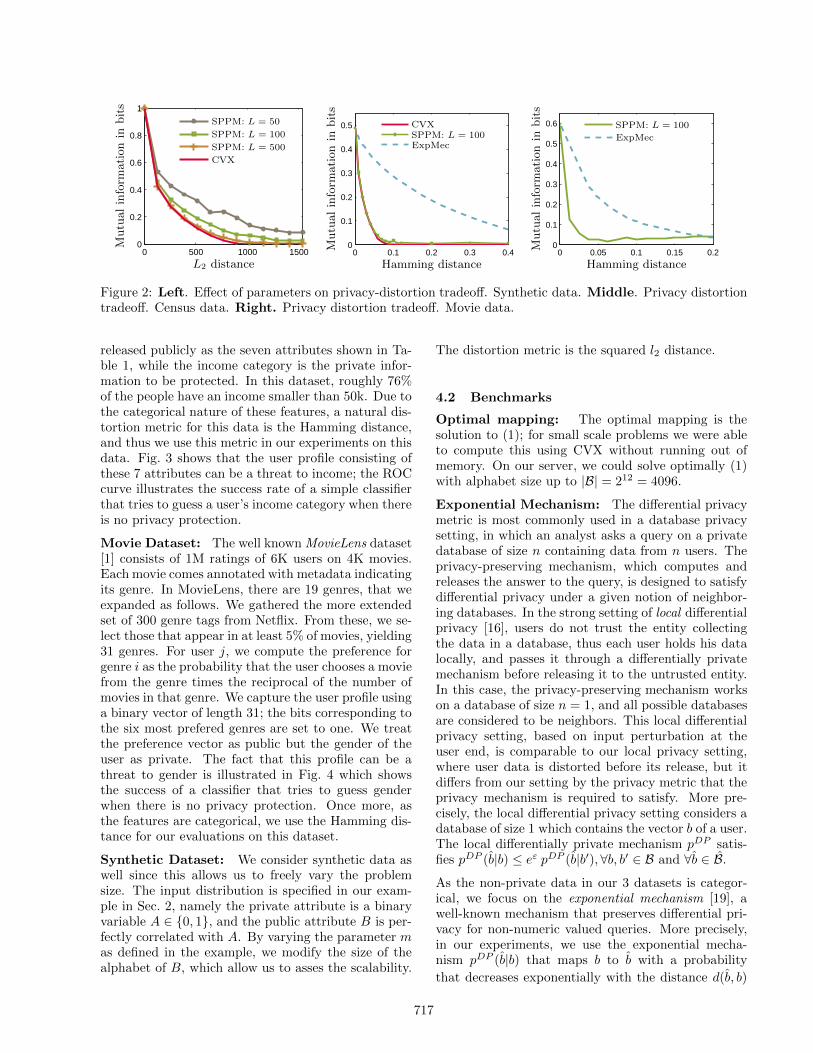
Figure 2: Left. Effect of parameters on privacy-distortion tradeoff. Synthetic data. Middle. Privacy distortiontradeoff. Census data. Right. Privacy distortion tradeoff. Movie data.
released publicly as the seven attributes shown in Ta-ble 1, while the income category is the private infor-mation to be protected. In this dataset, roughly 76%of the people have an income smaller than 50k. Due tothe categorical nature of these features, a natural dis-tortion metric for this data is the Hamming distance,and thus we use this metric in our experiments on thisdata. Fig. 3 shows that the user profile consisting ofthese 7 attributes can be a threat to income; the ROCcurve illustrates the success rate of a simple classifierthat tries to guess a user’s income category when thereis no privacy protection.
Movie Dataset: The well known MovieLens dataset[1] consists of 1M ratings of 6K users on 4K movies.Each movie comes annotated with metadata indicatingits genre. In MovieLens, there are 19 genres, that weexpanded as follows. We gathered the more extendedset of 300 genre tags from Netflix. From these, we se-lect those that appear in at least 5% of movies, yielding31 genres. For user j, we compute the preference forgenre i as the probability that the user chooses a moviefrom the genre times the reciprocal of the number ofmovies in that genre. We capture the user profile usinga binary vector of length 31; the bits corresponding tothe six most prefered genres are set to one. We treatthe preference vector as public but the gender of theuser as private. The fact that this profile can be athreat to gender is illustrated in Fig. 4 which showsthe success of a classifier that tries to guess genderwhen there is no privacy protection. Once more, asthe features are categorical, we use the Hamming dis-tance for our evaluations on this dataset.
Synthetic Dataset: We consider synthetic data aswell since this allows us to freely vary the problemsize. The input distribution is specified in our exam-ple in Sec. 2, namely the private attribute is a binaryvariable A ∈ {0, 1}, and the public attribute B is per-fectly correlated with A. By varying the parameter mas defined in the example, we modify the size of thealphabet of B, which allow us to asses the scalability.
The distortion metric is the squared l2 distance.
4.2 Benchmarks
Optimal mapping: The optimal mapping is thesolution to (1); for small scale problems we were ableto compute this using CVX without running out ofmemory. On our server, we could solve optimally (1)with alphabet size up to |B| = 212 = 4096.
Exponential Mechanism: The differential privacymetric is most commonly used in a database privacysetting, in which an analyst asks a query on a privatedatabase of size n containing data from n users. Theprivacy-preserving mechanism, which computes andreleases the answer to the query, is designed to satisfydifferential privacy under a given notion of neighbor-ing databases. In the strong setting of local differentialprivacy [16], users do not trust the entity collectingthe data in a database, thus each user holds his datalocally, and passes it through a differentially privatemechanism before releasing it to the untrusted entity.In this case, the privacy-preserving mechanism workson a database of size n = 1, and all possible databasesare considered to be neighbors. This local differentialprivacy setting, based on input perturbation at theuser end, is comparable to our local privacy setting,where user data is distorted before its release, but itdiffers from our setting by the privacy metric that theprivacy mechanism is required to satisfy. More pre-cisely, the local differential privacy setting considers adatabase of size 1 which contains the vector b of a user.The local differentially private mechanism pDP satis-fies pDP (b|b) ≤ eε pDP (b|b′), ∀b, b′ ∈ B and ∀b ∈ B.
As the non-private data in our 3 datasets is categor-ical, we focus on the exponential mechanism [19], awell-known mechanism that preserves differential pri-vacy for non-numeric valued queries. More precisely,in our experiments, we use the exponential mecha-nism pDP (b|b) that maps b to b with a probability
that decreases exponentially with the distance d(b, b)
717
0 0.5 10
0.2
0.4
0.6
0.8
1
False positive rate
Tru
e p
ositiv
e r
ate
replacemen
0 0.5 10
0.2
0.4
0.6
0.8
1
False positive rate
Tru
e p
ositiv
e r
ate
0 0.5 10
0.2
0.4
0.6
0.8
1
False positive rate
Tru
e p
ositiv
e r
ate
No privacy
CVX
ExpMec
Uninformed guess
SPPM: L = 100
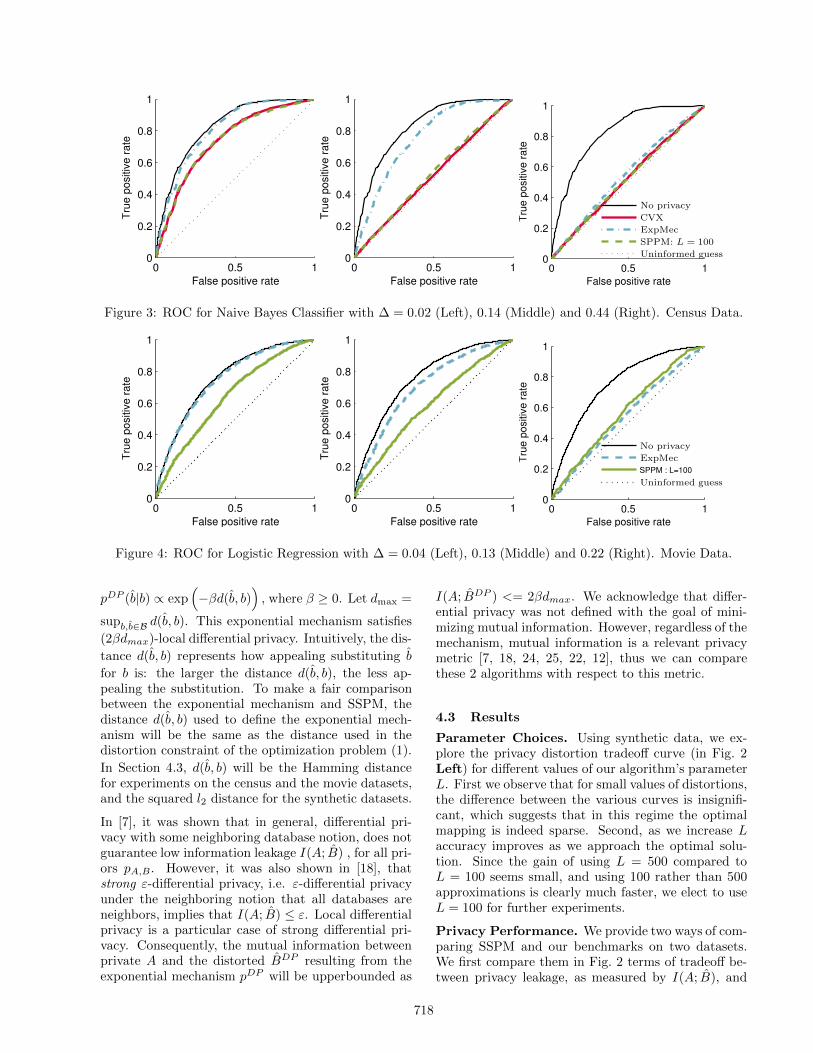
Figure 3: ROC for Naive Bayes Classifier with ∆ = 0.02 (Left), 0.14 (Middle) and 0.44 (Right). Census Data.
0 0.5 10
0.2
0.4
0.6
0.8
1
False positive rate
Tru
e p
ositiv
e r
ate
0 0.5 10
0.2
0.4
0.6
0.8
1
False positive rate
Tru
e p
ositiv
e r
ate
0 0.5 10
0.2
0.4
0.6
0.8
1
False positive rateT
rue
po
sitiv
e r
ate
SPPM : L=100
No privacy
ExpMec
Uninformed guess
Figure 4: ROC for Logistic Regression with ∆ = 0.04 (Left), 0.13 (Middle) and 0.22 (Right). Movie Data.
pDP (b|b) ∝ exp(−βd(b, b)
), where β ≥ 0. Let dmax =
supb,b∈B d(b, b). This exponential mechanism satisfies
(2βdmax)-local differential privacy. Intuitively, the dis-
tance d(b, b) represents how appealing substituting b
for b is: the larger the distance d(b, b), the less ap-pealing the substitution. To make a fair comparisonbetween the exponential mechanism and SSPM, thedistance d(b, b) used to define the exponential mech-anism will be the same as the distance used in thedistortion constraint of the optimization problem (1).
In Section 4.3, d(b, b) will be the Hamming distancefor experiments on the census and the movie datasets,and the squared l2 distance for the synthetic datasets.
In [7], it was shown that in general, differential pri-vacy with some neighboring database notion, does notguarantee low information leakage I(A; B) , for all pri-ors pA,B. However, it was also shown in [18], thatstrong ε-differential privacy, i.e. ε-differential privacyunder the neighboring notion that all databases areneighbors, implies that I(A; B) ≤ ε. Local differentialprivacy is a particular case of strong differential pri-vacy. Consequently, the mutual information betweenprivate A and the distorted BDP resulting from theexponential mechanism pDP will be upperbounded as
I(A; BDP ) <= 2βdmax. We acknowledge that differ-ential privacy was not defined with the goal of mini-mizing mutual information. However, regardless of themechanism, mutual information is a relevant privacymetric [7, 18, 24, 25, 22, 12], thus we can comparethese 2 algorithms with respect to this metric.
4.3 Results
Parameter Choices. Using synthetic data, we ex-plore the privacy distortion tradeoff curve (in Fig. 2Left) for different values of our algorithm’s parameterL. First we observe that for small values of distortions,the difference between the various curves is insignifi-cant, which suggests that in this regime the optimalmapping is indeed sparse. Second, as we increase Laccuracy improves as we approach the optimal solu-tion. Since the gain of using L = 500 compared toL = 100 seems small, and using 100 rather than 500approximations is clearly much faster, we elect to useL = 100 for further experiments.
Privacy Performance. We provide two ways of com-paring SSPM and our benchmarks on two datasets.We first compare them in Fig. 2 terms of tradeoff be-tween privacy leakage, as measured by I(A; B), and
718
0 10 20 300
0.05
0.1
0.15
0.2A
ve
rag
e p
rob
ab
ility
of
ma
pp
ing
ExpMec
SPPM: L = 100
Distance
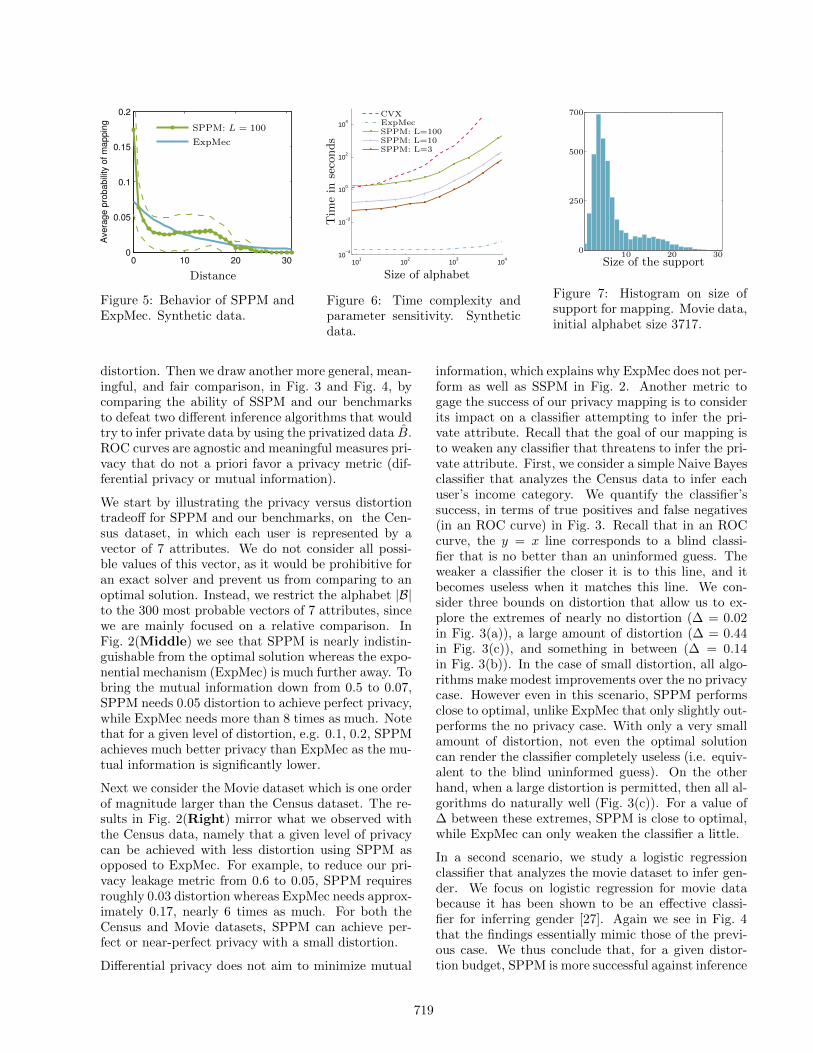
Figure 5: Behavior of SPPM andExpMec. Synthetic data.
101
102
103
104
10−4
10−2
100
102
104
CVX
Tim
ein
seco
nds
Size of alphabet
ExpMecSPPM: L=100SPPM: L=10SPPM: L=3
Figure 6: Time complexity andparameter sensitivity. Syntheticdata.
Size of the support0
250
500
700
10 20 30
Figure 7: Histogram on size ofsupport for mapping. Movie data,initial alphabet size 3717.
distortion. Then we draw another more general, mean-ingful, and fair comparison, in Fig. 3 and Fig. 4, bycomparing the ability of SSPM and our benchmarksto defeat two different inference algorithms that wouldtry to infer private data by using the privatized data B.ROC curves are agnostic and meaningful measures pri-vacy that do not a priori favor a privacy metric (dif-ferential privacy or mutual information).
We start by illustrating the privacy versus distortiontradeoff for SPPM and our benchmarks, on the Cen-sus dataset, in which each user is represented by avector of 7 attributes. We do not consider all possi-ble values of this vector, as it would be prohibitive foran exact solver and prevent us from comparing to anoptimal solution. Instead, we restrict the alphabet |B|to the 300 most probable vectors of 7 attributes, sincewe are mainly focused on a relative comparison. InFig. 2(Middle) we see that SPPM is nearly indistin-guishable from the optimal solution whereas the expo-nential mechanism (ExpMec) is much further away. Tobring the mutual information down from 0.5 to 0.07,SPPM needs 0.05 distortion to achieve perfect privacy,while ExpMec needs more than 8 times as much. Notethat for a given level of distortion, e.g. 0.1, 0.2, SPPMachieves much better privacy than ExpMec as the mu-tual information is significantly lower.
Next we consider the Movie dataset which is one orderof magnitude larger than the Census dataset. The re-sults in Fig. 2(Right) mirror what we observed withthe Census data, namely that a given level of privacycan be achieved with less distortion using SPPM asopposed to ExpMec. For example, to reduce our pri-vacy leakage metric from 0.6 to 0.05, SPPM requiresroughly 0.03 distortion whereas ExpMec needs approx-imately 0.17, nearly 6 times as much. For both theCensus and Movie datasets, SPPM can achieve per-fect or near-perfect privacy with a small distortion.
Differential privacy does not aim to minimize mutual
information, which explains why ExpMec does not per-form as well as SSPM in Fig. 2. Another metric togage the success of our privacy mapping is to considerits impact on a classifier attempting to infer the pri-vate attribute. Recall that the goal of our mapping isto weaken any classifier that threatens to infer the pri-vate attribute. First, we consider a simple Naive Bayesclassifier that analyzes the Census data to infer eachuser’s income category. We quantify the classifier’ssuccess, in terms of true positives and false negatives(in an ROC curve) in Fig. 3. Recall that in an ROCcurve, the y = x line corresponds to a blind classi-fier that is no better than an uninformed guess. Theweaker a classifier the closer it is to this line, and itbecomes useless when it matches this line. We con-sider three bounds on distortion that allow us to ex-plore the extremes of nearly no distortion (∆ = 0.02in Fig. 3(a)), a large amount of distortion (∆ = 0.44in Fig. 3(c)), and something in between (∆ = 0.14in Fig. 3(b)). In the case of small distortion, all algo-rithms make modest improvements over the no privacycase. However even in this scenario, SPPM performsclose to optimal, unlike ExpMec that only slightly out-performs the no privacy case. With only a very smallamount of distortion, not even the optimal solutioncan render the classifier completely useless (i.e. equiv-alent to the blind uninformed guess). On the otherhand, when a large distortion is permitted, then all al-gorithms do naturally well (Fig. 3(c)). For a value of∆ between these extremes, SPPM is close to optimal,while ExpMec can only weaken the classifier a little.
In a second scenario, we study a logistic regressionclassifier that analyzes the movie dataset to infer gen-der. We focus on logistic regression for movie databecause it has been shown to be an effective classi-fier for inferring gender [27]. Again we see in Fig. 4that the findings essentially mimic those of the previ-ous case. We thus conclude that, for a given distor-tion budget, SPPM is more successful against inference
719

threats because it can diminish the success of a clas-sifier more than the exponential mechanism. In otherwords, SPPM can provide more privacy than the ex-ponential mechanism for the same level of distortion.
Why is it that SPPM consistently outperforms Exp-Mec? Fig. 5 illustrates how these mappings work.We plot the average probability of being mapped tothe kth closest point, together with the standard er-ror that measures the variability among points. InExpMec, the probability of mapping one point to an-other decreases exponentially with distance and thesame mapping is applied to all points (in other wordsthe standard deviation is null). With SPPM, manypoints are mapped to themselves. This means thatthe privacy of these points cannot be improved withinthe distortion constraint. This can happen if a givenprofile is already very private, or if there is no hope ofproviding privacy. In both cases, the distortion budgetshould not be wasted on such profiles, and SPPM isable to detect these cases and save its budget for othercases. ExpMec wastes some distortion on those pointswhich are forced to be mapped to close neighbours.The key difference between SPPM and ExpMec is thatSPPM is not required to apply the same mapping toeach user, and can thus personalize the distortion, oradapt it as needed. This flexibility leads to a fair bit ofvariance as seen in Fig. 5. Because the probability ofmapping to another point does not decrease with thedistance from that point, we see a non-monotonicallydecreasing curve with distance: some points are bet-ter off being mapped to far neighbors rather than closeones; e.g. users whose profile is hard to disguise.
To further understand the effect of the mappings thatSPPM proposes, we examine which features in a userprofile are impacted most by our distortions. In Tab. 1we list the mutual information between a single pub-lic feature (e.g., Education) and the private attributewe wish to hide (e.g., income category). We see thatI(A; F ) is largest for Education, Marital status andOccupation, indicating these features are the most cor-related with the private attribute. This is intuitiveas, for example, more highly educated people tend tomake larger salaries. The table shows that these 3 fea-tures experience the largest reduction in mutual infor-mation after distortion, indicating that SPPM spentits distortion budget on the biggest threats. This in-tuitive property shows that the mappings learned de-pend on the underlying prior distribution in a smartway, such that with limited distortion budget the pri-ority is on the biggest privacy threats. Another pointcan be easily seen in the movie data in Tab. ??; herethe single features mutual information are rather low,whereas the mutual information of the full vector offeatures is significant. This means that a big part ofthe privacy threat comes from co-occurrence of fea-tures rather than individual features. This explains
I(A;F )Feature F Examples before afterAge 10-20, 20-30,... 0.1064 0.0408Education Bachelor, PhD,... 0.1502 0.0702Marital status Divorced, Married,... 0.1241 0.0440Occupation Manager, Scientist,... 0.1126 0.0367Race Black, White,... 0.0192 0.0084Gender Female, Male 0.0123 0.0082Country Mexico, USA,... 0.0470 0.0203
Table 1: Mutual information between private at-tribute A and public attributes F before and afterSPPM on Census dataset.
why it is not enough to simply reduce the mutual in-formation of a single feature to obtain good privacy.
Scalability. Having established good privacy perfor-mance, we now assess how the runtime performancescales in terms of the size of the problem, shown inFig. 6. We fix the distortion constraint to be propor-tional to the size of the problem, in order to keep asimilar difficulty as we grow the size. As stated inSec. 3.1, the time complexity is linear in L. Thistrend is evident as we observe the gaps between thelines for L = 3, 10, and 100. Importantly, we see thatour method scales with problem size better than theoptimal solution. We observe that the computationspeed of the exponential mechanism is very quick, andnote that indeed this is one of the salient propertiesof this mechanism. Overall, this figure shows that ourmethod is indeed tractable and can compute the dis-tortion maps within a few minutes for problems whosealphabet size is on the order of tens of thousands.
Recall that we designed for computation efficiency bysmartly selecting a limited number of alternate userprofiles to map each original profile to. This corre-sponds to the support size of p(B|bi) for all bi. InFig. 7 we show the histogram of the support sizes forour SPPM mapping on the movie data. Although theinitial alphabet size is very large (above 3500), for mostusers we don’t consider more than 10 alternate pro-files, and in the worst case we consider up to 30. Thisamounts to huge savings in computation and memory,without sacrificing privacy.
5 Conclusion
In this paper, for the first time, we apply large scale LPoptimization techniques to the problem of data distor-tion for privacy. We show that our privacy-preservingmappings can be close to optimal, and consistentlyoutperform a state of the art technique called the Ex-ponential Mechanism. Our solution achieves betterprivacy with less distortion than existing solutions,when privacy leakage is measured by a mutual infor-mation metric. We demonstrated that our method canscale, even for systems with many users and a largeunderlying alphabet that describes their profiles.
720

References
[1] MovieLens Dataset, GroupLens Research. http://www.grouplens.org/datasets/movielens/, 2010.
[2] Rakesh Agrawal and Ramakrishnan Srikant. Privacy-preserving data mining. ACM Sigmod Record, 2000.
[3] B. Fung and K. Wang and R. Chen and P. Yu. Pri-vacy Preserving Data Publishing: A Survey of RecentDevelopments. ACM Computing Surveys, 2010.
[4] Siddhartha Banerjee, Nidhi Hegde, and Laurent Mas-soulie. The price of privacy in untrusted recommen-dation engines. In IEEE Allerton, 2012.
[5] Dimitri Bertsekas. Nonlinear Programming. AthenaScientific, Belmont, MA, 1999.
[6] C. Jernigan and B. Mistree. Gaydar: FacebookFriendships expose sexual orientation. In First Mon-day, October 2009.
[7] Flavio Calmon and Nadia Fawaz. Privacy against sta-tistical inference. In IEEE Allerton, 2012.
[8] Kenneth L. Clarkson. Coresets, sparse greedy approx-imation, and the frank-wolfe algorithm. ACM Trans.Algorithms, September 2010.
[9] John C. Duchi, Michael I. Jordan, and Martin J.Wainwright. Local privacy and statistical minimaxrates. In IEEE FOCS, 2013.
[10] C. Dwork, F. Mcsherry, K. Nissim, and A. Smith. Cal-ibrating noise to sensitivity in private data analysis.In TCC, 2006.
[11] Cynthia Dwork. Differential privacy. In Automata,Languages and Programming. Springer, 2006.
[12] A. Evfimievski, J. Gehrke, and R. Srikant. Limitingprivacy breaches in privacy preserving data mining.In ACM PODS, 2003.
[13] Martin Jaggi. Sparse Convex Optimization Methodsfor Machine Learning. PhD thesis, 2011.
[14] Martin Jaggi. Revisiting frank-wolfe: Projection-freesparse convex optimization. submitted, 2012.
[15] Lee K. Jones. A simple lemma on greedy approxima-tion in hilbert space and convergence rates for projec-tion pursuit regression and neural network training.The Annals of Statistics, 1992.
[16] Shiva Prasad Kasiviswanathan, Homin K Lee, KobbiNissim, Sofya Raskhodnikova, and Adam Smith.What can we learn privately? SIAM Jour. on Com-puting, 2011.
[17] Ashwin Machanavajjhala, Daniel Kifer, JohannesGehrke, and Muthuramakrishnan Venkitasubrama-niam. l-diversity: Privacy beyond k-anonymity. ACMTKDD, 2007.
[18] Ali Makhdoumi and Nadia Fawaz. Privacy-utilitytradeoff under statistical uncertainty. In IEEE Aller-ton, 2013.
[19] Frank McSherry and Kunal Talwar. Mechanism de-sign via differential privacy. In FOCS, 2007.
[20] Nina Mishra and Mark Sandler. Privacy via pseudo-random sketches. In ACM PODS, 2006.
[21] J. Otterbacher. Inferring gender of movie reviewers:exploiting writing style, content and metadata. InCIKM, 2010.
[22] D. Rebollo-Monedero, J. Forne, and J. Domingo-Ferrer. From t-closeness-like privacy to postran-domization via information theory. IEEE Trans. onKnowledge and Data Engineering, 2010.
[23] I. S. Reed. Information Theory and Privacy in DataBanks. In AFIPS ’73, pages 581–587, 1973.
[24] Salman Salamatian, Amy Zhang, Flavio du Pin Cal-mon, Sandilya Bhamidipati, Nadia Fawaz, BranislavKveton, Pedro Oliveira, and Nina Taft. How to hidethe elephant- or the donkey- in the room: Practicalprivacy against statistical inference for large data. InIEEE GlobalSIP, 2013.
[25] L. Sankar, S. R. Rajagopalan, and H. V. Poor.Utility-privacy tradeoff in databases: An information-theoretic approach. IEEE Trans. Inf. Forensics Secu-rity, 2013.
[26] Latanya Sweeney. k-anonymity: A model for protect-ing privacy. Internat. Jour. Uncertainty, Fuzzinessand Knowledge-Based Systems, 2002.
[27] U. Weinsberg and S. Bhagat and S. Ioannidis and N.Taft. BlurMe: Inferring and Obfuscating User GenderBased on Ratings. In ACM RecSys, 2012.
[28] Stanley L Warner. Randomized response: A surveytechnique for eliminating evasive answer bias. Jour.American Statistical Association, 1965.
[29] H. Yamamoto. A source coding problem for sourceswith additional outputs to keep secret from the re-ceiver of wiretappers. IEEE Trans. Information The-ory, 29(6), 1983.
[30] Tong Zhang. Sequential greedy approximation for cer-tain convex optimization problems. IEEE Trans. Inf.Theor., 49(3):682–691, 2006.
[31] Martin Zinkevich. Online convex programming andgeneralized infinitesimal gradient ascent. In ICML,2003.
721