speech recognition liacs media lab leiden university seminar speech recognition project support e.m....
TRANSCRIPT

Speech Recognition LIACS Media Lab Leiden University
Seminar
Speech Recognition
Project Support
E.M. Bakker
LIACS Media Lab (LML)
Leiden University

Speech Recognition LIACS Media Lab Leiden University
Introduction What is Speech Recognition?
SpeechRecognition
Words“How are you?”
Speech Signal
Goal: Automatically extract from the speech signal the string of spoken words
• Other interesting area’s:– Who is talking (speaker recognition, identification)– Text to speech (speech synthesis)– What do the words mean (speech understanding, semantics)

Speech Recognition LIACS Media Lab Leiden University
MessageSource
LinguisticChannel
ArticulatoryChannel
AcousticChannel
Observable: Message Words Sounds Features
Bayesian formulation for speech recognition:
• P(W|A) = P(A|W) P(W) / P(A)
Recognition ArchitecturesA Communication Theoretic Approach
Objective: minimize the word error rate
Approach: maximize P(W|A) during training
Components:
• P(A|W) : acoustic model (hidden Markov models, mixtures)
• P(W) : language model (statistical, finite state networks, etc.)
The language model typically predicts a small set of next words based on knowledge of a finite number of previous words (N-grams).

Speech Recognition LIACS Media Lab Leiden University
Input Speech
Recognition ArchitecturesIncorporating Multiple Knowledge Sources
AcousticFront-end
AcousticFront-end
• The speech signal is converted to a sequence of feature vectors based on spectral and temporal measurements.
Acoustic ModelsP(A/W)
Acoustic ModelsP(A/W)
• Acoustic models represent sub-word units, such as phonemes, as a finite-state machine. States model spectral structure and transitions model temporal structure.
RecognizedUtterance
SearchSearch
• Efficient searching strategies are crucial to the system, since many combinations of words must be investigated to find the most probable word sequence.
• The language model predicts the next set of words, and controls which
(acoustic) models are hypothesized.Language Model
P(W)

Speech Recognition LIACS Media Lab Leiden University
FourierTransform
FourierTransform
CepstralAnalysis
CepstralAnalysis
PerceptualWeighting
PerceptualWeighting
TimeDerivative
TimeDerivative
Time Derivative
Time Derivative
Energy+
Mel-Spaced Cepstrum
Delta Energy+
Delta Cepstrum
Delta-Delta Energy+
Delta-Delta Cepstrum
Input Speech
• Knowledge of the nature of speech sounds is incorporated in the feature measurements.
• Utilize rudimentary models of human perception.
Acoustic ModelingFeature Extraction
• Measure features 100 times per sec. (10msec)
• Use a 25 msec window forfrequency domain analysis.
• Include absolute energy and 12 spectral measurements.
• Time derivatives are used to model spectral change.

Speech Recognition LIACS Media Lab Leiden University
• Acoustic models encode the temporal evolution of the features (spectrum).
• Gaussian mixture distributions are used to account for variations in speaker, accent, and pronunciation.
• Phonetic model topologies are simple left-to-right structures.
• Skip states (time-warping) and multiple paths (alternate pronunciations) are also common features of models.
• Sharing model parameters is a common strategy to reduce complexity.
Acoustic ModelingHidden Markov Models

Speech Recognition LIACS Media Lab Leiden University
Acoustic Models (HMM)
Some typical HMM topologies used for acoustic modeling in large vocabulary speech recognition:
a) typical triphone,b) short pausec) silence.
The shaded states denote the start and stop states for each model.

Speech Recognition LIACS Media Lab Leiden University
• Closed-loop data-driven modeling supervised only from a word-level transcription.
• The expectation/maximization (EM) algorithm is used to improve our parameter estimates.
• Computationally efficient training algorithms have been crucial.
• Batch mode parameter updates are typically preferred.
• Decision trees are used to optimize parameter-sharing, system complexity, and the use of additional linguistic knowledge.
Acoustic ModelingParameter Estimation
• Initialization
• Single Gaussian Estimation
• 2-Way Split
• Mixture Distribution Reestimation
• 4-Way Split
• Reestimation
•••

Speech Recognition LIACS Media Lab Leiden University
Language ModelingThe Wheel of Fortune

Speech Recognition LIACS Media Lab Leiden University
Language ModelingN-Grams (Words)
Bigrams (SWB):
• Most Common: “you know”, “yeah SENT!”, “!SENT um-hum”, “I think”• Rank-100: “do it”, “that we”, “don’t think”• Least Common: “raw fish”, “moisture content”,
“Reagan Bush”
Trigrams (SWB):
• Most Common: “!SENT um-hum SENT!”, “a lot of”, “I don’t know”
• Rank-100: “it was a”, “you know that”• Least Common: “you have parents”,
“you seen Brooklyn”
Unigrams (SWB):
• Most Common: “I”, “and”, “the”, “you”, “a”• Rank-100: “she”, “an”, “going”• Least Common: “Abraham”, “Alastair”, “Acura”

Speech Recognition LIACS Media Lab Leiden University
Language ModelingIntegration of Natural Language
• Natural language constraints can be easily incorporated.
• Lack of punctuation and search space size pose problems.
• Speech recognition typically produces a word-level
time-aligned annotation.
• Time alignments for other levels of information also available.

Speech Recognition LIACS Media Lab Leiden University
• Typical LVCSR systems have about 10M free parameters, which makes training a challenge.
• Large speech databases are required (several hundred hours of speech).
• Tying, smoothing, and interpolation are required.
Implementation Issues Search Is Resource Intensive
Megabytes of Memory
FeatureExtraction
(1M)
Acoustic Modeling
(10M)
LanguageModeling (30M)
Search(150M)
Percentage of CPUFeature
Extraction1%
LanguageModeling
15%
Search 25% Acoustic
Modeling 59%

Speech Recognition LIACS Media Lab Leiden University
• Dynamic programming is used to find the most probable path through the network.
• Beam search is used to control resources.
Implementation IssuesDynamic Programming-Based Search
• Search is time synchronous and left-to-right.
• Arbitrary amounts of silence must be permitted between each word.
• Words are hypothesized many times with different start/stop times, which significantly increases search complexity.

Speech Recognition LIACS Media Lab Leiden University
• Cross-word Decoding: since word boundaries don’t occur in spontaneous speech, we must allow for sequences of sounds that span word boundaries.
• Cross-word decoding significantly increases memory requirements.
Implementation IssuesCross-Word Decoding Is Expensive

Speech Recognition LIACS Media Lab Leiden University
Example ASR System: RES

Speech Recognition LIACS Media Lab Leiden University
Applications Conversational Speech
• Conversational speech collected over the telephone contains background noise, music, fluctuations in the speech rate, laughter, partial words, hesitations, mouth noises, etc.
• WER (Word Error Rate) has decreased from 100% to 30% in six years.
• Laughter
• Singing
• Unintelligible
• Spoonerism
• Background Speech
• No pauses
• Restarts
• Vocalized Noise
• Coinage

Speech Recognition LIACS Media Lab Leiden University
ApplicationsAudio Indexing of Broadcast News
Broadcast news offers some uniquechallenges:• Lexicon: important information in infrequently occurring words
• Acoustic Modeling: variations in channel, particularly within the same segment (“ in the studio” vs. “on location”)
• Language Model: must adapt (“ Bush,” “Clinton,” “Bush,” “McCain,” “???”)
• Language: multilingual systems? language-independent acoustic modeling?

Speech Recognition LIACS Media Lab Leiden University
• From President Clinton’s State of the Union address (January 27, 2000):
“These kinds of innovations are also propelling our remarkable prosperity...Soon researchers will bring us devices that can translate foreign languagesas fast as you can talk... molecular computers the size of a tear drop with thepower of today’s fastest supercomputers.”
Applications Real-Time Translation
• Imagine a world where:
• You book a travel reservation from your cellular phone while driving in your car without ever talking to a human (database query)
• You converse with someone in a foreign country and neither speakerspeaks a common language (universal translator)
• You place a call to your bank to inquire about your bank account and never have to remember a password (transparent telephony)
• You can ask questions by voice and your Internet browser returns answers to your questions (intelligent query)
• Human Language Engineering: a sophisticated integration of many speech and language related technologies... a science for the next millennium.

Speech Recognition LIACS Media Lab Leiden University
RES
• Copying the source code
• The Sound Files
• The Source Code
• The Modules
• The Examples
• Compiling the Code with MS Visual C++

Speech Recognition LIACS Media Lab Leiden University
RES: Copying the source code
• Copy all the files from the CD to a directory.– Right-click on the RES directory that was just copied and left-
click <Properties>– Deselect the read-only option.– Left-click <Apply>– Apply to all sub-folders
• <RES>– <Acrobat> Adobe Acrobat Reader– <Projects> Gpp for MS-DOS, Linux and MS Projects– <Sndfile> Sound, Annotation, and Feature Files– <Source> Source Code used in the Projects– <Test_Me> Compiled examples for testing

Speech Recognition LIACS Media Lab Leiden University
RES: The Sound Files
• Directory RES\Sndfile
• File types:– .wav 16 kHz, signed 16-bits, mono sound files– .phn annotated phoneme representation– .sgm annotated phoneme representation– .sro text string– .lsn text string– .fts FeaturesFile

Speech Recognition LIACS Media Lab Leiden University
RES: Speech Databases
Many distributed by the Linguistic Data Consortium www.ldc.upenn.edu
• TIMIT and ATIS are the most important databases used to build acoustic models of American English
• TIMIT (TI (Texas Instruments) + MIT)– 1 CD, 5.3 hours, 650Mbytes, 630 speakers of 8 main US regional varieties– 6300 sentences, divided in train (20-30%) and test database (70-80%)– none of the speakers appear in both sets– minimal coincidence of the same words in the two sets– phonetic database, all phonemes are included many times in different contexts– Every phrase is described by:
file.txt the orthographic transcription of the phrase (spelling) file.wav the wavefile of the sound file.phn the correspondence between the phonems and the samples file.wrd the correspondence between the words and the samples
– Furthermore: SX are phonetically compact phrases in order to abtain a good coverage of every pair of phones SI phonetically varied phrases, for different allophonic contexts SA for dialectal pronunciation

Speech Recognition LIACS Media Lab Leiden University
RES: Speech Databases
• ATIS (Air Travel Information System, 1989 ARPA-SLS project)– 6 CD, 10,2 hours, 2,38 Gbytes, 36 speakers, 10 722 utterances– natural speech in a system for air travel requests “What is the departure time of the flight to
Boston?”– word recognition applications– Every phrase is described by:
file.cat category of the phrase file.nli phrase text with point describing what the speaker had in mind file.ptx text in prompting form (question, exclamation,…) file.snr SNOR (Standard Normal Orthographic Representation) transcription of the
phrase (abbreviations and numbers explicitly expanded) file.sql additional information file.sro detailed description of the major acoustic events file.lsn SNOR lexical transcription derived from the .sro file.log scenario of the session file.wav the waveform of the phrase in NIST_1A format (sampling rate, LSB or MSB
byte order, min max amplitude, type of microphone, etc…) file.win references for the interpretation
– Phrase labeling: ‘s’ close-speaking (Sennheiser mic), ‘c’ table microphone (Crown-mic), ‘x’ lack of direct microphone, ‘s’ spontaneous speech, ‘r’ read phrases.
Speech Recognition LIACS Media Lab Leiden University
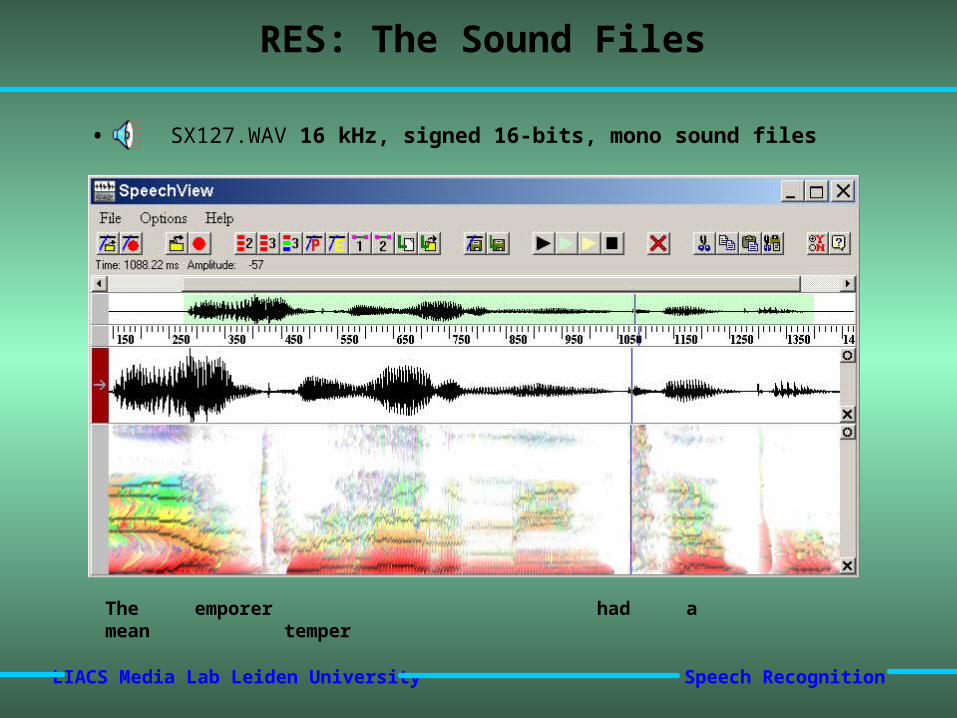
RES: The Sound Files
• SX127.WAV 16 kHz, signed 16-bits, mono sound files
The emporer had a mean temper

Speech Recognition LIACS Media Lab Leiden University
RES: The Sound Files
• SX127.WAV 16 kHz, signed 16-bits, mono sound files
• SX127.PHN and SX127.SGM annotated phoneme representation0 2231 h#2231 2834 dh2834 3757 iy3757 5045 q5045 6023 eh6023 6825 m6825 7070 pcl7070 7950 p7950 8689 r8689 9232 ix9232 10160 hv10160 11640 ae11640 12040 dx12040 12560 ix12560 14080 m14080 15600 iy15600 16721 n16721 17320 tcl17320 18380 t17320 18380 t18380 19760 eh19760 20386 m20386 21010 pcl21010 21480 p21480 22680 axr22680 24560 h#
0 2240 sil2240 2560 dh2560 4800 iy4800 4960 k4960 5760 eh5760 6720 m6720 7040 sil7040 8000 p8000 8320 r8320 9120 ih9120 10240 hh10240 11360 ae11360 12160 dx12160 12640 ih12640 13920 m13920 15840 iy15840 16960 n16960 17280 sil1728017280 1840018400 tt18400 19680 eh19680 20480 m20480 20960 sil20960 21600 p21600 22560 er22560 24512 sil
THE
EMPEROR
HAD
A
MEAN
TEMPER
THE
EMPEROR
HAD
AMEAN
TEMPER starts at ~17280/16000 = 1.08sec

Speech Recognition LIACS Media Lab Leiden University
RES: The Sound Files
• 4Y0021SS.WAV 16 kHz, signed 16-bits, mono sound files
• 4Y0021SS.PHN annotated phoneme representation
• 4Y0021SX.SRO “which airlines . depart from boston”
• 4Y0021SS.LSN “WHICH AIRLINES DEPART FROM BOSTON”
• 4Y0021SS.FTS FeaturesFile:
File=..\..\..\sndfile\4y0021ss.ftswindow_lenght=512window_overlap=352preemphasis_and_hamming_window:preemphasis=0.95mfcc_with_energy:num_features=12compute_energy=yescompute_log_of_energy=yesfeature_dim= 13feature_first_byte= 1024feature_n_bytes= 8feature_byte_format= 01end_head

Speech Recognition LIACS Media Lab Leiden University
RES: The Source Code
• baseclas_polymorf <baseclas>
– Tests the class implementing polymorphism. The class is used to implement “drivers” that handle different databases or different DSP operations.
• baseclas_testbase <baseclas> – Tests the classes handling memory and strings. The class handling
memory is the root class from which all the other classes are derived. Also diagnostics is tested.
• Ioclass <ioclass> – Tests the class that retrieves data from speech databases.
• Feature <feature>– Tests the class that performs feature extraction. This class is designed to
perform arbitrary sequences of digital signal processing on the input sequence according to the configuration file.
• Resconf <resconf>– This project tests the class that handles configuration services.

Speech Recognition LIACS Media Lab Leiden University
RES: The Source Code
• utils <utils>– This project shows a simple program that performs arbitrary
sequences of operations on a list of files according to the configuration file. The implemented operations are utilities for conversion from MS-DOS to Unix.
• Vetclas <vetclas>– This project shows and tests the mathematical operations over
vectors, diagonal matrices and full matrices.

Speech Recognition LIACS Media Lab Leiden University
RES: The Source Code
Projects related to programs required for speech recognition
• Print_feature– This project writes features of each single sound file. This is useful
to avoid recomputing features in the embedded training procedure.
• endpoint_feature– This project does the same as Print_feature but eliminates
silences.
• Print_phon_feature– This project writes features of the required files where all the same
phonemes of all the files are collected in one file, i.e. one output feature file for each phoneme. This is required for non-embedded training.

Speech Recognition LIACS Media Lab Leiden University
RES: The Source Code
Projects related to programs required for speech recognition
• Initiali– This project initializes the HMM models. HMM model parameters
are evaluated according to a clustering procedure
• training– This project re-estimates HMM models phoneme per phoneme
using the Baum–Welch algorithm. The bounds of each phoneme within the utterances are required, i.e. segmentation of all the training speech data.
• Embedded– This project re-estimates HMM models per utterance using the
Baum–Welch algorithm. Segmentation is not required.

Speech Recognition LIACS Media Lab Leiden University
RES: The Source Code
Projects related to programs required for speech recognition
• lessico– This project estimates language model parameters according to
various algorithms.
• Recog– This project performs phoneme/word recognition.
• Segmen– This project performs phonetic segmentation.
• eval_rec– This project evaluates accuracy of word/phoneme recognition.
• eval_segm– This project evaluates accuracy of segmentation.

Speech Recognition LIACS Media Lab Leiden University
RES Modules
• Common BaseClasses
• Configuration and Specification
• Speech Database, I/O
• Feature Extraction
• HMM Initialisation and Training
• Language Models
• Recognition: Searching Strategies
• Evaluators

Speech Recognition LIACS Media Lab Leiden University
RES Modules
Common BaseClassesConfiguration and Specification
Speech Database, I/O
Feature Extraction Recognition: Searching Strategies
Evaluators
Language Models
HMM Initialisation and Training

Speech Recognition LIACS Media Lab Leiden University
RES Modules: Files
baseclasbaseclas.cppBaseclas.hBaseclas.hppBoolean.hCompatib.hDefopt.hDiagnost.cppDiagnost.hPolymorf.cppPolymorf.hPolytest.cppTestbase.cppTextclas.cppTextclas.h
EmbeddedEmb_b_w.cppEmb_b_w.hEmb_Train.cpp
VetclasArraycla.cppArraycla.hArraycla.hppDiagclas.cppDiagclas.hDiagclas.hppTestvet.cppVetclas.cppVetclas.hVetclas.hpp
eval_recevalopt.cppevalopt.hEvaluate.cppEvaluate.heval_rec.cpp
eval_segmeval.cppeval.hmain_eval.cpp
FeaturesDSPPROC.CPPendpoint.cppFeature.cppFeature.hmean_feature.cppprint_file_feat.cppprint_ph_feat.cppTest_feature.cpp
InitialiIniopt.cppIniopt.hInitiali.cppInitiali.hProiniti.cpplabelcl.cpplabelcl.hSoundfil.cpp
ioclassSoundfil.hSoundlab.cppSoundlab.hTESTIONE.CPPTest_MsWav.cpp
Lessicolessico.cpplessico.hlexopt.cpplexopt.hmain_lessico.cpp
Recoghypolist.cppHypolist.hHypolist.hpprecog.cpprecopt.cpprecopt.h
resconfresconf.cppResconf.hTESTCONF.CPP
SegmentHypolist.cppHypolist.hhypolist.hpphypolistseg.cppSegment.cppSegopt.cppSegopt.h
TrainingBaumwelc.cppBaumwelc.hProtrain.cpp
tspecmodtesttspecbase.cppTspecbas.cppTspecbas.hTspecbas.hpp
utilsmultifop.cppmultifop.h

Speech Recognition LIACS Media Lab Leiden University
RES Modules: Files
baseclas
baseclas.cpp
Baseclas.h
Baseclas.hpp
Boolean.h
Compatib.h
Defopt.h
Diagnost.cpp
Diagnost.h
Polymorf.cpp
Polymorf.h
Polytest.cpp
Testbase.cpp
Textclas.cpp
Textclas.h
EmbeddedEmb_b_w.cppEmb_b_w.hEmb_Train.cpp
VetclasArraycla.cppArraycla.hArraycla.hppDiagclas.cppDiagclas.hDiagclas.hppTestvet.cppVetclas.cppVetclas.hVetclas.hpp
eval_recevalopt.cppevalopt.hEvaluate.cppEvaluate.heval_rec.cpp
eval_segmeval.cppeval.hmain_eval.cpp
FeaturesDSPPROC.CPPendpoint.cppFeature.cppFeature.hmean_feature.cppprint_file_feat.cppprint_ph_feat.cppTest_feature.cpp
InitialiIniopt.cppIniopt.hInitiali.cppInitiali.hProiniti.cpplabelcl.cpplabelcl.hSoundfil.cpp
ioclassSoundfil.hSoundlab.cppSoundlab.hTESTIONE.CPPTest_MsWav.cpp
Lessicolessico.cpplessico.hlexopt.cpplexopt.hmain_lessico.cpp
Recoghypolist.cppHypolist.hHypolist.hpprecog.cpprecopt.cpprecopt.h
resconfresconf.cppResconf.hTESTCONF.CPP
SegmentHypolist.cppHypolist.hhypolist.hpphypolistseg.cppSegment.cppSegopt.cppSegopt.h
TrainingBaumwelc.cppBaumwelc.hProtrain.cpp
tspecmodtesttspecbase.cppTspecbas.cppTspecbas.hTspecbas.hpp
utilsmultifop.cppmultifop.h

Speech Recognition LIACS Media Lab Leiden University
RES: The Examples
• Test_me/Phoneme/Start_me.bat:
“recog res.ini
eval_rec res.ini”
- The output here is the phoneme recognition. On a 2GHz machine it takes 7 seconds for 3 sentences.
• Test_me/Word_Rec/Start_me.bat– This test shows an example of word recognition with RES– The file recog.sol contains the recognized sentence,– the file recog.rsl is the true sentence– and result.txt is the result in term of accuracy and percent correct– The recognition module is many times slower than real-time on this
notebook, on a 2GHz machine the small example still takes 30 seconds

Speech Recognition LIACS Media Lab Leiden University
RES Compiling with MS Visual C++
Building the Executables
• Goto the directory “RES\Projects\projectMS”
• Double-click RES.dsw (Click yes, if it wants to convert to a workspace of the current version of MS Visual C++)
• Goto the MS Visual C++ menu-item <Build><Batch Build>
• Select the items you want to build.
• Select <Selection only>
• Left-click the <Build>-button.
Test_me Again
• Now the directories: \eval_rec and \recog contain the newly built executables “eval_rec.exe” and “recog.exe”, respectively, that can replace the executables in the directory “\Test_me\PHONEME”
• Then, by executing “Start_me.bat” you can run the examples with the newly built executable.