sparrow: distributed, low latency scheduling - …keo/publications/sosp13-final17.pdf · sparrow:...
TRANSCRIPT

Sparrow: Distributed, Low Latency Scheduling
Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion StoicaUniversity of California, Berkeley
Abstract
Large-scale data analytics frameworks are shifting to-wards shorter task durations and larger degrees of paral-lelism to provide low latency. Scheduling highly paralleljobs that complete in hundreds of milliseconds poses amajor challenge for task schedulers, which will need toschedule millions of tasks per second on appropriate ma-chines while offering millisecond-level latency and highavailability. We demonstrate that a decentralized, ran-domized sampling approach provides near-optimal per-formance while avoiding the throughput and availabilitylimitations of a centralized design. We implement anddeploy our scheduler, Sparrow, on a 110-machine clus-ter and demonstrate that Sparrow performs within 12%of an ideal scheduler.
1 Introduction
Today’s data analytics clusters are running ever shorterand higher-fanout jobs. Spurred by demand for lower-latency interactive data processing, efforts in re-search and industry alike have produced frameworks(e.g., Dremel [12], Spark [26], Impala [11]) that stripework across thousands of machines or store data inmemory in order to analyze large volumes of data inseconds, as shown in Figure 1. We expect this trend tocontinue with a new generation of frameworks target-ing sub-second response times. Bringing response timesinto the 100ms range will enable powerful new appli-cations; for example, user-facing services will be ableto run sophisticated parallel computations, such as lan-guage translation and highly personalized search, on aper-query basis.
Permission to make digital or hard copies of part or all of this work forpersonal or classroom use is granted without fee provided that copiesare not made or distributed for profit or commercial advantage and thatcopies bear this notice and the full citation on the first page. Copyrightsfor third-party components of this work must be honored. Forall otheruses, contact the Owner/Author.
Copyright is held by the Owner/Author(s).
SOSP ’13, Nov. 3–6, 2013, Farmington, Pennsylvania, USA.ACM 978-1-4503-2388-8/13/11.http://dx.doi.org/10.1145/2517349.2522716
10 min. 10 sec. 100 ms 1 ms
2004:
MapReduce
batch job
2009: Hive
query
2010: Dremel query
2010: In-memory
Spark query
2012: Impala query
Figure 1: Data analytics frameworks can analyzelarge volumes of data with ever lower latency.
Jobs composed of short, sub-second tasks present adifficult scheduling challenge. These jobs arise not onlydue to frameworks targeting low latency, but also as aresult of breaking long-running batch jobs into a largenumber of short tasks, a technique that improves fair-ness and mitigates stragglers [17]. When tasks run inhundreds of milliseconds, scheduling decisions must bemade at very high throughput: a cluster containing tenthousand 16-core machines and running 100ms tasksmay require over 1 million scheduling decisions persecond. Scheduling must also be performed with lowlatency: for 100ms tasks, scheduling delays (includ-ing queueing delays) above tens of milliseconds repre-sent intolerable overhead. Finally, as processing frame-works approach interactive time-scales and are used incustomer-facing systems, high system availability be-comes a requirement. These design requirements differfrom those of traditional batch workloads.
Modifying today’s centralized schedulers to supportsub-second parallel tasks presents a difficult engineer-ing challenge. Supporting sub-second tasks requireshandling two orders of magnitude higher throughputthan the fastest existing schedulers (e.g., Mesos [8],YARN [16], SLURM [10]); meeting this design require-ment would be difficult with a design that schedules andlaunches all tasks through a single node. Additionally,achieving high availability would require the replicationor recovery of large amounts of state in sub-second time.
This paper explores the opposite extreme in the designspace: we propose scheduling from a set of machinesthat operate autonomously and without centralized orlogically centralized state. A decentralized design offers

attractive scaling and availability properties. The systemcan support more requests by adding additional sched-ulers, and if a scheduler fails, users can direct requests toan alternate scheduler. The key challenge with a decen-tralized design is providing response times comparableto those provided by a centralized scheduler, given thatconcurrently operating schedulers may make conflictingscheduling decisions.
We present Sparrow, a stateless distributed schedulerthat adapts the power of two choices load balancing tech-nique [14] to the domain of parallel task scheduling.The power of two choices technique proposes schedul-ing each task by probing two random servers and placingthe task on the server with fewer queued tasks. We intro-duce three techniques to make the power of two choiceseffective in a cluster running parallel jobs:Batch Sampling: The power of two choices performspoorly for parallel jobs because job response time is sen-sitive to tail task wait time (because a job cannot com-plete until its last task finishes) and tail wait times remainhigh with the power of two choices. Batch samplingsolves this problem by applying the recently developedmultiple choices approach [18] to the domain of paralleljob scheduling. Rather than sampling for each task indi-vidually, batch sampling places them tasks in a job onthe least loaded ofd ·m randomly selected worker ma-chines (ford > 1). We demonstrate analytically that, un-like the power of two choices, batch sampling’s perfor-mance does not degrade as a job’s parallelism increases.Late Binding: The power of two choices suffers fromtwo remaining performance problems: first, server queuelength is a poor indicator of wait time, and second, dueto messaging delays, multiple schedulers sampling inparallel may experience race conditions. Late bindingavoids these problems by delaying assignment of tasksto worker machines until workers are ready to run thetask, and reduces median job response time by as muchas 45% compared to batch sampling alone.Policies and Constraints: Sparrow uses multiplequeues on worker machines to enforce global policies,and supports the per-job and per-task placement con-straints needed by analytics frameworks. Neither pol-icy enforcement nor constraint handling are addressedin simpler theoretical models, but both play an impor-tant role in real clusters [21].
We have deployed Sparrow on a 110-machine clus-ter to evaluate its performance. When scheduling TPC-H queries, Sparrow provides response times within 12%of an ideal scheduler, schedules with median queueingdelay of less than 9ms, and recovers from scheduler fail-ures in less than 120ms. Sparrow provides low responsetimes for jobs with short tasks, even in the presenceof tasks that take up to 3 orders of magnitude longer.In spite of its decentralized design, Sparrow maintains
aggregate fair shares, and isolates users with differentpriorities such that a misbehaving low priority user in-creases response times for high priority jobs by at most40%. Simulation results suggest that Sparrow will con-tinue to perform well as cluster size increases to tensof thousands of cores. Our results demonstrate that dis-tributed scheduling using Sparrow presents a viable al-ternative to centralized scheduling for low latency, par-allel workloads.
2 Design Goals
This paper focuses on fine-grained task scheduling forlow-latency applications.
Low-latency workloads have more demandingscheduling requirements than batch workloads do,because batch workloads acquire resources for long pe-riods of time and thus require infrequent task scheduling.To support a workload composed of sub-second tasks,a scheduler must provide millisecond-scale schedulingdelay and support millions of task scheduling decisionsper second. Additionally, because low-latency frame-works may be used to power user-facing services, ascheduler for low-latency workloads should be able totolerate scheduler failure.
Sparrow provides fine-grained task scheduling, whichis complementary to the functionality provided by clus-ter resource managers. Sparrow does not launch newprocesses for each task; instead, Sparrow assumes thata long-running executor process is already running oneach worker machine for each framework, so that Spar-row need only send a short task description (rather thana large binary) when a task is launched. These execu-tor processes may be launched within a static portionof a cluster, or via a cluster resource manager (e.g.,YARN [16], Mesos [8], Omega [20]) that allocates re-sources to Sparrow along with other frameworks (e.g.,traditional batch workloads).
Sparrow also makes approximations when schedulingand trades off many of the complex features supportedby sophisticated, centralized schedulers in order to pro-vide higher scheduling throughput and lower latency. Inparticular, Sparrow does not allow certain types of place-ment constraints (e.g., “my job should not be run on ma-chines where User X’s jobs are running”), does not per-form bin packing, and does not support gang scheduling.
Sparrow supports a small set of features in a way thatcan be easily scaled, minimizes latency, and keeps thedesign of the system simple. Many applications run low-latency queries from multiple users, so Sparrow enforcesstrict priorities or weighted fair shares when aggregatedemand exceeds capacity. Sparrow also supports basic
2

constraints over job placement, such as per-task con-straints (e.g. each task needs to be co-resident with in-put data) and per-job constraints (e.g., all tasks must beplaced on machines with GPUs). This feature set is simi-lar to that of the Hadoop MapReduce scheduler [23] andthe Spark [26] scheduler.
3 Sample-Based Scheduling forParallel Jobs
A traditional task scheduler maintains a complete viewof which tasks are running on which worker machines,and uses this view to assign incoming tasks to avail-able workers. Sparrow takes a radically different ap-proach: many schedulers operate in parallel, and sched-ulers do not maintain any state about cluster load. Toschedule a job’s tasks, schedulers rely on instantaneousload information acquired from worker machines. Spar-row’s approach extends existing load balancing tech-niques [14, 18] to the domain of parallel job schedulingand introduces late binding to improve performance.
3.1 Terminology and job model
We consider a cluster composed ofworker machinesthatexecute tasks andschedulersthat assign tasks to workermachines. A job consists ofm tasks that are each allo-cated to a worker machine. Jobs can be handled by anyscheduler. Workers run tasks in a fixed number of slots;we avoid more sophisticated bin packing because it addscomplexity to the design. If a worker machine is as-signed more tasks than it can run concurrently, it queuesnew tasks until existing tasks release enough resourcesfor the new task to be run. We usewait timeto describethe time from when a task is submitted to the sched-uler until when the task begins executing andservicetime to describe the time the task spends executing ona worker machine.Job response timedescribes the timefrom when the job is submitted to the scheduler untilthe last task finishes executing. We usedelayto describethe total delay within a job due to both scheduling andqueueing. We compute delay by taking the difference be-tween the job response time using a given schedulingtechnique, and job response time if all of the job’s taskshad been scheduled with zero wait time (equivalent tothe longest service time across all tasks in the job).
In evaluating different scheduling approaches, we as-sume that each job runs as a single wave of tasks. Inreal clusters, jobs may run as multiple waves of taskswhen, for example,m is greater than the number of slotsassigned to the user; for multiwave jobs, the schedulercan place some early tasks on machines with longerqueueing delay without affecting job response time.
We assume a single wave job model when we evalu-ate scheduling techniques because single wave jobs aremost negatively affected by the approximations involvedin our distributed scheduling approach: even a singledelayed task affects the job’s response time. However,Sparrow also handles multiwave jobs.
3.2 Per-task sampling
Sparrow’s design takes inspiration from the power oftwo choices load balancing technique [14], which pro-vides low expected task wait times using a stateless, ran-domized approach. The power of two choices techniqueproposes a simple improvement over purely random as-signment of tasks to worker machines: place each taskon the least loaded of two randomly selected workermachines. Assigning tasks in this manner improves ex-pected wait time exponentially compared to using ran-dom placement [14].1
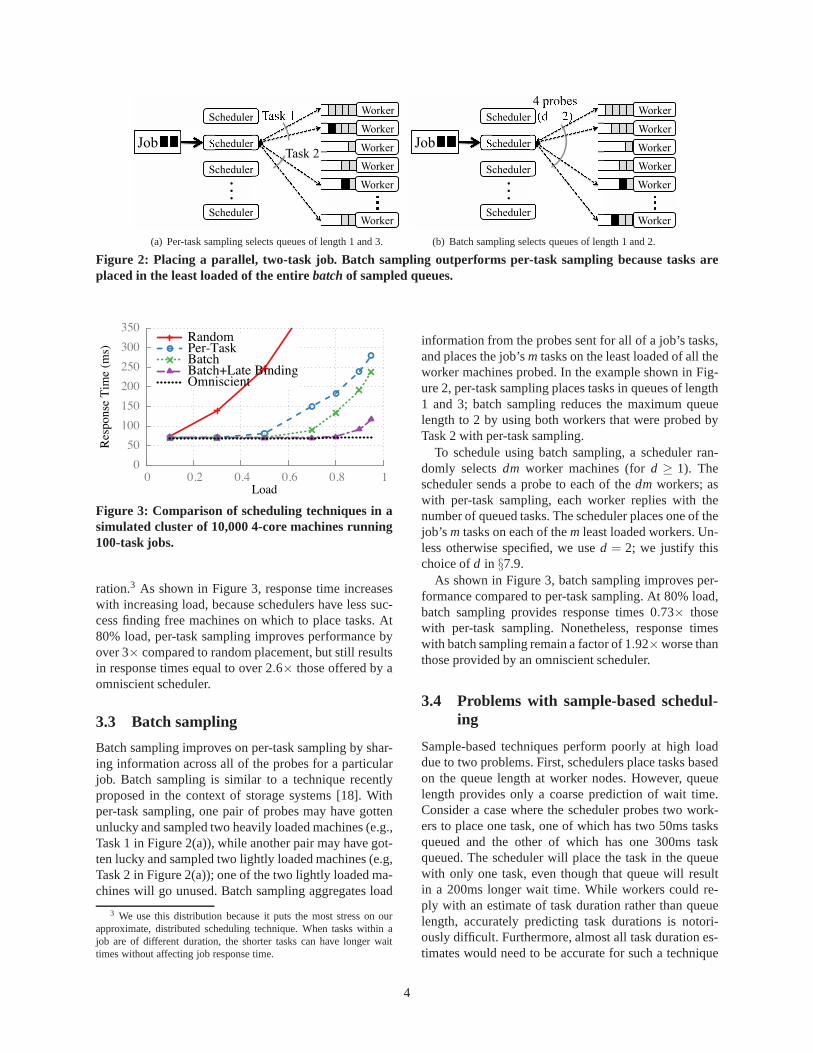
We first consider a direct application of the power oftwo choices technique to parallel job scheduling. Thescheduler randomly selects two worker machines foreach task and sends aprobe to each, where a probe isa lightweight RPC. The worker machines each reply tothe probe with the number of currently queued tasks, andthe scheduler places the task on the worker machine withthe shortest queue. The scheduler repeats this process foreach task in the job, as illustrated in Figure 2(a). We referto this application of the power of two choices techniqueasper-task sampling.
Per-task sampling improves performance compared torandom placement but still performs 2× or more worsethan an omniscient scheduler.2 Intuitively, the problemwith per-task sampling is that a job’s response time isdictated by the longest wait time of any of the job’s tasks,making averagejob response time much higher (and alsomuch more sensitive to tail performance) than averagetaskresponse time. We simulated per-task sampling andrandom placement in cluster composed of 10,000 4-coremachines with 1ms network round trip time. Jobs ar-rive as a Poisson process and are each composed of 100tasks. The duration of a job’s tasks is chosen from theexponential distribution such that across jobs, task du-rations are exponentially distributed with mean 100ms,but within a particular job, all tasks are the same du-
1More precisely, expected task wait time using random placementis 1/(1− ρ), whereρ represents load. Using the least loaded ofdchoices, wait time in an initially empty system over the firstT units
of time is upper bounded by∑∞i=1 ρ
di−dd−1 +o(1) [14].
2 The omniscient scheduler uses a greedy scheduling algorithmbased on complete information about which worker machines are busy.For each incoming job, the scheduler places the job’s tasks on idleworkers, if any exist, and otherwise uses FIFO queueing.
3
Worker
Scheduler
Scheduler
Scheduler
Scheduler Job
Task 1
Task 2
Worker
Worker
Worker
Worker
Worker
…
(a) Per-task sampling selects queues of length 1 and 3.
2
Scheduler
Scheduler
Scheduler
Scheduler
4 probes
(d = 2) Worker
Worker
Worker
Worker
Worker
Worker
…
Job
(b) Batch sampling selects queues of length 1 and 2.
Figure 2: Placing a parallel, two-task job. Batch sampling outperforms per-task sampling because tasks areplaced in the least loaded of the entirebatch of sampled queues.
0
50
100
150
200
250
300
350
0 0.2 0.4 0.6 0.8 1
Res
ponse
Tim
e (m
s)
Load
RandomPer-TaskBatchBatch+Late BindingOmniscient
Figure 3: Comparison of scheduling techniques in asimulated cluster of 10,000 4-core machines running100-task jobs.
ration.3 As shown in Figure 3, response time increaseswith increasing load, because schedulers have less suc-cess finding free machines on which to place tasks. At80% load, per-task sampling improves performance byover 3× compared to random placement, but still resultsin response times equal to over 2.6× those offered by aomniscient scheduler.
3.3 Batch sampling
Batch sampling improves on per-task sampling by shar-ing information across all of the probes for a particularjob. Batch sampling is similar to a technique recentlyproposed in the context of storage systems [18]. Withper-task sampling, one pair of probes may have gottenunlucky and sampled two heavily loaded machines (e.g.,Task 1 in Figure 2(a)), while another pair may have got-ten lucky and sampled two lightly loaded machines (e.g,Task 2 in Figure 2(a)); one of the two lightly loaded ma-chines will go unused. Batch sampling aggregates load
3 We use this distribution because it puts the most stress on ourapproximate, distributed scheduling technique. When tasks within ajob are of different duration, the shorter tasks can have longer waittimes without affecting job response time.
information from the probes sent for all of a job’s tasks,and places the job’sm tasks on the least loaded of all theworker machines probed. In the example shown in Fig-ure 2, per-task sampling places tasks in queues of length1 and 3; batch sampling reduces the maximum queuelength to 2 by using both workers that were probed byTask 2 with per-task sampling.
To schedule using batch sampling, a scheduler ran-domly selectsdm worker machines (ford ≥ 1). Thescheduler sends a probe to each of thedm workers; aswith per-task sampling, each worker replies with thenumber of queued tasks. The scheduler places one of thejob’s m tasks on each of them least loaded workers. Un-less otherwise specified, we used = 2; we justify thischoice ofd in §7.9.
As shown in Figure 3, batch sampling improves per-formance compared to per-task sampling. At 80% load,batch sampling provides response times 0.73× thosewith per-task sampling. Nonetheless, response timeswith batch sampling remain a factor of 1.92×worse thanthose provided by an omniscient scheduler.
3.4 Problems with sample-based schedul-ing
Sample-based techniques perform poorly at high loaddue to two problems. First, schedulers place tasks basedon the queue length at worker nodes. However, queuelength provides only a coarse prediction of wait time.Consider a case where the scheduler probes two work-ers to place one task, one of which has two 50ms tasksqueued and the other of which has one 300ms taskqueued. The scheduler will place the task in the queuewith only one task, even though that queue will resultin a 200ms longer wait time. While workers could re-ply with an estimate of task duration rather than queuelength, accurately predicting task durations is notori-ously difficult. Furthermore, almost all task duration es-timates would need to be accurate for such a technique
4

to be effective, because each job includes many paralleltasks,all of which must be placed on machines with lowwait time to ensure good performance.
Sampling also suffers from a race condition wheremultiple schedulers concurrently place tasks on a workerthat appears lightly loaded [13]. Consider a case wheretwo different schedulers probe the same idle worker ma-chine,w, at the same time. Sincew is idle, both sched-ulers are likely to place a task onw; however, only oneof the two tasks placed on the worker will arrive in anempty queue. The queued task might have been placedin a different queue had the corresponding schedulerknown thatw was not going to be idle when the taskarrived.
3.5 Late binding
Sparrow introduceslate bindingto solve the aforemen-tioned problems. With late binding, workers do not re-ply immediately to probes and instead place a reserva-tion for the task at the end of an internal work queue.When this reservation reaches the front of the queue, theworker sends an RPC to the scheduler that initiated theprobe requesting a task for the corresponding job. Thescheduler assigns the job’s tasks to the firstm workersto reply, and replies to the remaining(d−1)m workerswith a no-op signaling that all of the job’s tasks havebeen launched. In this manner, the scheduler guaranteesthat the tasks will be placed on them probed workerswhere they will be launched soonest. For exponentially-distributed task durations at 80% load, late binding pro-vides response times 0.55× those with batch sampling,bringing response time to within 5% (4ms) of an omni-scient scheduler (as shown in Figure 3).
The downside of late binding is that workers areidle while they are sending an RPC to request a newtask from a scheduler. All current cluster schedulerswe are aware of make this tradeoff: schedulers wait toassign tasks until a worker signals that it has enoughfree resources to launch the task. In our target set-ting, this tradeoff leads to a 2% efficiency loss com-pared to queueing tasks at worker machines. The frac-tion of time a worker spends idle while requesting tasksis (d ·RTT)/(t + d ·RTT) (whered denotes the num-ber of probes per task, RTT denotes the mean networkround trip time, andt denotes mean task service time). Inour deployment on EC2 with an un-optimized networkstack, mean network round trip time was 1 millisecond.We expect that the shortest tasks will complete in 100msand that scheduler will use a probe ratio of no more than2, leading to at most a 2% efficiency loss. For our tar-get workload, this tradeoff is worthwhile, as illustratedby the results shown in Figure 3, which incorporate net-work delays. In environments where network latencies
and task runtimes are comparable, late binding will notpresent a worthwhile tradeoff.
3.6 Proactive Cancellation
When a scheduler has launched all of the tasks for a par-ticular job, it can handle remaining outstanding probesin one of two ways: it can proactively send a cancel-lation RPC to all workers with outstanding probes, orit can wait for the workers to request a task and replyto those requests with a message indicating that no un-launched tasks remain. We use our simulation to modelthe benefit of using proactive cancellation and find thatproactive cancellation reduces median response time by6% at 95% cluster load. At a given loadρ , workers arebusy more thanρ of the time: they spendρ proportion oftime executing tasks, but they spend additional time re-questing tasks from schedulers. Using cancellation with1ms network RTT, a probe ratio of 2, and with tasks thatare an average of 100ms long reduces the time work-ers spend busy by approximately 1%; because responsetimes approach infinity as load approaches 100%, the1% reduction in time workers spend busy leads to a no-ticeable reduction in response times. Cancellation leadsto additional RPCs if a worker receives a cancellation fora reservation after it has already requested a task for thatreservation: at 95% load, cancellation leads to 2% ad-ditional RPCs. We argue that the additional RPCs are aworthwhile tradeoff for the improved performance, andthe full Sparrow implementation includes cancellation.Cancellation helps more when the ratio of network de-lay to task duration increases, so will become more im-portant as task durations decrease, and less important asnetwork delay decreases.
4 Scheduling Policies and Con-straints
Sparrow aims to support a small but useful set of poli-cies within its decentralized framework. This sectiondescribes support for two types of popular schedulerpolicies: constraints over where individual tasks arelaunched and inter-user isolation policies to govern therelative performance of users when resources are con-tended.
4.1 Handling placement constraints
Sparrow handles two types of constraints, per-job andper-task constraints. Such constraints are commonly re-quired in data-parallel frameworks, for instance, to runtasks on a machine that holds the task’s input dataon disk or in memory. As mentioned in§2, Sparrow
5

does not support many types of constraints (e.g., inter-job constraints) supported by some general-purpose re-source managers.
Per-job constraints (e.g., all tasks should be run ona worker with a GPU) are trivially handled at a Spar-row scheduler. Sparrow randomly selects thedmcandi-date workers from the subset of workers that satisfy theconstraint. Once thedm workers to probe are selected,scheduling proceeds as described previously.
Sparrow also handles jobs with per-task constraints,such as constraints that limit tasks to run on machineswhere input data is located. Co-locating tasks with inputdata typically reduces response time, because input datadoes not need to be transferred over the network. Forjobs with per-task constraints, each task may have a dif-ferent set of machines on which it can run, so Sparrowcannot aggregate information over all of the probes inthe job using batch sampling. Instead, Sparrow uses per-task sampling, where the scheduler selects the two ma-chines to probe for each task from the set of machinesthat the task is constrained to run on, along with latebinding.
Sparrow implements a small optimization over per-task sampling for jobs with per-task constraints. Ratherthan probing individually for each task, Sparrow sharesinformation across tasks when possible. For example,consider a case where task 0 is constrained to run inmachines A, B, and C, and task 1 is constrained to runon machines C, D, and E. Suppose the scheduler probedmachines A and B for task 0, which were heavily loaded,and probed machines C and D for task 1, which wereboth idle. In this case, Sparrow will place task 0 on ma-chine C and task 1 on machine D, even though both ma-chines were selected to be probed for task 1.
Although Sparrow cannot use batch sampling for jobswith per-task constraints, our distributed approach stillprovides near-optimal response times for these jobs, be-cause even a centralized scheduler has only a small num-ber of choices for where to place each task. Jobs withper-task constraints can still use late binding, so thescheduler is guaranteed to place each task on whicheverof the two probed machines where the task will runsooner. Storage layers like HDFS typically replicate dataon three different machines, so tasks that read input datawill be constrained to run on one of three machineswhere the input data is located. As a result, even anideal, omniscient scheduler would only have one addi-tional choice for where to place each task.
4.2 Resource allocation policies
Cluster schedulers seek to allocate resources accord-ing to a specific policy when aggregate demand for re-sources exceeds capacity. Sparrow supports two types of
policies: strict priorities and weighted fair sharing. Thesepolicies mirror those offered by other schedulers, includ-ing the Hadoop Map Reduce scheduler [25].
Many cluster sharing policies reduce to using strictpriorities; Sparrow supports all such policies by main-taining multiple queues on worker nodes. FIFO, earliestdeadline first, and shortest job first all reduce to assign-ing a priority to each job, and running the highest pri-ority jobs first. For example, with earliest deadline first,jobs with earlier deadlines are assigned higher priority.Cluster operators may also wish to directly assign pri-orities; for example, to give production jobs high prior-ity and ad-hoc jobs low priority. To support these poli-cies, Sparrow maintains one queue for each priority ateach worker node. When resources become free, Spar-row responds to the reservation from the highest prior-ity non-empty queue. This mechanism trades simplicityfor accuracy: nodes need not use complex gossip proto-cols to exchange information about jobs that are waitingto be scheduled, but low priority jobs may run beforehigh priority jobs if a probe for a low priority job ar-rives at a node where no high priority jobs happen tobe queued. We believe this is a worthwhile tradeoff: asshown in§7.8, this distributed mechanism provides goodperformance for high priority users. Sparrow does notcurrently support preemption when a high priority taskarrives at a machine running a lower priority task; weleave exploration of preemption to future work.
Sparrow can also enforce weighted fair shares. Eachworker maintains a separate queue for each user, andperforms weighted fair queuing [6] over those queues.This mechanism provides cluster-wide fair shares in ex-pectation: two users using the same worker will getshares proportional to their weight, so by extension, twousers using the same set of machines will also be as-signed shares proportional to their weight. We choosethis simple mechanism because more accurate mecha-nisms (e.g., Pisces [22]) add considerable complexity;as we demonstrate in§7.7, Sparrow’s simple mechanismprovides near-perfect fair shares.
5 Analysis
Before delving into our experimental evaluation, we ana-lytically show that batch sampling achieves near-optimalperformance,regardless of the task duration distribu-tion, given some simplifying assumptions. Section 3demonstrated that Sparrow performs well, but only un-der one particular workload; this section generalizesthose results to all workloads. We also demonstrate thatwith per-task sampling, performance decreases expo-nentially with the number of tasks in a job, making itpoorly suited for parallel workloads.
6

n Number of servers in the clusterρ Load (fraction non-idle workers)m Tasks per jobd Probes per taskt Mean task service time
ρn/(mt) Mean request arrival rate
Table 1: Summary of notation.
Random Placement (1−ρ)m
Per-Task Sampling (1−ρd)m
Batch Sampling ∑d·mi=m(1−ρ)iρd·m−i
(d·mi
)
Table 2: Probability that a job will experience zerowait time under three different scheduling tech-niques.
To analyze the performance of batch and per-tasksampling, we examine the probability of placing all tasksin a job on idle machines, or equivalently, providing zerowait time. Quantifying how often our approach placesjobs on idle workers provides a bound on how Sparrowperforms compared to an optimal scheduler.
We make a few simplifying assumptions for the pur-pose of this analysis. We assume zero network delay, aninfinitely large number of servers, and that each serverruns one task at a time. Our experimental evaluationshows results in the absence of these assumptions.
Mathematical analysis corroborates the results in§3demonstrating that per-task sampling performs poorlyfor parallel jobs. The probability that a particular task isplaced on an idle machine is one minus the probabilitythat all probes hit busy machines: 1−ρd (whereρ rep-resents cluster load andd represents the probe ratio; Ta-ble 1 summarizes notation). The probability thatall tasksin a job are assigned to idle machines is(1− ρd)m (asshown in Table 2) because allm sets of probes must hitat least one idle machine. This probability decreases ex-ponentially with the number of tasks in a job, renderingper-task sampling inappropriate for scheduling paralleljobs. Figure 4 illustrates the probability that a job expe-riences zero wait time for both 10 and 100-task jobs, anddemonstrates that the probability of experiencing zerowait time for a 100-task job drops to< 2% at 20% load.
Batch sampling can place all of a job’s tasks on idlemachines at much higher loads than per-task sampling.In expectation, batch sampling will be able to place allm tasks in empty queues as long asd ≥ 1/(1−ρ). Cru-cially, this expression does not depend on the numberof tasks in a job (m). Figure 4 illustrates this effect: forboth 10 and 100-task jobs, the probability of experienc-ing zero wait time drops from 1 to 0 at 50% load.4
4With the larger, 100-task job, the drop happens more rapidlybe-cause the job uses more total probes, which decreases the variance inthe proportion of probes that hit idle machines.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Pr(
zero
wai
t ti
me)
Load
10 tasks/job
Random Per-Task
0 0.2 0.4 0.6 0.8 1Load
100 tasks/job
Batch
Figure 4: Probability that a job will experience zerowait time in a single-core environment using randomplacement, sampling 2 servers/task, and sampling2mmachines to place anm-task job.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Pr(
zero
wai
t ti
me)
Load
10 tasks/job
Random Per-Task
0 0.2 0.4 0.6 0.8 1Load
100 tasks/job
Batch
Figure 5: Probability that a job will experience zerowait time in a system of 4-core servers.
Our analysis thus far has considered machines that canrun only one task at a time; however, today’s clusterstypically feature multi-core machines. Multicore ma-chines significantly improve the performance of batchsampling. Consider a model where each server can runup to c tasks concurrently. Each probe implicitly de-scribes load onc processing units rather than just one,which increases the likelihood of finding an idle process-ing unit on which to run each task. To analyze perfor-mance in a multicore environment, we make two simpli-fying assumptions: first, we assume that the probabilitythat a core is idle is independent of whether other coreson the same machine are idle; and second, we assumethat the scheduler places at most 1 task on each machine,even if multiple cores are idle (placing multiple tasks onan idle machine exacerbates the “gold rush effect” wheremany schedulers concurrently place tasks on an idle ma-chine). Based on these assumptions, we can replaceρ inTable 2 withρc to obtain the results shown in Figure 5.These results improve dramatically on the single-coreresults: for batch sampling with 4 cores per machine and100 tasks per job, batch sampling achieves near perfectperformance (99.9% of jobs experience zero wait time)at up to 79% load. This result demonstrates that, undersome simplifying assumptions, batch sampling performswell regardless of the distribution of task durations.
7

Sparrow Node Monitor
App X
Executor
Worker
Sparrow Scheduler
Spark
Frontend
App X
Frontend
Sparrow Scheduler
Spark
Frontend …
Spark
Executor
Sparrow Node Monitor
Worker
Spark
Executor
Sparrow Node Monitor
App X
Executor
Worker
…
Figure 6: Frameworks that use Sparrow are decom-posed into frontends, which generate tasks, and ex-ecutors, which run tasks. Frameworks schedule jobsby communicating with any one of a set of distributedSparrow schedulers. Sparrow node monitors run oneach worker machine and federate resource usage.
6 Implementation
We implemented Sparrow to evaluate its performanceon a cluster of 110 Amazon EC2 virtual machines. TheSparrow code, including scripts to replicate our exper-imental evaluation, is publicly available athttp://github.com/radlab/sparrow.
6.1 System components
As shown in Figure 6, Sparrow schedules from a dis-tributed set of schedulers that are each responsible forassigning tasks to workers. Because Sparrow does notrequire any communication between schedulers, arbi-trarily many schedulers may operate concurrently, andusers or applications may use any available schedulerto place jobs. Schedulers expose a service (illustrated inFigure 7) that allows frameworks to submit job schedul-ing requests using Thrift remote procedure calls [1].Thrift can generate client bindings in many languages,so applications that use Sparrow for scheduling are nottied to a particular language. Each scheduling request in-cludes a list of task specifications; the specification for atask includes a task description and a list of constraintsgoverning where the task can be placed.
A Sparrow node monitor runs on each worker, andfederates resource usage on the worker by enqueu-ing reservations and requesting task specifications fromschedulers when resources become available. Nodemonitors run tasks in a fixed number ofslots; slots canbe configured based on the resources of the underlyingmachine, such as CPU cores and memory.
Sparrow performs task scheduling for one or moreconcurrently operating frameworks. As shown in Fig-ure 6, frameworks are composed of long-livedfrontendand executorprocesses, a model employed by manysystems (e.g., Mesos [8]). Frontends accept high level
Application
Frontend Scheduler
Node
Monitor Application
Executor submitRequest()
enqueueReservation()
getTask()
launchTask()
reserve time
get task
time
queue time
Time
taskComplete()
service
time
taskComplete() taskComplete()
Figure 7: RPCs (parameters not shown) and timingsassociated with launching a job. Sparrow’s externalinterface is shown in bold text and internal RPCs areshown in grey text.
queries or job specifications (e.g., a SQL query) from ex-ogenous sources (e.g., a data analyst, web service, busi-ness application, etc.) and compile them into paralleltasks for execution on workers. Frontends are typicallydistributed over multiple machines to provide high per-formance and availability. Because Sparrow schedulersare lightweight, in our deployment, we run a scheduleron each machine where an application frontend is run-ning to ensure minimum scheduling latency.
Executor processes are responsible for executingtasks, and are long-lived to avoid startup overhead suchas shipping binaries or caching large datasets in memory.Executor processes for multiple frameworks may run co-resident on a single machine; the node monitor federatesresource usage between co-located frameworks. Spar-row requires executors to accept alaunchTask()RPC from a local node monitor, as shown in Figure 7;Sparrow uses thelaunchTask() RPC to pass on thetask description (opaque to Sparrow) originally suppliedby the application frontend.
6.2 Spark on Sparrow
In order to test Sparrow using a realistic workload,we ported Spark [26] to Sparrow by writing a Sparkscheduling plugin. This plugin is 280 lines of Scalacode, and can be found athttps://github.com/kayousterhout/spark/tree/sparrow.
The execution of a Spark query begins at a Sparkfrontend, which compiles a functional query definitioninto multiple parallel stages. Each stage is submitted asa Sparrow job, including a list of task descriptions andany associated placement constraints. The first stage istypically constrained to execute on machines that con-tain input data, while the remaining stages (which readdata shuffled or broadcasted over the network) are un-constrained. When one stage completes, Spark requestsscheduling of the tasks in the subsequent stage.
8

6.3 Fault tolerance
Because Sparrow schedulers do not have any logicallycentralized state, the failure of one scheduler does not af-fect the operation of other schedulers. Frameworks thatwere using the failed scheduler need to detect the failureand connect to a backup scheduler. Sparrow includes aJava client that handles failover between Sparrow sched-ulers. The client accepts a list of schedulers from the ap-plication and connects to the first scheduler in the list.The client sends a heartbeat message to the scheduler itis using every 100ms to ensure that the scheduler is stillalive; if the scheduler has failed, the client connects tothe next scheduler in the list and triggers a callback at theapplication. This approach allows frameworks to decidehow to handle tasks that were in-flight during the sched-uler failure. Some frameworks may choose to ignorefailed tasks and proceed with a partial result; for Spark,the handler instantly relaunches any phases that were in-flight when the scheduler failed. Frameworks that electto re-launch tasks must ensure that tasks are idempotent,because the task may have been partway through execu-tion when the scheduler died. Sparrow does not attemptto learn about in-progress jobs that were launched by thefailed scheduler, and instead relies on applications to re-launch such jobs. Because Sparrow is designed for shortjobs, the simplicity benefit of this approach outweighsthe efficiency loss from needing to restart jobs that werein the process of being scheduled by the failed scheduler.
While Sparrow’s design allows for scheduler failures,Sparrow does not provide any safeguards against rogueschedulers. A misbehaving scheduler could use a largerprobe ratio to improve performance, at the expensive ofother jobs. In trusted environments where schedulers arerun by a trusted entity (e.g., within a company), thisshould not be a problem; in more adversarial environ-ments, schedulers may need to be authenticated and rate-limited to prevent misbehaving schedulers from wastingresources.
Sparrow does not handle worker failures, as discussedin §8, nor does it handle the case where the entire clus-ter fails. Because Sparrow does not persist schedulingstate to disk, in the event that all machines in the clus-ter fail (for example, due to a power loss event), all jobsthat were in progress will need to be restarted. As in thecase when a scheduler fails, the efficiency loss from thisapproach is minimal because jobs are short.
7 Experimental Evaluation
We evaluate Sparrow using a cluster composed of 100worker machines and 10 schedulers running on Ama-zon EC2. Unless otherwise specified, we use a proberatio of 2. First, we use Sparrow to schedule tasks for
a TPC-H workload, which features heterogeneous an-alytics queries. We provide fine-grained tracing of theoverhead that Sparrow incurs and quantify its perfor-mance in comparison with an ideal scheduler. Second,we demonstrate Sparrow’s ability to handle schedulerfailures. Third, we evaluate Sparrow’s ability to isolateusers from one another in accordance with cluster-widescheduling policies. Finally, we perform a sensitivityanalysis of key parameters in Sparrow’s design.
7.1 Performance on TPC-H workload
We measure Sparrow’s performance scheduling queriesfrom the TPC-H decision support benchmark. The TPC-H benchmark is representative of ad-hoc queries on busi-ness data, which are a common use case for low-latencydata parallel frameworks.
Each TPC-H query is executed using Shark [24],a large scale data analytics platform built on top ofSpark [26]. Shark queries are compiled into multipleSpark stages that each trigger a scheduling request usingSparrow’ssubmitRequest()RPC. Tasks in the firststage are constrained to run on one of three machinesholding the task’s input data, while tasks in remainingstages are unconstrained. The response time of a queryis the sum of the response times of each stage. BecauseShark is resource-intensive, we use EC2 high-memoryquadruple extra large instances, which each have 8 coresand 68.4GB of memory, and use 4 slots on each worker.Ten different users launch random permutations of theTPC-H queries to sustain an average cluster load of 80%for a period of approximately 15 minutes. We report re-sponse times from a 200 second period in the middleof the experiment; during the 200 second period, Spar-row schedules over 20k jobs that make up 6.2k TPC-Hqueries. Each user runs queries on a distinct denormal-ized copy of the TPC-H dataset; each copy of the data setis approximately 2GB (scale factor 2) and is broken into33 partitions that are each triply replicated in memory.
The TPC-H query workload has four qualities repre-sentative of a real cluster workload. First, cluster utiliza-tion fluctuates around the mean value of 80% dependingon whether the users are collectively in more resource-intensive or less resource-intensive stages. Second, thestages have different numbers of tasks: the first stage has33 tasks, and subsequent stages have either 8 tasks (forreduce-like stages that read shuffled data) or 1 task (foraggregation stages). Third, the duration of each stage isnon-uniform, varying from a few tens of milliseconds toseveral hundred. Finally, the queries have a mix of con-strained and unconstrained scheduling requests: 6.2k re-quests are constrained (the first stage in each query) andthe remaining 14k requests are unconstrained.
9

0
500
1000
1500
2000
2500
3000
3500
4000
q3 q4 q6 q12
Res
ponse
Tim
e (m
s)
4217 (med.) 5396 (med.) 7881 (med.)
RandomPer-task sampling
Batch sampling
Batch + late bindingIdeal
Figure 8: Response times for TPC-H queries usingdifferent placement stategies. Whiskers depict 5thand 95th percentiles; boxes depict median, 25th, and75th percentiles.
To evaluate Sparrow’s performance, we compareSparrow to an ideal scheduler that always places all taskswith zero wait time, as described in§3.1. To compute theideal response time for a query, we compute the responsetime for each stage if all of the tasks in the stage had beenplaced with zero wait time, and then sum the ideal re-sponse times for all stages in the query. Sparrow alwayssatisfies data locality constraints; because the ideal re-sponse times are computed using the service times whenSparrow executed the job, the ideal response time as-sumes data locality for all tasks. The ideal response timedoes not include the time needed to send tasks to workermachines, nor does it include queueing that is inevitableduring utilization bursts, making it a conservative lowerbound on the response time attainable with a centralizedscheduler.
Figure 8 demonstrates that Sparrow outperforms al-ternate techniques and provides response times within12% of an ideal scheduler. Compared to randomly as-signing tasks to workers, Sparrow (batch sampling withlate binding) reduces median query response time by 4–8× and reduces 95th percentile response time by over10×. Sparrow also reduces response time compared toper-task sampling (a naı̈ve implementation based on thepower of two choices): batch sampling with late bind-ing provides query response times an average of 0.8×those provided by per-task sampling. Ninety-fifth per-centile response times drop by almost a factor of twowith Sparrow, compared to per-task sampling. Late bind-ing reduces median query response time by an averageof 14% compared to batch sampling alone. Sparrow alsoprovides good absolute performance: Sparrow providesmedian response times just 12% higher than those pro-vided by an ideal scheduler.
0
0.2
0.4
0.6
0.8
1
1 10 100
Cum
ula
tive
Pro
bab
ilit
y
Milliseconds
Reserve timeQueue time
Get task timeService time
Figure 9: Latency distribution for each phase in theSparrow scheduling algorithm.
0
20
40
60
80
100
120
140
Del
ay (
ms)
Constrained Stages Unconstrained Stages
535 219
Per-taskSparrow
Figure 10: Delay using both Sparrow and per-tasksampling, for both constrained and unconstrainedSpark stages. Whiskers depict 5th and 95 percentiles;boxes depict median, 25th, and 75th percentiles.
7.2 Deconstructing performance
To understand the components of the delay that Spar-row adds relative to an ideal scheduler, we deconstructSparrow scheduling latency in Figure 9. Each line cor-responds to one of the phases of the Sparrow schedul-ing algorithm depicted in Figure 7. The reserve timeand queue times are unique to Sparrow—a centralizedscheduler might be able to reduce these times to zero.However, the get task time is unavoidable: no matter thescheduling algorithm, the scheduler will need to ship thetask to the worker machine.
7.3 How do task constraints affect perfor-mance?
Sparrow provides good absolute performance and im-proves over per-task sampling for both constrained andunconstrained tasks. Figure 10 depicts the delay for con-strained and unconstrained stages in the TPC-H work-load using both Sparrow and per-task sampling. Sparrowschedules with a median of 7ms of delay for jobs withunconstrained tasks and a median of 14ms of delay forjobs with constrained tasks; because Sparrow cannot ag-gregate information across the tasks in a job when tasksare constrained, delay is longer. Nonetheless, even for
10

0
1000
2000
3000
4000
0 10 20 30 40 50 60Time (s)
0
1000
2000
3000
4000Q
uer
y r
esponse
tim
e (m
s)Failure
Node 1
Node 2
Figure 11: TPC-H response times for two frontendssubmitting queries to a 100-node cluster. Node 1 suf-fers from a scheduler failure at 20 seconds.
constrained tasks, Sparrow provides a performance im-provement over per-task sampling due to its use of latebinding.
7.4 How do scheduler failures impact jobresponse time?
Sparrow provides automatic failover between schedulersand can failover to a new scheduler in less than 120ms.Figure 11 plots the response time for ongoing TPC-Hqueries in an experiment parameterized as in§7.1, with10 Shark frontends that submit queries. Each frontendconnects to a co-resident Sparrow scheduler but is ini-tialized with a list of alternate schedulers to connect to incase of failure. At timet=20, we terminate the Sparrowscheduler on node 1. The plot depicts response times forjobs launched from the Spark frontend on node 1, whichfails over to the scheduler on node 2. The plot also showsresponse times for jobs launched from the Spark fron-tend on node 2, which uses the scheduler on node 2 forthe entire duration of the experiment. When the Sparrowscheduler on node 1 fails, it takes 100ms for the Spar-row client to detect the failure, less than 5ms to for theSparrow client to connect to the scheduler on node 2,and less than 15ms for Spark to relaunch all outstand-ing tasks. Because of the speed at which failure recov-ery occurs, only 2 queries have tasks in flight during thefailure; these queries suffer some overhead.
7.5 Synthetic workload
The remaining sections evaluate Sparrow using a syn-thetic workload composed of jobs with constant dura-tion tasks. In this workload, ideal job completion timeis always equal to task duration, which helps to isolatethe performance of Sparrow from application-layer vari-ations in service time. As in previous experiments, these
0
1000
2000
3000
4000
5000
6000
0 1000 2000 3000 4000 5000 6000
Res
ponse
Tim
e (m
s)
Task Duration (ms)
Spark native schedulerSparrow
Ideal
Figure 12: Response time when scheduling 10-taskjobs in a 100 node cluster using both Sparrow andSpark’s native scheduler. Utilization is fixed at 80%,while task duration decreases.
experiments run on a cluster of 110 EC2 servers, with 10schedulers and 100 workers.
7.6 How does Sparrow compare to Spark’snative, centralized scheduler?
Even in the relatively small, 100-node cluster in whichwe conducted our evaluation, Spark’s existing central-ized scheduler cannot provide high enough throughputto support sub-second tasks.5 We use a synthetic work-load where each job is composed of 10 tasks that eachsleep for a specified period of time, and measure job re-sponse time. Since all tasks in the job are the same du-ration, ideal job response time (if all tasks are launchedimmediately) is the duration of a single task. To stressthe schedulers, we use 8 slots on each machine (one percore). Figure 12 depicts job response time as a functionof task duration. We fix cluster load at 80%, and varytask submission rate to keep load constant as task du-ration decreases. For tasks longer than 2 seconds, Spar-row and Spark’s native scheduler both provide near-idealresponse times. However, when tasks are shorter than1355ms, Spark’s native scheduler cannot keep up withthe rate at which tasks are completing so jobs experienceinfinite queueing.
To ensure that Sparrow’s distributed scheduling isnecessary, we performed extensive profiling of the Sparkscheduler to understand how much we could increasescheduling throughput with improved engineering. Wedid not find any one bottleneck in the Spark sched-uler; instead, messaging overhead, virtual function calloverhead, and context switching lead to a best-casethroughput (achievable when Spark is scheduling onlya single job) of approximately 1500 tasks per second.Some of these factors could be mitigated, but at the ex-pense of code readability and understandability. A clus-
5 For these experiments, we use Spark’s standalone mode, whichrelies on a simple, centralized scheduler. Spark also allows for schedul-ing using Mesos; Mesos is more heavyweight and provides worse per-formance than standalone mode for short tasks.
11

0 50
100 150 200 250 300 350 400
0 10 20 30 40 50
Runnin
g T
asks
Time (s)
User 0User 1
Figure 13: Cluster share used by two users that areeach assigned equal shares of the cluster. User 0 sub-mits at a rate to utilize the entire cluster for the entireexperiment while user 1 adjusts its submission rateeach 10 seconds. Sparrow assigns both users theirmax-min fair share.
ter with tens of thousands of machines running sub-second tasks may require millions of scheduling deci-sions per second; supporting such an environment wouldrequire 1000× higher scheduling throughput, which isdifficult to imagine even with a significant rearchitectingof the scheduler. Clusters running low latency workloadswill need to shift from using centralized task schedulerslike Spark’s native scheduler to using more scalable dis-tributed schedulers like Sparrow.
7.7 How well can Sparrow’s distributedfairness enforcement maintain fairshares?
Figure 13 demonstrates that Sparrow’s distributed fair-ness mechanism enforces cluster-wide fair shares andquickly adapts to changing user demand. Users 0 and1 are both given equal shares in a cluster with 400 slots.Unlike other experiments, we use 100 4-core EC2 ma-chines; Sparrow’s distributed enforcement works betteras the number of cores increases, so to avoid over statingperformance, we evaluate it under the smallest numberof cores we would expect in a cluster today. User 0 sub-mits at a rate to fully utilize the cluster for the entireduration of the experiment. User 1 changes her demandevery 10 seconds: she submits at a rate to consume 0%,25%, 50%, 25%, and finally 0% of the cluster’s availableslots. Under max-min fairness, each user is allocated herfair share of the cluster unless the user’s demand is lessthan her share, in which case the unused share is dis-tributed evenly amongst the remaining users. Thus, user1’s max-min share for each 10-second interval is 0 con-currently running tasks, 100 tasks, 200 tasks, 100 tasks,and finally 0 tasks; user 0’s max-min fair share is the re-maining resources. Sparrow’s fairness mechanism lacksany central authority with a complete view of how manytasks each user is running, leading to imperfect fairness
HP LP HP response LP responseload load time in ms time in ms0.25 0 106 (111) N/A0.25 0.25 108 (114) 108 (115)0.25 0.5 110 (148) 110 (449)0.25 0.75 136 (170) 40.2k (46.2k)0.25 1.75 141 (226) 255k (270k)
Table 3: Median and 95th percentile (shown in paren-theses) response times for a high priority (HP) andlow priority (LP) user running jobs composed of 10100ms tasks in a 100-node cluster. Sparrow success-fully shields the high priority user from a low prior-ity user. When aggregate load is 1 or more, responsetime will grow to be unbounded for at least one user.
over short time intervals. Nonetheless, as shown in Fig-ure 13, Sparrow quickly allocates enough resources toUser 1 when she begins submitting scheduling requests(10 seconds into the experiment), and the cluster shareallocated by Sparrow exhibits only small fluctuationsfrom the correct fair share.
7.8 How much can low priority users hurtresponse times for high priority users?
Table 3 demonstrates that Sparrow provides responsetimes within 40% of an ideal scheduler for a high priorityuser in the presence of a misbehaving low priority user.This experiment uses workers that each have 16 slots.The high priority user submits jobs at a rate to fill 25%of the cluster, while the low priority user increases hersubmission rate to well beyond the capacity of the clus-ter. Without any isolation mechanisms, when the aggre-gate submission rate exceeds the cluster capacity, bothusers would experience infinite queueing. As describedin §4.2, Sparrow node monitors run all queued high pri-ority tasks before launching any low priority tasks, al-lowing Sparrow to shield high priority users from mis-behaving low priority users. While Sparrow prevents thehigh priority user from experiencing infinite queueingdelay, the high priority user still experiences 40% worseresponse times when sharing with a demanding low pri-ority user than when running alone on the cluster. This isbecause Sparrow does not use preemption: high prioritytasks may need to wait to be launched until low prior-ity tasks complete. In the worst case, this wait time maybe as long as the longest running low-priority task. Ex-ploring the impact of preemption is a subject of futurework.
12

0
50
100
150
200
250
300
1 1.1 1.2 1.5 2 3
Res
ponse
Tim
e (m
s)
Probe Ratio
9279 (95th)
574 (med.),4169 (95th)
Ideal
678 (med.), 4212 (95th)
80% load 90% load
Figure 14: Effect of probe ratio on job response timeat two different cluster loads. Whiskers depict 5thand 95th percentiles; boxes depict median, 25th, and75th percentiles.
7.9 How sensitive is Sparrow to the proberatio?
Changing the probe ratio affects Sparrow’s performancemost at high cluster load. Figure 14 depicts responsetime as a function of probe ratio in a 110-machine clus-ter of 8-core machines running the synthetic workload(each job has 10 100ms tasks). The figure demonstratesthat using a small amount of oversampling significantlyimproves performance compared to placing tasks ran-domly: oversampling by just 10% (probe ratio of 1.1)reduces median response time by more than 2.5× com-pared to random sampling (probe ratio of 1) at 90% load.The figure also demonstrates a sweet spot in the proberatio: a low probe ratio negatively impacts performancebecause schedulers do not oversample enough to findlightly loaded machines, but additional oversamplingeventually hurts performance due to increased messag-ing. This effect is most apparent at 90% load; at 80%load, median response time with a probe ratio of 1.1 isjust 1.4× higher than median response time with a largerprobe ratio of 2. We use a probe ratio of 2 throughoutour evaluation to facilitate comparison with the powerof two choices and because non-integral probe ratios arenot possible with constrained tasks.
7.10 Handling task heterogeneity
Sparrow does not perform as well under extreme taskheterogeneity: if some workers are running long tasks,Sparrow schedulers are less likely to find idle machineson which to run tasks. Sparrow works well unless a largefraction of tasks are longandthe long tasks are many or-ders of magnitude longer than the short tasks. We rana series of experiments with two types of jobs: shortjobs, composed of 10 100ms tasks, and long jobs, com-posed of 10 tasks of longer duration. Jobs are submitted
0
50
100
150
200
250
300
10s 100sShort
Job R
esp. T
ime
(ms)
Duration of Long Tasks
16 core, 50% long4 cores, 10% long
4 cores, 50% long
666 62782466
Figure 15: Sparrow provides low median responsetime for jobs composed of 10 100ms tasks, even whenthose tasks are run alongside much longer jobs. Er-ror bars depict 5th and 95th percentiles.
to sustain 80% cluster load. Figure 15 illustrates the re-sponse time of short jobs when sharing the cluster withlong jobs. We vary the percentage of jobs that are long,the duration of the long jobs, and the number of coreson the machine, to illustrate where performance breaksdown. Sparrow provides response times for short taskswithin 11% of ideal (100ms) when running on 16-coremachines, even when 50% of tasks are 3 orders of mag-nitude longer. When 50% of tasks are 3 orders of magni-titude longer, over 99% of the execution time across alljobs is spent executing long tasks; given this, Sparrow’sperformance is impressive. Short tasks see more signifi-cant performance degredation in a 4-core environment.
7.11 Scaling to large clusters
We used simulation to evaluate Sparrow’s performancein larger clusters. Figure 3 suggests that Sparrow willcontinue to provide good performance in a 10,000 nodecluster; of course, the only way to conclusively evaluateSparrow’s performance at scale will be to deploy it on alarge cluster.
8 Limitations and Future Work
To handle the latency and throughput demands of low-latency frameworks, our approach sacrifices featuresavailable in general purpose resource managers. Some ofthese limitations of our approach are fundamental, whileothers are the focus of future work.
Scheduling policiesWhen a cluster becomes over-subscribed, Sparrow supports aggregate fair-sharing orpriority-based scheduling. Sparrow’s distributed settinglends itself toapproximatedpolicy enforcement in or-der to minimize system complexity; exploring whetherSparrow can provide more exact policy enforcement
13

without adding significant complexity is a focus of fu-ture work. Adding pre-emption, for example, would be asimple way to mitigate the effects of low-priority users’jobs on higher priority users.
ConstraintsOur current design does not handleinter-job constraints(e.g. “the tasks for job A must not run onracks with tasks for job B”). Supporting inter-job con-straints across frontends is difficult to do without signif-icantly altering Sparrow’s design.
Gang scheduling Some applications require gangscheduling, a feature not implemented by Sparrow. Gangscheduling is typically implemented using bin-packingalgorithms that search for and reserve time slots in whichan entire job can run. Because Sparrow queues tasks onseveral machines, it lacks a central point from whichto perform bin-packing. While Sparrow often places alljobs on entirely idle machines, this is not guaranteed,and deadlocks between multiple jobs that require gangscheduling may occur. Sparrow is not alone: many clus-ter schedulers do not support gang scheduling [8, 9, 16].
Query-level policiesSparrow’s performance could beimproved by adding query-level scheduling policies. Auser query (e.g., a SQL query executed using Shark)may be composed of many stages that are each exe-cuted using a separate Sparrow scheduling request; tooptimize query response time, Sparrow should sched-ule queries in FIFO order. Currently, Sparrow’s algo-rithm attempts to schedule jobs in FIFO order; addingquery-level scheduling policies should improve end-to-end query performance.
Worker failures Handling worker failures is compli-cated by Sparrow’s distributed design, because when aworker fails, all schedulers with outstanding requestsat that worker must be informed. We envision handlingworker failures with a centralized state store that relieson occasional heartbeats to maintain a list of currentlyalive workers. The state store would periodically dissem-inate the list of live workers to all schedulers. Since theinformation stored in the state store would be soft state,it could easily be recreated in the event of a state storefailure.
Dynamically adapting the probe ratio Sparrowcould potentially improve performance by dynamicallyadapting the probe ratio based on cluster load; however,such an approach sacrifices some of the simplicity ofSparrow’s current design. Exploring whether dynami-cally changing the probe ratio would significantly in-crease performance is the subject of ongoing work.
9 Related Work
Scheduling in distributed systems has been extensivelystudied in earlier work. Most existing cluster schedulers
rely on centralized architectures. Among logically de-centralized schedulers, Sparrow is the first to sched-ule all of a job’s tasks together, rather than schedulingeach task independently, which improves performancefor parallel jobs.
Dean’s work on reducing the latency tail in servingsystems [5] is most similar to ours. He proposes usinghedged requests where the client sends each request totwo workers and cancels remaining outstanding requestswhen the first result is received. He also describes tiedrequests, where clients send each request to two servers,but the servers communicate directly about the status ofthe request: when one server begins executing the re-quest, it cancels the counterpart. Both mechanisms aresimilar to Sparrow’s late binding, but target an envi-ronment where each task needs to be scheduled inde-pendently (for data locality), so information cannot beshared across the tasks in a job.
Work on load sharing in distributed systems (e.g., [7])also uses randomized techniques similar to Sparrow’s.In load sharing systems, each processor both generatesand processes work; by default, work is processed whereit is generated. Processors re-distribute queued tasks ifthe number of tasks queued at a processor exceeds somethreshold, using either receiver-initiated policies, wherelightly loaded processors request work from randomlyselected other processors, or sender-initiated policies,where heavily loaded processors offload work to ran-domly selected recipients. Sparrow represents a combi-nation of sender-initiated and receiver-initiated policies:schedulers (“senders”) initiate the assignment of tasksto workers (“receivers”) by sending probes, but work-ers finalize the assignment by responding to probes andrequesting tasks as resources become available.
Projects that explore load balancing tasks in multi-processor shared-memory architectures (e.g., [19]) echomany of the design tradeoffs underlying our approach,such as the need to avoid centralized scheduling points.They differ from our approach because they focuson a single machine where the majority of the ef-fort is spent determining when toreschedule processesamongst cores to balance load.
Quincy [9] targets task-level scheduling in computeclusters, similar to Sparrow. Quincy maps the schedul-ing problem onto a graph in order to compute an optimalschedule that balances data locality, fairness, and starva-tion freedom. Quincy’s graph solver supports more so-phisticated scheduling policies than Sparrow but takesover a second to compute a scheduling assignment ina 2500 node cluster, making it too slow for our targetworkload.
In the realm of data analytics frameworks,Dremel [12] achieves response times of secondswith extremely high fanout. Dremel uses a hierarchical
14

scheduler design whereby each query is decomposedinto a serving tree; this approach exploits the inter-nal structure of Dremel queries so is not generallyapplicable.
Many schedulers aim to allocate resources at coarsegranularity, either because tasks tend to be long-runningor because the cluster supports many applicationsthat each acquire some amount of resources and per-form their own task-level scheduling (e.g., Mesos [8],YARN [16], Omega [20]). These schedulers sacrifice re-quest granularity in order to enforce complex schedul-ing policies; as a result, they provide insufficient latencyand/or throughput for scheduling sub-second tasks. Highperformance computing schedulers fall into this cate-gory: they optimize for large jobs with complex con-straints, and target maximum throughput in the tensto hundreds of scheduling decisions per second (e.g.,SLURM [10]). Similarly, Condor supports complex fea-tures including a rich constraint language, job check-pointing, and gang scheduling using a heavy-weightmatchmaking process that results in maximum schedul-ing throughput of 10 to 100 jobs per second [4].
In the theory literature, a substantial body of workanalyzes the performance of the power of two choicesload balancing technique, as summarized by Mitzen-macher [15]. To the best of our knowledge, no exist-ing work explores performance for parallel jobs. Manyexisting analyses consider placing balls into bins, andrecent work [18] has generalized this to placing multi-ple balls concurrently into multiple bins. This analysisis not appropriate for a scheduling setting, because un-like bins, worker machines process tasks to empty theirqueue. Other work analyzes scheduling for single tasks;parallel jobs are fundamentally different because a par-allel job cannot complete until thelastof a large numberof tasks completes.
Straggler mitigation techniques (e.g., Dolly [2],LATE [27], Mantri [3]) focus on variation in task ex-ecution time (rather than task wait time) and are com-plementary to Sparrow. For example, Mantri launches atask on a second machine if the first version of the taskis progressing too slowly, a technique that could easilybe used by Sparrow’s distributed schedulers.
10 Conclusion
This paper presents Sparrow, a stateless decentralizedscheduler that provides near optimal performance usingtwo key techniques: batch sampling and late binding. Weuse a TPC-H workload to demonstrate that Sparrow canprovide median response times within 12% of an idealscheduler and survives scheduler failures. Sparrow en-forces popular scheduler policies, including fair sharing
and strict priorities. Experiments using a synthetic work-load demonstrate that Sparrow is resilient to differentprobe ratios and distributions of task durations. In lightof these results, we believe that distributed schedulingusing Sparrow presents a viable alternative to central-ized schedulers for low latency parallel workloads.
11 Acknowledgments
We are indebted to Aurojit Panda for help with debug-ging EC2 performance anomalies, Shivaram Venkatara-man for insightful comments on several drafts of this pa-per and for help with Spark integration, Sameer Agarwalfor help with running simulations, Satish Rao for helpwith theoretical models of the system, and Peter Bailis,Ali Ghodsi, Adam Oliner, Sylvia Ratnasamy, and ColinScott for helpful comments on earlier drafts of this paper.We also thank our shepherd, John Wilkes, for helping toshape the final version of the paper. Finally, we thankthe reviewers from HotCloud 2012, OSDI 2012, NSDI2013, and SOSP 2013 for their helpful feedback.
This research is supported in part by a Hertz Founda-tion Fellowship, the Department of Defense through theNational Defense Science & Engineering Graduate Fel-lowship Program, NSF CISE Expeditions award CCF-1139158, DARPA XData Award FA8750-12-2-0331, In-tel via the Intel Science and Technology Center forCloud Computing (ISTC-CC), and gifts from AmazonWeb Services, Google, SAP, Cisco, Clearstory Data,Cloudera, Ericsson, Facebook, FitWave, General Elec-tric, Hortonworks, Huawei, Microsoft, NetApp, Oracle,Samsung, Splunk, VMware, WANdisco and Yahoo!.
References
[1] Apache Thrift. http://thrift.apache.org.
[2] G. Ananthanarayanan, A. Ghodsi, S. Shenker, andI. Stoica. Why Let Resources Idle? AggressiveCloning of Jobs with Dolly. InHotCloud, 2012.
[3] G. Ananthanarayanan, S. Kandula, A. Greenberg,I. Stoica, Y. Lu, B. Saha, and E. Harris. Reining inthe Outliers in Map-Reduce Clusters using Mantri.In Proc. OSDI, 2010.
[4] D. Bradley, T. S. Clair, M. Farrellee, Z. Guo,M. Livny, I. Sfiligoi, and T. Tannenbaum. An Up-date on the Scalability Limits of the Condor BatchSystem. Journal of Physics: Conference Series,331(6), 2011.
15

[5] J. Dean and L. A. Barroso. The Tail at Scale.Com-munications of the ACM, 56(2), February 2013.
[6] A. Demers, S. Keshav, and S. Shenker. Analysisand Simulation of a Fair Queueing Algorithm. InProc. SIGCOMM, 1989.
[7] D. L. Eager, E. D. Lazowska, and J. Zahor-jan. Adaptive Load Sharing in Homogeneous Dis-tributed Systems.IEEE Transactions on SoftwareEngineering, 1986.
[8] B. Hindman, A. Konwinski, M. Zaharia, A. Gh-odsi, A. D. Joseph, R. Katz, S. Shenker, and I. Sto-ica. Mesos: A Platform For Fine-Grained ResourceSharing in the Data Center. InProc. NSDI, 2011.
[9] M. Isard, V. Prabhakaran, J. Currey, U. Wieder,K. Talwar, and A. Goldberg. Quincy: Fair Schedul-ing for Distributed Computing Clusters. InProc.SOSP, 2009.
[10] M. A. Jette, A. B. Yoo, and M. Grondona.SLURM: Simple Linux Utility for Resource Man-agement. InProc. Job Scheduling Strategies forParallel Processing, Lecture Notes in ComputerScience, pages 44–60. Springer, 2003.
[11] M. Kornacker and J. Erickson. Cloudera Impala:Real Time Queries in Apache Hadoop, For Real.http://blog.cloudera.com/blog/2012/10/cloudera-impala-real-time-queries-in-apache-hadoop-for-real/, October 2012.
[12] S. Melnik, A. Gubarev, J. J. Long, G. Romer,S. Shivakumar, M. Tolton, and T. Vassilakis.Dremel: Interactive Analysis of Web-ScaleDatasets.Proc. VLDB Endow., 2010.
[13] M. Mitzenmacher. How Useful is Old Informa-tion? volume 11, pages 6–20, 2000.
[14] M. Mitzenmacher. The Power of Two Choicesin Randomized Load Balancing. IEEE Trans-actions on Parallel and Distributed Computing,12(10):1094–1104, 2001.
[15] M. Mitzenmacher. The Power of Two RandomChoices: A Survey of Techniques and Results. InS. Rajasekaran, P. Pardalos, J. Reif, and J. Rolim,editors,Handbook of Randomized Computing, vol-ume 1, pages 255–312. Springer, 2001.
[16] A. C. Murthy. The Next Generation of ApacheMapReduce. http://developer.yahoo.com/blogs/hadoop/next-generation-apache-hadoop-mapreduce-3061.html,February 2012.
[17] K. Ousterhout, A. Panda, J. Rosen, S. Venkatara-man, R. Xin, S. Ratnasamy, S. Shenker, and I. Sto-ica. The Case for Tiny Tasks in Compute Clusters.In Proc. HotOS, 2013.
[18] G. Park. A Generalization of Multiple ChoiceBalls-into-Bins. InProc. PODC, pages 297–298,2011.
[19] L. Rudolph, M. Slivkin-Allalouf, and E. Upfal. ASimple Load Balancing Scheme for Task Alloca-tion in Parallel Machines. InProc. SPAA, 1991.
[20] M. Schwarzkopf, A. Konwinski, M. Abd-El-Malek, and J. Wilkes. Omega: flexible, scalableschedulers for large compute clusters. InProc. Eu-roSys, 2013.
[21] B. Sharma, V. Chudnovsky, J. L. Hellerstein, R. Ri-faat, and C. R. Das. Modeling and SynthesizingTask Placement Constraints in Google ComputeClusters. InProc. SOCC, 2011.
[22] D. Shue, M. J. Freedman, and A. Shaikh. Per-formance Isolation and Fairness for Multi-TenantCloud Storage. InProc. OSDI, 2012.
[23] T. White. Hadoop: The Definitive Guide. O’ReillyMedia, 2009.
[24] R. S. Xin, J. Rosen, M. Zaharia, M. J. Franklin,S. Shenker, and I. Stoica. Shark: SQL and RichAnalytics at Scale. InProc. SIGMOD, 2013.
[25] M. Zaharia, D. Borthakur, J. Sen Sarma,K. Elmeleegy, S. Shenker, and I. Stoica. DelayScheduling: A Simple Technique For AchievingLocality and Fairness in Cluster Scheduling. InProc. EuroSys, 2010.
[26] M. Zaharia, M. Chowdhury, T. Das, A. Dave,J. Ma, M. McCauley, M. J. Franklin, S. Shenker,and I. Stoica. Resilient Distributed Datasets: AFault-Tolerant Abstraction for In-Memory ClusterComputing. InProc. NSDI, 2012.
[27] M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz,and I. Stoica. Improving MapReduce Performancein Heterogeneous Environments. InProc. OSDI,2008.
16