spark at scale
TRANSCRIPT

Spark At ScaleJoeOoura&YutaImai2016/5/20
©HortonworksInc.2011–2015.AllRightsReserved

2 ©HortonworksInc.2011–2016.AllRightsReserved
はじめに
à 質問はQUESTIONSというボタンからお願いします。プレゼンター以外には⾒えません。
à Twitter経由でもコメント、質問、⼤歓迎です! #hwxjp
à 資料はこちらにアップロード済みです。– http://www.slideshare.net/imaifactory/spark-at-scale

3 ©HortonworksInc.2011–2016.AllRightsReserved
自己紹介 Ã ⼤浦 譲太郎 Twitter:@JOOOURAÃ 5歳児と8歳児の⽗Ã サーバ、ストレージのシステム営業を経て2011年に フラッシュメモリストレージ企業の⽇本法⼈⽴ち上げに参画。Evangelist、プリセールスSE、広報、営業など⼀通りをカバーエンタープライズフラッシュの代名詞ともなるioDriveシリーズを⽇本国内の通信キャリア、⾦融機関、WEBサービス事業者、アドテク、DC事業者に多数導⼊。Ã 2016年1⽉より、ホートンワークスジャパンの⼆⼈⽬の
営業として参画。現在はエヴァンジェリスト活動及びエンタープライズ向けセールス、パートナー⽀援を⾏なっている。

4 ©HortonworksInc.2011–2016.AllRightsReserved
About Hortonworks
お客様との歩み • ~800社(2016年2月現在)• 152社は2015年第三四半期で• 2015年10月NASDAQへ上場:HDP
The Leader in Connected Data Platforms • HortonworksDataFlowfordatainmoNon• HortonworksDataPlaOormfordataatrest• PoweringnewmoderndataapplicaNons
Partner for Customer Success • Leaderinopen-sourcecommunity,focusedoninnovaNontomeetenterpriseneeds
• UnrivaledsupportsubscripNons
Founded in 2011
Yahoo! で初代の Hadoop 開発を手がけたアーキテクト、デベロッパー、オ
ペレータ 24名によって創立
1000+ E M P L O Y E E S
1500+ E C O S Y S T E M
PA R T N E R S

5 ©HortonworksInc.2011–2016.AllRightsReserved
Our Model: Drive an Enterprise-focused Roadmap
1. InnovateExis6ngProjects– Hive/SNnger,YARN,HDFS,commonops&securityviaAmbari&Ranger
2. IncubateNewProjects– Metron(wasOpenSOC),Ranger,Knox,Atlas,Falcon,Ambari,Tez,etc.
3. AcquireIP&Contribute
– AcquiredXASecureandcreatedApacheRanger;contributedOpenSOC
4. Partner&DeliverJointSolu6ons– Microsod,EMC,HP,SAS,Pivotal,RedHat,Teradata,etc.
5. RallytheEcosystem
– FastSQLviaSNngeriniNaNve,DataGovernanceiniNaNve,ODPi
Data
Acce
ss
(batc
h, int
erac
tive,
real
time)
Int
egra
tion &
Go
vern
ance
Op
erati
ons
Secu
rity
ApacheProject HortonworksCommiNers
HortonworksPMC
HWX%ofCommiNers
Hadoop 29 24 31%Accumulo 2 2 9%Calcite 6 3 43%HBase 8 5 17%Hive 19 11 38%NiFi 5 5 42%
Phoenix 5 5 22%Pig 5 5 24%
Slider 12 12 100%Spark 1 0 2%Storm 4 4 19%Tez 15 15 44%Atlas 7 0 35%Falcon 7 5 41%Flume 1 1 4%KaZa 0 0 0%Sqoop 1 1 4%Ambari 39 30 76%Oozie 4 2 22%
Zookeeper 2 1 13%Knox 12 2 80%Ranger 13 11 76%
TOTAL 197 144
Source:ApacheSodwareFoundaNon.AsofOctober5,2015.Acommi'erissomeonewhohas“earnedtheirstripes”withintheApachecommunityandhastheability
tocommitcodedirectlytotheircorrespondingApacheprojectsourcecoderepository

6 ©HortonworksInc.2011–2016.AllRightsReservedPage6 ©HortonworksInc.2011–2015.AllRightsReserved
100%OpenSourceConnectedDataPlaaorms
Eliminates Risk ofvendorlock-inbydelivering100%Apacheopensourcetechnology
Maximizes Community Innovation withhundredsofdevelopersacrosshundredsofcompanies
IntegratesSeamlesslythroughcommijedco-engineeringpartnershipswithotherleadingtechnologies
M A X I M U M C O M M U N I T Y I N N O VAT I O N
T H E I N N O VAT I O N A D VA N TA G E
P R O P R I E T A R Y H A D O O P
T I M E
INN
OV
AT
ION
O P E N C O M M U N I T Y

7 ©HortonworksInc.2011–2016.AllRightsReserved
自己紹介 à 今井 雄太 Twijer:@imai_factoryà SoluNonsEngineerà 広告配信サーバーのレポート作成のためにMapReduce(perl+streaming!)を使ったのがHadoopとの出会い。
à その後、AWSにてアドテクやゲームのお客様を担当しつつ、EMRやS3などのビッグデータなプロダクトを主に担当。そんなつながりでHortonworksに入社してHadoopをやっています。

8 ©HortonworksInc.2011–2016.AllRightsReserved
Agenda à HortonworksandSparkà WhySpark?à Sparkfeaturesà ApacheZeppelinà SparkandYARNà SparkInternals

9 ©HortonworksInc.2011–2016.AllRightsReserved
HortonworksandSpark

10 ©HortonworksInc.2011–2016.AllRightsReserved
What is Spark? • Apacheプロジェクトによるオープンソースの高速なデータ処理ソフトウェアフレームワーク • 豊富な言語サポート Scala, Python, R, Java
• SQL、機械学習、ストリーム処理、グラフ処理など多様な機能を備えている。またそれらをひとつのプログラミングパラダイム上で実装できる
• インメモリ処理
• 処理のコアとなるのはRDD (Resilient Distributed Data) というデータセット
– Resilient – the models can be recreated on the fly from known state
– Distributed – the dataset is often partitioned across multiple nodes for increased scalability and parallelism
11 ©HortonworksInc.2011–2016.AllRightsReserved
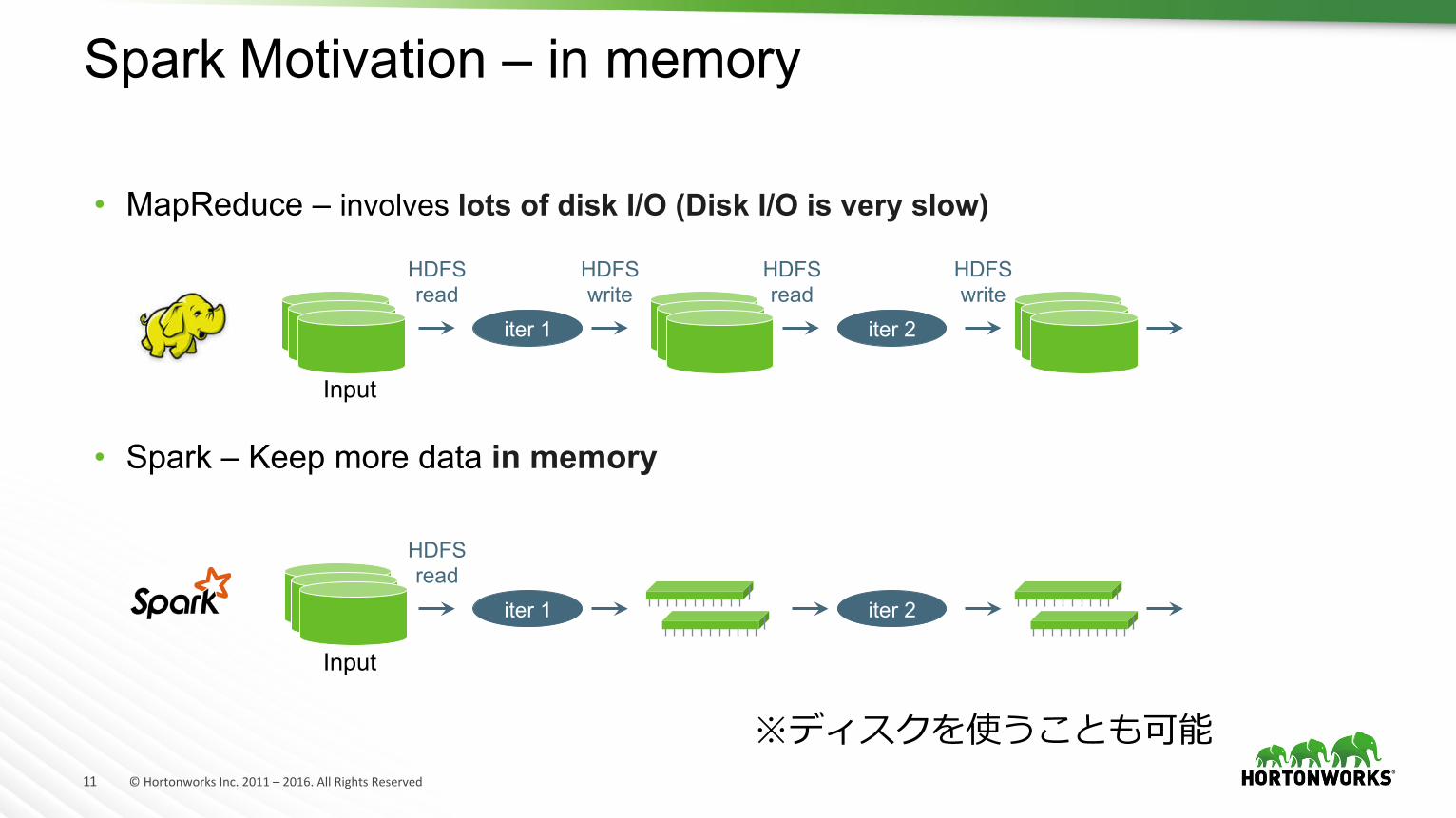
Spark Motivation – in memory
• MapReduce – involves lots of disk I/O (Disk I/O is very slow) • Spark – Keep more data in memory
iter 1 iter 2
HDFS read
HDFS write
HDFS read
HDFS write
Input
Input
iter 1 iter 2
HDFS read
※ディスクを使うことも可能

12 ©HortonworksInc.2011–2016.AllRightsReserved
Apache Spark Eco-System
Core Spark
Spark Streaming
DataFrames SparkSQL
MLlib ML GraphX
HDFS
Cluster Manager (standalone, YARN)
Scala Java Python SQL R
✔✔✔--
✔✔✔✔✔
✔✔✔-
(glmonly)
✔✔---

13 ©HortonworksInc.2011–2016.AllRightsReserved
Spark is certified as YARN Ready and is a part of HDP.
Hortonworks Data Platform 2.4
GOVERNANCE OPERATIONSBATCH,INTERACTIVE&REAL-TIMEDATAACCESS
YARN:DataOpera6ngSystem(ClusterResourceManagement)
Map
Redu
ce
ApacheFalcon
ApacheSqoop
ApacheFlume
ApacheKara
Apache
Hive
Apache
Pig
Apache
HBa
se
Apache
Accum
ulo
Apache
Solr
Apache
Spark
Apache
Storm
1 • • • • • • • • • • •
• • • • • • • • • • • •
HDFS(HadoopDistributedFileSystem)
ApacheAmbari
ApacheZooKeeper
ApacheOozie
DeploymentChoiceLinux Windows On-premises Cloud
ApacheAtlas
Cloudbreak
SECURITY
ApacheRanger
ApacheKnox
ApacheAtlas
HDFSEncrypNon
ISV
Engine
s
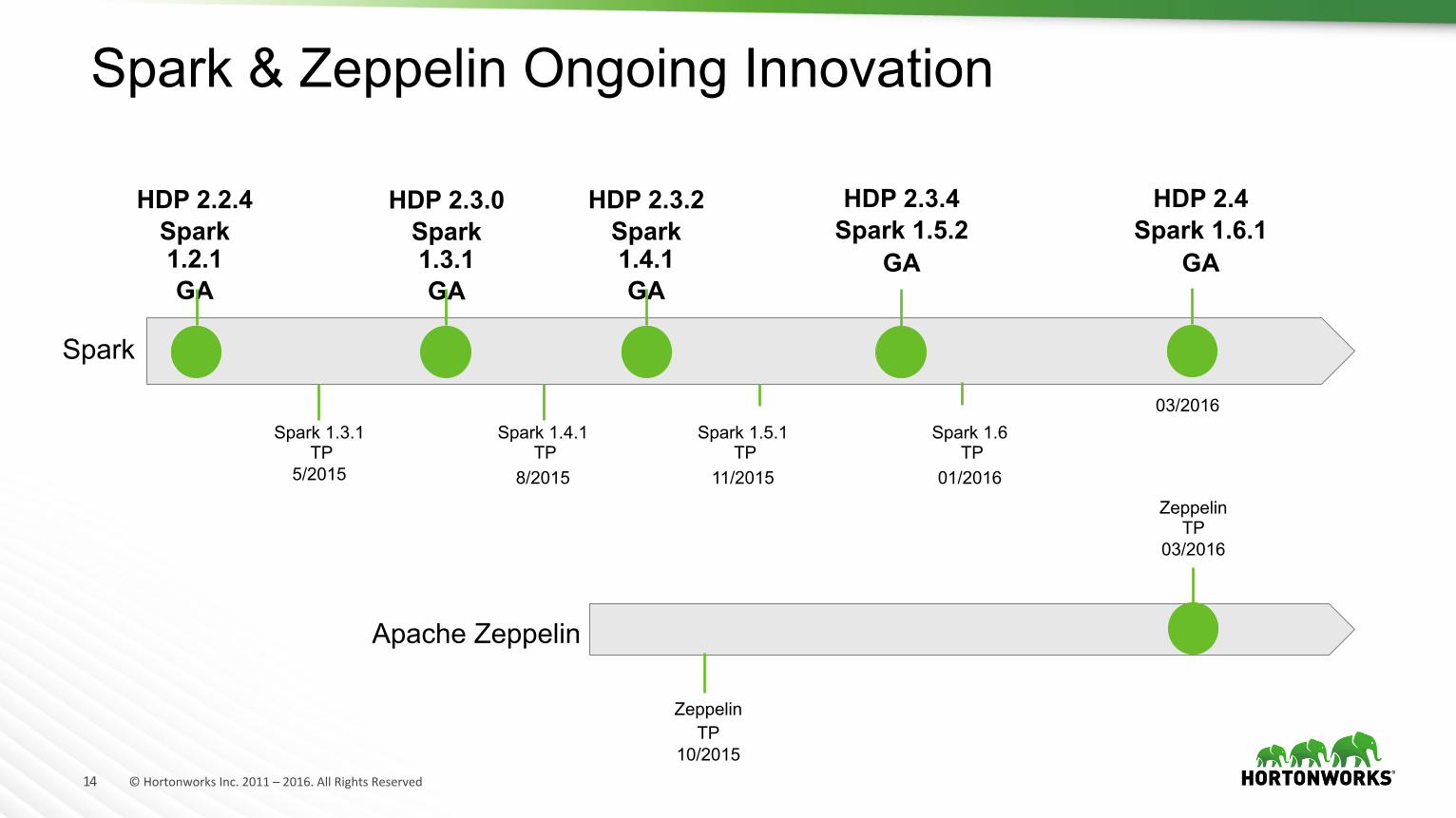
14 ©HortonworksInc.2011–2016.AllRightsReserved
Spark & Zeppelin Ongoing Innovation
HDP 2.2.4 Spark 1.2.1 GA
HDP 2.3.2 Spark 1.4.1 GA
HDP 2.3.0 Spark 1.3.1 GA
HDP 2.3.4 Spark 1.5.2
GA
Spark
Spark 1.3.1 TP
5/2015
Spark 1.4.1 TP
8/2015
Spark 1.5.1 TP
11/2015
Zeppelin TP
10/2015
Apache Zeppelin
HDP 2.4 Spark 1.6.1
GA
Zeppelin TP
03/2016
Spark 1.6 TP
01/2016
03/2016

15 ©HortonworksInc.2011–2016.AllRightsReserved
Spark 1.6.1 in HDP 2.4.2
GA and supported • Spark Streaming • Spark SQL • Spark SQL Thrift JDBC/ODBC
Server (incl. Ambari setup) • DataFrame API • Spark on YARN • Kerberos • Dynamic Resource Allocation
Tech Preview • GraphX • SparkR • Spark-HBase connector • Zeppelin Unsupported • Spark Standalone • Spark on Mesos • Jupyter • Oozie Spark action

16 ©HortonworksInc.2011–2016.AllRightsReserved
WhySpark?

17 ©HortonworksInc.2011–2016.AllRightsReserved
Why Spark?
MapReduceと比較しての速度 - In Memory – 100X faster - On Disk – 10X faster
アプリケーション開発の容易性 多様な機能のサポートと、それらをひとつの言語、フレームワーク下で取り扱える便利さ
*Spark SQL, Spark Streaming, Spark MLLIB for machine learning, GraphX for graph processing
YARNによるHadoopクラスタとの融合

18 ©HortonworksInc.2011–2016.AllRightsReserved
アプリケーション開発の容易性?
#build.sbtlibraryDependencies++=Seq("org.apache.spark"%"spark-core_2.10"%"1.6.1”)#codevaltext="HelloSpark,thisismyfirstSparkapplication."valtextArray=text.split("").map(_.replaceAll("",""))valresult=sc.parallelize(textArray).map(item=>(item,1)).reduceByKey((x,y)=>x+y).collect()
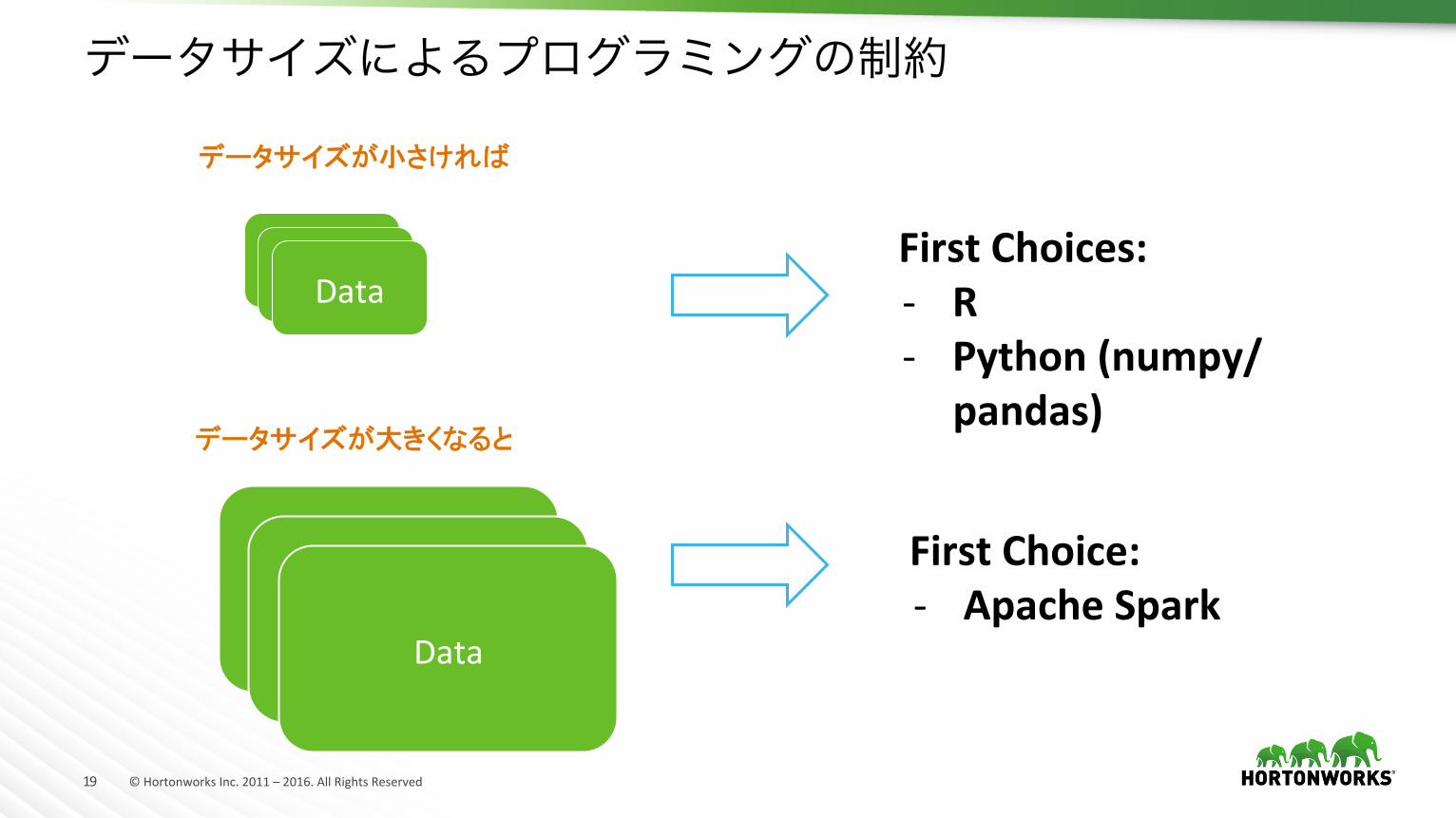
19 ©HortonworksInc.2011–2016.AllRightsReserved
データサイズによるプログラミングの制約
Data
Data
データサイズが小さければ
データサイズが大きくなると
FirstChoices:- R- Python(numpy/
pandas)
FirstChoice:- ApacheSpark

20 ©HortonworksInc.2011–2016.AllRightsReserved
Use Cases with Spark ⾦融 決算発表への迅速な対応React quickly to earnings reports• HBaseをデータソースとしたSparkによる計算• SparkはHbaseの効率的なscanを活かすためのPredicate
Pushdownが可能
医療患者ケアのためのシステム• ETL, Streaming, SparkSQL & ML• Need guidance on various ecosystem projects• How to size cluster for Spark and other workloads?• How does Spark run best on YARN?
オンラインストアキャンペーンやクーポンの最適化• Sparkʼs ML, SQL & Streamingの利⽤• クリックストリームや決済データのストリームデータを利
⽤したクーポンや割引のオファリング
オンライン決済SparkSQLによるEDWオフロード• EDWやBIツールのコスト最適化
保険 過払いや未払いの発⾒ • これまでは単体ノード上でのRで処理をしていたが、
データの増加に伴ってそれが難しくなってきた。• SparkRの活⽤。既存のリソース/アセットもRでな
ら有効活⽤できる• Rによるランダムフォレストを使った分析

21 ©HortonworksInc.2011–2016.AllRightsReserved
様々なデータソースが利用可能
09/02/16

22 ©HortonworksInc.2011–2016.AllRightsReserved
Sparkのコンポーネント群
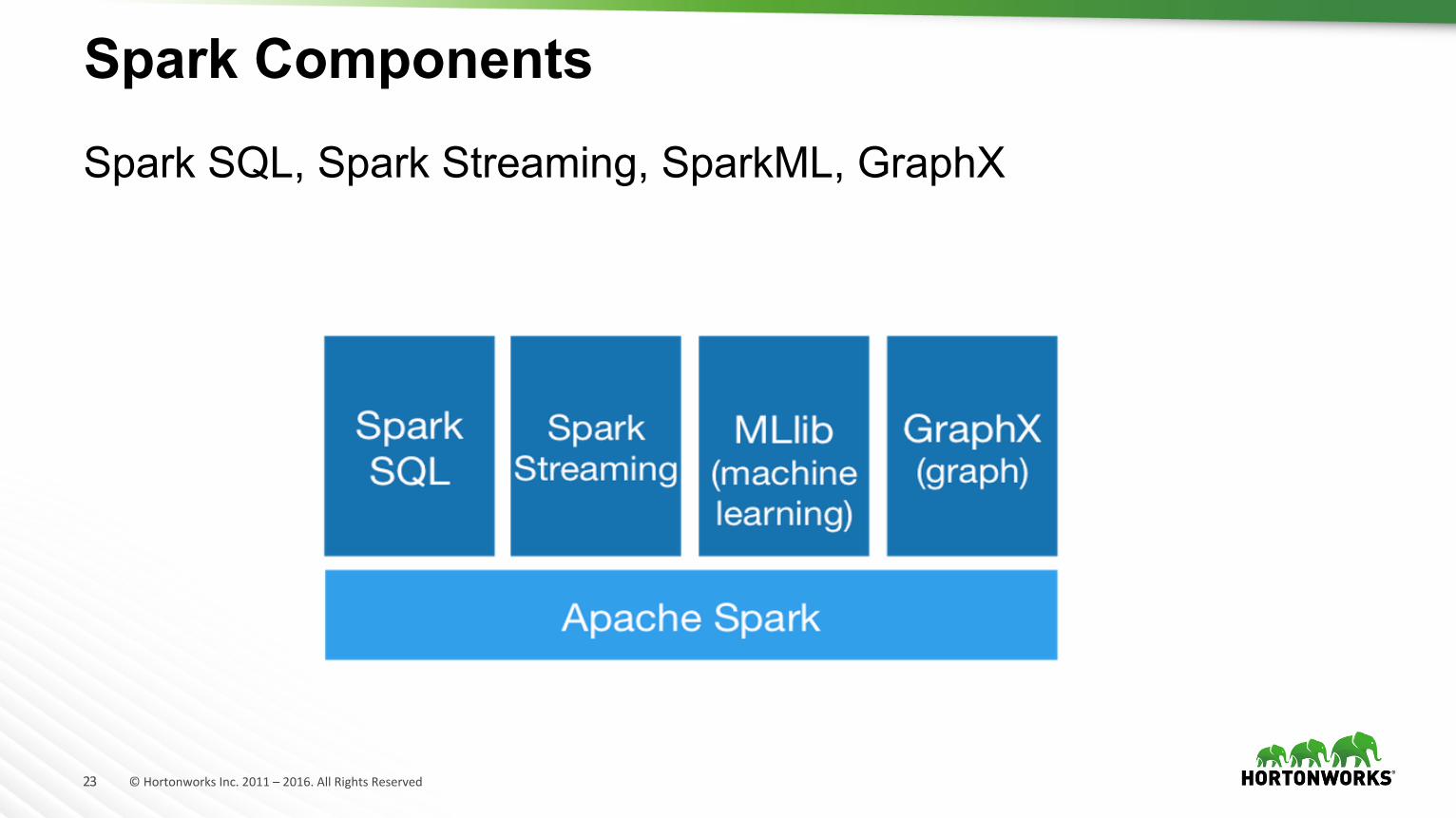
23 ©HortonworksInc.2011–2016.AllRightsReserved
Spark Components
Spark SQL, Spark Streaming, SparkML, GraphX

24 ©HortonworksInc.2011–2016.AllRightsReserved
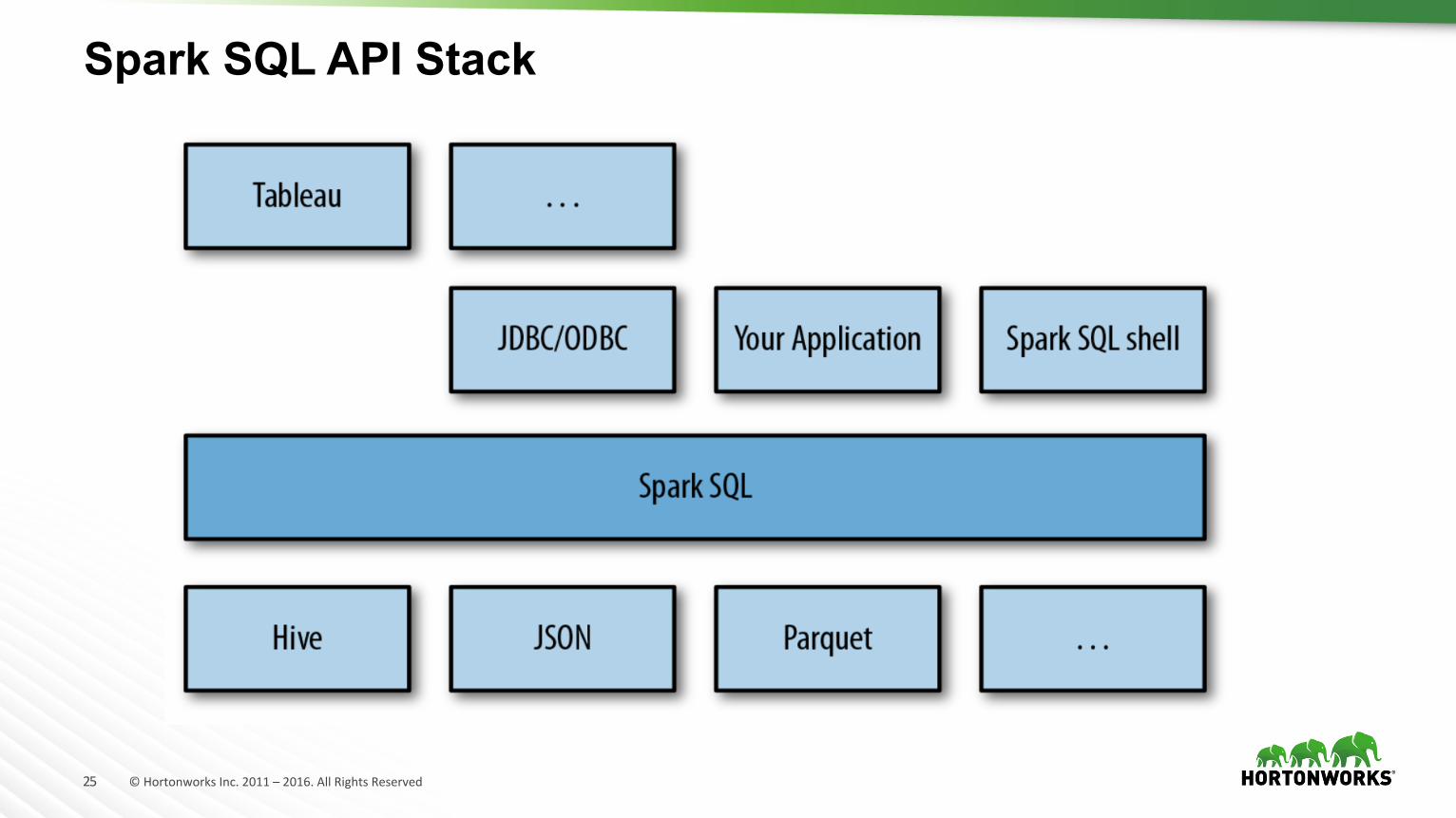
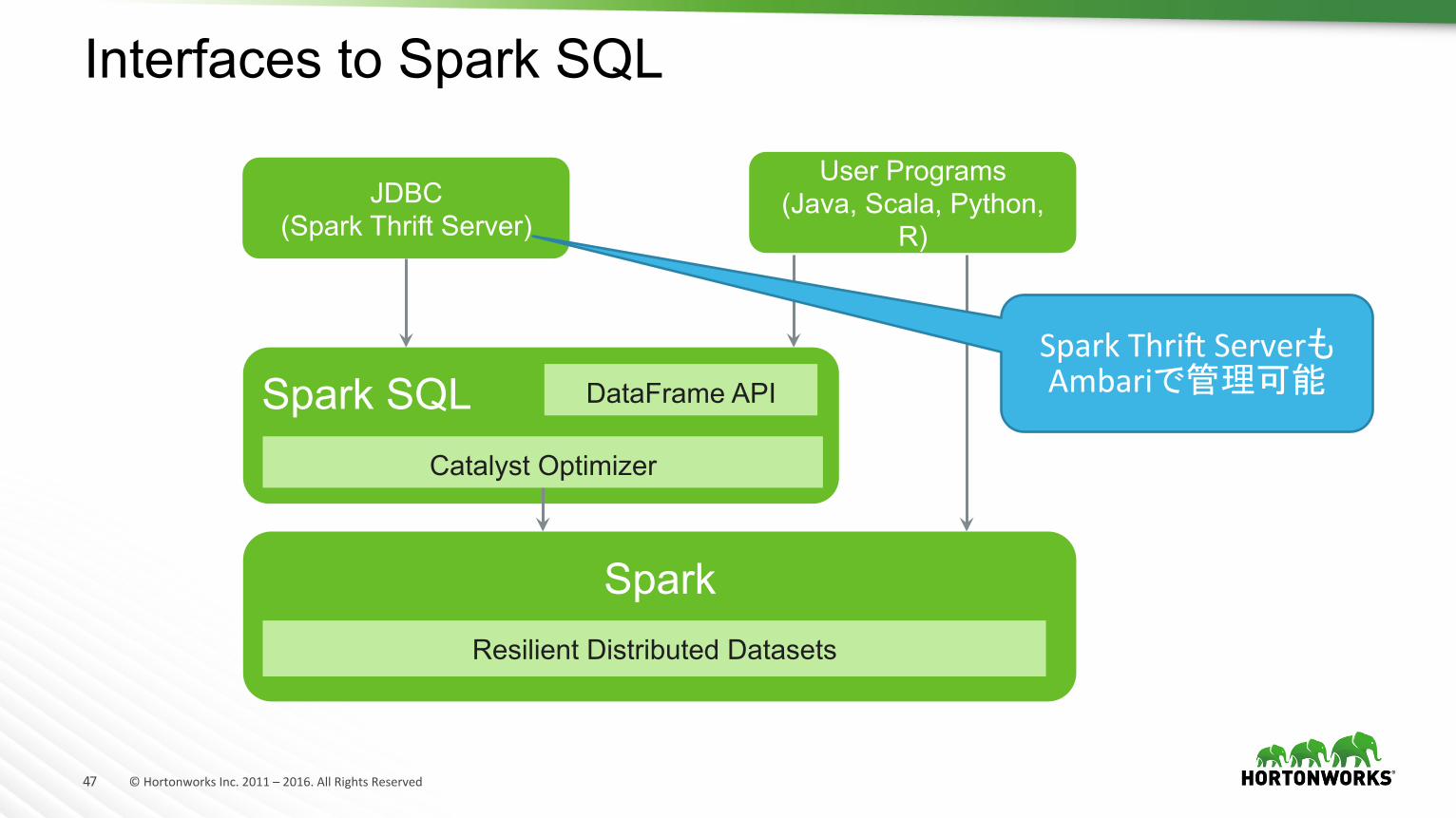
Spark SQL
• Spark SQL is in full release (v1.0 in May 2015) • Java, Scala, Python and R • Hiveのメタデータを利用するので、Hiveで定義したテーブルがそのまま利用できる。
• Spark Thrift ServerによるJDBC、ODBC接続 • Catalystオプティマイザによるルールベース、コストベースのクエリ最適化
• spark-sqlを使えばCLIでの利用も可能
25 ©HortonworksInc.2011–2016.AllRightsReserved
Spark SQL API Stack

26 ©HortonworksInc.2011–2016.AllRightsReserved
Spark SQL: JSON Support
JSONからDataFrameやRDDへの動的な読み込み。下記の2つのメソッドを使うだけ。 § jsonFile - loads data from a directory of JSON files where each line of the files is a JSON object
§ jsonRDD - loads data from an RDD where each element of the RDD is a JSON object

27 ©HortonworksInc.2011–2016.AllRightsReserved
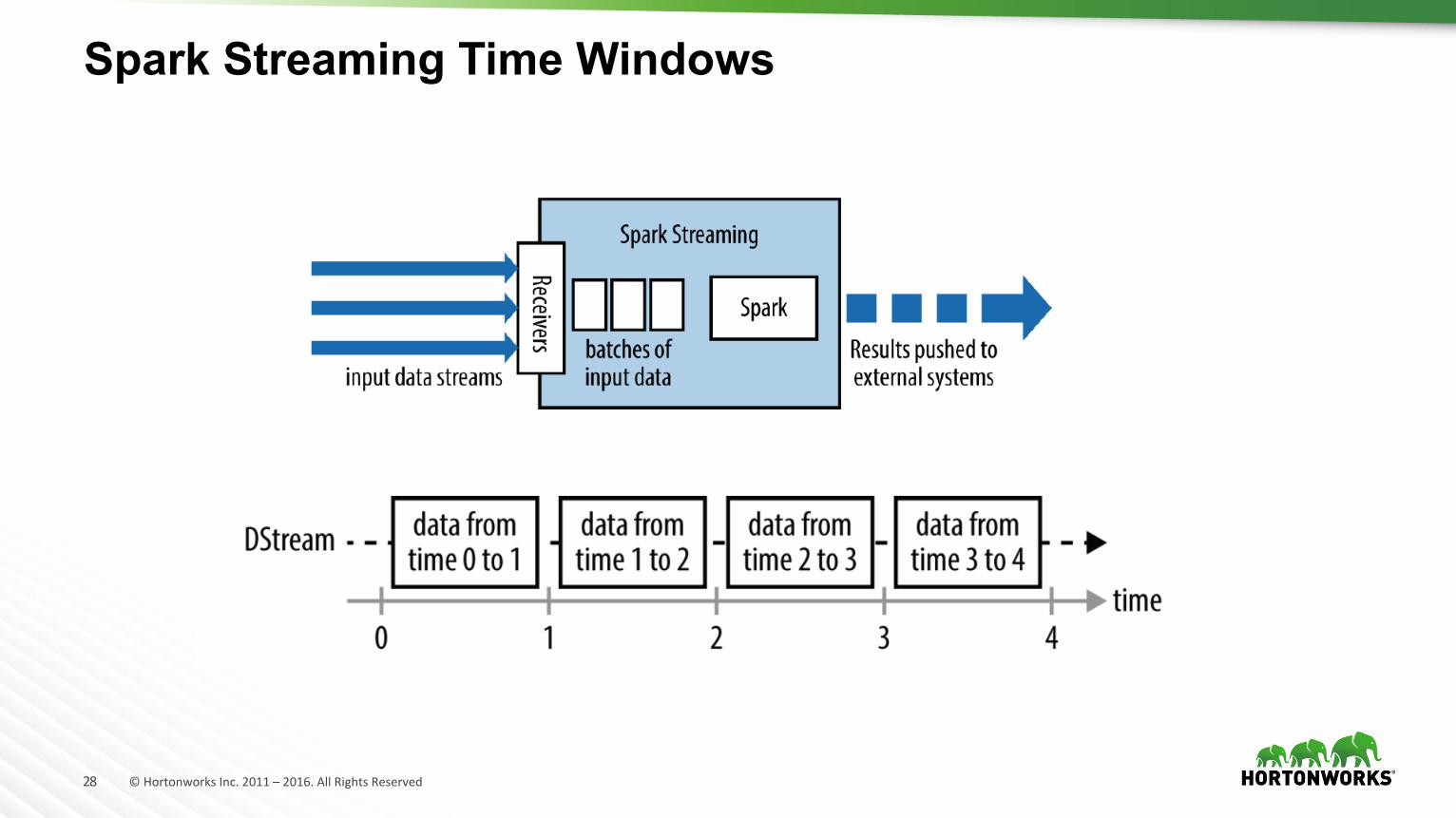
Spark Streaming (D-Streams)
• スケーラブル、高スループット、高耐久性のストリーム処理。 • マイクロバッチ • データソース: Kafka, Flume, Twitter, ZeroMQ, Kinesis or TCP sockets • 使いやすいライブラリ、メソッド:map, reduce, join, window • ユースケース:HDFSやデータベースへの逐次データロード。リアルタイムダッシュボード。
28 ©HortonworksInc.2011–2016.AllRightsReserved
Spark Streaming Time Windows

29 ©HortonworksInc.2011–2016.AllRightsReserved
words.foreachRDD(foreachFunc=(rdd:RDD[String],time:Time)=>{valsqlContext=SQLContextSingleton.getInstance(rdd.sparkContext)sqlContext.read.json(rdd).registerTempTable("words")valwordCountsDataFrame=sqlContext.sql(”””selectlevel,count(*)astotalfromwordsgroupbylevel”””)wordCountsDataFrame.show()})
RunSparkSQLonKinesisStream

30 ©HortonworksInc.2011–2016.AllRightsReserved
Spark MLlib
• Scala、Python、Rで利用可能な機械学習ライブラリ
• Classification、回帰、協調フィルタリング、クラスタリングなどのモデルを分散処理で実行
• インメモリで処理ができるため、何度も繰り返しを行う機械学習のような処理の実行はMapReduceに比べて非常に高速

31 ©HortonworksInc.2011–2016.AllRightsReserved
Spark MLlib modeling techniques
• Logistic regression and linear support vector machine (SVM) • Classification and regression tree • Random forest and gradient-boosted trees • Recommendation via alternating least squares (ALS) • Clustering via k-means, Gaussian mixtures (GMM) • Linear regression with L1, L2, and elastic-net regularization • Multinomial/binomial naive Bayes • Summary statistics and hypothesis testing • Feature transformations • Model evaluation and hyper-parameter tuning

32 ©HortonworksInc.2011–2016.AllRightsReserved
ApacheZeppelin

33 ©HortonworksInc.2011–2016.AllRightsReserved
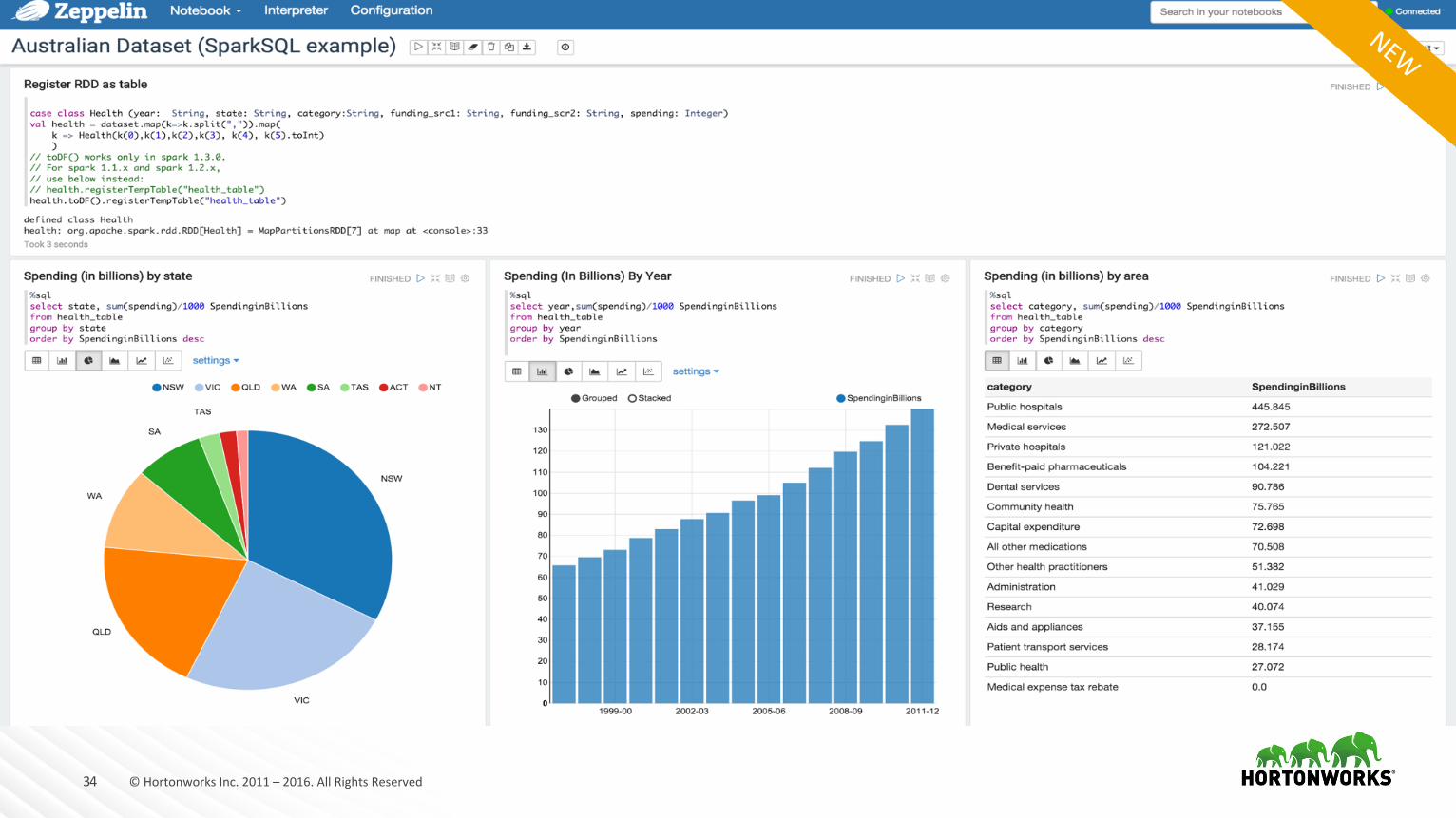
ApacheZeppelin
• Webベースのデータサイエンティストやアナリストのためのノートブックアプリケーション。• データ投入、探索、可視化、共有などができる
• モダンなデータサイエンス環境• ScalawithSpark• PythonwithSpark• SparkSQL• ApacheHive,andmore.
34 ©HortonworksInc.2011–2016.AllRightsReserved

35 ©HortonworksInc.2011–2016.AllRightsReserved
Apache Zeppelin
Features • Webベースのインタラクティブな分析環境(Ad-hoc experimentation with Spark, Hive, Shell, Flink, Tajo, Ignite, Lens, etc.)
• Spark、Hadoopとの密なインテ部レーション
• HDPとのインテグレーション (Can be managed via Ambari Stacks)
• 多言語サポート (Pluggable “Interpreters”)
• Incubating at Apache (100% open source and open community)
Use Cases • マイニングや探索
• 可視化
• インタラクティブで「ちょっとした思いつき」をさっと試す環境
• 共有やコラボレーション
• データ分析環境

36 ©HortonworksInc.2011–2016.AllRightsReserved
Zeppelin- 多言語サポート
Scala(with Apache Spark), Python(with Apache Spark), SparkSQL, Markdown Shell.
37 ©HortonworksInc.2011–2016.AllRightsReserved
SimplifiedSetup
• Ambariによるインストールと管理• 他HDPコンポーネントとの統合• hjps://jp.hortonworks.com/hadoop-tutorial/apache-zeppelin-hdp-2-4/
• もちろん手動インストールも可能

38 ©HortonworksInc.2011–2016.AllRightsReserved
NotebookImport/Export
• PortableopenJSONformat• EasiercollaboraNonbetweenusers
• EasiermigraNonthroughdev/test/producNon• SharingofNotebooksthroughforums
• E.g.HortonworksZeppelinGallery(Github)

39 ©HortonworksInc.2011–2016.AllRightsReserved
SparkandYARN

40 ©HortonworksInc.2011–2016.AllRightsReserved
SparkDeploymentModes• SparkModes
– Sparklocalmode(test/developinDeveloper’senv)– Standalone–Spark自体が持っているクラスタマネージャ
• SparkonYARN– yarn-cluster:ApplicaNonMaster上でSparkdriveが動作– yarn-client:クライアントマシン上でSparkdriverが動作
• ローカルでSparkアプリケーションの出力が受け取れるので開発時やデバッグ時に有用
Client
Executor
AppMaster
Client
Executor
AppMaster
SparkDriverSparkDriver
YARN-Client YARN-Cluster
41 ©HortonworksInc.2011–2016.AllRightsReserved
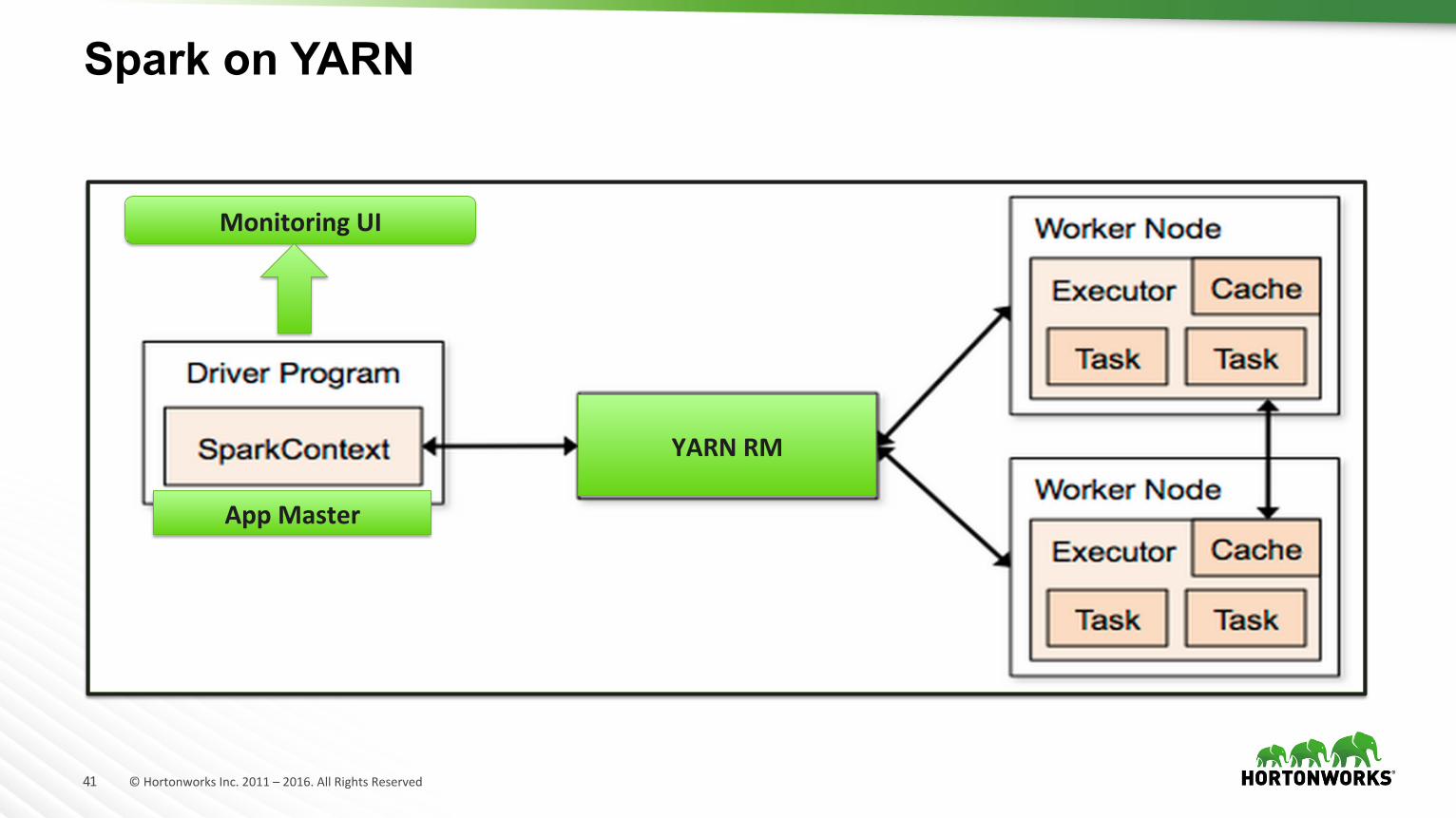
Spark on YARN
YARNRM
AppMaster
MonitoringUI
42 ©HortonworksInc.2011–2016.AllRightsReserved
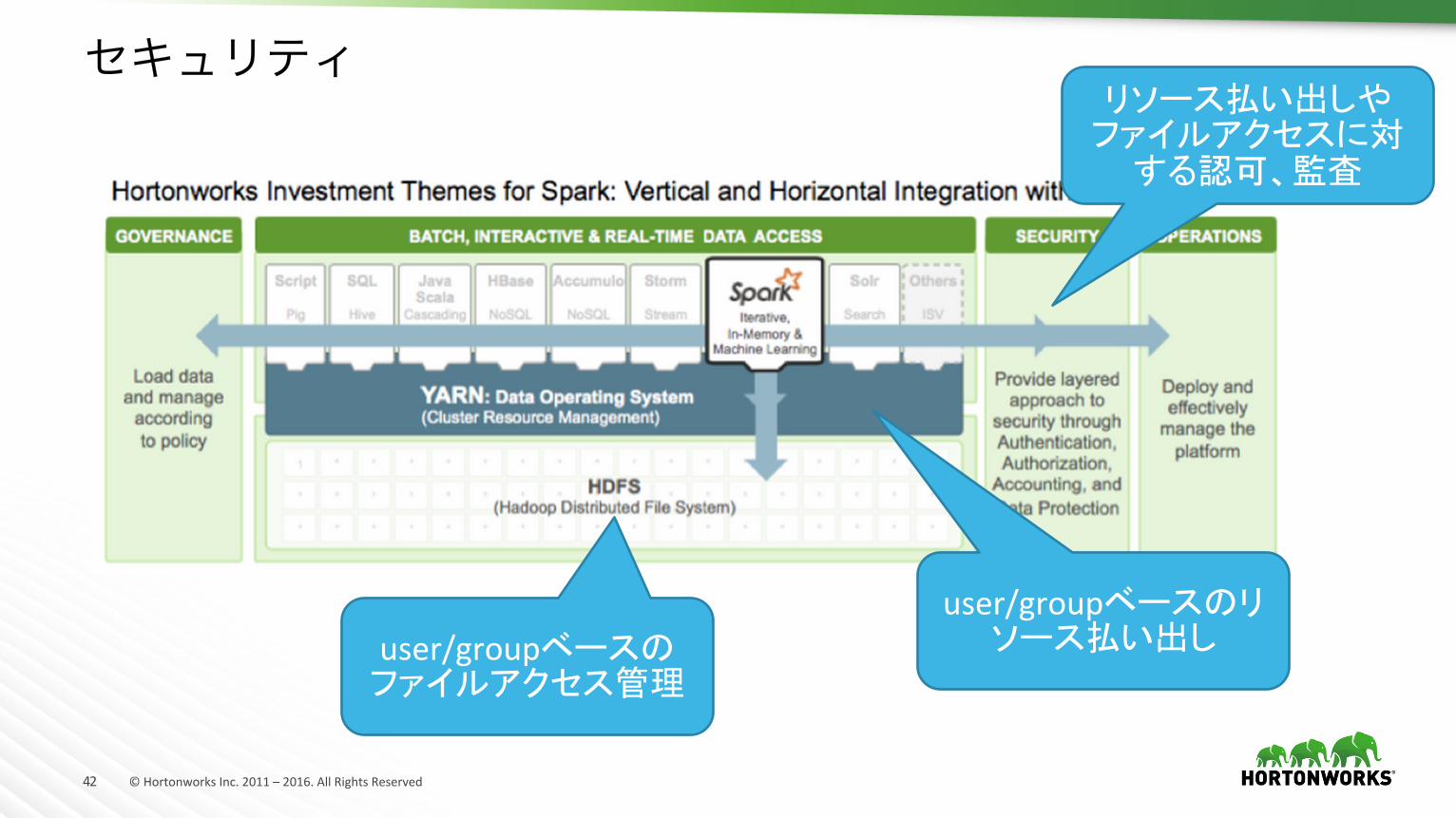
セキュリティ
user/groupベースのリソース払い出し
リソース払い出しやファイルアクセスに対する認可、監査
user/groupベースのファイルアクセス管理

43 ©HortonworksInc.2011–2016.AllRightsReserved
Spark on Yarn 基本的な設定項目
Key Spark Program YARN settings --num-executors: Executorの数を設定(デフォルト:2) --executor-memory: Executorのメモリ --executor-cores: Executorのコア数(Executorはスレッドプールで処理を実
行する) Dynamic Resource Allocation:
spark.dynamicAllocation.enabled spark.dynamicAllocation.minExecutors spark.dynamicAllocation.maxExecutors spark.dynamicAllocation.sustainedSchedulerBacklogTimeout (N) spark.dynamicAllocation.schedulerBacklogTimeout (M) spark.dynamicAllocation.executorIdleTimeout (K)

44 ©HortonworksInc.2011–2016.AllRightsReserved
Spark Application Execution Steps
1. ユーザーがspark-submitを使ってアプリケーションを起動 2. spark-submitがdriver programのmain()を起動 3. Driver Programがクラスタマネージャ(YARN)にExecutor用のリソース(コンテナ)を要求
4. クラスタマネージャがリソースを起動 5. Driver Programがプログラムに基づいたRDDの構築と実行プランをつくる 6. 実際の処理(タスク)がExecutor上で実行される
45 ©HortonworksInc.2011–2016.AllRightsReserved
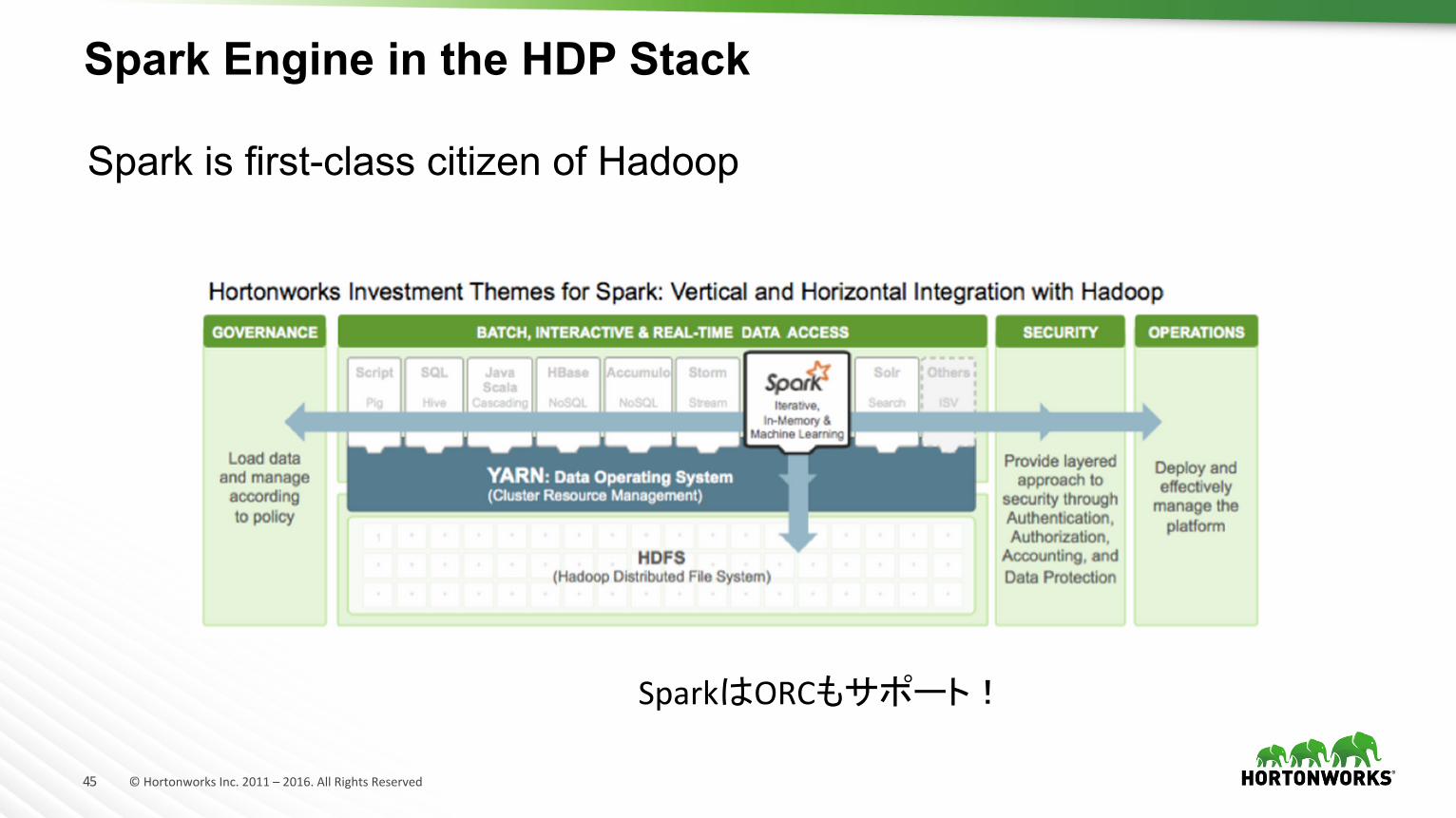
Spark Engine in the HDP Stack
Spark is first-class citizen of Hadoop
SparkはORCもサポート!
46 ©HortonworksInc.2011–2016.AllRightsReserved
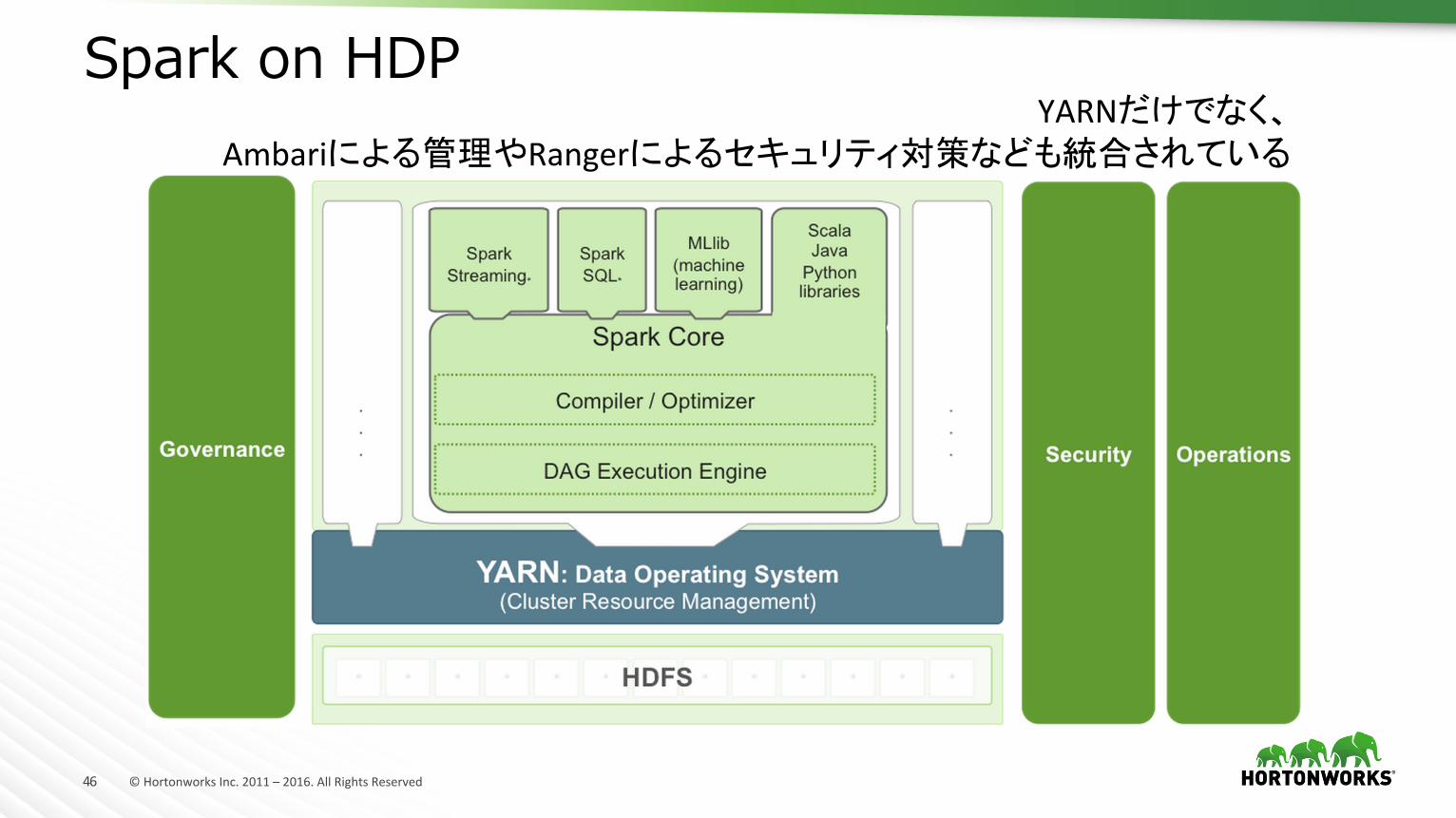
Spark on HDPYARNだけでなく、
Ambariによる管理やRangerによるセキュリティ対策なども統合されている
47 ©HortonworksInc.2011–2016.AllRightsReserved
Interfaces to Spark SQL
JDBC (Spark Thrift Server)
User Programs (Java, Scala, Python,
R)
Spark SQL Catalyst Optimizer
DataFrame API
Spark Resilient Distributed Datasets
SparkThridServerもAmbariで管理可能

48 ©HortonworksInc.2011–2016.AllRightsReserved
Access of Spark History UI
SparkHistoryUI:実行済のSparkアプリケーションの履歴を提供するサービスHDPではAmbariに統合されている⇒YARNResourceUI(hjp://<YOUR_CLUSTER>:8088/cluster)⇒Selectthe“RUNNNING”App⇒Clickon“ApplicaNonMaster”(maybechangeinternalnametoIP/externalnameofyourcluster)

49 ©HortonworksInc.2011–2016.AllRightsReserved
SparkInternal

50 ©HortonworksInc.2011–2016.AllRightsReserved
1.RDDGraph
valtext="HelloSpark,thisismyfirstSparkapplication."valtextArray=text.split("").map(_.replaceAll("",""))valresult=sc.parallelize(textArray).map(item=>(item,1)).reduceByKey((x,y)=>x+y).collect()

51 ©HortonworksInc.2011–2016.AllRightsReserved
Array ArrayParallelCollecNonRDD
ParNNon0
ParNNon1
ParNNon2
ParNNon3
MapParNNonsRDD
ParNNon0
ParNNon1
ParNNon2
ParNNon3
ShuffledRDD
ParNNon0
ParNNon1
sc.parallelize() .map(…) .reduceByKey(…) .collect()
2.DAGScheduler
NarrowDependency ShuffleDependency

52 ©HortonworksInc.2011–2016.AllRightsReserved
Array ArrayParallelCollecNonRDD
ParNNon0
ParNNon1
ParNNon2
ParNNon3
MapParNNonsRDD
ParNNon0
ParNNon1
ParNNon2
ParNNon3
ShuffledRDD
ParNNon0
ParNNon1
sc.parallelize() .map(…) .reduceByKey(…) .collect()
2.DAGScheduler
NarrowDependency ShuffleDependency
Stage0 Stage1
Task0
Task1
Task2
Task3
Task4
Task5
53 ©HortonworksInc.2011–2016.AllRightsReserved
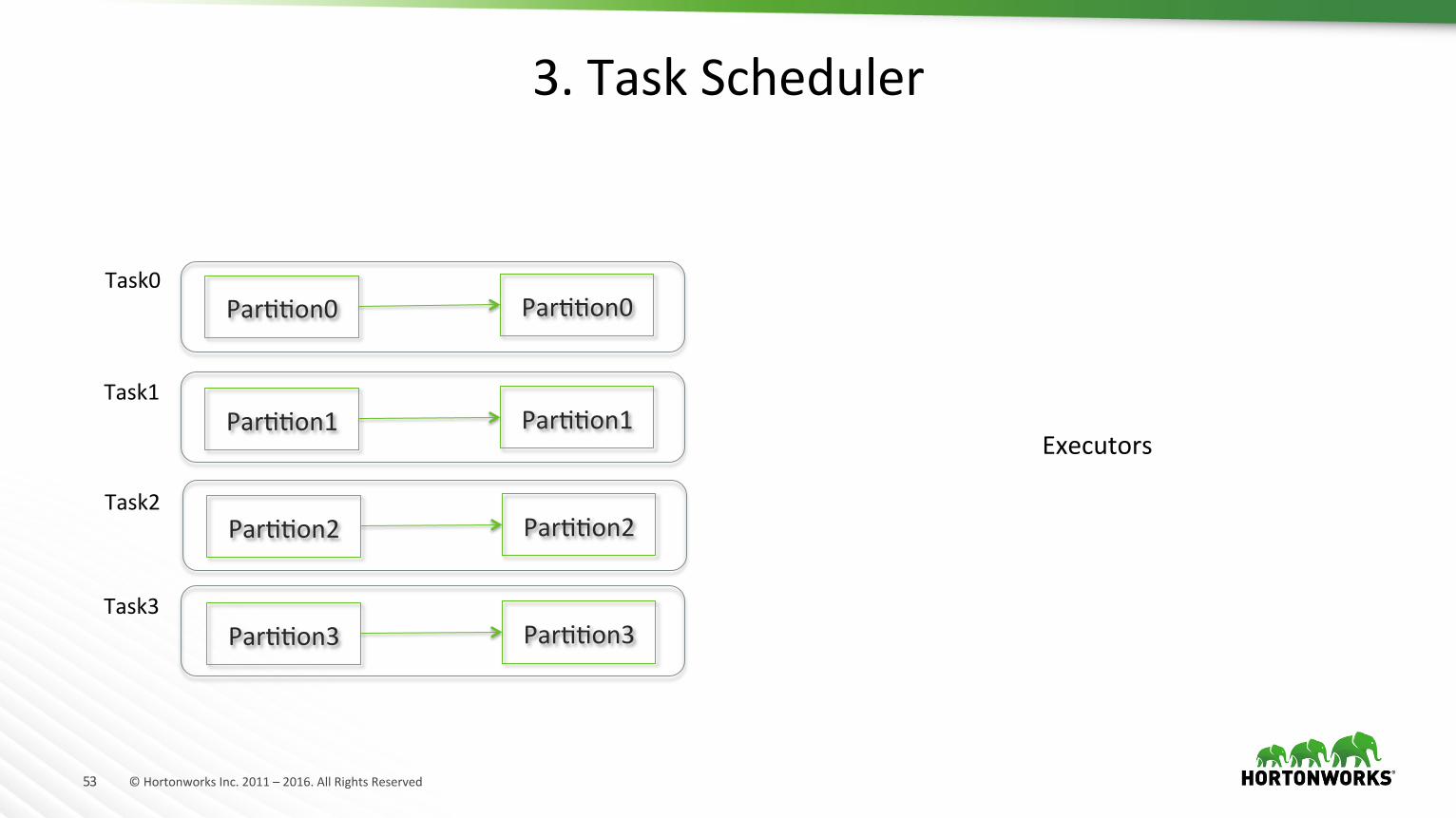
3.TaskScheduler
ParNNon0
ParNNon1
ParNNon2
ParNNon3
ParNNon0
ParNNon1
ParNNon2
ParNNon3
Task0
Task1
Task2
Task3
Executors
54 ©HortonworksInc.2011–2016.AllRightsReserved
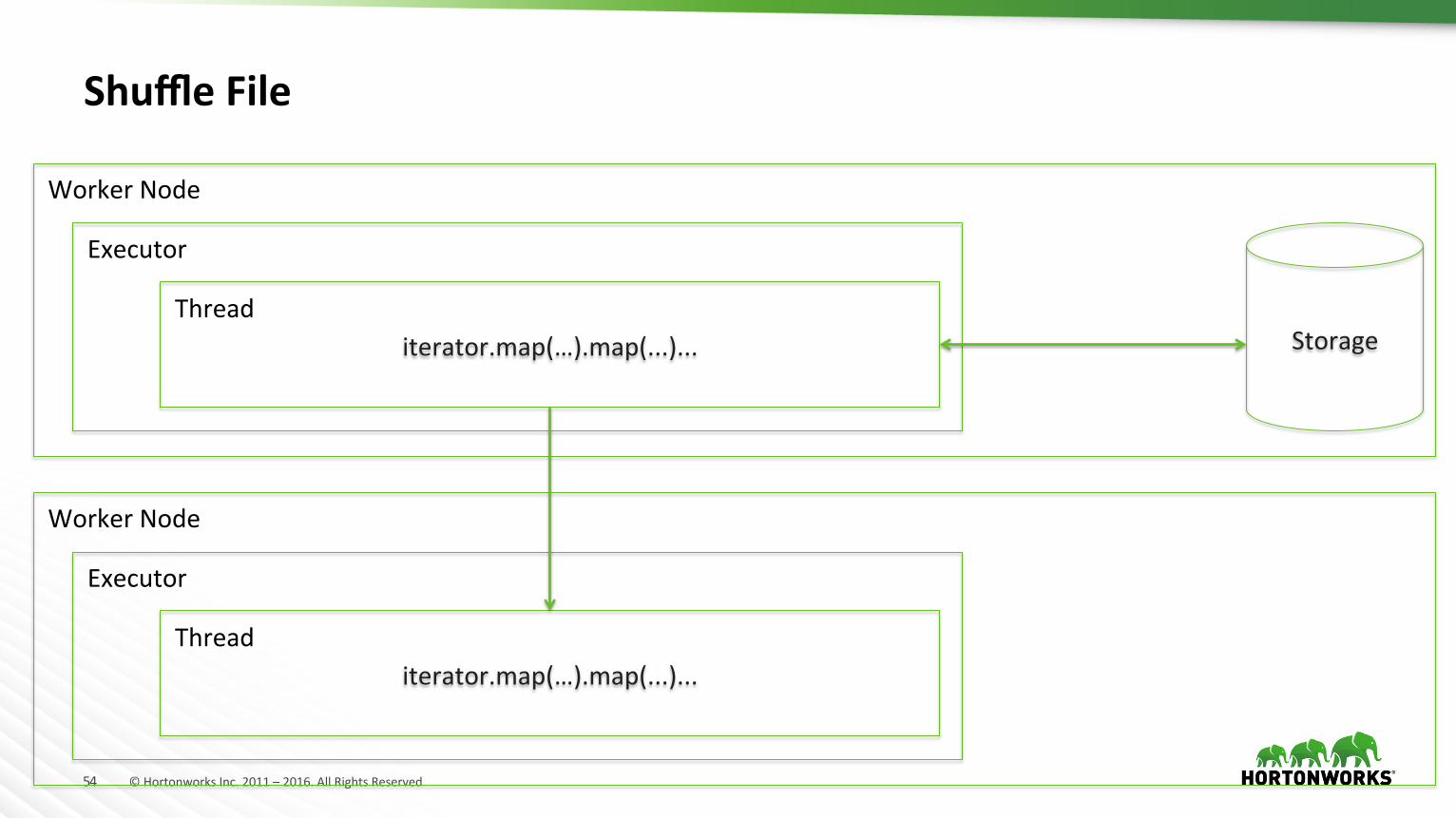
ShuffleFile
iterator.map(…).map(...)...
Executor
ThreadStorage
WorkerNode
iterator.map(…).map(...)...
Executor
Thread
WorkerNode

55 ©HortonworksInc.2011–2016.AllRightsReserved
RDD Graph
valc=sc.textFile("/tmp/LICENSE",4).flatMap(line=>line.split("")).map(word=>(word,1))).reduceByKey(_+_,3)c.collect()
mapflatMap reduceByKey collecttextFile
RDD[String]
STAGE 0 STAGE 1
SHUFFLE
Write to disk
Read from disk across
network
Partitions per RDD
RDD[List[String]]
RDD[(String, Int)]
RDD[(String, Int)]
Array[(String, Int)]
56 ©HortonworksInc.2011–2016.AllRightsReserved
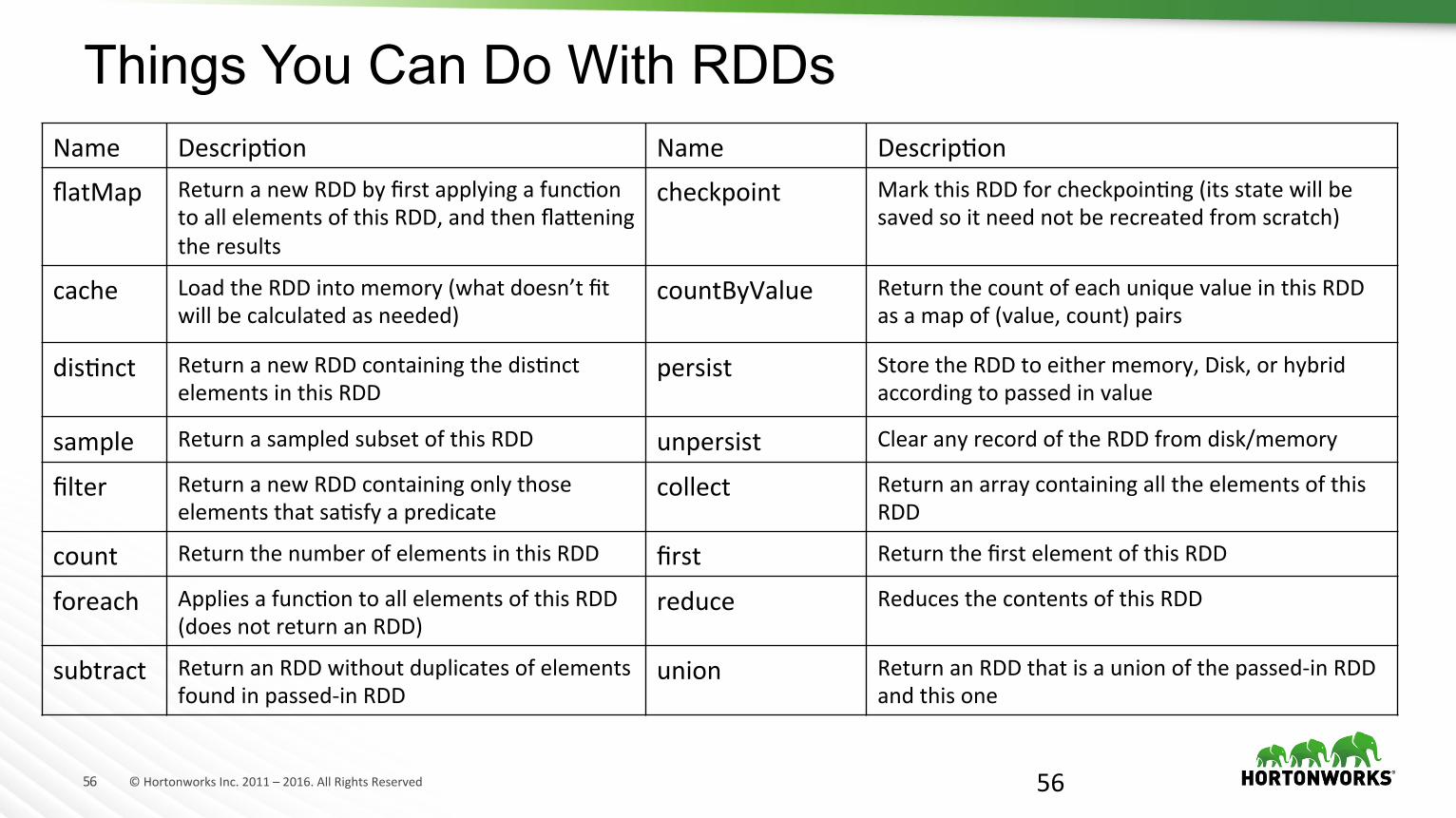
Things You Can Do With RDDs
56
Name DescripNon Name DescripNon
flatMap ReturnanewRDDbyfirstapplyingafuncNontoallelementsofthisRDD,andthenflajeningtheresults
checkpoint MarkthisRDDforcheckpoinNng(itsstatewillbesavedsoitneednotberecreatedfromscratch)
cache LoadtheRDDintomemory(whatdoesn’tfitwillbecalculatedasneeded)
countByValue ReturnthecountofeachuniquevalueinthisRDDasamapof(value,count)pairs
disNnct ReturnanewRDDcontainingthedisNnctelementsinthisRDD
persist StoretheRDDtoeithermemory,Disk,orhybridaccordingtopassedinvalue
sample ReturnasampledsubsetofthisRDD unpersist ClearanyrecordoftheRDDfromdisk/memory
filter ReturnanewRDDcontainingonlythoseelementsthatsaNsfyapredicate
collect ReturnanarraycontainingalltheelementsofthisRDD
count ReturnthenumberofelementsinthisRDD first ReturnthefirstelementofthisRDD
foreach AppliesafuncNontoallelementsofthisRDD(doesnotreturnanRDD)
reduce ReducesthecontentsofthisRDD
subtract ReturnanRDDwithoutduplicatesofelementsfoundinpassed-inRDD
union ReturnanRDDthatisaunionofthepassed-inRDDandthisone

57 ©HortonworksInc.2011–2016.AllRightsReserved
まとめ

58 ©HortonworksInc.2011–2016.AllRightsReserved
まとめ
à ApacheSpark– Sparkはプログラマやアナリスト、サイエンティストにとってとても使いやすいデータ分析のためのアプリケーションフレームワーク
– Zeppelinを利用することでさらに可視化や共有も簡単に
à SparkonHDP– ZeppelinのAmbariでの管理– YARNが提供するスケーラビリティの恩恵– YARNやHDFS、Rangerが提供するセキュリティの恩恵

59 ©HortonworksInc.2011–2016.AllRightsReserved
次回!
à 6/17(⾦) 12:00à タイトル: Apache Ambari
今⽇のウェビナーはオンデマンドでも閲覧可能です!品質改善のため、RATINGSからウェビナーの評価をお願いします!
※予定は変更になる可能性があります
