skos-2-hive gwu workshop. introductions ryan scherle ([email protected]) craig willis...
TRANSCRIPT

SKOS-2-HIVEGWU workshop


Afternoon Session Afternoon Session ScheduleSchedule
Overview
Using HIVE as a service
Installing and configuring HIVE
Using HIVE Core API
Understanding HIVE Internals
HIVE supporting technologies
Developing and customizing HIVE

Block 1: Introduction

Workshop OverviewWorkshop Overview Schedule
Interactive, less structure
Hands-on (work together)
Activities: Installing and configuring HIVE Programming examples (HIVE Core API, HIVE REST API)
What is your What is your background?background?
What is your background? Java Tomcat/Webapps REST SKOS/RDF Sesame Lucene
What are you most interested in getting out of this workshop?
HIVE OverviewHIVE Overview HIVE Website
http://hive.nescent.org/ Primarily for demonstration purposes
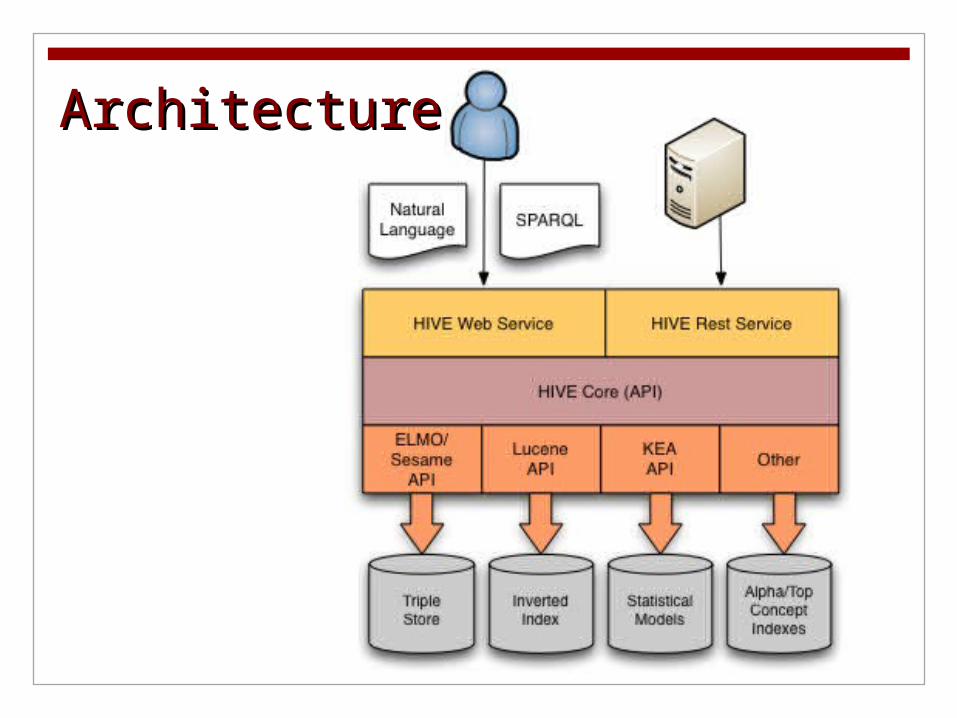
HIVE Architecture Consists of many technologies combined to provide a
framework for vocabulary services.

HIVE VocabulariesHIVE Vocabularies Partner vocabularies:
Library of Congress Subject Headings (LCSH) NBII Biocompexity Thesaurus (NBII) Integrated Taxonomic Information System (ITIS) Thesaurus of Geographic Names (TGN) LTERNet Vocabulary (LTER)
Other AGROVOC Medical Subject Headings (MeSH)
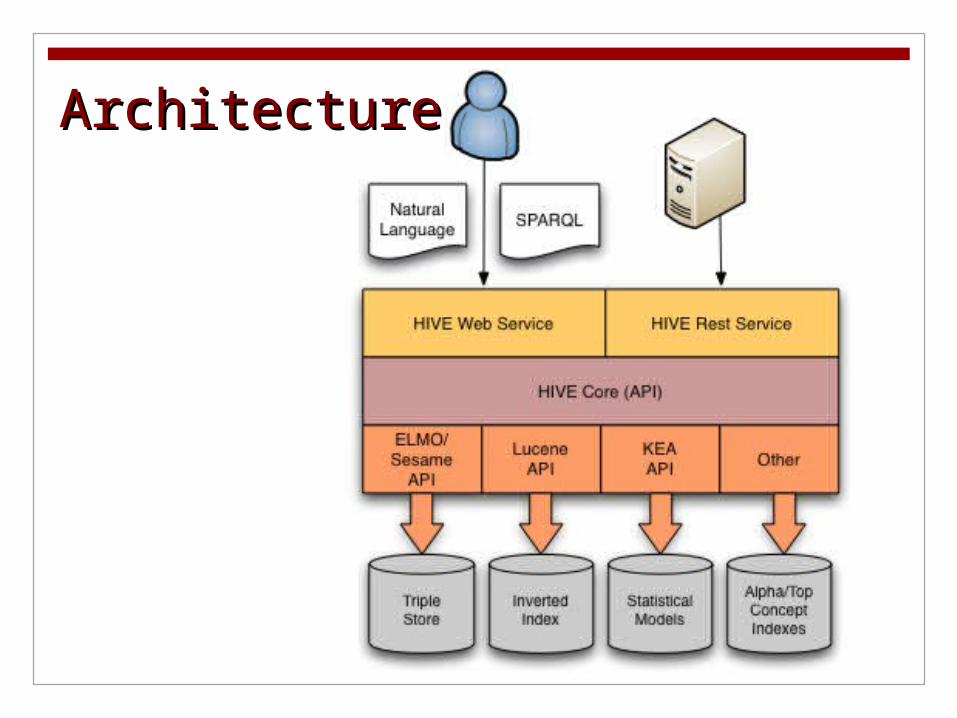
ArchitectureArchitecture

HIVE FunctionsHIVE Functions Conversion of vocabularies to SKOS
Rich internet application (RIA) for browsing and searching multiple SKOS vocabularies
Java API and REST application interfaces for programmatic access to multiple SKOS vocabularies
Support for natural language and SPARQLqueries
Automatic keyphrase indexing using multiple SKOS vocabularies. HIVE supports two indexers: KEA++ indexer Basic Lucene indexer

Block 2: Using HIVE as a service

Using HIVE as a ServiceUsing HIVE as a Service HIVE web application
http://hive.nescent.org/ Developed by Jose Perez-Aguera, Lina Huang Java servlet, Google Web Toolkit (GWT)
http://code.google.com/p/hive-mrc/wiki/AboutHiveWeb
HIVE REST service http://hive.nescent.org/rs Developed by Duane Costa, Long-Term Ecological Research
Network http://code.google.com/p/hive-mrc/wiki/AboutHiveRestService

Activity: Calling HIVE-RSActivity: Calling HIVE-RS Writing Java code to call the hive-rs web service

Block 3: Install and Configure HIVE
Installing and Configuring Installing and Configuring HIVEHIVE
Requirements Java 1.6 Tomcat (HIVE is currently using 6.x)
Detailed installation instructions: http://code.google.com/p/hive-mrc/wiki/InstallingHiveWeb http://code.google.com/p/hive-mrc/wiki/InstallingHiveRestServic
e
Installing and Configuring Installing and Configuring HIVE-webHIVE-web
Detailed installation instructions (hive-web) http://code.google.com/p/hive-mrc/wiki/InstallingHiveWeb
Quick start (hive-web) Download and extract Tomcat 6.x Download and extract latest hive-web war Download and extract sample vocabulary Configure hive.properties and agrovoc.properties Start Tomcat http://localhost:8080/

Installing and Configuring Installing and Configuring HIVE-web from sourceHIVE-web from source
Detailed installation instructions (hive-web) http://code.google.com/p/hive-mrc/wiki/DevelopingHIVE http://code.google.com/p/hive-mrc/wiki/InstallingHiveWeb
Requirements Eclipse IDE for J2EE Developers
Subclipse plugin Google Eclipse Plugin
Apache Ant Google Web Toolkit 1.7.1 Tomcat 6.x

Installing and Configuring Installing and Configuring HIVE REST ServiceHIVE REST Service
Detailed installation instructions (hive-rs) http://code.google.com/p/hive-mrc/wiki/
InstallingHiveRestService
Quick start (hive-rs) Download and extract latest webapp Download and extract sample vocabulary Configure hive.properties Start Tomcat

Importing SKOS VocabulariesImporting SKOS Vocabularies
http://code.google.com/p/hive-mrc/wiki/ImportingVocabularies
Note memory requirements for each vocabulary http://code.google.com/p/hive-mrc/wiki/HIVEMemoryUsage
java –Xmx1024m -Djava.ext.dirs=path/to/hive/lib edu.unc.ils.mrc.hive.admin.AdminVocabularies [/path/to/hive/conf/] [vocabulary] [train]

Block 4: Using the HIVE Core
Library
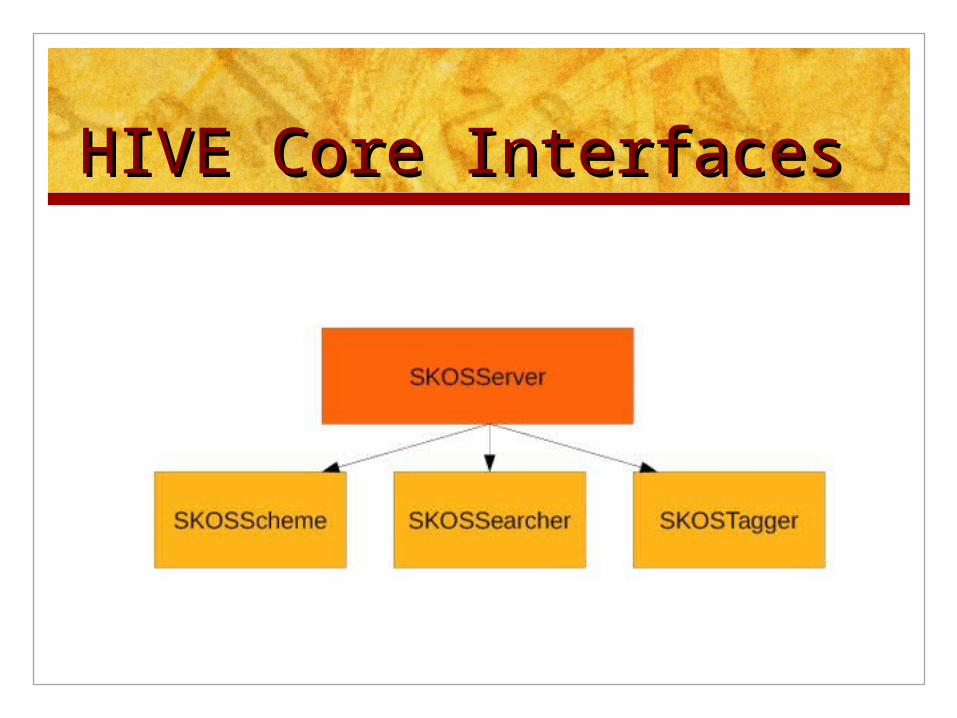
HIVE Core InterfacesHIVE Core Interfaces

HIVE Core PackagesHIVE Core Packages
edu.unc.ils.mrc.hive.api Main interfaces and implementations
edu.unc.ils.mrc.hive.converter SKOS converters (MeSH, ITIS, NBII, TGN)
edu.unc.ils.mrc.hive.lucene Lucene index creation and searching
edu.unc.ils.mrc.hive.ir.tagging KEA++ and “dummy” tagger implementations

edu.unc.ils.hive.apiedu.unc.ils.hive.api SKOSServer:
Provides access to one or more vocabularies
SKOSSearcher: Supports searching across multiple vocabularies
SKOSTagger: Supports tagging/keyphrase extraction across multiple
vocabularies
SKOSScheme: Represents an individual vocabulary

SKOSServerSKOSServer SKOSServer is the top-level class used to initialize the
vocabulary server.
Reads the hive.properties file and initializes the SKOSScheme (vocabulary management), SKOSSearcher (concept searching), SKOSTagger (indexing) instances based on the vocabulary configurations.
edu.unc.ils.mrc.hive.api.SKOSServer TreeMap<String, SKOSScheme> getSKOSSchemas(); SKOSSearcher getSKOSSearcher(); SKOSTagger getSKOSTagger(); String getOrigin(QName uri);
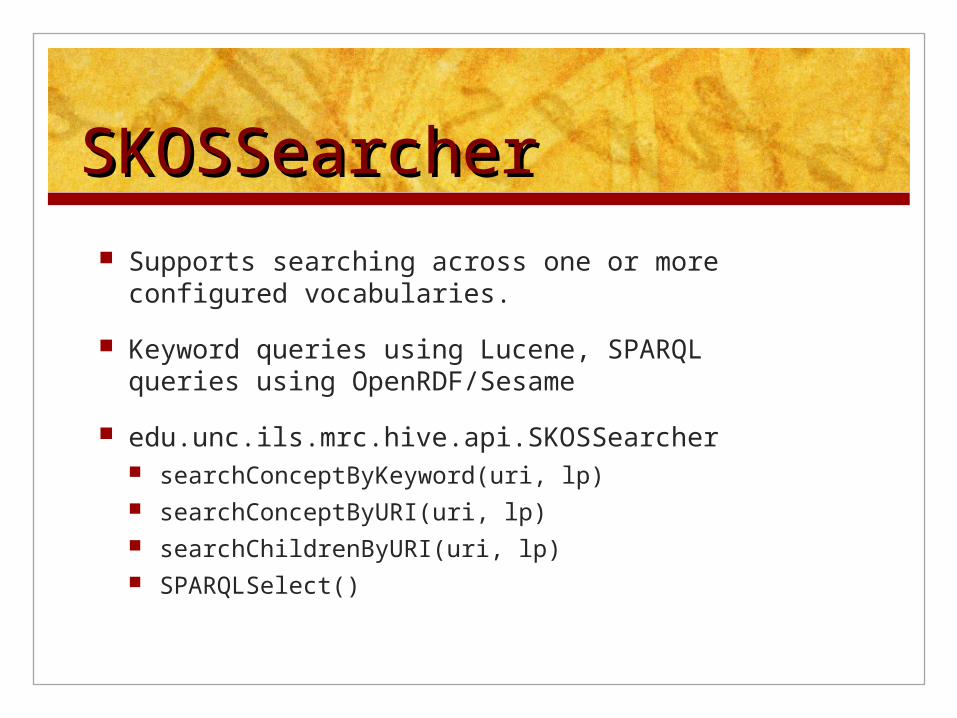
SKOSSearcherSKOSSearcher Supports searching across one or more configured
vocabularies.
Keyword queries using Lucene, SPARQL queries using OpenRDF/Sesame
edu.unc.ils.mrc.hive.api.SKOSSearcher searchConceptByKeyword(uri, lp) searchConceptByURI(uri, lp) searchChildrenByURI(uri, lp) SPARQLSelect()

SKOSTaggerSKOSTagger Keyphrase extraction using multiple vocabularies
Depends on setting in hive.properties
edu.unc.ils.mrc.hive.api.SKOSTagger “dummy” or “KEA” List<SKOSConcept> getTags(String text, List<String>
vocabularies, SKOSSearcher searcher);

SKOSSchemeSKOSScheme Represents an individual vocabulary, based on
settings in <vocabulary>.properties
Supports querying of statistics about each vocabulary (number of concepts, number of relationships, etc).

ActivityActivity Write a simple Java class that allows the user to
query for a given term
Write a Java class that can read a text file and call the tagger

Block 5: Understanding HIVE
Internals
ArchitectureArchitecture

Data Directory LayoutData Directory Layout
/usr/local/hive/hive-data vocabulary/
vocabulary.rdf SKOS RDF/XML vocabularyAlphaIndex Serialized map vocabularyH2 H2 database (used by KEA) vocabularyIndex Lucene Index vocabularyKEA KEA model and training data vocabularyStore Sesame/OpenRDF
store topConceptIndex Serialized map of top
concepts

KeywordKeywordSearchSearch

IndexingIndexing

HIVE Internals: Data HIVE Internals: Data ModelsModels
Lucene Index: Index of SKOS vocabulary (view with Luke)
Sesame/OpenRDF Store: Native/Sail RDF repository for the vocabulary
KEA++ Model: Serialized KEAFilter object
H2 Database: Embedded DB contains SKOS vocabulary in format used by KEA. (Can be queried using H2 command line)
Alpha Index: Serialized map of concepts
Top Concept Index: Serialized map of top concepts

HIVE Internals: HIVE WebHIVE Internals: HIVE Web
GWT Entry Points: HomePage ConceptBrowser Indexer
Servlets VocabularyService: Singleton vocabulary server FileUpload: Handles the file upload for indexing ConceptBrowserServiceImpl IndexerServiceImpl

HIVE Internals: HIVE-RSHIVE Internals: HIVE-RS
Details of HIVE-rs

Block 6: HIVE Supporting
Technologies
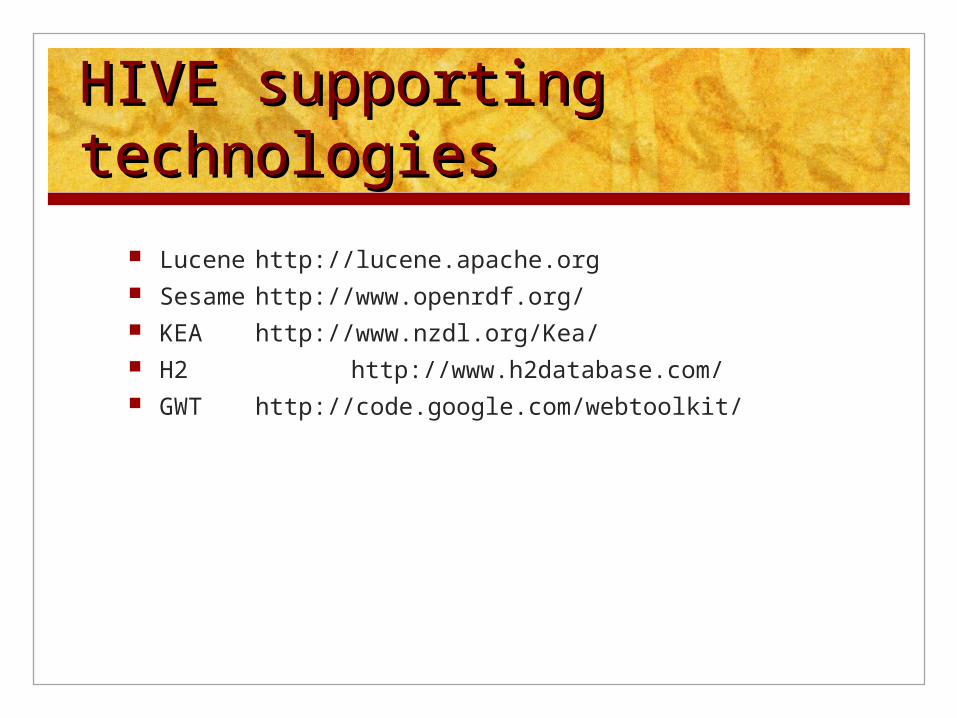
HIVE supporting HIVE supporting technologiestechnologies
Lucene http://lucene.apache.org Sesamehttp://www.openrdf.org/ KEA http://www.nzdl.org/Kea/ H2 http://www.h2database.com/ GWT http://code.google.com/webtoolkit/

ActivityActivity Explore Lucene index with Luke
http://luke.googlecode.com/
Explore Sesame store with SPARQL http://www.xml.com/pub/a/2005/11/16/introducing-
sparql-querying-semantic-web-tutorial.html http://www.cambridgesemantics.com/2008/09/sparql-
by-example/

Block 7: Customizing HIVE

Obtaining VocabulariesObtaining Vocabularies
Several vocabularies can be freely downloaded
Some vocabularies require licensing
HIVE Core includes converters for each of the supported vocabularies.
List of HIVE vocabularieshttp://code.google.com/p/hive-mrc/wiki/VocabularyConversion

Converting Vocabularies to Converting Vocabularies to SKOSSKOS
Additional information http://code.google.com/p/hive-mrc/wiki/VocabularyConversion
Each vocabulary has different requirements
LCSH Available in SKOS RDF/XML
NBII Convert from XML to SKOS RDF/XML (SAX)
ITIS Convert from RDB (MySQL) to SKOS RDF/XML
TGN Convert from flat-file to SKOS RDF/XML
LTER Available in SKOS RDF/XML
AGROVOC Available in SKOS RDF/XML
MeSH Convert from XML to SKOS RDF/XML (SAX)

Converting Vocabularies to Converting Vocabularies to SKOSSKOS
A Method to Convert Thesauri to SKOS (van Assem et al) Prolog implementation IPSV, GTAA, MeSH http://thesauri.cs.vu.nl/eswc06/
Converting MeSH to SKOS for HIVE Java SAX-based parser http://code.google.com/p/hive-mrc/wiki/MeshToSKOS

LTER Sample ServiceLTER Sample Service
http://scoria.lternet.edu:8080/lter-hive-prototypes

DiscussionDiscussion Pros and Con
HIVE Core vs. HIVE Web vs. HIVE-RS
Brainstorm applications that could benefit from HIVE, discuss implementations

Block 8: KEA++

About KEA++About KEA++ http://www.nzdl.org/Kea/
Algorithm and open-source Java library for extracting keyphrases from documents using SKOS vocabularies.
Developed by Alyona Medelyan (KEA++), based on earlier work by Ian Whitten (KEA) from the Digital Libraries and Machine Learning Lab at the University of Waikato, New Zealand.
Problem: How can we automatically identify the topic of documents?

Automatic IndexingAutomatic Indexing Free keyphrase indexing (KEA)
Significant terms in a document are determined based on intrinsic properties (e.g., frequency and length).
Keyphrase indexing (KEA++) Terms from a controlled vocabulary are assigned based on
intrinsic properties.
Controlled indexing/term assignment: Documents are classified based on content that corresponds to a
controlled vocabulary. e.g., Pouliquen, Steinberger, and Camelia (2003)
Medelyan, O. and Whitten I.A. (2008). “Domain independent automatic keyphrase indexing with small training sets.” Journal of the American Society for Information Science and Technology, (59) 7: 1026-1040).

KEA++ at a GlanceKEA++ at a Glance KEA++ uses a machine learning approach to keyphrase
extraction
Two stages:
Candidate identification: Find terms that relate to the document’s content
Keyphrase selection: Uses a model to identify the most significant terms.

KEA++: Candidate KEA++: Candidate identificationidentification Parse tokens based on whitespace and punctuation
Create word n-grams based on longest term in CV
Stem to grammatical root (Porter)
Stem terms in vocabulary (Porter)
Replace non-descriptors with descriptors using CV relationships
Match stemmed n-grams to vocabulary
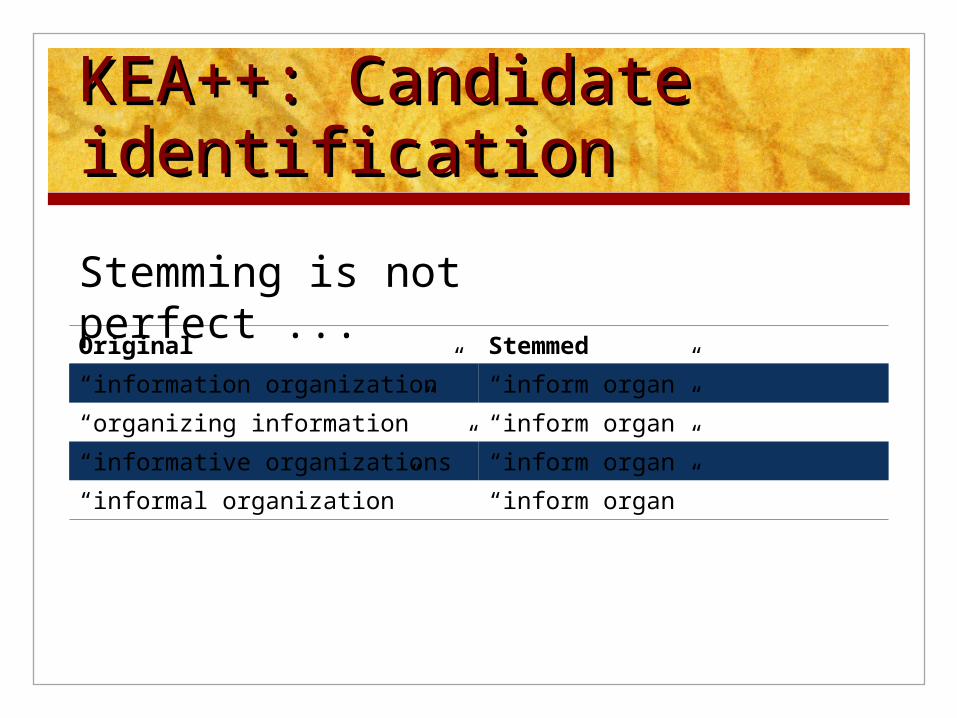
KEA++: Candidate KEA++: Candidate identificationidentification
Original Stemmed
“information organization” “inform organ”
“organizing information” “inform organ”
“informative organizations” “inform organ”
“informal organization” “inform organ”
Stemming is not perfect ...

KEA++: Feature KEA++: Feature definitiondefinition
Term Frequency/Inverse Document Frequency Frequency of a phrase’s occurrence in a document with
frequency in general use. Position of first occurrence:
Distance from the beginning of the document. Candidates with high/low values are more likely to be valid (introduction/conclusion)
Phrase length: Analysis suggests that indexers prefer to assign two-word
descriptors Node degree:
Number of relationships between the term in the CV.

DummyTaggerDummyTagger Primarily intended as baseline for analysis of KEA+
+
Uses LingPipe for part-of-speech identification (limits indexing to certain parts of speech)
Uses Lucene vocabulary index
Simple TF*IDF implementation
Configurable in hive.properties

PlansPlans Automatic updates to vocabularies Integration of other concept extraction algorithms
Maui Dryad integration Other
Maven integration Spring integration Data directory and property file restructuring Concept browser updates
CreditsCredits José Ramón Pérez Agüera
Lina Huang
Alyona Medelyan
Ian Whitten