sistema gerenciador de scripts orientadora: ana …cristina/gerenc_scripts.pdf · j2ee – java 2...
TRANSCRIPT

UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ
SISTEMA GERENCIADOR DE SCRIPTS
ORIENTADORA: ANA CRISTINA B. KOCHEM VENDRAMIN
CURITIBA
MAIO DE 2011
Bruno Romano Müller

SISTEMA GERENCIADOR DE SCRIPTS
CURITIBA
MAIO DE 2011
Pré-projeto apresentado à disciplina de
Trabalho de Diplomação, Curso de
Tecnologia em Sistemas para Internet,
Universidade Tecnológica Federal do
Paraná.
Orientadora: Ana Cristina B. Kochem
Vendramin.

TERMO DE APROVAÇÃO
BRUNO ROMANO MÜLLER
TÍTULO DO TRABALHO
SISTEMA GERENCIADOR DE SCRIPTS
Trabalho de Conclusão de Curso aprovado como requisito parcial à obtenção do grau de TECNÓLOGO EM SISTEMAS PARA INTERNET, do Departamento Acadêmico de Informática, pelo aluno BRUNO ROMANO MÜLLER, da Universidade Tecnológica Federal do Paraná – Campus Curitiba, pela seguinte banca examinadora:
Membro 1 – Prof. JOSÉ ANTONIO BUIAR Departamento Acadêmico de Informática (UTFPR)
Membro 2 – Prof. PAULO ROBERTO BUENO
Departamento Acadêmico de Informática (UTFPR)
Orientadora: Profª. ANA CRISTINA BARREIRAS KOCHEM VENDRAMIN Departamento Acadêmico de Informática (UTFPR)
Curitiba
2011

Sumário
1 Introdução .................................................................................................................................. 10 1.1 Apresentação ....................................................................................................................... 11
1.2 Justificativas ........................................................................................................................ 11 1.3 Objetivos ............................................................................................................................. 11 1.4 Estrutura do Documento ...................................................................................................... 12
2 Levantamento Bibliográfico ...................................................................................................... 13 2.1 WebMin ............................................................................................................................... 13
2.1.1 Pontos Positivos ........................................................................................................... 13 2.1.2 Pontos Negativos.......................................................................................................... 14
2.2 SDI....................................................................................................................................... 15 2.2.1 Pontos positivos ........................................................................................................... 15
2.2.2 Pontos Negativos.......................................................................................................... 16 2.3 Análise do estado da arte ..................................................................................................... 17
3 Metodologia ............................................................................................................................... 19
3.1 Recursos Empregados ......................................................................................................... 19 3.1.1 Recursos Financeiros ................................................................................................... 19 3.1.2 Recursos Pessoais ........................................................................................................ 19 3.1.3 Recursos de Hardware ................................................................................................. 19
3.1.4 Recursos de Software ................................................................................................... 19 3.1.5 Tecnologias Utilizadas ................................................................................................. 22
4 Resultados .................................................................................................................................. 25
4.1 Modelagem .......................................................................................................................... 25 4.1.1 Requisitos Funcionais .................................................................................................. 25
4.1.2 Requisitos não Funcionais ........................................................................................... 26 4.1.3 Descrição da arquitetura ............................................................................................... 27
4.1.4 Diagramas de Casos de Uso ......................................................................................... 39 4.1.5 Diagrama de Classes .................................................................................................... 50
4.1.6 Diagramas de Sequência .............................................................................................. 55 4.1.7 Diagrama Entidade-Relacionamento ........................................................................... 58
4.2 Implantação ......................................................................................................................... 63
5 Discussão ................................................................................................................................... 67
6 Conclusões ................................................................................................................................. 69 7 Referências ................................................................................................................................. 70

Lista de Figuras
Figura 1 - Sistema gerenciador de script servidor e computadores clientes ...................................... 28 Figura 2 - Módulo de troca de mensagens ......................................................................................... 29
Figura 3 - Exemplo para gerar dados consistentes ao sistema gerenciador de script ........................ 31 Figura 4 - Fluxograma do processo de gerenciamento de scripts e controle de processos ................ 32 Figura 5 - Modelo da Arquitetura do Servidor .................................................................................. 36 Figura 6 - Imagem do cliente do sistema gerenciador de script. ........................................................ 38 Figura 7 - Caso de Uso do sistema Servidor ...................................................................................... 39
Figura 8 - Caso de Uso do sistema Cliente ........................................................................................ 40 Figura 9 - Diagrama de classes do sistema de troca de mensagens RPC (remote procedure call). ... 51 Figura 10 - Diagrama de classes do sistema Servidor ....................................................................... 52 Figura 11 – Continuação do diagrama de classes do sistema Servidor ............................................. 53
Figura 12 - Diagrama de classes do sistema Cliente .......................................................................... 54 Figura 13 - Continuação do diagrama de classes do sistema Cliente ................................................ 55 Figura 14 - Diagrama de sequência para adicionar uma nova tarefa ................................................. 56
Figura 15 - Diagrama de sequência inserção das informações no banco de dados ........................... 57 Figura 16 - Diagrama de sequência execução de uma tarefa ............................................................. 58 Figura 17 - Diagrama de entidade do banco de dados do servidor .................................................... 59 Figura 18 - Diagrama de relacionamento do banco de dados do servidor ......................................... 60
Figura 19 - Diagrama de entidade do banco de dados do cliente ...................................................... 61 Figura 20 - Diagrama de relacionamento do banco de dados do cliente ........................................... 62 Figura 21 - Tela que possibilita adicionar um script ao banco de dados ........................................... 63
Figura 22 - Lista dos Scripts cadastrados no sistema ......................................................................... 64 Figura 23 - Criação de uma nova tarefa ............................................................................................. 64
Figura 24 - Lista de tarefas cadastradas no sistema ........................................................................... 65 Figura 25 - Resultados de uma tarefa ................................................................................................. 65
Figura 26 - Tela de gerenciamento dos usuários................................................................................ 66

LISTA DE TABELAS
Tabela 1 - Comparação entre sistemas existentes .............................................................................. 18 Tabela 2 - Caso de Uso Cadastrar novo Script .................................................................................. 40
Tabela 3 - Caso De Uso Excluir Script .............................................................................................. 41 Tabela 4 - Caso de Uso Pesquisar Script ........................................................................................... 41 Tabela 5 - Caso de Uso Alterar Script ............................................................................................... 42 Tabela 6 - Caso de Uso Criar Usuário ............................................................................................... 42 Tabela 7 - Caso de Uso Excluir Usuário ............................................................................................ 43
Tabela 8 - Caso de Uso Pesquisar Usuário ........................................................................................ 43 Tabela 9 - Caso de Uso Criar Tarefa .................................................................................................. 44 Tabela 10 - Caso de Uso excluir tarefa .............................................................................................. 45 Tabela 11 - Caso de Uso Pesquisar Tarefa ........................................................................................ 45
Tabela 12 - Caso de Uso Pesquisar Computador ............................................................................... 46 Tabela 13 - Caso de Uso Valida Permissão Usuário ......................................................................... 46 Tabela 14 - Caso de Uso Informa Computador ................................................................................. 47
Tabela 15 - Adicionar Tarefa ............................................................................................................. 48 Tabela 16 - Excluir Tarefa ................................................................................................................. 48 Tabela 17 - Executar Tarefa ............................................................................................................... 49 Tabela 18 - Gerenciar Tarefa ............................................................................................................. 49
Tabela 19 - Validar Script .................................................................................................................. 50

Lista de siglas API – Application Programming Interface
Bash – Bourne Again Shell
GPL – General Public License
HTTP – Hypertext Transfer Protocol
IDE – Integrated Development Environment
IP – Internet Protocol
J2EE – Java 2 Enterprise Edition
JAR – Java Archive
JDBC – Java Database Connection
JDK – Java Development Kit
JSP – Java Server Pages
JSF – Java Server Faces
JSTL – Java Server Pages Standard Tag Library
MVC – Model View Controller
RAID – Redundant Array of Independent Disks
RPC – Remote Procedure Call
SDI – Sistema de Diagnóstico Instantâneo
SQL – Structured Query Language
SSH – Secure Shell
SSL – Security Socket Layer
STL – Standard Template Library
TLS – Transport Layer Security
UML – Unified Modeling Language
XML – Extensible Markup Language
WAR – Web Archive

Resumo
O sistema, proposto neste trabalho, tem como objetivo documentar e implementar um
sistema para reduzir as dificuldades encontradas por profissionais responsáveis em
administrar informações em uma rede Linux, diante da necessidade de coletar dados,
gerar eventos e configurar uma rede de computadores. O sistema proposto contará com
um servidor central que concentrará todas as funcionalidades, fornecendo os scripts e as
informações necessárias para que as máquinas clientes coletem os dados necessários e
disponibilizem as informações ao administrador da rede através da interface web do
servidor.
Palavras chaves: Scripts, Linux, Gerenciamento de redes de computadores

Abstract
The proposed system aims to reduce the difficulties faced by administrators of
Information Technology in a Linux network, when they need to collect data, generate
events and set up a computer network. The system will rely on a central server where all
functionalities are maintained. This server will provide the necessary information and
scripts for client machines to collect the necessary data and make available the
information to the network administrator via the web interface of the server.
Keywords: Scripting, Linux, Network Management

10
1 Introdução
Em um mundo onde as mudanças tecnológicas são constantes e velozes, a
criatividade, a praticidade e o gerenciamento do tempo são fundamentais para o sucesso
de uma empresa. Com o aumento e diversificação das redes de comunicação, crescem
também as dificuldades de gerenciamento das mesmas, tornando quase que impossível
possuir uma rede bem administrada sem o suporte de bons programas.
A inexperiência de muitos profissionais e a falta de alguns atributos supracitados no
início do primeiro parágrafo contribuem para muitas soluções simples e criativas como
utilizar scripts para gerar dados em um arquivo e disponibilizá-los em um servidor web.
Este tipo de solução demanda tempo e testes para evitar erros no processo, o que acaba
justificando a necessidade da utilização de um sistema já desenvolvido e pensado para
estes casos.
A implementação para estas soluções, são problemas similares detectados e
resolvidos por outros gerenciadores de redes, como é o caso da necessidade de se obter
um inventário de hardware de uma rede. Estes programas são ótimos para necessidades
comuns, mas acabam apresentando dificuldades quando se tem um problema específico.
Em muitos casos, o problema pode envolver equipamentos ou serviços que não estão
sendo monitorados pela estação de gerência. Outra possibilidade ocorre quando a
quantidade de informação coletada não é suficiente para diagnosticar o problema. Além
disso, no nível de gerência do qual trata o presente trabalho, não se é capaz de descobrir,
através de uma estação de gerência, se um serviço está com problemas enquanto a infra-
estrutura de rede sob a qual ele se apóia não apresenta problemas. Nestes casos, o auxílio
de analisadores de protocolos e de outras ferramentas auxiliares é imprescindível (Lopes,
Sauvé, Nicolletti, 2003, p. 16).
Diante destes fatos supracitados, muitas empresas necessitam prover a manutenção
em mais de um software ao mesmo tempo, empregando diversos programas para resolver
seus problemas internos. Na tentativa de facilitar o processo, pode-se optar pela aquisição
de soluções pagas, sem uma real necessidade de todas as características que o produto
disponibiliza e que nem sempre apresentam um resultado positivo, ou então, adotam outra
solução muito comum que é ignorar o problema existente.

11
1.1 Apresentação
O presente trabalho propõe-se a documentar e implementar o sistema gerenciador de
script, que é voltado para o gerenciamento de uma rede de computadores utilizando o
sistema operacional GNU/Linux.
1.2 Justificativas
A maioria dos sistemas de controle de redes pesquisada para sistemas Linux está
voltada à coleta de dados nos servidores. Tais sistemas não apresentam um foco nos
ativos desta rede, servindo apenas para coletar dados e não para o controle destes
computadores. Geralmente, os sistemas não abrangem toda a necessidade que a rede
necessita.
Levando em conta que os desktops podem ser máquinas com um hardware modesto
como um Pentium 2, com 256 de memória de RAM , e que o usuário final pode necessitar
executar diversos programas e dividir seus recursos entre estes programas, o usuário final
poderá enfrentar uma lentidão ao efetuar suas atividades. Por este motivo, o sistema
proposto neste trabalho deve consumir o mínimo de recursos do computador e
desempenhar sua função de coleta de dados e envio destes para o servidor.
1.3 Objetivos
O trabalho proposto tem como objetivo documentar e desenvolver um sistema que
forneça um ambiente para executar scripts remotamente. Este sistema deverá incluir as
seguintes funcionalidades:
Uma interface Web para administrar o sistema;
Uma API (Application Programing Interface) genérica baseada em comandos
shell script para fornecer interação com o sistema;
Troca de mensagens entre cliente e servidor criptografados;
Uma forma de agendar a execução remota dos scripts e receber todas as
informações geradas por eles;
Um sistema inteiramente modular, ou seja, que possibilite a criação de um
módulo para o sistema de maneira simples sem comprometer outras áreas da
aplicação.

12
1.4 Estrutura do Documento
Este trabalho divide-se em seis capítulos, sendo que o primeiro capítulo apresenta os
objetivos do sistema e as motivações para o desenvolvimento do programa. O segundo
capítulo apresenta o estado da arte. O terceiro capítulo explica todos os programas e
bibliotecas que são utilizados no desenvolvimento do sistema. O quarto capítulo apresenta
toda a fase de modelagem do sistema, com descrições e diagramas. O quinto capítulo
descreve o processo de desenvolvimento, as dificuldades, e os resultados obtidos com o
desenvolvimento. Por fim, o último capítulo apresenta a conclusão do trabalho.

13
2 Levantamento Bibliográfico
Para a realização do presente trabalho foram pesquisados programas de
gerenciamento de rede que não precisam ser comprados para serem utilizados e que
desempenham funções parecidas com o sistema proposto. Não foram pesquisados
programas de grande porte que necessitam ser adquiridos comercialmente para serem
utilizados ou que necessitem ser comprados como forma de serviço.
2.1 WebMin
A ferramenta Webmin tem como objetivo oferecer aos administradores de redes e
sistemas, de maneira interativa, uma forma simples e eficaz de prover configurações e
manutenção para uma rede. Possui suporte para diversas tarefas que vão desde a
configuração de uma conta de usuário, até tarefas mais complexas como criar um Cluster
ou RAID, isto faz o Webmin ser uma ferramenta poderosa de configuração de uma rede
recomendada para administradores que possuem diversos serviços a serem configurados e
administrados. É fato que, várias outras ferramentas para realizar configurações a partir de
um ambiente gráfico existem, mas, o grande diferencial do Webmin é a sua capacidade de
reunir toda essa administração sob apenas uma interface, proporcionando assim, mais
organização e interatividade com o usuário (Badiella, 2009).
O Webmin é uma ferramenta para administração de sistemas que faz uso de uma
interface gráfica, desenvolvida por Jamie Cameron, utilizando a linguagem Perl. Ela foi
projetada para ser uma ferramenta de administração leve, funcional, e que possa ser
facilmente entendida.
A aplicação se propõe a administrar uma rede totalmente através de uma interface
integrada, evitando que o usuário necessite editar arquivos de configurações ou executar
comandos em um console texto, sendo que todas estas tarefas são facilitadas ou efetuadas
pelo Webmin, através da interface gráfica.
2.1.1 Pontos Positivos
É importante ressaltar os pontos positivos do sistema Webmin, pois são estes que
fazem com que um administrador de rede opte, ou não, por utilizar este sistema. Os pontos
positivos do sistema Webmin levantados através do trabalho de pesquisa apresentam-se a
seguir.

14
1. Suporte a diversos serviços: O Webmin provê suporte a diversos serviços que
podem ser necessários ao administrar uma rede. Com isso, o Webmin facilita ao
administrar diversos serviços, pois todos estão reunidos sob uma mesma
interface fácil, sendo que não é necessário manipular arquivos de configuração
e nem acessar as diferentes interfaces, ou comandos para gerenciar estes
serviços;
2. Licença aberta: O Webmin está licenciado sob a GPL, o que o torna um
programa aberto com gratuidade para utilização e todo o código fonte está
aberto para que novas pessoas, com novas necessidades, possam aperfeiçoá-
lo;
3. Facilidade na instalação: Como o Webmin é fácil de ser instalado, não necessita
de grandes configurações para sua instalação e funcionamento, basta executar
um simples script de instalação, e este, configurará todo o sistema para o uso do
Webmin;
4. Linguagem de script: Como o Webmin é todo escrito na linguagem de
programação Perl, isso o torna facilmente modificável e simples na correção de
problemas.
2.1.2 Pontos Negativos
É importante ressaltar os pontos negativos do sistema Webmin para ajudar o
administrador da rede na sua opção por utilizar, ou não, o sistema.
Os pontos negativos do sistema Webmin levantados apresentam-se a seguir.
1. Ausência de banco de dados: O Webmin guarda todos seus dados em arquivos,
o que dificulta a rapidez da pesquisa dos dados, pois não possui um banco de
dados que possa automatizar, facilitar e otimizar este processo. Pelo fato do
Webmin manter todos os dados coletados em arquivos, estes ficam vulneráveis
a possíveis roubos, se mal configurado. . Se um banco de dados for utilizado e
configurado corretamente, ele deixará as informações mais seguras;
2. Ausência de Otimização: Como o sistema é totalmente desenvolvido em Perl,
existe um overhead de informações e um gasto desnecessário de
processamento para manipular o arquivo texto que possui a lógica do sistema.
Por este motivo, existe um gasto desnecessário de recursos que podem ser
utilizados pelo usuário final nos processos necessários ao uso diário do
computador.

15
2.2 SDI
O SDI é um sistema simples e escalável para coletar dados de uma rede,
independente do seu tamanho. O sistema é desenvolvido para executar qualquer tipo de
script ou programa, com a finalidade de diagnosticar qualquer computador pertencente à
rede. O sistema é mantido e disponibilizado pelos colaboradores Bruno César Ribas, Diego
Giovane Pasqualin e Vinicius Kwiecien Ruoso (2010).
O SDI encontra-se instalado em diversas redes, com destaque para as redes do
Governo Estadual do Paraná, gerenciando as redes das escolas, coletando dados e
corrigindo falhas, remotamente, em todos os computadores da rede.
O SDI é um sistema inteiramente desenvolvido utilizando Shell Script e o servidor Web
Apache e seu código fonte está licenciado através da licença GPL.
O SDI tem como base os comandos de Shell Script existentes no Linux, em um
sistema de servidor que entra em contato com seus computadores clientes, através do
comando SSH, sendo possível executar scripts remotamente e transmitir os dados
gerados. O SDI, ao receber estas informações, grava-as em arquivos para que, ao ser
solicitada a visualização destes dados recebidos, estas sejam processadas e mostradas na
página WEB. Toda a configuração do SDI e criação de plugins devem ser feitas pelo
administrador do sistema e é necessário seguir algumas regras para que o programa
consiga interpretar a saída dos scripts, criados pelo administrador do programa (Ruoso,
Vinicius Kwiecien, 2010).
2.2.1 Pontos positivos
É importante ressaltar os pontos positivos do sistema SDI, pois são estes que fazem
com que um administrador o eleja, ou não, para sua utilização. Os pontos positivos do
sistema SDI, levantados através do trabalho de pesquisa são:
1. Facilidade na alteração do sistema: Como o SDI é totalmente desenvolvido
através de scripts, ele é um programa simples e de fácil alteração, dispensando
que o administrador tenha vasto conhecimento sobre outras tecnologias para
conseguir fazer alguma modificação;
2. Compacto e flexível: O SDI é um programa compacto e flexível, pois não possui
features que o acompanham. Porém, provê toda a infra-estrutura para o
gerenciador de uma rede criar os scripts necessários para atender a demanda, o
que o torna ideal para administradores de sistemas que não requeiram a
instalação de serviços específicos na rede, e sim, criar algum processo de
acordo com sua real necessidade;

16
3. Atualizações parciais: Como o SDI é totalmente desenvolvido em Shell Script,
isto proporciona facilidade em corrigir possíveis bugs encontrados, pois, basta
atualizar o arquivo que possua o problema;
4. Fácil configuração e resolução de problemas: Por utilizar o Servidor Web
Apache e comandos genéricos, o SDI torna simples a customização e a
resolução de problemas, através de buscas na internet, pois existem muitas
fontes de informação sobre estes. Outro ponto positivo é a facilidade de
configurar o sistema, pois ele possui um arquivo de configuração que basta
alterar e reiniciar a aplicação e o sistema se recarrega, utilizando as novas
informações aplicadas no arquivo de configuração;
5. Controle Via Web: Toda a visualização dos dados se dá através de uma
interface web simples e amigável que possibilita a visualização destes dados de
qualquer computador da rede. É possível filtrar os dados por script e coluna,
facilitando a busca de dados.
2.2.2 Pontos Negativos
É importante ressaltar os pontos negativos do sistema SDI, pois estes interferem na
escolha, ou não, pelo administrador da rede em utilizar o sistema. Os pontos negativos do
sistema SDI levantados são:
1. Sobrecarga de consumo de memória e processamento: O SDI é totalmente
desenvolvido utilizando Shell Script – e, como todo comando que o interpretador
BASH executa é um novo processo - e todo novo processo no Linux consome
muitos recursos do kernel, existe uma grande sobrecarga na execução deste
software. Mesmo que no Linux a chamada de sistema fork seja considerada
rápida, ela possui muito mais processamento e consumo de memória do que a
chamada a algumas funções na linguagem C. Com isso, acaba-se perdendo
muito do desempenho do sistema, por precisar sempre criar um novo processo
para fazer diversas funções, as quais poderiam ser resolvidas com métodos e
funções que não apresentam tais overheads;
2. Ausência de Otimização: Como o sistema é totalmente desenvolvido em Shell
Script, o mesmo não possibilita diversas otimizações que poderiam ser feitas
para melhorar os processos que o sistema efetua internamente, como é o caso
de guardar dados em memória, ao invés de guardar estes dados em arquivos
para não precisar ler sempre de um HD. Isto consome tempo de outras
aplicações que poderiam utilizar este recurso. Outro agravante na otimização do

17
sistema é a falta de outras linhas de execução thread, e a impossibilidade de
implementar formas assíncronas para consumir os recursos;
3. Ausência de banco de dados: O SDI guarda todos seus dados em arquivos,
podendo causar lentidão ao sistema quando houver uma grande quantidade de
arquivos.
2.3 Análise do estado da arte
Com base na análise realizada sobre os pontos negativos e positivos levantados nas
Seções 2.1 e 2.2, é possível descrever os pontos que o sistema gerenciador de script deve
oferecer. Vendo que os dois sistemas não privam pela eficiência na execução do código,
optou-se por desenvolver o sistema utilizando a linguagem de programação C++,
priorizando para que sejam utilizados os melhores recursos que o sistema operacional
pode prover como leitura e escrita assíncronas e espera de processo assíncrono.
Também se optou por utilizar um banco de dados para centralizar todas as
informações em apenas um ponto, possibilitando, também, colocar esta base de dados
junto a outras que o administrador eventualmente possa ter. Ao centralizar as informações
em apenas um ponto far-se-á desta, uma tarefa simples para a realização de backup das
informações do sistema, facilitando pesquisas, caso um usuário necessite de informações
específicas.
Analisando os pontos positivos dos sistemas, decidiu-se em manter uma estrutura
parecida com o SDI, implementando seus pontos positivos ou incorporando estes pontos a
alguma funcionalidade do sistema. Concluiu-se que o SDI possui um enfoque mais voltado
ao gerenciamento generalizado de uma rede, não provendo todas as ferramentas já
instaladas para esse controle. Na Tabela 1 é feita uma comparação dos dois sistemas
pesquisados.

18
Tabela 1 - Comparação entre sistemas existentes
Funcionalidades SDI Webmin
Flexibilidade X X
Facilidade de uso X X
Sistema Web X X
Utilização de Banco de
dados
- -
Suporte a serviços de rede - X
Utiliza linguagem de script X X
Atualização automática - X

19
3 Metodologia
Este capítulo está destinado a apresentar os métodos utilizados para a execução deste
trabalho, o planejamento realizado para o desenvolvimento, incluindo o levantamento dos
dados e custos para elaboração.
3.1 Recursos Empregados
Abaixo se encontram listados os recursos (financeiros, pessoal, hardware e software),
utilizados na composição do Projeto.
3.1.1 Recursos Financeiros
Para o desenvolvimento do projeto não houve necessidade de empregar qualquer
recurso financeiro, uma vez que os equipamentos de hardware são de propriedade do
pesquisador proponente deste trabalho. Também não foi necessário adquirir licença de
utilização de software proprietário uma vez que optou-se pelas ferramentas de
desenvolvimento e linguagens de programação baseadas em software livre.
3.1.2 Recursos Pessoais
Os recursos de pessoal, necessários para o desenvolvimento da aplicação e para a
composição da documentação, em todas as suas etapas, obedeceram à seguinte ordem:
Documentação e Análise do Sistema: Bruno Romano Muller Santos;
Desenvolvimento do Sistema: Bruno Romano Muller Santos.
3.1.3 Recursos de Hardware
Um computador com capacidade para escrever códigos, compilar, depurar e acessar a
internet para pesquisas, fornecido pelo pesquisador.
3.1.4 Recursos de Software
Para o desenvolvimento do trabalho foram utilizados softwares de desenvolvimento,
modelagem, sistema gerenciador de banco de dados, API, desenvolvidos por terceiros e
liberadas sob licenças abertas ao uso e, diversos programas desenvolvidos por terceiros
amplamente testados, também com licenças abertas. Estes recursos estão descritos a
seguir.

20
3.1.4.1 G++
O G++ é um compilador desenvolvido sob licença aberta, GPL, com o intuito de gerar
código nativo. O G++ é um dos compiladores mais utilizados para gerar programas
desenvolvidos utilizando a linguagem de programação C++ (G++, 2011).
3.1.4.2 GDB
O GDB é um software de licença aberta desenvolvido para depurar programas do
ambiente GNU/Linux utilizando a linguagem de programação C/C++. Um utilitário que
compõe o grupo de ferramentas que auxilia no desenvolvimento de programas para Linux
chamado GNU tools, onde o GDB é a ferramenta de depuração (GDB, 2011).
3.1.4.3 Mysql
O Mysql é um sistema de gerenciamento de banco de dados baseado em comandos
SQL (Structured Query Language), sendo atualmente um dos bancos de dados mais
populares, pois é baseado no conceito de free software. Uma de suas características é
possuir uma arquitetura cliente-servidor (MYSQL, 2011).
3.1.4.4 Tomcat
O Apache Tomcat é um container de servlets desenvolvido pela Apache Software
Foundation. Ele proporciona um servidor de aplicações Java para web que implementa as
tecnologias JavaServlets e JavaServer Pages. Ele também pode comportar-se como um
servidor web (HTTP - HiperText Transfer Protocol) ou funcionar integrado a um servidor
web, dedicado (como o Apache ou o IIS). Este programa é uma aplicação de código aberto,
nascido no Projeto Apache Jakarta e é oficialmente autorizado pela Sun Microsystems,
como a implementação de referência para as tecnologias Java Servlet e JavaServer Pages
(JSP). O Apache Tomcat é inteiramente escrito em Java e, portanto, para ser executado
corretamente ele necessita de uma Java Virtual Machine instalada (TomCat, 2011).
3.1.4.5 Subversion
O Subversion é um conhecido gerente de versão desenvolvido pela comunidade e
possuindo um código fonte livre. Cuida do gerenciamento da versão de um software,

21
possibilitando que o desenvolvedor possa gerenciar os arquivos pertencentes a aplicação e
mantém um histórico de alterações, possibilitando e auxiliando o trabalho em grupo
(Subversion, 2011).
3.1.4.6 Google Code
O Google Code é um projeto da empresa Google para que desenvolvedores possam
armazenar seus projetos em um gerente de versão remoto, não necessitando que o
desenvolvedor possua uma máquina em algum outro ponto da rede, ou que precise pagar
por este serviço. Para utilizá-lo, basta possuir uma conta no Google e criar um novo projeto
no repositório de versões. Após este procedimento, basta escolher um gerenciador de
versão que o Google suporta como subversion, ou mercurial e utilizá-lo (Google Code,
2011).
3.1.4.7 Eclipse IDE
O eclipse é uma IDE desenvolvida para trabalhar principalmente com Java, mas
contendo inúmeros plugins para que o habilita a dar suporte para diferentes linguagens,
como C/C++, PHP, entre outras (Eclipse, 2011).
3.1.4.8 Plugin CDT
O CDT é um plugin que habilita a IDE eclipse a dar suporte ao desenvolvimento
utilizando a linguagem C++. Este plugin proporciona facilidades quando do
desenvolvimento do C/C++ otimizando a compilação, mostrando os erros ocorridos, como
também, auxiliando na depuração do projeto (Eclipse CDT, 2011).
3.1.4.9 StarUML
O StarUML é um projeto open source para o desenvolvimento de diagramas UML
rápido, flexível e extensível, cheio de recursos e livremente disponível executado na
plataforma Win32. O objetivo do projeto StarUML é construir uma ferramenta de
modelagem de software e também da plataforma, que é um substituto convincente de
ferramentas comerciais, tais como UML Rational Rose, Together e assim por diante
(StarUML, 2011).

22
3.1.4.10 RapidSVN
O RapidSVN é um programa que auxilia na utilização do código versionado sob um
servidor subversion, o Google code utiliza um servidor subversion para guardar todo o
código fonte baseado em versões (RapidSVN, 2011).
3.1.5 Tecnologias Utilizadas
As tecnologias utilizadas no desenvolvimento do projeto encontram-se descritas
abaixo.
3.1.5.1 STL (Standard Template Library)
A STL (Standard Template Library) é uma biblioteca pensada e padronizada pelo
comitê ANSI/ISSO de padronização do C++, focada na programação genérica utilizando
templates, abstração sem a perda de eficiência. É uma biblioteca muito utilizada para
programação e muito aceita no ambiente corporativo, sendo excelência no que ela se
propõe (SGI, 2011).
3.1.5.2 Boost
O Boost é uma extensão da STL contendo diversas funcionalidades que dependem ou
aprimoram a sua aplicabilidade. É composta por uma coleção de várias pequenas
bibliotecas distintas, desenvolvidas e disponibilizadas com uma licença própria que segue a
filosofia free, por grupos de pessoas que necessitam de um suporte específico. O boost
referenda várias regras e padrões para um bom projeto, e todas suas bibliotecas devem
seguir estas referências a fim de torná-lo um conjunto supremo. Para uma biblioteca
integrar-se ao boost deve ser submetida à avaliação dos vários programadores que
integram, freqüentam e alimentam esta comunidade.
Um dos principais objetivos do boost é ser uma biblioteca multiplataforma assim, todas
as suas bibliotecas devem ser desenvolvidas e testadas em todos os sistemas
operacionais disponíveis para que qualquer desenvolvedor possa utilizar esta plataforma.
Isto faz com que o BOOST tenha uma ótima reputação e aceitabilidade do público
desenvolvedor.
O boost tem como uma de suas metas estar sempre atualizado, o que o faz ser
expoente em qualidade e eficiência para um sistema operacional, com um design de fácil

23
entendimento, extensível para que o desenvolvedor possa criar e utilizar aleatoriamente
novos componentes. O boost implementa os melhores e mais eficientes padrões de
projetos. Conta com uma comunidade ativa e sempre disposta a colaborar, contribuir com
dicas, soluções, correções de problemas ou simplesmente, reportando erros para que
possam ser corrigidos por desenvolvedores capacitados, o que o torna uma referência em
usabilidade e eficiência (Boost, 2011).
3.1.5.3 SQLite
O SQLite é uma biblioteca que implementa um banco de dados local baseado em um
único arquivo que são, geralmente utilizados para aplicativos que necessitam guardar
poucas informações locais (SQLite, 2011).
3.1.5.4 MysqlClient
O MYSQLClient é uma biblioteca livre que implementa todo o protocolo de
comunicação que o MYSQL precisa para conseguir se comunicar com programas externos.
Esta biblioteca é desenvolvida em C e possibilita que um programa feito nesta linguagem
possa acessar este banco de dados, executando querys, select, update, insert, delete e
storage procedures (Mysql, 2011).
3.1.5.5 Glibc
A GLIBC é uma biblioteca de base onde estão disponíveis as principais funções para o
desenvolvimento em C. Como o C++ é totalmente compatível com sua antecessora C, é
necessário utilizar a biblioteca GLIBC (Linux, 2011).
3.1.5.6 Java EE
A plataforma Java Enterprise Edition (Java EE) é projetada para ajudar os
desenvolvedores a criar aplicações de rede em larga escala, multi-camadas, escaláveis,
confiáveis e seguras. Outra maneira de referenciar tais aplicações é chamá-las de
"aplicações corporativas", porque os aplicativos são projetados para resolver os problemas
enfrentados por grandes empresas. As aplicações corporativas são úteis não apenas para
grandes corporações e governos. Os benefícios de um aplicativo corporativo são úteis, até
mesmo essenciais, para os desenvolvedores individuais e pequenas empresas em um
mundo cada vez mais conectado.

24
As características que fazem aplicações corporativas poderosas, como a segurança e
confiabilidade, muitas vezes, tornam essas aplicações complexas. A plataforma Java EE é
projetada para reduzir a complexidade do desenvolvimento de aplicativos permitindo que
os desenvolvedores possam se aplicar inteiramente em seu negócio (JavaEE, 2011).
3.1.5.7 Facelets
O Facelets é um subprojeto do JSF mantido pela Oracle. Ele é facilmente integrado ao
JSF. As principais características do Facelets são: Permite integração com JSF 1.1 e 1.2,
incluindo a especificação da antiga Sun, hoje Oracle e o Apache Myfaces; Facilidade na
criação de templates; O atributo “jsfc” que permite incluir trechos de código JSF nas tags
HTML; Elimina o "JSP Compiler to Servlet" incrementando de 30% a 50% a performance
do sistema; Facilidade para criar componentes reutilizáveis; Usa XHTML como tecnologia
de view do JSF; Precisão para reportar erros (JavaEE, 2011).

25
4 Resultados
Os resultados do trabalho abordam os detalhes que envolvem a produção do projeto
como modelagem (baseada em Análise Orientada a Objetos) e implantação.
No presente capítulo estão expostas, de maneira detalhada, as etapas posteriores ao
levantamento de requisitos. Na etapa de modelagem apresentam-se as informações
pertinentes a descrição da arquitetura, requisitos funcionais e requisitos não-funcionais,
diagramas de classes, diagramas de casos de uso, diagramas de sequência e diagrama
entidade-relacionamento.
4.1 Modelagem
A Modelagem de software é a atividade de construir modelos que expliquem as
características ou o comportamento de um software. Na construção do software os
modelos podem ser usados na identificação das características e funcionalidades que o
software deverá prover, e no planejamento de sua construção. Geralmente a modelagem
utiliza diagramas para representar a inter ligação entre as partes do software sendo comum
mais de um tipo de diagrama representando parte macro e micro de um sistema,
representando as ligações de seus componentes.
4.1.1 Requisitos Funcionais
A idéia do projeto surgiu através de uma analogia sobre os programas disponíveis para
gerenciamento de rede Linux em seus aspectos positivos e negativos para que, o sistema
desenvolvido neste projeto possa melhorar os pontos negativos dos sistemas analisados.
Outros fatores importantes e altamente considerados que determinaram a idéia do projeto é
o desejo de utilizar bibliotecas amplamente utilizadas no mercado, explorar ao máximo a
criatividade para focar no aprendizado e, utilizar uma linguagem atrativa focada em itens
importantes para o auto-aprendizado.
As tarefas necessárias que o sistema gerenciador de script deve prover são:
Gerenciamento de scripts: O sistema deve prover uma forma de cadastramento
de scripts com execução remota nos computadores clientes instalada, como
também, a coleta das informações que estes scripts possam gerar.
Suporte a scripts: O sistema deve prover uma infra-estrutura genérica para que
o administrador do sistema possa desenvolver qualquer script que for
necessário, sem adicionar serviços na rede ou configurações, como também,

26
prover comandos para que o script criado pelo usuário possa trocar informações
entre o cliente e o servidor.
Sistema de troca de mensagens: O sistema provê a troca de mensagens entre
cliente e servidor concentrando os dados gerados pelo sistema em uma única
máquina na rede e, desta forma, facilitar a pesquisa de informações para a
tomada de decisões e ou correções do administrador.
Criptografia: Toda a troca de informações entre cliente e servidor deve ser
criptografada, impossibilitando quaisquer roubos de informações que os
computadores possam trocar pela rede.
Geração de relatórios e pesquisas: O Sistema deve prover uma interface gráfica
intuitiva e genérica para pesquisas e geração de relatórios das informações
centralizadas no servidor do sistema.
Sistema multiusuário: O sistema deve gerenciar diversos usuários e grupos,
atribuir permissões aos usuários e incapacitar usuários não habilitados para
executar ações pelo administrador.
Atualização do sistema: O sistema possui uma forma de atualização a fim de
evitar que os clientes fiquem com bugs (erros) que possam avariar ou
incapacitar o perfeito funcionamento do sistema.
4.1.2 Requisitos não Funcionais
Requisitos não-funcionais são os requisitos relacionados ao uso da aplicação em
termos de desempenho, usabilidade, confiabilidade, segurança, disponibilidade,
manutenção e tecnologias envolvidas. O sistema proposto possui os seguintes requisitos
não funcionais:
O sistema utiliza uma linguagem de programação nativa ao sistema operacional
possuindo uma grande velocidade ao ser executado, com isso, não é necessário
um computador com um hardware muito potente para que o sistema seja
executado;
Como o sistema utiliza uma linguagem de programação nativa ao sistema
operacional, o programa não depende de outros programas, facilitando sua
instalação. O sistema possui baixa dependência com a iteração de outros
programas e todos os utilitários necessários para o funcionamento do sistema
são distribuídos juntamente com a instalação do sistema operacional
GNU/Linux;

27
O sistema não gera a necessidade de um grande espaço em disco, pois, o
programa é bastante compacto, principalmente por ser desenvolvido utilizando
uma linguagem nativa ao sistema operacional. O maior espaço necessário é
para o funcionamento do banco de dados no servidor;
O sistema foi pensado e desenvolvido de forma assíncrona a partir de
bibliotecas disponibilizadas para este fim. Assim, o sistema utiliza os melhores
recursos disponibilizados pelo sistema operacional para efetuar todas suas
funcionalidades;
O sistema priva por uma interface gráfica simples e intuitiva facilitando toda a
administração dos computadores, possuindo páginas enxutas com somente o
necessário para evitar dificuldades e dúvidas na hora de cadastrar ou pesquisar
novos itens.
4.1.3 Descrição da arquitetura
Este tópico se propõe a explicar todo o funcionamento do sistema juntamente com
todas suas dependências e módulos. Cada subitem descreve uma parte do sistema. E
todos estes itens juntos formam o sistema gerenciador de script.
O sistema implementa uma arquitetura cliente-servidor, cujas trocas de informações
são feitas através de um protocolo próprio que utiliza criptografia e foi desenvolvido
exclusivamente para este programa.
O servidor possui uma interface gráfica desenvolvida em Java para visualizar os dados
que o sistema gera. Todos os relatórios a serem mostrados ao usuário são pesquisas feitas
no banco de dados. As informações são inseridas pelo módulo servidor do sistema, o qual
recebe estas informações dos clientes e as insere no banco de dados para futuras
pesquisas pelo módulo de interface gráfica.
O módulo cliente recebe os scripts e os metadados destes pelo módulo de troca de
mensagens, cadastrando esses scripts para serem executados internamente. Quando
estes scripts são executados eles podem gerar inúmeras informações que o cliente irá
coletá-las interpretá-las e após isto serão enviadas ao servidor para que sejam inseridas no
banco de dados.
A Figura 1 representa uma visão geral do sistema gerenciador de script como um todo.
É demonstrado na imagem o servidor do sistema gerenciador de script, o banco de dados,
os clientes do sistema gerenciador de script, e a rede do sistema. Os cadeados na rede
significam que toda a comunicação entre os clientes e o servidor é criptografada.

28
Cliente
Conexão
criptografada
Conexão
criptografada
Conexão
criptografada
Conexão
criptografada
Cliente
Cliente
Cliente
Conexão
criptografada
Servidor
Banco de dados
Figura 1 - Sistema gerenciador de script servidor e computadores clientes
4.1.3.1 Módulo de troca de mensagens
O módulo de troca de mensagens é um sistema baseado no modelo de Remote
Procedure Call (RPC), sendo que o servidor e o cliente possuem a mesma implementação
de troca de mensagens. O que difere o sistema da troca de mensagens do servidor e do
cliente são as classes que eles implementam para processar as informações recebidas.
Optou-se por criar um sistema próprio de troca de mensagens, principalmente pelo
aprendizado e, também, pela falta de um sistema simples que não exija compilar classes
complexas e criar tipos de dados específicos para cada item. Sendo assim, foi criado um
modelo simples e sem muitas particularidades, fácil de trabalhar, entender e criar uma
aplicação prática.
Utilizando um protocolo próprio e criptografado é possível chamar um método remoto
passando parâmetros e recebendo a resposta desta chamada. Para um método ser
chamado remotamente ele precisa obedecer a determinadas regras que estejam definidas
no design do sistema de chamada remota. Todas as classes que podem ser invocadas
remotamente devem herdar da classe RPC definida no sistema, não podem possuir
estados e precisam ser cadastradas na classe RPCFactory que vai ser consultada toda vez
que uma chamada referenciando esta classe chegar. Os métodos disponíveis desta classe,

29
a serem chamados remotamente, devem possuir uma assinatura pré-definida recebendo
dois parâmetros: duas classes definidas no sistema (Request, Response), que guardam
todas as informações de solicitação e resposta da chamada.
A chamada remota inicia-se quando o cliente ou o servidor faz uma solicitação para
executar um método do lado oposto e termina quando este método retorna, não sendo
possível que a classe remota tenha um estado.
Para manter a segurança na rede, evitando o roubo de informações ou a alteração
destas, é utilizado o protocolo SSL que confere segurança de comunicação na troca de
dados de uma rede não confiável e, para garantir a confiabilidade das duas partes, é
utilizado um certificado digital.
O protocolo SSL provê a privacidade e a integridade de dados entre duas aplicações
que se comuniquem pela Internet. Isto ocorre através da autenticação das partes
envolvidas e da cifra dos dados transmitidos entre as partes. Esse protocolo ajuda a
prevenir que intermediários, entre as duas pontas da comunicação, tenham acesso
indevido ou falsifiquem os dados transmitidos. As chaves devem ser fornecidas pelo
administrador do sistema quando o software for instalado.
Baseado nestas informações foi elaborado uma imagem que demonstra a
comunicação entre os módulos de troca de mensagens do cliente e do servidor (ver Figura
2). O cadeado na rede entre os dois módulos é para simbolizar que esta rede esta
criptografada usando TLS.
Servidor do sistema
gerenciador de script
Módulo de troca
de mensagens Módulo de troca
de mensagens
Conexão criptografada
Cliente do sistema
gerenciador de script
Figura 2 - Módulo de troca de mensagens

30
4.1.3.2 Gerenciamento de Scripts e controle de processos
O Módulo de gerenciamento de scripts e controle de processos é responsável pelo
gerenciamento de todos os scripts que podem ser executados e, do ciclo de vida de um
processo em execução.
O módulo que controla os scripts mantém todos os arquivos indexados e verifica sua
consistência sempre que for necessário executá-los. Quando o sistema recebe um novo
script, são geradas informações únicas deste e estas informações são armazenadas na
base de dados.
Antes de executar qualquer script, estas informações são validadas evitando assim que
esses arquivos venham a ser alterados ou infectados por algum outro usuário, evitando que
o computador seja invadido ou danificado a partir de uma fragilidade do sistema.
O módulo cuida, também, do ciclo de vida de uma tarefa que consiste em esperar a
hora inicial do script para então iniciar sua execução. Esta tarefa não pode ser feita pelo
CRON, pois em sistemas baseado em Unix as formas para gerenciar um processo que não
foi criado pelo seu sistema é restrita a simples funções de consultas o que inviabiliza toda a
coleta de dados. Após o script iniciar começa a fase de geração de informações onde são
coletados todos os dados impressos na saída padrão do script até o mesmo ser finalizado.
Estas informações coletadas são processadas para gerar informações consistentes
para serem enviadas ao servidor e devem respeitar certas regras para que os dados
possam ser inseridos de forma correta no banco de dados, facilitando a pesquisas futuras.
Além das informações processadas também são enviadas ao servidor informações
referentes à execução do script como horário de início e término de execução e o código de
saída, respeitando a regra de quando um programa finalizar com retorno 0, significa que
executou com sucesso. Se for diferente de 0, ocorreu algum erro.
A última etapa do ciclo de vida da tarefa consiste em verificar se o script deve voltar a
ser executado outra vez, senão ele será finalizado.
Para que o sistema gerenciador de script possa inserir os dados de forma correta no
banco de dados é necessário que os dados gerados respeitem uma regra e esta regra é
composta por chave e valor toda chave contem um ou mais valores. Para gerar o conceito
de lista de dados são utilizadas chaves ({}), todos os dados que são pertinentes a um grupo
de informações devem estar contidas dentro das chaves e para separar os elementos
dentro destas chaves devem-se utilizar colchetes ([]). Segue um exemplo desta regra, a
seguir:

31
{[NOME_DE_UMA_PROPRIEDADE_1: VALOR1; VALOR_2]
[NOME_DE_UMA_PROPRIEDADE_2: VALOR_1; VALOR_4]}
{[NOME_DE_UMA_PROPRIEDADE_1; VALOR_1; VALOR_2]
[NOME_DE_UMA_PROPRIEDADE_2; VALOR_3; VALOR_4]}
A Figura 3, que exemplifica esta regra, nesta imagem é executado um comando e
gerado uma saída que o sistema gerenciador de script consegue inserir no banco de dados
de forma correta.
Figura 3 - Exemplo para gerar dados consistentes ao sistema gerenciador de script
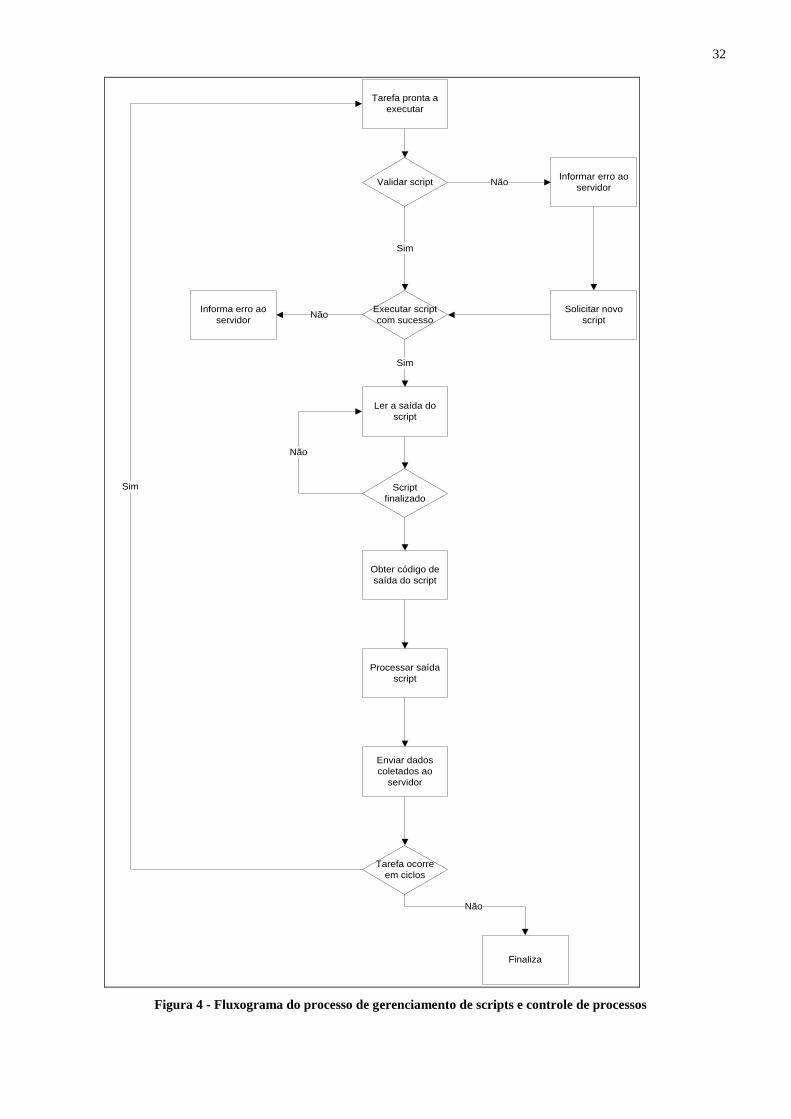
Baseado no ciclo de vida da execução de uma tarefa foi criado um fluxograma para
detalhar este processo. A Figura 4 é a explicação visual do ciclo de vida do gerenciamento
de scripts e processos.
32
Tarefa pronta a
executar
Validar script
Executar script
com sucesso
Informar erro ao
servidorNão
Sim
Solicitar novo
script
Informa erro ao
servidorNão
Ler a saída do
script
Script
finalizado
Sim
Não
Obter código de
saída do script
Processar saída
script
Enviar dados
coletados ao
servidor
Tarefa ocorre
em ciclos
Sim
Finaliza
Não
Figura 4 - Fluxograma do processo de gerenciamento de scripts e controle de processos

33
4.1.3.3 Arquitetura do servidor
O servidor do sistema de gerenciamento de script auxilia e centraliza toda a
manutenção, correção, coleta de informação e tomada de decisões da rede, não
necessitando que o administrador do sistema tenha acesso a alguma máquina cliente para
fazer alguma tarefa.
Todas as tarefas são feitas através de scripts que o administrador da rede deve
desenvolver. O sistema provê um suporte para que dados específicos sejam armazenados
para pesquisas e através de consultas à interface gráfica, pode-se obter os dados gerados
pelos scripts e armazenados no banco de dados central.
Para que o servidor funcione corretamente ele precisa de vários módulos, os quais,
juntos, compõem o sistema servidor. Os módulos que compõem este sistema são: O
módulo de troca de mensagem e o módulo de gerenciamento de scripts e controle de
processos, os quais já foram expostos anteriormente, somados aos módulos expostos a
seguir: módulo de controle de script e recebimento de dados, módulo do banco de dados e
módulo de controle de usuários e acessos.
4.1.3.3.1 Módulo de controle de scripts e recebimento de dados
O módulo de controle de scripts e recebimento de dados é responsável por gerenciar a
distribuição dos scripts na rede e o recebimento dos dados para armazenamento no
servidor.
Quando se cria uma nova tarefa, esta é atribuída a alguns computadores, então este
módulo envia o código fonte do script e todos os metadados para a execução deste script
para o computador cliente, inserindo no banco de dados todas as informações pertinentes
a esta operação.
O módulo recebe as informações geradas pelo computador cliente e localiza a
instância desta execução inserida no banco de dados e atualiza estes dados de acordo
com as informações recebidas. Essas informações servem de matéria prima para outras
análises e ficarão disponíveis para serem visualizadas pelo sistema web, e para a criação
de querys no banco de dados permitindo aos usuários do sistema fazer pesquisas
direcionadas à coleta de informações e avaliação da rede.

34
4.1.3.3.2 Banco de dados
Para que o sistema armazene todos os dados é necessário um banco de dados
relacional que guarda todas as informações para futuras pesquisas.
Este banco de dados centraliza todas as informações pertinentes ao sistema como
scripts, contas de usuários, computadores da rede, informações dos scripts gerados
através dos clientes.
No banco de dados, são armazenadas todas as informações que o sistema servidor
necessita para funcionar e manter um histórico de todo seu funcionamento como, dados
recebidos dos clientes, históricos passados, informações necessárias para execução de
scripts, usuários existentes no sistema, configurações dos clientes e resultados das
execuções dos scripts. Faz, também, a verificação dos dados para evitar inconsistências de
dados no servidor. Maiores detalhes podem ser visto na Figura 5.
Todos os dados são acessados através da biblioteca que o banco de dados
disponibiliza que estas bibliotecas já foram descritas.
4.1.3.3.3 Níveis de acessos dos usuários
O projeto foi pensando para ser um sistema que possa ser administrado por diversos
usuários, assim, foi desenvolvido um módulo de gerenciamento de usuários onde o
administrador central do programa cadastrará usuários e atribuirá permissões para
utilização do sistema, possibilitando a criação de grupos e suas respectivas permissões ou,
ainda, adicionar um usuário a um grupo específico.
As permissões habilitam, ou não, que os usuários façam pesquisas e novas tarefas
garantindo que nenhum usuário do sistema, que não seja autorizado, possa executar uma
tarefa nos computadores clientes causando invasões ou roubo de informações.
Todos os usuários podem possuir diferentes acessos ao sistema, sendo que para os
usuários mais simples são disponibilizados somente a pesquisa dos dados e, para os que
possuem permissão de administrador, lhes é atribuído o acesso total ao sistema.
Os usuários com permissões restritas estão delimitados a pesquisar os resultados dos
scripts e fazer querys baseados nos dados do banco. Já os usuários com direitos
administrativos têm acesso total ao sistema para criar, remover ou alterar scripts, e
também, pesquisar todos os tipos de dados.

35
4.1.3.3.4 Módulo Assistant
Pensando na fácil administração do sistema, foi criada uma interface gráfica intuitiva e
bastante amigável para manusear o sistema gerenciador de script. Todos os dados
coletados precisam ser pesquisados no banco de dados, e novas regras precisam ser
adicionadas ao sistema gerenciador de script para fazer a coleta dos dados. Toda esta
tarefa é feita pela assistant do gerenciador de script.
Para que o assistant do gerenciador de script possa mostrar todos os dados coletados,
é necessário que ele tenha acesso ao banco de dados em que são guardadas todas as
informações coletadas na rede. Também pensando na otimização e na modularização do
sistema, o assistant necessita implementar um pequeno protocolo para conversar com o
sistema gerenciador de script para assim informá-lo sobre novas configurações, adição de
usuários, criação e remoção de scripts e tarefas.
Todas essas informações são trocadas através de um protocolo pela rede, que o
sistema gerenciador de script provê para facilitar a troca de mensagens, não depender que
o banco de dados precise informar o sistema gerenciador de script caso algum dado seja
modificado e assim, mantendo a modularização do sistema.
A Figura 5 representa a topologia do sistema servidor, com seus módulos. É possível
ver na imagem que o servidor é composto por um módulo de controle de scripts, um
módulo de troca de mensagens, um módulo de gerenciamento de scripts e controle de
processos, um servidor web e um banco de dados.

36
Módulo de troca
de mensagens
Módulo Assistant
Gerenciador de
conexões e dados
Servidor do sistema
gerenciador de scripts
Módulo gerenciador de scripts
e controle processos
Módulo de controle
de scripts
Figura 5 - Modelo da Arquitetura do Servidor
4.1.3.4 Arquitetura do Cliente
Os clientes do sistema do gerenciador de script trabalham de maneira isolada nas
estações de trabalho, não necessitando nenhuma dependência da rede, apenas das
informações para trabalhar. Exemplo: tarefas a executar.
Todas estas informações, scripts e metadados são enviados através da rede pelo
servidor e o cliente, após processar as tarefas, envia as informações geradas ao servidor
para centralizar as informações.
O software cliente é baseado em alguns módulos que são o módulo de troca de
mensagens já explicado, o módulo de gerenciador de scripts e controle de processos
também já explicados, somados aos seguintes módulos específicos do cliente a saber,
módulo modo off-line, módulo banco de dados local e módulo arquivo de configuração.
4.1.3.4.1 Modo off-line
O funcionamento de uma rede é instável e, com isto, pode ocorrer que o servidor fique
inatingível para um computador, desta forma, os clientes precisam armazenar as
informações até que o servidor volte a ser encontrado na rede, evitando a perda de
informações. Para isto foi desenvolvido o estado off-line, que é ativado automaticamente
pelo sistema de troca de mensagens do cliente para guardar todas as informações que

37
seriam enviadas caso não localize o servidor na rede, assim, os clientes podem funcionar
de maneira isolada mesmo perdendo a conexão com o servidor.
Caso isso aconteça, o cliente armazena todas as informações que seriam enviadas ao
servidor em um arquivo temporário. A partir do momento em que o servidor for localizado
na rede, o cliente envia os dados armazenados localmente.
4.1.3.4.2 Banco de dados
O banco de dados do cliente utiliza a biblioteca SQLite, eleito por ser um pequeno e
compacto banco de dados, que guarda todas as informações em um único arquivo e todo o
seu acesso se dá através desta API.
Este banco de dados é utilizado somente para guardar informações temporárias ou
dados pertinentes a este computador, evitando a perda das mesmas, caso o sistema fique
off-line ou, caso aconteça um abrupto desligamento da máquina com o sistema, podendo
sempre retomar o funcionamento com mínima quantidade de perda de dados.
Também são guardadas, neste servidor, informações que o administrador da rede
queira armazenar através dos scripts por intermédio de um comando que provê uma forma
de armazenar estes dados.
4.1.3.4.3 Arquivo de configuração
O cliente necessita ser orientado, através de algumas informações para iniciar o
funcionamento do sistema para carregar seus módulos e entrar em contato com o servidor.
Para estabelecer essa comunicação com o servidor o cliente necessita do IP e da porta
do servidor. Necessita, também, da chave pública da autoridade certificadora para validar o
certificado que o servidor enviará para então estabelecer, com sucesso, a comunicação
entre eles.
É necessário, também, localizar o arquivo de banco de dados juntamente com seu
usuário e senha para que o cliente possa guardar dados, caso o servidor esteja
indisponível, para carregar todas as suas informações locais. O cliente necessita, ainda,
localizar a pasta onde se encontram guardados os seus scripts para, então, ter todas as
suas dependências externas resolvidas.
Estes são os dados que o arquivo de configuração guarda para o correto
funcionamento do programa.
38
4.1.3.4.4 Programas de Suporte
Os programas de suporte são pequenos executáveis com a finalidade de aumentar a
interatividade dos scripts com o sistema. Estes pequenos programas podem enviar
informações para o servidor que irá guardar no banco de dados para que o administrador
possa fazer pesquisas futuras no sistema, como também coletar informações do sistema
para auxiliar e aumentar o poder de interatividade com o sistema.
BD_access: Envia e obtém informações ao banco de dados do servidor ou
guarda no banco de dados local.
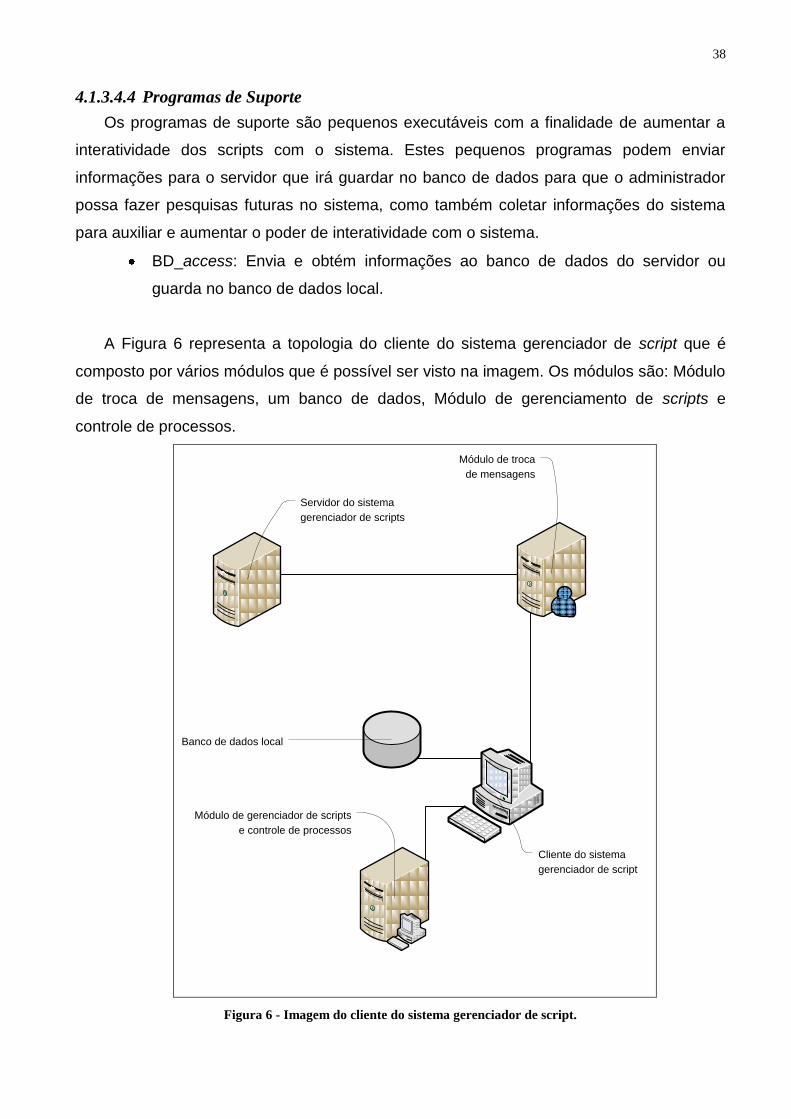
A Figura 6 representa a topologia do cliente do sistema gerenciador de script que é
composto por vários módulos que é possível ser visto na imagem. Os módulos são: Módulo
de troca de mensagens, um banco de dados, Módulo de gerenciamento de scripts e
controle de processos.
Servidor do sistema
gerenciador de scripts
Módulo de gerenciador de scripts
e controle de processos
Módulo de troca
de mensagens
Cliente do sistema
gerenciador de script
Banco de dados local
Figura 6 - Imagem do cliente do sistema gerenciador de script.
39
4.1.4 Diagramas de Casos de Uso
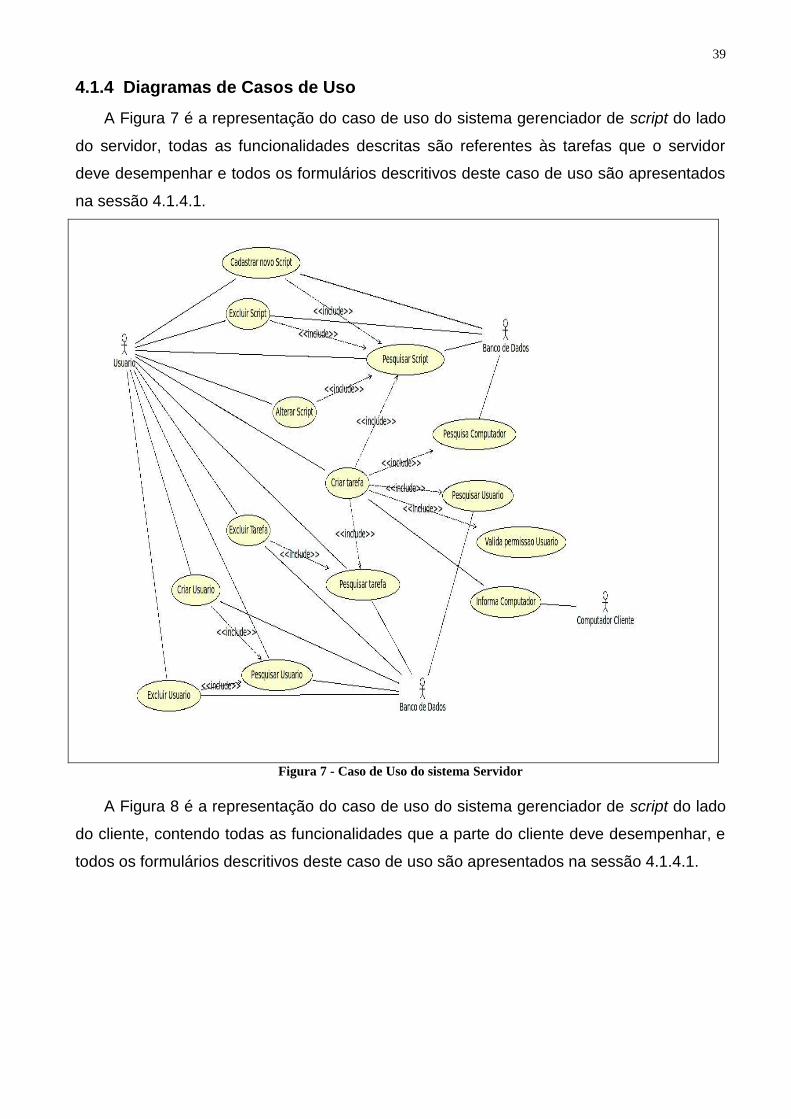
A Figura 7 é a representação do caso de uso do sistema gerenciador de script do lado
do servidor, todas as funcionalidades descritas são referentes às tarefas que o servidor
deve desempenhar e todos os formulários descritivos deste caso de uso são apresentados
na sessão 4.1.4.1.
Figura 7 - Caso de Uso do sistema Servidor
A Figura 8 é a representação do caso de uso do sistema gerenciador de script do lado
do cliente, contendo todas as funcionalidades que a parte do cliente deve desempenhar, e
todos os formulários descritivos deste caso de uso são apresentados na sessão 4.1.4.1.

40
Figura 8 - Caso de Uso do sistema Cliente
4.1.4.1 Formulários descritivos dos Casos de Uso
Nesta seção serão apresentadas as descrições dos casos de uso de forma detalhada,
apresentando os fluxos, atores e informações acessórias. A Tabela 2 representa a ação
Cadastrar novo script do caso de uso do servidor.
Tabela 2 - Caso de Uso Cadastrar novo Script
Nome do Caso de Uso Cadastrar novo Script
Descrição Permite cadastrar um novo script no
sistema, para ser usado por uma tarefa a
ser cadastrada
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução.
Pós-Condições Informações armazenadas no banco de
dados.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes ao script.
Utiliza o caso de uso {Pesquisar Script}
para verificar se já existe um script com as
informações, inserindo no banco de dados
o script caso o Script não exista ou
abortando a operação caso exista.
{Fim}
41
A Tabela 3 representa a ação Excluir Script do caso de uso do servidor.
Tabela 3 - Caso De Uso Excluir Script
Nome do Caso de Uso Excluir Script
Descrição Permite excluir um script existente
Atores Envolvidos Usuário, banco de Dados
Pré-Condições O banco de dados deve estar em execução
e o Script estar cadastrado no Banco de
Dados
Pós-Condições O Script não deve existir mais no Sistema
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Seleciona o script que deseja excluir
Utiliza o caso de uso {Pesquisar Script}
para verificar se o script existe, se existir
exclui o script senão aborta a operação
{FIM}
A Tabela 4 representa a ação Pesquisar Script do caso de uso do servidor.
Tabela 4 - Caso de Uso Pesquisar Script
Nome do Caso de Uso Pesquisar Script
Descrição Permite cadastrar se um script já existe
baseado em seu nome
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução.
Pós-Condições Retorno da Informação
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo ou do
Sistema interno}
Insere informações na interface gráfica
referentes ao script.
Recebe informação sobre o script que deve
ser pesquisado.
Pesquisa baseado no nome do script se ele
existe.
42
{Fim}
A Tabela 5 representa a ação Alterar Script do caso de uso do servidor.
Tabela 5 - Caso de Uso Alterar Script
Nome do Caso de Uso Alterar Script
Descrição Permite alterar um script existente no
sistema.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em execução
e o script deve existir no banco de dados.
Pós-Condições Script alterado no banco de dados.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes ao script.
Utiliza o caso de uso {Pesquisar Script}
para verificar se já existe um script com as
informações, alterando no banco de dados
o script caso ele exista senão aborta a
operação.
{Fim}
A Tabela 6 representa a ação Criar Usuário do caso de uso do servidor.
Tabela 6 - Caso de Uso Criar Usuário
Nome do Caso de Uso Criar Usuário
Descrição Permite cadastrar um novo usuário no
sistema.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução.
Pós-Condições Informações armazenadas no banco de
dados.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
43
Insere informações na interface gráfica
referentes ao novo usuário.
Utiliza o caso de uso {Pesquisar Usuário}
para verificar se já existe um usuário com
as informações, caso não exista insere o
usuário no banco de dados senão aborta a
operação.
{Fim}
A Tabela 7 representa a ação Excluir Usuário do caso de uso do servidor.
Tabela 7 - Caso de Uso Excluir Usuário
Nome do Caso de Uso Excluir Usuário
Descrição Permite excluir um usuário existente no
sistema.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução, o usuário a ser excluído deve
existir.
Pós-Condições Informações excluídas do banco de dados.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes ao usuário.
Utiliza o caso de uso {Pesquisar usuário}
para verificar se o usuário existe no banco
de dados, excluindo o usuário caso exista
senão aborta a operação.
{Fim}
A Tabela 8 representa a ação Pesquisar Usuário do caso de uso do servidor.
Tabela 8 - Caso de Uso Pesquisar Usuário
Nome do Caso de Uso Pesquisar Usuário
Descrição Permite pesquisar se um usuário existe no
sistema.
Atores Envolvidos Usuário, Banco de Dados
44
Pré-Condições O banco de dados deve estar em
execução.
Pós-Condições Informações armazenadas no banco de
dados.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo ou
interno}
Insere informações na interface gráfica
referentes ao usuário.
Insere informações a pesquisar
Pesquisa no banco de dados procurando
as informações do usuário, informando se
ele existe ou não.
{Fim}
A Tabela 9 representa a ação Criar Tarefa do caso de uso do servidor.
Tabela 9 - Caso de Uso Criar Tarefa
Nome do Caso de Uso Criar tarefa
Descrição Permite criar uma nova tarefa para o
sistema.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução, o script, o usuário e o
computador devem existir no banco de
dados.
Pós-Condições Informações armazenadas no banco de
dados e o computador alvo é informado da
nova tarefa.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes a tarefa.
Utiliza o caso de uso {Pesquisar Script},
{Pesquisar Usuário}, {Pesquisar tarefa},
45
{Pesquisar Computador} e {Valida
Permissão Usuário} para validar todas as
dependências da tarefa para então criar a
tarefa, caso ocorra um erro em qualquer
uma das operações incluídas é abortado a
operação.
{Fim}
A Tabela 10 representa a ação Excluir Tarefa do caso de uso do servidor.
Tabela 10 - Caso de Uso excluir tarefa
Nome do Caso de Uso Excluir Tarefa
Descrição Permite excluir uma tarefa existente.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em execução
e os dados a serem excluídos devem existir
no banco de dados.
Pós-Condições Os dados excluídos do banco de dados.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes a tarefa.
Utiliza o caso de uso {Pesquisar Tarefa}
para verificar se já existe uma tarefa com
as informações, se existir deleta senão
aborta a operação.
{Fim}
A Tabela 11 representa a ação Pesquisar Tarefa do caso de uso do servidor.
Tabela 11 - Caso de Uso Pesquisar Tarefa
Nome do Caso de Uso Pesquisar Tarefa
Descrição Permite pesquisar uma tarefa existente.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução.
Pós-Condições O retorno das informações.
46
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes a tarefa.
Recebe os dados para a pesquisa do
sistema.
Pesquisa no banco de dados se a tarefa
existe com base nos dados fornecidos.
Caso exista retorna esta tarefa. Senão,
aborta a operação.
{Fim}
A Tabela 12 representa a ação Pesquisar Computador do caso de uso do servidor.
Tabela 12 - Caso de Uso Pesquisar Computador
Nome do Caso de Uso Pesquisar Computador
Descrição Permite pesquisar se um computador
existe no banco de dados.
Atores Envolvidos Usuário, Banco de Dados
Pré-Condições O banco de dados deve estar em
execução.
Pós-Condições Informa o computador existente.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes ao computador.
Pesquisa no banco de dados se existe um
computador com os dados informados,
retornando os dados pedidos ou abortando
a operação.
{Fim}
A Tabela 13 representa a ação Valida Permissão Usuário do caso de uso do servidor.
Tabela 13 - Caso de Uso Valida Permissão Usuário
Nome do Caso de Uso Valida Permissão Usuário
Descrição Permite validar as permissões do usuário.
Atores Envolvidos Usuário, Banco de Dados
47
Pré-Condições O banco de dados deve estar em
execução, usuário deve existir no sistema.
Pós-Condições Informa se o usuário possui as permissões
para efetuar a operação.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação do sistema externo}
Insere informações na interface gráfica
referentes ao usuário.
Insere as informações do usuário
Utiliza o caso de uso {Pesquisar Usuário}
para utilizar as informações retornadas por
ele para validar as permissões do usuário,
informando se a validação foi retornada
com sucesso ou não.
{Fim}
A Tabela 14 representa a ação Informa Computador do caso de uso do servidor.
Tabela 14 - Caso de Uso Informa Computador
Nome do Caso de Uso Informa Computador
Descrição Utiliza o sistema de troca de mensagens
para informar um computador sobre uma
operação.
Atores Envolvidos Usuário, Computador cliente
Pré-Condições O banco de dados deve estar em
execução, dados a serem enviados ao
computador alvo devem ser válidos.
Pós-Condições .
Fluxo Básico
Sistema Externo Sistema
Dados a serem enviados ao cliente são
construídos usando a infra-estrutura de
troca de mensagens para enviar os dados
ao computador.
{Fim}
48
A Tabela 15 representa a ação Adicionar Tarefa do caso de uso do cliente.
Tabela 15 - Adicionar Tarefa
Nome do Caso de Uso Adicionar tarefa
Descrição Permite adicionar uma nova tarefa para
cliente executar.
Atores Envolvidos Servidor, Banco de Dados local
Pré-Condições O arquivo de banco de dados deve existir,
e a tarefa já deve ter sido criada
anteriormente no servidor.
Pós-Condições Informações armazenadas no banco de
dados local e a tarefa será executada
quando suas condições forem válidas.
Fluxo Básico
Sistema Externo Sistema
{Aguarda servidor informar da nova tarefa}
Servidor envia os dados sobre esta tarefa.
Utiliza o caso de uso {Gerenciar Tarefa},
para inserir os dados corretamente no
banco de dados local e cadastrar esta
tarefa para ser executada.
{Fim}
A Tabela 16 representa a ação Excluir Tarefa do caso de uso do cliente.
Tabela 16 - Excluir Tarefa
Nome do Caso de Uso Excluir tarefa
Descrição Permite excluir uma tarefa do sistema
cliente.
Atores Envolvidos Servidor, Banco de dados local
Pré-Condições O banco de dados local deve existir, e a
tarefa deve estar cadastrada no sistema
cliente.
Pós-Condições Informações deletadas do cliente.
Fluxo Básico
Sistema Externo Sistema
49
{Aguarda ação do servidor}
Informa o cliente que deve deletar a tarefa.
Utiliza o caso de uso {Gerenciar Tarefa}
para verificar se a tarefa existe e esta em
execução.
{Fim}
A Tabela 17 representa a ação Executar tarefa do caso de uso do cliente.
Tabela 17 - Executar Tarefa
Nome do Caso de Uso Executar tarefa
Descrição Permite executar uma tarefa.
Atores Envolvidos Servidor, Banco de Dados Local
Pré-Condições O banco de dados loca deve existir, e a
tarefa deve estar cadastrada no sistema
cliente.
Pós-Condições Tarefa executada.
Fluxo Básico
Sistema Externo Sistema
{Aguarda ação servidor}
Servidor informa o cliente que deve
executar a tarefa
Utiliza o caso de uso {Validar Script} para
verificar se o script existe e é valido,
executa o script, coleta seus dados
processa e envia ao servidor.
{Fim}
A Tabela 18 representa a ação gerenciar tarefa do caso de uso do cliente.
Tabela 18 - Gerenciar Tarefa
Nome do Caso de Uso Gerenciar tarefa
Descrição Permite gerenciar as tarefas do sistema
cliente.
Atores Envolvidos Banco de Dados local
Pré-Condições O banco de dados local deve existir.
Pós-Condições

50
Fluxo Básico
Sistema Externo Sistema
{Aguarda condição da tarefa ser válida}
Utiliza o caso de uso {Executar tarefa}, Fica
esperando que uma condição da tarefa
seja válida para executá-la.
{Fim}
A Tabela 19 representa a ação do caso de uso do cliente.
Tabela 19 - Validar Script
Nome do Caso de Uso Validar Script
Descrição Permite validar se o script é valido ou não
Atores Envolvidos Banco de Dados local
Pré-Condições O banco de dados local e o script devem
existir.
Pós-Condições Script validado.
Fluxo Básico
Sistema Externo Sistema
Sistema pesquisa dados no banco de
dados local sobre este script e o valida.
{Fim}
4.1.5 Diagrama de Classes
O diagrama de classes é uma representação da estrutura e relações das classes que
servem de modelo para objetos.
Neste tópico estão presentes todos os diagramas de classes do sistema, com suas
devidas explicações.
4.1.5.1 Troca de Mensagens
A Figura 9 é o diagrama de classes do módulo de troca de mensagens nele estão
descritos os principais itens do módulo. O módulo consiste em classes que herdam da
classe RPC, esta classe deve possuir todos os métodos que podem ser chamados
remotamente. Todos estes métodos devem ser incluídos no método method_possible_call,
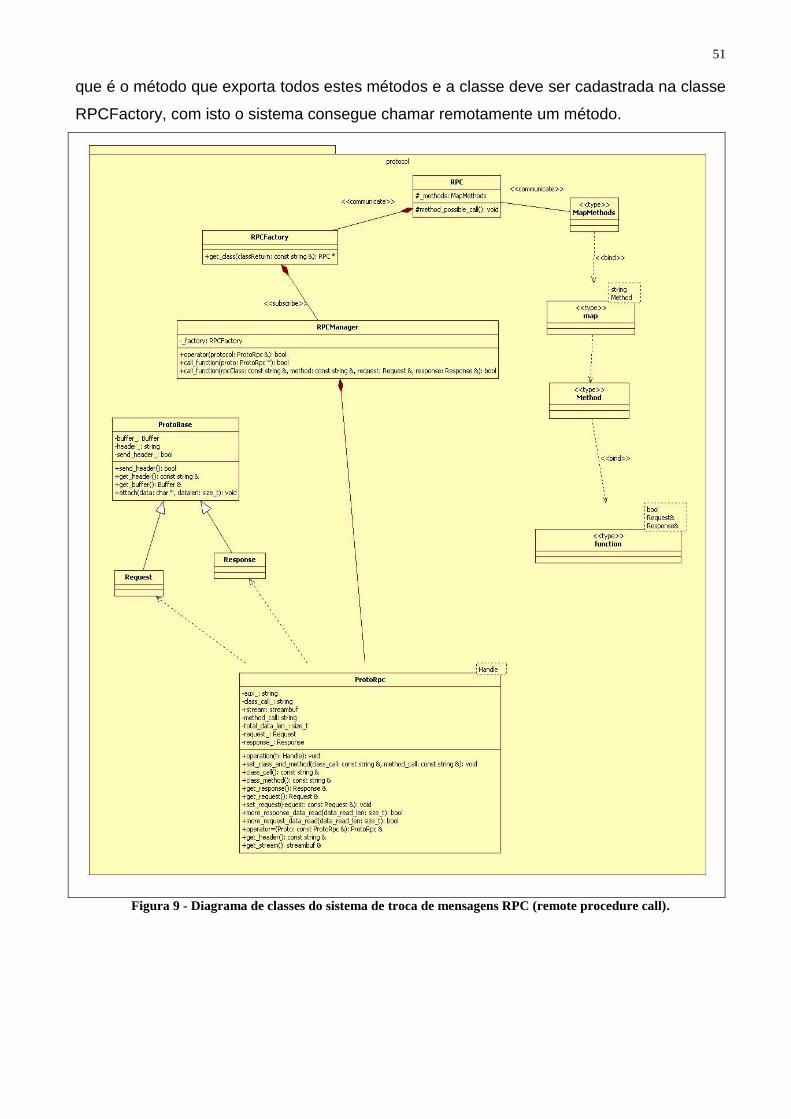
51
que é o método que exporta todos estes métodos e a classe deve ser cadastrada na classe
RPCFactory, com isto o sistema consegue chamar remotamente um método.
Figura 9 - Diagrama de classes do sistema de troca de mensagens RPC (remote procedure call).
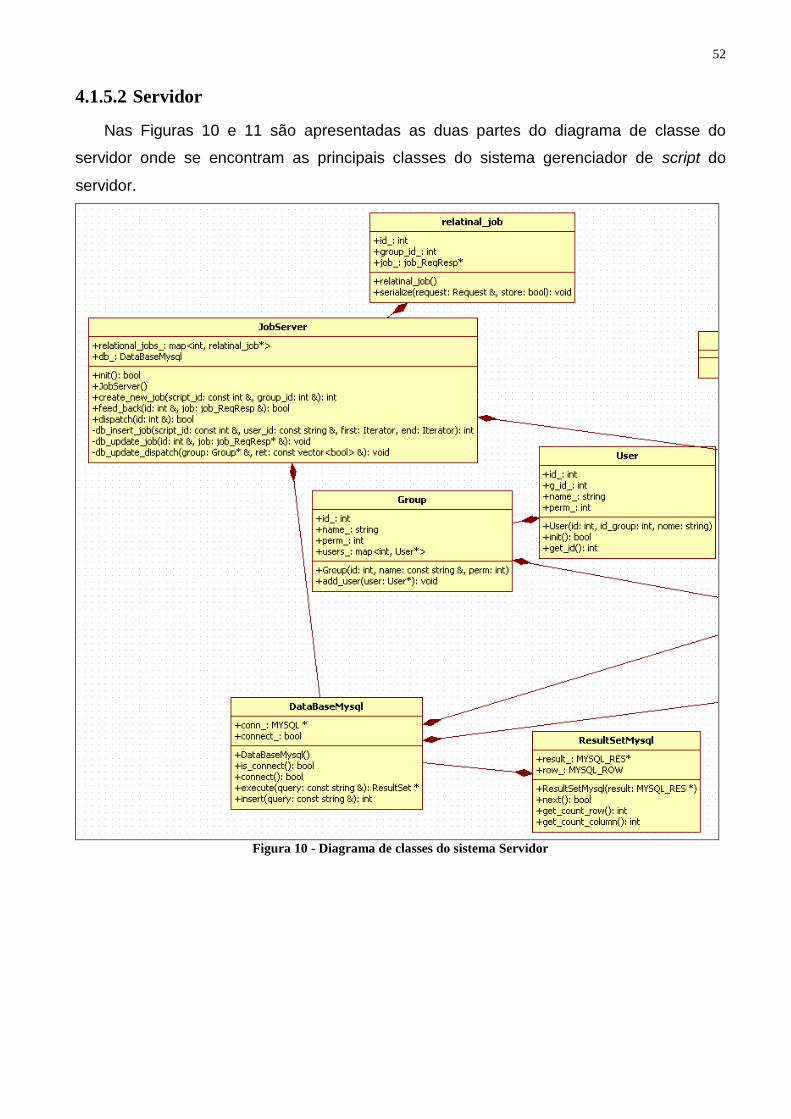
52
4.1.5.2 Servidor
Nas Figuras 10 e 11 são apresentadas as duas partes do diagrama de classe do
servidor onde se encontram as principais classes do sistema gerenciador de script do
servidor.
Figura 10 - Diagrama de classes do sistema Servidor
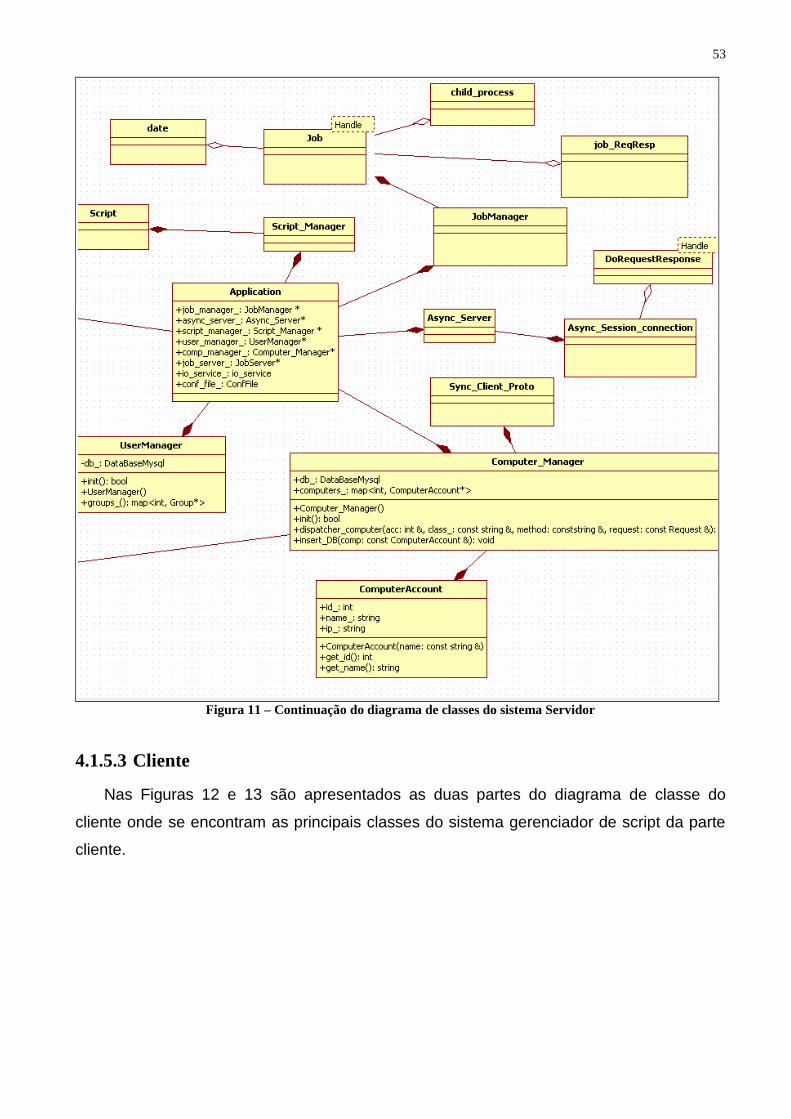
53
Figura 11 – Continuação do diagrama de classes do sistema Servidor
4.1.5.3 Cliente
Nas Figuras 12 e 13 são apresentados as duas partes do diagrama de classe do
cliente onde se encontram as principais classes do sistema gerenciador de script da parte
cliente.
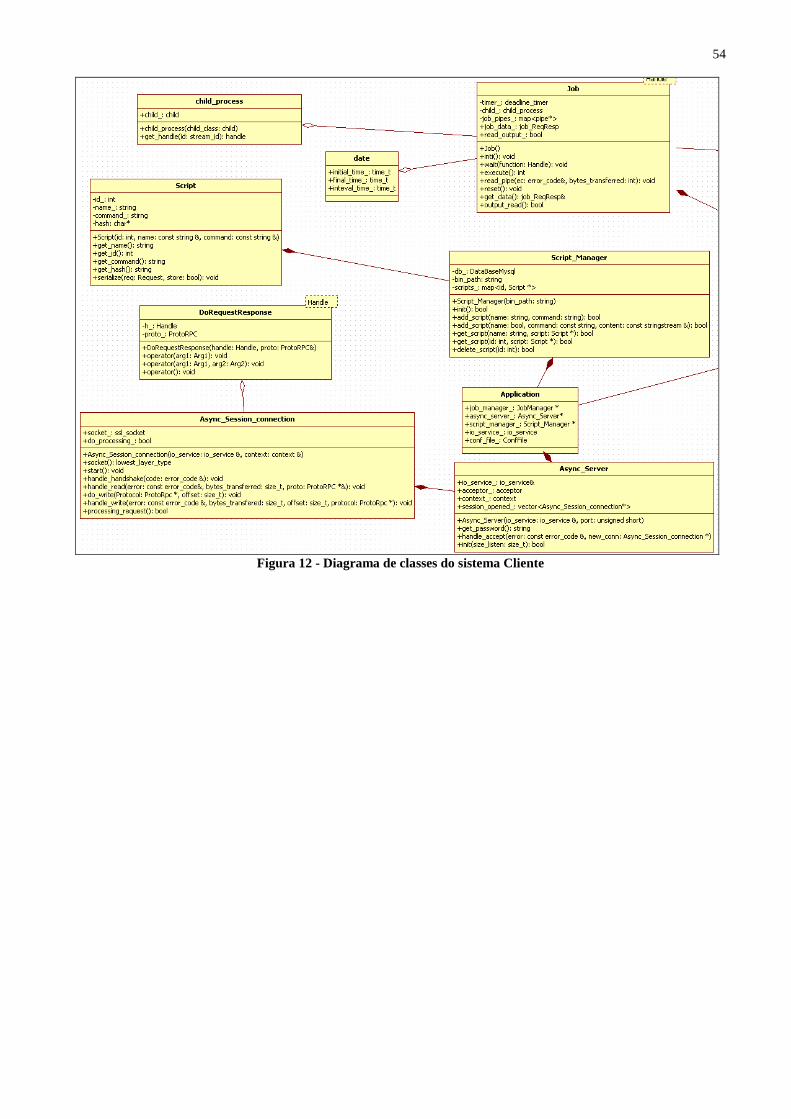
54
Figura 12 - Diagrama de classes do sistema Cliente
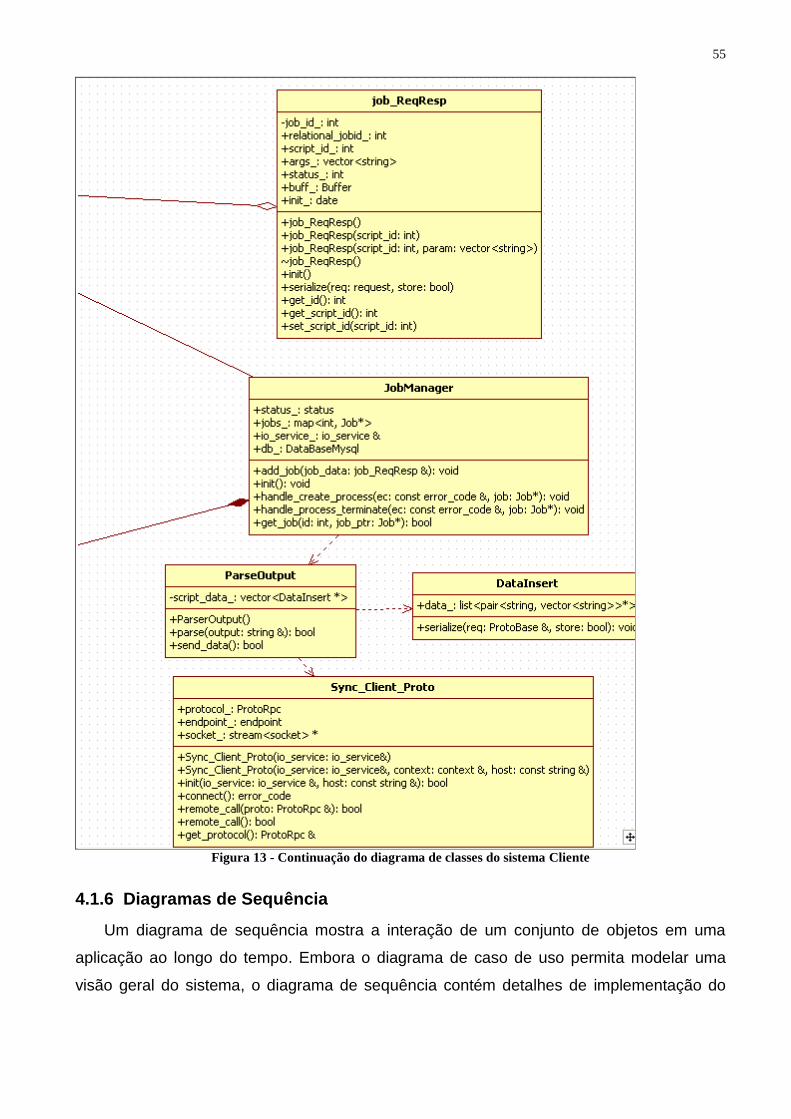
55
Figura 13 - Continuação do diagrama de classes do sistema Cliente
4.1.6 Diagramas de Sequência
Um diagrama de sequência mostra a interação de um conjunto de objetos em uma
aplicação ao longo do tempo. Embora o diagrama de caso de uso permita modelar uma
visão geral do sistema, o diagrama de sequência contém detalhes de implementação do

56
cenário, incluindo objetos e classes que são usadas para implementar o cenário, e as
mensagens trocadas entre os objetos.
Abaixo são descritos os principais diagramas de sequência do sistema, as principais
interações que o sistema exige para funcionar, que é a criação de uma nova tarefa, a
execução de uma tarefa no cliente e o servidor incluir as informações no banco de dados.
O diagrama de sequência apresentado na Figura 14 demonstra a adição de uma nova
tarefa ao sistema, o sistema espera da interface gráfica dados da nova tarefa para incluí-
los no banco de dados, e também informa o cliente da nova tarefa que ele deve executar.
Figura 14 - Diagrama de sequência para adicionar uma nova tarefa
O diagrama de sequência apresentado na Figura 15 demonstra quando o servidor
recebe as informações do cliente processadas, e insere-as no banco de dados para que
estejam disponíveis para pesquisas. O sistema espera que o módulo de troca de
mensagens informe-o dos dados recebidos para, então, inseri-los no banco de dados.

57
Figura 15 - Diagrama de sequência inserção das informações no banco de dados
O diagrama de sequência apresentado na Figura 16 demonstra quando o cliente
recebe uma tarefa do servidor e inicia o processamento desta, para futuramente informar
ao servidor sobre as informações geradas. O sistema espera que o módulo de troca de
mensagens informe-o sobre novas tarefas a serem processadas. Quando possuir uma
nova tarefa, o sistema aguarda até que a condição de execução seja válida para então
executá-la. Após isto, inicia-se um processo de leitura da saída padrão deste script até sua
finalização. Quando o sistema verifica que o script foi encerrado, são processadas as
informações recebidas e então, enviadas ao servidor para que sejam inseridas no banco de
dados central.

58
Figura 16 - Diagrama de sequência execução de uma tarefa
4.1.7 Diagrama Entidade-Relacionamento
O modelo de entidades e relacionamentos é um modelo abstrato cuja finalidade é
descrever, de maneira conceitual, os dados a serem utilizados em um sistema de
informações ou que pertencem a um domínio.
4.1.7.1 Servidor
Esta seção tem como objetivo explicar o banco de dados, do sistema de
gerenciamento de script.
A Figura 17 representa o diagrama de entidade do banco de dados do servidor, cuja
imagem representa a relação que existe entre as tabelas no banco de dados. As oito
tabelas que compõem o banco de dados são: DataValue, DataType, Computer,
JobInstance, Job, Script, User e GroupUser.
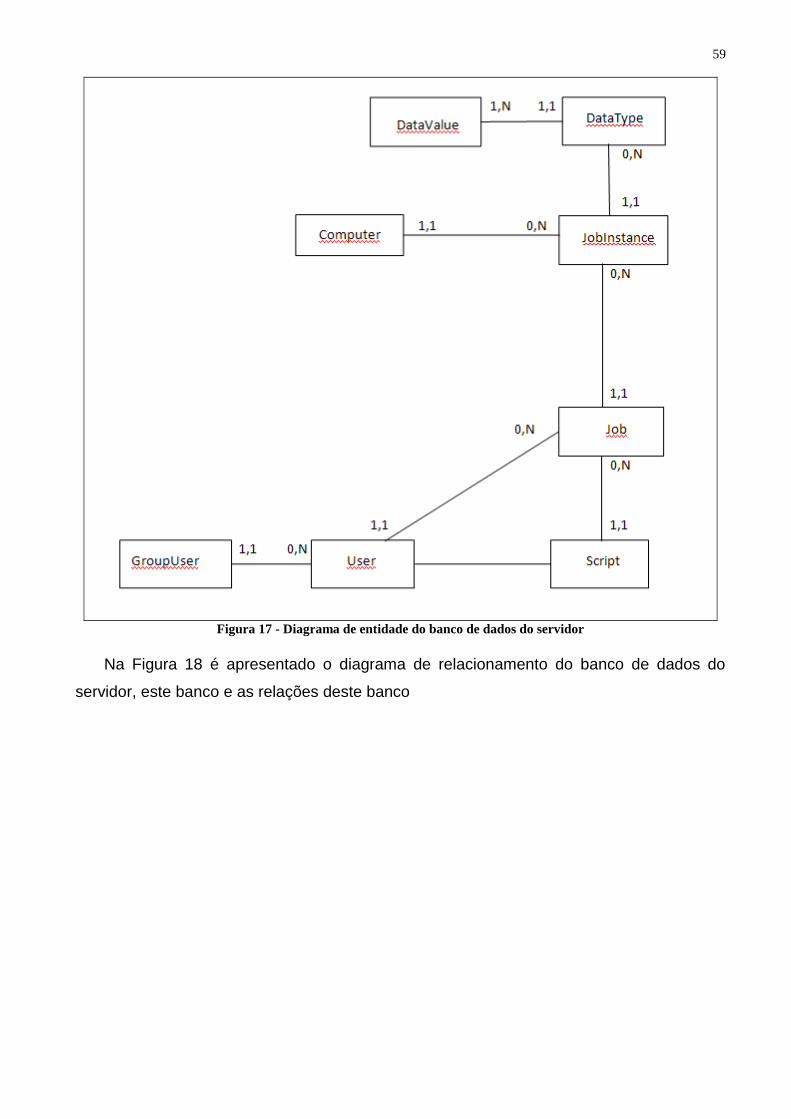
59
Figura 17 - Diagrama de entidade do banco de dados do servidor
Na Figura 18 é apresentado o diagrama de relacionamento do banco de dados do
servidor, este banco e as relações deste banco
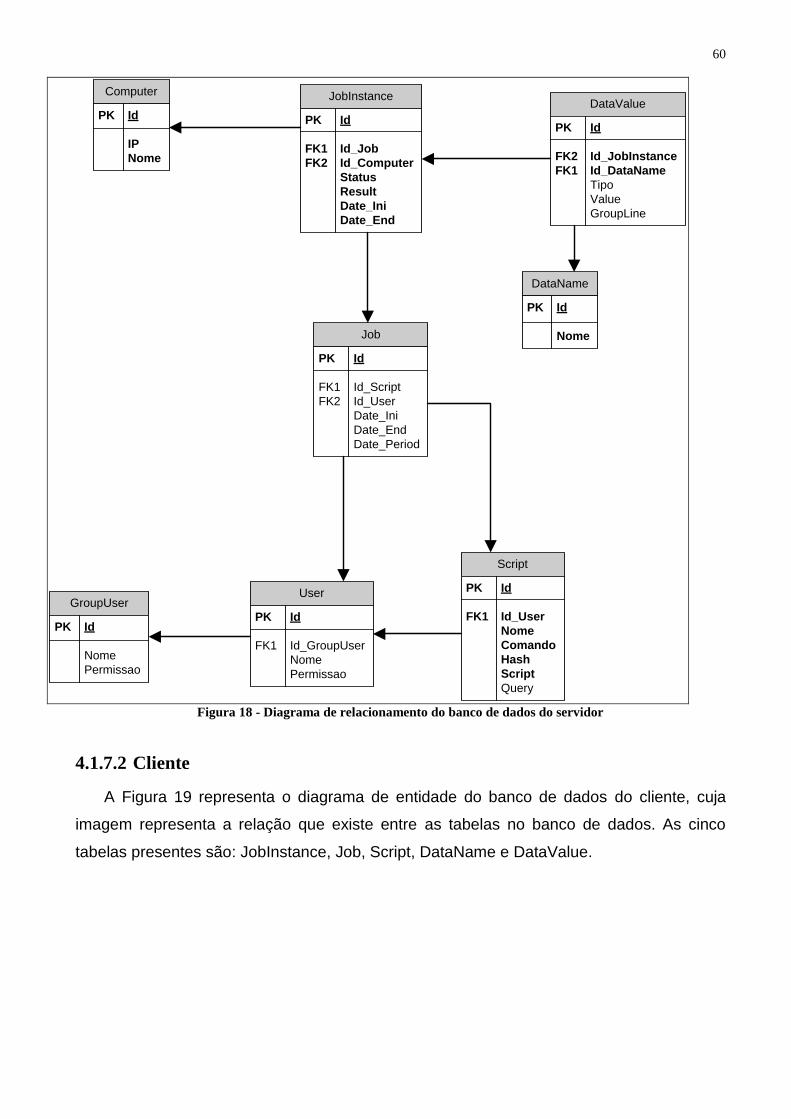
60
Job
PK Id
FK1 Id_Script
FK2 Id_User
Date_Ini
Date_End
Date_Period
JobInstance
PK Id
FK1 Id_Job
FK2 Id_Computer
Status
Result
Date_Ini
Date_End
Script
PK Id
FK1 Id_User
Nome
Comando
Hash
Script
Query
User
PK Id
FK1 Id_GroupUser
Nome
Permissao
Computer
PK Id
IP
Nome
GroupUser
PK Id
Nome
Permissao
DataName
PK Id
Nome
DataValue
PK Id
FK2 Id_JobInstance
FK1 Id_DataName
Tipo
Value
GroupLine
Figura 18 - Diagrama de relacionamento do banco de dados do servidor
4.1.7.2 Cliente
A Figura 19 representa o diagrama de entidade do banco de dados do cliente, cuja
imagem representa a relação que existe entre as tabelas no banco de dados. As cinco
tabelas presentes são: JobInstance, Job, Script, DataName e DataValue.
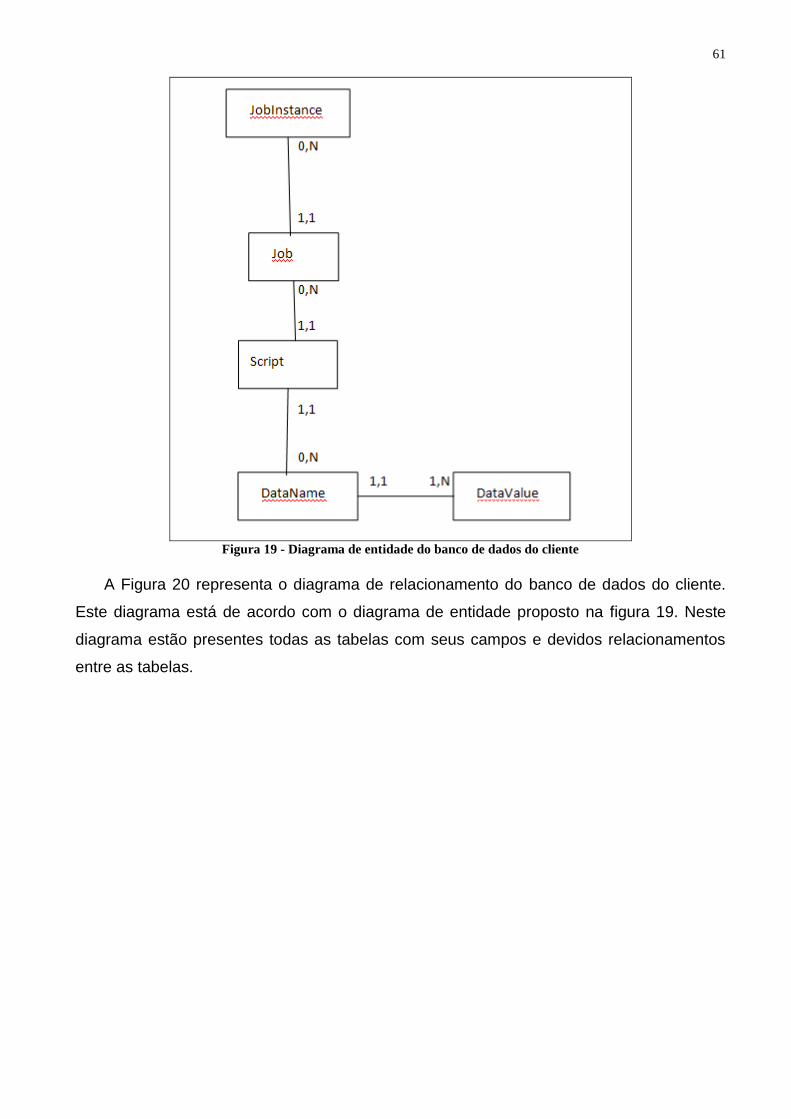
61
Figura 19 - Diagrama de entidade do banco de dados do cliente
A Figura 20 representa o diagrama de relacionamento do banco de dados do cliente.
Este diagrama está de acordo com o diagrama de entidade proposto na figura 19. Neste
diagrama estão presentes todas as tabelas com seus campos e devidos relacionamentos
entre as tabelas.

62
Job
PK Id
FK1 Id_Script
Date_Ini
Date_End
Date_Period
Script
PK Id
Nome
Hash
Comando
DataName
PK Id
FK1 Id_Script
Nome
DataValue
PK Id
FK1 Id_DataName
Value
Type
JobInstance
PK Id
FK1 Id_Job
Status
Result
Date_Ini
Date_End
Figura 20 - Diagrama de relacionamento do banco de dados do cliente

63
4.2 Implantação
Implantação é a fase do ciclo de vida de um software no qual ele é produzido. Este
processo é chamado de implantação, com todos os requisitos e diagramas gerados na fase
de projeto, na fase de implantação todos aqueles estudos e dados gerados viram o
software funcional. Esta etapa é muito difícil de especificar ou de seguir um padrão, pois,
cada software é único e seus processos também são únicos.
Na implantação do sistema gerenciador de script foram criados todos os dados que
foram levantados na fase de projeto, juntamente com a implementação de todos os
diagramas.
Abaixo são apresentadas as principais telas que o sistema possui.
A Figura 21 representa a tela de cadastro de um script. Neste exemplo é necessário
colocar um identificador do script, também deve ser inserido no Campo comando como
este será executado, no campo query deve ser inserido a query para a pesquisa dos
resultados obtidos e, no campo script deve-se importar o arquivo.
Figura 21 - Tela que possibilita adicionar um script ao banco de dados
A Figura 22 representa a lista de todos os scripts cadastrados no sistema. Mostrando
seus dados como nome, comando e query, sendo possível apagá-lo ao clicar no botão
deletar.

64
Figura 22 - Lista dos Scripts cadastrados no sistema
A Figura 23 representa a criação de uma nova tarefa no sistema. Esta tarefa possui o
campo nome que a identifica, juntamente com a lista dos scripts disponíveis no sistema
para serem usados nesta tarefa e com os computadores clientes que possuem o sistema
cadastrado e o intervalo de datas que esta tarefa será executada.
Figura 23 - Criação de uma nova tarefa
Na Figura 24 é apresentada a lista das tarefas que existem cadastradas no sistema,
prontas para serem executadas. É necessário clicar no nome da tarefa para visualizar os
seus resultados.

65
Figura 24 - Lista de tarefas cadastradas no sistema
Na Figura 25 são apresentados os resultados obtidos pela tarefa. Este resultado só é
possível se a query cadastrada no script for executada com sucesso, trazendo e analisando
os dados que retorna.
Figura 25 - Resultados de uma tarefa
Na Figura 26 é apresentada a tela de usuários e grupos, sendo possível adicionar e
remover usuários e grupos. Ao adicionar, é possível configurar se o usuário ou o grupo
possuem permissões administrativas.
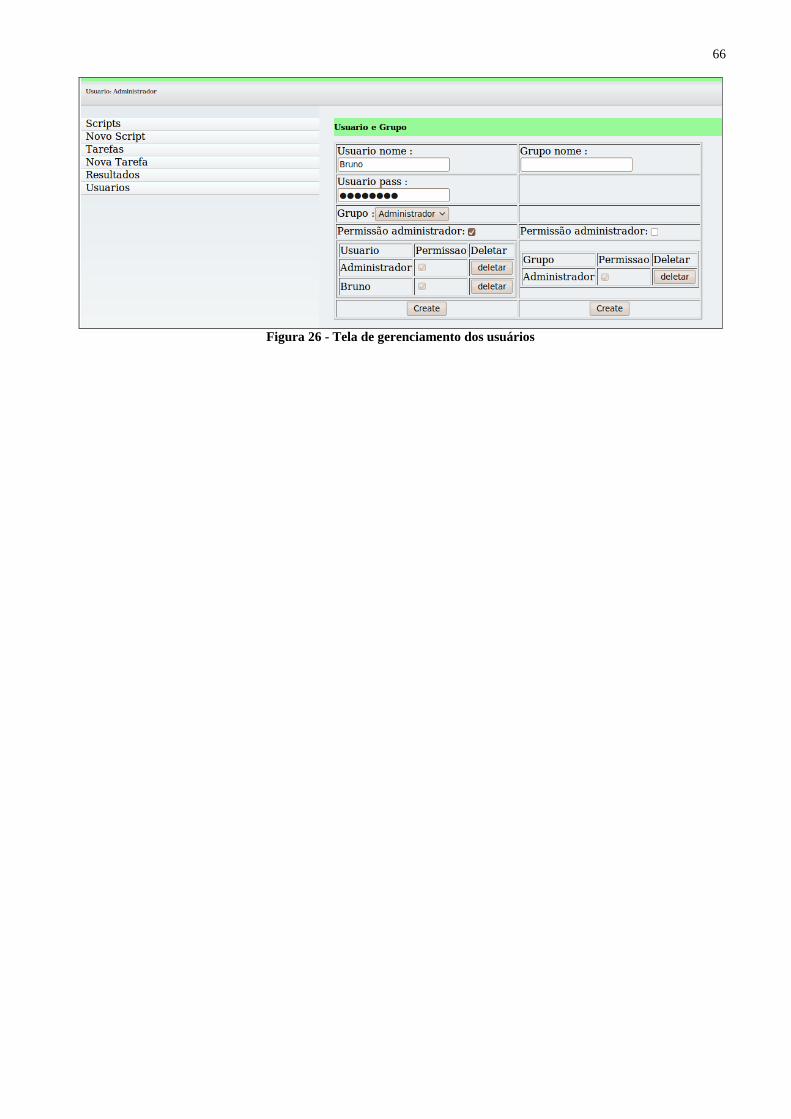
66
Figura 26 - Tela de gerenciamento dos usuários

67
5 Discussão
O início do projeto deu-se com a escolha do tema e a partir deste, foram analisados os
programas existentes e disponíveis que poderiam apresentar uma solução viável para o
objetivo proposto de criar um sistema gerenciador de rede para o sistema operacional
Linux. Foram estudados os programas, bem como seus pontos positivos e negativos e com
isso, chegou-se ao escopo do projeto que é documentar e desenvolver um sistema focado
no desempenho de modo a evitar que o sistema consuma muitos recursos da máquina
hospedeira se comparado com os programas que precisam ser executados por ela.
No processo de projeto e desenvolvimento foram encontrados diversos problemas de
análise, codificação e falta de conhecimentos específicos. Foi necessário o estudo de
diversos pontos do projeto, desde a fase de documentação até a fase de implementação.
Na fase de documentação foi pesquisado como criar diagramas de classe, diagramas de
sequência, diagramas de entidade relacionamento e na fase de implementação, como criar
um sistema assíncrono e trocar dados via socket utilizando SSL.
No quesito de testes foram encontrados diversos problemas quanto à falta de uma rede
disponível para realizar os testes, sendo necessário virtualizar esta rede, com isto
observou-se uma lentidão no sistema para fazer a depuração do programa.
No desenvolvimento apresentaram-se dificuldades quanto à correção de problemas,
pela falta da experiência na depuração de programa utilizando a linguagem C/C++ em um
sistema totalmente assíncrono, sendo necessário criar logs e então verificar por onde o
sistema passou e o que estava ocorrendo naquele momento para então, analisando os logs
gerados com o código fonte, localizar os erros e corrigí-los.
A pesquisa, durante o desenvolvimento do trabalho, elucidou muitos questionamentos
sobre os quesitos de criptografia, e conexões de socket utilizando TLS. Para atingir o
objetivo de construir um sistema totalmente assíncrono foi necessário abstrair o
pensamento da maneira procedural, pois em um programa totalmente assíncrono não é
possível prever o fluxo correto do mesmo, necessitando, desta forma, estar preparado para
tratar os erros e interromper o fluxo do programa de maneira correta para evitar a
desalocação prévia de recursos.
O desenvolvimento do sistema proporcionou um conhecimento nas funcionalidades
internas do sistema operacional Linux, como por exemplo, o tratamento de processos, o
funcionamento de escrita e leitura em pipes de arquivos ou de buffers.
Diante da necessidade de aplicar conceitos inovadores e buscar novas informações
que agregassem valor ao conhecimento, buscou-se desenvolver uma aplicação que

68
propiciasse liberdade de desenvolvimento, criatividade e de tomada de decisões,
apresentando um sistema que pudesse contribuir, significativamente, para os profissionais
da área, no gerenciamento de redes.
Ao analisar o trabalho final desta pesquisa, foi possível constatar que o processo como
um todo, agregou um grande conhecimento e pode trazer grandes contribuições para o
meio acadêmico, pois foi desenvolvido um sistema novo para o gerenciamento de uma
rede que utiliza sistema operacional Linux. Este sistema pode servir como base para
pesquisa de projetos similares com temas relacionados a thread, socket, sistema
assíncrono, SSL, bem como, para que administradores de rede Linux possam aplicar na
administração de redes.
O registro do conhecimento levantado, obtido com esta pesquisa, bem como, todo o
processo de desenvolvimento do sistema, encontra-se disponível na internet (Romano,
2011).

69
6 Conclusões
Concluiu-se que com o sistema instalado, e devidamente em funcionamento, em uma
rede, o mesmo apresenta a possibilidade de coletar informações dos computadores
executando scripts, armazenando-as no banco de dados, disponibilizando-as ao
administrador da rede para que este possa analisar os referidos dados, dando subsídios
concretos para a tomada de decisões.
Através do desenvolvimento do sistema foi possível verificar que para administrar uma
rede Linux é necessário um efetivo suporte na coleta de dados para que se possam coletar
quaisquer tipos de informações que possibilitem aplicar a configuração desejada. Com um
bom sistema de rede, a exemplo do que foi desenvolvido neste trabalho, é possível otimizar
o gerenciamento possibilitando que o administrador invista seu tempo na solução, e não na
busca dos problemas que a rede possa apresentar.
Para o efetivo e correto funcionamento do sistema é necessário que o administrador da
rede possua conhecimentos prévios em algumas linguagens que o auxilie na administração
de sua rede, a exemplo do gerenciador de scripts que exige do administrador
conhecimentos em Shell script e o desenvolvimento de querys eficientes para a pesquisa
dos dados.
Como sugestão de trabalhos futuros, destaca-se a implementação de um cliente para
uma rede Windows possibilitando, também, o gerenciamento de redes com computadores
Windows ou ambientes híbridos de Linux e Windows.

70
7 Referências
Andrei Alexandrescu; Modern C++ Design, 1.ª edição, San Franciso, CodeSaw, 2001.
Drozdek, Adam; Estrutura de dados e algoritmos em C++. São Paulo, Cengage, 2009.
Lopes, Raquel V.; Sauvé, Jacques P.; Nicolletti, Pedro; Melhores Práticas para Gerência de Redes de
Computadores, 1.ª edição, São Paulo, Editora Campus, 2003.
Miro Samek, Ph.D.; Practical Statecharts in C/C++, 1.ª edição, San Franciso, CMPBooks, 2002.
Stephen Prata; C++ Primer Plus Fifth Edition, 5.ª edição, Indianápolis, SAMS, 2004.
ASIO ASIO C++ Library. Disponível em: < http://think-async.com/>. Acesso em: 28 mar. 2011.
Badiella, Jaume. Webmin. Disponivel em: <http://www.webmin.com/devel.html>. Acesso em: 20
mar. 2011.
Boost: Boost. Disponivel em: <http://www.boost.org/doc/libs/1_44_1/>. Acesso em: 27 mar. 2011.
Cardoso , Ricardo. Webmin Solução em administração de sistemas. Disponível em:
<http://www.vivaolinux.com.br/artigo/Webmin-Solucao-em-administracao-de-sistemas/>. Acesso
em: 10 mar. 2011.
Cisneiros , Hugo. Webmin: Instalando o Webmin. Disponível em:
<http://www.devin.com.br/webmin/>.Acesso em: 11 mar. 2011.
CPlusplus: Cplusplus reference. Disponivel em: <http://www.cplusplus.com/reference/>. Acesso em:
27 mar. 2011.
Eclipse. Disponível em: < http://www.eclipse.org/ >. Acesso em: 25 maio 2011.
Eclipse CDT. Disponível em: < http://www.eclipse.org/cdt/ >. Acesso em: 25 maio 2011.
GNU Compiler Collection. Disponível em: < http://gcc.gnu.org/ >. Acesso em: 25 maio 2011.
Google Code. Disponível em: < http://code.google.com/ >. Acesso em: 25 maio 2011.
IETF - Network Working Group - RFC2246, The TLS Protocol Version 1.0. Disponível em: <
http://www.ietf.org/rfc/rfc2246.txt >. Acesso em: 28 mar. 2011.
Java: JavaTM 2 Platform Standard Edition 5.0. Disponível em: <
http://download.oracle.com/javase/1.5.0/docs/api/ >. Acesso em: 26 mar. 2011.
Linux: Linux Documentation. Disponivel em: < http://linux.die.net/ >. Acesso em: 28 mar. 2011.
Mysql: Mysql C API. Disponível em: < http://dev.mysql.com/doc/refman/5.0/en/c.html >. Acesso
em: 03 fev. 2011.
OpenSSL: SSL. Disponível em: < http://www.openssl.org/docs/ssl/ssl.html >. Acesso em: 27 mar.
2011.

71
RapidSVN. Disponível em: < http://rapidsvn.tigris.org/ >. Acesso em: 25 maio 2011.
Ribas , Bruno; Pasqualin , Diego; Ruoso Vinicius. SDI: SDI - Instant Diagnose System. Disponivel
em: < http://sdi.sourceforge.net/ >. Acesso em: 15 mar. 2011.
RNP – Introdução ao SSL. Disponivel em: < http://www.rnp.br/cgibin/newsgen-
cgi/webglimpse/usr/local/etc/httpd/htdocs/newsgen/?query=SSL >. Acesso em: 28 mar. 2011.
Romano, Bruno. Disponível em: < http://code.google.com/p/tccapishellscript/ >. Acesso em: 20 mar.
2011.
Schiffman, Allan - The Secure Sockets Layer Protocol and Applications (Terisa Systems,
Inc.). Disponivel em: < http://www.terisa.com/presentations/ams/ssl/index.htm >. Acesso em: 28
mar. 2011.
Silva Filho, Joel G. (UnB – ENE) - ENIGMA - Cryptography Related Links. Disponível em: <
http://www.enigma.ene.unb.br/pub/crypto/crypto.htm >. Acesso em: 28 mar. 2011.
SGI: Standard Template Library Programmer's Guide. Disponível em: < http://www.sgi.com/tech/stl/
>. Acesso em: 27 mar. 2011.
SQLite: C/C++ Interface For SQLite Version 3. Disponível em: <
http://www.sqlite.org/capi3ref.html >. Acesso em: 03 fev. 2011.
Subversion. Disponível em: < http://subversion.tigris.org/ >. Acesso em: 25 maio 2011.
The GNU Project Debugger. Disponível em: < http://www.gnu.org/software/gdb/ >. Acesso em: 25
maio 2011.
The Open Source UML/MDA Platform. Disponível em: < http://staruml.sourceforge.net/en/ >.
Acesso em: 25 maio 2011.
Tomcat: Apache Tomcat. Disponível em: < http://tomcat.apache.org/index.html >. Acesso em: 05
fev. 2011.
UFRGS – Curso de Redes. Disponível em: < http://penta.ufrgs.br/redes296/https/doc2.htm >. Acesso
em: 28 mar. 2011.
UNICAMP - Equipe de Segurança em Sistemas e Redes. Disponível em: <
http://www.security.unicamp.br/links.html >. Acesso em: 28 mar. 2011.