síntesis automática de circuitos analógicos utilizando algoritmos ... · s´ıntesis...
TRANSCRIPT

Síntesis Automática de Circuitos
Analógicos Utilizando Algoritmos
Evolutivos
Por
Miguel Aurelio Duarte Villaseñor
Maestro en Ciencias
Tesis sometida como requisito parcial para
obtener el grado de
Doctor en Ciencias en la especialidad de Electrónica
en el
Instituto Nacional de Astrofísica
Óptica y Electrónica. Diciembre, 2010
Tonantzintla, Puebla
Supervisada por:
Dr. Esteban Tlelo-Cuautle Investigador Titular del INAOE
©INAOE 2010
Derechos Reservados
El autor otorga al INAOE el permiso de
reproducir y distribuir copias de esta tesis en su
totalidad o en partes.

Esta hoja se dejo en blanco intencionalmente.

Sıntesis Automatica de Circuitos Analogicos
utilizando Algoritmos Evolutivos
Miguel Aurelio Duarte Villasenor
ResumenSe presenta una metodologıa de codificacion binaria, la cual ha sido imple-mentada como un sistema automatico para sintetizar circuitos analogicos,tales como: seguidores de voltaje (VF), espejos de voltaje (VM), seguidoresde corriente (CF) y espejos de corriente (CM); estas cuatro celdas de gananciaunitaria se combinan para realizar la sıntesis de current conveyors (CC), CC-inversos (ICC) y amplificadores operacionales retroalimentados en corriente(CFOA). El metodo de sıntesis se programo utilizando algoritmos evolutivos(EA), los cuales son tecnicas de busqueda basadas en los mecanismos de laseleccion natural de Darwin y en la genetica biologica de Mendel.Se comparan algunas herramientas de sıntesis con el metodo realizado eneste trabajo. Ademas se describe brevemente el EA, resaltando las opera-ciones geneticas y los tres tipos de EAs: algoritmos geneticos (GA), estrate-gias evolutivas (ES) y programacion genetica (GP). Las operaciones geneticasaplicadas son seleccion, cruza, mutacion y elitismo.Para realizar los algoritmos evolutivos se utilizo MatLab. Se muestra el es-quema del algoritmo propuesto y como fue realizada la comprobacion defuncionamiento de este. Se recurre a SPICE para evaluar el comportamien-to de las topologıas obtenidas con tecnologıa de circuitos integrados CMOS.De esta manera, el metodo selecciona solo los circuitos mas apropiados. Elparametro de evaluacion para la seleccion de los circuitos es calculado segunla respuesta de los circuitos en las simulaciones en SPICE.Como resultado, la principal aportacion de esta tesis es la propuesta delnuevo metodo de codificacion genetica para circuitos analogicos y la sıntesisde nuevas topologıas para el diseno de VFs, VMs, CFs, CMs. Finalmentese muestra que la combinancion de estas celdas analogicas genera el codigogenetico de circuitos con mas terminales, tales como los CCs, ICCs y CFOAs.
Palabras Clave: Automatizacion del Diseno Electronico, AlgoritmoEvolutivo, Algoritmo Genetico, nullor, sıntesis de circuitos, seguidor de volta-je, seguidor de corriente, espejo de voltaje, espejo de corriente, currentconveyor, CFOA.
i

Esta hoja se dejo en blanco intencionalmente.
ii

.
Dedicatorias
A mi mama, Magdalena Villasenorque sobrepasando su obligacion como madreme proporciono mas de lo que le correspondia
A la memoria de mi abuelita Evita,le doy garcias por tanto carinoy por el el ejemplo que me dio.
iii

Esta hoja se dejo en blanco intencionalmente.
iv

.
Agradecimientos
Mi agradecimiento al Dr. Esteban Tlelo Cuautle por su orientacion, sus con-sejos y por todo el apoyo brindado para el desarrollo de esta tesis, gracias.
A mis sinodales Dr. Francisco Fernandez, Dr. Arturo Sarmiento, Dr. Alejan-dro Dıaz, Dr. Luis Hernandez y Dr. Carlos Reyes. Agradezco sus sugerenciaspara mejorar la calidad de este trabajo.
A mi familia, a mi esposa, a mis amigos y a todas las personas que meapoyaron en la culminacion de esta tesis.
Este trabajo fue financiado por CONACyT con la beca para estudios de doc-torado No. 160533. Ademas la tesis forma parte del proyecto No. 48396-Y.“Electronica evolutiva: sıntesis automatica de circuitos integrados analogi-cos”.
v

Esta hoja se dejo en blanco intencionalmente.
vi

Indice general
1. Introduccion 11.1. Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2. Motivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3. Objetivos y metas . . . . . . . . . . . . . . . . . . . . . . . . . 41.4. Organizacion de la Tesis . . . . . . . . . . . . . . . . . . . . . 6
2. Marco Teorico 72.1. Herramientas de sıntesis de circuitos
analogicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.1.1. Sıntesis de circuitos analogicos usando EAs . . . . . . . 82.1.2. Herramientas de generacion de topologıas . . . . . . . . 11
2.2. Algoritmos Evolutivos . . . . . . . . . . . . . . . . . . . . . . 132.2.1. Genotipo y Fenotipo . . . . . . . . . . . . . . . . . . . 152.2.2. Operadores geneticos . . . . . . . . . . . . . . . . . . . 162.2.3. Algoritmos Geneticos . . . . . . . . . . . . . . . . . . . 262.2.4. Estrategias Evolutivas . . . . . . . . . . . . . . . . . . 302.2.5. Programacion Genetica . . . . . . . . . . . . . . . . . . 32
3. Metodo de sıntesis propuesto 353.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2. El elemento nullor . . . . . . . . . . . . . . . . . . . . . . . . . 363.3. Algoritmo Genetico realizado . . . . . . . . . . . . . . . . . . 38
3.3.1. Diagrama de Flujo . . . . . . . . . . . . . . . . . . . . 383.3.2. Pruebas al GA realizado . . . . . . . . . . . . . . . . . 423.3.3. Medida de aptitud para los UGC . . . . . . . . . . . . 47
3.4. Codificacion genetica de los circuitos . . . . . . . . . . . . . . 533.4.1. Genotipo y fenotipo de un VF . . . . . . . . . . . . . . 543.4.2. Genotipo y fenotipo de un CF . . . . . . . . . . . . . . 603.4.3. Genotipo y fenotipo de un CM . . . . . . . . . . . . . 623.4.4. Genotipo y fenotipo de un VM . . . . . . . . . . . . . 68
3.5. Genotipo y fenotipo de las uniones entre dos UGCs . . . . . . 73
vii

3.5.1. Union simple . . . . . . . . . . . . . . . . . . . . . . . 753.5.2. Duplicar salida . . . . . . . . . . . . . . . . . . . . . . 763.5.3. Duplicar salida intermedia . . . . . . . . . . . . . . . . 793.5.4. Creacion del nodo Z . . . . . . . . . . . . . . . . . . . 813.5.5. Combinacion de nullators-norators . . . . . . . . . . . 823.5.6. Genotipo y fenotipo de un CFOA . . . . . . . . . . . . 85
4. Resultados 894.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 894.2. Topologıas de VF generadas . . . . . . . . . . . . . . . . . . . 914.3. Topologıas de CF generadas . . . . . . . . . . . . . . . . . . . 954.4. Topologıas de CM generadas . . . . . . . . . . . . . . . . . . . 984.5. Topologıas de VM generadas . . . . . . . . . . . . . . . . . . . 1014.6. Topologıas de CCII generadas . . . . . . . . . . . . . . . . . . 1034.7. Topologıas de CFOAs generadas . . . . . . . . . . . . . . . . . 106
5. Conclusiones 1095.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1095.2. Ideas para trabajos a futuro . . . . . . . . . . . . . . . . . . . 112
A. Parametros de simulacion 113A.1. Parametros de 0.35µm, AMI Semiconductor . . . . . . . . . . 113A.2. Parametros de 0.50µm, AMI Semiconductor . . . . . . . . . . 114A.3. Parametros de 0.18µm, Taiwan Semiconductor (TSMC) . . . . 116A.4. Parametros de 0.25µm, Taiwan Semiconductor (TSMC) . . . . 117A.5. Parametros de 0.35µm, Taiwan Semiconductor (TSMC) . . . . 118A.6. Parametros de 0.18µm, IBM Semiconductor . . . . . . . . . . 120A.7. Parametros de 0.25µm, IBM Semiconductor . . . . . . . . . . 121A.8. Parametros de 0.35µm, IBM Semiconductor . . . . . . . . . . 122A.9. Parametros de 0.50µm, IBM Semiconductor . . . . . . . . . . 124
B. Publicaciones 127B.1. Publicaciones en congresos . . . . . . . . . . . . . . . . . . . . 127B.2. Publicaciones en revistas . . . . . . . . . . . . . . . . . . . . . 127B.3. Publicaciones en capıtulo de libro . . . . . . . . . . . . . . . . 128
C. Manual de usuario 129C.1. Descripcion de los archivos contenidos de la carpeta SBGU . . 129C.2. Antes de ejecutar el programa . . . . . . . . . . . . . . . . . . 130C.3. Ejecucion del programa CM. . . . . . . . . . . . . . . . . . . . 131C.4. Ejecucion del programa VF. . . . . . . . . . . . . . . . . . . . 131
viii

C.5. Ejecucion del programa CF. . . . . . . . . . . . . . . . . . . . 132C.6. Ejecucion del programa VM. . . . . . . . . . . . . . . . . . . . 133C.7. Notas Extras . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
ix

Esta hoja se dejo en blanco intencionalmente.
x

Capıtulo 1
Introduccion
1.1. Antecedentes
Actualmente, las herramientas clave para manipular la complejidad en
el proceso de diseno de Circuitos Integrados CMOS son generadas por la
industria de la Automatizacion del Diseno Electronico (EDA). Este tipo de
herramientas permiten acelerar el proceso de diseno ya que pretenden re-
presentarlo como una metodologıa estructurada [1, 2, 3, 4, 5]. En el proceso
de diseno de circuitos integrados, las herramientas EDA se enfocan en au-
tomatizar muchas de las tareas que son de rutina y repetitivas en el diseno
analıtico.
En algunos casos en el diseno de sistemas analogicos se pueden identificar
bloques funcionales, tales como: amplificadores, seguidores de voltaje, espe-
jos de corriente, entre otros. Los cuales pueden repetirse y ademas pueden
sintetizarse automaticamente aplicando metodologıas del EDA [1, 2, 3, 5].
De esta manera, las herramientas EDA incrementan la productividad en el
diseno, aun para bloques de circuitos que no sean repetitivos. Por ello, el
EDA analogico tiene un papel importante en el proceso de diseno. Sin em-
bargo, la automatizacion del diseno analogico es mas compleja comparandola
con el diseno digital, porque las relaciones entre sus especificaciones son mas
1

2 CAPITULO 1. INTRODUCCION
complejas.
Ademas, aun para los disenadores no ha sido posible automatizar todos
los niveles de abstraccion y la sıntesis de circuitos desde un diseno de al-
to nivel [1, 3, 4]. Esto se debe principalmente a que el diseno analogico
requiere de experiencia, intuicion y creatividad; ya que se trabaja con un
gran numero de parametros y de algunas interacciones complejas entre ellos.
Asimismo, debido a la gran variedad de circuitos analogicos, se busca de al-
guna manera automatizar ciertas tareas de diseno, tantas como sea posible
[1, 2, 3, 4, 5, 6, 7, 8, 9].
En los ultimos anos se han presentado algunos metodos para la sıntesis de
circuitos analogicos. Por ejemplo en [1] se muestran trabajos enfocados al
diseno de circuitos pasivos. Asimismo, con el fin de obtener nuevas topologıas
de circuitos analogicos se han desarrollo herramientas como ACACIA [15]
y ASTRX/OBLX [16]; ademas de trabajos como el de Grimbleby [17] y
Hajime Shibata con Nobuo Fuji [18]. De esta manera, ya sea para gene-
rar nuevos circuitos u optimizarlos, para encontrar mejoras a topologıas de
circuitos o para dimensionar ciertas topologıas conocidas, las herramientas
EDA han utilizado algoritmos inteligentes como los algoritmos evolutivos
(EA) [1, 2, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 17, 18, 19, 20, 21]. Por lo tanto,
el diseno de circuitos analogicos es muy adaptable para tecnicas evolutivas
y es un problema que se esta trabajando, como se demuestra en distintas
publicaciones [1, 2, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 17, 18, 19, 20, 21].
En esta Tesis, se propone un metodo de codificacion genetica capaz de sin-
tetizar celdas de ganancia unitaria (UGC), tales como: seguidores de voltaje
(VFs) [19, 22, 23, 24], seguidores de corriente (CFs) [8, 24, 25], espejos de
voltaje (VMs) [24, 26, 27] y espejos de corriente (CMs) [24, 25, 28]. Estas
celdas se combinan para realizar la sıntesis de circuitos mas complejos o con

1.2. MOTIVACION 3
mas terminales como los current conveyors (CCs) [25, 29, 30], CC inversos
(ICCs) [25, 27, 30, 31] y amplificadores operacionales retroalimentados en
corriente (CFOAs) [25, 32]; cuyas ecuaciones caracterısticas y sımbolos se
muestran en la figura 1.1.
Figura 1.1: (a) VF, (b) CF, (c) VM, (d) CM, (e) CCII+, (f) CFOA.
El proceso de sıntesis propuesto en esta Tesis esta basado en la apli-
cacion de algoritmos evolutivos (EA), principalmente para la generacion de
UGCs, CCs y CFOAs. Los EAs son tecnicas fundadas en los mecanismos de
seleccion natural y genetica biologica operando sobre el principio de sobre-
vivencia del mas apto. Ası que los EAs tienen la capacidad de generar nuevos
disenos de solucion para una poblacion de soluciones existentes y descar-
tan las soluciones que tienen una medida de aptitud inferior a la deseada
[2, 33, 34, 35, 36, 37].
Cabe mencionar que la principal aportacion de este trabajo es el desarrollo
del codigo genetico para la representacion de VFs, VMs, CFs, CMs, CCs,
ICCs y CFOAs; ademas de realizar la busqueda de nuevas topologıas.
1.2. Motivacion
Los circuitos analogicos como por ejemplo filtros y osciladores han ido
evolucionando al paso de los anos [6, 7, 14, 25, 29, 31, 38, 39, 40, 41, 42].

4 CAPITULO 1. INTRODUCCION
Esto debido a la busqueda de modificar una o mas cualidades de los circuitos
anteriores y es un progreso que no se ha detenido. De igual forma ha existido
una evolucion en las topologıas de los circuitos OPAMP, OTA, UGC y CC
entre otros [1, 2, 3, 4, 18, 19, 20, 21, 22, 25, 29, 31]. Esta es una evolucion
que continua en estos dıas, con el fin de encontrar cada vez topologıas que
se acerquen mas a las especificaciones ideales de estos circuitos.
Asimismo, en los ultimos anos se han presentado metodos para la sıntesis de
circuitos analogicos aplicando sistemas inteligentes; como se muestra en los
trabajos de Gielen y Rutenbar [1], Salem [2], Mazumder [4], Mattiussi [6],
entre otros [7, 8, 10, 11, 12, 13, 14, 17, 18, 19, 20, 21]. En su mayorıa son tra-
bajos enfocados al diseno de circuitos pasivos o circuitos con amplificadores
operacionales.
En la actualidad, no hay metodos automaticos genericos para el diseno de
topologıas en circuitos analogicos. En diseno digital las celdas basicas son las
compuertas NAND, NOR, NOT, con las cuales se pueden generar bloques
mas complejos. En diseno analogico, es posible generar bloques mas com-
plejos a partir de celdas de ganancia unitaria (UGCs). De esta manera, el
diseno de un sistema que permita la sıntesis automatica de topologıas tales
como VFs, VMs, CFs y CMs facilitara la busqueda de nuevas topologıas de
circuitos analogicos con mas terminales, tales como los CCs y los CFOAs.
Algunas de las aplicaciones de las UGCs estan reportadas en [38, 39, 40].
Asimismo, existen cuantiosas aplicaciones con CCs [29, 41, 42] y CFOAs
[32].
1.3. Objetivos y metas
El objetivo principal de la tesis es la propuesta de un codigo genetico
para la representacion de circuitos analogicos, tales como las UGCs. A par-

1.3. OBJETIVOS Y METAS 5
tir de estas UGCs se propone la combinacion de codigos geneticos para la
representacion de bloques con mas terminales como los CCs y CFOAs. El
uso de los codigos geneticos dentro de un procedimiento de sıntesis basado
en la aplicacion de algoritmos evolutivos, permitira la generacion de nuevas
topologıas de circuitos analogicos.
Como metas secundarias se tiene:
Proponer una codificacion genetica que represente topologıas de UGCs.
Desarrollar un EA para generar topologıas conocidas y nuevas de
UGCs. Para esto es necesario:
• Realizar los algoritmos de operaciones geneticas: seleccion, cruza,
mutacion y elitismo para este tipo de circuitos.
• Realizar el algoritmo de la operacion de evaluacion para el EA,
con el objetivo de elegir a las topologıas funcionales segun su simu-
lacion en SPICE.
Encontrar nuevas topologıas de UGCs: VF, CF, VM y CM.
Proponer una codificacion genetica que represente topologıas de CCs,
ICCs y CFOAs.
Desarrollar un EA para generar topologıas conocidas y nuevas de CCs,
ICCs y CFOAs. Obtener nuevas topologıas de CCIIs, ICCIIs y CFOAs.
Desarrollar un algoritmo que pueda evolucionar las UGCs a circuitos
con mas terminales; tales como: CCs y CFOAs.

6 CAPITULO 1. INTRODUCCION
1.4. Organizacion de la Tesis
En el capıtulo 2 se describen las herramientas de sıntesis de topologıas de
circuitos analogicos, muchas de estas utilizan algoritmos evolutivos (EA).
Se comparan estas herramientas con el metodo propuesto en esta Tesis.
Ademas, se describe brevemente los conceptos de EA, resaltando las opera-
ciones geneticas y los tres tipos de EA: algoritmos geneticos (GA), estrategias
evolutivas (ES) y programacion genetica (GP). Las operaciones geneticas de
los EA son seleccion, cruza, mutacion y elitismo.
En el capıtulo 3 se describe el metodo de sıntesis propuesto, desde el
planteamiento de la representacion ideal de los circuitos por medio de ele-
mentos nullor hasta la descripcion a bloques del sistema final a desarrollar.
En el capıtulo tres se muestran los cromosomas de UGCs y CCs propuestos.
Se presenta como se elaboro un GA que sirve para realizar la busqueda de las
topologıas de UGCs, CCs y CFOAs. Tambien en el capıtulo tres se describen
las pruebas de funcionamiento del GA realizado.
Los circuitos obtenidos se muestran en el capıtulo 4. Las conclusiones se
muestran en el capıtulo 5. Para finalizar, en el anexo A se muestran los
parametros de las tecnologıas utilizadas en esta Tesis, el anexo B muestra el
listado de publicaciones derivadas de este trabajo y en el anexo C se muestra
el manual de usuario de la herramienta realizada.

Capıtulo 2
Marco Teorico
2.1. Herramientas de sıntesis de circuitos
analogicos
Exısten varios trabajos previos acerca de herramientas de sıntesis de cir-
cuitos y sistemas analogicos, como por ejemplo: IDAC, OPASYN, OASYS,
O-ISAAC, STATIC, ARCHGEN, DARWIN, AMGIE o ANACONDA recopi-
lados en [1]. Algunos de estos dimensionan los MOSFET de los circuitos [47];
otros mejoran algun parametro en los dominios de CD, CA y/o tiempo de
una cierta topologıa o circuito conocido [61]; y otros realizan filtros o encuen-
tran funciones analogicas con circuitos CMOS [63].
Tambien existen trabajos desarrollados utlizando EAs, estos muestran una
codificacion de circuitos en un cromosoma, como se muestra en los trabajos de
Salem [2], Mattiussi [6], Kruiskamp y Leenaerts [47] entre otros [4, 5, 7, 8, 9].
Sin embargo, estas descripciones se enfocan a optimizar ciertos parametros
de un circuito en CD, CA y/o tiempo. Por lo que sus codificaciones repre-
sentan, en la mayorıa de trabajos, dimensiones de sus transistores y no como
estan realizadas estas topologıas, ya que principalmente optimizan topologıas
conocidas [1, 2, 4, 6, 7, 8, 12, 13, 14, 17, 15, 16, 18]. Ası, se tiene la necesidad
de realizar una codificacion diferente a las ya mencionadas. De esta manera,
7

8 CAPITULO 2. MARCO TEORICO
en la propuesta de esta Tesis se estan buscando nuevas topologıas, las cuales
se sintetizan a partir de la representacion de los circuitos con codigos bina-
rios.
El metodo de sıntesis propuesto utiliza Algoritmos Evolutivos, los cuales son
tecnicas de busqueda basadas en los mecanismos de seleccion natural y en la
genetica biologica. El principio de supervivencia del mas apto es el eje central
sobre el cual se desarrollan los EAs. Los EAs simulan el proceso evolutivo
en una computadora con la finalidad de resolver problemas de aprendizaje,
busqueda, clasificacion u optimizacion.
2.1.1. Sıntesis de circuitos analogicos usando EAs
La utilizacion de EAs no solo se enfoca a reproducir los cambios en los
individuos biologicos, sino se ha trabajado con estos algoritmos en distintas
areas del conocimiento, como: computo [33], medicina [43], matematicas [44],
optica [45, 46], entre otras [5, 34, 35]. Algunos de los trabajos que existen
acerca de las herramientas de sıntesis de circuitos y sistemas analogicos se
muestran en los cuadros 2.1 y 2.2.
Todos los algoritmos mostrados en los cuadros 2.1 y 2.2 realizan sıntesis de
circuitos analogicos y trabajan mediante algun tipo o metodo de EA. Se
observa en los cuadros 2.1 y 2.2 que tipo de circuito sintetizan, cual es su
metodo de evaluacion y el tipo de algoritmo evolutivo realizado en estos tra-
bajos.

2.1. HERRAMIENTAS DE SINTESIS DE CIRCUITOS ANALOGICOS 9
Cuadro 2.1: Trabajos de sıntesis de circuitos analogicos usando EAs.
REF EA Sintetiza Evaluacion Notas[6] GP
ESCircuitos de volta-je de referencia, sen-sor de temperatu-ra, generadores de lafuncion ‘campana deGauss’ y evolucionde una XOR a unared neuronal
Mono-objetivo.Promedio delmınimo de lasuma de loscuadrados
Tesis de doctorado.2005
[7] GP Amplificadores y fil-tros
16 objetivos en 5diferentes test
Han logrado realizarmas de 20 patentesde circuitos analogi-cos. 2004
[10] GPGA
OPAMP CMOS, Os-cilador de anillo yCompuerta XOR
Mono-objetivo.En CA, CD yTiempo
2005
[11] GA Osciladores sinu-soidales
Mono-objetivo,por frecuencia deoscilacion
Utiliza bloques RLCy OPAMP. 2003
[12] GP Filtros pasa-bajasy amplificadores devoltaje
— Escoje los compo-nentes de una libre-ria y los dimensiona.2007
[13] GP Filtros pasa-bajas,RLC
Multi-objetivo,sumatoria de lanorma
2006
[14] GA Osciladores sinu-soidales
Mono-objetivo Utiliza bloques UGCy RLC. 2004
[17] GA Filtros RLC Mono-objetivo,inverso de expo-nencial
Sintetiza circuitossencillos de realizar.2000
[19] ES VF y CF — Solo propuesta. 2006[20] GA Optimiza CCII que
se encuentran en unalibrerıa.
11 especificaciones Optimiza W y L.2002
[22] ES VF — Solo propuesta. 2005[47] GA OPAMP Mono-objetivo,
magnitud dBDARWIN, el circuitolo entrega dimen-sionado. 1995
[48,49]
GA OPAMP Multi-objetivo Realizan la sıntesisuniendo bloques ydespues optimizancon GA (dimensio-nando los CMOS).2003

10 CAPITULO 2. MARCO TEORICO
Cuadro 2.2: Continuacion del cuadro 2.1.
REF EA Sintetiza Evaluacion Notas[50] GA Filtros pasa-altas Multi-objetivo,
suma de objetivosparticulares
UMOAGA. Puedeextenderse estoa otros circuitosanalogicos y digi-tales. 2005
[51] GA Circuitos inte-gradores
Multi-objetivo,en competenciaslocales y globales
MESACGA. Puedeextenderse a masdisenos analogicos.2005
[52] GA Amplificadores y fil-tros RC-bipolares
Multi-objetivos,sumatoria deobjetivos
Solo propuesta. 2001
[53] GA Amplificadores devoltaje con bipolaresy filtros pasa-bajas
3 objetivos, sumasde respuestascuadraticas
2007
[54] GA OPAMP Multi-objetivo MOJITO. El espaciode busqueda esde 3528 posiblestopologıas, 2007
[55] ES VF 7 objetivos,promedio de losvalores meta.
Obtienen VFs alunir varios CMOS.No son viablespara CI por sucomplejidad. 2007
[56] GA OPAMP y os-ciladores de anillo
Multi-objetivo,suma normailiza-da
Realizado en C++,simulan en Hspice.2008
[57] ES Filtros RLC 2 objetivos Filtros pasa bajas,pasa banda y pasaaltas. 2009
[58] GA Filtros pasa-bajas,RLC
Multi-objetivo,Inverso de lasumatoria de lanorma
2010
[59] GA VF, CF, VM y CM Mono-objetivo,superar un niv-el mınimo ensu respuesta enganancia
Tesis de maestrıa deMiguel Duarte. 2007
Aquı GA VF, CF, VM, CM,CCII+/-, ICCII+/-y CFOA
Multi-objetivo,sumatoria de lanorma multipli-cada por pesos. 4objetivos o menos
Este trabajo de tesis.Puede extenderse amas objetivos. 2010

2.1. HERRAMIENTAS DE SINTESIS DE CIRCUITOS ANALOGICOS 11
2.1.2. Herramientas de generacion de topologıas
Entre los trabajos que existen acerca de las herramientas de sıntesis de
circuitos y sistemas analogicos, se encuentran los enfocados a la generacion
de topologıas. Algunos de estos trabajos generadores de topologıas se mues-
tran en los cuadros 2.3 y 2.4. En estos se menciona que tipo de topologıas
sintetizan estos trabajos y el metodo por el cual lo hacen.
Cuadro 2.3: Herramientas de generacion de topologıas.
REF Sintetiza Metodo Notas[7] OPAMP, OTA GP, con 16 objetivos
en 5 diferentes test2004
[8] CM de bajo voltaje Generacion degrafos por evolucion(EGG)
Este metodo con-tiene semejanzas conEA. 2007
[10] OPAMP con MOS-FET
GP-GA, mono-objetivo en CA, CDo Tiempo
2005
[18] Nuevos cir-cuitos, ejemplo:IOUT = (IIN )3
Matrices de super-imposicion
2001
[19] VF y CF Los circuitos crecena partir de un em-brion ideal. ES
Solo es una propues-ta de sıntesis, no serealizo ningun algo-ritmo. 2006
[32] CFOAs Desarrolla y opti-miza las topologıaspropuestas mediantediseno y analisisanalıtico
2006
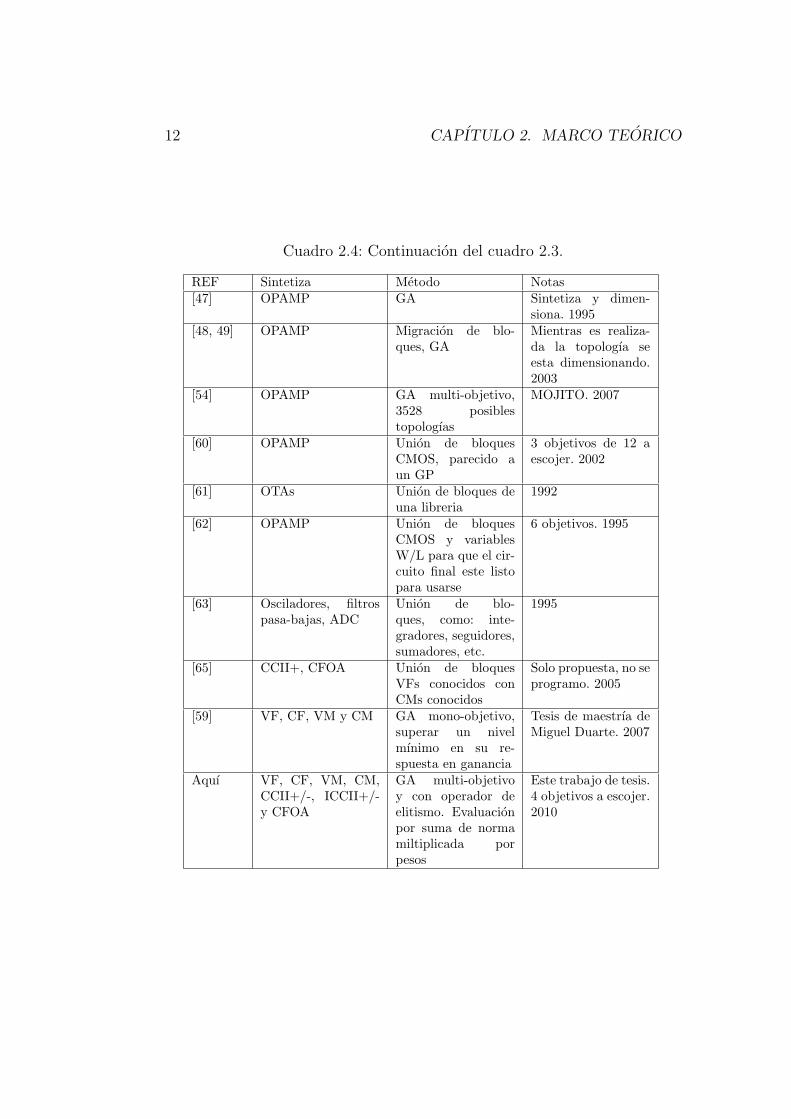
12 CAPITULO 2. MARCO TEORICO
Cuadro 2.4: Continuacion del cuadro 2.3.
REF Sintetiza Metodo Notas[47] OPAMP GA Sintetiza y dimen-
siona. 1995[48, 49] OPAMP Migracion de blo-
ques, GAMientras es realiza-da la topologıa seesta dimensionando.2003
[54] OPAMP GA multi-objetivo,3528 posiblestopologıas
MOJITO. 2007
[60] OPAMP Union de bloquesCMOS, parecido aun GP
3 objetivos de 12 aescojer. 2002
[61] OTAs Union de bloques deuna libreria
1992
[62] OPAMP Union de bloquesCMOS y variablesW/L para que el cir-cuito final este listopara usarse
6 objetivos. 1995
[63] Osciladores, filtrospasa-bajas, ADC
Union de blo-ques, como: inte-gradores, seguidores,sumadores, etc.
1995
[65] CCII+, CFOA Union de bloquesVFs conocidos conCMs conocidos
Solo propuesta, no seprogramo. 2005
[59] VF, CF, VM y CM GA mono-objetivo,superar un nivelmınimo en su re-spuesta en ganancia
Tesis de maestrıa deMiguel Duarte. 2007
Aquı VF, CF, VM, CM,CCII+/-, ICCII+/-y CFOA
GA multi-objetivoy con operador deelitismo. Evaluacionpor suma de normamiltiplicada porpesos
Este trabajo de tesis.4 objetivos a escojer.2010

2.2. ALGORITMOS EVOLUTIVOS 13
2.2. Algoritmos Evolutivos
Uno de los paradigmas centrales de la biologıa es el principio de la evolu-
cion, por el que los seres vivos experimentan cambios en el transcurso del
tiempo. Como resultado de estos cambios surgen nuevas especies de las que
derivan otras nuevas y ası sucesivamente. Entre otras explicaciones, el prin-
cipio de seleccion natural, propuesto por Darwin, representa desde su formu-
lacion uno de los mecanismos evolutivos mas populares [66], cuya trascen-
dencia se extiende mas alla del ambito de la biologıa. La simulacion de la
evolucion en la PC aplicando el principio de seleccion natural no solo tiene
interes teorico sino tambien practico [33, 34, 35, 36, 37].
Los organismos vivos poseen una destreza consumada en la resolucion de
problemas de adaptacion al medio que los rodea. Los organismos biologicos
obtienen sus habilidades de adaptacion, funcionamiento y comportamiento a
traves de mecanismos como la evolucion y la seleccion natural [34, 36, 37].
De acuerdo al modelo de Darwin de la evolucion de las especies, toda la vida
en nuestro planeta puede ser explicada a traves de un conjunto de procesos,
que actuan sobre y dentro de las poblaciones, individuos y especies; como por
ejemplo: la reproduccion, herencia, mutacion, competencia y seleccion de los
organismos [66].
La seleccion natural es el proceso donde los individuos mejor adaptados al
medio ambiente tienen mayor probabilidad de producir descendientes, que
aquellos que son menos aptos [66]. Adicionalmente a las teorıas de Darwin,
son necesarios los planteamientos de Mendel y de la Genetica Matematica
para comprender como estos procesos ayudan en la seleccion natural [67].
El principio de supervivencia del mas apto, es el eje central sobre el cual se
desarrollan tecnicas de aprendizaje que responden al nombre generico de Al-
goritmos Evolutivos (EAs) [33]. Los EAs simulan el proceso evolutivo en una

14 CAPITULO 2. MARCO TEORICO
computadora con la finalidad de resolver problemas de aprendizaje, busque-
da, clasificacion u optimizacion. El problema a resolver puede caer dentro de
una gran variedad de disciplinas, incluyendo la Biologıa, Ingenierıa, Servicios
Financieros y Ciencias Computacionales [2, 35, 44, 45, 46].
Los terminos de Computacion Evolutiva, Algoritmos Evolutivos, Algoritmos
Bio-inspirados, Computacion Natural y Vida Artificial son relativamente re-
cientes y representan un gran esfuerzo para acercar a los investigadores a
seguir los diferentes aspectos de la evolucion [34].
Dentro de las principales tecnicas de los EAs se encuentran: los Algoritmos
Geneticos (GA), las Estrategias Evolutivas (ES) y la Programacion Genetica
(GP). Las cuales tienen en comun que cada una de ellas se apoyan en la re-
produccion, la variacion aleatoria, la competencia y la seleccion de individuos
contendiendo dentro de una poblacion [34, 35]; lo cual es en sı la esencia de
la evolucion. Cabe aclarar que la evolucion es un proceso de optimizacion, el
cual no implica la perfeccion. Por lo tanto, la aplicacion de los EAs a un con-
junto de posibles soluciones para un problema, deberıa producir una buena
solucion (u optima, en el mejor de los casos) para ese problema [2, 33].
Algunas caracterısticas de los EAs son [33, 34, 35]:
Trabajan con un conjunto de soluciones, que representan las soluciones
al problema.
Buscan la solucion en una poblacion de posibles soluciones y no con
soluciones solitarias.
Utilizan una funcion de evaluacion, no utilizan funciones derivadas de
esta o algun otro metodo o conocimiento auxiliar.
Utilizan reglas de transicion probabilıstica y no determinıstica.

2.2. ALGORITMOS EVOLUTIVOS 15
Combina elementos de busqueda estocastica y directa que hace un
balance notable entre exploracion y aprovechamiento del espacio de
busqueda.
2.2.1. Genotipo y Fenotipo
Si un problema puede ser representado por un conjunto de parametros
(genes), y estos pueden ser unidos para formar una cadena de valores; a esta
cadena se le llama cromosoma y a este proceso se le conoce como codificacion
[33, 34].
Es comun que la representacion de individuos a traves de cromosomas se
haga con cadenas de dıgitos binarios, tal representacion es llamada genotipo;
entonces, es necesaria la conversion del genotipo a los valores que pertenecen
a un individuo. El individuo es llamado fenotipo [33, 34, 35, 36, 37].
Existen varios aspectos relacionados con la codificacion de un problema a ser
tomados en cuenta en el momento de su realizacion:
Se debe de usar la representacion mas pequena de los parametros, nor-
malmente se utiliza una representacion binaria.
Las variables que representan los parametros del problema deben ser
discretas para poder representar cadenas de genes.
La mayor parte de los problemas tratados con algoritmos geneticos son
no lineales y muchas veces existen relaciones entre las variables que
conforman las soluciones. Esta es la causa de que la codificacion puede
generar genotipos invalidos, estos representan una solucion que no se
puede (o debe) realizar fisicamente.
El tratamiento de los genotipos invalidos debe ser tomado en cuenta
para el diseno de la codificacion.

16 CAPITULO 2. MARCO TEORICO
En esta tesis se sintetizan circuitos analogicos donde los genotipos son
compuestos por cadenas de bits. Estos genotipos o cromosomas sintetizan
a un circuito analogico; la codificacion propuesta se muestra en el capıtulo
tres. Los circuitos realizados con transistores MOS son los fenotipos en los
EAs realizados.
2.2.2. Operadores geneticos
Los operadores geneticos son los diferentes metodos u operaciones que se
pueden realizar sobre una poblacion en un EA, estos se dividen en cuatro
categorıas:
Seleccion
Cruza o Recombinacion
Mutacion
Reemplazo, Reinsercion o Elitismo
Los dos procesos que principalmente contribuyen a la evolucion son los
operadores de cruza y mutacion. En los GA y ES el operador principal es la
cruza, mientras que en la GP el principal operador genetico es la mutacion
[34].
Operador de seleccion
El operador de seleccion es el proceso en el que se eligen a los miembros
de la poblacion actual que seran utilizados para la reproduccion o cruza.
Su objetivo es dar mas oportunidades de ser seleccionados a los miembros
mas aptos de la poblacion. El primer paso es la asignacion de una medida
de aptitud a cada individuo, la cual se puede realizar por medio de una

2.2. ALGORITMOS EVOLUTIVOS 17
asignacion proporcional, o basada en una clasificacion (ranking) [34, 35].
En la asignacion de aptitud proporcional se convierten los valores objetivos
de una poblacion en una medida de aptitud con un lımite superior conocido,
este lımite superior es determinado por el valor de la precision selectiva. Este
metodo generalmente utiliza alguna operacion de escalamiento lineal [33].
En la asignacion de aptitud basada en la clasificacion (ranking) la poblacion
es evaluada de acuerdo a su valor objetivo. La asignacion de aptitud para
cada individuo depende solamente de su posicion en la clasificacion individual
y no de su valor objetivo actual. La asignacion de aptitud basada en la
clasificacion puede ser lineal o no. En esta tesis la asignacion es lineal ya que
no se utilizaran terminos cuadraticos para el calculo de su clasificacion. Los
algoritmos para la clasificacion (lineal y no-lineal) primero ordenan los valores
de la funcion objetivo en orden descendente o ascendente. Por ejemplo: el
individuo menos apto es colocado en la primera posicion en el orden de la
lista de valores objetivos y el individuo mas apto es colocado en la posicion
N, donde N es el numero de individuos en la poblacion. Con lo cual, el valor
de aptitud es asignado a cada individuo dependiendo de su posicion en el
orden de la poblacion [33].
Habiendo asignado la aptitud a los individuos en la poblacion se procede a
la seleccion de los padres; lo cual se puede realizar mediante alguno de los
siguientes metodos [33, 34, 35]:
Seleccion de la rueda de la ruleta.
Muestreo estocastico universal.
Seleccion local.
Seleccion por truncamiento.

18 CAPITULO 2. MARCO TEORICO
Seleccion por torneo.
Estos metodos son descritos en [33], [34] y [35], para el desarrollo de la
tesis se consideraron los metodos de seleccion de la ruleta y el de truncamien-
to. Ambos presentaron resultados similares, ası que se eligio el que utilizo
el menor tiempo de computo: el metodo de seleccion por truncamiento. El
metodo de seleccion por truncamiento es un metodo de seleccion artificial.
Los individuos en la seleccion por truncamiento son sorteados de acuerdo a
su aptitud y solamente los mejores individuos son seleccionados como pare-
jas. En la figura 2.1 se ilustra el metodo de truncamiento utilizado en este
trabajo; de los N individuos existentes se tienen que formar N/2 parejas.
Los individuos mejor calificados se seleccionan para formar parejas hasta dos
veces; mientras que los peor calificados no se utilizaron en ninguna pareja.
Figura 2.1: (a) todos los individuos, (b) se califican del mejor al peor, (c)el metodo de seleccion forma las parejas que seran los padres de la proximageneracion.

2.2. ALGORITMOS EVOLUTIVOS 19
Operador de cruza
La cruza, tambien llamada recombinacion, consiste en combinar de alguna
forma los cromosomas de dos padres para formar uno o mas descendientes.
Este es el operador mas caracterıstico e importante de un GA, su finalidad
es acelerar el proceso de busqueda o exploracion de los mejores cromosomas
[33, 34, 35]. Existen diversas variaciones dependiendo del numero de puntos
de division a emplear o de la forma de sintetizar el cromosoma. Dependiendo
de la representacion de las variables en los cromosomas se pueden aplicar los
siguientes metodos [33, 34]:
Recombinacion de parametros reales:
Recombinacion Discreta.
Recombinacion Intermedia.
Recombinacion Lineal.
Recombinacion Lineal Extendida.
Recombinacion de parametros binarios:
Cruza de Punto Sencillo.
Cruza de Multiples Puntos.
Cruza Uniforme.
Cruza Aleatoria.
Cruza con Reduccion de Sustituto.
Estos operadores son descritos en [33, 34, 35]. La operacion de recombi-
nacion utilizada en este trabajo es llamada Cruza de Punto Sencillo, tam-
bien conocida como Sobrecruzamiento con un Punto de Corte. Al comparar

20 CAPITULO 2. MARCO TEORICO
la cruza de multiples puntos fijos usada anteriormente [59] con la cruza de
punto sencillo, esta ultima apresento mejores resultados, esto es debido a
que el tamano de cromosoma es pequeno (unos 22 bits). La cruza de punto
sencillo se ilustra en la figura 2.2; donde los desendientes estan formados con
caracterısticas de ambos padres y el punto de corte es aleatorio.
Figura 2.2: Operador de cruza de punto sencillo.
La cruza de punto sencillo es implementada de acuerdo con el algoritmo
que se describe a continuacion [34]:
Obtener las parejas de cromosomas padres, por algun operador de se-
leccion o aleatoriamente si este no es implementado.
En cada pareja de cromosomas obtener un numero aleatorio entero U
comprendido entre 1 y el tamano del cromosoma menos uno (L-1). El
numero U sera el punto de corte en la pareja de cromosomas.
El cromosoma hijo es formado con los genes procedentes del cromosoma
padre1 que esten ubicados antes del punto de corte y los genes del
cromosoma padre2 que esten situados despues del punto de corte. De
manera contraria se puede generar un hijo2 si se desea.
Los cromosomas hijos forman una nueva poblacion para ser utilizada
por el operador de reinsercion, si no existe tal operador los cromosomas
hijos sustituyen a los cromosomas padres.
Un ejemplo de esta cruza con circuitos analogicos se muestra en la figura
2.3; donde los padres son los circuitos (a) y (b) y los descendientes, resultado

2.2. ALGORITMOS EVOLUTIVOS 21
de la cruza, son los circuitos (c) y (d). En estos circuitos se observa que su
cromosoma esta formado por una parte del cromosoma (a) y una parte del
cromosoma (b).
Figura 2.3: Ejemplo de la cruza en circuitos CMOS. (a) y (b) padres, (c) y(d) descendientes.

22 CAPITULO 2. MARCO TEORICO
Operador de mutacion
Despues de la operacion de cruza los descendientes experimentan al ope-
rador de mutacion. El operador de mutacion es el operador mas caracterıstico
de la GP; sin embargo al ser utilizada demasiado en los GA los puede conver-
tir en una busqueda lenta y al azar. La mutacion se encarga de modificar en
forma aleatoria uno o mas genes del cromosoma de un descendiente. La re-
presentacion de las variables determinara el metodo de mutacion [33, 34, 35];
ası, dos de los principales metodos son los siguientes:
Mutacion de Parametros Binarios.
Mutacion de Parametros Reales.
Las variables de los descendientes son mutadas por la adicion de pequenos
valores aleatorios con una probabilidad baja, esto llamado Tamano de Paso
de Mutacion en algunas referencias [2, 33]. La probabilidad de mutar una
variable es puesta para ser inversamente proporcional al numero de variables
o dimension del cromosoma [33, 34, 35]; aunque puede ser un porcentaje fijo
del numero de descendientes y se recomienda que no sea mayor a 5%.
La operacion de mutacion utilizada en este trabajo es la mutacion de
parametros binarios. La cual consiste en cambiar uno o mas bits de un cromo-
soma; en este trabajo se modificara solo un bit. En la figura 2.4 se muestra un
ejemplo de esta mutacion que es implementada de acuerdo con el algoritmo
que se describe a continuacion [33]:
Obtener la descendencia del operador de cruza.
A cada cromosoma hijo se le otorga un numero aleatorio entre 0 y 1.
Si el numero asignado al cromosoma hijo es mayor al tamano de paso
de mutacion, al cromosoma no se le modificara ningun bit. En caso

2.2. ALGORITMOS EVOLUTIVOS 23
contrario se obtiene un numero aleatorio entero U comprendido entre
1 y L. El numero U sera el bit que cambiara de valor.
Los cromosomas hijos (mutados o no) forman una nueva poblacion para
ser utilizada por el operador de reinsercion, si no existe tal operador
los cromosomas hijos sustituyen a los cromosomas padres.
Figura 2.4: Operacion de mutacion de parametros binarios.
Como se observo en la figura 2.4, el operador de mutacion actua sobre
el genotipo o cromosoma. Para mostrar un ejemplo de este operador con
circuitos analogicos, en la figura 2.5 se muestra como fenotipo un circuito
seguidor de voltaje, con su correspondiente cromosoma. Si a este cromosoma
se le realiza la operacion de mutacion uno de sus bits debe cambiar de ‘0’ a
‘1’ o de ‘1’ a ‘0’. En la figura 2.6 se observan 4 posibles circuitos si se realizara
la operacion de mutacion al circuito de la figura 2.5.

24 CAPITULO 2. MARCO TEORICO
Figura 2.5: Circuito VF descrito con su cromosoma.
Operador de reinsercion
El operador de reinsercion es el metodo por el cual se insertan los hijos en
la nueva poblacion; por ejemplo, mediante la eliminacion de los individuos
mas debiles o al azar. Si el tamano de los descendientes es menor que el
tamano de la poblacion original, los descendientes seran reinsertados dentro
de la poblacion anterior. Sin embargo, si se quiere que todos los descendientes
sean reinsertados se buscara algun otro metodo de reinsercion [33, 35]. Los
metodos de reinsercion mas utilizados son la reinsercion global y la reinsercion
local, para poblaciones locales. Ambas operaciones son basadas en algun
metodo de seleccion.
La operacion utilizada en este trabajo sera un tipo de reinsercion global
conocida como reproduccion elitista o elitismo [33, 35, 46]; que consiste en
producir igual o menos descendientes que el numero de padres y remplazar
los peores padres con los hijos mas aptos. En otros terminos, los individuos
padres concursan con los hijos para que solo los mejores formen la proxima

2.2. ALGORITMOS EVOLUTIVOS 25
Figura 2.6: Circuitos resultantes de la operacion de mutacion al VF de lafigura 2.5.

26 CAPITULO 2. MARCO TEORICO
generacion, esto ilustrado en la figura 2.7.
Figura 2.7: Operacion de elitismo utilizada en esta tesis.
En esta tesis el operador de reinsercion utilizado sera el elitismo y es
implementada de acuerdo con el siguiente algoritmo [34, 35]:
Obtener la descendencia del operador de mutacion, los N cromosomas
hijos.
Evaluarlos para encontrar su valor de aptitud (fitness).
A esta lista de N hijos agregarle los N cromosomas padres con su medida
de aptitud.
Ordenar a todos los 2N cromosomas (hijos y padres) de acuerdo a su
aptitud (fitness).
Elegir solo a los N cromosomas mejores para que estos sean la nueva
generacion; estos seran los nuevos padres en la proxima generacion.
2.2.3. Algoritmos Geneticos
Los GA son tecnicas estocasticas de busqueda basadas en los mecanismos
de seleccion natural y en la genetica biologica [33, 35]. La modernizacion y

2.2. ALGORITMOS EVOLUTIVOS 27
simulacion de la evolucion con la PC es una de las ideas mas atractivas en la
inteligencia artificial. Esta posibilidad fue planteada por primera vez durante
la decada de 1950, tras la aparicion de los primeros ordenadores, por algunos
investigadores como John von Neumann y Ulam. Sin embargo, no seria has-
ta la decada de los anos 60 cuando Fraser (1960), Fogel, Owens y Walsh
(1966) realizaron los primeros experimentos de simulacion con poblaciones
pequenas en las que tienen lugar mutaciones. Bagley introdujo en 1967 el
termino algoritmo genetico. En 1975 el investigador John Holland publico el
libro Adaptation in Natural and Artificial Systems, una de las referencias mas
importantes sobre los GAs desde el punto de vista teorico [34, 35].
Los GAs son metodos adaptivos que pueden ser utilizados en la busqueda y
obtencion de soluciones a problemas de optimizacion. Estos algoritmos estan
basados en los procesos geneticos de los organismos biologicos, codificando
una posible solucion a un problema a traves de un codigo nombrado cromo-
soma.
Los GAs utilizan una analogıa directa del fenomeno de evolucion en la natu-
raleza. Comienzan con un conjunto inicial de soluciones aleatorias llamado
poblacion inicial. Cada individuo en la poblacion es llamado cromosoma y
representa una posible solucion al problema.
Un cromosoma es una cadena de sımbolos llamados genes; que por lo general
son representados por una cadena de dıgitos binarios. Los cromosomas evolu-
cionan a traves de iteraciones llamadas generaciones. En cada generacion los
cromosomas son evaluados, usando una medida de aptitud. A los mas aptos
se les da la oportunidad de reproducirse mediante recombinaciones con otros
individuos de la poblacion, produciendo descendientes con caracterısticas de
ambos padres [33, 34, 35, 37]. Los miembros menos adaptados poseen pocas
probabilidades de que sean seleccionados para la reproduccion, por lo tanto

28 CAPITULO 2. MARCO TEORICO
sus caracterısticas tienden a desaparecer.
La siguiente poblacion se forma usando una combinacion de los operadores
de seleccion, cruza, mutacion y/o elitismo [33, 34, 35, 36, 37]. Esta nue-
va generacion debe contener una proporcion mas alta de las caracterısticas
poseıdas por los mejores miembros de la generacion anterior. De esta forma,
a lo largo de varias generaciones, las mejores caracterısticas son difundidas
en la poblacion mezclandose con otras. Favoreciendo la recombinacion de los
individuos mejor adaptados, con esto es posible recorrer las areas mas prome-
tedoras del espacio de busqueda. Si el GA ha sido disenado correctamente,
la poblacion convergera a una solucion optima o casi-optima al problema
[2, 33, 34, 35, 37].
Generalmente, los GAs son implementados siguiendo el ciclo mostrado en la
figura 2.8. donde se pueden apreciar los pasos descritos a continuacion:
Se genera la poblacion inicial de manera aleatoria.
Se evalua la aptitud de todos los individuos de la poblacion.
Se crea una nueva poblacion mediante los operadores de seleccion,
cruza, mutacion y/o elitismo.
Se itera hasta que se encuentra una solucion satisfactoria.
El poder del GA proviene del hecho de que la tecnica es robusta y puede
ser utilizada exitosamente en un amplio rango de problemas como: la op-
timizacion de funciones numericas, transportacion, localizacion, en la opti-
mizacion de la velocidad de herramientas y en algunos problemas que son
difıciles de resolver por otros metodos [2, 3, 4, 6, 33, 34, 35, 36, 37, 44, 45,
46, 59].
Cabe mencionar que los GAs no garantizan que encontraran la solucion opti-

2.2. ALGORITMOS EVOLUTIVOS 29
Figura 2.8: Estructura general de los algoritmos geneticos.
ma al problema pero son generalmente buenos encontrando soluciones acep-
tables a problemas en corto tiempo.
Dado un individuo la funcion de evaluacion le asignara un valor de aptitud, el
cual es proporcional a la utilidad o habilidad del individuo representado. En
muchos casos el desarrollo de una funcion de evaluacion involucra hacer una
simulacion; en otros casos la funcion puede estar basada en el rendimiento y
representar solo una evaluacion parcial del problema. Adicionalmente debe
ser rapida, ya que hay que aplicarla para cada individuo de cada poblacion en
las generaciones sucesivas. Por lo cual, gran parte del tiempo de la ejecucion
del GA se emplea en la funcion de evaluacion.
Ademas existe un problema en los algoritmos geneticos debido a una mala
formulacion del modelo, en el cual los genes de unos pocos individuos rela-
tivamente bien adaptados, pero no optimos, puede rapidamente dominar la

30 CAPITULO 2. MARCO TEORICO
poblacion, causando que converja a un mınimo o maximo local. Una vez
que esto ocurre, la habilidad del modelo para buscar mejores soluciones es
practicamente eliminada, quedando solo la mutacion como vıa para buscar
soluciones alternativas; y el GA se convierte en una busqueda lenta y/o al
azar [33, 34, 35].
2.2.4. Estrategias Evolutivas
A pesar de su aparente similitud con los GAs, las ES son usadas
comunmente en experimentos empıricos, difıciles de modelar matematica-
mente. Ademas, las ES estan basadas en el principio de la causalidad fuerte,
el cual establece que causas similares, tienen efectos similares [33, 34].
Las ES fueron propuestas en 1963 en la Universidad Tecnica de Berlın por
Ingo Rechenberg, Peter Bienert y Hans Paul Schwefel, como metodo de solu-
cion para el diseno optimo del cuerpo de objetos colocados en un flujo de
aire, de tal forma que se redujera la resistencia al mınimo. Durante el de-
sarrollo del proyecto probaron tecnicas ya conocidas y tradicionales como la
ola del gradiente, entre otras; sin embargo, estas resultaron en vano, dada
la complejidad del problema. Fue Ingo Rechenberg, quien propuso probar
con cambios aleatorios en el conjunto de parametros, que definıan la forma
de los objetos, siguiendo el ejemplo de la mutacion natural. Peter Bienert
construyo un experimentador automatico, el cual trabajarıa de acuerdo a las
reglas de mutacion y seleccion. Por su parte, Hans-Paul Schwefel comenzo a
probar la eficiencia de los nuevos metodos, con la ayuda de una computadora,
principalmente porque existıan muchas objeciones a estas ‘estrategias aleato-
rias’. Para simular el proceso evolutivo en una computadora se requirio de
codificar las estructuras que se replicarıan, definir las operaciones que afec-

2.2. ALGORITMOS EVOLUTIVOS 31
tarıan a los individuos, una funcion de aptitud y un mecanismo de seleccion
[34]. La version original (1+1) usaba un solo padre y con el, se generaba un
solo hijo. Este hijo se mantenıa si era mejor que el padre, o de lo contrario se
eliminaba. En esta version, un individuo nuevo es generado por el operador
de mutacion.
Fue en 1973 cuando, en su tesis de doctorado, Ingo Rechenberg establecio las
bases teoricas para las ES, definio los conceptos de mutacion y seleccion, y
agrego el nuevo concepto de poblacion en una variante de las ES propuestas
inicialmente. Posteriormente, surgieron otras versiones para las ES propues-
tas por Schwefel, quien introdujo el uso de multiples hijos en las variantes
[34].
Ası, las ES fueron creadas como un metodo para resolver problemas de op-
timizacion tecnica; y hasta hace relativamente poco solo eran conocidas en
Ingenierıa Civil como alternativa de soluciones estandares [34, 46]. Por lo
general donde se utilizan las ES es cuando no existe una solucion analıtica
para estos problemas y por lo tanto no existe un metodo de solucion. La opti-
mizacion con ES se basa en la hipotesis cuya afirmacion es que las leyes de la
herencia han sido desarrolladas para una adaptacion genetica rapida. Las ES
imitan los efectos de los procedimientos geneticos que actuan directamente
sobre el fenotipo, en contraste con los GAs que trabajan sobre el genotipo.
Existen algunos tipos de problemas que son adecuados para aplicar ES, por
ejemplo cuando el espacio de busqueda es demasiado grande para ser explo-
rado a detalle [34]. Ya que las ES copian la evolucion biologica, las aplica-
ciones de estas estrategias tienden a eliminar a los individuos debiles, y a
todas las soluciones similares a ellos (o sea, sus descendientes) en las etapas
tempranas de la simulacion. De esta forma se restringe el espacio para en-
contrar una solucion adecuada.

32 CAPITULO 2. MARCO TEORICO
2.2.5. Programacion Genetica
La programacion genetica es una clase de algoritmos parecida a los GAs
solo que estos no contienen el operador de cruza. En un algoritmo realiza-
do con GP los individuos de la poblacion se reproducen asexualmente, esto
significa que un unico individuo sera capaz por si solo de tener descendencia
sin necesidad de la colaboracion de otro individuo [34]. La ausencia del ope-
rador de recombinacion conduce a que la unica fuente de variabilidad de los
individuos sea aquella que resulta de las mutaciones.
Figura 2.9: Estructura general de los algoritmos que se basan en GP.
En los algoritmos evolutivos de este tipo es frecuente seleccionar a un
solo individuo y una vez seleccionado por su puntuacion o fitness la nueva
generacion; es decir, su descendencia se obtiene por simple copia o clonacion
de su cromosoma, mutando una o mas posiciones en los cromosomas de los
individuos de la nueva generacion [34].
Un ejemplo llamativo de la GP es el de los biomorfos de Dawkins, uno de

2.2. ALGORITMOS EVOLUTIVOS 33
los algoritmos evolutivos mas conocidos que es capaz de obtener organismos
artificiales en dos dimensiones. Este algoritmo fue introducido en el libro
El reloj ciego (1986), que rapidamente se convertirıa en un clasico de la
divulgacion cientıfica. En resumen, en un GP las fases de reproduccion y
mutacion se repetiran iterativamente hasta que el algoritmo encuentre el
cromosoma que resuelva el problema, como se muestra en la figura 2.9.

34 CAPITULO 2. MARCO TEORICO
Esta hoja se dejo en blanco intencionalmente.

Capıtulo 3
Metodo de sıntesis propuesto
3.1. Introduccion
Existen trabajos previos acerca de herramientas de sıntesis de circuitos
y sistemas analogicos como se describio en el capıtulo 2. En este capıtulo se
presenta la propuesta de un algoritmo evolutivo para la sıntesis de circuitos
analogicos. Para realizar la codificacion de los UGCs, CCs y CFOAs se uti-
lizara como base el elemento nullor [68, 69]. Ası, en este capıtulo se presenta
la descripcion del nullor y sus propiedades.
Posteriormente se describe el proceso propuesto para la busqueda de
topologıas; donde se describe un GA generico que sera el pilar del meto-
do propuesto. La implementacion de este GA se ha programado en MatLab
y se utilizaron algunas funciones de prueba para verificar su funcionamiento.
Las respuestas del GA a las funciones de prueba se muestran en este capıtulo.
Para finalizar se muestran cada una de las codificaciones geneticas propuestas
para los distintos circuitos analogicos.
35

36 CAPITULO 3. METODO DE SINTESIS PROPUESTO
3.2. El elemento nullor
En [68] se encuentra una recopilacion de metodologıas de analisis, diseno
y sıntesis de circuitos analogicos usando nullors. Hanspeter Schmid [69] de-
mostro su utilidad para modelar el comportamiento ideal de varios disposi-
tivos activos, tales como: amplificador operacional (OPAMP), amplificador
operacional de transconductancia (OTA), current conveyor (CC), etc. El nu-
llor es un dispositivo ideal de dos puertos, compuesto por un elemento O
(nullator) y por un elemento P (norator); con cuatro variables asociadas. En
el puerto de entrada el voltaje y corriente del nullator y en el puerto de sali-
da el voltaje y la corriente del norator, como se muestra en la figura 3.1. El
voltaje y la corriente de nullator son siempre cero, mientras para el norator
el voltaje y la corriente son arbitrarios [30, 68, 69].
Figura 3.1: Nullor.
Las propiedades de los elementos O y P se pueden aprovechar para mode-
lar el comportamiento ideal de los bloques de ganancia unitaria. Por ejemplo,
para modelar el comportamiento ideal del VF se puede utilizar uno o mas
elementos O como se muestra en la figura 3.2 [19, 21]; donde se demuestra
que el voltaje a la salida del VF (Vo) es igual al voltaje de entrada (Vi), por
las propiedades del nullator. Dado que el voltaje y la corriente del nullator
son igual a cero, el puente de cuatro nullators modela el comportamiento de
uno simple.

3.2. EL ELEMENTO NULLOR 37
Figura 3.2: Modelos de VFs usando (a) uno y (b) cuatro nullators.
Para modelar un CF se utilizan celdas genericas formadas por uno, o mas
norators [19, 21]. En estos circuitos las variables electricas son las corrientes.
Dado que la corriente que circula a traves del norator siempre es la misma, se
cumple que la corriente de la salida (Io) es igual a la corriente de la entrada
(Ii).
El modelo de un transistor MOS utilizando el nullor se muestra en la figura
3.3. De esta manera, al agregar norators a los circuitos que esten represen-
tados por nullators y al agregar nullators a las topologıas que esten repre-
sentadas por norators se forman pares O-P; cada par O-P puede sintetizar
un transistor MOS. Se observa en la figura 3.3 que el punto de union O-P es
considerado como el source (S), la terminal libre del elemento O es el gate
(G) y la terminal libre del elemento P es el drain (D) del MOSFET.
Figura 3.3: Modelo del MOSFET usando el elemento nullor.

38 CAPITULO 3. METODO DE SINTESIS PROPUESTO
3.3. Algoritmo Genetico realizado
3.3.1. Diagrama de Flujo
Uno de los objetivos principales de esta tesis es desarrollar un sistema
capaz de sintetizar topologıas conocidas y nuevas de UGCs, CCs y CFOAs.
Para esto se desarrollo un programa basado en EAs. Aunque sean distintos
los objetivos de sıntesis para cada UGC, todos se encuentran siguiendo el
esquema mostrado en la figura 3.4.
El algoritmo inicia obteniendo los datos del usuario:
Variables del GA: Tamano de poblacion, Porcentaje de mutacion,
Numero maximo de generaciones y Mınimo error buscado.
Tipo de UGC a sintetizar: VF, CF, VM, CM.
Varibles deseadas: Ganancia, Ancho de banda, Impedancia de entrada
y/o salida.
Peso de los valores deseados en la funcion de evaluacion.
Tipo de simulador: TOP-SPICE, H-SPICE, Tanner-SPICE.
Tipo de tecnologıa:
• AMI Semiconductor: 0.35µm, 0.50µm.
• IBM Semiconductor: 0.18µm, 0.25µm, 0.35µm, 0.50µm.
• Taiwan Semiconductor (TSMC): 0.18µm, 0.25µm, 0.35µm.
Despues de obtener los datos se realiza una eleccion de celda ideal. Este
consiste en describir el UGC por medio de elementos nullators y/o norators.
Por ejemplo para representar un CF existen varias celdas genericas formadas
por uno o mas norators. En la figura 3.5 se muestran todas estas posibilidades
con uno y dos nullators; las combinaciones con tres nullators se observan en

3.3. ALGORITMO GENETICO REALIZADO 39
Figura 3.4: Diagrama de Flujo del programa que sintetiza circuitos analogi-cos.

40 CAPITULO 3. METODO DE SINTESIS PROPUESTO
la figura 3.6. Al utilizar cuatro nullators para describir un CF se encuentran
15 posibilidades diferentes (figura 3.7). Entonces el metodo de eleccion de
celda ideal se realiza con el fin de seleccionar cualquiera de las 23 posibles
descripciones ideales de CF; y no solo ocupar las tres clasicas: figura 3.5(a),
figura 3.5(b) y figura 3.7(l). Los circuitos que se representan con estas tres
celdas han sido estudiados por varios autores [8, 19, 21, 25]. Sin embargo,
existen 23 posibilidades de acomodar elementos norator que idealmente des-
criben un CF, las cuales no han sido estudiadas a fondo.
El metodo de eleccion de celda ideal tiene el mismo objetivo para los otros
tipos de UGC, explorar mas posibilidades de circuitos utiles.
Figura 3.5: Modelos ideales de CFs usando uno y dos norators.
Figura 3.6: Modelos ideales de CFs usando tres norators.
Despues de realizar la seleccion de celda ideal, se crean aleatoriamente
algunos individuos para generar una poblacion inicial. Se decodifican los cro-
mosomas y se generan los netlist de los circuitos para su simulacion en SPICE.
Se simulan los archivos en SPICE con la tecnologıa selecionada. Posterior-

3.3. ALGORITMO GENETICO REALIZADO 41
Figura 3.7: Modelos ideales de CFs usando cuatro norators.
mente se evalua a cada individuo, segun su repuesta en SPICE y se le asigna
una medida de aptitud. Cada individuo y su medida de aptitud se guarda
en memoria. Entre mejor desempeno muestre el circuito, mejor es el valor

42 CAPITULO 3. METODO DE SINTESIS PROPUESTO
calificado al cromosoma.
Una vez calificados los individuos estos seran los padres para un GA que itera-
ra hasta un numero maximo de generaciones o hasta encontrar una topologıa
que pueda ser util. Este GA realiza las operaciones de seleccion, cruza, mu-
tacion y elitismo descritas en el capıtulo 2. Cuando finaliza el GA entrega un
netlist del UGC, CC o CFOA buscado. Cabe mencionar que se espera que el
GA sintetize circuitos conocidos y nuevos.
3.3.2. Pruebas al GA realizado
En la figura 3.4 se muestra el esquema del EA a realizar, los bloques son
realizados por sub-programas. Algunos de estos son particulares para cada
UGC y otros sub-programas deben ser generales. Entendiendo por generales
que estos seran utilizados al sıntetizar cualquier UGC, como los operadores
geneticos de seleccion, cruza, mutacion y elitismo. En conclusion, se deben
de desarrollar estos bloques y probarlos con funciones de test estandar para
confirmar su funcionamiento. Puesto que es importante tener la seguridad del
buen funcionamiento de los operadores geneticos y del GA que se utilizara.
Es por esta razon que se realizo un primer GA, obedeciendo a la figura 2.8.
En este se han programado las operaciones de seleccion, cruza, mutacion y
elitismo que se utilizaran en el programa de la figura 3.4. MatLab le asigna
una calificacion a cada individuo (fitness). El programa se detendra cuando
se alcance el valor esperado por el usuario o se llegue a un numero maximo
de iteraciones.
La medida de aptitud utilizada es la suma de la norma, como se observa en
la ecuacion (3.1). Donde los valores esperados por el usuario son so1, so2,
etc.; y los valores evaluados del cromosoma son ev1, ev2, etc. El programa se

3.3. ALGORITMO GENETICO REALIZADO 43
detendra cuando PTotal sea igual a cero (mas una tolerancia de error) [33].
PTotal = |so1− ev1|+ |so2− ev2|+ |so3− ev3|+ · · · (3.1)
Las funciones de test sirven para evaluar, comparar, clasificar y probar
la eficiencia y efectividad del algoritmo. Existen varios tipos de funciones de
test para EA mono-objetivo y multi-objetivo, como las funciones de Binh,
Fonseca, Kursawe, Laumanns, Lis, Murata o Viennet, entre otras recopiladas
en [33]. La prueba de funcionamiento del GA consiste en la busqueda de
puntos de solucion de una o mas ecuaciones.
Las ecuaciones utilizadas para evaluar el GA realizado son las descritas en
la Ec. (3.2), todas con un espacio de busqueda delimitado entre x = [−1, 1],
y = [−1, 1]. Las graficas y los contornos de las ecuaciones se muestran en las
figuras 3.8, 3.9 y 3.10.
F1(x, y) = x2 − 2xy + 6x + y2 − 6y
F2(x, y) = 10x2 + 30y2 (3.2)
F3(x, y) = 20 + 10x2 + y2 − 10cos(2x)− 10cos(2y)
Figura 3.8: (a) Grafica y (b) contorno de F1(x,y).
Cada ecuacion tiene un espacio de busqueda delimitado entre [−1, 1] de
2R. El tamano de cromosoma elegido es de 34 bits, este se divide en dos

44 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Figura 3.9: (a) Grafica y (b) contorno de F2(x,y).
Figura 3.10: (a) Grafica y (b) contorno de F3(x,y).
numeros de 17 bits cada uno, variando en pasos simetricos de 0.00001526
(2/131072). Esto genera un espacio de busqueda de poco mas de 17 mil
millones de posibles soluciones (17,179,869,184) para cada funcion de prueba
a utilizar. Las descripciones de las funciones de prueba (FP) utilizadas se
muestran en el cuadro 3.1.
Las funciones de prueba FP1 a FP6 son mono-objetivo; es decir, el GA
busca la solucion a una sola ecuacion. Las funciones FP7 a FP13 son multi-
objetivo, el GA busca una solucion que satisfaga a dos o mas ecuaciones.
Las funciones de prueba buscan maximos, mınimos o valores particulares. En
la quinta columna del cuadro 3.1 se muestra el numero de soluciones analıticas
a la funcion de prueba. Las FP con una sola solucion comprueban que el EA
es capaz de encontrar esa solucion y no se estanque en soluciones locales; el

3.3. ALGORITMO GENETICO REALIZADO 45
Cuadro 3.1: Funciones de prueba utilizadas.
Ecuaciones Punto a Resultado Numero de Notasencontrar aritmetico soluciones
FP1 F1(x,y) mınimo -8 1FP2 F1(x,y) maximo 16 1FP3 F2(x,y) mınimo 0 1 El punto de solucion exis-
te, pero no esta decodifi-cado por los cromosomas.(x,y)=(0,0)
FP4 F2(x,y) maximo 40 4FP5 F3(x,y) mınimo 0 1 Contiene 8 mınimos locales,
ver figura 3.10.FP6 F3(x,y) maximo 40.5 4FP7 F1(x,y) maximo 16 1
F2(x,y) maximo 40FP8 F1(x,y) maximo 16 0 El mejor punto es segun la
ec. (3.2) esta cerca de:F3(x,y) maximo 40.5 (x,y) = (0.5,-0.5)
FP9 F2(x,y) maximo 40 0 Existen 4 puntos a conver-ger:
F3(x,y) mınimo 0 (x,y) = (±1, ±1)FP10 F1(x,y) valor en 0 1 El punto de solucion existe,
particular pero no esta decodificadoF2(x,y) mınimo 0 por los cromosomas.F3(x,y) mınimo 0 (x,y)=(0,0)
FP11 F1(x,y) maximo 16 1 Verificar analıticamenteF2(x,y) maximo 40 el mejor punto (x,y)=(1,-1)F3(x,y) mınimo 0 para la ec.(3.2) es demasia-
do complejo.FP12 F1(x,y) maximo 16 ¿? Encontrar analıticamente
F2(x,y) maximo 40 el mejor punto (x,y) paraF3(x,y) maximo 40.5 la ec.(3.2) es demasiado
complejo.FP13 F1(x,y) mınimo -8 ¿? Encontrar analıticamente
F2(x,y) mınimo 0 el mejor punto (x,y) paraF3(x,y) mınimo 0 la ec.(3.2) es demasiado
complejo.
GA ofrecera una solucion muy parecida a la ideal cuando el cromosoma no
lo puede decodificar a la solucion optima. Las FP con mas de una solucion
optima, se utilizan para observar que el GA es capaz de encontrar a todas

46 CAPITULO 3. METODO DE SINTESIS PROPUESTO
estas. El conjunto de las mejores soluciones es conocido en investigacion de
operaciones como ‘frente de Pareto’ [33, 34, 35]. El uso de EAs generalmente
es en problemas donde la solucion analıtica es muy compleja como en el caso
de FP11, FP12, y FP13; en estos casos se confıa que el EA sea capaz de
encontrar una solucion optima o casi-optima al problema [33].
Las pruebas fueron ejecutadas en una computadora marca eMachines modelo
M2352, con procesador Mobile AMD Athlon(tm) XP 3000+ a 524 MHz, con
448MB en RAM. El numero maximo de generaciones fue de 150; el tamano
de la poblacion es de 40 individuos. Ası, el numero maximo de evaluaciones
es de 6000 (150x40). El error mınimo pedido fue 0%, en todas las FP se
ejecutaron 10 veces por prueba.
Los resultados de las ejecuciones de las FP en el GA se muestran en el cuadro
3.2. Donde se observa el punto de solucion deseado y el encontrado por el
GA, promedio de tiempo de computo y promedio de numero de generaciones
realizadas para encontrar la solucion.
En el cuadro 3.2 se observa que el GA logra encontar los puntos de optimos
de solucion para FP1, FP2, FP4,FP7,FP9 y F11. Mientras que para FP3,FP5
y FP10 encuentra los puntos mas cercanos al optimo, esto es porque el cro-
mosoma del punto (0,0) no existe en esta codificacion. En FP6 el algoritmo
no encuentra los puntos (±0,5,±0,5), sin embargo sus respuestas son muy
cercanas a estos puntos; para lograr que el GA encuentre los puntos optimos
vasta con aumentar el numero de generaciones. Para las FP8, FP12 y FP13
se presentan en el cuadro 3.2 los puntos del mejor y peor caso, los otros
resultados son cercanos a esos puntos; lo que hace concluir que la solucion
son los mejores puntos encontrados o esta proxima a ellos. La proximidad
en el valor para estos puntos es suficiente para concluir que el GA funciona
correctamente.

3.3. ALGORITMO GENETICO REALIZADO 47
Cuadro 3.2: Resultados de las pruebas al GA realizado.
Funcion Punto(s) de Punto(s) Promedio de Promedio dede solucion encontrados Tiempo de GeneracionesPrueba por el AG computo (seg) realizadasFP1 (-1,1) (-1,1) 0.9634 60.5FP2 (1,-1) (1,-1) 0.9022 55.7FP3 (0,0) (±7.63, ±7.63) 1.7323 150
x10−6
FP4 (±1, ±1) (±1, ±1) 0.9682 58.7FP5 (0,0) (±7.63, ±7.63) 1.6534 150
x10−6
FP6 (±0.5, ±0.5) mejor(-0.4990,-0.5030) 1.7284 150peor (0.5024,0.4989)
FP7 (1,-1) (1,-1) 1.0734 63.4FP8 - - - mejor (0.5232,-0.5232) 1.7476 150
peor (0.5000,-0.5313)FP9 (±1, ±1) (±1, ±1) 1.7164 150FP10 (0,0) (±7.63, ±7.63) 1.6873 150
x10−6
FP11 (1,-1) (1,-1) 1.6513 150FP12 - - - mejor (0.5625,-1) 1.7014 150
peor (0.5000,-1)FP13 - - - mejor (-0.0147,0.0137) 1.6793 150
peor (7x10−6,0.0137)
3.3.3. Medida de aptitud para los UGC
La medida de aptitud en un EA es el resultado de la evaluacion de un
individuo. Esta puede ser dada por algun metodo lineal, cuadratico, exponen-
cial, logica difusa, etc. En este trabajo la evaluacion es realizada por la suma
de la norma (valor absoluto), este tipo de estimacion es suficiente para pro-
blemas de esta ındole [33]. Cada circuito sintetizado se ejecutara en SPICE
para obtener su comportamiento en ganancia, ancho de banda, impedancia
de entrada y/o salida en AC. Dependiendo de las respuestas obtenidas se le
asignara al circuito una medida de aptitud.

48 CAPITULO 3. METODO DE SINTESIS PROPUESTO
La Ec. (3.3) es la medida de aptitud que se utilizara en este trabajo; donde
las variables P1 a P4 son los pesos que el usuario define, para darle prioridad
a algun parametro sobre los otros. Las funciones f(ev1) a f(ev4) se calculan
segun las ecuaciones (3.4) a (3.7). En estas ecuaciones los valores espera-
dos por el usuario son: ganancia (gain), ancho de banda (BW ), impedancia
de entrada (Zin) e impedancia de salida (Zout). Los valores evaluados por
SPICE son ev1 a ev4. PTotal es la calificacion dada al circuito, es decir,
PTotal es la medida de aptitud del individuo; el circuito mejor calificado es
el mas cercano a cero.
PTotal = P1 · f(ev1) + P2 · f(ev2) + P3 · f(ev3) + P4 · f(ev4) (3.3)
f(ev1) = |gain− ev1| (3.4)
f(ev2) =
|BW−ev2|BW
ev2 < BW0,01|BW−ev2|
BWev2 < 10 ·BW
0,1 + 0,001|BW−ev2|BW
ev2 < 100 ·BW
0,2 + 0,0001|BW−ev2|BW
ev2 < 1000 ·BW
(3.5)
f(ev3) =
|Z−ev3|Z
ev3 < Z0,1|Z−ev3|
Zev3 ≥ Z
(3.6)
f(ev4) =
0,1|Z−ev4|
Zev4 < Z
|Z−ev4|Z
ev4 ≥ Z(3.7)
La Ec. (3.4) es la funcion que evalua a la ganancia. La figura 3.11 muestra
la grafica de esta ecuacion cuando gain = 1. El circuito mejor calificado es
aquel que cumpla con ev1 = 1, ya que f(ev1) = 0. La figura 3.12 muestra
el comportamiento de la Ec. (3.5), donde el valor definido por el usuario es
BW = 10, 000.
La Ec. (3.6) califica a la impedancia que idealmente debe ser grande;
como es la Zin para un VF o la Zout para un CM. La figura 3.13 muestra

3.3. ALGORITMO GENETICO REALIZADO 49
Figura 3.11: Grafica de la Ec. (3.4), con gain = 1.
Figura 3.12: Grafica de la Ec. (3.5), donde BW = 104.

50 CAPITULO 3. METODO DE SINTESIS PROPUESTO
a la Ec. (3.6), donde Z = 20KΩ. En forma inversa la Ec. (3.7) califica a la
impedancia que idealmente debe ser cero; como es la Zin para un VF o la
Zout para un CF. La figura 3.14 muestra a la grafica de la Ec. (3.7), donde
Z = 250Ω. Como se observa la funcion castiga a las impedancias lejanas a la
ideal (Z = 250Ω); pero es mas severa con las impedancias grandes.
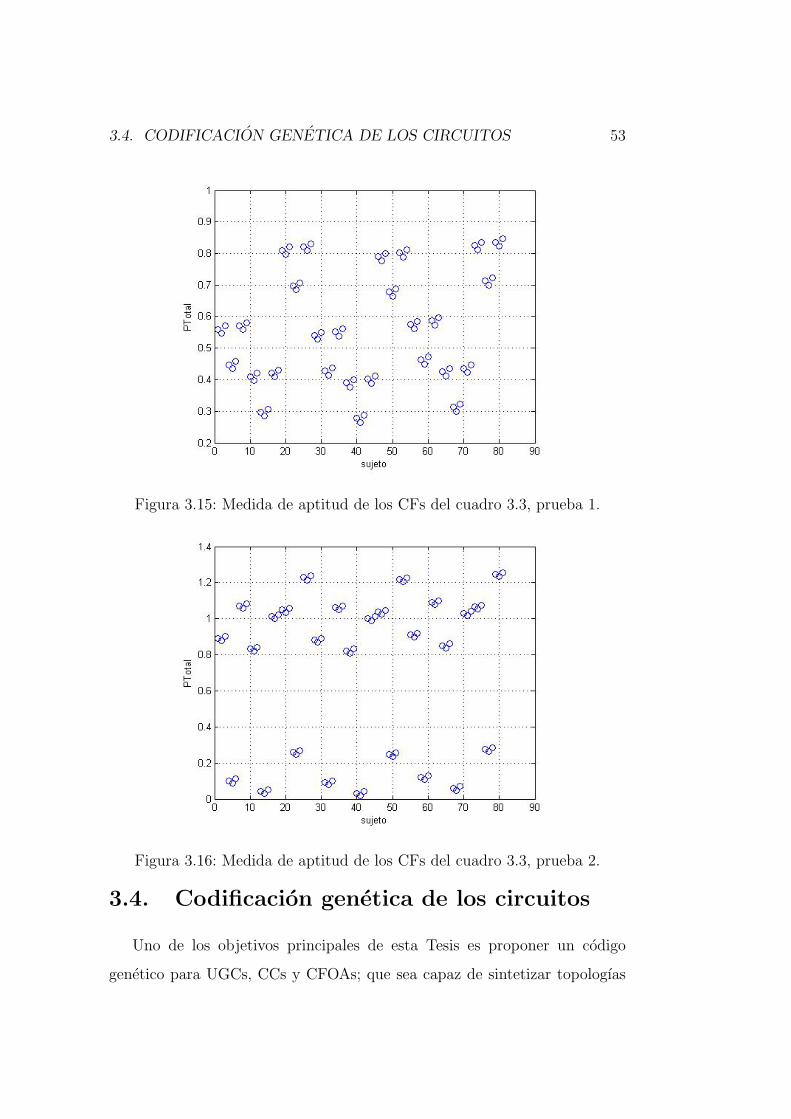
Para mostrar el funcionamiento de la Ec. (3.3); se ejecuta esta evaluacion
a los individuos mostrados en el cuadro 3.3. Este cuadro contiene 81 sujetos
(CFs) con diferentes valores de ganancia, ancho de banda e impedancias.
Cada una de las cuatro variables tiene tres posibles valores:
ganancia: 0.87, 0.91, 0.96.
ancho de banda: 10KHz, 100KHz, 1MHz.
impedancia de entrada: 70Ω, 100Ω, 150Ω.
impedancia de salida: 18.5KΩ, 20KΩ, 22KΩ.
Los resultados al ejecutar la Ec. (3.3) se muestran en la figura 3.15, donde
P1 = P2 = P3 = P4 = 0,25, y los valores buscados son: gain = 1, BW =
2MHz, Zout = 25KΩ y Zin = 50Ω. Se observa que los mejores individuos
son: 41, 40, 14, 42, 13, 68, 15, 67 y 69, en ese orden. En el cuadro 3.3 el
individuo que contiene los mejores valores es el 41.
Al modificar en la funcion de evaluacion el peso de las variables y los
valores a buscar, se obtiene otro tipo calificacion para cada individuo. Por
ejemplo, en una segunda prueba los valores a buscar son: gain = 0,98, BW =
500KHz, Zout = 21KΩ y Zin = 80Ω; y los pesos P1 = P3 = P4 = 0,25,
P2 = 1, es decir el ancho de banda tiene mayor prioridad sobre los otros
valores. El resultado de la evaluacion con la Ec. (3.3) se observa en la figura
3.16.

3.3. ALGORITMO GENETICO REALIZADO 51
Figura 3.13: Grafica de la Ec. (3.6), donde Z = 20KΩ.
Figura 3.14: Grafica de la Ec. (3.7), donde Z = 250Ω.

52 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Cuadro 3.3: Individuos de pueba para la Ec. (3.3). Valores de ganancia, anchode banda e impedancias de posibles circuitos CF.
No. ganancia BW ZIN ZOUT No. ganancia BW ZIN ZOUT
KHz Ω KΩ KHz Ω KΩ1 0.91 100 100 20 42 0.87 1000 70 222 0.96 100 100 20 43 0.91 10 70 223 0.87 100 100 20 44 0.96 10 70 224 0.91 1000 100 20 45 0.87 10 70 225 0.96 1000 100 20 46 0.91 100 150 226 0.87 1000 100 20 47 0.96 100 150 227 0.91 10 100 20 48 0.87 100 150 228 0.96 10 100 20 49 0.91 1000 150 229 0.87 10 100 20 50 0.96 1000 150 22
10 0.91 100 70 20 51 0.87 1000 150 2211 0.96 100 70 20 52 0.91 10 150 2212 0.87 100 70 20 53 0.96 10 150 2213 0.91 1000 70 20 54 0.87 10 150 2214 0.96 1000 70 20 55 0.91 100 100 18.515 0.87 1000 70 20 56 0.96 100 100 18.516 0.91 10 70 20 57 0.87 100 100 18.517 0.96 10 70 20 58 0.91 1000 100 18.518 0.87 10 70 20 59 0.96 1000 100 18.519 0.91 100 150 20 60 0.87 1000 100 18.520 0.96 100 150 20 61 0.91 10 100 18.521 0.87 100 150 20 62 0.96 10 100 18.522 0.91 1000 150 20 63 0.87 10 100 18.523 0.96 1000 150 20 64 0.91 100 70 18.524 0.87 1000 150 20 65 0.96 100 70 18.525 0.91 10 150 20 66 0.87 100 70 18.526 0.96 10 150 20 67 0.91 1000 70 18.527 0.87 10 150 20 68 0.96 1000 70 18.528 0.91 100 100 22 69 0.87 1000 70 18.529 0.96 100 100 22 70 0.91 10 70 18.530 0.87 100 100 22 71 0.96 10 70 18.531 0.91 1000 100 22 72 0.87 10 70 18.532 0.96 1000 100 22 73 0.91 100 150 18.533 0.87 1000 100 22 74 0.96 100 150 18.534 0.91 10 100 22 75 0.87 1000 150 18.535 0.96 10 100 22 76 0.91 1000 150 18.536 0.87 10 100 22 77 0.96 1000 150 18.537 0.91 100 70 22 78 0.87 1000 150 18.538 0.96 100 70 22 79 0.91 10 150 18.539 0.87 100 70 22 80 0.96 10 150 18.540 0.91 1000 70 22 81 0.87 10 150 18.541 0.96 1000 70 22
3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 53
Figura 3.15: Medida de aptitud de los CFs del cuadro 3.3, prueba 1.
Figura 3.16: Medida de aptitud de los CFs del cuadro 3.3, prueba 2.
3.4. Codificacion genetica de los circuitos
Uno de los objetivos principales de esta Tesis es proponer un codigo
genetico para UGCs, CCs y CFOAs; que sea capaz de sintetizar topologıas

54 CAPITULO 3. METODO DE SINTESIS PROPUESTO
conocidas y nuevas. Existen trabajos de circuitos electronicos desarrollados
con EAs; estos utilizan algun tipo de codificacion de los circuitos en un cro-
mosoma como se muestra en algunos trabajos [1, 2, 3, 4, 6, 7, 8]. Sin embargo,
estas descripciones se enfocan a optimizar ciertos parametros de un circuito
en CD, CA y/o tiempo, por lo que sus codificaciones representan en la mayo-
rıa de trabajos dimensiones de sus transistores y no como estan realizadas
estas topologıas [1, 2, 3, 4, 6, 7, 8, 12, 13, 14, 15, 16, 17, 18]. Ası, que esas
codificaciones no son utiles para trabajar en esta tesis y se tiene la necesidad
de realizar una codificacion diferente a las ya mencionadas. En las siguientes
secciones se describe cada uno de los cromosomas propuestos para cada tipo
de circuito.
3.4.1. Genotipo y fenotipo de un VF
Partiendo del modelo ideal de un VF utilizando solo un elemento O (figura
3.2.(a)), se procede a la generacion de un circuito hecho con transistores.
Primero, para proposito de sıntesis cada elemento O debe estar unido a un
elemento P. De esta manera, un elemento P puede agregarse a un elemento O
a la izquierda (nodo i), a la derecha (nodo j), o en paralelo (entre los nodos i
y j); como se ilustra en la figura 3.17 [21, 59]. Como puede inferirse, cada par
O-P se puede representar por un gen de 2 bits de longitud; esta codificacion
crea el gen de pequena senal (genSS), el cual se describe en el cuadro 3.4.
Cada par O-P se sintetiza por un MOSFET como se mostro en la figura
3.3. En este proceso se utiliza un gen de sıntesis del MOSFET (genSMos); el
cual consiste de un bit (a2) para describir el tipo de transistor. Ası cuando
genSMos es cero se sintetiza un N-MOS y cuando es uno se genera un P-MOS
(cuadro 3.5).

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 55
Figura 3.17: Adicion de un elemento P a un elemento O: (a) en el nodo i, (b)en el nodo j y (c) entre los nodos i y j.
Cuadro 3.4: Codificacion del genSS a partir de la figura 3.17.
a0 a1 Union Figura0 0 Pi 3.17.(a)0 1 Pj 3.17.(b)1 0 Pij, punto de union i. 3.17.(c)1 1 Pji, punto de union j. 3.17.(c)
Cuadro 3.5: Codificacion del genSMos.
a2 Tipo de transistor0 N-MOS1 P-MOS
Al circuito se le agregan dos fuentes de voltaje nombradas Vdd y Vss
(positiva y negativa, respectivamente). Posteriormente se agregan fuentes de
corriente utilizando un gen de polarizacion (genBias); este contiene dos bits
(a3a4) por cada nullator que describe al VF. La combinacion 00 significa
que el drain del MOSFET se conectara a Vdd mientras que el source se
conectara a una fuente de corriente conectada a Vss. El 01 significa que el
drain se conecta a Vss y el source a una fuente de corriente conectada a Vdd.
Las otras dos combinaciones (10 y 11) significan que tanto al drain como al
source se les conectaran fuentes de corriente a Vdd y a Vss; esto se resume

56 CAPITULO 3. METODO DE SINTESIS PROPUESTO
en el cuadro 3.6.
Cuadro 3.6: GenBias: Bits de asignacion para agregar fuentes de corriente.
a3a4 ConexionDrain Source
0 0 Vdd Iss0 1 Vss Idd1 0 Idd Iss1 1 Iss Idd
Una vez que se han agregado fuentes de polarizacion de voltaje y corriente
al circuito cada fuente de corriente (Idd o Iss) se sintetiza por un espejo de
corriente (CM), utilizando el genCM. El tamano del genCM depende de
cuantos tipos de espejo se tengan en una librerıa, en este trabajo se utilizan
cuatro diferentes CM; por lo tanto el genCM consta de dos bits (b0b1). En
el cuadro 3.7 se muestra el codigo del genCM.
Cuadro 3.7: GenCM: Sıntesis de fuentes de corriente por CM.
b0b1 Espejo de Corriente0 0 Simple0 1 Cascode1 0 Wilson1 1 Wilson Modificado
En resumen, para codificar un VF modelado con un nullator a partir de
la figura 3.2.(a), se tiene un cromosoma (codigo) de 7 bits: a0a1a2a3a4b0b1;
divididos en cuatro diferentes genes: genSS, genSMos, genBias y genCM. Esto
significa que existen 27 = 128 diferentes topologıas de circuitos que pueden
sintetizar un VF con la descripcion dada. Sin embargo, algunas topologıas no
son funcionales, ya que la entrada o la salida puede estar conectada a Vdd
o a Vss; asimismo, otras topologıas no cumpliran con la especificacion de un

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 57
VF (VOUT = VIN).
Para sintetizar un VF de dos, tres o de cuatro MOSFETs, la representacion
ideal es por medio del mismo numero de nullators. Por lo tanto, el cromosoma
crece segun el numero de nullators que lo representan idealmente; esto se
muestra en el cuadro 3.8, donde: genMOS=genSS-genSMos-genBias.
Cuadro 3.8: Numero de bits para cada cromosoma VF.
VF nullators cromosoma TOTAL1 MOS 1 genMOS(1)− genCM 7 bits2 MOS 2 genMOS(1)− genMOS(2)− genCM 12 bitsN MOS N genMOS(1)− · · · − genMOS(N)− genCM 5N+2
El cuadro 3.8 muestra que se tienen 212 = 4, 096 diferentes topologıas
posibles para realizar un VF partiendo de 2 nullators. Para sintetizar un VF
partiendo de 4 nullators se tienen 222 = 4, 194, 304 posibles topologıas dis-
tintas. Para todas las descripciones de cromosomas de VF existiran ciertas
topologıas que no tienen sentido ya que la entrada o la salida pueden estar
conectadas a Vdd o a Vss; y otras topologıas no cumplan con el compor-
tamiento de un seguidor de voltaje. El EA que se realizo en este trabajo es
capaz de seleccionar las topologıas que funcionan correctamente en AC.
A continuacion, a manera de ejemplo, se realizara la sıntesis de un VF a
partir de su cromosoma. Se propone partir de un modelo ideal de puente de
4 nullators (figura 3.2.(b)) y sintetizar el cromosoma 336860, el valor de los
genes es el mostrado en el cuadro 3.9.
El modelo de pares O-P que se obtiene, segun el cuadro 3.4, se muestra
en la figura 3.18; donde cada par O-P sintetizara un MOSFET. Para agregar
fuentes de corriente al circuito se obedece el cuadro 3.6. Por lo tanto para el
MOSFET M1 se conecta Idd al drain e Iss al source, de la misma manera M2;
para M3 y M4 se conecta Iss al drain e Idd al source. El circuito resultante se

58 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Cuadro 3.9: Codificacion del cromosoma 336860.
Decimal 336860Binario 0001010010001111011100
Cromosoma genMOS(1) genMOS(2) genMOS(3) genMOS(4) genCM00010 10010 00111 10111 00
genSS 00 10 00 10genSMos 0 0 1 1genBias 10 10 11 11
muestra en la figura 3.19. Donde se observa que se pueden eliminar las fuentes
de corriente Idd3, Iss1, Idd4 e Iss2 ya que estas no polarizan al circuito. El
programa realizado para la sintesis de VFs detecta este tipo de situaciones y
toma la decision de eliminar las fuentes sobrantes.
Figura 3.18: Modelo de pares O-P para el cromosoma 336860.
Los genSMos del cuadro 3.9 indican que los MOSFET sintetizados seran
N-M1, N-M2, P-M3 y P-M4 segun el cuadro 3.5. Quitando las fuentes de co-
rriente sobrantes y sintetizando estos transistores MOS, el circuito realizado
se muestra en la figura 3.20.(a); como se puede observar este es el modelo ideal
de un VF conocido [21, 22, 25]. Para finalizar con el ejemplo falta cambiar
las fuentes de corriente ideales por espejos de corriente. El genCM es 00,
ası que se agregaran espejos de corriente simples y el circuito sintetizado por

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 59
Figura 3.19: Polarizacion de la figura 3.18 segun los genBias del cuadro 3.9.
el cromosoma 336860 es el mostrado en la figura 3.20.(b).
Figura 3.20: (a) Modelo ideal de un VF conocido y (b)circuito VF represen-tado por el cromosoma 336860.

60 CAPITULO 3. METODO DE SINTESIS PROPUESTO
3.4.2. Genotipo y fenotipo de un CF
Partiendo del modelo ideal de un CF utilizando solo un norator, se pro-
cede a generar un CF con MOSFETs. De manera similar a la codificacion
del VF, cada elemento P debe estar unido a un elemento O para proposito
de sıntesis del transistor MOS. De esta manera, un elemento O puede agre-
garse a un elemento P a la izquierda (nodo i), a la derecha (nodo j), o en
paralelo (entre los nodos i y j); analogo a la figura 3.17. Cada par O-P se
puede representar por un gen de pequena senal (genSS), el cual se describe
en el cuadro 3.4.
Cada par O-P se sintetiza por un MOSFET, en este paso se utiliza el gen de
sıntesis del MOSFET (genSMos), el cual es identico al descrito para el VF
en el cuadro 3.5.
El siguiente paso consiste en agregar fuentes de polarizacion. Se utiliza el
gen de polarizacion (genBias); el cual contiene dos bits (a3a4). En todas las
combinaciones tanto al drain como al source se les conectaran fuentes de
corriente a Vdd y a Vss llamadas Idd e Iss, respectivamente. Despues a la
terminal gate del MOSFET se conectara una fuente de voltaje positiva (V+)
o negativa (V-); esto se resume en el cuadro 3.10. Cabe notar que la com-
puerta de los MOSFET siempre se conectara a una fuente de voltaje con el
fin de que el transistor trabaje en la region de saturacion.
Cuadro 3.10: GenBias: gen de fuentes de polarizacion.
a3a4 ConexionDrain Source Gate
0 0 Idd Iss V+0 1 Iss Idd V+1 0 Idd Iss V-1 1 Iss Idd V-

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 61
Al igual que para la sıntesis de VFs, cada fuente de corriente se debe
sintetizar por un CM, utilizando el genCM. El genCM, como ya se ha men-
cionado, depende del numero de tipos de espejos que contenga una librerıa.
Tomando en cuenta que la librerıa tiene los mismos espejos que en el caso de
los VFs, el codigo del genCM nuevamente es el mostrado el cuadro 3.7.
En resumen, para codificar un CF modelado con un solo norator a partir de
un solo nullator se tiene un cromosoma de 7 bits, divididos en cuatro dife-
rentes genes. Para sintetizar un CF de dos transistores MOS a partir de dos
o mas norators el cromosoma crece proporcionalmete al numero de norators.
Esto se observa en el cuadro 3.11, donde: genMOS=genSS-genSMos-genBias.
Cuadro 3.11: Numero de bits para cada cromosoma CF.
CF norators cromosoma TOTAL1 MOS 1 genMOS(1)− genCM 7 bits2 MOS 2 genMOS(1)− genMOS(2)− genCM 12 bitsN MOS N genMOS(1)− · · · − genMOS(N)− genCM 5N+2
Algunas topologıas representadas por los cromosomas no cumpliran con la
especificacion de un CF (IOUT = IIN); estas no son practicas para utilizarse
en circuitos. El EA realizado en esta tesis buscara seleccionar las topologıas
que tengan una respuesta correspondiente a la de un CF. Esto se realizara por
medio de simulaciones en SPICE.
Se realizara la sıntesis de un CF a partir de su cromosoma, para ejemplificar
la codificacion descrita. Se propone sintetizar el cromosoma 99324, a partir
de un modelo de puente de 4 norators (figura 3.7(l)); el valor de los genes es
el mostrado en el cuadro 3.12.
Realizando las sıntesis del cromosoma 99324 se obtienen el circuito de la
figura 3.21. Como se puede observar este es el modelo de un CF conocido
[21, 25]. Este circuito se obtiene despues de decodificar el significado de los

62 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Cuadro 3.12: Codificacion del cromosoma CF: 99324.
Decimal 99324Binario 0000011000001111111100
Cromosoma genMOS(1) genMOS(2) genMOS(3) genMOS(4) genCM00000 11000 00111 11111 00
genSS 00 11 00 11genSMos 0 0 1 1genBias 00 00 11 11
genes del cuadro 3.12; segun los cuadros 3.4 (genSS), 3.5 (genSMos), 3.10
(genBias) y 3.7 (genCM).
Figura 3.21: Circuito CF que corresponde al cromosoma 99324.
3.4.3. Genotipo y fenotipo de un CM
Los espejos de corriente son bloques basicos, generalmente utilizados en
la polarizacion de circuitos analogicos. Los espejos de corriente actuales se
pueden modelar con celdas de dos, tres y cuatro norator, figura 3.22. Por
ejemplo con la celda (a) se puede sintetizar un espejo simple, con la celda (c)
se puede sintetizar un espejo Wilson y con la celda (d) se pueden sintetizar
los espejos Cascode y Wilson modificado. Los nodos A, B, C y D se utilizan

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 63
para agregar nullators y/o fuentes polarizacion. En estas celdas se tiene un
punto de referencia, este puede considerarse como tierra del circuito o un
voltaje de polarizacion positivo o negativo.
Figura 3.22: Celdas genericas para formar espejos de corriente.
En este trabajo se realizo un solo cromosoma que puede sintetizar los
cuatro espejos mencionados. Partiendo del modelo ideal de un CM mostrado
en la figura 3.22.(d), se procede a insertar un elemento O a cada elemento
P. Este se agrega automaticamente al lado mas cercano a tierra (GND) para
que cada par O-P se sintetize por un MOSFET tipo N. Esta sıntesis es para
asegurar que los MOSFET estaran en saturacion ya que un MOS tipo P no
estarıa en saturacion. Ası, que para el cromosoma de un CM no es necesario
un gen de pequena senal (genSS) ni un gen de sıntesis del MOSFET (gen-
SMos) como en los anteriores cromosomas.
En todas las posibles combinaciones los nodos C y D se conectaran a fuentes
de corriente a Vdd (Idd) para polarizar al circuito. Cada terminal gate de los
transistores se puede conectar a los nodos A, B, C, D, un VBIAS, Vdd, o a un
nodo extra (NE). Se describe esta decodificacion para el gate del transistor

64 CAPITULO 3. METODO DE SINTESIS PROPUESTO
M1, en el cuadro 3.13. Donde el NE es un nodo que se utilizara en bloques
extra, para realizar el CM con fuentes de desplazamiento de nivel. El codigo
del genBias para los otros tres MOS es identico al del cuadro 3.13.
Cuadro 3.13: GenBias: Bits de polarizacion del circuito CM.
a0a1a2 Gate M10 0 0 Nodo A0 0 1 Nodo B0 1 0 Nodo C0 1 1 Nodo D1 0 0 Vdd1 0 1 VBIAS
1 1 0 NE11 1 1 NE2
Para que este cromosoma simule las celdas mostradas en la figura 3.22,
debe existir un gen que defina el nodo de entrada de senal (IIN) y el nodo de
salida de senal (IOUT ). Este gen es nombrado como genIO, el cual se describe
en el cuadro 3.14. Donde los nodos E y F son nodos utilizados en una librerıa
de bloques de transistores que pueden agregarse al CM con el fin de sintetizar
CMs con desplazamientos de nivel (figura 3.23).
Cuadro 3.14: GenIO, nodos de entrada y salida del CM.
a12a13a14 Entrada Salida0 0 0 Nodo A Nodo B0 0 1 Nodo A Nodo D0 1 0 Nodo A Nodo E0 1 1 Nodo A Nodo F1 0 0 Nodo C Nodo B1 0 1 Nodo C Nodo D1 1 0 Nodo C Nodo E1 1 1 Nodo C Nodo F

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 65
Figura 3.23: Circuitos extra para IOUT
Para finalizar la descripcion del cromosoma de los CM se sintetiza el gen
de desplazamiento de nivel genN. El cual contiene una librerıa de posibles
circuitos para unirse entre las conexiones de los transistores MOS del CM.
El tamano del genN depende del tamano de la librerıa utilizada, para este
trabajo el genN es de 3 bits y su codificacion se muestra en el cuadro 3.15.
En resumen el cromosoma realizado para la sıntesis de CM se muestra en
el cuadro 3.16. Como se observa el cromosoma a utilizar tiene 16 bits, este
es mas grande que los utilizados en [59] por 4 bits, ampliando el espacio de
busqueda. Pero como se menciono anteriormente este cromosoma sustituye
a 4 realizados en [59], uno por cada celda mostrada en la figura 3.22. Esta
ventaja lleva a solo realizar un algoritmo de sıntesis de CM y no uno por
cromosoma. Otra ventaja de esta descripcion genetica es que son sintetizables
espejos con desplazamientos de nivel que en [59] no eran sintetizables.
Como ejemplo de sıntesis se realizara el circuito CM descrito por el cro-
mosoma 1192, en el cuadro 3.17 se divide el cromosoma en genes. En la figura
3.24 se muestra la codificacion donde todos los pares O-P seran sintetizados
por N-MOS; y la entrada y salida esta dada por el genIO. Segun el genIO en
el cuadro 3.14 la entrada de senal (IIN) sera por el nodo C y la salida por el

66 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Cuadro 3.15: Descripcion del genN.
genN MOS 1 MOS 2 MOS 3 MOS 4a15a16a17
000
001
010
011
100
101 NG3=VBIAS
110 NG1=Nodo A NG2=Nodo A NG3=Nodo C
111 NG3=Nodo D
Cuadro 3.16: Cromosoma CM, dividido en 3 genes.
genBias genIO genN TOTAL12 bits 3 bits 3 bits 16 bits
a0 a1...a11 a12 a13 a14 a15 a16 a17cuadro 3.13 cuadro 3.14 cuadro 3.15
nodo D (IOUT ). El genN no sera utilizado ya que en la sıntesis del genBias
no se genero ningun nodo NE.
Utilizando el cuadro 3.14, se observa que el gate del transistor M1 se debe

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 67
Cuadro 3.17: Codificacion del cromosoma CM 1192.
Decimal 1192Binario 000000010010101000
Cromosoma genBias genIO genN000-000-010-010 1 0 1 0 0 0
Figura 3.24: Modelo de pares O-P para el CM segun el genIO=101.
conectar al nodo A (000), de igual forma el gate M2 se conecta al nodo A
(000). El gate M3 se conecta al nodo C (010), igual que la terminal gate de M4
(010). Realizando las conexiones correspondientes se obtiene la figura 3.25.
Finalmente, al sintetizar los pares O-P por N-MOS se obtiene la figura 3.26;
como puede observarse es un CM conocido como espejo Cascode [25, 26].
Figura 3.25: Modelo de pares O-P para el cromosoma CM 1192.

68 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Figura 3.26: CM sintetizado con el cromosoma 1192, espejo Cascode.
3.4.4. Genotipo y fenotipo de un VM
La representacion por nullators y norators de un VM ideal es la mostrada
en la figura 3.27 [26, 27]. De esta representacion ideal se desprenden los tres
circuitos mostrados en la figura 3.28; donde en la figura 3.28.(a) se sinteti-
zara un MOSFET con el par O1-P1 y el otro nullator por si solo representa
un VF, este VF puede ser sintetizado con cualquier numero de MOSFETs.
En las figuras 3.28.(b) y 3.28.(c) se ha agregado un norator en paralelo y en
serie, repectivamente. Este elemento P no afecta la descripcion ideal del VM
y se utilizara para formar pares O-P, y estos a su vez sintetizaran MOSFETs.
Cada par O-P de la figura 3.28 sintetiza un MOSFET, en la figura 3.29 se
muestran los circuitos sintetizados; estos MOSFETs pueden ser tipo P o tipo
N.
Figura 3.27: Representacion con nullator y norators de un VM ideal [26, 27].
Por lo descrito anteriormente, el VM debe ser representado por mas de

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 69
Figura 3.28: Representacion de un VM ideal, utilizada en este trabajo.
Figura 3.29: VMs de la figura 3.28, sintetizando los nullors por MOSFETs.
un cromosoma, uno por cada descripcion ideal mostrada en la figura 3.28. Es
necesario para los tres cromosomas tener un gen de sıntesis del CMOS (gen-
SMos), ya que este decidira si se sintetiza un NMOS o un PMOS, para ello se
utilizara nuevamente la tabla 3.5. Es necesario un genBias que polarizara al
circuito, este gen esta codificado en la tabla 3.18. Un genBias se agrega al

70 CAPITULO 3. METODO DE SINTESIS PROPUESTO
cromosoma por cada resistencia R que tenga en su representacion ideal; por
lo tanto para todos los VM de la figura 3.29 seran necesarios dos genBias.
Muchas topologıas en la salida de un VM colocan el circuito mostrado en la
figura 3.30; por lo tanto, se ha decidido incluir un gen que decida si al VM se
le agrega el circuito de la figura 3.30 o no, este gen esta descrito en la tabla
3.19.
Figura 3.30: genIO de los VMs.

3.4. CODIFICACION GENETICA DE LOS CIRCUITOS 71
Cuadro 3.18: genBias del VM.
0000 0001 0010 0011
0100 0101 0110 0111
1000 1001 1010 1011
1100 1101 1110 1111
N = nodo 1 o nodo 2NA = opuesto del nodo 1 o 2

72 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Cuadro 3.19: Codificacion del genIO.
genIO Descripcion0 Al circuito VM SI se le agregara la figura 3.30.1 Al circuito VM NO se le agregara la figura 3.30.
En resumen para el cromosoma de un VM descrito por la figura 3.29.(a)
se tienen diez bits, divididos en cuatro diferentes genes. Mientras que para
los circuitos mostrados en las figuras 3.29.(b) y 3.29.(c) son necesarios 11
bits, divididos en cuatro diferentes genes. Estos cromosomas se muestran en
el cuadro 3.20.
Cuadro 3.20: Cromosoma de un VM.
Cromosoma VM Total FiguragenSMos genBias1 genBias2 genIO
1 bit 4 bits 4 bits 1 bit 10 bits 3.29.(a)genSMos genBias1 genBias2 genIO
2 bits 4 bits 4 bits 1 bit 11 bits 3.29.(b)genSMos genBias1 genBias2 genIO
2 bits 4 bits 4 bits 1 bit 11 bits 3.29.(c)cuadro cuadro cuadro
3.5 3.18 3.19
Como ejemplo se sintetiza el cromosoma 53 de la figura 3.29.(a). Escrito
en binario es 0000110101, lo cual significa que el genSMos=0, genBias1=0001,
genBias2=1010 y genIO=1; utilizando los cuadros 3.5, 3.18 y 3.19, se obtiene
el circuito mostrado en la figura 3.31.(a). Este circuito es un VM conocido
[26, 27, 59]. La figura 3.31.(b) muestra al VM despues de sustituir el VF ideal
por el mostrado en la figura 3.20.

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS73
Figura 3.31: VM conocido, su cromosoma es 0000110101.
3.5. Genotipo y fenotipo de las uniones entre
dos UGCs
Los UGCs se pueden unir con el fin de realizar bloques con mas puertos.
Las posibles uniones de estos bloques se pueden visualizar en la figura 3.32;
entre estas se puede observar la representacion ideal de los CC. La repre-
sentacion de los CCII-/+ son las mostradas en las figuras 3.32.(e) y 3.32.(f),
respectivamente; los CCII inversos (ICCII) son representados por las figuras
3.32.(g) y 3.32.(h). Combinando los circuitos mostrados en las figuras 3.32.(f)
y 3.32.(k) se obtiene la representacion ideal de un CFOA: VF-CM-VF.
Para realizar los circuitos mostrados en la figura 3.32, lo mas sencillo de
pensar es, anexar un cable entre la salida del primer UGC y la entrada del
segundo. Esta union no es la mejor opcion para todos los circuitos de la figura
3.32. Por lo tanto, las estrategıas para realizar los circuitos representados en
la figura 3.32 deben ser diferentes de circuito a circuito. Las estrategias para

74 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Figura 3.32: Posibles uniones de los bloques de ganancia unitaria.
realizar las uniones de los UGC en este trabajo se han dividido en cinco
diferentes, estas seran descritas en las secciones siguientes y ordenadas por
su complejidad como:
Union simple.
Duplicar salida.
Duplicar salida intermedia.
Creacion del nodo Z.
Combinacion de nullatos-norators.

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS75
3.5.1. Union simple
Como se menciono anteriormente, lo mas sencillo para realizar los cir-
cuitos mostrados en la figura 3.32 es anexar un cable entre la salida del
primer UGC y la entrada del segundo. Esta union es la mejor opcion en
los circuitos de la figuras 3.32.(b), (d), (i), (j), (k) y (l); sus funciones ca-
racterısticas se muestran en la Ec. (3.8). Los cromosomas que describen a
estos circuitos pueden ser implementandos uniendo los cromosomas realiza-
dos previamente; como se muestra en el cuadro 3.21. Para realizar este tipo
de circuitos se propone seleccionar los UGC que lo conforman y despues solo
se une la entrada de uno con la salida del otro, como se muestra en la figura
3.32.
(b) V o1 = V in V o2 = −V in
(d) V o1 = −V in V o2 = V in
(i) Io = Iin V o = V in (3.8)
(j) Io = Iin V o = −V in
(k) Io = −Iin V o = V in
(l) Io = −Iin V o = −V in
Cuadro 3.21: Cromosoma de los circuitos de la figura 3.32, por union simple.
Fig. Cromosoma Ver cuadros(b) Cromosoma VF - Cromosoma VM 3.8 y 3.20(d) Cromosoma VM - Cromosoma VM 3.20(i) Cromosoma CF - Cromosoma VF 3.11 y 3.8(j) Cromosoma CF - Cromosoma VM 3.11 y 3.20(k) Cromosoma CM - Cromosoma VF 3.16 y 3.8(l) Cromosoma CM - Cromosoma VM 3.16 y 3.20
Como ejemplo de esta ‘union simple’ de UGC se sintetiza la figura

76 CAPITULO 3. METODO DE SINTESIS PROPUESTO
3.32.(k), esta une un CM con un VF. El circuito CMOS se observa en la
figura 3.33, donde el CM y el VF son los sintetizados previamente en las
figuras 3.20 y 3.26.
Figura 3.33: Ejemplo de la union simple.
3.5.2. Duplicar salida
La union nombrada ‘duplicar salida’ consiste en duplicar la circuiteria de
salida del UGC. Esta union es la mejor opcion en los circuitos de la figuras
3.32.(a), (c), (m) y (o), sus funciones caracterısticas se muestran en la Ec.
(3.9). Como puede observarse en la Ec. (3.9) se describe a los UGC con salidas
duales, positivas y negativas.
(a) V o2 = V o1 = V in
(c) V o2 = V o1 = −V in
(k) Io2 = Io1 = −Iin (3.9)
(m) Io2 = Io1 = Iin

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS77
Los cromosomas que describen a estos circuitos son implementandos sin
modificar a los cromosomas realizados previamente, como se muestra en el
cuadro (3.22). La modificacion no se realiza en los cromosomas pero si en el
programa ya que este duplicara la circuiterıa de salida del UGC. Como ejem-
plo de esta sıntesis se observa en la figura 3.34 un circuito tipo figura 3.32.(c),
en la figura 3.35 un circuito que es representado por la figura 3.32.(a). Los
circuitos de las figuras 3.32.(k) y 3.32.(m) estan mostrados con MOSFETs
en las figuras 3.36 y 3.37.
Cuadro 3.22: Cromosomas de los circuitos donde se duplica la salida.
Fig. 3.32 Cromosoma Cuadros(a) Cromosoma VF 3.8(c) Cromosoma VM 3.20(m) Cromosoma CF 3.11(o) Cromosoma CM 3.16
Figura 3.34: VM con dos salidas.
78 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Figura 3.35: VF con dos salidas.
Figura 3.36: CF con dos salidas.

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS79
Figura 3.37: CM con dos salidas.
3.5.3. Duplicar salida intermedia
La union llamada ‘duplicar salida intermedia’ consiste en duplicar la cir-
cuiteria de salida del primer UGC para obtener la entrada al segundo UGC.
Esta union es la mejor opcion en los circuitos de la figuras 3.32.(n) y (p), sus
caracterısticas se muestran en la Ec. (3.10). Los cromosomas que describen a
estos circuitos son implementados uniendo los cromosomas realizados previ-
amente, como se muestra en el cuadro (3.23). Como ejemplo de esta sıntesis
se observa en la figura 3.38 un circuito tipo 3.32.(n) y en la figura 3.39 se
muestra un circuito que ejemplifica a la figura 3.32.(p).
(n) Io2 = −Io1 = −Iin
(p) Io2 = −Io1 = Iin (3.10)
Cuadro 3.23: Cromosoma de los circuitos de la figura 3.32.(n) y (p).
Fig. Cromosoma Cuadros(n) Cromosoma CF - Cromosoma CM 3.11 y 3.16(p) Cromosoma CM - Cromosoma CM 3.16

80 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Figura 3.38: Ejemplo de CF-CM figura 3.32.(n), al CF se le duplica la salida.
Figura 3.39: Ejemplo de CM-CM figura 3.32.(p), al primer CM se le duplicala salida.

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS81
3.5.4. Creacion del nodo Z
La union de UGCs nombrada ‘creacion del nodo Z’ consiste en modificar
las fuentes de polarizacion del circuito VF o VM para obtener una salida en
corriente. Esta union es la utilizada en la sıntesis de los circuitos de la figuras
3.32.(f) y (h), sus funciones caracterısticas se muestran en la Ec. (3.11). Como
puede observarse las Ec. (3.11) corresponden a los circuitos CCII+ y ICCII+.
(f) V o = V in
Io = −Iin
(h) V o = −V in (3.11)
Io = −Iin
Los cromosomas que describen a los circuitos (I)CCII+ se realizan unien-
do los cromosomas realizados previamente, como se muestra en el cuadro
3.24. Donde en el genCM del VF (cuadro 3.8) sintetiza las fuentes de polari-
zacion de la entrada y las fuentes de polarizacion de la salida son sintetizadas
por el cromosoma CM (cuadro 3.16).
Cuadro 3.24: Cromosoma de los circuitos CCII+ y ICCII+, por creacion delnodo Z.
Fig. Cromosomas CCII+ y ICCII+ Cuadros3.32.(f) Cromosoma VF - Cromosoma CM 3.8 y 3.163.32.(h) Cromosoma VM - Cromosoma CM 3.20 y 3.16
Para realizar la codificacion genetica de un CCII+ primero se describe al
CC como un VF (figura 3.40.(a)); despues se utiliza el cromosoma del CM
para sintetizar las fuentes de polarizacion de los MOSFETs de salida. Esto
se muestra en la figura 3.40.(b); en este ejemplo los MOSFETs de salida son

82 CAPITULO 3. METODO DE SINTESIS PROPUESTO
M2 y M4. En la figura 3.40.(b) se observa el CCII+ 336860-1192, donde el
nodo Z se creo utilizando el CM 1192 sintetizado en la figura 3.26.
Figura 3.40: (a) Circuito VF sintetizado en la fig. 3.20; (b) circuito CCII+su cromosoma es 336860-1192.
3.5.5. Combinacion de nullators-norators
La union de UGCs llamada ‘combinacion de nullators-norators’ consiste
en combinar los nullators que describen a un VF ideal con los norators que
definen a un CF ideal. Esta union es la utilizada en la sıntesis de los circuitos
de la figuras 3.32.(e) y (g); sus funciones caracterısticas se muestran en la Ec.
(3.12). Como puede observarse estas ecuaciones corresponden a los circuitos
CCII- y ICCII-, respectivamente.

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS83
(e) V o = V in
Io = Iin
(g) V o = −V in (3.12)
Io = Iin
Debe recordarse que en este trabajo un VF ideal es representado por un
bloque de nullators, de igual forma un CF ideal es representado por un bloque
de norators. De esta forma un CCII- debe de ser representado por la union de
estos bloques ideales, como se observa en la figura 3.41.(a). Cada bloque es
realizado por varios elementos O o P; combinados de diferente forma como
se mostro en las figuras 3.5, 3.6 y 3.7.
Figura 3.41: (a) CCII- dividido en un bloque VF y un bloque CF; (b) CCII-ideal, realizado con 4 nullators y 4 norators.
En la figura 3.41.(b) se observa un CCII- ideal realizado con 4 nullators
y 4 norators. Si cada uno de estos elementos O y P sintetiza un MOSFET
se obtiene un circuito con 8 MOSFETs, esto es un VF de 4 MOSFETs unido
con un cable a un CF de 4 MOSFETs. La union ‘combinacion de nullators-
norators’ consiste en combinar los nullators de salida que describen a un VF

84 CAPITULO 3. METODO DE SINTESIS PROPUESTO
ideal con los norators de entrada que definen a un CF ideal. Por lo tanto, en
la figura 3.41.(b) los 2 nullators de salida del VF se unen con los 2 norators
de la entrada del CF; cada union sintetizara un MOSFET, y el CCII- que
se obtiene es un circuito realizado con 6 MOSFET. En la figura 3.42.(a) se
muestra un circuito VF realizado con 4 nullators; en la figura 3.42.(b) se
observa un circuito CF sintetizado con 4 norators. La union de estos UGC
forma el CCII- mostrado en la figura 3.42.(c), algunos autores llaman a esta
union superimposicion de circuitos [18]; que consiste en unir circuitos por sus
elementos mas parecidos.
Para describir a los cromosomas de los circuitos (I)CCII- primero se debe
recordar la descripcion de los cromosomas VF y CF segun los cuadros 3.8 y
3.11, donde genMOS=genSS-genSMos-genBias. Para realizar el cromosoma
del CCII- se divide en tres partes, primero la descripcion de los norators
solos (si es que existen), despues la descripcion de los pares nullator-norator
formados (nodo X), y por ultimo se codifican los norators solos (si es que
existen). Esto se muestra en el cuadro 3.25, donde genMOS=genSS-genSMos-
genBias ; el genSS esta codificado por el cuadro 3.4, en los pares nullator-
norators formados no es necesario este gen. El genSMos esta codificado en
el cuadro 3.5. Para el genBias se utilizan los cuadros 3.6 (nullators y pares
O-P) y 3.10 (norators). El genCM sintetiza por un espejo de corriente (CM)
las fuentes de corriente Idd y Iss, segun el cuadro 3.7.
Cuadro 3.25: Cromosoma CCII+, por combinacion de nullatos-norators.
Cromosoma CCII+nullators solos pares nullator-norator norator solos CM
genMOS(1)− genMOS(2)− · · · genMOS(1)− · · · genMOS(1)− · · · genCMgenMOS: genSS-genSMos-genBias genSMos-genBias genSS-genSMos-genBias genCM
cuadros: 3.4, 3.5, 3.6 3.5, 3.6 3.4, 3.5, 3.10 3.7

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS85
Figura 3.42: (a) Circuito VF sintetizado en la fig. 3.20; (b) Circuito CFsintetizado en la fig. 3.21; (c) CCII- obtenido por la union de (a) y (b).
3.5.6. Genotipo y fenotipo de un CFOA
Un amplificador operacional retroalimentado en corriente (CFOA) puede
ser representado por un CCII+ en serie con un VF, como se muestra en la
figura 3.43 [19, 25, 32].

86 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Figura 3.43: Diagrama a bloques de un CFOA.
De la figura 3.43 se deduce que para realizar el cromosoma de un CFOA
se tienen que realizar dos uniones de UGC: VF-CM-VF. La union VF-CM es
la llamada ‘creacion del nodo Z’; y la union CM-VF es la nombrada ‘union
simple’, ambas descritas anteriormente. Por lo tanto el cromosoma de un
CFOA esta descrito por cromosomas VF y CM como se muestra en el cuadro
3.26, donde N y M son el numero de nullators que describen idealmente al
primer y segundo VF. Como ejemplo de esta descripcion en la figura 3.44
se observa el CFOA 336860-1192-336860. Realizado con la union de dos VF
336860 (figura 3.20) y el CM 1192 (figura 3.26).
Cuadro 3.26: Cromosoma de un CFOA.
CFOA Cromosoma VF -Cromosoma CM- Cromosoma VFCuadro 3.8 3.11 3.8No. bits 5N+2 16 5M+2

3.5. GENOTIPO Y FENOTIPO DE LAS UNIONES ENTRE DOS UGCS87
Figura 3.44: CFOA 336860-1192-336860.

88 CAPITULO 3. METODO DE SINTESIS PROPUESTO
Esta hoja se dejo en blanco intencionalmente.

Capıtulo 4
Resultados
4.1. Introduccion
El algoritmo propuesto para la sıntesis de bloques de ganancia unitaria
(capıtulo 3) se implemento en MatLab. El programa desarrollado puede re-
alizar la sıntesis de las topologıas de UGCs mostradas en el cuadro 4.1. Cabe
aclarar que el programa CFOA.m no busca una topologıa, solo sintetiza un
CFOA preguntando el numero de cromosomas del CM y los dos VF, encon-
trados previamente con CM.m y VF.m. El manual de usuario del programa
desarrollado se encuentra en el anexo C.
En este capıtulo se muestran algunas topologıas obtenidas con la he-
rramienta desarrollada. Para mostrar el funcionamiento del algoritmo genetico,
se observa en la figura 4.1 la evaluacion del mejor individuo en cada gene-
racion; como se ve la medida de evaluacion tiende a acercarse mas al cero
en cada generacion, ya que cero es el valor ideal. En la figura 4.2 se mues-
tra el tiempo de ejecucion del programa, cuantos segundos tomo al orde-
nador realizar cada generacion y el tiempo total de la ejecucion del programa,
aproximadamente 71 minutos para este ejemplo. Las figuras 4.1 y 4.2 se ob-
tuvieron en una ejecucion del programa VF.m en una computadora minihp,
con procesador Atom(TM) a 1.6GHz y 1GB de RAM. El programa VF.m se
89

90 CAPITULO 4. RESULTADOS
Cuadro 4.1: Programas realizados en MatLab.
Nombre del UGC a Figura Ecuacionprograma sintetizar caracterısticaVF.m VF 1.1.(a) Vout = Vin
CF.m CF 1.1.(b) Iout = Iin
VM.m VM 1.1.(c) Vout = −Vin
CM.m CM 1.1.(d) Iout = −Iin
VF2out.m VF-VF 3.32.(a) Vout2 = Vout1 = Vin
VM2out.m VM-VF 3.32.(c) Vout2 = Vout1 = −Vin
CF2out.m CF-CF 3.32.(m) Iout2 = Iout1 = Iin
CM2out.m CM-CF 3.32.(o) Iout2 = Iout1 = −Iin
CFD.m CF-CM 3.32.(n) Iout2 = −Iout1 = −Iin
CMD.m CM-CM 3.32.(p) Iout2 = −Iout1 = Iin
VF CM.m CCII+ 3.32.(f) Vout = Vin
(VF-CM) Iout = −Iin
VM CM.m ICCII+ 3.32.(h) Vout = −Vin
(VM-CM) Iout = −Iin
VF CF.m CCII- 3.32.(e) Vout = Vin
(VF-CF) Iout = Iin
VM CF.m ICCII- 3.32.(g) Vout = −Vin
(VM-CF) Iout = Iin
CFOA.m CFOA 3.43 VX = VY , IZ = −IX
(VF-CM-VF) VZ = VW
ejecuto con las siguientes especificaciones:
Θ Simulador: Tanner-SPICE.
Θ Tecnologıa: 0.35µm AMI Semiconductor.
Θ Numero de individuos por generacion: 40.
Θ Porcentaje de mutacion: 0.3.
Θ Numero maximo de generaciones: 150.
Θ Ganancia (Vo/Vi) deseada: 1 (con peso de 1).
Θ Ancho de banda deseado: 1MHz (con peso de 0.5).
Θ Impedancia de entrada (Zin) deseada: 10KΩ (con peso de 0.5).
Θ Impedancia de salida (Zout) deseada: 250Ω (con peso de 0.5).

4.2. TOPOLOGIAS DE VF GENERADAS 91
4.2. Topologıas de VF generadas
Las topologıas mostradas en las figuras 4.3 y 4.4 fueron obtenidas por el
EA realizado. El algoritmo (VF.m) se ejecuto con diferentes simuladores y
tecnologıas para encontar esas topologıas. Se observa en las figuras 4.3 y 4.4
que el programa VF.m encuentra VFs que equivalen a trayectorias capaciti-
vas, es decir, estos circuitos no haran copias de voltaje en DC, esto se debe a
que el GA no contempla como un objetivo ganancia en DC, al implementar
este objetivo en la evaluacion del circuito se espera que esta desventaja quede
corregida. El cuadro 4.2 se realizo para comparar las topologıas encontradas;
en este cuadro se uso el simulador Tanner-SPICE y la tecnologıa de 0.35µm
en todas las simulaciones. Con las siguientes dimensiones de los transistores:
L=1.2µm, WN=1.0µm y WP=4.4µm.
Cuadro 4.2: Respuesta en CA de los circuitos VF obtenidos.
Figura Gain BW ZIN ZOUT
4.3.(a) 0.943 10.7 MHz 108 KΩ 7.63 KΩ4.3.(b) 1.001 9.13 MHz 110 KΩ 125 KΩ4.3.(c) 0.971 25.0 MHz 15.1 KΩ 7.0 KΩ4.3.(d) 0.958 24.8 MHz 24.7 KΩ 24.7 KΩ4.4.(a) 1.000 13.6 MHz 47.9 KΩ 94.7 KΩ4.4.(b) 0.758 33.7 MHz 40.2 KΩ 343 Ω4.4.(c) 0.947 100. MHz 5.94 KΩ 4.82 KΩ4.4.(d) 0.989 20.9 MHz 35.2 KΩ 35.0 MΩ

92 CAPITULO 4. RESULTADOS
Figura 4.1: Evaluacion del mejor individuo.
Figura 4.2: Tiempo de ejecucion del programa.
4.2. TOPOLOGIAS DE VF GENERADAS 93
Figura 4.3: Algunos VFs obtenidos con el EA.

94 CAPITULO 4. RESULTADOS
Figura 4.4: Algunos VFs obtenidos con el EA.

4.3. TOPOLOGIAS DE CF GENERADAS 95
4.3. Topologıas de CF generadas
Las topologıas mostradas en las figuras 4.5 y 4.6 fueron obtenidas por
el EA realizado. Se observa que los CFs encontrados simulan cables en AC,
esto es debido a que el GA encuentra ese tipo de respuesta como la mejor
opcion. Para encontar topologıas que realicen transconductancias como en la
figura 3.21 se debe de penalizar la generacion de cables que unan los MOS
de la entrada con los de la salida. El cuadro 4.3 se realizo para comparar las
topologıas encontradas; en este cuadro se uso el simulador Tanner-SPICE y
la tecnologıa de 0.35µm. Con las siguientes dimensiones de los transistores:
L=1.2µm, WN=1.0µm y WP=4.4µm.
Cuadro 4.3: Respuesta en CA de los circuitos CF obtenidos.
Figura Gain BW ZIN ZOUT
4.5.(a) 0.976 40.1 MHz 5.63 KΩ 5.95 KΩ4.5.(b) 0.984 26.3 MHz 6.13 KΩ 21.3 KΩ4.5.(c) 0.976 40.4 MHz 5.63 KΩ 5.95 KΩ4.5.(d) 0.940 7.81 MHz 6.22 KΩ 21.7 KΩ4.6.(a) 0.944 58.1 MHz 6.88 KΩ 91.7 KΩ4.6.(b) 0.977 22.8 MHz 2.81 KΩ 2.97 KΩ4.6.(c) 0.954 15.3 MHz 6.02 KΩ 128. KΩ4.6.(d) 0.977 22.9 MHz 2.81 KΩ 2.97 KΩ

96 CAPITULO 4. RESULTADOS
Figura 4.5: Cuatro CFs obtenidos con el EA.

4.3. TOPOLOGIAS DE CF GENERADAS 97
Figura 4.6: Ejemplo de CFs obtenidos con el EA.

98 CAPITULO 4. RESULTADOS
4.4. Topologıas de CM generadas
Se ejecuto el algoritmo CM.m con diferentes simuladores y tecnologıas
para encontar las topologıas de las figuras 4.7 y 4.8. El GA encuentra CMs
funcionales como el espejo simple, cascode, wilson o como el mostrado en
la figura 4.7(d); sin embargo, tambien encuentra topologıas no funcionales
como algunas de las figuras 4.7 y 4.8. Debe recordarse que el GA realizado
nos genera topologıas que cumplen con una simulacion en SPICE de una
especificacion dada por el usuario; es decir, en la mayorıa de los casos es
necesario que el disenador modifique las topologıas obtenidas por el programa
para realizar circuitos funcionales. El cuadro 4.4 se realizo para comparar
las topologıas encontradas, en estos circuitos se uso el simulador Tanner-
SPICE y la tecnologıa de 0.35µm en todas las simulaciones. Con las siguientes
dimensiones de los transistores: L=1.2µm y WN=12.0µm.
Cuadro 4.4: Respuesta en CA de los circuitos CM obtenidos.
Figura Gain BW ZIN ZOUT
4.7.(a) 0.80 540 MHz 4.08KΩ 6.86KΩ4.7.(b) 1.06 218 MHz 680 KΩ 4.94 KΩ4.7.(c) 0.98 10 GHz 1.17 GΩ –4.7.(d) 1.00 245 MHz 6.18 KΩ 62.3 GΩ4.7.(e) 0.72 56 MHz 4.23 KΩ 6.98 KΩ4.7.(f) 0.96 253MHz 4.79 KΩ 6.29 KΩ4.8.(a) 0.99 313 KHz 2.13 KΩ 61.9 GΩ4.8.(b) 0.825 10.8 MHz 10.0 KΩ 448 KΩ4.8.(c) 0.93 1.50 GHz – –4.8.(d) 1.00 10 GHz – 442 MΩ4.8.(e) 1.17 152 MHz 5.19 KΩ 5.90 KΩ4.8.(f) 1.00 10 GHz – 4.35 MΩ

4.4. TOPOLOGIAS DE CM GENERADAS 99
Figura 4.7: Algunos CMs obtenidos con el EA.

100 CAPITULO 4. RESULTADOS
Figura 4.8: Algunos CMs obtenidos con el EA.

4.5. TOPOLOGIAS DE VM GENERADAS 101
4.5. Topologıas de VM generadas
Las topologıas mostradas en la figura 4.9 fueron obtenidas por el programa
VM.m. Estos cuatro circuitos ya han sido reportados, lo que deja sin aporte
de nuevas topologıas a este programa (VM.m); sin embargo, el hecho de
que el GA encontro estas topologıas significa que funciona adecuadamente.
El cuadro 4.5 se realizo para comparar las topologıas de la figura 4.9. Para
comparar estos circuitos se uso el simulador Tanner-SPICE y la tecnologıa
de 0.35µm en todas las simulaciones. Con las siguientes dimensiones de los
transistores: L=1.2µm, WN=1.0µm y WP=4.4µm.
Cuadro 4.5: Respuesta en CA de los circuitos VM obtenidos.
Figura Gain BW4.9.(a) 0.906 1.61 GHz4.9.(b) 0.906 1.61 GHz4.9.(c) 1.920 5.0 MHz4.9.(d) 1.15 1.07 GHz

102 CAPITULO 4. RESULTADOS
Figura 4.9: Algunos VMs obtenidos con el EA.

4.6. TOPOLOGIAS DE CCII GENERADAS 103
4.6. Topologıas de CCII generadas
Las topologıas mostradas en las figuras 4.10, 4.11 y 4.12 fueron obtenidas
al combinar los UGCs encontrados por el EA realizado. El CCII+ de la figura
4.10 se obtiene al combinar el VF 196758 (figura 4.4.(a)), con el CM 69593766
(figura 4.7.(b))
Figura 4.10: CCII+ obtenidos de la combinacion del VF 196758 y el CM69593766.

104 CAPITULO 4. RESULTADOS
Figura 4.11: Dos CCII+s obtenidos con la combinacion de UGC.

4.6. TOPOLOGIAS DE CCII GENERADAS 105
Figura 4.12: CCII- obtenido con la combinacion del VF 67599 y el CF4610874.

106 CAPITULO 4. RESULTADOS
4.7. Topologıas de CFOAs generadas
El algoritmo no realiza la busqueda de nuevos CFOAs, solo combina las
topologıas de VFs y CMs encontradas con los programas VF.m y CM.m. Por
lo tanto este programa (CFOA.m) solo emula lo que un disenador de CI harıa
para unir tres UGCs. Tres CFOAs sintetizados de esta forma se observan en
las figuras 4.13 y 4.14. El CFOA de la figura 4.13 se obtiene al combinar el
VF 196758 (figura 4.4.(a)) con el CM 69593766 (figura 4.7.(b))
Figura 4.13: CFOA obtenido de la combinacion del VF 196758 y el CM69593766.

4.7. TOPOLOGIAS DE CFOAS GENERADAS 107
Figura 4.14: Dos CFOAs obtenidos de la combinacion de UGCs encontradoscon el EA.

108 CAPITULO 4. RESULTADOS
Esta hoja se dejo en blanco intencionalmente.

Capıtulo 5
Conclusiones
5.1. Conclusiones
Se realizo un sistema automatico para sintetizar topologıas de circuitos
analogicos; este sistema utiliza algoritmos evolutivos realizados en MatLab.
Se muestra el esquema del algoritmo propuesto y como fue realizada la com-
probacion de funcionamiento de este, concluyendo que el GA funciona ade-
cuadamente.
Se comparan algunas herramientas de sıntesis con el metodo realizado en
esta Tesis. Ademas se describe brevemente el EA, resaltando las operaciones
geneticas y los tres tipos de EAs: algoritmos geneticos (GA), estrategias evo-
lutivas (ES) y programacion genetica (GP). Las operaciones geneticas apli-
cadas son seleccion, cruza, mutacion y elitismo.
Se presento una codificacion binaria para representar topologıas de cir-
cuitos analogicos: VFs, CFs, VMs y CMs. Al elemento principal de esta
codificacion se le llama cromosoma, el cual esta compuesto por la union de
genes. Cada gen modela una parte del circuito analogico.
Los cromosomas de los VFs y los CFs son realizados por medio de
109

110 CAPITULO 5. CONCLUSIONES
cuatro genes:
• gen de pequena senal (genSS): Para los VFs este gen agrega un
elemento P a cada elemento O de la representacion ideal del VF,
generando pares O-P. Para los CFs agrega un elemento O a cada
elemento P.
• gen de sıntesis del MOS (genSMos): Cada par O-P es reemplazado
por un MOSFET, tipo P o N.
• gen de polarizacion (genBias): Genera la polarizacion del circuito,
agregando fuentes voltaje y de corriente.
• gen de sıntesis de espejos de corriente (genCM): Cada fuente de
corriente del circuito es reemplazada por un espejo de corriente.
Los cromosomas de los CMs son sintetizados por tres genes:
• gen de polarizacion (genBias): Genera la polarizacion del circuito,
seleccionando las conexiones internas de este.
• gen de entrada/salida (genIO): Elige a los nodos de entrada y
salida del CM.
• gen de desplazamiento de nivel (genN): Contiene una librerıa de
posibles sub-circuitos para unirse entre las conexiones de los MOS-
FETs del CM.
Los cromosomas de los VMs son realizados por cuatro genes:
• gen de sıntesis del MOS (genSMos): Cada par O-P del VM ideal
es reemplazado por un MOSFET, tipo P o N.
• gen de polarizacion 1 (genBias1): Contiene una librerıa de posibles
sub-circuitos para unirse a la conexion 1 de los VMs ideales (Figura
3.28).

5.1. CONCLUSIONES 111
• gen de polarizacion 2 (genBias2): Contiene una librerıa de posibles
sub-circuitos para unirse a la conexion 2 de los VMs ideales (Figura
3.28).
• gen de salida (genIO): Elige el nodo de salida del VM.
El numero de bits utilizado para cada cromosoma depende del numero de
elementos nullor usados para modelar el comportamiento ideal del circuito
analogico, por lo tanto se pueden sintetizar topologıas de UGCs represen-
tadas por celdad ideales que no han estudiado a fondo, ya que el numero de
MOS puede ser cualquiera.
El algoritmo realiza automaticamente el netlist de circuitos analogicos y
su simulacion en Tanner-SPICE, TOP-SPICE o H-SPICE. Las topologıas
sintetizadas se simulan con tecnologıa de CIs CMOS de:
AMI Semiconductor: 0.35µm, 0.50µm.
Taiwan Semiconductor: 0.18µm, 0.25µm, 0.35µm.
IBM Semiconductor: 0.18µm, 0.25µm, 0.35µm, 0.50µm.
Las simulaciones buscan caracterısticas en CA: ganancia, ancho de ban-
da e impedancias de entrada y/o salida; por lo tanto, el algoritmo genetico
realizado es considerado del tipo multi-objetivo (MOGA).
Se propuso como evolucionar los cromosomas de los circuitos UGCs para
sintetizar otros circuitos con mas terminales, compuestos por dos o mas cel-
das de ganancia unitaria como CCs, ICCs y CFOAS, demostrando que el
sistema realizado no es cerrado, puede crecer.

112 CAPITULO 5. CONCLUSIONES
Se mostraron algunas topologıas sintetizadas con el sistema realizado.
5.2. Ideas para trabajos a futuro
Los parametros de evaluacion para la seleccion de los circuitos (medida
de aptitud) pueden crecer, segun alguna especificacion en AC, DC y/o
tiempo y no limitarse a los cuatro mostrados en esta tesis.
Se puede cambiar el metodo de evaluacion por algun otro, por ejemplo
una evaluacion difusa serıa ideal para este tipo de problemas.
Los operadores geneticos (seleccion, cruza y mutacion) utilizados en
esta Tesis pueden ser cambiados por otro tipo de operadores, con el fin
de probar si se encuentran mejores resultados.
El programa realizado puede generar el netlist para tres diferentes si-
muladores (Tanner, TOP-SPICE y H-SPICE), pero el programa se
puede adaptar a otros simuladores.
Se puede ampliar este metodo para otros circuitos y dispositivos, por
ejemplo: OPAMPs,OTAs, filtros, etc. Tambien se puede ampliar este
incluyendo elementos pasivos y dimensiones de los MOSFETs.

Apendice A
Parametros de simulacion
Los parametros de las tecnologıas utilizadas en SPICE son:
A.1. Parametros de 0.35µm, AMI Semicon-
ductorT46W SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Sep 14/04
LOT: T46W WAF: 1102
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 8E-9
+XJ = 1E-7 NCH = 2.2E17 VTH0 = 0.4074928
+K1 = 0.4728294 K2 = 3.621074E-3 K3 = 70.0489524
+K3B = -10 W0 = 1.830495E-5 NLX = 2.193565E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.802594 DVT1 = 0.4276766 DVT2 = -0.3
+U0 = 361.3464355 UA = -9.67751E-10 UB = 2.889157E-18
+UC = 4.669186E-11 VSAT = 1.898742E5 A0 = 1.3381235
+AGS = 0.2592162 B0 = 2.220067E-6 B1 = 5E-6
+KETA = -9.077245E-3 A1 = 0 A2 = 0.3487525
+RDSW = 780.376869 PRWG = 0.0713836 PRWB = -7.21866E-3
+WR = 1 WINT = 1.389179E-7 LINT = 1.24319E-9
+DWG = -1.034792E-8 DWB = 9.824117E-9 VOFF = -0.0869274
+NFACTOR = 0.7366118 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 0.0346215
+ETAB = -7.988336E-3 DSUB = 0.3317286 PCLM = 1.9546403
+PDIBLC1 = 4.161735E-3 PDIBLC2 = 1.19743E-5 PDIBLCB = 0.1
+DROUT = 2.748338E-3 PSCBE1 = 7.42428E8 PSCBE2 = 1E-3
+PVAG = 0 DELTA = 0.01 RSH = 3.9
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 2.58E-10 CGSO = 2.58E-10
113

114 APENDICE A. PARAMETROS DE SIMULACION
+CGBO = 1E-12 CJ = 1.012513E-3 PB = 0.8
+MJ = 0.3510986 CJSW = 2.862666E-10 PBSW = 0.8
+MJSW = 0.1518459 CJSWG = 1.82E-10 PBSWG = 0.8
+MJSWG = 0.1518459 CF = 0 PVTH0 = -0.0100437
+PRDSW = -73.5674578 PK2 = 3.087074E-3 WKETA = 3.003636E-3
+LKETA = 2.647195E-3 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 8E-9
+XJ = 1E-7 NCH = 8.52E16 VTH0 = -0.6831778
+K1 = 0.3939412 K2 = 0.0308482 K3 = 0
+K3B = 15.35112 W0 = 1E-5 NLX = 1E-9
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 1.4617205 DVT1 = 0.3569339 DVT2 = -0.0368562
+U0 = 221.3795636 UA = 1.573901E-9 UB = 5E-18
+UC = 8.567678E-11 VSAT = 2E5 A0 = 1.999067
+AGS = 0.389467 B0 = 2.419633E-6 B1 = 5E-6
+KETA = -6.020293E-3 A1 = 4.394989E-5 A2 = 0.6320223
+RDSW = 4E3 PRWG = -0.2146377 PRWB = 0.1688991
+WR = 1 WINT = 1.569174E-7 LINT = 0
+DWG = -2.578547E-8 DWB = 9.89001E-9 VOFF = -0.1219424
+NFACTOR = 1.8063821 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 0.0518465
+ETAB = 4.735705E-3 DSUB = 0.4254421 PCLM = 2.7235598
+PDIBLC1 = 0 PDIBLC2 = 4.344554E-3 PDIBLCB = 4.528856E-3
+DROUT = 5.604876E-3 PSCBE1 = 8E10 PSCBE2 = 5.04016E-10
+PVAG = 4.6592572 DELTA = 0.01 RSH = 2.8
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 3.12E-10 CGSO = 3.12E-10
+CGBO = 1E-12 CJ = 9.916255E-4 PB = 0.8896731
+MJ = 0.392439 CJSW = 2.91776E-10 PBSW = 0.99
+MJSW = 0.1676363 CJSWG = 4.42E-11 PBSWG = 0.99
+MJSWG = 0.1676363 CF = 0 PVTH0 = 0.0107102
+PRDSW = -233.4720278 PK2 = 1.861393E-3 WKETA = -6.345721E-3
+LKETA = -0.0207051 )
A.2. Parametros de 0.50µm, AMI Semicon-
ductorT86J SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Aug 8/08
LOT: T86J WAF: 2102
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 1.39E-8
+XJ = 1.5E-7 NCH = 1.7E17 VTH0 = 0.6562322
+K1 = 0.8904346 K2 = -0.1045895 K3 = 31.9320563
+K3B = -10.0125815 W0 = 1E-8 NLX = 1E-9
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.7529817 DVT1 = 0.3375078 DVT2 = -0.499724
+U0 = 447.5504584 UA = 1E-13 UB = 1.31065E-18

A.2. PARAMETROS DE 0.50µM, AMI SEMICONDUCTOR 115
+UC = 9.202046E-13 VSAT = 1.671922E5 A0 = 0.6240224
+AGS = 0.1301256 B0 = 2.256574E-6 B1 = 5E-6
+KETA = -3.285812E-3 A1 = 1.540623E-6 A2 = 0.3413547
+RDSW = 1.095284E3 PRWG = 0.10786 PRWB = 0.0373216
+WR = 1 WINT = 2.462847E-7 LINT = 9.17502E-8
+XL = 1E-7 XW = 0 DWG = -5.382937E-9
+DWB = 4.188989E-8 VOFF = 0 NFACTOR = 1.1244911
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 6.932245E-3 ETAB = -9.478768E-5
+DSUB = 0.2087655 PCLM = 2.8051185 PDIBLC1 = 2.346151E-4
+PDIBLC2 = 2.759558E-3 PDIBLCB = -1.174842E-3 DROUT = 9.934542E-3
+PSCBE1 = 6.108196E8 PSCBE2 = 1.386889E-4 PVAG = 0
+DELTA = 0.01 RSH = 86.1 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 3.01E-10 CGSO = 3.01E-10 CGBO = 1E-9
+CJ = 4.221106E-4 PB = 0.9216664 MJ = 0.4420501
+CJSW = 3.160903E-10 PBSW = 0.8 MJSW = 0.2026465
+CJSWG = 1.64E-10 PBSWG = 0.8 MJSWG = 0.2026465
+CF = 0 PVTH0 = 9.852567E-3 PRDSW = 465.0982961
+PK2 = -0.0752562 WKETA = -0.0145101 LKETA = -9.714755E-4 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 1.39E-8
+XJ = 1.5E-7 NCH = 1.7E17 VTH0 = -0.9152268
+K1 = 0.553472 K2 = 7.871921E-3 K3 = 72.4320928
+K3B = -0.7655174 W0 = 5.614819E-6 NLX = 2.93007E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 1.1733882 DVT1 = 0.2736195 DVT2 = -0.0650979
+U0 = 201.3603195 UA = 2.408572E-9 UB = 1E-21
+UC = -1E-10 VSAT = 9.184541E4 A0 = 0.9091574
+AGS = 0.0833041 B0 = -5.020555E-8 B1 = 1.918495E-7
+KETA = -4.865785E-3 A1 = 0 A2 = 0.5990723
+RDSW = 3E3 PRWG = -0.030185 PRWB = -0.0442888
+WR = 1 WINT = 3.003833E-7 LINT = 1.185079E-7
+XL = 1E-7 XW = 0 DWG = 2.56059E-9
+DWB = 9.498718E-10 VOFF = -0.0728639 NFACTOR = 0.9934114
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 4.875675E-4 ETAB = -0.1014434
+DSUB = 0.7615044 PCLM = 2.4304643 PDIBLC1 = 0.041127
+PDIBLC2 = 2.84767E-3 PDIBLCB = -0.0194741 DROUT = 0.2421531
+PSCBE1 = 1E8 PSCBE2 = 3.33117E-9 PVAG = 0.0102618
+DELTA = 0.01 RSH = 109.8 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 4.05E-10 CGSO = 4.05E-10 CGBO = 1E-9
+CJ = 7.302729E-4 PB = 0.99 MJ = 0.5003729
+CJSW = 2.506646E-10 PBSW = 0.9824582 MJSW = 0.4179581
+CJSWG = 6.4E-11 PBSWG = 0.9824582 MJSWG = 0.4179581
+CF = 0 PVTH0 = 5.98016E-3 PRDSW = 14.8598424
+PK2 = 3.73981E-3 WKETA = 6.38143E-3 LKETA = -5.131381E-3)

116 APENDICE A. PARAMETROS DE SIMULACION
A.3. Parametros de 0.18µm, Taiwan Semi-
conductor (TSMC)
T77A SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Oct 17/07
LOT: T77A WAF: 3010
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 4.1E-9
+XJ = 1E-7 NCH = 2.3549E17 VTH0 = 0.3729594
+K1 = 0.5840975 K2 = 1.686187E-3 K3 = 1E-3
+K3B = 0.0296594 W0 = 1E-7 NLX = 1.542817E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 1.1680674 DVT1 = 0.4182499 DVT2 = 0.0268331
+U0 = 292.3966054 UA = -1.219746E-9 UB = 2.307456E-18
+UC = 6.953926E-11 VSAT = 1.704188E5 A0 = 1.8603725
+AGS = 0.4358979 B0 = 1.843628E-7 B1 = 5E-6
+KETA = -0.011523 A1 = 8.967934E-4 A2 = 0.3
+RDSW = 105.3073514 PRWG = 0.489299 PRWB = -0.2
+WR = 1 WINT = 0 LINT = 1.963253E-8
+XL = 0 XW = -1E-8 DWG = -5.54717E-9
+DWB = -1.072339E-8 VOFF = -0.0948017 NFACTOR = 2.1860065
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 1.925032E-3 ETAB = 6.028975E-5
+DSUB = 0.0193048 PCLM = 1.9022344 PDIBLC1 = 0.2550871
+PDIBLC2 = 1.417207E-3 PDIBLCB = -0.1 DROUT = 0.8645309
+PSCBE1 = 3.419362E10 PSCBE2 = 2.777738E-8 PVAG = 9.459578E-3
+DELTA = 0.01 RSH = 7 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 8.58E-10 CGSO = 8.58E-10 CGBO = 1E-12
+CJ = 9.465842E-4 PB = 0.8 MJ = 0.3722711
+CJSW = 1.90832E-10 PBSW = 0.8 MJSW = 0.1366398
+CJSWG = 3.3E-10 PBSWG = 0.8 MJSWG = 0.1366398
+CF = 0 PVTH0 = -4.904276E-3 PRDSW = -0.840458
+PK2 = 1.983844E-3 WKETA = -1.794821E-3 LKETA = -3.436309E-3
+PU0 = -3.6758958 PUA = -4.70421E-11 PUB = 8.241174E-24
+PVSAT = 1.61878E3 PETA0 = 1E-4 PKETA = -1.374594E-3 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 4.1E-9
+XJ = 1E-7 NCH = 4.1589E17 VTH0 = -0.3901812
+K1 = 0.5723512 K2 = 0.024177 K3 = 0.1578539
+K3B = 4.2732669 W0 = 1E-6 NLX = 1.121486E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.6119889 DVT1 = 0.2499582 DVT2 = 0.1
+U0 = 112.2285112 UA = 1.425392E-9 UB = 1.16772E-21
+UC = -1E-10 VSAT = 1.087139E5 A0 = 1.5950482
+AGS = 0.3203279 B0 = 4.957218E-7 B1 = 1.527303E-6
+KETA = 0.0275656 A1 = 0.3799265 A2 = 0.432073
+RDSW = 199.0599687 PRWG = 0.5 PRWB = -0.4953546
+WR = 1 WINT = 0 LINT = 2.940415E-8
+XL = 0 XW = -1E-8 DWG = -3.06329E-8
+DWB = -7.685822E-9 VOFF = -0.0937004 NFACTOR = 2

A.4. PARAMETROS DE 0.25µM, TAIWAN SEMICONDUCTOR (TSMC)117
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 1.291671E-4 ETAB = -2.161739E-4
+DSUB = 3.645549E-4 PCLM = 0.9284213 PDIBLC1 = 2.836414E-3
+PDIBLC2 = -8.750635E-6 PDIBLCB = -1E-3 DROUT = 1.827199E-4
+PSCBE1 = 8E10 PSCBE2 = 8.26364E-10 PVAG = 0.0202145
+DELTA = 0.01 RSH = 8.1 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 7.82E-10 CGSO = 7.82E-10 CGBO = 1E-12
+CJ = 1.169586E-3 PB = 0.8600389 MJ = 0.4153558
+CJSW = 2.172584E-10 PBSW = 0.8 MJSW = 0.3186705
+CJSWG = 4.22E-10 PBSWG = 0.8 MJSWG = 0.3186705
+CF = 0 PVTH0 = 1.231752E-3 PRDSW = 9.5225138
+PK2 = 1.102104E-3 WKETA = 0.0132876 LKETA = -2.410443E-3
+PU0 = -1.5247633 PUA = -5.27446E-11 PUB = 1E-21
+PVSAT = 50 PETA0 = 7.202744E-5 PKETA = -1.607078E-3 )
A.4. Parametros de 0.25µm, Taiwan Semi-
conductor (TSMC)T7CZ SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Feb 22/08
LOT: t7cz WAF: 4002
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 5.7E-9
+XJ = 1E-7 NCH = 2.3549E17 VTH0 = 0.3773132
+K1 = 0.4666921 K2 = 1.573176E-3 K3 = 1E-3
+K3B = 2.5895745 W0 = 1E-7 NLX = 1.689798E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.5858202 DVT1 = 0.7137904 DVT2 = -0.5
+U0 = 299.2752426 UA = -1.348885E-9 UB = 2.599223E-18
+UC = 3.914013E-11 VSAT = 1.326808E5 A0 = 1.6903065
+AGS = 0.3259201 B0 = -9.718698E-9 B1 = -9.965565E-8
+KETA = -5.277966E-3 A1 = 1.513887E-5 A2 = 0.4938152
+RDSW = 185.9342736 PRWG = 0.265936 PRWB = -0.2
+WR = 1 WINT = 0 LINT = 3.058404E-10
+XL = 0 XW = -4E-8 DWG = -1.468777E-8
+DWB = 6.177307E-9 VOFF = -0.0967134 NFACTOR = 1.5041374
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 6.166942E-3 ETAB = 4.961163E-4
+DSUB = 0.0429997 PCLM = 1.6343513 PDIBLC1 = 0.9894248
+PDIBLC2 = 2.371861E-3 PDIBLCB = -0.0707797 DROUT = 0.9990506
+PSCBE1 = 6.130234E10 PSCBE2 = 5E-10 PVAG = 6.152805E-3
+DELTA = 0.01 RSH = 3.5 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5

118 APENDICE A. PARAMETROS DE SIMULACION
+CGDO = 5.35E-10 CGSO = 5.35E-10 CGBO = 1E-12
+CJ = 1.730342E-3 PB = 0.99 MJ = 0.4756955
+CJSW = 4.161282E-10 PBSW = 0.99 MJSW = 0.4333201
+CJSWG = 3.29E-10 PBSWG = 0.99 MJSWG = 0.4333201
+CF = 0 PVTH0 = -7.791496E-3 PRDSW = -10
+PK2 = 3.801008E-3 WKETA = 6.639766E-3 LKETA = -7.838284E-3 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 5.7E-9
+XJ = 1E-7 NCH = 4.1589E17 VTH0 = -0.5607522
+K1 = 0.640796 K2 = -6.023941E-5 K3 = 0.0991578
+K3B = 5.8853724 W0 = 1E-6 NLX = 8.215136E-9
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 2.1276376 DVT1 = 0.819465 DVT2 = -0.212058
+U0 = 104.556335 UA = 1.107353E-9 UB = 1.019377E-21
+UC = -1E-10 VSAT = 1.692264E5 A0 = 1.1481061
+AGS = 0.1807162 B0 = 7.892988E-8 B1 = -9.286804E-8
+KETA = 7.717259E-3 A1 = 0.0236274 A2 = 0.3
+RDSW = 1.324806E3 PRWG = 0.0659066 PRWB = -0.1489776
+WR = 1 WINT = 0 LINT = 2.847114E-8
+XL = 0 XW = -4E-8 DWG = -3.689602E-8
+DWB = -2.422345E-9 VOFF = -0.1362918 NFACTOR = 1.1350531
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 0.5475114 ETAB = -0.1820788
+DSUB = 1.4054827 PCLM = 1.3456606 PDIBLC1 = 0.0116021
+PDIBLC2 = -1E-5 PDIBLCB = -1E-3 DROUT = 0.1557741
+PSCBE1 = 8E10 PSCBE2 = 5.792633E-10 PVAG = 8.269154E-3
+DELTA = 0.01 RSH = 2.9 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 6.79E-10 CGSO = 6.79E-10 CGBO = 1E-12
+CJ = 1.892369E-3 PB = 0.9415247 MJ = 0.4726146
+CJSW = 3.537563E-10 PBSW = 0.7513518 MJSW = 0.3249701
+CJSWG = 2.5E-10 PBSWG = 0.7513518 MJSWG = 0.3249701
+CF = 0 PVTH0 = 6.489441E-3 PRDSW = 18.0910536
+PK2 = 2.033324E-3 WKETA = 0.0146664 LKETA = -7.364886E-3 )
A.5. Parametros de 0.35µm, Taiwan Semi-
conductor (TSMC)T83U SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: May 23/08
LOT: T83U WAF: 5001
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 7.7E-9
+XJ = 1E-7 NCH = 2.2E17 VTH0 = 0.465403
+K1 = 0.605685 K2 = 7.401855E-4 K3 = 100
+K3B = -9.9978452 W0 = 3.104982E-5 NLX = 2.718863E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 2.9399069 DVT1 = 0.8628462 DVT2 = -0.3
+U0 = 364.9848005 UA = -7.38738E-10 UB = 2.285693E-18

A.5. PARAMETROS DE 0.35µM, TAIWAN SEMICONDUCTOR (TSMC)119
+UC = 3.664402E-11 VSAT = 1.566234E5 A0 = 1.1469517
+AGS = 0.1642206 B0 = 7.913741E-7 B1 = 5E-6
+KETA = 1.59443E-3 A1 = 0 A2 = 0.4470956
+RDSW = 957.4487567 PRWG = -0.075128 PRWB = -0.1078364
+WR = 1 WINT = 1.510787E-7 LINT = 0
+XL = -5E-8 XW = 1.5E-7 DWG = -5.692108E-9
+DWB = 5.225149E-9 VOFF = -0.0893518 NFACTOR = 1.3113023
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 1 ETAB = 0.0295297
+DSUB = 0.7823887 PCLM = 1.676311 PDIBLC1 = 1.547328E-4
+PDIBLC2 = 4.724954E-3 PDIBLCB = 0.0767737 DROUT = 3.365824E-4
+PSCBE1 = 7.16268E8 PSCBE2 = 1E-3 PVAG = 3.079663E-3
+DELTA = 0.01 RSH = 79.1 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 3.18E-10 CGSO = 3.18E-10 CGBO = 1E-12
+CJ = 9.324477E-4 PB = 0.8162386 MJ = 0.362829
+CJSW = 2.809158E-10 PBSW = 0.8 MJSW = 0.1824357
+CJSWG = 1.82E-10 PBSWG = 0.8 MJSWG = 0.1824357
+CF = 0 PVTH0 = -0.0279291 PRDSW = -98.8829593
+PK2 = 1.6222E-3 WKETA = -7.135466E-4 LKETA = 3.68571E-4 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 7.7E-9
+XJ = 1E-7 NCH = 8.52E16 VTH0 = -0.7104638
+K1 = 0.4314573 K2 = -0.0129797 K3 = 86.403366
+K3B = -4.9887168 W0 = 6.790634E-6 NLX = 1.01238E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.7043065 DVT1 = 0.7538793 DVT2 = -0.1364644
+U0 = 152.0101039 UA = 1.006463E-10 UB = 1.890539E-18
+UC = -1.74459E-11 VSAT = 2E5 A0 = 1.1765964
+AGS = 0.3405976 B0 = 2.107301E-6 B1 = 5E-6
+KETA = -6.90419E-3 A1 = 4.217794E-3 A2 = 0.9994396
+RDSW = 3.25395E3 PRWG = -0.0251462 PRWB = -0.0345874
+WR = 1 WINT = 1.513212E-7 LINT = 0
+XL = -5E-8 XW = 1.5E-7 DWG = -1.856889E-8
+DWB = 1.207799E-8 VOFF = -0.1270571 NFACTOR = 1.9223541
+CIT = 0 CDSC = 2.4E-4 CDSCD = 0
+CDSCB = 0 ETA0 = 0.0332936 ETAB = 3.097432E-3
+DSUB = 0.270751 PCLM = 5.2787472 PDIBLC1 = 1.57371E-3
+PDIBLC2 = -4.147325E-6 PDIBLCB = -1E-3 DROUT = 8.531668E-4
+PSCBE1 = 7.929595E10 PSCBE2 = 5.008484E-10 PVAG = 15
+DELTA = 0.01 RSH = 148.3 MOBMOD = 1
+PRT = 0 UTE = -1.5 KT1 = -0.11
+KT1L = 0 KT2 = 0.022 UA1 = 4.31E-9
+UB1 = -7.61E-18 UC1 = -5.6E-11 AT = 3.3E4
+WL = 0 WLN = 1 WW = 0
+WWN = 1 WWL = 0 LL = 0
+LLN = 1 LW = 0 LWN = 1
+LWL = 0 CAPMOD = 2 XPART = 0.5
+CGDO = 3.61E-10 CGSO = 3.61E-10 CGBO = 1E-12
+CJ = 1.397166E-3 PB = 0.99 MJ = 0.5775057
+CJSW = 3.172123E-10 PBSW = 0.99 MJSW = 0.3575424
+CJSWG = 4.42E-11 PBSWG = 0.99 MJSWG = 0.3575424
+CF = 0 PVTH0 = 0.0166636 PRDSW = -89.3748363
+PK2 = 2.060693E-3 WKETA = 4.168039E-3 LKETA = -4.428159E-3 )

120 APENDICE A. PARAMETROS DE SIMULACION
A.6. Parametros de 0.18µm, IBM Semicon-
ductor
T48W SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Nov 24/04
LOT: T48W WAF: 1001
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 4.5E-9
+XJ = 1E-7 NCH = 2.3549E17 VTH0 = 0.2996547
+K1 = 0.4856384 K2 = -1.286277E-3 K3 = 1E-3
+K3B = 6.5336462 W0 = 1E-7 NLX = 2.33038E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.5084664 DVT1 = 0.3284715 DVT2 = -0.254999
+U0 = 256.8438342 UA = -1.781605E-9 UB = 3.056852E-18
+UC = 5.926712E-11 VSAT = 1.125772E5 A0 = 2
+AGS = 0.4126701 B0 = 2.717631E-7 B1 = 5E-6
+KETA = -0.0153274 A1 = 2.526344E-4 A2 = 0.8496658
+RDSW = 105 PRWG = 0.4083755 PRWB = -0.2
+WR = 1 WINT = 1.73305E-10 LINT = 6.965779E-9
+DWG = 5.743223E-10 DWB = 2.501236E-8 VOFF = -0.0830387
+NFACTOR = 1.9532446 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 1.401733E-3
+ETAB = -1.842372E-6 DSUB = 3.613852E-3 PCLM = 1.2597524
+PDIBLC1 = 1 PDIBLC2 = 9.832679E-3 PDIBLCB = -0.1
+DROUT = 0.9721339 PSCBE1 = 6.277119E9 PSCBE2 = 5E-10
+PVAG = 0.4412268 DELTA = 0.01 RSH = 6.3
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 4.88E-10 CGSO = 4.88E-10
+CGBO = 1E-12 CJ = 8.405919E-4 PB = 0.8006956
+MJ = 0.5155273 CJSW = 2.236791E-10 PBSW = 0.8
+MJSW = 0.2172546 CJSWG = 3.3E-10 PBSWG = 0.8
+MJSWG = 0.2172546 CF = 0 PVTH0 = 1.86553E-3
+PRDSW = -5 PK2 = 1.544722E-6 WKETA = 2.846518E-3
+LKETA = -1.977883E-3 PU0 = 25.9785801 PUA = 1.477003E-10
+PUB = 0 PVSAT = 2.006318E3 PETA0 = -1E-4
+PKETA = -1.996966E-3 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 4.5E-9
+XJ = 1E-7 NCH = 4.1589E17 VTH0 = -0.3983536
+K1 = 0.5907658 K2 = 0.0112551 K3 = 0
+K3B = 20 W0 = 9.9999E-7 NLX = 2.834055E-8
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 1.1248497 DVT1 = 0.7302421 DVT2 = -0.3
+U0 = 100.760863 UA = 9.102011E-10 UB = 1E-21
+UC = -1E-10 VSAT = 1.628707E5 A0 = 1.4671452
+AGS = 0.3565835 B0 = 1.16212E-6 B1 = 2.390915E-6
+KETA = 0.0117436 A1 = 0.4468993 A2 = 0.3
+RDSW = 608.6993897 PRWG = 0.0792828 PRWB = -0.2503946
+WR = 1 WINT = 0 LINT = 3.024645E-8
+DWG = -2.833656E-8 DWB = -5.461534E-9 VOFF = -0.1053146
+NFACTOR = 1.4551122 CIT = 0 CDSC = 2.4E-4

A.7. PARAMETROS DE 0.25µM, IBM SEMICONDUCTOR 121
+CDSCD = 0 CDSCB = 0 ETA0 = 0.0040464 +ETAB = -0.0932592 DSUB = 0.69974 PCLM = 1.4932427
+PDIBLC1 = 0 PDIBLC2 = 0.0210559 PDIBLCB = -1E-3
+DROUT = 5.465719E-4 PSCBE1 = 1.4019E10 PSCBE2 = 4.057116E-9
+PVAG = 0 DELTA = 0.01 RSH = 6
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0 +LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 4.34E-10 CGSO = 4.34E-10
+CGBO = 1E-12 CJ = 1.174298E-3 PB = 0.8276062
+MJ = 0.4115923 CJSW = 1.330245E-10 PBSW = 0.8027251
+MJSW = 0.1 CJSWG = 4.22E-10 PBSWG = 0.8027251
+MJSWG = 0.1 CF = 0 PVTH0 = -8.407096E-4
+PRDSW = -3.0260529 PK2 = 3.38646E-4 WKETA = 0.0335243
+LKETA = 3.732539E-3 PU0 = 0.3701405 PUA = 3.085225E-11
+PUB = 0 PVSAT = 49.8420442 PETA0 = 1.003159E-4
+PKETA = -2.007487E-3 )
A.7. Parametros de 0.25µm, IBM Semicon-
ductorT62P SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Aug 17/06
LOT: T62P WAF: 1005
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 6.3E-9
+XJ = 1E-7 NCH = 2.3549E17 VTH0 = 0.5883023
+K1 = 0.7913731 K2 = -1.188662E-4 K3 = 51.2752977
+K3B = -10 W0 = 1.524436E-5 NLX = 3.116783E-8
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 1.3569508 DVT1 = 0.9575597 DVT2 = -0.5
+U0 = 363.0993338 UA = -9.8777E-10 UB = 3.115273E-18
+UC = 9.548732E-11 VSAT = 1.236873E5 A0 = 1.2442517
+AGS = 0.2374961 B0 = 1.460754E-8 B1 = -1E-7
+KETA = 3.55036E-3 A1 = 4.992937E-4 A2 = 0.552179
+RDSW = 196.9345484 PRWG = 0.3563494 PRWB = -0.2
+WR = 1 WINT = 2.689564E-8 LINT = 4.005104E-8
+DWG = -1.098287E-8 DWB = -1.449662E-8 VOFF = -0.1261175
+NFACTOR = 1.7834578 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 1.977308E-3
+ETAB = 4.64591E-5 DSUB = 4.17007E-3 PCLM = 1.149956
+PDIBLC1 = 0.7432404 PDIBLC2 = 5.003847E-4 PDIBLCB = -0.0329796
+DROUT = 1 PSCBE1 = 3.886418E8 PSCBE2 = 1.590717E-6
+PVAG = 0.0100106 DELTA = 0.01 RSH = 5.8
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 5.77E-10 CGSO = 5.77E-10
+CGBO = 1E-9 CJ = 1.319071E-3 PB = 0.9229666
+MJ = 0.4874629 CJSW = 1E-10 PBSW = 0.8

122 APENDICE A. PARAMETROS DE SIMULACION
+MJSW = 0.5999831 CJSWG = 3.29E-10 PBSWG = 0.8
+MJSWG = 0.5999831 CF = 0 PVTH0 = -1.793115E-3
+PRDSW = -10 PK2 = -3.462569E-4 WKETA = -3.747892E-3
+LKETA = -0.0115491 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 6.3E-9
+XJ = 1E-7 NCH = 4.1589E17 VTH0 = -0.4836985
+K1 = 0.8838919 K2 = -0.017304 K3 = 0.0974071
+K3B = 16.603282 W0 = 1E-6 NLX = 8.590332E-9
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 2.3400296 DVT1 = 1 DVT2 = -0.3
+U0 = 117.1986463 UA = 1.215987E-9 UB = 1.409597E-21
+UC = -1E-10 VSAT = 5.065058E4 A0 = 1.0073379
+AGS = 0 B0 = 1.66516E-6 B1 = 5E-6
+KETA = -0.0166512 A1 = 0.2504935 A2 = 0.5677392
+RDSW = 1.327779E3 PRWG = -0.0406725 PRWB = -0.059236
+WR = 1 WINT = 0 LINT = 4.7552E-8
+DWG = -2.926016E-8 DWB = -1.106451E-8 VOFF = -0.1187911
+NFACTOR = 1.1594321 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 8.704569E-3
+ETAB = -0.0236377 DSUB = 0.4527694 PCLM = 0.7208713
+PDIBLC1 = 2.164585E-3 PDIBLC2 = 1.296132E-5 PDIBLCB = -6.762296E-4
+DROUT = 0.0272751 PSCBE1 = 7.77449E9 PSCBE2 = 1.939984E-9
+PVAG = 0 DELTA = 0.01 RSH = 5.1
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 5.07E-10 CGSO = 5.07E-10
+CGBO = 1E-9 CJ = 1.054616E-3 PB = 0.8664519
+MJ = 0.4213406 CJSW = 1E-10 PBSW = 0.8
+MJSW = 0.5999942 CJSWG = 2.5E-10 PBSWG = 0.8
+MJSWG = 0.5999942 CF = 0 PVTH0 = -6.465101E-4
+PRDSW = 31.5603045 PK2 = 1.885034E-3 WKETA = 4.119477E-3
+LKETA = -0.0208437 )
A.8. Parametros de 0.35µm, IBM Semicon-
ductorT83Z SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Jul 8/08
LOT: T83Z WAF: 1009
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 8E-9
+XJ = 1.5E-7 NCH = 1.7E17 VTH0 = 0.5349718
+K1 = 0.588755 K2 = 0.0254668 K3 = -3
+K3B = 1.6858089 W0 = 1.227498E-8 NLX = 8.642006E-8
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.761841 DVT1 = 0.4987073 DVT2 = -0.2316534
+U0 = 479.1497581 UA = 1E-13 UB = 2.353051E-18
+UC = 7.582383E-11 VSAT = 1.27075E5 A0 = 1.3248394
+AGS = 0.2242515 B0 = -5.311696E-8 B1 = 0

A.8. PARAMETROS DE 0.35µM, IBM SEMICONDUCTOR 123
+KETA = -6.994863E-3 A1 = 1.184372E-4 A2 = 0.8678046
+RDSW = 907.3368938 PRWG = -1.04682E-11 PRWB = -0.0477616
+WR = 1 WINT = 7.928088E-8 LINT = 6.60445E-8
+DWG = -3.468893E-9 DWB = 4.473826E-9 VOFF = -0.15
+NFACTOR = 2.5 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 0.1266613
+ETAB = -0.0158833 DSUB = 0.7671483 PCLM = 0.5244762
+PDIBLC1 = 3.3302E-3 PDIBLC2 = 1.758025E-3 PDIBLCB = 0.1555155
+DROUT = 0.0436747 PSCBE1 = 4.19851E8 PSCBE2 = 1.1938E-5
+PVAG = 0.1158939 DELTA = 0.01 RSH = 4.9
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 3E-10 CGSO = 3E-10
+CGBO = 1E-10 CJ = 1.01656E-3 PB = 0.8
+MJ = 0.3550748 CJSW = 1.268097E-10 PBSW = 0.8315671
+MJSW = 0.1133079 CJSWG = 1.64E-10 PBSWG = 0.8315671
+MJSWG = 0.1133079 CF = 0 PVTH0 = -5.952237E-3
+PRDSW = -38.3128166 PK2 = -3.87392E-4 WKETA = 2.593342E-3
+LKETA = -0.0102902 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 8E-9
+XJ = 1.5E-7 NCH = 1.7E17 VTH0 = -0.4285512
+K1 = 0.924242 K2 = -0.023738 K3 = 0.0998258
+K3B = 3.2899638 W0 = 1E-8 NLX = 1E-9
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.5151769 DVT1 = 0.4419519 DVT2 = -0.2999229
+U0 = 115.1258843 UA = 1.225988E-9 UB = 1.560658E-21
+UC = -1E-10 VSAT = 1.308017E5 A0 = 0.9337807
+AGS = 0.1433303 B0 = 1.362185E-6 B1 = 5E-6
+KETA = 5.672277E-3 A1 = 0.0265845 A2 = 0.3
+RDSW = 2.638992E3 PRWG = -0.097254 PRWB = -0.2798661
+WR = 1 WINT = 6.932152E-8 LINT = 4.824682E-8
+DWG = -1.15594E-8 DWB = 5.681573E-10 VOFF = -0.0361606
+NFACTOR = 0.8753188 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 0.3791709
+ETAB = -0.1855246 DSUB = 1 PCLM = 1.1068997
+PDIBLC1 = 5.409427E-3 PDIBLC2 = 1.831529E-3 PDIBLCB = 7.871057E-3
+DROUT = 0.1340268 PSCBE1 = 8E10 PSCBE2 = 8.522193E-10
+PVAG = 0.0150018 DELTA = 0.01 RSH = 3.4
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 3E-10 CGSO = 3E-10
+CGBO = 1E-10 CJ = 8.416388E-4 PB = 0.7374487
+MJ = 0.3318444 CJSW = 8E-13 PBSW = 0.7500384
+MJSW = 0.91 CJSWG = 6.4E-11 PBSWG = 0.7500384
+MJSWG = 0.91 CF = 0 PVTH0 = 5.98016E-3
+PRDSW = 14.8598424 PK2 = 3.73981E-3 WKETA = -7.104992E-3
+LKETA = -0.0222588 )

124 APENDICE A. PARAMETROS DE SIMULACION
A.9. Parametros de 0.50µm, IBM Semicon-
ductor
T65P SPICE BSIM3 VERSION 3.1 PARAMETERS
SPICE 3f5 Level 8, Star-HSPICE Level 49, UTMOST Level 8
DATE: Aug 11/06
LOT: T65P WAF: 2001
Temperature parameters=Default
.MODEL CMOSN NMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 9.4E-9
+XJ = 1.5E-7 NCH = 1.7E17 VTH0 = 0.5937939
+K1 = 0.8559617 K2 = -0.0513295 K3 = -1.5882503
+K3B = 0.7791838 W0 = 1E-8 NLX = 1.701345E-7
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.7748499 DVT1 = 0.3435219 DVT2 = -0.2773813
+U0 = 440.213356 UA = 1.004424E-13 UB = 1.888848E-18
+UC = 5.204194E-11 VSAT = 1.474452E5 A0 = 0.7444561
+AGS = 0.1340889 B0 = 1.455423E-6 B1 = 5E-6
+KETA = 3.97852E-3 A1 = 1.625976E-4 A2 = 0.6451393
+RDSW = 1.392288E3 PRWG = 1.991091E-14 PRWB = -0.0841459
+WR = 1 WINT = 1.085578E-7 LINT = 8.790999E-8
+DWG = -1.196233E-8 DWB = -4.997169E-9 VOFF = -0.15
+NFACTOR = 2.5 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 0.1935584
+ETAB = -0.0481601 DSUB = 0.7649277 PCLM = 0.8375943
+PDIBLC1 = 1.63946E-3 PDIBLC2 = 5.174122E-3 PDIBLCB = -0.0143535
+DROUT = 0.0618671 PSCBE1 = 2.995561E8 PSCBE2 = 2.040162E-6
+PVAG = 1.766095E-3 DELTA = 0.01 RSH = 4.4
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 3.54E-10 CGSO = 3.54E-10
+CGBO = 7E-9 CJ = 8.707971E-4 PB = 0.8007133
+MJ = 0.3801167 CJSW = 1E-12 PBSW = 0.8
+MJSW = 0.9099502 CJSWG = 1.64E-10 PBSWG = 0.8
+MJSWG = 0.9099502 CF = 0 PVTH0 = 7.532778E-3
+PRDSW = -316.8520397 PK2 = -7.285099E-3 WKETA = -0.0138782
+LKETA = -0.0332824 )
.MODEL CMOSP PMOS ( LEVEL = 49
+VERSION = 3.1 TNOM = 27 TOX = 9.4E-9
+XJ = 1.5E-7 NCH = 1.7E17 VTH0 = -0.5626935
+K1 = 0.8590739 K2 = -0.1 K3 = 0
+K3B = 3.5926688 W0 = 1E-8 NLX = 1E-9
+DVT0W = 0 DVT1W = 0 DVT2W = 0
+DVT0 = 0.7787218 DVT1 = 0.3815193 DVT2 = -0.3
+U0 = 141.0319298 UA = 1.972665E-9 UB = 2.574014E-21
+UC = -3.53236E-11 VSAT = 1.506598E5 A0 = 0.6779443
+AGS = 0.2104972 B0 = 1.491067E-6 B1 = 5E-6
+KETA = -0.0244694 A1 = 3.740238E-4 A2 = 0.4428035
+RDSW = 3E3 PRWG = -0.0587204 PRWB = -0.1484781
+WR = 1 WINT = 8.391004E-8 LINT = 1.085068E-7
+DWG = -1.537537E-8 DWB = 1.086087E-8 VOFF = -0.0361606
+NFACTOR = 0.8753188 CIT = 0 CDSC = 2.4E-4
+CDSCD = 0 CDSCB = 0 ETA0 = 0
+ETAB = -0.1187015 DSUB = 1 PCLM = 1.5568892

A.9. PARAMETROS DE 0.50µM, IBM SEMICONDUCTOR 125
+PDIBLC1 = 0.0298699 PDIBLC2 = 3.253612E-3 PDIBLCB = -0.1
+DROUT = 0.2769531 PSCBE1 = 7.652872E9 PSCBE2 = 5.719075E-10
+PVAG = 0 DELTA = 0.01 RSH = 2.9
+MOBMOD = 1 PRT = 0 UTE = -1.5
+KT1 = -0.11 KT1L = 0 KT2 = 0.022
+UA1 = 4.31E-9 UB1 = -7.61E-18 UC1 = -5.6E-11
+AT = 3.3E4 WL = 0 WLN = 1
+WW = 0 WWN = 1 WWL = 0
+LL = 0 LLN = 1 LW = 0
+LWN = 1 LWL = 0 CAPMOD = 2
+XPART = 0.5 CGDO = 3.61E-10 CGSO = 3.61E-10
+CGBO = 7E-9 CJ = 9.64141E-4 PB = 0.8000055
+MJ = 0.2499898 CJSW = 8.001006E-13 PBSW = 0.5
+MJSW = 0.999 CJSWG = 6.4E-11 PBSWG = 0.5
+MJSWG = 0.999 CF = 0 PVTH0 = 5.98016E-3
+PRDSW = 14.8598424 PK2 = 3.73981E-3 WKETA = 5.45809E-3
+LKETA = -5.353868E-3)

126 APENDICE A. PARAMETROS DE SIMULACION
Esta hoja se dejo en blanco intencionalmente.

Apendice B
Publicaciones
En este anexo se muestran las publicaciones que han sido desarrolladasen este trabajo de Tesis.
B.1. Publicaciones en congresos
E. Tlelo-Cuautle, M.A. Duarte-Villasenor. Automatic Synthesis ofCMOS Compatible CCII+s. IEEE NEWCAS-TAISA, Montreal, June22-25, 2008.
B.2. Publicaciones en revistas
E. Tlelo-Cuautle, M.A. Duarte-Villasenor, I. Guerra-Gomez. Automat-ic synthesis of VFs and VMs by applying genetic algorithms. Circuits,Systems and Signal Processing, Vol. 27, No. 3, pp. 391-403, June 2008.
E. Tlelo-Cuautle, D. Moro-Frıas, C. Sanchez-Lopez, M.A. Duarte-Villasenor. Synthesis of CCII-s by superimposing VFs and CFs throughgenetic operations. IEICE Electronics Express, Vol. 5, No. 11, pp. 411-417, June 2008.
E. Tlelo-Cuautle, I. Guerra-Gomez, M.A. Duarte-Villasenor, Luis G.De la Fraga, G. Flores-Becerra, G. Reyes-Salgado, C.A. Reyes-Garcıa,G. Rodrıguez-Gomez. Applications of evolutionary algorithms in thedesign automation of analog integrated circuits. Journal of AppliedSciences, Vol. 10, pp. 1859-1872, July 2010.
127

128 APENDICE B. PUBLICACIONES
B.3. Publicaciones en capıtulo de libro
E. Tlelo-Cuautle, I. Guerra-Gomez, C.A. Reyes-Garcıa, M.A. Duarte-Villasenor. Synthesis of Analog Circuits by Genetic Algorithms andtheir Optimization by Particle Swarm Optimization. In Intelligent Sys-tems for Automated Learning and Adaptation: Emerging Trends andApplications, IGI Global, 2010.
M.A. Duarte-Villasenor, V.H. Carbajal-Gomez, E. Tlelo-Cuautle. De-sign of current-feedback operational amplifiers and their application tochaos-based secure communications. In Analog Circuits: Applications,Design and Performance, NOVA Science Publishers, Inc., 2011.

Apendice C
Manual de usuario
El software realizado se encuentra en la carpeta nombrada SBGU (Sınte-sis de Bloques de Ganancia Unitaria). Esta debe estar dentro de la carpetawork de Matlab.Contenido de este manual:
1. Descripcion de los archivos contenidos de la carpeta SBGU.
2. Antes de ejecutar el programa.
3. Ejecucion del programa CM.
4. Ejecucion del programa VF.
5. Ejecucion del programa CF.
6. Ejecucion del programa VM.
7. Notas extras.
C.1. Descripcion de los archivos contenidos
de la carpeta SBGU
1. Programa inicial.m. Contiene las variables de ejecucion del algoritmo:Tamano de la poblacion, porcentaje de mutacion, numero maximo degeneraciones, error mınimo buscado. Tambien en este se especifica quesimulador y tecnologıa se utilizara y si se desea graficar las iteracionesdel algoritmo VS tiempo del PC o no.
2. Programas varCF.m, varCM.m, varVF.m y varVM.m. Estos contienenlos valores de la ganancia e impedancias deseadas por el usuario.
129

130 APENDICE C. MANUAL DE USUARIO
3. Programas CF.m, CM.m, VF.m y VM.m. Estos son los programas debusqueda de topologıas, NO deben ser alterados por el usuario.
4. Carpeta tec. Esta carpeta contiene las tecnologıas a usar:
AMI Semiconductor: 0.35µm, 0.50µm.
IBM Semiconductor: 0.18µm, 0.25µm, 0.35µm, 0.50µm.
Taiwan Semiconductor (TSMC): 0.18µm, 0.25µm, 0.35µm.
5. Carpeta funciones. Contiene las funciones y los subprogramas que uti-lizan los programas de sıntesis de topologıas.
6. Carpeta archivos. Contiene archivos que seran utilizados por SPICE.
7. Carpeta salidas. En esta se generaran los netlist para SPICE y susresultados de simulacion, al finalizar la busqueda el mejor individuoesta con el nombre de CF1, CM1, VF1 o VM1 segun el programaejecutado.
C.2. Antes de ejecutar el programa
1. Se coloca la carpeta SBGU en la carpeta work de matlab, ejemplo:C:\MATLAB7\work\SBGU
2. Se abre el programa inicial.m, se elige el simulador a utilizar: Top-SPICE, HSPICE o Tanner SPICE. Se elige la tecnologıa a utilizarpor el simulador. Se declaran si se desea graficar las iteraciones o no. Sise desea, se cambian las variables del algoritmo genetico: el tamano depoblacion, porcentaje de mutacion, numero maximo de generaciones yel error mınimo buscado. Se guardan los cambios y se cierra el progra-ma.
3. Se abre el archivo direcciones.m (el cual esta contenido en la carpetafunciones).
Se escriben las direcciones de los SPICE a utilizar: TopSPICE,Tanner SPICE y HSPICE.
Se escriben las direcciones de las tecnologıas de simulacion a usaren su ordenador, ejemplo:C:\MATLAB7\work\SBGU\tec\ami035.lib.
Se corrigen, si es necesario, las direcciones de los archivos.
Al finalizar se guardan los cambios y se cierra el archivo.

C.3. EJECUCION DEL PROGRAMA CM. 131
C.3. Ejecucion del programa CM.
1. Se abre el archivo varCM.m; en este se colocan los valores de la gananciae impedancias deseadas.
2. Se abre el Matlab y se escribe en el Command Window:>> CMSe oprime la tecla enter y el programa se ejecuta.
3. Al terminar de ejecutarse (despues de unos 5 minutos) se muestra elnumero de generaciones que realizo, el numero del cromosoma del mejorindividuo y su error :Generacion MejorIndividuo Error
Donde el numero del cromosoma del mejor individuo esta dividido entre1e6 (1000000), esto es con el fin de poder desplegarlo en la pantalla.
4. El netlist del mejor cromosoma se encuentra en la carpeta salida conel nombre de: CM1. Se puede verificar que es la topologıa encontradaporque el archivo comienza con el numero de cromosoma y este debede coincidir con el ultimo valor de Generacion MejorIndividuo Error
desplegado en el Command Window.
C.4. Ejecucion del programa VF.
1. Se abre el archivo varVF.m; en el se colocan los valores de la gananciae impedancias deseadas. Ademas, se selecciona el archivo que describecuantos y como son colocados los nullators para describir el VF ideal;solo uno debe estar activo y los demas comentados con el signo% alinicio de la lınea. Si todos estan comentados el programa no correra, simas de uno esta activo el programa ejecutara el VF ideal descrito por lalınea que este mas abajo. Se pueden identificar los archivos ideales de losnorators al leer los archivos: m1 n.m, m2 Pnn.m,. . . , m4 SPnnnn.m;que estan en la carpeta funciones.
2. Se abre el Matlab y se escribe en el Command Window:>> VFSe oprime la tecla enter y el programa se ejecuta.
3. Al terminar de ejecutarse se muestra el numero de generaciones querealizo, el numero del cromosoma del mejor individuo y el error:Generacion MejorIndividuo Error

132 APENDICE C. MANUAL DE USUARIO
Donde el numero del cromosoma del mejor individuo esta dividido entre1e6 (1000000), esto es con el fin de poder desplegarlo en la pantalla.
4. El netlist del mejor cromosoma se encuentra en la carpeta salida conel nombre de: VF1. Se puede verificar que es la topologıa encontradaporque el archivo comienza con el numero de cromosoma y este debede coincidir con el ultimo valor de Generacion MejorIndividuo Error
desplegado en el Command Window.
C.5. Ejecucion del programa CF.
1. Se abre el archivo varCF.m en este se colocan los valores de la gananciae impedancias deseadas. Ademas, se selecciona el archivo que describecuantos y como son colocados los norators para describir el CF ideal;solo uno debe estar activo y los demas comentados con el signo% alinicio de la lınea. Si todos estan comentados el programa no correra, simas de uno esta activo el programa ejecutara el CF ideal descrito por lalınea que este mas abajo. Se pueden identificar los archivos ideales de losnorators al leer los archivos: m1 n.m, m2 Pnn.m,. . . , m4 SPnnnn.m;que estan en la carpeta funciones.
2. Se abre el Matlab y se escribe en el Command Window:>> CFSe oprime la tecla enter y el programa se ejecuta.
3. Al terminar de ejecutarse (despues de unos 5 minutos) se muestra elnumero de generaciones que realizo, el numero del cromosoma del mejorindividuo y el error :Generacion MejorIndividuo Error
Donde el numero del cromosoma del mejor individuo esta dividido entre1e6 (1000000), esto es con el fin de poder desplegarlo en la pantalla.
4. El netlist del mejor cromosoma se encuentra en la carpeta salida conel nombre de: CF1. Se puede verificar que es la topologıa encontradaporque el archivo comienza con el numero de cromosoma y este debede coincidir con el ultimo valor de Generacion MejorIndividuo Error
desplegado en el Command Window.

C.6. EJECUCION DEL PROGRAMA VM. 133
C.6. Ejecucion del programa VM.
1. Se abre el archivo varVM.m; en el se colocan los valores de la gananciae impedancias deseadas. Ademas, se selecciona el archivo que describecuantos y como son colocados los nullators para describir el VM ideal;solo uno debe estar activo y los demas comentados con el signo% alinicio de la lınea. Si todos estan comentados el programa no correra, simas de uno esta activo el programa ejecutara el VF ideal descrito porla lınea que este mas abajo.
2. Se abre el Matlab y se escribe en el Command Window:>> VMSe oprime la tecla enter y el programa se ejecuta.
3. Al terminar de ejecutarse se muestra el numero de generaciones querealizo, el numero del cromosoma del mejor individuo y el error:Generacion MejorIndividuo Error
Donde el numero del cromosoma del mejor individuo esta dividido entre1e6 (1000000), esto es con el fin de poder desplegarlo en la pantalla.
4. El netlist del mejor cromosoma se encuentra en la carpeta salida conel nombre de: VM1. Se puede verificar que es la topologıa encontradaporque el archivo comienza con el numero de cromosoma y este debede coincidir con el ultimo valor de Generacion MejorIndividuo Error
desplegado en el Command Window.
C.7. Notas Extras
Si se desea hacer alguna(s) modificacion(es) al programa se debe consi-derar:
1. Los archivos que describen como estan colocalos los nullators y norators(m1 n.m, m2 Pnn.m,. . . , m4 SPnnnn.m) NO deben ser modificados.Solo se abren para saber como es la descripcion de nullators y noratorsy se escoje la que se utilizara.
2. Al ejecutar el programa siempre borra todas las variables actuales delWorkspace y deja las de la nueva corrida. Ası que si se desea conservaralgunos datos se debe tener esto previsto, guardando los anteriores enun archivo .mat.
3. Si se desea cambiar el valor de Vdd, el valor de la fuente de corriente depolarizacion, las dimensiones W y L de los transistores o el valor de la

134 APENDICE C. MANUAL DE USUARIO
carga de la salida es necesario modificar los documentos de la carpetaarchivos. Esta carpeta contiene doce archivos como se muestra en elcuadro C.1. Solo modifique el archivo del UGC a encontrar.
Cuadro C.1: Documentos de la carpeta archivos.
TANNER-SPICE TOP-SPICE H-SPICECM tanCM.sp topCM.cir hspCM.spVF tanVF.sp topVF.cir hspVF.spCF tanCF.sp topCF.cir hspCF.spVM tanVM.sp topVM.cir hspVM.sp

Indice de figuras
1.1. (a) VF, (b) CF, (c) VM, (d) CM, (e) CCII+, (f) CFOA. . . . 3
2.1. (a) todos los individuos, (b) se califican del mejor al peor, (c)el metodo de seleccion forma las parejas que seran los padresde la proxima generacion. . . . . . . . . . . . . . . . . . . . . 18
2.2. Operador de cruza de punto sencillo. . . . . . . . . . . . . . . 202.3. Ejemplo de la cruza en circuitos CMOS. (a) y (b) padres, (c)
y (d) descendientes. . . . . . . . . . . . . . . . . . . . . . . . . 212.4. Operacion de mutacion de parametros binarios. . . . . . . . . 232.5. Circuito VF descrito con su cromosoma. . . . . . . . . . . . . 242.6. Circuitos resultantes de la operacion de mutacion al VF de la
figura 2.5. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.7. Operacion de elitismo utilizada en esta tesis. . . . . . . . . . . 262.8. Estructura general de los algoritmos geneticos. . . . . . . . . . 292.9. Estructura general de los algoritmos que se basan en GP. . . . 32
3.1. Nullor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.2. Modelos de VFs usando (a) uno y (b) cuatro nullators. . . . . 373.3. Modelo del MOSFET usando el elemento nullor. . . . . . . . . 373.4. Diagrama de Flujo del programa que sintetiza circuitos analogi-
cos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.5. Modelos ideales de CFs usando uno y dos norators. . . . . . . 403.6. Modelos ideales de CFs usando tres norators. . . . . . . . . . . 403.7. Modelos ideales de CFs usando cuatro norators. . . . . . . . . 413.8. (a) Grafica y (b) contorno de F1(x,y). . . . . . . . . . . . . . . 433.9. (a) Grafica y (b) contorno de F2(x,y). . . . . . . . . . . . . . . 443.10. (a) Grafica y (b) contorno de F3(x,y). . . . . . . . . . . . . . . 443.11. Grafica de la Ec. (3.4), con gain = 1. . . . . . . . . . . . . . . 493.12. Grafica de la Ec. (3.5), donde BW = 104. . . . . . . . . . . . . 493.13. Grafica de la Ec. (3.6), donde Z = 20KΩ. . . . . . . . . . . . 513.14. Grafica de la Ec. (3.7), donde Z = 250Ω. . . . . . . . . . . . . 51
135

136 INDICE DE FIGURAS
3.15. Medida de aptitud de los CFs del cuadro 3.3, prueba 1. . . . . 533.16. Medida de aptitud de los CFs del cuadro 3.3, prueba 2. . . . . 533.17. Adicion de un elemento P a un elemento O: (a) en el nodo i,
(b) en el nodo j y (c) entre los nodos i y j. . . . . . . . . . . . 553.18. Modelo de pares O-P para el cromosoma 336860. . . . . . . . 583.19. Polarizacion de la figura 3.18 segun los genBias del cuadro 3.9. 593.20. (a) Modelo ideal de un VF conocido y (b)circuito VF repre-
sentado por el cromosoma 336860. . . . . . . . . . . . . . . . . 593.21. Circuito CF que corresponde al cromosoma 99324. . . . . . . . 623.22. Celdas genericas para formar espejos de corriente. . . . . . . . 633.23. Circuitos extra para IOUT . . . . . . . . . . . . . . . . . . . . 653.24. Modelo de pares O-P para el CM segun el genIO=101. . . . . 673.25. Modelo de pares O-P para el cromosoma CM 1192. . . . . . . 673.26. CM sintetizado con el cromosoma 1192, espejo Cascode. . . . 683.27. Representacion con nullator y norators de un VM ideal [26, 27]. 683.28. Representacion de un VM ideal, utilizada en este trabajo. . . . 693.29. VMs de la figura 3.28, sintetizando los nullors por MOSFETs. 693.30. genIO de los VMs. . . . . . . . . . . . . . . . . . . . . . . . . 703.31. VM conocido, su cromosoma es 0000110101. . . . . . . . . . . 733.32. Posibles uniones de los bloques de ganancia unitaria. . . . . . 743.33. Ejemplo de la union simple. . . . . . . . . . . . . . . . . . . . 763.34. VM con dos salidas. . . . . . . . . . . . . . . . . . . . . . . . . 773.35. VF con dos salidas. . . . . . . . . . . . . . . . . . . . . . . . . 783.36. CF con dos salidas. . . . . . . . . . . . . . . . . . . . . . . . . 783.37. CM con dos salidas. . . . . . . . . . . . . . . . . . . . . . . . . 793.38. Ejemplo de CF-CM figura 3.32.(n), al CF se le duplica la salida. 803.39. Ejemplo de CM-CM figura 3.32.(p), al primer CM se le duplica
la salida. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 803.40. (a) Circuito VF sintetizado en la fig. 3.20; (b) circuito CCII+
su cromosoma es 336860-1192. . . . . . . . . . . . . . . . . . . 823.41. (a) CCII- dividido en un bloque VF y un bloque CF; (b) CCII-
ideal, realizado con 4 nullators y 4 norators. . . . . . . . . . . 833.42. (a) Circuito VF sintetizado en la fig. 3.20; (b) Circuito CF
sintetizado en la fig. 3.21; (c) CCII- obtenido por la union de(a) y (b). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.43. Diagrama a bloques de un CFOA. . . . . . . . . . . . . . . . . 863.44. CFOA 336860-1192-336860. . . . . . . . . . . . . . . . . . . . 87
4.1. Evaluacion del mejor individuo. . . . . . . . . . . . . . . . . . 924.2. Tiempo de ejecucion del programa. . . . . . . . . . . . . . . . 924.3. Algunos VFs obtenidos con el EA. . . . . . . . . . . . . . . . . 93

INDICE DE FIGURAS 137
4.4. Algunos VFs obtenidos con el EA. . . . . . . . . . . . . . . . . 944.5. Cuatro CFs obtenidos con el EA. . . . . . . . . . . . . . . . . 964.6. Ejemplo de CFs obtenidos con el EA. . . . . . . . . . . . . . . 974.7. Algunos CMs obtenidos con el EA. . . . . . . . . . . . . . . . 994.8. Algunos CMs obtenidos con el EA. . . . . . . . . . . . . . . . 1004.9. Algunos VMs obtenidos con el EA. . . . . . . . . . . . . . . . 1024.10. CCII+ obtenidos de la combinacion del VF 196758 y el CM
69593766. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1034.11. Dos CCII+s obtenidos con la combinacion de UGC. . . . . . . 1044.12. CCII- obtenido con la combinacion del VF 67599 y el CF
4610874. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1054.13. CFOA obtenido de la combinacion del VF 196758 y el CM
69593766. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1064.14. Dos CFOAs obtenidos de la combinacion de UGCs encontra-
dos con el EA. . . . . . . . . . . . . . . . . . . . . . . . . . . . 107

138 INDICE DE FIGURAS
Esta hoja se dejo en blanco intencionalmente.

Indice de cuadros
2.1. Trabajos de sıntesis de circuitos analogicos usando EAs. . . . . 92.2. Continuacion del cuadro 2.1. . . . . . . . . . . . . . . . . . . . 102.3. Herramientas de generacion de topologıas. . . . . . . . . . . . 112.4. Continuacion del cuadro 2.3. . . . . . . . . . . . . . . . . . . . 12
3.1. Funciones de prueba utilizadas. . . . . . . . . . . . . . . . . . 453.2. Resultados de las pruebas al GA realizado. . . . . . . . . . . . 473.3. Individuos de pueba para la Ec. (3.3). Valores de ganancia,
ancho de banda e impedancias de posibles circuitos CF. . . . . 523.4. Codificacion del genSS a partir de la figura 3.17. . . . . . . . . 553.5. Codificacion del genSMos. . . . . . . . . . . . . . . . . . . . . 553.6. GenBias: Bits de asignacion para agregar fuentes de corriente. 563.7. GenCM: Sıntesis de fuentes de corriente por CM. . . . . . . . 563.8. Numero de bits para cada cromosoma VF. . . . . . . . . . . . 573.9. Codificacion del cromosoma 336860. . . . . . . . . . . . . . . . 583.10. GenBias: gen de fuentes de polarizacion. . . . . . . . . . . . . 603.11. Numero de bits para cada cromosoma CF. . . . . . . . . . . . 613.12. Codificacion del cromosoma CF: 99324. . . . . . . . . . . . . . 623.13. GenBias: Bits de polarizacion del circuito CM. . . . . . . . . . 643.14. GenIO, nodos de entrada y salida del CM. . . . . . . . . . . . 643.15. Descripcion del genN. . . . . . . . . . . . . . . . . . . . . . . . 663.16. Cromosoma CM, dividido en 3 genes. . . . . . . . . . . . . . . 663.17. Codificacion del cromosoma CM 1192. . . . . . . . . . . . . . 673.18. genBias del VM. . . . . . . . . . . . . . . . . . . . . . . . . . 713.19. Codificacion del genIO. . . . . . . . . . . . . . . . . . . . . . . 723.20. Cromosoma de un VM. . . . . . . . . . . . . . . . . . . . . . . 723.21. Cromosoma de los circuitos de la figura 3.32, por union simple. 753.22. Cromosomas de los circuitos donde se duplica la salida. . . . . 773.23. Cromosoma de los circuitos de la figura 3.32.(n) y (p). . . . . 793.24. Cromosoma de los circuitos CCII+ y ICCII+, por creacion del
nodo Z. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
139

140 INDICE DE CUADROS
3.25. Cromosoma CCII+, por combinacion de nullatos-norators. . . 843.26. Cromosoma de un CFOA. . . . . . . . . . . . . . . . . . . . . 86
4.1. Programas realizados en MatLab. . . . . . . . . . . . . . . . . 904.2. Respuesta en CA de los circuitos VF obtenidos. . . . . . . . . 914.3. Respuesta en CA de los circuitos CF obtenidos. . . . . . . . . 954.4. Respuesta en CA de los circuitos CM obtenidos. . . . . . . . . 984.5. Respuesta en CA de los circuitos VM obtenidos. . . . . . . . . 101
C.1. Documentos de la carpeta archivos. . . . . . . . . . . . . . . . 134

Bibliografıa
[1] Rutenbar Rob A, Georges G. E. Gielen, and Brian A. Antao. Computer-Aided Design of Analog Integrated Circuits and Systems. IEEE Press.USA. 2002.
[2] Salem Zebulum, Ricardo; Marco Aurelio C. Pacheco, y Marley Maria B.R. Vellasco. Evolutionary Electronics, Automatic Design of ElectronicCircuits and Systems by Genetic Algorithms. Ed. CRC Press. USA.2002.
[3] Martens, E. and G. Gielen. Classification of analog synthesis tools basedon their architecture selection mechanisms. Integration the VLSI jour-nal, Elsevier, No.41, pp. 238-252. 2008.
[4] Mazumder, Pinaki; Elizabeth M. Rudnick. Genetic Algorithms for VLSIDesign, Layout & Test Automation. Ed. Prentice Hall PTR. USA. 1999.
[5] Rob A. Rutenbar, Georges G. E. Gielen, and Jaijeet Roychowdhury.Hierarchical Modeling, Optimization, and Synthesis for System-LevelAnalog and RF Designs. In Proceedings of the IEEE. Vol.95, No.3, pp.640-669. March 2007.
[6] Mattiussi, Claudio. Evolutionary synthesis of analog networks. Doctoralthesis. Laboratory of Intelligent Systems, Institute of System Engineer-ing Ecole Polytechnique Federale de Lausanne (EPFL). 2005.
[7] Koza John R, Jones Lee W, Keane Martin A, Streeter Matthew J, Al-Sakran Sameer H. Toward automated design of industrial-strength ana-log circuits by means of genetic programming. In Genetic ProgrammingTheory and Practice II. Boston: Kluwer Academic Publishers Chapter8, pp. 121-142. 2004.
[8] Masanori Natsui, Yoshiaki Tadokoro, Naofumi Homma, Takafumi Aoki,and Tatsuo Higuchi. Synthesis of current mirrors based on evolution-
141

142 BIBLIOGRAFIA
ary graph generation with transmigration capability. IEICE ElectronicsExpress. Vol.4, No.3, pp. 88-93. 2007.
[9] Gielen Georges. Design methodology and model generation of complexanalog blocks. In Analog Circuits Desing, Eds. Michiel Steyaert, JohanH. Huijsing and Arthur H.M. van Roermund. Springer. 2006.
[10] Tathagato Rai Dastidar, P. P. Chakrabarti, and Partha Ray. A synthesissystem for analog circuits based on evolutionary search and topologicalreuse. IEEE Transactions on Evolutionary Computation. Vol.9, No.2,pp. 211-224. April 2005.
[11] Varum Aggarwal. Evolving Sinusoidal Oscillators Using Genetic Algo-rithms. Proc. The 2003 NASA/DoD Conference on Evolvable Hardware.Chicago, USA, pp. 67-76. 2003.
[12] Feng Wang,Yuanxiang Li, and Kangshun Li. Automated analog circuitdesign using two-layer genetic programming. In Applied Mathematicsand Computation. Ed. ELSEVIER. Vol.185, No.2, pp. 1087-1097. Feb2007.
[13] Shoou-Jinn Chang, Hao-Sheng Hou, and Yan-Kuin Su. Automated Pas-sive Filter Synthesis Using a Novel Tree Representation and GeneticProgramming. IEEE transactions on Evolutionary Computation. Vol.10,No.1, pp. 93-100. February 2006.
[14] Aggarwal Varun. Novel Canonic Current Mode DDCC Based SRCOSynthesized Using a Genetic Algorithm. Analog Integrated Circuits Sig-nal Processing, No.40, pp. 83-85. 2004.
[15] Rutenbar, R.A., L.R. Carley, P.C. Maulik, E.S. Ochotta, T. Mukherjee.Synthesis and Layout for Analog and Mixed-Signal ICs in the ACA-CIA System. Analog Circuit Desing, Eds. J.H. Huijsing, R.Y. Van dePlassche, W.M.C. Sansen. Kluwer Academic Publishers, Netherlands,pp. 127-146. 1996.
[16] Ochotta, E.S., Rob A. Runtenbar, L.R. Carley. Synthesis of High-Performance Analog Circuits in ASTRX/OBLX. In DAC 94 Procedingsof the 31st annual Design Automation Conference. 1994.
[17] Grimbleby James B., Automatic analogue circuit synthesis using geneticalgorithms. IEEE Proc. Circuits Devices Syst., Vol.147, No.6, pp. 319-323. Dec. 2000.

BIBLIOGRAFIA 143
[18] Hajime Shibata, and Nobuo Fujii. Analog circuit synthesis by superim-posing of sub-circuits. IEEE ISCAS, Vol.V, pp. 427-430. 2001.
[19] Torres-Papaqui L., Torres-Munoz D. y Tlelo-Cuautle E. Synthesis of VFsand CFs by Manipulation of Genetic Cells. Analog Integrated Circuitsand Signal Processing. Vol.46, No.2, pp. 99-102. 2006.
[20] Somaya Kayed, Ramy Iskander, Sami Moussa, and Hani F. Ragai. Ge-netic algorithms based technology migration of 2nd generation currentconveyors. 2002.
[21] Tlelo-Cuautle, E. and, M.A. Duarte-Villasenor, Evolutionary electron-ics: automatic synthesis of analog circuits by GAs, in Success in Evo-lutionary Computation, Series: Studies in Computational Intelligence,Vol.92, Chapter 8, pp. 165-188, EDs. Ang Yang; Yin Shan; Lam ThuBui. Springer-Verlag, Berlin. 2008.
[22] Tlelo-Cuautle E., Torres-Munoz D., and Torres-Papaqui L. On the com-putational synthesis of CMOS voltage followers. IEICE Transactions onFundamentals of Electronics, Communications and Computer Sciences.Vol.E88-A, No.12, pp. 3479-3484, 2005.
[23] Patt Boonyaporn and Varakorn Kasemsuwan. A High Performance ClassAB CMOS Rail to Rail Voltage Follower. IEEE ASIA-Pacific Conferenceon ASIC 2002 (AP-ASIC), pp.161-163. 2002.
[24] Soliman, Ahmed M. Applications of voltage and current unity gain cellsin nodal admittance matrix expansion. In IEEE Circuits and SystemsMagazine. Vol.9, No.4, pp. 29-42. Dec. 2009.
[25] Palmesano, Giuseppe; Gaetano Palumbo, and Salvatore Pennisi. CMOSCurrent Amplifiers. Kluwer Academic Publishers. USA, 1999.
[26] Awad I.A., and A. M. Soliman. On the Voltage Mirrors and the CurrentMirrors. Analog Integrated Circuits and Signal Processing. Vol.32, pp.79-81. 2002.
[27] Inas A. Awad, and Ahmed M. Soliman. Inverting second generationcurrent conveyors: the missing building blocks, CMOS realizations andapplications. International Journal of Electronics. Vol.86, No.4, pp. 413-432. April 1999.
[28] Hung-Yu Wang, Sheng-Hsiung Chang, Yuan-Long Jeang, Chun-YuehHuang. Rearrangement of mirror elements. Analog Integr Circ Sig Pro-cess Vol 49, pp. 87-90. 2006.

144 BIBLIOGRAFIA
[29] Sedra A. S., Roberts G. W., and Gohn F. The current conveyor: history,progress and new result. IEE proceedings, Vol.137. No.2. pp. 78-86. April1990.
[30] Saad, R.A., and Soliman, A.M. Use of Mirror Elements in the Active De-vice Synthesis by Admittance Matrix Expansion. In IEEE Transactionson Circuits and Systems I: Regular Papers, Vol.55, No.9, pp. 2726-2735.Oct. 2008.
[31] Muhammed A. Ibrahim, and Hakan Kuntman. A CMOS realization ofInverting second generation current conveyor positive. 5th Nordic SignalProcessing Symposium, October 4-7 2002.www.norsig.no/norsig2002/Proceedings/papers/cr1055.pdf
[32] Pena Perez, Aldo. Diseno de CFOAs y su aplicacion en filtros. Tesis deMaestrıa en Ciencias. Instituto Nacional de Astrofısica optica y Elec-tronica. Tonantzintla, Puebla, Mexico, 2006.
[33] Coello Coello C.A., Van Veldhuizen D.A. and, G.B. Lamont. Evolution-ary Algorithms for Solving Multi-Objective Problems. Kluwer AcademicPublishers. USA. 2001.
[34] Lahoz-Beltran, Rafael. Bioinformatica. Simulacion, vida artificial e in-teligencia artificial. Ed. Dıaz de Santos. Espana, 2004.
[35] Engelbercht A.P. Fundamentals of computational swarm intelligence.Wiley, University of Pretoria, South Africa.
[36] Lawrence Davis. Handbook of genetic algorithms. Ed. Van NostrandReinhold. New York, 1991.
[37] Alfonso L. de Garay. Genetica de poblaciones y evolucion. Compor-tamiento de los genes en las poblaciones y efectos de las fuerzas de laevolucion biologica. Ed. textos-uap. Mexico, 1988.
[38] Gupta S.S., and Senani R. New voltage-model/current-mode universalbiquad filter using unity-gain cells. International Journal of Electronics,Vol.93, No.11, pp. 760-775. November 2006.
[39] Senani R., and Gupta S.S. Novel sinusoidal oscillators using only unity-gain voltage followers and current followers. IEICE Electronics Express,Vol.1, No.13, pp. 404-409. 2004.

BIBLIOGRAFIA 145
[40] Gupta S.S., and Senani R. New single resistance controlled oscillatoremploying a reduced number of unity-gain cells. IEICE Electronics Ex-press, Vol.1, No.16, pp. 507-512. 2004.
[41] Samir Ben Salem, Mourad Fakhfakh, Dorra Sellami Masmoudi, MouradLoulou, Patrick Loumeau, Nouri Masmoudi. A high performancesCMOS CCII and high frecuency applications. Analog Integr Circ SingProcees. Springer Science Business Media, LLC 2006.
[42] Kumar P., and Senani R. A systematic realization of current mode uni-versal biquad filters. International Journal of Electronics, Vol.93, No.9,pp. 623-636. September 2006.
[43] Cesare Valenti. A genetic algorithm for discrete tomography reconstruc-tion. Genetic programming and evolvable machines, Springer. Vol.9,No.1, pp.85-96. March 2009.
[44] Santos Gordillo, Jose angel. Algoritmo genetico para el calculo de φ-Tensores difusos. Tesis de Maestrıa en Ciencias. Instituto Nacional deAstrofısica, optica y Electronica. Tonantzintla, Puebla, Mexico, 2003.
[45] Vazquez y Montiel, Sergio. Diseno de sistemas opticos usando algorit-mos geneticos. Tesis doctoral. Instituto Nacional de Astrofısica, opticay Electronica. Tonantzintla, Puebla, Mexico, 1996.
[46] Salazar Romero, Marcos Arturo. Obtencion de la fase a partir de la fun-cion de punto extendido utilizando un algoritmo genetico. Tesis doctor-al. Instituto Nacional de Astrofısica, optica y Electrnica. Tonantzintla,Puebla, Mexico, 2005.
[47] Wim Kruiskamp, and Domine Leenaerts. DARWIN: CMOS opamp syn-thesis by means of a genetic algorithm. In DAC 95, 32nd Conference onDesign Automation. pp. 433-438. 1994.
[48] Aida A. El-Sabban, Ramy Iskander, Hisham Haddara, and Hani F. Ra-gai. GA-Based Analog Synthesis of CMOS Power Amplifiers in the 2.45GHz Band. Mediterranean Microwave Symposium (MMS’03), Cairo,Egypt, May 2003.
[49] Ramy Iskander, Mohamed Dessouky, Maie Aly, Mahmoud Magdy, No-ha Hassan, Noha Soliman, and Sami Moussa. Synthesis of CMOSAnalog Cells Using AMIGO. Design Automation and Test in Europe(DATE’03), Vol.02, No.2, pp. 20297-20302, March 2003.

146 BIBLIOGRAFIA
[50] Shuguang Zhao, Licheng Jiao, Jianxun Zhao, and Yuping Wang. Evo-lutionary Design of Analog Circuits with a Uniform-Design BasedMulti-Objective Adaptive Genetic Algorithm. Proceedings of the 2005NASA/DoD Conference of Evolution Hardware (EH 05). 2005.
[51] Abhishek Somani, P. P. Chakrabarti, Amit Patra. Mixing Global andLocal competition in Genetic Optimization based Design Space Explo-ration of Analog circuits. Proceedings of the Design, Automation andTest in Europe Conference and Exhibition (DATE 05). 2005.
[52] Navid Azizi, and Khoman Phang. Automated Analog Cir-cuit Design Using Genetic Algorithms. Department of Elec-trical and Computer Engineering University of Toronto. 2001.http://www.eecg.toronto.edu/∼kphang/papers/2001/navid GA.pdf
[53] Xuewen Xia, Yuanxiang Li, Weiqin Ying, and Lei Chen. AutomatedDesign Approach for Analog Circuit Using Genetic Algorithm. In ICCS2007, Part IV, LNCS 4490, pp. 1124-1130. 2007.
[54] Trent McConaghy, Pieter Palmers, Georges Gielen, Michiel Steyaert.Simultaneous Multi-Topology Multi-Objective Sizing Across Thousandsof Analog Circuit Topologies. In Proceedings of the 44th annual DesignAutomation Conference. pp. 944-947. 2007.
[55] de Sa, Leonardo Bruno, and Antonio Mesquita. Synthesis of VoltageFollower with Only CMOS Transistors Using Evolutionary Methods.Second NASA/ESA Conference on Adaptive Hardware and Systems,pp. 478-485. 2007.
[56] Das Angan, and Ranga Vemuri. ATLAS: An Adaptively formed Hierar-chical Cell Library based Analog Synthesis Framework. In IEEE Inter-national Symposium on Circuits and Systems, ISCAS, pp. 2542-2545.May 2008.
[57] Jingsong He, Mingguo Liu, and Yunbi Chen. A novel real-coded schemefor evolutionary analog circuit synthesis. In International Workshop onIntelligent Systems and Applications, ISA 2009. 23-24 May 2009.
[58] Torres Soto Aurora, Ponce de Leon Sentı Eunice, Hernandez AguirreArturo, Torres Soto Marıa, and Dıaz Dıaz Elva. A Robust EvolvableSystem for the Synthesis of Analog Circuits. Computacion y Sistemas.Vol.13 No.4, pp.409-421. 2010.

BIBLIOGRAFIA 147
[59] Duarte Villasenor, Miguel Aurelio. Sıntesis automatica de bloques deganancia unitaria utilizando algoritmos geneticos. Tesis de Maestrıa enCiencias. Instituto Nacional de Astrofısica optica y Electronica. To-nantzintla, Puebla, Mexico, 2007.
[60] Ramensh Harjani, Rob A. Rutenbar, L. Richar Carley. OASYS: Aframe-work for analog circuit synthesis. In Computer-Aided Design of AnalogIntegrated Circuits and Systems. Eds. Rutenbar Rob A, Georges G. E.Gielen, and Brian A. Antao. IEEE Press. USA, pp. 69-88. 2002.
[61] Paul Harvey, Mohamed I. Elmasry, Bosco Leung. STAIC: An interrac-tive framework for synthesizing CMOS and BiCMOS analog circuits.In IEEE Transactions on Computer-Aided Design of Analog IntegratedCircuits and Systems. No.11, pp.1402-1417. Nov 1992.
[62] Prabir C. Mavlik, L. Richard Carley, Rob Rutenbar. Integer program-ming based topology selection of cell level analog circuit. In IEEE Trans-actions on Computer-Aided Design of Analog Integrated Circuits andSystems. No.4, pp.401-412. Apr 1995.
[63] Brian A. Antao, and Arthur J. Brodersen. ARCHGEN: automatic syn-thesis of analog systems. In IEEE Transaction on Very Large Scale In-tegration Systems. No.2, pp. 231-244. Jun 1995.
[64] Danica Stefanovic, Maher Kayal and Marc Pastre. PAD: A New Inter-active Knowledge-Based Analog Design Approach. In Analog IntegratedCircuits and Signal Processing. Vol.42, No.3, pp. 291-299. 2005.
[65] Tlelo Cuautle, E., D. Torres Munoz, L. Torres Papaqui, and A. GaonaHernandez. Synthesis of CCII+s and CFOAs by manipulation of VFsand CMs. IEEE International Behavioral Modeling and Simulation Con-ference, BMAS 2005. 22-23 September 2005.
[66] Darwin Charles. El origen de las especies. Traduccion GuadalupeMelendez. 2da. Edicion, Mexico, 1985.
[67] Salamanca Fabio. El olvidado monje del huerto, Gregor Johann Mendel.Ed. PANGEA, Mexico, 1988.
[68] Kumar P., and R. Senani. Bibliography on Nullors and Their Appli-cations in Circuit Analysis, Synthesis and Design. Analog IntegratedCircuits and Signal Processing, Vol. 33, pp. 65-76. 2002.

148 BIBLIOGRAFIA
[69] Hanspeter Schmid. Approximating the Universal Active Element. IEEETrans. On Circuits and Systems II. Vol.47, No.11, pp.1160-1169. 2000.

Extended abstract in English
Keywords: Electronic Design Automation, Evolutionary Algorithm, Ge-netic Algorithm, nullor, circuit synthesis, voltage follower, current follower,voltage mirror, current mirror, current conveyor, CFOA.
Chapter 1. Introduction
History
Currently, the key tools for handling complexity in the design process forCMOS integrated circuits are generated by the industry of Electronic DesignAutomation (EDA); Such tools can accelerate the design process [1, 2, 3, 4, 5].In the process of IC design, EDA tools focus on automating many tasks thatare routine and repetitive in the analytic design.In some cases the design of analog blocks can be identified, such as amplifiers,voltage followers, current mirrors, among others. This blocks can be repeatedand synthesized automatically using EDA methodologies [1, 2, 3, 5]. Thus,EDA tools increase productivity in the design of ICs, even in the circuitblocks that are not repetitive. Though, the analog EDA has an importantrole in the design process, analog design automation is more complex com-pared to digital design automation, because the relationships among theirspecifications are more complex.Moreover, analog design requires experience, intuition and creativity; becauseit works with a large number of parameters and some complex interactionsamong them. Also, due to the huge variety of analog circuits the EDA de-velopers are looking for a way to automate certain design tasks, as many aspossible [1, 2, 3, 4, 5, 6, 7, 8, 9].In recent years several researchers have proposed some methods for analog cir-cuit synthesis. For example in [1] the work is focused on the design of passivecircuits. Furthermore, in order to obtain new analog circuit topologies, novelsynthesis methodologies are very much needed. Recently, some effors havebeen oriented to developing tools such as ACACIA [15] and ASTRX/OBLX
149

150 BIBLIOGRAFIA
[16], works like Grimbleby [17] and Hajime Shibata with Nobuo Fuji [18]. Inthis way, either to generate new circuits or to optimize them to find improve-ments to circuit topologies or for sizing certain topologies EDA tools usedintelligent algorithms such as evolutionary algorithms (EA) [1, 2, 4, 5, 6, 7, 8,10, 11, 12, 13, 14, 17, 18, 19, 20, 21]. Therefore, analog circuit design is veryadaptable to be performed by applying evolving techniques, as demonstratedin various publications [1, 2, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 17, 18, 19, 20, 21].In this thesis, a new methodology for the binary genetic encoding of unitygain cells (UGC) such as Voltage Followers (VFs) [19, 22, 23, 24], CurrentFollowers (CFs) [8, 24, 25] Voltage Mirrors (VMs) [24, 26, 27] and CurrentMirrors (CMs) [24, 25, 28], is introduced. These cells are further combinedamong them for the synthesis of active devices having more terminals suchas Current Conveyors (CCs) [25, 29, 30], Inverse CC (ICCs) [25, 27, 30, 31]and Current Feedback Operational Amplifiers (CFOAs) [25, 32]; whose char-acteristic equations and symbols are shown in Figure 1.1.The proposed synthesis approach described in this thesis is based on theapplication of evolutionary algorithms (EA) mainly for generating UGCs,CCs and CFOAs. EAs techniques are based on the mechanisms of naturalselection and biological genetics to operate on the principle of survival of thefittest. So the EAs are able to generate new design solutions from a popu-lation of existing solutions and discarding the solutions that have far belowthe desired performances [2, 33, 34, 35, 36, 37].
Motivation
Analog circuits such as filters and oscillators have been evolved dur-ing years [6, 7, 14, 25, 29, 31, 38, 39, 40, 41, 42]. This is because thesearch for modifying one or more attributes of previous circuits is a progressthat has not stopped. Likewise analog circuit design has had an evolu-tion in the circuit topologies: OPAMP, OTA, UGC, and CC, among others[1, 2, 3, 4, 18, 19, 20, 21, 22, 25, 29, 31]. This is an evolution that continuesto this day, to find topologies with performances nearly close to ideal speci-fications.Some recent developments for analog circuits synthesis using intelligent sys-tems; as for example in the work of Gielen and Rutenbar [1], Salem [2],Mazumder [4], Mattiussi [6], including [7, 8, 10, 11, 12, 13, 14, 17, 18, 19, 20,21]. They mostly are focused on the passive circuits design or circuits withoperational amplifiers.At present, there is no generic automatic methods for analog circuit topolo-gies design. In digital design basic cells are NAND, NOR, NOT, from whichone can generate more complex blocks. In analog design, this Thesis propos-

BIBLIOGRAFIA 151
es to generate more complex blocks from unity gain cells (UGCs). Thus, theproposed automatic system design is focused to synthesize devices such asVFs, VMs, CFs and CMs. This processes will facilitate the search for newanalog circuit topologies with more terminals, such as CCs and CFOAs.Some applications for UGCs are reported in [38, 39, 40]. There are also manyapplications with CCs [29, 41, 42] and, CFOAs [32].
Objectives and Goals
The main objective of this thesis is the introduction of a genetic codefor the representation of analog circuits, such as UGCs. From these UGCsis proposed the combination of genetic codes for the representation of moreterminal blocks such as CCs and CFOAs.As secondary goals we have:
To propose a genetic code for representing UGCs topologies.
To develop an EA to generate known and emerging topologies of UGCs.This requires:
• Development of algorithms of genetic operators: selection, crossover,mutation and elitism for this type of circuit.
• Development of the algorithm of fitness for the EA, with the aimof selecting functional topologies according to SPICE simulations.
To find new UGC topologies: VF, CF, VM and, CM.
To propose a genetic code for representing CCs, ICCs, and CFOAstopologies.
To develop an EA to generate known and new CCs, ICCs, and CFOAstopologies. Obtain new CCIIs, ICCIIs, and CFOAs topologies.
To develop an algorithm that can evolve UGCs circuits with more ter-minals, such as CCs and CFOAs.
Chapter 2. Theory
Analog Circuit Synthesis Tools
There are several previous works on analog circuits synthesis tools, includ-ing: IDAC, OPASYN, OASYS, O-ISAAC, STAIC, ARCHGEN, DARWIN,

152 BIBLIOGRAFIA
AMGIE and ANACONDA collected in [1]. Some of these sized MOSFETs cir-cuits [47]; others improve some parameter in the domains of DC, AC and/ortransient of certain circuit topologies [61], and others perform functions withanalog circuits [63].There are works developed by applying EAs, where the topology is rep-resented by a chromosome, as shown in the work of Salem [2], Mattiussi[6] Leenaerts and Kruiskamp [47] and others [4, 5, 7, 8, 9]. However, thesedescriptions are focused to optimize circuit parameters in DC, AC and/ortransient. So their encodings represent the size of transistors rather thantopologies [1, 2, 4, 6, 7, 8, 12, 13, 14, 17, 15, 16, 18]. Thus, there is the needfor the development of a different encoding to synthesize circuit topologies,instead of sizing a fixed one. In this way, this Thesis introduces a binary ge-netic encoding for the automatic synthesis of analog circuits to find alreadyknown or new topologies.The proposed synthesis method uses Evolutionary Algorithms, which aresearch techniques based on the mechanisms of natural selection and biologi-cal genetics. The principle of survival of the fittest is the backbone on whichEAs are developed. The EAs simulate the evolutionary process on a computerin order to solve problems of learning, searching, sorting or optimization.
Analog Circuits Synthesis using EAs
The use of EAs not only focuses to do changes in biological individu-als, but with these algorithms are suitable in different areas of knowledge,such as Computing [33], Medicine [43], Math [44], Optics [45, 46], and others[5, 34, 35]. Some of the works that exist on the analog circuits synthesis toolsare shown in Tables 2.1 and 2.2.All algorithms shown in Tables 2.1 and 2.2 made analog circuits synthesisand work through of some form or method of EA.
Topology Generation Tools
Among the works that exist on the analog circuits synthesis tools, arethe focus on the generation of topologies. Some of those works classified astopology generators are shown in Tables 2.3 and 2.4.

BIBLIOGRAFIA 153
Evolutionary Algorithms
One of the central paradigms of biology is the principle of evolution, bywhich living things undergo change over time. As a result of these changesare new species of deriving new ones and so on. Among other explanations,the principle of natural selection proposed by Darwin, from his formulationrepresents one of the most popular evolutionary mechanisms [66] whose sig-nificance extends beyond the realm of biology. The simulation of the evolutionon the PC using the principle of natural selection has not only theoreticalbut also practical interest in engineering [33, 34, 35, 36, 37].Living organisms have a consummate skill in solving problems of adapta-tion to their environment. Biological organisms obtain their coping skills,performance and behavior through mechanisms such as evolution and nat-ural selection [34, 36, 37]. According to the Darwinian model of evolutionof species, all life on our planet can be explained through a set of processesacting on and within populations, individuals and species; such as: reproduc-tion, inheritance, mutation, competition and selection of agencies [66].Natural selection is the process where individuals better adapted to the envi-ronment are more likely to produce offspring, those who are least able [66]. Inaddition to Darwin’s theories are necessary approaches like Genetics mathe-matics’ Mendel to understand how these processes help in natural selection[67].The principle of survival of the fittest is the backbone on which learning tech-niques that respond to the generic name of Evolutionary Algorithms (EAs),are developed [33]. The problems to be solved by EAs can fall into a variety ofdisciplines including Biology, Engineering, Financial Services and ComputerScience [2, 35, 44, 45, 46].The terms of Evolutionary Computation, Evolutionary Algorithms, Bio-Inspired Algorithms, Natural Computing and Artificial Life are relativelynews and represent a major effort to bring researchers to follow the differentaspects of evolution [34].Among the main EAs: Genetic Algorithms (GA), Evolution Strategies (ES)and Genetic Programming (GP). They have in common that each rely on re-production, random variation, competition and selection of individuals with-in a population contending [34, 35]; which is itself the essence of evolution.It is clear that evolution is an optimization process, which does not meanperfection. Therefore, the application of EAs to a set of possible solutionsto a problem, should produce a good solution (or optimal) for this problem[2, 33].Some features of EAs are [33, 34, 35]:
They work with a set of solutions that represent solutions to the prob-

154 BIBLIOGRAFIA
lem.
Seek the solution in a population of possible solutions rather than soli-tary solutions.
They use an fitness function, do not use functions under this or anyother method or auxiliary knowledge.
They use probabilistic transition rules not deterministic.
They combine elements of stochastic search and direct which makes aremarkable balance between exploration and advantage of the searchspace.
Genotype and Phenotype
If a problem can be represented by a set of parameters (genes) and thesecan be joined to form a value string; this string is called chromosome, andthis process is called encoding [33, 34].It is common for individuals to be represented by chromosomes is madewith strings of binary digits, such a representation is called genotype; thenconversion is necessary to genotype values which belong to an individual.The individual is called phenotype [33, 34, 35, 36, 37].There are several issues related to the encoding of a problem to be taken intoaccount at the time of completion:
Should use the smallest representation of the parameters, typically usea binary representation.
The variables that represent the parameters of the problem must bediscrete in order to represent strings of genes.
The most of the problems dealt with genetic algorithms are nonlinearand often there are relationships between the variables that make up thesolutions. This is because the encoding can generate invalid genotypes,they represent a solution that can not make (or should) physically.
The treatment of disabled genotypes must be taken into account in thedesign of coding.
In this work we synthesize analog circuits where the genotypes are com-posed of bits strings. The MOS transistor circuits are made phenotypes inEAs.

BIBLIOGRAFIA 155
Genetic Operators
Genetic operators are the different methods or operations that can beperformed on a population in an EA, these are divided into four categories:
Selection
Crossover
Mutation
Reinsertion or Elitism
The two processes that mainly contribute to the development are thecrossover and mutation operators. In the GA the main operator is thecrossover, while in the GP the principal genetic operator is mutation [34].
Selection Operator
The selection operator is the process in the election of members of thecurrent population to be used for crossover operator. Its aim is to give morechances to select fittest members of the population. The first step is to as-sign a measure of fitness to each individual, which can be performed by aproportional allocation, or based on a ranking [34, 35].In the allocation proportional fitness values become targets of a populationin a measure of fitness to know upper limit, this upper limit is determined bythe value of selective precision. This method generally uses a linear scalingoperation [33].In the allocation of competence based on the ranking the population is eval-uated according to their objective value. The assignment of fitness for eachindividual solely depends on its ranking and not its current target value. Thefitness assignment based on the classification may be linear or not. In thisthesis the mapping is linear and not used to quadratic terms for the calcu-lation. The algorithms for classification (linear and nonlinear) first order theobjective function values in descending or ascending. For example, the leastfit individual is placed in the top spot in the order of the list of target valuesand the fittest individual is placed in position N, where N is the numberof individuals in the population. Thus, the fitness value is assigned to eachindividual depending on their position in the order of the population [33].Having assigned the fitness of individuals in the population comes to theselection of parents; This can be done by any of the following methods[33, 34, 35]:
Roulette-Wheel Selection.

156 BIBLIOGRAFIA
Stochastic Universal Sampling.
Local Selection.
Truncation Selection.
Selection by Tournament.
These methods are described in [33], [34], and [35]. The development ofthis Thesis is considering methods of roulette-wheel and truncation selec-tions. Both showed similar results, so they chose the less time use the com-puter, the method of truncation selection. The truncation selection method isa method of artificial selection. Individuals in the selection by truncation aresorted according to their fitness and only the best individuals are selected aspartners. Figure 2.1 illustrates the truncation method used in this work; ofthe existing N individuals have to form N/2 pairs. The most highly qualifiedindividuals are selected to be paired up twice; while the worst performers arenot used in any couple.
Crossover Operator
The crossover combines the two parent chromosomes to form one or moreoffspring. This is the most characteristic and important operator of GA, itspurpose is to accelerate the process of search or exploration of the best chro-mosomes [33, 34, 35]. There are several variations depending on the numberof breakpoints to use or how to synthesize the chromosome. Depending onthe representation of variables in the chromosomes it is possible to apply thefollowing methods [33, 34]:Recombination of real parameters:
Discrete crossover.
Intermediate crossover.
Linear crossover.
Extended linear crossover.
Recombination of binary parameters:
One-point crossover.
Multi-point crossover.
Uniform crossover.

BIBLIOGRAFIA 157
Random crossover.
Crossover with Reduced Surrogate.
These operators are described in [33, 34, 35]. The operation of crossoverused in this work is called one-point crossover. By comparing the crossing ofmultiple fixed points used previously [59] with the one-point crossover, thelatter question presents better results, this is due to the chromosome size issmall (22 bits). The one-point crossover is illustrated in Figure 2.2; where theoffsprings are formed with characteristics of both parents and the cut-pointis random.The one-point crossover is implemented according to the algorithm describedbelow [34]:
Get the parent chromosome pairs, of a selection operator or random ifit is not implemented.
For each pair of chromosomes to get a whole random number U between1 and chromosome size minus one (L-1). The number U is the cutoff inthe pair of chromosomes.
The offspring chromosome is formed with genes from the chromosomeparent1 who is placed before the cutoff and parent2 chromosome genesthat is located after the cutoff. Conversely one can generate an off-spring2 if needed.
The offspring chromosomes form a new population to be used to thenew generation.
An example of this crossover with analog circuits is shown in Figure 2.3;where the parents are the circuits (a) and (b) and the offspring result fromcrossover the circuits (c) and (d). These circuits show that the chromosomeis formed by a portion of chromosome (a) and a portion of chromosome (b).
Mutation Operator
After of crossover operator the offspring experience the mutation opera-tor. The mutation operator is the most characteristic of GP; but when usedmuch on the GA can become a slow and random search. The mutation isresponsible of random change in one or more genes in the chromosome ofan offspring. The representation of the variables will determine the mutationmethod [33, 34, 35], so, two main methods are:
Binary mutation.

158 BIBLIOGRAFIA
Real mutation.
The variables of the offspring are mutated with a low probability, this iscalled Mutation Step Size in [2, 33]. The probability of mutating a variableis set to be inversely proportional to the number of variables or chromosomedimension [33, 34, 35]; although it may be a fixed percentage of the numberof offspring and it is recommended that not more than 5%.The mutation operator used to this work is the binary mutation. Which isto change one or more bits of a chromosome; in this work only one bit ismodified. Figure 2.4 is an example of this mutation that is implementedaccording to the algorithm described below [33]:
Get the offspring of crossover operator.
Each offspring chromosome gives a random number between 0 and 1.
If the number assigned to the offspring chromosome is greater than themutation step size, the chromosome will be not modified in any bit.In another case get a whole random number U between 1 and L. Thenumber U is the bit that will change in value.
The offspring chromosomes (mutated or not) form a new population tobe used by the next generation.
As shown in Figure 2.4, the mutation operator acts on the genotype orchromosome. To show an example of this operator with analog circuits, inFigure 2.5 phenotype is shown as a voltage follower circuit, with the corre-sponding chromosome. If this chromosome is mutated one of its bits shouldchange ‘0’ to ‘1’ or ‘1’ to ‘0’. Figure 2.6 show 4 different circuits if performedmutation operator to the circuit of Figure 2.5.
Elitism Operator
The operator of rehabilitation is the method by which offsprings are in-serted in the new population; for example, by eliminating the weakest in-dividuals or random. If the size of the offspring is less than the originalpopulation size, the offspring will be reinserted into the former new popula-tion. However, if one want all the offsprings that are reinserted other methodof reintegration, may be applied [33, 35]. Rehabilitation methods common-ly used are global reintegration and local reintegration. Both operations arebased on some method of selection.The operation used in this work is a kind of global reintegration known aselitist reproduction or elitism operator [33, 35, 46]; which produce the same

BIBLIOGRAFIA 159
or fewer offsprings than the number of parents and replace the worst parentswith fittest offsprings. In other words, the parents are competing with off-springs so that only the best form the next generation, Figure 2.7.In this thesis the reinsertion operator will be the elitism operator and isimplemented according to the following algorithm [34, 35]:
Get the offspring of the mutation operator, the N chromosomes chil-dren.
Find their fitness value.
List the N offspring chromosomes add the N parents chromosomes withtheir fitness.
Sort all 2N chromosomes according to their fitness.
Choose only the best N chromosomes, these are the new parents in thenext generation.
Genetic Algorithms
The GA are stochastic search techniques based on the mechanisms ofnatural selection and biological genetics [33, 35]. The modernization andsimulation of evolution with the PC is one of the most attractive ideas inartificial intelligence. This possibility was first raised during the 1950’s, afterof the onset of the computers, researchers such as John Von Neumann andUlam. However, It was not until the decade of the 60’s when Fraser (1960),Fogel, Owens and Walsh (1966) conducted the first simulation experimentswith small populations in which mutations occur. Bagley introduced in 1967the term genetic algorithm. In 1975, the researcher John Holland publishedhis book Adaptation in Natural and Artificial Systems, one of the most im-portant references on GAs from the theoretical point of view [34, 35].GAs are adaptive methods that can be used to seek and to obtain solutionsand optimization problems. These algorithms are based on genetic processesof biological organisms, encoding a possible solution to a problem through acode named chromosome.GAs use a direct analogy of the phenomenon of nature evolution. It beginswith an initial set of random solutions called initial population. Each individ-ual in the population is called chromosome and represents a possible solutionto the problem.A chromosome is a string of symbols called genes; usually are represented bya binary string. The chromosomes evolve through iterations called genera-tions. In each generation the chromosomes are evaluated using a measure of

160 BIBLIOGRAFIA
fitness. At the fittest are given the opportunity to reproduce by recombiningwith other individuals of the population, producing offspring with character-istics of both parents [33, 34, 35, 37]. Least adapted members have little tobe selected for recombined, so their features tend to disappear.The next population is formed using a combination of selection, crossover,mutation and/or elitism operators [33, 34, 35, 36, 37]. This new generationmust contain a higher proportion of the characteristics possessed by the bestmembers of the previous generation. Thus, over several generations, the bestfeatures are widespread in the population mixing with others. Favoring therecombination of the best adapted individuals, it is possible to tour the mostpromising areas into search space. If the GA is designed properly, the pop-ulation will converge to an optimal solution or near-optimal to the problem[2, 33, 34, 35, 37].Generally, GAs are implemented following the cycle shown in Figure 2.8.where one can see the steps listed below:
Initial population is generated randomly.
It evaluates the fitness of all individuals in the population.
A new population is created by selection, crossover, mutation and/orelitism operators.
It is iterated until a satisfactory resolution.
The GA can be used successfully in a wide range of problems: opti-mization of numerical functions, transportation, location, speed optimiza-tion tools and some problems that are difficult to solve by other methods[2, 3, 4, 6, 33, 34, 35, 36, 37, 44, 45, 46, 59].It is worth mentioning that GAs do not guarantee to find the optimal solu-tion to the problem but are generally good at finding acceptable solutions toproblems in a short time.As an individual evaluation function assigns a fitness value, which is propor-tional to the utility or ability of the individual depicted. In many cases thedevelopment of an fitness function involves a simulation; in other cases thefunction may be based on performance and represent only a partial evalu-ation of the problem. Additionally it must be quick, because it is appliedfor each individual in each population in successive generations. Therefore,much of the time of the execution of the GA is used in the fitness function.There is also a problem in genetic algorithms due to poor formulation of themodel, in which the genes of a few individuals, relatively well-adjusted, butnot optimal, can quickly dominate the population, causing it to converge to a

BIBLIOGRAFIA 161
local minimum or maximum. Once this happens, the model’s ability to seekbetter solutions is virtually eliminated, leaving only the mutation as a wayto find alternative solutions; and GA becomes slow search and/or random[33, 34, 35].
Evolutionary Strategies
Despite its apparent similarity to the GAs, the ES are commonly usedin empirical experiments that are difficult to model mathematically. In addi-tion, the ES is based on the principle of strong causality, which states thatsimilar causes have similar effects [33, 34].The ES were proposed in 1963 at the Technical University of Berlin by IngoRechenberg, and Hans Peter Bienert Paul Schwefel, as a method of solutionfor the optimal design of the body of objects placed in an air flow, so as toreduce resistance to a minimum. During the project tested and traditionaltechniques already known as the wave of the gradient, among others; howev-er, they were in vain, given the complexity of the problem. Ingo Rechenbergwas who set out to prove with random changes in the set of parameters defin-ing the shape of objects, following the example of natural mutation. PeterBienert constructed a machine experimenter, which would work according tothe rules of mutation and selection. To simulate the evolutionary process ona computer is required to encode the structures that would be replicating todefine the operations that affect to individuals, a fitness function and a se-lection mechanism [34]. The original version (1+1) used a single father withhim, generating a single offspring. This child is kept if it was better than thefather, or else be eliminated. In this version, a new individual is generatedby the mutation operator.In 1973, in his doctoral thesis, Ingo Rechenberg established the theoreticalbasis for the ES, defined the concepts of mutation and selection, and addedthe new concept of population in a variant of the ES originally proposed.Subsequently, there were other versions for the ES proposed by Schwefel,who introduced the use of multiple children in the variants [34].Thus, the ES were created as a method to solve technical optimization prob-lems; and until fairly recently were known only in Civil Engineering as analternative to standard solutions [34, 46]. Usually the ES is used when thereis no analytical solution for these problems and therefore there is no methodof solution. The ES optimization is based on the hypothesis whose claim isthat the laws of inheritance have been developed for rapid genetic adapta-tion. The ES mimic the effects of genetic processes that act directly on thephenotype, in contrast to GAs who work on the genotype.

162 BIBLIOGRAFIA
There are some types of problems that are appropriate for applying ES, forexample when the search space is too large to be explored in detail [34].Since ES copied biological evolution, the applications of these strategies aimto eliminate weak individuals, and all similar solutions to them (or their de-scendants) in the early stages of the simulation. This will restrict the spaceto find a solution.
Genetic Programming
Genetic programming is a class of algorithms like GAs just that these donot contain the crossover operator. In GP, the individuals of the populationare reproduced asexually. This means that a single individual will be able byitself to have children without the assistance of another person [34]. The ab-sence of the operator of recombination leads to the only source of variabilityof individuals is one resulting from mutations.In the evolutionary algorithms of this type is often to select a single indi-vidual, and once selected by their fitness score or the new generation; thatare, their offspring obtained by simply copying or cloning of chromosomes,mutating one or more positions in the chromosomes of individuals of the newgeneration [34].A striking example of the GP is the biomorphs Dawkins, one of the bestknown evolutionary algorithms is able to obtain two-dimensional artificialorganisms. This algorithm was introduced in the book the blind clock (1986),which quickly became a classic of popular science. In short, a GP stages ofreproduction and mutation is repeated iteratively until the algorithm findsthe chromosome that resolves the problem, as shown in Figure 2.9.
Chapter 3. Proposed Synthesis Method
Introduction
There are previous works about the analog circuits synthesis tools asdescribed in Chapter 2. This Chapter presents an Evolutionary Algorithmfor the analog circuits synthesis. To make the encoding of UGCs, CCs andCFOAs the element nullor [68, 69], is used herein. Thus, this Chapter is adescription of nullor and their properties.Subsequently it is described the proposed process for the search of topologies;which describes a generic GA as the pillar of the proposed method. Theimplementation of this GA was programmed in MatLab and used some test

BIBLIOGRAFIA 163
functions to check its performance. GA responses to the test functions areshown in this chapter. Finally, we show each one of the proposed geneticencoding for different analog circuits.
Nullor
In [68] is presented a collection of analysis methodologies collection, ana-log circuits design and synthesis using nullors. Hanspeter Schmid [69] proveduseful to model the ideal behavior of several active devices, such as Opera-tional Amplifier (OPAMP), Operational Transconductance Amplifier (OTA),Current Conveyor (CC), etc. The nullor is a two-port device consisting of anelement O (nullator) and an element P (norator) associated with four vari-ables. In the input port voltage and current nullator and the output portvoltage and current norator, as shown in Figure 3.1. The voltage and currentin the nullator are always zero, while for the norator the voltage and currentare arbitrary [30, 68, 69].The properties of the elements O and P can be exploited to model the idealbehavior of the unity gain blocks. For example, to model the ideal behaviorof VF one can use one or more nullator elements as shown in Figure 3.2[19, 21]; which shows that the output voltage VF (Vo) is equal to the inputvoltage (Vi), by the properties of nullator.To model a generic CF one or more norators, can be used [19, 21]. In thesecircuits the electrical variables are currents. Since the current flowing througha norator is always the same, it follows that the current (Io) is equal to theinput current (Ii).The model of a MOS transistor using the nullor is shown in Figure 3.3. Inthis way, adding norators to circuits that are represented by nullators leadsus to form the topologies that are represented by OP pairs; each pair OPcan synthesize a MOS transistor. Shown in Figure 3.3 the OP junction isregarded as the source (S), the free end of element O is the gate (G) and thefree terminal P element is the drain (D) of the MOSFET.
Genetic Algorithm
Flowchart
One of the main objectives of this thesis is to develop a system capableof synthesizing known and new UGCs, CCs and CFOAs topologies. For thiswe developed a program based on EAs. Although the goals are different foreach UGC, all are following the schema shown in figure 3.4.The algorithm starts by obtaining the user’s data:

164 BIBLIOGRAFIA
Variables GA: population size, mutation rate, generations and maxin-ima searched error.
UGC to synthesize: VF, CF, VM, CM.
Desired varible: Gain, bandwidth, input and/or output impedance.
Weight of the desired values in the evaluation function.
Type of simulator: TOP-SPICE, H-SPICE, Tanner-SPICE.
Type of technology:
• AMI Semiconductor: 0.35µm, 0.50µm.
• IBM Semiconductor: 0.18µm, 0.25µm, 0.35µm, 0.50µm.
• Taiwan Semiconductor (TSMC): 0.18µm, 0.25µm, 0.35µm.
After obtaining the data is an ideal choice cell. This is to describe theUGC through nullators elements and/or norators. For example to represent ageneric CF there are several cells formed by one or more norators. Figure 3.5shows all these possibilities with one and two nullators; combinations withthree nullators seen in Figure 3.6. To describe a CF are using four nullatorsthere are 15 different possibilities (Figure 3.7). Then the method of choicefor ideal cell is made to select any of the 23 possible descriptions ideals ofCF; and not just occupy the three classics: Figure 3.5 (a), Figure 3.5 (b),and Figure 3.7 (l). The circuits represented by these three cells have beenstudied by several authors [8, 19, 21, 25]. However, there are 23 possibilitiesto accommodate norator that ideally describes a CF, which have not beenstudied thoroughly.The method of choice for ideal cell has the same goal for other types of UGC,to explore possibilities of generating useful circuits.After the selection of an ideal cell, some individuals are created randomlyto generate an initial population. Chromosomes are decoded to generate thenetlist for circuit simulation in SPICE; with select technology files. Then as-sessed each individual, according to their response in SPICE and is assigneda measure of fitness. As each individual and their fitness is kept in memory.The better performance circuit, is best qualified to chromosome value.Once these qualified individuals will be parents for a GA to iterate up toa maximum number of generations or until a topology that can be useful.The GA performs the operators of selection, crossover, mutation and elitismdescribed in Chapter 2. When finish the GA provides a UGC, CC and CFOAnetlist. It is noteworthy that the GA is expected to synthesize known and

BIBLIOGRAFIA 165
novel circuits.
Testing the GA
Figure 3.4 shows the flowchart of the EA, the blocks are made by sub-programs. Some of these are specific to each UGC and other sub-programsmust be comprehensived. To guarantee a good performance of the GA, oneneed to test the blocks with standard test functions to confirm its operation.Since it has been important to be sure the proper functioning of the geneticoperators and GA to be used. It is for this reason, a first GA, obeying figure2.8.The operations are scheduled selection, crossover, mutation and elitism to beused in the program of Figure 3.4. MatLab assigned a rating to each individ-ual (fitness). The program stops when it reaches the value expected by theuser or it reaches a maximum number of iterations.The fitness measure is the sum of the standard, as is shown in equation (3.1).Where the values expected by the user are so1, so2, etc., And assessed valuesof the chromosome are ev1, ev2, etc. The program will stop when PTotal iszero (plus a tolerance of error) [33].The test functions are used to evaluate, compare, classify, and test the ef-ficiency and effectiveness of the algorithm. There are several types of testfunctions for EA mono-objective and multi-objective, as the functions ofBinh, Fonseca, Kursawe, Laumanns, Lis, Murata or Viennet, who are includ-ing compiled in [33]. The test run of the GA is searching for solution pointsor more equations.The equations used to evaluate the GA are described in Eq (3.2), all witha search space defined between x = [−1,1], y = [−1,1]. The graphics andcontours of the equations are shown in figures 3.8, 3.9 and 3.10.Each equation has a search space bounded between [−1,1] of 2R. So the cho-sen chromosome size is 34 bits, it splits into two 17-bit numbers each, varyingfrom 0.00001526 footwork (2/131072). This generates a search space of just17,179,869,184 possible solutions for each test function to use. Descriptionsof test functions (FP) used are shown in Table 3.1.The test functions FP1 to FP6 are mono-objective; i.e. the GA seeks to solvea single equation. FP7 to FP13 functions are multi-objective, the GA seeksa solution that satisfies two or more equations.Seek testing functions maximum, minimum or particular values. In the fifthcolumn of Table 3.1 shows the number of analytical solutions to test function.The FP solution with a single check shows that the EA will be able to findsuch a solution and does not stagnate on local solutions; the GA will provide

166 BIBLIOGRAFIA
a solution very similar to the ideal when the chromosome can not decode theoptimal solution. The FP with more than one optimal solution, are used toobserve that the GA is able to find all these. All the best solutions are knownas Pareto front [33, 34, 35]. The use of EA is usually in problems where theanalytical solution is very complex as in the case of FP11, FP12, and FP13;In these cases it is hoped that the EA is able to find an optimal solution ornear-optimal to the problem [33].The tests were executed on a computer model M2352 eMachines with Mo-bile AMD Athlon XP3000+ to 524MHz with 448MB RAM. The maximumnumber of generations was 150; population size is 40. Thus, the maximumnumber of evaluations is 6000 (150x40). The minimum error was 0% in allFP were executed 10 times per test.The results for the executions of the FP in the GA are shown in Table 3.2.Where the point the solution is observed and found by the GA, averagecomputation time and average number of generations performed to find thesolution.Table 3.2 shows that the GA manages to find the points of optimal solutionfor FP1, FP2, FP4, FP7, FP9 and F11. While for FP3, FP5 and FP10 thepoint are the most close to the optimum, this is because the chromosome ofthe point (0.0) does not exist in this encoding. In FP6 the algorithm doesnot find the points (±0,5, ±0,5), but their responses are very close to thesepoints; to ensure that the GA finds the optimal points only is increased thenumber of generations. For FP8, FP12 and FP13 are presented in Table 3.2points the best and worst case, the other results are closed to those points,which makes the conclusion that the best solution is found or are the pointsnext to them. The closeness in value for these points is sufficient to concludethat the GA is working properly.
Measurement of UGC fitness
The fitness in an EA is the result of the evaluation of an individual. Thiscan be given by any method linear, quadratic, exponential, fuzzy logic, etc.In this work the evaluation is conducted by the sum of the norm (absolutevalue), this type of estimate is sufficient for problems of this nature [33].Each synthesized circuit will run in SPICE to get their behavior in AC gain,bandwidth, input and/or output impedance. Depending on the answers givento the circuit is assigned a measure of fitness.Eq. (3.3) is a measure of fitness to be used in this work; where the variables P1to P4 are the weights that the user defines, to give priority to any parameteron the others. The functions f(ev1) to f(ev4) are calculated according to Eq.

BIBLIOGRAFIA 167
(3.4) to (3.7). In these equations the values expected by the user are: gain,bandwidth (BW ), input impedance (Zin) and output impedance (Zout).The values are evaluated by SPICE ev1 to ev4. PTotal is the rating givento the circuit, i.e. PTotal is the fitness of the individual; the best qualifiedthe circuit is the closest to zero.Eq. (3.4) is the function that evaluates the gain. Figure 3.11 shows the graphof this equation when gain = 1. The circuit best qualified is to ev1 = 1,f(ev1) = 0. Figure 3.12 shows the behavior of Eq. (3.5), where the user-defined value is BW = 10,000.Eq. (3.6) describes the impedance that ideally should be large; such as the Zin
for VF or Zout for a CM. Figure 3.13 shown in Eq. (3.6), where Z = 20KΩ.Eq. (3.7) describes the impedance ideally must be zero; such as the Zin
for VF or Zout for CF. Figure 3.14 shows the graph of the equation (3.7),where Z = 250Ω. As looking at the function far from the ideal impedance(Z = 250Ω) but is more severe with large impedances.To show the operation of Eq. (3.3); running this assessment to individualslisted in Table 3.3. This table contains 81 subjects (CFs) with different valuesof gain, bandwidth and impedances. Each variables has three possible values:
Gain: 0.87, 0.91, 0.96.
Bandwidth: 10KHz, 100KHz, 1MHz.
Input impedance: 70Ω, 100Ω, 150Ω.
Output impedance: 18.5KΩ, 20KΩ, 22KΩ.
The results by running Eq. (3.3) are shown in Figure 3.15 where P1 =P2 = P3 = P4 = 0,25, and the values sought are gain = 1, BW = 2MHz,Zout = 25KΩ and Zin = 50Ω. It is noted that the best individuals are: 41,40, 14, 42, 13, 68, 15, 67 and 69, in that order. Table 3.3 lists the individualcontaining the best value is 41.By modifying the fitness function in the weight of the variables and values toseek, are get another type rating for each individual. For example, in a secondtest values to look for are: gain = 0,98, BW = 500KHz, Zout = 21KΩ andZin = 80Ω; and weights P1 = P3 = P4 = 0,25, P2 = 1, i.e. the bandwidthhas a higher priority over other values. The result of the evaluation equation(3.3) are shown in Figure 3.16.
Genetic Encoding of Circuits
One of the main objectives of this thesis is to propose a geneticcode for UGCs, CCs and CFOAs; capable of synthesizing known and

168 BIBLIOGRAFIA
new topologies. There are developed electronic circuits works with EA;these use some kind of encoding circuits into a chromosome as shown in[1, 2, 3, 4, 6, 7, 8]. However, these descriptions are focused on optimizingparameters with a circuit in DC, AC and/or transient so their encodingsrepresented transistor size of its works and not how they made these topolo-gies [1, 2, 3, 4, 6, 7, 8, 12, 13, 14, 15, 16, 17, 18]. Thus, these encodings arenot useful to work in this thesis and have the need for a different encodingto the above.
Genotype and Phenotype of a VF
Starting from the ideal model of VF using only one element O (Figure3.2.(A)), the proposed algorithm proceeds to the generation of a circuit madeof transistors. First, for the purpose of synthesis every O element must becoupled with a P element Thus, a P element can be added to an item or left(node i), right (node j), or in parallel (between nodes i and j), as illustratedin Figure 3.17 [21, 59]. As can be seen, each pair OP can be represented bya gene of 2 bits in length; This creates the gene encoding the small-signal(genSMos) which is described in Table 3.5.Each pair OP is synthesized by a MOSFET as shown in Figure 3.3. This pro-cess uses a gene MOSFET (genSMos) which consists of a bit (a2) to describethe type of transistor. So when genSMos is zero it synthesize an N-MOS andwhen it is one generates a P-MOS (Table 3.5).The circuit will add two named sources Vdd and Vss voltage (positive andnegative, respectively). Subsequently current sources are added using a geneof polarization (genBias) This contains two bits (a3a4) per nullator describingthe VF. The combination 00 means that the MOSFET drain was connectedto Vdd while the source is connected to a power source connected to Vss.The 01 means that the drain is connected to Vss and the source to a powersource connected to Vdd. The other two combinations (10 and 11) meanthat both the source and the drain were connected to power supplies Vddand Vss, and this is summarized in Table 3.6.Once added sources of bias voltage and current to the circuit each currentsource (Idd and Iss) was synthesized by a current mirror (CM) using thegenCM. GenCM size depends on how many types of mirror are taken intoa bookstore, in this paper the proposed approach uses four different CM, sothe genCM consists of two bits (b0b1). Table 3.7 shown genCM code.In short, to codify a VF modeled with one nullator from figure 3.2.(a), wehave a chromosome (code) of 7 bits: a0a1a2a3a4b0b1; divided into four dif-ferent genes: genSMos, genSMos, genBias and genCM. This means that there

BIBLIOGRAFIA 169
are 27 = 128 different circuit topologies that can synthesize a VF with thedescription given. However, some topologies are not functional, as input oroutput can be connected to Vdd or Vss; also other topologies not meet thespecification of a VF (VOUT = VIN).To synthesize a two, three or four MOSFETs, the ideal representation isthrough the same number of nullators. Therefore, the chromosome grows asthe number of nullators that represent ideally, this is shown in Table 3.8where: GenMOS=genSS-genSMos-genBias.Table 3.8 shows that they have 212 = 4,096 different possible topologies fora 2-based VF nullators. To synthesize VF consisting of 4 nullators we have222 = 4, 194, 304 different possible topologies. For all the descriptions of cer-tain chromosomes of VF topologies exist that make no sense because theinput or output may be connected to Vdd or Vss; and other topologies donot comply with the behavior of a voltage follower. The EA carried out inthis paper is able to select topologies that work properly on AC.Then, by way of example, the synthesis of a VF from its chromosome. It isproposed to bridge an ideal model of 4 nullators (Figure 3.2.(b)) and synthe-size the chromosome 336860, the value of the genes is shown in Table 3.9.OP pair model is obtained from table 3.5 shown in Figure 3.18, where eachpair OP synthesize a MOSFET. To add power sources due to the circuit box3.6. Therefore for the MOSFET M1 is connected to the drain Idd and Iss thesource, just as M2; for M3 and M4 is connected to the drain and Idd Iss thesource. The resulting circuit is shown in Figure 3.19. Which shows that it ispossible to delete the current sources Idd3, Iss1, Iss2, Idd4 as they do notpolarize the circuit. The program developed for the synthesis of VFs detectsuch situations and the decision to eliminate the remaining sources.Table 3.9 genSMos indicate that the synthesized OP pairs are N-MOSFETM1-M2 N, P and P-M3-M4 as Table 3.5. Removing sources of excess co-currents and synthesizing these MOS transistors, the circuit made are dis-played in figure 3.20.(a); this is the ideal model of a VF-known [21, 22, 25].To finish the example need to change ideal current mirrors. The genCM is00, so they will add simple current mirrors and the circuit synthesized by336860 chromosome is shown in Figure 3.20.(b).
Genotype and Phenotype of a CF
Starting from the ideal model of a CF using only norator, we proceed togenerate a CF MOSFETs. Similar to the VF encoding, each element P shouldbe attached to an item or for the purpose of synthesis of MOS transistor.Thus, an O element is added to an element P to the left (node i), right (nodej), or in parallel (between nodes i and j) similar to the figure 3.17. Each pair

170 BIBLIOGRAFIA
OP can be represented by a small gene signal (genSMos), which is describedin Table 3.5.Each pair OP is synthesized by a MOSFET, this step uses the MOSFET genesynthesis (genSMos) which is identical to that described for VF in Table 3.5.The next step is to add sources of bias. Gene polarization (genBias) containstwo bits (a3a4). In all the combinations to both the drain and the source theyare connected to power sources and Vss Vdd Idd and Iss calls, respectively.After the MOSFET gate terminal will be connected to a positive voltagesource (V +) or negative (V-), and this is summarized in Table 3.10. Notethat the gate of the MOSFET is always connected to a voltage source to thetransistor working in saturation region.As for the synthesis of VFs, each power source must be synthesized by a CM,using the genCM. The genCM depends on the number of types of mirrorscontaining a library. Taking into account that the library has the same mir-rors that in the case of VF, the code is again shown genCM Table 3.7.In summary, to encode a single CF from a single norator it has a chromo-some 7 bits, divided into four different genes. To synthesize a CF of two MOStransistors from two or more chromosome the norators grow proportionally.This is shown in Table 3.11 where: genMOS=genSS-genSMos-genBias.Some topologies represented by the chromosomes do not comply with thespecification of a CF (IOUT = IIN); these are not practical for use in circuits.The EA conducted in this thesis aims to select topologies with a correspond-ing response to a CF. This is done using SPICE simulations.The synthesis of the chromosome 99324, from a 4-bridge model norators (Fig-ure 3.7(l)); the value of the genes is shown in Table 3.12.Performing the synthesis of the 99324 chromosome obtained the circuit ofFigure 3.21. This is the model of a known CF [21, 25]. This circuit is ob-tained after decoding the meaning of the genes in Table 3.12, according tothe tables 3.5 (genSMos), 3.5 (genSMos), 3.10 (genBias), and 3.7 (genCM).
Genotype and Phenotype of a CM
The current mirrors are basic blocks, generally used in biasing analog cir-cuits. The current mirrors can be modeled with two, three and four norator,as shown in figure 3.22. For example with the cell (a) can synthesize a simplemirror, with the cell (c) can be synthesized and Wilson mirror cell (d) canbe synthesized Cascode mirrors and Wilson changed. Nodes A, B, C and Dare used to add nullators and/or polarization sources. In these cells there is apoint of reference, this can be considered as circuit ground or a bias voltagepositive or negative.In this work, a single chromosome that can synthesize the four mirrors is

BIBLIOGRAFIA 171
proposed. Starting from the ideal model of a CM shown in Figure 3.22.(d)is necessary to add an item to each element P. This is automatically addedto the side closest to ground (GND) for each pair OP is synthesized by anN-type MOSFET This synthesis is to ensure that the MOSFET will be insaturation and a P-type MOS would not be in saturation. So, for the chromo-some of a CM does not require a small-signal gene (genSMos) or a MOSFETsynthesis gene (gene-SMOS) as in previous chromosomes.In all possible combinations of nodes C and D were connected to powersources to Vdd (Idd) to bias the circuit. Each terminal gate transistors canbe connected to nodes A, B, C, D, Va BIAS, Vdd, or an extra node (NE). Wedescribe this decoding for the gate of transistor M1, Table 3.13. Where NEis a node that was used in extra blocks to perform CM sources displacementlevel. GenBias code for the other three MOS is the same as in Table 3.13.To simulate this chromosome cells shown in Figure 3.22 there must be a genethat defines the signal input node (IIN) and the signal output node (IOUT ).This gene was named as a genIO, which is described in Table 3.14. Where thenodes E and F are nodes used in a library of blocks of transistors that canbe added to CM to synthesize CMs with displacement level (Figure 3.23).To end the description of the chromosome of the CM is synthesized gene levelshift genN. Which contains a library of possible circuits to be joined to theconnections of the MOS transistors CM. GenN size depends on the size ofthe library used, GenN for this work is 3 bits and its encoding is shown inTable 3.15.In summary, the chromosome made for the synthesis of CM is shown in Ta-ble 3.16. As shown the chromosome to be used is 16 bits, this is larger thanthose used in [59] by 4 bits, expanding the search space. But as mentionedpreviously this chromosome replaces 4 made in [59], one for each cell shownin Figure 3.22. This advantage leads to only conduct a synthesis algorithmof CM and not one per chromosome. Another advantage of this descriptionis that genetics are synthesizable level mirror movements in [59] were notsynthesizable.As an example of circuit synthesis is carried out as described by the chro-mosome CM 1192, in Table 3.17 divides the chromosome genes. Figure 3.24shows the encoding where all pairs OP will be synthesized by N-MOS; andthe input and output is given by the genIO. According to the genIO in Table3.14 signal input (IIN) will be for the C and the output node by node D(IOUT ). The genN not be used as in the synthesis of genBias not generatedany node NE.Using Table 3.14, it is noted that the gate of transistor M1 must be connect-ed to Node A (000), just as the gate M2 is connected to Node A (000). TheM3 gate connects to node C (010), like the gate terminal of M4 (010). Mak-

172 BIBLIOGRAFIA
ing connections is obtained the figure 3.25. Finally, by synthesizing pairs ofN-MOS OP gives the figure 3.26; As can be seen is known as mirror CascodeCM [25, 26].
Genotype and Phenotype of a VM
The representation of the VM is shown in Figure 3.27 [26, 27]. In thisideal representation emerge the three circuits shown in Figure 3.28; wherein figure 3.28.(a) will synthesize a MOSFET with the pair O1-P1 and theother nullator by itself represents a VF, the VF can be synthesized with anynumber of MOSFETs. In Figures 3.28.(b) and 3.28.(c) has added a nora-tor parallel and serial repectivamente. This element does not affect P idealdescription of the VM and is used to form pairs OP, and these in turn syn-thesize MOSFETs. Each pair OP in Figure 3.28 synthesizes a MOSFET, infigure 3.29 shows the synthesized circuits, these MOSFETs can be either Por N typeAs described above, the VM must be represented by more than one chromo-some, one for each ideal description shown in Figure 3.28. It is necessary forthe three chromosomes to have a gene for synthesis of CMOS (gene-SMOS),as this will decide whether to synthesize a NMOS or PMOS, this will againuse the table 3.5. GenBias is necessary to polarize the circuit, this gene isencoded in Table 3.18. A genBias chromosome is added to each resistor Rthat has at its ideal representation; therefore for every VM in Figure 3.29genBias will need two.Many topologies in the output of a VM put the circuit shown in Figure 3.30;therefore, it was decided to include a gene that decides whether the VM isadded to the circuit of Figure 3.30 or not, this gene is described in Table3.19.In summary for a VM chromosome described by Figure 3.29.(a) one haveten bits, divided into four different genes. As for the circuits shown in figures3.29.(b) and 3.29.(c) needed 11 bits, divided into four different genes. Thesechromosomes are shown in Table 3.20.As an example chromosome 53 is summarized in Figure 3.29.(a). Written inbinary is 0000110101, which means that the genSMos = 0, genBias1 = 0001,and genIO genBias2 = 1010 = 1, using tables 3.5, 3.18 and 3.19 we obtainthe circuit shown in Figure 3.31.(a). This circuit is a known VM [26, 27, 59].Figure 3.31.(b) shows the VM after replacing the ideal of the VF shown inFigure 3.20.

BIBLIOGRAFIA 173
Genotype and Phenotype of Two UGCs
The UGCs can be interconnected or superimposed to make blocks hav-ing more ports. The possible connections of these blocks can be viewed inFigure 3.32; among these we can see the ideal representation of the CC. Therepresentation of the CCII-/+ are shown in figures 3.32.(e) and 3.32.(f), re-spectively; the CCII inverse (ICCII) are represented by figures 3.32.(g) and3.32.(h). Combining the circuits shown in figures 3.32.(f) and 3.32.(k) givesthe ideal representation of a CFOA: VF-CM-VF.To make the circuit shown in Figure 3.32, the simplest of thinking is, attacha cable from the output of the first UGC and the input of the second. Thisunion is not the best choice for all the circuits of Figure 3.32. Therefore,the strategies for the circuits in figure 3.32 should be different from circuitto circuit. Strategies to make the joints of the UGC in this work have beendivided into five different, these will be described in the following sectionsand arranged by their complexity as:
Simple Union.
Double Output.
Double Intermediate Output.
Create Node Z.
Combination nullatos-norators.
Simple Union
As mentioned earlier, the easiest thing to make the circuit shown in Fig-ure 3.32 is to attach a cable between the output of the first UGC and theinput of the second. This union is the best option in the circuits of figures3.32.(b), (d) (i), (j) (k) and (l); ca-characteristics functions shown in Eq (3.8).Chromosomes that describe these circuits can be implemented joining chro-mosomes previously made; as shown in Table 3.21. To perform this type ofcircuit is proposed to select the UGC that conform and then binds only oneinput to the output of another, as shown in Figure 3.32.As an example of this ’simple joint’ of UGC is summarized in Figure 3.32.(k)This joins a CM with a VF. CMOS circuit shown in Figure 3.33, where theCM and VF are summarized in figures previously 3.20 and 3.26.

174 BIBLIOGRAFIA
Duplicate Output
The union named ‘double exit ’is to double the output circuitry of theUGC. This union is the best option in the circuits of figures 3.32.(a), (c),(m) and (o), their characteristic functions are shown in Eq (3.9). As shownin Eq (3.9) describes the UGC with dual outputs, positive and negative.Chromosomes that describe these circuits are implemented by chromosomespreviously made, as shown in the table (3.22). The amendment is not madein the chromosomes but in the program as this will double the output cir-cuitry of UGC. An example of this synthesis is shown in Figure 3.34 a circuittype Figure 3.32.(c) in Figure 3.35 a circuit that is represented by the figure3.32.(a). The circuits of Figure 3.32.(k) and 3.32.(m) with MOSFETs areshown in figures 3.36 and 3.37.
Intermediate Output Double
The union called intermediate output double is to double the output cir-cuitry of the first UGC to gain entry to the second UGC. This union is thebest option in the circuits of figures 3.32.(n) and (p) their characteristics areshown in Eq (3.10). Chromosomes that describe these circuits are implement-ed by connecting the chromosomes made previously, as shown in the table(3.23). An example of this synthesis is shown in Figure 3.38 circuit type 3.32.(N) and Figure 3.39 shows a circuit that exemplifies the figure 3.32.(p).
Creation Node Z
The union named UGCs Z node creation to amend the sources of bias orVM VF circuit for a current output. This union is used in the synthesis ofthe circuits of figures 3.32. (F) and (h) their characteristic functions shown inEq (3.11). As can be seen from the equation (3.11) correspond to the circuitsICCII+ and CCII+.The chromosomes which describe the circuit (I) CCII + chromosomes aremade by joining the previously made, as shown in Table 3.24. Where in thegenCM of VF (Table 3.8) summarizes the sources of polarization of the inputpolarization and power output are synthesized by CM chromosome (Table3.16).To perform the genetic coding of a CCII + is first described the CC as aVF (Figure 3.40.(a)); then used to synthesize CM Chromosome sources ofpolarization of the output MOSFETs. This is shown in Figure 3.40.(b) inthis example the output MOSFETs are M2 and M4. Figure 3.40.(b) showsthe CCII+ 336860-1192, where the node Z is created by using the CM 1192

BIBLIOGRAFIA 175
synthesized in figure 3.26.
Combining Nullators-Norators
The UGCs union called combination nullators-norators is to combine thenullators describing an ideal with norators VF defining an ideal CF. Thisunion is used in the synthesis of the circuits of figures 3.32.(e) and (g); theircharacteristic functions shown in Eq (3.12). As can be seen these equationscorrespond to the circuits, and ICCII CCII-, respectively.It must be remembered that an ideal VF is represented by a block of nulla-tors, the same way an ideal CF is represented by a block of norators. Thus,a CCII-must be represented by the union of these blocks ideal as shown inFigure 3.41.(a). Each block is made of several components O or P; combinedin different ways as shown in figures 3.5, 3.6, and 3.7.Figure 3.41.(b) shows an ideal CCII-nullators performed with 4 and 4 no-rators. If each of these elements O and P synthesizes a MOSFET circuit isobtained with 8 MOSFETs, this is a 4-VF MOSFETs with a cable attachedto a CF 4-MOSFETs. ‘Union-norators nullators combination’ is to combinethe nullators to norators. Therefore, in Figure 3.41.(b) output 2 VF nulla-tors join the 2 norators CF input, each union synthesize a MOSFET, andthe CCII- is made with 6 MOSFET circuit. Figure 3.42.(a) shows a circuitmade with 4 nullators VF; figure 3.42.(b) shows a circuit synthesized with 4norators CF. The union of these UGC is the CCII- shown in Figure 3.42.(c)Some authors call this union superimposition circuit [18].To describe the chromosomes of circuits (I) CCII, one must first recall thedescription of the VF and CF chromosomes according to the tables 3.8and 3.11 where GenMan = genSMos-genSMos-genBias. To realize the CCII-chromosome is divided into three parts first description of the norators alone(if any) After describing the nullator-norator pairs formed (node X) and final-ly encode norators alone (if any). This is shown in Table 3.25, where genMOS= genSS-genSMos-genBias ; the genSMos is encoded by the table 3.5 in pairsformed nullator-norators not need this gene. The genSMos is coded in Table3.5. For the tables used genBias 3.6 (nullators and OP pairs) and 3.10 (nora-tors). The genCM synthesized by a current mirror (CM) current sources Iddand Iss, as Table 3.7.

176 BIBLIOGRAFIA
Chapter 4. Results
Introduction
The proposed algorithm for the synthesis of unity gain cells (Chapter 3)was implemented in MatLab. The developed program can perform synthesisof UGCs topologies shown in Table 4.1. The program CFOA.m not lookingfor a topology only synthesizes a single CFOA asking the number of chromo-somes in the CM and the two VF previously found with CM.m and VF.m.The program’s user manual is developed in Apendix C.This chapter shows some topologies obtained with the developed tool. Todemonstrate the Genetic Algorithm, shown in Figure 4.1 best individual as-sessment of each generation; and as far as is closed assessment when tendsto zero in each generation, since zero is the ideal value. Figure 4.2 showsthe runtime of the program few seconds took the computer to get each gen-eration and the total time of execution of the program approximately 71minutes for this example. Figures 4.1 and 4.2 were obtained from a programexecution VF.m on a computer minihp with Atom Processor at 1.6GHz and1GB RAM. The program VF.m was run with the following specifications:Θ Simulator: Tanner-SPICE.Θ Technology: 0.35µm AMI Semiconductor.Θ Number individuals by generations: 40.Θ Percentage mutation: 0.3.Θ Max generations: 150.Θ Gain (Vo/Vi): 1 (with weight 1).Θ Bandwidth: 1MHz (with weight 0.5).Θ Input impedance (Zin): 10KΩ (with weight 0.5).Θ Output impedance (Zout): 250Ω (with weight 0.5).
Topologies generated for the VF
The topologies shown in figures 4.3 and 4.4 were obtained by the EA. Thealgorithm (VF.m) was run with various simulators and technologies to findtopologies. These are shown in figures 4.3 and 4.4 the program VF.m findVFs equivalent to capacitive paths, i.e., these circuits do not make copies ofDC voltage, the GA does not provide a profit target DC gain, to implementthis objective in the evaluation of the circuit is expected that this drawbackwill be corrected. Table 4.2 was conducted to compare the topologies found;in this table was used the Tanner-SPICE simulator and technology of 0.35µmin all simulations. With dimensions of transistors: L=1.2µm, WN=1.0µm and

BIBLIOGRAFIA 177
WP=4.4µm.
Topologies generated for the CF
The topologies shown in figures 4.5 and 4.6 were obtained by the EAdone. It is noted that the simulated CFs found in AC cables, this is due tothe GA find this kind of response as the best option. To find itself performingtransconductance topologies as in Figure 3.21 should criminalize the genera-tion of cables linking the MOS input with output. Table 4.3 was conductedto compare the topologies found; in this table use the Tanner-SPICE simu-lator and technology of 0.35µm. With dimensions of transistors: L=1.2µm,WN=1.0µm and WP=4.4µm.
Topologies generated for the CM
Running the algorithm CM.m with different simulators and technologiesto find topologies of Figures 4.7 and 4.8. The GA finds functional CMs assimple mirror, cascode, Wilson, or as shown in Figure 4.7.(d), althoughtalso It find non-functional topologies as some of the figures 4.7 and 4.8. Itmust be remembered that the GA generates topologies ready to be simulatedin SPICE. Table 4.4 was maded to compare the topologies found, in thesecircuits the GA use the Tanner-SPICE simulator and technology of 0.35µmin all simulations. With dimensions of transistors: L=1.2µm, WN=12.0µm.
Topologies generated for the VM
The topologies shown in Figure 4.9 were obtained by the program VM.m.These four circuits already have been reported, leaving without the addi-tion of new topologies for this program (VM.m), so that the fact that theGA found these topologies means that it works is properly. Table 4.5 wasconducted to compare the topologies of figure 4.9. To compare these cir-cuits was used the Tanner-SPICE simulator and technology of 0.35µm in allsimulations. With dimensions of transistors: L = 1.2µm, WN=1.0µm andWP=4.4µm.
Topologies generated for the CCII
The topologies shown in figures 4.10, 4.11 and 4.12 were obtained bycombining the UGCs found by the EA. The CCII+ of Figure 4.10 is obtainedby combining the VF 196758 (Figure 4.4.(a)), with 69593766 CM (Figure4.7.(b))

178 BIBLIOGRAFIA
Topologies generated for the CFOA
The algorithm does not search for new CFOAs, only combines VFs andCMs topologies. Therefore this program (CFOA.m) only emulates a designerIC to interconnect three UGCs. Three CFOAs synthesized in this way canbe seen in figures 4.13 and 4.14. The CFOA in Figure 4.13 is obtained bycombining the VF 196758 (Figure 4.4.(a)) with the CM 69593766 (Figure4.7.(b))
Chapter 5. Conclusions
An automatic synthesis approach for analog circuit topologies using Evo-lutionary Algorithms has been introduced and performed in MatLab. Isshown the proposed algorithm and how it was done the trial run of it, con-cluding that the GA works good.
Some synthesis tools were compared with the method in this thesis. Al-so EA is briefly described, highlighting the genetic operators and the threetypes of EAs: Genetic Algorithms (GA), Evolutionary Strategies (ES) andGenetic Programming (GP). The genetic operators are selection, crossover,mutation and elitism.
The main contribution is the introduction of a binary encoding to rep-resent analog circuit topologies: VFs, CFs, VMs and CMs. The principalelement of this encoding is called chromosome, which is made by the unionof genes. Each gene models a part of the analog circuit.
The chromosomes of the VFs and CFs are made using four genes:
• Small-signal gene (genSS): For the VFs this gene adds an elementP to each element O of the ideal representation of VF, resultingin OP pairs. For CFs adds an element O to each element P.
• Synthesis MOS gene (genSMos): Each OP pair is replaced by aMOSFET, P or N.
• Bias gene (genBias): It generates the polarization of the circuit,adding voltage and current sources.
• Synthesis of current mirrors gene (genCM): Each power supplycircuit is replaced by a current mirror.
The chromosomes of the CMs are synthesized by three genes:

BIBLIOGRAFIA 179
• Bias gene (genBias): It generates the polarization of the circuit,selecting the internal connections.
• Input/Output gene (genIO): It chooses to input and output nodesof the CM.
• Displacement-level gene (GenN): It contains a library of possiblesub-circuits to join between the connections of the CM MOSFETs.
The chromosomes of the VMs are made by four genes:
• Synthesis MOS gene (genSMos): Each OP pair ideal of VM isreplaced by a MOSFET, P or N.
• Bias gene 1 (genBias1): It contains a library of possible sub-circuitsto join the port 1 of the VMs ideal (Figure 3.28).
• Bias gene 2 (genBias2): It contains a library of possible sub-circuitsto bind to port 2 of the ideal VMs (Figure 3.28).
• Output gene (genIO): It selects the output node of the VM.
The number of bits used to each chromosome depends on the number ofelement nullors used to model. Therefore it is possible to synthesize UGCsrepresented by cells that have not fully considered, due to that the numberof MOS can be anything.
The algorithm does automatically performs the analogic circuit netlistsand their simulation in Tanner-SPICE, TOP-SPICE or H-SPICE. Synthe-sized topologies are simulated with CMOS IC technology:
AMI Semiconductor: 0.35µm, 0.50µm.
Taiwan Semiconductor: 0.18µm, 0.25µm, 0.35µm.
IBM Semiconductor: 0.18µm, 0.25µm, 0.35µm, 0.50µm.
The simulations seek features in AC: gain, bandwidth and input and/oroutput impedance. Therefore, the proposed Genetic Algorithm is consideredmulti-objetive (MOGA).
The chromosomes for UGCs circuits were evolved to synthesize other cir-cuits with more terminals, consisting of two or more unity gain cells as CCs,ICCs and CFOAs, demonstrating that the system is not closed, it can grow.

180 BIBLIOGRAFIA
Ideas for future work
The evaluation parameters for the selection of circuits (fitness) cangrow, according to a specification in AC, DC and/or transient andthey are not just the four shown in this thesis.
One can change the method of evaluation, for example a fuzzy evalua-tion will be ideal for this kind of problem.
Genetic operators (selection, crossover and mutation) used in this thesiscan be exchanged for other operators to try if one can find better results.
The program can generate the netlist performed for three different sim-ulators (Tanner, TOP-SPICE and H-SPICE), but the program can beadapted to other simulators.
One can extend this method to other circuits and devices, for example,OPAMPs, OTAs, filters, etc. One can also expand it including passiveelements and dimensions of the CMOS.